
Abstract
In natural language understanding, a crucial goal is correctly interpreting open-textured phrases. In practice, disagreements over the meanings of open-textured phrases are often resolved through the generation and evaluation of interpretive arguments, arguments designed to support or attack a specific interpretation of an expression within a document. In this paper, we discuss some of our work towards the goal of automatically generating and evaluating interpretive arguments. We have curated a set of rules from the code of ethics of various professional organizations and a set of associated scenarios that are ambiguous with respect to some open-textured phrase within the rule. We collected and evaluated arguments from both human annotators and state-of-the-art generative language models in order to determine the relative quality and persuasiveness of both sets of arguments. Finally, we performed a Turing test-inspired study in order to assess whether human annotators can tell the difference between human arguments and machine-generated arguments. The results show that machine-generated arguments, when prompted a certain way, can be consistently rated as more convincing than human-generated arguments, and to the untrained eye, the machine-generated arguments can convincingly sound human-like.
.Introduction
Natural languages are optimized for flexibility and expressiveness in order to adapt to ever-changing human needs. The expressiveness of language allows for new ideas to be expressed, and the flexibility of language allows for the application of statements to new contexts. This flexibility is especially apparent when it comes to the specification of rules, such as those seen in laws, contracts, codes of conduct, and so on – a certain amount of flexibility in the allowed interpretations of terms in rules can ensure that the rule can be applied to new scenarios which may not have been conceived of by the rule writers.
This feature of the language used by rule systems has been referred to as “open-texturedness” [9,41]. A natural language phrase is open-textured when there “always remains a set of (perhaps remote) possibilities under which there would be no right answer to the question of whether it applies” [3]. For example, consider the rule: “A teacher must behave in a manner that brings respect to their school and their profession.” The phrase ‘brings respect’ in this context is open-textured, as it is not very clear what this expression entails in all situations, and there always remains a set of circumstances where its applicability is an open question. It is implausible to exhaustively list an exception-free accounting of all possible scenarios and conditions that can be considered instances of this open-textured term, and such an attempt would inevitably limit the scope of the rule, making it inflexible in the face of unanticipated situations [7,9,18,19,29,31,40]. In order to decide whether a specific action conforms to or violates this rule, a process of interpretation must take place. One of the techniques to interpret texts is to generate different arguments for and against specific interpretations and assume that the interpretation that is supported by the strongest arguments is the correct interpretation. Such arguments are called interpretive arguments [19,22,23,33,35,44,45].
Formally, interpretive arguments are of the form: “If expression E occurs in document D, E has a setting of S, and E would fit this setting of S by having interpretation
We, therefore, focus specifically on interpretive argumentation in this paper. Our starting point is the game Aporia, created specifically to elicit interpretive argumentation so that it could be collected and studied [24]. We curated a set of rules from the code of ethics of various professional organizations and a set of associated scenarios that are ambiguous with respect to some open-textured phrase within the rule. Those scenarios were selected to allow for good arguments to be made on both sides of the issue (so that the issue would not be one-sided) and to allow both sides to plausibly win the argument. We also collected and evaluated arguments from both human annotators and OpenAI’s GPT-3 in order to find out the relative quality and persuasiveness of both sets of arguments. Figure 1 shows the general structure of the dataset created for this task.1 We carried out human studies where human annotators evaluated 5 different arguments for a specific scenario and a specific stance (i.e., arguments for either compliance or non-compliance with the given rule) for a number of scenario-stance pairs on a 5-point Likert scale. Finally, we performed a simplified version of the Turing test in order to assess if human annotators can tell the difference between human arguments and machine-generated arguments. Further details will be discussed in the

An exemplar of an interpretive argument. In this case, the argument is that the rule should be interpreted in such a way that the scenario will be considered an instance of the concept represented by the ambiguous phrase.
Our experimental setup was designed to answer the following research questions:
The contributions in this paper include:
An experimental design and associated surveys that can be used to assess and compare the persuasiveness of interpretive arguments generated by LLMs. The experimental design is used to evaluate OpenAI’s GPT-3 performance, and can be used to assess future LLMs in order to evaluate improvements and identify potential regressions. A dataset of human interpretive arguments for and against compliance of the aforementioned scenarios with respect to the ambiguous rule. A dataset of machine-generated interpretive arguments using different LLMs for the same set of scenarios. A dataset of human evaluations of all the aforementioned interpretive arguments. Datasets for testing annotators’ ability to tell the difference between human- and machine-generated interpretive arguments. Our findings demonstrate that interpretive arguments generated by SOTA LLMs are rated as more convincing than (non-expert) human interpretive arguments. Our findings demonstrate that non-expert human annotators, with no prior exposure to human and machine-generated arguments, are unable to distinguish between the two. This suggests that SOTA LLMs exhibit a level of fluency and human-like diction that convincingly mirrors humans.
Studying interpretive argumentation with Aporia. Aporia [24] is a game that pits players against each other in a competition to argue whether an open-textured rule applies to a scenario. The game is designed to be fun in order to encourage eager participation and obtain useful datasets of interpretive arguments. The Aporia game was developed with the express purpose of being a framework to automate reasoning about, and iteratively reducing, ambiguity in open-textured text. This framework is also designed to provide structure to the process of generating training data for interpretive argumentation through human gameplay or automated text generation.
The game can be played by any group of three or more people. It is recommended to be played with six players. The game is played in rounds. At the end of each round, points will be awarded to the winner. In each round, two players are randomly chosen to play against each other, with a third player designated as a judge. The gameflow is as follows:
Each round starts with a tuple consisting of:
Profession Rule that members of that profession are expected to follow. The rule must contain at least one open-textured phrase, which introduces ambiguity in its interpretation. Scenario describing an action taken by a member of that profession. The scenario is crafted to leverage the ambiguity of the associated rule. Player 1 chooses which side to argue for (stance); either the professional acted in a way that complies with the rule, or their actions were non-compliant. Player 1 provides an argument for their chosen stance Player 2 provides a counterargument Judge declares the winner Judge provides an explanation for their decision
Figure 2 shows an overview of Aporia as a framework. The players (including the judge) take as inputs the information for the current round of the game and generate arguments, judgments, and explanations as necessary to complete one training example. The players may optionally have access to previous game rounds that allow them to review existing data that they may use to improve their current arguments. Access to previous rounds is especially useful for automated argument generation, as they may be used for few-shot learning or other strategies to improve argument generation over time. Figure 3 shows a partial screenshot of the Aporia game in action.
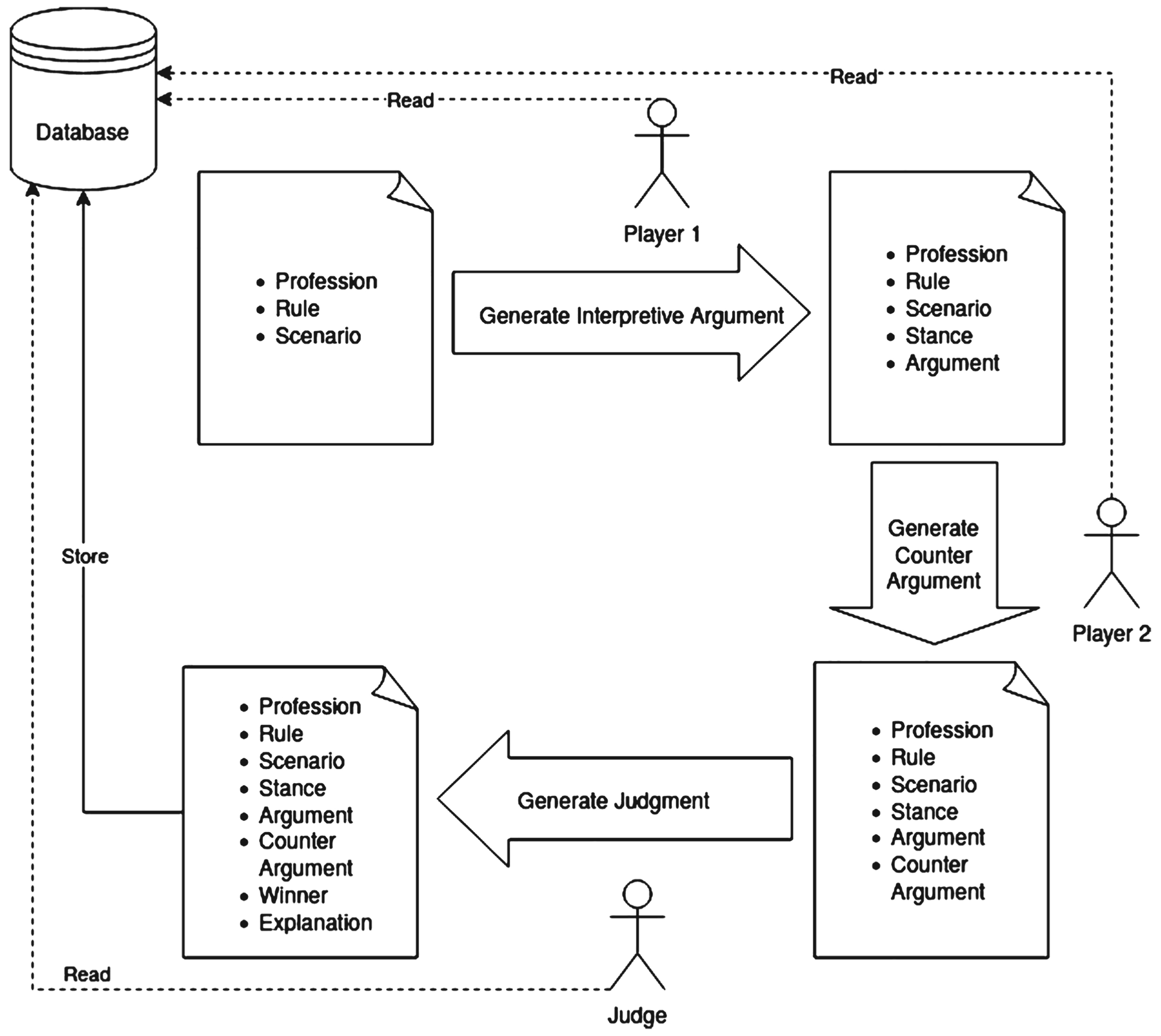
Aporia as a framework.

An example of Aporia after a round is complete.
In the paper introducing this game [24], a human study was conducted where human participants were invited to play the game using a set of rules and scenarios collected in a previous human study [19]. The data shows a clear preference for participants to argue for compliance (ie. the professional’s actions were compliant with the rule), and a tendency for arguments in favor of compliance to win. These findings indicate that the scenarios were not perfectly balanced. A balanced scenario in this context means that both sides of the argument are equally plausible, leading participants to choose to defend either side with roughly similar likelihood and having a similar chance to win the argument on either side. Moreover, many scenarios had issues where the source of the ambiguity in the scenarios was not directly caused by the ambiguity in the open-textured language of the rule. For example, many scenarios lacked essential facts about the scenario, which was the primary source of ambiguity. Those issues were present in some of the arguments that the players used. For those reasons, we decided in the present study to use the same set of rules from the original dataset, discard the provided scenarios, and generate new scenarios while paying closer attention to balance in order to avoid the aforementioned issues.
In another human study that used this game and its associated dataset, the impact of certain cognitive biases on persuasion [6] was studied where the empirical results show that human participants tended to rate the same argument as more persuasive if the participants were led to believe that a woman or a White person wrote the argument. These results indicate that cognitive biases may have non-negligible effects on persuasion.
Argument generation using LLMs. Large Language Models (LLMs) are statistical models (typically, artificial neural networks using the Transformer architecture [39,49]) trained on vast amounts of textual data collected from various sources. Specifically, generative LLMs are trained to predict the next word (or, more accurately, the next token) following a certain excerpt of text. Given a sequence of words (tokens), the LLM will produce a pseudo-probability distribution over all the possible next tokens. The next token is then selected based on the token with the highest pseudo-probability or using a weighted sampling strategy. Using this approach iteratively, LLMs are used to generate text by feeding them an initial excerpt of text (commonly called a prompt) and repeatedly predicting the next token, one token at a time. A textual response can be constructed by iterating this process until a special token indicating the end of the response is generated.
Large language models can effectively capture patterns, structures, and knowledge in the training data. When prompted with questions or tasks, they generate responses based on the learned knowledge and patterns [14,20,32,47]. This led to a new trend in learning paradigms that has emerged since the advent of generative LLMs called ‘pre-train, prompt, predict’ [20]. One of the main advantages of this paradigm is that it substantially reduces the need for large task-specific datasets that are required in the supervised learning paradigm. This paradigm is commonly referred to as prompt-based learning. Due to the knowledge embedded in LLMs, they were found to perform well on many tasks without any task-specific training data. These recent advancements in the learning paradigm were essential to enable this work, as the supervised learning paradigm has been prohibitively challenging, as the scarcity of training data on interpretive argumentation and the costs associated with collecting such training data in vast quantities using human studies or other means has stifled the ability to produce high-quality interpretive arguments. Prompt-based learning has been instrumental in overcoming those challenges and has enabled huge advancements in this area of research.
When machines are able to perform tasks without being specifically trained on those tasks, the machine is said to perform zero-shot learning. For example, to solve a sentiment analysis problem in a zero-shot setting, we can prompt an LLM (such as OpenAI’s GPT-3 [4]) with the text: “I have been stuck in traffic for over an hour. I feel so ___”. We presume that the model will generate an appropriate sentiment as a completion for that prompt or, alternatively, the completion will be restricted to a set of predetermined outputs. One-shot and few-shot learning paradigms [4,36] use similar prompts that include one or more solved examples to condition the model on the task at hand [46]. For example, the following prompt might be used to predict the rating of a movie from a textual review:
Prompt-based learning can be done using manual template engineering by using manually created templates [20,28,36]. Other approaches can learn such prompts automatically, including discrete prompts that typically correspond to natural language phrases [8,12,20,42], or continuous prompts that use sequences of embeddings directly that do not necessarily correspond to embeddings that occur in natural languages [20,21,50].
A recent trend in prompt-based learning that shows promise is explanation-based prompting [11,20], which started with chain-of-thought prompting [48] and many styles of prompting inspired by it, such as self-ask [30] and maieutic prompting [13]. For example, a chain-of-thought prompt may be a question-answering task, where the task is presented in a few-shot learning fashion such that the provided examples do not simply answer the question, and instead provide reasonable step-by-step inferences leading to the correct conclusion. Such a style of prompts will encourage the generative language model to provide explanations before committing to an answer to the question, which was experimentally found to improve accuracy, especially on arithmetic questions [48]. The original paper provides this example: “Q: The cafeteria had 23 apples. If they used 20 to make lunch and bought 6 more, how many apples do they have?”. The direct answer was “A: The answer is 27.” which is incorrect. However, using chain-of-thought the answer was: “A: The cafeteria had 23 apples originally. They used 20 to make lunch. So they had
In this paper, two of the most capable language models from OpenAI at the time of running this experiment were used for the main set of experiments. GPT-3 [4] is used to generate scenarios and arguments, as shown in the rest of the paper, while ChatGPT [25] is only used for scenario generation. ChatGPT (a chatbot powered by GPT-3.5) is not a fully documented model, as the parent company has not published any academic papers or any other resource that includes full details of how GPT-3.5 was trained. However, based on technical reports from the parent company, it is likely instruction-tuned [27] using reinforcement learning from human feedback (RLHF) [5] to follow a variety of written instructions. Since GPT-4 [26] was yet to be released at the time of our experimentation, our present work focuses on GPT-3. However, we report briefly on a small follow-up experiment designed to show that the lessons we learn from the present work about prompting styles are still applicable to GPT-4 and other state-of-the-art generative language models in Section 4.
The Turing test. The Turing Test, first introduced by British mathematician and computer scientist Alan Turing in 1950, remains one of the most influential concepts in the study of artificial intelligence. In his seminal paper, “Computing Machinery and Intelligence,” [38] Turing posited a scenario in which a human evaluator would engage in natural language conversations with both a human and a machine designed to generate human-like responses. If the evaluator could not reliably distinguish which participant was the machine based on the conversation alone, then the machine would be considered to have demonstrated human-like intelligence.
The original Turing test sets a relatively high threshold for a machine to pass the test, as a conversation with a machine is an interactive setting that allows the human evaluator to probe the limits of the understanding of the machine of the subject of the conversation. However, not all tests designed to tell humans and machines apart follow the same setup. For example, some CAPTCHA2 systems use text and image recognition as a form of a Turing test [37]. Hence, in the context of this paper, we address our third research question (
The experiment was carried out in 5 stages as follows:
.Overview and rationale
The overall goals of the methodology are summarized in the aforementioned research questions. The individual stages and the sequence in which they were carried out were designed to provide the necessary data to answer the research questions or to provide the necessary data for the subsequent stages. In order to answer
.Stage 1: Curating scenarios
Our goal at this stage was to curate a set of ambiguous scenarios for use in the subsequent stages. For this purpose, we started with a dataset of rules collected from the codes of ethics of various professional organizations, following [24]. However, we found some systematic issues with the scenarios used in that publication (see background section (§2)), so we decided to generate a new set of scenarios for this study.
When this experiment was conducted, GPT-3 and ChatGPT were the most advanced LLMs available. We used four different sources for the scenarios at this stage:
The machine-generated scenarios have been produced without human interference or oversight. On the other hand, human–machine collaboration means that a human was directly involved in the production of that set of scenarios. Specifically, for GPT-3, we used a multi-step introspective prompting style inspired by the self-ask prompting style [30] and similar chain-of-thought prompting styles. We used a 9-step prompt that starts by asking GPT-3 to identify an open-textured phrase in a given rule, generate multiple competing interpretations, generate arguments and counterarguments for each side, and iteratively improve those arguments. The prompt design has been developed through an iterative process of prompting the model, analyzing its outputs, identifying weaknesses, and either tweaking the prompt or adding additional intermediate prompts. Since the prompt got large at times, it was split into multiple steps, such that each step focused on one or a few goals. The full text of the prompt is provided in Appendix A.3. In the human–machine collaboration mode, a human reviewed, edited, or replaced the generated completions, including the intermediate steps leading to the final scenario.
Similarly, some of the scenarios were generated in collaboration with ChatGPT. This means that ChatGPT was instructed to generate appropriate scenarios. ChatGPT was given instructions to follow while generating the scenarios. Those instructions were typically provided in the first few messages in a conversation with the chatbot. The two most important sets of instructions given to ChatGPT are the guidelines for judging a scenario (Fig. 4) and the steps it needs to follow (Fig. 5). Those instructions were created through an iterated process of trial and error. Many of those instructions were added to guide the chatbot while generating the scenarios by manually reviewing the chatbot’s responses and attempting to address some of the common issues that arose in the manual review process, which is part of the human–machine collaboration effort.

The annotation guidelines that were given to ChatGPT for generating scenarios.

The steps that ChatGPT was instructed to follow for generating scenarios.
In total, 42 scenarios were generated using the aforementioned methods. A survey was created (using Qualtrics5) to assess those scenarios and was given to graduate students of our research lab. Figure 6 shows an example of a question in this survey. In total, 7 different annotators provided feedback, which was used to select 16 scenarios for the subsequent stages. The annotators were provided the same guidelines given to ChatGPT for reference. The scenarios were selected based on the recommendation of the annotators, where the provided scenarios met the guidelines and were believed to be balanced based on the total feedback we received at this stage.
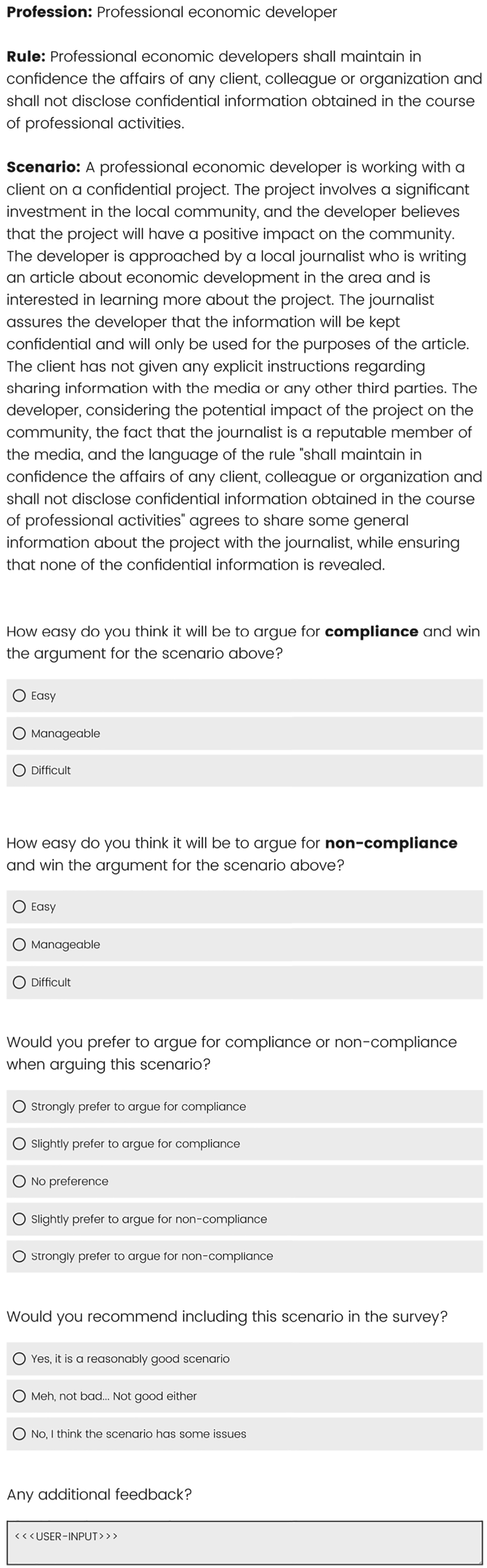
A survey question at stage 1.
At this stage, we had 16 scenarios from the previous stage. Our goal was to collect 10 different arguments for each scenario: 5 arguments in favor of compliance and 5 in favor of non-compliance. We created a survey with 10 questions each and used Amazon Mechanical Turk6 to recruit human annotators. Figure 7 shows an example of a question in the survey. Participants had to meet the following criteria to participate:
Participants must have at least 50 completed and approved tasks on the platform. Participants must have an approval rate of 92% or better.

A survey question at stage 2.
The collected arguments were reviewed for quality, bad faith, or low effort, and the offending submissions were removed. Such submissions were identified by manually reviewing a small sample of arguments from each user. Reasons for rejecting a submission include:
Submissions that were determined to be complaints or statements about the task itself rather than arguments made in the spirit of the task. These include rants about the scenario (e.g., “This is preposterous, I cannot believe we’re asked to argue in favor of (non-)compliance!”), or very short responses (e.g., “That’s clearly unethical!”). Arguing for the wrong stance (ie. arguing for compliance when asked to argue for non-compliance or vice versa). Very poor grammar that makes the submission ineligible for inclusion.
Only one submission fit the above criteria and was rejected for one or more of the above reasons. We also looked for arguments that were consistently rated as “This argument is meaningless, irrelevant, or nonsense” during the evaluation phase. However, we found no such submissions, which indicated that the manual screening process successfully excluded all such arguments.
Additionally, we used an online tool7 to detect any submissions that are likely to be generated using a GPT variant. We found, through informal tests, that this tool and similar tools frequently produced false positives and false negatives, which aligns with recent work on AI-generated text detectors [34], suggesting that such tools, at best, can only perform marginally better than random at distinguishing AI- from human-written text. However, some form of detection was necessary, so we only considered rejecting cases where the detector reported that two or more responses were AI-written text with a 95% confidence or higher. See our discussion in the conclusion section (§6) on the topic of bot detection for further discussion of this issue. We accepted submissions with one positive result in order to reduce the chances of rejecting legitimate submissions. This procedure identified only one submission where the participant was believed to have used an AI text generator in their submissions.
After collecting the human arguments, we had 16 scenarios, with 5 human arguments in favor of compliance and 5 human arguments in favor of non-compliance each, for a total of 160 human arguments. Our next goal was to evaluate the persuasiveness of the collected arguments by collecting at least 5 different annotations for each collected argument. For this purpose, we created a survey with two question formats. In the first question format, users were given a profession, a rule, a scenario, a stance, and an argument. They were asked to rate the argument on a Likert scale [1] from 1–5, going from “Very convincing” to “Very unconvincing” with an additional choice that reads “This argument is meaningless, irrelevant, or nonsense”. This additional option allows participants to indicate that there is an issue with the provided argument and that a standard Likert scale does not apply. This allowed us to detect if an argument was written in bad faith or did not conform to our expectations such as arguing for the wrong stance. Users were given 5 different arguments for the same scenario-stance pair. In the second question format, for each scenario-stance pair, users were asked to order the same arguments from the preceding Format 1 questions from most convincing to least convincing. Each user was given 5 randomly chosen scenario-stance pairs to annotate for a total of 25 questions of the first format and 5 questions of the second format. Refer to Appendix A.1 for the question templates used in those surveys.
In order to further ensure submission quality, a red-flags quality control system was developed that reviews the submissions for quality control signals that indicate issues with the submission. This system was developed by manually reviewing a small sample of submissions and tweaking the sensitivity of the criteria to ensure that submissions that were clearly of good quality or poor quality were classified correctly and iteratively refining the criteria until the automated quality assessment matched the results of the manual review. A random or low-effort submission is expected to generate 10 or more red flags. Any items with 4 or more red flags were removed from the dataset. The red flags are based on 3 types of quality control signals, each with their own subset of items. The major types of red flags were as follows:
For additional details about the quality control system, please refer to the GitHub page linked earlier.
In order to evaluate the collected human arguments, we found the median rating of each human argument. Responses were scored as follows: “Very convincing” (5), …, “Very unconvincing” (1), “This argument is meaningless, irrelevant, or nonsense” (−1). The median rating of the five available annotations is calculated for each argument. The median rating was chosen to represent the persuasiveness of each argument in order to exclude any outliers compared to the majority of the votes. Subsequently, the average for all human arguments is calculated. Similarly, the standard deviation is also calculated using the median ratings of all the human arguments. The average median for all human arguments is 3.06 with a standard deviation of 1.35. The item-weighted average (ie. where all arguments are given equal weight) is 2.91. Figure 8(a) shows the distribution of the median ratings of all human arguments.
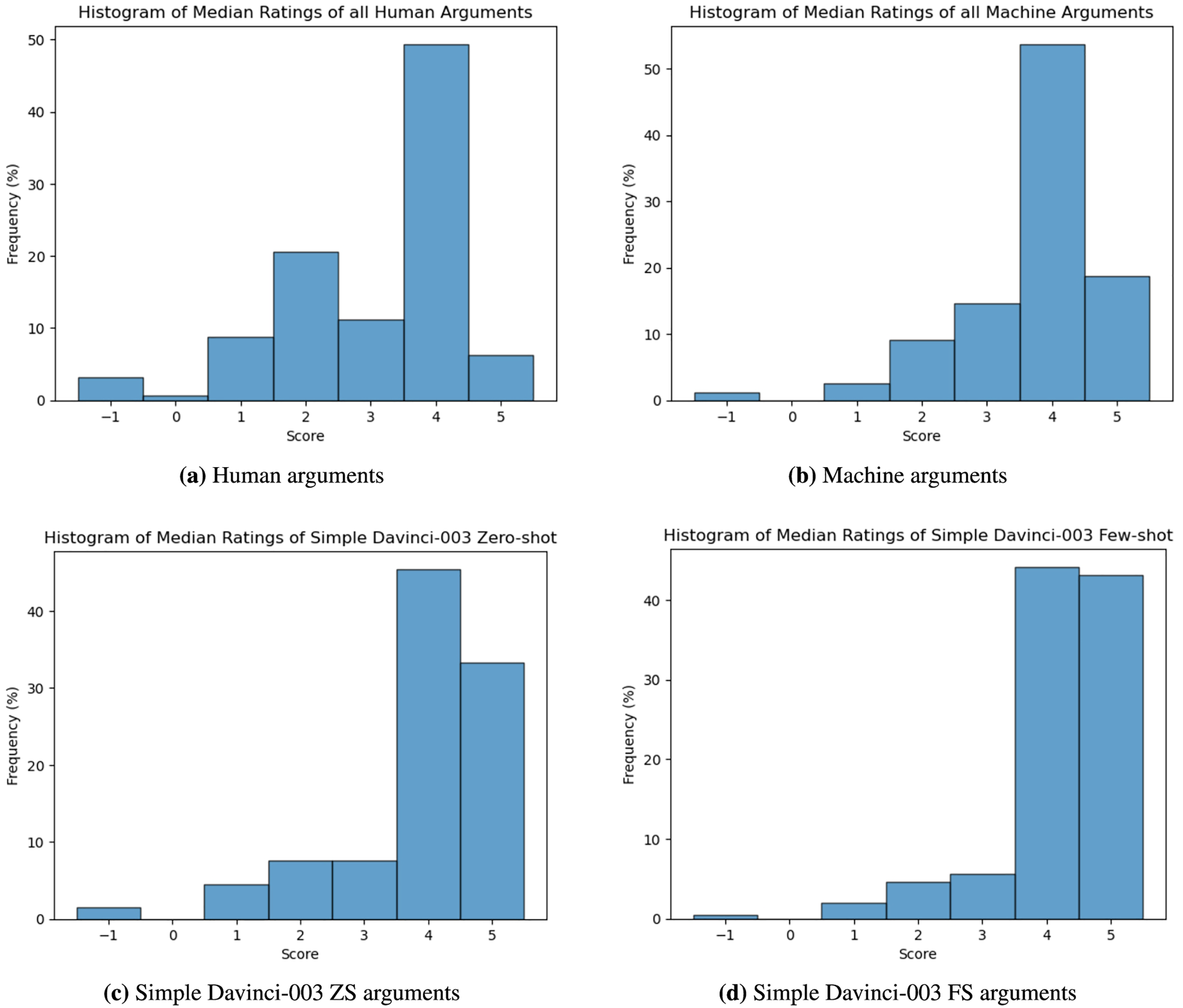
Histograms of median ratings.
At this stage, we had 16 scenarios with 5 human arguments in favor of compliance and 5 human arguments in favor of non-compliance for each scenario. All of those arguments had 5 different annotations of their persuasiveness. Our goal at this stage was to generate 20 different arguments for each scenario using LLMs: 10 arguments in favor of compliance and 10 in favor of non-compliance.
We used GPT-3 models of different sizes, prompt designs, and both zero-shot and few-shot prompting. Table 1 lists all the different arrangements that were used in this experiment. These choices were selected in order to answer
The second prompt design is a 10-step introspective design that allows the LLM to formulate and improve its arguments iteratively. The introspective prompt pipeline is based on a multitude of sources for inspiration. First of all, with analogy to the chain-of-thought prompting and similar approaches, these prompts break down the task of interpretive argumentation into discrete tasks, which, in concert, are designed to generate quality arguments. The individual questions and steps were inspired by multiple sources. Many publications provide systems that are targeted at human arguers in order to generate good arguments systematically. For example, some authors propose critical questions that a good interpretive argument must address [17,43,45]. These types of questions can be used to guide an LLM in producing high-quality arguments. The LLM is repeatedly asked to elaborate on critical aspects of its response, attempt to find weaknesses or omissions in its arguments, and iteratively improve those arguments as it follows the steps in the introspective pipeline. The full text of the introspective prompting pipeline is provided in Appendix A.5. The prompts used in this prompting style are significantly larger than the ones used in the simple prompting style. For this reason, the text-curie-001 context size of 2000 tokens was not a suitable choice for the introspective prompts, especially for the few-shot learning setting. That is why we chose only to use the models with the largest context size.
For the few-shot learning version of this prompt, we used 2-shot learning. Similar to the simple prompting style, the number of exemplars was made to ensure the prompt fits in the context size of 4000, the context size of the largest models. We have manually curated 4 exemplars that span all 10 steps of this prompt design. No profession occurs more than once in this set of exemplars. Figure 1 shows an argument generated in favor of compliance using this prompt design. For each argument, we first excluded all exemplars that match the profession of the argument in question. From the set of the remaining exemplars, we randomly selected a subset of 2 arguments for use and presented them as part of the prompt in a random order. The exemplars selected for each argument generation are part of the dataset.
Summary of the models and prompts used to generate arguments in stage 3.
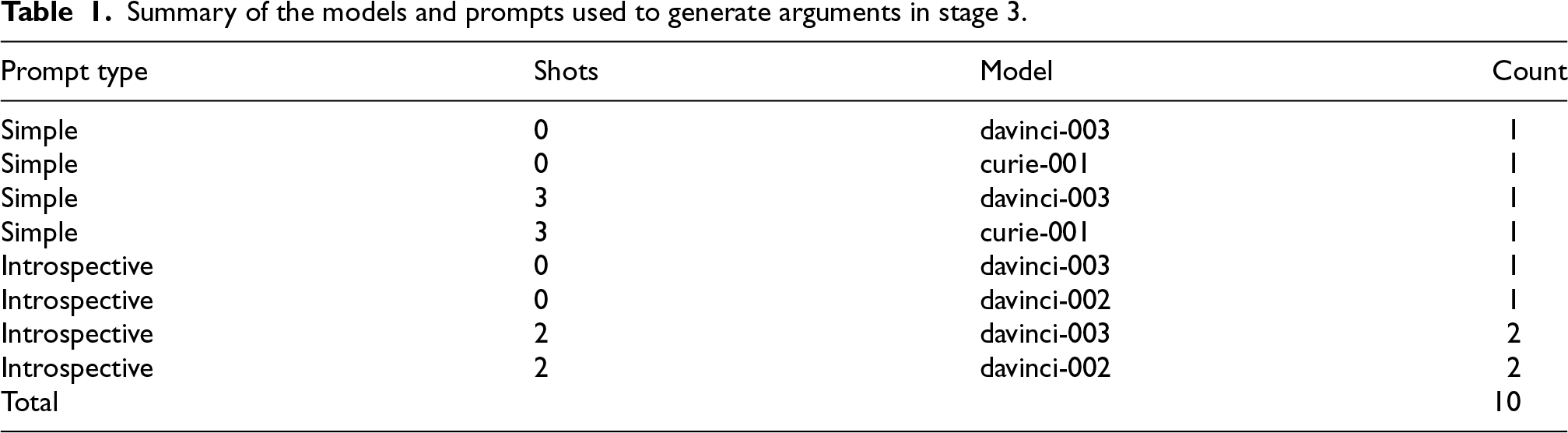
Summary of the models and prompts used to generate arguments in stage 3.
Those two prompt designs were chosen to help answer
At this point, we had 16 scenarios with 5 human arguments in favor of compliance and 5 human arguments in favor of non-compliance, as well as 10 machine arguments in favor of compliance and 10 machine arguments in favor of non-compliance for a total of 320 machine-generated arguments. All of the human arguments had 5 different annotations of their persuasiveness. Our goal was to evaluate the persuasiveness of the machine-generated arguments by collecting at least 5 different annotations for each of the machine-generated arguments. For this purpose, we created a survey using a format identical to the survey in Stage 2. Each question contained 5 arguments; therefore, we had double the number of questions at this stage compared to the previous one. Each scenario-stance pair had to be included twice with a different subset of five questions from the ten that were generated. We split the arguments based on their source deterministically, and hence, the Format 2 questions required participants to order arguments for one of the two available subsets consistently. We included the same number of questions in each survey as Stage 2, and therefore, we required (roughly) twice the number of participants to fill out the survey. Everything was identical to Stage 2 in terms of the surveys, except that the source of the arguments was machine-generated, which the participants were not made aware of as we did not make any claims about the source of the arguments in this stage or the previous one.
Using the same scoring scheme as the one in Stage 2, the average median rating for all machine-generated arguments is 3.63 with a standard deviation of 1.06. The item-weighted average is 3.45. Figure 8(b) shows the distribution of the median ratings for all machine arguments. These results indicate that human annotators believe that machine-generated arguments were consistently more persuasive than human-written arguments. Table 2 shows a detailed breakdown of all the experiments we carried out. In order to verify the statistical significance of those results, we conducted one-way ANOVA for all of the machine-generated arguments. We got an F-statistic of 30.5 and
Average median rating of each source of arguments from stages 2 and 3.
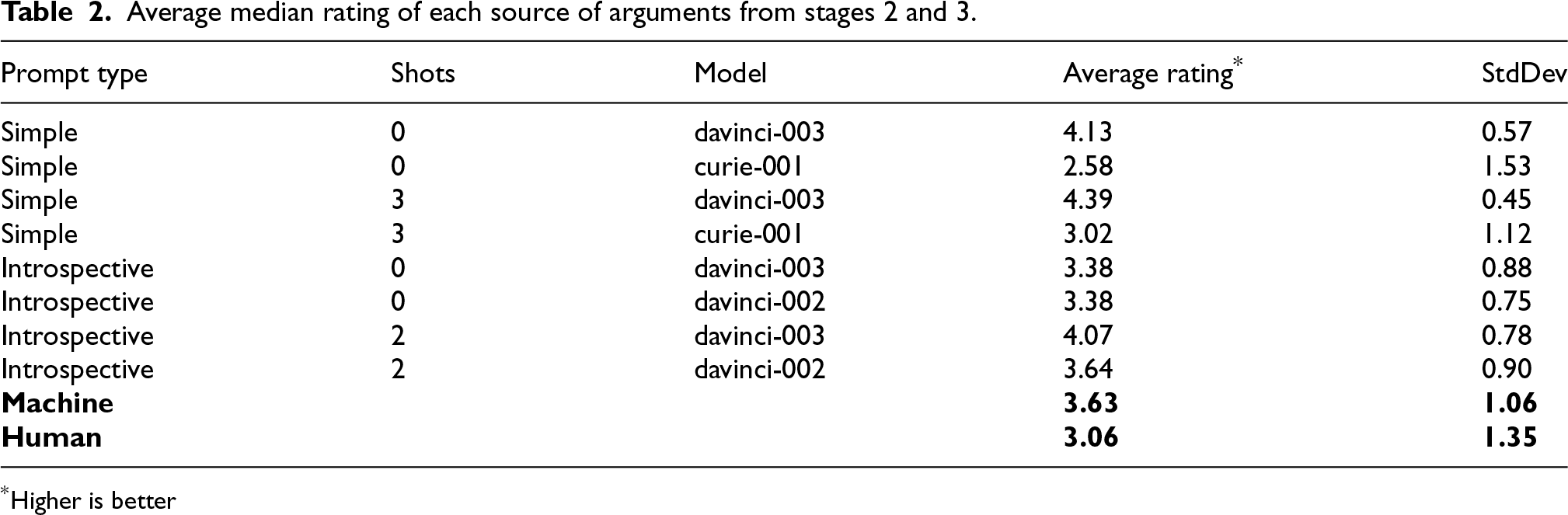
Average median rating of each source of arguments from stages 2 and 3.
*Higher is better
Examining those results, we find that few-shot learning clearly outperforms the zero-shot learning prompts which matches our expectations. We also find that the text-curie-001 model using 3-shot learning and simple prompts is roughly equivalent to the performance of the human arguments. The same model with zero-shot learning is the only model that underperforms compared to the human results. We also notice that the introspective prompt design underperforms compared to the simpler prompting approach. Overall, the machine-generated arguments outperform the human arguments. Tables 3 and 4 show the average median for all the machine-generated arguments. Since the argument sources were split deterministically, those tables show the results of each of the two subsets independently. The arguments that were labeled as most convincing (top) got a score of 1, while the ones labeled as least convincing (bottom) got a score of 5. The results show that the relative ordering of all sources of arguments is consistent with the average median rating in Table 2.
Average median order of each source of arguments from stage 3 (subset 1).
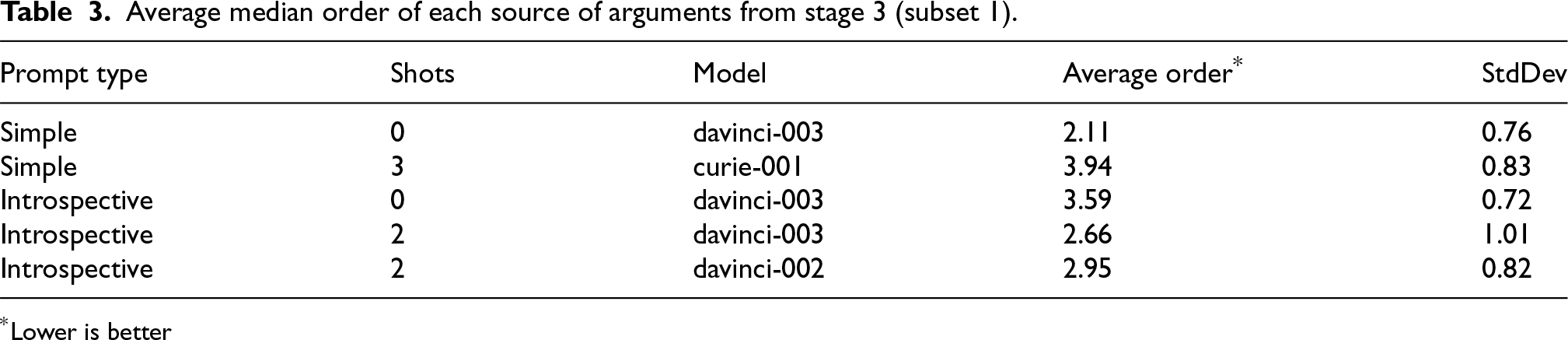
*Lower is better
Average median order of each source of arguments from stage 3 (subset 2).

At this stage, we had 16 scenarios with 5 human arguments and 10 machine arguments for each stance. All of those arguments had 5 annotations of their persuasiveness. Our goal at this stage was to test the human annotator’s ability to tell the difference between human and machine arguments. For this purpose, we created a survey with two question formats. In the first format, users were presented with a profession, a rule, a scenario, a stance, and an argument. They were asked to guess as to whether the argument was written by a human or generated by a machine. In the second format, we presented users with two arguments instead of one, informed them that one of those arguments was written by a human and the other was generated by a machine, and they had to guess which one was written by a human. Refer to Appendix A.1 for the question templates used in those surveys.
We refer to this as a Turing test-inspired variant, adapted specifically for interpretive arguments. As discussed earlier, the Turing test at the conceptual level is a test to evaluate a machine’s level of intelligence by assuming that if a machine could perform certain tasks in a way that is indistinguishable from humans performing the same task, then that machine can be reasonably said to have at least the same level of intelligence as humans. The original Turing test [38] allows humans to interact with the machine to stress test the machine’s ability to pass tailored tests to the satisfaction of the human testers. In our simplified version, such an interaction is absent, and we are simply asking human annotators to tell human and machine arguments apart.
.Results
Table 5 shows a detailed breakdown of all the human annotators’ accuracies on the Blind Turing test; if the supplied response was correct (ie. guessed as “Very likely [correct guess]” or “Somewhat likely [correct guess]”), the item was counted as correctly labeled, while incorrect or “Not sure” responses were counted as incorrectly labeled. The results also show that in the Blind Turing test, annotators correctly identified the human arguments only 52% of the time, which is basically no better than random chance. Responses were also scored as follows: “Very likely [correct guess]” (2), …, “Very likely [incorrect guess]” (−2), and the average scores are shown in the table as well. Table 6 shows the confusion matrix detailing how each source of arguments was classified based on a 3 categories classification of ‘Machine’, ‘Human’, and ‘Not sure’.
Blind Turing test results from stage 4(a).
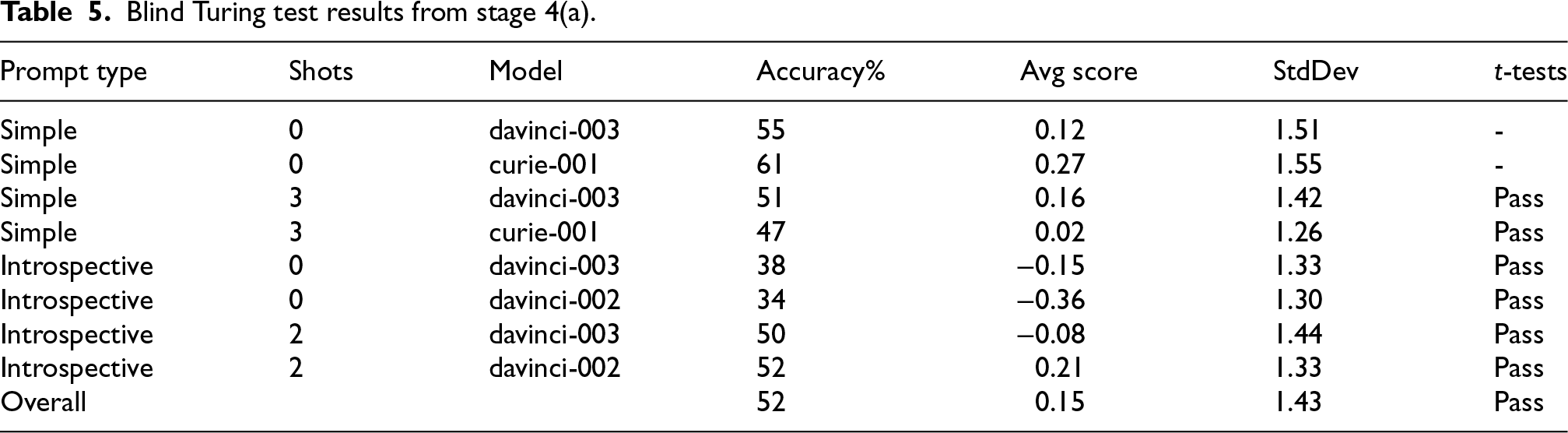
Blind Turing test results from stage 4(a).
Blind Turing test confusion matrix of format 1 questions.

In order to verify the statistical significance of those results, we conducted two one-tailed one-sample t-tests. For the first t-test, we defined the null hypothesis as the true mean is larger than or equal to 0.5. Recall that an annotation of “Not sure” is scored as 0, while an annotation of “Somewhat likely [correct guess]” is scored as 1. Therefore, a mean value larger than or equal to 0.5 indicates that participants could reliably identify the source of an argument. The alternative hypothesis is that the true mean is less than 0.5, which means that participants were unable to identify the source of the arguments correctly. If the test shows a statistically significant result, the Turing test is marked as a ‘Pass’ indicating that the machine passed the Turing test. If the test is inconclusive, a second t-test is performed. For the second t-test, we defined the null hypothesis as the true mean is less than or equal to 0. The alternative hypothesis is that the true mean is larger than 0, which means that participants were able to identify the source of the arguments correctly. If the test shows a statistically significant result, the Turing test is marked as a ‘Fail’, indicating that the machine failed the Turing test. Otherwise, the result is inconclusive and is marked with ‘-’. This procedure allows us to look for evidence that the annotators were unable to guess the correct source of the arguments reliably. The “Not sure” option is scored as a 0, and for the purposes of the first t-test, we define a mean in the range of
In the first one-tailed one-sample t-test, the overall sample size is 459. We find that the mean is 0.15, the standard deviation is 1.43, the t-statistic is
The blind Turing test was designed to evaluate whether machine-generated arguments were similar enough to human arguments in order to substitute for human-provided arguments in applications where the source of the argument is irrelevant or of low importance. However, could this be a consequence of the human participants’ lack of expertise in the task? I.e., is it the case that humans could learn to distinguish human- from machine-generated interpretive arguments? Our guided version of the test was therefore designed to evaluate whether machine-generated arguments had distinctive features differentiating them from human arguments that human annotators could learn.
This stage was carried out in an identical manner to the blind version of the test with one notable modification: We first provided users with 8 examples of human arguments and 8 examples of machine arguments as part of the survey instructions. Users were provided with a downloadable text file to refer to the provided examples when needed, rather than relying entirely on their memory. Everything else was identical to the previous stage.
.Results
Table 7 shows a detailed breakdown of all the human annotators’ accuracies on the Guided Turing test. The results also show that in the Guided Turing test, annotators correctly identified the human arguments
Guided Turing test results from stage 4(b).
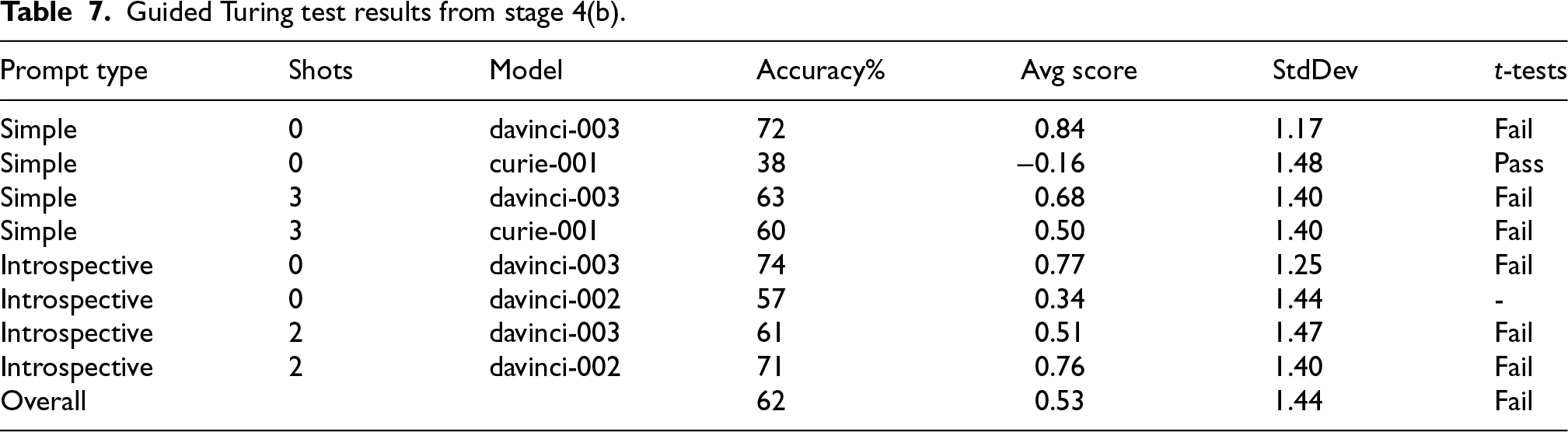
Guided Turing test results from stage 4(b).
Guided Turing test confusion matrix of format 1 questions.

At this stage, we wanted to perform some additional validation on our results. One of the crucial questions we attempted to address at this stage is whether or not annotators had a bias favoring either the human or machine arguments as such. For this reason, we decided to run the survey where we tell the users that an argument was human- or machine-generated, and observe how consistent the results were between the direct comparisons performed in Stage 4 (second question in the second format) and the indirect comparisons performed in Stages 2 and 3. Refer to Appendix A.1 for the question template used in this survey.
.Results
For this stage, we found the median rating of all human–machine argument pairs included in the survey. Responses were scored as follows: “Machine argument is significantly more convincing” (2), …, “Human argument is significantly more convincing” (−2).
The average median for all the evaluated pairs is 0.80 with a standard deviation of 1.20. Table 9 shows a detailed breakdown of all the experiments. In order to verify the statistical significance of those results, we conducted one-way ANOVA for all of the machine-generated arguments. The sample size is 575, and we got an F-statistic of 11.2 and
Average median rating of each source of arguments when compared to a human argument at stage 5.
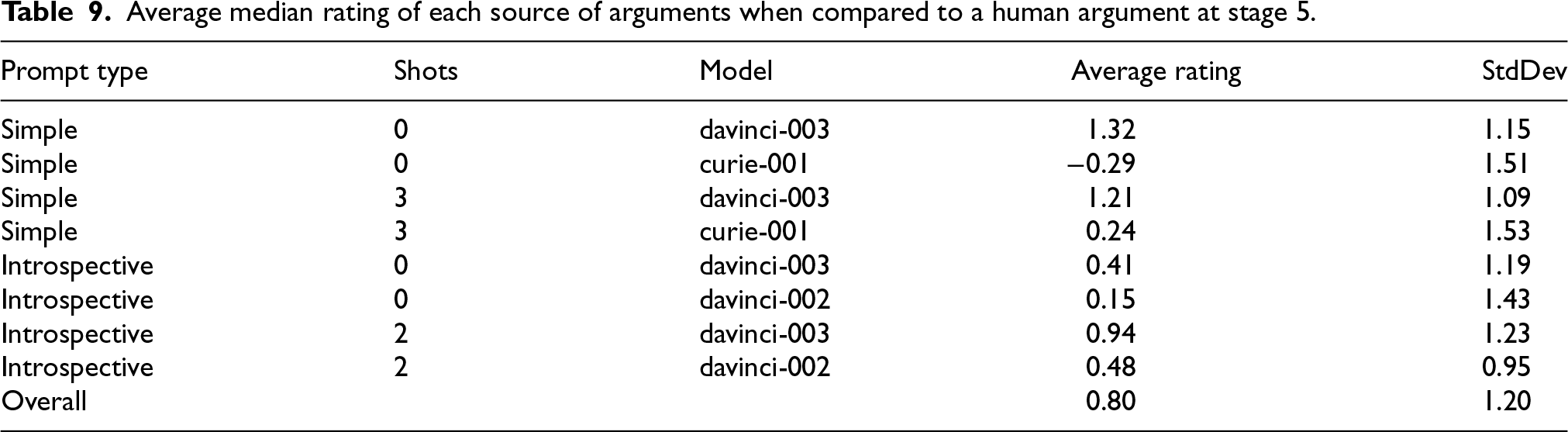
Average median rating of each source of arguments when compared to a human argument at stage 5.
GPT-4 [26] has been shown to outperform GPT-3 in virtually every measure available, and it is reasonable to assume that the ability to generate persuasive interpretive arguments is among those measures. Although GPT-4 was not available at the time of our experimentation, it would be worthwhile to see whether the lessons we learned above about which prompting styles generate the best interpretive arguments. We, therefore, report on a small experiment we carried out to do just that.
Using the same procedure in Stage 3, we generated 10 different arguments for each scenario using GPT-4 (specifically, gpt-4-0314): 5 arguments in favor of compliance and 5 in favor of non-compliance. We used the same prompt designs and both zero-shot and few-shot prompting. Table 10 shows the different arrangements that were used in this experiment.
However, unlike the previous set of experiments, which were carried out on Amazon Mechanical Turk, we used the Prolific8 platform to carry out this experiment. Additionally, we imposed some restrictions on participants that were not enforced in the previous set of experiments. Namely:
Participants are from the US or UK Participants must have a graduate degree Participants are balanced based on gender Participants must have completed at least 50 tasks on the platform Participants must have an acceptance rate of 92% or better Summary of the models and prompts used to generate arguments.

After we carried out the experiment, we had 16 scenarios with 5 arguments in favor of compliance and 5 arguments in favor of non-compliance for a total of 160 arguments generated using GPT-4. All arguments were evaluated for their persuasiveness by collecting at least 3 different annotations for each of the arguments. The surveys were in a format identical to the surveys in Stages 2 and 3.
We report two sets of results. One using a filtered subset of annotations, and another using an unfiltered subset. The filtered subset uses the red flags system explained in Section 3.4, while disabling the Consensus-based red flags subset. Those flags were disabled because they are based on the consensus of multiple annotations for each argument. Since those filters rely on the availability of at least 5 annotations that are validated through the other filtration criteria, not enough data was collected to allow those filters to be reliable. The other types of red flags evaluate submissions independently of other submissions and, hence, are not affected by the amount of available submissions. Since we still use a threshold of a maximum of 3 flags to accept a submission, the filtration process is slightly less strict compared to Stage 3 filters. Additionally, in Stage 3 we collected at least 5 annotations for all arguments after applying the filters. However, for this smaller experiment, we only have 3 annotations for each argument in the unfiltered set. Hence, some arguments have less than 3 annotations available with the filters.
Using the same scoring scheme as the one in Stage 3, the average median for all GPT-4 arguments in the unfiltered set is 3.69 with a standard deviation of 0.82, and the item-weighted average is 3.51. For the filtered subset, the average median is 3.64 with a standard deviation of 0.98, and the item-weighted average is 3.63. Table 11 shows a detailed breakdown of all the experiments we carried out. In order to verify the statistical significance of those results, we conducted one-way ANOVA for all of the machine-generated arguments and got an F-statistic of 4.59 and
Average median rating of each source of arguments.

Average median rating of each source of arguments.
Average median order of each source of arguments.

Examining those results, we find that the introspective prompt design underperforms compared to the simpler prompting approach. The results do not show a statistically significant difference between few-shot and zero-shot prompts (see Appendix A.8). The filtered subset shows results consistent with the pattern that few-shot learning outperforms zero-shot learning. In contrast, the unfiltered subset shows the opposite pattern with very small differences between the means. Again, since those differences are not statistically significant, we refrain from making any conclusions. However, it seems that the filters have some influence on the results. The filtered data is more consistent with the results of the experimental protocol developed for Stage 3. It should be considered more reliable as it excludes submissions that may represent lower effort or lower quality submissions. Nonetheless, additional experimentation is warranted to find out if the chat versions of LLMs that are instruction-tuned or optimized using reinforcement learning from human feedback (RLHF) might affect the performance of the LLMs in the few-shot learning setting on this task or the prompting style used which has been developed with the non-chat LLMs in mind.
Note that the ratings obtained in this experiment should not be interpreted to be directly comparable to the results in Stage 3 due to the fact that this experiment has been conducted on a different platform using different participation criteria, which influences the characteristics of the population of the participants. Therefore, we do not use those results to compare the performance of GPT-4 to the performance of GPT-3 in the previous experiments.
We can now address our three primary research questions.
RQ1: How well can state-of-the-art LLMs argue interpretively, and which prompting methods generate the best interpretive arguments?. The results from Stage 3, as summarized in Table 2, show that the best performing model is the largest model offered by OpenAI, namely text-davinci-003, which produced the best results using a simple prompting scheme combined with a few-shot learning approach. The model obtained an average median rating of 4.39 with a standard deviation of 0.45, which indicates that most annotators rated the generated arguments as either ‘Convincing’ (4) or ‘Very Convincing’ (5). This indicates that most annotators believed the model generated arguments of decent quality. The results also show that larger and newer models consistently and measurably outperformed smaller or older models.
The results also show that using few-shot learning yields substantially better results compared to zero-shot learning for all the models tested. This result is what we expected and demonstrates the value the training exemplars bring to this task.
We also observe that the introspective prompt design underperforms compared to the simpler prompting approach. While we believe that an introspective approach similar to the one used in those experiments may be of value, those results indicate that creating a prompting pipeline that outperforms the simple prompting approach is a non-trivial task and requires an iterative approach of design, test, and analysis. Since the introspective approach used in this set of experiments was the first attempt at such a prompt design, and did not benefit from any substantial feedback or analysis, we argue that those results are only a measure of the specific template used in this experiment and should not be used to conclusively dismiss similar prompting styles that are developed with the benefit of an iterative approach that incorporates additional feedback and analysis.
RQ2: How do human- and machine-generated interpretive arguments compare?. The results from Stage 2 and 3, as summarized in Table 2, show that the largest model offered by OpenAI, namely text-davinci-003, consistently produced arguments that were rated as more persuasive as compared to the human arguments. This is strong evidence in favor of LLMs compared to non-expert human arguers. Using text-curie-001 (which is a variant of GPT-3 that is advertised by OpenAI as a smaller, faster, cheaper, and capable alternative) produced arguments that were rated as equally persuasive as their human counterparts when using a few-shot learning approach while also rated as less persuasive compared to human arguments when using a zero-shot learning approach. This means that an LLM that matches or exceeds the performance of the text-curie-001 variant of GPT-3 can produce arguments that are competitive with non-expert human arguments.
All of those results are corroborated by the results from Stage 5, as summarized in Table 9, which produced consistent results using a different experimental setup.
RQ3: Can people distinguish between human- and machine-generated interpretive arguments?. The results from Stage 4(a), as summarized in Table 5, show that participants could not identify the source of an argument correctly at a rate that is statistically significantly better than random chance in the blind version of the Turing test. Conversely, the results from Stage 4(b), as summarized in Table 7, show that participants were able to correctly identify the source of an argument for all models except for the text-curie-001 using a simple prompt with zero-shots. Recall from Stage 3 that this model was the only one that underperformed compared to human arguments. This result implies that at least part of the reasoning used by the human annotators is the persuasiveness of the argument, where participants (seemingly) concluded based on the examples provided to them that the better arguments are usually the machine-generated arguments, and hence were more likely to incorrectly conclude that the arguments generated using text-curie-001 using the simple prompt with zero-shots were human arguments. This provides some limited evidence that the persuasiveness of arguments was an important signal that most annotators relied on when selecting the source of an argument.
.Conclusion
In this paper, we discussed the experimental design and the associated surveys and methods that were used to answer the research questions discussed earlier. Specifically, our goal was to develop experimental protocols to assess the persuasiveness of machine-generated arguments and to compare arguments generated using different SOTA LLMs to each other and human arguments. We also sought to find out if non-expert human annotators could distinguish human- and machine-generated arguments with and without prior exposure to such arguments. Our findings show that (non-expert) human annotators consistently rated machine-generated arguments as more convincing (when using LLMs beyond a certain size) than human arguments. The results also show that non-expert human annotators could not tell the human- and machine-generated arguments apart if they were not provided prior information about such arguments. This result indicates that machines are able to produce human-like text. The results also show that when provided with some examples of human- and machine-generated arguments, the annotators had a slightly improved ability to tell the two sources of arguments apart.
Those results are very encouraging for the future of automated interpretive argumentation as they demonstrate that the SOTA LLMs are capable of performing interpretive reasoning and interpretive argumentation with reasonable competence. Note that the comparisons carried out in those experiments were in comparison with non-expert human participants. A more thorough analysis of the available data is planned for future publication. Moreover, we recommend carrying out this experimental protocol while recruiting expert arguers for both the generation of human arguments and the evaluation of both the human and machine arguments. Insights from experts can definitely create a more accurate, reliable, and trustworthy assessment of the capabilities of current LLMs.
The use of this experimental protocol to compare the performance of different LLMs can be an essential tool to assess the capabilities of LLMs accurately. Interpretive argumentation is probably more challenging than many tasks that LLMs are tested on, making those assessments more meaningful for complex linguistic evaluation and making sure that newer LLMs are, in fact, improving in performance on some challenging tasks. Evaluating the performance of LLMs on the task of interpretive argumentation is not a trivial task. Automating such assessments is very difficult; hence, including human annotators is essential for this task. This experimental protocol provides clear guidance on how to carry out such evaluations.
Crowdsourced data in the post-ChatGPT age. An important point was raised by one of this manuscript’s reviewers, on which we should now say a few words. At the time of our primary data collection for this proposed work, OpenAI’s ChatGPT was barely a few months old and did not have the widespread adoption it has today. For this reason, we felt that our method of filtering out AI-generated participant responses – imperfect as it may be – was sufficient for our purposes. We also switched platforms mid-study from Amazon Mechanical Turk to Prolific, as we felt the latter had better internal quality controls and put more effort into ensuring that participants were not using AI tools. We present our methodology in sufficient detail that it can be replicated by those who seek to see whether the same results hold when carried out under stricter conditions (e.g., entirely in-person), and we encourage others to do so.
However, we feel it is important to observe that the tools and prompting methods available for carrying out online crowdsourced data collections are evolving at such a rapid pace that the entire future of such work is facing a crisis. Particularly in text-heavy work such as the present argumentation study, it is difficult to see how sufficient quality control can be upheld in future studies if administered remotely. We make this observation here in the hope that it inspires future work into solving this serious problem.
Future work. Another important future goal is to develop the introspective prompting approach further. Chain-of-thought prompting and similar approaches illustrate the value of allowing an LLM to reason in a step-by-step fashion, breaking the problem into smaller problems, and reflecting on its outputs. Using existing literature that may be used to guide or teach human arguers to produce good arguments could be used to encourage an LLM to use the same techniques to produce high-quality arguments. The introspective approach did not yield better results compared to the simple prompting approach in our experiments, which is counter-intuitive to what we suspected would be the case. However, considering the variability of performance that different prompting styles cause, we believe it is worthwhile to determine whether different prompts may yield better results. Possible reasons for the introspective prompting approach to underperform include:
The introspective approach requires more powerful LLMs to perform well. It is possible that LLMs need to cross some capability threshold in order for this approach to become viable. The introspective approach requires additional iterative improvements and redesign along with evaluations in order to find out what works and what does not. Since the introspective design relies on a pipeline consisting of a long sequence of steps, early reasoning defects in the output of an LLM, or the accumulation of errors over the consecutive steps, may negate any positive effects that the introspective design introduces. This intersects with the first point, that better LLMs are necessary, such that fewer reasoning defects are introduced during the execution of the pipeline.
Future work includes qualitative analysis to supplement and further explain the quantitative results. Some goals for the qualitative analysis include:
Identify some of the factors that affect the quality of the generated arguments. Analysis of argument quality measures (other than convincingness) for human- and machine-generated arguments, such as Cogency, Relevance, Clarity, and Defeasibility. Identify major factors leading to reduced performance when using introspective prompting.