
Abstract
Current retrieval and recommendation approaches rely on hard-wired data models. This hinders personalized customizations to meet information needs of users in a more flexible manner. Therefore, the paper investigates how similarity-based retrieval strategies can be combined with graph queries to enable users or system providers to explore repositories in the Linked Open Data (LOD) cloud more thoroughly. For this purpose, we developed novel content-based recommendation approaches. They rely on concept annotations of Simple Knowledge Organization System (SKOS) vocabularies and a SPARQL-based query language that facilitates advanced and personalized requests for openly available knowledge graphs. We have comprehensively evaluated the novel search strategies in several test cases and example application domains (i.e., travel search and multimedia retrieval). The results of the web-based online experiments showed that our approaches increase the recall and diversity of recommendations or at least provide a competitive alternative strategy of resource access when conventional methods do not provide helpful suggestions. The findings may be of use for Linked Data-enabled recommender systems (LDRS) as well as for semantic search engines that can consume LOD resources.
Introduction
A recommender system (RS) component is usually one of the key search features in online portals. It helps users to discover items that reflect their interests [3]. Personalized recommendations are based on a user profile that contains either implicit (e.g., access statistics or click behavior) or explicit preference information (e.g., ratings for items). Common RS techniques are collaborative filtering (CF) or content-based (CB) algorithms. CF approaches derive suggestions from users with similar tastes, whereas CB methods are based on similar items according to metadata descriptions [26]. Descriptions in CB engines are often structured in the table-like format of attribute-value pairs. The flat data structure tremendously reduces the multidimensionality of preferences as well as item characteristics and can therefore produce weak recommendations.
This is why the complex data structure of RDF graphs in the Linked Open Data (LOD) cloud can help to improve the representation of user tastes in CB engines. Consider the following example for illustration: Suppose a user has stated that s/he likes a particular movie director and would like to receive suggestions for other interesting filmmakers. A conventional RS would determine similar directors from these metadata. However, the director descriptions may be predominantly comprised of irrelevant information, e.g., the nationality or the won prizes of the filmmakers. Such metadata would not yield useful results in a purely content-based system and only achieve a few random hits. On the other hand, a request that is issued against the LOD collection DBpedia could explore the semantic network that surrounds the director. By this means, all movies that were shot by the favored director are identified. Additional interesting movies, that were not directed by the filmmaker, but share certain characteristics with his movies (e.g., the same genres or main actors) could enhance the metadata descriptions and user profile information further. The data web can answer such requests because the LOD technology stack provides the SPARQL Protocol and RDF Query Language (SPARQL) and suitable query engines that enable fast retrieval [55].
However, graph-based queries alone are not yet sufficient to generate personalized suggestions, since they only return results for graph patterns that exist in the repository. Consider the following example: Consumers may like to use recommendation engines that work on multiple domains simultaneously. For instance, a user who has stated that he likes certain items from one domain may like to receive suggestions from another domain as well (i.e., for cross-domain retrieval). In case a user profile contains feedback information for books, it would be desirable if the system could generate movie suggestions based on this data. While the approach of querying RDF graphs can be useful for this recommendation scenario (since it can identify matching objects based on entity type declarations or typed link information), it may also be the case that there are no direct links from a preferred book to a suitable movie in the RDF graph.
Therefore, RS designers should not rely too heavily on graph-based queries, but also explore possibilities of similarity-based retrieval. A possible solution would be to identify books that are similar to the ones in the user profile. In a subsequent processing step and through a graph-based query, the engine could explore whether the similar books have any connections to movie items in the repository. This approach can reveal implicit connections in the data and might help to return fewer empty result sets to the user. Therefore, the data should be processed in an ad-hoc fashion. This is because one processing step (identification of suitable movies through graph pattern matching) relies on the outcome of a preceding one (computation of similar book items). For this purpose, it is important that recommendations can be quickly generated on-the-fly without further preprocessing. Thus, graph matching and similarity-based calculations can be merged. This also has to be accompanied by a query language which facilitates flexible combinations of the two retrieval paradigms. By these means, users can specify at each key step of a recommendation workflow (i.e., user profile generation and item selection) if either graph- or similarity-based processing operations should be triggered.
Almost none of the existing Linked Data recommender systems (LDRS) addresses these issues, which prevents efficient usage of available knowledge sources for retrieval tasks. Instead, current LDRS rely on a fixed set of item features, which have to be extracted from the LOD cloud before suggestions can be generated [13,14,22,24,29,50,65]. However, the ad-hoc retrieval and processing of item features for similarity computation in combination with graph-based queries can be facilitated by concepts from Simple Knowledge Organization System (SKOS) vocabularies [38]. SKOS annotations occur in more than half of the repositories in the LOD cloud and often describe real-world entities [53]. For instance, in the DBpedia repository, an LOD resource representing a music act is characterized by SKOS-based subject descriptors (e.g. stating the genre or the label of the music act). The descriptors are part of the DBpedia category graph [11]. A recommendation framework that utilizes SKOS annotations for item-to-item similarity calculation is applicable to a wide range of data collections and domains. Additionally, SKOS subjects are uniquely identified URI resources. Therefore, they can be conveniently processed for ad-hoc querying without further preprocessing [38].
This paper presents novel retrieval strategies and a SKOS-based recommendation engine, called SKOSRecommender (SKOSRec), that can flexibly combine on-the-fly similarity calculation and SPARQL-like techniques to leverage the full potential of LOD repositories. Their effectiveness have been proven in a series of user studies. In summary, the paper addresses the following key points:
Comprehensive literature review of the state-of-the-art in LOD-enabled Information Retrieval (IR) and recommender systems (Section 2). Development of search strategies that are applicable to numerous LOD collections. The novel retrieval methods are facilitated by: Syntax and processing units for a SPARQL-based recommendation query language (Section 3). Flexible combinations of similar resource retrieval and graph pattern matching at different stages of the recommendation workflow (e.g., by being able to apply graph-based filter conditions on recommendation results or by utilizing recommendations as part of a SPARQL-based subquery) (Sections 3.2–3.5). Extensive evaluation of the novel retrieval approaches in a series of web-based user experiments, which have proven the effectiveness of the developed methods, especially in terms of diversity and recall (Section 4).
Related work
Effective answering of retrieval requests has been investigated by researchers for many years. Even before the evolution of the LOD cloud, scientists developed strategies for extracting relevant information from text data. The most prevalent IR systems perform relevance rankings for unstructured resources and offer means to state filter conditions that complement queries in a faceted search interface. The approaches can combine query constraints with similarity-based retrieval. In these systems, user requests are quickly answered due to extensive preprocessing and indexing of resources before runtime execution [58]. However, low latency of search results comes at the cost of a hard-wired data model which prevents flexible customizations and causes limitations in terms of ad-hoc retrieval [18].
Other researchers have developed query-based RS for table data. For instance, Adomavicius et al. [2] propose the REQUEST query language that generates suggestions from a relational database which contains information on both user profiles and items. Thus, personalized recommendation queries can be formulated. Another interesting approach in the category of query-based RS is the FlexRecs system by Koutrika et al. [32]. The key advantage of their course RS is that it enables highly individual requests in which different query parts (i.e., profile generation, filtering of recommendations or like-minded peers) can be flexibly combined into so called recommendation workflows. Hence, highly individual recommendation queries can be formulated with FlexRecs.
Despite the strengths and weaknesses of the discussed approaches, it has to be taken into account that they are not designed to consume LOD. LOD-enabled systems, on the other hand, use RDF data for retrieval. There exist many index-based Linked Data IR systems [4,9,10,20,25,40,43,45,61]. However, they index RDF resources before runtime retrieval and can therefore neither facilitate on-the-fly similarity calculation nor do they provide extensive SPARQL-based query options.
Another interesting engine category are on-the-fly Linked Data IR systems. These systems process information from the LOD cloud through spreading activation algorithms. While they enable fast retrieval, the downside of these approaches is that graph-based query constraints are only possible to a limited extent due to the applied probabilistic path traversal techniques [16,17,28,33,35,56].
Existing LDRS, on the other hand, mostly perform offline computation of item-to-item similarities from LOD metadata descriptions [14,22,24,29,50,65]. While this approach offers more control over the retrieval process, it prevents individual customizations and runtime responses.
To this date, there are only a few query-based LDRS [5,46,49]. Most of these systems rely on the assumption that user preferences and item metadata reside in the same repository. But this goes against the notion of the LOD cloud as a decentralized and openly accessible data space, which can be queried through API-like interfaces. Additionally, while query-based LDRS provide SPARQL-based query options to filter recommendation results, they are not capable to flexibly combine similar resource retrieval with graph filters (e.g, subquerying with recommendation results).
In summary, existing non-Linked Data as well as Linked Data-enabled retrieval and RS engines already provide useful features for personalized resource access. Nevertheless, the full potential of LOD for recommendation and search tasks has yet to be realized (see Table 1). The novel query strategies of the SKOSRec engine are attempts to tackle the previously outlined research gaps to improve existing RS as well as to offer new search strategies for LOD repositories that are guided by personal preferences.
Summary of existing retrieval and recommendation approaches
Summary of existing retrieval and recommendation approaches
System overview
The SKOSRecommender is designed to consume recommendation requests and was developed with the help of the Apache Jena framework.1

Grammar of the SKOSRec query language
In the given grammar, underlined parts represent SPARQL syntax elements that have been directly taken from the latest W3C specification [21]. Words in capital letters denote query keywords, which are also SPARQL expressions except for the ones listed in the language parts SimProjection and ServiceIntegration. As a regular SPARQL
Figure 1 depicts the overall architecture of the system with all its components. The most important parts are the SKOSRec query processing units (i.e., the parser and the compiler). They check the syntax of recommendation requests and regulate the correct execution of critical operations of the engine (e.g., graph-based filtering, result set joins, similarity calculation). The architecture does not dictate a particular SPARQL server implementation for LOD repositories since the system is decoupled from the endpoint that is accessed over HTTP during retrieval. However, the prototypical implementation of the SKOSRec engine utilizes the OpenLink Virtuoso server.2
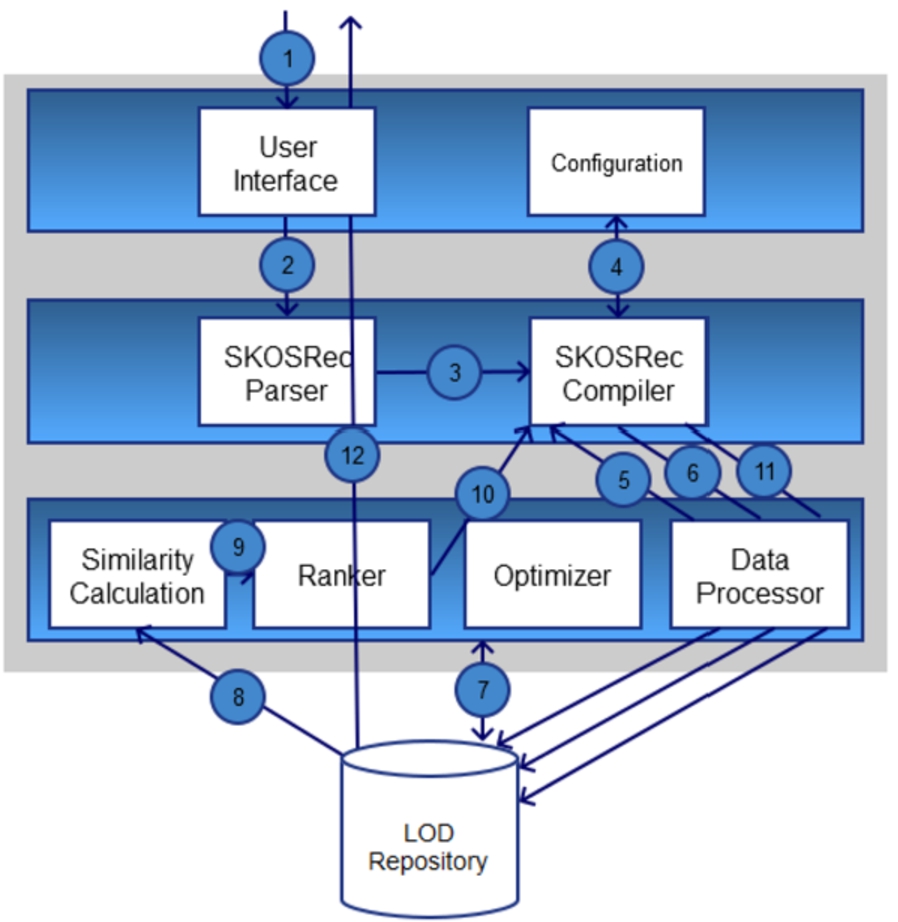
Architecture and workflow of the SKOSRec engine.
Figure 1 also shows the sequential order of a typical recommendation workflow for a complex request that consists of the following retrieval steps:
Issuing a SKOSRec query
Parsing the SKOSRec query
Compiling the SKOSRec query
Loading information on the LOD repository/SPARQL endpoint to be queried from the configuration
Retrieval of preferred items and setting up of the user profile (see Section 3.3Preference querying)
Retrieval and processing of relevant LOD resources upon application of prefilter conditions (see Section 3.4Prefiltering)
Optimizing the retrieval process through identifying the resources that can be omitted for the final ranking.3
For further information on optimized retrieval, please refer to [63].
Determination of similar LOD resources based on the user profile (see Section 3.2On-the-fly recommendations
Ranking of LOD resources
Sending of recommendation results to the compiler and joining them with postfilter constraints
Retrieval of the final result set (see Section 3.5Postfiltering & combinations)
Output to the user
A simple on-the-fly request is the most basic form of a SKOSRec query. It is based on the engine’s ability to generate ad-hoc recommendations from a user profile containing preference statements for LOD resources. Listing 2 depicts an example SKOSRec on-the-fly request that obtains suggestions based on a user’s preference for the western movie “They Call Me Trinity”. In the given query, the preferred movie is represented by the DBpedia resource (

A simple recommendation query for the movie domain (Q1)
In this basic form, the query does neither contain any pre- or postfilter conditions nor a preference query statement. Thus, the engine simply identifies all movies that are similar to the preference in the profile. When executed over DBpedia, the query returns the solution set that is depicted in Table 2.
Result set for Q1
For determining recommendations in an ad-hoc fashion, the system identifies SKOS annotations by matching a suitable property (i.e., annotation property) in an RDF dataset (Definition 1).
An annotation property is an IRI (Listing 3), that is defined in the Dublin Core Metadata Initiative (DCMI) specification for subject annotations. It can occur in conjunction with one of the two namespaces, which are stated by the standard [12].
Annotation property
These properties help to retrieve SKOS annotation triples for items preferred by a user (Definition 2).
A SKOS annotation triple (
The identification of SKOS annotation triples facilitates a fast retrieval of potential similar items. Therefore, the engine evaluates shared features between resources from the SKOS annotation dataset (Definition 3).
(SKOS annotation dataset).
A SKOS annotation dataset (
Before the similarity calculation process starts, the engine determines SKOS annotations for each LOD resource (r) from the user profile by issuing a subsequent SPARQL query to the LOD repository from which the user intends to receive suggestions. The notion of SKOS annotations is specified in Definition 4.
(SKOS annotations).
In the annotation dataset, LOD resources directly link to concepts of a SKOS system via a predefined annotation property. SKOS annotations for an input resource r are defined as in Equation (3).
Afterwards, the engine identifies which of the other resources in the dataset shares annotations with it. Similarities only have to be computed for items with matching concepts [14,52]. Therefore, triples can be efficiently joined along item features, since native RDF storage systems usually index triples rather than columns [41]. Thus, the quick identification of mutual annotations through SPARQL requests facilitates ad-hoc similarity calculation. Definition 5 specifies the notion of relevant resources and their annotations that are needed to identify similar items. The applied syntax follows Pérez et al. [44].
(Relevant resources and their annotations).
The conjunctive graph pattern
The mapping
Upon extraction of relevant resources and annotations, the process of similarity calculation can start. The engine determines the information content (IC) of the shared SKOS annotations of two resources. This approach is based on the hybrid similarity metric proposed by Meymandpour and Davis [37] for LOD-enabled RS. However, while their measure considers all types of IRI resources for the retrieval, our similarity metric purely relies on SKOS annotations (Definition 6).
(SKOS similarity).
Let
The IC of a set of SKOS concepts is measured by the sum of the inverse logarithms of each concept’s frequency in relation to the maximum frequency of occurrences among relevant resources (Definition 7).
(SKOS Information Content).
The SKOS IC is defined as an aggregation of the individual IC values of each concept that is contained in the set of shared features (
After having obtained resource annotations as well as IC values, similarity scores between the input resource r and each potentially relevant resource q can be calculated. When a user profile contains more than a single item, similarity values are aggregated through summation to determine the final recommendation score (Definition 8).
(Recommendation score).
The recommendation score of a potentially relevant resource q is quantified by the sum of similarities with each resource r that can be found in the profile (
Upon calculation of similarity values for each potentially relevant item q, the engine ranks the retrieved resources based on a given limit (k) that is specified by the user in the SKOSRec query.
With the presented methods of on-the-fly retrieval, recommendations can be generated from LOD repositories through an API interface without requiring local metadata or excessive preprocessing operations other than the mapping of profile items with LOD resources.4
Di Noia et al. describe, how a mapping procedure can be conducted for a real-world implementation. For their LDRS, they matched movie titles with the corresponding LOD resources in DBpedia. The authors extracted IRIs, labels and publication dates for all movie resources. They applied the Levenshtein distance on these resources to identify matching movies items [14].
In the previous subsection, it was assumed that users express their tastes in the form of preference statements for a certain item in the form of an IRI referring to a LOD resource. However, it may also be the case that likings are only vaguely known, for instance, when users prefer products with specific features but are not able or willing to specify the actual items. The engine obtains such a profile by issuing a subsequent SPARQL query that contains the preference graph pattern (

SKOSRec query to generate recommendations based on a preference query in the movie domain (Q2)
Table 3 shows the corresponding solution set to the preference query containing films from DBpedia that are similar to Quentin Tarantino movies.
Result set for Q2
The notion of a queried profile is specified in Definition 9.
A queried profile is a user profile that has been compiled by retrieving all LOD resources r that are part of an annotation graph
Prefiltering
To facilitate exploratory search in LOD repositories, users should also have the option to formulate conditions in their queries. A possible way to enable filters during retrieval is before similarity calculation. Thus, recommendation lists can be adjusted to individual needs.
Due to the expressiveness of RDF data, filter conditions can not only be applied on attributes that are directly connected to potentially relevant items but can also be declared as a graph pattern. By this means, it is possible to retrieve LOD resources that are both similar to the user profile as well as fulfill an advanced condition.
The strengths of the approach will be illustrated with a travel recommendation request that was executed over DBpedia. Suppose a customer expressed a preference for the Lake Baikal region (e.g., as indicated by a positive rating on a travel community site). With simple on-the-fly retrieval, s/he would receive a recommendation list that primarily consists of travel destinations that are located in the proximity to this geographical area. A graph-based filter, on the other hand, facilitates advanced retrieval options. In the given example, it enables the user to obtain suggestions for Southeast Asian travel destinations that have similar features as the Lake Baikal region, even though the resource
The advanced constraint ensures that the generated result set is not empty. A simple attribute-level filter, which is commonly utilized in faceted search systems, would not generate any search hits. By these means, graph-based filter patterns can help users to better explore knowledge graphs thereby overcoming data quality issues in LOD repositories. The corresponding SKOSRec query to this example is shown in Listing 5.

SKOSRec query with an expressive prefilter condition to retrieve southeast Asian destinations based on a preference for the Lake Baikal region (Q3)
Table 4 shows the solution to this query. It contains travel destinations and regions of interest that are both similar to the previously liked destination
Result set of Q3
The technical details for this type of query are given in the following definitions. Before the extraction of relevant resources and annotations, the recommendation engine identifies the resources that satisfy the filter. (Definition 10).
The mapping of filtered resources
After preselection, resources are brought together with user profile data to retrieve the final set of recommendations (Definition 11).
(Annotations and relevant resources (prefiltered retrieval)).
The solution mappings of annotations and relevant resources in prefiltered retrieval mode is obtained by joining the set of prefiltered resources with the mappings
After retrieving annotations and relevant resources in prefiltering mode, the system generates constraint-based recommendations. In this context, the ranking procedure is adapted to the restricted set of relevant resources and annotations. Hence, IC values of matching annotations and respective SKOS similarities are quantified according to the user filter. By this means, recommendation scores reflect the similarity of items for the actual set of filtered LOD resources. Except for this restriction, the system carries out the calculations (i.e., determination of similarity values, the ranking of LOD resources) in the same way as in non-filtering mode.
Postfiltering & combinations
The SKOSRec engine cannot only combine similarity calculation and graph pattern matching to prefilter relevant LOD resources, it can also apply user constraints after similar items have already been determined. By this means, recommendations are filtered ex-post to the similarity detection process. This feature enables novel retrieval patterns, in which suggestions are part of a subquery. As an example scenario for a postfilter recommendation task, consider the following SKOSRec query which obtains suggestions for movies and directors based on a user’s preference for the director

SKOSRec query to generate simple post-filtered recommendations in the movie domain (Q4)
Table 5 shows the solution the SKOSRec system returns when Q4 is issued against DBpedia. The ellipses in the displayed tables indicate records that have been excluded for brevity reasons.
Result set of Q4
However, this approach can still be improved upon. For instance, the engine only considers the metadata descriptions of the director, whereas related movies have to be retrieved anew, upon execution of the postfilter section. Thus, they are not ranked according to similarity in the final output table.
Another weakness is the biased semantics of the query. Usually, when a person favors a movie director, this preference refers to the movies this director has shot and not to the personal features of the person. Two directors might be similar according to certain features such as birth year, nationality or received awards, but the style and genre of the movies they have created can still be different. A third factor is that recommendation retrieval for movie directors should also take into account that a film artist is likely more relevant, the more movies s/he has shot that are in line with the preferred movies of the user. Hence, the SKOSRec engine enables another postfiltering strategy, which is called aggregation-based retrieval. This strategy can be helpful whenever an entity type is linked to a couple of LOD resources in a dataset, such that similarity scores of related entities (e.g., movies) can be aggregated to an overall recommendation score for a certain item (e.g., for a movie director).
Aggregation-based requests can be well combined with other retrieval patterns, such as preference queries. In the case of the movie recommendation scenario, a user could state that s/he enjoyed Quentin Tarantino movies in the past and would like to receive suggestions for directors that shot similar film (see Listing 7). Usually, this kind of question can typically only be answered by another human being, e.g., in a personal interaction among friends or in an online forum. The fact that the language facilitates these kinds of queries is one of its key advantages.

SKOSRec query to generate post-filtered recommendations based on a preference query in the movie domain (Q5)
Table 6 depicts the results of Q5 as retrieved from DBpedia. When comparing the solutions sets for Q4 and Q5, it becomes clear that they are totally different. While Q5 generated a list of directors, who have mostly created action and thriller movies with a twist (i.e., Tarantino’s unique filmmaking style5
Result set of Q5
We define this kind of aggregation-based request as a so-called rollup query. This definition was chosen because the final suggestions are based on summarized (i.e., rolled up) preferences for sublevel entities. Another example for a roll-up request stems from the application scenario of travel search. This recommendation query derives suggestions for city trip destinations from the points of interest (POI) a user has visited and liked in another city (e.g., London). Listing 8 shows the corresponding SKOSRec query for this scenario.

SKOSRec query to generate post-filtered recommendations (aggregation-based) for a preference profile containing the city of London (Q6)
The SKOSRec request contains subquery commands that refer to the user’s preferred POIs. It specifies, how similarity scores of the generated suggestions should be aggregated (i.e., sum-based). The retrieval is based on the 100 POIs that are most similar to the ones in the preference section. Additionally, the subquery part refers to the DBpedia resource that represents London (
Result set of Q6
The motivation for formulating such a query is that when searching for cities, preferences might be better represented through the sights a user has visited elsewhere rather than through a simple on-the-fly request solely containing a preference statement for a city in the user profile section.
Besides the above presented roll-up retrieval patterns, the SKOSRec grammar may facilitate the formulation of additional types of advanced recommendation queries. For instance, cross-domain queries are an interesting additional pattern to be explored for personalized retrieval. Listing 9 shows an example request that generates movie suggestions based on the preference for a music band (i.e.,
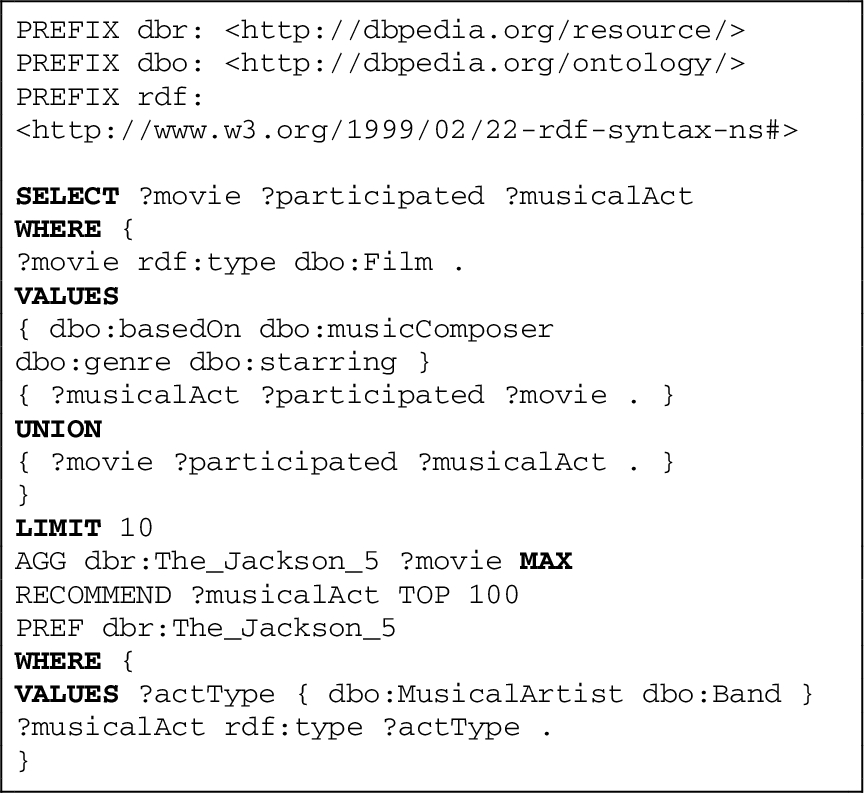
SKOSRec query to generate cross-domain recommendations (Q7)
The query contains a prefilter condition that triggers retrieval of music artists and bands. Afterwards, the scores of the top 100 suggestions are summarized with maximum-based aggregation. Thus, the highest similarity value among the set of music acts determines the ranking score of the film. Also, note because of the aggregation-based retrieval procedure, connections between movies and the LOD resource
As a point of reference, consider the SPARQL query for the given cross-domain scenario (Listing 10).

SPARQL query to generate cross-domain recommendations (Q8)
The query omits the similarity calculation part. Thus, it only retrieves movies linked to the resource
Result set of Q7
Result set of Q8
The following of definitions will formalize the postfiltered and aggregation-based retrieval forms. Definition 12 specifies the notion of SKOSRec recommendations that may potentially undergo postprocessing.
SKOSRec recommendations (
The approach of subquerying with recommendation results builds on the idea that SKOSRec suggestions
(Postfiltered recommendation mapping).
The postfiltered recommendation mapping is obtained by joining solution mappings generated from SKOSRec recommendations with the results of matching a postfilter graph pattern (
As the prefilter,
(Resources for aggregation-based retrieval).
The set of resources for aggregation-based retrieval is obtained by retrieving LOD resources that have a connection to a previously generated suggestion thereby excluding all resources that are linked to the specified superordinate item a in the profile (Eq. (15)).
For each potential aggregation-based suggestion (y), similarity scores of connected entities (x) have to be considered for the final ranking. In this context, different approaches to aggregation can be applied. In cases when both similar items and aggregation-based recommendations are entities on comparable levels of granularity, then choosing the maximum similarity score might be the best way to represent the relatedness of the resource to the user profile. On the other hand, when postfiltered recommendations are based on similarity scores of their sublevel entities (e.g., as in the movie recommendation example), the scores of related suggestions should be aggregated by the sum or the average of individual scores.
(Aggregation-based ranking score).
The ranking score of an LOD resource y that is connected to a set of recommended items is determined by aggregating scores of connected entities either by the maximum (Eq. (16)), the sum (Eq. (17)) or the average (Eq. (18)) of individual scores.
Evaluation of the SKOS recommender
Experimental setup
The novel recommendation strategies of the SKOSRec engine were evaluated in the context of web-based experiments for the usage scenarios of travel destination search and multimedia RS. The online approach helped to reach out to more participants with diverse demographic backgrounds, which would not have been possible in a laboratory experiment. Another positive side-effect of the web-based setting was that participants could test and rate recommendations without being directly observed by an experimenter, which might have caused biased results otherwise. Hence, the online approach softened common limitations of laboratory studies [19].
The experiments were carried out in the defined usage scenarios with metadata descriptions from DBpedia. The database containing the local mirror of DBpedia ran on a virtual server. Besides the triple store, a web application was hosted on the same machine. The website ran on an Apache Tomcat 7 application server and was implemented with the help of Java servlet technology.6

User profile generation, TC1 (music domain).
We conducted the online experiments between April 2016 and January 2017. Upon setting up the web application, a pretest was carried out to control for potential pitfalls, such as misleading navigation. Two test users ran step by step through the web interface and provided their feedback. Because of their insights, we slightly modified the interface (e.g., through rephrasing user instructions) to increase the chances of successful completion. In case the SKOSRec engine is applied in a live setting, the design of the user interface will have to be tested with more users. Our experimental series focused on algorithmic performance, which was tested with numerous participants.
Subjects were recruited through the clickworker.com platform.8
It enabled users to type in keywords (e.g., the name of a music act or the author of a book), for which matchings were instantaneously displayed without reloading the site. Hence, participants could quickly find and select their items of interest. Whenever a user entered a query through the AJAX interface, the system matched the query keywords against an Apache Solr/Lucene search index.10
Aside from the AJAX feature, the appeal of the interface was increased by a progress bar at the top of the webpage (see Fig. 2). Progress bars are commonly utilized tools for web surveys. In conventional paper-based studies, subjects usually see, how far ahead they are, while in a web survey they cannot check their progress immediately. This is especially true for studies that apply a screen-by-screen navigation, which was the chosen approach for the conducted web experiments. Progress bars prevent users from tiring of the questionnaire and withdrawing from the study altogether by showing, how close participants are to complete the experiment [15].
Upon profile generation, the SKOSRec engine calculated on-the-fly recommendations for a simple query (similar to Q1, Section 3), which were shown to users in a separate screen. Suggestions were displayed with a sufficient amount of information e.g., thumbnails, labels or a short description to help participants assess the quality of the recommendation. In addition to this information, users could also access the respective Wikipedia article by following the hyperlink on the label. Relevance sliders were used to assess the utility of each recommendation. They are often applied in evaluations of IR systems [51,54]. Scores were handled as points on a 0 to 100 scale of the relevance slider (outer left side: lowest relevance, outer right side: highest relevance, see Fig. 3).

Recommendations resulting from on-the-fly recommendation retrieval, TC1 (music domain).
This approach facilitated the calculation of an accurate precision score and the application of tests with higher statistical power than an ordinal 5-star scale. The score, called mean relevance (
In addition to the precision score, the web application also determined the size of the recommendation list produced by the engine as an indicator for recall. However, recommendation list size can only be utilized for this purpose when
While accurate recommendations are useful, because they build trust in a system [57], they only capture a narrow aspect of performance [36]. For instance, an online retailer can tremendously profit from an RS that provides both relevant and unobvious recommendations, since it enables users to explore the product catalog more thoroughly. On the other hand, in the case of an RS only suggesting popular products, it is likely that the user already knows them [3,23]. A pure accuracy-based evaluation disregards these aspects, which is why other performance indicators, such as novelty, were measured as well. Thus, the evaluation interface also contained a section, where subjects had to tick a radio button that indicated, whether an item was new. In the backend of the web application, novelty was measured as the ratio of relevant items not familiar to the user (
An item was considered relevant, when it achieved an
The content-based diversity scores (
The recommendations of list [...] are diverse.
The recommendations of list [...] are similar to each other.

Evaluation screen for recommendations resulting from on-the-fly recommendation retrieval, TC1 (music domain).
Besides the above listed algorithmic performance metrics, the authors gathered assessments from users regarding the overall usefulness of the suggestions. This approach is also in line with the empirically verified evaluation framework by Pu et al. [47], which proposes to measure the psychometric construct of Perceived Usefulness to get a comprehensive understanding of user opinions on recommendation results. Thus, participants were instructed to state their agreement to positive statements regarding the relevance of the suggestions. The statements were adapated to the specificities of each usage scenario. Figure 4 shows an example collection of Likert questions for the domain of music RS.

Web form for a contraint-based recommendation request (music domain).
After participants had provided the required information, their answers were saved in a log file and they were navigated to test case 2 (TC2), which evaluated the SKOSRec engine’s performance for constraint-based queries (similar to Q3, Section 3). We tried to find out if the engine was able to improve user satisfaction through filter conditions. Even though IR systems already successfully apply facet filters on result sets, the experiments still had to prove whether LOD-enabled constraints have the same effect on the Perceived Usefulness of recommendations. For the comparisons of non-filtered and filtered suggestions, we applied a within-subjects design, in which participants had to rate two recommendation lists resulting from regular (non-filtered) and filtered requests in TC2. We favored this setup over a between-subjects design, where subjects would have been assigned to only one result list. While the between-subjects design more closely resembles a real-world setting since it does not require participants to interact with more than one approach at a time, differences among subjects (e.g., regarding demographics or topic expertise) can potentially have a considerable impact on quality judgments [19]. Hence, when applying a between-subjects design one does not know whether differences in performance are caused by the approaches or by the variability among participants. Therefore, researchers need to conduct between-subjects experiments with a sufficient number of study subjects to level out these differences. Within-subjects studies, on the other hand, require fewer participants, while still achieving the same level of statistical power since between-subject variability is not an issue [30,31]. Beel et al. have shown that even small variations in an RS test setting could cause substantial differences in performance outcomes [6]. To keep the extent of variations even lower, comparisons between non-filter and constraint-based recommendations, were based on the same profile for each user in TC2. Therefore, the user profile from TC1 served as a starting point for filtered retrieval. The web application showed the recently generated profiles to users and asked them to provide an additional filter condition. Figure 5 depicts an example web form for a constraint-based recommendation request in the music domain. It comprises the user profile and an additional text field, where users stated their constraint.
Afterwards, the engine applied this filter condition on the set of potential recommendation results before similarity calculation started. For each usage scenario, different types of constraints were available. Regarding suitable filter options, the author sought to achieve a balance between assisting users in finding filter conditions that would adequately represent their information needs, while keeping the variability among users as low as possible. Therefore, the specificities of each scenario and the availability of the respective data sources were determined. For instance, for the multimedia domains (movie, music, and books) it was assumed that users would like to filter recommendations according to the specific genre of the item. Fortunately, the DBpedia dataset contains this kind of information for the music domain. In this domain, the genre can be retrieved through the properties

Travel – user profile generation, TC3.
In the experiment on travel destination search, the web interface offered two filters: a subject and a location-specific filter. The subject filter enabled users to state their preferences regarding the characteristics of a location (e.g., being a nature reserve). The location-specific filter, on the other hand, gave participants the option to specify, where the desired destination should be located.11
The second fundamental research issue of TC2 concerned the question whether expressive constraints can boost recommendation quality even further. Hence, apart from executing a constraint-based workflow with a simple filter (i.e., a direct attribute of an item), the SKOSRec engine generated suggestions with the help of an expressive filter as well. This second procedure, while still applying the same user constraint as the simple filter, utilized an expressive graph pattern to include additional LOD resources in the result set. For instance, in case a subject filter was selected, result set expansion was facilitated by exploring the wider semantic space of the DBpedia category graph through a property path declaration in the graph pattern (e.g.,
After study subjects had completed TC2, they were navigated to test case 3 (TC3). In the TC3 section of the travel experiment, participants could choose between three options for rollup query patterns (similar to Q6, Section 3). Users were able to obtain recommendations for travel destinations based on POIs, they had visited during the stay in another destination. They could either select a city (option 1), a region (option 2) or a country (option 3) as destination type. Upon entity type selection, the SKOSRec engine generated appropriate suggestions. Figure 6 shows the web form from the travel experiment that facilitated the formulation of advanced rollup requests in TC3.
Music – user profile generation, TC4 (page 9).
When users had selected an entity type, stated their favorite travel destination and three belonging POIs, the application generated a SKOSRec query from these parameters. A simple on-the-fly request was sent to the engine as well to retrieve baseline recommendations, with which the suggestions resulting from the advanced request were compared at a later stage of the experiment. The simple query only contained the user’s favorite travel destination and the selected entity type option thus omitting information on the POIs. During the travel experiment, the engine processed both the simple and the advanced query and produced two recommendation lists. As in the previous parts of the experiment, participants assessed the quality of the result sets, which appeared in random order on the screen.
The multimedia experiments also contained a section on rollup retrieval (TC3). As the advanced travel queries, the multimedia requests aggregated similarity scores of sublevel entities through summation, which the engine joined with a postfilter. In addition to these features, the pattern contained a preference query part. This section identified a set of preferred items through a single user statement. Participants either specified their favorite director/actor (music domain), music act (music domain) or author (book domain) and received recommendations based on the features of the works created by the artist (similar to Q5, Section 3). The SKOSRec engine generated recommendations based on the creative works of the favored artist. Participants also received suggestions from a simple on-the-fly query, which computed results according to the artist’s characteristics. As in the travel experiment, recommendations from the advanced rollup request were compared with the on-the-fly query without letting participants know which approach they were assessing and through random assignment of result set positions.
After participants of the multimedia experiments had evaluated the results of TC3, they were guided to test case 4 (TC4), which evaluated cross-domain queries. The experiment on travel RS ended with TC3 because no suitable graph patterns could be identified to facilitate these kinds of suggestions for the travel usage scenario. In the multimedia domain, however, the data from DBpedia was sufficient for this retrieval task. The entity type of the study (i.e., movie, music act or book) defined the source domain based on which the engine generated suggestions for items from another multimedia target domain (similar to Q7, Section 3). Figure 7 depicts the cross-domain web form of the music experiment.
The web form assisted subjects in formulating a request, which then obtained movie suggestions based on the favorite music act of the user. Parameters from users were entered in the placeholders of the query pattern in the backend of the application. We formulated the query templates in such a way that the query engine matched any properties or graph patterns that could potentially connect two items from the specified target and source domains. For instance, such matchings can occur when a user states his favorite movie that is written by a particular author. In case the same author has also written some books, they might be of interest to the user as well. Another example stems from the movie domain. Suppose in his/her profile, a consumer has declared a preference for a movie that links to the corresponding soundtrack. It might well be the case that the user likes the soundtrack and the music acts that were involved in creating it just as much as s/he likes the movie. The practice to distinguish homonymous LOD resources through the property
Cross-domain SPARQL queries (similar to Q8, Section 3) were posed as baseline requests in this test case. While the SPARQL query only matched cross-domain relations for a single LOD resource, the SKOSRec request expanded the search space by considering links from more than one item. As in the previous test cases, TC4 ended with an evaluation screen where users assessed the SPARQL-based as well as the SKOSRec suggestions in random order without knowing which recommendation list belonged to which method. Table 10 gives an overview of the test cases and the methods that were applied in the experiments in each usage scenario.
Test cases in the web experiments
In total, 257 people took part in the study.The gathered samples from the experiments contained answers from both genders with a slight overrepresentation of male participants (53.7%). The prevailing number of study subjects was between 20 and 40 years of age (65.8%). The evaluation of the demographics section also revealed that the majority of participants already perceives the search in their domain of interest as either “manageable” (38.5%) or even as “easy” or “very easy” (44.0%).
Prior to analyzing the performance results of the novel retrieval approaches of the SKOSRec engine, it was checked whether the respective Likert items for Perceived Usefulness and user-based diversity (
Cronbach’s α values for the concept of perceived usefulness
Cronbach’s α values for the concept of perceived usefulness
Performance results in TC1 (
Besides usefulness, user-based diversity scores were also measured by multiple Likert items. However, Cronbach’s α values for this concept did not reach acceptable levels. In order to avoid that valuable user assessments remained unused, agreements to the statement “The recommendations of list [...] are diverse” were taken into account as an ordinal variable (
Based on these results, subsequent tests could be carried out. The first part of the analysis concerned the performance of the on-the-fly retrieval method (baseline) of the SKOSRec engine in TC1. The outcome of this analysis confirms that the on-the-fly approach represents a viable recommendation strategy. Table 12 shows the mean (M),12
In case of the user-based diversity score (
In summary, the baseline approach achieved fairly good performance results in TC1. The findings demonstrate that LOD-enabled recommendations can potentially enhance a user’s search experience. They also allow for subsequent tests of advanced retrieval techniques, which can be compared to this standard method.
In the analysis of performance results from TC2 (constraint-based recommendations), particular attention was paid to participants’ agreements with the statement: “The filter has improved the recommendation results of the list”. Figure 8 shows the distribution of domain-wise agreement ratios. On average, they were fairly high. Throughout the domains, the vast majority of participants either selected 5 (“strongly agree”), 4 (“agree”) or 3 (“neutral”). Hence, a filter often had a positive impact on results.

Participants’ agreement with the statement that the filter has improved the result list (domain-wise) (TC2).
The authors gathered responses to the question on improvement for recommendation lists resulting from both the simple and the expressive filtering approaches. Hence, they give clues about the general performance of constraint-based retrieval. However, since this section of the study revealed the experimental condition to participants (i.e., application of a filter), answers to the Likert statement have to be interpreted cautiously. Results may be slightly biased as participants were able to guess the underlying agenda. However, these limitations do not exist for comparisons between simple and expressive filters. Since the web application randomly assigned the list order, participants did not know which approach they were assessing. This enables us to take a closer look at the differences between the two filtering approaches. It was hypothesized that advanced filters improve recommendation quality, as they may identify more relevant resources thereby overcoming problems of data quality or data sparsity in LOD repositories. Table 13 lists response rates of the two methods. The rate measures the ratio of non-zero result sets among all result sets. Throughout the domains, recommendation lists resulting from expressive filtering achieved higher response rates.
Response rates (TC2)
Performance results in TC2 (
In addition to response rates, user assessments and scores in the defined quality dimensions were compared. Table 14 depicts the outcome of this analysis. Significantly higher scores are marked in bold figures. In case statistical tests identified no meaningful variations, the results of the better performing approach are underlined. A-levels were adjusted with the false discovery rate (FDR) in order to decrease the probability of making a type I error due to multiple testing.
According to mean scores, expressive requests generated more comprehensive recommendation lists (size). This finding is in line with the increased response rates shown in Table 13. However, subsequently conducted t-tests confirmed significant differences only for the travel experiment (
Regarding Novelty, none of the approaches was superior. In the Diversity dimension, expressive filters generated suggestions that were at least as topically diversified as the results from simple constraint-based retrieval. Even though no significant differences were identified between the two approaches, increased mean scores (divU in the travel domain and divC in each domain) indicate a slight superiority of expanded filter requests in this quality dimension. The same applies to usefulness scores (mean values were higher in 3 out of 4 domains, when expressive filtering was applied). However, these statements are speculative at best, because statistical tests were not significant.
In summary, it can be concluded that expressive filters improve recall, potentially leading to a slight loss in precision scores (see Table 14). It may also be the case that expanded user constraints diversify as well as increase the usefulness of recommendation lists. However, these claims are unverified. In contrast, it is safe to say that expressive query patterns generate results of at least the same quality as simple patterns while increasing the number of relevant suggestions. The few differences may be explained by the high Jaccard scores (JI) (see Table 15) of recommendation lists. Throughout the domains, result sets were much alike. Given these similarities and the increases in list sizes for expressive filters, it is supposed that an expanded constraint produces an enhanced version of the recommendation list resulting from simple filtering. Therefore, expanded filters should be the default setting in a constraint-based retrieval context.
Jaccard indices (TC2)
In TC3 (i.e., evaluation of roll-up query patterns), the SKOSRec engine almost always generated non-empty recommendation lists (see Table 16). In the travel and the book experiment, the response rate was higher for aggregation-based queries, whereas in the movie domain, the engine more often provided recommendations for regular requests. However, these differences are only marginal and do not indicate a clear superiority of one method.
Response rates (TC3)
Figure 9 depicts participants general agreement to Likert statements concerning the Perceived Usefulness of the approaches in TC3. The diagram shows similar results for regular as well as advanced requests. On average, satisfaction scores reached levels, which lay slightly above neutral agreement. A subsequent t-test confirmed no significant differences between the two methods. In fact, the approach with the highest average score of Perceived Usefulness was different in each experiment. While mean values were higher for regular requests in the studies on travel and music RS, advanced queries produced higher scores in the movie and book experiments.
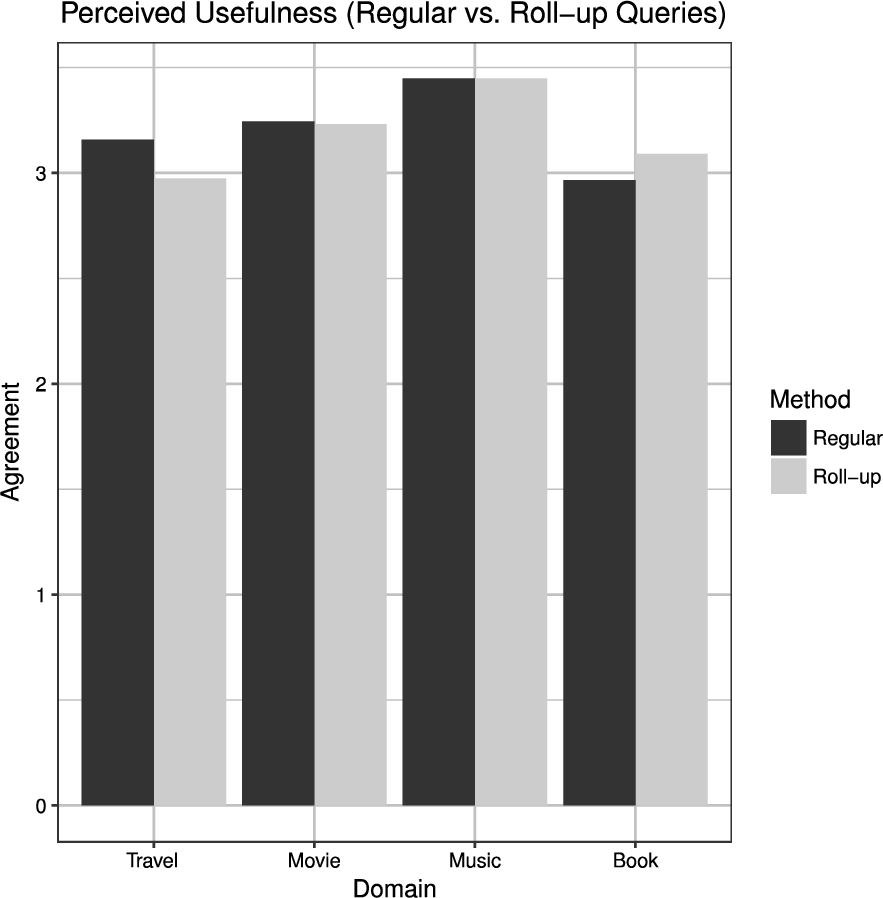
Participant’s overall satisfaction with regular and roll-up recommendation retrieval (TC3).
Content-based Diversity (
Performance results in TC3 (
Hence, it can be assumed that both approaches produce recommendation lists of similar quality and can provide benefits to potential consumers. Thus, it cannot be clearly stated which approach is superior, because neither of them outperformed the other in each domain. While the regular retrieval strategy was better in terms of usefulness in the travel and the music domains, the aggregation-based approach achieved higher scores in the domains of movie and book recommendations.
This conclusion is especially impressive, given the low mean Jaccard scores for recommendation lists resulting from regular and aggregation-based retrieval (see Table 18). The mean score never exceeded 0.1 throughout the domains. It indicates a low concordance between result sets. It is remarkable that participants perceived the recommendations as equally good, given the high dissimilarity of the lists. Thus, advanced queries have an added-value, as they provide additional interesting results. They can help to explore LOD repositories in different ways than a regular retrieval approach. Therefore, it is worthwhile to offer aggregation-based query patterns as an alternative retrieval strategy, when the regular approach has not produced any helpful recommendations.
Jaccard indices (TC3)
In addition to TC3, user assessments for TC4 (cross-domain recommendations) were also evaluated. However, since the authors conducted experiments for TC4 only in the multimedia domains, the samples were considerably smaller. Nevertheless, it is assumed that the amount of completed user sessions is only just enough to conduct further statistical analyses. Table 19 shows the response rates for the two retrieval methods. Cross-domain patterns had a higher success rate of generating non-zero result sets throughout the domains. Participants almost always received a recommendation for this query type, whereas in case a regular SPARQL query was executed, often they did not receive a single suggestion at all.
Response rates (TC4)
We applied non-parametric tests for the performance metrics
Performance results in TC4 (
However, the most important finding of the analysis was that SKOSRec cross-domain queries generated significantly more suggestions throughout the domains. (movie:

Mean recommendation list sizes for SPARQL and SKOSRec cross-domain requests (TC4).
Whenever the SPARQL request provided recommendations, which was the case in less than half of the user sessions (see Table 19), the SKOSRec suggestions were assessed to be of almost equal quality as the SPARQL recommendations (see Table 20, Usefulness). Hence, when SPARQL querying did not produce any results in more than the other half of the test cases, the SKOSRec approach may still have provided useful suggestions.
Jaccard indices (TC4)
Therefore, it is reasonable to assume that the capability of the SKOSRec engine to flexibly switch between processing steps of similarity calculation and pattern matching, can facilitate an improved exploration of LOD repositories. Table 21 also shows that the items in the two sets often did not match, as is indicated by low Jaccard indices. This finding further demonstrates that the execution of an additional step of similarity calculation can help to retrieve other relevant items.
This paper has presented the query-based SKOSRec engine that facilitates new types of recommendation requests for LOD repositories. The evaluations have shown that the SKOSRec system can often generate relevant and useful suggestions when certain query templates are utilized. In many cases, the application of expressive or advanced query patterns (i.e., in the context of constraint-based retrieval or cross-domain requests) helped to significantly improve recall values, while still providing the same level of quality in the remaining performance dimensions. Additionally, advanced recommendation requests can be used to generate diversified recommendation lists, in case users are not satisfied with the results of regular recommendation requests (i.e., roll-up or cross-domain retrieval vs. regular requests). While not being superior in each domain and test case, is at least safe to say that the novel recommendation approaches of the SKOSRec engine considerably extend common retrieval methods and at least provide an alternative search strategy when conventional methods fail to provide useful results. Additionally, the increase in diversity and recall is in line with findings from previous research on LOD-enabled RS [42].
It is a strength of the developed approaches that they facilitate combinations of graph-based and similarity-based retrieval at different stages of the recommendation workflow. This feature extends general search capabilities for semantic networks. It requires future research to investigate whether, in addition to SKOS, further RDF vocabularies can be used for ad-hoc item-to-item similarity computation to increase the range of potential usage scenarios, since not every LOD dataset contains SKOS annotations [53]. The application of additional properties could also boost the recommendation quality of some query patterns (e.g., such as the query types used in TC3). In this context, it also needs to be determined whether the representation of the user profile in the SKOSRec query language can be substituted with free-text expressions to enable search-like functionalities. LOD researchers have already developed engines that can process natural language queries over RDF data [34,59,67]. It will have to be investigated how the SKOSRec engine profitably fits into this landscape of existing retrieval tools.
Another open research question concerns the aspect of interfaces to other applications. In its standard configuration, the system is not an end-user retrieval engine, but a backend application, with which an administrator, who has domain knowledge (e.g., of RDF vocabularies and data models of a particular LOD repository and usage scenario), creates the respective query patterns. Although the websites of the online experiments represent possible implementations of suitable end-user applications for the SKOSRec engine, there are still many other possibilities and extensions to design such a user interface (UI). For instance, the selection of LOD items for the profile was made possible by previously storing the data in an index that could then be accessed and searched before issuing a recommendation query. However, this runs against the idea of ad-hoc retrieval. In this context, future research will have to determine whether it is feasible to generate an on-the-fly mapping from items to the respective LOD resources. In the case of a commercial application, the engine needs to match items with the corresponding entries in the product catalog. Even if it is not yet clear which UI components can make the best possible use of the SKOSRec engine’s features, the results from the user experiments can give at least a few suggestions.
The following retrieval options should be the default setting in an interface that contains a LOD-enabled RS component to assist users in finding interesting items: Since the regular approach of on-the-fly retrieval achieved good results throughout the domains, the display of simple recommendations generated from previously stated user preferences represents a suitable starting point for retrieval. On-the-fly queries could be refined by providing filter options. Since the evaluations have shown that expressive constraints often lead to increased recall values, the application of such a filter might be the best option for assisted retrieval. As in the preparations for the experiments, appropriate graph-based query patterns for the usage scenario in question would also have to be determined by a domain expert before setting up the application. The same applies to advanced retrieval patterns, which should be available to the end user to refine the query when both the simple as well as the constraint-based approach have failed to provide relevant items. This suggestion is made because roll-up queries were competitive with regular recommendations in the web-based experiments. Therefore, they represent a viable alternative retrieval strategy. For some domains (e.g., for multimedia retrieval) it is also possible to use an optional selection field to enable the formulation of cross-domain requests. Evaluations for this query type suggest that users might receive interesting results (i.e., diversified and comprehensive recommendation lists) from such a request.
In summary, the contributions of the paper are as follows:
Development and implementation of novel retrieval strategies in the SKOSRec system, which facilitate personalized requests and leverage the potential of knowledge graphs in order to address the research gap in state-of-the-art recommendation methods with regard to customized queries. Realization of web-based user experiments in four usage scenarios with the following outcomes: Successful demonstration that knowledge graph data is applicable in the context of live recommendation scenarios. Creation of suitable query patterns that can be applied to represent individual information needs in different application contexts. The set of query patterns can be extended with the help of the SKOSRec query language to meet the requirements of additional usage scenarios. Proof that the novel retrieval strategies can be successfully applied across various application contexts and recommendation tasks and that they outperform conventional content-based retrieval approaches, especially in the performance dimensions of diversity and recall.
The prototypical implementation and the evaluation of the SKOSRec engine in different usage scenarios have demonstrated that the freely available knowledge sources on the LOD cloud can be successfully applied to advance state-of-the-art methods in IR and recommender systems. The proposed personalized and customized retrieval strategies can leverage the potential of knowledge graphs by better matching information needs of users with the help of semantic search options.