
Abstract
The Web of Data has grown enormously over the last years. Currently, it comprises a large compendium of interlinked and distributed datasets from multiple domains. Running complex queries on this compendium often requires accessing data from different endpoints within one query. The abundance of datasets and the need for running complex query has thus motivated a considerable body of work on SPARQL query federation systems, the dedicated means to access data distributed over the Web of Data. However, the granularity of previous evaluations of such systems has not allowed deriving of insights concerning their behavior in different steps involved during federated query processing. In this work, we perform extensive experiments to compare state-of-the-art SPARQL endpoint federation systems using the comprehensive performance evaluation framework FedBench. In addition to considering the tradition query runtime as an evaluation criterion, we extend the scope of our performance evaluation by considering criteria, which have not been paid much attention to in previous studies. In particular, we consider the number of sources selected, the total number of SPARQL ASK requests used, the completeness of answers as well as the source selection time. Yet, we show that they have a significant impact on the overall query runtime of existing systems. Moreover, we extend FedBench to mirror a highly distributed data environment and assess the behavior of existing systems by using the same performance criteria. As the result we provide a detailed analysis of the experimental outcomes that reveal novel insights for improving current and future SPARQL federation systems.
Keywords
Introduction
The transition from the Web of Documents to the Web of Data has resulted in a large compendium of interlinked datasets from diverse domains. Currently, the Linking Open Data (LOD) Cloud1
Current evaluations [1,7,21,26,27,33,38] of SPARQL query federation systems compare some of the federation systems based on the central criterion of overall query runtime. While optimizing the query runtime of federation systems is the ultimate goal of the research performed on this topic, the granularity of current evaluations fails to provide results that allow understanding why the query runtimes of systems can differ drastically and are thus insufficient to detect the components of systems that need to be improved. For example, key metrics such as a smart source selection in terms of the total number of data sources selected, the total number of SPARQL ASK requests used, and the source selection time have a direct impact on the overall query performance but are not addressed in the existing evaluations. For example, the over-estimation of the total number of relevant data sources will generate extra network traffic, may result in increased query execution time. The SPARQL ASK queries returns boolean value indicating whether a query pattern matches or not. The greater the number of SPARQL ASK requests used for source selection, the higher the source selection time and therefore overall query execution time. Furthermore, as pointed out by [22], the current testbeds [6,23,31,32] for evaluating, comparing, and eventually improving SPARQL query federation systems still have some limitations. Especially, the partitioning of data as well as the SPARQL clauses used cannot be tailored sufficiently, although they are known to have a direct impact on the behavior of SPARQL query federation systems.
The aim of this paper is to experimentally evaluate a large number of SPARQL 1.0 query federation systems within a more fine-granular setting in which we can measure the time required to complete different steps of the SPARQL query federation process. To achieve this goal, we conducted a public survey2
Survey:
In the next step and like in previous evaluations, we compared the remaining six systems [1,7,20,25,33,38] with respect to the traditional performance criterion that is the query execution time using the commonly used benchmark FedBench. In addition, we also compared these six systems with respect to their answer completeness, source selection approach in terms of the total number of sources they selected, the total number of SPARQL ASK requests they used and source selection time. For the sake of completeness, we also performed a comparative analysis (based on the survey outcome) of the key functionality of the 14 systems which participated in our survey. The most important outcomes of this survey are presented in Section 3.3
All survey responses can be found
at
To provide a quantitative analysis of the effect of data partitioning on the systems at hand, we extended both FedBench [31] and SP2Bench [32] by distributing the data upon which they rely. To this end, we used the slice generation tool4
Our main contributions are summarized as follows:
We present the results of a public survey which allows us to provide a crisp overview of categories of SPARQL federation systems as well as provide their implementation details, features, and supported SPARQL clauses.
We present (to the best of our knowledge) the most comprehensive experimental evaluation of open-source SPARQL federations systems in terms of their source selection and overall query runtime using in two different evaluation setups.
Along with the central evaluation criterion (i.e., the overall query runtime), we measure three further criteria, i.e., the total number of sources selected, the total number of SPARQL ASK requests used, and the source selection time. By these means, we obtain deeper insights into the behavior of SPARQL federation systems.
We extend both FedBench and SP2Bench to mirror highly distributed data environments and test SPARQL endpoint federation systems for their parallel processing capabilities.
We provide a detailed discussion of experimental results and reveal novel insights for improving existing and future federation systems.
Our survey results points to research opportunities in the area of federated semantic data processing.
The rest of this paper is structured as follows: In Section 2, we provide an overview of state-of-the-art SPARQL federated query processing approaches. Section 3 provides a detailed description of the design of and the responses to our public survey of the SPARQL query federation. Section 4 provides an introduction to SPARQL query federation and selected approaches for experimental evaluation. Section 6 describes our evaluation framework and experimental results, including key performance metrics, a description of the used benchmarks (FedBench, SP2Bench, SlicedBench), and the data slice generator. Section 7 provides our further discussion of the results. Finally, Section 8 concludes our work and gives an overview of possible future extensions.
In this section, we provide a two-pronged overview of existing works. First, we give an overview of existing federated SPARQL query system evaluations. Here, we focus on the description of different surveys/evaluations of SPARQL query federation systems and argue for the need of a new fine-grained evaluation of federated SPARQL query engines. Thereafter, we give an overview of benchmarks for SPARQL query processing engines. In addition, we provide reasons for our benchmark selection in this evaluation.
Federation systems evaluations
Several SPARQL query federation surveys have been developed over the last years. Rakhmawati et al. [26] present a survey of SPARQL endpoint federation systems in which the details of the query federation process along with a comparison of the query evaluation strategies used in these systems. Moreover, systems that support both SPARQL 1.0 and SPARQL 1.1 are explained. However, this survey do not provide any experimental evaluation of the discussed SPARQL query federation systems. In addition, the system implementation details resp. supported features are not discussed in much detail. We address these drawbacks in Tables 1 resp. 2. Hartig [10] provide a general overview of Linked Data federation. In particular, they introduce the specific challenges that need to be addressed and focus on possible strategies for executing Linked Data queries. However, this survey do not provide an experimental evaluation of the discussed SPARQL query federation systems. Umbrich et al. [36] provide a detailed study of the recall and effectiveness of Link Traversal Querying for the Web of Data. Schwarte et al. [34] present an experimental study of large-scale RDF federations on top of the Bio2RDF data sources using a particular federation system, i.e., FedX [33]. They focus on design decisions, technical aspects, and experiences made in setting up and optimizing the Bio2RDF federation. Betz et al. [5] identify various drawbacks of federated Linked Data query processing. The authors propose that Linked Data as a service has the potential to solve some of the identified problems. Görlitz and Staab [8] present limitations in Linked Data federated query processing and implications of these limitations. Moreover, this paper presents a query optimization approach based on semi-joins and dynamic programming. Ladwig and Tran [18] identify various strategies while processing federated queries over Linked Data. Umbrich et al. [37] provide an experimental evaluation of the different data summaries used in live query processing over Linked Data. Montoya et al. [22] provide a detail discussion of the limitations of the existing testbeds used for the evaluation of SPARQL query federation systems. Some other experimental evaluations [1,7,21,22,27,33,38] of SPARQL query federation systems compare some of the federation systems based on their overall query runtime. For example, Gorlitz and Staab [7] compare their approach with three other approaches ([25,33], AliBaba5
Sesame AliBaba:
All experimental evaluations above compare only a small number of SPARQL query federation systems using a subset of the queries available in current benchmarks with respect to a single performance criterion (query execution time). Consequently, they fail to provide deeper insights into the behavior of these systems in different steps (e.g., source selection) required during the query federation. In this work, we evaluate six open-source federated SPARQL query engines experimentally on two different evaluation frameworks. To the best of our knowledge, this is currently the most comprehensive evaluation of open-source SPARQL query federation systems. Furthermore, along with central performance criterion of query runtime, we compare these systems with respect to their source selection. Our results show (Section 6) that the different steps of the source selection affect the overall query runtime considerably. Thus, the insights gained through our evaluation w.r.t. to these criteria provide valuable findings for optimizing SPARQL query federation.
Benchmarks for comparing SPARQL query processing systems have a rich literature as well. These include Berlin SPARQL Benchmark (BSBM), SP2Bench, FedBench, Lehigh University Benchmark (LUBM) and the DBpedia Sparql Benchmark (DBPSB). Both BSBM and SP2Bench are mainly designed for the evaluation of triple stores that keep their data in a single large repository. BSBM [6] was developed for comparing the performance of native RDF stores with the performance of SPARQL-to-SQL re-writers. SP 2 Bench [32] mirrors vital characteristics (such as power law distributions or Gaussian curves) of the data in the DBLP bibliographic database. This benchmark comprises both a data generator for creating arbitrarily large DBLP-like documents and a set of carefully designed benchmark queries. FedBench [31] is designed explicitly to evaluate SPARQL query federation tasks on real-world datasets with queries resembling typical requests on these datasets. Furthermore, this benchmark also includes a dataset and queries from SP2Bench. LUBM [9] is designed to facilitate the evaluation of Semantic Web repositories in a systematic way. It is based on a customizable and repeatable synthetic data. DBPSB [23] includes queries from the DBpedia query log and aims to reflect the behavior of triple stores when confronted with real queries aiming to access native RDF data.
FedBench is the only (to the best of our knowledge) benchmark that encompasses real-world datasets, commonly used queries and distributed data environment. Furthermore, it is commonly used in the evaluation of SPARQL query federation systems [7,21,29,33]. Therefore, we choose this benchmark as a main evaluation benchmark in this paper. We also decided on using SP2Bench in parts of our experiments to ensure that our queries cover most of SPARQL. Note that neither FedBench nor SP2Bench provide SPARQL 1.1 federated queries. Devising such a benchmark remains future work.
Federated engines public survey
In order to provide a comprehensive overview of existing SPARQL federation engines, we designed and conducted a survey of SPARQL query federation engines. In this section, we present the principles and ideas behind the design of the survey as well as its results and their analysis.
Survey design
The aim of the survey was to compare the existing SPARQL query federation engines, regardless of their implementation or code availability. To reach this aim, we interviewed domain experts and designed a survey with three sections: system information, requirements, and supported SPARQL clauses.6
The survey can be found at
The system information section of the survey includes implementation details of the SPARQL federation engine such as:
The questions from the requirements section assess SPARQL query federation engines for the key features/requirements that a developer would require from such engines. These include:
Overview of implementation details of federated SPARQL query engines
Notes:
The supported SPARQL clauses section assess existing SPARQL query federation engines w.r.t. the list of supported SPARQL clauses. The list of the SPARQL clauses is mostly based on the characteristics of the BSBM benchmark queries [6]. The summary of the used SPARQL clauses can be found in Table 3.
The survey was open and free for all to participate in. To contact potential participants, we used Google Scholar to retrieve papers that contained the keywords “SPARQL” and “query federation”. After a manual filtering of the results, we contacted the main authors of the papers and informed them of the existence of the survey while asking them to participate. Moreover, we sent messages to the W3C Linked Open Data mailing list7
Survey outcome: System’s features
Notes:
Based on our survey results,9
Available at
Each of the above main category can be further divided into three sub-categories (see Table 1).
Survey outcome: System’s Support for SPARQL Query Constructs
Notes: QP = Query Predicates, QS = Query Subjects
Table 1 provides a classification along with the implementation details of the 14 systems which participated in the survey. Overall, we received responses mainly for systems which implemented the SPARQL endpoint federation and hybrid query processing paradigms in Java. Only Atlas [16] implements DHT federation whereas WoDQA [2], LDQPS [18], and SIHJoin [19] implement federation over linked data (LDF). Most of the surveyed systems provides “General Public Licences” with the exception of [18] and [19] which provides “Scala” license whereas the authors of [4] and [11] have not yet decided which license type will hold for their tools. Five of the surveyed systems implement caching mechanisms including [2,4,24,29] and [33]. Only [1] and [2] provide support for catalog/index update whereas two systems do not require this mechanism by virtue of being index/catalog-free approaches.
Table 2 summarizes the survey outcome w.r.t. different features supported by systems. Only three systems ([24,33] and QWIDVD) claim that they achieve result completeness and only Avalanche [4] and DAW [29] support partial results retrieval for their implementations. Note that FedX claims result completeness when the cache that it relies on is up-to-date. Five (i.e., Avalanche, ANAPSID, ADERIS, LDQPS, SIHJoin) of the considered systems support adaptive query processing. Only DAW [29] supports duplicate detection whereas DHT and Avalanche [4] claim to support partial duplicate detection. Granatum [11,12,15] is the only system that implements privacy and provenance. None of the considered systems implement top-k query processing or query runtime estimation.
Table 3 lists SPARQL clauses supported by the each of 14 systems. GRANATUM and QWIDVD are only two systems that support all of the query constructs used in our survey. It is important to note that most of these query constructs are based on query characteristics defined in BSBM.
After having given a general overview of SPARQL query federation systems, we present six SPARQL endpoints federation engines [1,7,20,25,33,38] with public implementation that were used within our experiments. We begin by presenting an overview of key concepts that underpin federated query processing and are used in the performance evaluation. We then use these key concepts to present the aforementioned six systems used in our evaluation in more detail.
Federated query processing
Given a SPARQL query
Overview of the selected approaches
DARQ [25] makes use of an index known as service description to perform source selection. Each service description provides a declarative description of the data available in a data source, including the corresponding SPARQL endpoint along with statistical information. The source selection is performed by using distinct predicates (for each data source) recorded in the index as capabilities. The source selection algorithm used in DARQ for a query simply matches all triple patterns against the capabilities of the data sources. The matching compares the predicate in a triple pattern with the predicate defined for a capability in the index. This means that DARQ is only able to answer queries with bound predicates. DARQ combines service descriptions, query rewriting mechanisms and a cost-based optimization approach to reduce the query processing time and the bandwidth usage.
SPLENDID [7] makes use of VoiD descriptions as index along with SPARQL ASK queries to perform the source selection step. A SPARQL ASK query is used when any of the subject or object of the triple pattern is bound. This query is forwarded to all of the data sources and those sources which pass the SPARQL ASK test are selected. A dynamic programming strategy [35] is used to optimize the join order of SPARQL basic graph patterns.
Known variables that impact the behavior of SPARQL federated
Known variables that impact the behavior of SPARQL federated
Notes: #ASK = Total number of SPARQL ASK requests used during source selection, #TP = total triple pattern-wise sources selected
FedX [33] is an index-free SPARQL query federation system. The source selection relies completely on SPARQL ASK queries and a cache. The cache is used to store recent SPARQL ASK operations for relevant data source selection. As shown by our evaluation, the use of this cache greatly reduces the source selection and query execution time.
The publicly available implementation of LHD [38] only makes use of the VoiD descriptions to perform source selection. The source selection algorithm is similar to DARQ. However, it also supports query triple patterns with unbound predicates. In such cases, LHD simply selects all of the available data sources as relevant. This strategy often overestimates the number of capable sources and can thus lead to high overall runtimes. LHD performs a pipeline hash join to integrate sub-queries in parallel.
ANAPSID [1] is an adaptive query engine that adapts its query execution schedulers to the data availability and runtime conditions of SPARQL endpoints. This framework provides physical SPARQL operators that detect when a source becomes blocked or data traffic is bursty. The operators produce results as quickly as data arrives from the sources. ANAPSID makes use of both a catalog and ASK queries along with heuristics defined in [21] to perform the source selection step. This heuristic-based source selection can greatly reduce the total number of triple pattern-wise selected sources.
Finally, ADERIS [20] is an index-only approach for adaptive integration of data from multiple SPARQL endpoints. The source selection algorithm is similar to DARQ’s. However, this framework also selects all of the available data sources for triple patterns with unbound predicates. ADERIS does not support several SPARQL 1.0 clauses such as UNION and OPTIONAL. For the data integration, the framework implements the pipelined index nested loop join operator.
In the next section, we describe known variables that may impact the performance of the federated SPARQL query engines.
Table 4 shows known variables that may impact the behavior of
federated SPARQL query engines. According to [21],
these variables can be grouped into two categories (i.e., independent and dependent
variables) that affect the overall performance of federated query SPARQL engines. Dependent
(also called observed) variables are usually the performance metrics and are normally
influenced by independent variables. Dependent variables include: (1) total number of SPARQL
ASK requests used during source selection
Independent variables can be grouped into four dimensions: query, data, platform, and
endpoint [21]. The query dimension includes: the type of query (star, path, hybrid [29]), the number of
basic graph patterns, the instantiations (bound/unbound)
of tuples (subject, predicate, object) of the query triple
pattern, the selectivity of the joins between triple
patterns, the query result set size, and use of different
SPARQL clauses along with general predicates such as the dataset size, its type of partition
(horizontal, vertical, hybrid), and the data frequency
distribution (e.g., number of subject, predicates and objects)
etc. use of cache, number of processor,
and amount of RAM available.
The data dimension
comprises of:
The platform dimension consists of:
The
following parameters belong to the endpoints dimension:
the number of endpoints used in the federation and their types (e.g., Fuseki, Sesame, Virtuoso etc., and single vs. clustered server),
the relationship between the number of instances, graphs and endpoints of the systems used during the evaluation, and
network latency (in case of live SPARQL endpoints) and different endpoint configuration parameters such as answer size limit, maximum resultset size etc.
In our evaluation, we measured all of the five dependent variables reported in Table 4. Most of the query (an independent variable) parameters are covered by using the complete query set of both FedX and SP2Bench. However, as pointed in [21], the join selectivity cannot be fully covered due to the limitations of both FedX and SP2Bench. In data parameters, the data set size cannot be fully explored in the selected SPARQL query federation benchmarks. This is because both FedBench and SP2Bench do not contain very large datasets (the largest dataset in these benchmarks contains solely 108M triples, see Table 6) such as Linked TCGA (20.4 billion triples11
Linked
TCGA:
UniProt:
While the dependent variables source selection time, query runtime, and answer completeness are already highlighted in [21], we also measured the total number of data sources selected and total number of SPARQL ASK requests used during the source selection. Section 6 shows that both of these additional variables have a significant impact on the performance of federated SPARQL query engines. For example, an overestimation of the capable sources can lead through an increase of the overall runtime due to (1) increased network traffic and (2) unnecessary intermediate results which are excluded after performing all the joins between the query triple patterns. On the other hand, the smaller the number of SPARQL ASK requests used during the source selection, the smaller the source selection time and vice versa. Further details of the depended and independent variables can be found at [21].
In this section we present the data and hardware used in our evaluation. Moreover, we explain the key metrics underlying our experiments as well as the corresponding results.
Experimental setup
We used two settings to evaluate the selected federation systems. Within the first
evaluation, we used the query execution time as central evaluation parameter and made use
of the FedBench [31] federated SPARQL querying
benchmark. In the second evaluation, we extended both FedBench and SP2Bench to
simulate a highly federated environment. Here, we focused especially on analyzing the
effect of data partitioning on the performance of federation systems. We call this
extension SlicedBench as we created slices of each original datasets and
distributed them among data sources. All of the selected performance metrics (explained in
Section 6.2) remained the same for both evaluation
frameworks. We used the most recent versions (at the time at which the evaluation was
carried out), i.e., FedX2.0 and ANAPSID (December 2013 version). The remaining systems has
no versions. All experiments were carried out on a system (machine running federation
engines) with a 2.60 GHz i5 processor, 4 GB RAM and 500 GB hard disk. For systems with
Java implementation, we used Eclipse with default settings, i.e., Java Virtual Machine
(JVM) initial memory allocation pool (Xms) size of 40 MB and the maximum memory allocation
pool (Xmx) size of 512 MB. The permanents generation (MaxPermSize) which defines the
memory allocated to keep compiled class files was also set to default size of 256 MB. To
minimize the network latency we used a dedicated local network. We conducted our
experiments on local copies of Virtuoso (version 20120802) SPARQL endpoints with number of
buffers 1360000, maximum dirty buffers 1000000, number of server threads 20, result set
maximum rows 100000, and maximum SPARQL endpoint query execution time of 60 seconds. A
separate physical virtuoso server was created for each dataset. The specification of the
machines hosting the virtuoso SPARQL endpoints used in both evaluations is given in
Table 5. We executed each query 10 times and present the
average values in the results. The source selection time (ref. Section 6.3.4) and query runtime (ref. Section 6.3.5) was calculated using the function
System’s specifications hosting SPARQL endpoints
System’s specifications hosting SPARQL endpoints
Datasets statistics used in our benchmarks
Only used in SlicedBench
Query characteristics
Notes: #T = Total number of Triple patterns, #Res = Total number of query results,
Only used in SlicedBench
All of the data used in both evaluations along with the portable virtuoso SPARQL endpoints can be downloaded from the project website.13
FedBench is commonly used to evaluate performance of the SPARQL query federation systems [7,21,29,33]. The benchmark is explicitly designed to represent SPARQL query federation on a real-world datasets. The datasets can be varied according to several dimensions such as size, diversity and number of interlinks. The benchmark queries resemble typical requests on these datasets and their structure ranges from simple star [29] and chain queries to complex graph patterns. The details about the FedBench datasets used in our evaluation along with some statistical information are given in Table 6.
The queries included in FedBench are divided into three categories: Cross-domain (CD), Life Sciences (LS), Linked Data (LD). In addition, it includes SP2Bench queries. The distribution of the queries along with the result set sizes are given in Table 7. Details on the datasets and various advanced statistics are provided at the FedBench project page.14
In this evaluation setting, we selected all queries from CD, LS, and LD, thus performing (to the best of our knowledge) the first evaluation of SPARQL query federation systems on the complete benchmark data of FedBench. It is important to note that SP2Bench was designed with the main goal of evaluating query engines that access data kept in a single repository. Thus, the complete query is answered by a single data set. However, a federated query is one which collects results from multiple data sets. Due to this reason we did not include the SP2Bench queries in our first evaluation. We have included all these queries into our SlicedBench because the data is distributed in 10 different data sets and each SP2Bench query span over more than one data set, thus full-filling the criteria of federated query.
As pointed out in [22] the data partitioning
can affect the overall performance of SPARQL query federation engines. To quantify this
effect, we created 10 slices of each of the 10 datasets given in Table 6 and distributed this data across 10 local virtuoso SPARQL
endpoints (one slice per SPARQL endpoint). Thus, every SPARQL endpoint contained one
slice from each of the 10 datasets. This creates a highly fragmented data environment
where a federated query possibly had to collect data from all of the 10 SPARQL
endpoints. This characteristic of the benchmark stands in contrast to FedBench where the
data is not highly fragmented. Moreover, each of the SPARQL endpoint contained a
comparable amount of triples (load balancing). To facilitate the distribution of the
data, we used the Slice Generator tool employed in [29]. This tool allows setting a discrepancy across the slices, where the
discrepancy is defined as the difference (in terms of number of
triples) between the largest and smallest slice:
This tool generate slices based on horizontal partitioning of the data. Table 8 shows the discrepancy values used for slice generation for each of the 10 datasets. Our discrepancy value varies with the size of the dataset. For the query runtime evaluation, we selected all of the queries both from FedBench and SP2Bench given in Table 7: the reason for this selection was to cover majority of the SPARQL query clauses and types along with variable results size (from 1 to 40 million). For each of the CD, LS, and LD queries used in SlicedBench, the number of results remained the same as given in Table 7. Analogously to FedBench, each of the SlicedBench data source is a virtuoso SPARQL endpoint.
Evaluation criteria
We selected five metrics for our evaluation: (1) total triple pattern-wise sources selected, (2) total number of SPARQL ASK requests used during source selection, (3) answer completeness (4) source selection time (i.e. the time taken by the process in the first metric), and (5) query execution time.
Dataset slices used in SlicedBench
Dataset slices used in SlicedBench

Total triple pattern-wise selected sources example. (TP. = triple pattern-wise selected.)
The total number of triple pattern-wise selected sources for a query is calculated as
follows: Let
An overestimation of triple pattern-wise selected sources increases the source selection time and thus the query execution time. Furthermore, such an overestimation increases the number of irrelevant results which are excluded after joining the results of the different sources, therewith increasing both the network traffic and query execution time. In the next section we explain how such overestimations occur in the selected approaches.
Triple pattern-wise selected sources
Table 9 shows the total number of triple pattern-wise sources (TP sources for short) selected by each approach both for the FedBench and SlicedBench queries. ANAPSID is the most accurate system in terms of TP sources followed by both FedX and SPLENDID whereas similar results are achieved by the other three systems, i.e., LHD, DARQ, and ADERIS. Both FedX and SPLENDID select the optimal number of TP sources for individual query triple patterns. This is because both make use of ASK queries when any of the subject or object is bound in a triple pattern. However, they do not consider whether a source can actually contribute results after performing a join between results with other query triple patterns. Therefore, both can overestimate the set of capable sources that can actually contribute results. ANAPSID uses a catalog and ASK queries along with heuristics [21] about triple pattern joins to reduce the overestimation of sources. LHD (the publicly available version), DARQ, and ADERIS are index-only approaches and do not use SPARQL ASK queries when any of the subject or object is bound. Consequently, these three approaches tend to overestimate the TP sources per individual triple pattern. It is important to note that DARQ does not support queries where any of the predicates in a triple pattern is unbound (e.g., CD1, LS2) and ADERIS does not support queries which feature FILTER or UNION clauses (e.g., CD1, LS1, LS2, LS7). In case of triple patterns with unbound predicates (such as CD1, LS2) both LHD and ADERIS simply select all of the available sources as relevant. This overestimation can significantly increase the overall query execution time.
Comparison of triple pattern-wise total number of sources selected for FedBench and
SlicedBench
Comparison of triple pattern-wise total number of sources selected for FedBench and SlicedBench
Notes: NS stands for “not supported”, RE for “runtime error”, SPL for SPLENDID, ANA
for ANAPSID and ADE for ADERIS. Key results are in
The effect overestimation can be clearly seen by taking a fine-granular look at how the
different systems process FedBench query CD3 given in Listing 1. The optimal number of TP sources for this query is 5. This query has a
total of five triple patterns. To process this query, FedX sends a SPARQL ASK query to
all of the 10 benchmark SPARQL endpoints for each of the triple pattern summing up to a
total of 50 (

FedBench CD3. Prefixes are ignored for simplicity.
Comparison of number of SPARQL ASK requests used for source selection both in FedBench and SlicedBench
Notes: NS stands for “not supported”, RE for “runtime error”, SPL for SPLENDID, ANA
for ANAPSID and ADE for ADERIS. Key results are in
In the SlicedBench results, we can clearly see the TP values are increased for each of
the FedBench queries which mean a query spans more data sources, thus simulating a
highly fragmented environment suitable to test the federation system for effective
parallel query processing. The highest number of TP sources are reported for the second
SP2Bench query where up to a total of 92 TP sources are selected. This
query contains 10 triple patterns and index-free approaches (e.g., FedX) need 100
(
The queries for which some system’s did not retrieve complete results
The queries for which some system’s did not retrieve complete results
Notes: The values inside bracket shows the actual results size. “–” means the
results completeness cannot be determined due to query execution timed out.
Incomplete results are highlighted in
Table 10 shows the total number of SPARQL ASK requests used to perform source selection for each of the queries of FedBench and SlicedBench. Index-only approaches (DARQ, ADERIS, LHD) only make use of their index to perform source selection. Therefore, they do not necessitate any ASK requests to process queries. As mention before, FedX only makes use of ASK requests (along with a cache) to perform source selection. The results presented in Table 10 are for FedX(cold or first run), where the FedX cache is empty. This is basically the lower bound of the performance of FedX. For FedX(100% cached), the complete source selection is performed by using cache entries only. Hence, in that case, the number of SPARQL ASK requests is zero for each query. This is the upper bound of the performance of FedX on the data at hand. The results clearly shows that index-free (e.g., FedX) approaches can be very expensive in terms of SPARQL ASK requests used. This can greatly affect the source selection time and overall query execution time if no cache is used. Both for FedBench and SlicedBench, SPLENDID is the most efficient hybrid approach in terms of SPARQL ASK requests consumed during source selection.
For SlicedBench, all data sources are likely contains the same set of distinct predicates (because each data source contains at least one slice from each data dump). Therefore, the index-free and hybrid source selection approaches are bound to consume more SPARQL ASK requests. It is important to note that ANAPSID combines more than one triple pattern into a single SPARQL ASK query. The time required to execute these more complex SPARQL ASK operations are generally higher than SPARQL ASK queries having a single triple pattern as used in FedX and SPLENDID. Consequently, even though ANAPSID require less SPARQL ASK requests for many of the FedBench queries, its source selection time is greater than all other selected approaches. This behavior will be further elaborated upon in the subsequent section. Tables 9 and 10 clearly show that using SPARQL ASK queries for source selection leads to an efficient source selection in terms of TP sources selected. However, in the next section we will see that they increase both source selection and overall query runtime. A smart source selection approach should select fewer number of TP sources while using minimal number of SPARQL ASK requests.
As pointed in [21], an important criterion in performance evaluation of the federated SPARQL query engines is the result set completeness. Two or more engines are only comparable to each other if they provide the same result set for a given query. A federated engine may miss results due to various reasons including the type of source selection used, the use of an outdated cache or index, the type of network, the endpoint result size limit or even the join implementation. In our case, the sole possible reason for missing results across all six engines is the join implementation as all of the selected engines overestimate the set of capable sources (i.e., they never generate false negatives w.r.t. the capable sources), the cache, index are always up-to-date, the endpoint result size limit is greater than the query results and we used a local dedicated network with negligible network delay. Table 11 shows the queries and federated engines for which we did not receive the complete results. As an overall answer completeness evaluation, only FedX is always able to retrieve complete results. It is important to note that these results are directly connected to the answer completeness results presented in survey Table 2; which shows only FedX is able to provide complete results among the selected systems.
Source selection time

Comparison of source selection time for FedBench and SlicedBench.
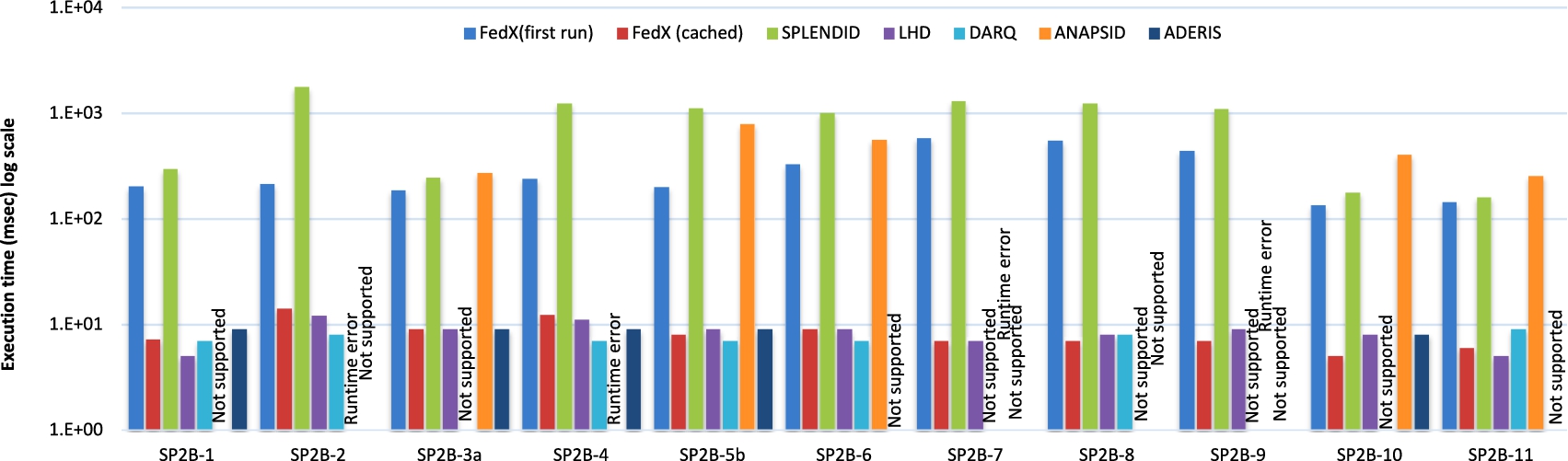
Comparison of source selection time for SP2Bench queries in SlicedBench.
Figures 2 and 3 show the source selection time for each of the selected approaches and for both FedBench and SlicedBench. Compared to the TP results, the index-only approaches require less time than the hybrid approaches even though they overestimated the TP sources in comparison with the hybrid approaches. This is due to index-only approaches not having to send any SPARQL ASK queries during the source selection process. The index being usually pre-loaded into the memory before the query execution means that the runtime the predicate look-up in index-only approaches is minimal. Consequently, we observe a trade-off between the intelligent source selection and the time required to perform this process. To reduce the costs associated with ASK operations, FedX implements a cache to store the results of the recent SPARQL ASK operations. Figure 2 shows that source selection time of FedX with cached entries is significantly smaller than FedX’s first run with no cached entries.
As expected the source selection time for FedBench queries is smaller than that for SlicedBench, particularly in hybrid approaches. This is because the number of TP sources for SlicedBench queries are increased due to data partitioning. Consequently, the number of SPARQL ASK requests grows and increases the overall source selection time. As mentioned before, an overestimation of TP sources in highly federated environments can greatly increase the source selection time. For example, consider query LD4. SPLENDID selects the optimal (i.e., five) number of sources for FedBench and the source selection time is 218 ms. However, it overestimates the number of TP sources for SlicedBench by selecting 30 instead of 5 sources. As a result, the source selection time is significantly increased to 1035 ms which directly affects the overall query runtime. The effect of such overestimation is even worse in SP2B-2 and SP2B-4 queries for the SlicedBench.
Lessons learned from the evaluation of the first three metrics is that using ASK queries for source selection leads to smart source selection in term of total TP sources selected. On the other hand, they significantly increase the overall query runtime where no caching is used. FedX makes use of an intelligent combination of parallel ASK query processing and caching to perform the source selection process. This parallel execution of SPARQL ASK queries is more time-efficient than the ASK query processing approaches implemented in both ANAPSID and SPLENDID. Nevertheless, the source selection of FedX could be improved further by using heuristics such as ANAPSID’s to reduce the overestimation of TP sources.

Comparison of query execution time for FedBench and SlicedBench.
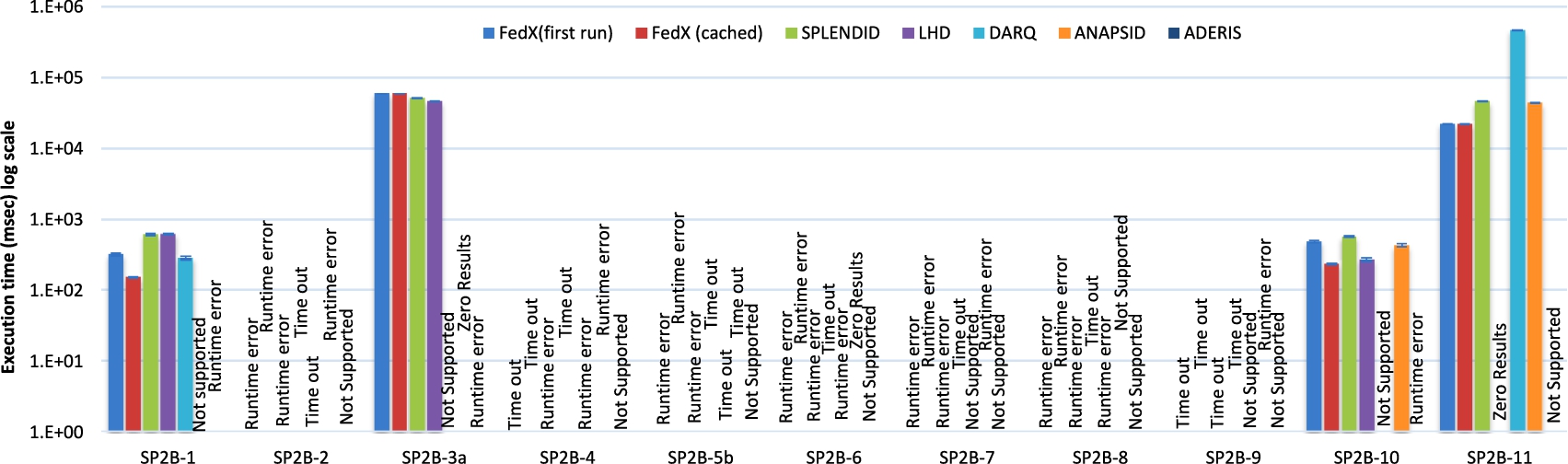
Comparison of query execution time forSlicedBench: SP2Bench queries.
Figures 4 and 5 show the query execution time for both experimental setups. The negligibly small standard deviation error bars (shown on top of each bar) indicate that the data points tend to be very close to the mean, thus suggest a high consistency of the query runtimes in most frameworks. As an overall query execution time evaluation, FedX(cached) outperforms all of the remaining approaches in majority of the queries. FedX(cached) is followed by FedX(first run) which is further followed by LHD, SPLENDID, ANAPSID, ADERIS, and DARQ. Deciding between DARQ and ADERIS is not trivial because the latter does not produce results for most of the queries. The exact number of queries by which one system is better than other is given in the next section (ref. Section 7.1). Furthermore, the number of queries by which one system significantly outperform other (using Wilcoxon signed rank test) is also given in the next section.
Interestingly, while ANAPSID ranks first (among the selected systems) in terms of triple pattern-wise sources selected results, it ranks fourth in terms of query execution performance. There are a couple of reason for this: (1) ANAPSID does not make use of cache. As a result, it spends more time (8 ms for FedX and 1265 ms for ANAPSID on average over both setups) performing source selection, which worsens its query execution time and (2) Bushy tress (used in ANAPSID) only perform better than left deep trees (used in FedX) when the queries are more complex and triple patterns joins are more selective [3,14]. However, the FedBench queries (excluding SP2Bench) are not very selective and are rather simple, e.g., triple patterns in a query ranges from 2 to 7. In addition, the query result set sizes are small (10 queries whose resultset size smaller than 16) and the average query execution is small (about 3 seconds on average for FedX over both setups). The SP2Bench queries are more complex and the resultset sizes are large. However, the selected systems were not able to execute majority of the SP2Bench queries. It would be interesting to compare these systems on more complex and Big Data benchmark. The use of a cache improves FedX’s performance by 10.5% in the average query execution for FedBench and 4.14% in SlicedBench.
The effect of the overestimation of the TP sources on query execution can be observed
on the majority of the queries for different systems. For instance, for FedBench’s LD4
query SPLENDID selects the optimal number of TP sources (i.e., five) and the query
execution time is 318 ms of which 218 ms are used for selecting sources. For
SlicedBench, SPLENDID overestimates the TP sources by 25 (i.e., selects 30 instead of 5
sources), resulting in a query execution of 10693 ms, of which 1035 ms are spent in the
source selection process. Consequently, the pure query execution time of this query is
only 100 ms for FedBench (318-218) and 9659 ms (10693-1035) for SlicedBench. This means
that an overestimation of TP sources does not only increase the source selection time
but also produces results which are excluded after performing join operation between
query triple patterns. These retrieval of irrelevant results increases the network
traffic and thwarts the query execution plan. For example, both FedX and SPLENDID
considered 285412 irrelevant triples due to the overestimation of 8 TP sources only for
In queries such as CD4, CD6, LS3, LD11 and SP2B-11 we observe that the query execution time for DARQ is more than 2 minutes. In some cases, it even reaches the 30 minute timeout used in our experiments. The reason for this behavior is that the simple nested loop join it implements overfloods SPARQL endpoints by submitting too many endpoint requests. FedX overcomes this problem by using a block nested loop join where the number of endpoints requests are dependent upon the block size. Furthermore, we can see that many systems do not produce results for SP2Bench queries. A possible reason for this is the fact that SP2Bench queries contain up to 10 triple patterns with different SPARQL clauses such as DISTINCT, ORDER BY, and complex FILTERS.
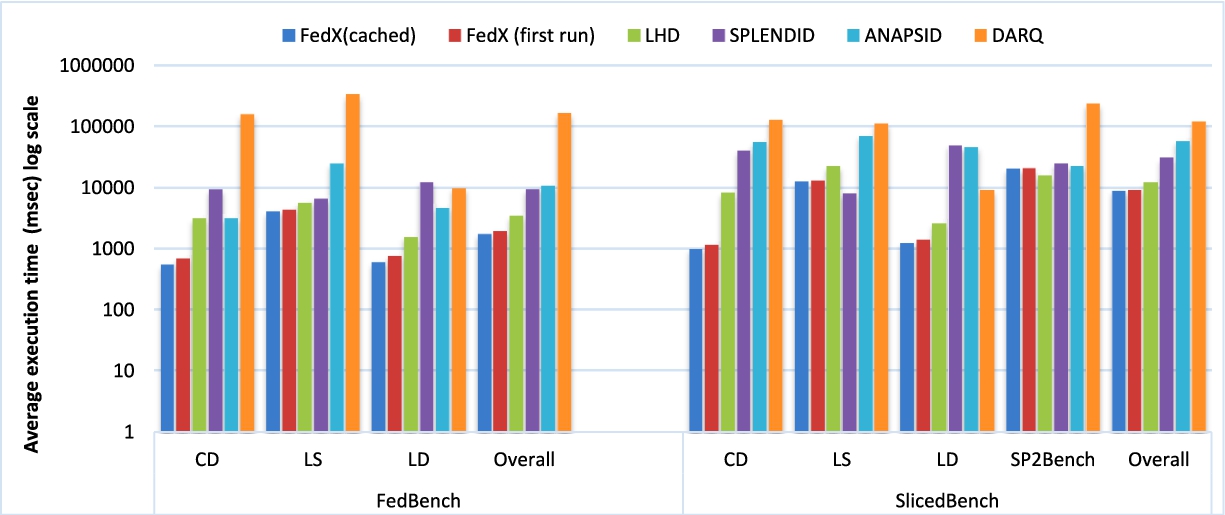
Overall performance evaluation (ms).
The comparison of the overall performance of each approach is summarized in Fig. 6, where we show the average query execution time for the queries in CD, LS, LD, and SP2Bench sub-groups. As an overall performance evaluation based on FedBench, FedX(cached) outperformed FedX(first run) on all of the 25 queries. FedX(first run) in turn outperformed LHD on 17 out of 22 commonly supported queries (LHD retrieve zero results for three queries). LHD is better than SPLENDID in 13 out of 22 comparable queries. SPLENDID outperformed ANAPSID in 15 out of 24 queries while ANAPSID outperforms DARQ in 16 out of 22 commonly supported queries. For SlicedBench, FedX(cached) outperformed FedX(first run) in 29 out of 36 comparable queries. In turn FedX(first run) outperformed LHD in 17 out of 24 queries. LHD is better than SPLENDID in 17 out of 24 comparable queries. SPLENDID outperformed ANAPSID in 17 out of 26 which in turn outperformed DARQ in 12 out of 20 commonly supported queries. No results were retrieved for majority of the queries in case of ADERIS, hence not included to this section. All of the above improvements are significant based on Wilcoxon signed ranked test with significance level set to 0.05.
Discussion
The subsequent discussion of our findings can be divided into two main categories.
Effect of the source selection time

Comparison of pure query execution time (without source selection time) for FedBench and SlicedBench.
To the best of our knowledge, the effect of the source selection runtime has not been considered in SPARQL query federation system evaluations [1,7,21,26,33] so far. However, after analyzing all of the results presented above, we noticed that this metric greatly affects the overall query execution time. To show this effect, we compared the pure query execution time (excluding source selection time). To calculate the pure query execution time, we simply subtracted the source selection time from the overall query execution and plot the execution time in Fig. 7.
We can see that the overall query execution time (including source selection given in Fig. 4) of SPLENDID is better than FedX(cached) in only one out of the 25 FedBench queries. However, Fig. 7 suggests that SPLENDID is better in 8 out of the 25 queries in terms of the pure query execution time. This means that SPLENDID is slower than FedX (cached) in 33% of the queries only due to the source selection process. Furthermore, our results also suggest that the use of SPARQL ASK queries for source selection is expensive without caching. On average, SPLENDID’s source selection time is 235 ms for FedBench and 591 ms in case of SlicedBench. On the other hand, FedX (cached)’s source selection time is 8 ms for both FedBench and SlicedBench. ANAPSID average source selection time for FedBench is 507 ms and 2014 ms for SlicedBench which is one of the reason of ANAPSID poor performance as compare to FedX (cached).

Effect of the data partitioning.
In our SlicedBench experiments, we extended FedBench to test the federation systems behavior in highly federated data environment. This extension can also be utilized to test the capability of parallel execution of queries in SPARQL endpoint federation system. To show the effect of data partitioning, we calculated the average for the query execution time of LD, CD, and LS for both the benchmarks and compared the effect on each of the selected approach. The performance of FedX(cached) and DARQ is improved with partitioning while the performance of FedX(first run), SPLENDID, ANAPSID, and LHD is reduced. As an overall evaluation result, FedX(first run)’s performance is reduced by 214%, FedX(cached)’s is reduced 199%, SPLENDID’s is reduced by 227%, LHD’s is reduced by 293%, ANAPSID’s is reduced by 382%, and interestingly DARQ’s is improved by 36%. This results suggest that FedX is the best system in terms of parallel execution of queries, followed by SPLENDID, LHD, and ANAPSID. The performance improvement for DARQ occurs due to the fact that the overflooding of endpoints with too many nested loop requests to a particular endpoint is now reduced. This reduction is due to the different distribution of the relevant results among many SPARQL endpoints. One of the reasons for the performance reduction in LHD is its significant overestimation of TP sources in SlicedBench. The reduction of both SPLENDID’s and ANAPSID’s performance is due to an increase in ASK operations in SlicedBench and due to the increase in triple pattern-wise selected sources which greatly affects the overall performance of the systems when no cache used.
In this paper, we evaluated six SPARQL endpoint federation systems based on extended performance metrics and evaluation framework. We kept the main experimental metric (i.e. query execution time) unchanged and showed that the three other metrics (i.e., total triple pattern-wise selected sources, total number of SPARQL ASK request used during source selection, and source selection time), which did not receive much attention so far, can significantly affect the main metric. We also measured the effect of the data partitioning on these systems to test the effective parallel processing in each of the federation system. Overall, our results suggest that a combination of caching and ASK queries with accurate heuristics for source selection (as implemented in ANAPSID) has the potential to lead to a significant improvement of the overall runtime of federated SPARQL query processing systems.
In future work, we will aim to get access to and evaluate the systems from our survey which do not provide a public implementation and those which are recently published, e.g., HiBISCuS [28] which emphasize on efficient source selection for SPARQL endpoint federation and SAFE [17] performs policy based source selection. We will also measure the effect of a range of various features (e.g., RAM size, SPARQL endpoint capabilities restrictions, vertical and hybrid partitioning, and duplicate detection) on the overall runtime of federated SPARQL engine. The resultset correctness is an important metric as well to be considered in future. A tool which automatically measures the precision, recall and F1 scores is on the road-map. Furthermore, we will assess these systems on big data SPARQL query federation benchmark.
Footnotes
Acknowledgements
This work was partially supported by the EU FP7 projects GeoKnow (GA: 318159) and BioASQ (GA: 318652) as well as the DFG project LinkingLOD and the BMWi project SAKE.