
Abstract
We describe SPARQLES: an online system that monitors the health of public SPARQL endpoints on the Web by probing them with custom-designed queries at regular intervals. We present the architecture of SPARQLES and the variety of analytics that it runs over public SPARQL endpoints, categorised by availability, discoverability, performance and interoperability. We also detail the interfaces that the system provides for human and software agents to learn more about the recent history and current state of an individual SPARQL endpoint or about overall trends concerning the maturity of all endpoints monitored by the system. We likewise present some details of the performance of the system and the impact it has had thus far.
Introduction
Thousands of Linked Datasets have been made publicly available in recent years.1
At the time of writing, LODstats [13] reports 9,960 datasets:
To entice new consumers, many publishers began hosting public SPARQL endpoints over their datasets such that clients can pose complex queries to the server as a single request and retrieve direct answers. Hundreds of public SPARQL endpoints have thus emerged on the Web in recent years [10]. These endpoints index content with a variety of topics and sizes and (in theory at least) accept arbitrary SPARQL queries from remote clients over the Web. However, applications using these endpoints have been slow to emerge. The convenience of SPARQL queries for clients translates into significant server-side costs maintaining such heavyweight query services, which translate into a variety of technical problems on the level of the SPARQL infrastructure itself [10].
With respect to what that SPARQL infrastructure consists of, the recent SPARQL 1.1 standard issued recommendations relating to the following:
The SPARQL 1.1 Query Language recommendation [17] extends the original SPARQL Query Language [25] with features such as property paths, sub-queries, aggregates, etc. The related SPARQL 1.1 Federated Query recommendation [24] specifies how a SPARQL engine can invoke a remote endpoint at runtime.
The SPARQL 1.1 Protocol recommendation [14] specifies how clients should interact with a SPARQL endpoint over HTTP, including how
The SPARQL 1.1 Service Description recommendation [34] provides a vocabulary with which the capabilities and configuration of a SPARQL endpoint can be described in RDF such that, for example, clients can discover endpoints with the features they need.
The SPARQL 1.1 Update specification [15] describes a language for inserting, deleting and updating the data present in a SPARQL engine.
The SPARQL 1.1 Entailment Regimes recommendation [16] describes how ontological entailments can be included when computing the answers for a SPARQL query.
With respect to public SPARQL endpoints, the latter two aspects of the SPARQL infrastructure are currently of lesser interest: updates to data are unlikely to be enabled on a public query service and we do not yet know of any public SPARQL endpoint supporting entailment regimes. Thus, for clients of current public endpoints, the former three aspects – query, protocol, and description – appear to be of most relevance.
With respect to these three infrastructural aspects, in previous work [10] we performed an empirical investigation of the maturity of public SPARQL endpoints from the perspective of the client, who we argue needs endpoints that are: (i) highly-available through the SPARQL protocol, thus allowing queries to be answered reliably at any time; (ii) described using standard vocabularies in well-known locations, thus allowing for the (automatic) discovery of relevant endpoints over the Web; (iii) capable of answering queries in acceptable time, thus enabling their use in real-time applications; (iv) compliant with respect to supporting the query features of SPARQL (1.1), thus enabling them to be interrogated alongside other endpoints in a uniform manner. If an endpoint has high availability, is well-described, supports all SPARQL 1.1 features, and returns query answers quickly, we consider it to meet all of the basic infrastructural requirements a client would have. However, these goals fall on a continuum rather than being binary or discrete: for example, endpoints may support a majority of features of SPARQL 1.1, or may only be able to answer certain queries within a given expected response time. Thus the question is to what extent endpoints are mature. We thus defined four general dimensions for assessing the maturity of public SPARQL endpoints, as follows.
First, we looked at
Second, we looked at
Third, we looked at
Finally, we looked at
Given mixed results in our initial experiments [10], we foresaw the need for an online system to track such aspects of public endpoints over time, and to help clients assess for themselves the maturity of individual endpoints based on empirical data. Along these lines, we initiated work on the SPARQL Endpoint Status (SPARQLES) system, which is currently available at
SPARQLES is also a predecessor of an older system that tracked only availability [31]:
The SPARQLES system currently focuses on the same dimensions we investigated in previous work [10]:
This paper then extends upon previous works [10,31] and describes the current SPARQLES system itself in detail: how it is constructed, what sorts of tests it performs, what queries it issues, what data it collects, what kinds of conclusions can be drawn, what interfaces and visualisations are provided, etc. In Section 2, we first discuss works relating to studies of public endpoints and monitoring Web services. In Section 3, we introduce the high-level SPARQLES architecture. In Section 4 we describe in more detail the analytics that SPARQLES runs over public endpoints and in Section 5 we describe the interfaces that we provide for agents to interact with the data collected. In Section 6 we present evaluation of the system including runtimes of analytics, growth in storage overheads, and A.P.I. performance. We later discuss the impact, limitations, and sustainability of SPARQLES in Section 7 before concluding with Section 8.
The SPARQLES system – both code and data – is published under a Creative Commons 4.0 license ( ), with code available from
), with code available from
A number of works and systems have dealt with issues relating to public SPARQL endpoints. The DataHub7
More generally, since public SPARQL endpoints can be considered as Web Services, our work also relates to the topic of monitoring Web Services, and in particular, the notion of Quality of Service (QoS). One of the seminal works in this area was by Ran [26], who proposed an influential list of twenty-three QoS dimensions for Web services in four categories: runtime (R), transaction support (T), configuration (C), and security (S). In this context, our work touches upon the following dimensions:
The response time, latency and throughput of the service.
The probability of a system being operational at any given point in time.
The degree to which a service can cope with diverse inputs.
The gracefulness with which errors are handled and explained.
The degree of compliance of the service with respect to some standards.
The ratio of advertised features that are found to work in practice.
Some of the other QoS dimensions defined by Ran [26] are either not currently relevant for public SPARQL endpoints – such as authentication, authorization, etc. – or cannot be easily tested in our setting – for example, the accuracy of results. On the other hand, we also consider the discoverability of endpoints, which refers to how well the service describes itself, which was not explicitly mentioned by Ran [26].
The SPARQLES system is designed to observe a set of public SPARQL endpoints over time. Currently SPARQLES is tracking all of the endpoints listed in the DataHub catalogue found using the DataHub APIs; we thus align the inclusion criteria of SPARQLES with that of the DataHub. SPARQLES performs a fixed set of analytics against each listed endpoint at fixed intervals, stores the historical results and allows these results to be accessed through online interfaces.
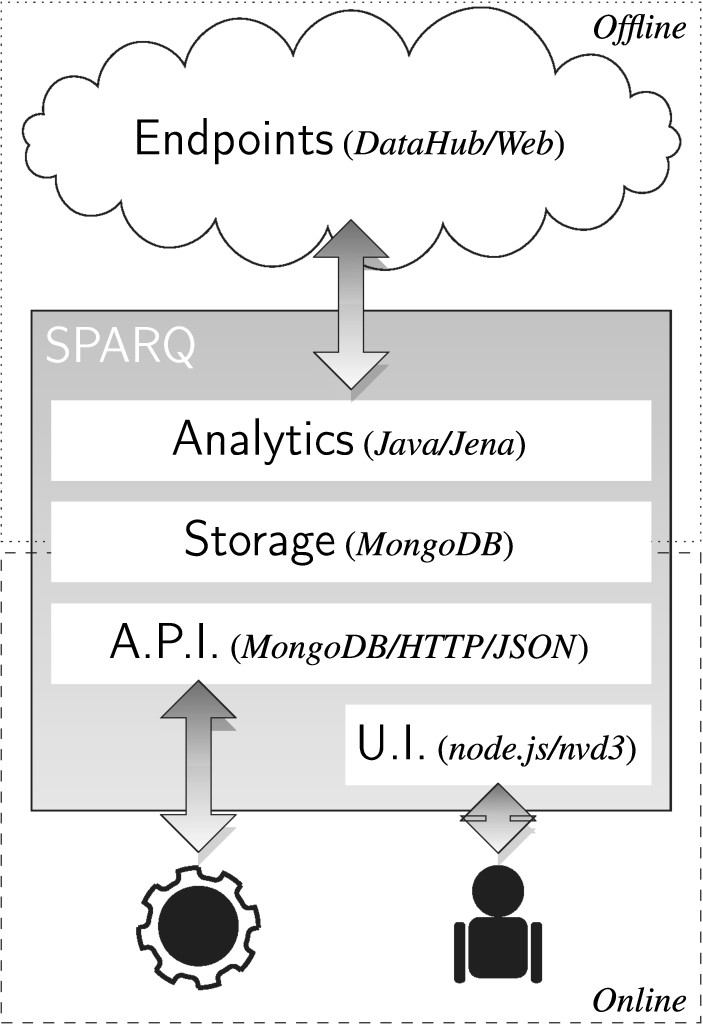
High-level System Architecture.
The high-level architecture for observing the selected endpoints is depicted in Fig. 1, where we show the offline and online parts of the system. The offline parts are responsible for collecting information about the endpoints. The online parts are responsible for presenting the results to the clients of the system. The main components are as follows:
responsible for performing analysis over endpoints at regular intervals, thus producing the raw observational data. This component is implemented with custom Java code that uses Jena as a query client to interact with endpoints over the SPARQL protocol. Analytics are scheduled using
offers persistence over the results of the offline
offers software agents a RESTful application programming interface through which to query key data about endpoints. Agents may access the A.P.I. through simple HTTP
offers human agents a user interface with a mix of aggregate visualisations and per-endpoint visualisations. The search and user interactions provided by the U.I. are built on top of the data delivered by the A.P.I. The user interface is implemented using the Node.js8
We describe these components in more detail in the following sections. In Section 4, we focus on the offline phase, and in particular, the types of analytics we run. Thereafter, in Section 5, we describe the storage and online parts of the system, including the types of interfaces that we provide for the public to interact with the collected data by the SPARQLES system.
We now provide details of the offline phase, and in particular, the analytics performed by the system.
The following analytics are implemented with custom Java code that uses Apache Jena (2.12.2) to coordinate making requests to and collecting responses from SPARQL endpoints.10
In our previous experiments we found that many endpoints have significant periods of downtime [10]. Some downtimes may be temporary, caused by network failures, sporadic high server loads, engine crashes, and so forth. Other downtimes appear permanent, indicating that an endpoint has probably been discontinued. Anticipating downtimes or distinguishing reliable endpoints from unreliable ones can be crucial for many clients. Hence SPARQLES closely monitors the historical availability of endpoints.
Availability analytics We define an endpoint as available if it can respond to a simple SPARQL query with some compliant response through the SPARQL protocol. For this reason, rather than perform a ping (which would only ensure that the host is accessible) or a generic HTTP lookup (which would only ensure that some web-page is available that could be, e.g., an under-maintenance notice), we wish to ensure that the endpoint can respond to basic queries. To avoid unnecessary load on remote servers, we send queries that should, in general, be simple to compute responses for.
Along these lines, to check availability, the system first issues a generic

Responding to this query should be trivial (is the index empty or not?). As soon as a valid response (positive or negative) is received, the system considers the request successful and concludes that the endpoint is available. However, some SPARQL endpoints cannot handle this

Again, this query should be cheap to compute: return any triple from the index (if any). We deem any endpoint responding to either query with any valid SPARQL response as available at that time.
Frequency We run availability tests once an hour, which allows us to monitor, e.g., the uptimes at different times of the day, including hours of peak Web-usage (performance will be discussed later). Availability results can then be aggregated per endpoint into a success rate for fixed time intervals, e.g., to compute availability over the past day, week, month, etc.
Limitations The local SPARQLES server may experience some downtimes or local network issues that may lead to remote endpoints being falsely reported as unavailable. In general however, when errors known to be local are omitted and when hourly results are aggregated into larger time intervals, such as weeks or months, such local effects should be smoothed out.
Discoverability
For a client, finding a SPARQL endpoint that contains content relevant for their needs [10,22] and the features that they require [10] can be challenging. The goal of the discoverability analytics is to determine the degree to which endpoints offer descriptions of themselves and their contents using (de facto) standards: to what extent an endpoint offers descriptions – in well-known locations using well-known vocabularies – of (i) its content and (ii) the features it supports. The SPARQLES system thus checks if a client can automatically find, for a given endpoint:
The type of engine (Fuseki, Virtuoso, etc.) powering a SPARQL endpoint can also be an important information for a client; for example, some engines support non-standard keyword search functions that a client may be interested in. We thus also look for:
The type of engine powering the endpoint, sometimes mentioned in the HTTP header [10].
SD analytics Endpoint capabilities – such as the version of SPARQL supported, query and update features, I/O formats, custom functions, and/or entailment regimes – can be described in RDF using the SPARQL 1.1 Service Description (SD) vocabulary, which became a W3C Recommendation in March 2013 [34]. Such descriptions, if made widely available, could help a client find public endpoints that support the features it needs (e.g., find SPARQL 1.1 endpoints).
The service description for an endpoint is retrieved by simply dereferencing the endpoint IRI itself [34]. As such, the SPARQLES system performs a
VoID analytics The Vocabulary of Interlinked Datasets (VoID) [3] has become the de facto standard for describing RDF datasets (in RDF). The vocabulary allows for specifying, e.g., the number of triples a dataset contains, the number of unique subjects, a list of properties and classes used, the number of triples with a given property as predicate, the number of instances of a given class, the number of triples used to describe instances of a given class, and so forth. If VoID descriptions were widely available for SPARQL endpoints, a client could leverage them to discover endpoints with potentially relevant content.
There are a number of best-practices regarding how VoID should be published; SPARQLES looks in three locations. First, the system looks in the content gotten by dereferencing the endpoint URL (i.e., the same document as the SD description). Second, the system checks the location denoted by the Well-Known IRI pattern

Server name analytics A variety of options are now available for SPARQL engines, including Virtuoso [12], Sesame [9], etc. However, performance and compliance across different vendors can vary quite dramatically. Knowing which engine – or even which version of an engine – powers a given SPARQL endpoint may be useful for (expert) clients to know which version of a query to send. For example, in previous works we found that certain analogous strategies for processing joins in a federated setting worked well for certain SPARQL engines but performed poorly or even outright failed for others [11].
Unfortunately, neither VoID nor the SD vocabulary provide terms for specifying an engine or version number to a client. Hints are available, such as scanning the frontpage or an error page for mention of a fixed list of engines. However, when dereferencing the endpoint URL, the type of engine and the version number is often (though not always) provided in the
Frequency When compared with availability, we do not expect discoverability to be so dynamic: once descriptions are published, they are likely to stay published (and as discussed later, we do not check that the descriptions are up-to-date). For this reason, we run discoverability analytics once a week; we have received no complaints from endpoint maintainers about the remote expense of these analytics.
Limitations SPARQLES only checks for the existence of meta-data, but does not attempt to validate the meta-data itself, nor does it try to measure the completeness of descriptions. Additionally, VoID descriptions or engine information may be extracted from locations or with vocabularies not checked by SPARQLES: however, to help clients, we believe it is important for publishers to offer such information using well-known vocabularies in discoverable locations.
Performance
SPARQLES runs a set of performance-related analytics that aims to compare the runtimes of different public endpoints for comparable queries from a client’s perspective (i.e., including HTTP overhead). Since we cannot control or know in detail about the content of endpoints, for the purpose of comparability, we must rely on generic queries that would execute in a similar manner independent of the exact content indexed by the endpoint. We test three fundamental aspects of a query engine: lookups, streaming and joins.
Lookup analytics The goal is to measure the time taken to perform an atomic lookup (according to different triple patterns). The query template is as follows:

Here
Since in the above example the subject is set, we call it an
Given that an atomic lookup should be fast to execute, we consider this query as estimating the latency of querying the endpoint, which would most likely be dominated by the HTTP network overhead.
Streaming analytics We measure the time taken for an endpoint to stream a large result-set that should be trivial to compute. The query is as follows:

Here we ask to stream 100,001 results. Since we have found that public endpoints may limit maximum result sizes to a “round number” – say 100,000 – we ask for one hundred thousand and one results to detect such a case. We also send queries for limits with 50,000, 25,000, 12,500, 6,250 and 3,125 results. Since the endpoint should be able to stream results contiguously from its index, we consider such queries as estimating the maximum throughput of the service.
Join analytics We use the following three queries to measure a generic notion of join performance:

These queries are designed – insofar as possible – to be comparable across endpoints no matter what content is indexed. In these queries,
Frequency Like availability, we expect performance to vary for different times of the day, different days of the week, etc. For this reason, like availability, we would like to have frequent experiments. However, unlike availability, the queries required to test performance are not so trivial for endpoints to compute (we present more details on this later). For this reason, we opted to run performance experiments once a day; at this level of frequency, we have received no complaints from endpoint maintainers.
Limitations The performance results do not indicate why specific queries are slow: is it due to the engine, the HTTP overhead, the content indexed? In general, we try to make the query load balanced irrespective of the content and our goal is to measure the costs from the perspective of a client who is concerned about the “bottom line” of response times.
Performance results may also be affected by local issues. For example, slow runtimes may be due to a busy network on the SPARQLES end (e.g., if other analytics happen to run simultaneously); to help mitigate this issue, in the system’s interfaces, we display the median value of the last ten performance runs. Other factors may be more difficult to control for; e.g., endpoints on servers that are geographically closer to the SPARQLES host may be given an advantage. Still, the performance results should serve as a useful guide.
Interoperability
If available, the Service Description of an endpoint should describe the query features and the version of SPARQL that an endpoint supports. However, we have seen that SD meta-data are often unavailable and, in any case, an endpoint may claim to support features that it does not, or may claim support for SPARQL 1.1 while only supporting a subset of new features.
SPARQLES thus offers analytics for interoperability, whose goal is to verify which SPARQL features – i.e. specific operators, solution modifiers, etc. – are supported, gathering data about what SPARQL features are available for the users of various endpoints.
Along these lines, SPARQLES takes a subset of queries from the W3C Data Access Working Group test-cases – designed to test all features from both versions of the standard – and issues them on a weekly basis to SPARQL endpoints. We consider the test as passed if a valid SPARQL response is returned. Since we cannot control the content of endpoints, we cannot verify that the returned response is actually correct; hence we may overestimate compliance with the standard. We expect that if an endpoint does not support a feature, an exception will be thrown (e.g., a parse exception). However, since an endpoint may time-out on a given query, we may also underestimate compliance where the feature may be supported but the endpoint cannot answer the query instance provided.
SPARQL 1.0 analytics First, the SPARQLES system tests the endpoints for the core SPARQL 1.0 query features that it supports. We issue endpoints a subset of the Data Access Working Group test-cases for SPARQL 1.0,11
Queries available at
SPARQL 1.1 analytics SPARQLES also performs tests on SPARQL 1.1 features using a test suite taken from the W3C SPARQL Working Group.13
We first test support for aggregates, where expressions such as average, maximum, minimum, sum and count can be applied over groups of solutions (possibly using an explicit
Frequency Much like discoverability, we do not expect interoperability to be a highly dynamic property of an endpoint; for example, we suppose that once an endpoint adds support for SPARQL 1.1 features, it will continue to support these features until it is discontinued. For this reason, we schedule interoperability analytics to run once a week. During the first year of operation, we began to receive complaints that the queries we were using – based on the W3C test-cases – were causing a high load on remote servers.14
See, e.g.,
Limitations As aforementioned, the main limitation of these experiments is that we classify an endpoint as implementing a specific SPARQL 1.1 feature if that endpoint returns any valid response without throwing an exception. If an endpoint times out, we will classify it as not implementing that feature, and conversely, if it returns an incorrect solution, we will count it as supporting that feature.15
Strictly speaking, a query timing out is not compliant with SPARQL 1.1; however, in spirit, we are more interested about whether a feature is supported in general and not about if a specific query instance runs or not.
Another limitation is that we do not test some features of the SPARQL 1.1 standard, such as SPARQL 1.1 Update – since we presume we should not have write privileges for public endpoints – or SPARQL 1.1 Entailment Regimes – since we do not know of any public SPARQL endpoints with this feature.
We now describe how SPARQLES manages the experimental data gathered during these analyses and the public interfaces through which software agents and users can interact with these data.
Storage
As tests are performed, the results and metrics collected are serialised using the Apache AVRO (1.7.5) library and sent to a MongoDB instance for storage. The MongoDB instance maintains 11 different collections that, loosely speaking, represent different materialised views over the data collected:
4 collections store the “raw” version of the data collected for the four analytical dimensions;
1 collection maintains the current list of endpoints registered in the DataHub;
6 collections correspond to aggregated views of the raw data as required by the User Interface.
The aggregate views are recomputed at regular intervals using
Application programming interfaces
SPARQLES provides seven RESTful APIs that facilitate remote access to the data collection. These APIs are designed to provide clients with both (i) information relating to specific endpoints, as well as (ii) information about all endpoints relating to a specific type of analytical experiment. Likewise we split the APIs into two groups, as follows.
The first group contains endpoint-specific APIs, which helps to find a specific endpoint, or returns detailed results for a specific endpoint:
takes no input and returns a list of all endpoints in SPARQLES: the URL of the endpoint, as well as the name and URL of the dataset they are associated with in the DataHub catalogue.
takes as input a string, such as “
takes as input the URL of a specific endpoint, and returns all data for that endpoint, including dataset URL and label; availability over the past day, week, month, and overall; performance results for cold/warm runs of ask and join queries and suspected threshold size; interoperability information regarding support for SPARQL and SPARQL 1.1 query features; and discoverability information regarding locations (if any) where VoiD and SD descriptions could be found, and the server-name extracted from the HTTP header.
The second group contains analytical APIs, which return aggregate results for all endpoints on a given analytical dimension:
returns uptimes for the last test, day, week, month – and overall – for all endpoints.
provides the server name, VoID locations and SD availability found (if any) for each endpoint in the most recent experiment.
counts the SPARQL 1.0 and SPARQL 1.1 queries passed by each endpoint in the most recent experiment.
provides the mean performance for join and ask queries in cold/warm runs from the most recent experiment for all endpoints.
The APIs are provided and described online at:
User interface
The SPARQLES user interface – available on the Web at
The homepage offers “at-a-glance” aggregated views of the four dimensions computed across all endpoints. In Fig. 2, for example, we see the aggregate view for availability, which shows the evolution of the number of endpoints falling into five different availability intervals ([0–5[, [5–75[, [75–95[, [95–99[, [99–100]). Other aggregate views likewise provide an overview of performance, interoperability and discoverability.

Screen capture of SPARQLES’ homepage focusing on the availability overview. The homepage offers “at-a-glance” aggregated views for the four dimensions of analytics described.
From the homepage, the user has a number of possible navigation steps, as illustrated in Fig. 3.

SPARQL user-interface sitemap.
The user can navigate to a page dedicated to each dimension to get an overview of key results for all endpoints in a list view, as follows:
lists the availability for each endpoint over the past 24 hours and the past 7 days.
lists the suspected result-size threshold and the median cold/warm run-times for
lists the ratio of SPARQL 1.0 and SPARQL 1.1 query test-cases passed by each endpoint in the most recent run.
indicates whether or not a VoID and/or SD description is available for each endpoint in some location, and what server name could be found (if any), in the most recent run.
Otherwise, either by using the auto-complete search function (available on all pages), or by clicking on a specific endpoint mentioned in one of the previous four list-view pages, the user can arrive to an endpoint-specific view with detailed information about all four dimensions for a given endpoint. An example for the main DBpedia endpoint is provided in Figs 4 and 5 (referring to the same page but split here for formatting purposes). The views provide information on the weekly availability for the past year, median performance for the past ten runs, the interoperability test queries failed or passed16
On hovering the mouse pointer over the query name, the user can see the full query, and on hovering over a red icon, the user can see details of the exception encountered.
From the homepage, there are also links to download data dumps or view the A.P.I. documentation.
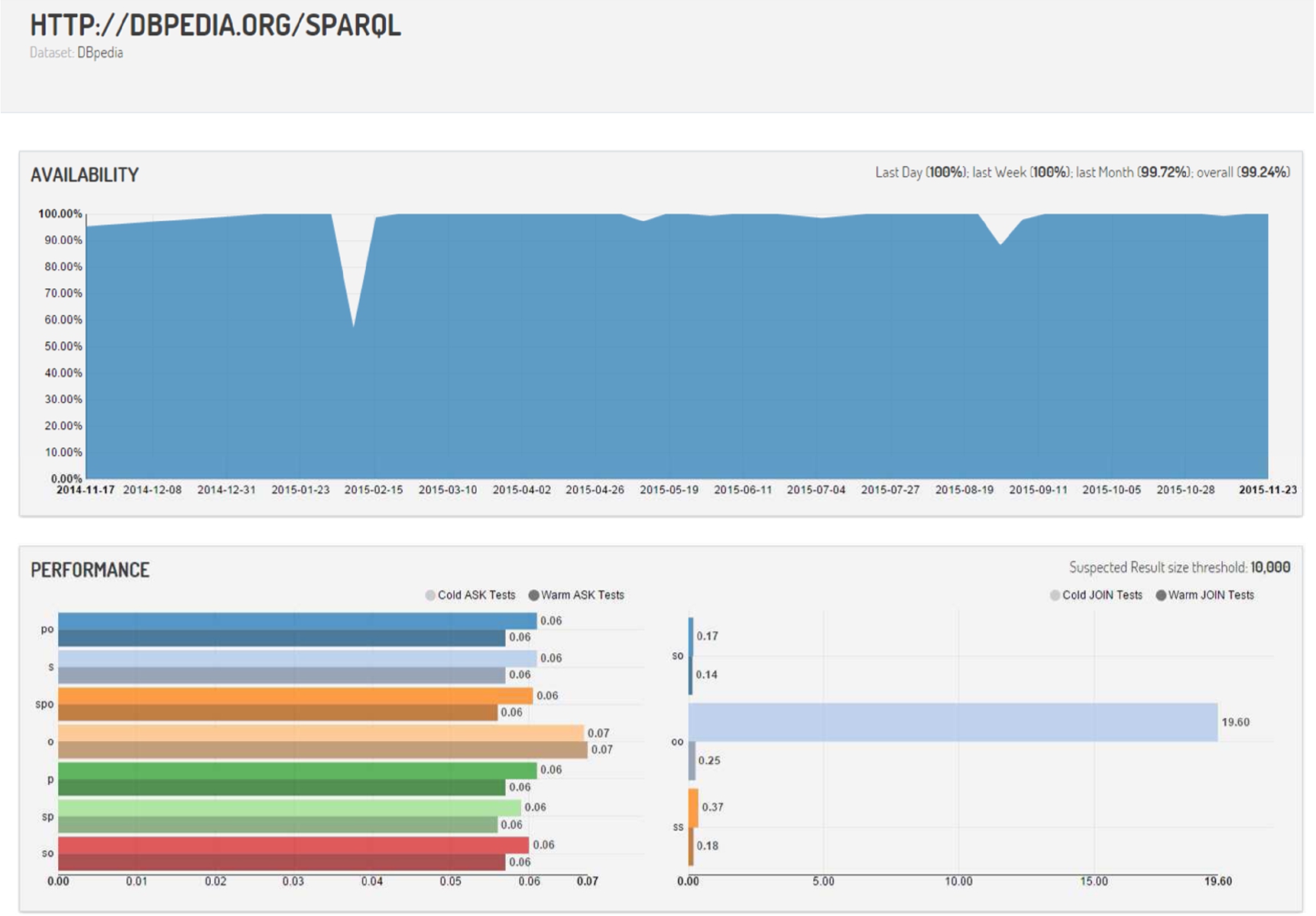
Screen capture of the detailed view for the DBpedia endpoint (

Screen capture of the detailed view for the DBpedia endpoint (
SPARQLES has been running since October 2013 where, as of November 2015, it monitors 545 public endpoints. We now present some high-level results with respect to operating, maintaining and improving various aspects of the SPARQLES system.
Analytics With respect to running the individual analytical tasks, we measured the time of the four most recent runs within the SPARQLES system.
The fastest were the
Second were the
Third were the
Fourth were the
Storage With respect to the growth of data in the SPARQLES system, the maximum amount of data we collect per endpoint is given in Table 1, where, each week, we store an upper limit of 177 JSON objects and 4,415 JSON key–value pairs per endpoint (we store fewer key–value pairs if an endpoint is unavailable). In terms of the growth of endpoints, one can see from Fig. 2 that the number of endpoints increases gradually. Hence we can conclude that the storage overhead of SPARQLES is sustainable, particularly given the ability of MongoDB to scale horizontally across machines. For example, as of November 2015, SPARQLES was monitoring 545 endpoints, and thus collecting 96,465 JSON objects and a max. of 2,406,1175 JSON key–value pairs per week, where the compressed dump of all historical data was 397 megabytes, corresponding to a live MongoDB index of 14 gigabytes.
Data items stored by SPARQLES per endpoint: Freq. denotes the frequency of experiments, KV denotes the maximum number of key–value pairs generated per experiment, O/W denotes the number of JSON objects generated per week (each experiment generates one JSON object), and KV/W denotes the maximum number of key–value pairs per week (i.e., KV/W = KV × O/W)
Data items stored by SPARQLES per endpoint: Freq. denotes the frequency of experiments, KV denotes the maximum number of key–value pairs generated per experiment, O/W denotes the number of JSON objects generated per week (each experiment generates one JSON object), and KV/W denotes the maximum number of key–value pairs per week (i.e., KV/W = KV × O/W)
A.P.I In order to ensure that our A.P.I.’s would perform well under high loads, we sent 1,000 requests to each of our A.P.I.’s from 10, 50 and 100 parallel clients respectively. Figure 6 provides box-plots of the individual runtimes encountered. Under this type of load, although we see that the slowest request can range in the tens of seconds (especially for a higher number of clients), typical performance in the lower three quartiles remains reliably below half a second. In summary, we encounter a few slow requests that require up to 20 seconds to complete, but the majority of requests are answered within 0.5 seconds, even with 100 clients simultaneously issuing 1,000 requests.
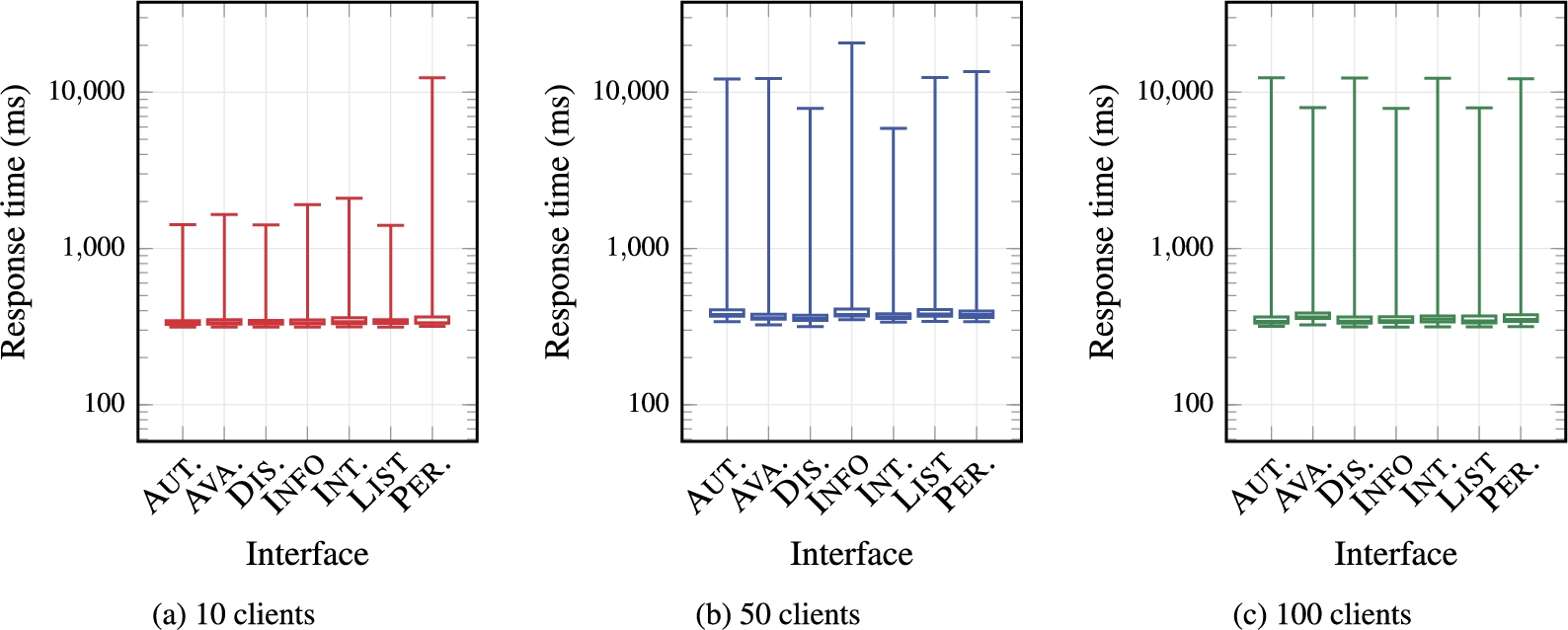
A.P.I. response times for 1,000 requests with 10, 50 and 100 parallel clients. On the x-axis,
Usability We collect and react to user feedback relating to bugs, feature-requests and usability on the issue tracker for the project, which as of 2015/01/30 contained 21 open issues and 24 closed issues; we refer the interested reader to https://github.com/pyvandenbussche/sparqles/issues for details on individual comments. Feedback has related to varied aspects, be it misreported statistics for the endpoints maintained by users, or the expense of certain queries for remote services, or problems with characters/escaping in the interface, or requests for various enhancements. This feedback has been invaluable for improving the usability, correctness and sustainability of the service. For example, one of the most important changes we have made based on this feedback was to modify the
We now discuss the use-cases, impact thus far, limitations and sustainability of SPARQLES.
Impact
One of the main goals of the system is to disseminate timely information about the health of individual endpoints. To help characterise the impact of SPARQLES, in the following we present some statistics collected from the Google Analytics for the site.
Over a 23 month period, SPARQLES has seen a total of 11,420 user sessions, averaging about 497 sessions per month. Figure 7 presents the data for the past 23 months, where we see a peak in October 2013, after which the number of user sessions was between 172 (February 2014) and 823 (June 2015). Table 2 presents the number of sessions along with the most visited first pages, second pages, and third pages.17
Please note that since we cannot access raw data, some of the figures may be rounded (for example, the Google Analytics system reports “

Number of unique sessions per month for SPARQLES.
Number of SPARQLES sessions over a 22 month period spanning from 2013/09/27–2015/07/27
Another indirect goal of the system is to encourage endpoints to follow best practices: we would hope that by tracking such metrics about endpoints, maintainers might be made aware of shortcomings with the SPARQL services they offer and rectify these accordingly. Though from personal communications with some endpoint maintainers we know that there have been anecdotal instances of this,18
See for example
Perhaps the most important impact of this work has been to formally acknowledge the kinks in the current public SPARQL infrastructure, which has helped motivate new lines of research. We can, for example, point to work on Linked Data Fragments, which points to our
For each of the analytics presented in Section 4, we discussed a variety of specific limitations, referring, e.g., to the difficulty in distinguishing local problems from remote problems. There are also a couple of global limitations of the system worth mentioning.
First, SPARQLES is subject to Goodhart’s law, which states: “When a measure becomes a target, it ceases to be a good measure.” An over-eager endpoint maintainer could, e.g., detect and artificially respond to SPARQLES’ queries so as to improve how the endpoint is “rated” by the system. We know of no such example of this happening but it is possible.
Second, as a more pragmatic issue, since we first put the system online in October 2013, we have had various local reliability issues, where data were not collected for certain weeks, where data were lost due to server migration, and where the site itself was offline. During this period, we have been resolving various issues as they occur such that, although there are still some known issues, we now believe that the system is reaching maturity. Likewise, we have received a lot of feedback from the community, which has been invaluable for improving the service in the past years.
Third, some of the analytics may be biased towards servers that are closer geographically to the SPARQLES host in Austria. One option to mitigate this bias – as well as local reliability issues – would be to replicate SPARQLES analytics in multiple remote locations and create a mechanism for aggregating a global consensus across all remote instances. Currently we do not have the resources available to host another instance of SPARQLES. However, the SPARQLES code is available for download, where the community can download and install their own instances, perhaps targeted at those endpoints of interest to them.
Sustainability
One indirect but important aspect of sustainability is the load that SPARQLES puts on the public SPARQL infrastructure. For example, we discussed before about how the original versions of the interoperability queries were causing a heavy load for a number of SPARQL services. To mitigate this, we run more expensive tasks less frequently: while simple availability tests are done hourly, performance analytics are run daily and interoperability tests are run weekly. Likewise we have revised the interoperability queries to make them less costly and have been attentive in addressing all complaints raised in our issue tracker relating to the cost SPARQL puts on remote servers.
With respect to the long term sustainability of SPARQLES, the system is currently hosted on a university server in Austria and we have the commitment of the university – including help from system administrators – to continue hosting the service for the foreseeable future. We also provide a weekly dump of historical data, which is backed-up internally, as well as the open-source code and instructions needed to generate a new SPARQLES instance. Assuming a worst case scenario where the university would no longer be able to host the service or the data and we were no longer contactable, someone from the community could create a fresh instance of SPARQLES, albeit (in that unlikely scenario) without historical data. We of course welcome the community to mirror the service and also the historical data. Again, all code and data are available under CC-BY ( ), Version 4.0.
), Version 4.0.
Future directions
As the system has been maturing, we have started to consider adding some new features as requested by the community. One of the most popularly requested features is to have data collected by the SPARQLES tool made available as Linked Data. Though we are (perhaps ironically) reluctant to make a SPARQL endpoint available, as a starting point, we are looking into creating Linked Data IRIs for individual endpoints that dereference to SPARQLES statistics about them. Other requested features included offering an email notification system to contact endpoint administrators when their system was not available, or offering badges for endpoints with high availability, and so forth. There are numerous directions in which SPARQLES could still be improved, which we will tackle as time progresses.
More in terms of research, we foresee a number of potential future directions relating to SPARQLES and the monitoring of public SPARQL endpoints. One possible direction would be to look, more systematically, at further dimensions of quality specific to SPARQL endpoints – perhaps in the broader context of the survey of Linked Data quality by Zaveri et al. [35] – and to design practical tests and more detailed metrics by which to monitor endpoints. Another potentially fruitful area for future investigation would be to perform formal usability studies for the system – testing times users need to perform set tasks, conducting AB tests, etc. – and adapting the SPARQLES infrastructure accordingly. Although we have been reacting to community feedback through the issue tracker and other sources, this has been in an ad hoc manner: controlled user studies would offer a more structured approach to improving SPARQLES.
We remain very much open to future collaboration with the community along these or other lines.
Conclusion
In this paper, we have presented the SPARQL Endpoint Status (SPARQLES) system for keeping track of the health and maturity of public SPARQL endpoints. We presented the high-level architecture, which consists of an offline component for running tests over endpoints, and an online component for providing visualisations and A.P.I.’s for the collected results. We presented four dimensions of analytics that the system runs over public endpoints. Thereafter, we presented some of the details of the interfaces SPARQLES provides for human and automated agents to interact with the underlying data collection. We also presented some measures with respect to the overall runtime of analytics, the growth in storage requirements, and the performance of our A.P.I.’s under load. Finally, we discussed some aspects relating to the high-level impact, limitations and sustainability of the tool.
In general, we believe that the SPARQLES system provides the community with a unique perspective on public SPARQL endpoints. The online system helps to shed light not only on some of the cobwebs and cracks in the SPARQL infrastructure, but also on the cream of the crop: those SPARQL endpoints that are highly-available, readily-discoverable, highly-performant and highly-interoperable.
Footnotes
Acknowledgements
This work was supported by Fujitsu Laboratories Limited, by CONICYT/FONDECYT Project no. 3130617, by FONDECYT Project no. 11140900, by DGIP Project no. 116.24.1, and by the Millennium Nucleus Center for Semantic Web Research under Grant NC120004. We would like to thank the reviewers of this and our previous paper, and various other members of the Linked Data community, for their feedback on SPARQLES. We also wish to thank the Open Knowledge Foundation for hosting the project for over a year.