
Abstract
Matching-related methods, i.e., entity resolution, entity search, or detecting evolution of entities, are essential parts in a variety of applications. The specific research area contains a plethora of methods focusing on efficiently and effectively detecting whether two different pieces of information describe the same real world object or, in the case of entity search and evolution, retrieving the entities of a given collection that best match the user’s description. A primary limitation of the particular research area is the lack of a widely accepted benchmark for performing extensive experimental evaluation of the proposed methods, including not only the accuracy of results but also scalability as well as performance given different data characteristics.
This paper introduces EMBench++, a principled system that can be used for generating benchmark data for the extensive evaluation of matching-related methods. Our tool is a continuation of a previous system, with the primary contributions including: modifiers that consider not only individual entity types but all available types according to the overall schema; techniques supporting the evolution of entities; and mechanisms for controlling the generation of not single data sets but collections of data sets. We also illustrate collections of entity sets generated by EMBench++ and discuss the benefits of using our system through the results of an experimental evaluation.
Introduction
Entity Matching is the task of efficiently and effectively detecting whether two different pieces of information describe the same real world object, such as a conference, a person, or a publication [12]. Strongly related to entity matching are the tasks of (i) entity search, focusing on efficiently and effectively retrieving the entities of a given collection that best match the user’s description [30,31], and (ii) evolution of entities, aiming at detecting entities that describe the same real world object even if their information is different due to evolution over time [8,20,29,39].
Matching-related methods are typically part of data integration or cleaning components that are considered essential in a variety of applications. The research community has already introduced a great deal of matching-related methods. These methods have been discussed in related surveys, such as [5,6,12,15], and [22]. A major limitation of the existing works in the particular research area is the lack of a widely accepted benchmark for performing extensive experimental evaluation of the proposed methods, including not only the accuracy of results but also the scalability and the performance for different data characteristics.
In our previous work, we had developed EMBench [21,23], a system for benchmarking matching-related methods in a generic, complete, and principled way. The system is based on a series of test cases aiming at capturing the majority of the matching situations. EMBench [21] is fully configurable with users being able to define the desired entities with their attributes as well as the modifications and modification level that will be incorporated in the entities. The system also provides an on-the-fly generation of the different test cases in terms of different sizes and complexities both at the schema and at the instance level.
Currently, we are witnessing research efforts for dealing with a number of new challenges. One such challenge is volatility. As explained elsewhere [33,34], applications, especially Web 2.0 applications, focus on enabling and encouraging users to constantly contribute and modify existing content. An analysis of different versions of DBPedia revealed that users modify the entity data, and only a small fraction of the entity data remain unchanged. Volatility is the result of many reasons like change on the requirements, on the topics of interest, performance reasons, or even semantic evolution that requires entity merging or splitting [29,40].
This publication introduces EMBench++, an extension of our previous system with additional mechanisms aiming at generating benchmark data for the evaluation of matching-related methodologies. Primarily, these extensions include the generation of entities with relationships and entities those data have evolved. EMBench++ allows thorough experimental evaluations by enabling the assessment of a plethora of aspects that influence quality and performance. Each aspect can be investigated following various scenarios and different assumptions, produced in a controlled and consistent manner. The main contributions we are making here is the set of extensions and new services in our entity matching benchmark. In particular,
We introduce modification mechanisms on existing data sets that consider not only individual entities but also sets of entities determined by their schema information. We provide mechanisms for generating collections of data sets that are able to capture and evaluate specific matching-related aspects. We provide mechanisms that allow the users to generate sequences of data sets, with the entities of each data set being the evolved version of the entities from the preceding one. We illustrate the abilities of our system by generating collections with appropriate data sets for the thorough experimental evaluation of matching-related methodologies.
Related work & open challenges
Existing related works can be separated into two main categories: those related to the generation of synthetic data for matching-related approaches (Section 2.1) and those related to approaches for performing entity matching (Section 2.2). In each category there are a number of open challenges.
Synthetic data generation
In 2004 the Ontology Alignment Evaluation Initiative (OAEI) started working on the controlled experimental evaluation of alignment and matching systems. With respect to EMBench++, the most interesting task is instance matching for which, currently, OAEI provides real and synthetic data [1].
Real data are static collections, typically of a much larger size than the synthetic ones. Such collections are extracted from real applications and reflect the matching problems that must be addressed. Thus, real data contain the possible, independent occurrences of the challenges that the matching-related techniques must handle (e.g., heterogeneities, schema absence, etc.) as well as situations in which such challenges appear in combination. Furthermore, we must always keep in mind that such real systems evolve, which means that additional data challenges can appear. Thus, regularly monitoring and extracting data from real applications (e.g., once per month) can assist in detecting such data challenges.
Given the reasons presented above, it is clear that real data should be the first source for the experimental evaluation of matching-related techniques. However, there are some aspects of real data collections that limit their usability. The first limitation is that ground truth is typically not fully correct. As an example consider the DBLP system that lists publications from researchers. For researchers with common, or even similar names, the system has difficulties separating them.1
Obviously, computing the quality of a matching technique cannot be accepted as being fully correct when using data with issues related to the ground truth. Another limitation of using real data is the lack of collections focusing on a particular challenge or challenges. For instance, one matching technique might focus on addressing the lack of schema and thus evaluating the technique over data that also include heterogeneities in the values could be considered unfair for the particular technique.Synthetic data is included in OAEI using the ISLab Instance Matching Benchmark [13]. The particular benchmark, includes entities from the OKKAM project [30,31]. These entities are then modified using: (i) value transformations, such as typographical errors; (ii) structural transformations, such as value deletions; (iii) logical transformations, such as creation of two entities for the same real world object; and (iv) combinations of various transformations.
Synthetic generation of benchmarking entity matching data is also possible with the SWING system [14]. SWING design principles and goals are similar to EMBench but EMBench [21,23] has more expressive power and offers more flexibility in the specification of the testing data. A detailed discussion is available in [21]. It compares the functionalities provided by EMBench with the ones of the SWING system, grouped according to (1) data acquisition, (2) data generation, and (3) matching scenarios.
One recent approach is
The research area of matching-related methods has been deeply investigated the last couple of decades and a plethora of methods have been suggested. The primary difference between the existing methods is what they consider as an entity representation and which information they use for performing the matching. We discuss these methods next. For ease of comprehension and discussion, we group them into categories according to the data included in the entity representation although there are many methods that span across more than one category.
A. Similarity Methods. The first category contains methods operating on entities that are either atomic string values or a set of string values. Here, we have various basic similarity techniques (see surveys [6] and [5]), such as Levenshtein distance [28], Jaro [24], Jaro–Winkler [47] and TF/IDF similarity [41]. Note that [7] and [5] describe and discuss an experimental comparison of various basic similarity techniques used for matching names. Merge-purge [18] is another method. It considers every database relation (i.e., record) as a representation and detects if relational records refer to the same real world object. Other methods focus on finding mappings between the representations using either transformations [45], such as abbreviation, stemming, and initials, or predefined rules [9] with knowledge about specific representations.
B. Collective Matching. The next category contains methods using collective matching, which means performing the matching using existing or discovered inner-relationships. A well-know method for this category is Reference Reconciliation [10]. The method first detects possible associations between the entities by comparing their corresponding attribute values. These associations are propagated to the rest of the entities in order to enrich their information and improve the quality of final matches. Other methods are [3,4] that use entity inner-relationships to create a graph between entities. Graph nodes are clustered and detected clusters are used to identify the common entities. The methods from [25,26] follow a similar methodology to create a graph. However, these methods also generate additional possible relationships to represent the candidate matches between entities. Matches between entities are discovered by analyzing the relationships in the graph.
C. Entity Evolution. The third category contains methods that deal with the volatile nature of the data. Handling volatility can be achieved by various mechanisms. For instance, a portion of the introduced methods handle volatility through probabilities that model the belief related to the current resolution status of the entities [8,20,29,39]. More specifically, [8,39] consider a small set of possible entity alternatives, with each alternative accompanied by a probability that indicates the belief we have that this reflects the correct entity. The approach in [20] addresses many challenges of heterogeneous data. It does not assume that the alternatives are known, but that an entity collection comes with a set of possible linkages between entities. Each linkage represents a possible match between two entities and is accompanied with a probability that indicates the belief we have that the specific representations are for the same real world object. Entities are compiled on-the-fly, by effectively processing the incoming query over representations and linkages, and thus, query answers reflect the most probable solution for the specific query.
Another example of methods aiming at handling volatility, focuses on using the newly arrived data to incrementally and efficiently update the detected entities. For this purpose, [46] focuses on maintaining the matches up-to-date with techniques that do not execute matching from scratch but exploit all previous matches. The approach in [16] considers clustering, i.e., each cluster corresponds to a specific entity. New data can be merged with existing clusters or can be used for correcting previous matching mistakes.
D. Blocking-based Methods. The last category includes blocking-based methods, focusing on processing data sets of large sizes. Instead of comparing each entity with all other entities, blocking-based methods separate entities into blocks, such that entities of the same block are more likely to be a match than entities from different blocks. Thus, only the entities of the same block are compared. The majority of the proposed methods typically associate each entity with a Blocking Key Value (BKV) summarizing the values of selected attributes and then operate exclusively based on the BKVs. One such example is [17]. It sorts blocks according to their BKV and then slides a window of fixed size over them, comparing the representations it contains. The most recent methods investigate building the blocks when having heterogeneous semi-structured data with loose schema binding, e.g., [35]. Among other, the authors introduce an attribute-agnostic mechanism for generating the blocks, and explain how efficiency can be improved by scheduling the order of block processing and identifying when to stop the processing. Iteratively block processing [38] provides a principled framework with message passing algorithms for generating a global solution for the resolution over the complete collection.
The architecture of EMBench++
We now present the new architecture of EMBench++ and discuss the additions and extensions included from the previous version of the system, which was described in [21] and [23].
Figure 1 provides a graphical illustration of the current architecture. The rectangle with dotted grey line denotes the components that were incorporated in EMBench. The remaining components have been included in the system in order to achieve the goals introduced in Sections 1 and 2.

An illustration of EMBench++’s architecture (grey dotted line denotes the components from the previous version).
The system includes a set of Shredders that are responsible for shredding a given data source (e.g., Wikipedia data, XML files) it into a series of Column Tables. The current implementation contains general purpose shredders, such as relational databases and XML files, and shredders that are specifically designed for popular systems, such as Wikipedia and DBLP. Each Column Table contains distinct and clean atomic values of a particular type, for example first names, surnames, cities, and universities. This is achieved through mechanisms that focus on cleaning the repetitive, overlapping, and complementary information in the resulted column tables.

(a) Definition for two entity types. (b) Data generated for Person entity type. (c) Data generated for Article entity type.
In addition, the system also uses rules that specify how the values of the column tables are to be combined together or modified and guide the creation of a new set of column tables. Data resulted from rules are stored in Derived Column Tables, and are actually used by the system in the same way as column tables. Our current implementation, supports an “identity function” rule meaning that the resulted derived table is identical to the column table without any modification. It also supports function rules that can be used to combine column tables and Strings. As an example, consider a derived column table for FullName. The rule for FullName represents the concatenation of values from FirstName with a space character and values from Surname (i.e., Column Table followed by a String and then another Colum Table). This is, for example, expressed in the system as ‘FirstName + “ ” + Surname’.
EMBench++ also maintains a Repository that maintains internal data, including the Column Tables, Derived Column Tables as well as generated entities and data sets. Note that the system contains a default repository with a number of Column Tables, for example 1,2 million first names, 293,5 thousands surnames, 8,6 thousands universities and 22,5 thousands titles of journal articles.
The system also contains a set of Entity Modifiers. Each modifier is responsible for incorporating a particular type of heterogeneity in the specified entities. As explained in [23], EMBench contains implementations for a set of Entity Modifiers, including misspellings, word permutations, acronyms and abbreviations.
In the updated version of the system, i.e., EMBench++, we have incorporated mechanisms for Volatility. In short, these mechanisms focus on heterogeneity that appears in entities due to time changes. The developed mechanisms for volatility are presented and discussed in Section 4.3.
User Configuration allows users to configure the parameters related to the generation of data. Primarily, this involves configuring the desired entities and data collections. With respect to the entities, users define the entity types to be generated by specifying the number of entities, the attributes of each entity and the source for the attribute values. The source is a (Derived) Column Table along with a distribution (i.e., normal or Zipf) or a random value within a given range.
In addition, EMBench++ has mechanisms that allow users to use a generated entity value as the source of entities, which basically means that the result will be not independent tables but a complete database with foreign keys among its tables. The details are introduced and discussed in Section 4.1.
EMBench++ does not only allow users to generate and apply modifiers over individual entities (as the previous version) but also allows generating collections that contain various data sets of entities. As we later describe (Section 4.2), users can specify a collection with a number of data sets. Each data set can contain a different set of Entity Modifiers or the same set but different levels of destruction. The system also provides different options, referred to as propagation type, for generating the data sets within the same collection. The mechanisms related to collection generation are described in Section 4.2.
The primary concern of EMBench++ is the generation of data that goes beyond individual entity types. In particular, we need the generated entity sets to capture all the aspects required for a complete and extensive evaluation of matching-related methods, which were discussed in Section 2. Two important aspects are the existence of inner-relationships between entities (also referred to as correlations) and the incorporation of all possible heterogeneities. To formally incorporate these aspects in the entity sets of our system, we use a model that assumes the existence of an infinite set of entity identifiers
An
An
Note that in the remaining text, we will only use
The fact that a value of an attribute in an entity can be an atomic value or the identifier of another entity, is the main mechanism that allows entities to relate to each other. In what follows, we will use notation
EMBench++ includes a set of modifiers responsible for incorporating particular types of heterogeneity (Section 3). A modifier
The modifiers are not executed on the whole entity set but on a subset of it. Initially, the entity set I is separated into two sets:
A
Each
The constant c is given to the system for selecting the number of entities from I that should be modified, i.e.,
Consider again a modified entity set, i.e.,
Let
Once EMBench++ generates the entity set I, as specified by the user, it executes the selected and configurated modifiers
The data models followed by RDF and relational databases support internal references (i.e., namely foreign keys in databases), which is considered as an essential aspect. The primary reason is that foreign keys model the real world relationships as references in the data. Also, they are especially useful for encoding cascading relationships, i.e., having multiple foreign keys in tables with each foreign key referring a different parent table. In addition, satisfying referential integrity, i.e., ensuring that foreign keys agree with the primary key that the foreign keys refer to, enforces data consistency. For being able to support foreign keys we have included special mechanisms in EMBench++.
The first mechanism is in the configuration. In the previous version of our benchmarking system, users could define entity sets using attributes that are either Column Tables or Derived Column Tables. EMBench++ enhanced this part and also allows defining entity sets in which the values of the entity attributes are identifiers to entities, either of the same set (i.e., type) or to entities from other entity sets. In other words, entities can now have references to other entities.
The second mechanism for enabling usage of foreign key relationships is incorporated in the Generator. More specifically, the Generator uses the configuration of each Entity Type and of each of its included attributes to create the entities. The foreign keys mechanism is applied when the configuration detects that the values of a particular attribute are another Entity Type. In this case, the Generator does not include an actual value, i.e., from a (Derived) Column table, but identifiers from the specified Entity Type.
The selection of identifiers from the specified Entity Type can be also influenced by the users (through configuration). More specifically, users can choose between a random or Zipfian option (Fig. 3). The random option will do a random selection among all the identifiers of the given Entity Type without repetitions. The Zipfian option will do the selection based on a Zipfian distribution of all identifiers of the given Entity Type. The latter implies that the majority of the selected identifiers would appear few times and only a small number of the select identifiers would appear many times.

Configuration of author attributes in the Person entity set.

Independent and Sequential propagation.
As discussed in Section 2.1, to have an extensive evaluation we need to examine how the matching-related methods behave when modifying important data characteristics, such as the size of the data set or the destruction level of the modifiers. For example, with respect to the level of the modifiers, it would be beneficial to apply the modifiers with the different level on the original entity set. On the contrary, with respect to the size of the data, it would reasonable to start from the original entity set and keep incrementally including entities, thus each time we use the previously created entity set.
Let
addition deletion adjust
As explained in Definition 2, a modified entity set results when we execute modifiers
As shown in Definition 4, a sequence of modifiers
Given an entity set I and a collection of modifier sets an a
According to the above definition, we consider collections as follows: starting by a modifier sequence
Figure 4 shows two example collections, each with three data sets. The data sets of the first collection, i.e., C-A, include an increasing level of misspelling in their entity sets. The first data set (i.e., C-A0) has a zero level of misspelling, the next (i.e., C-A1) has 10%, and the third one (i.e., C-A2) has 20%. C-A is an independent propagation with both C-A1 and C-A2 generated from C-A0. Note that the requested modifiers and level are executed on all entity types of the data sets, in this situation on Person as well as Article. C-B0 is similar example with one volatility modifier. As shown, C-B is a sequential propagation with C-B1 generated from C-B0 and C-B2 generated from C-B1.
Applications, especially Web 2.0 applications, focus on enabling and encouraging users to constantly contribute and to modify existing content. For example, an analysis of DBPedia [33,34] revealed that the data describing the entities were modified in time, with only some of the data remaining the same. Changes affect not only values but might also involve entities splitting or being merged, a form of semantic evolution [40]. As discussed in [40], an entity can either evolve into another entity, split into several other entities, or merge into another entity.
EMBench++ provides mechanisms that allow users to generate sequential data sets, with the entities of each succeeding data set being the evolved version of the entities from the preceding data set. Volatility mechanisms are either value-level or attribute-level, as follows:
A.1) Replacement: that substitutes the value of the attribute

Configuration of the volatility modifications.

A collection with data volatility.
A.2) Continuous: that is used on attributes that take values from a restricted set, e.g., job_title takes values from
A.3) Addition: which maintains the existing value but adds to it another one from a specific (Derived) Column Table. The existing and new value are separated using a given character, for example “-” or “ ”.
Figure 6 illustrates a collection with evolving data sets following the configuration shown in Fig. 5. Thus, the entities of C-B1 are the evolved version of the entities of C-B0, and the entities of C-B2 are the evolved version of the entities of C-B1. Consider again the configuration of the volatility modifications. It includes four modifications. The first is the addition of values from column table Surname to attribute fullname with “-” as the separator, e.g., the “Noela Kuglen” from C-B0 becomes “Noela Kuglen-Airta” in C-B1. The second modification is replacement of the value of fullname with a value from Surname, e.g., “Nikoline Paccini” from C-B1 appears as “Nikoline Saro” in C-B2. The third modification is similar to the second one. It involves the replacement of the value of university with a value from University, e.g., the university of entity with id “e_ p2” is “University of Dubrovnik” in C-B0, changes to “Goshen College” in C-B1, and to “Keele University” in C-B2. The last modification is for the job_title attribute. This was originally an ordered list of values and now the modifications is for taking the value either to the value found one place before in the list or up to two places afterwards. In the figure, this is present in entity with id “e_p3” that was a “PhD student” in C-B0 and a “researcher” in C-B1.
B.1) Elimination: this removes selected attributes from the entity set and thus eliminates the corresponding values from all entities. For example, if a user removes attribute
B.2) Expansion: this includes additional attribute names in an entity set while also generating the values for these attributes in all the corresponding entities. Expansion of I with attribute names
Comparison with publication-related collections
Comparison with collections of various entity types
1 Jan. 2018 & English Wikipedia articles.
2 May 2011 [44].
In this section we illustrate an empirical use and evaluation of the introduced benchmarking system. We aim at examining different aspects of EMBench++ and describe and report our different assessments.
More specifically, we start with an overview of the collections used in existing publications (i.e., static data) and discuss the advances offered by EMBench++ (Section 5.1). Next is an illustration of generated data collections focusing on collective resolution and entity evolution (Section 5.2). We then continue with a comparison between collections used in the literature with the data sets that EMBench++ can generate (Section 5.3). Finally, we provide an example illustration on how data collections generated by our system have been used for testing a real matching-related technique (Section 5.4).
Advances over static collections
The majority of data collections used in the literature are related to publications (i.e., include data of authors and citations) [10,19,36,37] and only few collections include entities of other types [11,27,32,36]. We follow this separation in our comparison. Table 1 focuses on one publication-related collections while Table 2 on collections of various entity types.
As Table 1 shows, most publication-related collections are of a small size. For instance, Cora contains 6.107 citations and DBLP/ACM contains 4.671. The largest collections are the KDD Cup 2003 and the Four PIMs. Unfortunately, the latter is from personal data and not publicly available. Furthermore, all these data collections do not contain evolution data.
The situation is a little better with respect to collections containing different entity types (i.e., Table 2). Here we have collections of larger sizes, for example IMDB/DBPedia containing 50.797 movies and Wikipedia containing 5,48M entities. Although this is a positive aspect, there are other issues when evaluating algorithms using these collections. The first is that these collections have a low number of duplicates (i.e., from 0 to 2 instances per entity). This is because the collections were typically created by merging two sources. For example, in the IMDB/DBPedia collection we would have one instance from IMDB and one instance from DBPedia describing the same real world object. Wikipedia, which is among the largest collections, does not have any duplicates, i.e., we see only one instance per entity. Another issue with these collections is the absence of evolution data. The only exception is with Wikipedia, since one can use the previous versions of the collection.
As previously discussed, EMBench++ is able to alleviate the aspects of existing collections that put limits on the possible evaluations. These aspects are the capability of generating collections of large sizes, containing various entity types, including various number of duplicates, and capturing evolution.
Illustration of generated data collections
Collective resolution
Evaluating collective matching methods, for example those briefly discussed in part B of Section 2.2, requires investigating the behavior of the methods under various data sets characteristics. We now explain how EMBench++ can be used for generating collections that allow investigating such characteristics.
For example, consider that we have a technique and would like to examine how it behaves when altering the following characteristics:
(a) collection size defined as the total number of entities in the data set on which the technique is executed. This would help to verify that the technique is scalable and thus able to efficiently process collection of various sizes, e.g., collections with 1.000 as well as collections with 1 million entities.
(b) cleanliness, which is the percentage of the total number of duplicates with respect to the total number of clean entities in the data set. For example, we would like to check what happens when only 1% of the entities in the collection are duplicates and what happens when 50% are duplicates.
(c) entity size, i.e., the number of attributes included in the entities. This could assist in testing whether the technique can handle small entities, e.g., composed by 1–2 attributes, as well as large entities, i.e., composed by 8–10 attributes.
(d) duplication, given the number of duplicates describing the same real world entity. For example, test if the technique can handle collections in which a maximum of 2 entities can refer to the same real world object as well as collections in which up to 25 entities might refer to the same real world entity.
We used EMBench++ to generate four collections containing a small number of data sets, with each collection related to one of the four investigated characteristics. The specific characteristic remained identical for all the data sets in the collection. The other characteristics were increased among the data sets of the collection. For the particular generation we focused on Person and Article entity sets, which are the most commonly used types in existing works (Section 5.1).
Figure 7 provides two illustrations of the collections (i.e., the two plots on top of the figure) as well as detailed statistics (i.e., the four tables) for their data sets. Collection A is related to the collection size, i.e., characteristic a. As shown in the figure, data set A-1 contains 38.000 entities, A-2 contains 76.000, A-3 contains 114.000 entities, and A-4 contains 152.000. Consider now data set A-1. It contains 38.000, out of which 36.000 are clean and 2.000 refer to the same real object. Thus, cleanliness is 5,6% (i.e.,
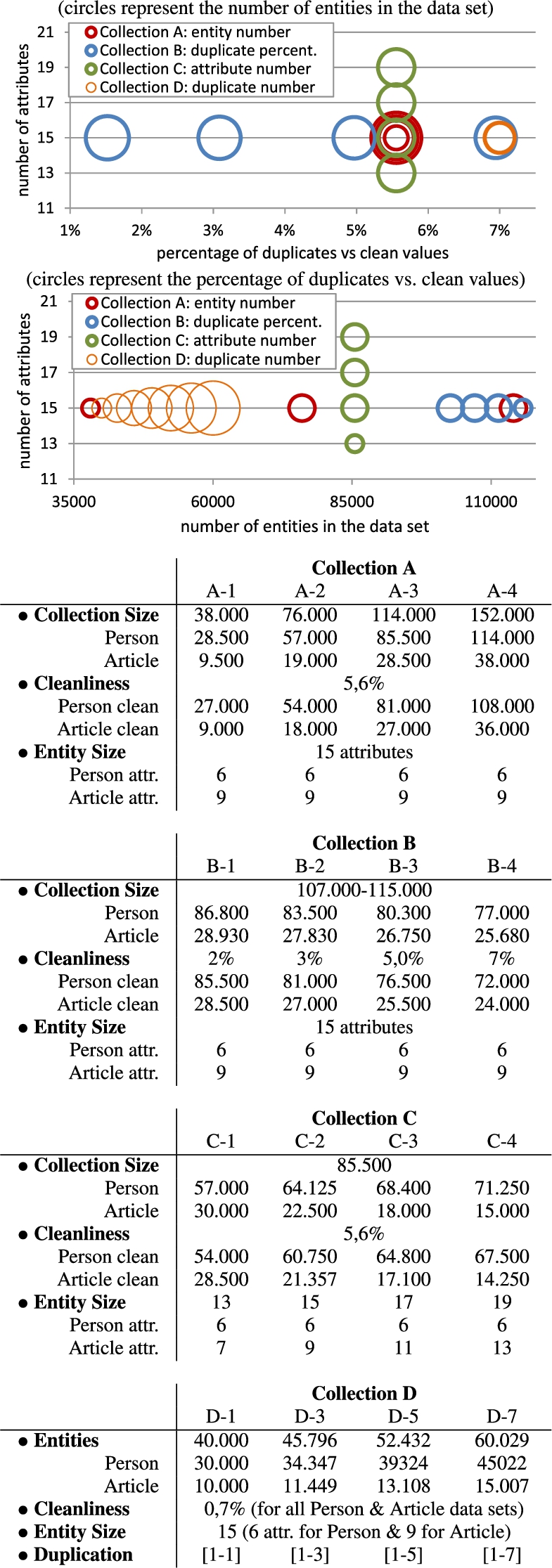
Two illustrations and statistics for the data sets in Collections A, B, C and D (can be used for evaluating collective resolution).

The number of evolved entities as well as the ones that remained the same in all the data sets in Collection E.

Distribution of the first names from (a) actors from DBPedia, and (b) authors generated by our system.
The percentage of evolved people entities between (a) two DBPedia versions, and (b) the E1-E2 collections.
Collection B is related to the cleanliness, meaning that only this increases among the data sets of the collection whereas the other characteristics remain the same. Note that in this situation the entity size could not be exactly the same but it is almost the same. Collection C is related to entity size and thus we see the same value for collection size, cleanliness, and duplication (i.e., 85.500, 5,5%, and 2). Lastly, Collection D is related to duplication. Thus, D-1 to D-7 data sets contain an increasing number of duplicates for the same real world entity while having the same cleanliness and entity size. Generating identical collection sizes for all data sets of collection D was not possible, so we see an only slightly increasing value.
As explained in part C of Section 2.2, a recently appeared research area focuses on dealing with the volatile nature of the data. Our second usability investigation generates data suitable for evaluating such methods.
Using EMBench++ we created a collection that contains data sets with entities evolved in time. We used Person entities with the configuration shown in Section 4.3. Starting from a data set of 30.000 Person entities, we created a total of five data sets (named E1, E2, E3, E4 and E5) with each data set containing an evolved version of 3.000 entities from the previous data set.
The resulted data sets are exactly the same except for the number of duplicated entities. More specifically, the total number of entities is 30.000 and the number of entity attributes is 5. Figure 8 provides a graphical illustration of the data sets in Collection E.
Representation of real world situations
We now continue with a comparison between data collections generated by EMBench++ with real world data from existing collections. The particular evaluation aims at illustrating that the introduced mechanisms are able to generate data that actually represent real world situations.
The first aspect we investigated is the distribution of the values generated by EMBench++. For this evaluation we retrieved people included in two data collections. The first corresponds to actors included in DBPedia movies and the second to authors included in publications generated by our system (e.g., publication collections shown in Fig. 7). From these two collections, we used the initial 15.500 distinct names, i.e., DBPedia actors and EMBench++ publication authors. We then extracted the first names and computed the appearance frequency of each first name. Figure 9 provides the distribution of the first names for the two collections. The plots illustrate the resemblance between the frequency of first name appearance and actually illustrate that for both collections the first names follow the Zipfian distribution.
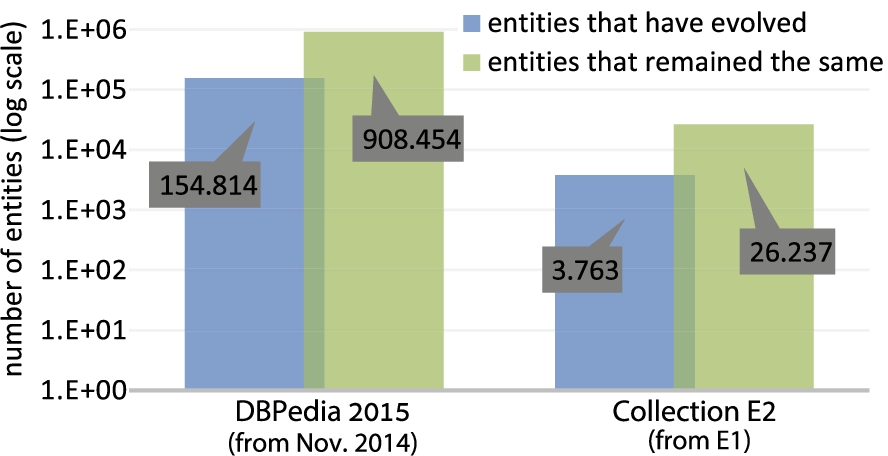
We also examined whether our system can capture evolution as this occurs in the real world applications. To examine this we used data from two different versions of DBPedia and in particular data from DBPedia November 2014 and from 2015. We then analyzed the “Persondata” data sets from both versions. More specifically, we computed the number of entities from the 2015 version that had different values than the November 2014 version. This showed that 154.814 entities evolved and 908.454 remained the same, giving a percentage of 14,5% of evolved entities.
Figure 10 shows the number of entities that have evolved as well as the entities that remained the same between the particular DBPedia versions. Furthermore, the plot also shows the same information for the entities evolved from the E1 to the E2 collection. It can be seen that the percentage of evolved entities in E2 is 13%, which is similar to the DBPedia data. In addition, our system is capable of going to larger percentages as for example the ones illustrated in Fig. 6.
Demonstration of testing a real matching-related technique
EMBench++ has been used for generating data to evaluating a real technique for holistic in-database query processing over information extraction pipelines [19]. The authors evaluated their technique on the real data sets of Cora, CiteSeer, DBLP/ACM, which we discussed in Section 5.1. The authors have also used generated data for being able to study the influence of a small set of particular characteristics, such as the number of instances in the collection.
More specifically, EMBench++ was used for generating 3 collections with a total of 12 data sets. Each collection had a fixed value on one of the investigated characteristics and an increased number for the other characteristics, similar to the ones discussed in Fig. 7. The data sets from these collections were used for evaluating various aspects of the introduced technique. The following list provides some of the performed tests:
Collection Size. The test examined efficiency and effectiveness of the technique when increasing the number of entities in the collection, for example on collections with 2.000 entities until 20.000 entities.
Number of Instances in Entities. The test investigated the technique with entities consisting of a different number of instances, for example with up to 2 instances match the same real world entities or with up to 7 instances match the same real world entities.
Ratio of Duplicates. The test valuated the technique on collections with different ratio of duplicated vs. clean entities. For example, only 4% of the collection instances can refer to the same real world entities, or 10% of the collection instances refer to the same real world entities.

A plot from the experimental evaluation include in [19], using data generated with EMBench++.
As an example, consider the evaluation result shown in Fig. 11 (originally shown in [19]). This uses two of the synthetic data sets, namely the C-1 and C-2 data sets. Both data sets contain 20.000 entities but a different number of duplicates with a different ration of duplicated vs. clean entities (i.e., 10% C-1 and 6% for C-2) and different number of maximum instances per entity (i.e., 7 for C-1 and 6 for C-2). The authors performed evaluations for each of these data sets and for each of the two supported query types, which are top-k and threshold. Then, they reported execution time (i.e., efficiency) according to the number of maximum instances per entity.
We have introduced a system for generating benchmark data that can be used for the extensive evaluation of matching-related methods. Our main contributions include the usage of the available schema information during the modification of entities, generating data sets with evolved versions of entities, and controlling not just the generation of single data sets but collections of data sets. Note that the implementation of EMBench++ with the default repository data as well as the configuration and collections involved in the usability experiments will be made available in the final version of the journal.