
Abstract
This paper presents ArtVision, a Semantic Web application that integrates computer vision APIs with the ResearchSpace platform, allowing for the matching of similar artworks and photographs across cultural heritage image collections. The field of Digital Art History stands to benefit a great deal from computer vision, as numerous projects have already made good progress in tackling issues of visual similarity, artwork classification, style detection, gesture analysis, among others. Pharos, the International Consortium of Photo Archives, is building its platform using the ResearchSpace knowledge system, an open-source semantic web platform that allows heritage institutions to publish and enrich collections as Linked Open Data through the CIDOC-CRM, and other ontologies. Using the images and artwork data of Pharos collections, this paper outlines the methodologies used to integrate visual similarity data from a number of computer vision APIs, allowing users to discover similar artworks and generate canonical URIs for each artwork.
Introduction
The matching of visually similar artworks across cultural heritage image collections, in particular when applied to two-dimensional works, has been a topic of growing interest to scholars and institutions [12,18]. Various conferences, symposia, and workshops have been organized over the years to explore the usefulness of applying Computer Vision (CV) technology to the arts.1
Searching Through Seeing: Optimizing Computer Vision Technology for the Arts | The Frick Collection. (n.d.). Retrieved March 10, 2019, from
“PHAROS: The International Consortium of Photo Archives.” Accessed March 15, 2021.
The ArtVision platform, published at
During the greater part of the 20th century, photo archives and slide libraries served as the primary source of images for art historians prior to a transition to a digital medium [21]. Institutions that held these archives have sought to digitize and catalog these images, providing valuable insights into the histories of these objects. Historical data pertaining to conservation, provenance, copies, and preparatory studies is contained on the backs of the photographs in the form of annotations written but scholars over last century and more [1]. Art historians have a long tradition of writing about images, one could say, transcribing a visual language to a textual one. As with all translation activities, there is a loss of meaning in this process. While the perception of images is instantaneous and universal, writing is bound by time and cultural bias [5]. This bias becomes especially evident when comparing the annotations on the backs of some historical photographs, as art historians and catalogers have often attributed these works to different artists, artistic schools, or time periods. Although also biased, Computer Vision has emerged as a powerful tool for the field of Digital Art History with the potential to bridge some of these gaps between images and text, allowing images to dialog with one another without the mediation or dependence on texts. While the analytical capacity of CV generally cannot surpass that of an art historian, the ability to perform specific tasks at a scale otherwise unattainable by humans makes it attractive to certain use-cases for art historians [13]. For the image collections of the Pharos Consortium, CV tools that can match artworks across collections are especially promising as they can provide an initial set of results to curators, who can then verify them through a manual process.
Related work
A good deal of work has already been done in applying CV to images of artworks: attempts to automatically classify paintings [19], recognize style [10], object detection studies to identify objects in artworks [2,3,6], evaluating influence [4], and large-scale analysis of broad concepts within artworks such as gesture [8,9]. The opportunities offered by this technology are numerous but the solutions are generally ad-hoc and are rarely made available to non-technical users. John Resig3
John Resig – Building an Art History Database Using Computer Vision.
A range of off-the-shelf Computer Vision and Machine Learning APIs were tested for their ability to find visually similar artworks. To gauge their usefulness, each tool was tested with specific use-cases. As outlined in the Table 1, three forms of visual search were evaluated: exact image match, visually similar, and partial image match. Although Google Cloud Vision did not allow for the loading of a custom image index, it was included in this study as a future integration could include the matching of Pharos images across the web using data provided by Google.
CV/ML tools tested for visual search
CV/ML tools tested for visual search
An exact image match, meaning that two images are nearly identical, proved to be the most broadly supported task. In this case, it is assumed that the crop and content of images would be nearly identical, or with minor variations. The implementation that proved to be the most robust and easy to deploy was Match,4
Crystal ball: Scalable Reverse Image Search Built on Kubernetes and Elasticsearch: Dsys/Match. 2016. Distributed Systems, 2019. GitHub,
EdjoLabs/Image-Match: Quickly Search over Billions of Images.
APIs that support searches for images with differing crops, color reproduction, angle of view, or physical alterations of a work were less consistent. This work expanded on and corroborated earlier tests by John Resig6
John Resig – Italian Art Computer Vision Analysis.
Pastec, the Open Source Image Recognition Technology for Your Mobile Apps.
Tools that were not accessible through an API (free or commercial), did not allow for searching within a set of images provided by the user, or were too outdated were not tested. These include Visual Search by Machine Box,8
Hernandez, David. “Visual Search by Machine Box.” Machine Box, 7 Oct. 2017,
Deep Video Analytics.
Bing Visual Search Developer Platform.
Diamond.
ArtPi – Artrendex.
Among the APIs or models that did allow for an internal index of images, Clarifai and InceptionV3 provided the least useful results. A sampling of the highest similarity scores produced by these tools showed false positives in over fifty percent of the results. This is likely because they were trained on images of real world objects and use Convolutional Neural Networks rather than the bag-of-words methodology [20] employed by Pastec or the pHash13
The Pastec API was able to produce the most useful results that were applicable to the ArtVision use case as it was able to find identical and visually similar artworks even where the images were significantly different from one another. Matches were found between images even when the frame was removed, when the crop was different, where one image was in grayscale and another in color, with variations in the angle in which the photograph was taken, or when one artwork was a copy of another.
The ArtVision ResearchSpace instance stores a minimal subset of data pertaining to each artwork image in its Blazegraph database backend. To add image data into the Pastec internal index (or any other CV API), an ArtVision API14
The ArtVision API architecture was designed by Lukas Klic and implemented by Manolis Fragiadoulakis of Advance Services.
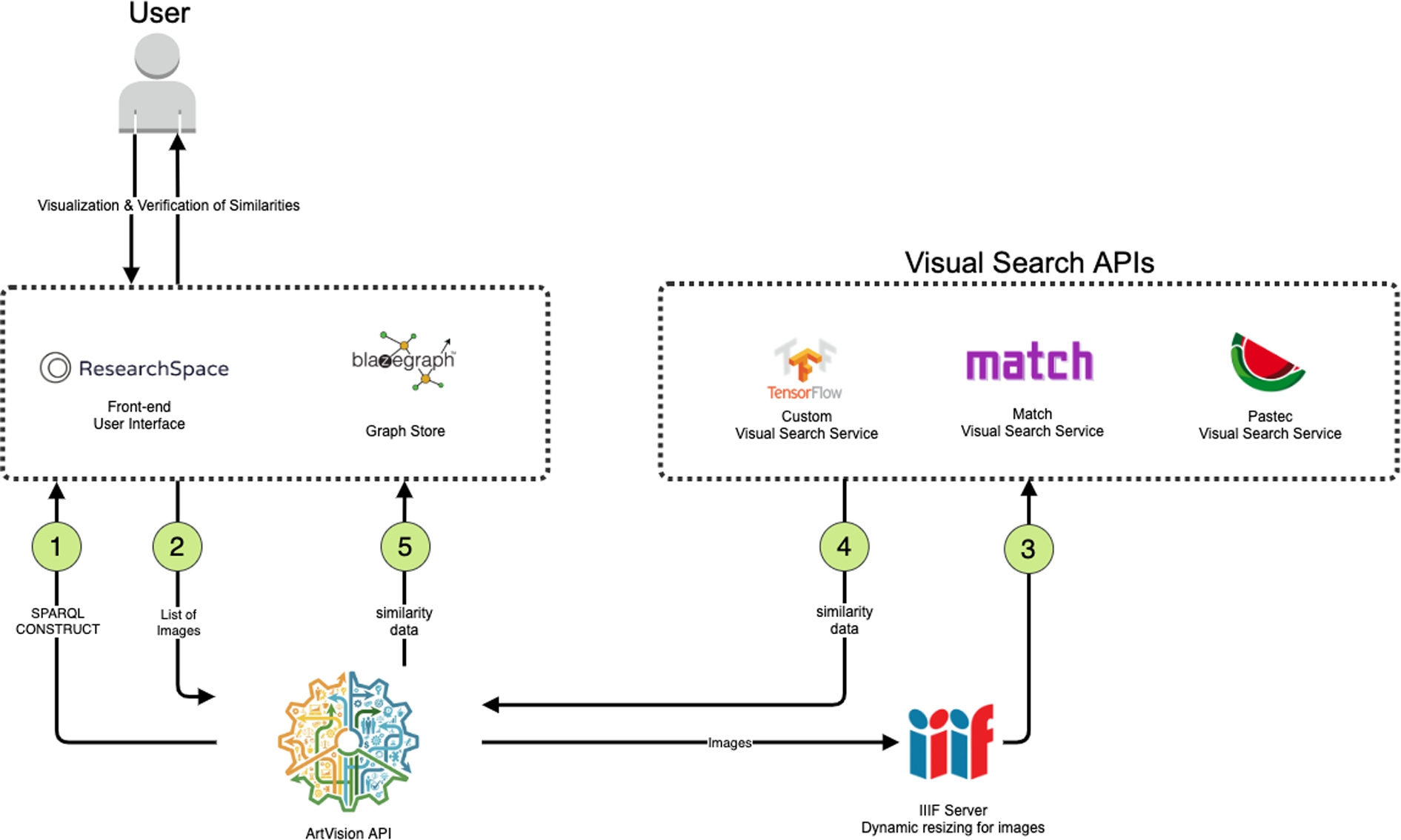
Software architecture for the ArtVision API.
First, the Blazegraph endpoint is queried through a SPARQL construct query (Fig. 1). This process returns a list of images(2) and saves them according to a predefined data model in a turtle file. The ArtVision API then iterates through this list of images and passes them to each CV API (3) for indexing after resizing them through a IIIF server.15
The underlying data model was instrumental in ensuring the interoperability and extensibility of similarity results from multiple CV APIs. At the most basic level, the requirement was to describe a level of similarity between two target images according to a specific association method (CV API) and have a similarity score for that methodology. When searching for either image in a given pair, results from CV APIs should always yield the same similarity score, resulting in a bidirectional similarity.

ArtVision data model.
As shown in Fig. 2, the Similarity Ontology,16
Linked Open Vocabularies (LOV).
One challenge with having a single similarity node connecting each pair of images was generating this URI programmatically without having to perform a lookup to see if one already existed. To allow for additional CV APIs to be added at a later date, the URI of the similarity node was generated as a hash based on the URL of the two connected images. The ability to calculate the URI of this node through SPARQL was a requirement in order to allow for the creation of these nodes through the ResearchSpace infrastructure.

URI hashing for ArtVision.
As seen in Fig. 3, the similarity node should be the sum of a hash of the two image URLs. This way, the sum of a hash of Image 1 + Image 2 (or the inverse Image 2 + Image 1), would equal that of the similarity node. This was implemented by obtaining a SHA1 hash of each image and removing all characters that are not integers through a regular expression, subsequently adding them together.

URI hashing.
Figure 4 illustrates how this hashing can be calculated through SPARQL, allowing for this to be implemented both in the separate java application of the ArtVision API as well as through ResearchSpace via SPARQL. Depending on the number of images in the dataset, other hashing functions such as SHA256 or SHA512 could also be implemented to avoid the possibility of clashing URIs.
Leveraging the RDF4J Storage and Inference Layer (SAIL) libraries, A SPARQL to REST API federation service within ResearchSpace enables end-users to paste an image URL into a webform and retrieve matched artworks from the Pharos dataset in real-time. This federation service was developed by researchers at the Harvard Digital Humanities Lab18
Gianmarco Spinaci,
Two user interfaces were developed within the ArtVision ResearchSpace instance to allow collection curators to log in and match up artwork records across institutions. In a more simplified view as illustrated in Fig. 5, staff are presented with a pair of visually similar images and a limited subset of metadata to quickly compare two artworks. In the Pharos dataset, each artwork as cataloged by a particular institution is stored in a named graph that allows for the tracking of the provenance of these data. Each artwork is represented by both an institutional URI as well as a canonical Pharos URI. By clicking the “same” button in the ArtVision platform, one of the Pharos URIs is marked as being deprecated and owl:sameAs links are created between the two institutional URIs and the remaining Pharos URI. These owl:sameAs links allow multiple artwork records to be merged into one on the main Pharos platform, enabling public users to compare and contrast data from multiple sources.

Simplified view: comparing images and metadata from Pharos collections.
A second interface, as shown in Fig. 6, allows staff to view both artwork records side-by-side with more detailed metadata. Clicking on an image, both images are shown in a IIIF viewer that allows users to zoom in and perform an in-depth comparison of these two images. Visual similarity scores for each CV API are shown between the two images, allowing users to visualize the raw results from multiple CV APIs. This interface also allows users to make assertions about different types of similarity using the CIDOC CRMInf Argumentation Model. Here, an assertion is created that describes the relationship between two images as one being a copy of another, one a preparatory drawing, or two photographs derived from the same negative.

Detailed view: comparing images and metadata from Pharos collections.

Matching iconographic themes.
Another (future) use case that could prove to be disruptive to libraries and archives needing to catalog images of artworks, is to leverage the functionality of partial image match or similar image matching to assist in the cataloging of images in batch. As seen in Fig. 7 the ability to use images to search for others with the same iconographic theme presents a powerful tool for institutions to be able to apply metadata to vast numbers of images. This is particularly useful in situations where image metadata are not available, potentially emboldening the publishing efforts of photograph collections by institutions that have no metadata.

Matching details of artworks to their whole.
Partial image match allows for cropped images or details of works to be found within images that contain the whole. There are numerous use cases for this kind of functionality, especially images of artworks that have been split up into pieces, as is often the case with altarpieces and triptychs. As seen in Fig. 8, a small detail of an artwork was matched with the Pastec API. With partial image match, visual cataloging can be implemented to search the verso of photographs. As illustrated by Fig. 9, this could be applied to photographer or institution stamps. These kinds of searches could be very useful for scholars researching the history of photography, tracking the works of particular photographers across collections that have not published these data. Visual cataloging can be implemented by allowing users to leverage the IIIF API to select a portion of an image and query the CV API to retrieve images with similar details in real-time. Users could then select groups of images to which they would like to apply metadata in batches.

Matching stamps and handwritten text on the verso of photographs.
The ArtVision platform can be used to find discrepancies in metadata, identify visually similar images, and merge records of artworks that are the same. A single artwork that was documented in two different photographs may have been cataloged as being by two separate artists or having different production dates. This is a fairly common practice when cataloging images of artworks that are lost, where the only data a cataloger has to work with is the photograph itself. Using visual similarity search, data about lost artworks can be easily merged and these histories can be reconstructed.
The ability to generate canonical URIs for artworks across collections is a first for the field of art history. While many vocabularies are available to disambiguate and provide identifiers for artists (ULAN19
Cultural Objects Name Authority (Getty Research Institute).
In addition to providing artwork disambiguation services to individuals and institutions seeking to match up images of artworks across the web, ArtVision enables the linking of visually similar artworks, copies, restorations, preparatory drawings and their subsequent works, cropped images of larger artworks, or two photographic prints that have been produced from the same negative. The platform aims to democratize the accessibility of CV functionality to non-technical users. Comparing similarity data generated by CV APIs with similarity data obtained through a supervised process will also enable the creation of Machine Learning models that are more fine-tuned to works of art. As the dataset of similarity data on artworks grows, new classification models can be trained to refine different notions of visual similarity.
The platform will also serve as an attractive tool for institutions that need to digitize image collections but do not have the capacity to catalog them, as is the case with many Pharos partners. Over time, image collections from museums and archives can be integrated, allowing for the linking of archival records to museum collection websites across the web. The platform could prove to be transformative for scholars who typically need to search through collections data from multiple siloed repositories. These data would otherwise be spread out in various databases across the web, with a sometimes limited ability to track them down if not with visual search. While Google image search has been useful to scholars when searching for copies of similar images, most images from institutional repositories are not indexed [11].
ArtVision continues to evolve in parallel to the main public-facing Pharos platform. As curators from collections perform matches through a supervised process, these data will provide a set of measurable metrics to evaluate the quality of results from CV APIs. Questionnaires will be administered to assess qualitative feedback on the user interface, and heuristics will capture possible issues with non predefined tasks [14]. Given the 20th century practice of collecting photographs that depict works of art, it is very likely that a sizeable portion of the consolidated Pharos collections will have some overlap. Once a critical mass of artwork matches has been completed through the supervised process, this will lead to new insights into the field of photography and the history of collecting.
Although the ArtVision platform was developed specifically to address the needs of institutions that publish data and images about artworks, the methodology is by no means restricted to this field. The open-source software could be reused by heritage institutions to match images across manuscript collections or historical documents that have some type of visual similarity. The broader scientific community could also stand to benefit where there is a need to match images in other domains. As many artworks are lacking in titles and unique identifiers, visual search has proven to be a manageable process through which to reconcile these records across collections. The platform has already made a substantial impact on the publishing efforts of the Pharos consortium, automating a task that would otherwise be impossible for humans. By exposing the APIs publicly and allowing non-technical users to perform visual searches across Pharos collections, ArtVision facilitates collection interoperability and the cross-pollination of collections data, disrupting barriers posed by proprietary databases where information is kept in silos. It opens new doors to performing large-scale analysis on artworks, providing unprecedented opportunities to individuals, institutions and the field of Digital Art History more broadly.
Footnotes
Acknowledgements
The Pharos platform is generously supported by the Andrew W. Mellon Foundation to work on a first phase of publishing six of the fourteen collections.![]()