
Abstract
The catalogue of the Biblioteca Virtual Miguel de Cervantes contains about 200,000 records which were originally created in compliance with the MARC21 standard. The entries in the catalogue have been recently migrated to a new relational database whose data model adheres to the conceptual models promoted by the International Federation of Library Associations and Institutions (IFLA), in particular, to the FRBR and FRAD specifications. The database content has been later mapped, by means of an automated procedure, to RDF triples which employ basically the RDA vocabulary (Resource Description and Access) to describe the entities, as well as their properties and relationships. This RDF-based semantic description of the catalogue is now accessible online through an interface which supports browsing and searching the information. Due to their open nature, these public data can be easily linked and used for new applications created by external developers and institutions. The methods applied for the automation of the conversion, which build upon open-source software components, are described here.
Introduction
Applying the linked open data concepts to the cultural heritage domain has become an active and challenging field [22]: many libraries, museums, and archives are currently exploring ways to convert their data into RDF1
The Resource Description Framework (

Schematic representation of the migration and conversion process.
In parallel, modern standards for cataloguing are emerging as an alternative to the traditional ones (such as ACCR2 [3]). For example, RDA (Resource, Description and Access) is a cataloguing standard [17] for descriptive metadata supporting resource discovery. RDA follows the concepts and terminology of the Functional Requirements for Bibliographic Records (FRBR, [15]) and the Functional Requirements for Authority Data (FRAD, [24]) – and it is working to adopt the Functional Requirements for Subject Authority Data (FRSAD, [20]) –, a family of models promoted by the IFLA which define entities, relationships, and attributes that should be used to describe resources. Recently, a linked data and semantic web representation of the elements and relationships of RDA was published.2
This paper describes the steps applied for the automation and control of the migration process from a MARC21 collection of records to a set of RDF triples containing bibliographic metadata in RDA, schematically represented in Fig. 1. The process relies on the creation of a relational database according to the FRBR family of conceptual models, and provides controlled generation of linked data in RDA. The implementation is strongly based on the currently available open-source technology.
Many libraries and organizations are in the process of transforming their legacy metadata into various RDF-based semantic descriptions, mainly FRBR-based. An early survey on FRBRization techniques was prepared by the Online Computer Library Center (OCLC) [9]. A more recent survey [7] provides a taxonomy of semi-automated techniques based on three criteria: type of FRBRization (methods), model expressiveness and specific enhancements to improve quality or performance.
Usually, the FRBRization builds an FRBR catalogue by applying mapping rules between the source bibliographic metadata and the FRBR attributes. For example, the TELPlus prototype developed an FRBR repository for the European Library [12,21] by applying rule-based interpretation of fields enhanced with cluster deduplication and evaluation metrics.
The LC Display Tool provided by the Library of Congress [27] was a simple XSLT template which transforms MARC data into XML and HTML formats. This approach can lead to very large files (due to the rich variety of relationships available in FRBR) which are difficult to visualize.
A different approach based on musical content was implemented at the Indiana University Library with the Variations project [26] where several XML schemas where used to publish FRBR records.3
Scherzo,
LibFRBR is a toolkit which can be used to convert bibliographic records into FRBR structures based on the Koha open-source integrated library system and also provides an interface for library cataloguers [6].
FRBR-ML [30] is based on an XML intermediate model which was designed to ease exporting data in various semantic formats. This tool takes MARC-XML records as input and produces a set of FRBR records and their relationships. The output is semantically enriched by linking external information sources.
The GLIMIR project [13,31] has developed software to create clusters of creations within WorldCat5
Some initiatives such as the RDA Steering Committee (RSC) and the International Working Group on FRBR and CIDOC CRM Harmonisation, are defining metadata according to international models for user-focused linked data applications. In January 2014, the RDA Steering Committee published stable forms of RDA elements and controlled vocabularies. These vocabularies provide elements, guidelines, and instructions based on FRBR principles. RDA elements applies to each of the FRBR entities as RDF properties and sub-properties, and a set of RDA values vocabularies to populate specific RDA elements such as carrier type or media type.
FRBROO6
An increasing number of cultural institutions are applying semantic web technologies and creating linked open data projects. For example, the Library of Congress Linked Data Service (id.loc.gov) provides access to authority data such as the LC subject headings and the MARC geographic areas.
The Bibliothèque nationale de France published data.bnf.fr in 2011 by aggregating information about authors, works, and subjects which was scattered among various catalogues. These data are published in RDF using a vocabulary based on the FRBR model where objects are referenced through ARK identifiers.7
The Archival Resource Key identifiers are persistent references to web-accessible objects.
The British National Bibliography Linked Data Platform (bnb.data.bl.uk/docs) provides access to the British National Bibliography (BNB), implements the SPARQL query language [25] and delivers RDF and JSON outputs. The dataset has been modelled using existing RDF vocabularies, such as Dublin Core, the Bibliographic Ontology (BIBO), and Friend of a Friend (FOAF). Exceptionally – for example, due to insufficient granularity of those vocabularies – a new term was coined and documented. FRBR was not initially used [8], since the identification of the entities in the source MARC records required extensive work. The records were therefore normalized for improved matching and later transformed into RDF using XSLT and Jena Eyeball.
The German National Library supplies its data in the RDF standard via its Linked Data Service (LDS;
The Europeana linked data at data.europeana.eu ensure a high level of consistency and interoperability by abstracting the original data to a common format (the Europeana Data Model). Unfortunately the richness of the original descriptions is partially lost in the homogenization process.
Traditionally, the descriptive metadata of bibliographic content – stored, for example, in MARC records – were created and interpreted by humans. Even if those records followed cataloguing rules such as AACR2 and ISBD [29], the textual descriptions therein could not be easily read and interpreted by computers, see for instance, the rich description under field 534 in Fig. 2. The FRBR family of conceptual models and the RDA specification provide a modern framework which facilitates the automatic processing of the information. However, the transformation of the old records into the new format has a significant cost and is not an easy task [2], since libraries usually host large catalogues which should be manually revised. Therefore, software tools for the automation of the migration process are called for, and the experience of the Biblioteca Virtual Miguel de Cervantes in their implementation is described below.

A MARC21 record for the novel El caballero de Illescas.
A MARC21 record describes one entry in the bibliographic catalogue or authority file,8
An authority files compiles the unique terms and possible variations used to describe names, titles, and subjects.
The transformation of MARC records into FRBR is not a simple task [2]. Some issues are common, see [1,21], while some other are particular to a library. For example, the 200,000 records in the Biblioteca Virtual Miguel de Cervantes are provided by a large number of institutions in Spain and Latin America where variable cataloguing practices are applied. Some of the challenges and the measures taken are listed below.
Missing or inconsistent uniform title. Uniform titles identify expressions or manifestations of a single work. However, often the uniform title is missing (only 2% of records contain a uniform title) or it has been inappropriately selected (for example, the source language has been sometimes appended to it, as in Don Quijote de la Mancha, inglés). Since records with identical uniform title are not guaranteed to describe the same work, the preferred title has been used to cluster works instead. Further work will be required to obtain a wider granularity. Variable encodings. Some information is encoded using different fields at different institutions. For example, the MARC control number (needed to link back the original record) has been found under fields 001, 856 and 909. Works using multiple languages have been sometimes encoded using multiple language subfields (one per language) while in other cases a single subfield lists all the language codes with custom separators. Specific rules have been created to parse the records with a common provenance. Markup errors. MARC tags are introduced manually and therefore, a number of mistakes can be expected. For example, some titles (MARC field 245) include a responsibility statement after the ISBD separator (a slash) instead of the required MARC prefix $c. The parser compiles a list of rules in order to handle such mistakes or inconsistencies. Textual errors. Many titles were found to contain spurious characters or unbalanced parenthesis. The migration also allowed to identify such typos and improve the normalization of titles. Multiple publication statements. Statements about publishers and distributors (MARC code 260) are not distinguished when the exportation employs a DublinCore-based gateway. For example, publication date of the source work and its digital version are both tagged dc:date. Again, specific rules for each provenance have been implemented. Unspecified roles. Secondary personal entries sometimes contain no information about the role played in the creation. By default, the contributor is associated to a particular manifestation (as in the case, for example, of a publisher). A set of rules has been defined for those cases where the context helps in the interpretation of the content. For example, the keyword trad. indicates a translator which must be associated to an expression. No unique identifiers for creators. Since no authority record number, such as VIAF or ISNI, has been associated to the creators, ambiguity arises when authors have identical names. Also similar names may correspond to a single author due to name variations and typos. An open-source software [5] has been applied in order to identify names which indeed correspond to a single person. Analytics cataloguing. Analytics cataloguing creates separate record for each item found in a larger resource, such as article within a journal, newspaper or serial. The information in MARC field 773 (host item) has been parsed in order to detect if the host resource is in the library catalogue. In such case, a relation isPartOf is added to the database.
The pre-processing applied a set of parsers (implemented in Java upon the MARC4j library) to normalize the information contained in data fields such as titles, roles or languages.
The FRBR family of conceptual models [15] are intended to be independent of any cataloguing code or implementation and they identify the principal entities, their attributes and the relationships between them. The FRBR model defines the products of intellectual or artistic endeavour (work, expression, manifestation, and item) and is complemented with the FRAD model, which defines the entities responsible for the content (person, family, and corporate body), and with the FRSAD model, which defines the entities that serve as the subjects of creations (concept, object, event, and place), see Fig. 3.
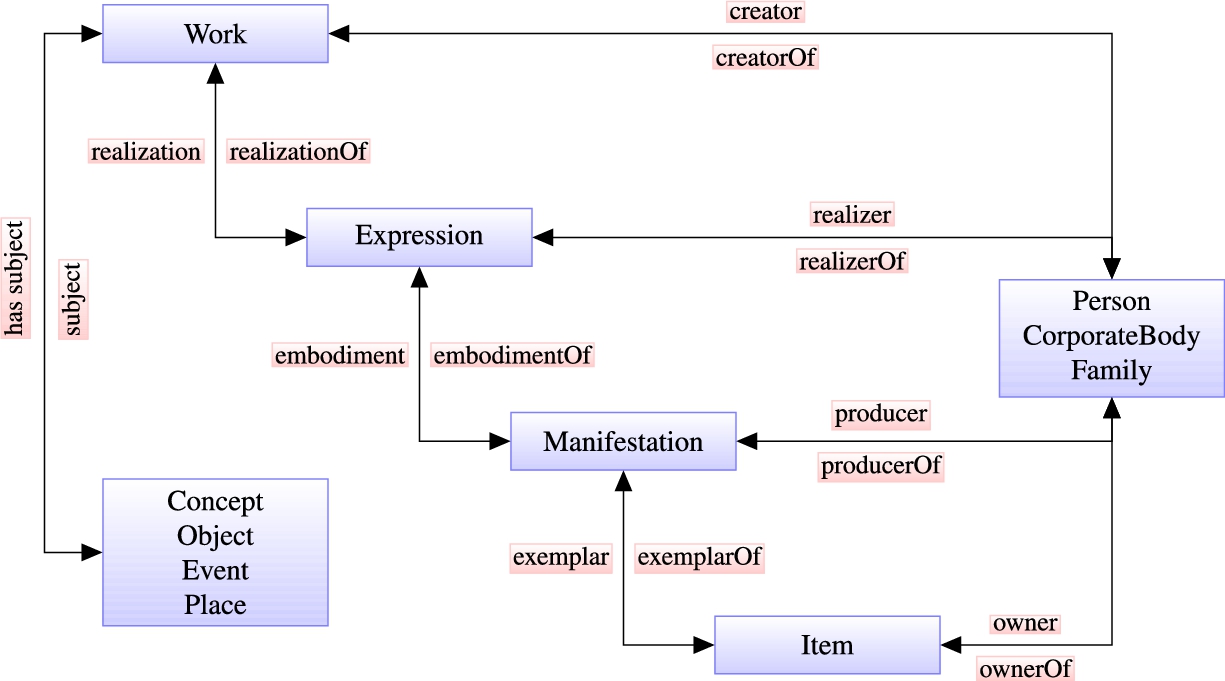
Entities defined in FRBR (Work, Expression, Manifestation, Item), FRAD (Person, CorporateBody, Family), and FRSAD (Concept, Object, Event, Place) with their primary relationships.

Diagram of the Entity-Relationship model of the relational database.

The ontology (concepts and relations) describing the catalogue entries is based on the RDA, RDF, OWL, FOAF and Dublin Core vocabularies. Tag prefixes denote different name-spaces (the source ontology): RDA Class (rdac), Work (rdaw), Expression (rdae), Manifestation (rdam), Item (rdai), or Agent (rdaa); Resource Description Framework (rdf); Dublin Core (dc); Library of Congress Metadata Authority Description Schema (mads); Friend of a Friend (foaf); OWL time ontology (owl-time).
Traditional data storage systems, in particular relational databases, are much more mature than semantic ones, and they offer reliable, extensively tested implementations. Inspired by the IFLA conceptual models, an Entity-Relationship (ER) model, schematically represented in Fig. 4, has been defined to store the Biblioteca Virtual Miguel de Cervantes descriptive metadata. Some additional elements were incorporated to the model in order to address the catalogue specificities. For example, Collection entities were needed to host arbitrary groupings of objects, such as works in a bibliography, items with a common provenance (e.g., a partner library holdings or items in a personal archive), which are not properly creations and usually have no associated descriptive metadata. Since authors are often the subject of a book in a library with a focus on literature, the subject element from Dublin Core have been used to describe creations having a particular agent as subject; conversely, agents play different roles when contributing to a document such as printer, editor or illustrator. A generic relationship between entities (partOf) was defined in order to describe nested inclusions, for example, journals publishing volumes, made of issues containing articles. The online manifestations are connected to their URL with the homepage attribute. Entities for the UDC and UNESCO classifiers and for VIAF persons were also added to the model. Since the RDA technical guidelines were created while several aspects of FRBR were still in flux, they include some additional entities (such as Agent) and rename some relations: for example, the FRBR embodiment becomes manifestationOfExpression in RDA, see Fig. 5.
As can be seen in Fig. 4, the abstract class creation generalizes the basic FRBR entities (work, expression and manifestation). This class has been added in order to avoid redundant descriptions and duplicate coding, since many properties, such as subject, are common to all types of entities.
The application of the FRBR model to an existing MARC collection needs to identify, create and connect FRBR entities [1]. Once the MARC records were normalized and enhanced through the applications of the actions listed in Section 3.1, the transformation was implemented in three consecutive steps:
Identification of FRBR entities. Extraction of relationships between entities. Semi-automatic clustering of entities.
The sequential nature of the migration process allows for simple incremental construction and update.
The identification of FRBR entities required the implementation of a detailed mapping between the original metadata and the FRBR attributes, in particular for those records containing multiple references to persons, subjects or related works. Duplications were minimized by searching for creators with similar names and compatible dates [5]. In parallel, complex subject headings were decomposed into their elementary components to reduce the number of different subject entities.
The extraction of relationships identifies connections, mainly involving works, as in creator or subject elements, but also expressions – for example, translators and editors – and, in a small number of cases, manifestations – for example, printers and illustrators. Relationships between complex works (for example, a journal with articles or a monograph with chapters) and the simple components are also extracted in this step. A standard practice has not emerged yet, and collections have been sometimes considered a single work, a manifestation of different works, or a collective work made of smaller works. The last approach has been used here in order to describe serial relationships, mapping MARC 773 entries to isPartOf relationships.
The statement of responsibility (MARC field 245 $c) contains useful information about persons or bodies contributing to the creation of the content, linking usually persons and expressions. Furthermore, reproduction notes (field 533) often relate a document to the source employed to create the digital version, which can be considered expressions of a single work. In order to extract such valuable relationships, these fields were parsed to find keywords such as edición ilustrada (an illustrated edition) or traducción (a translation) and the results were then mapped to FRBR relationships.
Since patterns are not sufficient to interpret the whole variety of relationships between entities, a web cataloguing interface was implemented for the supervision by librarians of the transformation and clustering process. The interface allows one to retrieve, modify and create relationships and supports the hierarchical navigation through the FRBR structure.
A final step reorganizes the catalogue by grouping manifestations and expressions of the same work, and employs data mining techniques to this purpose. Training sets including difficult cases were prepared by the cataloguing department. Preliminary inspection revealed that uniform titles were not suitable to merge expressions or manifestations of a work, since their main purpose is to provide a normalized form of the title and, only secondarily, to disambiguate works with identical name. The result is that many works sharing their uniform title and author were indeed different creations (for example, many documents had uniform title Laws and author Alfonso XIII, king of Spain).
The clustering process follows instead the principles of the OCLC FRBR Work-Set Algorithm [32] which identifies sets of works based on the information found in bibliographic and authority records: a key is created for every record by combining author and title and, secondarily, by using the uniform title (MARC 130) or the title with MARC 7XX fields. Sets contain works which share an identical key.

Overview of the RDF output for the work El ingenioso hidalgo Don Quijote de la Mancha.
Vocabularies employed in the RDF dataset
Two main approaches have been generally applied to the publication of linked open data. Transient RDF views are published as a top layer providing real-time access to the original data. Alternatively, persistent RDF views are generated and the data are published in asynchronous time intervals. Since bibliographic archives do not update their data very frequently and some delay is acceptable in delivering the metadata, persistent RDF views provide a more efficient approach in libraries [18]. Moreover, the adoption of RDF systems usually requires a gradual transition to allow heterogeneous data to be carefully adapted and tested while in parallel the personnel gains confidence with the new procedures to create descriptive metadata.
A parser has been implemented in Java that applies mapping rules between the FRBR database and the RDA vocabulary (classes, properties and relationships), based on the RDA recommendations.9
rdaw:titleOfTheWork links a work to the string by which the work is known.
rdae:languageOfExpression contains the language used in a particular expression.
rdam:carrierType assigns a manifestation to the format used for storage and the type of device required to access the content.
RDA provides also additional value vocabularies11
Whenever a relationship could not be described using RDA elements, then popular vocabularies were applied. For example, the OWL-Time ontology12
has been used to describe temporal events such as publication years; external content, hosted by partner libraries, was described with FOAF elements [4] and subjects triples were created with the Dublin Core13The output dataset adheres to established design patterns [10]. For example, the path to the resource provides a readable description of the entity, as shown in Table 2.
Design patterns followed by Uniform Resource Identifiers
Dots stand for the common prefix data.cervantesvirtual.com and the asterisk for a particular value.
Finally, the dataset has been enriched semantically by automatically linking objects to terms in other Linked Open Datasets. For example, links to DBpedia15
The automatic procedure described in Section 3 has been applied to transform over 200,000 bibliographic records and 70,000 authority entries, generating about 15 million RDF triples which are published through the gateway data.cervantesvirtual.com . The main features of the RDF data set are summarized in Table 3 and it provides high quality linked open data, what is called five-star open data [16]. The repository holds nearly 37,000 links to external repositories, as shown in the table. These links are described through the owl:sameAs relationship and they introduce the rich connectivity promoted by the linked open data philosophy. The Biblioteca Virtual Miguel de Cervantes data can be downloaded, navigated and queried using a SPARQL endpoint, and they are published under the Creative Commons Public Domain Dedication License.17
Some features of the RDF dataset
The RDF dataset has been evaluated using several methods:
Nearly 40 constraints were defined18
They are available at
RDFUnit [19] has been used to test DublinCore triples.
Acceptance sampling and manual revision was performed on several hundreds of records.
A procedure was implemented testing that the number of manifestations and creators matches the numbers in the original database.
These validation procedures allowed to identify and correct inaccuracies in the dataset. For example, the analysis of a random sample with 112 groups created by the clustering of FRBR entities found 8 false positives where works were grouped incorrectly. The wrong clusters mainly contained works with rather general or vague titles such as Real Decreto produced by the same author. The inspection of a random subset of 50 DBpedia links revealed 4 mistakes. In contrast, all roles which were manually revised (50 cases) and all relations to BNE records (50 links) were found to be correct.
Several options to provide SPARQL access to the RDF storage were evaluated, including OpenLink Virtuoso,20
For an extensive comparative study of platforms, see [14].
Yasgui,
The maintenance of the RDF data generated through the process described above is supported by three automatic procedures for the management of the content:
Rebuild all RDF triples from the database. Incremental addition of new RDF triples. Data backup and restore operations.
Fully rebuilding the dataset may require a few hours but the incremental construction runs in real time and can be scheduled to take place periodically so that the published data are synchronized with the database content.
The traditional online access of the Biblioteca Virtual Miguel de Cervantes25
A tool28
Some work is still to be done. For example, subject headings can be expressed in different languages, depending on the source library. This question has been addressed by a number of projects in the past [11] and a global solution needs still to be found. Further refinements are also needed for the recognition and extraction of implicit relationships expressed in natural language, such as named entities and temporal expressions. The description of subjects can be also enriched with the creation of a thesaurus based on SKOS, a W3C recommendation for the representation of subject headings. Additionally, limitations to the clustering arise from the fact that records imported from external repositories sometimes lack sufficient metadata or may be expressed in foreign languages. Finally, even if the SPARQL interface provides auto-completion for properties and relationships, further work is also needed to provide easier access to SPARQL for non-expert users.