
Abstract
Linked Open Data has been recognized as a valuable source for background information in many data mining and information retrieval tasks. However, most of the existing tools require features in propositional form, i.e., a vector of nominal or numerical features associated with an instance, while Linked Open Data sources are graphs by nature. In this paper, we present RDF2Vec, an approach that uses language modeling approaches for unsupervised feature extraction from sequences of words, and adapts them to RDF graphs. We generate sequences by leveraging local information from graph sub-structures, harvested by Weisfeiler–Lehman Subtree RDF Graph Kernels and graph walks, and learn latent numerical representations of entities in RDF graphs. We evaluate our approach on three different tasks: (i) standard machine learning tasks, (ii) entity and document modeling, and (iii) content-based recommender systems. The evaluation shows that the proposed entity embeddings outperform existing techniques, and that pre-computed feature vector representations of general knowledge graphs such as DBpedia and Wikidata can be easily reused for different tasks.
Keywords
Introduction
Since its introduction, the Linked Open Data (LOD) [81] initiative has played a leading role in the rise of a new breed of open and interlinked knowledge bases freely accessible on the Web, each of them being part of a huge decentralized data space, the LOD cloud. This latter is implemented as an open, interlinked collection of datasets provided in machine-interpretable form, mainly built on top of World Wide Web Consortium (W3C) standards, such as RDF1
Most data mining algorithms work with a propositional feature vector representation of the data, which means that each instance is represented as a vector of features
Typically, those strategies led to high-dimensional, sparse datasets, which cause problems for many data mining algorithms [1]. Therefore, dense, lower-dimensional representations are usually preferred, but less straight forward to generate.
In language modeling, vector space word embeddings have been proposed in 2013 by Mikolov et al. [43,44]. They train neural networks for creating a low-dimensional, dense representation of words, which show two essential properties: (a) similar words are close in the vector space, and (b) relations between pairs of words can be represented as vectors as well, allowing for arithmetic operations in the vector space. In this work, we adapt those language modeling approaches for creating a latent representation of entities in RDF graphs.
Since language modeling techniques work on sentences, we first convert the graph into a set of sequences of entities using two different approaches, i.e., graph walks and Weisfeiler–Lehman Subtree RDF graph kernels. In the second step, we use those sequences to train a neural language model, which estimates the likelihood of a sequence of entities appearing in a graph. Once the training is finished, each entity in the graph is represented as a vector of latent numerical features. We show that the properties of word embeddings also hold for RDF entity embeddings, and that they can be exploited for various tasks.
We use several RDF graphs to show that such latent representation of entities have high relevance for different data mining and information retrieval tasks. The generation of the entities’ vectors is task and dataset independent, i.e., we show that once the vectors are generated, they can be reused for machine learning tasks, like classification and regression, entity and document modeling, and to estimate the proximity of items for content-based or hybrid recommender systems. Furthermore, since all entities are represented in a low dimensional feature space, building the learning models and algorithms becomes more efficient. To foster the reuse of the created feature sets, we provide the vector representations of DBpedia and Wikidata entities as ready-to-use files for download.
This paper considerably extends [76], in which we introduced RDF2Vec for the first time. In particular, we demonstrate the versatility of RDF embeddings by extending the experiments to a larger variety of tasks: we show that the vector embeddings not only can be used in machine learning tasks, but also for document modeling and recommender systems, without a need to retrain the embedding models. In addition, we extend the evaluation section for the machine learning tasks by comparing our proposed approach to some of the state-of-the-art graph embeddings, which have not been used for the specified tasks before. In further sets of experiments, we compare our approach to the state-of-the-art entity relatedness and document modeling approaches, as well to the state-of-the-art graph embedding approaches.
Preliminary results for the recommender task have already been published in [78]. In this paper, we further extend the evaluation in recommendation scenarios by considering a new dataset (
The rest of this paper is structured as follows. In Section 2, we give an overview of related work. In Section 3, we introduce our approach. In Section 4 through Section 7, we describe the evaluation setup and evaluate our approach on three different sets of tasks, i.e., machine learning, document modeling, and recommender systems. We conclude with a summary and an outlook on future work.
While the representation of RDF as vectors in an embedding space itself is a considerably new area of research, there is a larger body of related work in the three application areas discussed in this paper, i.e., the use of LOD in data mining, in document modeling, and in content-based recommender systems.
Generally, our work is closely related to the approaches DeepWalk [67] and Deep Graph Kernels [95]. DeepWalk uses language modeling approaches to learn social representations of vertices of graphs by modeling short random-walks on large social graphs, like BlogCatalog, Flickr, and YouTube. The Deep Graph Kernel approach extends the DeepWalk approach by modeling graph substructures, like graphlets, instead of random walks. Node2vec [24] is another approach very similar to DeepWalk, which uses second order random walks to preserve the network neighborhood of the nodes. The approach we propose in this paper differs from these approaches in several aspects. First, we adapt the language modeling approaches on directed labeled RDF graphs, unlike the approaches mentioned above, which work on undirected graphs. Second, we show that task-independent entity vectors can be generated on large-scale knowledge graphs, which later can be reused on a variety of machine learning tasks on different datasets.
LOD in machine learning
In the recent past, a few approaches for generating data mining features from Linked Open Data have been proposed. Many of those approaches assume a manual design of the procedure for feature selection and, in most cases, this procedure results in the formulation of a SPARQL query by the user. LiDDM [50] allows the users to declare SPARQL queries for retrieving features from LOD that can be used in different machine learning techniques. Similarly, Cheng et al. [10] proposes an approach for automated feature generation after the user has specified the type of features in the form of custom SPARQL queries.
A similar approach has been used in the RapidMiner3
When dealing with Kernel Functions for graph-based data, we face similar problems as in feature generation and selection. Usually, the basic idea behind their computation is to evaluate the distance between two data instances by counting common substructures in the graphs of the instances, i.e., walks, paths and trees. In the past, many graph kernels have been proposed that are tailored towards specific applications [31,59], or towards specific semantic representations [13]. However, only a few approaches are general enough to be applied on any given RDF data, regardless the data mining task. Lösch et al. [41] introduce two general RDF graph kernels, based on intersection graphs and intersection trees. Later, the intersection tree path kernel was simplified by de Vries et al. [16]. In another work, de Vries et al. [15,17] introduce an approximation of the state-of-the-art Weisfeiler–Lehman graph kernel algorithm aimed at improving the computation time of the kernel when applied to RDF. Furthermore, the kernel implementation allows for explicit calculation of the instances’ feature vectors, instead of pairwise similarities.
Furthermore, multiple approaches for knowledge graph embeddings for the task of link prediction have been proposed [51], which could also be considered as approaches for generating propositional features from graphs. RESCAL [53] is one of the earliest approaches, which is based on factorization of a three-way tensor. The approach is later extended into Neural Tensor Networks (NTN) [85] which can be used for the same purpose. One of the most successful approaches is the model based on translating embeddings, TransE [6]. This model builds entity and relation embeddings by regarding a relation as translation from head entity to tail entity. This approach assumes that some relationships between words could be computed by their vector difference in the embedding space. However, this approach cannot deal with reflexive, one-to-many, many-to-one, and many-to-many relations. This problem was resolved in the TransH model [92], which models a relation as a hyperplane together with a translation operation on it. More precisely, each relation is characterized by two vectors, the norm vector of the hyperplane, and the translation vector on the hyperplane. While both TransE and TransH, embed the relations and the entities in the same semantic space, the TransR model [40] builds entity and relation embeddings in separate entity space and multiple relation spaces. This approach is able to model entities that have multiple aspects, and various relations that focus on different aspects of entities.
Both for entity and document ranking, as well as for the subtask of computing the similarity or relatedness of entities and documents, different methods using LOD have been proposed.
Entity relatedness
Semantic relatedness of entities has been heavily researched over the past couple of decades. There are two main direction of studies. The first are approaches based on word distributions, which model entities as multi-dimensional vectors that are computed based on distributional semantics techniques [2,21,29]. The second are graph-based approaches relying on a graph structured knowledge base, or knowledge graph, which are the focus of this paper.
Schuhmacher et al. [82] proposed one of the first approaches for entity ranking using the DBpedia knowledge graph. They use several path and graph based approaches for weighting the relations between entities, which are later used to calculate the entity relatedness. A similar approach is developed by Hulpus et al. [32], which uses local graph measures, targeted to the specific pair, while the previous approach uses global measures. More precisely, the authors propose the exclusivity-based relatedness measure that gives higher weights to relations that are less used in the graph. In [56] the authors propose a hybrid approach that exploits both textual and RDF data to rank resources in DBpedia related to the IT domain.
Entity and document similarity
As for the entity relatedness approaches, there are two main directions of research in the field of semantic document similarity, i.e., approaches based on word distributions, and graph-based approaches. Some of the earliest approaches of the first category make use of standard techniques like bag-of-words models, but also more sophisticated approaches. Explicit Semantic Analysis (ESA) [21] represents text as a vector of relevant concepts. Each concept corresponds to a Wikipedia article mapped into a vector space using the TF-IDF measure on the article’s text. Similarly, Salient Semantic Analysis (SSA) [27] uses hyperlinks within Wikipedia articles to other articles as vector features, instead of using the full body of text.
Nunes et al. [58] present a DBpedia based document similarity approach, in which they compute a document connectivity score based on document annotations, using measures from social network theory. Thiagarajan et al. [88] present a general framework showing how spreading activation can be used on semantic networks to determine similarity of groups of entities. They experiment with Wordnet and the Wikipedia Ontology as knowledge bases and determine similarity of generated user profiles based on a 1-1 annotation matching.
Schuhmacher et al. [82] use the same measure used for entity ranking (see above) to calculate semantic document similarity. Similarly, Paul et al. [62] present an approach for efficient semantic similarity computation that exploits hierarchical and transverse relations in the graph.
One approach that does not belong to these two main directions of research is the machine-learning approach by Huang et al. [30]. The approach proposes a measure that assesses similarity at both the lexical and semantic levels, and learns from human judgments how to combine them by using machine-learning techniques.
Our work is, to the best of our knowledge, the first to exploit the graph structure using neural language modeling for the purpose of entity relatedness and similarity.
Recommender systems
Providing accurate suggestions, tailored to user’s needs and interests, is the main target of Recommender Systems (RS) [70], information filtering techniques commonly used to suggest items that are likely to be of use to a user. These techniques have proven to be very effective to face the information overload problem, that is the huge amount of information available on the Web, which risks to overwhelm user’s experience while retrieving items of interest. The numerous approaches facilitate the access to information in a personalized way, building a user profile and keeping it up-to-date.
RS address the information overload issue in two different ways, often combined into hybrid systems [8]: the collaborative approach [70] exploits information about the past behaviour and opinions of an existing user community to predict which item the current user will be more interested in, while the content-based approach [70] relies on the items’ “content”, that is the description of their characteristics. In a collaborative setting, a profile of the user is built by estimating her choice pattern through the behaviour of the overall user community. The content-based approach, instead, represents items by means of a set of features and defines a user profile as an assignment of importance to such features, exploiting the past interaction with the system. To overcome the limitations of traditional approaches, which define the content based on partial metadata or on textual information optionally associated to an item, a process of “knowledge infusion” [83] has been performed for the last years, giving rise to the class of semantics-aware content-based recommender systems [14]. Many content-based RS have incorporated ontological knowledge [42], unstructured or semi-structured knowledge sources (e.g., Wikipedia) [83], or the wealth of the LOD cloud, and recently the interest in unsupervised techniques where the human intervention is reduced or even withdrawn, has significantly increased.
LOD datasets, e.g., DBpedia [39], have been used in content-based recommender systems, e.g., in [19] and [20]. The former performs a semantic expansion of the item content based on ontological information extracted from DBpedia and LinkedMDB [28], an open semantic web database for movies, and tries to derive implicit relations between items. The latter involves both DBpedia and LinkedMDB and adapts the Vector Space Model to Linked Open Data: it represents the RDF graph as a three-dimensional tensor, where each slice is an ontological property (e.g. starring, director, …) and represents its adjacency matrix.
It has been proved that leveraging LOD datasets is also effective for hybrid recommender systems [8], that is in those approaches that boost the collaborative information with additional knowledge about the items. In [57], the authors propose SPRank, a hybrid recommendation algorithm that extracts semantic path-based features from DBpedia and uses them to compute top-N recommendations in a learning to rank approach and in multiple domains, movies, books and musical artists. SPRank is compared with numerous collaborative approaches based on matrix factorization [35,69] and with other hybrid RS, such as BPR-SSLIM [55], and exhibits good performance especially in those contexts characterized by high sparsity, where the contribution of the content becomes essential. Another hybrid approach is proposed in [74], which builds on training individual base recommenders and using global popularity scores as generic recommenders. The results of the individual recommenders are combined using stacking regression and rank aggregation.
Most of these approaches can be referred to as top-down approaches [14], since they rely on the integration of external knowledge and cannot work without human intervention. On the other side, bottom-up approaches ground on the distributional hypothesis [26] for language modeling, according to which the meaning of words depends on the context in which they occur, in some textual content. The resulting strategy is therefore unsupervised, requiring a corpus of textual documents for training as large as possible. Approaches based on the distributional hypothesis, referred to as discriminative models, behave as word embedding techniques where each term (and document) becomes a point in the vector space. They substitute the term-document matrix typical of Vector Space Model with a term-context matrix, on which they apply dimensionality reduction techniques such as Latent Semantic Indexing (LSI) [18] and the more scalable and incremental Random Indexing (RI) [79]. The latter has been involved in [47] and [48] to define the so called enhanced Vector Space Model (eVSM) for content-based RS, where user’s profile is incrementally built summing the features vectors representing documents liked by the user and a negation operator is introduced to take into account also negative preferences, inspired by [94], that is according to the principles of Quantum Logic.
Word embedding techniques are not limited to LSI and RI. The word2vec strategy has been recently presented in [43] and [44], and to the best of our knowldge, has been applied to item recommendations in a few works [46,61]. In particular, [46] is an empirical evaluation of LSI, RI and word2vec to make content-based movie recommendation exploiting textual information from Wikipedia, while [61] deals with check-in venue (location) recommendations and adds a non-textual feature, the past check-ins of the user. They both draw the conclusion that word2vec techniques are promising for the recommendation task. Finally, there is a single example of product embedding [23], namely prod2vec, which operates on the artificial graph of purchases, treating a purchase sequence as a “sentence” and products within the sequence as words.
Approach
In our approach, we adapt neural language models for RDF graph embeddings. Such approaches take advantage of the word order in text documents, explicitly modeling the assumption that closer words in a sequence are statistically more dependent. In the case of RDF graphs, we consider entities and relations between entities instead of word sequences. Thus, in order to apply such approaches on RDF graph data, we first have to transform the graph data into sequences of entities, which can be considered as sentences. Using those sentences, we can train the same neural language models to represent each entity in the RDF graph as a vector of numerical values in a latent feature space.
RDF graph sub-structures extraction
We propose two general approaches for converting graphs into a set of sequences of entities, i.e, graph walks and Weisfeiler–Lehman Subtree RDF Graph Kernels.
An RDF graph is a labeled, directed graph
The objective of the conversion functions is for each vertex
In this approach, given a graph

Algorithm for generating RDF graph walks
In the case of large RDF graphs, generating all possible walks for all vertices results in a large number of walks, which makes the training of the neural language model highly inefficient. To avoid this problem, we suggest for each vertex in the graph to generate only a subset, with size n, of all possible walks. To generate the walks, the outgoing edge to follow from the currently observed vertex

Algorithm for generating weighted RDF graph walks
As an alternative to graph walks, we also use the subtree RDF adaptation of the Weisfeiler–Lehman algorithm presented in [15,17] to convert an RDF graph into a set of sequences. The Weisfeiler–Lehman Subtree graph kernel is a state-of-the-art, efficient kernel for graph comparison [84]. The kernel computes the number of sub-trees shared between two (or more) graphs by using the Weisfeiler–Lehman test of graph isomorphism. This algorithm creates labels representing subtrees in h iterations, i.e., after each iteration there is a set of subtrees, where each of the subtrees is identified with a unique label. The rewriting procedure of Weisfeiler–Lehman goes as follows: (i) the algorithm creates a multiset label for each vertex based on the labels of the neighbors of that vertex; (ii) this multiset is sorted and together with the original label concatenated into a string, which is the new label; (iii) for each unique string a new (shorter) label replaces the original vertex label; (iv) at the end of each iteration, each label represents a unique full subtree.
There are two main modifications of the original Weisfeiler–Lehman graph kernel algorithm in order to be applicable on RDF graphs [15,17]. First, the RDF graphs have directed edges, which is reflected in the fact that the neighborhood of a vertex v contains only the vertices reachable via outgoing edges. Second, as mentioned in the original algorithm, labels from two iterations can potentially be different while still representing the same subtree. To make sure that this does not happen, the authors in [15,17] have added tracking of the neighboring labels in the previous iteration, via the multiset of the previous iteration. If the multiset of the current iteration is identical to that of the previous iteration, the label of the previous iteration is reused.
The Weisfeiler–Lehman relabeling algorithm for an RDF graph is given in Algorithm 3, which is the same relabeling algorithm proposed in [15]. The algorithm takes as input the RDF graph

Weisfeiler–Lehman Relabeling for RDF
The procedure of converting the RDF graph to a set of sequences of tokens goes as follows: (i) for a given graph

Architecture of the CBOW and Skip-gram model.
Neural language models have been developed in the NLP field as an alternative to represent texts as a bag of words, and hence, a binary feature vector, where each vector index represents one word. While such approaches are simple and robust, they suffer from several drawbacks, e.g., high dimensionality and severe data sparsity, which limits their performance. To overcome such limitations, neural language models have been proposed, inducing low-dimensional, distributed embeddings of words by means of neural networks. The goal of such approaches is to estimate the likelihood of a specific sequence of words appearing in a corpus, explicitly modeling the assumption that closer words in the word sequence are statistically more dependent.
While some of the initially proposed approaches suffered from inefficient training of the neural network models, like Feedforward Neural Net Language Model (NNLM) [4,12,90], with the recent advances in the field several efficient approaches have been proposed. One of the most popular and widely used approaches is the word2vec neural language model [43,44]. Word2vec is a particularly computationally-efficient two-layer neural net model for learning word embeddings from raw text. There are two different algorithms, the Continuous Bag-of-Words model (CBOW) and the Skip-gram model. The efficiency of the models comes as a result from the simplicity of the models by avoiding dense matrix multiplication, i.e., the non-linear hidden layer is removed from the neural network and the projection layer is shared for all words. Furthermore, the Skip-gram model has been extended to make the training even more efficient, i.e., (i) sub-sampling of frequent words, which significantly improves the model training efficiency, and improves the vector quality of the less frequent words; (ii) using simplified variant of Noise Contrastive Estimation [25], called negative sampling.
Continuous bag-of-words model
The CBOW model predicts target words from context words within a given window. The model architecture is shown in Fig. 1(a). The input layer is comprised of all the surrounding words for which the input vectors are retrieved from the input weight matrix, averaged, and projected in the projection layer. Then, using the weights from the output weight matrix, a score for each word in the vocabulary is computed, which is the probability of the word being a target word. Formally, given a sequence of training words
Skip-gram model
The skip-gram model does the inverse of the CBOW model and tries to predict the context words from the target words (Fig. 1(b)). More formally, given a sequence of training words
In both cases, calculating the softmax function is computationally inefficient, as the cost for computing is proportional to the size of the vocabulary. Therefore, two optimization techniques have been proposed, i.e., hierarchical softmax and negative sampling [44]. The empirical studies in the original paper [44] have shown that in most cases negative sampling leads to a better performance than hierarchical softmax, which depends on the selected negative samples, but it has higher runtime.
Once the training is finished, all words (or, in our case, entities) are projected into a lower-dimensional feature space, and semantically similar words (or entities) are positioned close to each other.
Evaluation
We evaluate our approach on three different tasks: (i) standard machine-learning classification and regression; (ii) document similarity and entity relatedness; (iii) top-N recommendation both with content-based and hybrid RSs. For all three tasks, we utilize two of the most prominent RDF knowledge graphs [64], i.e., DBpedia [39] and Wikidata [91]. DBpedia is a knowledge graph which is extracted from structured data in Wikipedia. The main source for this extraction are the key-value pairs in the Wikipedia infoboxes. Wikidata is a collaboratively edited knowledge graph, operated by the Wikimedia foundation4
We use the English version of the 2015-10 DBpedia dataset, which contains
For the Wikidata dataset, we use the simplified and derived RDF dumps from 2016-03-28.6
The first step of our approach is to convert the RDF graphs into a set of sequences. As the number of generated walks increases exponentially [17] with the graph traversal depth, calculating Weisfeiler–Lehman subtrees RDF kernels, or all graph walks with a given depth d for all of the entities in the large RDF graph quickly becomes unmanageable. Therefore, to extract the entities embeddings for the large RDF datasets, we use only random graph walks entity sequences, generated using Algorithm 2. For both DBpedia and Wikidata, we first experiment with 200 random walks per entity with depth of 4, and 200 dimensions for the entities’ vectors. Additionally, for DBpedia we experiment with 500 random walks per entity with depth of 4 and 8, with 200 and 500 dimensions for the entities’ vectors. For Wikidata, we were unable to build models with more than 200 walks per entity, because of memory constrains, therefore we only experiment with the dimensions of the entities’ vectors, i.e., 200 and 500.
We use the corpora of sequences to build both CBOW and Skip-Gram models with the following parameters: window size = 5; number of iterations = 5; negative sampling for optimization; negative samples = 25; with average input vector for CBOW. The parameter values are selected based on recommendations from the literature [43]. To prevent sharing the context between entities in different sequences, each sequence is considered as a separate input in the model, i.e., the sliding window restarts for each new sequence. We used the gensim implementation7
In the evaluation section we use the following notation for the models: KB2Vec model #walks #dimensions depth, e.g. DB2vec SG 200w 200v 4d, refers to a model built on DBpedia using the skip-gram model, with 200 walks per entity, 200 dimensional vectors and all the walks are of depth 4.
Linking entities in a machine learning task to those in the LOD cloud helps generating additional features, which may help improving the overall learning outcome. For example, when learning a predictive model for the success of a movie, adding knowledge from the LOD cloud (such as the movie’s budget, director, genre, Oscars won by the starring actors, etc.) can lead to a more accurate model.
Experimental setup
For evaluating the performance of our RDF embeddings in machine learning tasks, we perform an evaluation on a set of benchmark datasets. The dataset contains four smaller-scale RDF datasets (i.e., AIFB, MUTAG, BGS, and AM), where the classification target is the value of a selected property within the dataset, and five larger datasets linked to DBpedia and Wikidata, where the target is an external variable (e.g., the metacritic score of an album or a movie). The latter datasets are used both for classification and regression. Details on the datasets can be found in [73].
For each of the small RDF datasets, we first build two corpora of sequences, i.e., the set of sequences generated from graph walks with depth 8 (marked as W2V), and set of sequences generated from Weisfeiler–Lehman subtree kernels (marked as K2V). For the Weisfeiler–Lehman algorithm, we use 3 iterations and depth of 4, and after each iteration we extract all walks for each entity with the same depth. We use the corpora of sequences to build both CBOW and Skip-Gram models with the following parameters: window size = 5; number of iterations = 10; negative sampling for optimization; negative samples = 25; with average input vector for CBOW. We experiment with 200 and 500 dimensions for the entities’ vectors.
We use the RDF embeddings of DBpedia and Wikidata (see Section 4) on the five larger datasets, which provide classification/regression targets for DBpedia/Wikidata entities (see Table 1).
Datasets overview. For each dataset, we depict the number of instances, the machine learning tasks in which the dataset is used (C stands for classification, and R stands for regression) and the source of the dataset. In case of classification, c indicates the number of classes
Datasets overview. For each dataset, we depict the number of instances, the machine learning tasks in which the dataset is used (C stands for classification, and R stands for regression) and the source of the dataset. In case of classification, c indicates the number of classes
We compare our approach to several baselines. For generating the data mining features, we use three strategies that take into account the direct relations to other resources in the graph [65,75], and two strategies for features derived from graph sub-structures [17]:
Features derived from specific relations. In the experiments we use the relations rdf:type (types), and dcterms:subject (categories) for datasets linked to DBpedia.
Features derived from generic relations, i.e., we generate a feature for each incoming (rel in) or outgoing relation (rel out) of an entity, ignoring the value or target entity of the relation. Furthermore, we combine both incoming and outgoing relations (rel in & out).
Features derived from generic relations-values, i.e., we generate a feature for each incoming (rel-vals in) or outgoing relation (rel-vals out) of an entity including the value of the relation. Furthermore, we combine both incoming and outgoing relations with the values (rel-vals in & out).
Kernels that count substructures in the RDF graph around the instance node. These substructures are explicitly generated and represented as sparse feature vectors.
The Weisfeiler–Lehman (WL) graph kernel for RDF [17] counts full subtrees in the subgraph around the instance node. This kernel has two parameters, the subgraph depth d and the number of iterations h (which determines the depth of the subtrees). Following the settings in [15], we use two pairs of settings,
The Intersection Tree Path kernel for RDF [17] counts the walks in the subtree that spans from the instance node. Only the walks that go through the instance node are considered. We will therefore refer to it as the root Walk Count (WC) kernel. The root WC kernel has one parameter: the length of the paths l, for which we test 4 (WC_4) and 6 (WC_6), following the settings in [15].
Classification results on the small RDF datasets. The best results are marked in bold. Experiments marked with “\” did not finish within ten days, or have run out of memory
Furthermore, we compare the results to the state-of-the art graph embeddings approaches: TransE, TransH and TransR. These approaches have shown comparable results with the rest of the graph embeddings approaches on the task of link predictions. But most importantly, while there are many graph embeddings approaches, like RESCAL [53], Neural Tensor Networks (NTN) [85], ComplEx [89], HolE [52] and others, the approaches based on translating embeddings approaches scale to large knowledge-graphs as DBpedia.9
Because of high processing requirements we were not able to build the models for the Wikidata dataset.
We perform no feature selection in any of the experiments, i.e., we use all the features generated with the given feature generation strategy. For the baseline feature generation strategies, we use binary feature vectors, i.e., 1 if the feature exists for the instance, 0 otherwise.
We perform two learning tasks, i.e., classification and regression. For classification tasks, we use Naive Bayes, k-Nearest Neighbors (
The complexity constant sets the tolerance for misclassification, where higher C values allow for “softer” boundaries and lower values create “harder” boundaries.
The strategies for creating propositional features from Linked Open Data are implemented in the RapidMiner LOD extension12
The results for the task of classification on the small RDF datasets are shown in Table 2.15
We do not consider the strategies for features derived from specific relations, i.e., types and categories, because the datasets do not contain categories, and all the instances are of the same type.
The results for the task of classification and regression on the five datasets using the DBpedia and Wikidata entities’ vectors are shown in Tables 3 and 4. We can observe that the latent vectors extracted from DBpedia and Wikidata outperform all of the standard feature generation approaches. Furthermore, the RDF2vec approaches built on the DBpedia dataset continuously outperform the related approaches, i.e., TransE, TransH, and TransR, on both tasks for all the datasets, except on the Forbes dataset for the task of classification. In this case, all the related approaches outperform the baseline approaches as well as the RDF2vec approach. The difference is most significant when using the C4.5 classifier. In general, the DBpedia vectors work better than the Wikidata vectors, where the skip-gram vectors with size 200 or 500 built on graph walks of depth 8 on most of the datasets lead to the best performance. An exception is the AAUP dataset, where the Wikidata skip-gram 500 vectors outperform the other approaches. Furthermore, in Table we can notice that the SVM model achieves very low accuracy on the AAUP dataset. The explanation for such poor performance might be that the instances in the dataset are not linearly separable, therefore the SVM is unable to correctly classify the instances.
On both tasks, we can observe that the skip-gram vectors perform better than the CBOW vectors. Furthermore, the vectors with higher dimensionality and longer walks lead to a better representation of the entities and better performance on most of the datasets. However, for the variety of tasks at hand, there is no universal approach, i.e., a combination of an embedding model and a machine learning method, that consistently outperforms the others.
Classification results. The first number represents the dimensionality of the vectors, while the second number represent the value for the depth parameter. The best results are marked in bold. Experiments marked with “\” did not finish within ten days, or have run out of memory
Regression results. The first number represents the dimensionality of the vectors, while the second number represent the value for the depth parameter. The best results are marked in bold. Experiments that did not finish within ten days, or that have run out of memory are marked with “\”
The structure and quality of the underlying knowledge graph may influence the results of the algorithms. For example, there are quite a few differences in the average degree of resources in different knowledge graphs [71], which influence the walks and ultimately the embeddings. For the datasets at hand, the entities are cities, movies, albums, universities, and companies. Table 5 shows the average outgoing degrees for the entities in those classes, in the respective knowledge graphs. This means that for most of the cases, the entities at hand are, on average, described at more detail in DBpedia, i.e., we can expect that also the embeddings for DBpedia will be of higher quality. It is further remarkable that the biggest discrepancy for the classification task between the best DBpedia and the best Wikidata embeddings occurs for the Metacritic albums dataset (with 15 percentage points), which is also the class with the highest difference in the degree distribution. On the other hand, for universities, which have a high level of detail in both knowledge graphs, the difference is not that severe (and Wikidata embeddings are even superior on the regression task). However, the number of datasets is still too small to make a quantitative statement about the relation between level of detail in the knowledge graph and performance of the embeddings. Similar observation holds in the entity and document modeling evaluation (see Section 6), and the recommender systems evaluation (see Section 7).
To analyze the semantics of the vector representations, we employ Principal Component Analysis (PCA) to project the entities’ feature vectors into a two dimensional feature space. We selected seven countries and their capital cities, and visualized their vectors as points in a two-dimensional space. Figure 2(a) shows the corresponding DBpedia vectors, and Fig. 2(b) shows the corresponding Wikidata vectors. The figure illustrates the ability of the model to automatically organize entities of different types, and preserve the relationships between different entities. For example, we can see that there is a clear separation between the countries and the cities, and the relation “capital” between each pair of country and the corresponding capital city is preserved. Furthermore, we can observe that more similar entities are positioned closer to each other, e.g., we can see that the countries that are part of the EU are closer to each other, and the same applies for the Asian countries.
Average outgoing degree for selected classes
Average outgoing degree for selected classes

Two-dimensional PCA projection of the 500-dimensional Skip-gram vectors of countries and their capital cities.
Finally, we conduct a scalability experiment, where we examine how the number of instances affects the number of generated features by each feature generation strategy. For this purpose we use the Metacritic Movies dataset. We start with a random sample of 100 instances, and in each next step we add 200 (or 300) unused instances, until the complete dataset is used, i.e.,
From the chart, we can observe that the number of generated features sharply increases when adding more samples in the datasets, especially for the strategies based on graph substructures.
In contrast, the number of features remains constant when using the RDF2Vec approach, as it is fixed to 200 or 500, respectively, independently of the number of samples in the data. Thus, by design, it scales to larger datasets without increasing the dimensionality of the dataset.

Features increase rate per strategy (log scale).
Calculating entity relatedness and similarity are fundamental problems in numerous tasks in information retrieval, natural language processing, and Web-based knowledge extraction. While similarity only considers subsumption relations to assess how two objects are alike, relatedness takes into account a broader range of relations, i.e., the notion of relatedness is wider than that of similarity. For example, “Facebook” and “Google” are both entities of the class company, and they have high similarity and relatedness score. On the other hand, “Facebook” and “Mark Zuckerberg” are not similar at all, but are highly related, while “Google” and “Mark Zuckerberg” are not similar at all, and have lower relatedness value compared to the first pair of entities.
Approach
In this section, we introduce several approaches for entity and document modeling based on the previously built latent feature vectors for entities.
Entity similarity
As previously mentioned, in the RDF2Vec feature embedding space (see Section 3), semantically similar entities appear close to each other in the feature space. Therefore, the problem of calculating the similarity between two instances is a matter of calculating the distance between two instances in the given feature space. To do so, we use the standard cosine similarity measure, which is applied on the vectors of the entities. Formally, the similarity between two entities
Document similarity
We use those entity similarity scores in the task of calculating semantic document similarity. We follow a similar approach as the one presented in [62], where two documents are considered to be similar if many entities of the one document are similar to at least one entity in the other document. More precisely, we try to identify the most similar pairs of entities in both documents, ignoring the similarity of all other pairs.
Given two documents
Extract the sets of entities
Calculate the similarity score
For each entity
Calculate the similarity score between the documents
Similarity-based relatedness Spearman’s rank correlation results
Similarity-based relatedness Spearman’s rank correlation results
In this approach we assume that two entities are related if they often appear in the same context. For example, “Facebook” and “Mark Zuckerberg”, which are highly related, are often used in the same context in many sentences. To calculate the probability of two entities being in the same context, we make use of the RDF2Vec models and the set of sequences of entities generated as described in Section 3. Given a RDF2vec model and a set of sequences of entities, we calculate the relatedness between two entities
In the case of a skip-gram model, the probability is calculated as:
Evaluation
For both tasks of determining entity relatedness and document similarity, we use existing benchmark datasets to compare the use of RDF2Vec models against state of the art approaches.
Context-based relatedness Spearman’s rank correlation results
Context-based relatedness Spearman’s rank correlation results
For evaluating the entity relatedness approach, we use the KORE dataset [29]. The dataset consists of 21 main entities, whose relatedness to the other 20 entities each has been manually assessed, leading to 420 rated entity pairs. We use the Spearman’s rank correlation as an evaluation metric.
We use two approaches for calculating the relatedness rank between the entities, i.e. (i) the entity similarity approach described in Section 6.1.1; (ii) the entity relatedness approach described in Section 6.1.3.
We evaluate each of the RDF2Vec models separately. Furthermore, we also compare to the Wiki2vec model,16
Table 6 shows the Spearman’s rank correlation results when using the entity similarity approach. Table 7 shows the results for the relatedness approach. The results show that the DBpedia models outperform the Wikidata models. Increasing the number of walks per entity improves the results. Also, the skip-gram models outperform the CBOW models continuously. We can observe that the relatedness approach outperforms the similarity approach.
Furthermore, we compare our approaches to several state-of-the-art graph-based entity relatedness approaches:
Spearman’s rank correlation results comparison to related work
baseline: computes entity relatedness as a function of distance between the entities in the network, as described in [82].
KORE: calculates keyphrase overlap relatedness, as described in the original KORE paper [29].
CombIC: semantic similarity using a Graph Edit Distance based measure [82].
ER: Exclusivity-based relatedness [32].
The comparison, shown in Table 8, shows that our entity relatedness approach outperforms all the rest for each category of entities. Interestingly enough, the entity similarity approach, although addressing a different task, also outperforms the majority of state of the art approaches.
To evaluate the document similarity approach, we use the LP50 dataset [37], namely a collection of 50 news articles from the Australian Broadcasting Corporation (ABC), which were pairwise annotated with similarity rating on a Likert scale from 1 (very different) to 5 (very similar) by 8 to 12 different human annotators. To obtain the final similarity judgments, the scores of all annotators are averaged. As a evaluation metrics we use Pearson’s linear correlation coefficient and Spearman’s rank correlation plus their harmonic mean.
Again, we first evaluate each of the RDF2Vec models separately. Table 9 shows document similarity results. As for the entity relatedness, the results show that the skip-gram models built on DBpedia with 8 hops lead to the best performances.
Document similarity results – Pearson’s linear correlation coefficient (r) Spearman’s rank correlation (ρ) and their harmonic mean μ
Document similarity results – Pearson’s linear correlation coefficient (r) Spearman’s rank correlation (ρ) and their harmonic mean μ
Furthermore, we compare our approach to several state-of-the-art graph-based document similarity approaches:
TF-IDF: Distributional baseline algorithm.
AnnOv: Similarity score based on annotation overlap that corresponds to traversal entity similarity with radius 0, as described in [62].
Explicit Semantic Analysis (ESA) [21].
GED: semantic similarity using a Graph Edit Distance based measure [82].
Salient Semantic Analysis (SSA), Latent Semantic Analysis (LSA) [27].
Graph-based Semantic Similarity (GBSS) [62].
The results for the related approaches were copied from the respective papers, except for ESA, which was copied from [62], where it is calculated via public ESA REST endpoint.17
Comparison of the document similarity approach to the related work
We do not compare our approach to the machine-learning approach proposed by Huang et al. [30], because that approach is a supervised one, which is tailored towards the dataset, whereas ours (as well as the others we compare to) are unsupervised.
As discussed in Section 2.3, the Linked Open Data (LOD) initiative [5] has opened new interesting possibilities to realize better recommendation approaches. Given that the items to be recommended are linked to a LOD dataset, information from LOD can be exploited to determine which items are considered to be similar to the ones that the user has consumed in the past, allowing to discover hidden information and implicit relations between objects. While LOD is rich in high quality data, it is still challenging to find an effective and efficient way of exploiting the knowledge for content-based recommendations. So far, most of the proposed approaches in the literature are supervised or semi-supervised, which means they cannot work without human interaction. New challenges, and at the same time new opportunities, arise from unsupervised approaches for feature learning.
RDF graph embeddings are a promising way to approach those challenges and build content-based recommender systems. As for entity similarity in the previous section, the cosine similarity between the latent vectors representing the items can be interpreted as a measure of reciprocal proximity and then exploited to produce recommendations.
In this section, we explore the development of a hybrid RS, leveraging the latent features extracted with RDF2Vec. The hybrid system takes advantage of both RDF graph embeddings and Factorization Machines (FMs) [68], an effective method combining Support Vector Machines with factorization models.
Factorization machines
Factorization Machines (FMs) [68] are a general predictor model which rely on the advantages of Support Vector Machines (SVMs) and factorization models. SVMs have been successfully applied in many classification and regression problems but they have been proved to be not effective in those settings like collaborative filtering which are characterized by huge sparsity. This happens since in sparse settings there is not enough data to estimate a “dense” factorization as SVMs would do. FM use a factorized parametrization, breaking the independence of the interaction parameters by factorizing them. The difference clearly emerges when the model equations of degree 2 for a factorization machine and for a SVM are directly compared. Being aware that in a prediction task the general goal is to estimate a function
The strength of FMs models is also due to linear complexity [68] and due to the fact that they can be optimized in the primal and they do not rely on support vectors like SVMs. Finally, [68] shows that many of the most successful approaches for the task of collaborative filtering are de facto subsumed by FMs, e.g., Matrix Factorization [80,86] and SVD
Experiments
We evaluate different variants of our approach on three datasets, and compare them to common approaches for creating content-based item representations from LOD, as well as to state of the art collaborative and hybrid approaches. Furthermore, we investigate the use of two different LOD datasets as background knowledge, i.e., DBpedia and Wikidata.
Datasets
In order to test the effectiveness of vector space embeddings for the recommendation task, we have performed an extensive evaluation in terms of ranking accuracy on three datasets belonging to different domains, i.e.,
The original datasets are enriched with background information using the item mapping and linking to DBpedia technique described in [60], whose dump is available publicly.21
The datasets are finally preprocessed to guarantee a fair comparison with the state of the art approaches described in [57]. Here, the authors propose to (i) remove popularity biases from the evaluation not considering the top 1% most popular items, (ii) reduce the sparsity of
Statistics about the three datasets
The ranking setting for the recommendation task consists of producing a ranked list of items to suggest to the user and in practical situations turns into the so-called top-N recommendation task, where just a cut-off of the ranked list of size N is provided to the user. This setting has recently replaced the rating prediction, because of the increasing awareness that the user is not interested in an accurate prediction of the item rating, but is looking for a (limited) list of items extracted from the pool of available ones.
As evaluation ranking protocol for our comparison, we adopted the all unrated items methodology presented in [87] and already used in [57]. This methodology asks to predict a score for each item not rated by a user, irrespective of the existence of an actual rating, and to compare the recommendation list with the test set.
The metrics involved in the experimental comparison are three well-known ranking measures for recommendation accuracy, i.e., precision, recall, F-score (F1) and nDCG.
precision@N [70] represents the fraction of relevant items in the top-N recommendations. recall@N [70] indicates the fraction of relevant items, in the user test set, occurring in the top-N list. As relevance threshold, we set 4 for The F1 score [70], i.e., the harmonic mean of precision and recall, is also pointed out to be thorough. Although precision and recall are good indicators to evaluate the accuracy of a recommendation engine, they are not rank-sensitive. The normalized Discounted Cumulative Gain nDCG@N [3] instead takes into account also the position in the recommendation list, being defined as
As suggested in [87] and set up in [57], in the computation of nDCG@N we fixed a default “neutral” value for those items with no ratings, i.e., 3 for
All the results have been computed @10, i.e., considering the top-10 list recommended to each user and then averaging across all users.
Experimental setup
The target of this experimental section is two-fold. On the one hand, we show that the proposed graph embeddings technique outperforms other strategies for feature creation. On the other hand, we combine it with a hybrid RS and compare the resulting system’s relative performances with state of the art approaches. The first goal is pursued by implementing an item-based K-Nearest Neighbor method, hereafter denoted as ItemKNN, with cosine similarity among features vectors. As data mining features, the approaches based on direct relations and graph substructures, as detailed in Section 5.1, are considered.
For what concerns the comparison against some of the most promising collaborative and hybrid approaches currently available, we consider the results recently published in [57]. There, the authors show that the best effectivenesses in terms of ranking accuracy is reached by the following algorithms:
In [57], it has been proved that
Results
We present the results by a purely content-based RS and a hybrid RS using RDF2Vec.
Content-based approach
The first experiment aims to point out the validity of the proposed graph embeddings technique for feature generation in the context of content-based RS, and relies on a relatively simple recommendation algorithm, i.e., the item-based K-Nearest Neighbor approach [70] with cosine similarity. Formally, this method evaluates the closeness of items through cosine similarity between the corresponding features vectors and then selects a subset of those – the neighbors – for each item, that will be used to estimate the rating of user u for a new item i as follows:
Results of the ItemKNN approach on Movielens dataset with reference to different computation of features
Results of the ItemKNN approach on
Results of the ItemKNN approach on
The vector representation of items made of latent features, output of the RDF graph embeddings with graph walks, is evaluated against all the other data mining features listed in Section 5.1. Tables 12, 13 and 14 contain the values of precision, recall, F-score (F1) and nDCG, respectively for
The first conclusion that can be drawn from Tables 12, 13 and 14 is that the best approach for all datasets is retrieved with a skip-gram model, 500 walks per entity and with a size of 200 for vectors built upon DBpedia. Altough on
Comparing the LOD datasets, it clearly emerges that DBpedia lets to gain higher values than Wikidata for each metric involved, but it turns out that Wikidata is quite effective on
Moving to the features extracted from direct relations, the contribution of the “categories” stands clearly out, together with relations-values “rel-vals”, especially when just incoming relations are considered: these features allow to achieve better results than the approaches based on translating embeddings, i.e., DB_TransE, DB_TransH and DB_TransR. The use of methods based on kernels for features extraction, i.e., WC_4 and WL_2_2 approaches, seems not to provide significant advantages to the recommendation algorithm.
To point out that the latent features built upon RDF graph are able to capture its structure, placing closely semantically similar items, some examples of the neighbouring sets retrieved using the graph embeddings technique are provided. These sets are directly exploited by the ItemKNN algorithm to produce recommendations. Table 15 is related to movies and to the strategy “DB2vec SG 500w 200v 4d”, and displays that neighboring items are highly relevant and close to the query item, i.e., the item for which neighbors are searched for. Figure 4 depicts the 2D PCA projection of the movies in that table, showing that similar movies are actually projected closely to each other.
To second goal of our experiments is to show that a hybrid recommender system, leveraging the item content built with the graph embeddings technique, can compete against some of the most promising state of the art approaches for recommendation. A hybrid RS based on Factorization Machines is utilized, namely the ranking factorization machine algorithm available in the Graphlab recommender toolkit.23
Tables 16, 17, and 18 report, respectively for
The complete version of these tables and the code for implementing the hybrid system are available at
Results of the ItemKNN approach on
Examples of K-Nearest Neighbor sets on
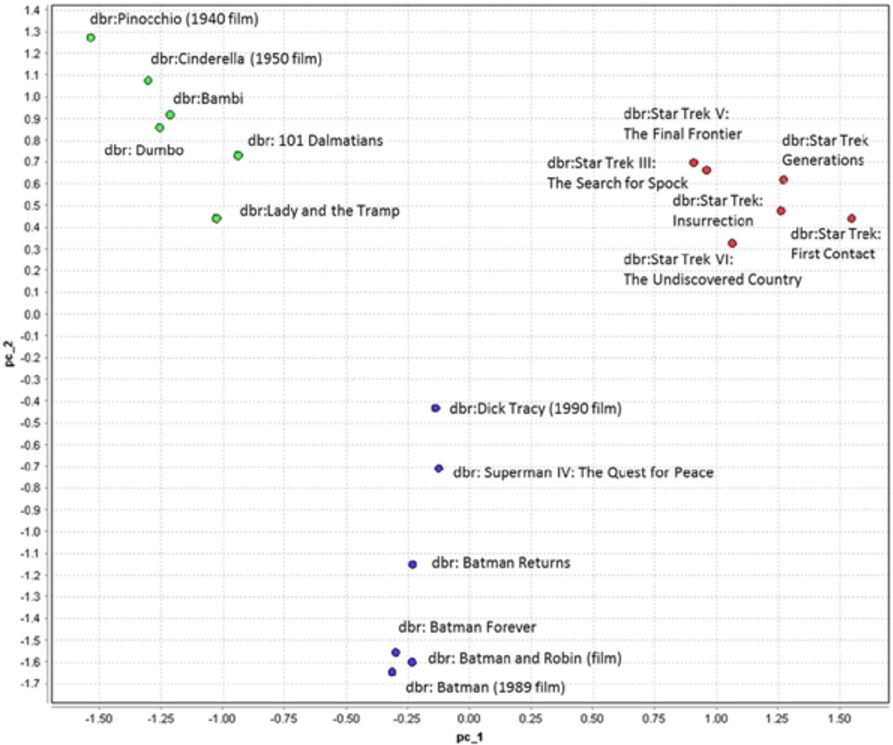
Two-dimensional PCA projection of the 200-dimensional Skip-Gram vectors of movies in Table 15.
Comparative results on
Comparative results on
Comparative results on
In this paper, we have presented RDF2Vec, an approach for learning latent numerical representations of entities in RDF graphs. In this approach, we first convert the RDF graphs in a set of sequences using two strategies, Weisfeiler–Lehman Subtree RDF Graph Kernels and graph walks, which are then used to build neural language models. The evaluation shows that such entity representations could be used in three different tasks. In each of those tasks, they were capable of outperforming standard feature generation approaches, i.e., approaches that turn (subsets of) RDF graphs into propositional models.
We have explored different variants of building embedding models. While there is no universally best performing approach, we can observe some trends. With respect to the first step of the transformation, i.e., the construction of sequences, kernel transformations lead to better results than (random) walks. However, they do not scale well to large-scale knowledge graphs, such as DBpedia or Wikidata. With respect to the second step, i.e., the actual computation of the embeddings, we have observed that Skip-Gram (SG) models in most cases outperform Continuous-Bag-of-Words (CBOW) models. The other characteristics of the models (e.g., the dimensionality of the embedding space) show less clear trends towards an optimal setting.
While constructing a vector space embedding for a large-scale knowledge graph, such as DBpedia or Wikidata, can be computationally expensive, we have shown that this step has to be taken only once, as the embeddings can be reused on various tasks. This is particularly interesting for such cross-domain knowledge graphs, which can be used in a variety of scenarios and applications.
For the moment, we have defined some constraints for the construction of the embeddings. We do not use literal values, and we do not particularly distinguish between the schema and the data level of a graph. The former constraint has some limitations, e.g., when it comes to the tasks of determining entity similarity: for example, the similarity of two movies in terms of release date and budget or the similarity of two cities in terms of area and population is currently not captured by the models. Schema level and data level similarity are currently implicitly interwoven, but in particular for knowledge graphs with richer schemas (e.g., YAGO with its type hierarchy of several hundred thousand types), distinguishing embeddings of the schema and data level might become beneficial.
Apart from using vector space embeddings when exploiting LOD data sources, they may also become an interesting technique for improving those sources as such, for example knowledge base completion [40]. Among others, the proposed approach could also be used for link prediction, entity typing, or error detection in knowledge graphs [64], as shown in [45,51]. Similarly to the entity and document modeling, the approach can be extended for entity summarization, which is also an important task when consuming and visualizing large quantities of data [9].
Summarizing, we have shown that it is possible to adapt the technique of word embeddings to RDF graphs, and that those embeddings lead to compact vector representations of entities. We have shown that those vector representations help building approaches which outperform many state of the art tools on various tasks, e.g., data mining with background knowledge or recommender systems. Furthermore, the proposed vector space representations are universal in the sense that they are not task specific, i.e., a vector space embedding for a general graph like DBpedia or Wikidata can be built once and reused for several tasks. As the embeddings used in this paper are publicly available, they are a versatile asset which can be exploited for various knowledge-intensive tasks in future research.
Footnotes
Acknowledgements
The work presented in this paper has been partly funded by the German Research Foundation (DFG) under grant number PA 2373/1-1 (Mine@LOD), partially funded by the project PON03 PE_00136_1 Digital Services Ecosystem: DSE, and by the Junior-professor funding programme of the Ministry of Science, Research and the Arts of the state of Baden-Württemberg (project “Deep semantic models for high-end NLP application”). Jessica Rosati also acknowledges support of I.B.M. Ph.D. fellowship 2015–2016.