
Abstract
We present Ontop, an open-source Ontology-Based Data Access (OBDA) system that allows for querying relational data sources through a conceptual representation of the domain of interest, provided in terms of an ontology, to which the data sources are mapped. Key features of Ontop are its solid theoretical foundations, a virtual approach to OBDA, which avoids materializing triples and is implemented through the query rewriting technique, extensive optimizations exploiting all elements of the OBDA architecture, its compliance to all relevant W3C recommendations (including SPARQL queries, R2RML mappings, and OWL 2 QL and RDFS ontologies), and its support for all major relational databases.
Introduction
Over the past 20 years we have moved from a world where most companies operated with a single all-knowing, self-contained, central database to a world where companies buy and sell their data, interact with several data sources, and analyze patterns and statistics coming from them. The focus is shifting from obtaining information to finding the right information. It has always been the case that information is power, but today attention rather than information becomes the scarce resource, and those who can distinguish valuable information from background clutter gain power [40]. To separate the wheat from the chaff, companies need a comprehensive understanding of their data and the ability to cope with diversity in the data.
Since the mid 2000s, Ontology-Based Data Access (OBDA) has become a popular approach for tackling this challenge [42]. In OBDA, a conceptual layer is provided in the form of an ontology that defines a shared vocabulary, models the domain, hides the structure of the data sources, and enriches incomplete data with background knowledge. Then, queries are posed over this high-level conceptual view, and the users no longer need an understanding of the data sources, the relation between them, or the encoding of the data. Queries are translated by the OBDA system into queries over potentially very large (usually relational and federated) data sources. The ontology is connected to the data sources through a declarative specification given in terms of mappings that relate symbols in the ontology (classes and properties) to (SQL) views over the data. The W3C standard R2RML [17] was created with the goal of providing a language for specifying mappings in the OBDA setting. The ontology together with the mappings exposes a virtual RDF graph, which can be queried using SPARQL, the standard query language in the Semantic Web community. This virtual RDF graph can be materialized, generating RDF triples to be used with RDF triplestores, or alternatively it can be kept virtual and queried only during query execution. The virtual approach avoids the cost of materialization and can profit from more than 30 years’ maturity of relational database systems (efficient query answering, security, robust transaction support, etc.).
To illustrate these concepts and different notions in this article, we will use the following running example. All the material required to run this example in the OBDA system Ontop (and a complementary tutorial) can be found online.1
We consider a hospital database with a single table NSCLC: SCLC:
The stage of the cancer is encoded by a positive integer value
Our sample table contains the following data:

Suppose we need a simple piece of information from this database: “Give me the names of patients with a tumor of stage IIIa”. Even this simple query in this tiny database already presents some challenges, because in order to formulate the query and to understand and analyze the results we need to know how the information is encoded in the data. In this article, we describe how to use the Ontop system to address this challenge by enhancing the database with a semantic layer. □
We present the OBDA system Ontop,2
The structure of the article is as follows. Section 2 presents a high-level overview of the architecture of Ontop. Section 3 surveys additional tools that can be used with Ontop for creating, deploying, and querying OBDA systems. Section 4 describes the SPARQL query answering techniques implemented in Ontop. Section 5 outlines the applications of Ontop, in particular the Statoil and Siemens use cases in the context of the Optique EU project. Related SPARQL query answering systems are surveyed in Section 6. Section 7 is a retrospective on the development of Ontop over the past five years. Finally, Section 8 concludes the article.
Ontop is an open-source3
The architecture of Ontop, which is illustrated in Fig. 1, can be divided in four layers: (i) the inputs, i.e., the domain-specific artifacts such as the ontology, mappings, database, and queries; (ii) the core of the system in charge of query translation, optimization, and execution; (iii) the APIs exposing standard Java interfaces to users of the system; and (iv) the applications that allow end-users to execute SPARQL queries over databases. We explore each of these components in turn.
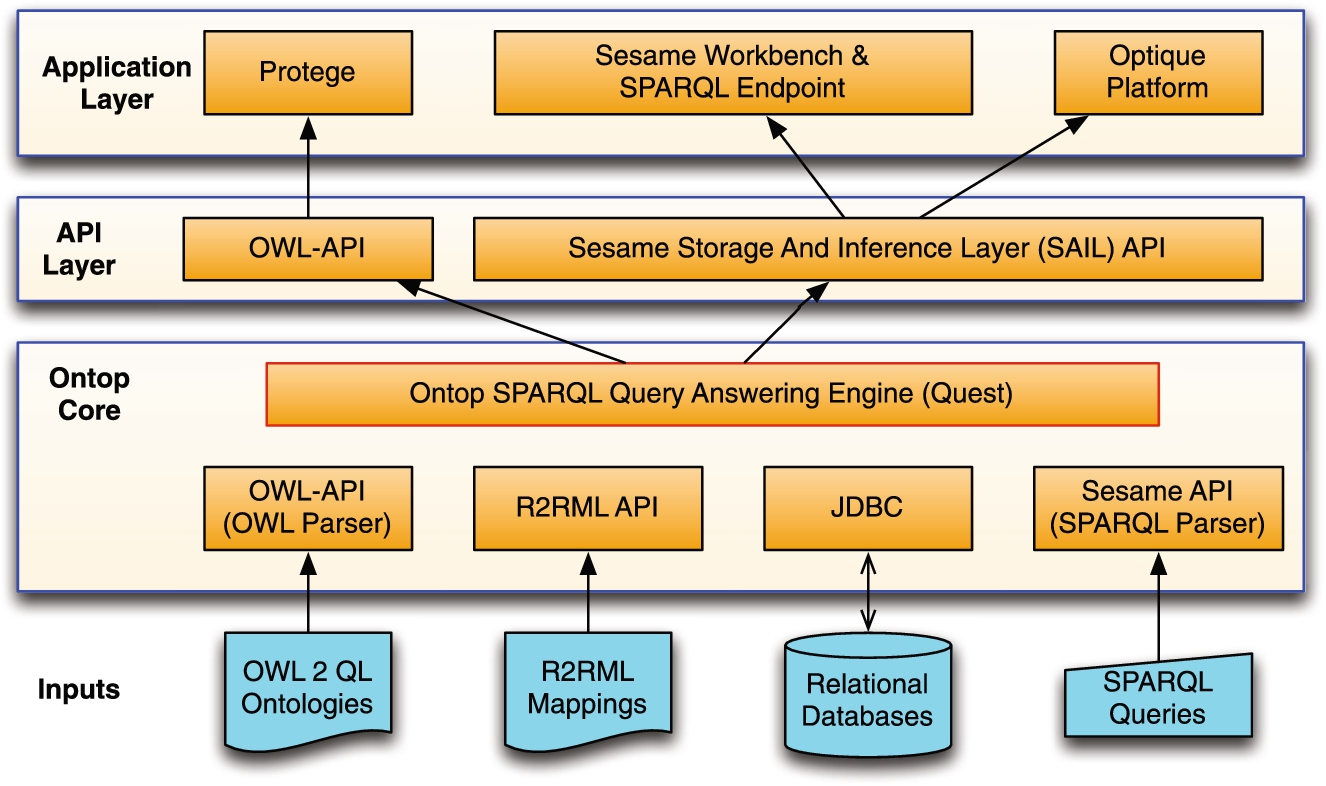
Architecture of the Ontop system.
To the best of our knowledge, Ontop is the first OBDA system that supports all the W3C recommendations related to OBDA: OWL 2 QL, R2RML, SPARQL, SWRL, and the OWL 2 QL entailment regime in SPARQL.4
SWRL and the OWL 2 QL entailment regime are currently supported experimentally.
As ontology languages, Ontop uses RDFS [8] and OWL 2 QL [38]. OWL 2 QL is based on the DL-Lite family of lightweight description logics [3,11], which guarantees that queries over the ontology can be rewritten into equivalent queries over the data alone. Recently Ontop has been extended to support also a fragment of SWRL [61].
The following ontology captures the domain knowledge of our running example. It describes the concepts of cancer and cancer patient with the following OWL axioms:

In particular, classes
Two mapping languages are suppored by Ontop: the W3C RDB2RDF Mapping Language (R2RML), which is a widely used standard; and the native Ontop mapping language, which is easier to learn and use. Ontop includes tools for converting native mappings into R2RML mappings and vice versa. Intuitively, a mapping assertion consists of a source, which is an SQL query retrieving values from the database, and a target, which constructs RDF triples with values from the source.
The ontology in Example 2.1 can be populated from the database in Example 1.1 by means of the following mappings in the simplified Ontop native mapping syntax:

In this example, IRIs like
Mappings are also used for data integration. To model an entity, for instance, a patient, that is represented by different objects in different datasources, there are in principle two options. First, one can virtually merge different objects representing the same entity by generating the same URI for them. Second, when the first option is not available, one can use
Ontop supports essentially all features of the query langugage SPARQL 1.0 as well as the OWL 2 QL entailment regime of SPARQL 1.1 [34]. Implementation of other features of SPARQL 1.1 (e.g., aggregates, property path queries, negation) is ongoing work.
Recall our information need in Example 1.1: the names of all patients who have a neoplasm (tumor) at stage IIIa. This can be represented by the following SPARQL query:
On our sample database, the query would return 
Standard relational database engines are supported by Ontop via JDBC. These include all major commercial relational databases (DB2, Oracle, MS SQL Server) and the most popular open-source databases (PostgreSQL, MySQL, H2, HSQL). In addition, Ontop can be used with federated databases (e.g., Teiid5
The core of Ontop is the SPARQL engine Quest, which is in charge of rewriting SPARQL queries over the virtual RDF graph and ontology into SQL queries over the relational database (see Section 4).
API layer
System developers can use Ontop as a Java library: Ontop implements two widely-used Java APIs, which are also available as Maven artifacts.
Application layer
Ontop is also available through a simple command-line interface and through several applications accessing it via the aforementioned APIs. We describe three such applications, which we have developed and maintained together with Ontop over the past years.

Screenshots of the Ontop Protégé plugin.
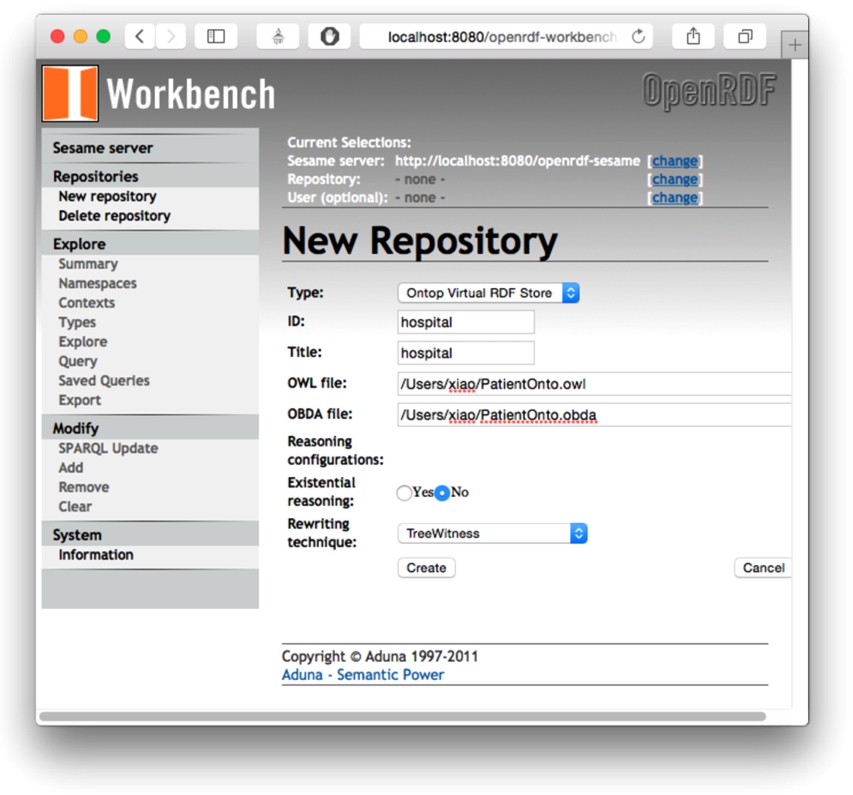
Screenshot of the Ontop Sesame Workbench.
Complementary to Ontop’s core functionalities, there are additional tools that support the tasks involved in creating and deploying OBDA systems. We now provide a brief overview of some of the tools for bootstrapping mappings and ontologies, for federating data sources at SQL and SPARQL levels, and for formulating queries.
Mapping generation
The process of creating mappings is probably the most complex step in setting up an OBDA system. It involves writing individual queries for each table and column that needs to be aligned with the ontology’s vocabulary. A number of tools for (semi-)automatic creation of mappings have been implemented.
Mapping bootstrappers automatically generate mappings and vocabularies from database schemas. Ontop includes a mapping bootstrapper, which is available as a command-line tool and as part of the Protégé plugin. Most of the existing tools generate mappings that follow the Direct Mapping7
It is important to note, however, that a direct mapping is usually not sufficient to capture the semantics of the data such as class hierarchies encoded in columns with codes or IDs (e.g.,
Once mappings have been generated with any of these tools, any query engine for virtual RDF graphs like Ontop can use them.
Mappings can also be constructed semi-automatically: the system suggests new mappings by analyzing the data sources and the existing mappings and the user guides the process. Such systems, e.g., Karma [33] and Clio [20], rely on schema matching techniques developed for data integration [18].
A basic vocabulary of classes and properties can be obtained from the table and column names in a database. However, such a vocabulary lacks ontological axioms that describe its semantics. Ontology bootstrappers are tools that extract RDFS or OWL axioms using schema information (such as integrity constraints) and/or the data in the database. For instance, BootOX [27] can be used for ontology bootstrapping.
However, the quality of automatically bootstrapped ontologies is usually not sufficient to allow their direct use for querying data sources. Moreover, users might want to use also well-established domain ontologies in combination with bootstrapped ones. So, the bootstrapped and domain ontologies need to be aligned. Ontology matching techniques [19], which are able to perform such alignment, can be seen as an extension of the schema matching techniques mentioned earlier. For example, BootOX uses the ontology matching tool LogMap [26].
SQL federation
One way in which Ontop supports data integration scenarios is through SQL federation. A federated database is a DBMS that maps multiple independent databases into a single virtual schema. The designer of a federated database chooses how to map the independent databases into the virtual schema by, e.g., creating one-to-one mappings, renaming elements of the schema, or creating virtual tables from SQL views. Some federated databases also use wrappers for non-SQL databases (e.g., XML) to provide a uniform user interface for the client. SQL execution is coordinated by the federation engine, which exploits techniques for planning and executing cross-database joins with guarantees of concurrency and transaction control.
Most major DBMSs support federated schemas that integrate independent servers of their own kind: for example, MySQL creates federated schemas over independent MySQL servers. Federated schemas with databases from multiple vendors are supported by systems like UnityJDBC, IBM Websphere, MS SQL Server, and Oracle; open-source solutions are provided by JBoss’s Teiid and Exareme, both of which are supported by Ontop.
SPARQL federation
Another setup in which Ontop can be used in data integration scenarios is through SPARQL federation. As with federated SQL databases, SPARQL federation involves multiple and independent SPARQL end-points that are queried through a single entry point. We distinguish two forms of federation available: seamless federation and SPARQL 1.1 SERVICE federation.
Seamless federation is very similar to SQL federation. That is, a system manager creates a federated SPARQL end-point where she configures access to independent and remote end-points. Clients submit plain SPARQL queries to the federated end-point, unaware of the existence of the remote end-points. As with SQL federation, the federation system is responsible for finding the most efficient way of executing queries (in particular, it is extremely important to minimize the amount of data transferred between end-points). Anapsid [2] and FedX [55] are examples of such systems.
In contrast, SERVICE federation involves direct references to remote end-points in SPARQL 1.1 queries: the

When a
In contrast to seamless federation, using the
Ontop can be used in both of these setups by deploying an Ontop SPARQL end-point (see Section 2.4).
Ontology-based query interface
The task of formulating SPARQL queries can be challenging for end-users. There are several ontology-based visual query interfaces to ease this task, e.g., OptiqueVQS [58], QueryVOWL [24], SEWASIE VQS [15], and Faceted search [60]. These tools can be used together with Ontop. In particular, OptiqueVQS is the query interface in the Optique platform.
Answering SPARQL queries
Ontop answers end-user’s SPARQL queries by rewriting them into SQL queries and delegating execution of the SQL queries to the data sources. With this approach there is no need to apply rules to the data sources to materialize all the facts entailed by the ontology. The workflow of Ontop can be divided into an off-line and online stages and is illustrated in Fig. 4. The most critical task during start-up (the off-line stage) is generating the so-called T-mappings [49] by compiling the ontology into the mappings. During query execution (the online stage), Ontop transforms an input SPARQL queries into an optimized SQL query using the T-mappings and database integrity constraints. We now explain each of the two stages.

The Ontop workflow.
The off-line stage of Ontop processes the ontology, mappings, and database integrity constraints. This stage can be thought of as consisting of three phases: (1) ontology classification, (2) T-mapping construction, and (3) T-mapping optimization. In the implementation of Ontop, however, the last two phases are performed simultaneously.
In Phase 1, the ontology is loaded through OWL API and is classified using the built-in OWL 2 QL reasoner. The resulting complete hierarchy of properties and classes is stored in memory as a directed acyclic graph. For example, in the ontology in Example 2.1, both 
The classification algorithm is based on a variant of graph reachability [45] (a similar procedure was later described in [36]).
In Phase 2, T-mappings are constructed by compiling the complete class and property hierarchies into the mappings [49,51]. For example, consider concept 
Finally, in Phase 3, the T-mappings are optimized by using disjunction (
Such optimizations are known to be relatively expensive (for example, SQO is based on an NP-complete conjunctive query containment check) but are performed only once, during the off-line stage of Ontop, and therefore have no negative effect on the online stage of query processing. On the other hand, the resulting T-mappings define all the triples in the virtual RDF graph that includes all the inferences due to the ontology (under the entailment regime). Thus, during the online stage, the T-mappings are used directly for the translation of individual triple patterns in SPARQL queries into SQL.

Online stage: Query answering
The online stage takes a SPARQL query and translates it into SQL by using the T-mappings. We focus only on the translation of SELECT queries (ASK and DESCRIBE queries are treated analogously). In this process Ontop also optimizes the SQL query by applying SQO techniques [16,32]. We distinguish three phases in the query answering process. (1) The SPARQL query is translated into SQL using T-mappings. (2) The resulting SQL query is optimized for efficient execution by the database engine. (3) The optimized SQL query is then executed by the database engine, and the result set is translated into the answer to the original SPARQL query by creating the necessary RDF terms. Note, however, that Phases 1 and 2 are handled together in the implementation of Ontop and we separate them here only for the sake of clarity. We elaborate now on the three phases of query answering.
From SPARQL to SQL
Ontop internally represents the SPARQL query as a tree of the algebra expression (generated by the Sesame SPARQL parser). Each node of the tree is transformed into the respective SQL expression. To illustrate the transformation, we continue with the running example.
Consider the fragment of the query in Example 2.3 that retrieves all tumors of stage IIIa:


Next we explain how to produce the SQL expression from a SPARQL query using T-mappings. Algorithm 1 is a simplified version of the process. It iterates over the nodes of the SPARQL algebra tree in a bottom-up fashion; more precisely, it goes through the list S of nodes in the tree of query Q in the topological sorting order. In our running example this list is [T1, T2, JOIN, PROJECT]. So, the algorithm starts by replacing each leaf of the tree, which is a triple pattern of the form

Translating SPARQL into SQL
Once it finishes processing the leaves, it continues to the upper levels in the tree (lines 7–17), where the SPARQL operators (JOIN, OPTIONAL, UNION, FILTER, and PROJECT) are translated into the corresponding SQL operators (InnerJoin, LeftJoin, Union, Filter, and Project, respectively). Once the root is translated, the process is finished and the resulting SQL expression is returned.
Ontop translates the SPARQL query in Example 4.1 into an SQL query of the following structure (see Fig. 5(a)):

The leaves, Q1 and Q2, are the SQL definitions of the concept

Example of SQL translation and optimization.
For the sake of simplicity we do not describe the translation of filter expressions and OPTIONAL (an optimal translation of unions and empty expressions in the second argument is particularly challenging) and how to handle data types and functions in SQL expressions. Instead, we refer the interested reader to [34,53].
The generated SQL queries can already be executed by the database engine but they are inefficient: they often contain subqueries, redundant self-joins, and joins over complex expressions such as string concatenations (the latter, for instance, prevent the database engine from using indexes). Ontop employs a number of structural and semantic optimizations to simplify and improve performance of produced SQL queries.
Ontop applies three main structural optimizations: (i) pushing the joins inside the unions, (ii) pushing the functions as high as possible in the query tree, and (iii) eliminating sub-queries. Returning to the running example, the SQL query obtained by these optimizations is shown in Fig. 5(b): optimizations (ii) and (iii) convert the join over the complex expressions into a join over the attributes of the relations (effectively de-IRIing the join) and subsequently remove the subqueries.
Ontop adopts techniques from the area of Semantic Query Optimization (SQO) [16,32]. In general, SQO refers to the semantic analysis of SQL queries and use of database integrity constraints, such as primary and foreign keys, to reduce the size and complexity of the query, e.g., by removing redundant self-joins, and detecting unsatisfiable or trivially satisfiable conditions. In our running example, SQO eliminates the self-join, which is redundant because
Observe that these optimizations interact with and complement each other. The optimization step is critical [35] and nontrivial. This simple example illustrates the basic principles. The translation of complex queries is more involved and takes account of the gap between the SQL and SPARQL semantics. The interested reader is referred to [34,53].
Executing queries over the database
Since different database engines support slightly different SQL dialects, we have to adjust the SQL syntax accordingly. For instance, the string concatenation operator is
As the final step, Ontop sends the generated SQL query to the database engine and translates the result into RDF terms (URIs or literals) to construct the answers to the SPARQL query. In the implementation, Ontop wraps the result set obtained from the database via JDBC and creates corresponding Java objects for OWL API or Sesame API.
Performance
The cost of query answering in Ontop can be split into three parts: (i) the cost of generating the SQL query, (ii) the cost of execution by the RDBMS, and (iii) the cost of fetching and transforming the SQL results into RDF terms. We have studied the performance of Ontop using several benchmarks (e.g., BSBM, FishMark, LUBM, and NPD) and settings (e.g., various database engines, number of clients, dataset size) [34,35,51,54]. The obtained results suggest that the performance of Ontop depends more on the complexity of the combination of ontology and mappings than on the size of the dataset. On the one hand, this is in line with the well-known theoretical results on the price of OBDA: the transformation of the query suffers an exponential blow-up in the worst case [23]. On the other hand, on the standard query rewriting benchmarks (LUBM, Adolena, etc.), the tree-witness query rewriting algorithm implemented in Ontop produces rewritings shorter and simpler than all other tools; moreover, it is also faster [51]. As a consequence, Ontop can efficiently perform ontological inferences in the virtual RDF graph mode without any need for materialization: on IMDb, for example, it is competitive with such materialization-based systems as OWLIM (GraphDB) [51] and, on LUBM, it outperforms reasoner-based systems, especially on large data instances [34]. In benchmarks like BSBM and FishMark, where the number of mappings is small and the datasets range from 25 to 200 million triples, Ontop outperforms its competitors (D2RQ, OWLIM, Stardog, Virtuoso) by orders of magnitude [54]. This performance is the result of (i) the fast SPARQL-to-SQL translation (4–15 ms); (ii) the efficient optimization of the SQL; and (iii) the well-known efficiency of relational databases. For instance, in BSBM with 200 million triples, Ontop can run more than 400.000 queries per hour (44 k query mixes per hour).
To better understand the performance of OBDA systems, we developed a more challenging benchmark, the NPD Benchmark [35], which reveals the strengths and pitfalls of OBDA. It is based on the original NPD FactPages ontology, mappings and queries [57]. The NPD FactPages original data is published by the Norwegian Petroleum Directorate (NPD) and the query set was obtained by interviewing users of NPD FactPages.8
Adoption of Ontop by the community has been growing steadily in the past six years. In 2015, the Ontop bundle was downloaded more than 1800 times,9
Reported by SourceForge for the period May–December, 2015.
Ontop is actively used in academia.10
Ontop is the core component of the Optique Platform, which is developed in the EU large scale integrating project Optique [22] and commercialized by fluid Operations (fluidOps).12
Statoil is an international energy company with main activities in gas and oil extraction. It is headquartered in Norway and present in over 30 countries around the world. Geologists at Statoil require access to a number of large databases on a daily basis. One of them, for example, the Exploration and Production Data Store (EPDS), comprises over 1500 SQL tables with information on historical exploration data (e.g., layers of rocks, porosity), production logs, and maps, among others. It also contains business information such as license areas and companies. The schema is organized in such a way that the direct data access by engineers (and geologists in particular) often becomes challenging or even impossible. The main problem lies not only in the size of the schema and the data but also in the complex structure of this legacy database. The solution currently adopted by Statoil relies on tools that provide domain experts with a few different pre-defined queries. However, these pre-defined queries are often too specific, or too general, and cannot be easily combined to obtain the desired results.
Siemens Energy is one of the four sectors of Siemens AG corporation. It is in charge of generating and delivering power from numerous sources. Siemens Energy runs several service centers for power plants. Each center monitors thousands of devices related to power generation, including gas and steam turbines, compressors, and generators. Each device is monitored by a number of sensors. All dynamic (observational) data from the sensors is stored in one large relational database (PostgreSQL) using more than 150 tables per device. About 30 GB of new sensor and event data is generated every day, resulting in a total of 100 TB of timestamped data. One of the main tasks for service engineers monitoring these devices is to promptly solve issues detected by gathering the relevant sensor data and analyzing it.
The data gathering phase is often the bottleneck of the process because it takes about 80% of the engineers’ time. This is partly due to the complexity and quantity of the data. Ideally, the engineers should be able to access the data directly, by creating and combining queries in an intuitive way that is compatible with their knowledge. However, the data is often organized to better serve the applications rather than the domain experts.
In scenarios such as at Statoil and Siemens, the OBDA approach to solving these problems consists in enriching the legacy databases with an ontological layer that uses a terminology familiar to the engineers. The ontology helps the engineers in formulating their own queries autonomously using the domain vocabulary [22,30], thus effectively mediating between the engineers and the data. The role of Ontop (and Optique) is to make the OBDA approach feasible, by automating the process of translating the queries that the engineers pose over the ontology into queries over the legacy databases that can be executed efficiently.
Feature matrix of SPARQL query answering systems
Feature matrix of SPARQL query answering systems
indicates limited support
We now briefly review the most popular SPARQL query answering systems, which can be categorized into two major types: triplestores and OBDA systems. Table 1 summarizes their main features.
Triplestores provide a flexible generic logical model for storing any set of RDF triples. However, if the triples are generated from external sources (e.g., relational databases) then an intermediate ETL (Extract, Transform, and Load) process is required to transfer data between these external sources and the triplestore. The ETL process can be expensive, especially when data sources are frequently updated.
OBDA systems, on the other hand, are set up over existing relational datasources and exploit their domain-specific schemas. By using ontologies and mappings, they expose the database as a virtual RDF graph that can be queried using SPARQL (thus, the additional ETL process is not required).
Some triplestores and OBDA systems have reasoning capabilities. The most common strategy for triplestores is forward-chaining, which consists in extending the set of RDF triples by means of inferences according to a given set of rules. Thus, the OWL 2 RL profile of OWL 2 (and similar rule-based ontology languages) are most suitable for triplestores. Forward-chaining has certain drawbacks: inferences can be costly in terms of both time and space; moreover, updates and deletions of triples require additional book-keeping for incremental reasoning. Also, this approach cannot be adopted without sacrificing completeness of query answering when the ontology language (such as OWL 2 QL) is capable of inferring new individuals in the data.
In contrast to triplestores, the most common strategy for OBDA systems is query rewriting, and so OWL 2 QL is the OWL 2 profile most suitable in this setting. To guarantee rewritability, certain features, such as recursion and property chains, are not allowed in OWL 2 QL.
In the remainder of this section, we review various implementations of the two types.
Virtuoso universal server13
GraphDB,14
Stardog15
RDFox17
D2RQ18
Mastro19
Ultrawrap20
Morph-RDB,21
Ontop has its roots in our early work on QuOnto and Mastro [1,10]. QuOnto is a reasoner for the description logic DL-Lite with plain conjunctive query (CQ) answering and Mastro is its extension with GAV (global as view) mappings for relational databases [42] (both systems are maintained by the Sapienza University of Rome). Our work enabled the use of these systems through the ontology editor Protégé 3 [43] and the DIG reasoner API [48].
Using these tools we interacted with third parties to develop several OBDA applications [10,13,28,47,52] (for a full list, see [47]). In the process we tested both the performance of the state-of-the-art query rewriting techniques and the feasibility of this technology for data integration and data access. We obtained insights on techniques and optimizations on the one hand, and on APIs and required features on the other hand. These two strands of development characterized our work from then on. We now briefly elaborate on them.
Reasoning, optimization, and performance The main issue initially was the large number of CQs produced by the rewriting algorithm (PerfectRef [11]) implemented in QuOnto, which often returned hundreds of thousands of CQs (even for simple ontologies and mappings). And although database systems do perform very well in general, commercial and non-commercial engines alike have problems with large generated queries. To deal with the issue, we extended PerfectRef by a Semantic Query Optimization (SQO) component, which removes redundant CQs and eliminates redundant self-joins using database integrity constraints (foreign and primary keys) [47].
The work in this direction materialized in the first version of Ontop (2010), which was called Quest (the name now refers only to the query processing engine). Quest can work in (i) the virtual mode, which supports virtual RDF graphs via mappings, and (ii) the triplestore mode, which stores RDF triples directly in a relational database. We developed the theory of T-mappings to improve performance in the virtual mode [34,49] (cf. Section 4.1) and the Semantic Index for the triplestore mode [50]. Then, the tree-witness query rewriting algorithm [31] replaced PerfectRef to drastically reduce the size of rewritings and take advantage of T-mappings and the Semantic Index. We also observed [47] that the generic database-centric SQO is insufficient in the OBDA setting and proposed novel techniques: e.g., simplification of join conditions by de-IRIing, cf. Section 4.2.2.
More recent lines of research on Ontop include (i) the formalization of SPARQL in the context of OBDA [34,53], (ii) the OWL 2 QL entailment regime [34], (iii) the SWRL rule language with a limited form of recursion handled by SQL Common Table Expressions [61], (iv)
API, features, and accessibility With the first version of Ontop, we shifted our focus from the Description Logic domain to Semantic Web technologies, gradually increasing the level of compliance with the RDF, RDFS, OWL 2 QL, SPARQL, and R2RML standards. To support the OWL community, we include the OWL API and Protégé 4 (and more recently Protégé 5) interfaces for Ontop. To support the Linked Data community, we provide the Sesame API interface for Ontop, as well as an HTTP SPARQL endpoint.
Ontop was initially released under a non-commercial use license before adopting the permissive Apache 2.0 license in 2013. The project is now hosted in GitHub so that anybody can download it and contribute to the code. On the software engineering side, to facilitate integration, building, testing, and distribution, Ontop was repackaged as a Maven project and has been available from the official Maven repository since 2013. We gradually introduced project-wide testing, starting with functional tests for the reasoning modules, query answering modules (including the DAWG tests for SPARQL 1.0), and virtual RDF modules (including the DAWG tests for R2RML). Now most JUnit tests (∼2000) are automatically run with Travis-CI whenever new changes are pushed to GitHub.
Conclusion
We presented Ontop, a mature open-source OBDA system, which allows users to access relational databases through a conceptual representation of the domain of interest in terms of an ontology. The system is based on solid theoretical foundations and has been designed and implemented towards compliance with relevant W3C standards. It supports all major relational databases and implements numerous optimization techniques to offer a good level of performance. Ontop has been adopted in several academic and industrial use cases.
In the future, we plan to develop Ontop in the following directions.
In order to further improve performance, we will investigate data-dependent optimizations.
We plan to support larger fragments of SPARQL (e.g., aggregation, negation, and path queries) and R2RML (e.g., named graphs).
For end-users, we will improve the GUI and extend utilities to make Ontop even more user-friendly.
We plan to go beyond relational databases and support other kinds of data sources (e.g., graph and document databases).
Footnotes
Acknowledgements
This article is supported by the EU under the large-scale integrating project (IP) Optique (Scalable End-user Access to Big Data), grant agreement n. FP7-318338.