
Abstract
Attempts to express information from various documents in graph form are rapidly increasing. The speed and volume in which these documents are being generated call for an automated process, based on machine learning techniques, for cost-effective and timely analysis. Past studies responded to such needs by building knowledge graphs or technology trees from the bibliographic information of documents, or by relying on text mining techniques in order to extract keywords and/or phrases. While these approaches provide an intuitive glance into the technological hotspots or the key features of the select field, there still is room for improvement, especially in terms of recognizing the same entities appearing in different forms so as to interconnect closely related technological concepts properly. In this paper, we propose to build a patent knowledge network using the United States Patent and Trademark Office (USPTO) patent filings for the semiconductor device sector by fine-tuning Huggingface’s named entity recognition (NER) model with our novel edge weight updating neural network. For the named entity normalization, we employ edge weight updating neural network with positive and negative candidates that are chosen by substring matching techniques. Experiment results show that our proposed approach performs very competitively against the conventional keyword extraction models frequently employed in patent analysis, especially for the named entity normalization (NEN) and document retrieval tasks. By grouping entities with named entity normalization model, the resulting knowledge graph achieves higher scores in retrieval tasks. We also show that our model is robust to the out-of-vocabulary problem by employing the fine-tuned BERT NER model.
Introduction
With the rapid increase in the volume of documents, studies on techniques for analyzing these documents and organizing textual information are continuing. Among information representation techniques, knowledge graphs are receiving more attention recently [1, 2, 3]. This increasing interest can be attributed to their effectiveness in various domains, such as drug purposing [2], stock market analysis [3], and generative knowledge graph construction [1] for general domains. Knowledge graphs express information from various documents in intuitive forms. By representing the information in more intuitive form, knowledge graph can foster the transfer and the concoction of knowledge. The construction of a knowledge graph consists of the following major processes: a data acquisition, a natural language processing (NLP), and entity pair creation [4]. NLP includes text preprocessing, part of speech tagging, named entity recognition (NER), named entity normalization (NEN). Many previous works for document knowledge graph construction utilize those text mining techniques. However, many of these studies are focused on connecting keywords and key phrases to documents. We find it would be more intuitive if the named entity knowledge graph is constructed especially for the domain professionals who will benefit from using knowledge graphs. For example, the named entity “NASA” is more intuitive for the domain experts than the descriptive key phrase, “the agency of U.S. for the civil space program and space research.” To construct the knowledge graph based on named entities, connecting named entities with the same meaning but with different surface forms should be conducted. We implement NEN techniques to overcome these problems. To be more specific, with our proposed NEN model, our goal is to link “NASA” and “National Aeronautics and Space Administration.”
Although this paper has mainly discussed NLP techniques, especially NER and NEN, and the construction of named entity knowledge graphs, it is essential to acknowledge related literature in fields such as entity resolution (ER) and reference matching. NEN and Entity resolution share the commonality of distinguishing and connecting entities with different representations with similar meanings. Reference matching is another technique that is widely used in retrieving the relative bibliographic records which involves identifying and matching different documents and citations that points to the same source. These fields share some similarities with the problem we address in this paper, as they all involve linking entities with different surface forms but the same underlying meaning. Our NEN model which connects the entities with different surface form is influenced by the ideas from ER studies. Incorporating insights from such studies leads more robust and a more effect model NEN model that ultimately improving the quality of the end product, the semiconductor-related patent knowledge graph. Our end-product, semiconductor-related patent knowledge graph, is tested to perform document retrieval from given named entity which is influence by the reference matching techniques.
In this paper, we present a novel named entity knowledge graph construction framework that can be applied to various text data. Specifically, we focus on patent documents. Patent documents are open to the public, there is a relatively larger amount of documents, and they contain many named entities including neologisms.
Recent advances in technology have been actively witnessed through a wide range of venues, one of which includes the patent claims. Patent claims contains information on the new breakthroughs at the forefront of the industry and academia in the rawest form, which may potentially help solve various tasks such as discovering contemporary technological trends, forecasting future developments in specific domains, evaluating ideas for R&D investment decisions, identifying competitors in the technological horse-races, or developing strategic technological planning [5].
The rapid speed and the vast volume of patent filings have been worsening the challenge of distillation of useful information from the claims, which is calling for the automation, at least in part, of patent analysis. Until recently, research on patent analysis has generally involved extracting technology trees based on the bibliographic connections of the claim filings [6] or extracting keywords using text mining techniques [7, 8, 9]. While these keyword-based approaches have provided meaningful insights on the current technological developments, only few attempts have been made to extract a more complicated form of information from the patent filings, such as named entities. Named entities, which include technological concepts, specific techniques used, names of the devices or the end products, and the associated company names, are of a significant importance for richer and deeper understanding of the innovations and technology underlying the patent filings.
Moreover, past efforts have failed to provide information on the intricate connectivity among the concepts extracted from the patent-related documents. For example, a well-designed keyword detection models may successfully determine the term “Gate-All-Around” to be the arising keyword alongside the word “transistors” from the patent filings within the field of semiconductor devices, yet it will not be able to show through which patent documents and other keywords these two phrases are interconnected. Furthermore, the conventional NLP approach will parse the terms “Gate-All-Around” and “GAA” separately as two independent terms, leaving the task of recognizing them as the same entities to additional human efforts.
In this study, we address the issues of interconnecting key technological concepts and matching the same entities appearing in different forms by constructing a semiconductor-related patent knowledge graph from patent filings using the NER and NEN models with a novel edge weight updating neural network. More specifically, we constructed the NEN dataset based on the patent documents. We fine-tuned the NER model [10] using Huggingface’s Python repository, pre-trained with the CoNLL-2003 NER dataset [11]. Our BERT token concatenator for NER tasks provides more complete named entity phrases. We propose a state-of-the-art NEN model with an edge weight updating neural network with triplet loss to extract named entities and connect them through the semiconductor related patent documents and present them in the form of a knowledge graph. Our proposed NEN model achieves the highest performance for not only the conventional candidate retrieval task in NEN but also pairwise named entity matching task.
Extensive experiment results show that our proposed approach performs, against the conventional keyword extraction models frequently employed in patent analysis, very competitively, especially for the NEN and document retrieval tasks. We also show that our knowledge graph construction method is robust to the out-of-vocabulary problem. Finally, we further contribute to the existing literature by releasing our semiconductor-related patent knowledge graph online, available for all non-commercial purposes. The remainder of this paper is organized as follows. We survey the literature related to our work in Section 2. In Section 3, we introduce our proposed method in detail. Section 4 reports experiment setting details. We report experiment results in Section 5, and Section 6 concludes the paper.
Related work
The importance of knowledge graphs is emphasized in [12, 13]. Knowledge graphs have attracted academic and industrial attention as a form of structured knowledge representation. We conduct the literature survey regarding the key components in our proposed framework for creating the technical document knowledge graph. Section 2.1 describes the dataset used for the NEN model training in various fields. Section 2.2 reports the studies involving NEN. Section 2.3 outlines the knowledge graph construction of documents from various subjects.
Named entity normalization dataset
To fulfill the need for the domain-specific NEN dataset which is used to train NEN models, many NEN datasets are developed. For example, IUPAC [14] and SCAI [15] are two commonly used chemical name matching datasets. Weston et al. [16] developed the NEN dataset for material engineering. The NCBI [17] dataset gathered the disease names from the PubMed abstracts and linked disease names with the same intrinsic meanings. By linking the disease names in clinical notes, ShARe/CLEF [18] is commonly used bioinformatics NEN datasets Similar to disease names, drug labels are linked in TAC2017ADR [19]. Datasets such as BioNLP09 [20], and BioNLP-OST19 [21] are also distributed by academic conferences’ for various NLP challenges. BioNLP09 [20], and BioNLP-OST19 [21] are NEN dataset for proteins and bacteria, respectively. BC2GM [22], BC5CDR-disease [23], BC5CDR-chemical [23] are distributed by BioCreative for the NEN challenges in the biological domain. Above studies developed engineering and science-related NEN datasets. On the other hand, NEN datasets to satisfy the more general NEN tasks are also introduced. Sun et al. [24] constructed the NEN dataset which consists of product entity names. Francis et al. [25] extracted the International Bank Account Number (IBAN) of the beneficiary, invoice number, invoice date, and due date from the financial invoices and constructed the financial NEN dataset based on the extracted information.
Named entity normalization
Various NEN models adopt string matching techniques such as Siamese neural network [26, 27, 28]. The morphological similarity between strings was linked by the Siamese RNN model [29]. Siamese Graph Neural Network is used in [30] for company name normalization. Sun et al. [24] utilized pre-constructed product ontology for product name NEN. Rahmani et al. [31] proposed random walk applied on the augmented graph to link similar entities in genealogical graphs. More recently, attention model [32] and transformer-based model [33] were applied to medical entity normalization and linked the entity from the Wikipedia knowledge graph.
For a gene name NEN tasks, GenNorm [34] and GNAT [35] are widely used toolkits. ChemSpot [36] is trained on the SCAI [15] chemical NEN dataset and achieved an F1 measure of 79%. Cho et al. [37] listed existing NEN products and services such as ProMiner [38] and MetaMap [39]. ProMiner [38] and MetaMap [39] are the NEN tools for biomedical domain. DNorm [40] used pairwise entity ranking scoring for NEN. TaggerOne [41] utilized semi-Markov model for NEN. For documents in the material science domain, MatScholar [16] is a python repository for general text mining including NEN tasks.
In 2015, D‘Souza et al. [42] constructed the rule-based NEN model. The rule-based NEN model is one of the earlier NEN models. The machine learning-based NEN model was introduced in 2016 by Leaman et al. [41]. Leaman et al. [41] proposed TaggerOne [41] which is the model based on semi-Markov model. Deep learning algorithms such as convolutional neural network (CNN), long short-term memory (LSTM), and gated recurrent unit (GRU) based model was adapted to NEN research. Li et al. [43] introduced the word-level CNN ranking NEN model. Recurrent neural network-based models are also implemented [44]. Wright and Dustin [44] proposed BiGRU based NEN model. Phan et al. [45] also suggested the BiLSTM-based NEN model. Recently, the transformer-based NEN model achieved higher performances. BERT ranking model [46] and BioSyn [47] utilized BERT architecture and fine-tuned with distinct objective functions. BERT Ranking model [46] was trained with a ranking-based objective function. BioSyn [47] is the one of highest performing NEN models that the model used a pre-trained BioBERT [48] model and was trained by a synonym marginalization algorithm. Our proposed NEN model, Edge weight updating neural network with triplet loss, successfully capture the semantic similarity between entities by trained with hard positive and negative entities for each epoch. Furthermore, incorporating the substrings for generating the hard positive and negative entities enables to capture the morphological similarity between the matched entities.
Knowledge graph construction
Text mining techniques and their applications have received remarkable and rapidly growing attention as a means to acquire useful information from corpora of various backgrounds and characteristics. Technology management fields have responded by actively utilizing text mining approaches to process and analyze professionally written technological reports and other technology-related documents [49]. One of the most prevailing examples includes text-mining-based patent analysis: to date, numerous studies have attempted to analyze the patent documents to investigate contemporary technological trends, assess technological capabilities, and/or analyze the commercial value of select technologies [50]. Kim et al. [7], for instance, built a semantic network to analyze the “ubiquitous computing technology” by merging pre-determined keywords, recommended by experts in the field, from the patent claims. Patent claims were queried based on those pre-determined keywords, and the returned documents were characterized further by employing the k-means clustering algorithm. It is, however, very costly to pre-define manually the target technology-related keywords as the authors did in their study because it requires a great amount of background knowledge, time, and human labor during the process.
The number of studies on knowledge graph construction has grown rapidly. Relatively earlier knowledge representations through the ontological graph and semantic web approaches for manufacturing are listed in [51]. Rahmani et al. [52, 53] proposed human disease network and human drug network based on protein-protein interaction. DDREL [2] is more recent research on constructing the drug-drug relation graph. Li et al. [54] constructed the knowledge graph from electronic medical records (EMRs). EMR2vec [55] suggested the platform which incorporated patient data and clinical trials by a medical ontological graph. Bipartite graph [56] and hypergraph [57] are also used to represent knowledge in graph form. Technology topic network which was built based on the patent documents aided to establish the improved R&D plannings [58]. Liu et al. [59] constructed the industrial knowledge graph based on various industrial documents and applied the knowledge graph to few-shot text classification problems.
Recently, the availability of NLP tools has led to the introduction of a wide range of automatic keyword extraction models. TechNet [60] is the leading example of such efforts, which was derived by applying word embedding algorithms to a massive amount of patent filings to establish the semantic relations between the technological terms presented as vectors on the same linear space. While these studies suggest meaningful approaches for extracting insights from patent filings, they still suffer from several limitations, such as lacking the implementation of entity matching and normalization. For example, the terms “CNN” and “convolutional neural networks” convey virtually the same meaning; yet, the standard word embedding approaches would vectorize these terms separately as independent entities. In this study, we attempt to address such issues by normalizing the named entities whose definitions are supposed to be aligned as identical by exploiting the edge updating neural network of our novel design, with triplet loss, as first proposed by [61].
Proposed method
Our approach consists of three major components: (1) NER using the Huggingface’s pre-trained NER model; (2) NEN by relying on our novel edge updating neural network; and (3) construction of the semiconductor-related patent knowledge graph. Figure 1 shows the overall framework of the proposed method.
Overall framework.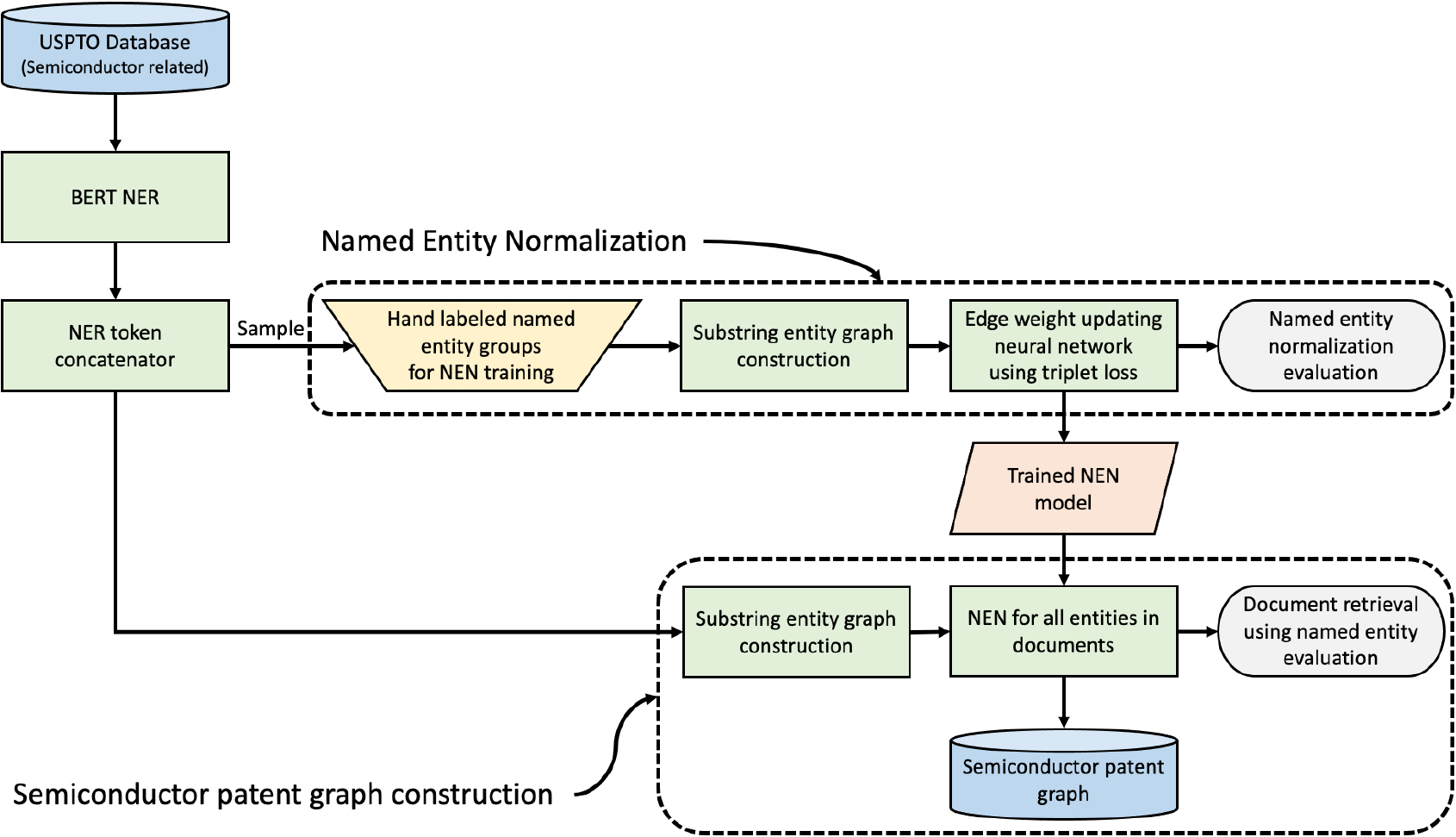
To extract named entities from the patent claims, we rely on the BERT NER model [10] provided by Huggingface’s1
Four types of named entities are provided by the CoNLL-2003 dataset: persons (PER), organizations (ORG), locations (LOC), miscellaneous names (MISC), and those not recognizable by the given dataset (O). Because our main focus is to extract technological concepts and terms, we detect entities labeled as ORG and MISC tags only.
Figure 2 depicts an example of the NER case using the pre-trained BERT model on the sentence “The FinFET device structure includes a second fin structure embedded in the isolation structure,” which actually appears in one of the semiconductor-related patent documents considered in our experiment.
The raw output of the BERT NER model is in the form of WordPiece [63] tokens, which are very difficult to interpret to the human eye at first glance. In this study, we enhance the human understanding of the preliminary NER results by conducting further token concatenation. More specifically, we construct a rigorous, rule-based token concatenation model to detect the named entities. Table 1 lays out the token concatenation scenarios we propose by the different concatenation types.
Example of named entity token concatenation
BERT named entity recognition example.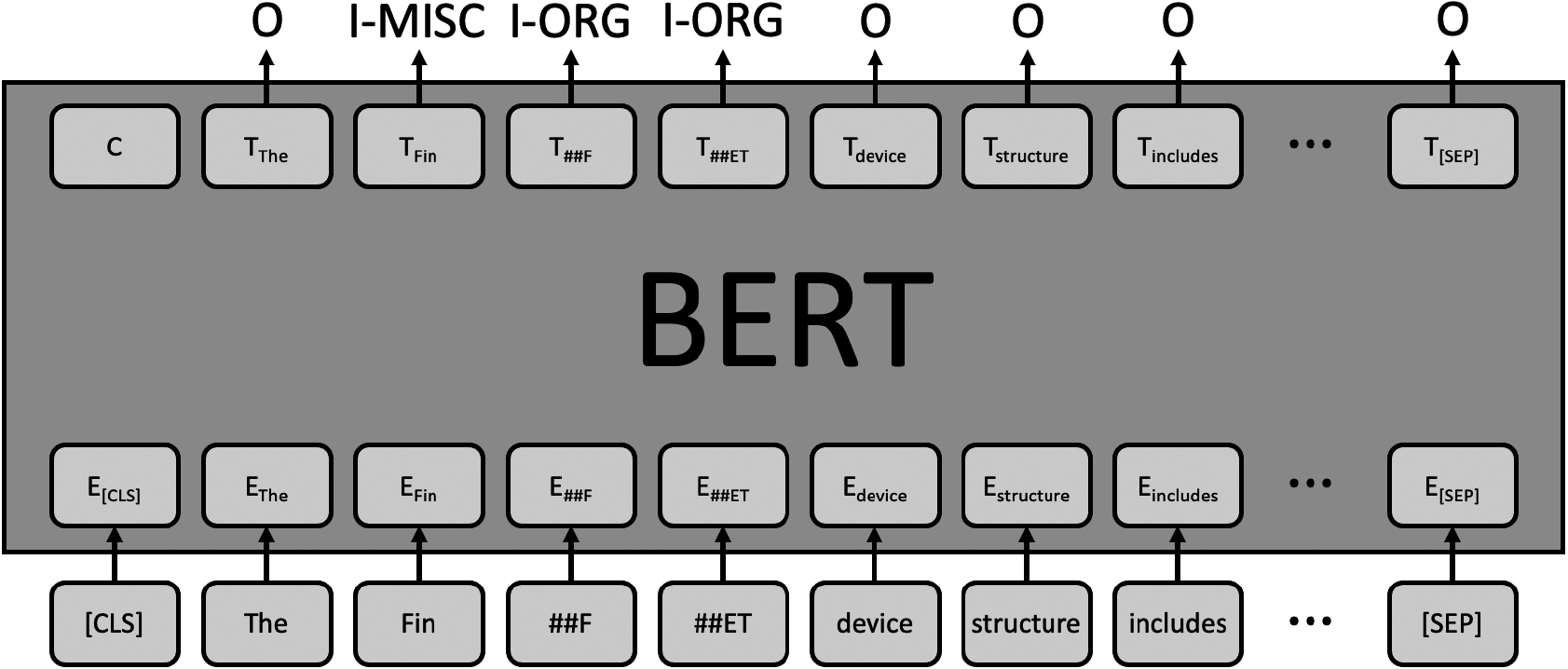
The first case listed, where the tokens “Fin”, “##F”, and “##ET” are successfully recognized, is the simplest case that can be detected and easily concatenated utilizing Huggingface’s default concatenation package. The term “FinFET” refers to one of the field effect transistors, and it will make sense only if the tokens “Fin” and the acronym “FET” are concatenated together. The tag of the token following “Fin” begins with “##”, which indicates that it should be joined with the token appearing before itself. The following token, which ends with “##ET” suggests that the formerly merged term should be completed with the letters “F” and “ET”, hence leading to the final form of the detected named entity as “finFET”.
The next case is slightly more complicated yet easily solvable. Entities whose name includes punctuation marks such as periods (.) or commas (,), “Amazon.com, Inc”, for example, require an extra step to be properly concatenated because these punctuation marks are recognized with the other (o) tags. In this case, we join the (o)-tagged token with the surrounding tokens if they are labeled with ORG tags.
Meanwhile, a compound noun, whose meaning changes owing to the combination with prefixes, such as “Anti-Hebbian” in the given example, should be distinguished from its original root word, “Hebbian”. In this case, one needs to carefully concatenate the prefix “Anti-” with the following token “Hebbian” in order not to deteriorate the implication of the original wording.
The next row in the table presents the case where the major named entity token is decorated with a descriptive word or phrase, in this case “Micro USB”. We aim to keep as many information in the named entity as possible.
Our proposed token concatenator model binds such descriptive named entity tokens together effectively, hence providing richer understanding of the given corpus without misleading results.
The last token concatenation scenario presents the case of the recognition and concatenation of tokens appearing in parentheses. For example, the pre-trained BERT NER model dissects the given token “(NFC) tag” into pieces; our proposed token concatenator model, in contrast, preserves the parentheses intact with the acronym within as a unified entity. Thus, it provides the accurate interpretation that the detected entity is an acronym. Such instances are quite prevailing, especially in scientific documents, because acronyms appear rather frequently. To detect these acronyms in NEN tasks, we preserve acronyms in parentheses and their corresponding expansions. For example in NEN task, given the input text “Near Field Communication (NFC) tag”, the NEN model would detect that “NFC” is an acronym by recognizing the pattern within parentheses, and associates it with the preceding full name “Near Field Communication”. Preserving these additional context is crucial for a deeper understanding of the text and enables more accurate entity recognition.
Our token concatenator was manually built to address the above issues better than the existing BERT NER token concatenator. The semiconductor-related patent documents covered in this paper are domain-specific, and there is no NER dataset available for this domain, making it impossible to train an NER model. We manually examined various cases within the documents and developed a rule-based token concatenator to extract named entities for the final knowledge graph while preserving the meaning of the named entities as much as possible.
Named entity graph construction based on named entities’ substrings.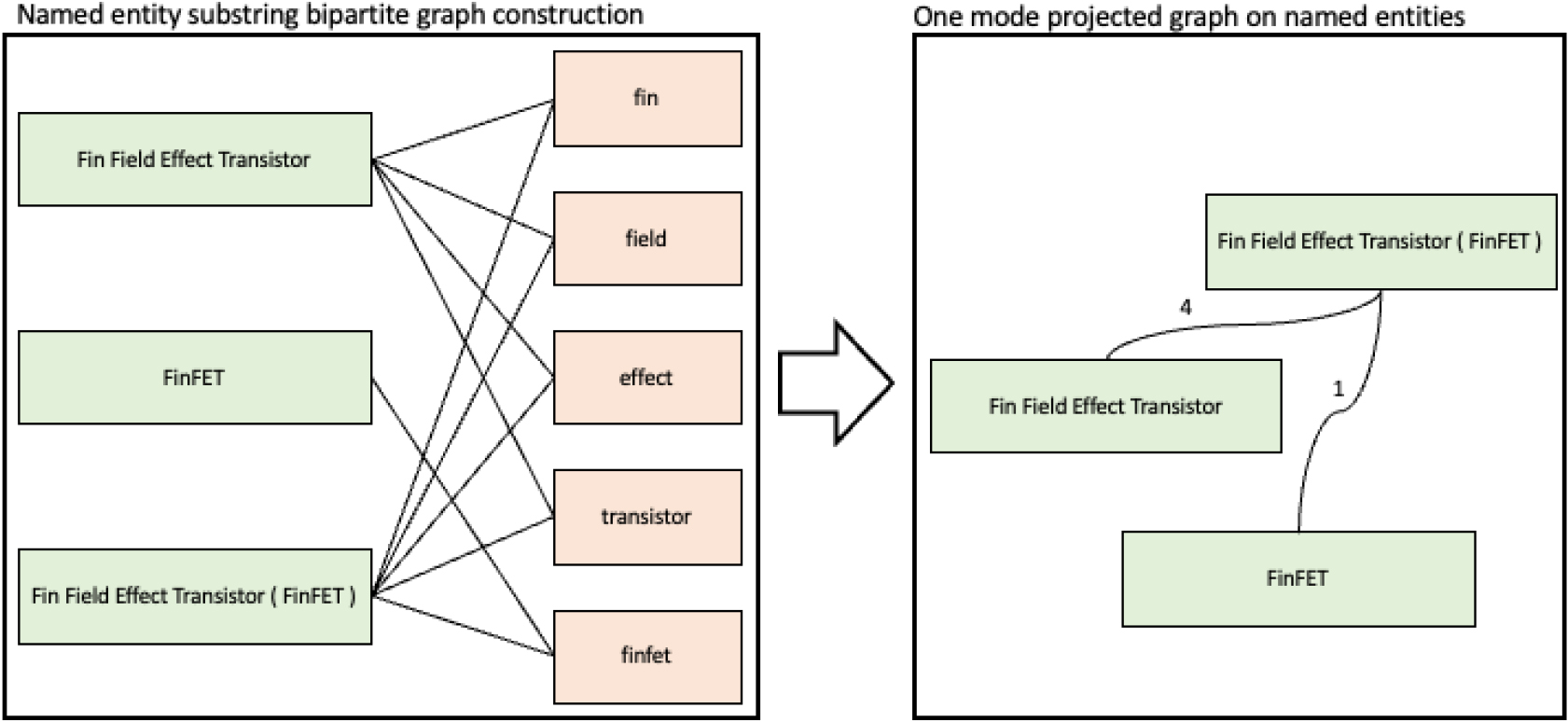
With the named entities concatenated as described in Section 3.1, we initialize the construction of the named entity graph by connecting the substrings of the extracted named entities, and the process is summarized graphically in Fig. 3.
Our proposed model, which fine-tunes the BERT model as its backbone, has already successfully detected the semantic similarity between two entities. However, to also detect morphological similarity, we construct a substring graph and extract the hard positive candidate with the lowest embedding similarity among the connected entities and the hard negative candidate with the highest embedding similarity among the unconnected entities at each epoch for training with triplet loss. In addition, we aimed to reflect morphological similarity by calculating a simple similarity between entities using the substring graph of entities as shown in Eq. (3.2.1). Detecting the morphological similarities between entities is possible by using graph measures such as Random Walk-based SimRank [64] and Graph Edit Distance [65] in the proposed substring graph to calculate the similarity between entities.
Our named entity graph construction proceeds as follows: first, we parse the named entities, resulting from the concatenation stage, using the whitespaces. For example, the entity “Fin Field Effect Transistor”, after the parsing, will result in the token pieces “fin”, “field”, “effect”, and “transistor”. Please note that we exclude the punctuation and the common stopwords during the parsing process. We repeat the parsing process on every named entity and construct a bipartite graph with the named entities as one group, and the associated substrings resulting after the parsing, as another, as illustrated in the left panel of Fig. 3. Then, we one-mode project the bipartite graph on the named entity level. The resulting network consists of named entities as its nodes and the number of shared substrings between each pair of named entities as the edge weights, as depicted in the right box of Fig. 3.
At this time, the entities “FinFET” and “Fin Field Effect Transistor” are not directly connected by an edge, but only indirectly via the common neighbor node “Fin Field Effect Transistor (FinFET)”. Given that these indirectly connected components of entities imply similar ideas, our goal is to determine and connect nodes of the exact same concept/definition. To do so, we compute the relative strength between the two named entities by normalizing the edge attributes based on Eq. (3.2.1) as follows:
where
In Fig. 3, let “Fin Field Effect Transistor (FinFET)” be the source entity and “Fin Field Effect Transistor” be the target entity. This case,
We first learn the named entities using the pre-trained BERT embedding model, and then we fine-tune the parameters with our novel edge weight updating neural network [61], which employs a triplet loss [66] instead of using KL divergence. This decision was made because of the instability caused by the cases of scarce number of connected entities (relatively fewer entities in a entity group) compared to the relatively large number of negative entities available for the query entity. By using the triplet loss with hard positive and hard negative samples, which are retrieved for every epoch, we aim to provide a more stable learning process and improve the performance of the edge weight updating neural network.
The triplet loss function we employ is mathematically defined by Eq. (3.2.2), where
For training the model using the triplet loss function, several issues need to be considered. First, because the loss function takes triplets as its input, the number of triplet combinations explodes as the size of the data increases. At the same time, the model performance is found to be sensitive to the quality of the triplets used during the training. In other words, a selection of adequate triplets for the training is necessary.
Previous studies have suggested promising solutions to this challenge. Hermans et al. [67] proposed the batch-hard triplet loss, which chooses the most definitively positive and negative samples when constructing the triplets for the online training. Yu et al. [68], averaged the negative and positive samples instead of constructing sample-to-sample triplets.
In this study, we adopt the batch-hard triplet loss approach as implemented in [67]. Furthermore, we make use of a scarcely labeled dictionary of named entities with its variant identities as supplementary data source because the use of external information during the training process exploiting the triplet loss function leads to a significant increase in the quality of the positive and the negative samples [61].
We begin our training by using the graph resulting from Section 3.2. The similarity between the two BERT vectors is then determined by computing the inner products. After the first epoch of training, the positive and negative samples are determined as follows: among the entities connected on the network, the entity pair with the greatest similarities, yet labeled as unmatched (that is, labeled as “0”) in the dictionary, is considered as the negative input of the triplet loss. In contrast, the entity pair labeled as matched (labeled as “1”), yet the inner product of its BERT vectors, is the lowest and is considered as the positive input of the triplet loss. The positive and negative samples are then consumed as inputs in the next training epoch, given the BERT vector similarity of the previous epoch among connected entities in the substring graph.
This approach resembles the gradient descent method, as it concentrated on the errors (false positive and true negative) of the each model iteration. By re-calculating both positive and negative samples for each epoch, harder positive and negative samples are generated. Utilizing the triplet loss trains the model to train and to perform better by emphasizing these challenging cases and improving the overall performance of the model.
Mathematically speaking, let the set of named entities be denoted by
We further illustrate our approach using an example. An entity group refers to a set of semantically related entities that share common attributes, which can be represented as connected components within the semiconductor-related patent knowledge graph. Each connected component consists of nodes representing entities that are closely related, and edges representing the relationships between these entities. For instance, consider an anchor entity, “Fin Field Effect Transistor (FinFET)”, and another one, “FinFET”, from the same entity group, meaning they are part of the same connected component in the graph. These entities share only one substring, whereas “Metal Oxide Semiconductor Field Effect Transistor (MOSFET)”, which should be placed in a different entity group (i.e., a separate connected component), shares the three substrings “Field”, “Effect”, and “Transistor”. In this case, “FinFET” will serve as the positive input for the entity “Fin Field Effect Transistor (FinFET)”, while “Metal Oxide Semiconductor Field Effect Transistor (MOSFET)” will be the negative sample.
Edge weight updating neural network with triplet loss.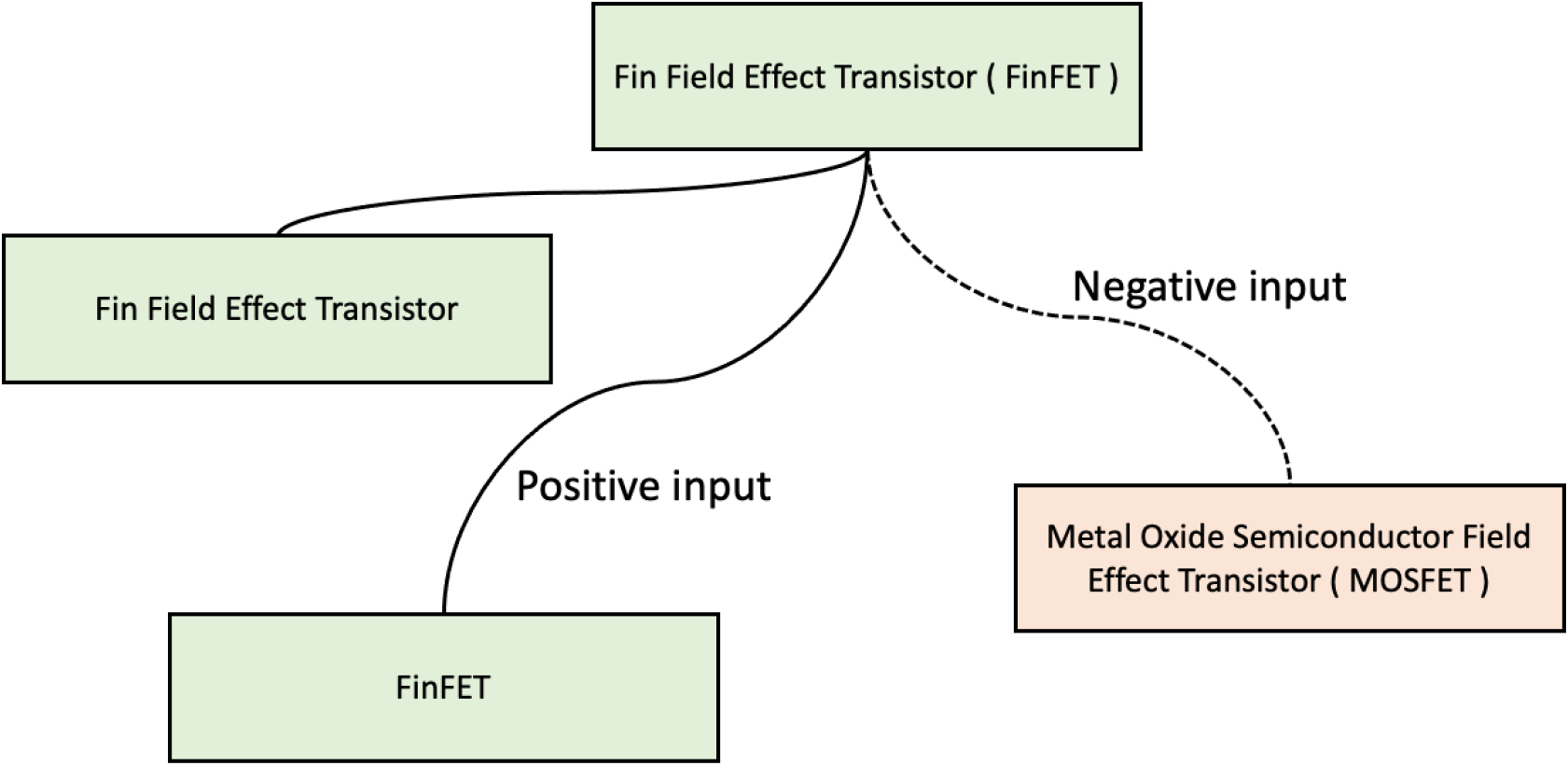
Figure 4 shows the example of the positive and negative inputs to train the edge weight updating neural network with triplet loss.
The semiconductor-related patent knowledge graph is completed using the following process. We employ a logistic regression model to assess the linkage of the two given named entity pairs, initially represented by fine-tuned BERT embeddings in the substring graph Section 3.2. The logistic regression model evaluates if these pairs are still connected after the training process described in Section 3.2.2. All of the linked entities in the substring named entity graph are tested and updated. Then, the connected components of the final graph are considered the unique named entity groups. These groups are expressed as separate nodes of a different mode, which corresponds to the named entity groups. Finally, the semiconductor patent knowledge is completed by linking the patent document, in which the named entity appeared.
Experiment settings
Data
In our experiment, we exploit USPTO data2
For the NEN evaluation, we manually built a scarcely labeled dictionary matching named entities of different forms, yet with the same meanings. Out of 69,812 named entities, we hand-labeled 6,797 named entities to be matched with 1,000 unique named entity groups.
Building a domain-specific dictionary manually makes the paper specific to the “semiconductor-related patent” domain. We also have made the dictionary publicly available, allowing researchers to access and utilize it in related works. Furthermore, the dictionary is included as an appendix to the paper in Appendix A.1, making it accessible to who wish to understand the preview of the named entities and NEN dictionary used in this study.
We hand-matched entities of the following six types: (1) synonyms, (2) abbreviations, (3) acronyms, (4) different combinations of punctuation and alphabets, (5) descriptive phrases, and (6) possible parsing errors. We report the examples of the matching named entities by type in Table 2.
Matching categories and example for the named entity normalization dataset
Matching categories and example for the named entity normalization dataset
Description of CPC subclass H01L.
Table 3 presents an example of the resulting, manually built dictionary for semiconductor-related patent NEN.
Excerpt from the semiconductor patent named entity normalization dataset
We report the positive and negative entity pairs based on the matching status on the substring graph, as described in Section 3.2, in cross-check with our manually built dictionary, as mentioned in Section 4.2. Given the entity pairs connected on the substring graph, if the two entities are labeled to be in the same named entity group in our manually built dictionary, the two entities are labeled positive. In contrast, if the two entities connected in the substring graph are placed in different groups, the two entities are labeled negative.
The detailed statistics are listed in Table 4.
Statistics of the pairwise named entity matching evaluation dataset
Finally, we provide the basic summary statistics for the training and test sets in Table 5.
Statistics of the semiconductor patent named entity normalization dataset
We tested our proposed approach against conventional and standard text mining models: Word2vec [69], Glove [70], Fasttext [71], and BERT [10]. SciBERT [72] is the variant of the original BERT model, pre-trained with scientific text, which might be more suitable for patent-related analysis. Hence, we also included SciBERT in our experiment. BioSyn [47] is one of the state-of-the-art NEN models. The Bio-medical documents were used for training in the original BioSyn paper. We trained the BioSyn model with our patent NEN dataset and compared the performance with other models including our proposed model. The weighted averaged vectors of each word embedding model were used for the embedding of the named entities. Table 6 summarizes the basic characteristics of the baseline models in terms of the NEN and document retrieval tasks.
Models used for the evaluation
Models used for the evaluation
The experiments were executed using an Intel Core-i9-10940X CPU with 128 GB of memory and three NVIDIA GeForce Titan RTX GPUs. For training the edge weight updating neural network using triplet loss as described in Section 3.2.2, the batch size was set at 64, and the learning rate was
In order to provide a more in depth analysis of the parameter tuning process, we have included additional evaluation metrics such as accuracy, precision, recall, and F-score per each epoch. This allows us to track the model’s performance over training progresses.
Figure 6 shows the performance of the model for each epoch, where the x-axis represents the epoch, and the y-axis represents the corresponding evaluation metrics. It can be observed that the model’s performance improves relatively steeper for the first three epochs. Between five to ten iterations of training, the model’s performance reaches the plateau which is typical in deep learning models. By analyzing the trends in these metrics, we can observe the optimal set of parameters and epochs for the model and further fine-tune the model’s performance.
Model accuracy, precision, recall, F-score, V-measure per epoch.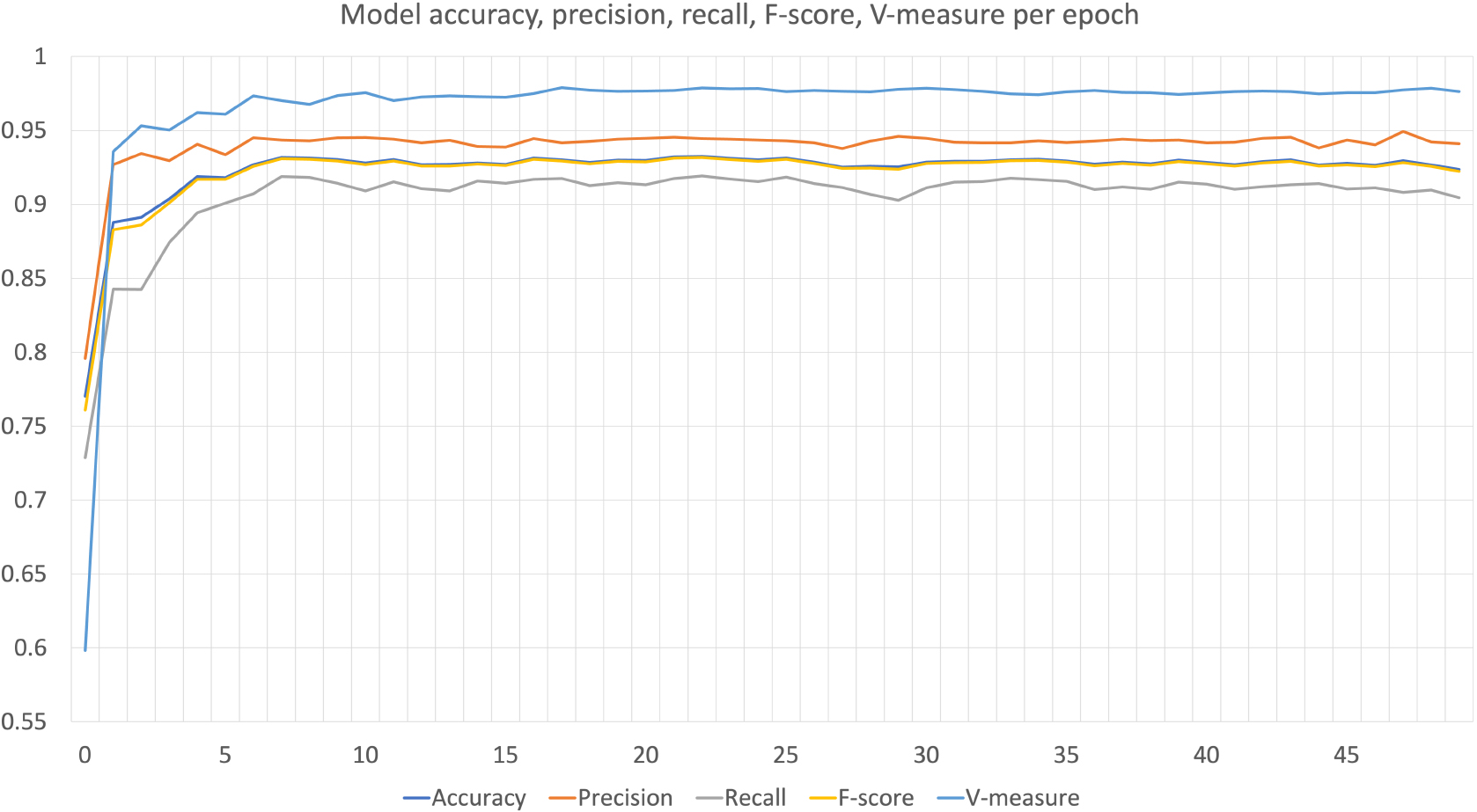
Quantitative evaluations
Named entity normalization: candidate retrieval
Many NEN models from previous studies are evaluated by the candidate retrieval tasks [43, 45, 46, 47]. We evaluated the performance of the candidate retrieval for NEN with various models. An evaluation was conducted to validate the efficacy under the same conditions as those for the previous NEN models including BioSyn [47], the current state-of-the-art NEN model. The evaluation was reported based on whether the group id of query entity and the group id of the most similar entity from the dictionary dataset were the same. The performance of the models is presented in Table 7.
Named entity normalization by candidate retrieval performances
Named entity normalization by candidate retrieval performances
BERT [10] and SciBERT [72] models not specifically trained for NEN tasks. We utilized the similarity ranking model described in the study of Ji et al. [46], but the retrieval of a single entity was unsuccessful for many entities. Smoothing the dictionary vectors by averaging the entity vectors in the named entity group gave relatively higher accuracy. Among the models we tested, our proposed model achieved the highest performance in candidate retrieval tasks for NEN.
the model performances were tested by precision, recall, f-score, and accuracy, computed as defined in Eq. (5.1.2), which are standard metrics for evaluating the pairwise named entity matching tasks.
We detected connected components from the semiconductor-related patent knowledge graph as the unique named entity groups. Thus, we evaluated to which extent these connected components matched well as compared to the ground truth groups by computing the V-measure [75]. The V-measure calculates the harmonic mean of the other two widely used clustering evaluation metrics, homogeneity and completeness, to assess the range of the overlap between the given clusters and the ground truth grouping. The mathematical definition is expressed by Eq. (5).
In our evaluation, we assumed that the weight was equal across homogeneity and completeness by setting
Table 8 reports the performance of our proposed approach against the baseline models. The results show that our model beats the conventional embedding methods in almost every case. In particular, only our model achieved over 90% in precision and recall in the pairwise entity matching tasks. By scoring over 0.97 in V-measure, the named entity groups constructed by our proposed model highly resembled the ground truth named entity groups. SciBERT with the substring graph showed the best performance in terms of recall, yet compared to our model, the measure is very close, and it differs by 0.1%. Such outstanding performances against the baseline models, we believe, is largely owed to the out of vocabulary problems. To support our claims, we additionally report the number of out of vocabularies at the end of Table 8. Word2vec, Glove, and Fasttext are known to perform relatively less robust to the words unseen during the training process, hence deteriorating performance when they met newly rising concepts. Given the recent fast-paced technological developments, however, handling out-of-vocabulary concepts is critical in scientific documents. The experiment results show that our proposed model performs well in such cases and works robustly when faced with newly introduced words never seen before.
V-measure, precision, recall, F-score, and accuracy of models
In this section, we report the performance of our proposed model in relation to the document retrieval task. To be as fair as possible, we restrained from querying named entities as we conducted the test. For the competing embedding models such as Word2vec, Glove, Fasttext, BERT, and SciBERT, the representations of each entity and each document was computed as the weighted average of all the tokens associated with the respective named entity or the documents. BioSyn is a model that specifically focuses on NEN tasks, so BioSyn is not used for the retrieval tasks. As for our proposed model, because our end-product has the form of a network, we take advantage of the structural characteristics of the knowledge graph. When given the query, we return the document with the highest edge weight connected to the given named entity’s group. We test the relevance of the document recommendations in response to the given query based on whether the named entity and the retrieved documents are from same CPC group (total: 50) and CPC subgroups (total: 449). The performances of each model are reported in Table 9.
Accuracy of document retrieval from the named entities
Accuracy of document retrieval from the named entities
Across CPC groups and subgroups, our proposed model reports the highest accuracy. Our model achieved over 77% accuracy on retrieving the relevant documents with respect to the CPC subgroups. This, in particular, is an impressive result given that there were 449 subgroups. Due to the granularity of the sub-groupings, all of the other baseline models suffer gravely in terms of accuracy.
Retrieving the relevant named entities from patent documents is another important task. The most related named entity was retrieved using the following procedures. For Word2vec, Glove, Fasttext, BERT, and SciBERT, the embedding vectors of the named entities that appeared in each document were averaged. Based on the embedding obtained for each document, the named entity with the highest similarity was recommended. As for our proposed model, we returned the named entity within the group that had the highest connected edge weight to the given document’s named entities. For the named entity recommendations, the named entities that appeared directly in the document were excluded from the candidates. We evaluated the performance of the named entity recommendations in response to the given query based on whether the documents and the retrieved named entities were from same CPC group (total: 50) and CPC subgroups (total: 449). The performances of each model are reported in Table 10.
Accuracy of the named entity retrieval from the patent documents
Accuracy of the named entity retrieval from the patent documents
Our proposed model reports the highest accuracy for the named entity retrieval tasks. Our model achieved over 83% accuracy on retrieving the relevent named entity with respect to the CPC subgroups. The second best performing model was word2vec, which showed an accuracy of 73%, and the difference in performance compared to that of our model was approximately 10%. The proposed model has a significant improvement in performance compared to that of other models, and it can provide insights by accurately retrieving the related named entities from the document.
Examples of false positives of pairwise named entity normalization task
Examples of false negative of pairwise named entity normalization task
Confidence of our model to predict the entity pair as the label 0 (the non-matching entity pair).
Statistics of the semiconductor patent named entity knowledge graph
Semiconductor patent named entity knowledge graph.
Subgraph of USB type C related groups.
Subgraph of DNN related groups.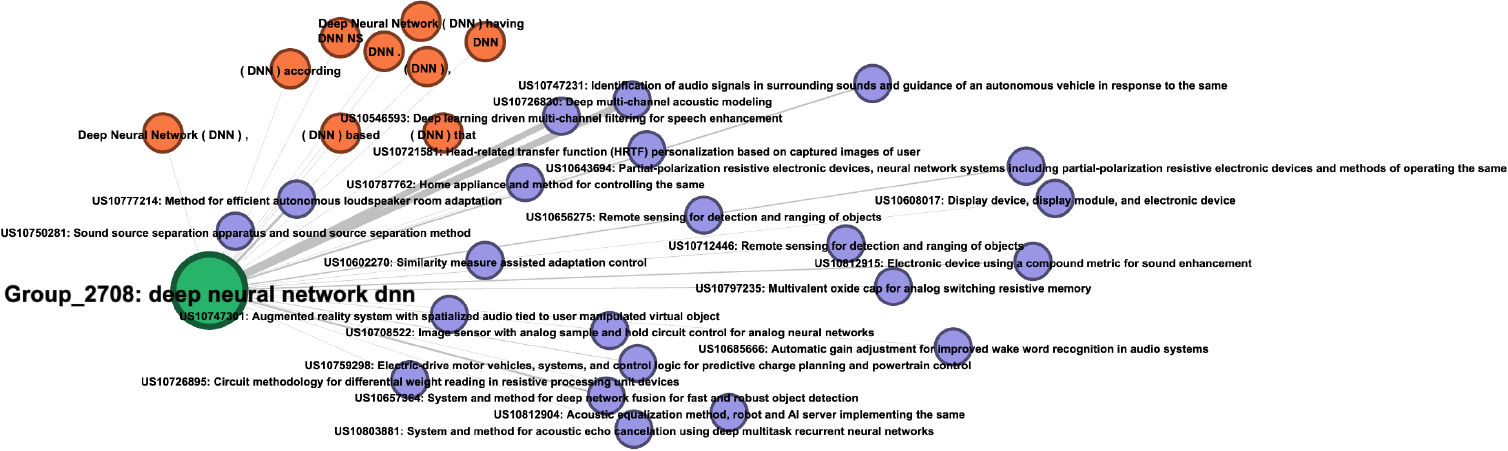
Subgraph of Samsung Galaxy related groups.
Error analysis on the pairwise named entity normalization
As the quality of the semiconductor-related patent knowledge graph relies heavily on the performance of the NEN process, we report the result of the error analysis we conducted on the pairwise NEN in this section. More particularly, we report the false positive examples in Table 11 and the false negative examples in Table 12 on the pairwise NEN tasks with the model’s confidence.
In general, both false positive and false negative results have relatively low confidence. This implies that, when constructing the semiconductor patent named entity graph, connecting the undesired entity pairs can be prevented by connecting the entities with higher confidence. However, it is important to examine some cases where the model might have been misled. For example, the proposed model linked “DC-AC inverter” and “(AC) power” with a confidence of 0.52, likely due to the sharing term “AC”. Moreover, “inverter” and “power” are closely related concepts within the same domain of electricity, which might have contributed to the model’s confusion in distinguishing between these two entities.
The model not considering the “Linux OS” and “Linux
Knowledge graph visualization and exemplary investigation
By training the NEN model as discussed in Section 3, with our hand-labeled dataset as described in Section 4.2, we have successfully recognized 69,812 named entities and connected the entity pairs with a confidence over 0.999 to maximize precision. After pruning the false positive links, we ended up with a knowledge graph with 25,938 named entities assigned to the total of 8,525 unique named entity groups. The overall statistics of the semiconductor patent named entity knowledge graph are listed in Table 13.
We present the graphical visualization of the entire knowledge graph in Fig. 7. The resulting graph may also be accessed freely online via an interactive environment, available for all non-commercial purposes3
The purple nodes represent the patent documents; the green nodes, the named entity groups, and; the orange nodes, the associated named entities.
As it is difficult to distinguish visually the graph with almost 70,000 nodes, we selected three named entity groups, “USB type C”, “deep neural network”, and “Samsung Galaxy ” and report the resulting subgraphs in Figs 8–10, respectively, for demonstrative purposes. As can be easily observed in these subgraphs, the named entity nodes of similar technological concepts are successfully grouped. For example, the terms “Universal Serial Bus” is well connected to the entities “USB” and “USB Type C” in the subgraph in Fig. 8, and the patent connected to those named entity nodes well encompasses these terms.
A similar pattern is observed for the subgraph reported in Fig. 9, which shows the connection between the original phrase, “deep neural network”, with its abbreviation, “DNN”, correctly established.
The example reported in Fig. 10 shows that our model, in addition to the technological jargon, also successfully extracted and connected brand and product names.
The knowledge graph has been recently attracting attention in the field of patent analysis as a useful tool to summarize and represent information from patent filings. Past research has mainly relied on extracting keywords to summarize and represent the information enclosed in patent filings. While keyword extraction models do deliver meaningful insights, named entities such as technological concepts, specific techniques used, name of the devices or end product, and the associated company names may additionally provide richer and deeper understanding of the innovations and technology underlying the patent filings.
In this study, we construct a semiconductor-related concept and entity knowledge graph by applying a novel edge updating neural network algorithm on patent claims. More specifically, our proposed model builds a knowledge network of semiconductor-related named entities from the patent filings. During this process, named entities with different surface forms, but of identical meanings, are placed into unique groups, hence providing a clearer picture and better understanding of the patent filings in hand. Our proposed model shows the highest performance on both the NEN and document retrieval tasks against that of standard baseline models. Further, experiment results show that the proposed knowledge graph construction method is robust to the out-of-vocabulary problem.
While the proposed model has showed great performances, there still is a room for further development. Currently, our research focuses only on the topics involving semiconductor devices. A focus switch to other fields may lead to a clearer understanding of a different area of innovations, while an extension to encompass a greater range of topics will help assemble a more complete picture of the recent technological advances in general. In addition, this study uses the edge updating neural network approach to discover the inter-connectivity among named entities and connect these named entity groups to the patent documents to construct the knowledge graph. However, in the constructed knowledge graph, a relationship between patent documents and entity groups is defined as existence of named entity in certain patent document. Research on the detection of more complex relationships between an entity and a patent document or another entity is our next research topic.
Footnotes
Acknowledgments
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (No. 2021R1A2C2093785 and No. 2018R1D1A1A02045842). This work was supported by the Artificial Intelligence Graduate School Program (Seoul National University) (NO.2021-0-01343).