
Abstract
Arsenic is a toxic metalloid that causes skin cancer and binds to cysteine residues—a property that could be used to infer arsenic responsiveness of a target protein. Non-synonymous Single Nucleotide Polymorphisms (nsSNPs) result in amino acid substitutions and may alter arsenic binding with cysteine residues. Thus, the objective of this investigation was to identify and analyze nsSNPs that lead to substitutions to or from cysteine residues as an indication of increased or decreased arsenic responsiveness. We hypothesize that integration of data on molecular impacts of nsSNPs and arsenic-gene relationships will identify nsSNPs that could serve as arsenic responsiveness markers. We have analyzed functional and structural impacts data for 5,811 nsSNPs linked to 1,224 arsenic-annotated genes. In addition to the identified candidate nsSNPs for increased or reduced arsenic responsiveness, we observed i) a nsSNP that results in the breakage of a disulfide bond, as candidate marker for reduced arsenic responsiveness of KLK7, a secreted serine protease participate in normal shedding of the skin; and ii) 6 pairs of vicinal cysteines in KLK7 protein that could be binding sites for arsenic. In summary, our analysis identified non-synonymous SNPs that could be used to evaluate responsiveness of a protein target to arsenic. In particular, an epidermal expressed serine protease with crucial function in normal skin physiology was prioritized on the basis of abundance of vicinal cysteines for further research on arsenic-induced keratinocyte carcinogenesis.
Keywords
Introduction
Arsenic (As) is recognized as an environmental toxicant of concern for global public health and a leading cause of toxicity and carcinogenicity.1,2 Arsenic targets the human skin and long-term exposure to arsenic, principally through drinking water, has been correlated with increased risk of skin cancer.3–5 The cellular toxicity of arsenic has been well documented from case studies of poisoning incidents and medicinal use.2,6 However, due to increased epidemiological reports of arsenic related cancers in places such as Southeastern Michigan (USA), Taiwan, China, India and Bangladesh, public health concerns about long-term exposure have arisen.2,6–8 Inorganic arsenic is classified by the United States Environmental Protection Agency (U.S. EPA) as a Group A carcinogen based on sufficient evidence of carcinogenicity in humans. 9 Chronic oral exposure to inorganic arsenic can have adverse effects on tissues in the human body systems. 10 However, the human skin is the critical organ of arsenic toxicity because arsenic has a strong affinity for the keratin proteins which are rich in the sulphur containing cysteine residues.11–13 Chronic exposure to arsenic induces sequential changes in the skin epithelium, proceeding from hypopigmentation to hyperkeratosis which may eventually lead to skin cancer. 11 Arsenic-induced skin lesions are early warning markers for development of cancers in internal organs.14,15 A well-known beneficial use of arsenic is that arsenic trioxide is used for treatment of relapsed or refractory acute promyelocytic leukemia.16–20 However, side effects of treatment with arsenic trioxide include significant adverse cardiac effects. 21
The avalanche of genome sequences combined with genome-enabled datasets from high-throughput gene expression, genotyping, haplotyping and protein assays is making it possible to gain biological insights into previously unknown gene-toxicant interactions. Arsenicogenomics, an aspect of toxicogenomics, therefore, provides a means to i) understand how various genes respond to arsenic and ii) how arsenic modifies the function and expression of specific genes in the genome. Early physical manifestations of arsenic toxicity in endemic areas are skin lesions including melanosis and keratosis. However, not everyone exposed to arsenic in an endemic region would develop skin lesions. 22 Therefore, future research on arsenic-induced cancers and, in particular, skin lesions should consider the impact of genetic variation in individual susceptibilities to arsenic toxicity.
Single nucleotide alterations in the DNA sequence represent a major source of genetic heterogeneity 23 and the most common type of genetic variation in the human genome. The diversity of single nucleotide polymorphisms (SNPs) derived from arsenic responsive genes in different populations could provide biomarkers for an individual's susceptibility to arsenic-induced diseases. Genomic and bioinformatics techniques now exist to identify and analyze the presence of SNPs in populations. 24 Furthermore, the dense distribution of SNPs across the genome makes them ideal markers for large-scale genome-wide association studies to discover genes in common complex diseases, such as cancer. A SNP- induced amino acid substitution in the coding region can be broadly divided into synonymous (no change in amino acid) or non-synonymous (change in amino acid). 25 Furthermore, the functional impact of the SNP on protein function has been described as deleterious (disruptive) or non-deleterious (benign/neutral). 26 Non-synonymous substitutions could lead to missense or nonsense mutations in the encoded polypeptide. In particular, nonsense mutations that generate premature termination codons (PTCs) are responsible for approximately one-third of human genetic diseases. 27 In addition, substitutions in one or two amino acids of a protein sequence can alter the quantity of encoded protein during expression in mammalian cells. 28 Considering that arsenic trioxide is also used for treatment of acute promyelocytic leukemia,16,18,19,29 genetic variation may also affect response to therapy.
Arsenic binds to sulfhydryl (SH) groups of cysteine (Cys) residues to form arsenic-thiol linkages, a property that could be used to infer arsenic responsiveness of a protein target as well as contribute to oxidative and protein folding stresses.30–32 In the human arsenic (+3 oxidation state) methyltransferase (hAS3MT) sequence, Cys residues at positions 156, 206 and 250 play important roles in the enzymatic function and structure. 33 Mutation of the arsenic-sensing Cys151 in Kelch-like ECH-associated protein 1 (Keap1) abolished arsenic activation of nuclear factor erythroid 2-related factor 2, a transcription factor responsible for induction of antioxidative cytoprotective genes. 34
Non-synonymous Single Nucleotide Polymorphisms (nsSNPs) result in amino acid substitutions and may alter the number of cysteine residues available to arsenic for binding to a protein cellular target. Therefore, the objective of this investigation was to identify and analyze nsSNPs that lead to substitutions to or from cysteine residues as an indication of increased or decreased arsenic responsiveness of a protein. We hypothesize that integration of data on molecular impacts of non-synonymous single nucleotide polymorphisms and arsenic-gene relationships will help identify nsSNPs that are candidate arsenic responsiveness markers.
An integrative approach combining results from selected web-based toxicogenomics and genomics databases as well as bioinformatics tools was used to prioritize candidate nsSNPs markers for arsenic responsiveness of protein targets. In the first step, a list of genes annotated to interact with arsenicals was retrieved from the Comparative Toxicogenomics Database. 35 Subsequently, the nsSNPs linked to these arsenic-annotated genes were extracted from SNPs3D 36 and analyzed for functional and structural impacts data on protein isoforms. Significant amino acid substitutions to or from cysteine residues were then prioritized based on structural effect resulting in breakage of a disulphide bond as well as function in skin cells. Furthermore, structural homology modeling was used to identify vicinal (neigboring) cysteines in prioritized protein targets of arsenic. In order to facilitate additional investigations on prioritized SNPs, protein targets and molecular mechanisms of arsenic action, we have constructed a collection of over 100,000 sentences from over 16,000 PubMed 37 abstracts on arsenic. Finally, a web resource Arsenic Sentence Database was developed to enable web-based search of the sentences by keywords and PubMed identifiers.
Methods
Functional and structural impacts of single nucleotide polymorphisms on arsenic annotated genes
The molecular functional effects of non-synonymous SNPs based on sequence and structure analysis were retrieved from the SNPs3D web resource and database 36 for genes curated in the Comparative Toxicogenomics Database (CTD) 35 to have a relationship with arsenic. In the CTD, the term gene also includes mRNA and proteins. We described relationship in terms of arsenic modifying the function and/or expression of genes. Furthermore, we referred to the genes as arsenic-responsive genes or proteins. In SNPs3D, the classification into in vivo functional impact categories of the SNP was based on two Support Vector Machine (SVM) models: protein sequence conservation profiling and protein structure stability. In both machine learning models, an SVM is trained using 5 sequence profiles and 15 protein stability features. Additional details on the methods are available at the SNPs3D website http://www.snps3d.org/help/method.html. The nsSNPs were ranked according to SVM score. For both sequence and structure SVM scores, a nsSNP with negative score was classified as deleterious while a nsSNP with a positive score was classified as non- deleterious. We observed that some nsSNPs in SNPs3D were assigned a SVM score of −0.00. However, they were not tagged as deleterious. Thus, these nsSNP were classified in this investigation as non- deleterious. Furthermore, High Confidence (HC) SVM scores were greater than 0.50 or less than −0.50. 38
The computational workflow consisting of a suite of customized Perl and Unix scripts was developed to process results obtained from CTD and SNPs3D. The Entrez Gene 37 Identifiers and Gene Symbols were extracted from XML formatted results of arsenic-gene interactions from CTD. Furthermore, the Entrez Gene identifiers were then used to remotely download the SNP Analysis page in SNPs3D for each CTD arsenic-annotated gene. For example, the SNP Analysis page for a known arsenic-interacting gene Glutathione S-transferase Omega 1 (Gene Symbol: GSTO1 and Entrez Gene Identifier: 9446) in SNPs3D is http://www.snps3d.org/modules.php?name=SnpAnalysis&locus_ac=9446.
The collection of html files was processed to mine for relevant data to construct a dataset. The fields of the dataset were the dbSNP identifier, 37 RefSeq protein isoform identifier, 37 mutation, SVM sequence profile score, SVM structure score and description of impact of nsSNP on protein stability. There were instances that no data were predicted for the SVM structure score and the protein impact. However, scores were predicted for all the SVM sequence profile. The gene symbols were also extracted from the CTD and combined with the dataset from SNPs3D. The final integrated dataset consisted of the Entrez Gene Identifier, Gene Symbol, the SNP Identifier, the Amino Acid Substitution, the SVM score computed for the sequence and structure profile models and the structural consequence of the SNP. In SNPs3D, we preferred to remotely download the SNP Analysis pages so as to extract data and links to additional information such as i) sequence alignment evidence of tolerance of the amino acid position to mutation and ii) values associated with the 15 protein stability factors. These additional datasets were not available in the files available for download.
Arsenic responsiveness based on substitution to or from cysteine residues
We conjectured that substitution to or from a cysteine residue could lead to increased or decreased responsiveness of a protein isoform to arsenic. In order to identify these cysteine substitutions, a suite of customized Perl and Unix scripts was developed to extract records that met the criteria from the integrated CTD and SNPs3D dataset. For example, in SNPs3D SNP Analysis page for GSTO1, nsSNP rs45529437 is linked to substitution from cysteine to tyrosine in position 32 (C32Y). Furthermore, rs11509436 is linked to substitution to cysteine from serine in position 86 (S86C).
Structural homology modeling
Structural models of protein mutants link to candidate SNPs that alter arsenic responsiveness were generated using MODELLER 7v7 39 with appropriate homologous high resolution X-ray crystal structure templates from the Protein Data Bank (PDB). 40 SYBYL (Tripos Inc) was used to identify vicinal cysteines following a quick minimization routine using AMBER force field.
Construction of sentences collection from PubMed abstracts on arsenicals
In order to identify descriptors of interest in sentences and cluster sentences with identical descriptors, we implemented a sentence splitting algorithm on a collection of PubMed 37 abstracts annotated with at least one of the Medical Subject Heading (MeSH) terms: arsenic or arsenicals. The sentence splitting algorithm implemented uses Perl regular expressions to enhance the Comprehensive Perl Archive Network (CPAN) Text: Sentence splitter module (http://search.cpan.org/) to achieve a high accuracy in sentence disambiguation. A web interface for searching the catalog of sentences was also developed.
Results
Functional and structural impacts of single nucleotide polymorphisms on arsenic annotated genes
The set of genes for predicting potential responsiveness to arsenic was obtained from the Comparative Toxicogenomics Database (CTD). 35 A total of 1,604 genes consisting of 1,492 human genes and 112 non-human genes documented to have a relationship with arsenicals (Medical Subject Heading Identifier [MeSH ID]: D001152) were retrieved on May 10, 2010 (Supplementary Data). We describe the gene set as a list of arsenic-annotated genes and their protein isoforms as arsenic-annotated proteins. The functional impacts of SNPs on protein function, as predicted by support vector machine (SVM), were retrieved from SNPs3D. 36 Support Vector Machines (SVM) are supervised machine learning techniques that have been applied to numerous classification tasks to predict the class of an example based on training examples. The SNPs3D database provides an SVM profile score for the functional impact (deleterious or non deleterious) of an nsSNP as well as 3-dimensional protein structure of the impact of the nsSNP on protein stability. According to Yue et al 36 the SVM used in SNPs3D is trained on monogenic disease data, thus deleterious is defined as “sufficiently damaging to protein function in vivo as to be consistent with a monogenic disease outcome”. A screenshot of a section of SNPs3D page for a gene is presented in Figure 1. The pages of the arsenic-annotated genes available in the SNPs3D database were the data source for extracting relevant data. The protein stability impacts in SNPs3D were i) Four classes of electrostatic interaction: reduction of charge–charge, charge–polar or polar–polar energy, or introduction of electrostatic repulsion; ii) three solvation effects: burying of charge or polar groups, and reduction in non-polar area buried on folding; iii) and two terms representing steric strain: backbone strain and over-packing; cavity formation (affecting van der Waals energy); iv) and loss of a disulfide bridge.

Screenshot of a SNPs3D page for a gene. The functional and structural impacts, molecular effect and frequency of non-synonymous SNPs associated with the protein isoforms (RefSeq accession) is documented on the page. The negative SVM score (value in red) indicates a deleterious substitution.
From SNPs3D, we extracted the Entrez Gene Identifier, the SNP Identifier, the Amino Acid Substitution and the SVM score computed for the sequence and structure profile models. The dataset constructed consisted of 5,811 nsSNPs linked to 1,224 arsenic-annotated genes. Furthermore, a total of 8,992 nsSNP-induced substitutions (3,700 deleterious, 5,292 non-deleterious) were linked to 1,872 protein isoforms in the National Center for Biotechnology Information (NCBI) Reference Sequence Database. 37 The SVM scores observed for the substitutions ranged from −4.73 to 6.59 with 743 unique scores (Fig. 2). Of the 3,700 nsSNP-predicted substitutions, there were 2,739 high confidence deleterious substitutions (SVM sequence profile score <–0.5) linked to 745 genes, 1,785 nsSNPs and 1,094 protein isoforms. Furthermore, there were 4,191 high confidence non-deleterious substitutions (SVM sequence profile score >0.5) linked to 964 genes, 2,829 and 1,459 nsSNPs. A summary of the dataset is presented in Table 1. In order to facilitate selection of nsSNPs according to confidence of SVM score, we classed substitutions into categories with a 0.5 interval (Table 2).

Plot of frequencies of unique Support Vector Machine (SVM) scores for dataset of non-synonymous SNPs linked to arsenic-annotated genes. The SVM score predicted for each nsSNP substitution was extracted from the SNPs3D page.
Summary of datasets.

SVM sequence profile score:
SVM <–0.5;
SVM >0.5
Distribution of SVM scores for nsSNP substitutions.

Absolute values.
Arsenic responsiveness based on substitution to or from cysteine residues
A total of 196 nsSNPs linked to 144 genes and 225 protein isoforms were observed to cause substitutions to cysteine residues. In the case of substitutions from cysteine residues, 92 nsSNPs linked to 79 genes and 122 protein isoforms were observed. In the protein isoforms analyzed, the substitutions to or from cysteine residues were restricted to the following six amino acid residues: Phenylalanine (F), Glycine (G), Arginine (R), Serine (S), Tryptophan (W) and Tyrosine (Y).
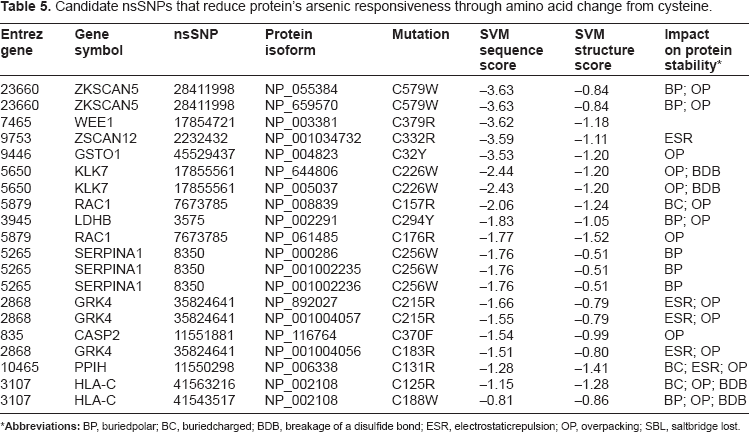
Four classes of nsSNPs were identified on the basis of significant deleterious and non-deleterious effects on protein function as well as SNP-associated residue changes to or from cysteine (Table 3). The 111 nsSNPs that resulted in non-deleterious substitutions to or from cysteine are candidates for evaluating increased or decreased responsiveness to arsenic, respectively (Supplementary Data). A set of nsSNPs that mutates the residue to or from cysteine with significant impact on protein function and structure (with agreement of both SVM scores for sequence and structure profiles) are presented in Table 4 and Table 5, respectively. All the identifiers for SNP are from the dbSNP and begin with “rs”.
Categories of nsSNPs observed in analysis of arsenic-annotated genes.

Candidate nsSNPs that increase protein's arsenic responsiveness through amino acid change to cysteine.

*
Candidate nsSNPs that reduce protein's arsenic responsiveness through amino acid change from cysteine.
Structural homology modeling
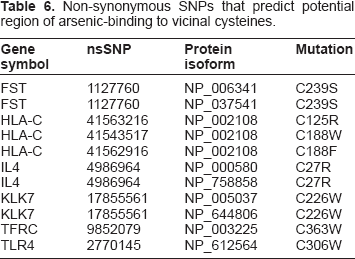
In SNPs3D, breakage of a disulfide bond is assigned to any mutation that replaces a cysteine residue in an S–S bond with a non-cysteine residue. Eight nsSNPs from 6 genes (9 protein isoforms) were identified to result in breakage of a disulfide bond (Table 6). The impact of these nsSNPs on protein stability has pointed us to potential regions of arsenic binding to vicinal (neigboring) cysteines. Since, we are interested in arsenic-induced skin cancer, we further analyzed the stratum corneum chymotryptic serine protease KLK7 (kallikrein-related peptidase 7) for annotated structural consequences of SNP marker for reduced responsiveness, the effects of arsenic on expression as well as distribution of cysteine residues. A screenshot of SNPs3D page on structural impact of nsSNP rs17855561 is presented in Figure 3. The nsSNP rs17855561 in both KLK7 protein isoforms is predicted to result in breakage of a disulfide bond and potentially reducing responsiveness to arsenic by changing the Cys in position 226 to Tryptophan (W) (Table 6). Furthermore, according to data extracted from Bae et al 41 by CTD curators, sodium arsenite results in decreased expression of KLK7 mRNA in the virally immortalized human keratinocyte cell line RHEK-1. Structures of KLK7 from protein sequences NP_005037 and NP_644806 were generated using high resolution X-ray crystal structure of human kallikrein (PDB ID: 2QXI). Structural homology models of wild type KLK7 structure revealed six cysteine pairs 36–165; 55–71; 137–239; 144–211; 176190 and 201–226 (Fig. 4).
Non-synonymous SNPs that predict potential region of arsenic-binding to vicinal cysteines.

Screenshot of predicted structural impact of nsSNP rs17855561 on human kallikrein-7 preproprotein (NP_005037). The nsSNP results in steric strain (over-packing) and breakage of a disulfide bond by changing Cysteine (C) residue in position 226 to a Tryptophan (W).
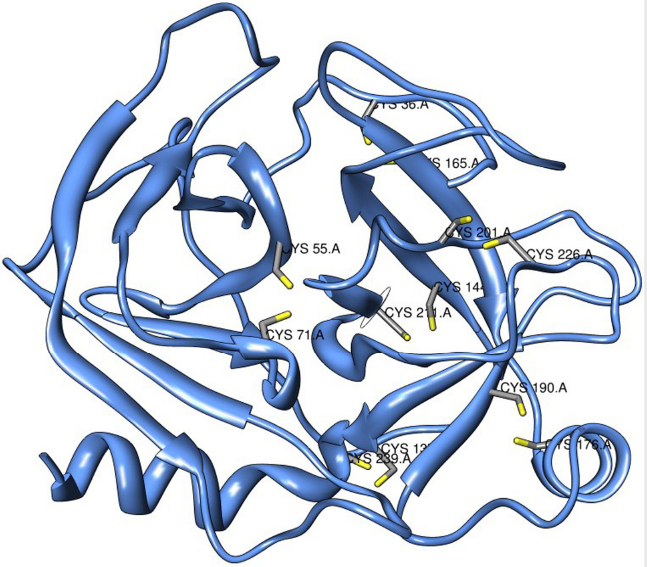
Predicted structure of human kallikrein-7 preproprotein (NP_005037). The vicinal cysteine pairs are 36–165; 55–71; 137–239; 144–211; 176–190; 201–226. The homology structure shows that the Cys201 pairs with Cys226. Arsenic is known to reduce the expression of KLK7 in an epidermal cell line.
Construction of sentence collection from PubMed abstracts on arsenicals
In order to facilitate further studies on these identified genes, single nucleotide polymorphisms and other aspects of arsenic, we have segmented 16,057 PubMed abstracts into a collection of 108,235 sentences. The abstracts were selected based on annotation of the abstract in PubMed with at least one of the Medical Subject Heading (MeSH) terms: arsenic or arsenicals. An Arsenic Sentence Database that facilitates query of the sentences with keywords as well as retrieval of sentences for specific PubMed abstracts is available at http://compbio.jsums.edu/arsenic_pubmed.
The utility of the database was demonstrated by a search for “GSTO1” the symbol for gene encoding the enzyme glutathione S-transferase omega 1 which catalyzes the monomethyl arsenate reduction, the rate-limiting step for inorganic arsenic biotransformation in humans.42,43 A cluster of 80 sentences containing the symbol were retrieved from the database. Furthermore, a subset of the GSTO1 sentences and containing the word “polymorphism” allowed us to identify 13 sentences from 7 PubMed abstracts (Table 7). These abstracts were on genetic variation observed in GSTO1 and other genes involved in arsenic metabolism.
Cluster of sentences from PubMed abstracts on GSTO1 polymorphism.

Sentence identifier consists of PubMed identifier (PMID) and the location of the sentence in the abstract with abstract title as the first sentence.
Discussion
Since amino acid substitutions to or from cysteine residues attributed to SNPs might be a determinant of responsiveness of target proteins to arsenic and possibly arsenic-induced skin cancer, we under took to prioritize genes and SNPs to understand keratinocyte carcinogenesis resulting from arsenic exposure. Our analysis of the functional and structural impacts of 5,811 nsSNPs associated with 1,224 putative arsenic responsive genes identified i) 196 candidate nsSNPs for increased arsenic responsiveness by substitutions to cysteine residues for 144 genes; ii) 92 candidate nsSNP for decreased arsenic responsiveness by substitutions from cysteine residues for 79 genes; iii) nsSNP rs17855561 that results in breakage of a disulfide bond, as candidate marker for reduced arsenic responsiveness in KLK7, a secreted serine protease that has been demonstrated to participate in normal shedding of the skin 44 and iv) 6 pairs of vicinal cysteines in KLK7 protein.
The bioinformatics analysis pipeline identified genes with evidence for potential SNP-induced increased or decreased responsiveness to arsenic. To the best of our knowledge this report is the first large-scale analysis of SNP-induced substitutions evaluating the abundance of cysteines in putative protein targets of arsenic. A recent large-scale analysis of the curation of chemical-gene relationships from biomedical literature has provided over 1,400 genes whose activity were perturbed by arsenic in a variety of conditions and/or cell types. 35 Our analysis extends the curation efforts by CTD by integrating SNP data that could help understand the molecular mechanisms of arsenic action in diverse cell types including keratinocytes.
We have used the structural impact annotation “breakage of a disulfide bond” as an evidence of the presence of potential arsenic-binding vicinal cysteines in a protein sequence. The function and structure of proteins are often determined by Cys residues since many proteins folding are dependent on disulfide bonds. 33 Arsenic binding to target protein depends on the number, accessibility and relative positioning of Cys residues. 45 Furthermore, the ability for trivalent arsenicals to bind to thiol groups of biomolecules is an accepted mechanism for being more toxic than pentavalent arsenicals. The mRNA from the tissue serine protease KLK7 that was identified by our pipeline was down-regulated by arsenic in human keratinocyte cell line RHEK-1. 41 The proposed functions of KLK7 in the normal skin physiology include i) activating interleukin 1 beta (IL-1b) and ii) basal permeability barrier function of stratum corneum by degrading two major lipid processing enzymes beta-glucocerebrosidase and acidic sphingomyelinase.44,46,47 The crucial function of KLK7 in normal skin function and potential perturbation by arsenic justifies a need to determine the potential energy of each Cys residues in KLK7 combined with their proximity to enzyme active sites or other functional regions of the protein. We hypothesize that arsenic binds to at least one of the 6 pairs of vicinal cysteines resulting in conformational changes that down regulate KLK7 function. Our hypothesis for KLK7 can be tested using similar experiments conducted to determine the role of the 8 Cys residues in arsenic binding for human beta-tubulin. 32 In this investigation, we have verified the sequence-based prediction of vicinal cysteine with structural homology modeling.
The functional implications of SNP modified polypeptides of KLK7 warrant further investigation. Our text mining approach using the gene symbol GSTO1 as a search term in a collection of over 100,000 sentences from over 16,000 PubMed abstracts retrieved publications that could guide further research on the impact of arsenic as well as SNP-induced polymorphism on KLK7 function. In the case of the two enzymes Glutathione S-transferase omega 1 and omega 2 (GSTO1 and GSTO2) that catalyze monomethyl arsenate reduction, variant allozymes have been shown to degrade more rapidly than their respective wild type allozymes. 48 Similar protein degradation experiments for KLK7, could unravel the impact of molecular differences resulting in susceptibility of arsenic-induced skin cancer in arsenicosis-endemic populations.
Conclusions
Single nucleotide polymorphisms (SNPs) can alter the physico-chemical properties of proteins. The susceptibility to arsenic-induced diseases as well as response to arsenic-based drugs has been linked to single nucleotide polymorphisms. Our analysis identified non-synonymous SNPs that could be used to evaluate responsiveness of a protein target to arsenic. Furthermore, an epidermal expressed serine protease KLK7 with crucial function in normal skin physiology was prioritized on the basis of abundance of vicinal cysteines to understand arsenic-induced keratinocyte carcinogenesis.
Footnotes
Supplementary Data
BBI-4-Isokpehi-Supplementary.xls
Acknowledgements
Research Centers in Minority Institutions (RCMI)—Center for Environmental Health at Jackson State University (NIH-NCRR 2G12RR013459); Mississippi NSF-EPSCoR Grant Awards (EPS-0556308, EPS-0903787); Mississippi Computational Biology Consortium Seed Grant Program; Pittsburgh Supercomputing Center's National Resource for Biomedical Supercomputing (T36 GM008789); U.S. Department of Homeland Security Science and Technology Directorate (2007-ST-104-000007; 2009-ST-062-000014; 2009-ST-104-000021) and NIH RIMI Grant 1P20MD002725-01 to Tougaloo College. We thank Dr. Robert Rice and Dr. Susan Bridges for their suggestions. Disclaimer: The views and conclusions contained in this document are those of the authors and should not be interpreted as necessarily representing the official policies, either expressed or implied, of the funding agencies.
This manuscript has been read and approved by all authors. This paper is unique and not under consideration by any other publication and has not been published elsewhere. The authors and peer reviewers report no conflicts of interest. The authors confirm that they have permission to reproduce any copyrighted material.