
Abstract
Traditional approaches for querying the Web of Data often involve centralised
warehouses that replicate remote data. Conversely, Linked Data principles allow
for answering queries live over the Web by dereferencing URIs to traverse remote
data sources at runtime. A number of authors have looked at answering SPARQL
queries in such a manner; these link-traversal based query
execution (LTBQE) approaches for Linked Data offer up-to-date
results and decentralised (i.e., client-side) execution, but must operate over
incomplete dereferenceable knowledge available in remote documents, thus
affecting response times and “recall” for query answers. In this paper, we study
the recall and effectiveness of LTBQE, in practice, for the Web of Data.
Furthermore, to integrate data from diverse sources, we propose lightweight
reasoning extensions to help find additional answers. From the state-of-the-art
which (1) considers only dereferenceable information and (2) follows
Introduction
A rich collection of RDF data has been published on the Web as Linked Data, by governments, academia, industry, communities and individuals alike [39]. The resulting collective of interlinked contributions from a wide variety of Linked Data publishers has been dubbed the “Web of (Linked) Data”: a novel corpus of structured data distributed across the entire Web, described using the Semantic Web standards and made available under the Linked Data principles.
An open challenge is how to query this novel Web of Data in an effective manner [6]. SPARQL [54]—the W3C standardised RDF query language—provides a powerful declarative means to formulate structured queries over RDF data. However, processing SPARQL queries over the Web of Data broaches many technical challenges. Traditional centralised approaches cache information from the Web of Data in local optimised indexes, executing queries over the replicated content. However, maintaining up-to-date coverage of a broad selection of the Web of Data is exceptionally costly; centralised caches of the Web of Data must settle for either limited coverage and/or for indexing some out-of-date information [43,63,66]. Users of centralised query engines will thus often encounter stale or missing results with respect to the current Web of Data [66].
Conversely, per Linked Data principles, the URIs that name resources (often) map through HTTP to the physical location of structured data about them (called dereferencing). The Web of Data itself can thus be viewed as a scale-free, decentralised database, consisting of millions of Web documents indexing structured data [37,39]. Furthermore, agents can traverse and navigate the Web of Data through typed “RDF links” to discover related information [39, § 4.5].
This perspective suggests that queries can be answered directly over the Web of Data using HTTP, where a number of live querying approaches have recently been proposed that take a (SPARQL) query, find query-relevant sources on the Web of Data, and dynamically retrieve data from these sources for runtime query processing. In one such approach, Hartig et al. [34] followed the view of the Web of Data as a global database and proposed to rely on dereferenceable URIs and RDF links for discovering sources relevant to answer a SPARQL query. Later work by Hartig [32] calls this idea “Link Traversal Based Query Execution” (which we abbreviate to LTBQE).
However, in the LTBQE approach, each HTTP lookup can take seconds to yield content, many such lookups may be required, and subsequent lookups to the same remote server may need to be artificially delayed to ensure “polite” access (i.e., to avoid inadvertent denial-of-service attacks). In the live querying scenario, remote sources are accessed while a user is waiting for answers to their queries: thus response times are often (necessarily) much slower when compared with centralised query engines operating over locally replicated content. Thus, a core challenge for LTBQE is to retrieve a minimal number of relevant sources while maximising the number of answers returned. Relatedly, the success of LTBQE is premised on the assumption that query relevant data about a resource can be found in its dereferenced document; as we show later, this assumption only partially holds.
Herein, we look at the performance and recall of LTBQE in practice. We also propose
that lightweight reasoning extensions—specifically relating to
Paper contributions and structure This paper extends previous work [64] where we first introduced our reasoning extensions. Herein, we propose new mechanisms for collecting schema data, test additional benchmarks, and greatly extend discussion throughout. This paper is then structured as follows:
We first present some background work in the area of Linked Data querying
and reasoning. We present some formal preliminaries for RDF, Linked Data, SPARQL, RDFS
and OWL. We reintroduce the LTBQE approach using concrete HTTP-level methods. We introduce LiDaQ (Linked
Data Query engine): our
implementation of LTBQE with novel reasoning extensions and
optimisations. We analyse a crawl of ∼7.4 m RDF/XML documents from the Web of Data
(BTC’11), looking at issues of dereferenceability. We survey SPARQL benchmarks and how live-querying papers have evaluated
their works. We then propose a new benchmark called QWalk. We test LTBQE and our reasoning extensions for three query benchmarks in
native Web settings. We conclude with a summary of contributions and remarks on future
directions.
Background and related work
Our work relates to research on querying over RDF data; more precisely, we focus on executing SPARQL queries over the Web of Data in a manner adhering to the Linked Data principles. A comprehensive and recent overview of existing approaches to query Linked Data was published by Hose et al. [42]. We similarly classify relevant query approaches into three categories (1) materialised systems and data warehouses, (2) systems that federate SPARQL engines and (3) live query approaches. Although our own work falls into the third category, in order to provide a broader background, in this section we also summarise developments in the first two categories. Additionally, we briefly remark on “hybrid” proposals that combine different methods, as well as proposals for new languages (aside from SPARQL) to query/navigate the Web of Data. Finally, since our extensions for LTBQE further relate to research on reasoning over Linked Data, we also cover some background in this area.
Materialised systems
Materialised query-engines use a crawler or other data-acquisition methods to replicate (i.e., materalise) remote Web of Data content into a local quad store over which queries are executed. Such services include “FactForge” [13]1
The typical goals of such materialised engines are to maintain broad and up-to-date coverage of the Web of Data and to process SPARQL queries efficiently. These objectives are (partially) met using distribution techniques, replication, optimised indexes, compression techniques, data synchronisation strategies, and so on [12,22,30,50]. Still, given that such services often index millions of documents, they require large amounts of resources to run. In particular, maintaining a local, optimal, up-to-date index with good coverage of the Web of Data is a Sisyphean task.
Unlike these materialised approaches, the LTBQE approach and our extensions do not require all content to be indexed locally prior to query execution.
Given the recent spread of independently operated SPARQL endpoints on the Web of Data hosting various closed datasets with varying degrees of overlap,4
A primary challenge for federated SPARQL engines is to decide which parts of a
query are best routed to which endpoint. Many such engines rely on “service
descriptions” or “catalogues”, which describe the contents of remote endpoints.
One of the earliest such works (predating SPARQL by over three years) was by
Stuckenschmidt et al. [60], who
proposed summarising the content of distributed RDF repositories using schema
paths (non-empty property chains). More recently, a variety of proposals have
looked at using service descriptions or catalogues to enable routing in a
federated scenario, including DARQ [55], SemWIQ [46],
SPLENDID [25], ANAPSID [1], etc. Instead of relying (solely) on
pre-computed service descriptions or catalogues, FedX [59] and SPLENDID (also) probe SPARQL endpoints with
New federation features were also introduced with SPARQL 1.1: the
However, in recent work, we analysed a broad range of SPARQL endpoints available
on the Web [5]. We found that half of
the endpoints listed in the public
Like the LTBQE approach and our proposed extensions, federated SPARQL engines may involve retrieving content from remote sources at runtime. However, unlike federated SPARQL, LTBQE operates over raw data sources on the level of HTTP, and does not require the availability of SPARQL interfaces.
Live querying approaches access raw data sources at runtime to dynamically select, retrieve and build a dataset over which SPARQL queries can be evaluated. Ladwig & Tran [44] identify three categories of such query evaluation approaches: (1) top-down, (2) bottom-up, and (3) mixed strategy.
Top-down evaluation determines the query relevant sources before the actual query execution using knowledge about the available sources stored in a “source-selection index”. These source-selection indexes can vary from simple inverted-index structures [47,50], to query-routing indexes [61], schema-level indexes [60], and lightweight hash-based structures [65].
The bottom-up query evaluation strategy involves discovering query-relevant sources on-the-fly during the evaluation of queries. The LTBQE approach [17,29,33–35] we extend herein falls into this category (we define LTBQE in Section 4). The unique challenges for such an approach are (1) to find as many query-relevant sources as possible to improve recall of answers; (2) to conversely minimise the amount of sources accessed to avoid traffic and slow query-response times; (3) to optimise query execution in the absence of typical selectivity estimates, etc. [32,34]. In this paper, we focus on the first two challenges.
As its name suggests, the third strategy, the mixed approach, combines top-down and bottom-up techniques. This strategy uses (in a top-down fashion) some knowledge about sources to map query terms or query sub-goals to sources which can contribute answers, then discovering additional query relevant sources using a bottom-up approach [44].
Hybrid and navigational query engines
A mature Linked Data query service could require a hybrid strategy that combines complementary approaches: for example to use a materialised approach for static datasets, a federated approach for dynamic datasets where a first-party SPARQL endpoint is available, or a live approach for dynamic datasets that have no SPARQL endpoint [43]. A number of works have investigated such combinations on a variety of levels (see, e.g., [37,45,66]). In previous works we combined LTBQE with a materialised approach for getting fresher SPARQL query answers from the Web than the materialised indexes could offer but at a fraction of the runtime of pure LTBQE [66]. We believe that live query approaches, such as LTBQE, are most useful in combination with other query paradigms.
Some authors have also questioned whether or not SPARQL is the only language needed to query the Web of Data [6]. There have also been a number of proposals to extend SPARQL with regular expressions that capture navigational patterns,5
SPARQL 1.1 includes a similar notion called property paths [28].
In this paper, we propose lightweight reasoning extensions for LTBQE, which leverage (some of) the semantics of the RDFS and OWL standards to perform inferencing and find additional answer and query relevant sources. We now cover some related works in the area of RDFS/OWL reasoning over the Web of Data.
We investigate a terse profile of reasoning targeted for Web data. Similarly,
Glimm et al. [24] surveyed the use of
RDFS and OWL features in a large crawl of the Web of Data
(viz., BTC’11), applying PageRank over documents and summating
the rank of all documents using each feature. They found that RDF(S) features
were the most prominently used. From OWL,
With respect to scalable rule-based reasoning over RDFS (and OWL), a number of authors have proposed separating schema data (aka. terminological data or T-Box) from instance data (aka. assertional data or A-Box) during inferencing [40,67,68]. The core assumptions are that the volume of schema data is much smaller than instance data, that schema data are frequently accessed during reasoning, that schema data are more static than instance data, and that schema-level inferences do not depend on instance data. Where these assumptions hold, the schema data can be separated from the main body of data and “compiled” into an optimised form in preparation for reasoning over the bulk of instance data. We use similar techniques herein when computing RDFS inferences: we consider schema data separately from instance data.
Aside from scalability, the freedom of the Web—where anyone can say anything (almost) anywhere—raises concerns about the trustworthiness of data for automated inferencing. On a schema level, for example, various obscure documents on the Web of Data make nonsensical definitions that would (naïvely) affect reasoning across all other documents [16]. Numerous authors have proposed mechanisms to incorporate notions of provenance for schema data into the inferencing process. One such procedure, called authoritative reasoning, only considers the schema definitions for a class or property term that are given in its respectively dereferenceable document [16,18,40]. We later use authoritative reasoning to avoid the unwanted effects of third-party schema contributions during RDFS reasoning. Delbru et al. [20] propose another solution called context-dependent reasoning (or quarantined reasoning), where a closed scope is defined for each document being reasoned over, incorporating only the document itself and other documents it (recursively) imports or links, thus excluding the claims of arbitrary Web documents. We later use a similar import mechanism to dynamically collect schemata from the Web during RDFS reasoning.
Our extensions involving
Finally, we are not the first work to look at incorporating reasoning into SPARQL querying over the Web of Data. Various materialised approaches for querying Linked Data have incorporated forward-chaining rule-based reasoners to find additional answers, including the SAOR reasoner [40] for YARS2 (which we use later), Sindice’s context-dependent reasoning [20], Factforge [13], etc. In terms of reasoning for top-down querying systems, Li and Heflin [47] also use reasoning techniques to find additional results through query rewriting and bottom-up inferencing.
Novelty of present work
We briefly highlight our novelty. First and foremost, we evaluate the bottom-up LTBQE approach using various benchmarks—all in an uncontrolled, real-world setting—to see what kinds of practical expectations one can have for answering queries directly over the Web of Data. Second, we propose and evaluate reasoning extensions for LTBQE to find additional sources on-the-fly and to generate further answers. To the best of our knowledge, no other work has looked at evaluating live querying approaches over diverse sources live on the Web, nor has any other work looked at the benefits of incorporating reasoning techniques into link-traversal querying techniques for the Web of Data.
Preliminaries
In this section, we cover some necessary preliminaries and notation relating to RDF (Section 3.2), Linked Data (Section 3.3), SPARQL (Section 3.4) and RDFS & OWL (Section 3.5). Before we continue, however, we introduce a running example used to explain later concepts.
Running Example

Snippets taken from five documents on the Web of Data. Individual documents are associated with individual background panes. The URI of each document is attached to its pane with a shaded tab. The same resources appearing in different documents are joined using “bridges”. Links from URIs to the documents they dereference to are denoted with dashed links. RDF triples are denoted following usual conventions within their respective document.
Snippet from the Friend Of A Friend (FOAF) Ontology: a schema document on the Web of Data. External terms have dashed lines.
Figure 1 illustrates an RDF (sub-)graph taken from five real-world interlinked documents on the Web of Data.6
As last accessed on 2013-07-02.
refer to the personal FOAF profile documents that each author created for themselves;
refer to information exported from the “DBLP Computer Science Bibliography”7
provides information about the co-authored paper exported from DBLP.
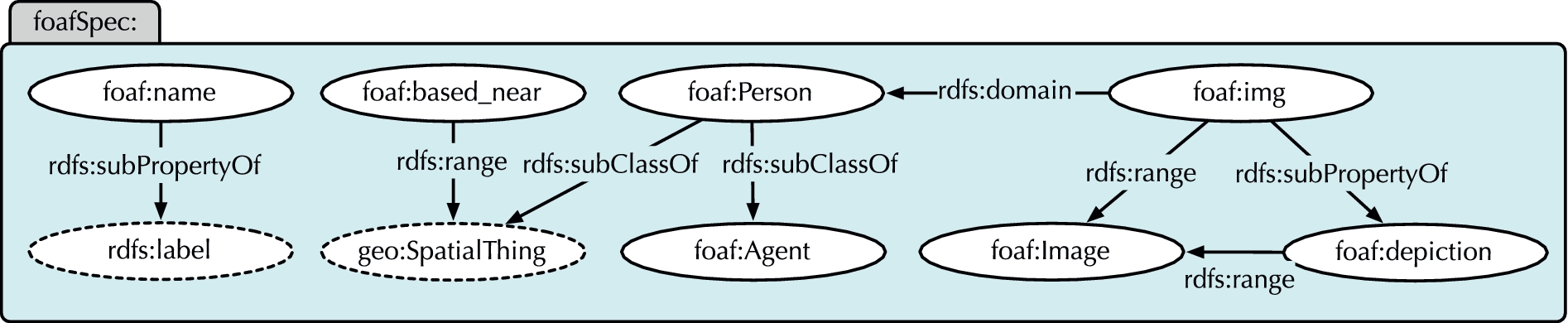
In addition, Fig. 2 illustrates a subset of RDFS
definitions in a “schema document” extracted from the real-world FOAF ontology.
Although left implicit, all terms in the
In order to define our methods later, we must first provide notation for
RDF [38]. The set of RDF terms consists of the
set of URIs (RDF Term, Triple and
Graph).
Linked Data
The four Linked Data principles [10] are as follows:
URIs are used
to identify
things
URIs
should be dereferenceable through
HTTP
Useful
RDF content should be provided when URIs are
dereferenced
Links
should be offered within that
content
(Data Source and Linked Dataset).
We define the http-download function
Taking Fig. 1, e.g.,
A URI may redirect to another URI with a
In relation to the formal model of Hartig [33], we favour concrete HTTP-level methods used for Linked Data. He
models the Web of Linked Data as a triple Taking
Fig. 1,
We now introduce some concepts relating to the query language SPARQL [52,54]. We herein focus on evaluating simple, conjunctive,
basic graph patterns (BGPs), where although supported by
our implementation, we do not formally consider more expressive parts of the
SPARQL language, which—with the exception of non-monotonic features that assume
a closed dataset like
(Variables, Triple Patterns & BGPs).
Let
SPARQL allows literals in the subject position [54], though such patterns cannot match RDF triples as currently defined.
In this paper, we only look at evaluating queries representing BGPs. We denote
the answers to a query Q with respect to a Linked Dataset as
Call the partial function
Taking Γ from Fig. 1, let
Q be: Then

In preparation for defining our reasoning extensions to LTBQE, we now give some preliminaries relating to RDFS and OWL. Our RDFS rules are the subset of the ρDF rules proposed by Muñoz et al. [49] that deal with instance data entailments (as opposed to schema-level entailments).9
We drop implicit typing [49] rules as we allow generalised RDF in intermediate inferences.
RDFS (ρDF subset)
and
An entailment rule is a pair
Since our rules are a syntactic subset of Datalog, there is a unique and finite least model (assuming finite inputs).
Let R denote the set of rules in Table 1. Also, consider Γ as the Linked Dataset comprising of

These (real-world) triples can be retrieved by dereferencing a FOAF term;
e.g., 
Subsequently, 
As before, 
This is then the closure since
Having covered some necessary preliminaries, in the following section, we cover the Link Traversal Based Query Execution (LTBQE) approach first proposed by Hartig et al. [33,34] for executing SPARQL queries over the Web of Data (Section 4.1).
Overview of baseline LTBQE
Given a SPARQL query, the core operation of LTBQE is to identify and retrieve a
focused set of query-relevant RDF documents from the Web of Data from which
answers can be extracted. The approach begins by dereferencing URIs found in the
query itself. The documents that are returned are parsed, and triples matching
patterns of the query are processed; the URIs in these triples are also
dereferenced to look for further information, and so forth. The process is
recursive up to a fixpoint wherein no new query-relevant sources are found. New
answers for the query can be computed on-the-fly as new sources arrive. We now
formally define an idea of query-relevant documents in the context of LTBQE.
This is similar in principle to the generic notion of reachability introduced
previously [33,35], but relies here on concrete HTTP
specific operations: First
let In
practice, URIs need only be dereferenced once; i.e., only URIs
in (Query Relevant Sources & Answers).
Taking Fig. 1, let Q be the following
query looking for the author-names of a given paper: 
First, the process
extracts all raw query URIs:
Second, LTBQE looks to extract additional query relevant
URIs by seeing if any query patterns are matched in the current dataset.
By reference to the graph
LTBQE
repeats the above process until no new sources are found. At the current
stage,
Furthermore, no other query-relevant URIs are found and so a fixpoint
is reached and the process terminates:
The decidability of LTBQE—and indeed the decidability of the more general problem of evaluating a SPARQL query over the Web of Data—depends on how one scopes the sources of data considered for evaluation and which features of SPARQL are used.
If one considers an infinite Web of Data—aiming for what Hartig calls
“Web completeness” [33]—then the evaluation of a SPARQL query is not finitely computable
in the general case, even if one considers only the monotonic features of
SPARQL [33]: there are (countably)
infinite documents that may contain relevant data but that cannot be processed
in finite steps. If non-monotonic features of SPARQL—such as
If one rather considers a reachability condition—whereby, for example, only the query-relevant sources in an LTBQE sense are considered in-scope—for similar reasons, Hartig [33] shows that queries are still not finitely computable unless it can be proven that the number of reachable sources is finite under the given conditions. This does not hold for the set of query relevant sources given in Definition 7.
The following query asks for a general description of people known by

The initial query-relevant sources (per Definition 7) are the documents dereferenced from

This would end up crawling the connected Web of FOAF documents, as are linked
together by dereferenceable
Partly addressing this problem, Hartig et al. [34] defined an iterator-based execution model for LTBQE, which
rather approximates the answers provided by Definition 7. This execution model defines an ordering of triple patterns in
the query, similar to standard nested-loop join evaluation. The most selective
patterns (those expected to return the fewest bindings) are executed first and
initial bindings are propagated to bindings further up the tree. Crucially,
later triple patterns are partially bound when looking for query-relevant
sources. Thus, taking the previous example, the pattern “
Relatedly, Harth and Speiser [29] also consider an order-dependent version of LTBQE. Similar to Hartig [34], they remark that although the Web-completeness of SPARQL evaluation is useful as a theoretical notion, since the Web of Data cannot be materialised, more practical but weaker notions of completeness are also necessary. They propose another two completeness conditions: seed-complete considers answers from the set of documents that are within a fixed-length traversal path from the seed URIs in the query (the authors propose using the number of query patterns to decide the maximum hops) and query-reachable-complete considers a closed dataset of documents reachable through the LTBQE process under some ordering of the query patterns. The authors then demonstrate how Web-complete and query-reachable-complete conditions coincide if only certain authoritative triples—triples containing URIs that dereference to the container document—are considered.
We now give some practical examples as to why LTBQE (be it order-dependent or order-independent) cannot be Web-complete in the general case.
No dereferenceable query URIs The LTBQE approach cannot return results in cases where the query does not contain dereferenceable URIs. For example, consider posing the following query against Fig. 1:

As previously explained, the URI
Unconnected query-relevant documents Relating to reachability, results can be missed where documents are “connected” by a join on literals, blank-nodes or non-dereferenceable URIs. The following query illustrates such a case:

Answers (other than
Dereferencing partial information In the general case, the
effectiveness of LTBQE is heavily dependent on the amount of data returned by
the

This simple query cannot be answered since the triple “
We now present the details of LiDaQ: our proposal to extend the baseline LTBQE
approach with components that leverage lightweight RDFS and
LTBQE extensions
Partly addressing some of the shortcomings of the LTBQE approach in terms of
“recall”, Hartig et al. [34] proposed
extending the set of query relevant sources to consider
We now describe, formally define and provide motivating examples for each of the
three extensions: following
Following rdfs:seeAlso links
We first motivate the legacy
Consider executing the following simple query, asking for images of the
friends of 
LTBQE first dereferences the content of the query URI
Hartig et al. [34] thus proposed to
extend LTBQE to consider Given a
dataset Γ, a set of URIs U and a predicate URI
p, first define: Note that
Following and reasoning over owl:sameAs
links
We now motivate the need for
Consider the following query for Fig. 1
asking for friends of 
Baseline LTBQE returns no answers: LTBQE requires
We now formalise the details of our extension. We define an
extension of LTBQE to consider
Incorporating RDFS schemata and reasoning
Finally, we cover our novel extension for RDFS inferencing, starting with a motivating example.
Take the following query over Fig. 1 asking
for the images(s) depicting 
From Fig. 2, we know that

In this case, we know from the FOAF schema that
We define an extension of LTBQE to consider RDFS schema data and a subset
of RDFS inferences. Let
We are then left to define how A static
corpus of schema data Ψ can be provided as input, such that
The class and property terms used in
Class and property
terms can be dereferenced and schema-level links followed.
For a Linked Dataset Γ, let

LTBQE architecture diagram.
The second and third methods involve dynamically collecting schemata at runtime. The third method of schema-collection is potentially problematic in that it recursively follows links, and may end up collecting a large amount of schema documents (a behaviour we encounter in evaluation later). However, where, for example, class or property hierarchies are split across multiple schema documents, this recursive process is required to “recreate” the full hierarchy.
All three extensions—following
The LiDaQ prototype (implemented in Java) draws together a variety of techniques proposed in the literature [34,36,45] and has five main components, as depicted in Fig. 3.
uses Jena ARQ to parse and process input SPARQL queries and format the output results.12
decides which query and solution URIs should be dereferenced and which links should be followed.
an adapted version of the LDSpider crawling framework performs the
live Linked Data lookups required for LTBQE. LDSpider respects the
a custom implementation of an in-memory quad store (similar to [36]) is used to cache the content of all query relevant data (including inferences and schema data), as well as indexing triple patterns from the query to match against the data. Triple-pattern “listeners” match cached data in a continuous fashion, feeding the iterators.
the Java-based SAOR reasoner is used to support rule-based reasoning extensions [16] and executes inferencing over the local repository.
The query processing algorithm is based on a nested-loop strategy. During LTBQE, retrieving certain sources may involve high latency. Thus rather than blocking while waiting for the result of a particular request, special non-blocking operators are required [34,45], where we adopt a strategy analogous to the symmetric-index-hash join [45]. When a data-access operator receives a lookup request, it: (i) registers the pattern in a hash-table, (ii) pulls all relevant data, currently found in the local repository, as bindings into the hash-table, (iii) co-ordinates with the source-selector to request remote accesses as necessary, and (iv) registers a listener with the local repository that will push new relevant data into the operator’s hash-table as they arrive. Join operators use these hash-tables to asynchronously concatenate compatible tuples and return them to higher operators. By caching intermediate bindings, this asynchronous model ensures that all relevant data are consumed—in a bottom-up, nested-loop sense—as they arrive, no matter when or from where they arrive [45].
We further investigate some practical optimisations to minimise the number of query-relevant sources retrieved while maximising results. First, we avoid dereferencing URIs that do not appear in join positions. We illustrate this with a simple example:
Consider the following query issued against the example graph of Fig. 1, asking for friends of

Assuming the
By reducing the amount of sources and raw data that are accessed—and given that
anyone in principle can say anything, anywhere—we may also reduce the number of
answers that are returned. Taking the previous example, for all we know, the
document dereferenced through
Aside from this optimisation to avoid dereferencing URIs bound to non-join
variables, we note that URIs in certain positions of a triple pattern may not be
worth dereferencing to look for matching information. For example, given the
pattern “
LTBQE relies on the assumption that relevant data are dereferenceable, which may not always hold in practice. In this section, we analyse a large sample of the Web of Data to see what ratio of information is available in dereferenceable documents versus the total information available in the entire sample. This provides insights as to what percentage of raw data is available to LTBQE versus, e.g., a materialised approach with a complete index over a large crawl of the Web of Data. We can also test how much additional raw information is made available by our extensions.
Empirical corpus
We take the dataset crawled for the Billion Triple Challenge 2011 (BTC’11) in
mid-May 2011 as our corpus. The dataset consists of 7.4 million RDF/XML
documents spanning 791 pay-level domains (data providers). URIs extracted from
all RDF triples positions (excluding common non-RDF/XML extensions like
Alongside the RDF data, all relevant HTTP information, such as response codes,
redirects, etc., are made available. However, being an incomplete crawl, not all
URIs mentioned in the data were looked up. As such, we only have knowledge of
Again, this corpus is only a sample of the Web of Data: we can only analyse the HTTP lookups and the RDF data provided for the corpus. Indeed, a weakness of our analysis is that the BTC’11 dataset only considers dereferenceable RDF/XML documents and not other syntaxes like RDFa or Turtle. Thus, our estimate of what ratios of relevant data are dereferenceable should be considered as an upper bound since there are many documents on the Web of Data that we do not (or cannot [63]) know about.
Static schema data
Breakdown of authoritative schema
triples extracted from the corpus
Breakdown of authoritative schema triples extracted from the corpus
We first measure the average dereferenceability of information in our sample. Let
We also measure analogues of
Table 3 presents the results, where for different triples positions we present:
Dereferenceability results for
different triple positions
Dereferenceability results for different triple positions
A number of observations are directly relevant to LTBQE. Given a HTTP URI
(without a common non-RDF/XML extension), we have a
Table 3 also features high standard-deviation
values: these indicate that dereferenceability is often “all or nothing”. In
relative terms, predicate and type-object deviations were the highest. Although
most such terms return little or no relevant information—e.g., dereferencing the
predicate in a triple pattern rarely yields triples where the dereferenced term
appears as predicate—we observed a few predicates and values for
Many such examples for both classes and properties come from the SUMO ontology: see, e.g., http://www.ontologyportal.org/ SUMO.owl#subsumingRelation for a large extension of ontology terms provided by the ontology itself.
Additional raw data made
available through LTBQE
extensions
Additional raw data made available through LTBQE extensions
The percentage of dereferenceable URIs in
Benefit of owl:sameAs extension
We measured the percentage of dereferenceable URIs in

Distribution of relative information increases by materialising
We conclude that
With respect to our authoritative static schema data
Discussion
Before looking at specific queries, in this section we find that, in the general
case, LTBQE works best when a subject URI is provided in a query-pattern, works
adequately when only (non-class) object URIs are provided, but works poorly when
it must rely on property URIs bound to the predicate position or class URIs
bound to the object position. Furthermore, we see that
As discussed previously, we can use these results to justify a variant of LTBQE
that tries to minimise wasted remote lookups: aside from skipping URIs bound to
non-join variables, and unless collecting schema data dynamically, this variant
skips dereferencing predicate URIs bound in triple patterns, or URIs bound to
the objects of triples patterns where the predicate is bound to
Query benchmarks

Binning of relative information increases by materialising
We wish to evaluate LiDaQ in a realistic, uncontrolled environment: answering SPARQL queries directly over a diverse set of Web of Data sources. To guide this evaluation, we first survey existing Linked Data SPARQL benchmarks and look at how other systems evaluate their approaches (Section 7.1). We conclude that no benchmark offers a large and diverse range of benchmark SPARQL queries and thus propose QWalk: a novel benchmark methodology tailored for testing LTBQE-style query-answering approaches over the broader Web of Data (Section 7.2). Final evaluation setup and results are presented later in Section 8.
Since we aim to run our evaluation over Linked Data sources in
situ, we ignore benchmarks designed to run over synthetic datasets
such as LUBM [26],
BSBM [15], or
SP
offers three data collections for testing Linked Data querying
scenarios: a
Life Science Data Collection, which includes datasets
like KEGG, ChEBI, DrugBank and
DBPedia; a
synthetic dataset from the SP a general Linking Open Data Collection,
which includes datasets like DBpedia, GeoNames, Jamendo,
LinkedMDB, The New York Times and Semantic Web Dog
Food.
A query set is defined for
each. The first query set focuses on features of particular interest
for federated query engines, such as the number of involved sources,
(interim) query results size, and so forth. The second query set
consists of the original SP
(the DBpedia SPARQL Benchmark) contains SPARQL queries distilled from
real-world DBpedia logs, consisting of 31.5 million queries issued
by various users and agents over a four-month time-frame in 2010.
The raw set of queries is reduced to a total of 35 thousand queries
after less frequently-occuring query shapes were removed. These 35
thousand queries are clustered to generate 25 templates that
characterise the larger set. These templates can be “instantiated”
to create new queries from DBpedia data. The core of the templates
consist of Basic Graph Pattern queries with 1–5 triple patterns, but
may also include various combinations of SPARQL query features
(e.g.,
A variety of Linked Data querying papers have also defined once-off evaluation frameworks. The methods used by a selection of papers are summarised in Table 5. We see that two approaches (FedX [59] and SPLENDID [25]) evaluate their methods using Fedbench, but do not run their queries live. Most papers simulate HTTP lookups or replicate SPARQL endpoints locally. We see that only two papers feature evaluation of queries that are run live over HTTP, both by Hartig [31,32], one involving six hand-crafted queries over real-world sources [32], the other proposing a “FOAF Letter” application to keep track of social connections where five query templates are instantiated for 23 people, giving a total of 115 queries.
Summary of evaluation
setups in the Linked Data querying
literature
Summary of evaluation setups in the Linked Data querying literature
Given the shortcomings of existing benchmarks, we propose QWalk: a new benchmark framework that automatically builds a large set of queries that are answerable (e.g., by LTBQE) over a diverse set of real-world sources. The core idea is to take a large crawl of the Web of Data (in this case, the BTC’11 dataset) and to conduct random walks of different shapes and lengths through the corpus to generate Basic Graph Patterns. The walk is guided to ensure that it crosses documents through dereferenceable links: generated queries should thus be answerable by LTBQE.
Query shapes
To inform the types of queries we generate, we take observations from the work of Gallego et al. [7], who analyse the SPARQL queries logs of the DBPedia and Semantic Web Dog Food (SWDF) servers. They found that most queries contain a single triple pattern (66.41% in DBPedia, 97.25% in SWDF). The maximum number of patterns found was 15, but such complex queries occurred only rarely. The most common forms of joins involved subject–subject (59–61%), subject–object (32–36%) and object–object (4–5%); few joins involving predicate variables were found in general. As such, most queries with multiple patterns are star-shaped, with a few path shaped queries. Star-shaped joins typically had a low “fan-out”, where 27% of the DBpedia queries had a fan-out of three, and 3.7% had a fan-out of two; the bulk of the remaining queries were single-pattern with a trivial fan-out of one, but went up to a maximum of nine. The lengths of paths in the query were mostly one (98%) or two (1.8%); very few longer paths were found.
Along similar lines, for our benchmark we generate queries of elemental graph shapes as depicted in Fig. 6, viz., edge, star and path queries. We now describe these query types in more detail.

Visualisation of example query shapes
(
fetch all triples (edges) for an entity. We generate three
sub-types of edge queries, asking for triples where a URI
appears as the subject (
consist of three acyclic triple patterns that share exactly one
URI (called the centre node). These queries are similar to edge
queries but have only constant predicates, asking for specific
attributes of a given entity. Each query has 4 constants and 3
variables. We generate four sub-types of star queries, differing
in the number of triple patterns in which the centre node
appears at the subject (
consist of 2 or 3 triple patterns with constant predicates that
form a path such that precisely two triple patterns share a
given join variable. Precisely two patterns contain one join
variable, and the remaining patterns contain two join variables.
Precisely one triple pattern has a URI at either the subject or
object position. We generate four different sub-types: path
shaped queries of length 2 and 3 in which either the subject or
object term of one of the triple patterns is a constant. An
example for 
Query generation We generate queries from the
aforementioned BTC’11 dataset. In total, we generate 100
We randomly pick a
pay-level-domain available in the set of confirmed
dereferenceable URIs We then randomly select a URI from
We generate appropriate triple patterns from the
dereferenceable document of the selected URI based on the query
shape being generated. If path-shaped queries are being
generated, the URI for the next triple pattern is
selected from the dereferenceable URIs connected to the
previous URI, as per a random
walk. One variable is randomly chosen as distinguished
(returned in the
By randomly selecting a pay-level-domain first (as opposed to randomly
selecting a URI directly), we achieve a greater spread of URIs across
different datasets. The result of the QWalk process is a large set of
diverse queries with different elemental shapes that—according to the
sampled data—should be answerable through LTBQE methods over real-world data
in a realistic scenario (accessing remote sources).
When running queries directly over remote sources, various challenges come to the
fore, including slow HTTP lookups, unpredictable remote server behaviour, high
fan-out of links to traverse, the need for polite access (in terms of delays between
lookups and respecting
Based on the discussion of the previous section, we select three complementary benchmarks to run with LiDaQ, where we execute all queries directly over the Linked Data Web:
DBpedia SPARQL Benchmark (DBPSB), which generates many queries designed to run over one domain based on real-world query logs (we encountered difficulties running DBPSB with LTBQE as summarised later);
FedBench Linked Data Queries, which offers some manually crafted queries designed to run over a small selection of different domains;
QWalk, which offers a large selection of synthetic queries that can be run directly over a diverse set of sources.
We first discuss the experimental setup and measures (Section 8.1). Next we introduce the configurations of LiDaQ that we evaluate (Section 8.2). We then briefly summarise the problems we encountered when running DBPSB queries (Section 8.3). Finally, we present detailed results for FedBench (Section 8.4) and QWalk (Section 8.5).
Experimental setup and measures
All evaluation is run on one server: 4 GB RAM, Debian OS, 2.2 GHz single core. To ensure polite behaviour, we enforce a per-domain (specifically per-PLD) minimum delay of 500 ms between two sequential HTTP lookups on one domain. Furthermore, we use a (generous) query timeout of 2 hours.
When running queries live over HTTP, we often encounter some “non-deterministic” behaviour: a source may be readily accessible during some query runs, but may be unresponsive or not return at all in others. Different HTTP-level issues can occur at different times for the same source. During initial experiments, we thus encountered that result size and execution time can differ for the same query and setup between several benchmark runs. This “inconsistent” query behaviour is explained by the fact that we encountered various HTTP-level issues between different executions for the same query and setup. We thus define the straightforward notion of a benchmark stable query to help with comparability across different setups. We assume that a query has a core set of relevant documents, which are accessed in all configurations (introduced in the following section). A benchmark stable query is a query for which the response codes for each of the core URIs is the same across all setups runs.
For each query in each evaluation framework, we record the number of unique
In initial experiments, we found that raw counts of unique query results sometimes exhibit outliers due to redundancy caused by joins. We illustrate the problem with an example QWalk query:
Take the following QWalk query: 
Without reasoning, upon dereferencing the
The query results in this example contain many repetitions of terms: each term
bound to
For LiDaQ, given the various extensions, various ways of collecting RDFS data, and the option to turn off/on our reduction of sources, we have thirty-two combinations of possible setups, where we choose the following ten configurations to evaluate:
we dereference all URIs appearing in the query and during the query execution, independent from their triple position or role in joins. No extensions are included. This setup serves primarily as reference to the basic LTBQE profile.
Our reduced configuration uses our optimised source selection to
decide which URIs are query relevant and should be dereferenced. We
do not dereference URIs bound to non-join variables, or (unless
dynamically retrieving schemata) URIs bound to predicates or values
for
this configuration extends the
this benchmark setup extends the
this benchmark setup extends the uses
the static schema extracted earlier
from the BTC’11
dataset; collects
direct schemata by dynamically
dereferencing predicates and values for
collects
extended schemata by dynamically
following recursive links from the direct
schemata.
this benchmark setup combines all extensions for the previously mentioned configurations of schema collection. With this configuration, we expect the highest number of results, query time and processed and inferred statements.
Overview of the ten LiDaQ benchmark
configurations
Overview of the ten LiDaQ benchmark configurations
We first briefly summarise our experiences in trying to use DBpedia SPARQL
benchmark (DBPSB) to test LTBQE and our extensions. DBPSB involves 25 query
templates generated from real-world DBpedia query logs, which are not designed
specifically to be run with LTBQE. Our experiments had broadly negative results.
Full details of the experiments are available in [62, § 4.5.2.2]. To summarise, of the 25 query templates,
we identified that 16 could not be run by LTBQE, due to either containing an
In SPARQL,
Next we tried to generate 25 sample queries for each of the remaining 9 DBPSB templates. We ran the template queries provided for the benchmark against the public DBpedia SPARQL endpoint16
All template instances are available online: http://code.google. com/p/lidaq/source/browse/queries/dbpsb.swj.25.tar.gz.
The detailed discussion and results for the 3 remaining templates are available
in [62, § 4.5.2.2]. To summarise,
these three templates involved (1) listing the types of a given entity
(
The observation that so few query templates (based on real-world user logs) could be run by LTBQE is in itself a negative result and also makes it difficult to meaningfully interpret the results of our DBPSB experiments. Acknowledging this, we now rather focus on the results of the FedBench and QWalk benchmarks, which are designed with LTBQE in mind.
We now use the FedBench Linked Data Queries (Section 7.1) to measure the potential benefit of our proposed extensions and
optimisations. These 11 cross-domain queries (denoted
Query testing We had to make some amendments to the original 11
FedBench queries. First, since we count results, we add the
Other queries returned no results. Two queries (
See
Average result size and standard deviation across four query runs
Detailed results Given the number of queries (10), configurations (11) and measures (6), we leave detailed discussion of results for individual FedBench queries to Appendix A.
Summarising, we observe that LTBQE works well for some simpler FedBench queries,
but struggles in an uncontrolled environment for complex queries that require
accessing a lot of sources. For example, even in the baseline
In addition, results sizes can become quite large (e.g.,
In general, we would also expect that the results given by
Reliability results Running complex queries live over networks of remote sources raises the question of reliability and repeatability. We now focus on how the results varied across the four runs to get a better idea of the repeatability of LTBQE/LiDaQ in a realistic setting. We summarise the average number of results and the corresponding standard deviation for each configuration and query across all four runs in Table 7.
Conclusions When running the queries live over remote sources,
we see complex and unpredictable behaviour across different configurations and
across time: remote sources may give different responses at different times
(e.g., may give
The FedBench queries predominantly request data from a few central sites: the
first four queries (
In summary, from the 11 original FedBench queries, which were designed to be run
using LTBQE-style approaches, 4 queries show promising results, 3 return no
results (2 involving access disallowed by
Having briefly looked at the DBPSB queries, which target only the DBpedia domain; and having looked in more detail at the FedBench queries, which target a handful of domains; we now look at the results of the QWalk benchmark (Section 7.2), which builds a large set of queries answerable over a wide range of real-world sources. Using random walk techniques over the BTC’11 corpus, we created 100 queries for each of the 11 elemental shapes of the QWalk benchmark, giving 1100 initial queries. We then ran these live over remote sources using various configurations of LiDaQ.
Stable edge queries with and
without dynamic schema extensions
Stable edge queries with and without dynamic schema extensions
Summary of stable/unstable/empty queries for QWalk benchmark

Percentiles for ratio of increase in total runtimes, result latency and
result sizes vs.

Percentiles for ratio of increase in total runtimes, result latency and
result sizes vs.
Detailed results We now look at the average measures for
results across all (non-empty stable) queries per query class: we begin with
edge queries, then progress to star queries and eventually to path queries.
Detailed results for each of our measures can be found for reference in
Table 21 of Appendix B. Herein, we plot the total runtime, result latency and result
sizes in bar plots, where we measure the ratio of the analogous figure for
Edge queries have the most simple query shape and are used in a wide range of
applications to gather all available information about a certain entity, e.g.,
for the user interfaces of entity search engines. They are also often (but not
always) used as a simple mechanism to support SPARQL
We can see from the 50th percentile in Fig. 7a that
the
We also see that

Percentiles for ratio of increase in total runtimes, result latency and
result sizes vs.
Star-shaped queries retrieve selected attributes of an entity. The results for star-shaped queries are presented in Fig. 8 following the same format as before.
Some similar conclusions can again be drawn as for edge queries. Again, the query
time can often be reduced without a significant effect on query results by
opting for
Again, we see that
Path-shaped queries allow for exploring recursive relations in the graph, or to get information about neighbouring nodes. When compared with edge and star queries, we would expect path queries to generally be more expensive for LTBQE to process since they explicitly require traversing a number of sources.
For path queries, we again show the analogous increases in runtimes for the five
configurations in Fig. 9. Again, we see the savings
in time for selecting
Conclusion Across the hundreds of queries run for the 11 query
classes, we consistently find that compared with
To help summarise these results, Table 10 presents the average throughput (results per second) achieved across all queries per query class.20
Given that there is a lot of variance in the raw figures, we acknowledge that average figures are a coarse way to present the results, but they do help to summarise overall trends.
Results per second for all query classes with configurations shaded from best (lightest) to worst (darkest) throughput

In theory, link-traversal query approaches for Linked Data have the benefit of up-to-date results and decentralised execution. However, a thorough evaluation of such methods in realistic uncontrolled environments—for a diverse Web of Data—had not yet been conducted. We have focused on evaluating LTBQE approaches in this manner and have investigated the possibility of combining lightweight reasoning methods with LTBQE to gather and integrate data from diverse sources during query-answering.
We have characterised what percentage of data is missed by only considering dereferenceable information, we have looked at what percentage of raw data is made available to LTBQE through various extensions, and we have tested LTBQE and various extensions in uncontrolled environments for three complimentary query benchmarks. Our results show that LTBQE works well for simple queries with a dereferenceable subject, but, in uncontrolled environments, struggles for more complex queries that involve accessing many remote sources at runtime. Furthermore, we showed that runtimes in uncontrolled environments are often a factor of politeness policies, since queries frequently access many documents from few domains.
In terms of the extensions, we have shown that the selection of sources can be
successfully reduced by ignoring predicate URIs, object URIs for type-triples, and
URIs bound to non-join positions. We have also shown that the
Future directions The combination of reasoning and LTBQE has shown
the potential to find additional answers, and at a higher rate than without
reasoning, but with the potential to make query-answering unstable. At the moment we
focus on very lightweight reasoning, supporting an important subset of the semantics
inherent in published Linked Data. Extending the inference rules to support a
broader selection of OWL features—based on the observations of use by Glimm et
al. [24]—would obviously help to find
more answers. However, even for our lightweight reasoning, we already encounter
practical problems. In particular, we showed that following
In general, due to various fundamental (e.g., no support for
Taking an alternative view, although not a solution for SPARQL, LTBQE is an interesting technique for SPARQL and is complementary to other techniques for querying Linked Data, such as materialised or federated approaches. LTBQE offers the potential to get fresh answers when dynamic information is involved, or to get sensitive data when user-specific access-control is in place for some Linked Data source; this is not possible through centralised approaches. Furthermore, it does not rely on SPARQL interfaces like federated approaches; also, there are currently no mechanisms to discover endpoints in the same manner that LTBQE discovers sources. As such, the greatest potential for LTBQE is in combination with other querying techniques, for example to dynamically freshen-up results returned by a centralised SPARQL endpoint that replicates remote content. We have already begun to investigate this use of LTBQE—as a wrapper for the public LOD Cache and Sindice SPARQL endpoints–such that query patterns involving dynamic data are delegated to LTBQE rather than to replicated indexes, which are likely to be stale [66]. In such scenarios, LTBQE is required to deal with simple sub-queries, which we have shown to be feasible in this paper.
As the Web of Data continues to expand and diversify, and as it becomes more dynamic, new querying techniques will be required to keep up with its developments. Though various Web search engines have shown the power and potential of centralisation, even the preeminent Google machinery struggles to give up-to-date answers over dynamic sources. Linked Data presents new opportunities in this regard: URI names appearing in queries also correspond to addresses from which up-to-date data can be found. Although centralised approaches will always be relevant—a point of view which this paper partly confirms—exploring and combining complementary Linked Data querying techniques is an important area of research if we are to meet future challenges. In this paper, we have studied the realistic strengths and weaknesses of the LTBQE approach and various extensions. Next steps are to further explore how it can be combined with centralised query engines in an effective manner to freshen up answers over dynamic data, or to find answers from data-sources outside of the coverage of cached data.
Links Our source code and queries are available at
Footnotes
Acknowledgements
We would like to thank the reviewers for helping us to improve the paper and we would also like to thank Olaf Hartig for helpful discussion. The research presented herein has been supported in part by Science Foundation Ireland (SFI) under Grant Number SFI/12/RC/2289, by the Vienna Science and Technology Fund (WWTF) through project ICT12-015, and by the Millennium Nucleus Center for Semantic Web Research under Grant NC120004.
FedBench queries
Herein, we present the results for the individual FedBench queries. We run the queries four times for each of the ten LiDaQ experiments, and for comparability across different configurations, we present the best run in terms of results returned, and if tied, by time; we thus select the run which provided the most stable behaviour and returned the most results. The variation between the four runs has already been analysed in Section 8.4. We also show results for the SQUIN library (v.0.1.3): we highlight that we only run the SQUIN implementation once since (to the best of our knowledge) it does not implement politeness policies, and thus the LiDaQ configurations may have an advantage in comparison—in any case, we show that SQUIN is generally faster in total query time than LiDaQ (likely due to shorter politeness delays) but slower for first-result times. We do not have measurements for the intermediate triples processed by SQUIN.
To avoid repetition, we discuss results incrementally; we may only briefly remark again on observations that have already been made for earlier queries.
Benchmark results for query
Setup
Terms
Results
Time
(s)
First
(s)
HTTP
Data
Inferred
582
333
342.9
4.9
633
23,968
—
582
333
343.5
3.7
628
23,013
—
582
333
361.5
3.6
704
25,229
—
668
529
391.4
3.9
761
26,269
8109
615
380
478.8
3.8
628
23,013
11,501
615
380
350.3
5.2
666
23,013
13,984
615
380
356.1
6.6
865
23,013
18,587
715
692
571.9
4.4
842
29,212
26,804
713
680
461
8.4
1002
28,485
27,745
715
692
512.6
15.8
1269
29,212
35,418
582
333
86.8
28
703
—
—
The results for this query come mostly from one site: the
In this case, we see that
The additional answers available for RDFS and same-as reasoning can be seen from, e.g., http://data.semanticweb.org/person/ mathieu-daquin/rdf.
Although
Benchmark results for query Benchmark results for query
Setup
Terms
Results
Time
(s)
First
(s)
HTTP
Data
Inferred
236
185
260.3
3.9
478
20,356
—
236
185
69.8
3.5
128
3662
—
236
185
70
3.5
128
3662
—
236
185
70.3
3.6
128
3662
—
236
185
202.5
4
128
3662
2139
236
185
73.6
5.7
148
3662
8193
236
185
77.7
7
363
3662
12,312
236
185
219
4.8
128
3662
2139
236
185
76.9
12.8
148
3662
8124
236
185
79.7
22.9
363
3662
12,162
236
185
24
4.4
171
—
—
Setup
Terms
Results
Time
(s)
First
(s)
HTTP
Data
Inferred
247
191
388.1
4
760
27,538
—
247
191
342.8
8.1
628
23,013
—
247
191
360
8.2
704
25,229
—
394
951
389.5
4.2
763
26,248
8014
263
246
474.7
5
628
23,013
11,501
263
246
349.5
4.9
666
23,013
13,991
263
246
355.8
4.8
865
23,013
18,775
422
1469
569.3
10.4
839
28,485
25,797
425
1583
461.8
18.8
1008
29,212
28,814
425
1583
511.6
19.1
1269
29,212
35,547
247
191
87.3
32.2
728
—
—
This query adds a triple pattern to query
Benchmark results for query
Setup
Terms
Results
Time
(s)
First
(s)
HTTP
Data
Inferred
60
50
986.9
33.5
1805
74,635
—
60
50
984.5
50.9
1801
73,767
—
60
50
1019.4
51.9
1982
81,864
—
105
146
1167.4
56.5
2462
102,286
104,431
60
50
1140.2
17.5
1801
73,767
45,352
60
50
1003
66
1843
73,767
45,943
60
50
1023.2
11.5
2173
73,767
58,374
162
203
4658.4
68.9
2834
115,707
297,620
162
203
2249.4
172.4
3383
115,663
557,880
80
126
7211.6
52.9
9225
109,858
1,702,602
60
50
244.3
236.7
1981
—
—
Again, this query is an extension of
Benchmark results for query
Setup
Terms
Results
Time
(s)
First
(s)
HTTP
Data
Inferred
85
43
63.3
6
121
9017
—
85
43
66.8
9
116
8285
—
85
43
65.2
7.2
116
8285
—
313
271
212.7
14
593
15,179
119,907
85
43
218.3
23.5
116
8284
7115
83
42
417.7
9.4
698
8203
163,163
36
18
4886.6
12.9
9729
4087
302,609
0
0
7341.5
—
780
17,027
745,534
15
14
7200.6
353.7
1452
14,450
958,611
—
—
—
—
—
—
—
85
43
16.2
3.9
115
—
—
This query shifts the focus to the
Although
Benchmark results for query
Setup
Terms
Results
Time
(s)
First
(s)
HTTP
Data
Inferred
0
0
9.6
—
12
17,864
—
0
0
6.8
—
2
10,001
—
0
0
3.6
—
2
10,001
—
0
0
49.5
—
7
10,067
20,090
0
0
145.2
—
2
10,001
4580
0
0
27.3
—
49
10,001
1329
0
0
215.3
—
7
10,067
24,922
0
0
59
—
64
10,067
71,560
0
0
7223.5
—
945
10,067
427,421
0
0
5.9
—
1
—
—
This query intends to span the DBpedia (first three patterns), LinkedMDB (fourth
pattern) and GeoNames (fifth pattern) data providers. However, as we can see in
Table 16, no setup returned any results. At
the time of running the experiments, the dereferenced document for
LiDaQ will not run this query since the
Benchmark results for query
Setup
Terms
Results
Time
(s)
First
(s)
HTTP
Data
Inferred
39
19
78.9
17.6
351
20,655
—
39
19
61.9
25.5
257
7245
—
39
19
96.2
21.4
334
7309
—
294
21,071
1374.4
67.1
856
12,839
515,297
39
19
198.5
15.9
257
7245
4979
8
4
181.4
132.6
231
774
43,814
24
12
7514.8
155.5
7175
5491
143,236
347
29,139
7354.9
35.5
1217
15,209
407,741
0
0
7212.1
—
1289
11,416
73,304
—
—
—
—
—
—
—
22
10
120.9
10.5
482
—
—
From the results in Table 17, we see the
improvements of
We refer the reader to https://groups.google.com/forum/ ?fromgroups#!topic/pedantic-web/rXQPcFLMOi0 for detailed discussion.
Benchmark results for query
Setup
Terms
Results
Time
(s)
First
(s)
HTTP
Data
Inferred
0
0
147.3
—
266
29,326
—
0
0
147.4
—
260
27,821
—
0
0
136.4
—
260
27,821
—
0
0
182.6
—
337
7915
92,485
0
0
299.2
—
202
22,791
19,642
0
0
904.8
—
1512
19,133
227,663
0
0
1607.5
—
3488
4928
33,810
0
0
7342.9
—
984
28,211
558,187
0
0
7202
—
1437
16,109
1,432,297
—
—
—
—
—
—
—
0
0
25.6
—
247
—
—
As we can see from the results in Table 18, none of
the setups returned any content. At the time of the experiments, the document
for the Brazilian national football team (the answer to
This query tries to combine the
Table 20 shows that this query involves the largest amount of results and source lookups of all the FedBench queries. The combination of over 300 players, each of which typically has labels in several languages and has two or three birth-places, each of which in turn has labels in several languages, leads to large results sets, even without reasoning. The number of HTTP lookups also reflects the breadth of this query, primarily due to lookups on players and places. The reasoning extensions again exhibit unstable behaviour, either eventually timing-out or throwing an exception.
QWalk results
Table 21 presents the detailed average results for
the QWalk experiments across all query classes. For space reasons, we only
present standard deviations for terms, results and time. Detailed QWalk results for all query
classes (Continued.)
Setup
Term
Results
Time (s)
First (s)
HTTP
Data
Inferred
avg.
σ
avg.
σ
avg.
σ
19.35
±37.75
16.78
±37.94
16.79
±8.19
6.6
17.78
8676.43
—
19.33
±37.72
16.77
±37.91
9.99
±4.81
6.6
2.92
5772.5
—
19.33
±37.72
16.77
±37.91
10.04
±5.05
6.42
3.15
5778.68
—
25.28
±63.42
22.73
±63.76
10.57
±5.47
6.93
3.27
5579.42
67.82
24.13
±37.95
21.77
±38.01
16.93
±35.6
6.57
4.55
22,591.2
16,328.55
30.07
±63.66
27.73
±63.91
18.08
±38.58
9.5
5.07
22,424.57
16,423.52
54.16
±382.48
53.53
±382.42
13.49
±8.5
6.19
7.18
3517.61
—
54.18
±382.47
53.51
±382.42
8.25
±5.72
6.17
2.61
1284.07
—
54.19
±382.47
53.53
±382.42
8.69
±5.65
6.16
2.77
1832.04
—
55.04
±382.37
54.35
±382.32
9.53
±8.07
6.08
3.37
1984.7
171.67
54.28
±382.46
54.04
±382.38
10.06
±13.42
6.12
2.61
4557.19
2789.54
55.14
±382.35
54.88
±382.27
12.52
±17.02
6.37
3.46
5043.68
3171.05
16.32
±15
35.34
±51.01
17.49
±8.08
6.65
19.86
3853.07
—
16.14
±15.04
34.66
±49.83
12.28
±6.41
6.79
6.46
1296.02
—
16.17
±15.02
34.68
±49.82
13.01
±7.22
6.65
7.49
2551.37
—
18.19
±17.4
56.14
±93.8
15.15
±11.48
6.68
8.53
1776.64
393.93
19.71
±17.52
52.86
±73.08
14.19
±14.12
6.65
8.64
4600.24
2833.88
21.78
±19.66
81.22
±122.66
16.84
±17.08
6.7
11.32
6317.88
4121
3.49
±4.46
2.64
±4.4
14.9
±16.5
7.43
13.76
2099.61
—
3.49
±4.46
2.64
±4.4
7.47
±2.57
6.95
1.9
595.42
—
3.49
±4.46
2.64
±4.4
7.94
±4.64
7.43
1.91
595.42
—
4.03
±6.4
8.76
±49.72
9.31
±6.82
7.44
2.31
3098.49
54.58
3.49
±4.46
2.64
±4.4
10.88
±25.86
7.24
1.9
10,328.1
6816.55
4.03
±6.4
8.76
±49.72
12.83
±31.08
7.78
2.33
9920.43
6876.52
9.05
±31.78
11.35
±53.6
65.84
±391.73
7.25
13.26
1709.11
—
9.05
±31.78
11.35
±53.6
7.08
±2.18
6.72
1.82
48.74
—
9.08
±31.79
11.68
±53.8
8.68
±10.44
6.65
2.21
62.81
—
9.53
±31.83
13.02
±54.21
8.15
±3.94
6.71
2.4
323.32
52.97
12.56
±53.7
644
±5028.56
9.07
±12.49
6.88
1.82
856.34
556.48
13.06
±53.7
645.95
±5028.32
10.98
±17.91
6.68
2.74
1354.61
1017.95
5.53
±12.82
7.44
±30.09
12.77
±16.11
6.41
11.79
515.37
—
5.51
±12.82
7.43
±30.09
6.63
±2.13
6.25
1.73
104.11
—
5.51
±12.82
7.43
±30.09
7.46
±3.37
6.23
1.93
104.5
—
5.66
±12.8
7.57
±30.07
7.25
±2.69
6.57
1.79
372.14
14.16
6.1
±13.5
17.04
±87.46
7.98
±10.98
6.31
1.73
814.74
409
6.24
±13.47
17.19
±87.44
9.84
±13.66
6.99
1.99
797.06
435.4
2.2
±0.79
1.15
±0.56
10.18
±5.65
7.1
6.79
1242.77
—
2.2
±0.79
1.15
±0.56
7.16
±3.26
6.69
1.53
949.88
—
2.2
±0.79
1.15
±0.56
7.76
±3.99
6.75
1.76
964.27
—
2.29
±1.15
1.24
±1.01
8.33
±5.6
6.93
1.83
2138.38
68.39
3.67
±2.57
2.7
±2.61
11.46
±26.25
7.51
1.53
8817.83
6742.48
3.77
±2.66
2.8
±2.7
13.8
±36.07
9.58
1.95
9411.11
7203.71
6.89
±38.25
6.35
±38.27
14.42
±34.39
7.05
14.02
575.45
—
6.89
±38.25
6.35
±38.27
8.86
±4.98
6.38
2.8
236.39
—
6.89
±38.25
6.35
±38.27
9.38
±5.35
6.37
3.08
236.45
—
7.08
±38.24
6.74
±38.32
9.62
±5.74
6.25
3.52
757.2
71.17
7.79
±38.17
7.62
±38.28
9.14
±5.25
6.49
2.86
2016.91
1325.12
8
±38.17
8.03
±38.32
10.25
±5.95
6.43
3.98
2214.55
1502.45
48.14
±237.92
28.55
±122.05
16.21
±22.62
6.61
16.53
2605.86
—
48.1
±237.89
28.43
±121.89
11.6
±6.73
6.89
4.59
1302.96
—
49.35
±237.82
29.06
±121.83
11.37
±8.02
6.51
5.94
1305.53
—
48.14
±237.89
28.47
±121.88
11.59
±5.82
6.74
4.71
4612.86
4.04
48.69
±237.78
29.02
±121.76
11.94
±6.84
7.1
4.61
13,502.16
8601.94
51.59
±238.09
30.49
±121.85
14.54
±17.97
6.88
7.76
13,329.9
8657.35
Setup
Term
Results
Time (s)
First
(s)
HTTP
Data
Inferred
avg.
σ
avg.
σ
avg.
σ
96.02
±379.55
94.26
±376.01
68.52
±262.1
7.34
107.06
2942.29
—
96.02
±379.55
94.26
±376.01
11.23
±7.84
7.16
4.18
1260.85
—
96.02
±379.55
94.26
±376.01
12.15
±7.95
6.87
4.52
1261.71
—
140.79
±566.69
139.19
±564.44
13.19
±9.95
7.24
6.21
7333.55
1146.18
96.08
±379.59
96.03
±377.18
15.09
±23.65
7.14
4.18
14,604.69
10,073.15
140.87
±566.71
140.98
±565.07
20.47
±36.77
7.32
6.69
18,734.92
12,521.85
83.49
±268.83
86.06
±288.12
90.78
±268.35
7.41
157.46
7293.86
—
83.51
±268.87
86.09
±288.15
15.1
±8.86
7.9
7.43
1105.51
—
83.51
±268.87
86.09
±288.15
14.75
±8.35
7.51
7.49
1105.66
—
83.51
±268.87
86.09
±288.15
14.16
±8.98
7.09
7.43
3854.49
—
83.51
±268.87
86.09
±288.15
17.1
±15.34
7.14
7.43
9336.74
5481.91
83.51
±268.87
86.09
±288.15
18.38
±18.07
8.01
7.51
9332.71
5477.31
CURIE prefixes
The CURIE prefixes used in this paper are enumerated in Table 22. Mappings for all prefixes
used
Prefix
URI