
Abstract
Nowadays it is becoming increasingly necessary to query data stored in different datasets of public access, such as those included in the Linked Data environment, in order to get as much information as possible on distinct topics. However, users have difficulty to query those datasets with different vocabularies and data structures. For this reason it is interesting to develop systems that can produce on demand rewritings of queries. Moreover, a semantics preserving rewriting cannot often be guaranteed by those systems due to heterogeneity of the vocabularies. It is at this point where the quality estimation of the produced rewriting becomes crucial. In this paper we present a novel framework that, given a query written in the vocabulary the user is more familiar with, the system rewrites the query in terms of the vocabulary of a target dataset. Moreover, it informs about the quality of the rewritten query with two scores: a similarity factor which is based on the rewriting process itself, and a quality score offered by a predictive model. This Machine Learning based model learns from a set of queries and their intended (gold standard) rewritings. The feasibility of the framework has been validated in a real scenario.
Introduction
The increasing adoption of the Linked Open Data (LOD) paradigm has generated a distributed space of globally interlinked data, usually known as the Web of Data. This new space opens up the possibility of querying over a huge set of updated data. However, many users find difficulties when formulating queries over it, due to the fact that they are not familiar with the data, links and vocabularies of many heterogeneous datasets that constitute the Web of Data. In this scenario it becomes necessary to provide the users with tools and mechanisms that help them to exploit the vast amount of available data.
We can find in the specialized literature different proposals that have considered the goal of facilitating the task of querying heterogeneous datasets. We can highlight three main approaches among those proposals: 1) those that generate a kind of centralized repository that contains all the data of different datasets and then queries are formulated over that repository (e.g. [22]); 2) those that follow the federated query processing approach (e.g. [12]) in which a query against a federation of datasets is split into sub-queries that can be answered in the individual nodes where datasets are stored; and 3) those that follow the exploratory query processing approach (e.g. [13]), which take advantage of the dereferenceable IRIs principle promoted by Linked Data. In this approach, query execution begins in a source dataset and is intertwined with the traversal of the HTTP dereferenceable IRIs to retrieve more data, from different nodes, that incorporate additional data for answering parts of the query and include more IRIs that can be successively dereferended to augment the queried dataset until the initial query is sufficiently answered. The two first approaches require a costly preparation task and the last one is mainly oriented to leverage the dereferencing architecture of Linked Data.
In the centralized and federated approaches, users pose queries using the vocabulary chosen for the global schema and can only expect answers from the centralized repository or from federated datasets. However, it is very common that several datasets offer data on the same or overlapped domains. For example, GeoData and Geo Linked Data in the geographic domain, BNE (Biblioteca Nacional de España) and BNF (Bibliothèque National de France) in the bibliographic domain, MusicBrainz and Jamendo in the music domain, or Drugbank and Diseasome in the bio domain. Each centralized repository or a datasets federation only considers a limited collection of datasets and, therefore, cannot help a user with datasets that are out of the collection. Moreover, it seems interesting for the users to pose queries to a preferred dataset whose schema and vocabulary is sufficiently known by them and then a system could help those users enriching the answers to the query with data taken from a domain sharing dataset although with different vocabulary and schema. Our approach considers that type of systems. Notice that a proper rewriting of the query must be eventually managed by those systems.
In general, those kind of systems can be very useful in different scenarios. For example, an ordinary user posing a keyword-based query to a question answering system, which constructs a SPARQL query to be run on a source dataset, and then demanding for more answers from a dataset with different vocabulary. Another scenario can be that of scientists formulating queries over source datasets they are familiar with, and then, demanding more answers by accessing other different datasets, not requiring strict query equivalence but giving a chance to serendipity (notice that scientists need not be aware of the internal structure/vocabulary of the new target datasets). A third scenario can be that of an application programmer trying to query the English DBpedia using terms extracted from the user defined Spanish Wikipedia infoboxes (or whatever language Wikipedia), which are not mapped with official DBpedia terms. Then, in order to get some answers, a transformation of the source query is needed in order to be adequately expressed for the English DBpedia. The relevant common feature of all these scenarios is the need to cope with the vocabulary and schema heterogeneity of the stored data. Notice that such heterogeneity may reach the conceptual level leading to different granularity knowledge and to the point that some notions are conceptualized in one dataset but not in the others.
Our system deals with a query rewriting process where the preservation of the semantics is not a strong requirement and therefore it considers semantics-preserving and non-semantics-preserving rewritings in order to increase the opportunities of getting results. When a non-semantics-preserving scenario is considered, the definition of a quality estimation of the rewritten query becomes crucial because the user needs to be aware of the confidence that can be deposited on the results obtained from the new dataset.
As a motivating example, let us imagine a user that is only familiar with the LinkedMDB vocabulary (a dataset about movies and their related people). This user asks for the films and the names of art directors working on those films directed by Woody Allen and performed by Sean Penn. The SPARQL query constructed by the user could be as in Listing 1. The obtained results are listed on Table 1.

Films and names of art directors working on those films directed by Woody Allen and performed by Sean Penn
Query results from LinkedMDB
Given the scarcity of the response or its inadequacy, the user would find useful to execute the same query in other datasets, perhaps more recognized ones or more active ones, trying to obtain more results. A good example of those datasets may be DBpedia. Using our system the user could obtain the following reformulation of the query, according to the DBpedia vocabulary (see Listing 2).

Films and names of cinematographers working on those films directed by Woody Allen and performed by Sean Penn
This reformulation was based on some declared mapppings. In particular, mdb:director was declared an equivalent property to dbo:director in a set of RDF triples published as an Open Linked Data file,1
Query results from DBpedia. dbr:<
Notice that new results appeared when querying the DBpedia dataset, which may be of interest to the user. Moreover, which further enriches the answer is the provision of some quality estimation of the reformulated query. It is at this point where a main contribution of this paper plays a relevant role. In this particular case, our system offered a similarity factor of 0.86 and a quality score of
In general, quality estimation can be defined in terms of a query similarity measure between the source and target queries (source query, formulated over the initial dataset, and target query, formulated over another dataset of the Web of Data indicated as target). However, when comparing two queries, different similarity dimensions can be considered [7]: (1) the query structure, expressed as a string or a graph structure; (2) the query content, its triple patterns and ontological terms and literal values; (3) the language features, such as query operators and modifiers; and (4) the results set retrieved by the query. Queries may be assessed with respect to one or several of that considered dimensions. And it is widely accepted that the application context heavily determines the choice for a similarity measure. We think that the more relevant dimensions to be taken into account in the scenario considered in this paper are (2) the content and (4) the result set. After all, structure and language features of a target query seem to be of less relevance to inform the user about the intended similarity spirit to the formulated source query. Therefore, (1) structure and (3) language dimensions are not considered in the proposed assessment. Although the result set is what matters to the user, it is crucial to notice that the intention of issuing the query to a target dataset is to look for more or different results than those obtained by the source query. Therefore, the intended result set of the target query cannot be compared with that of the source query in terms of exact matching and the query similarity measure must take into account this distinctive feature.
In summary, a main contribution of this paper is an approach that estimates the quality of rewritten queries, including non-semantics-preserving rewriting, to search the distributed space of globally interlinked data, that is different from the centralized repository, federated, and exploratory aforementioned approaches. Terms for the source query can be selected from a preferred schema or vocabulary instead of that offered by the centralized approach or federated schema. Moreover, target datasets are not limited to those comprising the centralized repository or the federation. Technical contributions to support the proposed approach are: (1) A proposal of a general framework for the deployment and management of a query rewriting system concerning the scenario previously explained. And, (2) the validation of the framework in a real context, including the machine learning and optimization techniques used to estimate the quality of the rewriting outcome.
Proposal of a general framework We propose a new framework that groups the following components: query rewriting rules, an algorithm to manage the rules, a set of similarity measures, and a predictive model. This framework would be oriented to two types of users:
End users, who formulate a query over a source dataset and then the system issues a new query, which mimics the original one, over a target dataset (of the Web of Data) whose results further enrich the answer. The new issued query is annotated with a similarity factor between queries and a quality score.
Expert/technical users who, in addition to benefiting from the functionalities provided for end users, can also include in the framework: new rewriting rules, algorithms to process them, and similarity measures to qualify the query rewriting. The framework would also provide them with facilities to tune the introduced similarity measures by means of optimization techniques. The rewriting rules, similarity measures and training queries introduced could be stored in the log of the framework with the idea of serving as experimental and comparison benchmark.
Validation of the framework The framework has been tested in a real context. For that, we have instantiated the framework with the following elements:
Query rewriting rules. Apart from some rules dealing with the rewriting of terms by their specified equivalents, via synonym mappings or EDOAL (Expressive and Declarative Ontology Alignment Language) [9] alignment rules, the framework also deals with some other heuristic based rules which conform a carefully controlled set of cases.
An algorithm to schedule the application of the rules.
Similarity measures. The computation of the similarity factor takes into account different similarity measures depending on the motif of the rule being applied. Those motifs range from relational to ontological structure, and from language based to context based similarity.
Queries. 100 queries were formulated over the previously selected datasets. Three domain areas were considered for the datasets: media-domain, bibliographic, and life science. From the media-domain six datasets were selected, five datasets from the bibliographic domain, and five more from the life science domain, respectively. When selecting the queries, our aim was to get a set that would contain a broad spectrum of SPARQL query types [1]. Concerning provenance we selected queries that appeared in well known benchmarks such as QALD4 or FedBench, and we also considered queries that belonged to LOD SPARQL endpoints logs from the selected datasets.
Predictive model. A model has been created using a supervised machine learning method applied to the considered experimental scenario to predict the F1 score of each rewritten query.
The rest of the paper is organized as follows. Section 2 presents some related work in the scope of resource matching and query rewriting. Section 3 introduces a description of the main features of the proposed framework. Section 4 shows a framework embodiment. Section 5 describes the framework validation results. Finally, some conclusions are presented.
The impressive growth of the Web of Data has pushed the research on Data Linking [25]: “the task of determining whether two object descriptions can be linked one to the other to represent the fact that they refer to the same real-world object in a given domain or the fact that some kind of relation holds between them”. Those object descriptions can be expressed with diverse structural relationships, depending on different contexts, using classes and properties from different ontologies. Research on object similarity and class matching has issued a considerable amount of techniques and systems in the field of Ontology Matching [10], although less work has been devised for property alignment [3,19]. The work in [18] presents an unsupervised learning process for instance matching between entities. Queries considered in this paper involve terms for classes, properties and individuals. Therefore, techniques for discovering similarity for any of them are relevant. However, the topic of this paper regards query similarity, which can be recognized as a different problem. As has been noticed in [7], the appropriate notion of query similarity depends on the goal of the task. In our case, the task is to estimate the similarity of the intended semantics between a query designed for a source dataset and a rewriting to a different vocabulary, to be evaluated in a different target dataset.
Some works, for example [5,20], have approached a restricted version of the task carried out in our case. They restrict themselves to produce semantic preserving translations (i.e. total similarity) and so they assume that enough equivalent correspondences exist among entities in datasets. Taking into account that such an assumption is too strong in real scenarios we consider situations where different types of correspondences exist (not only of equivalence type) and even more, situations where some correspondences are missing. This consideration implies that query semantics is sometimes not preserved in the rewriting process and therefore the estimation of similarity of the produced rewriting becomes crucial.
The aim of our considered rewriting is to look for more answers in a target dataset than those obtained from the source dataset. Some other works have the goal of obtaining more answers (including approximate ones) for an original query; however, all of them restrict their scope to a single source dataset. In [17] they propose a logical relaxation of conditions in conjunctive queries based on RDFS semantics. Those conditions are successively turned more general and a ranking in the successively obtained answers is generated. [15,16] use the same kind of relaxations as [17], but propose different ranking models. In [15], similarity of relaxed queries is measured with a model based on the distance between nodes in the ontology hierarchy. In [16], they use an information content based model to measure similarity of relaxed queries. The work in [8] addresses the query relaxation problem by broadening or reformulating triple patterns of the queries. Their framework admits replacement of terms by other terms or by variables and also removal of entire triple patterns. In that work, generation and ranking of relaxed queries is guided by statistical techniques: a distance between the language models associated to entity documents is defined. All those works can be situated under the topic of query relaxation.
With different use cases in mind, the papers [6,14,24] present different possibilities for approaching the querying of Linked Data. In [14] a framework for relaxation of star-shaped SPARQL queries is proposed. They present different matchers (functions that map pairs of values to a relaxation score) for different kinds of attributes (numeric, lexical or categorical). The framework may involve multiple matchers. The matchers generate a tuple of numeric distances between a query and an entity (answer for the query). Notice that the distance is defined between an entity and a query, not between two queries as in our approach. [6] proposes a measure to evaluate the similarity between a graph representing a query and a graph representing the dataset. With a suitable relaxation of the notion of alignment between query graph paths and dataset graph paths they generate approximate answers to queries. In [24] a method for query approximation, query relaxation, and their combination is proposed for providing flexible querying capabilities that assist users in formulating queries. Query answers are ranked in order of increasing distance from the user’s original query.
In summary, cited works that transform the query or reformulate the notion of answer in order to provide users with more answers from the source dataset, do not try to reformulate the query in a different dataset with different vocabulary and data structure; and this is a distinguishing feature of our use case.
It is worth mentioning another data access paradigm that uses query rewriting. In the Ontology Based Data Access (OBDA) paradigm, an ontology provides a conceptual view of the data and a vocabulary for user queries [23]. Users pose queries in terms of a convenient conceptualization and familiar vocabulary, without being aware of the details of the structure of data sources. SPARQL can be considered as a query language in this paradigm [2], and the SPARQL query must be rewritten in an appropriate query language for the underlying data source which, for instance, could be SQL for relational databases. Such rewritting is based on mappings between terms in the ontology and (in case of relational databases) views of the relational schema. R2RML [4] is a W3C standard language for specifying those mappings. A sufficiently complete set of mappings must be specified in order to rewrite the query, since OBDA paradigm intends to process a query, over the underlying data source, which is semantically equivalent to the query posed by the user with the ontology vocabulary. Notwithstanding the relevance of OBDA paradigm, we point out that it tackles with a different problem to the stated one in this paper. OBDA rewrites a query to adapt it to another data model. The problem tackled in this paper is to rewrite a SPARQL query to adapt it to another vocabulary without considering complete mappings between the respective vocabularies.
Abstract framework
An abstract representation of the proposed framework for rewriting a query and estimating the quality of the rewritten query, can be expressed as a structure (
The part of a SPARQL query to be rewritten by rules in

The REPLACE clause presents a template that should be matched to a part of the graph pattern in the query being rewritten. This matching is the trigger of the rule. A template is a graph pattern including three kinds of tokens: IRI tokens, variable tokens, and wild tokens. A IRI token only binds to IRIs in the graph pattern of the query, a variable token only binds to variables, and a wild token binds to both. IRI tokens are prefixed by s: or t: meaning that they only bind to IRIs in the source or target dataset, respectively. Variable tokens are prefixed with a question mark. Wild tokens are prefixed with a hash, for instance #u. The matched part in the graph pattern of the query will be replaced by the binded template in the BY clause if the graph pattern in the WHEN clause find matches with the data graph of the datasets in question (the BY clause resembles the CONSTRUCT clause and the WHEN clause resembles the WHERE clause in SPARQL queries, but for replacement of triple patterns in a graph pattern).
For instance, the following rule:

applied to the query in Listing 1, produces the query (see Listing 3) by rewriting the triple pattern (?movie mdb:director ?woody) by (?movie dbo:director ?woody) due to the appearance of (mdb:director owl:sameAs dbo:director) in the consulted data graph, in this particular case in the local Virtuoso RDF store.

mdb:director replaced with dbo:director
This rule language is sufficiently expressive since WHEN clauses can use the full expressivity of graph patterns in SPARQL 1.1. The core of the implementation of those rules can be supported by an almost direct generation of SPARQL queries from the rule expression. For instance, the query supporting the previous sample rule could be constructed in the following way: Assume that the template (#s s:p #o) (appearing in the REPLACE clause) matches a part of the graph pattern in the query being rewritten and yields a binding of the IRI token s:p to the IRI s:IRIp in the source dataset. Then, the triple pattern (s:IRIp owl:sameAs ?t0p) (originated from the WHEN clause) will be the WHERE clause and ?t0p will be the projected variable in the SELECT clause due to the BY clause in the rule (see Listing 4).
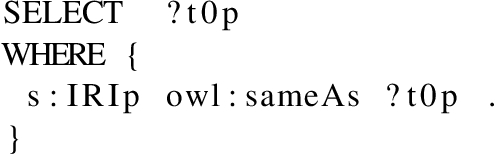
Query supporting rule implementation
Then, the results of that query can be used to form the corresponding replacements specified in the BY clause.
Rules in this paper only consider the basic RDF entailment regime. Nevertheless, if the mediating SPARQL endpoint managing the query processing implements another entailment regime over the dataset of interest, the rewriting process leverages on that enriched regime without any harm.
A rewriting rule set requires an algorithm to manage the rewriting process, this is the role of element
The rewriting system of the proposed framework takes a given query
We say that a term is adequate for a dataset if its IRI prefix follows the proprietary format of the dataset or it appears in the dataset vocabulary.
Every application of a rule r is considered as a step in the progress to the target query, and such steps are valuated with a factor computed by the associated similarity measure
The function
As previously said in the introduction section, the intention of issuing a query to the selected target dataset is to look for more or different results than those obtained in the source dataset. Therefore, although the target query should try to maintain the spirit of the source query, the intended result set of the target query cannot be compared with the source query retrieved set but with that of an ideal expression of such source query in terms of the vocabulary acceptable by the target dataset. Notice that, due to the previously mentioned heterogeneity reasons, such ideal expression cannot be trivially constructed. In fact, we consider that the finding of such ideal expression, in the considered scenario, should be realized by a human expert who knows vocabularies of source and target datasets. And, therefore, the reference query against which the target query should be compared is a human designed one, that tries to express the most similar intention to the source query but in the context of the target dataset. We consider such a query our gold standard query against which the target query should be compared.
In the presence of a gold standard query, its results can be compared with those obtained by the target query. Statistical measures such as precision, recall and F1 score can be used to measure the quality of a target query. Of course, gold standards can only exist in an experimental scenario but not in the real setting, and that is the reason to incorporate machine learning techniques in the framework. The predictive model
Note that this framework establishes, principally, a scenario for experimentation, where different materializations of each element of the framework can be assessed and compared.
In particular, it should be taken into account that the provision of gold standard queries involves a delicate work: knowledge of different vocabularies is needed and sometimes different choices can be considered as appropriate gold standard of a query. Furthermore, the production of desired quantities of training queries is a time consuming task. The editors of the gold standard queries considered in the experiment reported in this paper were just the authors of the paper. Queries were grouped by domain and each domain group was assigned to a different author. Then, the work was reviewed jointly. Therefore, the results of our experiments could be considered to be improved if we had a larger and much more supervised collection of queries.
This section presents a brief explanation of a specific embodiment of the abstract framework (
The set of rules
Five kinds of rules have been considered, each kind based on a different motif: Equivalence (E), Hierarchy (H), Answer-based (A), Profile-based (P), and Feature-based (F).
Furthermore, a pragmatic scenario has been considered in which a bridge dataset can be taken into account in the process of rewriting a query adequate for a source dataset into another query adequate for a target dataset. In order to favour the possibilities of finding alignments between resources, mappings between both the source (

where UNION(t:u #p #o) represents the UNION pattern of all the triple patterns constructed with the IRIs binded with t:u.
The similarity measure associated to equivalence rules (E) is simply the constant function

where AND(#s t:p #o) represents the conjunction pattern of all the triple patterns constructed with the IRIs binded with t:p. Three successive applications of this hierarchy rule to the query in Listing 3 rewrites it to the following query (see Listing 5) by rewriting the properties mdb:director_name, mdb:actor_name and mdb:film_art_director_name by the property foaf:name due to the appearance of (mdb:director_name rdfs:subPropertyOf foaf:name), (mdb:actor_name rdfs:subPropertyOf foaf:name) and (mdb:film_art_director_name rdfs:subPropertyOf foaf:name) as mappings provided by the own LinkedMDB dataset.4

mdb:director_name,mdb:actor_name and mdb:film_art_director_name replaced with foaf:name
Similarity estimation of hierarchy related terms is usually based on a distance measure. It is generally considered that the depth associated to the compared terms in the hierarchy influences the conceptual distance between the terms. Low depth correspond to more general terms and high depth correspond to more specific terms. Nearby high depth terms tend to be more semantic similar than low depth ones. Consequently, the similarity function selected for hierarchy rules (H) was an adaptation of a distance proposed in [32] and elsewhere. Each term u in the hierarchy is associated with a milestone value m(u) depending on its depth in the hierarchy. Then, the distance between two terms u and v in the hierarchy is
However, in the context considered in this paper, where u and v belong to different vocabularies and, therefore, different hierarchies, the notion of ccp(u,v) is not directly applicable. Then, we have adapted such distance. The intuition behind is that the deepest term (i.e. that with the least milestone) carries more information than the higher term:
The number of terms involved in the replacement of a term u and its triple pattern can be more than one, depending on the particular bindings of the applied rewriting rule. In such a case, if there are n bindings (
Equivalence and hierarchy rules can be applied when direct mappings for the term to be replaced are found. But, if the involved datasets are not completely aligned and those direct mappings are missing, new kinds of rules trying to leverage mappings of terms surrounding the focussed term should be considered. And that is precisely what our proposed Profile-based, Answer-based, and Feature-based kinds of rules do.
Let us call the profile of a resource x in a dataset D to the set of resources that are related to x, as subjects or objects, through triples in D. More specifically:
For instance, the following triples:

are only some of the triples in LinkedMDB that would determine the profile of mdb:film_art_director. Considering only such small set, the profile would be the set:

For the sake of the example, let us consider only one of those resources in the profile. For instance, mdb:film/38778. A mapping of equivalence was found betweeen mdb:film/38778 and the resource dbr:Sweet _and_Lowdown in DBpedia. And some triples were found in DBpedia involving dbr:Sweet_and_Lowdown. For instance:

The same process should be done with all the resources of the profile. Next, calculating the similarity between mdb:film_art_ director and any of the predicates appearing in the preceding set of triples we found the following values:

Then, the resource with the maximum similarity value was selected to replace mdb:film_art_director, namely dbo:cinematography. And the value of the similarity measure was
Next, the expression of the profile rule responsible of the previous replacement is presented:

Regarding the notion of sufficient similarity, we decided to establish a threshold h to be exceeded by the value of a similarity function between resources
In the current framework, the similarity function of two resources is defined as a linear combination of some other three similarity measures, which are selected to compare a context of the terms.
Definition of
Then, the similarity measure associated to u after the application of a Profile-based rule is
This kind of rule was used to replace mdb:film_art_director by dbo:cinematography, and also mdb:actor by dbo:starring, in the working example presented in the introduction, with a
However, after the application of some query rewriting rules, some non adequate terms of the query could still be unreplaced. The proposal in this paper considers two more kinds of rules in order to cover some more interesting circumstances.

Information about The Other Side of the Wind.
For instance, consider the query for DBpedia as source dataset and consider LinkedMDB as the target dataset. Then, dbr:The_Other_Side _of_the_Wind and dbo:Agent are not adequate for LinkedMDB. Consider the following set of triples in the source dataset (DBpedia):

Consider the five bindings of variable

Then, triples about those answer samples in the target dataset could probably resemble expected answers of the original query. For each one of those answer samples in the target dataset (LinkedMDB), triples as the following are found in the dataset:

As a crude approximation, the most frequent resource appearing in such a context could be considered to replace the non adequate term dbr:The_Other_Side_of_the _Wind in the query. In this case, mdb:film/46921 appeared 11 times in the running experiment and was selected for the replacement. Then, its similarity value was calculated, yielding
Then, the rewritten query obtained after applying that answer-based rule would be the following (see Listing 7).
The rule expression capturing the process described above could be as follows:

Information about movie:46921

Only a restricted set of templates is selected for applying the Answer-based rewriting rules. In particular, triple patterns where only one term remains non adequate for the target dataset. The other two terms of the triple pattern are an adequate term for the target dataset and a variable or else two variables. Namely, the selected templates are: (?x t:p s:u), (s:u t:p ?x), (?x s:p t:o), (t:o s:p ?x), (?x ?p s:o), (s:u ?p ?x). The adequate term may be there from the beginning (i.e. some terms can be adequate for both source and target dataset) or else be the result of a previously applied rewriting rule.
As has been previously noted, when the number of terms involved in the replacement of the term u is more than one (let us say
Values for parameter
The last kind of rules we are considering in the present embodiment is

A summary of the rules considered for this framework embodiment is presented in Tables 11, 12, 13, 14, 15, in the Appendix.
The algorithm 
The similarity factor
Finally, the score selected to inform about the quality of the obtained target query was the F1 score calculated by comparing the answers retrieved by the target query with those retrieved by the corresponding Gold standard query. We call Relevant answers (Rel) to the set of answers obtained by running the Gold standard query, and Retrieved answers (Ret) to the set of answers obtained by running the target query. Then, the values Precision (P), Recall (R), and F1 score (F1) are calculated with the following formulae.
This section presents the main results of the process carried out to validate the proposed framework. The following resources are presented: (a) the LOD datasets selected for querying data, (b) the collection of training queries, (c) the optimization algorithm used to determine the proper parameter values for computing similarity measures and a discussion of its results, (d) the collection of features gathered from data to construct the learning datasets used by the machine learning algorithms and the results obtained by them, (e) the processing times needed by the framework implementation to get the answers in the corresponding SPARQL endpoints.
Datasets and queries
To validate the framework we trusted on well known datasets of the Linked Open Data environment, with accessible endpoints that facilitate the assessment of our experiments. Three domain areas were considered for the datasets: media-domain, bibliographic, and life science. For each one, a set of recognized datasets were selected. With respect to media-domain, the selected ones were: DBpedia, MusicBrainz, LinkedMDB, Jamendo, New York Times and BBC. With respect to bibliographic domain, we considered BNE (Biblioteca Nacional de España), BNF (Bibliothèque National du France), BNB (British National Bibliography), LIBRIS, and Cambridge. And finally for the life science area: Drugbank, SIDER, CHEBI, DISEASOME, and KEGG were the selected ones. Moreover, to achieve greater plurality in the tests, we used the SP2Bench, which is based on a synthetic dataset. In addition, our framework implementation also considered DBpedia, VIAF, Freebase, and GeoNames as bridge datasets. The available SPARQL endpoint for each mentioned dataset was used to answer the queries. In summary, we considered 17 different datasets (16 real + 1 synthetic) along with 4 bridge datasets that assisted us on the framework implementation. This is a evidence of the broad coverage of the experiments performed.
The set of experimental queries were selected after analyzing heterogeneous benchmarks such as QALD,5
Regarding the syntactic structure of the queries, a variety of the SPARQL operators (UNION, OPTIONAL, FILTER) and different patterns for joins of variables appeared in the queries. The number of triple patterns of each query ranges from 1 to 7.
A very important source of knowledge that supports this framework are repositories containing mappings between terms from different vocabularies and interlinkings between different IRIs for the same resource. For instance, we can find files with mapping triples in the DBpedia project6
The similarity factor
The similarity measure, presented in Section 4, is based on similarity functions ϕ (associated to each rule application
We selected a method based on a genetic algorithm, specifically the Harmony Search (HS) algorithm [11]. Harmonies represent sets of variables to optimize, whereas the quality of the harmony is given by the fitness function of the optimization problem at hand.
In our case the variables to optimize are the parameters (
In order to carry out the optimization process the query set (see 5.1) was considered, and five-fold cross validation were performed. The sample data (initial query set) are divided into five subsets. One of the subsets is used as test data and the other four as training data. The cross-validation process is repeated five times (folds), with each of the five subsamples used exactly once as the test data. For each iteration (fold), the first step was to execute the HS algorithm on the set of training queries (composed by four subsets), in order to obtain the parameter values that achieve optimal fitness. For this, the algorithm was parametrized with the number of iterations and initial values for the parameters. The HS optimization process may obtain different solutions depending on the initial random values chosen for the parameters and the number of iterations allowed. With 100 iterations and an initialization defined by the HS algorithm itself, we obtained the parameter values shown in Table 3, according to different values of β (
Optimal parameter values for similarity function calculated from training subsamples for each fold
Optimal parameter values for similarity function calculated from training subsamples for each fold
One example of convergence of the HS optimization process for the training dataset and

Convergence of fitness with the training dataset and
To assess the validity of the parameter values obtained by the algorithm, the similarity factor was computed for each fold over the set of remaining test queries (in this case using the alphas obtained in the different scenarios with
Taking into account that a tighter threshold as
In the following we discuss the validity of the similarity factor
Figure 2 shows a scatter plot of the 100 points with coordinates (F1 score,
Fitness values for different thresholds
Fitness values for different thresholds
Finally, in 25 of them the similarity factor was higher than the F1 score. In those cases the similarity factor was too optimistic because the actual results provided by the target query were quite different from those provided by the gold standard query and there were cases where the F1-measure value was very low. This circumstance support the idea that would be interesting to complement the information to the user with a quality score reflecting the F1-score. As long as gold standard queries are not present in a real scenario, devising a prediction model for such a score is an option. Next, Section 5.4 will explain an implementation of such a predictive model. There were also 2 queries where the retrieved results were empty (Q28, Q40).

Scatterplot for F1 score and Similarity factor (using similarity parameter values calculated for training dataset and
Concluding this comparison, it can be said that
As discussed above, three domain areas were considered for the datasets: media-domain, bibliographic, and life science. Table 7 presents some statistics about the queries distribution and their
Summary of the comparison between
In that Table 7 we can observe that
Selected features for the 8 different datasets
Finally, we found interesting to know what was the correlation between the computed similarity factor and the F1 score. The Pearson correlation coefficient (usually named Pearson’s r) is a popular measure of the strength and direction of the linear relationship between two variables. Pearson’s correlation coefficient for continuous data ranges from
We think that the results in Table 5 allow us to say that the similarity factor defined in Section 4 is quite informative about the quality of the target query from an intensional point of view. Nevertheless, one goal of the presented framework is to serve as a tool for establishing benchmarks which promote improvement of query rewriting systems, and the embodiment presented in this paper could be considered a baseline.
As we have already mentioned, gold standard queries are not available in a real scenario, that is the reason why a predictive model
The construction of that predictive model was based on learning datasets that contain features of data that represent underlying structure and characteristics of the data subject of the prediction. In our scenario, features related to the structure of the source query such as number of triple patterns or number of operators, along with features related to rules that take part during the rewriting process, and finally features concerning the involved LOD datasets, were considered to build the feature datasets.
Following we present the 21 considered features:
Similarity and rules features, numbered from 1 to 11: (1) Number of times the equivalence rules are applied, (2) Similarity measure value associated to the equivalence rules application, (3) Number of times the hierarchy rules are applied, (4) Similarity measure value associated to the hierarchy rules application, (5) Number of times the answer-based rules are applied, (6) Similarity measure value associated to the answer-based rules application, (7) Number of times the profile-based rules are applied, (8) Similarity measure value associated to the profile-based rules application, (9) Number of times the feature-based rules are applied, (10) Similarity measure value associated to the feature-based rules application, and (11) the similarity factor calculated for the target query.
Query structure features, numbered from 12 to 18: (12) Number of triple patterns of the source query, (13) number of terms of the source query, (14) number of non adequate terms for the target dataset, (15) number of union operators, (16) number of projected variables, (17) number of optional operators, and (18) number of filter operators.
LOD Datasets features, numbered from 19 to 21: (19) categorical data associated to the source dataset depending on its size. Three values are possible: 1, for small datasets with less than
In order to select a best fit model, we experimented with the following off-the-shelf algorithms [21,31]: Linear regression (LR), Support Vector Machines (SVM), and Random Forest; and with 8 different datasets (F.1 to F.8) corresponding to distinct feature selection (see Table 8).
The values used in the experiment were obtained from the rewriting of the 100 aforementioned queries. This set of queries were divided in three fragments: 80% for the training process, 15% for the validation process, and 5% for the test process, respectively. The score of each of those models was measured based on a 20-fold cross-validated average mean squared error-R2 metric. The results are presented in the Table 9, where each cell of the table represents the coefficient of determination for each model trained with the feature dataset indicated by the row.
As can be seen, the model that best fit is that obtained using the Random Forest-RF algorithm with F.1 dataset, with a R2 equals to 0.8219 for validation set. Moreover, notice that the features datasets F.6, F.7, and F.8 are the ones that, in general, show a better behaviour with all the models. Therefore, the similarity factor (11), number of terms (13), and number of non-adequate terms (14) features can be considered the most significant ones. And it points out again the validity of the computed similarity factor. To asses the generalization error of the final chosen model, the value of R2 over the test set was computed, yielding a value of 0.8014.
R2 metric of the predictive models
R2 metric of the predictive models
The framework is placed into the Linked Open Data environment, leveraging datasets SPARQL endpoints. In order to asses the performance of the framework we want to show runtimes and the evaluation conditions in which it was implemented.
The rewriting process (rules and algorithm) has been implemented with Attributed Graph Grammar System (AGG) [27]. For similarity computation, we relied on the libraries Wordnet Similarity for Java (WS4J)9
Processing times in ms
(Continued)
Table 10 displays the processing times for each query in benchmark executed over the corresponding dataset. The TT column indicates the time needed by the framework to obtain the rewritten query. In column AT the time to get the answers of the query over the SPARQL endpoint is indicated, and finally the column TAT is the sum of the previous times (TT+AT). The same information is graphically showed in Fig. 3. The TT times, that really represents the performance of our system, are between a minimum value of 137 ms (Q15) and a maximum value of 11264 ms (Q18), regardless of the values of 0 ms (Q45, Q47). And

Answering times plus rewriting times.
The current state of the Web of Data with so many different datasets of a heterogeneous nature makes it difficult for users to query those datasets in order to exploit the vast amount of data they contain. Different proposals are appearing to overcome that limitation. In this paper we have detailed the features of a framework that allows end users to obtain results from different datasets expressing the query using only the vocabulary which the users are more familiar with, and informs them about the quality of the answer. Moreover, this framework serves technical users as a tool for establishing query rewriting benchmarks.
The framework has been embodied with a selected set of rules, rule scheduling algorithm, similarity measures, and quality estimation model composed of similarity factor function and F1 score predictive model. Moreover, the framework has been validated in a real scenario and the results obtained are promising, and they could be considered a baseline to be improved considering smarter rewriting rules and better shaped similarity measures.
Footnotes
Acknowledgements
This work is supported by FEDER/TIN2013-46238-C4-1-R and FEDER/TIN2016-78011-C4-2-R projects, and also by the ELKARTEK program (BID3ABI project).
Summary of rewriting rules
Summary of Feature-based rewriting rules
| Rule | REPLACE | WHEN | BY | |
| F23 | ( ) | ( ) ( ) | ( ) ( ) a new variable | |
| F24 | ( ) | ( ) ( ) | ( ) ( ) a new variable | |
| F25 | ( ) | ( ) ( ) | ( ) ( ) a new variable |