
Abstract
The world is losing some of its 7,000 languages. Hypothesizing that language attrition might subside if all languages were intertranslatable, the PanLex project supports panlingual lexical translation by integrating all known lexical translations. Semantic Web technologies can flexibly represent and reason with the content of its database and interlink it with linguistic and other resources and annotations. Conversely, PanLex, with its collection of translation links between more than a billion pairs of lexemes from more than 9,000 language varieties, can improve the coverage of the Linguistic Web of Data. We detail how we transformed the content of the PanLex database to RDF, established conformance with the lemon and GOLD data models, interlinked it with Lexvo and DBpedia, and published it as Linked Data and via SPARQL.
Introduction
There are about 7,000 living languages,1
The PanLex project is making all languages’ lexicons intertranslatable. In some contexts (e.g., profiles, catalogs, tags, search, and web navigation), lexical translation can be most of the translation load. PanLex systematically integrates lexical translations, found in diverse sources, into a database for research, applications, and public use. The content can be interpreted as a graph linking lexemes in “is-a-translation-of” relations, and permitting automated inference to additional, unattested relations.
The Semantic Web initiative has led to the development of standards and technologies supporting a machine-readable and -i nterpretable Linked Data network, known as the Web of Data.2
Here we describe how we connected PanLex to this Linked Data network. In Section 2 we introduce the dataset, present a PanLex RDF vocabulary, and explain how we transformed the one into the other and established conformance with additional data models. Section 3 shows how we linked to other datasets of the LLOD cloud, and Section 4 is about the publication of the dataset. Usage scenarios are given in Section 5, and related work is discussed in Section 6. Finally, Section 7 concludes this paper.
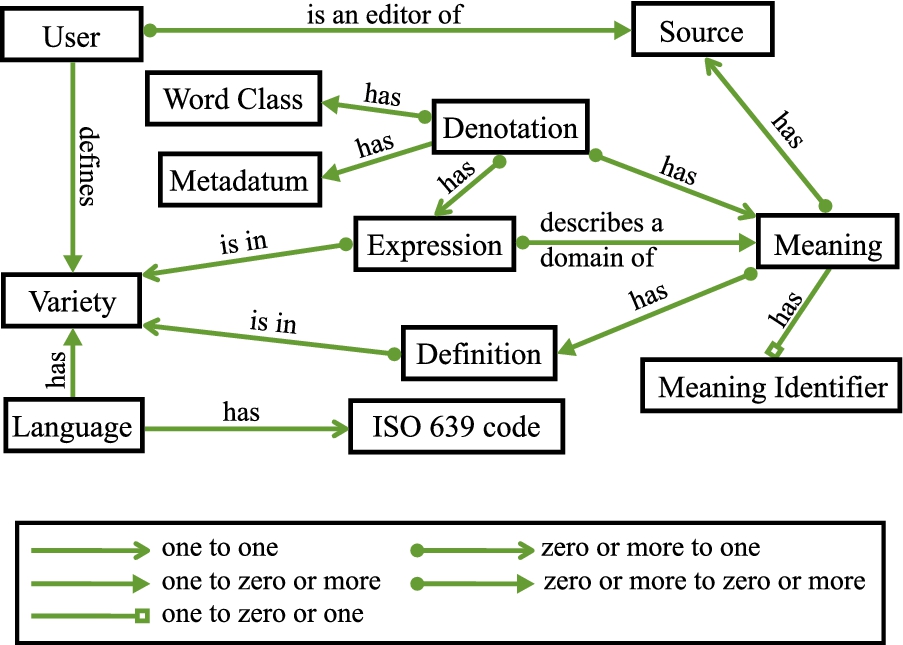
In this section, we analyze the PanLex dataset, introduce our URI and vocabulary design, which resemble PanLex’s conceptual model, summarize how we classified PanLex’s instance data with additional data models and explain our transformation of the data to RDF.
Analysis of the original dataset
The PanLex database is created by editors who consult information sources,4
The source entity is the authority to which an editor attributes assertions about lexical translations.
Expressions are lexical entities, each uniquely identified with a text, i.e. a string of (Unicode) characters, and a variety of a language. Expressions resemble lemmas or dictionary-entry headwords, but differ from them in at least two ways. (1) Homographs, such as the verb “hide” (conceal) and the noun “hide” (animal skin) in English, are treated as a single expression in PanLex. (2) Multiword expressions, such as “fall in love”, traditionally found in an entry headed by one of their words, such as “fall” or “love”, are treated as independent expressions in PanLex.
Languages in PanLex are identified using ISO 639-36
Language varieties are collections of expressions. Each has a unique identifier: a language code and a distinguishing integer. For example, six dialects of Ahtna are identified as “aht-000” through “aht-005”. These labels are, themselves, treated as a (controlled) language variety, whose expressions (i.e. the labels) are translated into natural languages and other controlled languages (such as the IETF standard BCP 47).9
Meanings are entities assigned to expressions, thereby identifying expressions as translations or synonyms. For example, a source’s translation of the German expression “klingen” into English as “ring, sound, seem” can be interpreted as (1) the assignment of a single meaning to all four expressions or (2) the assignment of two or three meanings to “klingen” and of one of those to each of the English expressions. Meanings are source-specific. The identification and consolidation of equivalent meanings of distinct sources is a research topic, not a database feature. Meanings can have properties of three types. (1) Definitions are descriptions of a meaning, consisting of text strings annotated as being in particular language varieties. (2) Domains are expressions (e.g., “medicine”) that characterize a meaning, but do not express it. (3) Meaning identifiers are strings acting as references to identifiers in a source.
Denotations are assignments of meanings to expressions. A denotation may have one or more word classes (a closed set based on OLIF, the Open Lexicon Interchange Format) and/or metadata (arbitrary strings paired as keys and values).
Users may define sources, attribute data to them, and define language varieties.
Among the properties of sources are licenses. Some of the license categories are public domain, request (author invites inquiries), GNU Free Documentation License (FDL), and PanLex Use Permission (specific permission for use in PanLex). The distribution of licenses is shown in Table 1.
Number of sources using a certain license
The PanLex database schema.
Number of instances of main entities in the PanLex database
The entities and relations described above are the base for the PanLex RDF vocabulary. In general, all PanLex RDF resources reside in the namespace
Expressions are modeled as instances of the class
For language and language varieties the classes
The RDF analog of the PanLex meaning is the
Meanings and expressions are linked via denotations. These are entities of the
All sources share the

Example of the PanLex RDF vocabulary showing one meaning of the expression ‘between’ and the corresponding source and definition.
Classes and properties used in the PanLex RDF vocabulary. Note that all
The PanLex vocabulary is based on PanLex’s conceptual schema and enables all of PanLex’s data to be directly exposed as RDF. Additionally, we also re-use existing vocuabularies, namely the Lexicon Model for Ontologies (lemon) [7] as well as the General Ontology for Linguistic Description (GOLD) [4]. Since these models differ from the PanLex one, we follow an incremental approach of aligning the PanLex data with them. Table 4 shows PanLex classes with their current counterparts in lemon and GOLD respectively. The parts implemented in our RDF conversion are displayed in Fig. 3.

Parts of the GOLD (left) and lemon model (right) re-used in PanLex (URI prefixes are omitted for brevity).
Classes considered to be similar across the re-used vocabulary
Since new sources are added to the PanLex database on almost a daily basis and because of its current size (~18 GB), the recurrent conversion of the database to capture changes in it is impractical. As the PanLex data already reside in a relational database, the use of a virtual RDB2RDF10

An excerpt of an SML view definition for PanLex’s languages. This example also demonstrates how “is-a” relations to schema.org and links to Lexvo are established.
The SML view in (Fig. 4) establishes the interlinking of languages in PanLex with Lexvo [3]. Here we outline the interlinking with DBpedia [5], where we were interested in creating valid and dereferenceable links. Therefore, we iterated the titles datasets,12
Number of DBpedia links per language
With our RDF conversion work, we complement existing APIs14

PanLex architecture.
There are general benefits of using Semantic Web technologies, such as the potential for simplified data integration due to RDF and vocabulary reuse, the possibility of enriching data based on interlinking, drawing advantage from reasoning and the exploration of the data through the use of generic Semantic Web tools. Moreover, some applications, like the TeraDict translation lookup service,21
PanLex is a project whose editors integrate information discovered from many lexical resources. The extraction of information from linguistic sources, and techniques for automatically inferring translations, are relevant work discussed in [6]. An important related initiative is the Global Wordnet Association (GWA),23
In this dataset description we detailed the PanLex database and its conversion to RDF. Based on our URI and vocabulary design, we created appropriate view definitions for the Sparqlify system, which carries out the actual RDF transformation. Furthermore, we interlinked the languages in PanLex with Lexvo, and created about 2.5 million links to DBpedia for expressions in 16 languages. With the integration of lemon and GOLD we also support data access via external linguistic ontologies.
We intend to address some limitations in the future: The relations among PanLex’s information sources, if treated as distinct datasets, could be modeled with the VoID vocabulary.25