
Abstract
In this paper we describe
Keywords
Introduction
An important research problem in Big Data is how to provide end-users with transparent access to the data, abstracting from storage details. The paradigm of Ontology-based Data Access (OBDA) [7,27] provides an answer to this problem that is very close to the spirit of the Semantic Web. In OBDA, the data stored in a relational database is presented to the end-users as a virtual RDF graph, whose vocabulary is provided by the classes and properties of an ontology, over which SPARQL queries can be posed. This solution is realized through mappings that establish a link between the ontology and the database, by specifying how to instantiate the classes and properties in the ontology by means of queries over the database.
A lot of research on optimization techniques for OBDA has been carried out recently, with the aim of making this paradigm effective in practice [4,5,11,15,19,23,28]. In order to evaluate the effectiveness of optimizations, some benchmarks have been proposed and applied to the OBDA setting.1
Data scaling [26] is a recent approach that tries to overcome this problem by automatically tuning the generation parameters through statistics collected over an initial data instance. Hence, the same generator can be reused in different contexts, as long as an initial data instance is available. A measure of quality for the produced data is defined in terms of results for the available queries, which should be similar to the ones observed for real data of comparable volume.
In the context of OBDA, however, taking as the only parameter for generation an initial data instance does not produce data of acceptable quality, since the generated data has to comply with constraints deriving from the structure of the mappings and the ontology, which in turn derive from the application domain.
In this work we present the
To evaluate
The rest of the paper is structured as follows. In Section 2, we introduce the basic notions and notation to understand this paper. In Section 3, we define the scaling problem and discuss important measures on the produced data that define the quality of instances in a given OBDA setting. In Section 4, we discuss the
This paper is a revised and significantly extended version of an article containing preliminary results that was presented at the Workshop on Benchmarking Linked Data (BLINK) 2016 [18].2
With respect to [18], apart from providing many more details on the
We assume that the reader has moderate knowledge of OBDA, and refer for it to the abundant literature on the subject, like [6]. Moreover, we assume familiarity with basic notions from probability calculus and statistics.
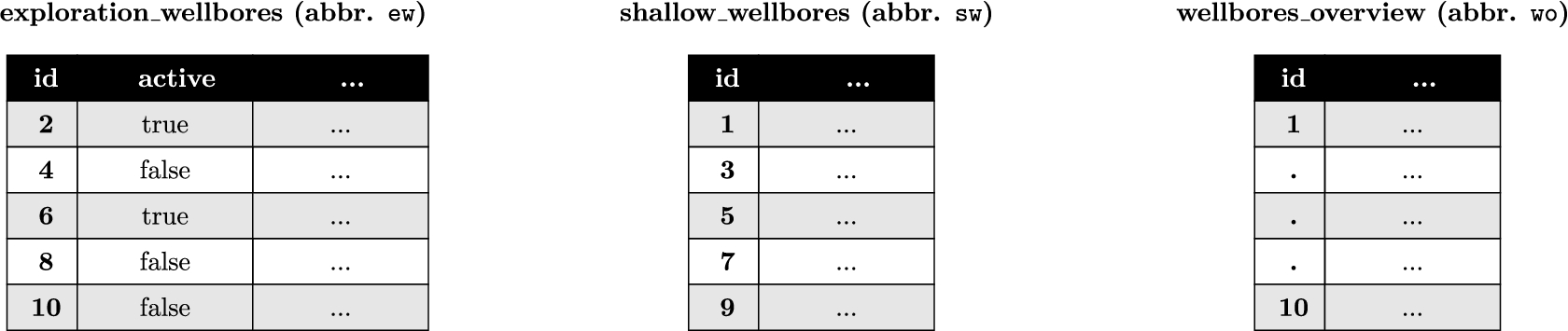
Portion of the ontology for the NPD benchmark. The first three axioms (left to right) state that the classes Exploration Wellbore (
), Shallow Wellbore (
), and Suspended Wellbore (
) are subclasses of the class
. The fourth axiom states that the classes
and
are disjoint
Portion of the ontology for the NPD benchmark. The first three axioms (left to right) state that the classes Exploration Wellbore (
The W3C standard ontology language for OBDA is OWL 2 QL [20]. For the sake of conciseness, we consider here its mathematical underpinning
Queries for our running example
Mappings from the NPD benchmark
Results from the evaluation of the queries on the source part build assertions in the ontology. For example, each tuple
The W3C standard query language in OBDA is SPARQL [14], with queries evaluated under the OWL 2 QL entailment regime [16]. Intuitively, under these semantics each basic graph pattern (BGP) can be seen as a single conjunctive query (CQ) without existentially quantified variables. As in our examples we only refer to SPARQL queries containing exactly one BGP, we use the more concise syntax for CQs rather than the SPARQL syntax. Table 2 shows the two queries used in our running example.
The mapping component links predicates in the ontology to queries over the underlying relational database. To present our techniques, we need to introduce this component in a formal way. The standard W3C language for mappings is R2RML [10], however here we use a more concise syntax that is common in the OBDA literature. Formally, a mapping assertion
For the rest of the paper we fix an OBDA instance
The data scaling problem introduced in [26] is formulated as follows:
(Data Scaling Problem).
Given a database instance
The notion of similarity is application-based. Being our goal benchmarking, we define similarity in terms of execution times for the evaluation of the queries in the benchmark. More precisely, consider a (real world) database instance
Concerning the size, similarly to other approaches,
Similarity measures for OBDA and their rationale
Our notion of similarity is an ideal one, but also an abstract one, as it does not provide any guideline on how the data should be generated. In this section we overview the concrete similarity measures which are used by
Schema dependencies The scaled instance
In a relational database, a weak entity is an entity that cannot be uniquely identified by its attributes alone.
Column-based duplicates and
The number of classes in the ontology does not depend on the size of the data instance.

The VIG algorithm.
Size of columns clusters, and disjointness Query
On the other hand, a standard OBDA translation of
Therefore, between such identified sets of columns a join could occur during the evaluation of a user query.
In this section we show how
Algorithm 1 shows a high-level view of
At the high-level, the
From now on, let s be a scale factor, and let
Input data instance
The goal of this phase is to create intervals of indexes for each column that will be used as an input to the generation phase. These intervals are created while satisfying certain constraints over the database schema, mappings, and statistical information on the source database. The analysis phase consists of the following 5 stages:
initialization: reading of the database schema and statistics over the source database;
creation of intervals: creation, starting from the statistics, of initial intervals of indexes to associate to each column;
satisfaction of primary keys: ensuring that primary key constraints are satisfied in the scaled instance by adapting the intervals boundaries;
columns cluster analysis: identification of semantically related columns through schema and mappings analysis, and adaptation of the intervals boundaries;
satisfaction of foreign keys: ensuring that foreign key constraints are satisfied in the scaled instance by adapting the intervals boundaries.
We now detail each of these stages.
Initialization For each table T,
For the tables in Fig. 2,
Creation of intervals When C is a numerical column,
Following on our running example,
Satisfaction of primary keys The generation of distinct tuples depends on the pseudo-random number generator adopted. Formally, a pseudo-random number generator is a sequence of integers
We now explain how such number generator can be used to generate tuples of values satisfying the primary key constraints in the schema. Let
Columns cluster analysis In this phase,
A qualified column name is a string of the form
For our running example, we have
We recall that
In our example we have that  . In fact,
. In fact,
After identifying columns clusters,
Consider the columns cluster
Thus,
Without loss of generality, we assume that the intervals generated by
CSP program for foreign keys satisfaction
In this program, S is the set of intervals for the columns in the columns cluster
Satisfaction of foreign keys At this point, foreign key columns D for which there is no columns cluster
CSP instance for the running example
Table 4 shows the CSP program that encodes the problem of establishing the intervals for the columns in
At this point, the intervals found by
Observe that these intervals violate the foreign key
From this solution,

Scaled instance
We analyze the complexity of the 5 stages of the analysis phase.
Initialization: The gathering of each statistic is performed by issuing Creation of intervals: We need to create Satisfaction of primary keys: This requires a repeated computation of the least common multiple of numbers of distinct values for the columns participating in a primary key. The number of such repetitions is expected to be very small. Columns cluster analysis: The complexity of this stage depends on the number and size of the columns clusters. The number of (non-singleton) columns clusters can range from a single columns cluster containing all the columns in For NPD, we have 17 columns clusters mostly of size 2 or 3, and there is a single largest group of size 11.
Satisfaction of foreign keys: From Table 4, it is immediate to see that for each columns cluster
At this point, each column in At this stage, Association of columns to intervals. The columns in the considered tables are associated to intervals in the following way:
Number of tuples to generate for each table. From Example 4.1, we know that Association of indexes to database values. Without loss of generality, we assume that the injective function used by Figure 3 shows the generated data instance
In
vig in action
The data generation techniques presented in the previous sections have been implemented in the
Overview of the data and design of the experiments
In this section we present an extensive evaluation of
In Section 5.1 we describe the design of our experiments, in Sections 5.2 to 5.4 we present three experiments of
For each dataset in our experiments, we consider the following characteristics:
generator: whether the dataset includes a data generator;
real-world data: whether the dataset includes real-world data for evaluation;
mappings: whether the dataset includes mappings;
ontology: whether the dataset includes an ontology.
Then we design the following experiments according to the characteristics of each dataset:
Data generation: it compares the performance of data generation between the generator provided by the dataset and
Query evaluation: it evaluates the test queries over different scaled data generated by
Predicate growth: it evaluates how scaling affects the growth of classes and properties.
Use of domain info: it evaluates the impact on the quality of the produced data of using, for the data generation, the domain information provided by the mappings and the ontology.
For the evaluation, we provide three experiments. In the first experiment we use the BSBM benchmark [2] to compare the synthetic data generated by
The characteristics of these datasets and the designed experiments are summarized in Table 6, in which “✓” means yes and “-” means no or impossible. In particular, we only evaluate data generation in BSBM because the other datasets do not include a generator, and we only evaluate the impact of an ontology in NPD as only NPD includes an expressive ontology.
We do not evaluate here the ability of
Global setting for all experiments For the DBLP and BSBM experiments we used two different OBDA systems, namely D2RQ v0.8.1 and Ontop v1.18.0 [5]. We used PostgreSQL v9.6.2 and MySQL v5.7.17 as underlying database engines. The choice to test on multiple systems and RDBMSs was made in order to ensure that the observed results do not depend on the actual implementation details of the considered system/RDBMS. The hardware used is a PC desktop with 4 Intel(R) Xeon(R) E5-2680 0 @ 2.70 GHz processors and 8 GB of RAM. The OS is Ubuntu 16.04 LTS.
For the NPD experiment, we changed our hardware, and used an HP Proliant server with 2 Intel Xeon X5690 Processors (each with 12 logical cores at 3.47 GHz), 106 GB of RAM and five 1TB 15K RPM HDs. We underline that the change of hardware does not affect the validity of the experiments, as we never compare results run on different machines.
The experiments were run in the OBDA-Mixer system,13
All the material used for the experiments is made available online.14
For data instances, generators, mappings, queries, etc., see
TheBSBMbenchmarkisbuiltaroundane-commerce use case in which different vendors offer products that can be reviewed by customers. It comes with a set of template-queries, an ontology, mappings, and a native ad-hoc data generator (
Experiment on data generation
Setup We used the two generators to create six data instances, denoted as
Results and discussion Figure 4 shows the resources (time and memory) used by the two generators for creating the instances. For both generators the execution time grows approximately as the scale factor, which suggests that the generation of a single column value is in both cases independent from the size of the data instance to be generated. Observe that

Generation time and memory comparison.
We compare the execution times for the queries in the BSBM benchmark evaluated over the instances produced by
Setup The experiment was run on a variation of the BSBM benchmark over the testing platform, the mappings, and the considered queries. We now briefly discuss and motivate the variations, before introducing the results.
The testing platform of the BSBM benchmark instantiates the queries with concrete values coming from binary configuration files produced by
Another important difference regards the mapping component. The BSBM mapping contains some URI templates with two arguments where one of them is a unary primary key. This is commonly regarded as a bad practice in OBDA, as it is likely to introduce redundancies in terms of retrieved information. For instance, consider the template

used to construct objects for the class
We tested the 9
Overview of the BSBM experiment (D2RQ-MySQL)
Overview of the BSBM experiment (D2RQ-MySQL)
Overview of the BSBM experiment (D2RQ-PostgreSQL)
Overview of the BSBM experiment (Ontop-MySQL)
Overview of the BSBM experiment (Ontop-PostgreSQL)
Results and discussion Tables from 7 to 10 contain the results of the experiment in terms of various performance measures, namely the average execution time for the queries in mix (
Setup In this experiment we evaluate how scaling with
To perform this experiment, we have created a query for each class C and property P in the ontology retrieving all the individuals or tuples of individuals belonging to C or P. We evaluate each such query on the data instances generated by
Results and discussion Table 11 shows the deviation, in terms of number of elements for each predicate (class, object property, or data property) in the ontology, between the instances generated by
An object property defined under the BSBM namespace.
Predicates growth comparison
The DBLP computer science bibliography16
Setup We used
We manually crafted a set of 16 queries resembling some real-world information needs from DBLP (e.g., “list all the authors of a journal”, “list all coauthors of an author”, “list all publications directly referencing a publication from one author”, or “list publications indirectly referencing18
Under a bound on the length of the chain of indirect references.
Overview of the DBLP experiment (D2RQ-MySQL)
Overview of the DBLP experiment (D2RQ-PostgreSQL)
Overview of the DBLP experiment (Ontop-MySQL)
Overview of the DBLP experiment (Ontop-PostgreSQL)
Results and discussion Tables from 12 to 15 contain the results of the experiments. We observe that the measured performances for query evaluation over the instances
Since already at the scale factor 1,
Setup In this experiment we evaluate how scaling with
Predicates growth comparison
Predicates growth comparison
Results and discussion Table 16 shows the deviation, in terms of number of elements for each predicate (class, object property, or data property) in the ontology, between
Overview of the NPD experiment (NPD-MySQL)
The NPD Benchmark [17] is a benchmark for OBDA systems based on the the Norwegian Petroleum Directorate (NPD) FactPages.20
Setup We used
For the test, we used the 24 queries from the NPD benchmark that are supported by Ontop (i.e., all queries without aggregation operators), and evaluated them against the instances produced by
Results and discussion Tables 17 and 18 contain the results of the experiments. We observe that the measured performances for query evaluation over the instances
Looking at the other scaled instances, we observe that the average execution time and the mix time over the evaluations for PostgreSQL grow roughly proportionally to the scale factor. This is not the case for the MySQL evaluations, due to the presence of a few queries which timeout and flatten the overall mix times.
Overview of the NPD experiment (NPD-PostgreSQL)
Overview of the NPD experiment (NPD-PostgreSQL)
Setup In this experiment we evaluate how scaling with
Results and discussion Table 19 shows the deviation, in terms of number of elements for each predicate (class, object property, or data property) in the ontology, between
Predicates growth comparison
Predicates growth comparison
Setup The query discussed in our running example is at the basis of the three hardest real-world queries in the NPD Benchmark, namely queries 6, 11, and 12. In this section we compare these three queries on two modalities of
Selectivity analysis
Selectivity analysis
Results and discussion Table 20 contains the selectivities (i.e., number of results) of all four possible joins between the three tables
Table 21 shows the impact of the wrong selectivities on the performance (response time in milliseconds) of evaluation for the queries under consideration. Observe that the performance measured over the DB instances differ sensibly from the one measured over OBDA instances, or over the original NPD instance. This is due to the higher costs for the join operations in DB instances, which in turn derive from the wrong selectivities discussed in the previous paragraph.
Evaluations for queries 6, 11, and 12
In our experiments, we observed that the performance for query answering over the instances generated by
However, the encouraging conclusion will not apply to every setting. In fact, observe that
Moreover, an intrinsic weakness of
Discussion on multi-attribute foreign keys
We have discussed how VIG can produce data that retain certain statistics observed on the initial seed of data, while complying with schema constraints such as primary keys and single-attribute foreign keys. In this section we discuss the impact of multi-attribute foreign keys, and why it is non-trivial to satisfy this kind of constraint while retaining the discussed statistics. We carry out our discussion by means of an example.
Consider a database schema Σ with three tables 
For each
Multi-attribute Foreign Key Satisfaction. The X axis lists all allowed values for the attributes 


Suppose that, after an analysis phase over a database instance 
Then, the problem of satisfying the dependencies 

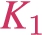



In general, if there are k attributes used for foreign key constraints, then this is a search problem in a k-dimensional space. Observe that, even if this search could be done in polynomial time, it would still be dramatically slower than the current implementation of
In this section we discuss the relation between
UpSizeR [26] replicates two kinds of distributions observed on the values for the key columns, called joint degree distribution and joint distribution over co-clusters.22
The notion of co-cluster has nothing to do with the notion of columns-cluster introduced here.
In terms of similarity measures, the approach closest to
In RDF graph scaling [25], an additional parameter, called node degree scaling factor, is provided as input to the scaler. The approach is able to replicate the phenomena of densification that have been observed for certain types of networks. However, the quality of the data generated by an RDF scaler and by
Observe that all the approaches above do not consider ontologies or mappings. Therefore, many measures important in a context with mappings and ontologies and discussed here, like selectivities for joins in a co-cluster, class disjointness, or reuse of values for fixed-domain columns, are not taken into consideration in such approaches. This leads to problems like the one we discussed through our running example, and for which we showed in Section 5 how it affects the benchmarking analysis.
In this work we presented
We have evaluated
The current work plan is to enrich the quality of the generated data by adding support for multi-attribute foreign keys, joint-degree and value distributions, and intra-row correlations (e.g., objects from “Suspended Wellbore” might not have a “Completion Year”). Unfortunately, we expect that some of these extensions will conflict with the current feature of constant time for the generation of tuples. In fact, they might require access to previously generated tuples in order to correctly compute new tuples (e.g., to take into account joint-degree distribution [26]).
A related problem is how to extend the notion of “scaling” to the other components forming an input for the OBDA system, like the mappings, the ontology, or the queries. We see this as an interesting research problem to be addressed in the future.
Footnotes
Acknowledgements
This research has been partially supported by the projects “Ontology-based analysis of temporal and streaming data” (OBATS) and “High Quality Data Integration with Ontologies” (QUADRO) funded through the 2017 and 2018 research budgets of the Free University of Bozen-Bolzano, and by the project “South Tyrol Longitudinal study on Longevity and Ageing” (STyLoLa), funded through the 2017 Interdisciplinary Call issued by the Research Committee of the Free University of Bozen-Bolzano.