
Abstract
Hand gesture recognition is important in human-computer interaction with wide applications in many fields. Different from common hand gesture recognition based on 2D images acquired from RGB camera, the utilization of 3D images provides additional spatial information about the target and attracts more and more attention in hand gesture recognition. However, most 3D images for hand gesture recognition are based on depth maps, which only take the distance information as a channel of 2D images, without taking full use of the 3D information. Besides, greater data volume of 3D images brings challenges to the arithmetic facility of hand gesture recognition. Here, we proposed a point cloud based method for hand gesture recognition. To fully use the 3D information, plane points for template matching were extracted based on their normal distributions, which leads to the average recognition rate over 97%. Pre-classification was implemented to ensure a high-efficient recognition without additional requirements for the computer. The proposed method may provide approach for accurate and efficient hand gesture recognition based on 3D images.
Introduction
Compared with verbal communication, non-verbal communication is more direct and effective. As the representation of non-verbal communication, gesture plays an important role in human-computer interaction, and gesture recognition has been a hot topic in computer vision. Nowadays, hand gesture recognition has been widely used in many areas like sign language recognition, virtual reality, smart home, etc.
According to the data acquisition devices, the methods of gesture recognition can be mainly classified into two categories: methods based on wearable devices and methods based on machine vision [1]. The wearable devices can be used to capture the position and posture information of hand to send to computer for real-time processing. This kind of scheme has sufficient information acquisition, but the requirement of high precision for sensors makes the costs higher. In addition, the contact of devices and hand will affect the user’s state, making it difficult to get the information in natural state. Hence, the contactless and cheaper machine vision method is more popular.
Due to the development of imaging devices, RGB camera is the most basic and common input device of vision-based methods. Many highly efficient recognition methods based on 2D RGB images have been demonstrated including CNN [2], image processing [3], deep learning [4]. For RGB image that captured by camera, segmentation of the region of interest (ROI) is the critical issue that researchers already explored many different methods. The most widely used one for hand gesture recognition is the color-based method. The color-based method classifies pixels as skin or no-skin based on the color difference between them. Mostly, the classification process takes place in color space like RGB [5], HSV [6], and YCbCr [7]. HSV has the best effect on skin detection, and YCbCr is most robust to illumination varies [8]. However, it is obvious that extracting ROI by color difference is environmental demanded, there should be neither a background close to skin color nor extreme illumination. Besides, there are many other methods for hand region extraction, such as background subtraction [9], and movement detection, but the high-quality requirements for background elimination are still not met.
On the other hand, 3D devices like LIDAR and ToF camera can obtain the distance information from image, which makes the foreground division easier. In the case that hands have no occlusion, the palm region can be easily extracted by setting a threshold of distance [10, 11]. However, the threshold value is experimental that needs extensive testing, and to be adjusted with different input devices. In addition, the region segmented by distance threshold mostly involves parts of forearm, which needs further refinement. Ren et al. [12] combined RGB and depth map to segment the hand region. In their work, the users are required to wear a black belt on wrists, so the forearm can be segmented by color difference in RGB image. After the extraction of hand region, the finger earth-mover distance (FEMD) has been used to measure the dissimilarity between input and template. The FEMD just measures the similarity between fingers not whole hand, so Ren’s method has a good performance for gestures with extended fingers. Wang et al. proposed super-pixel-based method, using super-pixel earth mover’s distance (SP-EMD) for dissimilarity measuring [13]. Same as Ren’s method, the combination of RGB and depth map proposed 6D feature for super-pixel’s growing, and template matching was used for final recognition. Zhang et al. segmented hand region by distance threshold, proposed a descriptor called Histogram of 3D Facet (H3DF) as feature, and used support vector machine (SVM) for gesture recognition. Sharma et al. [10] used SVM for gesture recognition, too. In their work, forearm parts are removed by a circle centered in the palm center, which was located by Gaussian blurring. The feature for SVM is combined with four feature vectors: geometrical features, distance features, local binary patterns, and number of extended fingers. Plouffe et al. [11] proposed a framework that without forearm removing. In their work, the recognition was based on Dynamic Time Warping (DTW) that palm center and finger tips had been chosen as input. After boundary estimation of the extracted region, the K-curvature algorithm had been applied for fingertip location, and the palm center was set at the center of largest circumscribed circle of boundary. For the hand segmentation that based on distance threshold, Zhu et al. [14] proposed a descriptor based on the appearance of hand called 3D shape context (3D-SC) and the recognition has been explored via DTW using 3D-SC.
Although the works mentioned above show many different methods for gesture recognition based on 3D images, they all rely on the depth map, which make distance information just a channel of 2D image for background removal and cannot take full use of 3D information. Template matching method has been considered as an effective way to fully use the 3D images. The acquired hand information will be fitted to the virtual model of the hand, and then recognized based on the overall information of the virtual model. Tekin et al. [15] proposed a model to understand the interaction between 3D hand template and object by using a single RGB image, which used a neural network to train end-to-end on a single image and jointly estimated hand and object. Wan et al. [16] used a set of spheres to approximate the surface of the hand and proposed a self-supervised neural network to estimate the 3D hand gesture. Ge et al. [17] proposed a full 3D hand shape and pose estimation method based on a single RGB image. Graph Convolutional Neural Network (Graph CNN) is used to reconstruct the full 3D mesh of the hand surface. Taylor et al. [18] proposed a human hand tracking system that combined the surface model with an energy equation. Malik et al. [19] applied depth maps to CNNS and proposed an automatic learning algorithm, which included the segmentation of the hand from the depth map and the estimations of hand gestures and bone structures. Chen et al. [20] proposed a self-organizing hand network (SO-Hand Net), which realized the estimation of 3D gestures through semi-supervised learning. Wu et al. [21] proposed a hand gesture recognition method based on a single depth image by combining the detection-based method with the regression-based method. The experimental results show that the combination of the two methods improves the recognition accuracy. Cai et al. [22] proposed a method to adapt a weakly labeled real-world dataset from a fully annotated synthetic dataset with the help of low-cost depth images and adopt RGB input for 3D joint recognition.
For the above template matching method for 3D hand gesture recognition, the classification process of such algorithms is mostly implemented based on deep learning [23–26], which is caused by the characteristics of 3D models. As a virtual 3D model, it needs to fit the user’s hand in enough degrees of freedom to fully represent the complete hand information. Therefore, the algorithms of template matching method for 3D hand gesture recognition often lead to high cost of time and computing power for the training of the classifier. In addition, these algorithms are sensitive to the view angle.
In this study, to make full use of the 3D geometrical information, we choose 3D point clouds as input, and propose a hand gesture recognition method based on template matching. In the proposed method, we build point cloud models of different gestures as templates and extract plane points by normal distribution after hand segmentation and pre-classification. Iterative closet point (ICP) algorithm is used to register plane points between gestures and templates without complex training, and the diversity is evaluated to acquire the result of recognition.
Proposed method
The proposed method is based on the idea of template matching and consists of three main parts. Its flowchart is shown in Fig. 1. For the input point cloud, the hand region will be segmented from the rest of the scene firstly, and the number of extended fingers is counted as a feature for pre-classification. Secondly, the normal of the hand point cloud and corresponding template models are estimated, and the plane points between gestures and templates will be extracted according to their normal distributions. Finally, the extracted points will be divided into three parts for registration. The diversity will be estimated based on registration error, and the template model with the smallest diversity will be output.
Flowchart of the proposed algorithm.
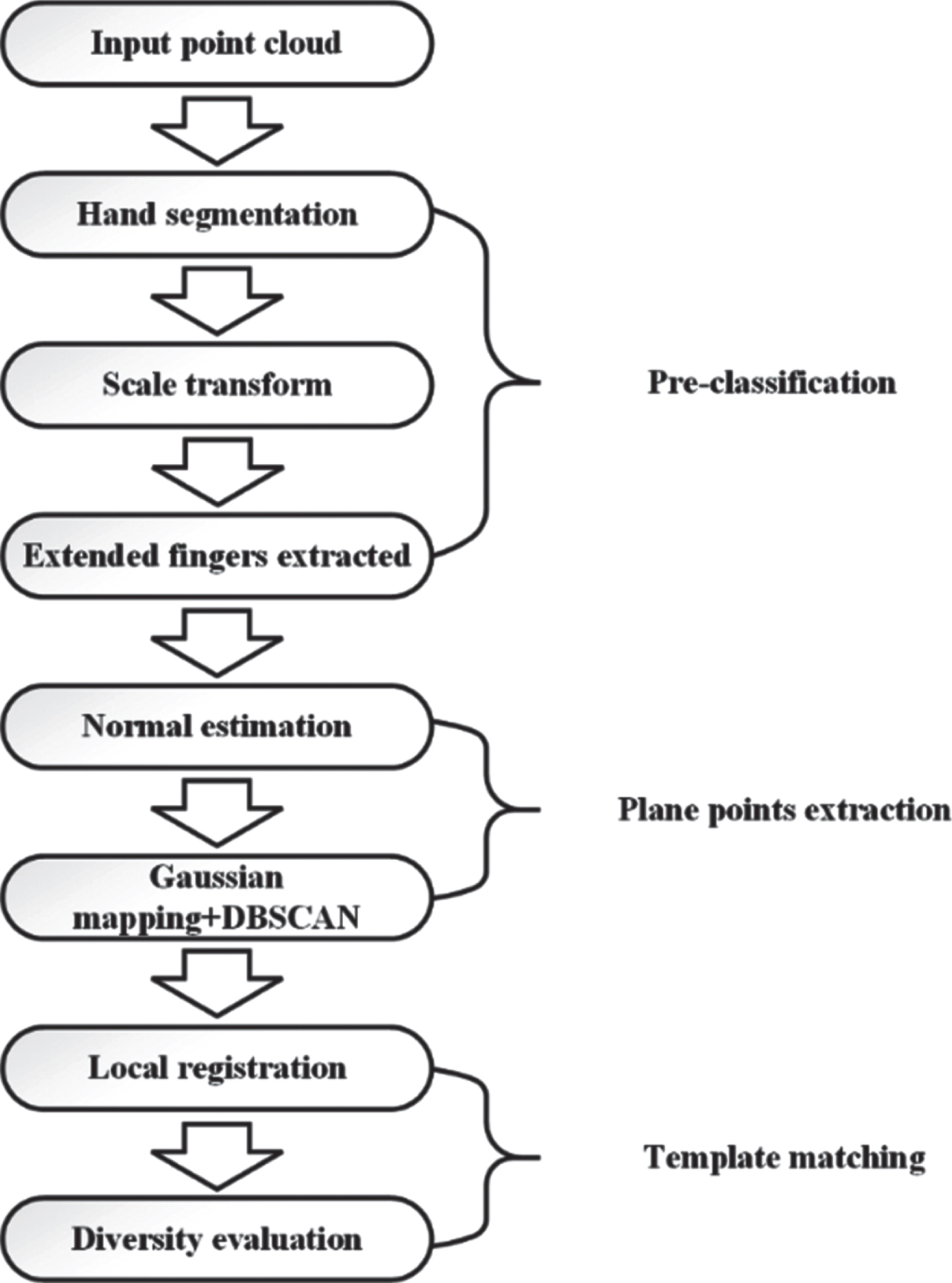
The first step consists of two parts: ROI extraction and gesture pre-classification. Compared with RGB images, point cloud has great advantages in segmentation of background. So, for the most scenarios that user in the natural state, we can easily extract the hand region by setting the maximum Z values points as the seed points and using region growing (RG) algorithms. The result of RG is shown in Fig. 2, and we could figure out that the point cloud extracted by RG containing partial forearm, which will interference the recognition results and needs to be removed. In order to facilitate further processing, the principal component analysis (PCA) has been applied here for main direction estimation, and gesture point cloud has been rotated to make sure its main direction is consistent with coordinate axis.
Region growing segmentation: (a) initial point cloud data; (b) result of segmentation.
From the structure of human’s hand, we could find that the variety of gestures is provided by the degree of freedom (DOF) of joints, and the palm part remains stable when gestures changing. Therefore, the forearm can be eliminated by determining the palm area. In order to find the center of palm, the distance transform (DT) [27] is applied to gesture point cloud. DT is a 2D image processing algorithm widely used in pattern recognition. For point cloud, the boundary points can be easily found by analyzing the angle between vectors of their nearest neighbors [28]. Denote the set of boundary points as B = b1, b2, . . . bn, the set of inner points as I = i1, i2, . . . in, and the Euclidean distance between inner point p(i, j, k) and boundary point q(u, v, w)represented as:
Denote the set of distance between p and every boundary points as D(p):
The distance between p and its nearest boundary points be denoted as dm
p
, and set as Dm:
The point with maximum dm will been chosen as the central point C (x, y, z):
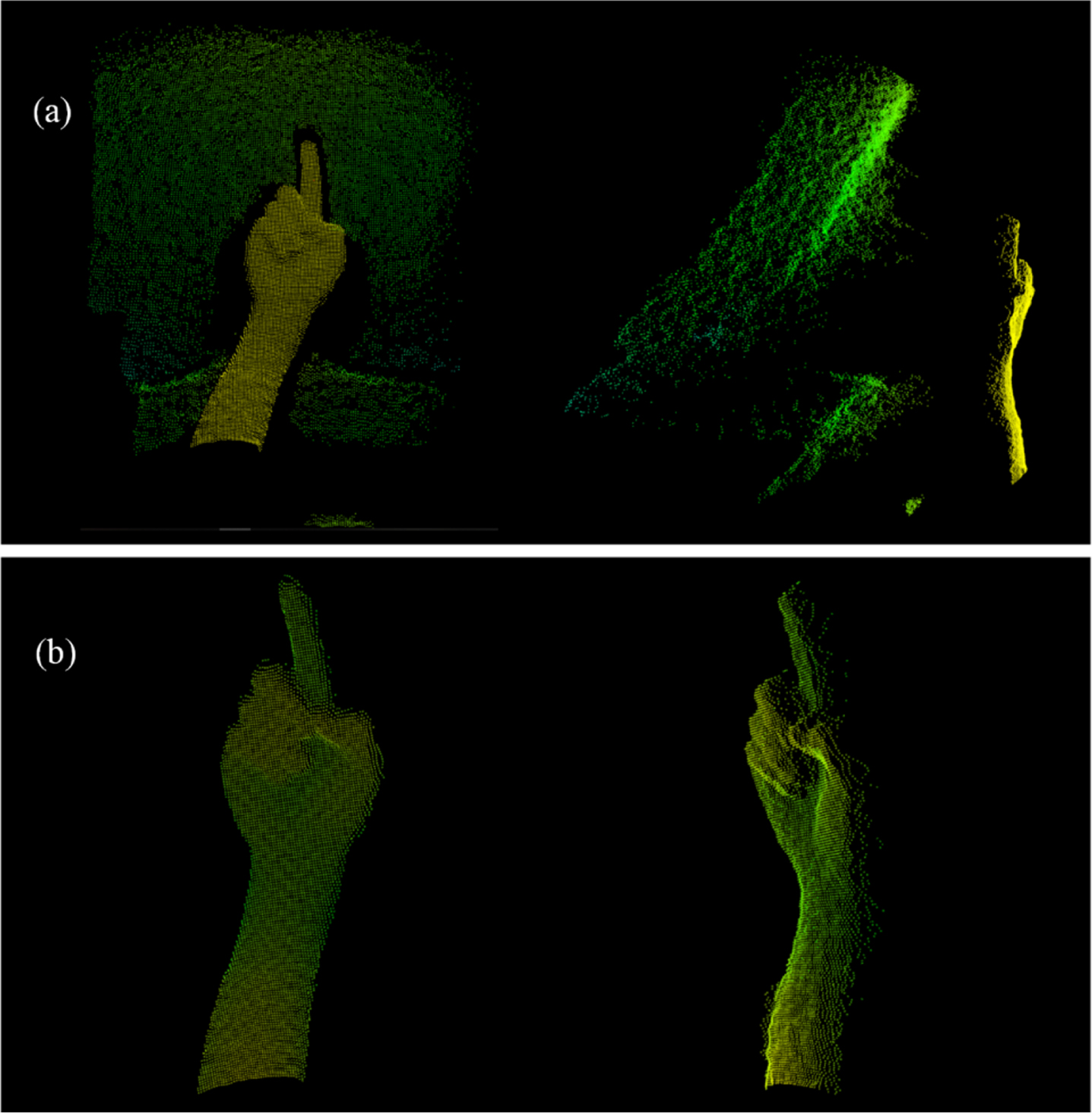
Because the main directions of gesture point cloud have already on the coordinate axis, the forearm part can be easily segmented by eliminating the points with y coordinates below y–dm k . The result of DT is shown in Fig. 3. In addition, making a circle O that with C as the center and dm k as the radius, the extended fingers can be extracted by removing the points in circle O. The number of extended fingers can be counted by Euclidean cluster as a feature for pre-classification. We have found that extended fingers can be precisely extracted when α= 215%. The result of extended fingers extraction is shown in Fig. 3(c)
Hand region segmentation: (a) distance transform of hand, central point in red and boundary points in green; (b) result of segmentation; (c) extended finger that extracted by 215% radius.
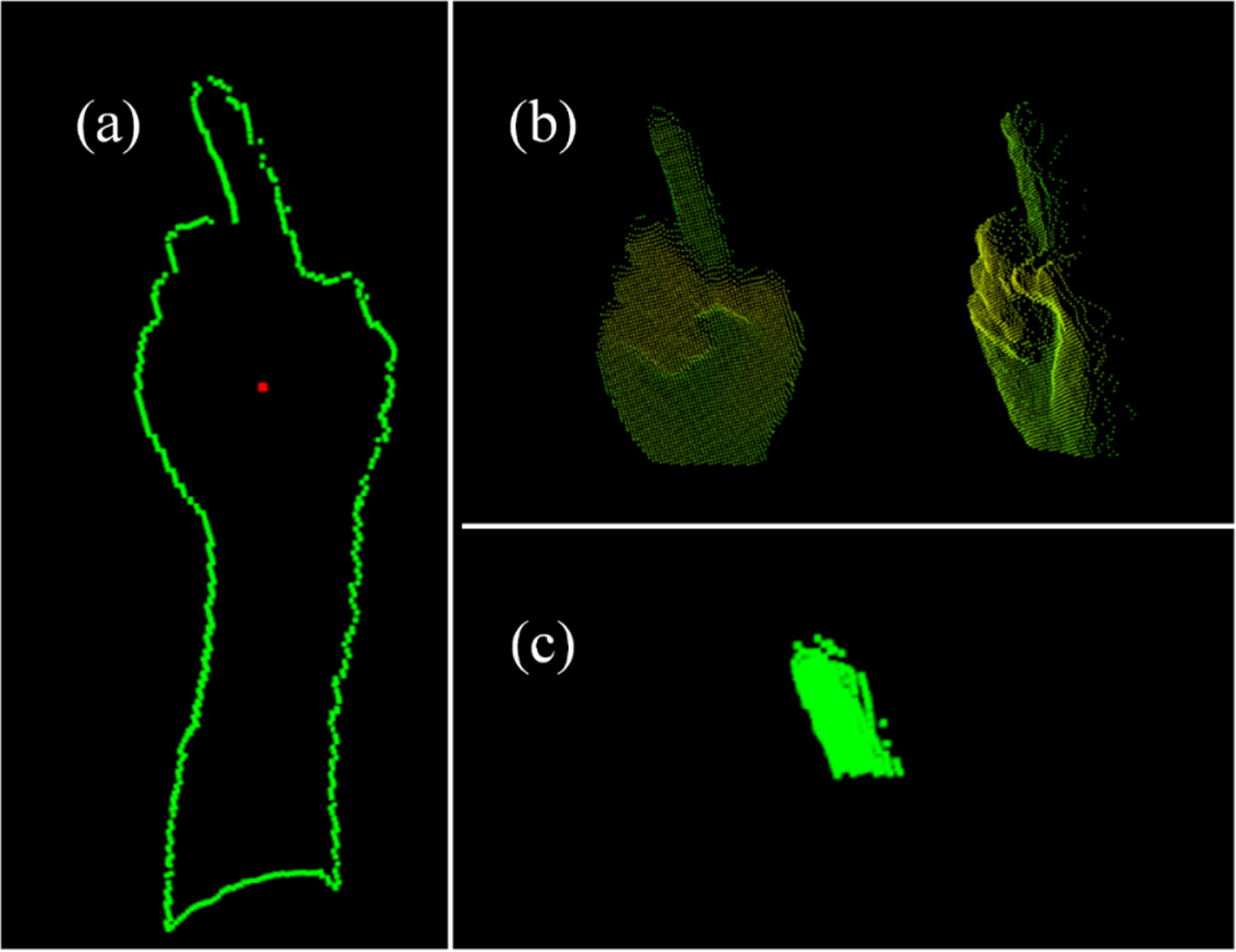
To reduce the influence of hardware and palm size on results, the size of gestures should be consistent with corresponding models. Therefore, it’s necessary to scale the gestures point cloud. During the scaling process, Oriented Bounding Box (OBB) is used to measure the size difference between two point clouds. After the rotation that based on PCA, the main direction of both gesture and model should stay the same, and the scale factor can be estimated by the area ratio of the two 2D-OBB. The results of scaling are shown in Fig. 4 and Fig. 5. It can be seen that the area difference between gesture and correct model can be kept in a small range. For the models that obviously incorrect as shown in Fig. 5, although the area difference of boundary boxes remains the same, the difference between two point clouds varies greatly, which makes the registration difficult and leads to a higher errors.
Scale variation results of correct gestures: (a) front view; (b) left view.
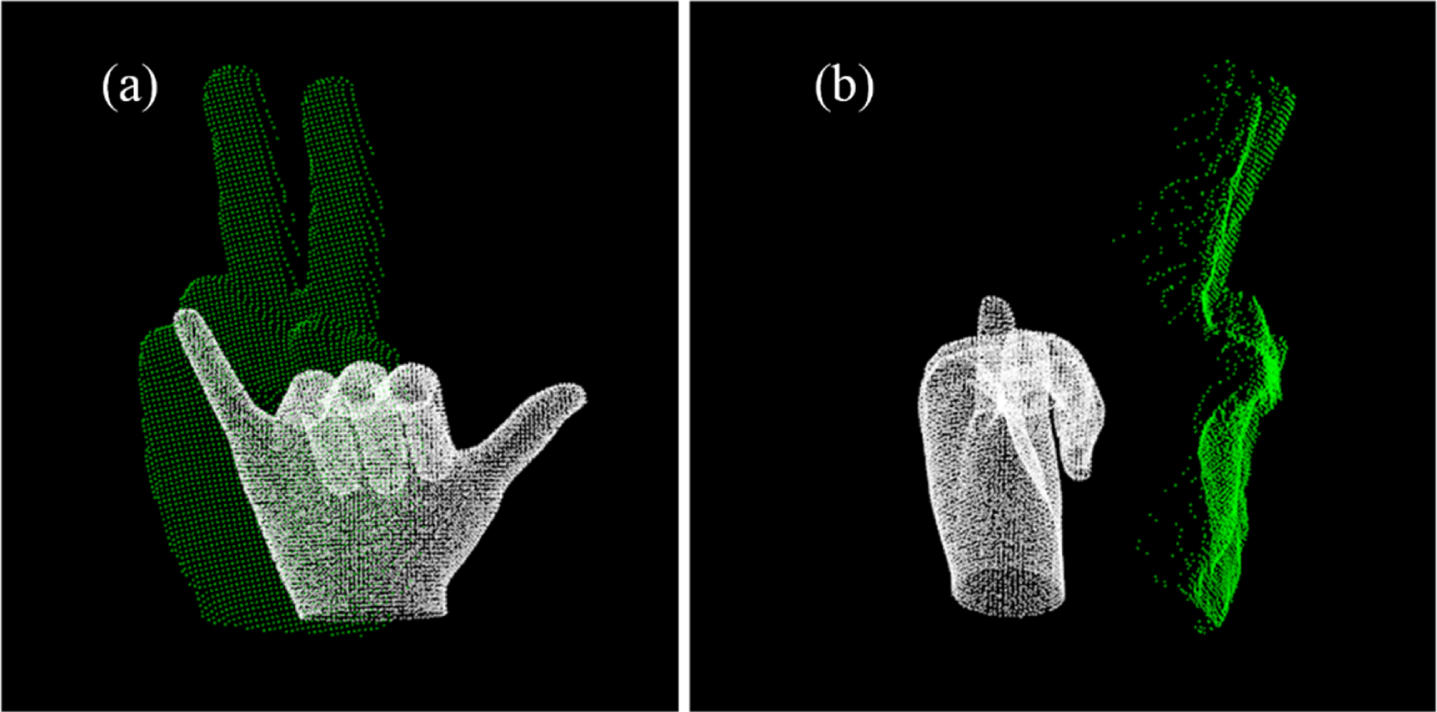
Scale variation results of incorrect gestures: (a) front view; (b) left view.
The variation of gestures is entirely provided by the DOF of finger joints, but the high DOF increases the difficulty of registration. Mostly, the joints are hard to register even when the gestures are correct. Therefore, to reduce the influence of joints on registration, we eliminate the joint points based on their high curvature, and reserve the plane points in gestures for registration to improve the accuracy. The plane-points extraction is based on the normal distribution of gestures, so the normal estimation should be carried out at first.
There are many ways to estimate the normal distribution of 3D point cloud, but the simplest one is to approximate the normal of point as that of its tangent plane. In this case, the point normal estimation will be transformed into the calculation of three-dimensional fist-order plane fitting, which can be completed by PCA and K-nearest neighbor (KNN) algorithms. However, the result of plane fitting is a pair of vectors that have opposite directions without mathematical way to clarify the sign. This issue can be solved by setting a view point. For the input point cloud I, the view point p
v
can be set in the front of central point C as p
v
= (x, y, z + a). For the point p
i
ϵI, we set the normal
All normals point to the viewpoint, which is the front of gesture. The result of normal redirection is shown in Fig. 6. After redirection, the normal of gesture points will be changed from disordered to ordered with a unified viewpoint in front of the gesture.
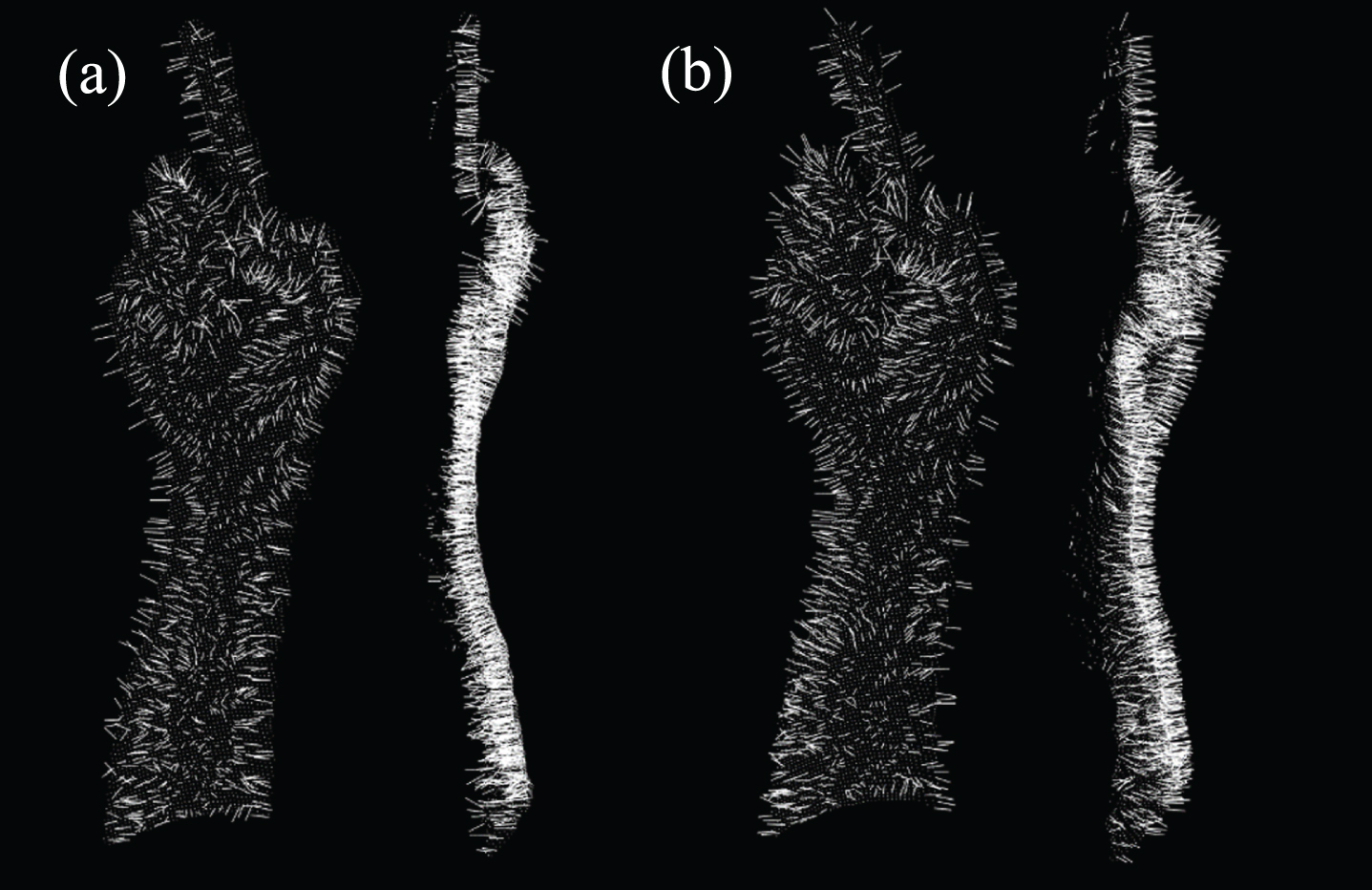
Result of normal redirection: (a) normals without redirection; (b) normals after redirection.
After normal estimation, plane points can be extracted through the normal distribution of their neighbor points based on Gaussian mapping and density-based clustering. For surface X, the Gaussian mapping is defined as a continue mapping from Euclidean space R3 to a unit sphere S2: N: X ⟶S2. N(p) is the unit vector at point P orthogonal to X, that is, the normal vector. The unit sphere obtained above called Gaussian sphere, and can be defined as [29]:
The Gaussian mapping directly reflects normal distribution of surface, which makes the extraction of plane points with special normal direction easier. In the proposed method, we mapping both the gesture and template model into Gaussian sphere to construct higher density for the points with similar normal distribution. Density-based clustering is a method widely used in data analysis, which classifies samples according to their tightness. The most representative one is density-based spatial clustering of applications with noise (DBSCAN) [30]. DBSCAN judges the continuity of samples based on their density, and the results of clustering are obtained by extending the continuous samples. For input point cloud D = d1, d2, . . . dn, DBSCAN random choose a central point d
i
, 0 < i< n. Then, the point whose distance from d
i
is less than radius ɛ are marked as neighbor N:
If the size of N is greater than threshold, it means that N is dense enough that can be a new cluster, and all points belong to N will be the new central to evaluate the density iteratively till no more points are added. Otherwise, d i will be marked as noise. This process will be repeated until all points have been marked. The points with similar normal direction can be extracted by using DBSCAN on Gaussian sphere, and for gestures point cloud they are plane points. The extraction of plane points is shown in Fig. 7.
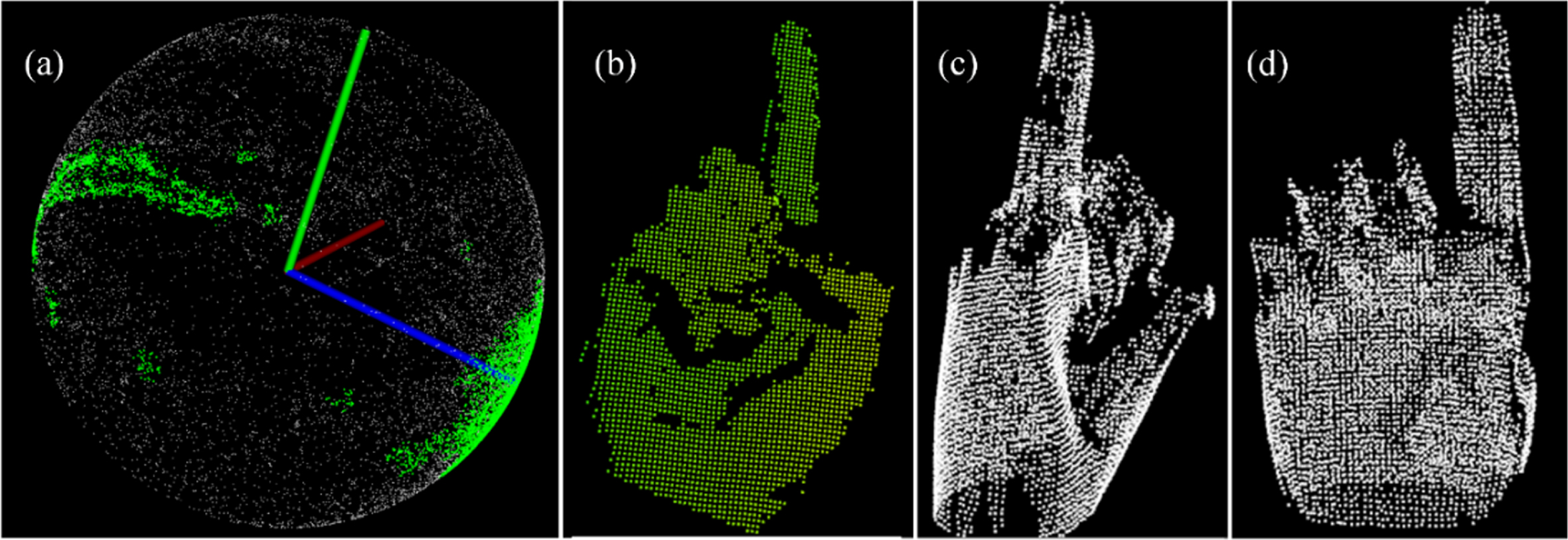
Gaussian mapping and DBSCAN: (a) clustering result when threshold was 0.45; (b) extracted gesture points; (c) left view of extracted model points; (d) front view of extracted model points.
In this part, the obtained gesture point cloud will be matched with template model, and the diversity will be estimated by registration error. The iterative closet points (ICP) algorithm is chosen for point cloud registration. For the source point S = s1, s2, . . . snand target point cloud G = g1, g2, . . . gn, the registration can be regarded as the process of finding the rotation matrix R and translation matrix t [31]:
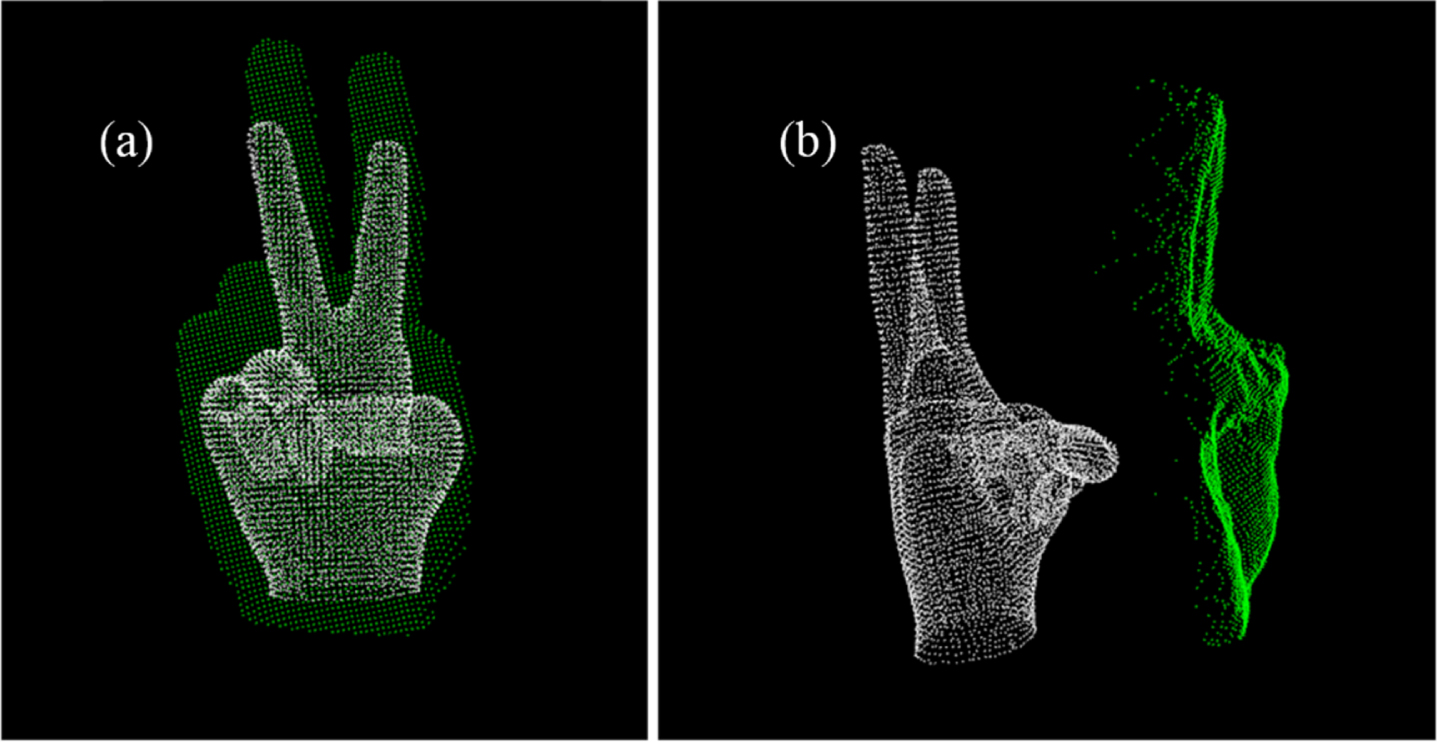
ICP algorithm iteratively obtains and applies these two matrixes to transform the source point cloud, until the total error is under the threshold or the numbers of iterations reached the limit. As the process of scaling and main direction rotating have been applied, the palm of gesture matches the template model. In this case, the focus of registration will be on the palm, and the fingers cannot be registered. Therefore, the extended fingers will be registered first, and the obtained transform matrix will be applied to the whole gesture to provide a good initial position for ICP. Then, in order to prevent ICP from falling into the local optimal solution, the whole point cloud will be segmented into three vertical cells to register separately. The comparison of the whole point cloud registration and segmented point cloud registration is shown in Fig. 8. It can be seen that the result of partial registration is more suitable for the further template matching than the whole registration.
Result of registration: (a) whole registration; (b) partial registration.
The diversity of gestures can be calculated based on the root mean square error (RMSE) of registration:
The performances of the proposed method are tested through experiments based on the NTU dataset [12] and the real environment., and compared with other gesture recognition methods to clarify the feasibility of this method.
Boundary estimation is an important step for distance transform which directly affects the accuracy of results. In the proposed method, boundary estimation is based on the angle analysis between neighbor points, which means the determination of neighborhood is the key point. To adapt to different resolutions of input devices, KNN has been used to find the neighbors and evaluate the angles with their constructed vectors. Therefore, the number of neighbors K has a directly impact on the boundary estimation [32, 33]. The results when K = 12 and K = 100 are shown in Fig. 9, and we could figure out that the lower K makes boundary clutter and more stereo, which contains more 3D characteristics of the gesture. On the other hand, higher K will make the boundary smoother, more similar to the boundary of 2D images. For a point cloud with 4060 points, the relationship between number boundary points and K is shown in Fig. 10. When K < 3, the angles cannot be evaluated correctly, which makes the whole point cloud inner. As K increases, the number of boundary point decrease, leading to a more accurate result. When K is over 50, the number of boundary point tends to converge as constant, and the corresponding results have no different. Therefore, we choose K = 50 in our case. Although there are some missing points in boundary, the result of distance transform is not significantly affected, and the hand can be segmented fully.
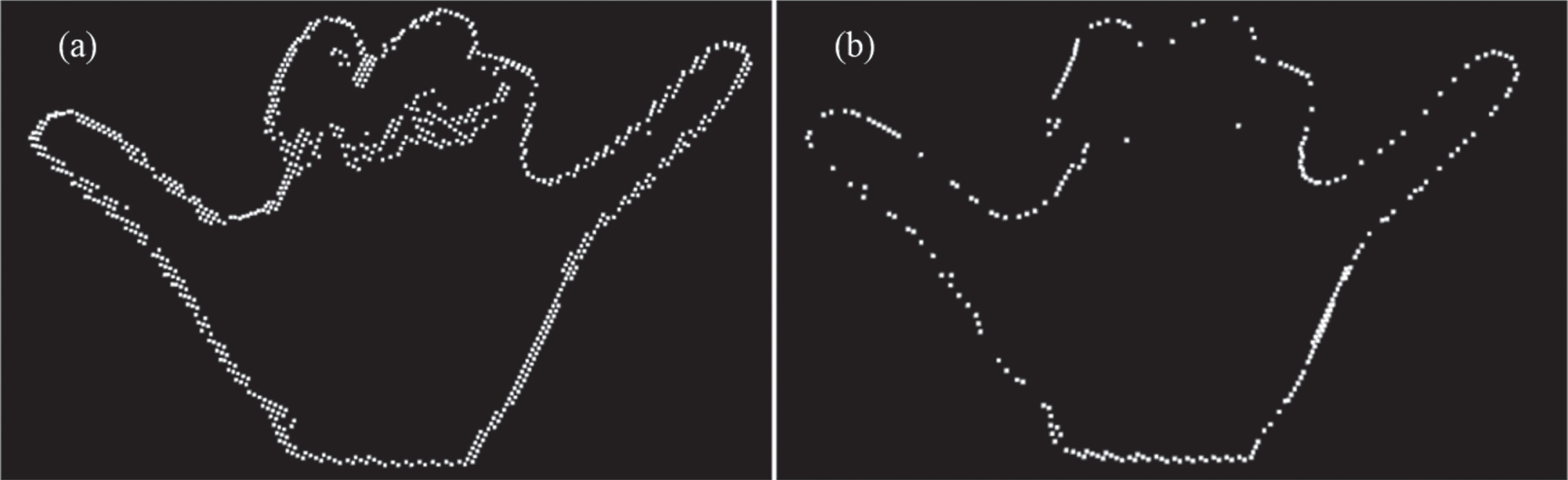
The effect of K on boundary estimation: (a) K = 12; (b) K = 100.
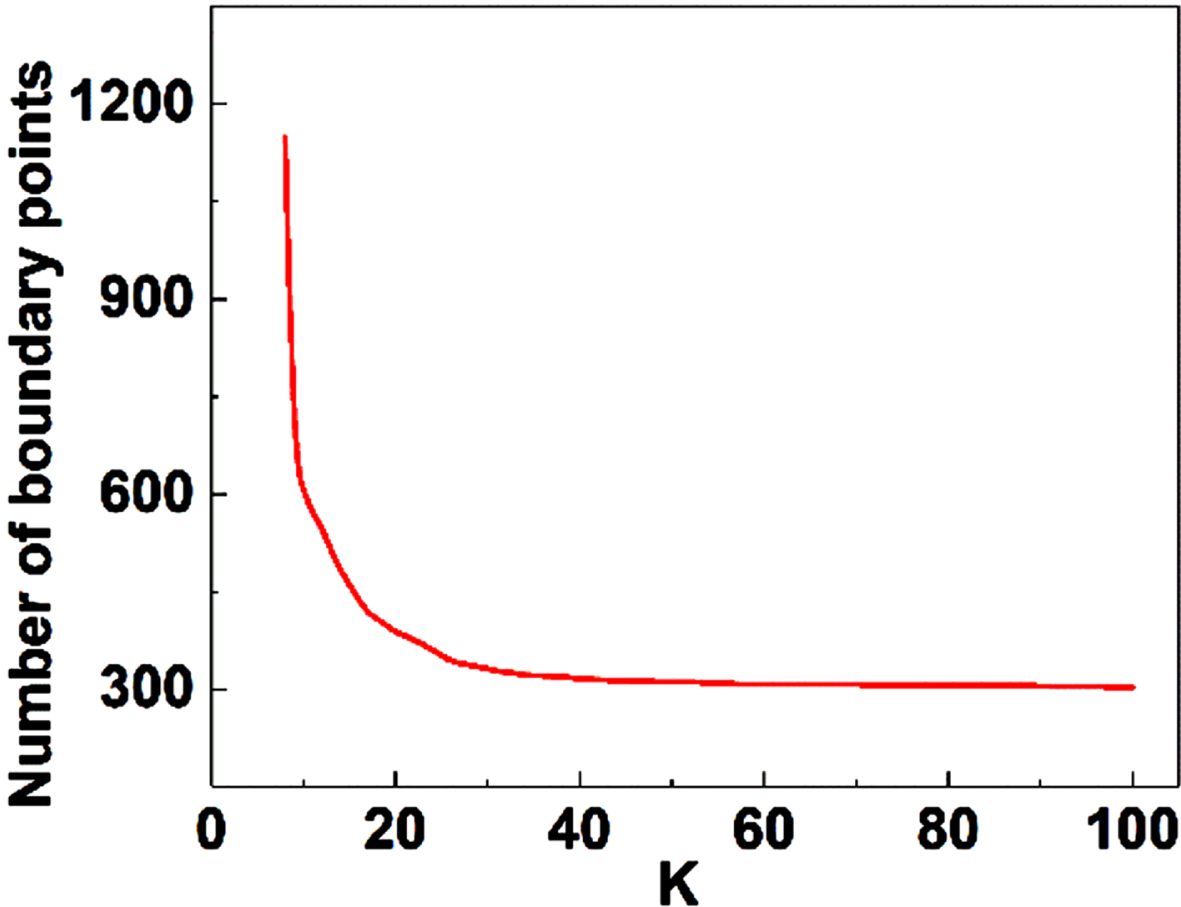
Number of boundary points varies with K.
The number of extended fingers has been chosen as a feature for pre-classification in proposed method. Normally, in the case that the distance D between center point and nearest boundary point has already get by distance transform, the hand region can be easily removed by setting a circle that radius slightly greater than D. But sometimes, the low-resolution input or uneven point cloud will make the roots of adjacent fingers connected, and the extended finger cannot be segmentation correctly. We test more than 300 point clouds, and the results turn out that setting α= 215% will lead to the best accuracy. In this case, the root of fingers can be completely removed, while the thumb fingertip can be reserved for clustering. The accuracy for extended finger segmentation is shown in Fig. 11.
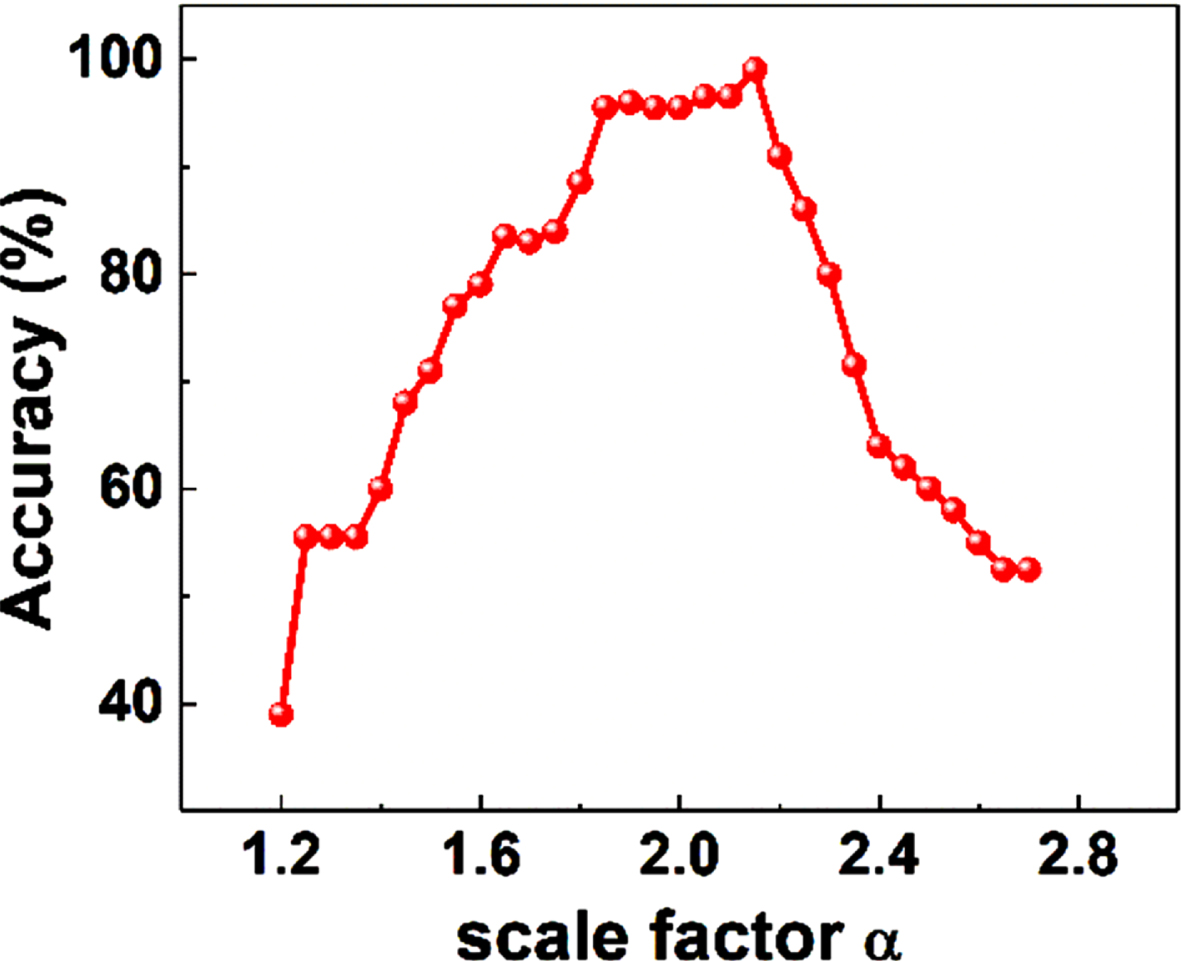
Accuracy of extended finger segmentation with different scale factors.
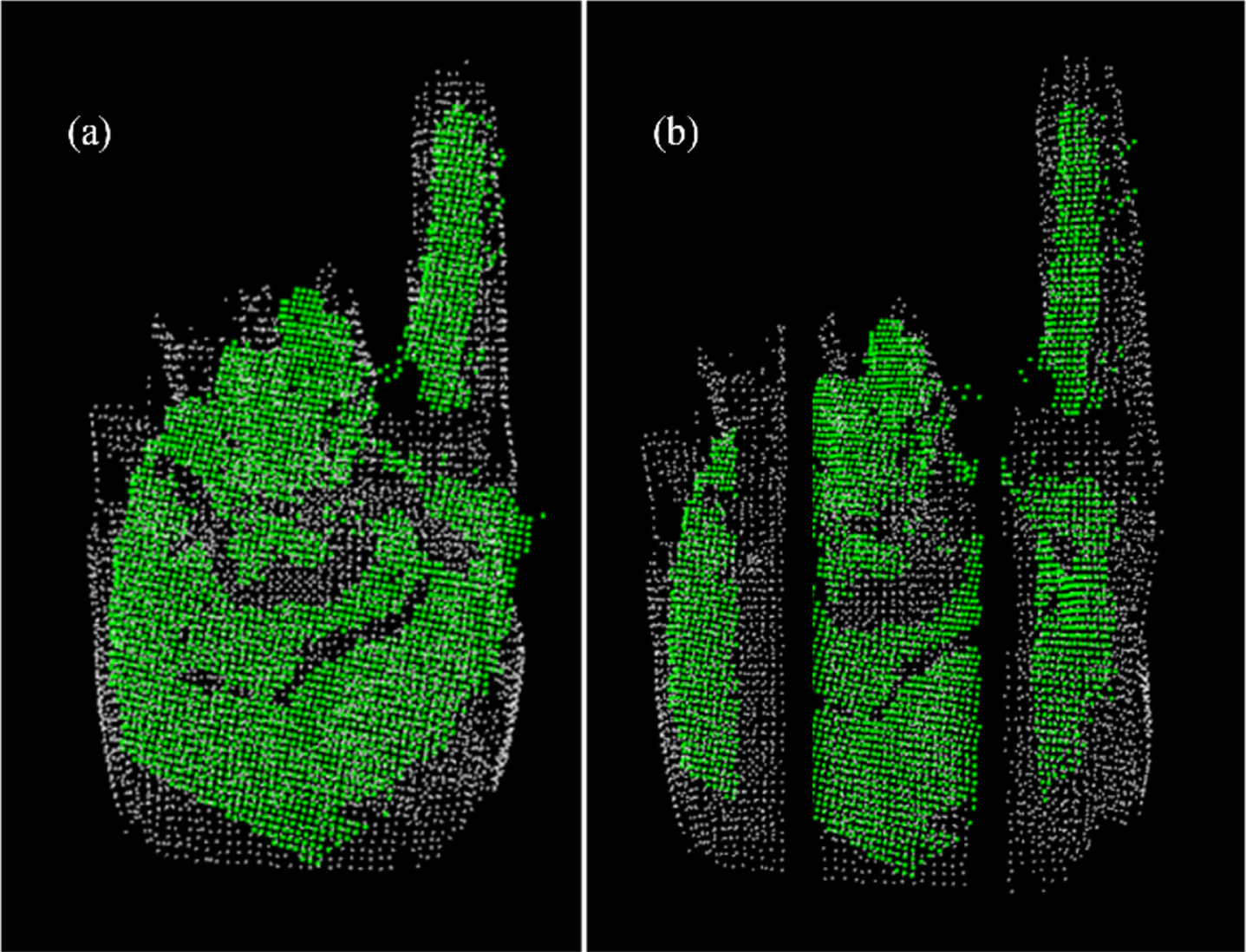
Clustering on Gaussian mapping is the key to make sure that the registration can processed between two point clouds. The quality of result is highly depended on a suitable growing threshold ɛ which ensures the effective extraction of plane points for further high-efficiency template matching. The clustered results when ɛ = 0.02, 0.04, and 0.06 are shown in Fig. 12. As shown in Fig. 12(a), when the ɛ = 0.02, the extracted plane points are unable to effectively present the characteristics of hand gesture as the growing threshold is too small and too many high-frequency features are ignored. As shown in Fig. 12(b), the flat surface can be extracted well and the high curvature parts are eliminated when we set ɛ = 0.04, which will make the distinguish of different gestures easier. As the growing threshold continues to increase as shown in Fig. 12(c), some high curvature parts will be extracted in the flat surface, however, the key characteristics of hand gesture are not significant enhanced. The effect of ɛ on clustering is shown in Fig. 13, and we could find that the number of plane points by both model and gesture are tend to a constant when ɛ greater than 0.06, which means the plane points are extracted fully when ɛ = 0.06.

Clustered results when: (a) ɛ= 0.02; (b) ɛ= 0.04; (c) ɛ= 0.06.
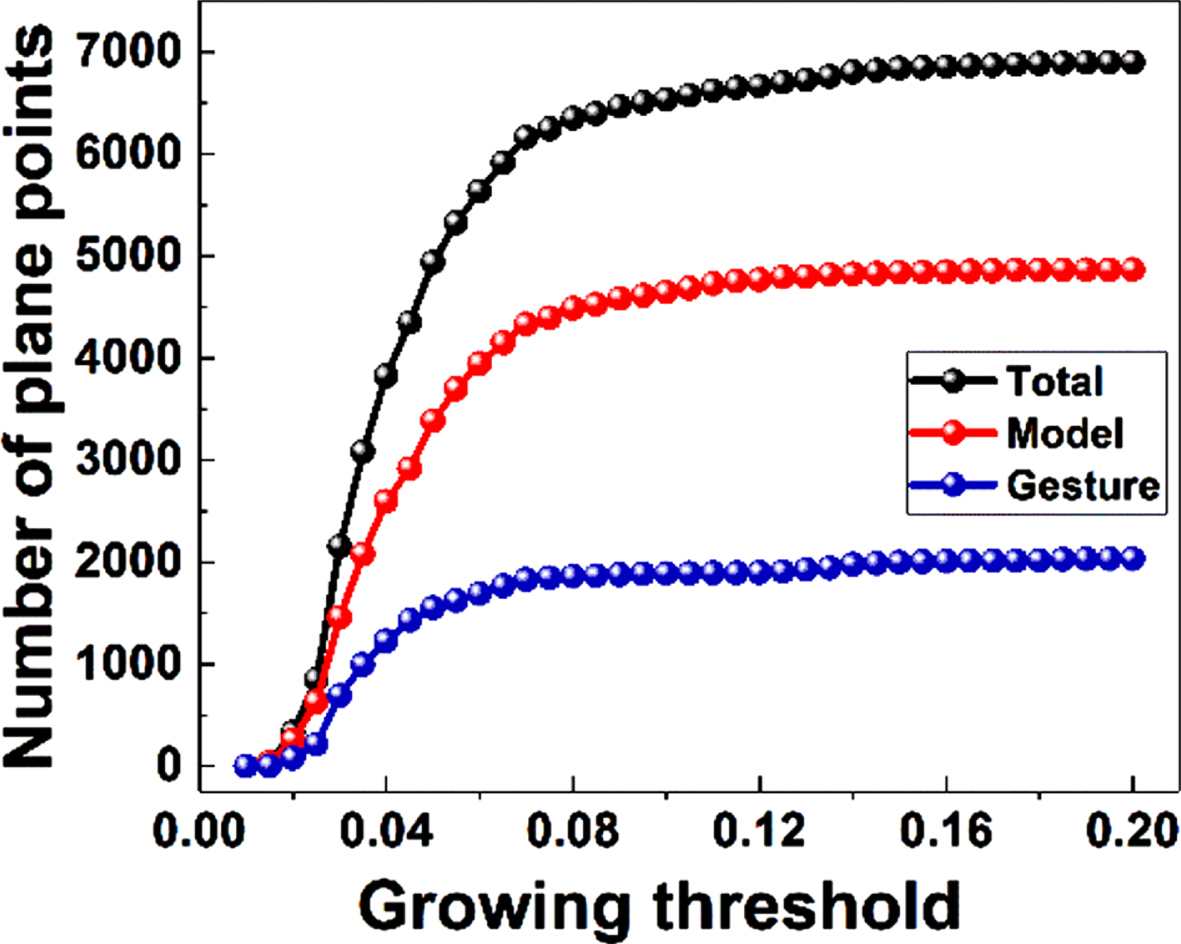
Effect of growing threshold for plane points extraction.
The disadvantage of ICP, which is the discontinuous point cloud is easy to fall into the locally optimal, makes the result of registration uncontrollable. To decrease the influence of incorrect registration, the input point cloud has been divided into 3 parts and weighted by their correct point pair number. Obviously, because of the density difference between input point cloud and template, the registration cannot be perfect. After many tests, we found that for the correct gesture and template, the points that can be correctly registered account for 75% of the total points, so ω was set to 0.7 to control the weight of different part by their correctness of registration.
The NTU dataset included 10 classes of different gestures with cluttered backgrounds, which captured by Microsoft Kinect. Every class has 100 gestures that performed by 10 different subjects with variations including hand scale and orientation. The examples of gestures, corresponding depth maps and contour images are shown in Fig. 14. Since the origin point cloud has not been provided in the dataset, the transformation of depth map to point cloud should be performed firstly.

Gestures in NTU dataset.
The process of camera imaging can be regarded as the coordinate transformation from the world coordinate to image coordinate, and the transformation from depth map to point cloud is reverse. Set the coordinates in depth map to be (u, v), and the coordinate of corresponding point is (x, y, z), we could get:

Template point cloud models of NTU dataset.
Extended finger gestures in NTU dataset
The normal estimation of template models is a critical issue. Compared with gesture point cloud captured by camera, the model point cloud cannot get the right direction of normals by setting a viewpoint. Therefore, a framework is constructed for the normal estimation of models. Building 3D bounding box for the model, and filling the bounding box with voxels; Eliminating the voxels that contain surface point to extract the inner voxels of the model; Use KNN to search the nearest voxel as view point for every point of the model to judge the direction.
The results of the framework are shown in Fig. 16.
To verify the effect of our algorithm on the NTU dataset, experiments were conducted on Intel I7-8750H 2. 2 GHz processer, where the average running time is 1.4 s. The confusion matrix is shown in Table 2, where 100 independent data for each gesture corresponding to Fig. 14 and Table 1 are tested. The results shown in Table 2 indicate the times of gesture recognition. For gestures in NTU dataset, the accuracy of proposed method is over 97%, and the mean accuracy is 98.1%. All gestures included in NTU dataset have natural postures and clear extended fingers, which makes the recognition easier. It means that gestures with simple structure and no self-occlusion can be recognized by this method with high accuracy. Besides, we found that some fingers are occluded or adhered to each other, which makes the extended finger cannot be extracted accurately. This may be caused by improper parameters selection during the conversion from depth map to point cloud.
Confusion matrix of the proposed method

Normal estimation of gesture model: (a) initial model with messy normal direction; (b) voxel box with model surface voxel removed; (c) inner voxel of model; (d) after correction.
We choose some different methods tested on NTU dataset for comparison, as shown in Table 3. It can be seen the proposed method has an advantage in recognition rate compared with these methods. The utilization and appropriate processing of the 3D point cloud achieve a higher recognition accuracy without significantly increasing the running time. Besides, the proposed method has a lower level of abstraction, which means it is easy to change templates to adapt to different scenes.
Accuracy of different methods
In order to verify the feasibility and applicability of the proposed method, real-time experiments are conducted to evaluate the performance. The experimental point clouds are obtained by Stellar-200 depth camera with a 240×180 ToF array, 0.3 m to 2 m measuring distance, and 72° FOV. To distinguish from NTU dataset, Chinese number gestures are used as template. The models of gestures are shown in Fig. 17, and the confusion matrix of the experimental results is listed in Table 4.

Point cloud models of Chinese number gesture.
Confusion matrix of proposed method in Chinese number gestures
As shown in Table 4, the proposed method still maintains a high recognition rate for simple gestures with an average recognition rate of 97.1%, expect G7 all fingers were curled. Theoretically, the extended fingers number of G7 should be 0. However, it is found in experiment that if fingers are excessively curled, the center that obtained by distance transform would be located at the left part of palm, which makes the second fingertip joint of index finger and middle finger both remained after finger extraction and leads to a wrong result. Besides, the curl of fingers also affects PCA, which will cause a slight error in main direction estimation. The proposed method is tested on i7-8750H + Ubuntu 18.04 and Raspberry Pi 3B + Ubuntu-mate 16.04, and average running time are 0.25 s and 0.93 s, respectively. As the results show, the proposed method based on the 3D point cloud has a high recognition rate of hand gesture with acceptable running time comparing with previous works. It can meet the real-time requirements on high performance platform like PC. For the embedded platform like Raspberry Pi, the efficiency of this method can meet simple interaction tasks. Besides, taking full use of 3D information of point cloud, the proposed method may be extended for recognizing other gestures or objects with great distinction in 3D profile.
In this paper, we proposed a method for hand gesture recognition based on template matching of point cloud, which mainly consists of three main steps: pre-classification, normal based plane points extraction, and template matching. Taking point cloud as input, the extended fingers are extracted by distance transform and the number of fingers is counted as a feature for pre-classification, which reduces the matching time and improve the efficiency. Then, after normal estimation, the plane points in both gestures and templates are extracted based on Gaussian mapping and DBSCAN, and the registration errors is used for final diversity evaluation. The proposed method is tested on both NTU dataset and real experiments, and the mean accuracy is over 98% in dataset and 97% in real application. In addition, the proposed method has been tested on different platforms with real application, the average running time consuming for one recognition is 0.25 s on PC and 0.93 s on raspberry Pi. The results show that our method is comparable in accuracy with state-of-the-art methods that use depth map as input, and the efficiency can meet real-time application on computer with a low memory consumption. Because of the characteristic of point cloud, it is also robust to cluttered background and variation of hand scale and orientation. Besides, the proposed method is based on template matching, which has a low abstraction level and does not need training. It means that it’s easier to be transplant and modify templates. Taking full use of 3D information of point cloud data, the proposed method may be extended for recognizing other gestures or objects. The parameters in the proposed algorithm need to be adjusted according to actual application scenarios and input devices, which may limit the applicability of our method. This problem can be solved by reducing the number of parameters, or setting adaptive parameters to enhance the adaptability of the algorithm.
Funding
Research Project of Tianjin Municipal Education Commission (2021KJ006).