
Abstract
There is an emerging demand on efficiently archiving and (temporal) querying different versions of evolving semantic Web data. As novel archiving systems are starting to address this challenge, foundations/standards for benchmarking RDF archives are needed to evaluate its storage space efficiency and the performance of different retrieval operations. To this end, we provide theoretical foundations on the design of data and queries to evaluate emerging RDF archiving systems. Then, we instantiate these foundations along a concrete set of queries on the basis of a real-world evolving datasets. Finally, we perform an extensive empirical evaluation of current archiving techniques and querying strategies, which is meant to serve as a baseline of future developments on querying archives of evolving RDF data.
Introduction
Nowadays, RDF data is ubiquitous. In less than a decade, and thanks to active projects such as the Linked Open Data (LOD) [5] effort or schema.org, researchers and practitioners have built a continuously growing interconnected Web of Data. In parallel, a novel generation of semantically enhanced applications leverage this infrastructure to build services which can answer questions not possible before (thanks to the availability of SPARQL [21] which enables structured queries over this data). As previously reported [23,42], this published data is continuously undergoing changes (on a data and schema level). These changes naturally happen without a centralized monitoring nor pre-defined policy, following the scale-free nature of the Web. Applications and businesses leveraging the availability of certain data over time, and seeking to track data changes or conduct studies on the evolution of data, thus need to build their own infrastructures to preserve and query data over time. Moreover, at the schema level, evolving vocabularies complicate re-use as inconsistencies may be introduced between data relying on a previous version of the ontology.
Thus, archiving policies of Linked Open Data (LOD) collections emerges as a novel – and open – challenge aimed at assuring quality and traceability of Semantic Web data over time. While sharing the same overall objectives with traditional Web archives, such as the Internet Archive,1
This paper discusses the emerging problem of evaluating the efficiency of the required retrieval demands in RDF archives. To the best of our knowledge, few and very initial works have been proposed to systematically benchmark RDF archives. EvoGen [27] is a recent suite that extends the traditional LUBM benchmark [19] to provide a dataset generator for versioned RDF data. However, the system is limited to a unique dataset and very constrained synthetic data. The recent HOBBIT2
In order to fill this gap, our main
We analyse current RDF archiving proposals and provide theoretical foundations on the design of benchmark data and specific queries for RDF archiving systems;
We provide a concrete instantiation of such queries using AnQL [48], a query language for annotated RDF data.
we present a prototypical BEnchmark of RDF ARchives (referred to as BEAR), a test suite composed of three real-world datasets from the Dynamic Linked Data Observatory [23] (referred to as BEAR-A), DBpedia Live [22] (BEAR-B) and the European Open Data portal3
we implement RDF archiving systems on different RDF stores and archiving strategies, and we evaluate them, together with other existing archiving systems in the literature, using BEAR. This evaluation is aimed at establishing an (extensible) baseline and illustrate our foundations.
The paper is organized as follows. First, Section 2 reviews current RDF archiving proposals. We establish the theoretical foundations in Section 3, formalizing the key features to characterize data and queries to evaluate RDF archives. Section 4 instantiates these guidelines and presents the proposed BEAR test suite. In Section 5, we detail the implemented RDF archives and we evaluate BEAR with different archiving systems. Finally, we conclude and point out future work in Section 6. Appendixes A, B and C provide further details on the BEAR-A, BEAR-B and BEAR-C test suite respectively.

Example of RDF graph versions.
Classification and examples of retrieval needs
We briefly summarise the necessary findings of our previous survey on current archiving techniques for dynamic Linked Open Data [13]. The use case is depicted in Fig. 1, showing an evolving RDF graph with three versions
Retrieval functionality
Given the relative novelty of archiving and querying evolving semantic Web data, retrieval needs are neither fully described nor broadly implemented in practical implementations (described below). Table 1 shows a first classification [13,39] that distinguishes six different types of retrieval needs, mainly regarding the query type (materialisation or structured queries) and the main focus (version/delta) of the query.
See the Internet Archive effort,
Main efforts addressing the challenge of RDF archiving fall in one of the following three storage strategies [13]: independent copies (IC), change-based (CB) and timestamp-based (TB) approaches.
A query mediator for this policy manages a materialised version and the subsequent deltas. Thus, CB requires additional computational costs for delta propagation which affects version-focused retrieving operations. Although an alternative policy could always keep a materialisation of the current version and store reverse deltas with respect to this latter [39], such deltas still need to be propagated to access previous versions.
Finally, [41] builds a partial order index keeping a hierarchical track of changes. This proposal, though, is a limited variation of delta computation and it is only tested with datasets having some thousand triples.
Evaluation of RDF archives: Challenges and guidelines
Previous considerations on RDF archiving policies and retrieval functionality set the basis of future directions on evaluating the efficiency of RDF archives. The design of a benchmark for RDF archives should meet three requirements:
The benchmark should be
Early benchmarks should mainly focus on simpler queries against an increasing number of snapshots and introduce complex querying once the policies and systems are better understood.
While new retrieval features must be incorporated to benchmark archives, one should consider lessons learnt in previous recommendations on benchmarking RDF data management systems [1].
Although many benchmarks are defined for RDF stores [1,6] (see the Linked Data Benchmark Council project [7] for a general overview) and related areas such as relational databases (e.g. the well-known TPC5
We next formalize the most important features to characterize data and queries to evaluate RDF archives. These will be instantiated in the next section to provide a concrete experimental testbed.
We first provide semantics for RDF archives and adapt the notion of temporal RDF graphs by Gutierrez et al. [20]. In this paper, we make a syntatic-sugar modification to put the focus on version labels instead of temporal labels. Note, that time labels are a more general concept that could lead to time-specific operators (intersect, overlaps, etc.), which is complementary – and not mandatory – to RDF archives. Let
(RDF Archive).
A version-annotated triple is an RDF triple
(RDF Version).
An RDF version of an RDF archive
As basis for comparing different archiving policies, we introduce four main features to describe the dataset configuration, namely data dynamicity, data static core, total version-oblivious triples and RDF vocabulary.
Data dynamicity
This feature measures the number of changes between versions, considering these differences at the level of triples (low-level deltas [47]). Thus, it is mainly described by the change ratio and the data growth between versions. We note that there are various definitions of change and growth metrics conceivable, and we consider our framework extensible in this respect with other, additional metrics. At the moment, we consider the following definitions of change ratio, insertion ratio, deletion ratio and data growth:
(Change ratio).
Given two versions
That is, the change ratio between two versions should express the ratio of all triples in
(Insertion ratio, deletion ratio).
The insertion
Finally, the data growth rate compares the number of triples between two versions:
(data growth).
Given two versions
In archiving evaluations, one should provide details on three related aspects,
The accumulated change ratio
The rationale here is that
Note that most archiving policies are affected by the frequency and also the type of changes, that is both absolute change metrics and accumulated change rates play a role. For instance, IC policy duplicates the static information between two consecutive versions
Data static core
It measures the triples that are available in all versions:
For an RDF archive
This feature is particularly important for those archiving policies that, whether implicitly or explicitly, represent such static core. In a change-based approach, the static core is not represented explicitly, but it inherently conforms the triples that are not duplicated in the versions, which is an advantage against other policies such as IC. It is worth mentioning that the static core can be easily computed taking the first version and applying all the subsequent deletions.
Total version-oblivious triples
This computes the total number of different triples in an RDF archive independently of the timestamp. Formally speaking:
(Version-oblivious triples).
For an RDF archive
This feature serves two main purposes. First, it points to the diverse set of triples managed by the archive. Note that an archive could be composed of few triples that are frequently added or deleted. This could be the case of data denoting the presence or absence of certain information, e.g. a particular case of RDF streaming. Then, the total version-oblivious triples are in fact the set of triples annotated by temporal RDF [20] and other representations based on annotation (e.g. AnQL [48]), where different annotations for the same triple are merged in an annotation set (often resulting in an interval or a set of intervals).
RDF vocabulary
In general, we cover under this feature the main aspects regarding the different subjects (
(RDF vocabulary per version).
For an RDF archive
(RDF vocabulary per delta).
For an RDF archive
(RDF vocabulary set dynamicity).
The dynamicity of a vocabulary set K, being K one of
Likewise, the vocabulary set dynamicity for insertions and deletions is defined by
The evolution (cardinality and dynamicity) of the vocabulary is specially relevant in RDF archiving, since traditional RDF management systems use dictionaries (mappings between terms and integer IDs) to efficiently manage RDF graphs. Finally, whereas additional graph-based features (e.g. in-out-degree, clustering coefficient, presence of cliques, etc.) are interesting and complementary to our work, our proposed properties are feasible (efficient to compute and analyse) and grounded in state-of-the-art of archiving policies.
Design of benchmark queries
There is neither a standard language to query RDF archives, nor an agreed way for the more general problem of querying temporal graphs. Nonetheless, most of the proposals (such as T-SPARQL [16], stSPARQL [3], SPARQL-ST [35] and the most recent SPARQ-LTL [14]) are based on SPARQL modifications.
In this scenario, previous experiences on benchmarking SPARQL resolution in RDF stores show that benchmark queries should report on the query type, result size, graph pattern shape, and query atom selectivity [37]. Conversely, for RDF archiving, one should put the focus on data dynamicity, without forgetting the strong impact played by query selectivity in most RDF triple stores and query planning strategies [1].
Let us briefly recall and adapt definitions of query cardinality and selectivity [1,2] to RDF archives. Given a SPARQL query Q, where we restrict to SPARQL Basic Graph Patterns (BGPs6
Sets of triple patterns, potentially including a FILTER condition, in which all triple patterns must match.
The archive-driven result cardinality of Q over the RDF archive
(Version-driven result cardinality).
The version-driven result cardinality of Q over a version
(Version-driven result dynamicity).
The version-driven result dynamicity of the query Q over two versions
Likewise, we define the version-driven result insertion
The archive-driven result cardinality is reported as a feature directly inherited from traditional SPARQL querying, as it disregards the versions and evaluates the query over the set of triples present in the RDF archive. Although this feature could be only of peripheral interest, the knowledge of this feature can help in the interpretation of version-agnostic retrieval purposes (e.g. ASK queries).
As stated, result cardinality and query selectivity are main influencing factors for the query performance, and should be considered in the benchmark design and also known for the result analysis. In RDF archiving, both processes require particular care, given that the results of a query can highly vary in different versions. Knowing the version-driven result cardinality and selectivity helps to interpret the behaviour and performance of a query across the archive. For instance, selecting only queries with the same cardinality and selectivity across all version should guarantee that the index performance is always the same and as such, potential retrieval time differences can be attributed to the archiving policy. Finally, the version-driven result dynamicity does not just focus on the number of results, but how these are distributed in the archive timeline.
In the following, we introduce five foundational query atoms to cover the broad spectrum of emerging retrieval demands in RDF archiving. Rather than providing a complete catalog, our main aim is to reflect basic retrieval features on RDF archives, which can be combined to serve more complex queries. We elaborate these atoms on the basis of related literature, with special attention to the needs of the well-established Memento Framework [43], which can provide access to prior states of RDF resources using datetime negotiation in HTTP.
Within the Memento Framework, this operation is needed to provide mementos (URI-M) that encapsulate a prior state of the original resource (URI-R).
A particular case of delta materialisation is to retrieve all the differences between
Within the Memento Framework, change materialisation is needed to provide timemap information to compile the list of all mementos (URI-T) for the original resource, i.e. the basis of datetime negotiation handled by the timegate (URI-G).
These query features can be instantiated in domain-specific query languages (e.g. DIACHRON QL [28]) and existing temporal extensions of SPARQL (e.g. T-SPARQL [16], stSPARQL [3], SPARQL-ST [35], and SPARQ-LTL [14]). We include below an instantiation of these five queries in AnQL [48], as well as a discussion of how these AnQL queries could be evaluated over off-the-shelf RDF stores using “pure” SPARQL. However, since such an approach would typically render rather inefficient SPARQL queries, in the following sections, we focus on tailored implementations using optimized storage techniques to serve these features.
Instantiation in a concrete query language: AnQL
In order to “ground” the five concrete query cases outlined above, we herein propose the syntactic abstraction of AnQL [48], a query language that provides some syntactic sugar for (time-)annotated RDF data and queries on top of SPARQL. This abstraction helps us – as a tradeoff between concrete instantiation in SPARQL as a query language and implementation issues underneath – to illustrate differences between IC, CB and TB as storage strategies from the viewpoint of an off-the shelf RDF store.
AnQL is a query language defined as a – relatively straightforward – extension of SPARQL, where a SPARQL triple pattern t is allowed to be annotated with a (temporal7
Note that in [48] we also discuss various other annotation domains.
Moreover, for simplicity, we extend an AnQL BAP (basic annotated pattern), that is, a SPARQL Basic graph pattern (BGP) which may contain such annotated triple patterns as follows: Let P be a SPARQL graph pattern, then we write
Using this notation, we can “instantiate” the queries from above as follows in AnQL.


Here, the newly bound variable



Based on these queries, a naive implementation of IC, TB and CB on top of an off-the-shelf triple store could now look as follows:
All triples of each instance/version would be stored in named graphs with the version name being the graph name and respective metadata about the version number on the default graph. That is, a triple
Then, each annotated pattern 
TB
All triples appearing in any instance/version could be stored as a single reified triple, with additional meta-information in which version the triple is true in disjoint from-to ranges to indicate the version ranges when a particular triple was true. That is, a triple

Note that this representation allows for a compact representation of several disjoint (maximal) validity intervals of the same triple, thus causing less overhead than the graph-based representation discussed for IC. The translation for annotated query patterns

Unfortunately, this “recipe” does not work for
As for

Let us call the BGP translated this way
Note that, unfortunately, strictly speaking the function min() and max() used here exist in SPARQL only as aggregates for subqueries and not as functions over value lists, but for instance an expression

Analogously,

Note that this works because
Finally, let us note that the implementation sketched here only works for Q being a BGP (as we originally assumed). As for more complex patterns such as OPTIONAL, MINUS, NOT EXISTS or patterns involving complex FILTERS or even aggregations, a simple translation like the one sketched here would not return correct results in the general case.
We emphasize that a change-based storage of RDF triples has no trivial implementation in an off-the shelf RDF store. Again, change -deltas (triple additions and deletions between versions could be stored in separate graphs, starting with an original graph

Then the validity of a triple pattern t in a particular version

The translation of whole AnQL queries in the case of CB is therefore, by no means trivial, as this covers only single triple patterns. Whereas we do not provide the full translation for CB here, we hope that the sketch here, along with the translations for IC and TB above, have served to illustrate that an implementation of RDF archives and queries in off-the-shelf RDF stores and using SPARQL is a non-trivial exercise – even the translated patterns for CB and IC sketched above would likely not scale to large archives of dynamic RDF data and complex queries. Therefore, in our current evaluation (Section 5), we focus on tailored implementations using efficient, optimized storage techniques to implement these features, using rather simple triple pattern queries and joins of triple patterns, as opposed to full SPARQL BGPs.
BEAR: A test suite for RDF archiving
This section presents BEAR, a prototypical (and extensible) test suite to demonstrate the new capabilities in benchmarking the efficiency of RDF archives using our foundations, and to highlight current challenges and potential improvements in RDF archiving. BEAR comprises three main datasets, namely BEAR-A, BEAR-B, and BEAR-C, each having different characteristics. We first detail the dataset descriptions and the query set covering basic retrieval needs for each of these datasets in Sections 4.1–4.3. In the next section (5) we will evaluate BEAR on different archiving systems. The complete test suite (data corpus, queries, archiving system source codes, evaluation and additional results) is available at the BEAR repository.9
The first benchmark we consider provides a realistic scenario on queries about the evolution of Linked Data in practice.
Dataset description
BEAR-A Dataset configuration
BEAR-A Dataset configuration

Dataset description.
We build our RDF archive on the data hosted by the Dynamic Linked Data Observatory,10
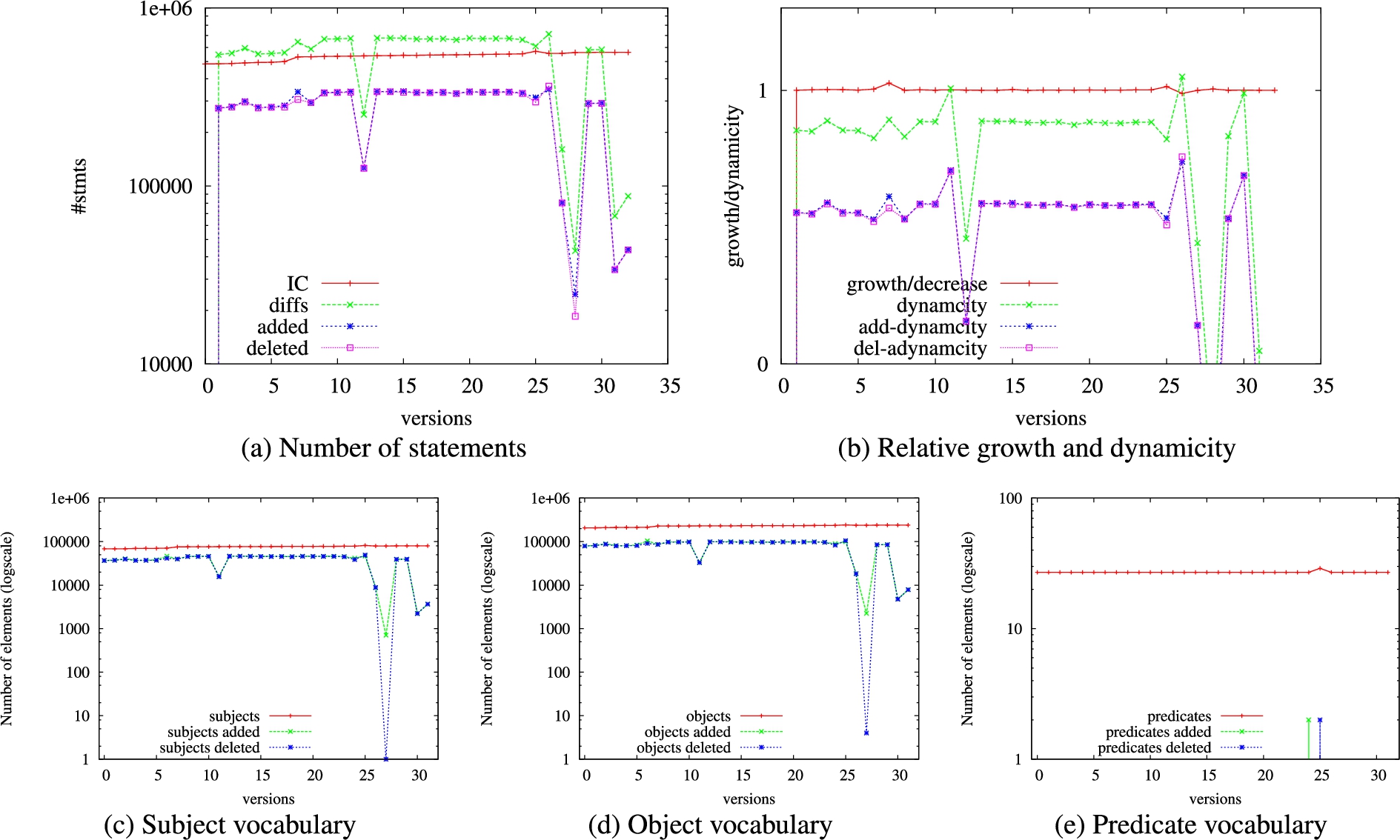
We report the data configuration features (cf. Section 3) that are relevant for our purposes. Table 2 lists basic statistics of our dataset, further detailed in Fig. 2, which shows the figures per version and the vocabulary evolution. Data growth behaviour (dynamicity) can be identified at a glance: although the number of statement in the last version (
A closer look to Fig. 2 (a) allows to identify that the latest versions are highly contributing to this increase. Similarly, the version change ratios12
Note that
Conversely, the number of version-oblivious triples (
Finally, Figs 2 (c)–(e) show the RDF vocabulary (different subjects, predicates and objects) per version and per delta (adds and deletes). As can be seen, the number of different subjects and predicates remains stable except for the noticeable increase in the latests versions, as already identified in the number of statements per versions. However, the number of added and deleted subjects and objects fluctuates greatly and remain high (one order of magnitude of the total number of elements, except for the aforementioned
BEAR-A provides triple pattern queries Q to test each of the five atomic operations defined in our foundations (Section 3). Note that, although such queries do not cover the full spectrum of SPARQL queries, triple patterns (i) constitute the basis for more complex queries, (ii) are the main operation served by lightweight clients such as the Linked Data Fragments [45] proposal, and (iii) they are the required operation to retrieve prior states of a resource in the Memento Framework. For simplicity, we present here atomic lookup queries Q in the form (S??), (?P?), and (??O), which are then extended to the rest of triple patterns (SP?), (S?O), (?PO), and (SPO).13
The triple pattern (???) retrieves all the information, so no sampling technique is required.

Materialization of a (?P?) triple pattern in version 3
As for the generation of queries, we randomly select such triple patterns from the 58 versions of the Dynamic Linked Data Observatory. In order to provide comparable results, we consider entirely dynamic queries, meaning that the results always differ between consecutive versions. In other words, for each of our selected queries Q, and all the versions
Then, we follow the foundations and try to minimise the influence of the result cardinality on the query performance. For this purpose, we sample queries which return, for all versions, result sets of similar size, that is,
Thus, the previous selected dynamic queries are effectively run over each version in order to collect the result cardinality. Next, we split subject, objects and predicate queries producing low (
Overview of BEAR-A lookup queries
Section 5 provides an evaluation of (i) version materialisation, (ii) delta materialisation and (iii) version queries for these lookup queries under different state-of-the-art archiving policies. Appendix A extends the lookup queries to triple patterns (SP?), (S?O) and (?PO). We additionally sample 50 (SPO) queries from the static core.
BEAR-B Dataset configuration
Our next benchmark, rather than looking at arbitrary Linked Data, is focung on the evolution of DBpedia, which directly reflect Wikipedia edits, where we can expect quite different change/evolution characteristics.
Dataset description
The BEAR-B dataset has been compiled from DBpedia Live changesets14
As dataset updates in DBpedia Live occur instantly, for every single update the dataset shifts to a new version. In practice, one would possibly aggregate such updates in order to have less dataset modifications. Therefore, we also aggregated these updates on an hourly and daily level. Hence, we get three time granularities from the changesets for the very same dataset: instant (21,046 versions), hour (1,299 versions), and day (89 versions).
Detailed characteristics of the dataset granularities are listed in Table 4. The dataset grows almost continuously from 33,502 triples to 43,907 triples. Since the time granularities differ in the number of intermediate versions, they show different change characteristics: a longer update cycle also results in more extensive updates between versions, the average version change ratio increases from very small portions of 0.011% for instant updates to 1.8% at the daily level. It can also be seen that the aggregation of updates leads to omission of changes: whereas the instant updates handle 234,588 version-oblivious triples, the daily aggregates only have 83,134 (hourly: 178,618), i.e. a reasonable number of triples exists only for a short period of time before they get deleted again. Likewise, from the different sizes of the static core, we see that triples which have been deleted at some point are re-inserted after a short period of time (in the case of DBpedia Live this may happen when changes made to a Wikipedia article are reverted shortly after).
BEAR-B allows one to use the same sampling methodology as BEAR-A to retrieve dynamic queries. Nonetheless, we exploit the real-world usage of DBpedia to provide realistic queries. Thus, we extract the 200 most frequent triple patterns from the DBpedia query set of Linked SPARQL Queries dataset (LSQ) [36] and filter those that produce results in our BEAR-B corpus. We then obtain a batch of 62 lookup queries, mixing (?P?) and (?PO) queries, evaluated in Section 5. The full batch has a

Example of a join query in BEAR-B
The third dataset is taken from the Open Data Portal Watch project, a framework that monitors over 260 Open Data portals in a weekly basis and performs a quality assessment. The framework harvests the dataset descriptions in the portals and converts them to their DCAT representation. We refer to [31] for more details.
Dataset description
For BEAR-C, we decided to take the datasets descriptions of the European Open Data portal15
BEAR-C Dataset configuration
Dataset description.
Selected triple patterns in BEAR-A cover queries whose dynamicity is well-defined, hence it allows for a fine-grained evaluation of different archiving strategies (and particular systems). In turn, BEAR-B adopts a realistic approach and gather real-word queries from DBpedia. Thus, we provide complex queries for BEAR-C that, although they cannot be resolved in current archiving strategies in a straightforward and optimized way (as discussed in Section 3.3 for the CB approach), they could help to foster the development and benchmarking of novel strategies and query resolution optimizations in archiving scenarios.
With the help of Open Data experts, we created 10 queries that retrieve different information from datasets and files (referred to as distributions, where each dataset refers to one or more distributions) in the European Open Data portal. For instance,

BEAR-C Q1: Retrieve portals and their files
Note that queries are provided as group graph pattern, such that they can be integrated in the AnQL notation16
BEAR-C queries intentionally included UNION and OPTIONAL to extend the application beyond Basic Graph Patterns.
We illustrate the use of our foundations to evaluate RDF archiving systems. To do so, we built two RDF archiving systems using the Jena’s TDB store17
Note that we considered these particular open RDF stores given that they are (i) easy to extend in order to implement the suggested archiving strategies, (ii) representative in the community and (iii) useful for potential archiving adopters. Jena is widely used in the community and can be considered as the de-facto standard implementation of most W3C efforts in RDF querying (SPARQL) and reasoning. In turn, HDT is a compressed store that considerably reduces space requirements of state-of-the-art stores (e.g. Virtuoso), hence it perfectly fits space efficiency requirements for archives. Furthermore, HDT is the underlying store of potential archiving adopters such as the crawling system LOD Laundromat,18
LOD Laundromat only serves the last crawled version of a dataset.
We implemented the different policies in Jena as follows. For the IC policy (referred to as Jena-IC), we index each version in an independent TDB instance. Likewise, for the CB policy (Jena-CB), we create an index for each added and deleted statements, again for each version and using an independent TDB store. In the TB policy (Jena-TB), we indexed all triples in one single TDB instance, using named graphs to indicate the versions of each triple. Listing 4 shows an example (in TriG notation [4]) with a triple (_:Jon foaf:name "Doe") in versions 1 and 2 and a triple (:Jon foaf:email "j@example.org") in versions 1 and 3. The graph

Example of realization of a TB approach
Then, we implemented the hybrid
We follow the same strategy to develop the IC and CB strategies in HDT [12] (referred to as HDT-IC, HDT-CB and HDT-
We use the HDT C++ libraries at
In addition, we compare these systems with three state-of-the-art RDF archiving systems: R43ples [17] (v. 0.8.721
R43ples stores the recent version fully materialized, and previous versions can be queried by applying deltas in a reverse way.
Tests were performed on a computer with 2× Intel Xeon E5-2650v2 @ 2.6 GHz (16 cores), RAM 171 GB, 4 HDDs in RAID 5 config. (2.7 TB netto storage), Ubuntu 14.04.5 LTS running on a VM with QEMU/KVM hypervisor. We report elapsed times in a warm scenario, given that all systems are based on disk except for HDT and v-RDFCSA, which perform on memory.
Space of the different archiving systems and policies
Table 6 shows the required on-disk space for the raw data of the corpus, the GNU diff of such data, and the space required by the Jena and HDT24
We include the space overheads of the provided HDT indexes to solve all lookups.
Several comments are in order. As expected, the diff data take much less space than the raw gzipped data, and the space savings are highly affected by the dynamicity of the data. For example, Both BEAR-A and BEAR-C are highly dynamic (
A comparison of these figures against the size of the different systems and policies allows for describing their inherent overheads. First, Jena-CB and HDT-CB highly reduce the space needs of their IC counterparts, following the same tendency as the diff, i.e., CB policies achieve better space results in less dynamic (i.e. small δ) datasets. For instance, in BEAR-B-day, Jena-CB only takes 10% the space of IC, and only 5% in BEAR-B-instant. The only exception is BEAR-C where data are so dynamic that the additional index overhead in CB (for adds and deletes) produces slightly bigger sizes than IC, both in Jena and HDT. Interestingly, R43ples shows a similar behaviour given its
TailR shares similar remarks: for those indexed datasets, TailR shows very competitive performance in space in datasets with low dynamicity, given that it makes use of a
In turn, the IC policy is highly affected by the number of versions. In BEAR-A and BEAR-C, both comprising a reasonable number of versions (less than 60), the IC policy indexing in Jena requires roughly ten times more space than the raw data, mainly due to the data decompression and the built-in Jena indexes. In turn, the compact HDT indexes in the IC policy just double the size of the gzipped raw data, serving the required retrieval operations in such compressed space. In contrast, in BEAR-B Jena-IC and HDT-IC are both penalized by the increasing number of versions. For instance, in BEAR-B instant, Jena-IC takes 13 times the space of the raw gzipped data, while HDT requires 5 times such space. It is worth noting that both Jena and HDT have structures with a minimum fixed size, then the IC strategy has a fixed minimum increase disregarding the small size of each version, such as in BEAR-B-instant.
Finally, the TB policy in Jena and v-RDFCSA reports overall good space figures, as it stores each triple once (i.e. the final size depends on the version-oblivious triples
Space of Jena and HDT Hybrid-Based approaches (HB)
Table 7 shows the space for the selected hybrid approaches in HDT and Jena, i.e.,
Results firstly show that Jena-
Finally, the
These initial results confirm current RDF archiving scalability problems at large scale, where specific RDF compression techniques such as HDT and RDFCSA emerge as an ideal solution [13]. For example, Jena-IC requires overall almost 4 times the size of HDT-IC, whereas Jena-CB takes more than 10 times the space required by HDT-CB. Results also point to the influence of the number of versions and the dynamicity of the dataset, considered in our δ metrics, in the selection of the proper strategy (as well as an input for hybrid approaches in order to decide when and how to materialize a version).

Query times for
From our foundations, we consider the five aforementioned query atoms: (i) version materialisation, (ii) delta materialisation, (iii) version queries, (iv) cross-version joins and (v) change materialisation. As stated, we focus on evaluating the well-described triple patterns in the selected BEAR-A queries (see Section 4.1.2) and the real-world patterns in BEAR-B queries (see Section 4.2.2). In both cases, each triple pattern act as the target query Q in the version materialisation, delta materialisation, version queries and change materialisation. The evaluation of cross-version joins makes use of the joins defined for BEAR-B.
In general, our evaluation confirmed our assumptions about the characteristics of the policies (see Section 2), but also pointed out differences between the archiving systems. The IC, TB and CB/TB policies show a very constant behaviour in all our tests, while the retrieval times of the CB and IC/CB policies increase if more deltas have to be queried. Next, we present and discuss selected plots for each query operation. For the sake of clarity, we present below only the results for the subject lookup queries (with high number of results) in BEAR-A, and the selected queries in BEAR-B-hour. Results for the rest of queries show a very similar tendency, and are presented in Appendix A (for BEAR-A) and Appendix B (for BEAR-B).

BEAR-B

Query times for
First, we can observe from Fig. 4 (a) that v-RDFCSA, which implements a TB policy, outperforms any of the other systems, remaining close to HDT with an IC policy. In practice, v-RDFCSA makes use of fast and self-compresses indexes to represent both the triples and their annotated versions, hence it speeds up materialisation queries irrespective of the concrete retrieved version. Appendix A shows that HDT is slightly faster than v-RDFCSA in object lookups, although it remains competitive in any case. In turn, as shown in Fig. 4 (d), R43ples is significantly slower than any of the other systems, in particular when initial versions are demanded, making its use impractical with a large number of versions. In fact, given its delays, we report only sampled versions
In turn, Figs 4 (a) and (d) show that the HDT archiving system generally outperforms Jena. In turn, in both systems, the IC policy provides the best and most constant retrieval time. In contrast, the CB policy shows a clear trend that the query performance decreases if we query a higher version since more deltas have to be queried and the adds and delete information processed. The degradation of the performance highly depends on the system and the type of query. For instance, HDT-CB seems to degrade faster in BEAR-A than Jena-CB but, conversely, the performance degradation is more skewed in Jena-CB in BEAR-B-hour (Fig. 4 (d)), due to the large number of versions. In turn, the TB policy in Jena performs worse than IC, as TB has to query a single but potentially large dataset (and Jena indexes are not as optimized as in v-RDFCSA). This causes the remarkable poor performance of Jena-TB in BEAR-A (cf. Fig. 4 (a)), where the volume of data is high. In contrast, Jena-TB can outperform Jena-CB in BEAR-B when the number of versions is large.
Then, Figs 4 (b) and (e) show the behaviour of hybrid IC/CB approaches in HDT for the selected BEAR-A and BEAR-B datasets respectively. As expected, the performance degrades as soon as the archive has to query the CB copies, while it drops to the IC time when the fully materialized version is available.
Figures 4 (c) and (f) present the hybrid IC/CB approaches in Jena, which share a similar behaviour as discussed above, and compare the hybrid TB/CB approach. For this latter, it is interesting to note that it first retrieve all results matching the query, ordered by named graphs (adds and deletes per version [17,44]), and then process the graphs in order to apply the changes. Nonetheless, this latter is negligible with respect to the first operation (in particular in large datasets), hence the time is almost stable at incremental number of versions. As such, the performance is always worse than IC, but it can highly improve CB in the presence or a large number of versions, such as BEAR-B (cf. Fig. 4 (f)).
Finally, in order to test the performance of TailR (and v-RDFCSA), with limited subject lookup retrieval, we extend the real-world BEAR-B queries and we consider lookups of its 100 different subjects, named
As expected, the TB policy in v-RDFCSA and Jena behaves similarly than the
Average query time (in ms) for
Last, the hybrid approaches reported in Figs 4 (b)–(f) show a similar behaviour than in mat queries. The only consideration is that the performance of IC/TB highly depends on the particular two versions in the diff, and they report the expected IC or CB times depending on which of the versions is already materialized (IC).
As can be seen, v-RDFCSA is again the fastest approach in BEAR-A (1–2 order of magnitude faster), while the HDT archiving system clearly outperforms Jena in all scenarios, taking advantages of its efficient indexing. Nonetheless, the policies plays an important role: As opposed to the previous Mat and Diff operations, Jena-CB outperforms Jena-IC in these version queries, being even more noticeable in BEAR-B with a large number of versions. The explanation of such behaviour is that, in version queries, all versions have to be queried, hence the query of a version
Note that R43ples shows poor performance in
Finally, it is worth mentioning that the Jena-

Query times for join queries with increasing intervals.

Example of a cross-version join query in BEAR-B
Figure 7 (a) shows the plots for the selected joins in BEAR-B-hour for all supported systems, whereas Fig. 7 (b) and (d) reports the HDT and Jena hybrid approaches, respectively. The figures show similar tendency as
Average query time (in ms) for

Example of a change query in R43ples
In turn, in all HDT and Jena cases, we optimize the resolution by marking a change between two versions as soon as we find the first different result between two versions, hence we avoid a full inspection of the
Table 9 reports the average query time over each
RDF archiving is still in an early stage of research. Novel solutions have to face the additional challenge of comparing the performance against other archiving policies or storage schemes, as there is not a standard way of defining neither a specific data corpus for RDF archiving nor relevant retrieval functionalities. To this end, we have provided foundations to guide future evaluation of RDF archives. First, we formalized dynamic notions of archives, allowing to effectively describe the data corpus. Then, we described the main retrieval facilities involved in RDF archiving, and have provided guidelines on the selection of relevant and comparable queries. We provide a concrete instantiation of archiving queries using AnQL [48] and instantiate our foundations in a prototypical benchmark suit, BEAR, composed of three real-world and well-described data corpus and query testbeds. Finally, we have implemented state-of-the-art archiving policies using independent copies (IC), change-based (CB), timestamp (TB) and hybrid (HB) approaches in two stores (Jena TDB and HDT). We use BEAR to evaluate our implementations as well as existing state-of-the-art archiving systems (v-RDFCSA, TailR, R43ples). Results clearly confirm challenges (in terms of scalability) and strengths of current archiving approaches, and highlight the influence of the number of versions and the dynamicity of the dataset in order to select the right strategy (as well as an input for hybrid approaches in order to decide when and how to materialize a version), guiding future developments. In particular, in terms of space, CB, TB and hybrid policies (such as TB/CB in R43ples and IC/CB in TailR) achieve better results than IC in less dynamic datasets, but they are penalized in highly dynamic datasets due to index overheads. In this case, the TB policy reports overall good space figures but it can be penalized at increasing number of versions. Regarding query resolution performance, the evaluated archiving policies excel at different operations but, in general, the IC, TB and CB/TB policies show a very constant behaviour, while CB and IC/CB policies degrade if more deltas have to be queried. Results also show that specific functional RDF compression techniques such as HDT and RDFCSA emerge as promising solutions for RDF archiving in terms of space requirements and query performance.
We currently focus on exploiting the presented benchmark to build a customizable generator of evolving synthetic RDF data which can preserve user-defined characteristics while scaling to any dataset size and number of versions. We also work on extending the benchmark for multiple versioned graphs in a federated scenario.
Footnotes
Acknowledgements
Funded by Austrian Science Fund (FWF): M1720-G11, European Union’s Horizon 2020 research and innovation programme under grant 731601 (SPECIAL), MINECO-AEI/FEDER-UE ETOME-RDFD3: TIN2015-69951-R, by Austrian Research Promotion Agency (FFG): grant no. 849982 (ADEQUATe) and grant 861213 (CitySpin), and the German Government, Federal Ministry of Education and Research under the project number 03WKCJ4D. Javier D. Fernández was funded by WU post-doc research contracts, and Axel Polleres was supported by the “Distinguished Visiting Austrian Chair” program as a visiting professor hosted at The Europe Center and the Center for Biomedical Research (BMIR) at Stanford University. Special thanks to Sebastian Neumaier for his support with the Open Data Portal Watch.
BEAR-A performance results
This appendix comprises the performance results for all subject, predicate and object lookups (S??, ?P? and ??O respectively) in BEAR-A (see Section 4.1 for a description of the corpus), and the corresponding triple patterns (SP?), (S?O), (?PO) and (SPO). Figures 8 and 9 show the results for Mat queries with pure IC, CB and TB approaches in HDT and Jena. Figures 10 and 11 compare such results with hybrid IC/CB approaches with HDT, whereas Figs 12 and 13 perform the comparison with IC/CB and TB/CB approaches. Diff queries are presented in Figs 14-19. Finally, Tables 10 and 11 report the results for the Ver query, and Tables 12 and 13 show the Change queries.
BEAR-B queries
This appendix shows the performance results of BEAR-B (see Section 4.2 for a description of the corpus). We focus here on reporting BEAR-B-day and BEAR-B-hour results, whereas current systems were unable to efficiently query the 21,046 versions in BEAR-B-instant and a report can be found in the BEAR repository (
Figures 20–22 show the results for Mat queries with pure IC, CB and TB approaches, hybrid IC/CB approaches with HDT and hybrid IC/CB and TB/CB approaches in Jena, respectively. Figures 23–25 present Diff queries, and Fig. 26 report join performance. Last, Table 14 reports the results for the Ver query and Table 15 shows the results for Change queries.