
Abstract
Alzheimer’s disease (AD) prediction is a critical task in the field of healthcare, and researchers have been exploring various techniques to improve its accuracy. This research paper focuses on the major contributions of a hybrid deep convolutional neural network (CNN) with denoising using a multilayer perceptron (MLP) and pooling layers in AD prediction. The proposed hybrid model leverages the power of deep CNNs to extract meaningful features from molecular or imaging data related to AD. The model incorporates denoising techniques using MLP to enhance the quality of the input data and reduce noise interference. Additionally, pooling layers are employed to summarize the extracted features and capture their essential characteristics. Several experiments and evaluations were conducted to assess the performance of the proposed model. Comparative analyses were carried out with other techniques such as PCA, CNN, Resnet18, and DCNN. The results were presented in a comparison chart, highlighting the superiority of the hybrid deep CNN with denoising and pooling layers in AD prediction. The research paper further discusses the accuracy, precision, and recall values obtained through the proposed model. These metrics provide insights into the model’s ability to accurately classify AD cases and predict disease progression. Overall, the hybrid deep CNN with denoising using MLP and pooling layers presents a promising approach for AD prediction. The combination of these techniques enables more accurate and reliable predictions, contributing to early detection and improved patient care. The findings of this research contribute to the advancement of AD prediction methodologies and provide valuable insights for future studies in this domain.
Keywords
Introduction
Alzheimer’s disease (AD) is determined a neurologic condition that impairs a patient’s capacity for rational thought, memory, communication, learning new information, and other cognitive skills [1, 2]. Most Alzheimer’s patients are older than 60, generally in their early 60s. Of all physical alterations, brain cell damage is the most severe. The most severely affected brain areas are the amygdala, hippocampus, and a few others that control the majority of the signs of AD [3, 4, 5]. Prior to other grey matter cells being destroyed, learning cells are initially damaged, and leaving the patient unable to carry out even the most fundamental tasks. As a result, those who have Alzheimer’s disease experience severe behavior-related, cognitive, and memory loss [6]. The early 1960s saw AD’s consequences. According to a 2019 “National Institute on Ageing, U.S.A.” study, more than six million Americans have AD [7]. “Alzheimer’s and Dementia Resources” reported that more than four million people in India had AD [8]. The proportion of AD sufferers globally is increasing rapidly and dangerously.
The vast majority of AD patients have reached MCI, the earliest stage of alzheimer [9, 10]. While in a milder form, MCI symptoms are nearly comparable to AD symptoms. The early stages of AD can be referred to as MCI. The majority of individuals with MCI go on to acquire AD, according to a study [10]. Neuron-experts and professionals in psychology perform a variety of psychological and physical tests, involving a health history analyze [11], physical assessment and screening assessments [12], a neurophysiologic evaluation [13], the MMSE [14], an anxiety review [15], and other people. All of these tasks require a variety of tools, which is a lengthy and inefficient procedure.
For acquiring tissue-by-tissue information on the neurological system, the use of MRI, is a common technique [16]. A number of conditions, include cancer, tumours, and others, can be accurately diagnosed by MRI often [17]. Image processing tools can compare cells in AD, MCI, and CN persons. The traditional AD diagnostic method involves a variety of tests, such as physicals, cognitive tests, DNA testing, and so on. The use of brain imaging for AD categorization may be quicker and require fewer tools than the conventional diagnosis method. Additionally, effective brain processing of images may locate important biomarkers years before an individual experiences the onset of Alzheimer’s disease [18]. Conventional image processing methods cannot detect AD due to complicated pixel configurations by analyzing modifications to tissue [19]. The suggested model combines integration methods in machine learning to increase the precision in AD prediction, which is comparable to the data provided above. The following list summarizes the framework’s main contributions:
The model employs a multilayer perceptron (MLP) for denoising, which helps to remove noise and enhance the quality of input data. The denoising procedure is essential for increasing the precision and dependability of AD forecasts. The proposed model significantly improves the accuracy of predictions in the context of deep convolutional neural networks (CNN). By incorporating hybridization techniques, it leverages the strengths of different algorithms and architectures, leading to improved performance in AD prediction. The utilization of pooling layers enables the model to perform downsampling and information compression, reducing the computational complexity and improving efficiency. The hierarchical representation of features learned through pooling layers aids in capturing both local and global patterns, leading to improved AD prediction.
Scientists in the medical professions are increasingly using machine learning. The invention of AD identification and forecasting is one topic of intense focus [17]. Machine learning methods, especially those incorporating biological or image information, may diagnose AD. The most recent developments in deep learning frameworks for AD evaluation and forecasting are examined in this article. A DCNNs algorithm for four-class AD identification utilizing MRI images was created by Islam and Zhang [18]. On the OASIS a database, they trained and assessed the Inception-V4 approach, yielding an accuracy of 73.70%. The precision of this mathematical framework was constrained, nonetheless, by the dearth of accessible data. An extremely learning machine -based classification framework for bilateral AD was put out by Zhang et al. [19]. Voxel-based morphology pictures representing 627 patients in the ADNI collection were individually separated.
Shanmugam et al. [20] developed the first transferable learning-based technique for multi-class diagnosis of AD phases and cognitive decline. They developed and evaluated the GoogLeNet, AlexNet, and ResNet-18 networks using 6000 MRI scans from the ADNI collection. The ResNet-18 networks obtained an identification precision of 98.63%, which was the highest. Kong et al. [21] created a specific PET-MRI combining images and a 3D CNN for the deep learning multi-classification of AD. 740 different 3D photos from the ADNI database were used in total. The research suggested utilizing the A3C-TL-GTO algorithm to categorize MRI scans and detect AD. The empirical methodology A3C-TL-GTO for automated and effective AD detection was built and tested using the Alzheimer’s Database (four image classes) and the ADNI.
These papers show how deep learning approaches are still being used to diagnose and predict AD. DCNN, ELM, and model transfers have been tested on imaging databases. These developments aid in the creation of computerized and accurate AD categorization techniques. Alzheimer’s disease (AD) was sourced from publicly available databases such as the Alzheimer’s Disease Neuroimaging Initiative (ADNI), the Australian Imaging, Biomarker & Lifestyle Flagship Study of Ageing (AIBL), and the National Alzheimer’s Coordinating Center (NACC) database. Reduce pre-processing bias and fine-tuning volatility in model classification and information sets using the provided method. It uses MRI-validated methodologies to improve patient care. The research uses MRI brain images from the ADNI’s online Alzheimer’s disease database. Experimental findings show that the recommended strategy is 96.65% accurate on the Alzheimer’s Database and 96.25% accurate on the ADNI Database. The databases’ lack of illustrations raises the possibility of excessive fitting, which reduces the efficiency of models built using deep learning. Orouskhani et al. [22] provide a few-shot learning approach termed deep metrics tracking to overcome this difficulty. They present a unique deep triplet networks that evaluates brain MRIs and detects Alzheimer’s disease via the use of measurement learning. The deep a triplet matrix uses an adaptive function for loss that helps enhance the accuracy of the model and adjust for low data from training. The model’s primary network design depends on the VGG16 system, and tests are carried out utilizing openly accessible imaging research datasets like OASIS. The suggested studies uses the hybrid model for estimating and improve a CNN building layout utilizing a multiobjective functional and several hyperparameters.
Proposed methodology for AD prediction
Preprocessing of data using MLP
Both the real and fake sections of the image are affected by Gaussian distribution noise, which distorts the MR magnitude image. Gaussian noise was added to the input data during training to introduce a controlled level of randomness, encouraging the model to learn more robust and generalizable features. Dropout, on the other hand, was applied within the MLP layers to prevent overfitting and enhance the network’s ability to denoise by training it with partial information. This combination improved the quality of the input data by reducing overfitting and making the model more resilient to noise, ultimately resulting in more accurate and reliable predictions. The probability variation in noisy MRI pixel brightness is a Rician distribution, according to earlier studies. DL can replicate this type of corruption by learning from examples using Multi-Layer Perceptron (MLPs), without considering the underlying physical process. The MLP is trained using the noisy and clean image pairs. The input to the MLP is the noisy image, and the output is the denoised image. During training, the network adjusts its internal parameters (weights and biases) based on the comparison between the denoised output and the corresponding clean image.
The Eq. (1) represents the relationship between the noise-free picture (
The suggested DCNN framework for MR image processing includes three parts: the reconstruction (REC) element, a local feature collection network, and a global feature extracting networks. Figure 1 depicts the pipeline for denoising. DeepCNet and DeepSCNet are used in the beginning stages to extract both regional and global characteristics.
Denoising cum Feature extraction module.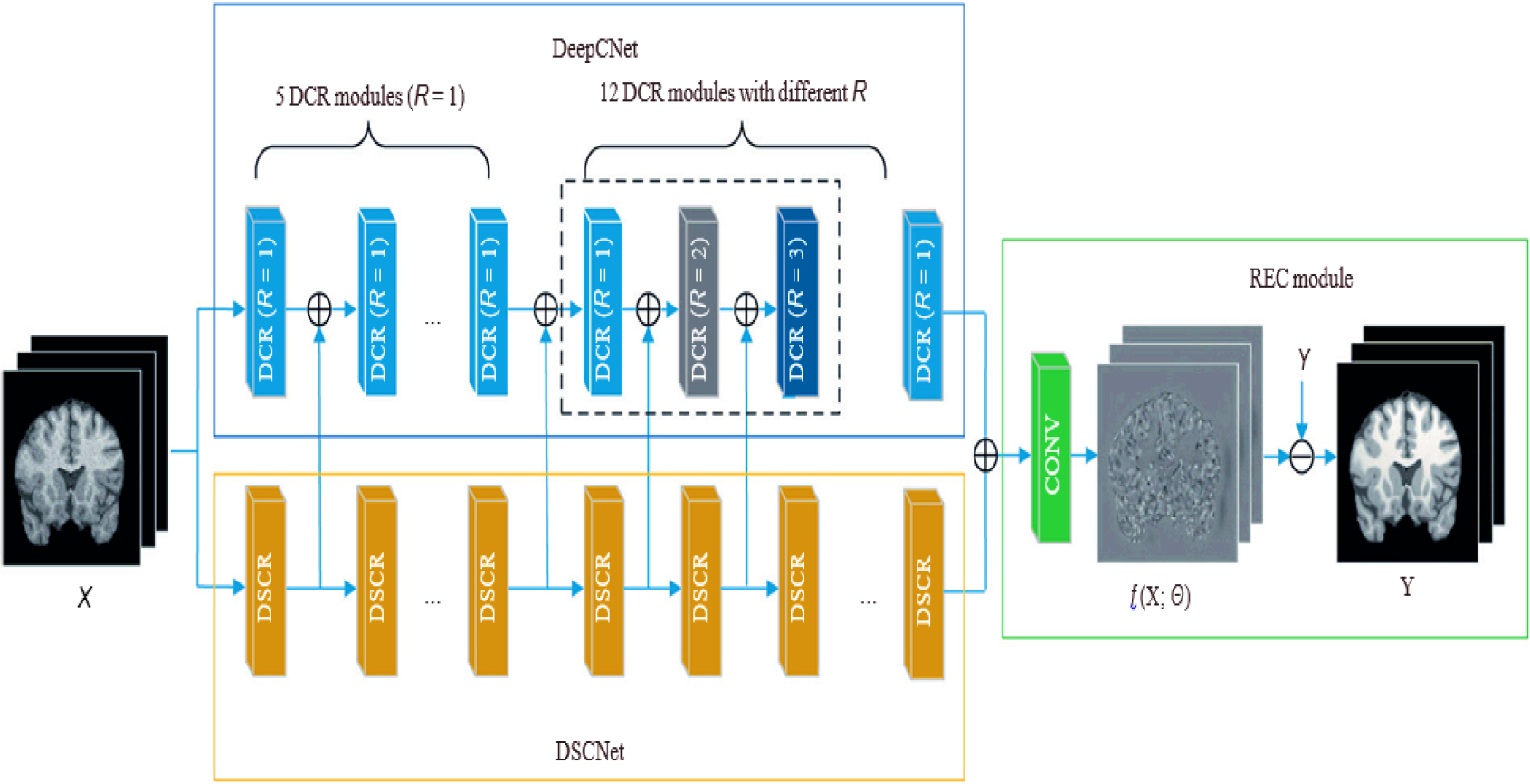
The local as well as global data are then combined using a second layer, producing detailed features that accurately match the properties of the genuine Rician pattern. We produce the anticipated clear magnetic resonance image X using the REC component. The proposed architecture is made up of 18 sequential DCR sections with different R values, collectively called as DCRNet. A kernel size of 33333 is used for 2D slices and 3D patches. Dilated convolution with a high R value proves effective in attenuating low-frequency noise. However, excessively large R values hinder the capture of subtle contextual details, leading to wasted receptive fields. Setting R to 1 ensures each channel retains the same convolution as before. In DeepCNet, we equally pad zeros across borders before convolution to match a map of features size with inputs. As the thickness of the convolutional layers increases, the receptive field size progressively expands. Dilated convolution is associated with a gridding issue, as mentioned in reference [26, 27]. In our investigation, we used DCR units with varying dilatation velocities to solve this issue. The dilation speeds for every layer are individually determined by the following method: 1, 1, 1, 1, 1, 1, 2, 3, 1, 2, 3, and 1 result in a 61-square-meter total reception area. Multiple DCR components with different dilation rates allow multiscale universal feature determination. Each module contains 16 filters, and this implementation helps mitigate the influence of irrelevant information and prevents the occurrence of gridding effects.
DeepSCNet compensates for ignored nearby data by widening the receptive area. DeepSCNet’s cascades is made up of 18 DSCR components, for every uses a 3
To gradually integrate global and local information, we combine the characteristics gathered from each module of DeepCNet and DeepSCNet. By using this strategy, significant visual characteristics are preserved in both local as well as global areas. As a result, the 3D-Parallel-RicianNet architecture is more effective than previous eliminating techniques. In the pipeline, the REC module is essential. It calculates the estimated deviation,
Loss of function
It measures the discrepancy between the denoised output and the corresponding clean image. Mean squared error (MSE) is a commonly used loss function for image denoising:
where:
We suggest a brand-new CNN algorithm that combines the fundamental ideas of both ResNet and Inception systems. Our approach integrates the ResNet paradigm with the Inception framework utilizing the positive aspects of these two topologies. Previous research has shown that the ResNet and Inception algorithms can manage hundreds of thousands of levels with exceptional effectiveness and performance.
These blocks enable the network to learn residual connections and facilitate training of very deep networks. On the other hand, the Inception model is composed of several convolutional networks that form a deep convolutional network. This architecture allows the model to capture multi-scale features and enhance its representational power.
By combining these concepts, our proposed CNN model aims to leverage the benefits of both ResNet and Inception models, resulting in improved performance and efficiency.
Proposed hybrid CNN with ResNet18-Inception model.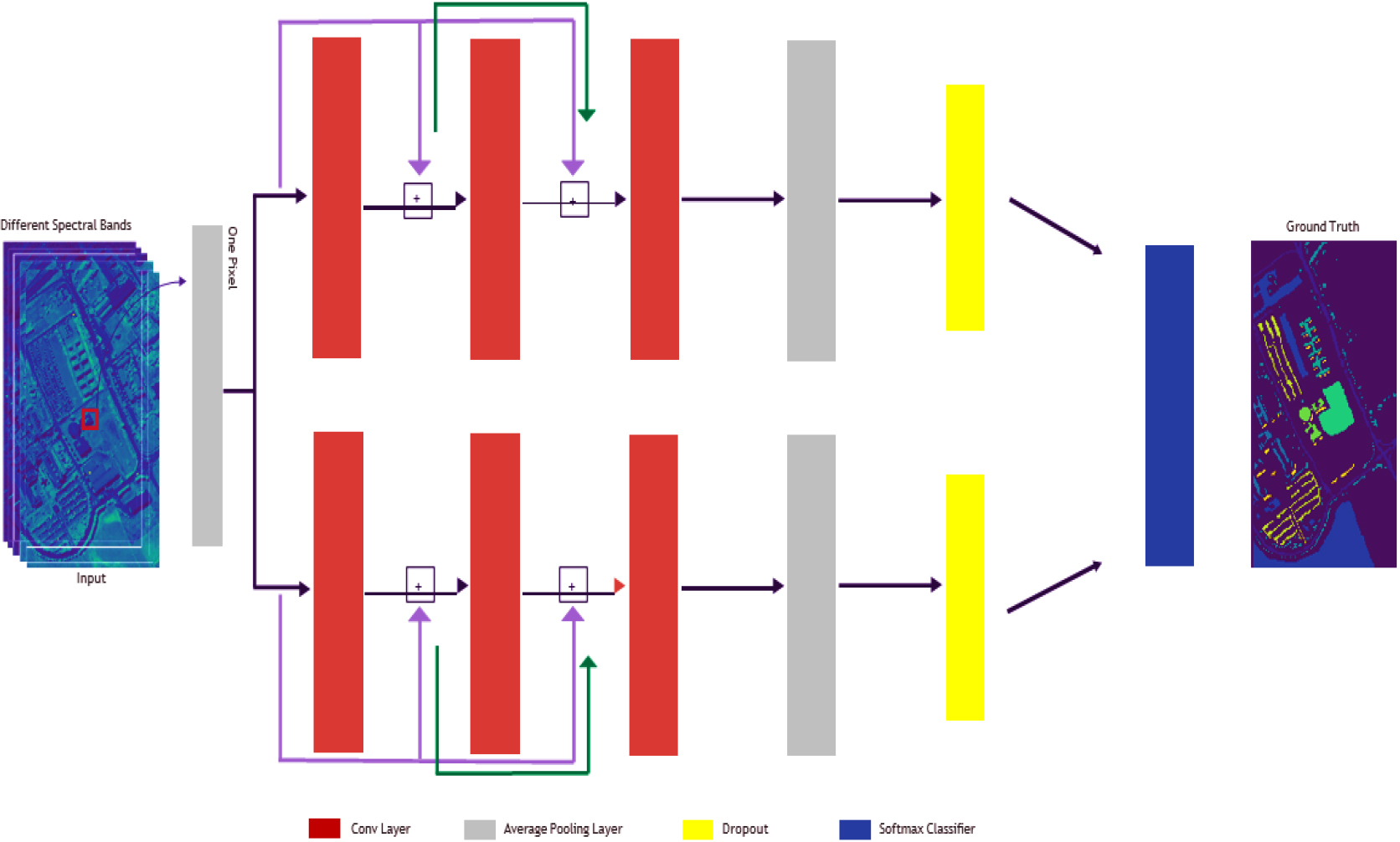
The goal of hyperspectral imaging (HSI) categorization is to categorize each pixel’s land cover according to its various frequency bands. In this study, we introduce a deep hypernetwork framework that facilitates deep HSI component development effectively without the need for additional datasets or laborious preprocessing.
Figure 2 illustrates our initial hybrid architecture, which combines elements from both ResNet and Inception networks. Two leftover blocks make up the suggested construction, as seen in Fig. 2. Three layers of convolution will be followed by a standard pooling layer. Each layer’s output is used as the input for the subsequent layer, creating a cascaded structure. Within this architecture, a single fully connected cascaded residual block is employed, where information from the layer of convolution before it is received by the subsequent layer of convolution. We found that the three layers of convolution are the best number for our model via empirical assessment.
The final pooling layer performs average pooling on the data and then passes it to the classifier. Contrarily, the convolutional layers perform operations called convolution on the supplied information. We use the Adam optimization approach (Kingma and Ba, 2014) instead of stochastic gradient descent to improve network optimization effectiveness. The Adam algorithm for optimization has benefits including computational efficacy and interference resistance.
We optimized the teaching method by setting the starting rate of learning to 0.001 and the batch size to 17 for the College of Pavia a database, Salinas a database, and Pavia Center scene database.
After convolution, the convolutional layers use the ReLU function to change the information. Three convolutional layers, each with nine kernels (filters), provide nine maps of features. Equation (3) explains kernel functioning.
The
Our suggested model comprises 16 units per layer of convolutional neural networks (1D convolution frame) and 9 layers each layer. The convolution process uses a stride length of one. We use the Glorot uniform (Xavier) value inflation approach, as advised by Glorot and Bengio (2010), for setting the weightings (kernels) of the layers of convolutional neural networks. Initial values of zero are used for biased components.
The ReLU activating operation, which performs an element-wise action on the given input information
Because they are better suited to the architecture of the HSI information, we decided to utilize 1D convolutional kernels rather than 2D or 3D kernels. The format of the HSI information is such that every pixel and the associated band can be saved as one vector with only one label. Our approach includes two remainder estimates that are finally coupled.
Equations (5) to (8) describes how the higher residual model works:
The below equations represents the formulation of the lower residual model.
Inspired by the parallelism feature of the Inception module, we incorporate it into our architecture, enabling the simultaneous operation of the top and lower residual models, which eventually merge. The first three lines in every formula describe data pooling. Following transferring the outcomes of the third layers of convolution (X3 and X03) to the average pooled level, we employ the dropout approach. Additional details on the mean pooled and dropouts methods are provided in the next section.
Our approach uses a pooling layer for a typical pooling with a filter’s size of 2 with a stride width of 2. The typical pooled process is carried out by this layer. The average pooled functional is described in Eq. (13).
We include an average layer of pooling which executes the average pooling procedure in our framework. This process, designated as AvgP, uses the input data
The first level of convolution comprises 153 parameters that can be trained The second and third layer of convolutional neural networks contain 1,305 parameters to train apiece. The penultimate FC layer comprises 4,140 parameters to train for the University of Pavia database and the Pavia Central scene database. There nonetheless exist 8,109 parameters that may be trained in the Indian Pines database and 14,704 for the Salinas database. This discrepancy results from the many result classifications included in each dataset. There are nine categories of output in the University of Pavia and Pavia Centre scenario information sets, 16 in the Salinas a database, and 8 in the Indian Pines database.
In total, for the University of Pavia and Pavia Centre scene datasets, there are 8,208 trainable parameters. The Indian Pines database has 10,872 parameters that are trainable, whereas the Salinas database has 18,772. Our goal is to minimize the loss functional during training stage, as shown in Fig. 3a, in order to maximize the efficiency of the model’s parameters. The chart shows that our algorithm efficiently arrived at a regional minimum in only 50 iterations. The convergence of our model can be observed by examining the training and testing accuracies, which are presented in Fig. 3b.
A second test dataset made up of 512 MRI scans and 112 PET images is used to evaluate the effectiveness and generalization of the suggested methods. This test a database, which is different from the source information set, makes up 60% of the total amount of information. This test database is being used to assess the model’s capacity to predict outcomes accurately for fresh information. The categories in the two collections are tiered to guarantee the same representation.
For the results presented in Table 1, the hybridized model is rigorously evaluated and assessed over 20 epochs to ensure the dependability and outcomes.
Data obtained from 20 epochs is analyzed to examine the loss of training and techniques of test accuracy
Data obtained from 20 epochs is analyzed to examine the loss of training and techniques of test accuracy
Showcases the progression of our model’s performance during the convergence phase. Subfigure (a) displays the changes in the loss function, indicating how it is minimized over time. In subfigure (b), the corresponding accuracy values for both training and testing data are depicted, illustrating the model’s improvement as it converges.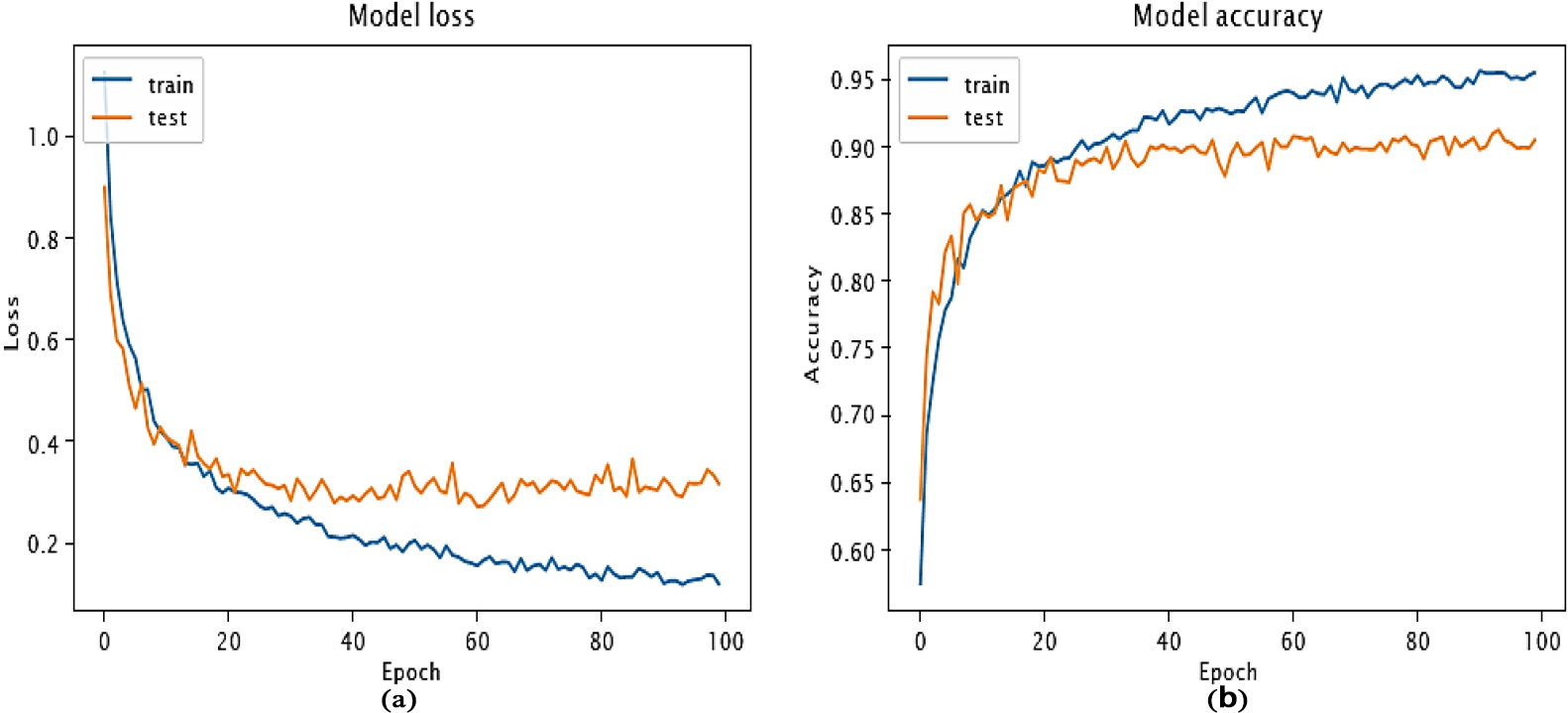
The proposed model achieves a high level of accuracy on the test dataset, with a standard accuracy of 92.8% and 98.5%. With a median range from 0.80 to 0.83 for the ROC & AUC the model operates even better. Figure 4’s boxplots show that conversion and risk classification have equivalent correctness and ROC. In comparison to risk, the specific conversions ratios vary from 7.6% to 92.76%.
In terms of identifying patients with progressing mild cognitive impairment (pMCI) and estimating the time to admission, the model outperforms random categorization. The combined model is 19.8% more accurate than probability in discriminating pMCI from stabilized MCI (sMCI). Furthermore, the model more reliably places patients with pMCI in the category with the shortest duration to treatment by 33.89% when contrasted with random error. The goal of this project is to create a hybrid CNN system that can tell people with moderate cognitive decline and AD apart from those who are steady. The suggested model also takes taken into consideration how long it generally takes for AD to develop by putting people into various categories of risk depending on whether they are likely to develop AD inside 24 months (high risk), outside 24 months (low risk), or not at all (sMCI).
The baseline measurements used in this study are obtained from the initial visit of each individual, providing an accurate representation of their initial healthcare encounter.
AD diagnosis using pre-imaging database values.
The suggested hybrid model includes a number of cutting-edge, outstanding durability methods. Recent developments in preprocessing and ML techniques, especially for early AD forecasting investigation, are covered in a literature analysis that was undertaken. Many existing approaches for pMCI & sMCI include MRI image analysis as part of their preprocessing pipeline. Furthermore, the successful results achieved, with cross-validation accuracy and area under the curve (AUC) above 80%, can be attributed to domain learning. Domain acquisition entails the extraction of useful auxiliary traits from a related area, such as the classification of AD patients vs intellectually healthy people. Each study that makes use of domain expertise raises the validity of the results.
Performance comparison
MRI image categorization results reveal classification 0 as no Alzheimer’s disease and classification 1 as an Alzheimer-afflicted brain.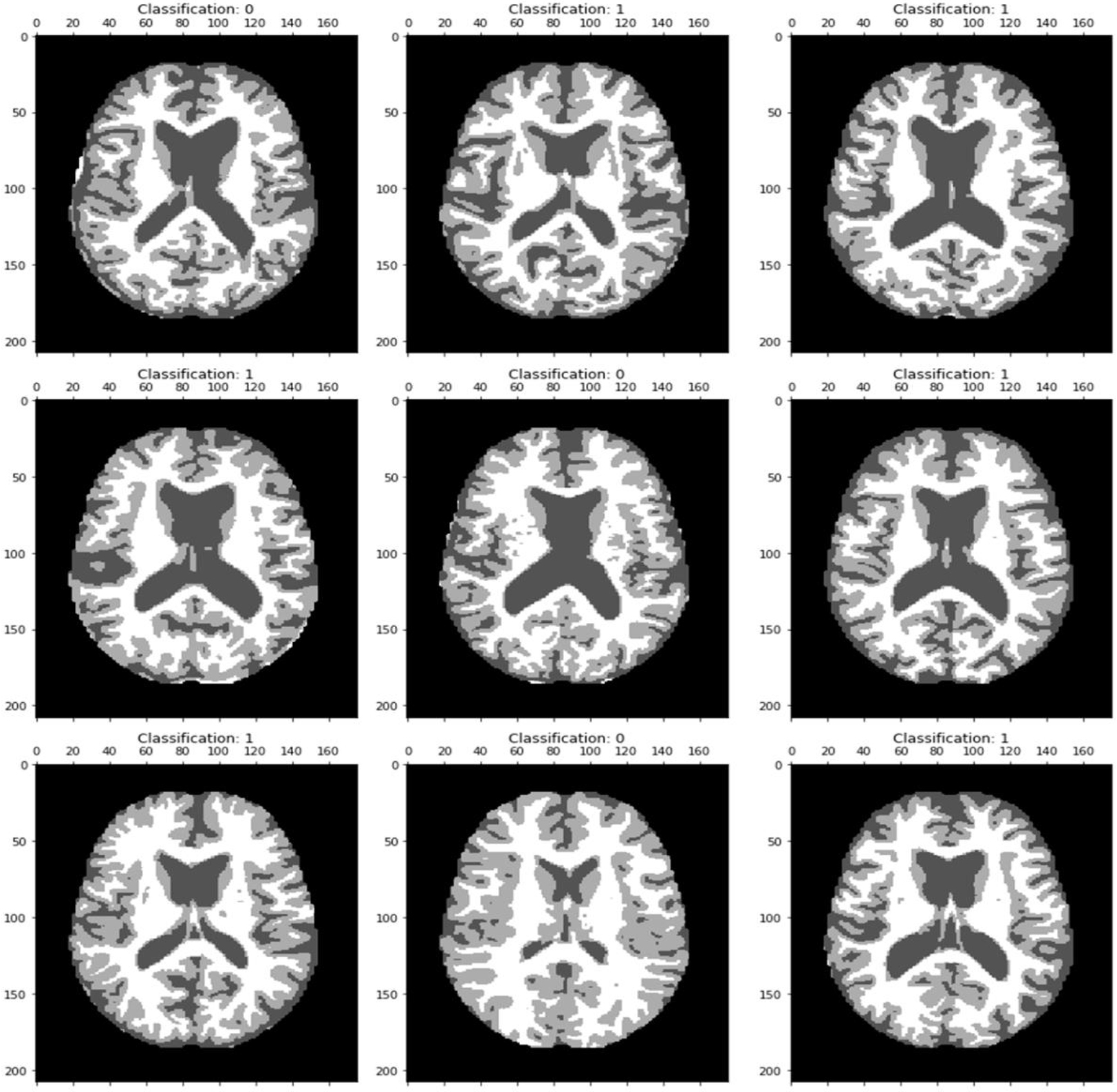
ROC curve with 0.82 TPR & FPR.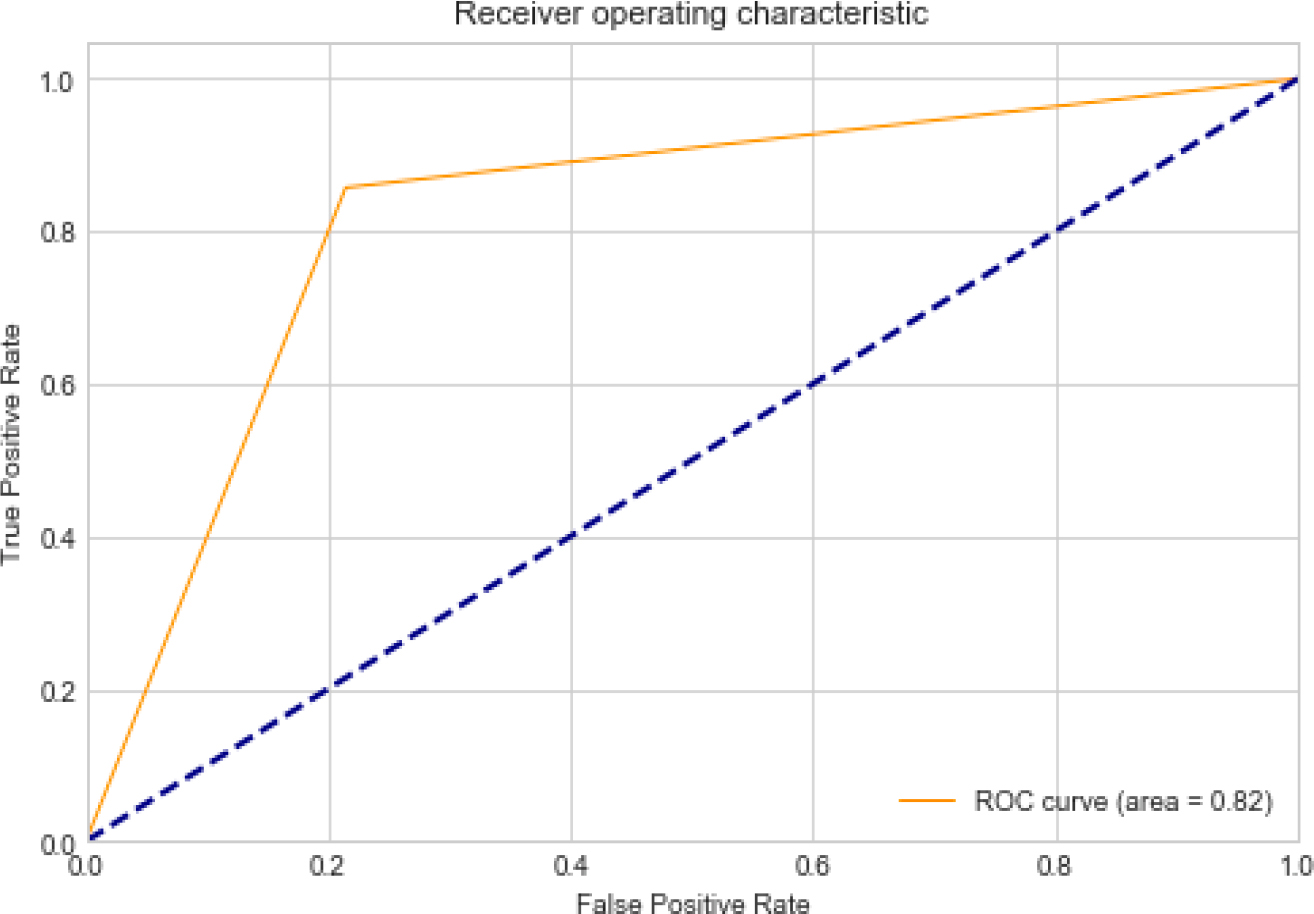
A first 20 epochs’ validation and training loss reveal a constant difference, pointing to a well-fitted curve.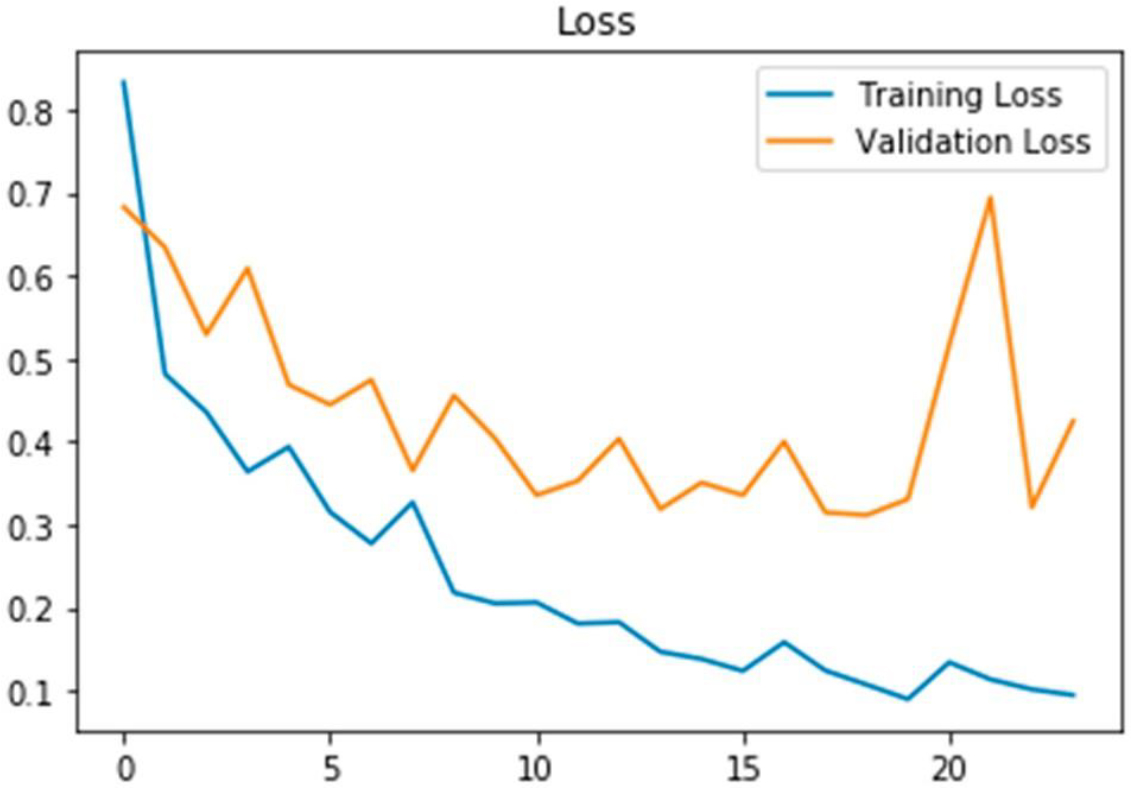
A good fit model is demonstrated by both the training and validation accuracy values having the smallest difference between them.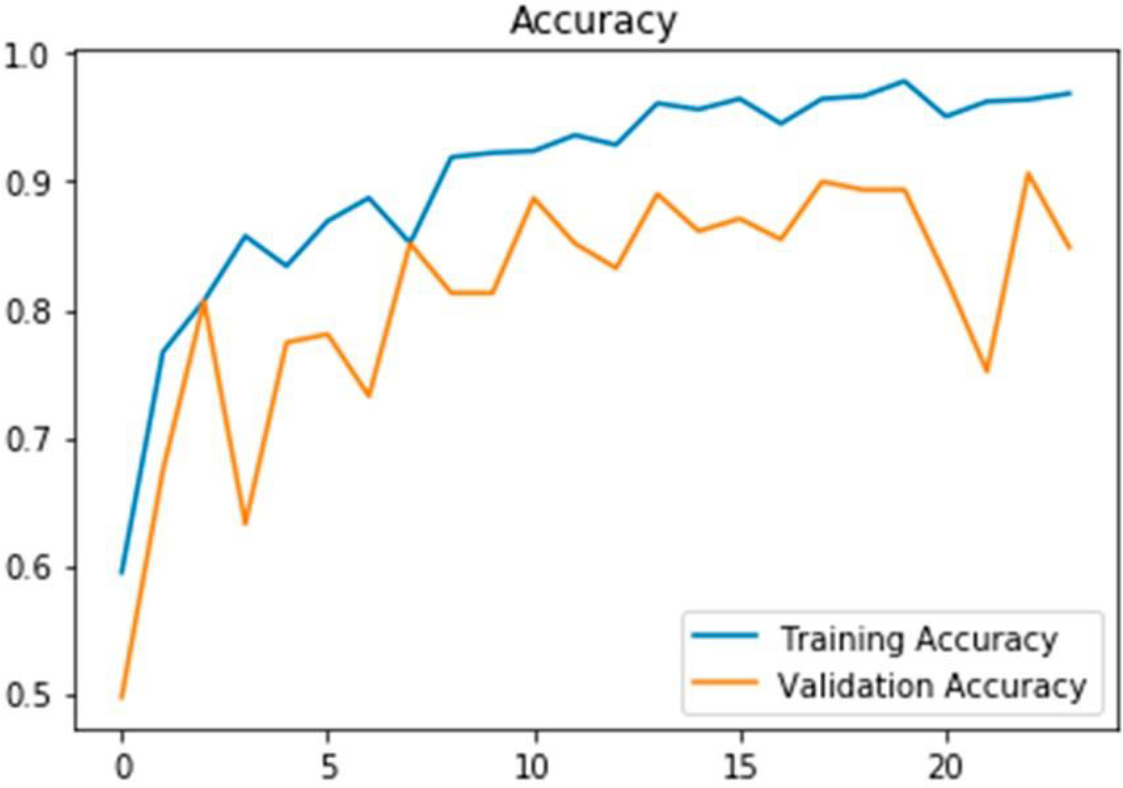
Performance comparison of proposed model.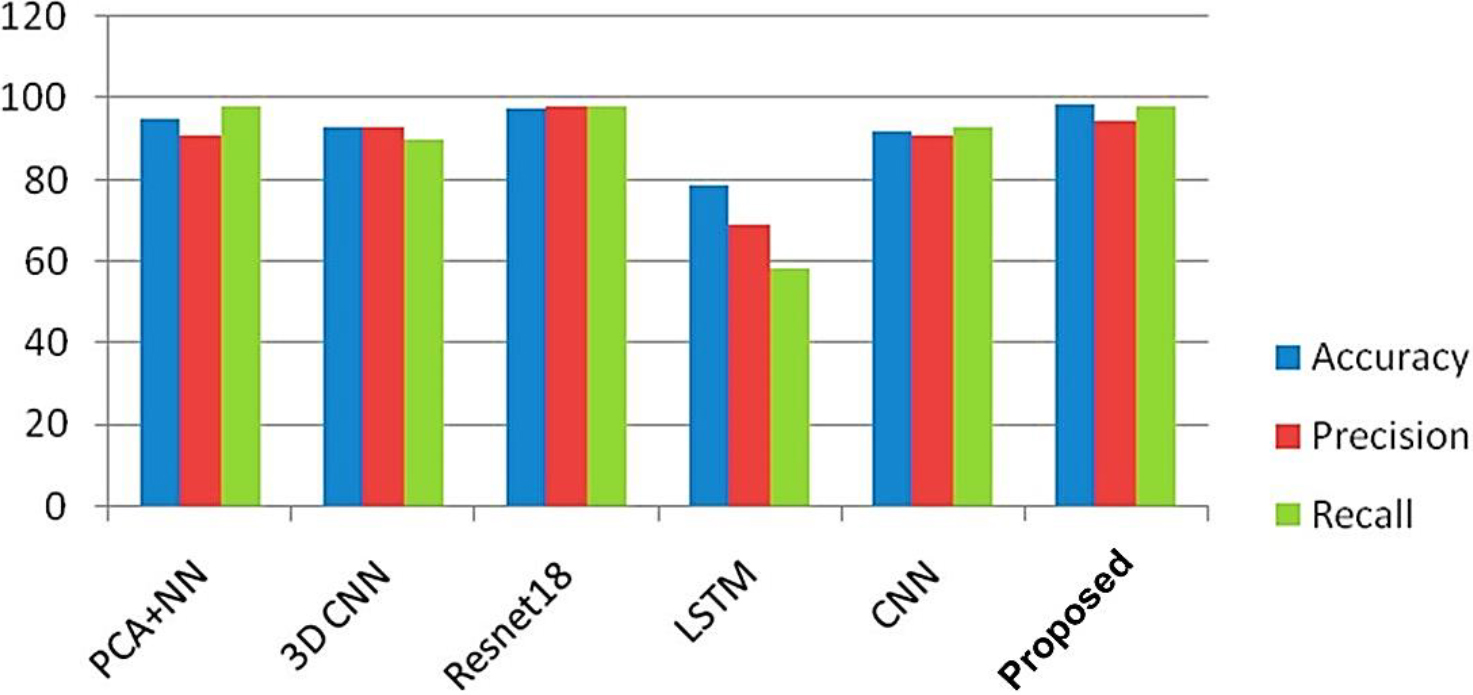
Figure 5 presents the findings of the MRI image classification, where dementia is categorized in specific locations within the images. The link between the TPR & FPR is shown by the ROC curve, which is shown in Fig. 6. It offers a graphic depiction of how well the suggested approach performs in differentiating between events that are positive or negative. With the help of Fig. 7, which shows the loss of training & validity over the course of 20 epochs, it is possible to assess how the model is progressing in its learning process and how well it can generalize to new data. The model’s performance on the training and validation datasets is demonstrated in Fig. 8 by the training and validation accuracy after 20 iterations, which demonstrates how well the model works over time. The performance of various techniques, such as PCA, CNN, Resnet18, and DCNN, has been compared to the proposed model. The comparison results are presented in Fig. 9, which provides a visual representation of the performance metrics.
The creation of a mixture of models effectively satisfies the paper’s goals since it can detect the change from stability to progressive MCI and make better forecasts about how long AD will continue for. The outcomes of Multi-validation DL, however, emphasize the necessity for more work on the framework of the model and hyperparameter optimization techniques. Given the restricted information and requirements, enhancing the extraction of features and performance involves altering these processes. In a field with little information, obtaining the best possible use of it is vital.
Domain learning has shown promise in enhancing model performance, as evidenced by the number of publications employing this strategy. While training the model’s weights to detect auxiliary AD categories alongside non-AD categories may not immediately improve efficiency on the core issue, it could accelerate resolution and minimize training time. Brain partitioning is an additional tactic that may be used to enhance efficiency. More accurate data may be gleaned from certain brain regions (temporal, parietal, prefrontal, and occipital) utilizing parallel 3-D convolutional layers of data, thereby condensing the complicated structure of features. This approach could simplify the identification of valuable features within a smaller feature area.
In summary, the goal of this research was to increase the precision of AD predictions using a hybrid model that combines CNNs and denoising methods with a MLP. We evaluated the effectiveness of our suggested model in comparison to a number of different techniques, such as PCA with NN, 3D
In future study, greater and more varied information could potentially be used to test the blended model’s generalization and resilience. Additionally, fine-tuning and optimization of the model’s hyperparameters could be explored to further improve its performance.