
Abstract
We provide a comprehensive survey of the research literature that applies Information Extraction techniques in a Semantic Web setting. Works in the intersection of these two areas can be seen from two overlapping perspectives: using Semantic Web resources (languages/ontologies/knowledge-bases/tools) to improve Information Extraction, and/or using Information Extraction to populate the Semantic Web. In more detail, we focus on the extraction and linking of three elements: entities, concepts and relations. Extraction involves identifying (textual) mentions referring to such elements in a given unstructured or semi-structured input source. Linking involves associating each such mention with an appropriate disambiguated identifier referring to the same element in a Semantic Web knowledge-base (or ontology), in some cases creating a new identifier where necessary. With respect to entities, works involving (Named) Entity Recognition, Entity Disambiguation, Entity Linking, etc. in the context of the Semantic Web are considered. With respect to concepts, works involving Terminology Extraction, Keyword Extraction, Topic Modeling, Topic Labeling, etc., in the context of the Semantic Web are considered. Finally, with respect to relations, works involving Relation Extraction in the context of the Semantic Web are considered. The focus of the majority of the survey is on works applied to unstructured sources (text in natural language); however, we also provide an overview of works that develop custom techniques adapted for semi-structured inputs, namely markup documents and web tables.
Keywords
Introduction
The Semantic Web pursues a vision of the Web where increased availability of structured content enables higher levels of automation. Berners-Lee [20] described this goal as being to “enrich human readable web data with machine readable annotations, allowing the Web’s evolution as the biggest database in the world”. However, making annotations on information from the Web is a non-trivial task for human users, particularly if some formal agreement is required to ensure that annotations are consistent across sources. Likewise, there is simply too much information available on the Web – information that is constantly changing – for it to be feasible to apply manual annotation to even a significant subset of what might be of relevance.
While the amount of structured data available on the Web has grown significantly in the past years, there is still a significant gap between the coverage of structured and unstructured data available on the Web [248]. Mika referred to this as the semantic gap [206], whereby the demand for structured data on the Web outstrips its supply. For example, in an analysis of the 2013 Common Crawl dataset, Meusel et al. [202] found that of the 2.2 billion webpages considered, 26.3% contained some structured metadata. Thus, despite initiatives like Linking Open Data [275], Schema.org [201,205] (promoted by Google, Microsoft, Yahoo, and Yandex) and the Open Graph Protocol [128] (promoted by Facebook), this semantic gap is still observable on the Web today [202,206].
As a result, methods to automatically extract or enhance the structure of various corpora have been a core topic in the context of the Semantic Web. Such processes are often based on Information Extraction methods, which in turn are rooted in techniques from areas such as Natural Language Processing, Machine Learning and Information Retrieval. The combination of techniques from the Semantic Web and from Information Extraction can be seen from two perspectives: on the one hand, Information Extraction techniques can be applied to populate the Semantic Web, while on the other hand, Semantic Web techniques can be applied to guide the Information Extraction process. In some cases, both aspects are considered together, where an existing Semantic Web ontology or knowledge-base is used to guide the extraction, which further populates the given ontology and/or knowledge-base (KB).1
Herein we adopt the convention that the term “ontology” refers primarily to terminological knowledge, meaning that it describes classes and properties of the domain, such as person, knows, country, etc. On the other hand, we use the term “KB” to refer to primarily “assertional knowledge”, which describes specific entities (aka. individuals) of the domain, such as Barack Obama, China, etc.
In the past years, we have seen a wealth of research dedicated to Information Extraction in a Semantic Web setting. While many such papers come from within the Semantic Web community, many recent works have come from other communities, where, in particular, general-knowledge Semantic Web KBs – such as DBpedia [171], Freebase [26] and YAGO2 [139] – have been broadly adopted as references for enhancing Information Extraction tasks. Given the wide variety of works emerging in this particular intersection from various communities (sometimes under different nomenclatures), we see that a comprehensive survey is needed to draw together the techniques proposed in such works. Our goal is then to provide such a survey.
Survey Scope: This survey provides an overview of published works that directly involve both Information Extraction methods and Semantic Web technologies. Given that both are very broad areas, we must be rather explicit in our inclusion criteria.
With respect to Semantic Web technologies, to be included in the scope of a survey, a work must make non-trivial use of an ontology, knowledge-base, tool or language that is founded on one of the core Semantic Web standards: RDF/RDFS/OWL/SKOS/SPARQL.2
Works that simply mention general terms such as “semantic” or “ontology” may be excluded by this criteria if they do not also directly use or depend upon a Semantic Web standard.
By Information Extraction methods, we focus on the extraction and/or linking of three main elements from an (unstructured or semi-structured) input source.
Entities: anything with named identity, typically an individual (e.g.,
Concepts: a conceptual grouping of elements. We consider two types of concepts:
Classes: a named set of individuals (e.g.,
Topics: categories to which individuals or documents relate (e.g,
Relations: an n-ary tuple of entities (
More formally, we can consider entities as atomic elements from the domain, concepts as unary predicates, and relations as n-ary (
Returning to “extracting and/or linking”, we consider the extraction process as identifying mentions referring to such entities/concepts/relations in the unstructured or semi-structured input, while we consider the linking process as associating a disambiguated identifier in a Semantic Web ontology/KB for a mention, possibly creating one if not already present and using it to disambiguate and link further mentions.
Information Extraction Tasks: The survey deals with various Information Extraction tasks. We now give an introductory summary of the main tasks considered (though we note that the survey will delve into each task in much more depth later):
demarcate the locations of mentions of entities in an input text:
aka. Entity Recognition, Entity Extraction; e.g., in the sentence “
associate mentions of entities with an appropriate disambiguated KB identifier:
involves, or is sometimes synonymous with, Entity Disambiguation;3 In some cases Entity Linking is considered to include both recognition and disambiguation; in other cases, it is considered synonymous with disambiguation applied after recognition.
e.g., associate “
We use well-known IRI prefixes as consistent with the lookup service hosted at: http://prefix.cc. All URLs in this paper were last accessed on 2018/05/30.
extract the main phrases that denote concepts relevant to a given domain described by a corpus, sometimes inducing hierarchical relations between concepts;
aka. Term Extraction, often used for the purposes of Ontology Learning; e.g., identify from a text on Oncology that “ optionally identify that both of the above concepts are specializations of “ terms may be linked to a KB/ontology.
extract the main phrases that categorize the subject/domain of a text (unlike Terminology Extraction, the focus is often on describing the document, not the domain);
aka. Keyword Extraction, which is often generically applied to cover extraction of multi-word phrases; often used for the purposes of Semantic Annotation; e.g., identify that the keyphrases “ keyphrases may be linked to a KB/ontology.
Cluster words/phrases frequently co-occurring together in the same context; these clusters are then interpreted as being associated to abstract topics to which a text relates;
aka. Topic Extraction, Topic Classification; e.g., identify that words such as “
For clusters of words identified as abstract topics, extract a single term or phrase that best characterizes the topic;
aka. Topic Identification, esp. when linked with an ontology/KB identifier; often used for the purposes of Text Classification; e.g., identify that the topic {“
Extract potentially n-ary relations (for
a goal of the area of Open Information Extraction; e.g., in the sentence “ binary relations may be represented as RDF triples after linking entities and linking the predicate to an appropriate property (e.g., mapping n-ary (
Note that we will use a more simplified nomenclature {
Again we are only interested in such tasks in the context of the Semantic Web. Our focus is on unstructured (text) inputs, but we will also give an overview of methods for semi-structured inputs (markup documents and tables) towards the end of the survey.
Related Areas, Surveys and Novelty: There are a variety of areas that relate and overlap with the scope of this survey, and likewise there have been a number of previous surveys in these areas. We now discuss such areas and surveys, how they relate to the current contribution, and outline the novelty of the current survey.
As we will see throughout this survey, Information Extraction (IE) from unstructured sources – i.e., textual corpora expressed primarily in natural language – relies heavily on Natural Language Processing (NLP). A number of resources have been published within the intersection of NLP and the Semantic Web (SW), where we can point, for example, to a recent book published by Maynard et al. [191] in 2016, which likewise covers topics relating to IE. However, while IE tools may often depend on NLP processing techniques, this is not always the case, where many modern approaches to tasks such as Entity Linking do not use a traditional NLP processing pipeline. Furthermore, unlike the introductory textbook by Maynard et al. [191], our goal here is to provide a comprehensive survey of the research works in the area. Note that we also provide a brief primer on the most important NLP techniques in a supplementary appendix, discussed later.
On the other hand, Data Mining involves extracting patterns inherent in a dataset. Example Data Mining tasks include classification, clustering, rule mining, predictive analysis, outlier detection, recommendation, etc. Knowledge Discovery refers to a higher-level process to help users extract knowledge from raw data, where a typical pipeline involves selection of data, pre-processing and transformation of data, a Data Mining phase to extract patterns, and finally evaluation and visualization to aid users gain knowledge from the raw data and provide feedback. Some IE techniques may rely on extracting patterns from data, which can be seen as a Data Mining step;5
In fact, the title “Information Extraction” pre-dates that of the title “Data Mining” in its modern interpretation.
With respect to our survey, both Natural Language Processing and Data Mining form part of the background of our scope, but as discussed, Information Extraction has a rather different focus to both areas, neither covering nor being covered by either.
On the other hand, relating more specifically to the intersection of Information Extraction and the Semantic Web, we can identify the following (sub-)areas:
aims to annotate documents with entities, classes, topics or facts, typically based on an existing ontology/KB. Some works on Semantic Annotation fall within the scope of our survey as they include extraction and linking of entities and/or concepts (though not typically relations). A survey focused on Semantic Annotation was published by Uren et al. [301] in 2006.
refers to leveraging the formal knowledge of ontologies to guide a traditional Information Extraction process over unstructured corpora. Such works fall within the scope of this survey. A prior survey of Ontology-Based Information Extraction was published by Wimalasuriya and Dou [313] in 2010.
helps automate the (costly) process of ontology building by inducing an (initial) ontology from a domain-specific corpus. Ontology Learning also often includes Ontology Population, meaning that instance of concepts and relations are also extracted. Such works fall within our scope. A survey of Ontology Learning was provided by Wong et al. [316] in 2012.
aims to lift an unstructured or semi-structured corpus into an output described using a knowledge representation formalism (such as OWL). Thus Knowledge Extraction can be seen as Information Extraction but with a stronger focus on using knowledge representation techniques to model outputs. In 2013, Gangemi [112] provided an introduction and comparison of fourteen tools for Knowledge Extraction over unstructured corpora.
Other related terms such as “Semantic Information Extraction” [110], “Knowledge-Based Information Extraction” [140], “Knowledge-Graph Completion” [179], and so forth, have also appeared in the literature. However, many such titles are used specifically within a given community, whereas works in the intersection of IE and SW have appeared in many communities. For example, “Knowledge Extraction” is used predominantly by the SW community and not others.6
Here we mean “Knowledge Extraction” in an IE-related context. Other works on generating explanations from neural networks use the same term in an unrelated manner.
Intended Audience: This survey is written for researchers and practitioners who are already quite familiar with the main SW standards and concepts – such as the RDF, RDFS, OWL and SPARQL standards, etc. – but are not necessarily familiar with IE techniques. Hence we will not introduce SW concepts (such as RDF, OWL, etc.) herein. Otherwise, our goal is to make the survey as accessible as possible. For example, in order to make the survey self-contained, in Appendix x we provide a detailed primer on some traditional NLP and IE processes; the techniques discussed in this appendix are, in general, not in the scope of the survey, since they do not involve SW resources, but are heavily used by works that fall in scope. We recommend readers unfamiliar with the IE area to read the appendix as a primer prior to proceeding to the main body of the survey. Knowledge of some core Information Retrieval concepts – such as TF–IDF, PageRank, cosine similarity, etc. – and some core Machine Learning concepts – such as logistic regression, SVM, neural networks, etc. – may be necessary to understand finer details, but not to understand the main concepts.
Nomenclature: The area of Information Extraction is associated with a diverse nomenclature that may vary in use and connotation from author to author. Such variations may at times be subtle and at other times be entirely incompatible. Part of this relates to the various areas in which Information Extraction has been applied and the variety of areas from which it draws influence. We will attempt to use generalized terminology and indicate when terminology varies.
Survey Methodology: Based on the previous discussion, this survey includes papers that:
deal with extraction and/or linking of entities, concepts and/or relations,
deal with some Semantic Web standard – namely RDF, RDFS or OWL – or a resource published or otherwise using those standards,
have details published, in English, in a relevant workshop, conference or journal since 1999,
consider extraction from unstructured sources.
For finding in-scope papers, our methodology begins with a definition of keyphrases appropriate to the section at hand. These keyphrases are divided into lists of IE-related terms (e.g., “
Keywords used to search for candidate papers.
Our survey methodology consists of four initial phases to search, extract and filter papers. For each defined keyphrase, we (I) perform a search on Google Scholar for related papers, merging and deduplicating lists of candidate papers (numbering in the thousands in total); (II) we initially apply a rough filter for relevance based on the title and type of publication; (III) we filter for relevance by abstract; and (IV) finally we filter for relevance by the body of the paper.
To collect further literature, while reading relevant papers, we also take note of other works referenced in related works, works that cite more prominent relevant papers, and also check the bibliography of prominent authors in the area for other papers that they have written; such works were added in phase III to be later filtered in phase IV. Table 2 presents the numbers of papers considered by each phase of the methodology.7
Table 2 refers to papers considering text as input; a further 20 papers considering semi-structured inputs are presented later in the survey, which will bring the total to 109 selected papers.
Number of papers included in the survey (by phase).
We provide further details of our survey online, including the lists of papers considered by each phase.8
We may include out-of-scope papers to the extent that they serve as important background for the in-scope papers: for example, it is important for an uninitiated reader to understand some of the core techniques considered in the traditional Information Extraction area and to understand some of the core standards and resources considered in the core Semantic Web area. Furthermore, though not part of the main survey, in Section 5, we provide a brief overview of otherwise related papers that consider semi-structured input sources, such as markup documents, tables, etc.
Survey Structure: The structure of the remainder of this survey is as follows:
discusses extraction and linking of entities for unstructured sources.
discusses extraction and linking of concepts for unstructured sources.
discusses extraction and linking of relations for unstructured sources.
discusses techniques adapted specifically for extracting entities, concepts and/or relations from semi-structured sources.
concludes the survey with a discussion.
Additionally, Appendix x provides a primer on classical Information Extraction techniques for readers previously unfamiliar with the IE area; we recommend such a reader to review this material before continuing.
Entity Extraction & Linking (EEL)9
We note that naming conventions can vary widely: sometimes Named Entity Linking (NEL) is used; sometimes the acronym (N)ERD is used for (Named) Entity Recognition & Disambiguation; sometimes EEL is used as a synonym for NED; other phrases can also be used, such as Named Entity Extraction (NEE), or Named Entity Resolution, or variations on the idea of semantic annotation or semantic tagging (which we consider applications of EEL).
Entity Extraction can be performed using an off-the-shelf Named Entity Recognition (NER) tool as used in traditional IE scenarios (see Appendix A.1); however such tools typically extract entities for limited numbers of types, such as persons, organizations, places, etc.; on the other hand, the reference KB may contain entities from hundreds of types. Hence, while some Entity Extraction & Linking tools rely on off-the-shelf NER tools, others define bespoke methods for identifying entity mentions in text, typically using entities’ labels in the KB as a dictionary to guide the extraction.
Once entity mentions are extracted from the text, the next phase involves linking – or disambiguating – these mentions by assigning them to KB identifiers; typically each mention in the text is associated with a single KB identifier chosen by the process as the most likely match, or is associated with multiple KB identifiers and an associated weight (aka. support) indicating confidence in the matches that allow the application to choose which entity links to trust.
Example: In Listing 1, we provide an excerpt of an EEL response given by the online DBpedia Spotlight demo10
in JSON format. Within the result, the “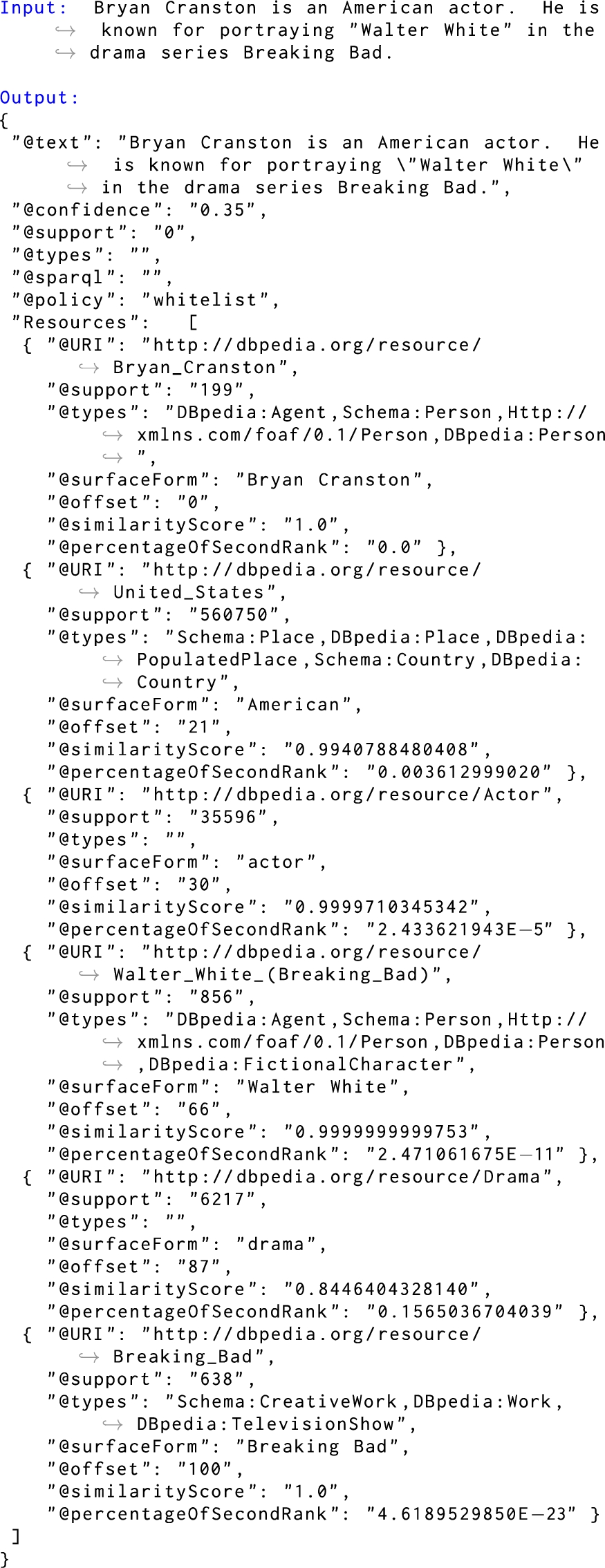
DBpedia spotlight EEL example
Of course, the exact details of the output of an EEL process will vary from tool to tool, but such a tool will minimally return a KB identifier and the location of the entity mention; a support will also often be returned.
Applications: EEL is used in a variety of applications, such as semantic annotation [41], where entities mentioned in text can be further detailed with reference data from the KB; semantic search [296], where search over textual collections can be enhanced – for example, to disambiguate entities or to find categories of relevant entities – through the structure provided by the KB; question answering [300], where the input text is a user question and the EEL process can identify which entities in the KB the question refers to; focused archival [81], where the goal is to collect and preserve documents relating to particular entities; detecting emerging entities [137], where entities that do not yet appear in the KB, but may be candidates for adding to the KB, are extracted.11
Emerging entities are also sometimes known as Out-Of Knowledge-Base (OOKB) entities or Not In Lexicon (NIL) entities.
Process: As stated by various authors [62,154,243,246], the EEL process is typically composed of two main steps: recognition, where relevant entity mentions in the text are found; and disambiguation, where entity mentions are mapped to candidate identifiers with a final weighted confidence. Since these steps are (often) loosely coupled, this section surveys the various techniques proposed for the recognition task and thereafter discusses disambiguation.
The goal of EEL is to extract and link entity mentions in a text with entity identifiers in a KB; some tools may additionally detect and propose identifiers for emerging entities that are not yet found in the KB [231,238,247]. In both cases, the first step is to mark entity mentions in the text that can be linked (or proposed as an addition) to the KB. Thus traditional NER tools – discussed in Appendix A.1 – can be used. However, in the context of EEL where a target KB is given as input, there can be key differences between a typical EEL recognition phase and traditional NER:
In cases where emerging entities are not detected, the KB can provide a full list of target entity labels, which can be stored in a dictionary that is used to find mentions of those entities. While dictionaries can be found in traditional NER scenarios, these often refer to individual tokens that strongly indicate an entity of a given type, such as common first or family names, lists of places and companies, etc. On the other hand, in EEL scenarios, the dictionary can be populated with complete entity labels from the KB for a wider range of types; in scenarios not involving emerging entities, this dictionary will be complete for the entities to recognize. Of course, this can lead to a very large dictionary, depending on the KB used.
Relating to the previous point, (particularly) in scenarios where a complete dictionary is available, the line between extraction and linking can become blurred since labels in the dictionary from the KB will often be associated with KB identifiers; hence, dictionary-based detection of entities will also provide initial links to the KB. Such approaches are sometimes known as End-to-End (E2E) approaches [247], where extraction and linking phases become more tightly coupled.
In traditional NER scenarios, extracted entity mentions are typically associated with a type, usually with respect to a number of trained types such as person, organization, and location. However, in many EEL scenarios, the types are already given by the KB and are in fact often much richer than what traditional NER models support.
In this section, we thus begin by discussing the preparation of a dictionary and methods used for recognizing entities in the context of EEL.
Dictionary
The predominant method for performing EEL relies on using a dictionary – also known as a lexicon or gazetteer – which maps labels of target entities in the KB to their identifiers; for example, a dictionary might map the label “
Thus, with respect to dictionaries, the first important aspect is the selection of entities to consider (or, indeed, the source from which to extract a selection of entities). The second important aspect – particularly given large dictionaries and/or large corpora of text – is the use of optimized indexes that allow for efficient matching of mentions with dictionary labels. The third aspect to consider is the enrichment of each entity in the dictionary with contextual information to improve the precision of matches. We now discuss these three aspects of dictionaries in turn.
Selection of entities: In the context of EEL, an obvious source from which to form the dictionary is the labels of target entities in the KB. In many Information Extraction scenarios, KBs pertaining to general knowledge are employed; the most commonly used are:
A KB extracted from Wikipedia and used by ADEL [247], DBpedia Spotlight [200], ExPoSe [238], Kan-Dis [145], NERSO [125], Seznam [96], SDA [42] and THD [84], as well as works by Exner and Nugues [97], Nebhi [226], Giannini et al. [118], amongst others;
A collaboratively-edited KB – previously hosted by Google but now discontinued in favor of Wikidata [294] – used by JERL [184], Kan-Dis [145], NEMO [67], Neofonie [158], NereL [281], Seznam [96], Tulip [181], as well as works by Zheng et al. [330], amongst others;
A collaboratively-edited KB hosted by the Wikimedia Foundation that, although released more recently than other KBs, has been used by HERD [284];
Another KB extracted from Wikipedia with richer meta-data, used by AIDA [140], AIDA-Light [230], CohELL [122], J-NERD [231], KORE [138] and LINDEN [278], as well as works by Abedini et al. [1], amongst others.
These KBs are tightly coupled with
On the other hand, many of the entities in these general-interest KBs may be irrelevant for certain application scenarios. Some systems support selecting a subset of entities from the KB to form the dictionary, potentially pertaining to a given domain or a selection of types. For example, DBpedia Spotlight [200] can build a dictionary from the DBpedia entities returned as results for a given SPARQL query. Such a pre-selection of relevant entities can help reduce ambiguity and tailor EEL for a given application.
Conversely, in EEL scenarios targeting niche domains not covered by Wikipedia and its related KBs, custom KBs may be required. For example, for the purposes of supporting multilingual EEL, Babelfy [216] constructs its own KB from a unification of Wikipedia, WordNet, and BabelNet. In the context of Microsoft Research, JERL [184] uses a proprietary KB (Microsoft’s Satori) alongside Freebase. Other approaches make minimal assumptions about the KB used, where earlier EEL approaches such as SemTag [82] and KIM [250] only assume that KB entities are associated with labels (in experiments, SemTag [82] uses Stanford’s TAP KB, while KIM [250] uses a custom KB called KIMO).
Dictionary matching and indexing: In order to match mentions with the dictionary in an efficient manner – with
A major challenge is that desirable matches may not be an exact match, but may rather only be captured by an approximate string-matching algorithm. While one could consider, for example, approximate matching based on regular expressions or edit distances, such measures do not lend themselves naturally to index-based approaches. Instead, for large dictionaries, or large input corpora, it may be necessary to trade recall (i.e., the percentage of correct spots captured) for efficiency by using coarser matching methods. Likewise, it is important to note that KBs such as DBpedia enumerate multiple “alias” labels for entities (extracted from the redirect entries in Wikipedia), which if included in the dictionary, can help to improve recall while using coarser matching methods.
A popular approach to index the dictionary is to use some variation on a prefix tree (aka. trie), such as used by the Aho–Corasick string-searching algorithm, which can find mentions of an input list of strings within an input text in time linear to the combined size of the inputs and output. The main idea is to represent the dictionary as a prefix tree where nodes refer to letters, and transitions refer to sequences of letters in a dictionary word; further transitions are put from failed matches (dead-ends) to the node representing the longest matching prefix in the dictionary. With the dictionary preloaded into the index, the text can then be streamed through the index to find (prefix) matches. Phrases are typically indexed separately to allow both word-level and phrase-level matching. This algorithm is implemented by GATE [68] and LingPipe [38], with the latter being used by DBpedia Spotlight [200].
The main drawback of tries is that, for the matching process to be performed efficiently, the dictionary index must fit in memory, which may be prohibitive for very large dictionaries. For these reasons, the Lucene/Solr Tagger implements a more general finite state transducer that also reuses suffixes and byte-encodings to reduce space [70]; this index is used by HERD [284] and Tulip [181] to store KB labels.
In other cases, rather than using traditional Information Extraction frameworks, some authors have proposed to implement custom indexing methods. To give some examples, KIM [250] uses a hash-based index over tokens in an entity mention;12
This implementation was later integrated into GATE: https://gate.ac.uk/sale/tao/splitch13.html.
Of course, the problem of indexing the dictionary is closely related to the problem of inverted indexing in Information Retrieval, where keywords are indexed against the documents that contain them. Such inverted indexes have proven their scalability and efficiency in Web search engines such as Google, Bing, etc., and likewise support simple forms of approximate matching based on, for example, stemming or lemmatization, which pre-normalize document and query keywords. Exploiting this natural link to Information Retrieval, the ADEL [247], AGDISTIS [302], Kan-Dis [145], TagMe [101] and WAT [243] systems use inverted-indexing schemes such as Lucene13
and Elastic.14https://www.elastic.co; note that ElasticSearch is in fact based on Lucene.
To manage the structured data associated with entities, such as identifiers or contextual features, some tools use more relational-style data management systems. For example, AIDA [140] uses the PostgreSQL relational database to retrieve entity candidates, while ADEL [247] and Neofonie [158] use the Couchbase15
and Redis16 NoSQL stores, respectively, to manage the labels and meta-data of their dictionaries.Contextual features: Rather than being a flat map of entity labels to (sets of) KB identifiers, dictionaries often include contextual features to later help disambiguate candidate links. Such contextual features may be categorized as being structured or unstructured.
Structured contextual features are those that can be extracted directly from a structured or semi-structured source. In the context of EEL, such features are often extracted from the reference KB itself. For example, each entity in the dictionary can be associated with the (labels of the) types of that entity, but also perhaps the labels of the properties that are defined for it, or a count of the number of triples it is associated with, or the entities it is related to, or its centrality (and thus “importance”) in the graph-structure of the KB, and so forth.
On the other hand, unstructured contextual features are those that must instead be extracted from textual corpora. In most cases, this will involving extracting statistics and patterns from an external reference corpus that potentially has already had its entities labeled (and linked with the KB). Such features may capture patterns in text surrounding the mentions of an entity, entities that are frequently mentioned close together, patterns in the anchor-text of links to a page about that entity, in how many documents a particular entity is mentioned, how many times it tends to be mentioned in a particular document, and so forth; clearly such information will not be available from the KB itself.
A very common choice of text corpora for extracting both structured and unstructured contextual features is Wikipedia, whose use in this setting was – to the best of our knowledge – first proposed by Bunescu and Pasca [33], then later followed by many other subsequent works [39,40,42,66,101,243,246,255]. The widespread use of Wikipedia can be explained by the unique advantages it has for such tasks:
The text in Wikipedia is primarily factual and available in a variety of languages.
Wikipedia has broad coverage, with documents about entities in a variety of domains.
Articles in Wikipedia can be directly linked to the entities they describe in various KBs, including DBpedia, Freebase, Wikidata, YAGO(2), etc.
Mentions of entities in Wikipedia often provide a link to the article about that entity, thus providing labeled examples of entity mentions and associated examples of anchor text in various contexts.
Aside from the usual textual features such as term frequencies and co-occurrences, a variety of richer features are available from Wikipedia that may not be available in other textual corpora, including disambiguation pages, redirections of aliases, category information, info-boxes, article edit history, and so forth.17
Information from info-boxes, disambiguation, redirects and categories are also represented in a structured format in DBpedia.
We will further discuss how contextual features – stored as part of the dictionary – can be used for disambiguation later in this section.
We now assume a dictionary that maps labels (e.g., “
Token-based: Given that entity mentions may consist of multiple sequential words – aka. n-grams – the brute-force option would be to send all n-grams in the input text to the dictionary, for n up to, say, the maximum number of words found in a dictionary entry, or a fixed parameter. We refer generically to these n-grams as tokens and to these methods for extracting n-grams as tokenization. Sometimes these methods are referred to as window-based spotting or recognition techniques.
A number of systems use such a form of tokenization. SemTag uses the TAP ontology for seeking entity mentions that match tokens from the input text. In AIDA-Light [230], AGDISTIS [302], Lupedia [204], and NERSO [125], recognition uses sliding windows over the text for varying-length n-grams.
Although relatively straightforward, a fundamental weakness with token-based methods relates to performance: given a large text, the dictionary-lookup implementation will have to be very efficient to deal with the number of tokens a typical such process will generate, many of which will be irrelevant. While some basic features, such as capitalization, can also be taken into account to filter (some) tokens, still, not all mentions may have capitalization, and many irrelevant or incoherent entities can still be retrieved; for example, by decomposing the text “
POS-based: A natural way to try to improve upon lexical tokenization methods in End-to-End systems is to try use some initial understanding of the grammatical role of words in the text, where POS-tags are used in order to be more selective with respect to what tokens are sent to be matched against the dictionary.
A first idea is to use POS-tags to quickly filter individual words that are likely to be irrelevant, where traditional NLP/IE libraries can be used in a preprocessing step. For example, ADEL [247], AIDA [140], Babelfy [216] and WAT [243] use the Stanford POS-tagger to focus on extracting entity mentions from words tagged as NNP (proper noun, singular) and NNPS (proper noun, plural). DBpedia Spotlight [200] rather relies on LingPipe POS-tagging, where verbs, adjectives, adverbs, and prepositions from the input text are disregarded from the process.
On the other hand, entity mentions may involve words that are not nouns and may be disregarded by the system; this is particularly common for entity types not usually considered by traditional NER tools, including titles of creative works like “
See Listing 8 where “
Parser-based: Rather than developing custom methods, one could consider using more traditional NER techniques to identify entity mentions in the text. Such an approach could also be used, for example, to identify emerging entities not mentioned in the KB. However, while POS-tagging is generally quite efficient, applying a full constituency or dependency parse (aka. deep parsing methods) might be too expensive for large texts. On the other hand, recognizing entity mentions often does not require full parse trees.
As a trade-off, in traditional NER, shallow-parsing methods are often applied: such methods annotate an initial grouping – or chunking [191] – of individual words, materializing a shallow tier of the full parse-tree [68,88]. In the context of NER, noun-phrase chunks (see Listing 9 for an example NP/noun phrase annotation) are particularly relevant. As an example, the THD system [84] uses GATE’s rule-based Java Annotation Patterns Engine (JAPE) [68,295], consisting of regular-expression-like patterns over sequences of POS tags; more specifically, to extract entity mentions, THD uses the JAPE pattern NNP+, which will capture sequences of one-or-more proper nouns. A similar approach is taken by ExtraLink [34], which uses SProUT [88]’s XTDL rules – composed of regular-expressions over sequences of tokens typed with POS tags or dictionaries – to extract entity mentions.
As discussed in Appendix x, machine learning methods have become increasingly popular in recent years for parsing and NER. Hoffert et al. [137] propose combining AIDA and YAGO2 with Stanford NER – using a pre-trained Conditional Random Fields (CRF) classifier – to identify emerging entities. Likewise, ADEL [247] and UDFS [78] also use Stanford NER, while JERL [184] uses a custom unified CRF model that simultaneously performs extraction and linking. On the other hand, WAT [243] relies on OpenNLP’s NER tool based on a Maximum Entropy model. Going one step further, J-NERD [231] uses the dependency parse-tree (extracted using a Stanford parser), where dependencies between nouns are used to create a tree-based model for each sentence, which are then combined into a global model across sentences, which in turn is fed into a subsequent approximate inference process based on Gibbs sampling.
One limitation of using machine-learning techniques in this manner is that they must be trained on a specific corpus. While Stanford NER and OpenNLP provide a set of pre-trained models, these tend to only cover the traditional NER types of person, organization, location and perhaps one or two more (or a generic miscellaneous type). On the other hand, a KB such as DBpedia may contain thousands of entity types, where off-the-shelf models would only cover a fraction thereof. Custom models can, however, be trained using these frameworks given appropriately labeled data, where for example ADEL [247] additionally trains models to recognize professions, or where UDFS [78] trains for ten types on a Twitter dataset, etc. However, richer types require richly-typed labeled data to train on. One option is to use sub-class hierarchies to select higher-level types from the KB to train with [231]. Furthermore, as previously discussed, in EEL scenarios, the types of entities are often given by the KB and need not be given by the NER tool: hence, other “non-standard” types of entities can be labeled “
On the other hand, a benefit of using parsers based on machine learning is that they can significantly reduce the amount of lookups required on the dictionary since, unlike token-based methods, initial entity mentions can be detected independently of the KB dictionary. Likewise, such methods can be used to detect emerging entities not yet featured in the KB.
Hybrid: The techniques described previously are sometimes complementary, where a number of systems thus apply hybrid approaches combining various such techniques. One such system is ADEL [247], which uses a mix of three high-level recognition techniques: persons, organizations and locations are extracted using Stanford NER; mentions based on proper nouns are extracted using Stanford POS; and more challenging mentions not based on proper nouns are extracted using an (unspecified) dictionary approach; entity mentions produced by all three approaches are fed into a unified disambiguation and pruning phase. A similar approach is taken by the FOX (Federated knOwledge eXtraction Framework) [289], which uses ensemble learning to combine the results of four NER tools – namely Stanford NER, Illinois NET, Ottawa BalIE, and OpenNLP – where the resulting entity mentions are then passed through the AGDISTIS [302] tool to subsequently link them to DBpedia.
We assume that a list of candidate identifiers has now been retrieved from the KB for each mention of interest using the techniques previously described. However, some KB labels in the dictionary may be ambiguous and may refer to multiple candidate identifiers. Likewise, the mentions in the text may not exactly match any single label in the dictionary. Thus an individual mention may be associated with multiple initial candidates from the KB, where a distinguishing feature of EEL systems is the disambiguation phase, whose goal is to decide which KB identifiers best match which mentions in the text. To achieve this, the disambiguation phase will typically involve various forms of filtering and scoring of the initial candidate identifiers, considering both the candidates for individual entity mentions, as well as (collectively) considering candidates proposed for entity mentions in a region of the text. Disambiguation may thus result in:
mentions being pruned as irrelevant to the KB (or proposed as emerging entities),
candidates being pruned as irrelevant to a mention, and/or
candidates being assigned a score – called a support – for a particular mention.
In some systems, phases of pruning and scoring may interleave, while in others, scoring is applied first and pruning is applied (strictly) thereafter.
A wide variety of approaches to disambiguation can be found in the EEL literature. Our goal, in this survey, is thus to organize and discuss the main approaches used thus far. Along these lines, we will first discuss some of the low-level features that can be used to help with the disambiguation process. Thereafter we discuss how these features can be combined to select a final set of mentions and candidates and/or to compute a support for each candidate identifier of a mention.
Features for disambiguation
In order to perform disambiguation of candidate KB identifiers for an entity mention, one may consider information relating to the mention itself, to the keywords surrounding the mention, to the candidates for surrounding mentions, and so forth. In fact, a range of features have been proposed in the literature to support the disambiguation process. To structure the discussion of such features, we organize them into the following five high-level categories:
Such features rely on information about the entity mention itself, such as its text, capitalization, the recognition score for the mention, the presence of overlapping mentions, or the presence of abbreviated mentions.
Such features rely on collecting contextual keywords for candidates and/or mentions from reference sources of text (often using Wikipedia). Keyword-based similarity measures can then be applied over pairs or sets of contexts.
Such features rely on constructing a (weighted) graph representing mentions and/or candidates and then applying analyses over the graph, such as to determine cocitation measures, dense-subgraphs, distances, or centrality.
Such features rely on categorical information that captures the high-level domain of mentions, candidates and/or the input text itself, where Wikipedia categories are often used.
Such features rely on the grammatical role of words, or on the grammatical relation between words or chunks in the text (as produced by traditional NLP tools).
These categories reflect the type of information from which the features are extracted and will be used to structure this section, allowing us to introduce increasingly more complex types of sources from which to compute features. However, we can also consider an orthogonal conceptualization of features based on what they say about mentions or candidates:
A feature about the mention independent of other mentions or candidates.
A feature between two or more mentions independent of their candidates.
A feature about a candidate independent of other candidates or mentions.
A feature about the candidate of a mention independent of other mentions.
A feature between two or more candidates independent of their mentions.
A feature that may involve multiple of the above, or map mentions and/or candidates to a higher-level (or latent) feature, such as domain.
We will now discuss these features in more detail in order of the type of information they consider.
Mention-based: With respect to disambiguation, important initial information can be gleaned from the mentions themselves, both in terms of the text of the mention, the type selected by the NER tool (where available), and the relation of the mention to other neighboring mentions in a specific region of text.
To begin, the strings of mentions can be used for disambiguation. While recognition often relies on matching a mention to a dictionary, this process is typically implemented using various forms of indexes that allow for efficiently matching substrings (such as prefixes, suffixes or tokens) or full strings. However, once a smaller set of initial candidates has been identified, more fine-grained string-matching can be applied between the respective mention and candidate labels. For example, given a mention “
More specifically, each input string is decomposed into a set of 3-character substrings, where the Jaccard coefficient (the cardinality of the intersection over union) of both sets is computed.
Whenever the recognition phase produces a type for entity mentions independently of the types available in the KB – as typically happens when a traditional NER tool is used – this NER-based type can be compared with the type of each candidate in the KB. Given that relatively few types are produced by NER tools (without using the KB) – where the most widely accepted types are person, organization and location – these types can be mapped manually to classes in the KB, where class inference techniques can be applied to also capture candidates that are instances of more specific classes. We note that both ADEL [247] and J-NERD [231] incorporate such a feature (both recently proposed approaches). While this can be a useful feature for disambiguating some entities, the KB will often contain types not covered by the NER tool (at least using off-the-shelf pre-trained models).
The recognition process itself may produce a score for a mention indicating a confidence that it is referring to a (named) entity; this can additionally be used as a feature in the disambiguation phase, where, for example, a mention for which only weakly-related KB candidates are found is more likely to be rejected if its recognition score is also low. A simple such feature may capture capitalization, where HERD [284] and Tulip [181] mark lower-case mentions as “tentative” in the disambiguation phase, indicating that they need stronger evidence during disambiguation not to be pruned. Another popular feature, called keyphraseness by Mihalcea and Csomai [203], measures the number or ratio of times the mention appears in the anchor text of a link in a contextual corpus such as Wikipedia; this feature is considered by AIDA [140], DBpedia Spotlight [200], NERFGUN [126], HERD [284], etc.
We already mentioned how spotting may result in overlapping entity mentions being recognized, where, for example, the mention “
We can further consider abbreviated forms of mentions where a “complete mention” is used to introduce an entity, which is thereafter referred to using a shorter mention. For example, a text may mention “
Keyword-based: A variety of keyword-based techniques from the area of Information Retrieval (IR) are relevant not only to the recognition process, but also to the disambiguation process. While recognition can be done efficiently at large scale using inverted indexes, for example, relevance measures can be used to help score and rank candidates. A natural idea is to consider a mention as a keyword query posed against a textual document created to describe each KB entity, where IR measures of relevance can be used to score candidates. A typical IR measure used to determine the relevance of a document to a given keyword query is TF–IDF, where the core intuition is to consider documents that contain more mentions (term-frequency: TF) of relatively rare keywords (inverse-document frequency: IDF) in the keyword query to be more relevant to that query. Another typical measure is to use cosine similarity, where documents (and keyword queries) are represented as vectors in a normalized numeric space (known as a Vector Space Model (VSM) that may use, for example, numeric TF–IDF values), where the similarity of two vectors can be computed by measuring the cosine of the angle between them.
Systems relying on IR-based measures for disambiguation include: DBpedia Spotlight [200], which defines a variant called TF–ICF, where ICF denotes inverse-candidate frequency, considering the ratio of candidates that mention the term; THD [84], which uses the Lucene-based search API of Wikipedia implementing measures similar to TF–IDF; SDA [42], which builds a textual context for each KB entity from Wikipedia based on article titles, content, anchor text, etc., where candidates are ranked based on cosine-similarity; NERFGUN [126], which compares mentions against the abstracts of Wikipedia articles referring to KB entities using cosine-similarity;20
The term “abstracts of Wikipedia articles” refers to the first paragraph of the Wikipedia article, which is seen as providing a textual overview of the entity in question [126,171].
Other approaches consider an extended textual context not only for the KB entities, but also for the mentions. For example, considering the input sentence “
Other more modern approaches adopt a similar distributional approach – where words are considered similar by merit of appearing frequently in similar contexts – but using more modern techniques. Amongst these, CohEEL [122] build a statistical language model for each KB entity according to the frequency of terms appearing in its associated Wikipedia article; this model is used during disambiguation to estimate the probability of the observed keywords surrounding a mention being generated if the mention referred to a particular entity KB. A related approach is used in the DoSeR system [336], where word embeddings are used for disambiguation: in such an approach, words are represented as vectors in a fixed-dimensional numeric space where words that often co-occur with similar words will have similar vectors, allowing, for example, to predict words according to their context; the DoSeR system then computes word embeddings for KB entities using known entity links to model the context in which those entities are mentioned in the text, which can subsequently be used to predict further mentions of such entities based on the mention’s context.
Another related approach is to consider collective assignment: rather than disambiguating one mention at a time by considering mention–candidate similarity, the selection of a candidate for one mention can affect the scoring of candidates for another mention. For example, considering the sentence “
This idea of collective assignment would become influential in later works linking entities to RDF-based KBs. For example, the KORE [138] system extended AIDA [140] with a measure called keyphrase overlap relatedness,21
... not to be confused with overlapping mentions.
Graph-based: During disambiguation, useful information can be gained from the graph of connections between entities in a contextual source such as Wikipedia, or in the target KB itself. First, graphs can be used to determine the prior probability of a particular entity; for example, considering the sentence “
A variety of entity disambiguation approaches rely on the graph structure of Wikipedia, where a seminal approach was proposed by Medelyan et al. [198] and later refined by Milne and Witten [209]. The graph-structure of Wikipedia is used to perform disambiguation based on two main concepts: commonness and relatedness. Commonness is measured as the (prior) probability that a given entity mention is used in the anchor text to point to the Wikipedia article about a given candidate entity; as an example, one could consider that the plurality of anchor texts in Wikipedia containing the (ambiguous) mention “
Further approaches then built upon and refined Milne and Witten’s notion of commonness and relatedness. For example, Kulkarni et al. [168] propose a collective assignment method based on two types of score: a compatibility score defined between a mention and a candidate, computed using a selection of standard keyword-based approaches; and Milne and Witten’s notion of relatedness defined between pairs of candidates. The goal then is to find the selection of candidates (one per mention) that maximizes the sum of the compatibility scores and all pairwise relatedness scores amongst selected candidates. While this optimization problem is NP-hard, the authors propose to use approximations based on integer linear programming and hill climbing algorithms.
Another approach using the notions of commonness and relatedness is that of TagMe [101]; however, rather than relying on the relatedness of unambiguous entities to disambiguate a context, TagMe instead proposes a more complex voting scheme, where the candidates for each entity can vote for the candidates on surrounding entities based on relatedness; candidates with higher commonness have stronger votes. Candidates with a commonness below a fixed threshold are pruned where two algorithms are then used to decide final candidates: Disambiguation by Classifier (DC), which uses commonness and relatedness as features to classify correct candidates; and Disambiguation by Threshold (DT), which selects the top-ϵ candidates by relatedness and then chooses the remaining candidate with the highest commonness (experimentally, the authors deem
While the aforementioned tools link entity mentions to Wikipedia, other approaches linking to RDF-based KBs have followed adaptations of such ideas. One such tool is AIDA [140], which performs two main steps: collective mapping and graph reduction. In the collective mapping step, the tool creates a weighted graph that includes mentions and initial candidates as nodes: first, mentions are connected to their candidates by a weighted edge denoting their similarity as determined from a keyword-based disambiguation approach; second, entity candidates are connected by a weighted edge denoting their relatedness based on (1) the same notion of relatedness introduced by Milne and Witten [209], combined with (2) the distance between the two entities in the YAGO KB. The resulting graph is referred to as the mention–entity graph, whose edges are weighted in a similar manner to the measures considered by Kulkarni et al. [168]. In the subsequent graph reduction phase, the candidate nodes with the lowest weighted degree in this graph are pruned iteratively while preserving at least one candidate entity for each mention, resulting in an approximation of the densest possible (disambiguated) subgraph.
The concept of computing a dense subgraph of the mention–entity graph was reused in later systems. For example, the AIDA-Light [230] system (a variant of AIDA with focus on efficiency) uses keyword-based features to determine the weights on mention–entity and entity–entity edges in the mention–entity graph, from which a subgraph is then computed. As another variant on the dense subgraph idea, Babelfy [216] constructs a mention–entity graph but where edges between entity candidates are assigned based on semantic signatures computed using the Random Walk with Restart algorithm over a weighted version of a custom semantic network (BabelNet); thereafter, an approximation of the densest subgraph is extracted by iteratively removing the least coherent vertices – considering the fraction of mentions connected to a candidate and its degree – until the number of candidates for each mention is below a specified threshold.
Rather than trying to compute a dense subgraph of the mention–entity graph, other approaches instead use standard centrality measures to score nodes in various forms of graph induced by the candidate entities. NERSO [125] constructs a directed graph of entity candidates retrieved from DBpedia based on the links between their articles on Wikipedia; over this graph, the system applies a variant on a closeness centrality measure, which, for a given node, is defined as the inverse of the average length of the shortest path to all other reachable nodes; for each mention, the centrality, degree and type of node is then combined into a final support for each candidate. On the other hand, the WAT system [243] extends TagMe [101] with various features, including a score based on the PageRank22
PageRank is itself a variant of eigenvector centrality, which can be conceptualized as the probability of being at a node after an arbitrarily long random walk starting from a random node.
In a variant of the centrality theme, Kan-Dis [145] uses two graph-based measures. The first measure is a baseline variant of Katz’s centrality applied over the candidates in the KB’s graph [237], where a parametrized sum over the k shortest paths between two nodes is taken as a measure of their relatedness such that two nodes are more similar the shorter the k shortest paths between them are. The second measure is then a weighted version of the baseline, where edges on paths are weighted based on the number of similar edges from each node, such that, for example, a path between two nodes through a country for the relation “resident” will have less effect on the overall relatedness of those nodes than a more “exclusive” path through a music-band with the relation “member”.
Other systems apply variations on this theme of graph-based disambiguation. KIM [250] selects the candidate related to the most previously-selected candidates by some relation in the KB; DoSeR [336] likewise considers entities as related if they are directly connected in the KB and considers the degree of nodes in the KB as a measure of commonness; and so forth.
Category-based: Rather than trying to measure the coherence of pairs of candidates through keyword contexts or cocitations or their distance in the KB, some works propose to map candidates to higher-level category information and use such categories to determine the coherence of candidates. Most often, the category information from Wikipedia is used.
The earliest approaches to use such category information were those linking mentions to Wikipedia identifiers. For example, in cases where the keyword-based contexts of candidates contained insufficient information to derive reliable similarity measures, Bunescu and Pasca [33] propose to additionally use terms from the article categories to extend these contexts and learn correlations between keywords appearing in the mention context and categories found in the candidate context. A similar such idea – using category information from Wikipedia to enrich the contexts of candidates – was also used by Cucerzan [66].
A number of approaches also use categorical information to link entities to RDF KBs. An early such proposals was the LINDEN [278] approach, which was based on constructing a graph containing nodes representing candidates in the KB, their contexts, and their categories; edges are then added connecting candidates to their contexts and categories, while categories are connected by their taxonomic relations. Contextual and categorical information was taken from Wikipedia. A cocitation-based notion of candidate–candidate relatedness similar to that of Medelyan et al. [198] is then combined with another candidate–candidate relatedness measure based on the probability of an entity in the KB falling under the most-specific shared ancestor of the categories of both entities.
As previously discussed, AIDA-Light [230] determines mention–candidate and candidate–candidate similarities using a keyword-based approach, where the similarities are used to construct a weighted mention–entity graph; this graph is also enhanced with categorical information from YAGO (itself derived from Wikipedia and WordNet), where category nodes are added to the graph and connected to the candidates in those categories; additionally, weighted edges between candidates can be computed based on their distance in the categorical hierarchy. J-NERD [231] likewise uses similar features based on latent topics computed from Wikipedia’s categories.
Linguistic-based: Some more recent approaches propose to apply joint inference to combine disambiguation with other forms of linguistic analysis. Conceptually the idea is similar to that of using keyword contexts, but with a deeper analysis that also considers further linguistic information about the terms forming the context of a mention or a candidate.
We have already seen examples of how the recognition task can sometimes gain useful information from the disambiguation task. For example, in the sentence “
Recognizing this interdependence of recognition and disambiguation, one of the first approaches proposed to perform these tasks jointly was NereL [281], which applies a first high-recall NER pass that both underestimates and overestimates (potentially overlapping) mention boundaries, where features of these candidate mentions are combined with features for the candidate identifiers for the purposes of a joint inference step. A more complex unified model was later proposed by Durrett [91], which captured features not only for recognition (POS-tags, capitalization, etc.) and disambiguation (string-matching, PageRank, etc.), but also for coreference (type of mention, mention length, context, etc.), over which joint inference is applied. JERL [184] also uses a unified model for representing the NER and NED tasks, where word-level features (such as POS tags, dictionary hits, etc.) are combined with disambiguation features (such as commonness, coherence, categories, etc.), subsequently allowing for joint inference over both. J-NERD [231] likewise uses features based on Stanford’s POS tagger and dependency parser, dictionary hits, coherence, categories, etc., to represent recognition and disambiguation in a unified model for joint inference.
Aside from joint recognition and disambiguation, other types of unified models have also been proposed. Babelfy [216] applies a joint approach to model and perform Named Entity Disambiguation and Word Sense Disambiguation in a unified manner. As an example, in the sentence “
Summary of features: Given the breadth of features covered, we provide a short recap of the main features for reference:
Given the initial set of mentions identified and the labels of their corresponding candidates, we can consider:
A mention-only feature produced by the NER tool to indicate the confidence in a particular mention; Mention–candidate features based on the string similarity between mention and candidate labels, or matches between mention (NER) and candidate (KB) types; Mention–mention features based on overlapping mentions, or the use of abbreviated references from a previous mention.
Considering various types of textual contexts extracted for mentions (e.g., varying length windows of keywords surrounding the mention) and candidates (e.g., Wikipedia anchor texts, article texts, etc.), we can compute:
Mention–candidate features considering various keyword-based similarity measures over their contexts (e.g., TF–IDF with cosine similarity; Jaccard similarity, word embeddings, and so forth); Candidate–candidate features based on the same types of similarity measures over candidate contexts.
Considering the graph-structure of a reference source such as Wikipedia, or the target KB, we can consider:
Candidate-only features, such as prior probability based on centrality, etc.; Mention–candidate features, based on how many links use the mention’s text to link to a document about the candidate; Candidate–candidate coherence features, such as cocitation, distance, density of subgraphs, topical coherence, etc.
Considering the graph-structure of a reference source such as Wikipedia, or the target KB, we can consider:
Candidate–category features based on membership of the candidate to the category; Text–category coherence features based on categories of candidates; Candidate–candidate features based on taxonomic similarity of associated categories.
Considering POS tags, word senses, coreferences, parse trees of the input text, etc., we can consider:
Mention-only features based on POS or other NER features; Mention–mention features based on dependency analysis, or the coherence of candidates associated with them; Mention–candidate features based on coherence of sense-aware contexts; Candidate–candidate features based on connection through semantic networks.
This list of useful features for disambiguation is by no means complete and has continuously expanded as further Entity Linking papers have been published. Furthermore, EEL systems may use features not covered, typically exploiting specific information available in a particular KB, a particular reference source, or a particular input source. As some brief examples, we can mention that NEMO [67] uses geo-coordinate information extracted from Freebase to determine a geographical coherence over candidates, Yerva et al. [320] consider features computed from user profiles on Twitter and other social networks, ZenCrowd [77] considers features drawn from crowdsourcing, etc.
As we have seen, a wide range of features have been proposed for the purposes of the disambiguation task. A general question then is: how can such features be weighted and combined into a final selection of candidates, or a final support for each candidate?
The most straightforward option is to consider a high-level feature used to score candidates (potentially using other features on a lower level), where for example AGDISTIS [302] relies on final HITS authority scores, DBpedia Spotlight [200] on TF–ICF scores, NERSO [125] on closeness centrality and degree; THD [84] on Wikipedia search rankings, etc.
Another option is to parameterize weights or thresholds for features and find the best values for them individually over a labeled dataset, which is used, for example, by Babelfy [216] to tune the parameters of its Random-Walk-with-Restart algorithm and the number of candidates to be pruned by its densest-subgraph approximation, or by AIDA [140] to configure thresholds and weights for prior probabilities and coherence.
An alternative method is to allow users to configure such parameters themselves, where AIDA [140] and DBpedia Spotlight [200] offer users the ability to configure parameters and thresholds for prior probabilities, coherence measures, tolerable level of ambiguity, and so forth. In this manner, a human expert can configure the system for a particular application, for example, tuning to trade precision for recall, or vice-versa.
Yet another option is to define a general objective function that then turns the problem of selecting the best candidates into an optimization problem, allowing the final candidate assignment to be (approximately) inferred. One such method is Kulkarni et al.’s [168] collective assignment approach, which uses integer linear programming and hill-climbing methods to compute a candidate assignment that (approximately) maximizes mention–candidate and candidate–candidate similarity weights. Another such method is JERL [184], which models entity recognition and disambiguation in a joint model over which dynamic programming methods are applied to infer final candidates. Systems optimizing for dense entity–mention subgraphs – such as AIDA [140], Babelfy [216] or Kan-Dis [144] – follow similar techniques.
Overview of entity extraction & linking systems. KB denotes the main knowledge-base used; Matching and Indexing refer to methods used to match/index entity labels from the KB; Context refers to the sources of contextual information used; Recognition refers to the process for identifying entity mentions; Disambiguation refers to the types of high-level disambiguation features used (M:Mention, K:Keyword, G:Graph, C:Category, L:Linguistic); “—” denotes no information found, not used or not applicable
Overview of entity extraction & linking systems.
A final approach is to use classifiers to learn appropriate weights and parameters for different features based on labeled data. Amongst such approaches, we can mention that ADEL [247] performs experiments with k-NN, Random Forest, Naive Bayes and SVM classifiers, finding k-NN to perform best; AIDA [140], LINDEN [278] and WAT [243] use SVM variants to learn feature weights; HERD [284] uses logistic regression to assign weights to features; and so forth. All such methods rely on labeled data to train the classifiers over; we will discuss such datasets later when discussing the evaluation of EEL systems.
Overview of disambiguation features used by EEL systems. (M:Metric-based, K:Keyword-based, G:Graph-based, C:Category-based, L:Linguistic-based) (mo:mention-only, mm:mention–mention, mc:mention–candidate, co:candidate-only, cc:candidate–candidate; v:various)
Such methods for scoring and classifying results can be used to compute a final set of mentions and their candidates, either selecting a single candidate for each mention or associating multiple candidates with a support by which they can be ranked.
Table 3 provides an overview of how the EEL techniques discussed in this section are used by highlighted systems that: deal with a resource (e.g., a KB) using one of the Semantic Web standards; deal with EEL over plain text; have a publication offering system details; and are standalone systems. Based on these criteria, we exclude systems discussed previously that deal only with Wikipedia (since they do not directly relate to the Semantic Web). In this table,
With respect to the EEL task, given the breadth of approaches now available for this task, a challenging question is then: which EEL approach should I choose for application X? Different options are associated with different strengths and weaknesses, where we can highlight the following key considerations in terms of application requirements:
KB selection: While some tools are general and accept or can be easily adapted to work with arbitrary KBs, other tools are more tightly coupled with a particular KB, relying on features inherent to that KB or a contextual source such as Wikipedia. Hence the selection of a particular target KB may already suggest the suitability of some tools over others. For example, ADEL and DBpedia Spotlight relies on the structure provided by DBpedia; AIDA and KORE on YAGO2; while ExtraLink, KIM, and SemTag are focused on custom ontologies.
Domain selection: When working within a specific topical domain, the amount of entities to consider will often be limited. However, certain domains may involve types of entity mentions that are atypical; for example, while types such as persons, organizations, locations are well-recognized, considering the medical domain as an example, diseases or (branded) drugs may not be well recognized and may require special training or configuration. Examples of domain-specific EEL approaches include Sieve [89] (using the SNOMED-CT ontology), and that proposed by Zheng et al. [329] (based on a KB constructed from BioPortal ontologies23
).Text characteristics: Aside from the domain (be it specific or open), the nature of the text input can better suit one type of system over another. For example, even considering a fixed medical domain, Tweets mentioning illnesses will offer unique EEL challenges (short context, slang, lax capitalization, etc.) versus news articles, webpages or encyclopedic articles about diseases, where again, certain tools may be better suited for certain input text characteristics. For example, TagMe [101] focuses on EEL over short texts, while approaches such as UDFS [78] and those proposed by Yerva et al. [320] and Yosef et al. [322] focus more specifically on Tweets.
Language: Language can be an important factor in the selection of an EEL system, where certain tools may rely on resources (stemmers, lemmatizers, POS-taggers, parsers, training datasets, etc.) that assume a particular language. Likewise, tools that do not use any language-specific resources may still rely to varying extents on features (such as capitalization, distinctive proper nouns, etc.) that will be present to varying extents in different languages. While many EEL tools are designed or evaluated primarily around the English language, others offer explicit support for multiple languages [269]; amongst these multilingual systems, we can mention Babelfy [216], DBpedia Spotlight [71] and MAG [217].
Emerging entities: As data change over time, new entities are constantly generated. An application may thus need to detect emerging entities, which is only supported by some approaches; for example, approaches by Hoffert et al. [137] and Guo et al. [124] extract emerging entities with NIL annotations in cases where the confidence of KB candidates is below a threshold. On the other hand, even if an application does not need recognition of emerging entities, when considering a given approach or tool, it may be important to consider the cost/feasibility of periodically updating the KB in dynamic scenarios (e.g., recognizing emerging trends in social media).
Performance and overhead: In scenarios where EEL must be applied over large and/or highly dynamic inputs, the performance of the EEL system becomes a critical consideration, where tools can vary in orders of magnitude with respect to runtimes. Likewise, EEL systems may have prohibitive hardware requirements, such as having to store the entire dictionary in primary memory, and/or the need to collectively model all mentions and entities in a given text in memory, etc. The requirements of a particular system can then be an important practical factor in certain scenarios. For example, the AIDA-Light [230] system greatly improves on the runtime performance of AIDA [321], with a slight loss in precision.
Output quality: Quality is often defined as “fit for purpose”, where an EEL output fit for one application/purpose might be unfit for another. For example, a semi-supervised application where a human expert will later curate links might emphasize recall over the precision of the top-ranked candidate chosen, since rejecting erroneous candidates is faster than searching for new ones manually [77]. On the other hand, a completely automatic system may prefer a cautious output, prioritizing precision over recall. Likewise, some applications may only care if an entity is linked once in a text, while others may put a high priority on repeated (short) mentions also being linked. Different purposes provide different instantiations of the notion of quality, and thus may suggest the fitness of one tool over another. Such variability of quality is seen in, for example, GERBIL [303] benchmark results,24
where the best system for one dataset may perform worse in another dataset with different characteristics.Various other considerations, such as availability of software, availability of appropriate training data, licensing of software, API restrictions, costs, etc., will also often apply.
In summary, no one EEL system fits all and EEL remains an active area of research. In order to exploit the inherent strengths and weaknesses of different EEL systems, a variety of ensemble approaches have been proposed. Furthermore, a wide variety of benchmarks and datasets have been proposed for evaluating and comparing such systems. We discuss ensemble systems and EEL evaluation in the following sections.
As previously discussed, different EEL systems may be associated with different strengths and weaknesses. A natural idea is then to combine the results of multiple EEL systems in an ensemble approach (as seen elsewhere, for example, in Machine Learning algorithms [80]). The main goal of ensemble methods is to thus try to compare and exploit complementary aspects of the underlying systems such that the results obtained are better than possible using any single such system. Five such ensemble systems are:
(Named Entity Recognition and Disambiguation) uses an ontology to integrate the input and output of ten NER and EEL tools, namely AlchemyAPI, DBpedia Spotlight, Evri, Extractiv, Lupedia, OpenCalais, Saplo, Wikimeta, Yahoo! Content Extractor, and Zemanta. Later works proposed classifier-based methods (Naive Bayes, k-NN, SVM) for combining results [265]. (Bagging for Entity Linking) Recognizes entity mentions through Stanford NER, later retrieving entity candidates from YAGO that are disambiguated by means of a majority-voting algorithm according to various ranking classifiers applied over the mentions’ contexts. uses TagMe and WikiMiner combined with a collective linking approach to match entity mentions in a text with Wikipedia identifiers, where they propose to be able to switch approaches depending on the features of the input document(s), such as domain, length, etc. performs EEL with respect to Freebase using a combination of DBpedia Spotlight and TagMe results, extended with a custom EEL method using the Freebase search API. Thresholds are applied over all three methods and overlapping mentions are filtered. uses Stanford NER & ADEL to recognize entity mentions, subsequently merging the output of four linking systems, namely AIDA, Babelfy, DBpedia Spotlight and TagMe.
Evaluation
EEL involves two high-level tasks: recognition and disambiguation. Thus, evaluation may consider the recognition phase separately, or the disambiguation phase separately, or the entire EEL process as a whole. Given that the evaluation of recognition is well-covered by the traditional NER literature, here we focus on evaluations that consider whether or not the recognized mentions are deemed correct and whether or not the assigned KB identifier is deemed correct.
Given the wide range of EEL approaches proposed in the literature, we do not discuss details of the evaluations of individual tools conducted by the authors themselves. Rather we will discuss some of the most commonly used evaluation datasets and then discuss evaluations conducted by third parties to compare various selections of EEL systems.
Datasets: A variety of datasets have been used to evaluate the EEL process in different settings and under different assumptions. Here we enumerate some datasets that have been used to evaluate multiple tools:
The CoNLL-2003 dataset25
consists of 1,393 Reuters’ news articles whose entities were manually identified and typed for the purposes of training and evaluating traditional NER tools. For the purposes of training and evaluating AIDA [140], the authors manually linked the entities to YAGO. This dataset was later used by ADEL [247], AIDA-Light [230], Babelfy [216], HERD [284], JERL [184], J-NERD [231], KORE [138], amongst others.The AQUAINT dataset contains 50 English documents collected from the Xinhua News Service, New York Times, and the Associated Press. Each document contains about 250–300 words, where the first mention of an entity is manually linked to Wikipedia. The dataset was first proposed and used by Milne and Witten [209], and later used by AGDISTIS [302].
The ELMD dataset contains 47,254 sentences with 92,930 annotated and classified entity mentions extracted from a collection of Last.fm artist biographies. This dataset was automatically annotated through the ELVIS system,26
which homogenizes and combines the output of different Entity Linking tools. It was manually verified to have a precision of 0.94 and is available online.27The IITB dataset contains 103 English webpages taken from a handful of domains relating to sports, entertainment, science and technology; the text of the webpages is scraped and semi-automatically linked with Wikipedia. The dataset was first proposed and used by Kulkarni [168] and later used by AGDISTIS [302].
This dataset contains 562 manually annotated tweets sampled from 20 “verified users” on Twitter and linked with Wikipedia. The dataset was first proposed by Meij et al. [199], and later used by Cornolti et al. [62] to form part of a more general purpose EEL benchmark.
The KORE-50 dataset contains 50 English sentences designed to offer a challenging set of examples for Entity Linking tools; the sentences relate to various domains, including celebrities, music, business, sports, and politics. The dataset emphasizes short sentences, entity mentions with a high number of occurrences, highly ambiguous mentions, and entities with low prior probability. The dataset was first proposed and used for KORE [138], and later reused by Babelfy [216] and Kan-Dis [145], amongst others.
The MEANTIME dataset consists of 120 English Wikinews articles on topics relating to finance, with translations to Spanish, Italian and Dutch. Entities are annotated with links to DBpedia resources. This dataset has been recently used by ADEL [247].
The MSNBC dataset contains 20 English news articles from 10 different categories, which were semi-automatically annotated. The dataset was proposed and used by Cucerzan [66], and later reused to evaluate AGDISTIS [302], LINDEN [278] and by Kulkarni et al. [168].
The VoxEL dataset contains 15 news articles (on politics) in 5 different languages sourced from the VoxEurop website.28
It was manually annotated with the NIFify system 29 using two different criteria for labelling: a strict version containing 204 annotated mentions (per language) of persons, organizations and locations; and a relaxed version containing 674 annotated mentions (per language) of Wikipedia entities.The WP dataset samples English Wikipedia articles relating to heavy metal musical groups. Articles with related categories are retrieved and sentences with at least three named entities (found by anchor text in links) are kept; in total, 2019 sentences are considered. The dataset was first proposed and used for the KORE [138] system and also later used by AIDA-Light [230].
Aside from being used for evaluation, we note that such datasets – particular larger ones like AIDA-CoNLL – can be (and are) used for training purposes. Moreover, although varied gold standard datasets have been proposed for EEL, Jha et al. [152] stated some issues regarding such datasets, for example, data consensus (there is a lack of consensus on standard rules for annotating entities), updates (KB links change over time), and annotation quality (regarding the number and expertise of evaluations and judges of the dataset). Thus, Jha et al. [152] propose the Eaglet system for detecting such issues over existing datasets.
Metrics Traditional metrics such as Precision, Recall, and F-measure are applied to evaluate EEL systems. Moreover, micro and macro variants are also applied in systems such as AIDA [321], DoSeR [336] and frameworks such as BAT [62] and GERBIL [303]; taking Precision as an example, macro-Precision considers the average Precision over individual documents or sentences, while micro-Precision considers the entire gold standard as one test without distinguishing the individual documents or sentences. Other systems and frameworks may use measures that distinguish the type of entity or the type of mention, where, for example, the GERBIL framework distinguishes results for KB entities from emerging entities.
Third-party comparisons: A number of third-party evaluations have been conducted in order to compare various EEL tools. Note that we focus on evaluations that include a disambiguation step, and thus exclude studies that focus only on NER (e.g., [135]).
As previously discussed, Rizzo and Troncy [264] proposed the NERD approach to integrate various Entity Linking tools with online APIs. They also provided some comparative results for these tools, namely Alchemy, DBpedia Spotlight, Evri, OpenCalais and Zemanta [263]. More specifically, they compared the number of entities detected by each tool from 1,000 New York Times articles, considering six entity types: person, organization, country, city, time and number. These results show that while the commercial black box tools managed to detect thousands of entities, DBpedia Spotlight only detected 16 entities in total; to the best of our knowledge, the quality of the entities extracted was not evaluated. However, in follow-up work by Rizzo et al. [265], the authors use the AIDA–CoNLL dataset and a Twitter dataset to compare the linking precision, recall and F-measure of Alchemy, DataTXT, DBpedia Spotlight, Lupedia, TextRazor, THD, Yahoo! and Zemanta. In these experiments, Alchemy generally had the highest recall, DataTXT or TextRazor the highest precision, while TextRazor had the best F-measure for both datasets.
Gangemi [112] presented an evaluation of tools for Knowledge Extraction on the Semantic Web (or tools trivially adaptable to such a setting). Using a sample text obtained from an extract of an online article of The New York Times30
as input, he evaluated the precision, recall, F-measure and accuracy of several tools for diverse tasks, including Named Entity Recognition, Entity Linking (referred to as Named Entity Resolution), Topic Detection, Sense Tagging, Terminology Extraction, Terminology Resolution, Relation Extraction, and Event Detection. Focusing on the EEL task, he evaluated nine tools: AIDA, Stanbol, CiceroLite, DBpedia Spotlight, FOX, FRED+Semiosearch, NERD, Semiosearch and Wikimeta. In these results, AIDA, CiceroLite and NERD had perfect precision (1.00), while Wikimeta had the highest recall (0.91); in a combined F-measure, Wikimeta fared best (0.80), with AIDA (0.78) and FOX (0.74) and CiceroLite (0.71) not far behind. On the other hand, the observed precision (0.75) and in particular recall (0.27) of DBpedia Spotlight was relatively low.Cornolti et al. [62] presented an evaluation framework for Entity Linking systems, called the BAT-framework.31
The authors used this framework to evaluate five systems – AIDA, DBpedia Spotlight, Illinois Wikifier, M&W Miner and TagMe (v2) – with respect to five publicly available datasets – AIDA–CoNLL, AQUAINT, IITB, Meij and MSNBC – that offer a mix of different types of inputs in terms of domains, lengths, densities of entity mentions, and so forth. In their experiments, quite consistently across the various datasets and configurations, AIDA tended to have the highest precision, TagMe and W& M Miner tended to have the highest recall, while TagMe tended to have the highest F-measure; one exception to this trend was the IITB dataset based on long webpages, where DBpedia Spotlight had the highest recall (0.50), while AIDA had very low recall (0.04); on the other hand, for this dataset, M&W Miner had the best F-measure (0.52). An interesting aspect of Cornolti et al.’s study is that it includes performance experiments, where the authors found that TagMe was an order of magnitude faster for the AIDA–CoNLL dataset than any other tool while still achieving the best F-measure on that dataset; on the other hand, AIDA and DBpedia Spotlight were amongst the slowest tools, being around 2–3 orders of magnitude slower than TagMe.Trani et al. [40] and Usbeck et al. [303] later provided evaluation frameworks based on the BAT-framework. First, Trani et al. proposed the DEXTER-EVAL, which allows to quickly load and run evaluations following the BAT framework.32
Later, Usbeck et al. [303] proposed GERBIL,33 where the tasks defined for the BAT-framework are reused. GERBIL additionally packages six new tools (AGDISTIS, Babelfy, Dexter, NERD, KEA and WAT), six new datasets, and offers improved extensibility to facilitate the integration of new annotators, datasets, and measures. However, the focus of the paper is on the framework and although some results are presented as examples, they only involve particular systems or particular datasets.Derczynski et al. [79] focused on a variety of tasks over tweets, including NER/EL, which has unique challenges in terms of having to process short texts with little context, heavy use of abbreviated mentions, lax capitalization and grammar, etc., but also has unique opportunities for incorporating novel features, such as user or location modeling, tags, followers, and so forth. While a variety of approaches are evaluated for NER, with respect to EEL, the authors evaluated four systems – DBpedia Spotlight, TextRazor, YODIE and Zemanta – over two Twitter datasets – a custom dataset (where entity mentions are given to the system for disambiguation) and the Meij dataset (where the raw tweet is given). In general, the systems struggled in both experiments. YODIE – a system with adaptations for Twitter – performed best in the first disambiguation task (note that TextRazor was not tested). In the second task, DBpedia had the best recall (0.48), TextRazor had the highest precision (0.65) while Zemanta had the best F-measure (0.41) (note that YODIE was not run in this second test).
Challenge events: A variety of EEL-related challenge events have been co-located with conferences and workshops, providing a variety of standardized tasks and calling for participants to apply their techniques to the tasks in question and submit their results. These challenge events thus offer an interesting format for empirical comparison of different tools in this space. Amongst such events considering an EEL-related task, we can mention:
is a challenge at the Special Interest Group on Information Retrieval Conference (SIGIR), where the ERD’14 challenge [37] featured two tasks for linking mentions to Freebase: a short-text track considering 500 training and 500 test keyword searches from a commercial engine, and a long-text track considering 100 training and 100 testing documents scraped from webpages.
is a track at the NIST Text Analysis Conference (TAC) with an Entity Linking Track, providing a variety of EEL-related tasks (including multi-lingual scenarios), as well as training corpora, validators and scorers for task performance.34
is a workshop at the World Wide Web Conference (WWW) with a Named Entity rEcognition and Linking (NEEL) Challenge, providing a gold standard dataset for evaluating named entity recognition and linking tasks over microposts, such as found on Twitter.35
is a challenge hosted by the European Semantic Web Conference (ESWC), which typically contains two tasks, the first of which is an EEL task using the GERBIL framework [303]; ADEL [247] won in 2015 while WESTLAB [41] won in 2016.36
is hosted by the Annual Meeting of the Association for Computational Linguistics (ACL), which provides training and development data based on the CoNLL data format.37
We highlight the diversity of conferences at which such events have been hosted – covering Linguistics, the Semantic Web, Natural Language Processing, Information Retrieval, and the Web – indicating the broad interest in topics relating to EEL.
Many EEL approaches have been proposed in the past 15 years or so – in a variety of communities – for matching entity mentions in a text with entity identifiers in a KB; we also notice that the popularity of such works increased immensely with the availability of Wikipedia and related KBs. Despite the diversity in proposed approaches, the EEL process is comprised of two conceptual steps: recognition and disambiguation.
In the recognition phase, entity mentions in the text are identified. In EEL scenarios, the dictionary will often play a central role in this phase, indexing the labels of entities in the KB as well as contextual information. Subsequently, mentions in the text referring to the dictionary can be identified using string-, token- or NER-based approaches, generating candidate links to KB identifiers. In the disambiguation phase, candidates are scored and/or selected for each mention; here, a wide range of features can be considered, relying on information extracted about the mention, the keywords in the context of the mentions and the candidates, the graph induced by the similarity and/or relatedness of mentions and candidates, the categories of an external reference corpus, or the linguistic dependencies in the input text. These features can then be combined by various means – thresholds, objective functions, classifiers, etc. – to produce a final candidate for each mention or a support for each candidate.
Open questions
While the EEL task has been widely studied in recent years, many important research questions remain open, where our survey suggests the following:
Defining “Entity”: A foundational question that remains open is to rigorously define what is an “entity” in the context of EEL [152,180,270]. The traditional definition from the NER community considers mentions of entities from fixed classes, such as Person, Place, or Organization. However, EEL is often conducted with respect to KBs that contain entities from potentially hundreds of classes. Hence some tools and datasets choose to adopt a more relaxed notion of “entity”; for example, the KORE dataset contains the element Multilingual EEL: EEL approaches have traditionally focused on English texts. However, more and more approaches are considering EEL over non-English texts, including Babelfy [216], MAG [217], THD [84], and updated versions of legacy systems such as DBpedia Spotlight [71]. Such systems face a number of open challenges, including the development of language-specific or language-agnostic components (e.g., having POS taggers for different languages), the disparity of reference information available for different languages (e.g., Wikipedia is more complete for English than other languages), as well as being robust to language variations (e.g., differences in alphabet, capitalization, punctuation) [269]. Specialized Settings: While the majority of EEL approaches consider relatively clean and long text documents as input – such as news articles – other applications may require EEL over noisy or short text. One example that has received attention recently is the application of EEL methods over Twitter [78,79,320,322], which presents unique challenges – such as the frequent use of slang and abbreviations, a lack of punctuation and capitalization, as well as having limited context – but also present unique opportunities – such as leveraging user profiles and social context. Beyond Twitter, EEL could be applied in any number of specialized settings, each with its own challenges and opportunities, raising further open questions. Novel Techniques: Improving the precision and recall of EEL will likely remain an open question for years to come; however, we can identify two main trends that are likely to continue into the future. The first trend is the use of modern Machine Learning techniques for EEL; for example, Deep Learning [121] has been investigated in the context of improving both recognition [87] and disambiguation [107]. The second trend is towards approaches that consider multiple related tasks in a joint approach, be it to combine recognition and disambiguation [184,231], or to combine word sense disambiguation and EEL [145,216], etc. Novel techniques are required to continue to improve the quality of EEL results. Evaluation: Though benchmarking frameworks such as BAT [62] and GERBIL [303] represent important milestones towards better evaluating and comparing EEL systems, potentially much more work can be done along these lines. With respect to datasets, creating gold standards often requires significant manual labor, where mistakes may sometimes be introduced in the annotation process [152], or datasets may be labeled with respect to incompatible notions of “entity” [152,180,270]. Moreover, the domains [89] and languages [269] covered by existing datasets are limited. Aside from the need for more labeled datasets, evaluations tend to consider EEL systems as complex black boxes, which obfuscates the reasons for a particular system’s success or failure; more fine-grained evaluation of techniques – rather than systems – could potentially offer more fundamental insights into the EEL process, leading to further research questions.
Concept extraction & linking
A given corpus may refer to one or more domains, such as Medicine, Finance, War, Technology, and so forth. Such domains may be associated with various concepts indicating a more specific topic, such as “
For the purposes of this section, we coin the generic phrase Concept Extraction & Linking to encapsulate the following three related but subtly distinct Information Extraction tasks – as discussed in Appendix x – that can be brought to bear in terms of gaining a greater understanding of the concepts spoken about in a corpus, which in turn can help, for example, to understand the important concepts in the domain that a collection of documents are about, or the topic of a document.
Given a corpus we know to be in a given domain, we may be interested to learn what terms/concepts are core to the terminology of that domain.38
Also known as Term Extraction [100], Term Recognition [3], Vocabulary Extraction [85], Glossary Extraction [60], etc.
This task focuses on extracting important keyphrases for a given document.39
In contrast with TE, which focuses on extracting important concepts relevant to a given domain, KE is focused on extracting important concepts relevant to a particular text. (See Listing 13, Appendix x, for an example.)The goal of Topic Modeling is to analyze cooccurrences of related keywords and cluster them into candidate grouping that potentially capture higher-level semantic “topics”.40
(See Listing 14, Appendix x, for an example.)There is a clear connection between TE and KE: though the goals are somewhat divergent – the former focuses on understanding the domain itself while the latter focuses on categorizing documents – both require extraction of domain terms/keyphrases from text and hence we summarize works in both areas together.
Likewise, the methods employed and the results gained through TE and KE may also overlap with the previously studied task of Entity Extraction & Linking (EEL). Abstractly, one can consider EEL as focusing on the extraction of individuals, such as “
However, we can draw some clear general distinctions between EEL and the domain extraction tasks discussed in this section: the goal in EEL is to extract all entities mentioned, while the goal in TE and KE is to extract a succinct set of domain-relevant keywords that capture the terminology of a domain or the subject of a document. When compared with EEL, another distinguishing aspect of TE, KE and TM is that while the former task will produce a flat list of candidate identifiers for entity mentions in a text, the latter tasks (often) go further and attempt to induce hierarchical relations or clusters from the extracted terminology.
In this section, we discuss works relating to TE, KE and TM that directly relate to the Semantic Web, be it to help in the process of building an ontology or KB, or using an ontology or KB to guide the extraction process, or linking the results of the extraction process to an ontology or KB. We highlight that this section covers a wide diversity of works from authors working in a wide variety of domains, with different perspectives, using different terminology; hence our goal is to cover the main themes and to abstract some common aspects of these works rather than to capture the full detail of all such heterogeneous approaches.
Example: A sample of TE and KE results are provided in Listing 2, based on the examples provided in Listings 12 and 13 (see Appendix x). One motivation for applying such techniques in the context of the Semantic Web is to link the extracted terms with disambiguated identifiers from a KB. The example output consists of (hypothetical) RDF triples linking extracted terms to categorical concepts described in the DBpedia KB. These linked categories in the KB are then associated with hierarchical relations that may be used to generalize or specialize the topic of the document.

Concept extraction and linking example
Applications: In the context of the Semantic Web, a core application of CEL tasks – and a major focus of TE in particular – is to help with the creation, validation or extension of a domain ontology. Automatically extracting an expressive domain ontology from text is, of course, an inherently challenging task that falls within the area of ontology learning [31,51,186,225,316]. In the context of TE, the focus is on extracting a terminological ontology [100,169] (aka. lexicalized ontology [227], termino-ontology [227] or simple ontology [43]), which captures terms referring to important concepts in the domain, potentially including a taxonomic hierarchy between concepts or identifying terms that are aliases for the same concept. The resulting concepts (and hierarchy) may be used, for example, in a semi-automated ontology building process to seed or extend the concepts in the ontology.41
In the context of ontology building, some authors distinguish an onomasiological process from a semasiological process, where the former process relates to taking a known concept in an ontology and extracting the terms by which it may be referred to in a text, while the latter process involves taking terms and extracting their underlying conceptual meaning in the form of an ontology [36].
Other applications relate to categorizing documents in a corpus according to their key concepts, and thus by topic and/or domain; this is the focus of the KE and TM tasks in particular. When these high-level topics are related back to a particular KB, this can enable various forms of semantic search [123,173,296], for example to navigate the hierarchy of domains/topics represented by the KB while browsing or searching documents. Other applications include text enrichment or semantic annotation whereby terms in a text are tagged with structured information from a reference KB or ontology [73,74,162,308].
Process: The first step in all such tasks is the extraction of candidate domain terms/keywords in the text, which may be performed using variations on the methods for EEL; this process may also involve a reference ontology or KB used for dictionary or learning purposes, or to seed patterns. The second step is to perform a filtering of the terms, selecting only those that best reflect the concepts of the domain or the subject of a document. A third optional step is to induce a hierarchy or clustering of the extracted terms, which may lead to either a taxonomy or a topic model; in the case of a topic model, a further step may be to identify a singular term that identifies each cluster. A final optional step may be to link terms or topic identifiers to an existing KB, including disambiguation where necessary (if not already implicit in a previous step). In fact, the steps described in this process may not always be sequential; for example, where a reference KB or ontology is used, it may not be necessary to induce a hierarchy from the terms since such a hierarchy may already be given by the reference source.
We consider a term to be a textual mention of a domain-specific concept, such as “
In fact, approaches to extract raw candidate terms follow a similar line to that for extracting raw entity mentions in the context of EEL. Generic preprocessing methods such as stop-word removal, stemming and/or lemmatization are often applied, along with tokenization. Some term extraction methods then rely on window-based methods, extracting n-grams up to a predefined length [100]. Other term extractors apply POS-tagging and then define shallow syntactic patterns to capture, for example, noun phrases (“
There are, however, subtle differences when compared with extracting entities, particularly when considering traditional NER scenarios looking for names of people, organizations, places, etc.; when extracting terms, for example, capitalization becomes less useful as a signal, and syntactic patterns may need to be more complex to identify concepts such as “
Filtering
Once a set of candidate terms have been identified, a range of features can be used for either automatic or semi-automatic filtering. These features can be broadly categorized as being linguistic or statistical; however, other contextual features can be used, which will be described presently. Furthermore, filtering can be applied with respect to a domain-specific dictionary of terms as taken from a reference KB or ontology.
Linguistic features relate to lexical or syntactic aspects of the term itself, where the most basic such feature would be the number of words forming the term (more words indicating more specific terms and vice-versa). Other linguistic features can likewise include generic aspects such as POS tags [73,123,173,215,220], shallow syntactic patterns [60,85,119,215], etc.; such features may be used in the initial extraction of terms or as a post-filtering step. Furthermore, terms may be filtered or selected based on appearing in a particular hierarchical branch of terminology, such as terms relating to forms of cancer; these techniques will be discussed in the next subsection.
As explained in Appendix x, producing and maintaining linguistic patterns/rules is a time consuming task, which in turn results in incomplete rules. Statistical measures look more broadly at the usage of a particular term in a corpus. In terms of such measures, two key properties of terms are often analyzed in this context [60]: unithood and termhood.
Unithood refers to the cohesiveness of the term as referring to a single concept, which is often assessed through analysis of collocations: expressions where the meaning of each individual word may vary widely from their meaning in the expression such that the meaning of the word depends directly on the expression; an example collocation might be “
The second form of statistical measure, called termhood, refers to the relevance of the term to the domain in question. To measure termhood, variations on the theme of the TF–IDF measure are commonly used [60,85,100,123,173,308], where, for example, terms that appear often in a (domain) specific text (high TF) but appear less often in a general corpus (high IDF) indicate higher termhood. Note that termhood relates closely to Topic Modeling measures, where the context of terms is used to find topically-related terms; such approaches will be discussed later.
Other features can rather be contextual, looking at the position of terms in the text [252]; such features are particularly important in the context of identifying keyphrases/terms that capture the domain or topic of a given document. The first such feature is known as the phrase depth, which measures how early in the document is the first appearance of the term: phrases that appear early on (e.g., in the title or first paragraph) are deemed to be most relevant to the document or the domain it describes. Likewise, terms that appear throughout the entire document are considered more relevant: hence the phrase lifespan – the ratio of the document lying between the first and last occurrence of the term – is also considered as an important feature [252].
A KB can also be used to filter terms through a linking process. The most simple such procedure is to filter terms that cannot be linked to the KB [162]. Other proposed methods rather apply a graph-based filtering, where terms are first linked to the KB and then the sub-graph of the KB induced by the terms is extracted; subsequently, terms in the graph that are disconnected [46] or exhibiting low centrality [144] can be filtered. This process will be described in more detail later.
Hierarchy induction
Often the extracted terms will refer to concepts with some semantic relations that are themselves useful to model as part of the process. The semantic relations most often considered are synonymy (e.g., “
In terms of detecting hypernymy from the text itself, a key method relies on distinguishing the head term, which signifies the more general hypernym in a (potentially) multi-word term; from modifier terms, which then specialize the hypernym [7,32,153,227,306]. For example, the head term of “
Of course, analyzing head/modifier terms will miss hypernyms not involving modifiers, and synonyms; for example, the hyponym “
Another approach that potentially offers higher recall is to use statistical analyses of large corpora of text. Many such approaches (e.g., [6,51,52,58]) are based, for example, on distributional semantics, which aggregates the context (surrounding terms) in which a given term appears in a large corpus. The distributional hypothesis then considers that terms with similar contexts are semantically related. Within this grouping of approaches, one can then find more specific strategies based on various forms of clustering [51], Formal Concept Analysis [52], LDA [58], embeddings [6], etc., to find and induce a hierarchy from terms based on their context. These can then be used as the basis to detect synonyms; or more often to induce a hierarchy of hypernyms, possibly adding hidden concepts – fresh hypernyms of cohyponyms – to create a connected tree of more/less specific domain terms.
Of course, reference resources that already contain semantic relations between terms can be used to aid in this process. One important such resource is WordNet [208], which, for a given term, provides a set of possible semantic senses in terms of what it might mean (homonymy/polysemy [304]), as well as a set of synonyms called synsets. Those synsets are then related by various semantic relations, including hypernymy, meronymy (part of), etc. WordNet is thus a useful reference for understanding the semantic relations between concepts, used by a variety of systems (e.g., [55,153,225,325], etc.). Other systems rather rely on, for example, Wikipedia categorizations [6,7,197] in combination with reference KBs. A core challenge, however, when using such approaches is the problem of word sense disambiguation [224] (sometimes called the semantic interpretation problem [225]): given a term, determine the correct sense in which it is used. We refer to the survey by Navigli [225] for discussion.
An alternative to extracting semantic relations between terms in the text is to instead rely on the existing relations in a given KB [6,46,144,305]. That is to say, if the terms (or indeed simply entities) can be linked to a suitable existing KB, then semantic relations can be extracted from the KB itself rather than the text. This approach is often applied by tools described in the following section (e.g., [46,144,305]), whose goal is to understand the domain of a document rather than attempting to model a domain from text.
Topic modeling
While the previous methods are mostly concerned with extracting a terminology from a corpus that describes a given domain (e.g., for the purposes of building a domain-specific ontology), other works are concerned with modeling and potentially identifying the domain to which the documents in a given corpus pertain (e.g., for the purposes of classifying documents). We refer to these latter approaches generically as Topic Modeling approaches [177,198]. Such approaches are based on analysis of terms (or sometimes entities) extracted from the text over which Topic Modeling approaches can be applied to cluster and analyze thematically related terms (e.g., “
For applying Topic Modeling, one can of course first consider directly applying the traditional methods proposed in the literature: LSA, pLSA and/or LDA (see Appendix x for discussion). However, these approaches have a number of drawbacks. First, such approaches typically work on individual words and not multi-word terms (though extensions have been proposed to consider multi-word terms). Second, topics are considered as latent variables associated with a probability of generating words, and thus are not directly “labeled”, making them difficult to explain or externalize (though, again, labeled extensions have also been proposed, for example for LDA). Third, words are never semantically interpreted in such models, but are rather considered as symbolic references over which statistical/probabilistic inference can be applied. Hence a number of approaches have emerged that propose to use the structured information available in KBs and/or ontologies to enhance the modeling of topics in text. The starting point for all such approaches is to extract some terms from the text, using approaches previously outlined: some rely simply on token- or POS-based methods to extract terms, which can be filtered by frequency or TF–IDF variants to capture domain relevance [5,149,150], whereas others rather prefer entity recognition tools (which are subsequently mapped to higher-level topics through relations in the KB, as we describe later) [46,170,298].
With extracted terms in hand, the next step for many approaches – departing from traditional Topic Modeling – is to link those terms to a given KB, where the semantic relations of the KB can be exploited to generate more meaningful topics. The most straightforward such approach is to assume an ontology that offers a concept/class hierarchy to which extracted terms from the document are mapped. Thus the ontology can be seen as guiding the Topic Modeling process, and in fact can be used to select a label for the topic. One such approach is to apply a statistical analysis over the term-to-concept mapping. For example, in such a setting, Jain and Pareek [149] propose the following: for each concept in the ontology, count the ratio of extracted terms mapped to it or its (transitive) sub-concepts, and take that ratio as an indication of the relevance of the concept in terms of representing a high-level topic of the document. Another approach is to consider the spanning tree(s) induced by the linked terms in the hierarchy, taking the lowest common ancestor(s) as a high-level topic [144]. However, as noted by Hulpuş et al. [144], such approaches relying on class hierarchies tend to elect very generic topic labels, where they give the example of “
Other approaches apply traditional Topic Modeling methods (typically pLSA or LDA) in conjunction with information extracted from the KB. Some approaches propose to apply Topic Modeling in an initial phase directly over the text; for example, Canopy [144] applies LDA over the input documents to group words into topics and then subsequently links those words with DBpedia for labeling each topic (described later). On the other hand, other approaches apply Topic Modeling after initially linking terms to the KB; for example, Todor et al. [298] first link terms to DBpedia in order to enrich the text with annotations of types, categories, hypernyms, etc., where the enriched text is then passed through an LDA process. Some recent approaches rather extend traditional topic models to consider information from the KB during the inference of topic-related distributions. Along these lines, for example, Allahyari [5] propose an LDA variant, called “OntoLDA”, which introduces a latent variable for concepts (taken from DBpedia and linked with the text), which sits between words and topics: a document is then considered to contain a distribution of (latent) topics, which contains a distribution of (latent) concepts, which contains a distribution of (observable) words. Another such hybrid model, but rather based on pLSA, is proposed by Chen et al. [46] where the probability of a concept mention (or a specific entity mention42
They use the term entity to refer to both concepts, such as person, and individuals, such as Barack Obama.
The result of these previous methods – applying Topic Modeling in conjunction with a KB-linking phase – is a set of topics associated with a set of terms that are in turn linked with concepts/entities in the KB. Interestingly, the links to the KB then facilitate labeling each topic by selecting one (or few) core term(s) that help capture or explain the topic. More specifically, a number of graph-based approaches have recently been proposed to choose topic labels [5,144,150], which typically begin by selecting, for each topic, the nodes in the KB that are linked by terms under that topic, and then extracting a sub-graph of the KB in the neighborhood of those nodes, where typically the largest connected component is considered to be the topical/thematic graph [5,150]. The goal, thereafter, is to select the “label node(s)” that best summarize(s) the topic, for which a number of approaches apply centrality measures on the topical graph: Janik and Kochut [150] investigate use of a closeness centrality measure, Allahyari and Kochut [5] propose to use the authority score of HITS (later mapping central nodes to DBpedia categories), while Hulpuş et al. [144] investigate various centrality measures, including closeness, betweenness, information and random-walk variants, as well as “focused” centrality measures that assign special weights to nodes in the topic (not just in the neighborhood). On the other hand, Varga et al. [305] propose to extract a KB sub-graph (from DBpedia or Freebase) describing entities linked from the text (containing information about classes, properties and categories), over which weighting schemes are applied to derive input features for a machine learning model (SVM) that classifies the topics of microposts.
Domain knowledge extracted through the previous processes may be represented using a variety of Semantic Web formats. In the ontology building process, induced concepts may be exported to RDFS/OWL [136] for further reasoning tasks or ontology refinement and development. However, RDFS/OWL makes a distinction between concepts and individuals that may be inappropriate for certain modeling requirements; for example, while a term such as “
It is worth noting that OWL does provide means for meta-modeling (aka. punning), where concepts can be simultaneous considered as groups of individuals when reasoning at a terminological level, and as individuals when reasoning at an assertional level.
Aside from these Semantic Web standards, a number of other representational formats have been proposed in the literature. The Lexicon Model for Ontologies, aka. LEMON [53], was proposed as a format to associate ontological concepts with richer linguistic information, which, on a high level, can be seen as a model that bridges between the world of formal ontologies to the world of natural language (written, spoken, etc.); the core LEMON concept is a lexical entry, which can be a word, affix or phrase (e.g., “
Overview of concept extraction & linking systems.
Along related lines, Hellmann et al. [131] propose the NLP Interchange Format (NIF), whose goal is to enhance the interoperability of NLP tools by using an ontology to describe common terms and concepts; the format can provide Linked Data as output for further data reuse. Other proposals have also been made in terms of publishing linguistic resources as Linked Data. Cimiano et al. [54] propose such an approach for publishing and linking terminological resources following the Linked Data principles, combining the LEMON, SKOS, and PROV-O vocabularies in their core model; OnLit was proposed by Klimek et al. [166] as a Linked Data version of the LiDo Glossary of Linguistic Terms; etc. For further information, we refer the reader to the editorial by McCrae et al. [195], which offers an overview of terminological/linguistic resources published as Linked Data.
Based on the previously discussed techniques, in Table 5, we provide an overview of highlighted CEL systems that deal with the Semantic Web in a direct way, and that have a publication offering details; a legend is provided in the caption of the table. Note that in the
The approaches reviewed in this section might be applied for diverse and heterogeneous cases. Thus, comparing CEL approaches is not a trivial task; however, we can mention some general aspects and considerations when choosing a particular CEL approach.
Target task: As per the
Language: Although the approaches described in this section provide strategies for processing text in English, different languages can also be covered in the TE/KE tasks using similar techniques (e.g., the approach proposed by Lemnitzer et al. [173]). Moreover, term translation is the focus of some approaches, such as OntoLearn [225,306]. Finally, KBs such as DBpedia or BabelNet offer multilingual resources that can support the extraction of terms in varied languages.
Output quality. The quality of CEL tasks depends on numerous factors, such as the ontologies and datasets used, the manual intervention involved in their processes, etc. For example, approaches such as OSEE [161,162], OntoLearn [225,306], or that proposed by Chemudugunta et al. [43], rely on ontologies for recognizing or filtering terms; while this strategy could provide an increased precision, new terms may not be identified at all and thus, a low recall may be produced. On the other hand, approaches by Cardillo et al. [36] and Zhang et al. [325] involve manual intervention; although this is a costly process, it can help ensure a higher quality result over smaller input corpora of text.
Domain: Although a specific domain is commonly used for testing (e.g. Biomedical, Finance, News, Terrorism, etc.), CEL approaches rely on NLP tools that can be employed for varied domains in a general fashion. However, some CEL approaches may be built with a specific KB in mind. For example, Cardillo et al. [36] and Lossio et al. [308] use SNOMED-CT for the medical domain, while F-STEP [197], Distiller [73], and Dolby et al. [85] use DBpedia. On the other hand, KB-agnostic approaches such as OntoLT [32] and OwlExporter [314] generalize to any KB/domain.
Text characteristics/Recognition. Different features can be used during the extraction and filtering of terms and topics. For example, some systems deal with the recognition of multi-word expressions (e.g., OntoLearn [225,306]), or contextual features provided by the FCA (as proposed by Cimiano et al. [52]) or position of words in a text (e.g., PIRATES [252]). Such a selection of features may influence the results in different ways for particular applications; it may be difficult to anticipate a priori how such factors may influence an application, where it may be best to evaluate such approaches for a particular setting.
Efficiency and scalability. When faced with a large input corpus, the efficiency of a CEL approach can become a major factor. Some CEL approaches rely on computationally-expensive NLP tasks (e.g., deep parsing), while other approaches rely on more lightweight statistical tasks to extract and filter terms. Further steps to extract a hierarchy or link terms with a KB may introduce a further computational cost. Unfortunately however, efficiency (in terms of runtimes) is generally not reported in the CEL papers surveyed, which rather focus on metrics to assess output quality.
We can conclude that comparing CEL approaches is complicated not only by the diversity of methods proposed and the goals targeted, but also by a lack of standardized, comparative evaluation frameworks; we will discuss this issue in the following subsection.
Given the diversity of approaches gathered together in this section, we remark that the evaluation strategies employed are likewise equally diverse. In particular, evaluation varies depending on the particular task considered (be it TE, KE, TM or some combination thereof) and the particular application in mind (be it ontology building, text classification, etc.). Evaluation in such contexts is often further complicated by the potentially subjective nature of the goal of such approaches. When assessing the quality of the output, some questions may be straightforward to answer, such as: Is this phrase a cohesive term (unithood/precision)? On the other hand, evaluation must somehow deal with more subjective domain-related questions, such as: Is this a domain-relevant term (termhood/precision)? Have we captured all domain-relevant terms appearing in the text (recall)? Is this taxonomy of terms correct (precision)? Does this label represent the terms forming this topic (precision)? Does this document have these topics (precision)? Are all topics of the document captured (recall)? And so forth. Such questions are inherently subjective, may raise disagreement amongst human evaluators [173], and may require expertise in the given domain to answer adequately.
Datasets: For evaluating CEL approaches, notably there are many Web-based corpora that have been pre-classified with topics or keywords, often annotated by human experts – such as users, moderators or curators of a particular site – through, for example, tagging systems. These can be reused for evaluation of domain extraction tools, in particular to see if automated approaches can recreate the high-quality classifications or topic models inherent in such corpora. Some such corpora that have been used include: BBC News46
[144,298], British Academic Written Corpus47 [5,144], British National Corpus48 [52], CNN News [150], DBLP49 [46], eBay50 [74], Enron Emails,51 Twenty Newsgroups52 [46,298], Reuters News53http://www.daviddlewis.com/resources/testcollections/reuters21578/ and http://www.daviddlewis.com/resources/testcollections/rcv1/.
Rather than employing a pre-annotated gold standard, an alternative strategy is to apply the approach under evaluation to a non-annotated corpus and thereafter seek human judgment on the output, typically in comparison with baseline approaches from the literature. Such an approach is employed in the context of TE by Nédellec et al. [227], Kim and Tuan [162], and Dolby et al. [85]; or in the context of KE by Muñoz-García et al. [220]; or in the context of TM by Hulpuş et al. [144] and Lauscher et al. [170]; and so forth. In such evaluations, TM approaches are often compared against traditional approaches such as LDA [5], PLSA [46], hierarchical clustering [127], etc.
Metrics: The most commonly used metrics for evaluating CEL approaches are precision, recall, and
Particular tasks may be associated with specialized measures. Evaluations in the area of Topic Modeling may also consider perplexity (the log-likelihood of a held-out test set) and/or coherence [266], where a topic is considered coherent if it covers a high ratio of the words/terms appearing in the textual context from which it was extracted (measured by metrics such as Pointwise Mutual Information (PMI) [60], Normalized Mutual Information (NMI), etc.). On the other hand, for Terminology Extraction approaches with hierarchy induction, measures such as Semantic Cotopy [52] and Taxonomic Overlap [52] may be used to compare the output hierarchy with that of a gold-standard ontology.
In cases where a fixed number of users/judges are in charge of developing a gold-standard dataset or assessing the output of systems in an a posteriori manner, the agreement among them is expressed as Cohen’s or Fleiss’ κ-measure. In this sense, Randolph [254] provides a typical description (and usage examples) of the κ-measure, where the considered aspects are the number of cases or instances to evaluate, the number of human judges, the number of categories, and the number of judges who assigned the case to the same category.
Third-party comparisons: To the best of our knowledge, there has been little work on third-party evaluations for comparing CEL approaches, perhaps because of the diversity of goals and methods applied, the aforementioned challenges associated with evaluating CEL systems, etc. Among the available results, Gangemi [112] compared three commercial tools – Alchemy, OpenCalais and PoolParty – for Topic Extraction, where Alchemy had the highest F-measure. In a separate evaluation for Terminology Extraction – comparing Alchemy, CiceroLite, FOX [288], FRED [113] and Wikimeta – Gangemi [112] reported that FRED [113] had the highest F-measure.55
We do not include Alchemy, CiceroLite, nor Wikimeta in the discussion of Table 5 since we have not found any publication providing details on their implementation. Though FOX [288] and FRED [113] do have publications, few details are provided on how CEL is implemented. We will, however, discuss FRED [113] in the context of Relation Extraction in Section 4.
In this section, we gather together three approaches for extracting domain-related concepts from a text: Terminology Extraction (TE), Keyphrase Extraction (KE), and Topic Modeling (TM). While the first task is typically concerned with applications involving ontology building, or otherwise extracting a domain-specific terminology from an appropriate corpus, the latter two tasks are typically concerned with understanding the domain of a given text. As we have seen in this section, all tasks relate in important aspects, particularly in the identification of domain-relevant concepts; indeed, TE and TM further share the goal of extracting relationships between the extracted terms, be it to induce a hierarchy of hypernyms, to find synonyms, or to find thematic clusters of terms.
While all of the discussed approaches rely – to varying degrees – on techniques proposed in the traditional IE/NLP literature for such tasks, the use of reference ontologies and/or KBs has proven useful for a number of technical aspects inherent to these tasks:
using the entity labels and aliases of a domain-specific KB as a dictionary to guide the extraction of conceptual domain terms in a text [162,308];
linking terms to KB concepts and using the semantic relations in the KB to find (un)related terms [5,46,144,150,197];
enriching text with additional information taken from the KB [298];
classifying text with respect to an ontological concept hierarchy [149];
building topic models that include semantic relations from the KB [5,46];
determining topic labels/identifiers based on the centrality of nodes in the KB graph [5,46,144];
representing and integrating terminological knowledge [36,53,54,131,195,207].
On the other hand, such processes are also often used to create or otherwise enrich Semantic Web resources, such as for ontology building applications, where TE can be used to extract a set of domain-relevant concepts – and possibly some semantic relations between them – to either seed or enhance the creation of a domain-specific ontology [49,51,55,225,306,316].
Open questions
Although the tasks involved in CEL are used in varied applications and domains, some general open questions can be abstracted from the previous discussion, where we highlight the following:
Interrelation of Tasks: Under the heading of CEL, in this survey we have grouped three main tasks: Terminology Extraction (TE), Keyphrase Extraction (KE) and Topic Modeling (TM). These tasks are often considered in isolation – sometimes by different communities and for different applications – but as per our discussion, they also share clear overlaps. An important open question is thus with respect to how these tasks can be generalized, how approaches to each task can potentially complement each other or, conversely, where the objectives of such tasks necessarily diverge and require distinct techniques to solve. Specialized Settings/Multilingual CEL: As was previously discussed for EEL, most approaches for CEL consider complete texts of high quality, such as technical documents, papers, etc. On the other hand, CEL has not been well explored in other settings, such as online discussion fora, Twitter, etc., which may present a different set of challenges. Likewise, most focus has been on English texts, where works such as LEMON [53] highlight the impact that approaches considering multiple languages could have. Contextual Information: As previously discussed, TE, KE, and TM can be used to support the extraction of topics from text. As a consequence, such topics can be used to enrich the input text and existing KBs (such as DBpedia). This would be useful in scenarios where input documents need to include further contextual information or to be organized into (potentially new) categories. Crowdsourcing: A challenging aspect of CEL is the inherent subjectivity with respect to evaluating the output of such methods. Hence some approaches have proposed to leverage crowdsourcing, amongst which we can mention the creation of the Crowd500 dataset [189] for evaluating KE approaches. An open question is to then further develop on this idea and consider leveraging crowdsourcing for solving specific sub-tasks of CEL or to support evaluation, including for other tasks relating to TE or TM (though of course such an approach may not be suitable for specialist domains requiring expert knowledge). Linking: While a variety of approaches have been proposed to extract terminology/keyphrases from text, only more recently has there been a trend towards linking such mentions with a KB [5,46,144,150,162]. While such linking could be seen as a form of EEL, and as being related to word sense disambiguation, it is not necessarily subsumed by either: many EEL approaches tend to focus on mentions of named entities, while word sense disambiguation does not typically consider multi-term phrases. Hence, an interesting subject is to explore custom techniques for linking the conceptual terminology/keyphrases produced by the TE and KE processes to a given KB, which may include, for example, synonym expansion, domain-specific filtering, etc. Benchmark Framework: In Section 3.7, we discussed the diverse ways in which CEL approaches are evaluated. While a number of gold standard datasets have been proposed for specific tasks [163,189], we did not encounter much reuse of such datasets, where the only systematic third-party evaluation we could find for such approaches was that conducted by Gangemi [112]. We thus observe a strong need for a standardized benchmarking framework for CEL approaches, with appropriate metrics and datasets. Such a framework would need to address a number of key open questions relating to the diversity of approaches that CEL encompasses, as well as the subjectivity inherent in its goals (e.g., deciding what terminology is important to a domain, what keyphrases are important to a document, etc.).
Relation extraction & linking
At the heart of any Semantic Web KB are relations between entities [279]. Thus an important traditional IE task in the context of the Semantic Web is Relation Extraction (RE), which is the process of finding relationships between entities in the text. Unlike the tasks of Terminology Extraction or Topic Modeling that aim to extract fixed relationships between concepts (e.g., hypernymy, synonymy, relatedness, etc.), RE aims to extract instances of a broader range of relations between entities (e.g., born-in, married-to, interacts-with, etc.). Relations extracted may be binary relations or even higher arity n-ary relations. When the predicate of the relation – and the entities involved in it – are linked to a KB, or when appropriate identifiers are created for the predicate and entities, the results can be used to (further) populate the KB with new facts. However, first it is also necessary to represent the output of the Relation Extraction process as RDF: while binary relations can be represented directly as triples, n-ary relations require some form of reified model to encode. By Relation Extraction and Linking (REL), we then refer to the process of extracting and representing relations from unstructured text, subsequently linking their elements to the properties and entities of a KB.
In this section, we thus discuss approaches for extracting relations from text and linking their constituent predicates and entities to a given KB; we also discuss representations used to encode REL results as RDF for subsequent inclusion in the KB.
Example: In Listing 3, we provide a hypothetical (and rather optimistic) example of REL with respect to DBpedia. Given a textual statement, the output provides an RDF representation of entities interacting through relationships associated with properties of an ontology. Note that there may be further information in the input not represented in the output, such as that the entity “

Relation extraction and linking example
Note that Listing 3 exemplifies direct binary relations. Many REL systems rather extract n-ary relations with generic role-based connectives. In Listing 4, we provide a real-world example given by the online FRED demo;56
for brevity, we exclude some output triples not directly pertinent to the example. Here we see that relations are rather represented in an n-ary format, where for example, the relation “
FRED relation extraction example
Applications: One of the main applications for REL is KB Population,57
where relations extracted from text are added to the KB. For example, REL has been applied to (further) populate KBs in the domains of Medicine [236,273], Terrorism [148], Sports [260], among others. Another important application for REL is to perform Structured Discourse Representation, where arguments implicit in a text are parsed and potentially linked with an ontology or KB to explicitly represent their structure [12,109,113]. REL is also used for Question Answering (Q&A) [300], whose purpose is to answer natural language questions over KBs, where approaches often begin by applying REL on the question text to gain an initial structure [317,333]. Other interesting applications have been to mine deductive inference rules from text [178], or for pattern recognition over text [120], or to verify or provide textual references for existing KB triples [106].Process: The REL process can vary depending on the particular methodology adopted. Some systems rely on traditional RE processes (e.g., [92,93,223]), where extracted relations are linked to a KB after extraction; other REL systems – such as those based on distant supervision – use binary relations in the KB to identify and generalize patterns from text mentioning the entities involved, which are then used to subsequently extract and link further relations. Generalizing, we structure this section as follows. First, many (mostly distant supervision) REL approaches begin by identifying named entities in the text, either through NER (generating raw mentions) or through EEL (additionally providing KB identifiers). Second, REL requires a method for parsing relations from text, which in some cases may involve using a traditional RE approach. Third, distant supervision REL approaches use existing KB relations to find and learn from example relation mentions, from which general patterns and/or features are extracted and used to generate novel relations. Fourth, an REL approach may apply a clustering procedure to group relations based on hypernymy or equivalence. Fifth, REL approaches – particularly those focused on extracting n-ary relations – must define an appropriate RDF representation to serialize output relations. Finally, in order to link the resulting relations to a given KB/ontology, REL often considers an explicit mapping step to align identifiers.
The first step of REL often consists of identifying entity mentions in the text. Here we distinguish three strategies, where, in general, many works follow the EEL techniques previously discussed in Section 2, particularly those adopting the first two strategies.
The first strategy is to employ an end-to-end EEL system – such as DBpedia Spotlight [200], Wikifier [97], etc. – to match entities in the raw text. The benefit of this strategy is that KB identifiers are directly identified for subsequent phases.
The second strategy is to employ a traditional NER tool – often from Stanford CoreNLP [11,113,213,223,233] – and potentially link the resulting mentions to a KB. This strategy has the benefit of being able to identify mentions of emerging entities, allowing to extract relations about entities not already in the KB.
The third strategy is to rather skip the NER/EL phrase and rather directly apply an off-the-shelf RE/OpenIE tool or an existing dependency-based parser (discussed later) over the raw text to extract relational structures; such structures then embed parsed entity mentions over which EEL can be applied (potentially using an existing EEL system such as DBpedia Spotlight [109] or TagMe [101]). This has the benefit of using established RE techniques and potentially capturing emerging entities; however, such a strategy does not leverage knowledge of existing relations in the KB for extracting relation mentions (since relations are extracted prior to accessing the KB).
In summary, entities may be extracted and linked before or after relations are extracted. Processing entities before relations can help to filter sentences that do not involve relationships between known entities, to find examples of sentences expressing known relations in the KB for training purposes, etc. On the other hand, processing entities after relations allows direct use of traditional RE and OpenIE tools, and may help to extract more complex (e.g., n-ary) relations involving entities that are not supported by a particular EEL approach (e.g., emerging entities), etc. These issues will be discussed further in the sections that follow.
In the context of REL, when extracting and linking entities, Coreference Resolution (CR) plays a very important role. While other EEL applications may not require capturing every coreference in a text – e.g., it may be sufficient to capture that the entity is mentioned at least one in a document for semantic search or annotation tasks – in the context of REL, not capturing coreferences will potentially lose many relations. Consider again Listing 3, where the second sentence begins “
Parsing relations
The next phase of REL systems often involves parsing structured descriptions from relation mentions in the text. The complexity of such structures can vary widely depending on the nature of the relation mention, the particular theory by which the mention is parsed, the use of pronouns, and so forth. In particular, while some tools rather extract simple binary relations of the form
In terms of parsing more simple binary relations, as mentioned previously, a number of tools use existing OpenIE systems, which apply a recursive extraction of relations from webpages, where extracted relations are used to guide the process of extracting further relations. In this setting, for example, Dutta et al. [93] use NELL [214] and ReVerb [99], Liu et al. [182] use PATTY [223], while Soderland and Mandhani [285] use TextRunner [16] to extract relations; these relations will later be linked with an ontology or KB.
In terms of parsing potentially more complex n-ary relations, a variety of methods can be applied. A popular method is to begin with a dependency-based parse of the relation mention. For example, Grafia [109] uses a Stanford PCFG parser to extract dependencies in a relation mention, over which CR and EEL are subsequently applied. Likewise, other approaches using a dependency parser to extract an initial syntactic structure from relation mentions include DeepDive [233], PATTY [223], Refractive [98] and works by Mintz et al. [213], Nguyen and Moschitti [232], etc.
Other works rather apply higher-level theories of language understanding to the problem of modeling relations. One such theory is that of frame semantics [103], which considers that people understand sentences by recalling familiar structures evoked by a particular word; a common example is that of the term “
A related theory used to parse complex n-ary relations is that of Discourse Representation Theory (DRT) [156], which offers a more logic-based perspective for reasoning about language. In particular, DRT is based on the idea of Discourse Representation Structures (DRS), which offer a first-order-logic (FOL) style representation of the claims made in language, incorporating n-ary relations, and even allowing negation, disjunction, equalities, and implication. The core idea is to build up a formal encoding of the claims made in a discourse spanning multiple sentences where the equality operator, in particular, is used to model coreference across sentences. These FOL style formulae are contextualized as boxes that indicate conjunction.
Tools such as Boxer [28] then allow for extracting such DRS “boxes” following a neo-Davidsonian representation, which at its core involves describing events. Consider the example sentence “
Here we use a rather distinct representation of arguments in the relation for space/visual reasons and to follow the notation used by Boxer (which is based on variables).
One may note that this is analogous to the same process of representing n-ary relations in RDF [134].
There are a number of significant practical shortcomings of using resources such as FrameNet, VerbNet, and PropBank to extract relations. First, being manually-crafted, they are not necessarily complete for all possible relations and syntactic patterns that one might consider and, indeed, are often only available in English. Second, the parsing method involved may be quite costly to run over all sentences in a very large corpus. Third, the relations extracted are complex and may not conform to the typically binary relations in the KB; creating a posteriori mappings may be non-trivial.
An alternative data-driven method for extracting relations – based on distant supervision61
Also known as weak supervision [141].
The first step for distant supervision methods is to find sentences containing mentions of two entities that have a known binary relation in the KB. This step essentially relies on the EEL process described earlier and can draw on techniques from Section 2. Note that examples may be drawn from external documents, where, for example, Sar-graphs [167] proposes to use Bing’s Web search to find documents containing both entities in an effort to build a large collection of example mentions for known KB relations. In particular, being able to draw from more examples allows for increasing the precision and recall of the REL process by finding better quality examples for training [233].
Once a list of sentences containing pairs of entities is extracted, these sentences need to be analyzed to extract patterns and/or features that can be applied to other sentences. For example, as a set of lexical features, Mintz et al. [213] propose to use the sequence of words between the two entities, to the left of the first entity and to the right of the second entity; a flag to denote which entity came first; and a set of POS tags. Other features proposed in the literature include matching the label of the KB property (e.g.,
Aside from shallow lexical features, systems often parse the example relations to extract syntactic dependencies between the entities. A common method, again proposed by Mintz et al. [213] in the context of supervision, is to consider dependency paths, which are (shortest) paths in the dependency parse tree between the two entities; they also propose to include window nodes – terms on either side of the dependency path – as a syntactic feature to capture more context. Both the lexical and syntactic features proposed by Mintz et al. were then reused in a variety of subsequent related works using distant supervision, including Knowledge Vault [86], DeepDive [233], and many more besides.
Once a set of features is extracted from the relation mentions for pairs of entities with a known KB relation, the next step is to generalize and apply those features for other sentences in the text. Mintz et al. [213] originally proposed to use a multi-class logistic regression classifier: for training, the approach extracts all features for a given entity pair (with a known KB relation) across all sentences in which that pair appears together, which are used to train the classifier for the original KB relation; for classification, all entities are identified by Stanford NER, and for each pair of entities appearing together in some sentence, the same features are extracted from all such sentences and passed to the classifier to predict a KB relation between them.
A variety of works followed up on and further refined this idea. For example, Riedel et al. [257] note that many sentences containing the entity pair will not express the KB relation and that a significant percentage of entity pairs will have multiple KB relations; hence combining features for all sentences containing the entity pair produces noise. To address this issue, they propose an inference model based on the assumption that, for a given KB relation between two entities, at least one sentence (rather than all) will constitute a true mention of the relation; this is realized by introducing a set of binary latent variables for each such sentence to predict whether or not that sentence expresses the relation. Subsequently, for the MultiR system, Hoffman et al. [141] proposed a model further taking into consideration that relation mentions may overlap, meaning that a given mention may simultaneously refer to multiple KB relations; this idea was later refined by Surdeanu et al. [292], who proposed a similar multi-instance multi-label (MIML-RE) model capturing the idea that a pair of entities may have multiple relations (labels) in the KB and may be associated with multiple relation mentions (instances) in the text.
Another complication arising in learning through distant supervision is that of negative examples, where Semantic Web KBs like Freebase, DBpedia, YAGO, are necessarily incomplete and thus should be interpreted under an Open World Assumption (OWA): just because a relation is not in a KB, it does not mean that it is not true. Likewise, for a relation mention involving a pair of entities, if that pair does not have a given relation in the KB, it should not be considered as a negative example for training. Hence, to generate useful negative examples for training, the approach by Surdeanu et al. [292], Knowledge Vault [86], the approach by Min et al. [211], etc., propose a heuristic called (in [86]) a Local Closed World Assumption (LCWA), which assumes that if a relation
A further complication in distant supervision is with respect to noise in automatically labeled relation mentions caused, for example, by incorrect EEL results where entity mentions are linked to an incorrect KB identifier. To tackle this issue, a number of DS-based approaches include a seed selection process to try to select high-quality examples and reduce noise in labels. Along these lines, for example, Augenstein et al. [11] propose to filter DS-labeled examples involving ambiguous entities; for example, the relation mention “
Other approaches based on distant supervision rather propose to extract generalized patterns from relation mentions for known KB relations. Such systems include BOA [117] and PATTY [223], which extract sequences of tokens between entity pairs with a known KB relation, replacing the entity pairs with (typed) variables to create generalized patterns associated with that relation, extracting features used to filter low-quality patterns; an example pattern in the case of PATTY would be “<
We also highlight a more recent trend towards alternative distant supervision methods based on embeddings (e.g., [179,312,324]). Such approaches have the benefit of not relying on NLP-based parsing tools, but rather relying on distributional representations of words, entities and/or relations in a fixed-dimensional vector space that, rather than producing a discrete parse-tree structure, provides a semantic representation of text in a (continuous) numeric space. Approaches such as proposed by Lin et al. [179] go one step further: rather than computing embeddings only over the text, such approaches also compute embeddings for the structured KB, in particular, the KB entities and their associated properties; these KB embeddings can be combined with textual embeddings to compute, for example, similarity between relation mentions in the text and relations in the KB.
We remark that tens of other DS-based approaches have recently been published using Semantic Web KBs in the linguistic community, most often using Freebase as a reference KB, taking an evaluation corpus from the New York Times (originally compiled by Riedel et al. [257]). While strictly speaking such works would fall within the scope of this survey, upon inspection, many do not provide any novel use of the KB itself, but rather propose refinements to the machine learning methods used. Hence we consider further discussion of such approaches as veering away from the core scope of this survey, particularly given their number. Herein, rather than enumerating all works, we have instead captured the seminal works and themes in the area of distant supervision for REL; for further details on distant supervision for REL in a Semantic Web setting, we can instead refer the interested reader to the Ph.D. dissertation of Augenstein [10].
Relation mentions extracted from the text may refer to the same KB relation using different terms, or may imply the existence of a KB relation through hypernymy/sub-property relations. For example, mentions of the form “
An early approach applying such clustering was Artequakt [4], which leverages WordNet knowledge – specifically synonyms and hypernyms – to detect which pairs of relations can be considered equivalent or more specific than one another. A more recent version of such an approach is proposed by Gerber et al. [116] in the context of their RdfLiveNews system, where they define a similarity measure between relation patterns composed of a string similarity measure and a WordNet-based similarity measure, as well as the domain(s) and range(s) of the target KB property associated with the pattern; thereafter, a graph-based clustering method is applied to group similar patterns, where within each group, a similarity-based voting mechanism is used to select a single pattern deemed to represent that group. A similar approach was employed by Liu et al. [182] for clustering mentions, combining a string similarity measure and a WordNet-based measure; however they note that WordNet is not suitable for capturing similarity between terms with different grammatical roles (e.g., “
An alternative clustering approach for generalized relation patterns is to instead consider the sets of entity pairs that each such pattern considers. Soderland and Mandhani [285] propose a clustering of patterns based on such an idea: if one pattern captures a (near) subset of the entity pairs that another pattern captures, they consider the former pattern to be subsumed by the latter and consider the former pattern to infer relations pertaining to the latter. A similar approach is proposed by Nakashole et al. [223] in the context of their PATTY system, where subsumption of relation patterns is likewise computed based on the sets of entity pairs that they capture; to enable scalable computation, the authors propose an implementation based on the MapReduce framework. Another approach along these lines – proposed by Riedel et al. [258] – is to construct what the authors call a universal schema, which involves creating a matrix that maps pairs of entities to KB relations and relation patterns associated with them (be it from training or test data); over this matrix, various models are proposed to predict the probability that a given relation holds between a pair of entities given the other KB relations and patterns the pair has been (probabilistically) assigned in the matrix.
RDF representation
In order to populate Semantic Web KBs, it is necessary for the REL process to represent output relations as RDF triples. In the case of those systems that produce binary relations, each such relation will typically be represented as an RDF triple unless additional annotations about the relation – such as its provenance – are also captured. In the case of systems that perform EEL and a DS-style approach, it is furthermore the case that new IRIs typically will not need to be minted since the EEL process provides subject/object IRIs while the DS labeling process provides the predicate IRI from the KB. This process has the benefit of also directly producing RDF triples under the native identifier scheme of the KB. However, for systems that produce n-ary relations – e.g., according to frames, DRT, etc. – in order to populate the KB, an RDF representation must be defined. Some systems go further and provide RDFS/OWL axioms that enrich the output with well-defined semantics for the terms used [113].
The first step towards generating an RDF representation is to mint new IRIs for the entities and relations extracted. The BOA [117] framework proposes to first apply Entity Linking using a DS-style approach (where predicate IRIs are already provided), where for emerging entities not found in the KB, IRIs are minted based on the mention text. The FRED system [113] likewise begins by minting IRIs to represent all of the elements, roles, etc., produced by the Boxer DRT-based parser, thus skolemizing the events: grounding the existential variables used to denote such events with a constant (more specifically, an IRI).
Next, an RDF representation must be applied to structure the relations into RDF graphs. In cases where binary relations are not simply represented as triples, existing mechanisms for RDF reification – namely RDF n-ary relations, RDF reification, singleton properties, named graphs, etc. (see [134,272] for examples and more detailed discussion) – can, in theory, be adopted. In general, however, most systems define bespoke representations (most similar to RDF n-ary relations). Among these, Freitas et al. [109] propose a bespoke RDF-based discourse representation format that they call Structured Discourse Graphs capturing the subject, predicate and object of the relation, as well as (general) reification and temporal annotations; LODifier [12] maps Boxer output to RDF by mapping unary relations to
Rather than creating a bespoke RDF representation, other systems rather try to map or project extracted relations directly to the native identifier scheme and data model of the reference KB. Likewise, those systems that first create a bespoke RDF representation may apply an a posteriori mapping to the KB/ontology. Such methods for performing mappings are now discussed.
Relation mapping
While in a distant supervision approach, the patterns and features extracted from textual relation mentions are directly associated with a particular (typically binary) KB property, REL systems based on other extraction methods – such as parsing according to legacy OpenIE systems, or frames/DRS theory – are still left to align the extracted relations with a given KB.
A common approach – similar to distant supervision – is to map pairs of entities in the parsed relation mentions to the KB to identify what known relations correspond to a given relation pattern.62
More specifically, we distinguish between distant supervision approaches that use KB entities and relations to extract relation mentions (as discussed previously), and the approaches here, which extract such mentions without reference to the KB and rather map to the KB in a subsequent step, using matches between existing KB relations and parsed mentions to propose candidate KB properties.
In the case of systems that natively extract n-ary relations – e.g., those systems based on frames or DRS – the process of mapping such relations to a binary KB relation – sometimes known as projection of n-ary relations [167] – is considerably more complex. Rather than trying to project a binary relation from an n-ary relation, some approaches thus rather focus on mapping elements of n-ary relations to classes in the KB. Such an approach is adopted by Gerber et al. [116] for mapping elements of binary relations extracted via learned patterns to DBpedia entities and classes. The FRED system [113] likewise provides mappings of its DRS-based relations to various ontologies and KBs, including WordNet and DOLCE ontologies (using WSD) and the DBpedia KB (using EEL).
On the other hand, other systems do propose techniques for projecting binary relations from n-ary relations and linking them with KB properties; such a process must not only identify the pertinent KB property (or properties), but also the subject and object entities for the given n-ary relation; furthermore, for DRS-style relations, care must be taken since the statement may be negated or may be part of a disjunction. Along those lines, Exner and Nugues [97] initially proposed to generate triples from DRS relations by means of a combinatorial approach, filtering relations expressed with negation. In follow-up work on the Refractive system, Exner and Nugues [98] later propose a method to map n-ary relations extracted using PropBank to DBpedia properties: existing relations in the KB are matched to extracted PropBank roles such that more matches indicate a better property match; thereafter, the subject and object of the KB relation are generalized to their KB class (used to identify subject/object in extracted relations), and the relevant KB property is proposed as a candidate for other instances of the same role (without a KB relation) and pairs of entities matching the given types. Legalo [251] proposes a method for mapping FRED results to binary KB relations by concatenating the labels of nodes on paths in the FRED output between elements identified as (potential) subject/object pairs, where these concatenated path labels are then mapped to binary KB properties to project new RDF triples. Rouces et al. [272], on the other hand, propose a rule-based approach to project binary relations from FrameNet patterns, where dereification rules are constructed to map suitable frames to binary triples by mapping frame elements to subject and object positions, creating a new predicate from appropriate conjugate verbs, further filtering passive verb forms with no clear binary relation.
Based on the previously discussed techniques, an overview of the highlighted REL systems is provided in Table 6, with a column legend provided in the caption. As before, we highlight approaches that are directly related with the Semantic Web and that offer a peer-reviewed publication with novel technical details regarding REL. With respect to the
Overview of relation extraction and linking systems. Entity Recognition denotes the NER or EEL strategy used; Parsing denotes the method used to parse relation mentions (Cons.: Constituency Parsing, Dep.: Dependency Parsing, DRS: Discourse Representation Structures, Emb.: Embeddings); PS refers to the Property Selection method (PG: Property Generation, RM: Relation Mapping, DS: Distant Supervision); Rep. refers to the reification model used for representation (SR: Standard Reification, BR: Binary Relation); KB refers to the main knowledge-base used; “—” denotes no information found, not used or not applicable
Overview of relation extraction and linking systems.
Choosing an RE strategy for a particular application scenario can be complex given that every approach has pros and cons regarding the application at hand. However, we can identify some key considerations that should be taken into account:
Binary vs. n-ary: Does the application require binary relations or does it require n-ary relations? Oftentimes the results of systems that produce binary relations can be easier to integrate with existing KBs already composed of such, where DS-based approaches, in particular, will produce triples using the identifier scheme of the KB itself. On the other hand, n-ary relations may capture more nuances in the discourse implicit in the text, for example, capturing semantic roles, negation, disjunction, etc., in complex relations.
Identifier creation: Does the application require finding and identifying new instances in the text not present in the KB? Does it require finding and identifying emerging relations? Most DS-based approaches do not consider minting new identifiers but rather focus on extracting new triples within the KB’s universe (the sets of identifiers it provides). However, there are some exceptions, such as BOA [117]. On the other hand, most REL systems dealing with n-ary relations mint new IRIs as part of their output representation.
Language: Does the application require extraction for a language other than English? Though not discussed previously, we note that almost all systems presented here are evaluated only for English corpora, the exceptions being BOA [117], which is tested for both English and German text; and the work by Fossati et al. [106], which is tested for Italian text. Thus in scenarios involving other languages, it is important to consider to what extent an approach relies on a language-specific technique, such as POS-tagging, dependency parsing, etc. Unfortunately, given the complexity of REL, most works are heavily reliant on such language-specific components. Possible solutions include trying to replace the particular component with its equivalent in another language (which has no guarantees to work as well as those tested in evaluation), or, as proposed for the FRED [113] tool, use an existing API (e.g., Bing!, Google, etc.) to translate the text to the supported language (typically English), with the obvious caveat of the potential for translation errors (though such services are continuously improving in parallel with, e.g., Deep Learning).
Scale & Efficiency: In applications dealing with large corpora, scalability and efficiency become crucial considerations. With some exceptions, most of the approaches do not explicitly tackle the question of scale and efficiency. On the other hand, REL should be highly parallelizable given that processing of different sentences, paragraphs and/or documents can be performed independently assuming some globally-accessible knowledge from the KB. Parallelization has been used, e.g., by Nakashole et al. [223], who cluster relational patterns using a distributed MapReduce framework. Indeed, initiatives such as Knowledge Vault – using standard DS-based REL techniques to extract 1.6 billion triples from a large-scale Web corpus – provide a practical demonstration that, with careful engineering and selection of techniques, REL can be applied to corpora at a very large (potentially Web) scale.
Various other considerations, such as availability or licensing of software, provision of an API, etc., may also need to be taken into account.
Of course, a key consideration when choosing an REL approach is the quality of output produced by that approach, which can be assessed using the evaluation protocols discussed in the following section.
REL is a challenging task, where evaluation is likewise complicated by a number of fundamental factors. In general, human judgment is often required to assess the quality of the output of systems performing such a task, but such assessments can often be subjective. Creating a gold-standard dataset can likewise be complicated, particularly for those systems producing n-ary relations, requiring an expert informed on the particular theory by which such relations are extracted; likewise, in DS-related scenarios, the expert must label the data according to the available KB relations, which may be a tedious task requiring in-depth knowledge of the KB. Rather than creating a gold-standard dataset, another approach is to apply a posteriori assessment of the output by human judges, i.e., run the process over unlabeled text, generate relations, and have the output validated by human judges; while this would appear more reasonable for systems based on frames or DRS – where creating a gold-standard for such complex relations would be arduous at best – there are still problems in assessing, for example, recall.63
Likewise we informally argue that a human judge presented with results of a system is more likely to confirm that output and give it the benefit of subjectivity, especially when compared with the creation of a gold standard dataset where there is more freedom in choice of relations and more ample opportunity for subjectivity.
In summary, then, approaches for evaluating REL are quite diverse and in many cases there are no standard criteria for assessing the adequacy of a particular evaluation method. Here we discuss some of the main themes for evaluation, broken down by datasets used, how evaluators are employed to judge the output, how automated evaluation can be conducted, and what are the typical metrics considered.
Datasets: Most approaches consider REL applied to general-domain corpora, such as Wikipedia articles, Newspaper articles, or even webpages. However, to simplify evaluation, many approaches may restrict REL to consider a domain-specific subset of such corpora, a fixed subset of KB properties or classes, and so forth. For example, Fossati et al. [106] focus their REL efforts on the Wikipedia articles about Italian soccer players using a selection of relevant frames; Augenstein et al. [11] apply evaluation for relations pertaining to entities in seven Freebase classes for which relatively complete information is available, using the Google Search API to find relevant documents for each such entity; and so forth.
A number of standard evaluation datasets have, however, emerged, particularly for approaches based on distant supervision. A widely reused gold-standard dataset, for example, was that initially proposed by Riedel et al. [257] for evaluating their system, where they select Freebase relations pertaining to people, businesses and locations (corresponding also to NER types) and then link them with New York Times articles, first using Stanford NER to find entities, then linking those entities to Freebase, and finally selecting the appropriate relation (if any) to label pairs of entities in the same sentence with; this dataset was later reused by a number of works [141,258,292]. Other such evaluation resources have since emerged. Google Research64
provides five REL corpora, with relation mentions from Wikipedia linked with manual annotation to five Freebase properties indicating institutions, date of birth, place of birth, place of death, and education degree. Likewise, the Text Analysis Conference often hosts a Knowledge Base Population (TAC–KBP) track, where evaluation resources relating to the REL task can be found;65For example, see https://tac.nist.gov/2017/KBP/ColdStart/index.html.
For example, see Task 3: https://github.com/anuzzolese/oke-challenge-2016.
Note that all prior evaluation datasets relate to binary relations of the form subject–predicate–object. Creating gold standard datasets for n-ary relations is complicated by the heterogeneity of representations that can be employed in terms of frames, DRS or other theories used. To address this issue, Gangemi et al. [114] proposed the construction of RDF graphs by means of logical patterns known as motifs that are extracted by the FRED tool and thereafter manually corrected and curated by evaluators to follow best Semantic Web practices; the result is a corpus annotated by instances of such motifs that can be reused for evaluation of REL tools producing similar such relations.
Evaluators: In scenarios for which a gold standard dataset is not available – or not feasible to create – the results of the REL process are often directly evaluated by humans. Many papers assign experts to evaluate the results, typically (we assume) authors of the papers, though often little detail on the exact evaluation process is given, aside from a rater agreement expressed as Cohen’s or Fleiss’ κ-measure for a fixed number of evaluators (as discussed in Section 3.7).
Aside from expert evaluation, some works leverage crowdsourcing platforms for labeling training and test datasets, where a broad range of users contribute judgments for a relatively low price. Amongst such works, we can mention Mintz et al. [213] using Amazon’s Mechanical Turk67
for evaluating relations, while Legalo [251] and Fossati et al. [106] use the Crowdflower68 platform (now called Figure Eight).Automated evaluation: Some works have proposed methods for performing automated evaluation of REL processes, in particular for testing DS-based methods. A common approach is to perform held-out experiments, where KB relations are (typically randomly) omitted from the training/DS phase and then metrics are defined to see how many KB relations are returned by the process, giving an indicator of recall; the intuition of such approaches is that REL is often used for completing an incomplete KB, and thus by holding back KB triples, one can test the process to see how many such triples the process can reinstate. Such an approach avoids expensive manual labeling but is not very suitable for precision since the KB is incomplete, and likewise assumes that held-out KB relations are both correct and mentioned in the text. On the other hand, such experiments can help gain insights at larger scales for a more diverse range of properties, and can be used to assess a relative notion of precision (e.g., to tune parameters), and have thus been used by Mintz et al. [213], Takamatsu et al. [293], Knowledge Vault [86], Lin et al. [179], etc. On the other hand, as mentioned previously, some works – including Knowledge Vault [86] – adopt a partial Closed World Assumption as a heuristic to generate negative examples taking into account the incompleteness of the KB; more specifically, extracted triples of the form
Metrics: Standard evaluation measures are typically applied, including precision, recall, F-measure, accuracy, Area-Under-Curve (AUC–ROC), and so forth. However, given that relations may be extracted for multiple properties, sometimes macro-measures such as Mean Average Precision (MAP) are applied to summarize precision across all such properties rather than taking a micro precision measure [92,213,293]. Given the subjectivity inherent in evaluating REL, Fossati et al. [106] use a strict and lenient version of precision/recall/F-measure, where the former requires the relation to be exact and complete, while the latter also considers relations that are partially correct; relating to the same theme, the Legalo system includes confidence as a measure indicating the level of agreement and trust in crowdsourced evaluators for a given experiment. Some systems produce confidence or supports for relations, where P@k measures are sometimes used to measure the precision for the top-k results [179,182,213,257]. Finally, given that REL is inherently composed of several phases, some works present metrics for various parts of the task; as an example, for extracted triples, Dutta [93] considers a property precision (is the mapped property correct?), instance precision (are the mapped subjects/objects correct?), triple precision (is the extracted triple correct?), amongst other measures to, for example, indicate the ratio of extracted triples new to the KB.
Third-party comparisons: While some REL papers include prior state-of-the-art approaches in their evaluations for comparison purposes, we are not aware of a third-party study providing evaluation results of REL systems. Although Gangemi [112] provides a comparative evaluation of Alchemy, CiceroLite, FRED and ReVerb – all with public APIs available – for extracting relations from a paragraph of text on the Syrian war, he does not publish results for a linking phase; FRED is the only REL tool tested that outputs RDF.
Despite a lack of third-party evaluation results, some comparative metrics can be gleaned from the use of standard datasets over several papers relating to distant supervision; we stress, however, that these are often published in the context of evaluating a particular system (and hence are not strictly third-party comparisons69
We remark that the results of Gangemi [112] are strictly not third-party either due to the inclusion of results from FRED [113].
This section presented the task of Relation Extraction and Linking in the context of the Semantic Web. The applications for such a task include KB Population, Structured Discourse Representation, Machine Reading, Question Answering, Fact Verification, amongst a variety of others. We discussed relevant papers following a high-level process consisting of: entity extraction (and coreference resolution), relation parsing, distant supervision, relation clustering, RDF representation, relation mapping, and evaluation. It is worth noting, however, that not all systems follow these steps in the presented order and not all systems apply (or even require) all such steps. For example, entity extraction may be conducted during relation parsing (where particular arguments can be considered as extracted entities), distant supervision does not require a formal representation nor relation-mapping phase, and so forth. Hence the presented flow of techniques should be considered illustrative, not prescriptive.
In general, we can distinguish two types of REL systems: those that produce binary relations, and those that produce n-ary relations (although binary relations can subsequently be projected from the latter tools [251,272]). With respect to binary relations, distant supervision has become a dominating theme in recent approaches, where KB relations are used, in combination with EEL and often CR, to find example mentions of binary KB relations, generalizing patterns and features that can be used to extract further mentions and, ultimately, novel KB triples; such approaches are enabled by the existence of modern Semantic Web KBs with rich factual information about a broad range of entities of general interest. Other approaches for extracting binary relations rather rely on mapping the results of existing OpenIE systems to KBs/ontologies. With respect to extracting n-ary relations, such approaches rely on more traditional linguistic techniques and resources to extract structures according to frame semantics or Discourse Representation Theory; the challenge thereafter is to represent the results as RDF and, in particular, to map the results to an existing KB, ontology, or collection thereof.
Open questions
REL is a very important task for populating the Semantic Web. Several techniques have been proposed for this task in order to cover the extraction of binary and n-ary relations from text. However, some aspects could still be improved or developed further:
Relation types: Unlike EEL where particular types of entities are commonly extracted, in REL it is not easy to define the types of relations to be extracted and linked to the Semantic Web. Previous studies, such as the one presented by Storey [290], provide an organization of relations – identified from disciplines such as linguistics, logic, and cognitive psychology – that can be incorporated into traditional database management systems to capture the semantics of real world information. However, to the best of our knowledge, a thorough categorization of semantic relationships on the Semantic Web has not been presented, which in turn, could be useful for defining requirements of information representation, standards, rules, etc., and their representation in existing standards (RDF, RDFS, OWL). Specialized Settings/Multilingual REL: In brief, we can again raise the open question of adapting REL to settings with noisy text (such as Twitter) and generalizing REL approaches to work with multiple languages. In this context, DS approaches may prove to be more successful given that they rely more on statistical/learning frameworks (i.e., they do not require curated databases of relations, roles, etc., which are typically specific to a language), and given that KBs such as Wikidata, DBpedia and Babelnet can provide examples of relations in multiple languages. Datasets: The preferred evaluation method for the analyzed approaches is through an a posteriori manual assessment of represented data. However, this is an expensive task that requires human judges with adequate knowledge of the domain, language, and representation structures. Although there are a couple of labeled datasets already published (particularly for DS approaches), the definition of further datasets would benefit the evaluation of approaches under more diverse conditions. The problem of creating a reference gold standard would then depend on the first point, relating to what types of relations should be targeted for extraction from text in domain-specific and/or open-domain settings, and how the output should be represented to allow comparison with the labeled relations for the dataset. Evaluation: Existing REL approaches extract different outputs relating to particular entity types, domains, structures, and so on. Thus, evaluating/comparing different approaches is not a straightforward task. Another challenge is to allow for a more fine-grained evaluation of REL approaches, which are typically complex pipelines involving various algorithms, resources, and often external tools, where noisy elements extracted in some early stage of the process can have a major negative effect on the final output, making it difficult to interpret the cause of poor evaluation results or the key points that should be improved.
Semi-structured information extraction
The primary focus of the survey – and the sections thus far – is on Information Extraction over unstructured text. However, the Web is full of semi-structured content, where HTML, in particular, allows for demarcating titles, links, lists, tables, etc., imposing a limited structure on documents. While it is possible to simply extract the text from such sources and apply previous methods, the structure available in the source, though limited, can offer useful hints for the IE process.
Hence a number of works have emerged proposing Information Extraction methods using Semantic Web languages/resources targeted at semi-structured sources. Some works are aimed at building or otherwise enhancing Semantic Web KBs (where, in fact, many of the KBs discussed originated from such a process [139,171]). Other works rather focus on enhancing or annotating the structure of the input corpus using a Semantic Web KB as reference. Some works make significant reuse of previously discussed techniques for plain text – particularly Entity Linking and sometimes Relation Extraction – adapted for a particular type of input document structure. Other works rather focus on custom techniques for extracting information from the structure of a particular data source.
Overview of information extraction systems for markup documents. Task denotes the IE task(s) considered (EEL: Entity Extraction & Linking, CEL: Concept Extraction & Linking, REL: Relation Extraction & Linking); Structure denotes the type of document structure leveraged for the IE task; “—” denotes no information found, not used or not applicable
Overview of information extraction systems for markup documents.
Our goal in this section is thus to provide an overview of some of the most popular techniques and tools that have emerged in recent years for Information Extraction over semi-structured sources of data using Semantic Web languages/resources. Given that the techniques vary widely in terms of the type of structure considered, we organize this section differently from those that came before. In particular, we proceed by discussing two prominent types of semi-structured sources – markup documents and tables – and discuss works that have been proposed for extracting information from such sources using Semantic Web KBs.
We do not include languages or approaches for mapping from one explicit structure to another (e.g., R2RML [72]), nor that rely on manual scraping (e.g., Piggy Bank [146]), nor tools that simply apply existing IE frameworks (e.g., Magpie [94], RDFaCE [159], SCMS [229]). Rather we focus on systems that extract and/or disambiguate entities, concepts, and/or relations from the input sources and that have methods adapted to exploit the partial structure of those sources (i.e., they do not simply extract and apply IE processes over plain text). Again, we only include proposals that in some way directly involve a Semantic Web standard (RDF(S)/OWL/SPARQL, etc.), or a resource described in those standards, be it to populate a Semantic Web KB, or to link results with such a KB.
The content of the Web has traditionally been structured according to the HyperText Markup Language (HTML), which lays out a document structure for webpages to follow. While this structure is primarily perceived as a way to format, display and offer navigational links between webpages, it can also be – and has been – leveraged in the context of Information Extraction. Such structure includes, for example, the presence of hyperlinks, title tags, paths in the HTML parse tree, etc. Other Web content – such as Wikis – may be formatted in markup other than HTML, where we include frameworks for such formats here. We provide an overview of these works in Table 7. Given that all such approaches implement diverse methods that depend on the markup structure leveraged, we will not discuss techniques in detail. However, we will provide more detailed discussion for IE techniques that have been proposed for HTML tables in a following section.
(Conceptual Open Hypermedia Service) uses a reference taxonomy to provide personalized semantic annotation and hyperlink recommendation for the current webpage that a user is browsing. A use-case is discussed for such annotation/recommendation in the biomedical domain, where a SKOS taxonomy can be used to recommend links to further material on more/less specific concepts appearing in the text, with different types of users (e.g., doctors, the public) receiving different forms of recommended links.
is a prominent initiative to extract a rich RDF KB from Wikipedia. The main source of extracted information comes from the semi-structured info-boxes embedded in the top right of Wikipedia articles; however, further information is also extracted from abstracts, hyperlinks, categories, and so forth. While much of the extracted information is based on manually-specified mappings for common attributes, components are provided for higher-recall but lower-precision automatic extraction of info-box information, including recognition of datatypes, etc.
uses Keyphrase Extraction to semantically annotate webpages, linking keywords to DBpedia. The approach breaks webpages down into “semantic blocks” describing specific elements based on HTML elements; Keyphrase Extraction is the applied over individual blocks. Evaluation is conducted in the E-Commerce domain, adding RDFa annotations using the Goodrelations vocabulary [132].
aims to semantically annotate webpages with RDFa, incorporating embedded links to existing Linked Data KBs. The process is based on an input KB, where labels of instances, classes and properties are extracted. A custom IE pipeline is then defined to chunk text and match it with the reference labels, with disambiguation performed based on existing relations in the KB for resolved entities. Facts from the KB are then matched to the resolved instances and used to embed RDFa annotations in the webpage.
was discussed before in the context of Relation Extraction & Linking over text. However, the system also includes a component for extracting features from the structure of HTML pages. More specifically, the system extracts the Document Object Model (DOM) from a webpage, which is essentially a hierarchical tree of HTML tags. For relations identified on the webpage using a DS approach, the path in the DOM tree between both entities (for which an existing KB relation exists) is extracted as a feature.
applies Relation Extraction based on the hyperlinks of webpages that describe entities, with the intuition that the anchor text (or more generalized context) of the hyperlink will contain textual hints about the relation between both entities. More specifically, a frame-based representation of the textual context of the hyperlink is extracted and linked with a KB; next, to create a label for a direct binary relation (an RDF triple), rules are applied on the frame-based representation to concatenate labels on the shortest path, adding event and role tags. The label is then linked to properties in existing vocabularies.
(Link the entIties in wEb lists with the knowledGe basE) performs EEL with respect to YAGO and Wikipedia over the text elements of HTML lists embedded in webpages. The authors propose specific features for disambiguation in the context of such lists where, in particular, the main assumption is that the entities appearing in an HTML list will often correspond to the same concept; this intuition is captured with a similarity-based measure that, for a given list, computes the distance of the types of candidate entities in the class hierarchy of YAGO. Other typical disambiguation features for EEL, such as prior probability, keyword-based similarities between entities, etc., are also applied.
propose a method for using Linked Data to perform enhanced wrapper induction: leveraging the often regular structure of webpages on the same website to extract a mapping that serves to extract information in bulk from all its pages. LODIE then proposes to map webpages to an existing KB to identify the paths in the HTML parse tree that lead to known entities for concepts (e.g., movies), their attributes/relations (e.g., runtime, director), and associated values. These learned paths can then be applied to unannotated webpages on the site to extract further (analogous) information.
focus on Topic Modeling for webpages guided by a reference ontology. The overall process involves applying Keyphrase Extraction over the textual content of the webpage, mapping the keywords to an ontology, and then using the ontology to decide the topic. However, the authors propose to leverage the structure of HTML, where keywords extracted from the title, the meta-tags or the section-headers are analyzed first; if no topic is found, the process resorts to using keywords from the body of the document.
is another major initiative for extracting information from Wikipedia in order to create a Semantic Web KB. Most information is extracted from info-boxes, but also from categories, titles, etc. The system also combines information from GeoNames, which provides geographic context; and WordNet, which allows for extracting cleaner taxonomies from Wikipedia categories. A distinguishing aspect of YAGO2 is the ability to capture temporal information as a first-class dimension of the KB, where entities and relations/attributes are associated with a hierarchy of properties denoting start/end dates.
It is interesting to note that KBs such as DBpedia [171] and YAGO2 [139] – used in so many of the previous IE works discussed throughout the survey – are themselves the result of IE processes, particularly over Wikipedia. This highlights something of a “snowball effect”, where as IE methods improve, new KBs arise, and as new KBs arise, IE methods improve.70
Though of course, we should not underestimate the value of Wikipedia itself as a raw source for IE tasks.
Tabular data are common on the Web, where HTML tables embedded in webpages are plentiful and often contain rich, semi-structured, factual information [35,65]. Hence, extracting information from such tables is indeed a tempting prospect. However, web tables are primarily designed with human readability in mind rather than machine readability. Web tables, while numerous, can thus be highly heterogeneous and idiosyncratic: even tables describing similar content can vary widely in terms of structuring that content [65]. More specifically, the following complications arise when trying to extract information from such tables:
Although Web tables are easy to identify (using the
Even tables containing factual data can vary greatly in structure: they may be “transposed”, or may simply list attributes in one column and values in another, or may represent a matrix of values. Sometimes a further subset – called “relational tables” [35] – are thus extracted, where the table contains a column header, with subsequent rows comprising tuples in the relation.
Even relational tables may contain irregular structure, including cells with multiple rows separated by an informal delimiter (e.g., a comma), nested tables as cell values, merged cells with vertical and/or horizontal orientation, tables split into various related sections, and so forth [245].
Although column headers can be identified as such using (
Column names and cell values often lack clear identifiers or typing: Web tables often contain potentially ambiguous human-readable labels.
There have thus been numerous works on extracting information from tables, sometimes referred to as table interpretation, table annotation, etc. (e.g., [35,45,65,245,307,318], to name some prominent works). The goal of such works is to interpret the implicit structure of tables so as to categorize them for search; or to integrate the information they contain and enable performing joins over them, be it to extend tables with information from other tables, or extracting the information to an external unified representation that can be queried.
More recently, a variety of approaches have emerged using Semantic Web KBs as references to help with extracting information from tables (sometimes referred to as semantic table interpretation, semantic table annotation, etc.). We discuss such approaches herein.
Process: While proposed approaches vary significantly, more generally, given a table and a KB, such works aim to link tables/columns to KB classes, link columns or tuples of columns to KB properties, and link individual cells to KB entities. The aim can then be to annotate the table with respect to the KB (useful for, e.g., later integrating or retrieving tables), and indeed to extract novel entities or relations from the table to further populate the KB. Hence we consider this an IE scenario. While methods discussed previously for IE over unstructured sources can be leveraged for tables, the presence of a tabular structure does suggest the applicability of novel features for the IE process. For example, one might expect in some tables to find that elements of the same column pertain to the same type, or pairs of entities on the same row to have a similar relation as analogous pairs on other rows. On the other hand, cells in a table have a different textual context, which may be the caption, the text referring to the table, etc., rather than the surrounding text; hence, for example, distributional approaches intended for text may not be directly applicable for tables.
Overview of information extraction systems for Web tables. EEL and REL denotes the entity extraction & linking and relation extraction & linking strategies used; Annotation denotes the elements of the table considered by the approach (P: Protagonist, E: Entities, S: Subject column, T: Column types, R: Relations, T′: Table type); KB denotes the reference KB used (WDC: WebDataCommons, BTC: Billion Triple Challenge 2014); ‘—’ denotes no information found, not used or not applicable
Overview of information extraction systems for Web tables.
Example: Consider an HTML table embedded in a webpage about the actor Bryan Cranston as follows:
We see that the table contains various entities, and that entities in the same column tend to correspond to a particular type. We also see that entities on each row often have implicit relations between them, organized by column; for example, on each row, there are binary relations between the elements of the
In fact, we could consider each tuple as an n-ary relation involving Bryan Cranston; however, this goes more towards a Direct Mapping representation of the table [8,83]; rather the methods we discuss focus on extraction of binary relations.
The approaches we enumerate here attempt to identify entities in table cells, assign types to columns, extract binary KB relations across columns, and so forth.
However, we also see some complications in the table structure, where some values span multiple cells. While this particular issue is relatively trivial to deal with – where simply duplicating values into each spanned cell is effective [245] – a real-world collection of (HTML) tables may exhibit further such complications; here we gave a relatively clean example.
Systems: We now discuss works that aim to extract entities, concepts or relations from tables, using Semantic Web KBs. We also provide an overview of these works in Table 8.72
We also note that many such works were covered by the recent survey of Ristoski and Paulheim [261], but with more of an emphasis on data mining aspects. We are interested in such papers from a related IE perspective where raw entities/concepts/relations are extracted; hence they are also included here for completeness.
is primarily an Entity Linking tool (discussed in more detail previously in Section 2), but it provides parsers for extracting and linking entities in HTML tables; however, no table-specific features are discussed in the paper.
aims to extract relations in the form of DBpedia triples from Wikipedia’s tables. The process uses internal Wikipedia hyperlinks in tables to link cells to DBpedia entities. Relations are then analyzed on a row-by-row basis, where an existing relation in DBpedia between two entities in one row is postulated as a candidate relation for pairs of entities in the corresponding columns of other rows; implicit relations from the entity of the article containing the table and the entities in each column of the table are also considered for generating candidate relations. These relations – extracted as DBpedia triples – are then filtered using classifiers that consider a range of features for the source cells, columns, rows, headers, etc., thus generating the final triples.
extracts relations from 570 million Web tables. First, an EEL process is applied to identify entities in a given table. Next, these entities are matched to Freebase and compared with existing relations. These relations are then proposed as candidates relations between the two columns of the table in question. Thereafter, ambiguous columns are discarded with respect to the existing KB relations and extracted facts are assigned a confidence score based on the EEL process. A total of 9.4 million Freebase facts are ultimately extracted in the final result.
propose a probabilistic model that, given YAGO as a reference KB and a Web table as input, simultaneously assigns entities to cells, types to columns, and relations to pairs of columns. The core intuition is that the assignment of a candidate to one of these three aspects affects the assignment of the other two, and hence a collective assignment can boost accuracy. A variety of features are thus defined over the table in relation to YAGO, over which joint inference is applied to optimize a collective assignment.
(Mannheim Search Join Engine) aims to extend a given input (HTML) table with additional attributes (columns) and associated values (cells) using a reference data corpus comprising of Linked Data KBs and other tables. The engine first identifies a “subject” column of the input table deemed to contain the names of the primary entities described; the datatype (domain) of other columns is then identified. This meta-description is used to search for other data with the same entities using information retrieval techniques. Thereafter, retrieved tables are (left-outer) joined with the input table based on a fuzzy match of columns, using the attribute names, ontological hierarchies and instance overlap measures.
aim to annotate tables with respect to a reference KB by linking columns to classes, cells to (fresh) entities or literals, and pairs of columns to properties denoting their relation. The KB that they consider combines DBpedia, YAGO and Wikipedia. Candidate entities are derived using keyword search on the cell value and surrounding values for context; candidate column classes are taken as the union of all classes in the KB for candidate entities in that column; candidate relations for pairs of columns are chosen based on existing KB relations between candidate entities in those columns; thereafter, a joint inference step is applied to select a suitable collective assignment of cell-to-entity, column-to-class and column-pair-to-property mappings.
uses specialized ontologies to guide the annotation and subsequent extraction of information from Web tables. A core ontology encodes general concepts, unit concepts for quantities, and relations between concepts. On the other hand, a domain ontology is used to capture a class hierarchy in the domain of extraction, where classes are associated with labels. Table columns are then categorized by the ontology classes and tuples of columns are categorized by ontology relations, using a combination of cosine-similarity matching on the column names and the column values. Fuzzy sets are then used to represent a given annotation, encoding uncertainty, with an RDF-based representation used to represent the result. The extracted fuzzy information can then be queried using SPARQL.
enumerate and evaluate a variety of features that can be brought to bear for extracting information from tables. They consider a taxonomy of features that covers: features extracted from the table itself, including from a single (header/value) cell, or multiple cells; and features extracted from the surrounding context of the table, including page attributes (e.g., title) or free text. Using these features, they then consider three matching tasks with respect to DBpedia and an input table: row-to-entity, column-to-property, and table-to-class, where various linking strategies are defined. The scores of these matchers are then aggregated and tested against a gold standard to determine the usefulness of individual features, linking strategies and aggregation metrics on the precision/recall of the resulting assignments.
focuses on the task of EEL for tables with respect to YAGO, where they begin by applying a standard EEL process over cells: extracting mentions and generating candidate KB identifiers. Multiple entities can be extracted per cell. Thereafter, various features are assigned to candidates, including prior probabilities, string similarity measures, and so forth. However, they also include special features for tables, including a repetition feature to check if the mention has been linked elsewhere in the table and also a measure of semantic similarity for entities assigned to the same row or table; these features are encoded into a model over which joint inference is applied to generate a collective assignment.
annotates tables with respect to Freebase by first identifying a subject column considered to contain the names of the entities being primarily described. Next, a learning phase is applied on each entity column (distinguished from columns containing datatype values) to annotate the column and the entities it contains; this process can involve sampling of values to increase efficiency. Next, an update/refinement phase is applied to collectively consider the (keyword-based) similarity across column annotations. Relations are then extracted from the subject column to other columns based on existing triples in the KB and keyword similarity metrics.
focus on the problem of assigning a DBpedia type to each column of an input table. The process involves three steps. First, a set of candidate identifiers is extracted for each cell. Next, the types (both classes and categories) are extracted from each candidate. Finally, for a given column, the type most frequently extracted for the entities in its cells is assigned as the type for that column.
Summary: Hence we see that exploring custom IE processes dedicating to tabular input formats using Semantic Web KBs is a burgeoning but still relatively recent area of research; techniques combine a mix of traditional IE methods as described previously, as well as novel low-level table-specific features and high-level global inference models that capture the dependencies in linking between different columns of the same table, different cells of the same column or row, etc.
Also, approaches vary in what they annotate. For example, while Zwicklbauer et al. [335] focus on typing columns, and AIDA [140] and TabEL [21] focus on annotating entities, most works annotate various aspects of the table, in particular for the purposes of extracting relations. Amongst those approaches extracting relations, we can identify an important distinction: those that begin by identifying a subject column to which all other relations extend [172,262,327], and those that rather extract relations between any pair of columns in the table [30,86,176,218,219]. All approaches that we found for Relation Extraction, however, rely on extracting a set of features and then applying machine learning methods to classify likely-correct relations; similarly, almost all approaches rely on a “distant supervision” style algorithm, where seed relations in the KB appearing in rows of the table are used as a feature to identify candidate relations between column pairs. In terms of other annotations, we note that DRETa [219] extracts the protagonist of a table as the main entity about which the containing webpage is about (considered an entity with possible relations to entities in the table), while Ritze and Bizer [262] extract a type for each table that is based on the type(s) of entities in the subject column.
Information Extraction has also been applied to various other formats in conjunction with Semantic Web KBs and/or ontologies. Amongst these, a number of works have proposed specialized EEL techniques for multimedia formats, including approaches for performing EEL with respect to images [17], audio (speech) [19,253], and video [175,204,310]. Other works have focused on IE techniques in the context of social platforms, such as for Twitter [79,320,322], tagging systems [160,287], or for other user-generated content, such as keyword search logs [63], etc.
Techniques inspired by IE have also been applied to structured input formats, including Semantic Web KBs themselves. For example, a variety of approaches have been recently proposed to model topics for Semantic Web KBs themselves, either to identify the main topics within a KB, or to identify related KBs [25,240,267,283]. Given that such methods apply to structured input formats, these works veer away from pure Information Extraction and head more towards the related areas of Data Mining and Knowledge Discovery – as discussed already in a recent survey by Ristoski and Paulheim [261] – where the goal is to extract high-level patterns from data for applications including KB refinement, recommendation tasks, clustering, etc. We thus consider such works as outside the current scope.
Discussion
In this survey, we have discussed a wide variety of works that lie at the intersection of the Information Extraction and Semantic Web areas. In particular, we discussed works that extract entities, concepts and relations from unstructured and semi-structured sources, linking them with Semantic Web KBs/ontologies.
Trends: The works that we have surveyed span almost two decades. Interpreting some trends from Tables 3, 5, 6, 7 & 8, we see that earlier works (prior to ca. 2009) in this intersection related more specifically to Information Extraction tasks that were either intended to build or populate domain-specific ontologies, or were guided by such ontologies. Such ontologies were assumed to model the conceptual domain under analysis but typically without providing an extensive list of entities; as such, traditional IE methods were used involving NER of a limited range of types, machine-learning models trained over manually-labeled corpora, handcrafted linguistic patterns and rules to bootstrap extraction, generic linguistic resources such as WordNet for modeling word sense/hypernyms/synsets, deep parsing, and so forth.
However, post 2009, we notice a shift towards using general-domain KBs – DBpedia, Freebase, YAGO, etc. – that provide extensive lists of entities (with labels and aliases), a wide variety of types and categories, graph-structured representations of cross-domain knowledge, etc. We also see a related trend towards more statistical, data-driven methods. We posit that this shift is due to two main factors: (i) the expansion of Wikipedia as a reference source for general domain knowledge – and related seminal works proposing its exploitation for IE tasks – which, in turn, naturally translate into using KBs such as DBpedia and YAGO extracted from Wikipedia; (ii) advancement in statistical NLP techniques that emphasize understanding of language through relatively shallow analyses of large corpora of text (for example, techniques based on the distributional hypothesis) rather than use of manually crafted patterns, training over labeled resources, or deep linguistic parsing. Of course, we also see works that blend both worlds, making the most of both linguistic and statistical techniques in order to augment IE processes.
Another general trend we have observed is one towards more “holistic” methods – such as collective assignment, joint models, etc. – that consider the interdependencies implicit in extracting increasingly rich machine-readable information from text. On the one hand, we can consider intra-task dependencies being modeled where, for example, linking one entity mention to a particular KB entity may affect how other surrounding entities are linked. On the other hand, more and more in the recent literature we can see inter-task dependencies being modeled, where the tasks of NER and EEL [184,231], or WSD and EEL [145,216], or EEL and REL [11], etc., are seen as interdependent. We see this trend of jointly modeling several interrelated aspects of IE as set to continue, following the idea that improving IE methods requires looking at the “bigger picture” and not just one aspect in isolation.
Communities: In terms of the 109 highlighted papers in this survey for EEL, CEL, REL and Semi-Structured Inputs – i.e., those papers referenced in the first columns of Tables 3, 5, 6, 7 & 8 – we performed a meta-analysis of the venues (conferences or journals) at which they were published, and the primary area(s) associated with that venue. The results are compiled in Table 9, showing 18 (of 55) venues with at least two such papers; for compiling these results, we count workshops and satellite events under the conference with which they were co-located. While Semantic Web venues top the list, we notice a significant number of papers in venues associated with other areas.
Top venues where highlighted papers are published. Venue denotes publication series,
In order to perform a higher-level analysis of the areas from which the highlighted works have emerged, we mapped venues to areas (as shown for the venues in Table 9). In some cases the mapping from venues to areas was quite clear (e.g., ISWC → Semantic Web), while in others we chose to assign two main areas to a venue (e.g., WSDM → Web/Data Mining). Furthermore, we assigned venues in multidisciplinary or otherwise broader areas (e.g., Information Science) to a general classification: Other. Table 10 then aggregates the areas in which all highlighted papers were published; in the case that a paper is published at a venue assigned to two areas, we count the paper as
Most generally, we see that works developing Information Extraction techniques in a Semantic Web context have been pursued within a variety of communities; in other words, the use of Semantic Web KBs has become popular in variety of other (non-SW) research communities interested in Information Extraction.
Top areas where highlighted papers are published.
Final remarks: Our goal with this work was to provide not only a comprehensive survey of literature in the intersection of the Information Extraction and Semantic Web areas, but also to – insofar as possible – offer an introductory text to those new to the area.
Hence we have focused on providing a survey that is as self-contained as possible, including a primer on traditional IE methods, and thereafter an overview on the extraction and linking of entities, concepts and relations, both for unstructured sources (the focus of the survey), as well as an overview of such techniques for semi-structured sources. In general, methods for extracting and linking relations, for example, often rely on methods for extracting and linking entities, which in turn often rely on traditional IE and NLP techniques. Along similar lines, techniques for Information Extraction over semi-structured sources often rely heavily on similar techniques used for unstructured sources. Thus, aside from providing a literature survey for those familiar with such areas, we believe that this survey also offers a useful entry-point for the uninitiated reader, spanning all such interrelated topics.
Likewise, as previously discussed, the relevant literature has been published by various communities, using sometimes varying terminology and techniques, with different perspectives and motivation, but often with a common underlying (technical) goal. By drawing together the literature from different communities, we hope that this survey will help to bridge such communities and to offer a broader understanding of the research literature at this now busy intersection where Information Extraction meets the Semantic Web.
Footnotes
Acknowledgements
This work was funded in part by the Millennium Institute for Foundational Research on Data (IMFD) and Fondecyt, Grant No. 1181896. We would also like to thank the reviewers as well as Henry Rosales-Méndez and Ana B. Rios-Alvarado for their helpful comments on the survey.
Primer: Traditional information extraction
Information Extraction (IE) refers to the automatic extraction of implicit information from unstructured or semi-structured data sources. Along these lines, IE methods are used to identify entities, concepts and/or semantic relations that are not otherwise explicitly structured in a given source. IE is not a new area and dates back to the origins of Natural Language Processing (NLP), where it was seen as a use-case of NLP: to extract (semi-)structured data from text. Applications of IE have broadened in recent years, particularly in the context of the Web, including the areas of Knowledge Discovery, Information Retrieval, etc.
To keep this survey self-contained, in this appendix, we will offer a general introduction to traditional IE techniques as applied to primarily textual sources. Techniques can vary widely depending on the type of source considered (short strings, documents, forms, etc.), the available reference information considered (databases, labeled data, tags, etc.), expected results, and so forth. Rather than cover the full diversity of methods that can be found in the literature – for which we rather refer the reader to a dedicated survey such as that provided by Sarawagi [274] – our goal will be to cover core tasks and concepts found in traditional IE pipelines, as are often (re)used by works in the context of the Semantic Web. We will also focus primarily on English-centric examples and tools, though much of the discussion generalizes (assuming the availability of appropriate resources) to other languages, which we discuss as appropriate.