
Abstract
The European Parliament represents the citizens of the member states of the European Union (EU). The accounts of its meetings and related documents are open data, promoting transparency and accountability, and are used as source data by researchers. However, the official portal of these documents provides limited search facilities. This paper presents LinkedEP, a Linked Open Data translation of the verbatim reports of the plenary meetings of the European Parliament. These data are integrated with a database of political affiliations of the Members of Parliament, and enriched with detected topics from the EU’s topic hierarchy and links to four other Linked Open Datasets. The results of this work are available through a SPARQL endpoint and a user interface with extensive browse and search facilities. It is now possible to combine in one query the time and topic of the debate, the spoken words – in any available translation – and information about the speaker uttering these, such as affiliations to countries, parties and committees. This paper discusses the design and creation of the vocabulary, data and links, as well as known use of the data.
Introduction
The European Parliament (EP) is the only directly elected body of the European Union (EU), composed of the representatives of the member states. During the plenary meetings, it debates and votes upon the laws and budget of the EU. To residents of the European Union, access to the documents of the European Parliament is a formal right1
Regulation (EC) No 1049/2001 of the European Parliament and of the Council.
From a scientific perspective, the proceedings of the EU parliament are a valuable source of data, in particular for studies in Political Science and Public Administration. For instance, Proksch and Slapin [12] relate the speeches held in the EP to the speakers’ political ideology and country of representation. By virtue of their multilingualism, the proceedings of the EP have further proven a valuable resource for studies into Natural Language Processing and Machine Translation [8,13].
The European Parliament publishes its proceedings as Open Data. A search portal2
This paper demonstrates how the EU proceedings can be published as Linked Open Data to support a wider range of queries. It provides an account of the choices made in the design of the data and vocabulary, especially with regard to multilingualism and speaker roles. The proceedings are linked to other Open Data on the Web, including a general-purpose encyclopedia to provide information about the Members of Parliament, a geographical knowledge base for the EU countries, and a topic hierarchy covering the activities of the EP. The resulting dataset, which is called LinkedEP, thus allows users to formulate queries of greater complexity and expressiveness than is currently supported, combining speech content with speaker and country information. In the seven months following its release, LinkedEP has been queried 7500 times on our servers.
The work presented here fits in a series of efforts to translate government data into the machine readable Semantic Web standard RDF. Some of these are realized by governments (e.g. the parliaments of Italy3
In the next section the source materials of the dataset are presented. Section 3 gives an overview of how we represented the data in RDF classes and properties, and the rationale behind the modelling choices. The links to other RDF sources are presented in Section 4. Section 5 describes the data portal and Section 6 demonstrates observed uptake of the data. In Section 7 we reflect on the quality of the dataset and on directions for future work.
The plenary meetings of the European Parliament are organised in four- or two-day sessions11
Also called part-sessions.
The proceedings of the plenary meetings are published on the website of the European Parliament. Supplemented with an external database with background information about the parliamentary members, they form the basis of our dataset. The content of the two source corpora of the dataset is discussed below. Reports, vote statistics and other documents available on the EU website are beyond the scope of this endeavour.
The account of the plenary meetings in the proceedings includes the structure of the parliamentary events from the session up to the speech level, and the content of the speeches. The proceedings provide dates and ordering information, the titles of agenda items, and for each speech, the language in which it is spoken, the speaker name, the speaker’s official numerical ID (when applicable), the spoken text, and additional annotations. These annotations serve many purposes, for instance, to quote the speaker when his words are difficult to translate, or to mark special events or circumstances, for instance when a speech is received with applause or is spoken on behalf of a party. Speeches are presented in the proceedings as single-actor events, except when multiple speakers speak out collectively, for instance in a collaborative statement. There may be speeches without text, for instance to indicate a non-verbal act, which may be clarified by an annotation.
The account of what is said in the plenary meetings is multilingual, and parallel proceedings are available for each of the EU languages. Members of Parliament have (limited) rights to request translations [15] of their speeches for the proceedings if these are not already provided.
Members of Parliament in ADEP
The publicly available online Automated Database of the European Parliament (henceforth referred to as ADEP) [6] provides the source for the background information on the Members of Parliament. For each Member is given, in comma-separated format: the official ID, the first and last name, birth date, country of representation, and partisan history. The latter includes affiliations to EU committees, EU parties (including role descriptions), and national parties. ADEP is linked to the EP data through the Members of Parliament’ unique numerical identifier.
Data model
This chapter explains the modelling principles we followed, and discusses and visualises the various sections of the resulting schema, such as the structure of the plenary events, the textual information and translations, and the Members of Parliament and their roles. Finally, it elucidates the choice of URIs and noteworthy translations from the source data to the schema.
Modelling principles
The data and vocabulary of LinkedEP are designed to facilitate use, re-usability, and interoperability.
To promote uptake, querying the data should be as straightforward as possible. For this reason, the backbone of the model is a direct translation of the structure of the events in Parliament. Moreover, a number of properties are introduced that are redundant but enable shorter and less complex queries, or avoid the need for reasoning engines. While this increases the number of RDF statements, the modest size of the dataset allows us to prioritise ease of use over the price of data storage. Finally, intuitive names are chosen for properties and classes. Experts from the information services of the European Union were consulted about the vocabulary used in practice, leading us to adopt, for instance, the term session instead of part-session.
The vocabulary for LinkedEP accommodates reuse for other proceedings and political datasets, such as EP committee meetings, national parliament meetings, and other types of events that cannot be foreseen at this moment. For this reason we call it the
To increase interoperability with other Linked Open Datasets, properties from widely used vocabularies are reused or linked to where possible, in particular FOAF12
The backbone of the model, depicted in Fig. 1, consists of the hierarchical structure of the events in Parliament, with classes denoting the sessions, session days, agenda items and speeches. The
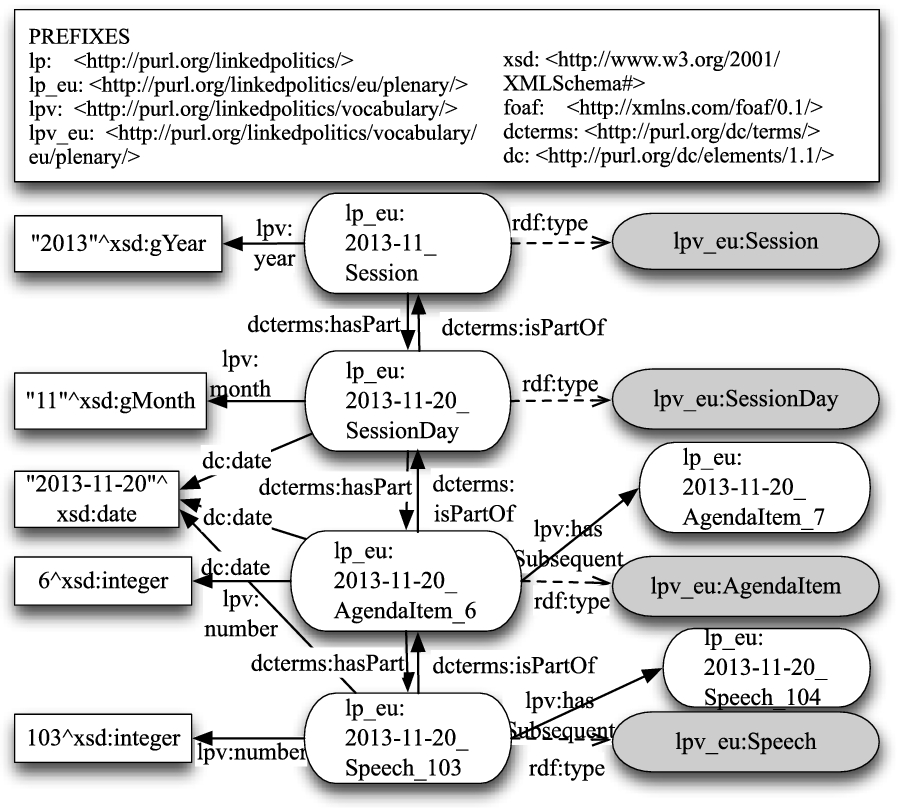
The exemplified backbone of the model, which expresses the hierarchy and order of the parliamentary events. The coloured boxes denote classes. The namespaces are clarified at the top.
Additionally, the model contains redundant predicates
As illustrated in Fig. 2,

The content-level information in the model, exemplified. Parenthesized are the superproperties, where applicable. The coloured boxes denote classes.
All textual data – titles of agenda items, speech transcripts, and unclassified metadata – are subject to translation. Each
The data model includes two auxiliary properties for speech contents:
Speakers and members of Parliament
The
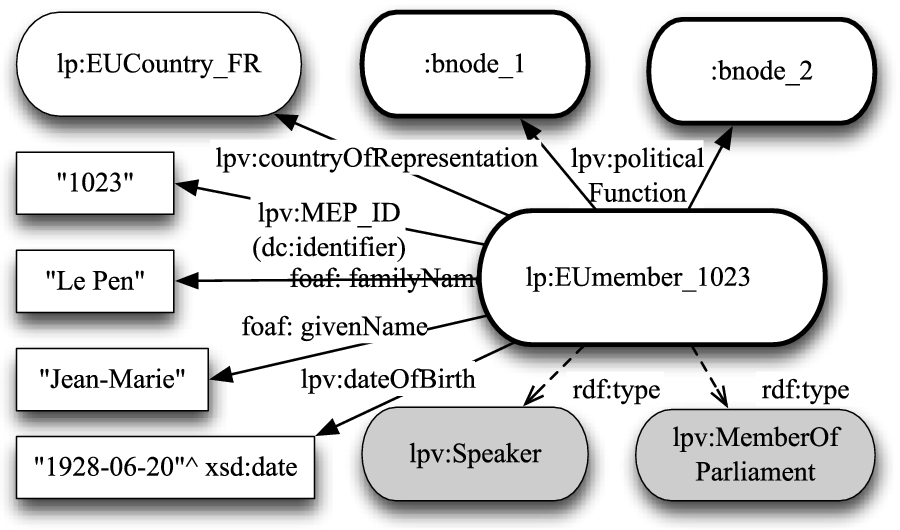
Example representation of a Member of Parliament. The coloured boxes denote classes and thick-edged boxes denote entities that reoccur in Fig. 4.
While non-MEP speaker instances have just a
Figure 4 shows how the political affiliations of MEPs are modelled, building on the example in Fig. 3. A

Example representation of the political functions of a Member of Parliament, as defined by a role, institution, and time span. The coloured boxes denote classes and thick-edged boxes denote entities that reoccur in Fig. 3.
A supplementary relation,
The content and provenance of the data and vocabulary are described using the
The namespace
Conversion process
The proceedings were extracted from the website of the European Parliament following the method of Gielissen and Marx [5], who proposed an XML Document Type Definition for parliamentary proceedings. The raw XML data were then translated into the LinkedEP RDF data model using a SWI Prolog toolkit for converting XML to RDF.18
Textual properties such as paragraphs within speeches (separated by white space) were left out. Also, entities were introduced for Members of Parliament, which were denoted as literals in the raw XML data.
The value of the
The auxiliary properties
A start has been made with connecting LinkedEP to the LOD cloud with links to four external knowledge sources: two about politicians’ backgrounds, one geographical database, and a topic taxonomy. Additionally, the dataset has been linked to from a third party source: the European Union Data Portal20

Examples of links to and from LinkedEP: inlinks from JRC-Names to LinkedEP MEPs, outlinks from LinkedEP MEPs to DBpedia and the Italian parliament, from LinkedEP countries to GeoNames, and from agenda items to the Eurovoc thesaurus.
The country entities in LinkedEP are connected to their counterparts in GeoNames,21
The Members of Parliament are linked to their entries in DBpedia,22
The politicians representing Italy are matched to the official RDF database23
of the Italian parliament. This connection allows users to compare politicians’ utterances in the European and the national setting. The cues taken for this mapping are the name and birth date of the politicians. Because of the modest number of Italian MEPs, the mapping results were manually checked for correctness and completeness.Finally, the agenda items are related to a topic hierarchy. EuroVoc24
The LinkedEP data are available under an open license26
CC0 1.0 Universal.
The data portal runs on the Semantic Web server ClioPatria [20]. It displays summaries of each RDF graph, allowing users to browse through the classes and properties up to the instance level. A free-text search bar accommodates keyword queries. ClioPatria provides a SPARQL endpoint and query editor implementing most features of the latest SPARQL version, 1.1. Through an environment called SWISH, it supports querying using SWI Prolog, which features libraries for federated querying amongst other functionalities. The RDF graphs can be downloaded in Turtle and RDF/XML serialisations.
All URIs are dereferenceable and return an overview of the triples defined for the given resource. To guarantee their persistence, the domain
In the 29 weeks following its announcement, the homepage of LinkedEP was visited more than five thousand times and the dataset was queried through our service 7504 times, of which 3654 times in SWISH/SWI-Prolog and 3850 times in SPARQL. Manual inspection of the logs reveals that queries containing regular expressions are particularly prevalent, as well as queries with count operations. In total, 1648 out of the 3850 SPARQL queries in our logs include a regular expression. 1600 queries have a count operation, and 906 have both.
While query log analysis gives a good indication of the use of the data, it does not identify the information need or envisaged application behind the queries. In the remainder of this section, we will delve deeper into a selection of the logged queries. For each of these queries we have had contact with the user that ran the query to determine the underlying research questions and application scenarios. The interaction with users took place in the context of three week-long workshops that were organised by the authors.31
www.talkofeurope.eu/creative-camp-1/, www.talkofeurope.eu/creative-camp-2/, www.talkofeurope.eu/creative-camp-3/.
Use case 1: A study into the role of higher education in the EP Birkholz [2] studies how higher education is proposed as a solution to various policy problems that are not in themselves related to higher education. She thereby considers the role of parliamentary committees, individual members of the EP, political parties, coalitions, and nation-states. Displayed below is a query that was used within this study to select speeches with the keyword ‘education’, and that returns their identifier, text, and the name of the EU party of the corresponding speaker.
Use case 1 is an example of a frequently observed usage pattern of selecting potentially relevant items for further close reading, a pattern that was also identified by Traub et al. [16] among users of digital historical archives. In the LinkedEP dataset, speeches are typically selected based on dates, the occurrence of a keyword or topic in the debate, and/or information about the speaker, such as country, party or committee membership. Other use cases that we observed that follow this pattern include a study of debates about data privacy and transparency, a study into the perspectives of the different parliamentary groups on the financial crisis, and an analysis of the use of emotionally charged words by MEPs.
Use case 2: A comparison of the discourse of political groups The discursive practices of MEPs affect public opinion on the issues debated in the EP. Nerghes et al. [10] explore speeches during the recent Eurozone financial crisis to expose discursive practices of the two largest political groups on either side of the left-right political ideology spectrum. Using a text mining tool, they semi-automatically code the English speech texts and carry out semantic network analysis. The query below retrieves the data for one of the selected parties.
In a similar study [3], the evolution of the discourse during the financial crisis is explored. The query below searches for speeches that contain mentions of financial or economic crisis (or crises), as is captured by a regular expression, and returns the counts by date. This query was repeated with various keywords to verify the occurrence of the targeted keywords and their correspondence with the economic crisis. This task corresponds to the usage pattern of investigating quantitative results over time as identified by Traub et al. [16].
In use case 2, relevant speeches are retrieved for consecutive offline processing by other tools. Other examples of this usage pattern were encountered: (1) for a visualisation of (statistically) salient words used by MEPs per country and per month [17] (2) in a study about how the EP talks about rulings of the European Court of Justice [19], in which speeches that mention the court in combination with the word ‘ruling’ or ‘case’ were processed offline by a custom matching algorithm to link the speech to a specific court case in the EUR-Lex database.
Usage logs of Linked Data servers typically capture only part of the actual use of the data; downloading all RDF onto a local disk for further querying and processing is a common practice on the Semantic Web. Also, the usage of the links to the LinkedEP data provided by the European Union Data Portal cannot be tracked.
In the star system by Berners-Lee [1], LinkedEP is a five-star collection. The first three stars are credited for, respectively, the open license, the structured format, and the non-proprietariness of the latter. The use of URIs and the links to other data grant LinkedEP the fourth and fifth star.
Dataset quality Zaveri et al. [21] provide an inventory of indicators of the intrinsic quality of linked datasets. We have checked32
Source code (Prolog rules) available on GitHub.
Vocabulary quality Janowicz et al. [7] propose quality indicators for vocabularies. Following their rating scheme, the
Known shortcomings and future work The translation service of the EP translates debates into a selection of other languages, depending on the topic and importance of the debate. In cases where a translation into a particular language is not available, the quality of the language tags of the speech literals in LinkedEP drops. This is due to the fact that LinkedEP is based on the website of the EP, where the same problem exists: speeches without translation in the selected language are displayed in their original language without warning. A start has been made to remedy this: all
There is considerable room for outreach to a wide range of other datasets, including the records of national parliaments and other open government data, encyclopedic sources such as the CIA Factbook, and news media archives. For instance, the EU parties, national parties and EU committees in our dataset can be linked to their entries in DBpedia or country-specific Open Datasets. The sources that are currently linked to were chosen either because of their low cost (e.g. country names are relatively unambiguous and therefore easy to match) or high gain (e.g. DBpedia’s central position in the LOD cloud means that it gives access to many other datasets). Future work includes expanding the links to more Open Datasets.
LinkedEP is an RDF translation of the verbatim proceedings of the plenary sessions of the European Parliament, supported by a newly introduced vocabulary,
Footnotes
Acknowledgements
This work was done in the Talk of Europe project, funded by Clarin ERIC and Clarin-NL. To generate the dataset, we gratefully used scripts from Political Mashup. Jan Wielemaker assisted us with ClioPatria and SWI-Prolog. The connection to the Italian Parliament data was made by Silvia Giannini during the Creative Camp organised by Talk of Europe. We thank Adina Nerghes, Jonathan Gray and Julie Birkholz for involving us in their research and writing queries together. Ingelise de Boer from the European Parliament Information Office taught us everything we needed to know about the workings of the European Parliament.