Knowledge Graphs (KGs) have become useful sources of structured data for information retrieval and data analytics tasks. Enabling complex analytics, however, requires entities in KGs to be represented in a way that is suitable for Machine Learning tasks. Several approaches have been recently proposed for obtaining vector representations of KGs based on identifying and extracting relevant graph substructures using both uniform and biased random walks. However, such approaches lead to representations comprising mostly popular, instead of relevant, entities in the KG. In KGs, in which different types of entities often exist (such as in Linked Open Data), a given target entity may have its own distinct set of most relevant nodes and edges. We propose specificity as an accurate measure of identifying most relevant, entity-specific, nodes and edges. We develop a scalable method based on bidirectional random walks to compute specificity. Our experimental evaluation results show that specificity-based biased random walks extract more meaningful (in terms of size and relevance) substructures compared to the state-of-the-art and the graph embedding learned from the extracted substructures perform well against existing methods in common data mining tasks.
Knowledge Graphs (KGs), i.e., graph-structured knowledge bases, store information as entities and the relationships between them, often following some schema or ontology [3]. With the emergence of Linked Open Data [4], DBpedia [2], and Google Knowledge Graph,1
large-scale KGs have drawn much attention and have become important data sources for many data mining and other knowledge discovery tasks [9,16,25,32,33,46,52] As such algorithms work with the propositional representation of data (i.e., feature vectors) [35], several adaptations of language modeling approaches such as word2vec [24] and GloVe [30] have been proposed for generating graph embedding for entities in a KG. As a first step for such approaches, a representative subgraph for each target entity in the KG must be acquired. Each entity (represented by a node) in a heterogeneous KG is surrounded by other entities (or nodes) connected by directed labeled edges. For a node representing a film, there can be a labeled edge director connecting it to a node representing the director of the film. Another labeled edge releaseYear may exist that connects the film to an integer literal, also represented by a node in the KG. If we want to extract a subgraph representing the film, ideally such relevant information (labeled edges and nodes) must be a part of the extracted subgraph. On the other hand, relationships linked to, say, the Director such as birthYear or deathYear, which are at two hops from a film, e.g. , may not be useful or relevant for representing a film. Therefore, in order to extract a useful representation (as a subgraph) of a given entity, we first need to automatically determine the most relevant edges and nodes in its neighborhood. An extracted representation of any target entity2
Since entities are represented as nodes in a KG; we use entity and node interchangeably throughout the text.
in a KG can only be considered representative if it includes only the most relevant nodes and edge w.r.t. the target entity. To accomplish this task approaches based on biased random walks [6,13] have been proposed. Such approaches use weighting schemes to make a particular set of edges and nodes more likely to be included in the extracted subgraphs than others. However, weighting schemes based on metrics such as frequency or PageRank [6,48] tend to favor popular (or densely connected) nodes in the representative subgraphs of target entities at the expense of semantically more relevant nodes and edges.
KGs which are encoded using the Resource Description Framework (RDF) syntax and constitute Linked Open Data [18,27]. We assert that the representative subgraphs of different types of entities (e.g., book, film, drug, athlete) in RDF KGs may comprise distinct sets of relationships. Our objective is to automatically identify such relationships and use them to extract entity-specific representations. This is in contrast to the scenario where extracted representations are KG-specific because of the inclusion of popular nodes and edges, irrespective of their semantic relevance to the target entities.
The main contributions of this paper are as follows:
We propose Specificity as an accurate measure for assigning weights to those semantic relationships which constitute the most intuitively relevant representations for a given set or type of entities.
We provide a scalable method of computing specificity for semantic relationships of any depth in large-scale KGs.
We show that specificity-based biased random walks enable more compact extraction of relevant subgraphs for target entities in a KG as compared to the state-of-the-art.
To demonstrate the usefulness of our specificity-based approach for real-world applications, we train the neural language model (Skip-Gram [23]) for generating graph embedding from the extracted subgraphs and use the generated embeddings for the tasks of entity recommendation, regression, and classification for select entities in DBpedia. This paper considerably extends [43], in which we introduced the metric of specificity for the first time. We provide additional experiments to show that the vector embeddings can not only be used for entity recommendation but also regression and classification tasks. We also propose a variation of specificity called which takes into account the hierarchy of classes in the schema ontology associated with a KG, discussed in Section 4.2.
The rest of this paper is structured as follows. In Section 2, we provide a brief overview of related work. In Section 3, we provide the necessary background. In Section 4 we motivate and introduce the concept of specificity. In Section 5, we present a scalable method for computing specificity. In Section 6, we present results highlighting beneficial characteristics of specificity on DBpedia. In Section 7 we conclude with a summary and an outlook on future work.
Linked open data [source: http://lod-cloud.net/].
Related work
Linked Open Data (LOD) [51] is a massive KG shown in Fig. 1 where each node itself is a Knowledge Graph. Each of these individual KGs comes from semantically annotating and integrating unstructured data and publishing as structured data on the web using the principles of Linked Data or Semantic Web [15,29,39,42]. LOD cloud currently comprise 1205 KGs.4
Due to its open availability, heterogeneity, and cross-domain nature, LOD is increasingly becoming a valuable source of information in many data mining tasks. However, most data mining algorithms work with a propositional feature vector representation of the data [35]. Recently, graph embedding techniques have become a popular area of interest in the research community. Embeddings map entire graph or individual nodes into low dimensional vector space, preserving as much information as possible related to its neighborhood [12,34,45].
Numerous techniques have been proposed for generating appropriate representations of KGs for knowledge discovery tasks. Graph kernel-based approaches simultaneously transverse the neighborhoods of a pair of entities in the graph to compute kernel functions based on metrics such as the number of common substructures (e.g., paths or trees) [8,22] or graphlets [44,50]. Neural language models such as word2vec [24] and GloVe [30], proposed initially for generating word embedding, have been adapted for KGs [7,13,35]. Deep Graph Kernel [50] identifies graph substructures (graphlets) and uses neural language models to compute a similarity matrix between identified substructures. For large scale KGs, embedding techniques based on random walks have been proposed in the literature. DeepWalk [31] learns graph embedding for nodes in the graph using neural language models while generating truncated uniform random walks. node2vec [13] is a more generic approach than DeepWalk and uses 2nd order biased random walks for generating graph embedding, preserving roles and community memberships of nodes. RDF2Vec [35], an extension of DeepWalk and Deep Graph Kernel, uses BFS-based random walks for extracting subgraphs from RDF graphs, which are converted into feature vectors using word2vec [24]. Random walk-based approaches such as RDF2Vec have been shown to outperform graph kernel-based approaches in terms of scalability and their suitability for ML tasks for large-scale KGs [12,35]. The main limitation of approaches using uniform (or unbiased) random walks is the lack of control over the explored neighborhood which can lead to the inclusion of less relevant nodes in identified subgraphs of target entities. To address this challenge biased random walks based approaches have been recently proposed [2,6,43]. Such approaches use different weighting schemes for nodes and edges. The weights create the bias by making specific nodes or edges more likely to be visited during random walks. The work closest to ours is biased RDF2Vec approach [6] which uses frequency-, degree-, and PageRank-based metrics for weighting schemes. Our proposed approach also uses biased random walks to extract entity representations. However, unlike [6], we use our proposed metric of specificity as an edge- and path-weighting scheme for biased random walks for identifying most relevant subgraphs for extracting entity representations in the KGs.
Semantic similarity and relatedness between two entities have been relatively well explored [1,11,19,29]. Searching for similar or related entities given a search query is a common task in the field of Information Retrieval [14,21,27]. To facilitate the search for similar entities the notion of similarity and the set of attributes used for its computation must first be defined. Semantic similarity and relatedness are often used interchangeably in literature [1,29,41,47], where the similarity between two entities is sometimes computed based on common paths between them. This definition allows computation of similarity between any two given entities, including entities of different types. For example, Kobe Bryant and Kareem Abdul-Jabbar (athletes) are each related to LA Lakers (team) based on path-based similarity. The other kind of similarity is between Kobe Bryant and Kareem Abdul-Jabbar who are entities of the same type, i.e., athletes. Both are athletes, basketball players, and have played for the same team. These attributes in KG, e.g. DBpedia, are represented through semantic relationships rdf:type and dct:subject. For this paper, our objective is to automatically identify such semantic relationships that constitute the representative neighborhoods of entities of the same given type. Therefore, we limit the computation of similarity to be between two entities of the same type.
Preliminaries
An RDF graph is represented by a knowledge base of triples [49]. A triple consists of three parts: ⟨subject (s), predicate (p), object (o)⟩.
(RDF Graphs).
Assuming that there is a set U of Uniform Resource Identifiers (URIs), a set B of blank nodes, a set L of literals, a set O of object properties, and a set D of datatype properties, an RDF graph G can be represented as a set of triples such that:
We can also represent an RDF graph G as such that and , where E is a set of directed labeled edges. In an RDF graph, URIs are used as location-independent addresses of entities (both nodes and properties), whereas blank nodes are assigned internal IDs. Literals can have any values conforming to the XML schema definitions. Thus, (1) signifies that any entity with a URI can be subject, predicate, or object. In practice, only entities with URIs defined as Object or Datatype properties are used predicates. However, these properties can also be subjects or objects in other triples, which is an interesting feature of an RDF graph that an edge can be between two edges which makes it different from the traditional definition of a graph. Blanks nodes can either be subject or object, whereas literals can only be objects. An RDF graph is a set of all such RDF triples [26,49]. Ontologies are a key concept in the domain of Semantic Web. An ontology is a formal conceptualization of a particular domain containing a hierarchy of concepts (or classes), their relationships (object properties) and attributes (data properties). Such semantic relationships are the fundamental aspect of knowledge representation in Semantic Web as they provide information about how entities are linked together. Thus, the ontologies are used to enforce a schema over RDF instance data [38].
(Semantic relationship).
A semantic relationship in an RDF graph can be defined as where represents a path comprising d successive predicates and intermediate nodes between s and o. When , becomes equivalent to a single triple , where or p represents a single predicate or edge between two nodes s and o.
For this paper, we define semantic relationship of depth or length d, as a template for a path (or a walk) in G, that comprises of d successive predicates . Thus, represents all paths (or walks) between any two entities s and o that traverse through intermediate nodes, using the same d successive predicates that constitute . To understand the difference between a triple, a path, and a template, assume that an RDF KG consists of only the following four triples: , , , and . and constitute a complex relationship between and . These two triples together are an example of a semantic relationship of form which consists of two successive predicates a and b and one intermediate node x. If we treat a, b as a template of a path, then in this KG there are two instances of this template: the semantic relationship between and (first and second triples) and the semantic relationship between and (third and fourth triples). This also means that for an arbitrary s and o, , where . We will formulate the expression for specificity using this notation in Section 4.
(Graph walk).
Given a graph , a single graph walk of depth d starting from a node comprises a sequence of d edges (predicates) and nodes: .
Random graph walks provide a scalable method of extracting entity representations from large scale KGs [13]. Starting from a node , in the first iteration, a set of randomly selected outgoing edges is explored to get a set of nodes at depth 1. In the second iteration, from every , outgoing edges are randomly selected for exploring the next set of nodes at depth 2. This is repeated until a set of nodes at depth d is explored. The generated random walks are the union of explored triples during each of the d iterations. This simple scheme of random walks resembles a randomized breadth-first search. In literature, both breadth-first and depth-first search strategies and interpolation between the two have been proposed for extracting entity representations from large-scale KGs [13,31,35].
(Representative subgraph).
The representative subgraph (neighborhood) of an entity or a node v is the set of other nodes S in the graph that represent the most relevant information related to v. The edges or paths that link v to every are also part of the representative subgraph.
Using our running example from Section 1, the representative subgraph of a film may contain depth-1 edges such as director, producer that link it to nodes representing its director(s) and producer(s). Some examples of depth-2 relationships are and . On the other hand, our intuition suggests that semantic relationships such as is not as relevant to represent a film and hence must not be part of the representative subgraph.
Specificity: An intuitive relevance metric
In this section, we introduce and motivate the use of specificity as a novel metric for quantifying relevance.
Random walks from node Batman (1989).
Specificity
Consider the example shown in Fig. 2. Starting from the entity Batman (1989) in DBpedia, a random walk explores the three shown semantic relationships (descriptive names used for brevity instead of actual DBpedia URIs). Our intuition suggests that the style of a director (represented by Gothic Films) is more relevant to a film than his year and place of birth. Frequency-, degree-, or PageRank-based metrics of assigning relevance may assign higher scores to nodes representing broader categories or locations. For example, PageRank scores (non-normalized) computed for DBpedia entities Gothic Films, 1958-births, and Burbank, CA are 0.586402, 161.258, and 57.1176 respectively (calculated based on [48]). PageRank-based biased random walks may include these popular nodes and exclude intuitively more relevant information related to the target entity. Our objective is to develop a metric that assigns a higher score to more relevant nodes and edges in such a way that the node Gothic Films becomes more likely to be captured for Batman (1989) than 1958 births and Burbank, CA. This way, the proposed metric captures our intuition behind identifying more relevant information in terms of its specificity to the target entity.
Illustration of specificity.
To quantify this relevance we determine if Gothic Films represents information that is specific to Batman (1989). We trace all paths of depth d reaching Gothic Films and compute the ratio of the number of those paths that originate from Batman (1989) to the number of all traced paths. This gives specificity of Gothic Films to Batman (1989) as a score between 0.0–1.0. A specificity score of 1.0 means that all paths of depth d reaching Gothic Films have originated from Batman (1989). For , this node-to-node specificity of a node to , such that , and being any arbitrary path, can be defined as:
Computing specificity between every pair of nodes in a large scale KG is impractical. Instead of defining specificity as a metric of relevance between each pair of entities (or nodes), we make two simplifying assumptions. First, we assert that each class or type of entities (e.g., films, books, athletes, politicians) has a distinct set of characteristic semantic relationships. This enables us to compute specificity as a metric of relevance of a node (Gothic Films) to a class or type of entities (Film), instead of every instance of that class (Batman (1989)). Second, we measure the specificity of a semantic relationship (director, knownFor), instead of an entity (Gothic Films), to the class of target entities. Here, we are assuming that if the majority of the entities (nodes) reachable via a given semantic relationship represents entity-specific information, we consider that semantic relationship to be highly specific to the given class of target entities. From our example, this means that instead of measuring specificity of Gothic Films to Batman (1989), we measure specificity of semantic relationship director, knownFor to the class or entity type Film. Based on these assumptions we redefine specificity as
(Specificity).
Given an RDF graph , a semantic relationship of depth d, and a set of all entities s of type t, let be the set of all nodes reachable from S via . We define the specificity of to S as
where represents any arbitrary semantic relationship of length d. Figure 3 provides visual representation of Equation (3). S is a set of all nodes with a given type t and . S and are shown as disjoint sets only for illustrative purposes. when creates a loop or when for is a self-property.
: Incorporating hierarchy of classes into specificity computations
We also present an extension of specificity which takes into account the class hierarchy of the schema ontology of the KG for its computation. In Equation (3), the numerator only counts those semantic relationships that originate from . This definition is rigid because a given semantic relationship can be specific to multiple classes of entities.
In other words, certain semantic relationships can apply to a broader class and by extension to multiple of its subclasses. When computing specificity of a given semantic relationship to instances of one of these subclasses, e.g., Film, the specificity score may get penalized due to the relevance of the semantic relationships to the other subclasses such as TelevisionShow. To rectify this and make the specificity computations more flexible, we leverage the hierarchical relationships represented by the schema ontology. One of the most common relationships in an ontology is hyponymy, also called is-a relationship [5,37]. Hyponymy represents the relationship between hypernym (the broader category) and hyponyms (more specific categories). Figure 4 shows a subset of the hierarchical structure of DBpedia ontology. Film, MusicalWork, WrittenWork are hyponyms to the hypernym Work and co-hyponyms of each other. Assume that the class hierarchy in the schema ontology of the KG is structured as an n-ary tree, i.e., a class can have more than one subclasses but not more than one superclass. Moreover, there is only one class that has no superclass which is the root of the entire class hierarchy.
A subset of DBpedia class hierarchy.
Let the given entity type t be at height (or depth) h from the root such that t and root can be labeled as and respectively, which results in a hierarchy of classes . Subclasses of are co-hyponyms of . Our objective is to include the instances of hypernyms of entity type t () in the computation of specificity. In Equation (3), we only consider , all of which are of type t (or instances of class t). We add a term to the numerator to include instances of hypernyms of t in the computation of specificity as follows:
Additional constraints for Equation (4) are: and . This is to ensure that each instance of type t or any of its superclasses is only considered once in the computation. The factor β ensures diminishing influence of broader concepts on the computation of specificity for more specific concepts. For example, from Fig. 4, when computing specificity of a given semantic relationship for class Film other instances of class Work that are not films have a higher influence than the more broader class Thing.
Bidirectional random walks for computing specificity
Computing Equation (4) requires accessing large parts of the knowledge graph. In this section, we present an approach that uses bidirectional random walks to compute specificity. To understand, consider an entity type t and a semantic relationship , for which we want to compute . We start with a set S containing a small number of randomly selected nodes of type t. From nodes in S, forward random walks via are performed to collect a set of nodes (ignoring intermediate nodes, for ). From nodes in set , reverse random walks in G (or forward random walks in ) are performed using arbitrary paths of length d to determine the probability of reaching any node of type t. Specificity is computed as the number of times a reverse walk lands on a node of type t divided by the total number of walks. This idea is the basis for the algorithm presented next which builds a list of most relevant semantic relationships up to depth d sorted by their specificity to a given entity type t.
Specifically, and hold the set of semantic relationships, unsorted and sorted by specificity respectively. is initialized as an array of size d to hold sorted semantic relationships for every depth up to d. specify the size of . is the number of bidirectional walks performed for computing specificity for each semantic relationship in . A set S of randomly selected nodes of type t is generated in line 3. For each ith iteration (), a set of semantic relationships is selected in line 5. The function computeSpecificity, in line 6, computes specificity for each semantic relationship in and returns results in . Each element of is an array of dictionaries. Each dictionary contains – pairs sorted by , where is the semantic relationship and is its specificity. For each ith iteration of for in Algorithm 1, can be populated from scratch with semantic relationships of depth i by random sampling of outgoing paths from S. Alternatively, for iterations , can be populated by expanding from most specific semantic relationships in .
Algorithm 2 shows the function computeSpecificity which computes specificity for a given set of semantic relationships in Q ( from Algorithm 1). In lines 7 and 8, for each semantic relationship , a node is randomly selected to get a node v reachable from s via semantic relationship q in G (forward walk). In line 9, by using v and selecting an arbitrary path via any semantic relationship of depth d, a node is reached (reverse walk, reverse walk in G or forward walk in ). If implementing specificity based on Equation (3), the algorithm needs to check if t is one of the types associated with and simply increment an integer variable count [40,43]. To implement specificity based on Equation (4), we first need to acquire the class hierarchy of entity type t in H in line 2. The first index of H holds t and every subsequent entry for holds the hypernym or superclass of entry . For example, for entity type Film (Fig. 4), H = [“Film”, “Work”, “Thing”]. Starting from the first element in H at index , the existence of triple is checked in G. If such a triple exists, count is incremented by a factor of . This process of bidirectional walks is repeated N times for each q. At line 17, specificity is computed as . Lines 4–18 are repeated until specificity for each has been computed. The return variable L contains semantic relationships and their specificity scores as – pairs.
Evaluation
We evaluate our approach in multiple ways. We analyze the behavior of specificity computed for most relevant semantic relationships up to depth 3. We evaluate the compactness of the extracted subgraphs by specificity-based biased random walk scheme against other metrics used as baselines. We generate embeddings from the extracted subgraphs to perform tasks of entity recommendation, regression, and classification. We analyze the ability of generated embeddings in preserving the semantics associated with the entities extracted from the KG. We study the sensitivity of specificity to the parameter (number of bidirectional walks) and (seed set size). We provide an empirical analysis of the running time of Algorithm 2.
Extracted subgraphs are represented as a sequence of edge and node labels resulting in a document-like representation. The specificity scores shown are with respect to the entity type Film. The relationship starring has a specificity score of 79.1%, whereas starring → spouse has a score of 34.16%. Only those nodes connected to semantic relationships of specificity higher than 50% are considered for the extracted representation.
Datasets
We use DBpedia for evaluation which is one of the largest RDF repositories publicly available [20]. We use the English version of DBpedia dataset from 2016-04 (http://wiki.dbpedia.org/dbpedia-version-2016-04). We create graph embeddings for 5000 entities each of types: Film, Book, and Album. We also generate embeddings for 500 and 3000 entities of types Country and City respectively.
We use three different datasets for the tasks of classification and regression which provide classification and regression targets for DBpedia cities, films, and music albums:
For our experiments, we hosted the DBpedia dataset using OpenLink Virtuoso11
https://virtuoso.openlinksw.com/
on a server. All data transactions between the implemented modules and the repository occurr as SPARQL queries.
Implementation of baselines and proposed approach
In the first step, we compute and SpecificityH to find the set of most relevant semantic relationships for entities of selected types. Unless otherwise specified, we use following values for the parameters of the Algorithms 1 and 2: , , . Starting from a random seed set S for each type of entities, we randomly sample semantic relationships originating from entities in S and select top-25d semantic relationships based on the frequency of occurrence for each depth d. This becomes the frequency-based baseline, where the relevance of semantic relationships is based on how frequently they occur in the KG. After computing specificity for each of the most frequent semantic relationship, we only consider those as relevant that have specificity scores . For creating the PageRank-based baseline, we use the PageRank DBpedia dataset provided by Thalhammer et al. [48] (available at http://people.aifb.kit.edu/ath/#DBpedia_PageRank).
Comparison of frequency- and specificity-based metrics for top-15 semantic relationships.
Biased random walks for subgraph extraction
Using the lists of most relevant semantic relationships based on frequency-, PageRank-, and specificity-based metrics, we perform subgraph extraction using biased random walks. We use weighted randomized DFS for subgraph extraction for each target entity. The DFS algorithm traverses the paths starting from each target node using the list of most relevant semantic relationships. The nodes linked by more relevant semantic relationships have a greater likelihood to become part of the extracted subgraphs. The subgraphs are extracted as a set of unique graph walks (Definition 3) and can be represented as a sequence of edge and node labels, in the order in which they are visited [6,35]. An example of document-based representation of extracted subgraph is shown in Fig. 5. The semantic relationships such as starring and director have higher specificity than the threshold of and thus are included in the extracted representation. The two depth-2 relationships starring → spouse and director → birthplace which have low specificity scores are excluded. For our experiments, we include up to a maximum of 1000 distinct paths in the extracted subgraphs for each entity for proposed and baseline approaches.
Embedding generation using word2vec
With the document-based representation, we use the Python library gensim12
https://radimrehurek.com/gensim/index.html
which provides the implementation of word2vec [24] to estimate representation of each label in the generated document into vector space creating embedding for the RDF entities [35].
Specificity as a metric for measuring relevance
Figure 6 shows the top 15 semantic relationships for entities of three types sorted by their up to depth 3. The frequency represents the percentage of number of times a path representing a particular semantic relationship is traversed when the neighborhoods of randomly selected nodes are explored. For depth 1, the topmost plot of each subplot in Fig. 6 shows that there are only a few relatively high-frequency semantic relationships (represented by the peaks) whereas the rest show a uniform trend of frequency. As depth d increases, frequency exhibits a flattened trend due to a rapid increase in the number of possible semantic relationships at each depth. This trend makes it difficult to define a frequency-based cut-off value for choosing a certain set of semantic relationships as most relevant. This may require manual examination of the set of semantic relationships for choosing an appropriate frequency threshold. Alternatively, we can choose a value k such that top-k high-frequency semantic relationships are selected as the most relevant. For example, in Table 1, assuming that we wish to include the intuitively relevant semantic relationship dbo:director in the selected semantic relationships, we can either choose a frequency threshold of or choose . However, this ad-hoc method of selecting thresholds is impractical since it has to be done for every different class of entities, every depth, and every different RDF KG.
Top semantic relationships based on frequency with corresponding specificity scores for dbo:Film
Semantic relationship
Freq. (%)
Spec. (%)
Spec.H (%)
rdf:type
38.46
74.69
79.15
dct:subject
16.94
87.9
89.09
owl:sameAs
11.88
98.4
98.4
dbo:starring
5.82
79.06
84.43
dbo:writer
1.68
76.48
81.86
dbo:producer
1.34
83.9
88.22
dbo:director
1.08
81.76
87.42
dbo:musicComposer
0.92
70.77
80.28
dbo:distributor
0.84
74.08
83.22
dbo:language
0.72
38.65
53.42
dbo:editing
0.66
91.65
92.82
dbo:cinematography
0.64
92.99
94.49
The threshold of Specificity is drawn at 50% in all plots in Fig. 6. The specificity of a semantic relationship is the probability of reaching any node of a given type from a set of nodes ( in Definition 5) by reverse walks in G (or forward walks in ) using any arbitrary path of length d. We can define a universal cut-off for specificity at 50%. Specificity score above this threshold means that the selected semantic relationship links the instances of given class (or entity type) t to the set such that more than half the incoming edges to this set originate from instances of class t. This means that the information represented by nodes in on average is more specific to t.
In literature, other approaches such as [29] have employed a decaying factor (where ) as a function of depth d that is used to equally penalize the relevance score of all nodes at depth d from target nodes. This is done to implement the idea that the relevance of nodes decreases as we move farther away from the target nodes. Specificity, on the other hand, has a more fine-grained mechanism of assigning relevance score across different depths. Figure 6 shows that there are multiple instances of semantic relationships at depth d that have higher specificity than semantic relationships at depth . This way specificity exhibits a more fine-grained behavior of relevance across depths, meaning that all semantic relationships at depth d do not simultaneously become less relevant as compared to those on depth , as d increases. There are variations in the specificity-based relevance scores of semantic relationships at the same depth as well as across depths. This allows both shallow (breadth-first) and deep (depth-first) exploration of the relevant neighborhoods around target entities by specificity-based biased random walks.
Comparison of relevance metrics for example in Fig. 2
Semantic relationships
Spec.
PR
Freq.
director, knownFor
59.14
6.2
345
director, subject
1.05
823.53
73,752
director, birthPlace
0.03
200.33
7087
Average number of walks per entity for subgraph extraction.
Table 2 shows computed relevance of the three semantic relationships from example in Fig. 2 (Section 4.1) based on their specificity, PageRank, and frequency. The given PageRank values in column 3 are the average of non-normalized PageRank scores [48] of top-25 nodes linked to DBpedia entities of type Film by corresponding semantic relationship. The values of frequency in the last column represent the number of occurrences of the corresponding semantic relationship in DBpedia dataset. We argue that the semantic relationship director,knownFor is more relevant to a film as compared to the other two. Table 2 shows that the proposed specificity based relevance metric is closer to our intuition as compared to other metrics.
Comparison of Specificity and scores ()
Semantic relationships
Entity type
Spec. (%)
SpecH (%)
dbo:language
dbo:Film
38.65
53.42
dbo:genre
dbo:Album
43.29
50.8
dbo:recordLabel
dbo:Album
43.41
56.34
dbp:genre
dbo:Book
46.85
52.29
dbo:previousWork
dbo:Book
40.0
55.0
dbo:litrerayGenre
dbo:Book
46.22
51.52
As discussed in Section 4.1 that only includes those nodes in its computation that are dominantly exclusive or specific to nodes of a given type. However, many types of entities require both specific as well as generic nodes and relationships for complete characterization. For example, assume that a node representing is associated with all instances of the class and its subclasses (Fig. 4). Since nodes representing languages can be linked to multiple different entity types, therefore the specificity of the semantic relationship that links language-related nodes will be low. In other words, if the algorithm performs reverse walks from dbo:English, it can potentially land on multiple different types of nodes (e.g., films, books, songs, plays, games).
Table 3 shows a few examples of intuitively relevant semantic relationships with specificity scores below the threshold of 50%, resulting in the exclusion from the representative subgraphs of instances of corresponding entity types. computed using Algorithm 2 takes into account the applicability of such relationships to co-hyponyms and hypernyms of the given entity types, resulting in an increase in the specificity score. This is evident in all plots in Fig. 6 where the curve of lie on or above the corresponding curve of .
Comparison of sizes of representative subgraphs
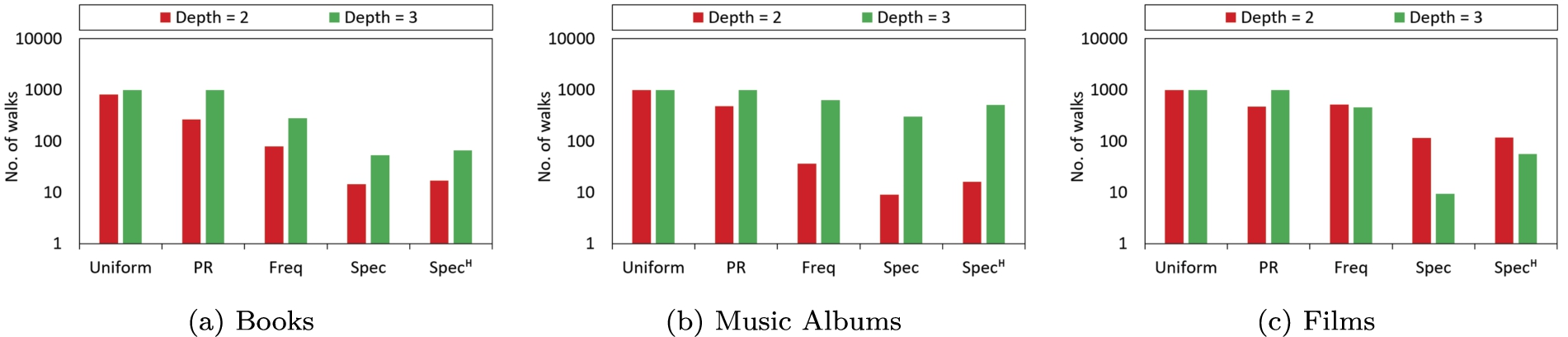
Figure 7 shows that specificity-based random walk schemes enable the extraction of relevant subgraphs with fewer number of walks. Specificity-based schemes use extraction template based on semantic relationships with ⩾50% specificity which enables collection of comparatively fewer but more relevant nodes and edges than the baselines for all three of the chosen entity-types. , as seen in Fig. 6 assigns higher specificity scores, resulting in a few more semantic relationships meeting the 50% threshold. This results in an increase in the collected number of walks which, nevertheless, is still below the baseline approaches.
Figure 7(a) shows that the average size of the subgraph of each entity of type dbo:Book for is smaller by a factor of 48, 16, and 5 w.r.t uniform, PageRank, and Frequency-based approaches respectively. Similarly, Fig. 7(b) shows that the average size of the subgraph of each entity of type dbo:Book for is smaller by a factor of 62, 30, and 2 w.r.t uniform, PageRank, and Frequency-based approaches respectively. We will revisit this discussion in the context of its impact on the recommendation task in Section 6.5.1.
Figure 7(a) shows that the average subgraph size is larger for depth-3 than depth-2. One of the reasons is that the most specific depth-2 property for dbo:Book entities adds on average one walk to each of the extracted subgraphs, whereas the most specific depth-3 property adds 15 walks on average. On the other hand, Fig. 7(c) shows the opposite effect where depth-2 subgraph size is larger than depth-3 for Specificity (). The top specific semantic relationships at depth-2 and depth-3 add 100.8 and 9.4 walks on the average to each extracted subgraph respectively. The main underlying reason is that having a higher number of specific semantic relationships does not necessarily indicate a larger extracted subgraph or vice versa. The size of the subgraph depends on the number of nodes a particular semantic relationship connects to the target entities to include in the extracted subgraph. For example, for film nodes, on average dbo:director and dbo:cinematographer add 1.06 and 1.07 walks to the extracted subgraphs whereas rdf:type and dct:subject add 28 and 8 walks respectively.
Embeddings as an application of specificity-based extracted subgraphs
We have shown that the specificity-based biased random walks extract more compact subgraphs representing entities as compared to other schemes. However, to show that the compactness of the extracted subgraphs is not a disadvantage, we use the graph embeddings as an application to evaluate their effectiveness. Using the extracted subgraphs extracted as documents (Section 6.2), we train Skip-gram models using the following parameters: dimensions of generated vectors = 500, window size = 10, negative samples = 25, iterations = 5 for each scheme and depth. All models for depth are trained using sequences generated for both depths 1 and d. The parameters for this experiment are based on RDF2Vec [35].
Comparison of precision and recall for entity recommendation tasks ( for ).
Suitability for entity recommendation task
To show that the compactness of the extracted subgraphs is not a disadvantage, we use the generated graph embeddings for the task of entity recommendation. Given a vectorized entity as the search key, we list its top-k most similar results. We use the metrics of precision@k to quantify the performance of the recommendation tasks. Evaluating retrieved results requires ground truth. For music albums and books, the ground truth straightforwardly consists of other works by the same artists and authors respectively. For films, we select franchises or series as ground truth. Films in a franchise or a series usually share common attributes (e.g., director, actors, genre, characters) and are more likely to be similar to each other. For example, for any of the three The Lord of the Rings (LOTR) films the other two films in the trilogy are its more likely top-2 similar results because of the same director, cast members, genre, and characters. In our experiments, King Kong (2005) also frequently appeared among the results similar to LOTR since it also has the same director. Other films may also occur among top-k results based on any number of other factors, e.g., cinematography, editing, distributor, all of which have high specificity to dbo:Film (from Table 1). Creating exhaustive lists of films for the ground truth to encompass all such scenarios is laborious. That is why we include only those films in the ground truth that are either in a franchise (e.g., all Batman films) or are part of a series (e.g., prequels or sequels). Similarity among such films is relatively stronger and easier to interpret. Assuming that there are n entities in the ground truth for a given franchise, series, author, or artist (e.g., for LOTR or for Agatha Christie in our DBpedia dataset), we chose one entity at a time to retrieve top-k similar entities (for to ), resulting in a total of recommendation tasks per franchise, author, or music artist. We perform 59,616, 221,280, and 124,032 recommendation tasks for films, books, and music albums for each random walk scheme respectively.
Results Figure 8 shows the results of recommendation tasks for each scheme. Here, we have chosen for computing . The baselines are shown as colored bars whereas is drawn as a line to make the comparison clearer. is generally slightly better than other baseline schemes except in Fig. 8(c) where PageRank-based extracted subgraphs have a better performance.
Effect of β on recommendation task.
Here, it is important to note that the compactness of the extracted subgraphs is the main contribution of our approach. We use recommendation as an application to show that despite extracting less information from the KG, there is not a significant deterioration in performance when using the specificity-based approach with such applications. The results of the recommendation task must be interpreted in conjunction with our primary metric of the size of the extracted subgraph. Figure 9 shows the average precision of recommendation tasks performed along with the average size of the subgraph extracted per entity from which the embeddings were generated. For dbo:Book, Fig. 9(a) shows that the average size of the subgraph for each entity is 48, 16, and 5 times smaller for w.r.t uniform, PageRank, and Frequency-based approaches respectively, whereas the precision values for and the three baselines lie in . Similarly, for music albums (Fig. 9(b)), the subgraph size for is reduced by factors of 62, 30, and 2 respectively with precision lying . Figure 9(c) shows that the average size of the subgraph for PageRank-based approach for each entity is 4.2 times larger than with with an advantage of in precision. The size of the subgraph for each entity for unbiased (uniform) approach is ten times larger than -based approach for films. The range of precision values for and the baselines lie in the range . This shows that a substantial reduction in extracted information still allows us to have comparable performance in entity recommendation task with the specificity-based approach.
For the recommendation task, we have used a purely content-based recommendation system. In future work, we intend to use collaborative information in conjunction with the extracted semantic information and compare against hybrid approaches such as SPRank [28] and -DB2Vec (a hybrid RDF2Vec-based approach). Such approaches have shown favorable outcome for ranking-related tasks on multiple datasets [36].
Results of regression and classification tasks –
Model
Depth
Classification
Regression
Cities
Films
Albums
Cities
Films
Albums
Uniform
1
0.935
1.0585
0.983
0.9011
1.0079
1.0002
Uniform
2
0.9359
1.0273
1.0374
0.9131
0.9976
1.0056
PageRank
1
1.0985
1.029
0.9663
0.9546
0.9955
1.0033
PageRank
2
1.0135
0.9849
1.0484
0.9347
0.9935
1.0019
Frequency
1
1.0709
1.0118
0.9421
0.9506
0.998
0.9926
Frequency
2
0.9558
1.0294
0.9886
1.0328
1.0002
0.9996
SpecificityS
1
1.1098
1.0341
0.9894
1.0601
0.9967
1.0017
SpecificityS
2
0.9161
1.023
1.0401
0.8882
0.9985
1.0027
Effects of β on specificity Increasing the value of β means that the score (for ) for any semantic relationship will be equal or higher than its score. This is also evident from Fig. 6 where () ⩾ (). This will result in more semantic relationships having higher specificity than the cut-off set at . With a higher number of relevant semantic relationships used for subgraph extraction, the size of extracted subgraphs can increase. Therefore, the function of β is to select between better performance versus smaller size of the extracted subgraphs.
Figure 9 also shows the effect of changing β on the size of the extracted subgraphs and the recommendation task. Here first we refer back to discussion of Algorithm 1 in Section 5. In Line 5 holds the set of selected semantic relationships which are then re-ordered and filtered in Line 6 using the metric of specificity. In our implementation, the semantic relationships for populating are selected based on their frequency of occurrence. For , every semantic relationship in gets a high specificity score in Line 6, i.e., the variable in Line 12 gets incremented by 1 irrespective of the type of in Line 9. This means that all frequent semantic relationships are also deemed specific for . Figure 9 shows the average sizes of extracted subgraphs for Frequency and are the same in each subplot.
Suitability for regression and classification tasks
We perform the tasks of classification and regression on the Mercer Cities, Metacritic Movies, and Metacritic Music Albums datasets using the embeddings generated for DBpedia entities. We use SVM for classification and Logistic Regression for regression tasks. We measure accuracy for classification tasks and root mean squared error (RMSE) for regression tasks. The numeric values shown in Table 4 can be interpreted as factor of improvement () when -based embeddings are compared to the baselines and . The results show that all schemes are comparable with no scheme consistently outperforming the others. However, these results are achieved using embeddings generated from smaller extracted subgraphs, proving that specificity-based embeddings can be suitable for data mining tasks.
Semantics of specificity-based vector representations
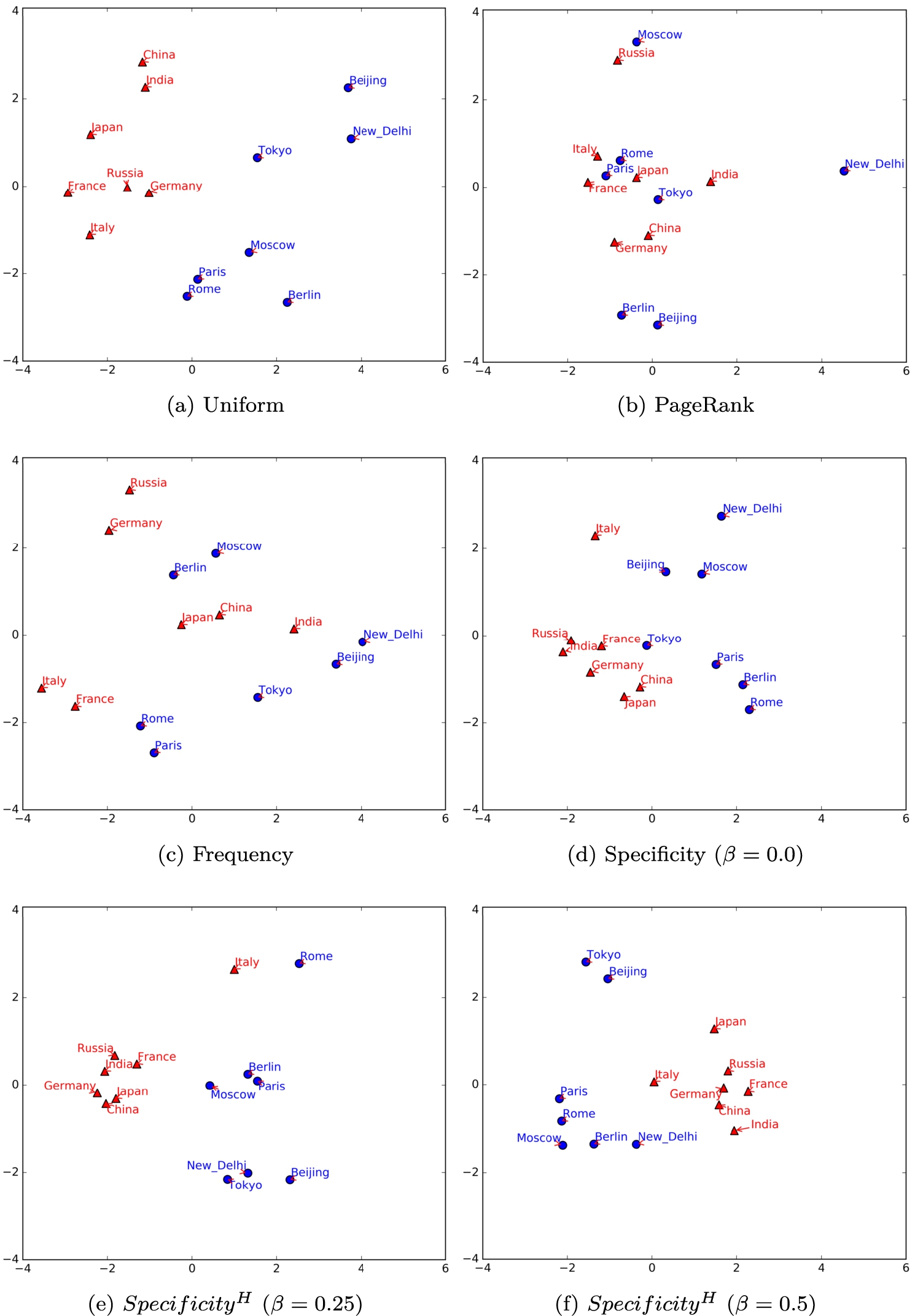
To analyze the semantics of the vector representations, we employ Principal Component Analysis (PCA) to project the generated embeddings into a two-dimensional feature space. We selected seven countries (similar to evaluation done for RDF2Vec [35]) and their capital cities and visualized the vectors as shown in Fig. 10. Figures 10(d) and 10(e) show that specificity-based embeddings are capable of organizing entities of different types and preserving some semantic context among them. For instance, there is a separation between two different types of entities: dbo:Country and dbo:City, preserving the rdf:type relationship. Compared to , has comparatively better, although not perfect, organization of capitals in correspondence to their respective countries. Third, in Fig. 10(e), cities are grouped together based on the continents. The information regarding continents is represented via the semantic relationship dct:subject which links each city to different DBpedia categories including one that represents information about continents, e.g. dbc:Capitals_in_Asia.
Figures 10(b) and 10(c) show that rdf:type relationship is not preserved by frequency and PageRank-based projections respectively. There exists some, but inconsistent, organization of countries and capitals with respect to each other and a grouping based on continents. There is also no clear segregation based on entity types. Figure 10(a) shows that semantic associations are also preserved using uniform random walks. However, it can be seen in Fig. 11 that the average size of extracted subgraphs is order of magnitude more than the Specificity-based approach.
Parameter sensitivity
The algorithms for computing specificity use bidirectional random walks, governed by two parameters: number of bidirectional walks () and size of seed set S. In this section, we evaluate the sensitivity of specificity to these parameters.
Sensitivity of specificity to
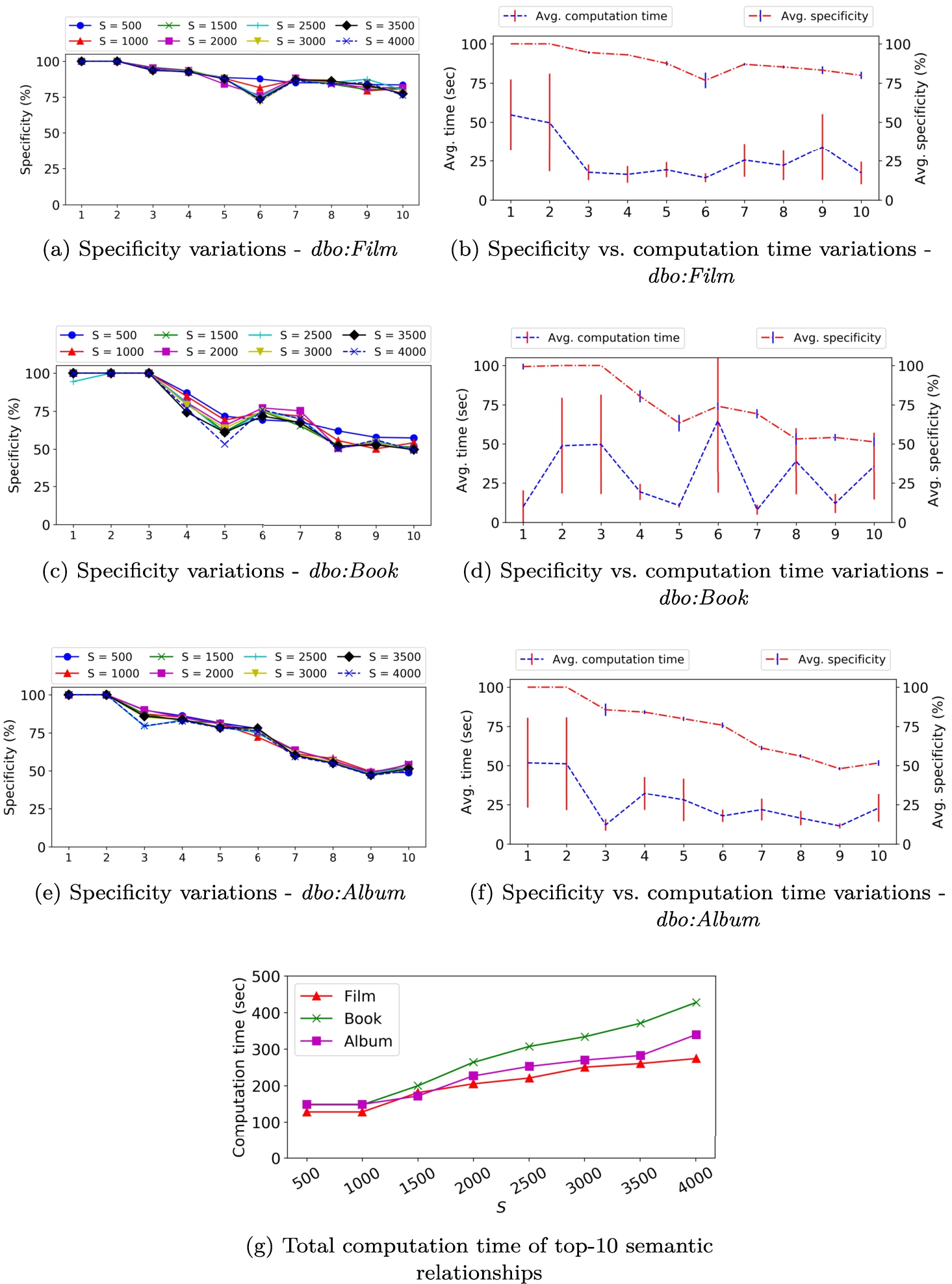
The algorithm for computing specificity uses the parameter for the number of bidirectional walks. To understand the effect of this parameter on specificity, we first compute specificity for . Figures 12(a), 12(c), and 12(e) show the comparison between specificity scores computed for different values of for top-10 semantic relationships for entity type dbo:Film, dbo:Book, and dbo:Album. The semantic relationships are sorted on the x-axis (from left to right) in order of decreasing specificity computed based on for comparison. Figure 12(g) shows the total time taken to compute specificity for the top-10 semantic relationships for each value of . The computation time increases with increasing number of bidirectional walks. Figures 12(b), 12(d), and 12(f) show the average specificity and corresponding computation time for each semantic relationship for all values of for the three chosen entity types. We use standard deviation to show the variations in the specificity scores and computation times observed for different values of . It can be observed that generally large variations in computation time do not lead to significant changes in the specificity scores. Choosing a larger value of will simply increase the total computation time without having significant effect on the computed specificity scores. If we select as a suitable value for computing specificity, it can be seen from Fig. 12(g) that the time for computing specificity scores w.r.t. either entity-type is ⩽150 s. Moreover, this computation is only needed to be performed once for each type of target entities in a KG.
Sensitivity of specificity to
Similar to previous discussion for , Figs 13(b), 13(d), and 13(f) also shows that the large variations in computation time do not lead to major change in the specificity. Choosing a larger value of increases the total computation time without having a significant effect on the computed specificity scores. If we choose as a suitable value for computing specificity, it will result in computation time of ≈150 s for computing specificity of top-10 most specific semantic relationships.
Projection of countries and capitals in 2D space using embeddings generated from RDF subgraphs of depth 2.
Average number of walks per entity of types dbo:City and dbo:Country for subgraph extraction for different values of β.
Analysis of running time of specificity computations
The specificity computations are performed by Algorithm 2. Algorithm 1 is used for setting up parameters and inputs for Algorithm 2. Since, the algorithm for computing specificity is based on random sampling governed by specific parameters, so instead of purely theoretical formulation here we provide a limited complexity analysis supplemented by empirical analysis of the running time of the algorithm.
Algorithm 2 computes specificity for a list of semantic relationships provided as input parameter Q. The complexity of Algorithm 2 as presented is the complexity of computing specificity of a single semantic relationship multiplied by the size of Q. Therefore, we analyze the complexity of computing specificity of a single semantic relationship which is accomplished in Lines 5–17. Lines 6–16 repeat N (or ) times, which is the number of bidirectional walks. In each iteration, the Algorithm 2 performs a forward walk in G and or a forward and then a reverse walk in G (Lines 8 and 9). After completing the bidirectional walk, a node is identified in Line 9. Lines 10–15 determine if has the type t or some other type in the class hierarchy, and the count is updated accordingly.
Effect of on computation of specificity.
Effect of on computation of specificity.
Empirical analysis of computation time of specificity.
There are two distinct tasks being performed in each iteration of the loop (Lines 6–16): (i) a bidirectional walk starts from a random node s of type t and lands at a node and (ii) determining the position of the type of in the class hierarchy. Assuming a tree-like class hierarchy where the height of the tree is H, the running time of the Lines 6–16 can be represented as where and correspond to the two tasks described above. Tasks and require information that is gathered by issuing SPARQL queries in our implementation. Therefore, the complexity of these tasks depends on how the query engine of Virtuoso optimizes the query execution. Instead of further expanding the relation for complexity mathematically, we treat the query engine as a black box and measure the query execution times of the issued SPARQL queries. In our implementation, we compute specificity using three sets of SPARQL queries, each of which performs one of the tasks below:
Starting from the seed set S, get a set V of N number of nodes using the semantic relationship of depth d, i.e., N iterations of Lines 7–8 of Algorithm 2.
Starting from the acquired set V, perform N number of reverse walks to get a set using any arbitrary path of depth d, i.e., N iterations of Line 9 of Algorithm 2.
Determine type of each and update count in Line 12 accordingly.
Table 5 shows the distribution of classes at different heights in the class hierarchy of DBpedia. Level 0 corresponds to dbo:Thing, the root of the class hierarchy. The maximum height of the tree H is 8. We replace H with a constant term and rewrite the running time relation for our DBpedia-based experiments as . Since the time complexity of tasks and depends on the query optimizations performed by the SPARQL query engine, therefore, we empirically measure the behavior of the term in the parentheses.
In the Fig. 14(a), each marker represents a single computation of specificity. We compute specificity for five classes (dbo:Film, dbo:Book, dbo:Album, dbo:City, and dbo:Country, depths , different seed set S sizes (100–1000), and , resulting in 23,908 data points. The red curve shows the average of computation time averaged against each value of . Figure 14(b) shows the distribution of computation times which shows 75% of all the data points shown in Fig. 14(a) represent a computation time of less than 20 s for DBpedia KG. Moreover, this computation is only needed to be performed once for each type of target entities in a KG.
Distribution of classes at different heights in DBpedia hierarchy
Height in the class hierarchy
Number of classes
0
1
1
49
2
126
3
209
4
271
5
72
6
23
7
4
Conclusion and future work
Graph embedding is an effective method of preparing KGs for AI and ML techniques. However, to generate appropriate representations, it is imperative to identify the most relevant nodes and edges in the neighborhood of each target entities. In this paper, we presented specificity as a useful metric for finding the most relevant semantic relationships for target entities of a given type. Our bi-directional random walks-based approach for computing specificity is suitable for large-scale KGs of any structure and size. We have shown through experimental evaluation that the metric of specificity incorporates a fine-grained decaying behavior for semantic relationships. It has the inherent ability to interpolate between extreme exploration strategies: BFS and DFS. We used specificity-based biased random walks to extract compact representations of target entities for generating graph embedding. These generated representations have similar performance as compared to baseline approaches when used for our selected tasks of entity recommendation, regression, and classification.
We presented the variable β for as a hyperparameter that controls the trade-off between better precision and smaller extracted subgraph sizes. We experimented with fixed values of β. In future extensions, we will explore estimating β based on the structure of the given KG. We also intend to use collaborative information in conjunction with the specificity-based extracted semantic information to improve the performance of the recommendation tasks. Finally, we intend to study other tasks for which specificity-based graph embedding can be useful such as KG completion and ontology alignment.
Footnotes
Acknowledgement
This work is supported by Chevron Corp. under the joint project, Center for Interactive Smart Oilfield Technologies (CiSoft), at the University of Southern California.
References
1.
N.Aggarwal, K.Asooja, H.Ziad and P.Buitelaar, Who are the American vegans related to Brad Pitt?: Exploring related entities, in: Proceedings of the 24th International Conference on World Wide Web Companion, WWW 2015 – Companion Volume, Florence, Italy, May 18–22, 2015, 2015, pp. 151–154. doi:10.1145/2740908.2742851.
2.
M.Atzori and A.Dessi, Ranking DBpedia properties, in: Proceedings of the 23rd IEEE International Conference on Enabling Technologies: Infrastructure for Collaborative Enterprises, WETICE 2014, Parma, Italy, 23–25 June, 2014, 2014, pp. 441–446. doi:10.1109/WETICE.2014.78.
3.
T.Berners-Lee, J.Hendler and O.Lassila, The semantic web, Scientific American284(5) (2001), 34–43. doi:10.1038/scientificamerican0501-34.
4.
C.Bizer, T.Heath and T.Berners-Lee, Linked data – the story so far, Int. J. Semantic Web Inf. Syst.5(3) (2009), 1–22. doi:10.4018/jswis.2009081901.
5.
S.Cederberg and D.Widdows, Using LSA and noun coordination information to improve the recall and precision of automatic hyponymy extraction, in: Proceedings of the Seventh Conference on Natural Language Learning, CoNLL 2003, Held in Cooperation with HLT-NAACL 2003, Edmonton, Canada, May 31–June 1, 2003, 2003, pp. 111–118.
6.
M.Cochez, P.Ristoski, S.P.Ponzetto and H.Paulheim, Biased graph walks for RDF graph embeddings, in: Proceedings of the 7th International Conference on Web Intelligence, Mining and Semantics, WIMS 2017, Amantea, Italy, June 19–22, 2017, 2017, pp. 21:1–21:12. doi:10.1145/3102254.3102279.
7.
M.Cochez, P.Ristoski, S.P.Ponzetto and H.Paulheim, Global RDF vector space embeddings, in: Proceedings, Part I, The Semantic Web – ISWC 2017 – 16th International Semantic Web Conference, Vienna, Austria, October 21–25, 2017, 2017, pp. 190–207. doi:10.1007/978-3-319-68288-4_12.
8.
G.K.D.de Vries and S.de Rooij, Substructure counting graph kernels for machine learning from RDF data, Journal of Web Semantics35 (2015), 71–84. doi:10.1016/j.websem.2015.08.002.
9.
D.Diefenbach and A.Thalhammer, Pagerank and generic entity summarization for RDF knowledge bases, in: The Semantic Web – 15th International Conference, ESWC 2018, Proceedings, Heraklion, Crete, Greece, June 3–7, 2018, 2018, pp. 145–160. doi:10.1007/978-3-319-93417-4_10.
10.
M.Färber, F.Bartscherer, C.Menne and A.Rettinger, Linked data quality of dbpedia, freebase, opencyc, wikidata, and YAGO, Semantic Web9(1) (2018), 77–129. doi:10.3233/SW-170275.
11.
E.Gabrilovich and S.Markovitch, Computing semantic relatedness using Wikipedia-based explicit semantic analysis, in: IJCAI 2007, Proceedings of the 20th International Joint Conference on Artificial Intelligence, Hyderabad, India, January 6–12, 2007, 2007, pp. 1606–1611.
12.
P.Goyal and E.Ferrara, Graph embedding techniques, applications, and performance: A survey, Knowl.-Based Syst.151 (2018), 78–94. doi:10.1016/j.knosys.2018.03.022.
13.
A.Grover and J.Leskovec, Node2vec: Scalable feature learning for networks, in: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, August 13–17, 2016, 2016, pp. 855–864. doi:10.1145/2939672.2939754.
14.
B.Heitmann and C.Hayes, Using linked data to build open, collaborative recommender systems, in: Linked Data Meets Artificial Intelligence, Papers from the 2010 AAAI Spring Symposium, Technical Report SS-10-07, Stanford, California, USA, March 22–24, 2010, 2010.
15.
P.Hitzler and F.van Harmelen, A reasonable semantic web, Semantic Web1(1–2) (2010), 39–44. doi:10.3233/SW-2010-0010.
16.
Y.Huang, V.Tresp, M.Nickel, A.Rettinger and H.Kriegel, A scalable approach for statistical learning in semantic graphs, Semantic Web5(1) (2014), 5–22. doi:10.3233/SW-130100.
17.
A.Ismayilov, D.Kontokostas, S.Auer, J.Lehmann and S.Hellmann, Wikidata through the eyes of dbpedia, Semantic Web9(4) (2018), 493–503. doi:10.3233/SW-170277.
18.
A.Lausch, A.Schmidt and L.Tischendorf, Data mining and linked open data – new perspectives for data analysis in environmental research, Ecological Modelling295 (2015), 5–17. doi:10.1016/j.ecolmodel.2014.09.018.
19.
J.P.Leal, V.Rodrigues and R.Queirós, Computing semantic relatedness using dbpedia, in: 1st Symposium on Languages, Applications and Technologies, SLATE 2012, Braga, Portugal, June 21–22, 2012, 2012, pp. 133–147. doi:10.4230/OASIcs.SLATE.2012.133.
20.
J.Lehmann, R.Isele, M.Jakob, A.Jentzsch, D.Kontokostas, P.N.Mendes, S.Hellmann, M.Morsey, P.van Kleef, S.Auer and C.Bizer, Dbpedia – A large-scale, multilingual knowledge base extracted from Wikipedia, Semantic Web6(2) (2015), 167–195. doi:10.3233/SW-140134.
21.
P.Lops, M.de Gemmis and G.Semeraro, Content-based recommender systems: State of the art and trends, in: Recommender Systems Handbook, 2011, pp. 73–105. doi:10.1007/978-0-387-85820-3_3.
22.
U.Lösch, S.Bloehdorn and A.Rettinger, Graph kernels for RDF data, in: The Semantic Web: Research and Applications – 9th Extended Semantic Web Conference, ESWC 2012, Proceedings, Heraklion, Crete, Greece, May 27–31, 2012, 2012, pp. 134–148. doi:10.1007/978-3-642-30284-8_16.
23.
T.Mikolov, K.Chen, G.Corrado and J.Dean, Efficient estimation of word representations in vector space, CoRRabs/1301.3781 (2013).
24.
T.Mikolov, I.Sutskever, K.Chen, G.S.Corrado and J.Dean, Distributed representations of words and phrases and their compositionality, in: Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013. Proceedings of a Meeting Held, Lake Tahoe, Nevada, United States, December 5–8, 2013, 2013, pp. 3111–3119.
25.
M.Nickel, K.Murphy, V.Tresp and E.Gabrilovich, A review of relational machine learning for knowledge graphs, Proceedings of the IEEE104(1) (2016), 11–33. doi:10.1109/JPROC.2015.2483592.
26.
X.Ning, H.Jin, W.Jia and P.Yuan, Practical and effective ir-style keyword search over semantic web, Inf. Process. Manage.45(2) (2009), 263–271. doi:10.1016/j.ipm.2008.12.005.
27.
T.D.Noia, R.Mirizzi, V.C.Ostuni, D.Romito and M.Zanker, Linked open data to support content-based recommender systems, in: I-SEMANTICS 2012 – 8th International Conference on Semantic Systems, I-SEMANTICS ’12, Graz, Austria, September 5–7, 2012, 2012, pp. 1–8. doi:10.1145/2362499.2362501.
28.
T.D.Noia, V.C.Ostuni, P.Tomeo and E.D.Sciascio, Sprank: Semantic path-based ranking for top-N recommendations using linked open data, ACM TIST8(1) (2016), 9:1–9:34. doi:10.1145/2899005.
29.
C.Paul, A.Rettinger, A.Mogadala, C.A.Knoblock and P.A.Szekely, Efficient graph-based document similarity, in: The Semantic Web. Latest Advances and New Domains – 13th International Conference, ESWC, 2016.
30.
J.Pennington, R.Socher and C.D.Manning, Glove: Global vectors for word representation, in: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP, a Meeting of SIGDAT 2014, a Special Interest Group of the ACL, Doha, Qatar, October 25–29, 2014, 2014, pp. 1532–1543. doi:10.3115/v1/D14-1162.
31.
B.Perozzi, R.Al-Rfou and S.Skiena, Deepwalk: Online learning of social representations, in: The 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD’14, New York, NY, USA, August 24–27, 2014, 2014, pp. 701–710. doi:10.1145/2623330.2623732.
32.
G.Piao and J.G.Breslin, Transfer learning for item recommendations and knowledge graph completion in item related domains via a co-factorization model, in: The Semantic Web – 15th International Conference, Proceedings, ESWC 2018, Heraklion, Crete, Greece, June 3–7, 2018, 2018, pp. 496–511. doi:10.1007/978-3-319-93417-4_32.
33.
A.Rettinger, U.Lösch, V.Tresp, C.d’Amato and N.Fanizzi, Mining the semantic web – statistical learning for next generation knowledge bases, Data Min. Knowl. Discov.24(3) (2012), 613–662. doi:10.1007/s10618-012-0253-2.
34.
P.Ristoski, S.Faralli, S.P.Ponzetto and H.Paulheim, Large-scale taxonomy induction using entity and word embeddings, in: Proceedings of the International Conference on Web Intelligence, Leipzig, Germany, August 23–26, 2017, 2017, pp. 81–87. doi:10.1145/3106426.3106465.
35.
P.Ristoski and H.Paulheim, RDF2Vec: RDF graph embeddings for data mining, in: Proceedings, Part I, The Semantic Web – ISWC 2016 – 15th International Semantic Web Conference, Kobe, Japan, October 17–21, 2016, 2016, pp. 498–514. doi:10.1007/978-3-319-46523-4_30.
36.
P.Ristoski, J.Rosati, T.Di Noia, R.De Leone and H.Paulheim, Rdf2vec: Rdf graph embeddings and their applications, Semantic Web 1–32. Preprint. http://www.semantic-web-journal.net/system/files/swj1738.pdf.
37.
M.A.Rodríguez and M.J.Egenhofer, Determining semantic similarity among entity classes from different ontologies, IEEE Trans. Knowl. Data Eng.15(2) (2003), 442–456. doi:10.1109/TKDE.2003.1185844.
38.
M.R.Saeed, C.Chelmis and V.K.Prasanna, Automatic integration and querying of semantic rich heterogeneous data: Laying the foundations for semantic web of things, in: Managing the Web of Things: Linking the Real World to the Web, 2017, pp. 251–273. doi:10.1016/B978-0-12-809764-9.00012-3.
39.
M.R.Saeed, C.Chelmis and V.K.Prasanna, Asqfor: Automatic SPARQL query formulation for the non-expert, AI Commun.31(1) (2018), 19–32. doi:10.3233/AIC-170746.
40.
M.R.Saeed, C.Chelmis and V.K.Prasanna, Not all embeddings are created equal: Extracting entity-specific substructures for RDF graph embedding, CoRRabs/1804.05184, 2018.
41.
M.R.Saeed, C.Chelmis and V.K.Prasanna, Smart oilfield SafetyNet – an intelligent system for integrated asset integrity management, in: SPE Annual Technical Conference and Exhibition (ATCE), 2018.
42.
M.R.Saeed, C.Chelmis, V.K.Prasanna, R.House, J.Blouin and B.Thigpen, Semantic web technologies for external corrosion detection in smart oil fields, in: SPE Western Regional Meeting, Garden Grove, California, USA, April 27–30, 2015, 2015. doi:10.2118/174042-MS.
43.
M.R.Saeed and V.K.Prasanna, Extracting entity-specific substructures for RDF graph embedding, in: 2018 IEEE International Conference on Information Reuse and Integration, IRI, Salt Lake City, UT, USA, July 6–9, 2018, 2018, pp. 378–385. doi:10.1109/IRI.2018.00063.
44.
N.Shervashidze, S.V.N.Vishwanathan, T.Petri, K.Mehlhorn and K.M.Borgwardt, Efficient graphlet kernels for large graph comparison, in: Proceedings of the Twelfth International Conference on Artificial Intelligence and Statistics, AISTATS 2009, Clearwater Beach, Florida, USA, April 16–18, 2009, pp. 488–495.
45.
B.Shi and T.Weninger, Proje: Embedding projection for knowledge graph completion, in: Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, California, USA, February 4–9, 2017, 2017, pp. 1236–1242.
46.
P.Shiralkar, A.Flammini, F.Menczer and G.L.Ciampaglia, Finding streams in knowledge graphs to support fact checking, in: 2017 IEEE International Conference on Data Mining, ICDM 2017, New Orleans, LA, USA, November 18–21, 2017, 2017, pp. 859–864. doi:10.1109/ICDM.2017.105.
47.
Y.Sun, J.Han, X.Yan, P.S.Yu and T.Wu, Pathsim: Meta path-based top-k similarity search in heterogeneous information networks, PVLDB4(11) (2011), 992–1003.
48.
A.Thalhammer and A.Rettinger, Pagerank on Wikipedia: Towards general importance scores for entities, in: The Semantic Web – ESWC 2016 Satellite Events, Heraklion, Crete, Greece, May 29–June 2, 2016, 2016, pp. 227–240. Revised Selected Papers. doi:10.1007/978-3-319-47602-5_41.
49.
Y.Tzitzikas, C.Lantzaki and D.Zeginis, Blank node matching and RDF/S comparison functions, in: Proceedings, Part I, The Semantic Web – ISWC 2012 – 11th International Semantic Web Conference, Boston, MA, USA, November 11–15, 2012, 2012, pp. 591–607. doi:10.1007/978-3-642-35176-1_37.
50.
P.Yanardag and S.V.N.Vishwanathan, Deep graph kernels, in: Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, August 10–13, 2015, 2015, pp. 1365–1374. doi:10.1145/2783258.2783417.
L.Zhu, M.Ghasemi-Gol, P.A.Szekely, A.Galstyan and C.A.Knoblock, Unsupervised entity resolution on multi-type graphs, in: Proceedings, Part I, The Semantic Web – ISWC 2016 – 15th International Semantic Web Conference, Kobe, Japan, October 17–21, 2016, 2016, pp. 649–667. doi:10.1007/978-3-319-46523-4_39.