
Abstract
Knowledge bases are nowadays essential components for any task that requires automation with some degrees of intelligence. Assessing the quality of a knowledge base is a complex task as it often means measuring the quality of structured information, ontologies and vocabularies, and queryable endpoints. Popular knowledge bases such as DBpedia, YAGO2, and Wikidata have chosen the RDF data model to represent their data due to its capabilities for semantically rich knowledge representation. Despite its advantages, there are challenges in using RDF data model, for example, data quality assessment and validation. In this paper, we present a novel knowledge base quality assessment approach that relies on evolution analysis. The proposed approach uses data profiling on consecutive knowledge base releases to compute quality measures that allow detecting quality issues. Our quality characteristics are based on the evolution analysis and we used high-level change detection for measurement functions. In particular, we propose four quality characteristics: Persistency, Historical Persistency, Consistency, and Completeness. Persistency and historical persistency measure the degree of changes and lifespan of any entity type. Consistency and completeness identify properties with incomplete information and contradictory facts. The approach has been assessed both quantitatively and qualitatively on a series of releases from two knowledge bases, eleven releases of DBpedia and eight releases of 3cixty. The capability of Persistency and Consistency characteristics to detect quality issues varies significantly between the two case studies. Persistency gives observational results for evolving knowledge bases. It is highly effective in case of knowledge bases with periodic updates such as the 3cixty one. The Completeness characteristic is extremely effective and was able to achieve 95% precision in error detection for both use cases. The measures are based on simple statistical operations that make the solution both flexible and scalable.
Introduction
The Linked Data approach consists in exposing and connecting data from different data sources available on the Web via semantic web technologies. Tim Berners-Lee1
Such KBs evolve over time: their data (instances) and schemas can be updated, extended, revised and refactored [15]. In particular, the instances evolve over time given that new resources are added, old resources are removed, and links to resources are updated or deleted. For example, the DBpedia KB [2] has been already available for a long time, with various versions that have been released periodically. Along with each release, DBpedia proposed changes at both instance and schema level. The changes at the schema level involve classes, properties, axioms, and mappings to other ontologies [28]. Usually, instance-level changes include resources typing, property values, or identify links between resources.
In this context, the KB evolution is important for a wide range of applications: effective caching, link maintenance, and versioning [20]. However, unlike in more controlled types of knowledge bases, the evolution of KBs exposed in the LOD cloud is usually unrestrained, what may cause data to suffer from a variety of quality issues, both at a semantic level and at a data instance level. This situation clearly affects negatively data stakeholders such as consumers, curators. Therefore, ensuring the quality of the data of a knowledge base that evolves over time is vital. Since data is derived from autonomous, evolving, and increasingly large data providers, it is impractical to do manual data curation, and at the same time it is very challenging to do continuous automatic assessment of data quality.
Data quality, in general, relates to the perception of the “fitness for use” in a given context [43]. One of the common preliminary task for data quality assessment is to perform a detailed data analysis. Data profiling is one of the most widely used techniques for data analysis [32]. Data profiling is the process of examining data to collect statistics and provide relevant metadata [30]. Based on data profiling we can thoroughly examine and understand each KB, its structure, and its properties before usage. In this context, monitoring the KB evolution using data profiling can help to identify quality issues.
The key concept behind this work is based on the work from Papavasileiou et al. [33] where they formalize KB evolution using simple changes at low-level and complex changes at high-level. The authors considered low-level, and high-level changes are more schema-specific and dependent on the semantics of data. More specifically, the KB evolution can be analyzed using fine-grained “change” detection at low-level or using “dynamics” of a dataset at high-level. Fine-grained changes of KB sources are analyzed with regard to their sets of triples, set of entities, or schema signatures [7,31]. For example, fine-grained analysis at the triple level between two snapshots of a KB can detect which triples from the previous snapshots have been preserved in the later snapshots. Furthermore, it can detect which triples have been deleted, or which ones have been added.
On the other hand, the dynamic features of a dataset give insights into how it behaves and evolves over a certain period [31]. Ellefi et al. [8] explored the dynamic features considering the use cases presented by Käfer et al. [20]. KB evolution analysis using dynamic features helps to understand the changes applied to an entire KB or parts of it. It has multiple dimensions regarding the dataset update behavior, such as frequency of change, change pattern, change impact and causes of change. More specifically, using dynamicity of a dataset, we can capture those changes that happen often; or changes that the curator wants to highlight because they are useful or interesting for a specific domain or application; or changes that indicate an abnormal situation or type of evolution [31,33].
Based on the high-level change detection, we aim to analyze quality issues in any knowledge base. The main hypothesis that has guided our investigation is: Dynamic features from data profiling can help to identify quality issues.
In this paper, we address the challenges of quality measurements for evolving KB using dynamic features from data profiling. We propose a KB quality assessment approach using quality measures that are computed using KB evolution analysis. We divide this research goal into three research questions:
Which dynamic features can be used to assess KB quality characteristics?
We propose evolution-based measures that can be used to detect quality issues and address quality characteristics.
Which quality assessment approach can be defined on top of the evolution-based quality characteristics?
We propose an approach that profiles different releases of the same KB and measures automatically the quality of the data.
How to validate the quality measures of a given KB?
We propose both quantitative and qualitative experimental analysis on two different KBs.
Traditional data quality is a largely investigated research field, and a large number of quality characteristics and measures is available. To identify a set of consistent quality characteristics using KB evolution analysis, in our approach we explored the guidelines from two data quality standards, namely ISO/IEC 25024 [19] and W3C DQV [18]. We also explored the comprehensive survey presented by Zaveri et al. [47] on linked open data quality. Concerning the KB evolution, we explored dynamic features at the class level and at the property level. We thus defined four evolution-based quality characteristics based on dynamic features. We use basic statistics (i.e., counts, and diffs) over entities from various KB releases to measure the quality characteristics. More specifically, we compute the entity count and instance count of properties for a given entity type. Measurement functions are built using entity count and the amount of changes between pairs of KB releases. We presented an experimental analysis that is based on quantitative and qualitative approaches. We performed manual validation for qualitative analysis to compute precision by examining the results from the quantitative analysis.
The main contributions of this work are:
We propose four quality characteristics based on change detection of a KB over various releases;
We present a quality assessment method for analyzing quality issues using dynamic features over different KB releases;
We report about the experimentation of this approach on two KBs: DBpedia [2] (encyclopedic data) and 3cixty [38] (contextual tourist and cultural data).
This paper is organized as follows: Section 2, presents motivational examples that demonstrate various important aspects of our quality assessment approach. In Section 3, we present the related work focusing on Linked Data dynamics and quality measurement of linked data. Section 4 contains the definition of the proposed evolution-based quality characteristics and measurement functions. Section 5 describes our approach that relies on the KB evolution analysis and generates automatic measures concerning the quality of a KB. In Section 6, we present our empirical evaluation conducted on two different KBs, namely DBpedia and 3cixty Nice KB. Section 7 discusses the initial hypothesis, research questions and insights gathered from the experimentation. We conclude in Section 8, by summarizing the main findings and outlining future research activities.
Resource Description Framework (RDF)3
In our approach we used two KBs namely, 3cixty Nice KB and DBpedia KB. Here we report a few common prefixes used in the paper:
DBpedia ontology URL5
DBpedia resource URL6
FOAF Vocabulary Specification URL7
Wikipedia URL8
3cixty Nice event type URL9
3cixty Nice place type URL10
RDF has proven to be a good model for data integration, and there are several applications using RDF either for data storage or as an interoperability layer [33]. One of the drawbacks of RDF data model is the unavailability of explicit schema information that precisely defines the types of entities and their properties [31]. Furthermore, datasets in a KB are often inconsistent and lack metadata information. The main reason for this problem is that data has been extracted from unstructured datasets and their schema usually evolves. Within this context, our work explores two main areas: (1) evolution of resources and (2) impact of erroneous removal of resources in a KB. In particular, in our approach the main use case for exploring KB evolution from data is quality assessment.
Taking into consideration KB evolution analysis, performing a fine grained analysis based on low-level changes means substantial data processing challenges. On the other hand, a coarse grained analysis using high-level changes can help to obtain an approximate indication of the quality a data curator can expect.
In general, low-level changes are easy to define and have several interesting properties [33]. Low-level change detection compares the current with the previous dataset version and returns the delta containing the added or deleted entities. For example, two DBpedia versions – 201510 and 201604 – have the property dbo:areaTotal in the domain of dbo:Place. Low-level changes can help to detect added or deleted instances for dbo:Place entity type. One of the main requirements for quality assessment would be to identify the completeness of dbo:Place entity type with each KB releases. Low-level changes can help only to detect missing entities with each KB release. Such as those entities missing in the 201604 version (e.g. dbr:A_Rúa, dbr:Sandiás,dbr:Coles_Qurense). Furthermore, these instances are auto-generated from Wikipedia Infobox keys. We track the Wikipedia page from which DBpedia statements were extracted. These instances are present in the Wikipedia Infobox as Keys but missing in the DBpedia 201604 release. Thus, for a large volume of the dataset, it is a tedious, time-consuming, and error-prone task to generate such quality assessment manually.
The representation of changes at low-level leads to syntactic and semantic deltas [45] from which it is more difficult to get insights to complex changes or changes intended by a human user. On the other hand, high-level changes can capture the changes that indicate an abnormal situation and generates results that are intuitive enough for the human user. High-level changes from the data can be detected using statistical profiling. For example, total entity count of dbo:Place type for two DBpedia versions – 201510 and 201604 – is 1,122,785 and 925,383 where the entity count of 201604 is lower than 201510. This could indicate an imbalance in the data extraction process without fine grain analysis. However, high-level changes require fixed set of requirements to understand underlying changes happened in the dataset. For example, assuming that the schema of a KB remains unchanged, a set of low-level changes from data correspond to one high-level change.
In our work, we analyze high-level changes to identify quality issues for evolving KBs. We defined a quality assessment method, which, given two entity type versions computes their difference and then based on detected changes identifies potential quality issues. The ISO/IEC 25012 standard [19] defines data quality as the degree to which a set of characteristics of data fulfills requirements. Such characteristics include completeness, accuracy or consistency of the data. Each of the quality characteristics identifies a specific set of quality issues. A data quality issue is a set of anomalies that can affect the knowledge base exploitation and any application usage. Such as under the completeness characteristics we can find problems regarding missing information. In this paper, we focused on three main quality issues of a knowledge base: (i) Lack of consistency, (ii) Lack of completeness, and (iii) Lack of persistency.
As an example, let us consider DBpedia version 201510 where we can find the resource of type foaf:Person dbpedia:X. Henry Goodnough that represents an entity. While we find (as expected) a dbo:birthDate property for the entity, we unexpectedly find the property dbo:Infrastructure/length. This is a clear inconsistency: in fact, if we look at the ontology, we can check that the latter property can be used for a resource of type dbo:Infrastructure, not for a person.

Example of inconsistent Wikipedia data.
To better understand where the problem lies, we need to look at the corresponding Wikipedia page wikipedia-en:X._Henry_Goodnough. Even though the page reports the information about an engineer who graduated from Harvard, it contains an info-box, which is illustrated in Fig. 1, that refers to a dam, the Goodnough Dike. The inconsistency issue derives from the data present in the source page that resulted into the resource being typed both as a person and as a piece of infrastructure. We can expect such kind of structure to be fairly rare – in fact the case we described is the only case of a person with a dbo:Infrastructure/length property – and can be potentially detected by looking at the frequency of the predicates within a type of resource. For instance, considering the DBpedia version 201604, for the resources of type foaf:Person there are 1035 distinct predicates, among which 142 occur only once. Such anomalous predicates suggest the presence of consistency issues that can be located either in the original data source or – i.e. Wikipedia for this case – or in the lack of filtering in the data extraction procedure.
Of course it is possible the item was never present in the KB at any time during its evolution, though this kind of mistake is not detectable just by looking at the evolution of the KB.

Example of incomplete Wikipedia data.
While it is generally difficult to spot that kind of incompleteness, for the case under consideration it is easier because that property was present for the resource under consideration in the previous version of DBpedia, i.e. the 2015-10 release. That is an incompleteness introduced by the evolution of the knowledge base. It can be spotted by looking at the frequency of predicates inside a resource type. In particular, in the release of 2016-04 there are 419 occurrences of the dbo:Astronaut/TimeInSpace predicate over 634 astronaut resources (66%), while in the previous version they were 465 out of 650 astronauts (72%). Such a significant variation suggests the presence of a major problem in the data extraction procedure applied to the original source, i.e. Wikipedia.
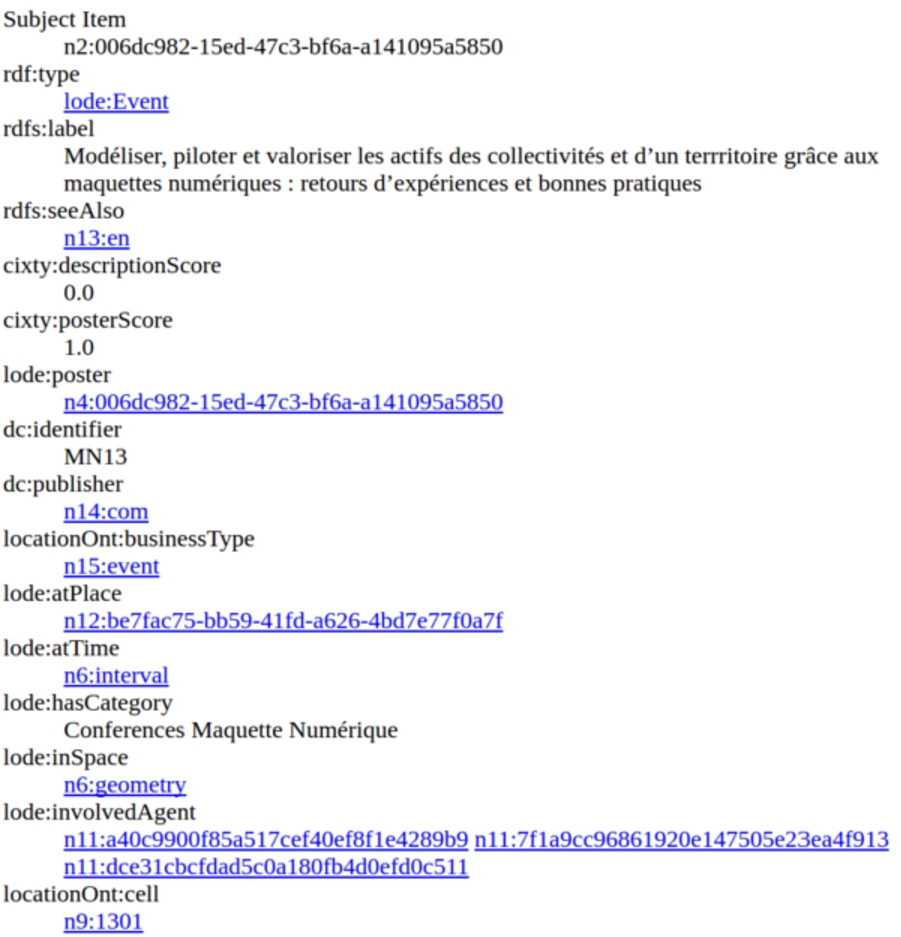
Example of a 3cixty Nice KB resource that unexpectedly disappeared from the release of 2016-06-15 to the other 2016-09-09.
This issue can be spotted by looking at the total frequency of entities of a given resource type. For example, lode:Event type two releases – 2016-06-15 and 2016-09-09 – total entity count 2,182 and 689. In particular in the investigated example we have observed an (unexpected) drop of resources of the type event between the previous release dated as 2016-06-15 and the considered released from 2016-09-09. Such count drop indicates a problem in the processing and integration of the primary data sources.
Such problems are generally complex to be traced manually because they require a per-resource check over different releases. When possible, a detailed, low-level and automated analysis is computationally expensive and might result into a huge number of fine-grained issue notifications. Such amount of information might cause an information overload for the user of the notifications. If the low-level notifications are filtered, then they can be useful to KB end-users for any type of knowledge exploitation.
The proposed approach provides an assessment of the overall quality characteristic and is not aimed at pinpointing the individual issues in the KB but it aims to identify potential problems in the data processing pipeline. Such approach produces a smaller number of coarse-grained issue notifications that are directly manageable without any filtering and provide a useful feedback to data curators. Table 1 summarizes the features of the two types of analysis.
Features of the two analysis type features

The Quality Assessment Procedure proposed in this paper.
In Fig. 4, we present a conceptual representation of our quality assessment procedure that is framed in three steps:
(i) Requirements: When a data curator initiates a quality assessment procedure, he/she needs to select an entity type. Furthermore, it is essential to ensure that the selected entity is present in all KB releases to verify schema consistency.
(ii) Coarse grain analysis: High-level changes help to identify more context dependent features such as dataset dynamicity, volume, the design decision. We used statistical profiling to detect high-level changes from dataset.
(iii) Fine grain analysis: High-level changes, being coarse-grained, cannot capture all possible quality issues. However, it helps to identify common quality issues such as an error in data extraction and integration process. On the other hand, fine grained analysis helps to detect detailed changes. In our approach we propose coarse grained analysis using data profiling and evaluate our approach using fine grained analysis. We use manual validation for fine grained analysis.
The research activities related to our approach fall into two main research areas: (i) Linked Data Dynamics, and (ii) Linked Data Quality Assessment.
Linked data dynamics
Various research endeavours focus on exploring dynamics in linked data on various use cases.
Umbrich et al. [44] present a comparative analysis on LOD dataset dynamics. In particular, they analyzed entity dynamics using a labeled directed graph based on LOD, where a node is an entity and an entity is represented by a subject.
Pernelle et al. [36] present an approach that detects and semantically represents data changes in RDF datasets. Klein et al. [21] analyze ontology versioning in the context of the Web. They look at the characteristics of the release relation between ontologies and at the identification of online ontologies. Then they describe a web-based system to help users to manage changes in ontologies.
Käfer et al. [20] present a design and results of the Dynamic Linked Data Observatory. They setup a long-term experiment to monitor the two-hop neighbourhood of a core set of eighty thousand diverse Linked Data documents on a weekly basis. They look at the estimated lifespan of the core documents, how often it goes on-line or offline, how often it changes as well as they further investigate domain-level trends. They explore the RDF content of the core documents across the weekly snapshots, examining the elements (i.e., triples, subjects, predicates, objects, classes) that are most frequently added or removed. In particular they investigate at how the links between dereferenceable documents evolve over time in the two-hop neighbourhood.
Papavasileiou et al. [33] address change management for RDF(S) data maintained by large communities, such as scientists, librarians, who act as curators to ensure high quality of data. Such curated KBs are constantly evolving for various reasons, such as the inclusion of new experimental evidence or observations, or the correction of erroneous conceptualizations. Managing such changes poses several research problems, including the problem of detecting the changes (delta) among versions of the same KB developed and maintained by different groups of curators, a crucial task for assisting them in understanding the involved changes. They addressed this problem by proposing a change language that allows the formulation of concise and intuitive deltas.
Gottron and Gottron [15] analyse the sensitivity of twelve prototypical Linked Data index models towards evolving data. They addressed the impact of evolving Linked Data on the accuracy of index models in providing reliable density estimations.
Ruan et al. [40] categorized quality assessment requirements into three layers: understanding the characteristics of data sets, comparing groups of data sets, and selecting data sets according to user perspectives. Based on this, they designed a tool – KBMetrics – to incorporate the above quality assessment purposes. In the tool, they focused to incorporate different kinds of metrics to characterize a dataset, but it has also adopted ontology alignment mechanisms for comparison purposes.
Nishioka et al. [31] present a clustering techniques over the dynamics of entities to determine common temporal patterns. The quality of the clustering is evaluated using entity features such as the entities’ properties, RDF types, and pay-level domain. In addition, they investigated to what extent entities that share a feature value change together over time.
Linked data quality assessment
The majority of the related work on Linked Data quality assessment are focused on defining metrics to quantify the quality of data according to various quality dimensions and designing framework to provide tool support for computing such metrics.
Most early work on Linked Data quality were related to data trust. Gil and Arts [13] focus their work on the concept of reputation (trust) of web resources. The main sources of trust assessment according to the authors are direct experience and user opinions, which are expressed through reliability (based on credentials and performance of the resources) and credibility (users view of the truthfulness of information). The trust is represented with a web of trust, where nodes represent entities and edges are trust metrics that one entity has towards the other.
Gamble and Goble [12] also focus on evaluating trust of Linked Data datasets. Their approach is based on decision networks that allow modeling relationships between different variables based on probabilistic models. Furthermore, they discuss several dimensions of data quality: 1. Quality dimension, which is assessed against some quality standard and which intends to provide specific measures of quality; 2. Trust dimension, which is assessed independently of any standard and is intended to asses the reputation; 3. Utility dimension, which intends to assess whether data fits the purpose and satisfies users’ need.
Shekarpour and Katebi [42] focus on assessment of trust of a data source. They first discuss several models of trust (centralized model, distributed model, global model and local model), and then develop a model for assessment of trust of a data source based on: 1. propagation of trust assessment from data source to triples, and 2. aggregation of all triple assessments.
Golbeck and Mannes [14] focus on trust in networks and their approach is based on the interchange of trust, provenance, and annotations. They have developed an algorithm for inferring trust and for computing personal recommendations using the provenance of already defined trust annotations. Furthermore, they apply the algorithm in two examples to compute the recommendations of movies and intelligent information.
Bonatti et al. [4] focus on data trust based on annotations. They identify several annotation dimensions: 1. Blacklisting, which is based on noise, on void values for inverse functional properties, and on errors in values; 2. Authoritativeness, which is based on cross-defined core terms that can change the inferences over those terms that are mandated by some authority (e.g., owl:Thing), and that can lead to creation of irrelevant data; 3. Linking, which is based on determining the existence of links from and to a source in a graph, with a premise that a source with higher number of links is more trustworthy and is characterized by higher quality of the data.
Later on, we can find research work focused on various other aspects of Linked Data quality such as accuracy, consistency, dynamicity, and assessibility. Furber and Hepp [11] focus on the assessment of accuracy, which includes both syntactic and semantic accuracy, timeliness, completeness, and uniqueness. One measure of accuracy consists of determining inaccurate values using functional dependence rules, while timeliness is measured with time validity intervals of instances and their expiry dates. Completeness deals with the assessment of the completeness of schema (representation of ontology elements), completeness of properties (represented by mandatory property and literal value rules), and completeness of population (representation of real world entities). Uniqueness refers to the assessment of redundancy, i.e., of duplicated instances.
Flemming [10] focuses on a number of measures for assessing the quality of Linked Data covering wide-range of different dimensions such as availability, accessibility, scalability, licensing, vocabulary reuse, and multilingualism. Hogan et al. [17] focus their work in assessment of mainly errors, noise and modeling issues. Lei et al. [24] focus on several types of quality problems related to accuracy. In particular, they evaluate incompleteness, existence of duplicate instances, ambiguity, inaccuracy of instance labels and classification.
Rula et al. [41] start from the premise of dynamicity of Linked Data and focus on assessment of timeliness in order to reduce errors related to outdated data. To measure timeliness, they define a currency metric which is calculated in terms of differences between the time of the observation of data (current time) and the time when the data was modified for the last time. Furthermore, they also take into account the difference between the time of data observation and the time of data creation.
Gueret et al. [16] define a set of network measures for the assessment of Linked Data mappings. These measures are: 1. Degree; 2. Clustering coefficient; 3. Centrality; 4. sameAs chains; 5. Descriptive richness.
Mendes et al. [26] developed a framework for Linked Data quality assessment. One of the peculiarities of this framework is to discover conflicts between values in different data sources. To achieve this, they propose a set of measures for Linked Data quality assessment, which include: 1. Intensional completeness; 2. Extensional completeness; 3. Recency and reputation; 4. Time since data modification; 5. Property completeness; 6. Property conciseness; 7. Property consistency.
Kontokostas et al. [23] developed a test-driven evaluation of Linked Data quality in which they focus on coverage and errors. The measures they use are the following: 1. Property domain coverage; 2. Property range coverage; 3. Class instance coverage; 4. Missing data; 5. Mistypes; 6. Correctness of the data.
Knuth et al. [22] identify the key challenges for Linked Data quality. As one of the key factors for Linked Data quality they outline validation which, in their opinion, has to be an integral part of Linked Data lifecycle. Additional factor for Linked Data quality is version management, which can create problems in provenance and tracking. Finally, as another important factor they outline the usage of popular vocabularies or manual creating of new correct vocabularies.
Emburi et al. [9] developed a framework for automatic crawling the Linked Data datasets and improving dataset quality. In their work, the quality is focused on errors in data and the purpose of developed framework is to automatically correct errors.
Assaf et al. [1] introduce a framework that handles issues related to incomplete and inconsistent metadata quality. They propose a scalable automatic approach for extracting, validating, correcting and generating descriptive linked dataset profiles. This approach applies several techniques in order to check the validity of the metadata provided and to generate descriptive and statistical information for a particular dataset or for an entire data portal.
Debattista et al. [6] describes a conceptual methodology for assessing Linked Datasets, proposing Luzzu, a framework for linked data quality assessment. Luzzu is based on four major components: 1. An extensible interface for defining new quality metrics; 2. An interoperable, ontology-driven back-end for representing quality metadata and quality problems that can be re-used within different semantic frameworks; 3. Scalable dataset processors for data dumps, SPARQL endpoints, and big data infrastructures; 4. A customisable ranking algorithm taking into account user-defined weights.
Zaveri et al. [47] present a comprehensive systematic review of data quality assessment methodologies applied to LOD. They have extracted 26 quality dimensions and a total of 110 objective and subjective quality indicators. They organized linked data quality dimensions into following categories, 1. Contextual dimensions; 2. Trust dimensions; 3. Intrinsic dimensions; 4. Accessibility dimensions; 5. Representational dimensions; 6. Dataset dynamicity. They explored dataset dynamicity features based on three dimensions: 1. Currency (speed of information update regarding information changes); 2. Volatility (length of time which the data remains valid); 3. Timeliness (information is available in time to be useful). The work presented in this paper is related to intrinsic, contextual and dataset dynamicity dimensions.
Ellefi et al. [8] present a comprehensive overview of the RDF dataset profiling feature, methods, tools, and vocabularies. They present dataset profiling in a taxonomy and illustrate the links between the dataset profiling and feature extraction approaches. They organized dataset profiling features into seven top-level categories: 1. General; 2. Qualitative; 3. Provenance; 4. Links; 5. Licensing; 6. Statistical. 7. Dynamics. In the qualitative features, they explored the data quality perspectives and presented four categories: 1. Trust (data trustworthiness); 2. Accessibility (process of accessing data); 3. Representativity (analyze data quality issues); 4. Context/Task Specificity (data quality analysis with respect to a specific tasks). We used the qualitative features to summarize the aforementioned linked data quality assessment studies and presented in Table 2.
Summary of Linked Data Quality Assessment Approaches
Summary of Linked Data Quality Assessment Approaches
There is a significant effort in the Semantic Web community to evaluate the quality of Linked Data. However, in the current state of the art, less focus has been given toward understanding knowledge base resource changes over time to detect anomalies over various releases, which is instead the main contribution of our approach.
The definition of our quality characteristics started with the exploration of two data quality standard reference frameworks: ISO/IEC 25012 [19] and W3C DQV [18]. ISO/IEC 25012 [19] defines a general data quality model for data retained in structured format within a computer system. This model defines the quality of a data product as the degree to which data satisfies the requirements set by the product owner organization. The W3C Data on the Web Best Practices Working Group has been chartered to create a vocabulary for expressing data quality. 1 The Data Quality Vocabulary (DQV) is an extension of the DCAT vocabulary.13
Besides, to further compare our proposed quality characteristics14
In our work we will identify the quality aspects using the term quality characteristics from ISO-25012 [19] that corresponds to the term quality dimension from DQV [18].
Since the measurement terminology suggested in these two standards differs, we briefly summarize the one adopted in this paper and the relative mappings in Table 3.
Measurement terminology
Large Knowledge Bases (KBs) are often maintained by communities that act as curators to ensure their quality [46]. KBs naturally evolve over time due to several causes: i) resource representations and links that are created, updated, and removed; ii) the entire graph can change or disappear [39]. The kind of evolution that a KB is subjected to depends on several factors, such as:
Frequency of update: KBs can be updated almost continuously (e.g. daily or weekly) or at long intervals (e.g. yearly);
Domain area: depending on the specific domain, updates can be minor or substantial. For instance, social data is likely to be subject to wide fluctuations than encyclopedic data, which are likely to undergo smaller knowledge increments;
Data acquisition: the process used to acquire the data to be stored in the KB and the characteristics of the sources may influence the evolution; for instance, updates on individual resources cause minor changes when compared to a complete reorganization of a data source infrastructure such as a change of the domain name;
Link between data sources: when multiple sources are used for building a KB, the alignment and compatibility of such sources affect the overall KB evolution. The differences of KBs have been proved to play a crucial role in various curation tasks such as the synchronization of autonomously developed KB versions, or the visualization of the evolution history of a KB [33] for more user-friendly change management.
In this context, we focus on the aspects of data profiling for KB evolution analysis. According to Ellefi et al. [8], the dynamic features used in our approach are the following:
Lifespan: Knowledge bases contain information about different real-world objects or concepts commonly referred as entities. Lifespan measures the change patterns of a knowledge base. Change patterns help to understand the existence and kinds of categories due to updates or change behavior. Also, lifespan represents the time period when a certain entity is available. Stability: It helps to understand to what extent the degree of changes impacts the overall state of the knowledge base. In this account, the degree of changes helps to identify what are the causes that trigger changes as well as the propagation effects. Update history: It contains basic measurement elements regarding the knowledge base update behaviour such as frequency of changes. The frequency of changes measures the update frequency of a KB resource. For example, the instance count of an entity type for various versions.
Evolution-based quality characteristics and measures
In this section, we define four temporal quality characteristics that allow addressing the aforementioned issues.
Zaveri et al. [47] classified quality dimensions into four groups: i) intrinsic, those that are independent of the user’s context; ii) contextual, those that highly depend on the context of the task at hand, iii) representational, those that capture aspects related to the design of the data, and iv) accessibility, those that involve aspects related to the access, authenticity and retrieval of data. The quality dimensions we propose fall into the groups of intrinsic and representational.
In the context of RDF data model our approach focuses on two different types of elements in a KB: classes and properties. At triple level we only explored subjects and predicates thus disregarding the objects either resources or literals. To measure if a certain data quality characteristic is fulfilled for a given KB, each characteristic is formalized and expressed in terms of a measure with a value in the range
Basic measure elements
The foundation of our approach is the change at the statistical level regarding the variation of absolute and relative frequency count of entities between pairs of KB versions.
In particular, we aim to detect variations of two basic statistical measures that can be evaluated with the most simple and computationally inexpensive operation, i.e. counting. The computation is performed on the basis of the classes in a KB (V), i.e. given an entity type of C, we collected all the entities t of the type C:
The
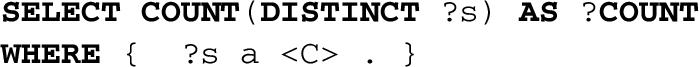
The second measure element focuses on the frequency of the properties, within a class C. We define the frequency of a property (in the scope of class C) as:
The

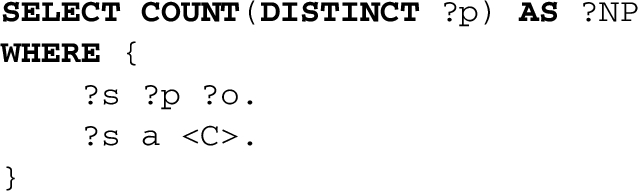
There is an additional basic measurement element that can be used to build derived measures: the number of properties present for the entity type C in the release i of the KB.
The
In the remainder, we will use a subscript to indicate the release the measure refers to. The releases are numbered progressively as integers starting from 1 and, by convention, the most recent release is n. So, for instance,
Persistency
We define the Persistency characteristics as the degree to which erroneous removal of information from the current version may impact the stability of resources. Ellefi et al. [8] present stability feature as an aggregation measure of the dataset dynamics. In this context, Persistency characteristic measures help to understand a stability feature that provides insights into whether there are any missing resources in the last KB release.
An additional important feature to be considered when analyzing a knowledge base is that the information stored is expected to grow, either because of new facts appearing in the reality, as time passes by, or due to an extended scope coverage [44]. Persistency measures provide an indication of the adherence of a knowledge base to such continuous growth assumption. Using this quality measure, data curators can identify the classes for which the assumption is not verified.
The Persistency of a class C in a release
Persistency at the knowledge base level – i.e. when all classes are considered – can be computed as the proportion of persistent classes:
Historical persistency
Historical persistency is a derived measurement function based on the persistency quality characteristic. It captures the whole lifespan of a KB with the goal of detecting quality issues, in several releases, for a specific entity-type [8]. It considers all entities presented in a KB and provides an overview of the whole KB. It also helps data curators to decide which knowledge base release can be used for future data management tasks.
The Historical Persistency measure is computed as the average of the pairwise persistency measures for all releases.
Similarly to Persistency, it is possible to compute Historical Persistency at the KB level:
Consistency
Consistency checks whether inconsistent facts are included in a KB. This quality characteristic relates to the Consistency quality characteristic defined in the ISO/IEC 25012 standard. The standard defines it as the “degree to which data has attributes that are free from contradictions and are coherent with other data in a specific context of use. It can be either or both among data regarding one entity and across similar data for comparable entities” [19]. Zaveri et al. also explored the Consistency characteristics. In detail, a knowledge base is defined to be consistent if it does not contain conflicting or contradictory facts.
We assume that extremely rare predicates are potentially inconsistent, see e.g. the dbo:Infrastructure/length property discussed in the example presented in Section 2. We can evaluate the consistency of a predicate on the basis of the frequency distribution for an entity type.
We define the consistency of a property p in the scope of a class C:
We started our threshold value analysis by using a histogram of property frequencies distribution. From our initial observation, it is suitable to say that a good threshold value could be a point where there is a trend present in the distribution. Here the word trend should be interpreted as “the way things are heading,” as it, e.g., a possible variation in the property frequency distribution. Concluding this reasoning, we come to the assumption that a good threshold point should be located at an extreme value in the first derivative of our histogram. To identify these changes in the histogram, we simply focus on the kernel density estimation (KDE) [34]. In general, it is a non-parametric way of the estimation of the density function of a univariate probability distribution [5].
In our approach, we use the local minimum of the KDE based on the property frequency distribution as a threshold value. However, in most cases, a priori knowledge must be applied to select the most appropriate threshold [25]. In this account, we chose various threshold values such as 50, 100, 200, and 500 to maximize the precision of the qualitative analysis results. On the other hand, the number of properties varies with each KB release. Therefore, we also evaluated the last three releases of a KB to further validate our assumption. From our empirical analysis (Section 6.2.3), we considered 100 as the threshold value that optimizes the performance of our approach.
Completeness
ISO/IEC 25012 defines the Completeness quality characteristic as the “degree to which subject data associated with an entity has values for all expected attributes and related entity instances in a specific context of use” [19].
In Zaveri et al., Completeness consists in the degree to which all required information is present in a particular dataset. In terms of Linked Data, completeness comprises the following aspects: i) Schema completeness, the degree to which the classes and properties of an ontology are represented, thus can be called “ontology completeness”; ii) Property completeness, measure of the missing values for a specific property, iii) Population completeness is the percentage of all real-world objects of a particular type that are represented in the datasets, and iv) Interlinking completeness, which has to be considered especially in Linked Data, refers to the degree to which instances in the dataset are interlinked.
Evolution-based completeness focuses on the removal of information as a negative effect of the KB evolution. It is based on the continuous growth assumption as well; as a consequence we expect properties of subjects should not be removed as the KB evolves (e.g. dbo:Astronaut/TimeInSpace property described in the example presented in Section 2).
The basic measure we use is the frequency of predicates, in particular, since the variation in the number of subjects can affect the frequency, we introduce a normalized frequency as:
On the basis of this derived measure we can thus define completeness of a property p in the scope of a class C as:
At the class level the completeness is the proportion of complete predicates and can be computed as:
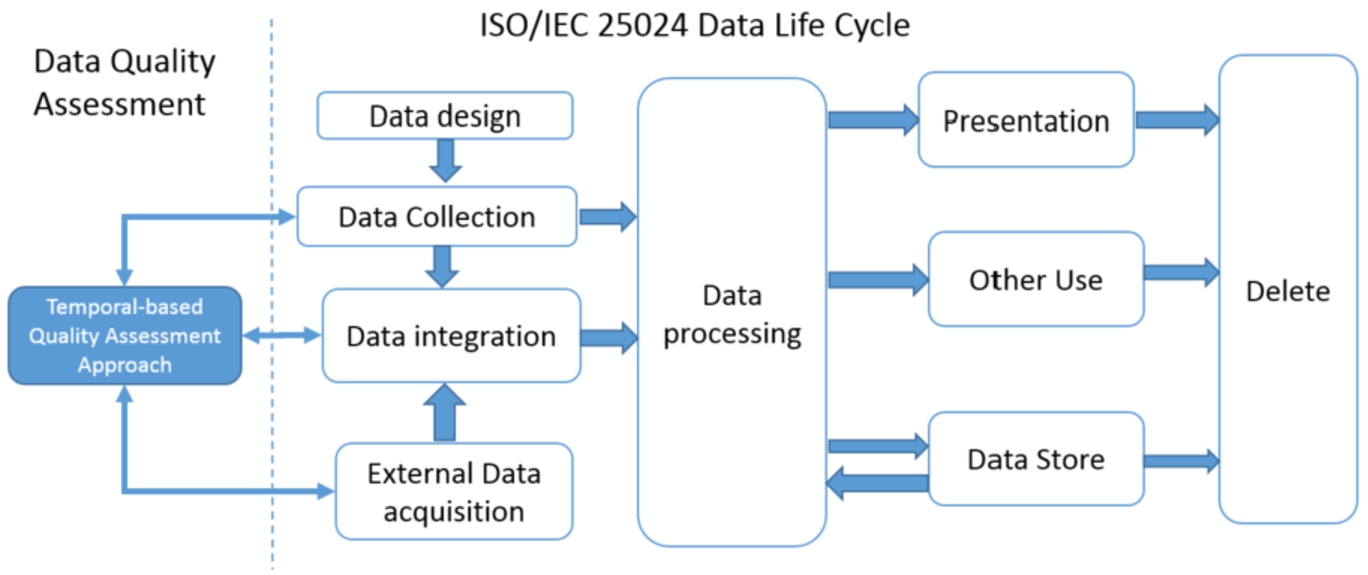
ISO/IEC 25024 Data Life Cycle [19] with proposed quality assessment approach.

Workflow of the proposed Quality Assessment Approach.
The Data Life Cycle (DLC) provides a high level overview of the stages involved in a successful management and preservation of data for any use and reuse process. In particular, several versions of the DLC exist with differences attributable to variations in practices across domains or communities [3]. The DLC generally includes the identification of quality requirements and relevant metrics, quality assessment, and quality improvement [6,29]. Debattista et al. [6] present a data quality life cycle that covers the phases from the assessment of data, to cleaning and storing. They show that in the lifecycle quality assessment and improvement of Linked Data is a continuous process. However, we explored the features of quality assessment based on KB evolution. Our reference Data Life Cycle is defined by the international standard ISO 25024 [19]. We extend the reference DLC to integrate a quality assessment phase along with the data collection, data integration, and external data acquisition phase. This phase ensures data quality for the data processing stage. The extended DLC is reported in Fig. 5. The first step in building the quality assessment approach was to identify the quality characteristics.
Based on the quality characteristics presented in Section 4.2, we propose a KB quality assessment approach. In particular, our evolution-based quality assessment approach computes statistical distributions of KB elements from different KB releases and detects anomalies based on evolution patterns. Figure 6 illustrates the workflow based on the quality assessment procedure we outlined in Section 2 and framed as a three-stage process: (1) input data (multiple releases of a knowledge base), (2) quality evaluation process, and (3) quality reporting. We implemented a prototype, which we implemented using the R statistical package, that we share as open source in order to foster reproducibility of the experiments.15
In our approach, we consider an entity type and history of KB releases as an input. The acquisition of KB releases can be performed by querying multiple SPARQL endpoints (assuming each release of the KB is accessible through a different endpoint) or by loading data dumps. The stored dataset can be organized based on the entity type and KB release. We thereby build an intermediate data structure constituting an entity type and KB releases. We use this intermediate data structure as an input to the next step. Figure 7 reports the intermediary data structure that is used in the following stage.

Intermediary data structure that is used as input for the Evaluation Process.
In our implementation, we create a data extraction module that extends Loupe [27], an online tool that can be used to inspect and to extract automatically statistics about the entities, vocabularies used (classes, and properties), and frequent triple patterns of a KB. We use SPARQL endpoint as an input and save the results extracted from SPARQL endpoints into CSV files. We name each CSV file based on the knowledge base release and corresponding class name. In Fig. 8, we illustrate the entity type base grouping of extracted CSV files for all DBpedia KB releases. For instance, we extracted all triples of the 11 DBpedia KB releases belonging to the class foaf:Person and saved them into CSV files named with the names of the DBpedia releases.

Structure of input module.
We argue that anomalies can be identified using a combination of data profiling and statistical analysis techniques. We adopt a data-driven measurements of changes over time in different releases. The knowledge base quality is performed based on quality characteristics presented in Section 4.2. Firstly, the quality characteristics are evaluated by analyzing multiple KB releases; then, the result of quality assessment consists of quality information for each assessed knowledge base. This generates a quality problem report that can be as detailed as pinpointing specific issues at the level of individual triples. These issues can be traced back to a common problem and can be more easily identified starting from a high-level report.
The evaluation process includes the following three steps:
i) number of distinct predicates; ii) number of distinct subjects; iii) number of distinct entities per class; iv) frequency of predicates per entity; To identify the KB release changes, we count the frequency of property values for a specific class. Also, we consider the distinct entity count for a specific class that we presented as measurement elements in Section 4.2.1. We compute change detection between two KB releases by observing the variation of key statistics. We divide our quality characteristics in class and property level. For class level quality characteristics, we consider entity count as the basic measurement elements for change detection. For a particular class, we measure the property level quality characteristics using frequency of properties as basic measurement elements for change detection. Elaborating further, this component does the following tasks: (i) it provides statistical information about KB releases and patterns in the dataset (e.g. properties distribution, number of entities and RDF triples); (ii) it provides general information about the KB release, such as dataset description of class and properties, release or update dates; (iii) it provides quality information about the vector of KB releases, such as quality measure values, list of erroneous analyzed triples.
Quality problem report
We generate a quality report based on the quality assessment results. The reports contain quality measure computation results as well as summary statistics for each class. The quality problem report provides detailed information about erroneous classes and properties. Also, the quality measurement results can be used for cataloging and preservation of the knowledge base for future data curation tasks. In particular, the Quality Problem Reporting enables, then, a fine-grained description of quality problems found while assessing a knowledge base. We implement the quality problem report visualization using R markdown documents. R markdown documents are fully reproducible and easy to perform analyses that include graphs and tables. We published an example of a quality problem report in this repository. 15
Experimental assessment
This section reports an experimental assessment of our approach that has been conducted on both DBpedia and 3cixty Nice knowledge bases. The analysis is based on the quality characteristics and measures described in Section 5, the measurement has been conducted with a prototype implementation of a tool as described in Section 5. Table 4 reports the interpretation criteria we adopted for each quality characteristic measure. We first present the experimental setting of the implementation, then we report the results of both i) a quantitative and ii) a qualitative validation.
Verification conditions of the quality measures
Verification conditions of the quality measures
In our experiments, we selected two KBs according to three main criteria: i) popularity and representativeness in their domain: DBpedia for the encyclopedic domain, and 3cixty Nice for the tourist and cultural domain; ii) heterogeneity in terms of content being hosted, iii) diversity in the update strategy: incremental and, usually, as batch for DBpedia, continuous update for 3cixty Nice. More in details:
DBpedia16
3cixty Nice is a knowledge base describing cultural and tourist information concerning the city of Nice. This knowledge base was initially developed within the 3cixty project,18
We present a detailed summary of the extracted datasets for each KB.
3cixty Nice: We used the public SPARQL endpoint of the 3cixty Nice KB in our data extraction module. As the schema in 3cixty KB remains unchanged, we used the same SPARQL endpoint for collecting 8 different releases of 3cixty Nice KB from 2016-03-11 to 2016-09-09. We considered those instances having the rdf:type19
3cixty Nice KB Entity Count
Variation of instances of 3cixty classes lode:Event and dul:Place over 8 releases.
DBpedia: In our data extraction module, we directly used Loupe to access multiple DBpedia KB releases. We collected triples of ten classes: dbo:Animal dbo:Artist, dbo:Athlete, dbo:Film, dbo:MusicalWork, dbo:Organisation, dbo:Place, dbo:Species, dbo:Work, foaf:Person. The above entity types are the most common according to the total number of entities. A total of 11 DBpedia releases have been considered for this analysis. We extracted 4477 unique properties from DBpedia. Table 6 presents the breakdown of frequency per class.
DBpedia 10 Classes entity count (all classes have dbo: prefix except the last one)
We applied our quantitative analysis approach based on the proposed quality characteristics. In particular, we analyzed the aforementioned selected classes from the two KBs to investigate persistency, historical persistency, consistency, and completeness quality characteristics. The goal was to identify classes and properties affected by quality issues. In Table 4, we present the interpretation criteria for each quality characteristic measure. We discuss in this section the quality characteristic analysis performed on each knowledge base.
Persistency
Similarly, concerning dul:Place-type instances, from the dataset we can see that
We computed 3cixty Nice KB percentage of persistency based on lode:Events and dul:Places class persistency measure value of 0 or 1. The 3cixty Nice KB percentage of
DBpedia Persistency and Historical Persistency
DBpedia Persistency and Historical Persistency
In the case of the 3cixty Nice KB, lode:Event class,
In the case of DBpedia KB, the analysis conducted using the persistency measure, only the foaf:Person class has persistency measure value of 1 indicating no issue. Conversely, all the remaining nine classes show persistency issues as indicated by a measure value of 0. The DBpedia version with the highest number of inconsistent classes is 201604, with a percentage of persistency is equal to
The Persistency measure is an observational measure. It only provides an overview of the KB degree of changes. It is effective in the case of rapid changes such as the lode:Event class.
Similarly, for dul:Place, the number of persistency variation with value of 1 present over 8 releases
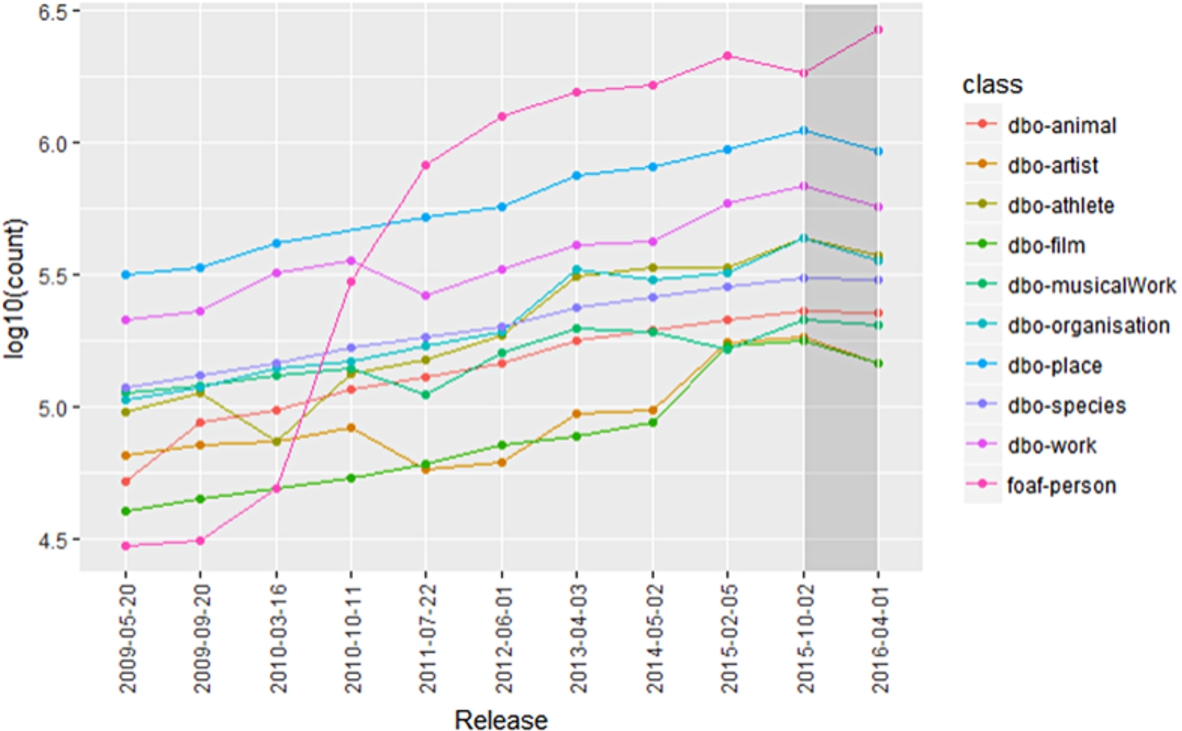
DBpedia 10 Classes instance variation over 11 releases.
In the case of the 3cixty Nice KB, the lode:Event class has one drop (2016-06-15, 2016-09-09) and dul:Place class has two (2016-04-09, 2016-05-3), (2016-5-13, 2016-05-27). Thus, the overall historical persistency measure of lode:Event class is higher than dul:Place class.
In the case of the DBpedia KB, looking at the Historical Persistency results, foaf:Person has persistency value of 0 over the releases of 201504 and 201510. Such values may represent a warning to any data curator. From the release 3.3 to 201604, dbo:MusicalWork shows the lowest values of persistency as a result the historical persistence is
Historical Persistency is mainly an observational measure and it gives insights on lifespan of a KB. Using this measure value, a data curators can study the behaviour of the KB over the different releases. An ideal example is represented by the foaf:Person class. From the results, we observe that for the last two releases (201510, 201604) foaf:Person is the only class without persistency issues.
From the foaf:Person class kernel density estimation based on three releases, the average value of local minimum is 87.63. In this account, the threshold value of 50 is lower than the local minimum and has the lowest number of properties. On the other hand, the threshold value of 100 is near to the local minimum. Also, the threshold value of 100 has the maximum number of properties which is optimized for our qualitative analysis approach. Thus, we chose 100 since from the empirical analysis at property level it allowed to maximize the precision of the approach.

DBpedia foaf:Person class property frequencies distribution.
Properties for the DBpedia classes and Consistency measures. Results are based on Version 201604 with threshold
The consistency measure identifies only those properties whose frequency is below the threshold value, which triggers a warning to a data curator concerning a potential consistency issue exists.
In the 3cixty Nice KB latest release (2016-09-09), we only found ten properties for lode:Event-type and twelve for dul:Place-type resources. We further investigate this output in the qualitative analysis.
In the last release (201604) of the DBpedia KB, we have identified consistent properties for 10 classes. Consistency measure results illustrated in Table 8. For example foaf:Person class has 158 inconsistent properties. We further investigate this measure for foaf:Person class through manual evaluation.

3cixty lode:Event completeness measure results.

3cixty dul:Place completeness measure results.
The percentage of completeness for lode:Event-type is
The percentage of completeness for the dul:Place-type is equal to
Looking at the two latest releases (2016-06-15, 2016-09-09) of the 3cixty Nice KB, we have identified those properties with completeness value of 0 as issue indicator. The total number of properties of the latest two versions are 21 excluding those properties not presented in both releases. For instance, the lode:Event class property lode:atPlace20
For DBpedia KB looking at the last two releases (201510, 201604) we identified incomplete properties for 10 classes. Completeness measure results are listed in Table 9. For instance, we identified a total of 131 incomplete properties for foaf:Person class. The foaf:Person class property dbo:firstRace exhibits an observed frequency of 796 in release 201510, while it is 788 in release 201604. As a consequence the completeness measure evaluated to 0, thus it indicates an issue of completeness in the KB. We further validate our results through manual inspection. In DBpedia, the (foaf:Person) class percentage of completeness is 66.92%, such figure indicates a high number of incomplete instances in the last release (201604).
DBpedia 10 class Completeness measure results based on release 201510 and 201604
The general goal of our study is to verify how the evolution analysis of the changes observed in a set of KB releases helps in quality issue detection. In the quantitative analysis, we identified classes and properties with quality issues. We, then, summarize on the qualitative analysis based on the results of the quantitative analysis.
Given the large number of resources and properties, we considered just a few classes and a portion of the entities and properties belonging to those classes in order to keep the amount of manual work to a feasible level. The selection has been performed in a total random fashion to preserve the representativeness of the experimental data. In particular we considered a random subset of entities. In general, a quality issue can identify a potential error in the KB. In this account, we focused on the effectiveness of the quality measures when it is able to detect an actual problem in the KB.
In general, the goal of this step is to extract, inspect, and perform manual validation for identifying the causes of quality issues. More in details, manual validation tasks are based on the following four steps:
i) Instances: we have selected a portion of the properties with quality issues from the quantitative analysis. The proposed quality characteristics are based on the results from statistical profiling. However, for manual validation we have extracted all the entities from both versions of a given KB. Then, we performed a set of disjoint operations to identify those missing entities in the last release of the KB.
ii) Inspections: using the dataset from instance extraction phase, we explored each missing instances for manual validation and report. In general, KBs use automatic approaches to gather data from the structured or unstructured data sources. For example, the DBpedia KB uses an automatic extraction process based on the mapping with Wikipedia pages. For the manual validation, we have inspected the sources using the missing instances to identify the causes of quality issues. In particular, we manually checked if the information is present in the data sources but missing in the KB.
iii) Report: the validation result of an entity is reported as true positive (the subject presents an issue, and an actual problem was detected) or false positive (the item presents a possible issue, but none actual problem is found).
Selected classes and properties for manual evaluation
Selected classes and properties for manual evaluation
In particular, using the interpretation criteria reported in Table 4, from the measure value we can identify a quality issue. The results are a set of potential problems, part of them are accurate – they point to actual problems, – while others are not – they point to false problems. We decided to measure the precision for evaluating the effectiveness of our approach. Precision is defined as the proportion of correct results of a quality measure over the total results. More in detail, for a given quality measure, we define an item – either a class or a property – as true positive (TP) if, according to the interpretation criteria, the item presents an issue and an actual problem was detected in the KB. An item represents a false positive (FP) if the interpretation identifies a possible issue but none actual problem is found. The precision can be computed as follows:
We evaluated the precision manually by inspecting the results marked as issues from the completeness and consistency measures. For persistency and historical persistency, we have investigated a subset of resources for an entity type. The primary motivation is to detect the causes of quality issues for that entity type. Furthermore, historical persistency is a derived measure from persistency therefore we only performed the validation for persistency.
We considered the results obtained by the quantitative analysis for the entity types and properties attached to the class lode:Event for the 3cixty Nice KB; we considered entities and properties related to the classes dbo:Place, dbo:Species, dbo:Film and foaf:Person for the DBpedia KB. We designed a set of experiments to measure the precision as well as to verify quality characteristics. In Table 10, we present an overview of our selected classes and properties along with the experiments and, in Table 11, we summarize the manual evaluation results.
Summary of manual validation results
For what concerns DBpedia, out of the ten classes under investigation, nine of them have persistency value of 0, which implies that they have persistency issue. We investigated both dbo:Species and dbo:Film that show issues.
Historical persistency is derived from persistency characteristic. It evaluates the percentage of persistency issues present over all KB releases. We argue that by persistency measure validation, we also verified historical persistency results.
lode:Event: From the extracted KB release on 2016-06-15, there are
dbo:Species: We analyzed entity counts of class dbo:Species for the latest two releases of DBpedia (201510 and 201604). The counts are
dbo:Film: We performed fine grain analysis based on a subset of dbo:Film entities for the latest two releases of DBpedia (201510 and 201604). The counts are
lode:Event properties: We found only 10 inconsistent properties. After a manual inspection of those properties we were unable to identify any actual error in the resources, so we classified all of the issues as false positives. The 3cixty KB schema remains consistent for all the releases. We found no erroneous conceptualization in the schema presentation.
foaf:Person properties: We extracted all the properties attached to entities of type foaf:Person and we identified 158 inconsistent properties. From the property list, we inspected each of the property resource in detail. We observe that properties with low frequency contain actual consistency problems. For example, the property dbo:Lake present in the class foaf:Person has a property frequency of 1. From further investigations, this page relates to X. Henry Goodnough an engineer and chief advocate for the creation of the Quabbin Reservoir project. However, the property relates to a person definition. This indicates an error present due to wrong mapping with Wikipedia Infobox keys. From the manual validation, the precision of the identified issues using the consistency measure accounts to
dbo:Place properties: We have evaluated a total of 114 properties with consistency issues for dbo:Place class. We extracted all the data instances for the properties with consistency issues. From the manual inspection in dbo:Place class, we identify data instances with erroneous conceptualization. For example, the property dbo:weight has 26 data instances mapped with dbo:Place type. From a manual investigation we can identity dbo:weight property erroneously mapped with dbo:Place type. Such as one of the data instance wikipedia-en:Nokia_X5 is about mobile devices is mapped with dbo:Place type. This indicates an inconsistency issue due to wrong schema presentation. Based on the manual validation results we evaluate precision of
lode:Event properties: From the analysis of the 2016-06-06 and 2016-09-09 releases of the 3cixty KB releases, we found eight properties showing completeness issues. Based on the eight lode:Event class properties, we investigated all entities and attached properties. We first investigated five instances for each property, manually inspecting 40 different entities. From the investigation we observed that those entities that are present in 2016-06-06 are missing in 2016-09-09 leading to a completeness issue. Entities are missing in the 2016-09-09 release due to an error of the reconciliation algorithm. Based on this manual investigation, the completeness measure generates an output that has a precision of
foaf:Person properties: We have randomly selected 50 properties from foaf:Person class which is identified as incomplete in the quantitative experiment. In our manual inspection, we investigated a small number of the subjects presented in each property. More specifically, we first checked five subjects for manual evaluation for each property. For DBpedia, we checked a total of 250 entities. For example, we identified that the property bnfId has completeness issue. We extracted all the subjects for the releases of 201510 and 201610.
In detail, the property dbo:bnfId for version 201604 has only 16 instances and for version 201510 has 217 instances. We performed an entity comparison between these two releases to identify the missing instances of the given property dbo:bnfId in the 201604 release. After a comparison between the two releases, we found 204 distinct instances missing in 201610 version of DBpedia. We perform a further manual investigation on the instances to verify the result.
One of the results of the analysis is John_Hartley_ (academic)23
dbo:Place properties: From the incomplete properties list of dbo:Place class we randomly selected 50 properties. We checked first five entities for manual evaluation. For dbo:Place class, we checked a total of 250 entities. For example, we identified that the property dbo:parish has completeness issue. We extracted all the instances for the releases of 201510 and 201610. Then we performed a manual inspection for each entity and compared with the Wikipedia sources to identify the causes of quality issues.
For example, property dbo:parish has 26 entities for 201510 and 20 entities in 201604. We collected missing resources after performing a set disjoint operation. One of the results of this operation is Maughold_(parish) that is missing in the 201604 version. To further validate such an output, we checked the source Wikipedia page using foaf:primaryTopic about wikipedia-en:Maughold_(parish). In the Wikipedia page Parish is presented as title definition of the captain of parish militia. In particular, in DBpedia from 201510 version to 201604 version update, this entity has been removed from the property dbo:parish. Based on the investigation of the properties, we computed a precision of
In this paper, we have proposed an approach to detect quality issues leveraging four quality characteristics derived by an evolution analysis. In this section, we first summarize our findings. Then, we discuss the limitations that we have identified and outlined the planning of future activities.
Evolution analysis to drive quality assessment
Similarly to Radulovic et al. [37], we present a discussion of our approach with respect to the following four criteria:
Frequency of knowledge base changes
KBs can be classified according to application areas, schema changes, and frequency of data updates. The two KBs we analyzed fall into two distinct categories: i) continuously changing KB with high frequency updates (daily updates), and ii) KB with low frequency updates (monthly or yearly updates).
i) KBs continuously grow because of an increase in the number of instances and predicates, while they preserve a fixed schema level (T-Box). These KBs are usually available via a public endpoint. For example DBpedia Live25
ii) KBs grow at intervals since the changes can be observed only when a new release is deployed. DBpedia is a prime example of KBs with a history of releases. DBpedia consists of incremental versions of the same KB where instances and properties can be both added or removed and the schema is subjected to changes. In our approach we only considered subject changes in a KB over all the releases. In particular, we only considered those triples T from common classes
We performed experimental analysis based on each quality characteristics. From the quantitative analysis, we identified properties with quality issues from consistency and completeness measures. We validated the observed results via a manual check. From this operation, we observed that those properties that have quality issues may contain an error in literal values. We then further investigated our assumption in the case of DBpedia. We choose one random property of the foaf:Person-type entities. We finally examined the literal values to identify any error present.
From our quantitative analysis on the completeness characteristics of DBpedia, we detected the property dbo:bnfId triggered a completeness issue. Only 16 resources in DBpedia 201604 version had such an issue, while 217 resources in 201510 version. We, therefore, further investigated the property dbo:bnfId in details on the 201604 release. We explored the property description that leads to Wikidata link26
From the initial inspection, we assume that it can be possible to identify an error in any literal value using our approach. However, to detect errors in literal values, we need to extend our quality assessment framework to inspect literal values computationally. We considered this extension of literal value analysis as a future research endeavour.
A sample of 6 subjects and objects of bnfId property
On the basis of the dynamic feature [8], a further conjecture poses that the growth of the knowledge in a mature KB ought to be stable. From our analysis on the 3cixty Nice and the DBpedia KB, we observed that variations in the knowledge base growth could affect quality issues. Furthermore, we argue that quality issues can be identified through monitoring lifespan of RDF KBs.

3cixty two classes KB growth measure.
We can measure growth level of KB resources (instances) by measuring changes presented in different releases. In particular, knowledge base growth can be measured by detecting the changes over KB releases utilizing trend analysis such as the use of simple linear regression. Based on the comparison between observed and predicted values, we can detect the trend in the KB resources, thus detecting anomalies over KB releases if the resources have a downward trend over the releases. Following, we derive KB lifespan analysis regarding change patterns over time as well as experiments on the 3cixty Nice KB and the DBpedia KB. To measure the KB growth, we applied linear regression analysis of entity counts over KB releases. In the regression analysis, we checked the latest release to measure the normalized distance between an actual and a predicted value. In particular, in the linear regression we used entity count (
We start with a linear regression fitting the count measure of the class
We define the normalized distance as:
Based on the normalized distance, we can measure the KB growth of a class C as:
More specifically, the value is 1 if the normalized distance between actual value is higher than the predicted value of type C otherwise it is 0. In particular, if the KB growth measure has the value of 1 then the KB may have an unexpected growth with unwanted entities otherwise the KB remains stable.
From the linear regression, the 3cixty Nice KB has a total of
The residuals,
So the normalized distance for, 8th lode:Event entity
For the lode:Event class,
In the case of the 3cixty Nice KB, the lode:Event class clearly presents anomalies as the number of distinct entities drops significantly on the last release. In Fig. 14, the lode:Event class growth remains constant until it has errors in the last release. It has higher distance between actual and predicted value based on the lode:Event-type entity count. However, in the case of dul:Place-type, the actual entity count in the last release is near to the predicted value. We can assume that the 3cixty Nice KB has improved the quality of data generation matching the expected growth on the last release.
For instance while inspecting the different trends over the KB releases and calculating the normalized distance, we identified that foaf:Person-type last release (201604) entity count has a higher growth (over the expected). Such as foaf:Person has KB growth measure of 1 where normalized distance
DBpedia 10 class Summary

DBpedia 10 classes KB growth measure.
We define this KB growth measure as stability characteristic. A simple interpretation of the stability of a KB is monitoring the dynamics of knowledge base changes. This measure could be useful to understand high-level changes by analyzing KB growth patterns. Data curators can identify persistency issues in KB resources using lifespan analysis. However, a further exploration of the KB lifespan analysis is needed, and we consider this as a future research activity. In particular, we want to explore (i) which factors are affecting KB growth and (ii) validating the stability measure.
We have identified the following two limitations. First, as a basic measurement element, we only considered aggregated measures from statistical profiling such as frequency of properties in a class. For the qualitative analysis, we considered raw knowledge base differences among releases. In order to detect actual differences, we would need to store two releases of a KB in a single graph, and perform the set difference operation. We performed manual validation by inspecting data sources. However, this approach of qualitative analysis has several drawbacks from a technical point of view. Furthermore, regardless of the technical details, the set difference operation is, computationally-wise, extremely expensive. As a future work, we plan to extend our manual validation approach by cross-referencing GitHub issues or mailing lists.
Second, KBs are growing over time with new resources that are added or deleted. In this study, we only considered the negative impact of erroneous deletion of resources. As a future work, we plan to investigate the negative impact of the erroneous addition of resources in the KBs.
Conclusion and future work
The main motivation for the work presented in this paper is rooted in the concepts of Linked data dynamics [20] on the one side and knowledge base quality on the other side. Knowledge about Linked Data dynamics is essential for a broad range of applications such as effective caching, link maintenance, and versioning [20]. However, less focus has been given toward understanding knowledge base resource changes over time to detect anomalies over various releases. To verify our assumption, we proposed four quality characteristics, based on the evolution analysis. We designed a quality assessment approach by profiling quality issues using different knowledge base releases. In particular, we explored the benefits of aggregated measures using quality profiling. The advantage of our approach that performs coarse-grained analysis lies in the fact that it captures anomalies for an evolving knowledge base that can trigger alerts to the data curators in quality repairing processes. Although coarse-grained analysis cannot detect all possible quality issues, it helps to identify common quality issues such as erroneous deletion of resources in the data extraction and integration processes. Moreover, the drawback of fine-grained analysis using raw change detection is the significant space and time complexity.
In this paper, we proposed completeness and consistency quality characteristics from the ISO 25012 standard. Also, we proposed persistency and historical persistency quality characteristics based on dynamic features presented by Ellefi et al. [8]. We defined a quality assessment approach that explores changes over various releases of the same knowledge base. The proposed approach is able to provide a quality problem report to KB curators.
To assess our approach, we performed an experimental analysis based on quantitative and qualitative procedures. The assessment was conducted on two knowledge bases, namely DBpedia and 3cixty Nice. For the quantitative analysis, we applied our quality characteristics over eight releases of the 3cixty Nice KB and 11 releases of the DBpedia KB. Furthermore, we applied a qualitative analysis technique to validate the effectiveness of the approach. We can summarize the main findings of our work as follows:
The analysis of Persistency and Historical Persistency on the 3cixty Nice KB shows that changes over the releases lead to detecting missing values. Missing values could happen due to algorithm error as in the case of the 3cixty Nice KB lode:Event class. However, in the case of the DBpedia KB, Persistency issues do not always indicate actual errors. We observed that dbo:Species subjects with the wrong type in the version 201510 are fixed in the version 201610.
From the quantitative and qualitative analysis of consistency measure, we only identify issues in case of DBpedia KB. We did not find any consistency issue for the 3cixty Nice KB. We observe that continuously changing KBs with high-frequency updates (daily updates) such as the 3cixty Nice KB, remain stable in case of the consistency issue. On the other hand, KBs with low-frequency updates (monthly or yearly updates), such as DBpedia KB, seem to have more inconsistency issues.
We observed extremely good performances of the completeness characteristics for both the 3cixty Nice and DBpedia KB. The Completeness measure was able to detect actual issues with very high precision –
The future research activities we envision are as follows:
We plan to expand our evolution based quality analysis approach by analyzing other quality characteristics presented in literature such as Zaveri et al. [47]. Also, we intend to apply our approach to KBs in other domain to further verify our assumption;
A limitation of the current approach is that we only considered negative impact of deletion of resources. We plan to study how we can dynamically adapt the impact of addition of resources in a KB;
We chose 100 since from the empirical analysis at property level it allowed to maximize the precision of the approach. However, the process of threshold value selection needs further investigation. As a future work, we plan to perform additional statistical analysis to motivate the choice of this threshold.
From the initial experiments, we assume that it can be possible to identify an error in literal value using our approach. We want to extend our quality assessment approach to inspect literal values;
We argue that quality issues can be identified through monitoring lifespan of a KB. This has led to conceptualize the Stability quality characteristics, which is meant to detect anomalies in a KB. We plan to monitor various growth rates to validate this assumption.
Footnotes
Acknowledgements
This research has been partially supported by the 4V: Volumen, Velocidad, Variedad y Validez en la gestin innovadora de datos (TIN2013-46238-C4-2-R) project with the BES-2014-068449 FPI grant.