
Abstract
We present the Linked SPARQL Queries (LSQ) dataset, which currently describes 43.95 million executions of 11.56 million unique SPARQL queries extracted from the logs of 27 different endpoints. The LSQ dataset provides RDF descriptions of each such query, which are indexed in a public LSQ endpoint, allowing interested parties to find queries with the characteristics they require. We begin by describing the use cases envisaged for the LSQ dataset, which include applications for research on common features of queries, for building custom benchmarks, and for designing user interfaces. We then discuss how LSQ has been used in practice since the release of four initial SPARQL logs in 2015. We discuss the model and vocabulary that we use to represent these queries in RDF. We then provide a brief overview of the 27 endpoints from which we extracted queries in terms of the domain to which they pertain and the data they contain. We provide statistics on the queries included from each log, including the number of query executions, unique queries, as well as distributions of queries for a variety of selected characteristics. We finally discuss how the LSQ dataset is hosted and how it can be accessed and leveraged by interested parties for their use cases.
Introduction
Since its initial recommendation in 2008 [70], the SPARQL query language for RDF has received considerable adoption, where it is used on hundreds of public query endpoints accessible over the Web [93]. The most prominent of these endpoints receive millions of queries per month [12], or even per day [57]. There is much to be learnt from queries received by such endpoints, where research on SPARQL would benefit – and has already benefited – from access to real-world queries to help focus both applied and theoretical research on commonly seen forms of queries [59].
To exemplify how access to real-world queries can directly benefit research on SPARQL, first consider the complexity results of SPARQL [67], which show that evaluation of SPARQL queries is intractable (PSPACE-hard). But do the worst cases predicted in theory actually occur in practice? Is it possible to define fragments of the language that avoid computationally difficult cases and lead the way to efficient algorithms dedicated to these common cases? The answer is yes, where a number of restricted fragments of SPARQL queries have been identified that are less computationally costly for important tasks. These fragments include well-designed queries that use the
Another use case for a large collection of real-world queries pertains to benchmarking. For over a decade, the SPARQL community has relied on synthetic datasets and queries (e.g., LUBM [40], Berlin [19]), or real-world datasets and hand-crafted queries (e.g., BTC [63], FedBench [84]) to perform benchmarking. However, Aluç et al. [7] and Saleem et al. [83] find the queries of these benchmarks to often be too narrow and simplistic. Building benchmarks from real-world queries can help tune implementations and guide research towards better support for the types of queries most commonly encountered in practical settings [13,16,62,65,79,101]. Yet another use case is caching [50,54,100]. Here, real-world queries can be used to simulate practical workloads experienced by endpoints. The usability of SPARQL interfaces [24,25,52,73] can also benefit from query logs, as these logs can reveal patterns in how users incrementally build their queries, as has recently been studied by Bonifati et al. [24] in DBpedia logs. These use cases and others will be discussed in more detail in Section 2.
Recognising the value of query logs, a number of such collections have been published previously, including contributions from USEWOD [55],1
In this dataset description paper, we extend upon our previous work [77], which reported on the initial release of the Linked SPARQL Query Dataset (LSQ). The goal of LSQ is to publish queries from a variety of SPARQL logs in a consistent format and associate these queries with rich metadata, including both static metadata (i.e., considering only the query) and runtime metadata (i.e., considering the query and the dataset). In particular, we propose an RDF representation of queries that captures their source, structure, static metadata and runtime metadata. These RDF descriptions of queries are indexed in a SPARQL endpoint. Thus, they allow clients to retrieve the queries of interest to their use case declaratively, potentially sourced from several endpoints at once. In comparison to our previous work [77], which described the initial release of the dataset in 2015:
The LSQ dataset has grown considerably: LSQ 2.0 now features logs from 27 endpoints (22 of which are from Bio2RDF) compared with 4 initial endpoints. As a result, the number of query executions described by the LSQ 2.0 dataset has grown from 5.68 million to 43.95 million.
Based on the experiences gained from the first version of LSQ, we have improved the RDF model to provide better modularisation and more detailed metadata, facilitating new ways in which clients can select the queries of interest to them; we have likewise updated the LSQ vocabulary accordingly.
We have re-engineered the extraction framework, which takes as input raw logs produced by a variety of popular SPARQL engines and Web servers, producing an output RDF graph in the LSQ 2.0 data model describing the queries. The RDFization process can now be scaled as it leverages Apache Spark.2
We have evaluated the new queries locally in a Virtuoso instance in order to gain runtime statistics (including estimates of the number of results, the selectivity of patterns, overall runtimes, etc.), and have updated the statistical analysis of the queries featured by LSQ to include the additional data provided by the new endpoints.
Since the initial release, LSQ has been used by a variety of diverse research works on SPARQL [2,3,11,14,15,17,18,21,22,26,30–32,34,35,37,39,41,42,49,58,69,71,74–76,78–80,83,85–87,89–91,94,97–99,102]. To exemplify the value of LSQ, we discuss the various ways in which the dataset has been used in these past years.
LSQ 2.0 is available at
The rest of the paper is structured as follows:
Section 2 describes use cases envisaged for LSQ. Section 3 details the model and vocabulary used by LSQ to represent and describe SPARQL queries. Section 4 describes how LSQ is published following Linked Data principles and best practices. Section 5 first describes the datasets for which LSQ indexes queries, and then provides details on the raw logs from which queries are extracted. Section 6 provides an analysis of the LSQ dataset itself, as well as the queries it contains. Section 7 describes how LSQ has been adopted for the past six years since its initial release. Section 8 concludes and discusses future directions for the LSQ dataset.
To help motivate the Linked SPARQL Queries dataset, we first discuss some potential use cases that we envisage. We then list some general requirements for LSQ that arise from these use cases.
A number of benchmarks have been proposed recently based on real-world queries observed in logs [16,62,79,101]. The LSQ dataset can support the creation of such benchmarks, allowing users to select queries from a diverse selection of logs based on custom criteria matching the metadata provided by LSQ. Queries may be selected so as to provide a general benchmark that is representative of real-world workloads, or a specialised benchmark focused on particular query characteristics, such as path expressions, multi-way joins, and aggregation queries.
Various works have analysed SPARQL query logs in order to understand how features of the SPARQL standard are used “in the wild” as well as to extract structural properties of real-world queries [12,21,23,24,57,68,72]. In turn, this family of works has led to the definition of tractable fragments of queries that are common in practice [20,58]. LSQ can facilitate further research on the use of SPARQL in the wild as it compiles logs from different domains.
Techniques for SPARQL caching [50,60,66,100] aim to re-use solutions across multiple queries. Caching allows for reducing the computational requirements needed to evaluate a workload, particularly in cases where queries are often repeated and the underlying data do not change too frequently. The LSQ dataset can again provide a sequence of real-world queries for benchmarking caching systems in realistic settings.
Aside from efficiency, a crucial aspect of SPARQL research and development is to explore techniques that allow non-expert users to express queries against endpoints more easily. A number of techniques have been proposed to enhance the usability of SPARQL endpoints, including works on auto-completion [25,52,73], query relaxation [38,43,96] and query builders [10,27,44,95]. Such works could use the LSQ dataset to investigate patterns in how users iteratively formulate more complex queries, causes for queries with empty results, as well as to detect the most important features that interfaces must support.
Understanding the most common cases encountered in real-world queries can allow for optimising implementations towards those cases. One such optimisation is to define workload-aware schemes for local [8,9] and distributed [4,28,45] indexing that attempt to group data commonly requested together in the same region of storage; other optimisations look at scheduling the execution of parallel query requests in an effective and fair manner [56], or propose efficient algorithms for frequently encountered patterns in queries [58]. The LSQ dataset can provide diverse examples of real workloads to help configure and evaluate such techniques.
The final use case is admittedly more speculative. By meta-querying, we refer to LSQ being used to query for queries of interest, for example, to find the (most common) queries that are asked about specific resources, such as finding out what queries are being asked involving
These six use cases are intended to help motivate the dataset, to give ideas of potential applications, and also to help distil some key requirements for the design of the dataset. The list should not be considered complete, as other use cases will naturally arise in future. We identify the following facets of the dataset as relevant to support the aforementioned six use cases.
LSQ should describe the key features of each query independently of the dataset. These include SPARQL keywords (e.g.,
LSQ should provide provenance meta-data about the execution of each query, including the endpoint it was issued to, a timestamp of when it was executed, and an anonymised identifier for the client. Timestamps are of particular importance to
LSQ should include statistics of the evaluation of the query over the original dataset, including the number of results returned, the estimated runtime, and the selectivity of individual patterns in the query. Again, making such statistics available allows clients to select and analyse queries with regard to these features without having to execute them over the original dataset. Runtime statistics are of particular importance to
These facets guide the design of the LSQ dataset in terms of what is included, and how the descriptions of individual queries are represented in RDF.
Data model & vocabulary
In this section, we describe the data model and vocabulary employed by LSQ for describing SPARQL queries. First, we identify a number of desiderata:
The data model should facilitate a variety of use cases and cover at least the aforementioned facets (
With logs containing millions of queries, the data model should be relatively concise – in terms of triples produced per query – to keep LSQ at a manageable volume of data.
Core competency questions over the dataset (e.g., find all queries using a particular feature) should be expressible in terms of simple queries that are efficient to evaluate.
Core of the LSQ data model: dashed lines indicate sub-classes; datatype properties are embedded within their associated class nodes to simplify presentation; external classes are shown with dotted borders. For clarity, we do not show details of the SPIN representation, or the execution of query elements more fine-grained than BGPs (which follow a similar pattern).
URIs should be dereferenceable so as to abide by the Linked Data Principles. Terms from external well-known vocabularies should be re-used where appropriate. Links to other datasets should be provided.
It is important to note that some of these desiderata are incompatible. For example,
In Fig. 1 we provide an overview of the model used to represent queries in RDF, while in Listing 1 we provide a snippet of the top-level data generated for a query found in the
Note that for the purposes of presentation, we abbreviate some of the details of the query, including the IRIs used to identify local query executions.
Query instance We define a “query” to be uniquely identified by the syntactic query string (independently of the endpoint, the particular execution, etc.). We type these queries with

An example LSQ/RDF representation of a SPARQL query in Turtle syntax
Static features Next we define some static features of the query, independent of the dataset over which it is evaluated. These include links to its individual join variables, triple patterns, and basic graph patterns; the SPARQL features that is uses; its number of projected variables, basic graph patterns, join variables, triple patterns; the maximum, mean and median degree of its join variables; and the maximum and minimum size of its basic graph patterns. The triple patterns and basic graph patterns themselves link to the SPIN representation of the query included in the description (and discussed presently); the triple patterns, in turn, link to the resources used by the query. The join variables, on the other hand, are described separately, indicating the degree of the variable and type of join [81] it induces.
SPIN representation While the static features aim to capture some high-level descriptions of the query that may be of interest to specific use cases, some details may be missing. In the interest of generality, we also include for each query a SPARQL Inferencing Notation (SPIN) [48] representation of the query, which essentially captures a fine-grained translation of the SPARQL query to RDF. This SPIN encoding can be translated back to a SPARQL query equivalent to the original.4
Given a query Q and dataset D, let
Remote execution(s) Next, individual queries are associated with one or more executions on the original endpoint, including a timestamp of when the query was executed, as well as an anonymised ID for the client – based on their cryptographically-hashed and salted I.P. – to identify which queries are run by the same agent.5
A “salt” in cryptography is a privately-held arbitrary string that is combined (e.g., concatenated) with the input being hashed in order to avoid attacks based on precomputed tables (e.g., of common values or, in this case, of a collection of I.P.’s of interest).
Although there exist properties called “endpoint” – such as
Local execution In most cases, the log of the remote executions will not provide statistics about the execution of the query in terms of how many results were returned, how long it took, how selective were the individual patterns, and so forth. Hence we re-execute the queries offline against the original dataset to generate runtime statistics about the query. Local executions were run on a machine with 64 core Intel(R) Xeon(R) CPU E5-2683 v4 @ 2.10 GHz, and 528 GB RAM running Ubuntu 18.04.5 LTS using Virtuoso 7.2.7
The configuration used for Virtuoso was
The selectivity of the triple pattern is the ratio of triples from the dataset that it selects.
Summary The meta-data described in this section aim to strike a balance in terms of the four desiderata mentioned previously. In terms of
The LSQ dataset is published as Linked Data. Before describing the current contents of LSQ, we discuss in more detail how LSQ has been published.
Access methods We provide a number of ways to access LSQ. Firstly, following Linked Data principles, all IRIs under the
Locations from which LSQ can be accessed including an example Linked Data IRI, the vocabulary, dumps, the SPARQL endpoint, as well as locations where LSQ is indexed, including DataHub, Linked Open Vocabularies (LOV) and prefix.cc
Vocabulary As seen in Fig. 1, we use a mixture of a custom vocabulary in the
With respect to the fifth star, which requires that our LSQ vocabulary be linked to from external vocabularies, we are not aware of such links, though we do know, for example, that Varga et al. [94] incorporate elements of the LSQ vocabulary within their own Analytical Metadata (AM) model, while Singh et al. [86] also use the LSQ vocabulary within their benchmark.
Discoverability The LSQ dataset has been registered in the DataHub catalogue, while the LSQ vocabulary has been listed on Linked Open Vocabularies (LOV) [92] as well as prefix.cc. We provide these locations in Table 1. We also compute and publish meta-data about the LSQ dataset using the Vocabulary of Interlinked Datasets (VoID) [5]. More specifically, we compute a separate VoID description for each log and make the resulting description accessible via both a downloadable file and a named graph of the SPARQL endpoint.
Availability The LSQ dataset has been hosted for over six years (at the time of writing) by the Agile Knowledge Engineering and Semantic Web (AKSW) group. As discussed in Section 7, it has been widely adopted in that time. The dataset is available to all under a CC-BY license. We further make the source code used for generating the LSQ dataset from the raw query logs available on Github
High-level statistics for queries in the LSQ dataset (QE = Query Executions, UQ = Unique Queries, RE = Runtime Error, ZR = Zero Results,
We now describe the content of the LSQ 2.0 dataset. In order to collect raw SPARQL query logs, we sent mails both to the
We also acquired logs for the British Museum and UniProt endpoints, but decided to omit them due to having few unique queries.
is a biomedical Linked Dataset describing probesets found in DNA microarrays [33].
is a biomedical Linked Dataset describing mathematical models of biological systems [33].12
The external SPARQL endpoint is spelt
is a biomedical Linked Dataset cataloguing biomedical ontologies [33].
is a biomedical Linked Dataset that describes how environmental chemicals relate to diseases [33].
is a cross-domain Linked Dataset that is primarily extracted from Wikipedia [53].
is a biomedical Linked Dataset that describes single base nucleotide substitutions and short deletion and insertion polymorphisms [33].
is a biomedical Linked Dataset that describes drugs and drug targets [33].
is a biomedical Linked Dataset that describes human and other genes linked with ageing [33].
is a biomedical Linked Dataset that describes genes associated with dietary restrictions [33].
is a biomedical ontology that describes gene, gene products, and their functions [33].
is a biomedical Linked Dataset that provides annotations on proteins, RNA and protein complexes [33].
is a biomedical Linked Dataset that describes human gene nomenclature [33].
is a biomedical Linked Dataset that indexes interaction data for proteins [33].
is a biomedical Linked Dataset that describes functions of genes and biological systems [33].
is a geographical Linked Data extracted primarily from Open Street Map [88].
is a biomedical Linked Dataset that contains meta-data about drug labels sourced from DailyMed [33].
is a biomedical Linked Dataset that describes mouse genes, alleles, and strains [33].
is a biomedical Linked Dataset that describes gene-related information given by the National Center for Biotechnology Information (NCBI) [33].
is a biomedical Linked Dataset that catalogues human genes as well as genetic traits and disorders [33].
is a biomedical Linked Dataset describing how genetic variations impact drug responses [33].
is a biomedical Linked Dataset that describes biochemical reactions [33].
is a biomedical Linked Dataset describing the biology and genetics of the yeast Saccharomyces cerevisiae [33].
is a biomedical Linked Dataset describing the side effects of drugs [33].
is a bibliographical Linked Dataset describing papers, presentations and people participating in top Semantic Web related conferences and workshops [61].
is a biomedical Linked Dataset that describes all organisms found in genetic databases [33].
is a collaboratively edited knowledge graph hosted by the Wikimedia foundation [57].
is a biomedical Linked Dataset that describes the biology and genome of worms [33].
We now look in more detail at the composition of the queries currently included in the LSQ dataset. In particular, we first look at some high-level statistics for queries in the dataset, before looking at the static features of the query, the agents making the queries, as well as runtime statistics computed against the corresponding dataset. Finally we discuss the composition of the LSQ dataset itself.
High-level statistics Table 2 provides a high-level analysis of the queries (both query executions and unique queries) appearing in each of the logs considered. From the overall row, we see that LSQ contains 43.95 million query executions and 11.56 million unique queries, implying that each query is executed, on average, 3.8 times within each log. Of the unique queries, 7.7 million (66.9%) have runtime errors; and 2.3 million (20.0%) have no errors but return empty results. A high ratio of runtime errors come from the Bio2RDF logs. The majority of queries are
Static features Turning to static features, we first look at the percentages of unique queries without parse errors using different SPARQL features (note that we will analyse joins in BGPs and property paths later). Table 3 provides statistics for the usage of different features of SPARQL. We see that
Percentage of unique queries without parse errors using the specified SPARQL feature (Sol. Mod. includes the solution modifiers ORDER BY , OFFSET , and LIMIT ; Agg. includes aggregation features GROUP BY , HAVING , AVG , SUM , COUNT , MAX , and MIN ; Neg. includes MINUS , NOT EXISTS , and EXISTS ; Bind. includes VALUES and BINDING ; Graph includes FROM , FROM NAMED , and GRAPH ; Func. includes SPARQL functions and expressions)
Percentage of unique queries without parse errors using the specified SPARQL feature (
Next, in Table 4, we provide three types of statistics about the basic graph patterns and property path features used. First, we present the unique number of subject, predicate and object terms used in the BGPs of the logs in order to characterise their diversity. We see that has multiple outgoing but no incoming links. has one incoming and one outgoing link. has at least one incoming and outgoing link and three or more links overall. has multiple incoming but no outgoing links.
These statistics may be helpful for consumers to choose which dataset/log to work with. For example, for the purposes of benchmarking joins, a dataset such as
Analysis of basic graph patterns and property paths including number of unique subject/predicate/object terms, percentage of unique queries containing different types of joins (a query may contain multiple join types), and number of queries using different types of property path expressions (
Provenance: Executions and agents Next we look at how many clients (anonymised IPs) and unique queries underlie the executions registered in order to compare the diversity of the different datasets. Note that client information is not available for
Lorenz curves visualise (in)equality in distributions for a given quantity over a given set of elements: a coordinate
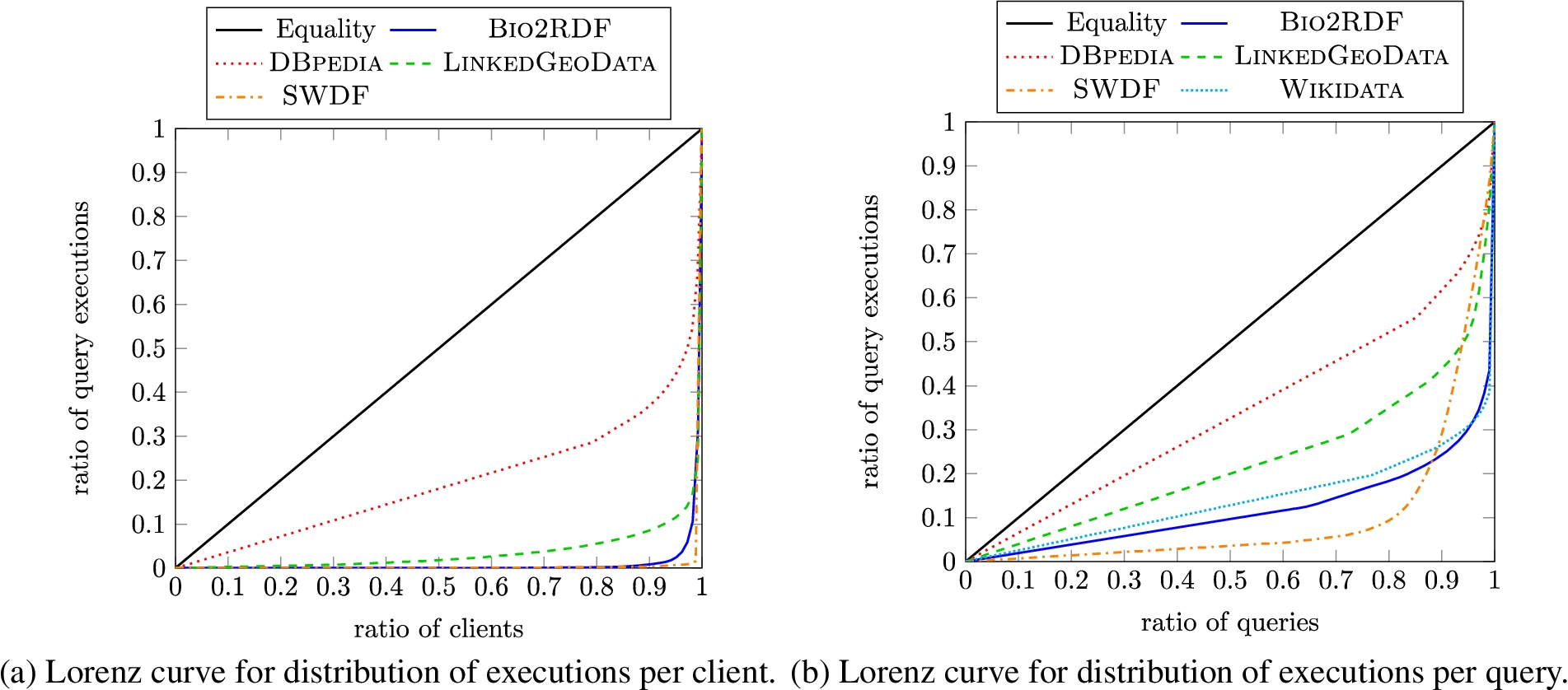
Lorenz curves for the LSQ dataset
Static and runtime statistics Next, in order to characterise how complex the queries are to evaluate, in Table 5 we present some relevant static and runtime statistics, where static statistics can be computed from the query string, while runtime statistics require evaluating the query locally (only queries that were successfully run are counted; see Table 2 for statistics on runtime errors). Regarding runtimes, we recall that these were run with a one minute timeout, which represents the max runtime. We see that
Comparison of the mean values of runtime statistics across all query logs (PVs = Project Variables, BGPs = Basic Graph Patterns, TPs = Triple Patterns, JVs = Join Vertices, MJVD = Mean Join Vertex Degree, MTPS = Mean Triple Pattern Selectivity)
LSQ dataset statistics The LSQ 2.0 dataset, describing 43.95 million executions of 11.56 million unique queries, contains 1.24 billion triples, split into 27 named graphs (one for each of the datasets listed).14
We exclude some named graphs created by Virtuoso.
In this section we present how LSQ has been adopted since its initial release with four logs in 2015. We organise this discussion following the motivational use cases we originally envisaged, as presented in Section 2. Table 6 provides an overview of the research works that have used LSQ, and the relevant use case(s) that they target. We now discuss these works in more detail; note that in the case of works that relate to multiple use cases, we will discuss them once in what we identify to be the “primary” related use case. We further discuss some works that have used the LSQ dataset for use cases beyond the six we had originally envisaged.
Research works making use of the LSQ dataset since its initial release, ordered by year and then alphabetically by author name, with relevant use cases indicated (UC1: Custom Benchmarks; UC2: SPARQL Adoption; UC3: Caching; UC4: Usability; UC5: Optimisation; UC6: Meta-Querying)
Research works making use of the LSQ dataset since its initial release, ordered by year and then alphabetically by author name, with relevant use cases indicated (UC1: Custom Benchmarks; UC2: SPARQL Adoption; UC3: Caching; UC4: Usability; UC5: Optimisation; UC6: Meta-Querying)
(Continued)
UC1: Custom Benchmarks LSQ has been adopted in various works for creating custom benchmarks.
Saleem et al. [79] present a framework for generating benchmarks that can be used to evaluate SPARQL endpoints under typical workloads; the benchmarks generate query types depending on the features of the queries submitted to the endpoint, where LSQ is used for testing.
Later works by Saleem et al. further propose frameworks for generating benchmarks from LSQ for the purposes of evaluating query containment [80,82] and federated query evaluation [78], as well as comparing existing SPARQL benchmarks against LSQ in order to understand how representative they are of real workloads [83].
Hernández et al. [42] present an empirical study of the efficiency of graph database engines for answering SPARQL queries over Wikidata; they refer to LSQ to verify that the query shapes considered for evaluation correspond with other analyses of real-world SPARQL queries.
Fernández et al. [35] evaluate various archiving techniques and querying strategies for RDF archives that store historical data; in their evaluation, they select the 200 most frequent triple patterns from the
Azzam et al. [15] use LSQ for retrieving highly-demanding queries from the dataset in order to evaluate their system for dividing the load processed by different SPARQL servers.
Bigerl et al. [18] develop a tensor-based triple store, where they used LSQ as input to the FEASIBLE framework to generate a custom benchmark.
Azzam et al. [14] present a system that dynamically delegates query processing load between clients and servers. The authors use the Linked Data Fragments client/server approach improving it with the aforementioned technique and use 16 queries from LSQ to complement their evaluation.
Davoudian et al. [30] present a system that partitions graphs depending on the access frequency to their nodes. In this way the system implements workload-aware partitioning. The authors use LSQ for evaluating their approach.
Desouki et al. [32] propose a method to generate synthetic benchmark data. To generate these synthetic data they use other RDF graphs available, such as
Röder et al. [74] develop a method to predict the performance of knowledge graph query engines; to do so the authors use a stochastic generation model that is able to generate graphs of arbitrary sizes similar to the input graph. They use LSQ as a benchmark of real-world queries.
UC2: SPARQL adoption Other works have used LSQ to understand how SPARQL is being used in practice.
Han et al. [41] provide a statistical analysis of the queries of LSQ, surveying both syntactic features, such as the number of triple patterns, the SPARQL features used, the frequency of well-designed patterns; as well as semantic properties, such as montonicity, weak-monotonicity, non-monotonicity and satisfiability.
Bonifati et al. [21,22] conduct detailed analysis of the queries in various logs, including LSQ; they study a variety of phenomena in these queries, including their shape, their (hyper)treewidth, common abstract patterns found in the property paths, “streaks” that represent a sequence of user reformulations from a seed query, and more besides.
UC3: Caching LSQ can also be used to simulate real workloads for systems that explore caching techniques.
Knuth et al. [49] propose a middleware component to which applications register and get notifications when the results of their SPARQL queries change; the authors study the problem of scheduling refresh queries for a large number of registered queries and use LSQ to validate their approach.
Akhtar et al. [2,3] propose an approach to capture changes in an RDF dataset and update a cache system in front of the SPARQL endpoint exposing that data; their approach consists of a change metric that quantifies the changes in an RDF dataset, and a weighting function that assigns importance to recent changes; they use LSQ to verify their approach for real workloads.
Salas and Hogan [76] propose a method for query canonicalisation, which consists in mapping congruous queries – i.e., queries that are equivalent modulo variable names – to the same query string; their main use case is to increase the hit rate of SPARQL caches, where they use LSQ to test efficiency on real-world queries and to see how many congruent queries can be found in real workloads.
Savafi et al. [75] study SPARQL adoption using LSQ so they can later provide queries to summarise the Knowledge Graphs such that they can be more efficiently accessed from and stored on mobile devices with limited resources.
UC4: Usability LSQ also has applications for improving the usability of SPARQL endpoints.
Arenas et al. [11] propose a method for reverse-engineering SPARQL queries, which attempts to construct a query that will return a given set of positive examples as results, but not a second set of negative examples; the authors use LSQ to show that the approach scales well in the data size, number of examples, and in the size of the smallest query that fits the data.
Benedetti and Bergamaschi [17] present a system (LODeX) that allows users to explore SPARQL endpoints more easily through a formal model defined over the endpoint schema; they show that LODeX is able to generate 77.6% of the 5 million queries contained in the original LSQ dataset.
Dellal et al. [31] proposes query relaxation methods for queries with empty results, based on finding minimal failing subqueries (generating empty results) and maximal succeeding subqueries (generating non-empty results) to aid the user [37]. The paper refers to LSQ to establish that queries with empty results are common in practice.
Stegemann and Ziegler [89] propose new operators for the SPARQL language that allow for composing path queries more easily; the authors evaluated their approach with a user study and analysis of the extent to which their language is able to express the real-world queries found in LSQ.
Viswanathan et al. [97] propose a different form of query relaxation, which generalises a specific resource to a variable on which specific restrictions are added that correspond to relevant characteristics of the resource; they use LSQ to understand how entities are queried in practice.
Potoniec [69] proposes an interactive system for learning SPARQL queries from positive and negative examples;15
Notably the system is called Learning SPARQL Queries (LSQ).
Wang et al. [99] present an approach for explaining missing results for a SPARQL query – based on answering “why-not” questions that ask why a specific result is not included – to help users refine their initial queries; the authors search LSQ for queries useful for their approach.
Bonifati et al. [24] analyse “streaks” in DBpedia query logs,16
In fact, these logs were gathered directly from OpenLink, though we include discussion since similar analysis could have been applied to the LSQ logs, and LSQ logs where used in other analyses.
Jian et al. [47] use LSQ to evaluate their approach for SPARQL query relaxation (to generalise users’ queries) and query restriction (to refine users’ queries) based on approximation and heuristics.
Zhang et al. [102] propose a method to model client behaviour when formulating SPARQL queries in order to predict their intent and optimise queries. They use LSQ for their evaluation.
Almendros-Jimenez et al. [6] present two methods for discovering and diagnosing “wrong” SPARQL queries based on ontology reasoning. They evaluate their approach using LSQ queries.
Wang et al. [98] focus on providing explanations for SPARQL query similarity measures. The authors provide similarity scores using several explainable models based on Linear Regression, Support Vector Regression, Ridge Regression, and Random Forest Regression. They use LSQ to evaluate their query classification.
UC5: Optimisation The LSQ dataset can also be used to identify and study fragments that are commonly used in practice and can be evaluated efficiently using dedicated algorithms.
The aforementioned analyses by Han et al. [41] and Bonifati et al. [21,22] suggest that well-designed patterns, queries of bounded treewidth, etc., make for promising fragments.
In the context of probabilistic Ontology-Based Data Access (OBDA), Schoenfisch and Stuckenschmidt [85] analyse the ratio of safe queries – whose evaluation is tractable in data complexity – versus unsafe queries – whose evaluation is #P-hard; they show that over 97.9% of the LSQ queries are safe, and can be efficiently evaluated.
Song et al. [87] use LSQ to analyse how nested
Martens and Trautner [58] later take the property paths extracted by Bonifati et al. [21] from LSQ and other sources, defining simple transitive expressions that subsume almost all property path expressions seen in practice, while allowing more efficient evaluation than the general case.
Cheng and Hartig [26] introduce a monotonic version of the
Building upon the work of Martens and Trautner [58], Figueira et al. [36] specifically study the containment problem for restricted classes of Conjunctive Regular Path Queries (CRPQs), which are akin to BGPs with property paths; aside from complexity results, they show the coverage of the different classes for logs that include LSQ [24].
UC6: Meta-querying A handful of works have also used LSQ in the context of meta-querying, where queries are found based on the resources they contain.
Rico et al. [71] observe that analogous
Varga et al. [94] provide an RDF-based metamodel for BI 2.0 systems, which allows for capturing the schema of a dataset, as well as previous queries that have been posed against that dataset by other users; the authors propose to re-use parts of the LSQ vocabulary in their model; they further instantiate their model using LSQ to retrieve queries asked about countries.
Other use cases A number of works have used LSQ (mostly for evaluation) in contexts that were not originally anticipated by the aforementioned use cases.
Georgala et al. [39] propose a method to predict temporal relations between events represented by RDF resources following Allen’s interval algebra; they use LSQ to validate their approach considering query executions as events.
Darari et al. [29] present a theoretical framework for augmenting RDF data sources with completeness statements, which allows for reasoning about the completeness of SPARQL query results; they evaluate their method using LSQ.
Fafalios and Tzitzikas [34] present a query evaluation strategy, called SPARQL-LD, that combines link traversal and query processing at SPARQL endpoints; they provide a method for checking if a SPARQL query can be answered through link traversal, and analyse a large corpus of real SPARQL query logs – including LSQ – for finding the frequency and distribution of answerable and non-answerable query patterns; they also use LSQ to evaluate their approach.
Singh et al. [86] use the LSQ vocabulary for providing a benchmark for Question Answering over Linked Data. The authors use the LSQ vocabulary to represent the SPARQL query related features prior to generating the benchmark.
Thost and Dolby [91] present QED: a system for generating concise RDF graphs that are sufficient to produce solutions from a given query, which can be used for benchmarking, for compliance testing, for training query-by-example models, etc.; they apply their system over LSQ queries to generate datasets from
Aebeloe et al. [1] present a decentralised architecture based on blockchain that allows users to propose updates to faulty or outdated data, tracing back their origin, and query older versions of the data. They use LSQ queries for their evaluation.
Discussion Per Table 6, we see that the original version of LSQ has been used in a wide variety of research works for a variety of purposes. Complementing other SPARQL query logs such as Wikidata’s [57], we believe that LSQ 2.0, with its extended set of queries, will likewise serve as a useful resource to help align the theory and practice of SPARQL research.
In this paper, we have described the Linked SPARQL Queries v.2 (LSQ 2.0) dataset, which represents queries in logs as RDF, allowing clients to quickly find real-world queries that may be of interest to them. We have described a number of use cases for LSQ, including the generation of custom benchmarks, the analysis of how SPARQL is used in practice, the evaluation of caching systems, the exploration of techniques to improve the usability of SPARQL services, the targeted optimisation of queries with characteristics commonly found in real workloads, as well as the ability to find queries relating to specific resources. We then described the model and vocabulary used to represent LSQ, including static features of queries, a SPIN representation, provenance encoding the agents and endpoints from which the query originate, as well as runtime statistics generated through local executions of the queries against their corresponding dataset. We then discussed how LSQ is published, thereafter describing the datasets and queries featured in the current version of LSQ. Finally we discussed how LSQ has been used for research purposes since its initial release in 2015.
As discussed in Section 7, since its initial release, LSQ has been adopted by a variety of research works for a variety of purposes. In terms of future directions, we will look to continue adding further logs with further queries to the dataset. Looking at how LSQ has been adopted in the literature has also revealed ways in which the metadata for LSQ could be extended in a future version, such as to add information about monotonicity and satisfiability [41], or information about (hyper)treewidth [21,22], for example. It may also be useful to provide a canonical version of the query string [76]; this could perhaps be leveraged, for example, when evaluating caching methods. Another useful feature would be to add questions in natural language that verbalise each query, which could be used, for example, in order to create datasets for training and testing question answering systems, as well as enabling users to find relevant queries through keyword search; given the large number of queries in the dataset, an automated approach may be applicable [64].
As discussed by Martens and Trautner [59], query logs allow to bridge the theory and practice of SPARQL. They serve an important role, ensuring that the research conducted by the community is guided by the requirements and trends that emerge in practice. We thus believe that LSQ (2.0) will continue to serve an important role in SPARQL research in the coming years.
Footnotes
Acknowledgements
We thank the OpenLink Software team for hosting the DBpedia SPARQL endpoint and for making the logs available to us. Hogan was supported by Fondecyt Grant No. 1181896 and by ANID – Millennium Science Initiative Program – Code ICN17_002. Buil-Aranda was supported by Fondecyt Iniciación Grant No. 11170714 and by ANID – Millennium Science Initiative Program – Code ICN17_002. This work was also partially supported by the German Federal Ministry of Education and Research (BMBF) within the EuroStars project E!114681 3DFed under the grant no 01QE2114, project RAKI (01MD19012D) and project KnowGraphs (No 860801).