
Abstract
The proliferation of large and ever-growing resource description framework (RDF) datasets has sparked a need for robust and performant RDF archiving systems. In order to tackle this challenge, several solutions have been proposed throughout the years, including archiving systems based on independent copies, time-based indexes, and change-based approaches. In recent years, modern solutions combine several of the above mentioned paradigms. In particular, aggregated changesets of time-annotated triples have showcased a noteworthy ability to handle and query relatively large RDF archives. However, such approaches still suffer from scalability issues, notably at ingestion time. This makes the use of these solutions prohibitive for large revision histories. Furthermore, applications for such systems remain often constrained by their limited querying abilities, where SPARQL is often left out in favor of single triple-pattern queries. In this article, we propose a hybrid storage approach based on aggregated changesets, snapshots, and multiple delta chains that additionally provides full querying SPARQL on RDF archives. This is done by interfacing our system with a modified SPARQL query engine. We evaluate our system with different snapshot creation strategies on the BEAR benchmark for RDF archives and showcase improvements of up to one order of magnitude in ingestion speed compared to state-of-the-art approaches, while keeping competitive querying performance. Furthermore, we demonstrate our SPARQL query processing capabilities on the BEAR-C variant of BEAR. This is, to the best of our knowledge, the first openly available endeavor that provides full SPARQL querying on RDF archives.
Introduction
The exponential growth of resource description framework (RDF) data and the emergence of large collaborative knowledge graphs have driven research in the field of efficient RDF archiving (Fernández et al., 2019; Pelgrin et al., 2021), the task of managing the change history of RDF graphs. This offers invaluable benefits to both data maintainers and consumers. For data maintainers, RDF archives serve as the foundation for version control (Arndt et al., 2019). This not only enables data mining tasks, such as identifying temporal and correction patterns (Pellissier Tanon et al., 2019), but in general opens the door to advanced data analytics of evolving graphs (Brunsmann, 2010; Gür et al., 2018; Hose, 2021; Polleres et al., 2023; Roussakis et al., 2015). For data consumers, RDF archives provide a valuable means to access historical data and delve into the evolution of specific knowledge domains (Aebeloe et al., 2021; Huet et al., 2013; Tanon & Suchanek, 2019). In essence, these archives offer a way to query past versions of RDF data, allowing for a deeper understanding of how knowledge has developed over time.
However, building and maintaining RDF archives presents substantial technical challenges, primarily due to the large size of contemporary knowledge graphs. For instance, DBpedia, as of April 2022, comprises 220 million entities and 1.45 billion triples. 1 The number of changes between consecutive releases can reach millions (Pelgrin et al., 2021). Yet, dealing with large changesets is not the sole obstacle faced by state-of-the-art RDF archive systems. Efficient querying also remains an open challenge, since support for full SPARQL is rare among existing systems (Fernández et al., 2019; Pelgrin et al., 2021).
To address these challenges, we propose an approach for ingesting, storing, and querying long revision histories on large RDF archives. Our approach, which combines multiple snapshots and delta chains, has been previously detailed in our prior work (Pelgrin et al., 2023) and outperforms existing state-of-the-art systems in terms of ingestion time and query runtime for archive queries on single triple patterns. This article builds on top of this prior work and extends it with the following contributions:
The design and implementation of a full SPARQL querying middle-ware on top of our multi-snapshot RDF archiving engine. A novel representation for the versioning metadata stored in our indexes. This representation is designed to improve ingestion time and disk usage without increasing query runtime. An evaluation of the two aforementioned contributions in addition to an extended evaluation of our prior work with additional baselines.
In general, we evaluate the effectiveness of our enhanced approach using the BEAR benchmark (Fernández et al., 2019), our results demonstrate remarkable improvements, namely, up to several order of magnitude faster ingestion times, reduced disk usage, and overall improved querying speed compared to existing baselines. Additionally, we showcase our new SPARQL querying capabilities on the BEAR-C variant of the BEAR benchmark. This is the first time, to the best of our knowledge, that a system complete this benchmark suite and publish its results.
The remainder of this article is organized as follows: Section 2 explains the background concepts used throughout the paper. In Section 3, we discuss the state-of-the-art in RDF archiving, in particular existing approaches to store and query RDF archives. In Section 4, we detail our storage architecture that builds upon multiple delta chains, and proposes several strategies to handle the materialization of new delta chains. Section 5 details the algorithms employed for processing single triple patterns over our multiple-delta-chain- architecture, while Section 6 describes our new versioning metadata serialization method, and showcases how it improves ingestion times and disk usage. In Section 7, we explain our solution to support full SPARQL 1.1 archives queries on top of our storage architecture. Section 8 describes our extensive experimental evaluation. The article concludes with Section 9, which summarizes our contributions and discusses future research directions.
An RDF graph
An RDF archive

An resource description framework (RDF) graph archive
Notations Summary.

RDF = resource description framework.
In this section, we discuss the current state of RDF archiving in the literature. We will first present how RDF archives are usually queried. We then discuss the existing storage paradigms for RDF archives and how they perform on the different query types. We conclude this section by detailing the inner-workings of OSTRICH (Taelman et al., 2019), a prominent solution for managing RDF archives, which we use as baseline for our proposed design.
Querying RDF Archives
In contrast to conventional RDF, the presence of multiple versions within an RDF archive requires the definition of novel query categories. Some categorizations for versioning queries over RDF Archives have been proposed in the literature (Fernández et al., 2019; Papakonstantinou et al., 2017; Polleres et al., 2023). In this work, we build upon the proposal of Fernández et al. (2019) due to its greater adoption by the community. They identify five query types, which we explain in the following through a hypothetical RDF archive that stores information about countries and their diplomatic relationships: Version materialization (VM). These are standard SPARQL queries run against a single version Delta materialization (DM). These are queries defined on changesets Version query (V). These are standard SPARQL queries that provide results annotated with the versions where those results hold. An example is Cross-version (CV). CV queries combine results from multiple versions, for example: which of the countries in the latest version have diplomatic relationships with the countries in revision 0? Cross-delta (CD). CD queries combine results from multiple changesets, for example: in which versions were the most countries added?
Both CV and CD queries build upon the other types of queries, that is, V and DM queries. Therefore, full support for VM, DM, and V queries is the minimum requirement for applications relying on RDF archives. Papakonstantinou et al. (2017), on the other hand, propose a categorization into two main categories, version and delta queries, which can be of any of three types: materialization, single version, or Cross-version. As such, materialization queries request the full set of triples present in a given version, while single version queries are answered by applying restrictions or filters on the triples of that version. Cross-version queries instead need access to multiple versions of the data. In practice, the categorizations of Papakonstantinou et al. (2017) and Fernández et al. (2019) are equally expressive. Polleres et al. (2023) propose two categories of versioned queries: version materialization and delta materialization. These are identical to the categories used by Fernández et al. (2019) described above. Queries applied to multiple versions are categorized as cross-version, which includes the version queries (V) from Fernández et al.’s (2019) classification.
SPARQL is the recommended W3C standard to query RDF data, however adapting versioned query types to standard SPARQL remains one of the main challenges in RDF archiving. Indeed, current RDF archiving systems are often limited to queries on single triple patterns (Pelgrin et al., 2021; Taelman et al., 2019). This puts the burden of combining the results of single triple pattern queries onto the user, further raising the barrier for the adoption of RDF archiving systems. While support for standard SPARQL on RDF archives is nonexistent, multiple endeavors have proposed either novel query languages or temporal extensions for SPARQL. Fernández et al. (2019), for example, formulate their categories of versioning queries using the AnQL (Zimmermann et al., 2012) query language. AnQL is a SPARQL extension operating on quad patterns instead of triples pattern. The additional component can be mapped to any term
All in all, there is currently no widely accepted standard for the representation of versioned queries over RDF archives within the community. Instead, current proposals are often tailored to specific use cases and applications, and no standardization effort has been proposed.
In this work, we formulate complex queries on RDF archives as standard SPARQL queries, but we assume that revisions in the archive are modeled logically as RDF graphs named according to a particular convention (explained in Section 7). This design decision makes our solution suitable for any standard RDF/SPARQL engine with support for named graphs.
Several solutions have been proposed for storing the history of RDF graphs efficiently. We review the most prominent approaches in this section and refer the reader to Pelgrin et al. (2021) for a detailed survey. We distinguish three main design paradigms: independent copies (IC), change-based solutions (CB), and timestamp-based systems (TB).
Independent copies (IC) systems, such as SemVersion (Volkel et al., 2005), implement full redundancy: all triples present in a version
Change-based (CB) solutions store their initial version as a full snapshot and subsequent versions
Timestamp-based (TB) systems store triples annotated with versioning metadata such as temporal validity intervals, addition/deletion timestamps, and list of valid versions, among others. This makes TB solutions usually well suited to efficiently answer V queries, while VM and DM queries still necessitate further processing. The storage efficiency of TB solutions depends on the representation chosen to serialize the versioning metadata. TB systems notably include x-RDF-3X (Neumann & Weikum, 2010), Dydra (Anderson & Bendiken, 2016), and v-RDFCSA/v-HDT (Cerdeira-Pena et al., 2023). The latter has been shown to provide excellent storage efficiency and query performance. However, this is achieved at the cost of flexibility, by limiting itself to storing and indexing existing full archives, and leaving out the possibility of subsequent updates. Moreover, no implementation of their method has been made publicly available at the time of writing. Dydra is only available through their cloud service and is otherwise closed source, which makes a fair comparative evaluation in an independent and controlled setup impossible.
Finally, recent approaches borrow inspiration from more than one paradigm. QuitStore (Arndt et al., 2019), for instance, stores the data in fragments, for which it implements a selective IC approach. This means that only modified fragments generate new copies, whereas the latest version is always materialized in main memory. OSTRICH (Taelman et al., 2019) proposes a customized CB based approach based on aggregated changesets with version-annotated triples. This approach has shown great potential both in terms of scalability and query performance (Pelgrin et al., 2021; Taelman et al., 2019). For this reason, our solutions use this system as underlying architecture. We describe OSTRICH in detail in the following section.
OSTRICH’s Architecture and Storage Paradigm
Change-based (CB) approaches work by storing the first revision of an archive as a fully materialized snapshot, and subsequent versions as deltas
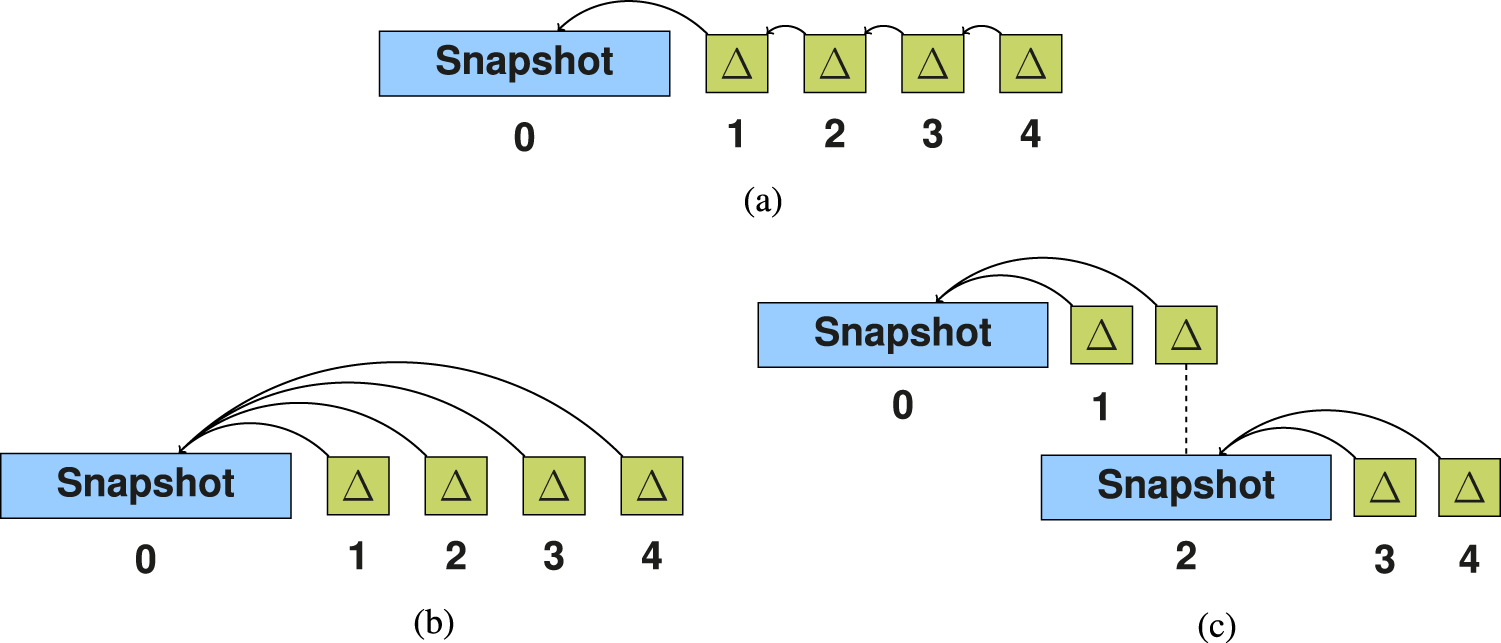
As such, OSTRICH (Taelman et al., 2019) proposes instead the use of aggregated delta chains, as illustrated in Figure 2(b). An aggregated delta chain works by storing an initial reference snapshot, as conventional delta chains do, and then storing subsequent versions as deltas
OSTRICH stores the initial snapshot in an HDT file (Fernández et al., 2013), which provides a dictionary and a compressed, yet easy to read, serialization for the triples. As standard for RDF engines, the dictionary maps RDF terms to integer identifiers, which are used in all data structures for efficiency.
In contrast to the initial snapshot, the delta chain is stored in two separate triple stores, one for additions and one for deletions. Each triple store consists of three differently ordered indexes (SPO, POS, and OSP), as illustrated in Figure 3. Those indexes are stored as clustered B+ trees (Taelman et al., 2019). Each triple is annotated with versioning metadata, which is used for several purposes: First, this reduces data redundancy in the delta chain, allowing each triple to be stored only once. Secondly, the metadata can be used to accelerate query processing. As shown in Figure 3, this metadata differs between additions and deletions triples. All triples feature a collection of mappings from version to a local change flag, which indicates whether the triple reverts a previous change in the delta chain. For example, consider the quad
OSTRICH delta chain storage overview.
We notice that deleted triples are associated to an additional vector that stores the triple’s relative position in the delta for every possible triple pattern order. This allows OSTRICH to optimize for offset queries, and enables fast computation of deletion counts for any triple pattern and version. Since HDT files cannot be edited, the delta chain also has its own writable dictionary for the RDF terms that were added after the first snapshot. More details about OSTRICH’s storage system can be found in the original paper (Taelman et al., 2019).
Based on our running example from Figure 1, we illustrate the contents of the additions and deletions stores in Figure 4.

Contents of the additions and deletions store contents based on the running example from Figure 1. Column

Delta chain architectures: (a) single delta chain, (b) single aggregated delta chain, and (c) multiple aggregated delta chains.
OSTRICH supports VM, DM, and V queries on single triple patterns natively. Aggregated changesets have been shown to speed up VM and DM queries significantly w.r.t. a standard CB approach. As shown by Pelgrin et al. (2021) and Taelman et al. (2019), OSTRICH is the only available solution that can handle histories for large RDF graphs, such as DBpedia. That said, scalability still remains a challenge for OSTRICH because aggregated changesets grow monotonically. This leads to prohibitive ingestion times for large histories (Pelgrin et al., 2021; Taelman et al., 2022)—even when the original changesets are small. In this article, we build upon OSTRICH and propose a solution to this problem.
Multiple Delta Chains
As discussed in Section 3.3, ingesting new revisions as aggregate changesets can quickly become prohibitive for long revision histories when the RDF archive is stored in a single delta chain (see Figure 2(b)). In such cases, we propose the creation of a fresh snapshot that becomes the new reference for subsequent deltas. Those new deltas will be smaller and thus easier to build and maintain. They will also constitute a new delta chain as depicted in Figure 2(c).
While creating a fresh snapshot with a new delta chain should presumably reduce ingestion time for subsequent revisions, its impact on query efficiency remains unclear. For instance, V queries will have to be evaluated on multiple delta chains, becoming more challenging to answer. In contrast, VM queries defined on revisions already materialized as snapshots should be executed much faster. Storage size and DM response time may be highly dependent on the actual evolution of the data. If a new version includes many deletions, fresh snapshots may be smaller than aggregated deltas. We highlight that in our proposed architecture, revisions stored as snapshots also exist as aggregated deltas w.r.t. the previous snapshot—as shown for revision 2 in Figure 2(c). Such a design decision allows us to speed up DM queries as explained later.
It follows from the previous discussion that introducing multiple snapshots and delta chains raises a natural question: When is the right moment to create a snapshot? We elaborate on this question from the perspective of storage, ingestion time, and query efficiency next. We then explain how to query archives in a multi-snapshot setting in Section 5.
Strategies for Snapshot Creation
A key aspect of our proposed design is to determine the right moment to place a snapshot, as this decision is subject to a trade-off among ingestion speed, storage size, and query performance. We formalize this decision via an abstract snapshot oracle
Creation of Snapshots According to the Different Strategies on the Toy RDF Archive From Figure 1.

Creation of Snapshots According to the Different Strategies on the Toy RDF Archive From Figure 1.
Here
Baseline. The baseline oracle never creates snapshots, except for the very first revision, that is,
Periodic. A new snapshot is created when a fixed number
Change-ratio. Long delta chains not only incur longer ingestion times, but also higher disk consumption due to redundancy in the aggregated changesets. When low disk usage is desired, the snapshot strategy may take into account the editing dynamics of the RDF graph. This notion has been quantified in the literature via the change ratio score (Fernández et al., 2019):

Time. If we denote by
We implemented the proposed snapshot creation strategies and query algorithms for RDF archives on top of OSTRICH (Taelman et al., 2019). We briefly explain the most important aspects of our implementation.
Storage. In OSTRICH, an RDF archive consists of a snapshot for revision 0 and a single delta chain of aggregated changesets for the upcoming revisions (Figure 2(b)). The snapshot is stored as an HDT (Fernández et al., 2013) file, whereas the delta chain is materialized in two stores: one for additions and one for deletions. Each store consists of three indexes in different triple component orders, namely SPO, OSP, and POS, implemented as B+trees. Keys in those indexes are individual triples linked to version metadata, that is, the revisions where the triple is present and absent. Besides the change stores, there is an index with addition and deletion counts for all possible triple patterns, for example,
Dictionary. As common in RDF stores (Neumann & Weikum, 2010; Weiss et al., 2008), RDF terms are mapped to an integer space to achieve efficient storage and retrieval. Two disjoint dictionaries are used in each delta chain: the snapshot dictionary (using HDT) and the delta chain dictionary. Hence, our multi-snapshot approach uses
Ingestion. The ingestion routine depends on whether a revision will be stored as an aggregated delta or as a snapshot. For revision 0, our ingestion routine takes as input a full RDF graph to build the initial snapshot. For subsequent revisions, we take as input a standard changeset
Change-ratio estimations. The change-ratio snapshot strategy computes the cumulative change ratio of the current delta chain w.r.t. a reference snapshot
Single Queries on Archives With Multiple Delta Chains
In the following, we detail our algorithms to compute version materialization (VM), delta materialization (DM), and V (version) queries on RDF archives with multiple delta chains. Our algorithms focus on answering single triple patterns queries, since they constitute the building blocks for answering arbitrary SPARQL queries—which we address in Section 7. All the routines described next are defined w.r.t. to an implicit RDF archive
VM Queries
In a single delta chain with aggregated deltas and reference snapshot

Algorithm 1 provides a high level description of the query algorithm used for version materialization queries (VM). Our baseline, OSTRICH, uses a similar algorithm where
DM Queries

Algorithm 2 describes the procedure

We now turn our attention to archives with multiple delta chains. The procedure queryDM in Algorithm 3 describes how to answer a DM query on two revisions
We now have the elements to explain the main DM query procedure (queryDM). First, the procedure checks whether both revisions are in the same delta chain, that is, if they have the same reference snapshot (line 14). If so, the problem boils down to a single delta chain DM query that can be answered with
If revisions
V Queries

Algorithm 4 describes how V queries are executed in a single delta chain setup. This is akin to how our baseline, OSTRICH, processes queries, and is used by our multiple snapshot query algorithm. We assume that each triple is annotated with its version validity, that is, a vector of versions in which the triple exists. In OSTRICH, this is stored directly in the delta chain as versioning metadata, and, therefore, does not need additional computation. For the deletion triples, this metadata contains the list of versions where the triple is absent instead. The core of the algorithm iterates over the triples (line 6) that match triple pattern

Algorithm 5 describes the process of executing a V query
Optimization of Versioning Metadata Serialization
The versioning metadata stored in the delta chain indexes is paramount to the functioning of our solution and influences multiple aspects of the system’s performance. One of the current limitations of our architecture based on aggregated deltas is that it does not scale well in terms of ingestion speed and disk usage, when the number of versions grows. As we show in this section, this happens because the delta chain indexes still contain a lot of redundancy that could be removed with a proper compression scheme. In this section, we therefore discuss the limitations of the current serialization of the versioning metadata, and propose an alternative serialization scheme that brings significant improvements in terms of ingestion speed and disk usage.
Versioning Metadata Encoding
As discussed in Section 3.3, OSTRICH indexes additions and deletions in separate triple stores for each delta chain. Because aggregated deltas introduce redundancy, OSTRICH annotates triples with additional version metadata that prevents the system from storing the same triple multiple times. This versioning metadata is, in turn, leveraged during querying to filter triples based on their version validity.
In Table 3, we show side by side the versioning metadata of an arbitrary triple as stored by OSTRICH (see Section 3.3), and as stored using our proposed representation. Although triples are stored only once, we observe that the index entries still store a lot of repeated information. Consider the example in Table 3(a) where we can see that the local change flag is always set to true for each version. Our proposed representation compresses this information by storing intervals of versions where the value does not change. In our example, in Table 3(b), the local change flag is stored as an interval
Representation of the Versioning Metadata in the Indexes for Arbitrary Example Triples in OSTRICH and Compressed in Our New Implementation.

Representation of the Versioning Metadata in the Indexes for Arbitrary Example Triples in OSTRICH and Compressed in Our New Implementation.
LC denotes the local change flag.
Deletion indexes contain more metadata than the addition indexes. Indeed, they also store the relative position of the triple within its respective delta for all triple pattern combinations, as illustrated in Table 3(c). This data can be large, especially for long delta chains, and can be both costly to create during ingestion and to deserialize during querying. OSTRICH alleviates these issues by restricting this metadata to the SPO index. We propose to replace this representation with a delta-compressed vector list, as illustrated in Table 3(d). This first position vector in the list is stored plainly, as before, but we only store deltas for subsequent changes. In case where no changes occur in a given revision, like in version 4 of our example, the vector is empty. In the next section, we elaborate on the implementation details of this serialization scheme.
As depicted in Figure 4(d), some of the entries in the position vectors of the deleted triples can be empty. We handle those empty entries by means of a 8-bit header mask that precedes the position vector. Consider the second column vector (version 3) in our example Table 3(d). This vector contains two values:

Representation of the positions vectors for version 3 of our example, without and with compression.
Furthermore, we highlight a key advantage of delta encoding: since most vector entries consist of small values, our representation can benefit from further compression via variable size integer encoding—which we also evaluate in our experimental section. The compression ultimately depends on how often the value of the positions changes between versions. Our experiments (Section 8.4) demonstrate the efficacy of our approach in practice.
Section 5 describes the algorithms to answer versioned queries on single triple patterns on top of our multi-snapshot storage engine. In this section, we describe our solution to support SPARQL queries over RDF archives. We will first discuss how to formulate versioned queries using SPARQL. We then provide details of the proposed architecture and query engine.
SPARQL Versioned Queries
As discussed in Section 2, there have been a few efforts to write versioned queries comprising multiple triple patterns. All those endeavors rely on ad-hoc extensions to the SPARQL language. For this reason, none of these extensions has reached broad community acceptance. As consequence, we have opted for a query middleware based on native SPARQL that models revisions as named graphs (Graube et al., 2014). Versioning requirements are, therefore, expressed using the SPARQL GRAPH keyword on named graphs with URIs of the form
We illustrate the different queries with an example RDF Archive
Example of SPARQL Representation and Results for VM, DM, and V Queries Using the GRAPH Keyword.

Example of SPARQL Representation and Results for VM, DM, and V Queries Using the GRAPH Keyword.
In order to support full SPARQL query processing over RDF archives, we make use of the Comunica (Taelman et al.) query engine deployed on top of our multi-snapshot storage layer and our algorithms for processing single triple patterns (described in Section 5). Comunica is a scalable and extensible query engine written in TypeScript with full support for the SPARQL 1.1 language. Due to its modularity, it is a natural choice for extending our system, and initial work was already done by Taelman et al. (2018) to support archives queries (although without V queries support). We have adapted this implementation to our multi-snapshot storage architecture and extended it to support V queries. We have also implemented several optimizations, notably in regard to the communication between the query engine and the storage layer. Previously, results from a triple pattern query would be buffered in OSTRICH until all results have been gathered. Because Comunica is designed to work with streams of triples, this incurs locking in the query processing while waiting for the availability of the triples. Instead, we now buffer triples into smaller buffers of configurable size. When a buffer is filled, the triples it contains can be sent to Comunica without waiting for the remaining triples. This allows for shorter locking time in Comunica and allows us to take better advantage of its asynchronous query processing capabilities.
Figure 6 illustrates the query processing pipeline of our solution for SPARQL queries on RDF archives. There are two main software components interacting with each other: the first is the storage layer consisting of our multi-snapshot version of OSTRICH (see Sections 4 and 5), and the second is the Comunica (Taelman et al.) query engine, which includes several modules.

SPARQL query processing pipeline.
A versioned SPARQL query like the ones in Table 4 (Section 7.1), is first transformed back to a graph- and filter-free SPARQL query, that is, without the special GRAPH URIs and/or FILTER clauses, and annotated with a versioning context. This versioning context depends on the query type (e.g., revisions for VM queries and changesets for DM queries) and the target version(s) when relevant, and is used to select the type of triple pattern queries to send for execution by OSTRICH. The communication between Comunica and OSTRICH is done through a NodeJS native addon. Our implementation is open source2,3 and a demonstration system is available at Pelgrin et al. (2023).
To determine the effectiveness of our multi-snapshot approach for RDF archiving, we evaluate the four proposed snapshot creation strategies described in Section 4 along three dimensions: ingestion time (Section 8.2.1), disk usage (Section 8.2.2), and query runtime for VM, DM, and V queries (Section 8.3). Thereafter, in Section 8.4, we delve into the effectiveness of our versioning metadata representation described in Section 6. This is done by comparing its performance against the original representation—across the three aforementioned evaluation dimensions. Section 8.5 concludes our experiments with an evaluation of our full SPARQL query capabilities. The source code of our implementation as well as the experimental scripts to reproduce our results are available in a Zenodo archive. 4
Experimental Setup
We resort to the BEAR benchmark for RDF archives (Fernández et al., 2019) for our evaluation. BEAR comes in three flavors: BEAR-A, BEAR-B, and BEAR-C, which comprise a representative selection of different RDF graphs and query loads. Table 5 summarizes the characteristics of the experimental datasets and query loads. We use OSTRICH (Taelman et al., 2019) as baseline solution and excluded approaches such as QuitStore (Arndt et al., 2019) or RDF43ples (Graube et al., 2014), as Pelgrin et al. (2021) showed that OSTRICH is the only system that can handle archives and changesets with millions of triples. We also excluded the BEAR benchmark systems as they have been outperformed by OSTRICH (Taelman et al., 2019). That said, OSTRICH could only ingest one-third of BEAR-B’s long history (7,063 out of 21,046 revisions) after one month of execution—before crashing. In a similar vibe, OSTRICH took one month to ingest the first 18 revisions (out of 58) of BEAR-A. Despite the dataset’s short history, changesets in BEAR-A are in the order of millions of changes, which also makes ingestion intractable in practice. On these grounds, the original OSTRICH paper (Taelman et al., 2019) excluded BEAR-B instant from its evaluation, and considered only the first 10 versions of BEAR-A. Multi-snapshot solutions, on the other hand, allow us to manage these datasets. We provide, nevertheless, the results of the baseline strategy (OSTRICH) for entire history of BEAR-A. We emphasize, however, that ingesting this archive was beyond what would be considered reasonable for any use case: it took more than five months of execution. We provide those results as a baseline (although an easy one) to highlight the challenge of scaling to large datasets. All our experiments were run on a Linux server with a 16-core CPU (AMD EPYC 7281), 256 GB of RAM, and 8 TB hard disk drive.
Dataset Characteristics.

Dataset Characteristics.
We evaluate the different strategies for snapshot creation detailed in Section 4.2 along ingestion speed, storage size, and query runtime. Except for our baseline (OSTRICH), all our strategies are defined by parameters that we adjust according to the dataset:
Periodic. This strategy is defined by the period
Change-ratio (CR). This strategy depends on a cumulative change-ratio budget threshold
Time. This strategy depends on the ratio
Table 6 summarizes the important information about evaluated methods and systems. We omit the reference systems included with the BEAR benchmark since they are outperformed by OSTRICH (Taelman et al., 2019).
List of the Evaluated Storage Strategies and the Resulting Number of Snapshots per BEAR Dataset.

A dash ‘–’ means that the architecture was not evaluated on the given dataset.
Ingestion Time
Table 7(a) depicts the total time to ingest the experimental datasets. Since we always test two different values of

Detailed ingestion times (log scale) per revision. We include the first 1,500 revisions for BEAR-B instant since the runtime pattern is recurrent along the entire history: (a) BEAR-B daily, (b) BEAR-B hourly, and (c) BEAR-B instant.
Time and Disk Usage Used by Our Different Strategies to Ingest the Data of the BEAR Benchmark Datasets.

BEAR = BEnchmark of RDF ARchives; CR = change-ratio.
Unlike ingestion time, where shorter delta changes are clearly beneficial, the gains in terms of disk usage depend on the dataset as shown in Table 7(b). Overall, more delta chains tend to increase disk usage because snapshots can be large. For BEAR-B daily, the most space efficient multi-snapshot strategy uses twice as much space as the baseline where frequent snapshots (high periodicity

Disk usage evolution per revision for the BEAR-A and BEAR-B datasets: (a) BEAR-A, (b) BEAR-B daily, (c) BEAR-B hourly, and (d) BEAR-B instant.
Interestingly, for BEAR-A, the change-ratio
In this section, we evaluate the impact of our snapshot creation strategies on query runtime. We use the queries provided with the BEAR benchmark for BEAR-A and BEAR-B. These are DM, VM, and V queries on single triple patterns. Each individual query was executed 5 times and the runtimes averaged. All the query results are depicted in Figure 9.

Query results for the BEAR benchmark: (a) BEAR-A VM, (b) BEAR-A DM, (c) BEAR-A V, (d) BEAR-B daily VM, (e) BEAR-B daily DM, (f) BEAR-B daily V, (g) BEAR-B hourly VM, (h) BEAR-B hourly DM, (i) BEAR-B hourly V, (j) BEAR-B instant VM, (k) BEAR-B instant DM, and (l) BEAR-B instant V. VM = version materialization; DM = delta materialization; V = version query.
We report the average runtime of the benchmark VM queries for each version
Using multiple delta chains is consistently beneficial for VM query runtime, which is best when the target revision is materialized as a snapshot. When it is not the case, runtime is proportional to the size of the delta chain, which depends on its length and the volume of changes that must be applied to the snapshot before running the query. This is obvious for BEAR-A with the baseline strategy or with the time
DM Queries
We report for each revision
V Queries
Figure 9(c), (f), (i), and (l) shows the total runtime of the benchmark V queries on the different datasets. V queries are the most challenging queries for the multi-snapshot archiving strategies as suggested in Figure 9(f) and (i). As described in Algorithm 5, answering V queries requires us to query each delta chain individually, buffer the intermediate results, and then merge them. It follows that runtime scales proportionally to the number of delta chains, which means that, contrary to DM and VM queries, many short delta chains are detrimental to V query performance. The only exception is BEAR-A, where the change-ratio strategies can outperform the baseline strategy. This indicates that delta chains with very large aggregated deltas can also be detrimental to V query performance. However, BEAR-A is the only dataset showcasing such a behavior in our experiments. Nonetheless, due to their prohibitive ingestion cost, querying datasets such as BEAR-A and BEAR-B instant is only possible with a multi-snapshot solution.
Experiments on the Metadata Representation
We now evaluate our proposed encoding for versioning metadata, described in Section 6. We conduct the evaluation across the dimensions of ingestion time, disk usage, and query performance on the BEAR-B variants of the BEAR benchmark. For the sake of legibility, we apply our new encoding on archives stored using a single-snapshot strategy, that is, the baseline OSTRICH, and one multi-snapshot strategy. We chose the change-ratio (CR) strategy with
In a first stage we study the performance of using variable-size (also variable-length) integer encoding (VSI)—a common and simple compression scheme—in the delta chains. We first evaluate it without our novel versioning metadata encoding on both the baseline OSTRICH and our multi-snapshot strategy. Figure 10 shows the results for VSI alone according to our different evaluation criteria on the BEAR-B daily datasets—the results from the other datasets lead to the same conclusions. We first highlight that VSI has a negligible impact on ingestion time for both the baseline and our method (Figure 10(a)). In terms of disk usage, VSI alone reduces disk consumption by 25% in storage consumption for the baseline OSTRICH, however its benefits are less evident in a multi-snapshot setting (Figure 10(b)). This happens because HDT snapshots account for most of the disk usage in the archive and they do not use VSI. Like any other compression scheme, VSI increases query performance, however its impact is minimal on V queries (see Figure 10(c)) and still reasonable for V and VM queries (Figure 10(d) and (e)). Based on this analysis, we decided to adopt VSI by default, that is, all subsequent experiments have enabled this compression scheme.

BEAR-B daily performance impact on ingestion time, storage, and VM, DM, and V query runtime for the compression using variable size integer (VSI) on both OSTRICH and our multi-snapshot strategy with change ratio
Figure 11 shows the ingestion time and disk usage of the BEAR-B variants with the original versioning metadata encoding as used in OSTRICH and our proposed compressed encoding—denoted with the “Comp.” prefix in the graphs. The new encoding incurs a drastic decrease in ingestion time. This is particularly notable for the baseline strategy, where ingestion times are reduced by as much as a factor of 40 on the BEAR-B hourly dataset, as illustrated in Figure 11(b). Here, the ingestion time drops from 1,473 min to just 36 min. Disk usage is also notably improved with the new encoding. This is particularly obvious for the baseline strategy, because larger delta chains imply more redundancy, which in turn means more room for compression. In the most remarkable case, disk usage is reduced from 615 to just 25 MB for BEAR-B hourly when using the baseline strategy. The improvements in disk usage are more modest on multiple snapshot strategies, as expected from the smaller delta chains. In these cases, the snapshots account for more of the disk usage of the entire archive. For example, on BEAR-B hourly, disk usage is only reduced from 212 to 193 MB. The fact that metadata compression makes the baseline beat the change-ratio strategy on BEAR-B hourly suggest that the optimal parameters of the snapshot strategies may not always be the same for the compressed and uncompressed versions of the delta chains.

Ingestion times (top row) and disk usage (bottom row) for OSTRICH and a multi-snapshot storage strategy applied on the different BEAR-B flavors with the original version metadata representation and our new compressed representation: (a) BEAR-B daily ingestion times, (b) BEAR-B hourly ingestion times, (c) BEAR-B instant ingestion times, (d) BEAR-B daily disk usage, (e) BEAR-B hourly disk usage, and (f) BEAR-B instant disk usage.
In Figure 12, we show the performance of queries with the two encodings of versioning metadata. Contrary to ingestion times and disk usage, the picture for query runtime is more nuanced. Overall, our new encoding scheme does not provide a clear advantage over the previous encoding in terms of query performance. For BEAR-B daily, as shown in Figure 12(a) to (c), the archives using the new encoding are systematically slower at resolving queries than the archives with the original encoding. As for BEAR-B hourly, Figure 12(d), (e), and (c), we note that queries are faster with the new encoding on the baseline strategy, but slightly slower with the change-ratio strategy. We can explain this by the large amounts of data that must be retrieved from long delta chains. In such cases, the gains obtained by reading less data—thanks to compression—outweight the costs of decompression, which translates into overall faster retrieval times. Finally, for BEAR-B instant, the compressed representation is slower for VM queries, similar for DM queries, and slightly faster for V queries when compared to the original representation. All in all, compressing the versioned metadata reduces the redundancy in the delta chains, which goes in the same direction as using shorter delta chains. This explains why the compressed representation performs worst for querying on multiple delta chains: redundancy has already (or partially) been reduced by the use of multiple snapshots. This diminishes the gains of further compression with our approach, which comes with a performance penalty due to decompression.

Query results for the BEAR benchmark with the original version metadata encoding and the new compressed encoding: (a) BEAR-B daily VM, (b) BEAR-B daily DM, (c) BEAR-B daily V, (d) BEAR-B hourly VM, (e) BEAR-B hourly DM, (f) BEAR-B hourly V, (g) BEAR-B instant VM, (h) BEAR-B instant DM, and (i) BEAR-B instant V. VM = version materialization; DM = delta materialization; V = version query.
We evaluate our solution for full SPARQL support on the BEAR-C dataset. BEAR-C is based on 32 weekly snapshots of the European Open Data Portal taken from the Open Data Portal Watch project (Neumaier et al., 2016). Each version contains between 485K and 563K triples, which puts BEAR-C between BEAR-B daily and BEAR-A in terms of size. Table 5 in Section 8.1 summarizes the characteristics of the datasets. BEAR-C’s query workload consists of 11 full SPARQL queries. The queries contain between two and 12 triple patterns and include the operators
Figure 13 illustrates the average execution time for each category of versioned query (VM, DM, and V) on BEAR-C. The results are displayed per individual query and averaged across all revisions for VM queries, and pairs of revisions

BEAR-C average query execution time in seconds for (a) VM, (b) DM, and (c) V queries. (log scale). VM = version materialization; DM = delta materialization; V = version query.
In Figure 14, we plot the runtime of VM and DM queries across revisions for queries #1 and query #2 of BEAR-C. The figures for all the other queries can be found in Appendix A. We selected those queries due to their representative runtime behavior. Query #1 has a relatively stable runtime for VM queries, with a slight increase in later revisions. Oppositely, query #2 sees a linear increase in runtime for VM queries as the target revision increases. In contrast, the runtime of DM queries is stable. We can observe that the CR strategies consistently outperform the baseline strategy on VM queries, while the baseline is faster on average for DM queries on query #1, and on par with CR

BEAR-C average query execution time in seconds for VM, DM, and V queries: (a) DM and VM runtime for BEAR-C query #1 and (b) DM and VM runtime for BEAR-C query #2. VM = version materialization; DM = delta materialization; V = version query.
A queryable SPARQL endpoint on BEAR-C deployed using our multi-snapshot storage architecture is available online5 and described by Pelgrin et al. (2023).
We now summarize our findings in previous sections and draw a few design lessons for efficient RDF archiving.
Ingestion time
For storage architectures based on aggregated deltas, our results confirm that multi-snapshot strategies pay off in terms of ingestion time. We argue they could compete or even beat pure IC systems. To see why we remind the reader that a baseline IC system has to process
While our approach could beat IC implementations at ingestion time, it cannot compete with classical pure CB approaches, because those have an ingestion complexity of
Disk usage
The more redundancy a delta chain contains, the more storage efficient a multi-snapshot strategy will be. This redundancy can be caused by various factors, such as large changesets, long change histories, but also by the nature of the changes, for example, changes that revert previous changes. It then follows that for small datasets, small changesets, or relatively short histories, multi-snapshot strategies induce an overhead as the performance of the baseline OSTRICH on BEAR-B daily suggest. In such cases frequent snapshots are not a good idea. As our results on BEAR-A show, bulky updates benefit from snapshots at a moderate periodicity. Having said that, we expect multiple delta chains to be consistently more storage efficient than an IC approach if the snapshot frequency is judiciously set. In contrast, pure CB systems would be more difficult to beat by the uncompressed version of our approach—in particular if the CB system uses also uses HDT for the changesets. Since we can see our delta chains as TB stores of the triples that changed after a snapshot revision, we expect our solution to have a better storage footprint than a pure TB store. To see why, bear in mind that the size of our stores is capped every time a new delta chain is started. Depending on the edition patterns of the changesets, new delta chains could avoid storing deleted triples that will not be added again.
Query performance
For “easy” archives (small and/or with short histories), the overhead of multi-snapshot strategies does not pay off in terms of query runtime. This observation is particularly striking for V queries for which runtime increases with the number of delta chains. Conversely, short delta chains are mostly beneficial for VM and DM queries because these query types require us to iterate over changes within two delta chains in the worst case (for DM queries). They also systematically translate into faster ingestion times while being detrimental to storage consumption.
That said, when individual deltas are very bulky, as in BEAR-A and BEAR-C, multiple delta chains can be beneficial to V query performance, and can use less disk space than a single-snapshot storage strategy. Change-ratio strategies strike an interesting trade-off because they take into account the amount of data stored in the delta chain as criterion to create a snapshot. This ultimately has a direct positive effect on ingestion time, VM/DM querying, and storage size. Given that our solution outperforms the baseline OSTRICH for VM and DM queries, we argue that multi-snapshot architectures should outperform CB and TB approaches (as they are outperformed by OSTRICH (Taelman et al., 2019)) for these types of queries. They could be competitive to IC approaches with efficient storage, for example, HDT. The situation is different for V queries, which as reported by Taelman et al. (2019), are best handled by TB and CB approaches with HDT. Since multiple delta chains add an overhead to V query processing, we do not expect our solution to beat the classical systems in this scenario.
Finally, we highlight that the performance of full SPARQL queries on RDF archives is subject to same performance trade-off as queries on single triple patterns. Like most query engines, Comunica relies upon cardinality estimates for triple patterns to determine its query plans. Since our approach is able to accurately provide such estimates, Comunica is able to produce reasonable query plans: both VM and DM queries do not take longer than 1,000 s and some queries, such as
Compression
In general, compressing the version metadata stored in the delta chain is a sensible alternative: compression increases ingestion speed and reduces disk storage. While it can increase query runtime, its impact is usually minimal and depends on the amount of data that needs to be fetched from disk. For very large delta chains (e.g., delta chains with big deltas), compression can even be beneficial for query performance because the overhead of decompression is insignificant compared to the savings in terms of retrieved data. This observation holds promise for distributed settings. Since compression mitigates redundancy in the delta chain, we cannot expect the snapshot strategies to have the same performance on the compressed and uncompressed versions of the archive.
Design lessons
The bottom line is that the snapshot creation strategy for RDF archives is subject to a trade-off among ingestion time, disk consumption, and query runtime for VM, DM, and V queries. As shown in our experimental section, there is no one-size-fits-all strategy. The suitability of a strategy depends on the application, namely the users’ priorities or constraints, the characteristics of the archive (snapshot size, history length, and changeset size), and the query load. For example, implementing version control for a collaborative RDF graph will likely yield an archive like BEAR-B instant, that is, a very long history with many small changes and VM/DM queries mostly executed on the latest revisions. Depending on the server’s capabilities and the frequency of the changes, the storage strategy could therefore rely on the change ratio or the ingestion time ratio and be tuned to offer arbitrary latency guarantees for ingestion. On a different note, a user doing data analytics on the published versions of DBpedia (as done by Pelgrin et al. (2021)) may be confronted to a dataset like BEAR-A and, therefore, resort to numerous snapshots, unless their query load includes many real-time V queries. Table 8 summarizes these lessons for different common requirements when managing RDF archives.
Design Recommendations for Multi-Snapshot RDF Archives.

Design Recommendations for Multi-Snapshot RDF Archives.
VM = version materialization; DM = delta materialization; V = version query.
Furthermore, we showcased our results for full SPARQL processing over RDF archives on the BEAR-C benchmark. To the best of our knowledge, this is the first approach that provides a solution for BEAR-C. We believe this work unlocks several perspectives for efficient querying over RDF archives. Firstly, our integration with Comunica enables support for CV and CD archive queries, because these query types build upon the composition of simpler queries (VM, DM, and V). It follows that our approach can now support those CD and CV queries that are expressible in SPARQL. Secondly, our proposal highlights the lack of standardization for SPARQL querying on RDF archives, which has encouraged solution providers to come up with their own language extensions and ad-hoc implementations. None of them, however, has attained wide acceptance within the research and developer communities. Our solution relies on standard SPARQL and can be easily adopted by the managers of RDF archives—at least until a canonical SPARQL extension for archives arrives. Thirdly, our work reveals the limited diversity of benchmarks for SPARQL query workloads on RDF (Pelgrin et al., 2023). In BEAR, for example, only the BEAR-C dataset offers full SPARQL queries. Those 11 queries, are alas, insufficient to provide a comprehensive evaluation of the capabilities of novel systems as they target a single application case and consider queries of similar topology (star-shaped patterns joined on one variable). Alternatives, such as SPBv (Papakonstantinou et al., 2017), have not seen similar adoption by the community, probably because they are not easy to deploy.7 We expect this work to prepare the ground for the emergence of more efficient, standardized, and expressive solutions for managing RDF archives.
In this article, we have presented a hybrid storage architecture for RDF archiving based on multiple snapshots and chains of aggregated deltas with support for full SPARQL versioned queries. We have evaluated this architecture with several snapshot creation strategies on ingestion times, disk usage, and query performance using the BEAR benchmark. The benefits of this architecture are bolstered thanks to a novel and efficient compression scheme for versioning metadata, which has yielded impressive improvements over the original serialization scheme. This has further improved the scalability of our system when handling large datasets with long version histories. All these building blocks cleared the way to introduce a new SPARQL processing system on top of our storage architecture. We are now capable of answering full SPARQL VM, DM, or V queries over RDF archives.
Our evaluation shows that our architecture can handle very long version histories, at a scale not possible before with previous techniques. We used our experimental results on the different snapshot creation strategies to draw a set of design lessons that can help users choose the best storage policy based on their data and application needs. We showcased our ability to handle the BEAR-C variant of the BEAR benchmark—the first evaluation on this dataset to the best of our knowledge. This is a first step towards the support of more sophisticated applications on top of large RDF archives, and we hope it will expedite research and development in this area.
As future work, we plan to further explore different snapshot creation strategies, for example, using machine learning, to further improve the management of complex and large RDF archives. Furthermore, we plan to investigate novel approaches in the compact representation of semantic data (Perego et al., 2021; Sagi et al., 2022), which could lead to a promising alternative to the use of B+ trees. Future experiments could also evaluate the performance of our storage solutions on solid-state disks that perform better on I/O operations. We envision further efforts towards the practical implementation of versioning use cases of RDF, such as the implementation of version control features, like branching and tagging, into our system. Such features are paramount to real world usages of versioning software, and can benefit RDF dataset maintainers (Arndt et al., 2019; Graube et al., 2014). With the recent popularity of RDF-star (Abuoda et al., 2023; Hartig, 2017), which can be used to capture versioning in the form of metadata, we also plan to look into recent advances in this area. Finally, the lack of an accepted standard for expressing versioning queries with SPARQL limits the wider adoption of RDF archiving systems. We aim to work towards a standardization effort, notably on a novel syntax and a formal definition of the semantics of versioned queries.
Footnotes
Acknowledgments
This research was partially funded by the Danish Council for Independent Research (DFF) under grant agreement no. DFF-8048-00051B, the Poul Due Jensen Foundation, and the TAILOR Network (EU Horizon 2020 research and innovation program under GA 952215). Ruben Taelman is a postdoctoral fellow of the Research Foundation – Flanders (FWO) (1202124N).
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.