
Abstract
Large language models (LLMs) have been a dominating trend in artificial intelligence (AI) in the past years. At the same time, neuro-symbolic systems employing LLMs have also received increasing interest due to their advantages over purely statistical generative models: They can make explicit use of expert knowledge and can be understood and inspected by humans thus providing explainability. However, with an increasing variety of approaches, it is currently difficult to compare the different ways in which designing, training, fine-tuning, and applying such approaches take place. In this work, we use and extend the modular design patterns for hybrid learning and reasoning systems and the Boxology language of van Bekkum et al. for this purpose. These patterns provide a general language to describe, compare, and understand the different architectures and methods used for LLM-based neuro-symbolic systems. The primary goal of this work is to support a better understanding of specific classes of such systems, namely LLM-based models that are used in conjunction with knowledge-based (symbolic) systems. In order to demonstrate the usefulness of this approach, we explore existing LLM-based neuro-symbolic architectures and approaches, as well as use cases for these design patterns.
Introduction
A major driving force for the origin and growth of the field of artificial intelligence (AI) has been the goal of ‘making computers solve really difficult problems’ (Minsky, 1961). Today, many contemporary observers agree that AI has taken a leap in recent years (Savage, 2020) and has now reached a level of capacity and productivity that was unprecedented in previous decades (OECD, 2023). Since 2010, AI systems have reached a close-to-human or even superior-to-human level in many computer vision tasks (Khanday & Sofi, 2021). Since 2020, an increasing number of AI systems have been introduced that are able to successfully complete complex text generation tasks in natural language processing (NLP) (Min et al., 2023), such as text summarisation, translation, and question answering. More recently, the concept of generation has even been extended to multi-modal approaches involving, for example, text input and image output (Betker et al., 2023; Jin et al., 2024; Rombach et al., 2021; Wang et al., 2024a; Zhang et al., 2024). Many of these systems have demonstrated NLP capabilities at a level very close-to-human capabilities (Zhong et al., 2023).
These developments are largely attributed to advances in deep learning techniques, in particular in the form of generative AI and Large language models (LLMs). A wealth of different LLM models have been and are being developed and published, both open-source and proprietary (Chen et al., 2023; Dubey et al., 2024; Kukreja et al., 2024; Minaee et al., 2024). The key technology most current LLMs use is the transformer architecture. The original transformer architecture published by Vaswani et al. (2017) proposed using two interacting models, an encoder and a decoder. These can be trained end-to-end (such as flan-T5 Chung et al., 2022). Alternatively, architectures have been proposed using encoder-only (BERT Devlin, 2018) or decoder-only (GPT Brown et al., 2020, BLOOMZ Muennighoff et al., 2022, PaLM Chowdhery et al., 2023) models. As only a few LLMs based on other architectures have been proposed Peng et al. (2023) and Beck et al. (2024), in this paper, we focus on transformer-based LLMs and consider encoder-only, decoder-only, and encoder-decoder systems to be possible types of LLMs.
These different categories of transformers provide different advantages and disadvantages, depending on the intended scenario. Encoder-only transformers, such as BERT (Devlin, 2018), specialise in contextual encoding, often named base models. They use context to encode input sentences and represent them as machine-interpretable representations, such as vector representations. Decoder-only systems are complementary to the encoder-only paradigm, but structurally different (Min et al., 2023). A decoder-only system decodes the input data directly, without being transformed into a higher and more abstract representation to the desired representation (text, images, or otherwise). Examples of this are generative models from the GPT family (Brown et al., 2020). Decoder-only architectures can be further divided into causal decoder architectures and prefix decoder architectures. Causal decoder architectures, such as GPT (Brown et al., 2020; Radford et al., 2019) and BLOOMZ (Muennighoff et al., 2022), use only unidirectional attention to the input sequence by using a specific mask. Prefix decoder architectures, such as PaLM (Chowdhery et al., 2023), use bidirectional attention for tokens in the prefix while maintaining unidirectional attention to generate subsequent tokens.
Despite the many impressive achievements and capabilities of many LLMs, a wide variety of challenges remain for purely statistical LLMs (Kaddour et al., 2023). This includes not only substantial costs for training (Schwartz et al., 2020) and inference (Samsi et al., 2023), but also the infamous phenomenon of hallucination: Situations where a trained LLM generates outputs presented as plausible or authoritative information that are factually incorrect, nonsensical, or unfaithful to the input or context (Ji et al., 2023). In general, this phenomenon is attributed to the lack of training data for certain outputs, often indicating a lack of domain-specific knowledge (Zhao et al., 2023). While this may in part be corrected by retrieval-augmented generation (RAG) (Gao et al., 2023) and fine-tuning (Zhang et al., 2023), they introduce novel challenges by themselves; fine-tuning, for example, may well raise significant additional training costs and may lead to catastrophic forgetting. A challenge in using RAG is that the performance is highly dependent on the quality and accuracy of the information retrieved. Moreover, both hallucinations and lack of domain-specific knowledge are often hard to identify or contextualise due to the inherent lack of explainability and interpretability of LLMs (Pan et al., 2024; Zhao et al., 2024). It is therefore fair to state that current LLM-based systems and applications lack a sufficient degree of trustworthiness (Huang et al., 2024; Lin et al., 2024), rendering them unusable where reliable output is essential (e.g., in scientific discovery Schmidt et al., 2024).
In response to these challenges, a variety of novel neuro-symbolic approaches to LLM-based AI systems have recently emerged (Hitzler et al., 2022; Wei et al., 2021). Due to the quantity and diversity of emerging generative techniques, it becomes increasingly challenging to keep track of the ever-growing variety of models with different LLM architectures and capabilities (Colelough & Regli, 2024). This becomes even more challenging with the growing diversity in combining LLMs with symbolic AI techniques using different strategies on different architectural levels and training stages (Amador-Domínguez et al., 2024; De Raedt et al., 2020). A practical solution to tackle the issue of analysing and understanding these approaches in a systematic way is to apply a high-level conceptual framework to discuss, compare, configure, and combine different models. Such a framework is provided by the Boxology, introduced by Van Harmelen and Ten Teije (2019) in 2019. The Boxology was extended in 2021 van Bekkum et al. (2021) by providing a taxonomically organised vocabulary to describe both processes and data structures used in hybrid systems. The Boxology represents a flexible and widely applicable framework for representing AI design patterns.
In this paper, which is an extension of our previous work on LLM-based neuro-symbolic systems (de Boer et al., 2024), we propose to use and extend Boxology to gain insight into a variety of LLMs, specifically on LLMs used in a neuro-symbolic approach. To this end, this paper provides two contributions: Firstly, we propose novel design patterns as an extension of the current Boxology to promote transparency and trustworthiness in system design, by providing interpretable, high-level component descriptions of LLM-based neuro-symbolic systems. Our modular approach supports new architectures and engineering approaches to LLM-based systems. Secondly, we test validity and usefulness of the Boxology and our extensions in this field on example architectures and applications, such as ChatGPT, KnowGL, GENOME and Logic-LM.
The remainder of the paper is organised as follows. In the next section, we give a more detailed overview of the related work regarding LLMs and LLM-based neuro-symbolic systems. In the third section, we propose to extend the Boxology by three novel basic patterns in order to be able to handle LLMs, and in the fourth section we explain several compositional design patterns in this field. In section 5, we dive into specific applications and tasks in which LLMs, specifically in neuro-symbolic systems, are used. We conclude with a discussion (section 6) and a conclusion summarising our key findings and outlining future work in section 7.
Related Work
Neuro-Symbolic Systems and Design Patterns
For a long time, the field of AI developers had been shaped by an opposition between ‘imitators of the mind’ favouring symbolic AI approaches and ‘imitators of the brain’, favouring statistical approaches, such as artificial neural networks (Cordeschi, 2007). Today, however, combining the complementary strengths and weaknesses of symbolic and statistical approaches is considered crucial for the creation of reliable, trustworthy, and effective AI systems (Martin, 2023). After a first wave of symbolic approaches and a second wave of statistical approaches, the combination of symbolic and statistical approaches is therefore anticipated as the latest, third wave of AI (Garcez & Lamb, 2023; van Harmelen, 2022). Starting in the early 1990s, neuro-symbolic AI has been emerging with a large variety of diverse approaches. This characteristic has been recognised early with descriptive classification approaches (Hilario, 1994; Medsker, 1994) and workshops that showcase and celebrate the diversity of neuro-symbolic systems (Sun & Alexandre, 1997). A basic yet widely recognised and applicable taxonomy published by McGarry et al. in 1999 differentiates three main classes of hybrid neural systems (McGarry et al., 1999): Unified hybrid systems, translational hybrid systems and modular hybrid systems.
Unified and translational hybrid systems as defined by McGarry have been a popular area of study within the neuro-symbolic AI community during the last two decades (Besold et al., 2021; Yu et al., 2021). At the same time, modular hybrid systems have also gained wider interest due to its relevance for designing modern AI systems under industrial conditions (Schmid, 2023). In general, the design paradigm of modularisation is characterised and motivated by the possibility to reuse and/or reorganise modules. Identifying and characterising design patterns for modular approaches of neuro-symbolic has led to the development of the so-called Boxology framework described below (van Bekkum et al., 2021; Van Harmelen & Ten Teije, 2019). This framework has been used and extended in different ways, such as the formalisation of the notions from the Boxology and implementation in the heterogeneous tool set (Mossakowski, 2022), the extension of the Boxology for (teams of) actors (Meyer-Vitali et al., 2021), the characterisation of emerging data-driven knowledge engineering trends (Sabou et al., 2024), and the systematic study of nearly 500 papers published in the past decade in the area of Semantic Web Machine Learning (Breit et al., 2023). While the original Boxology framework focussed on architectural aspects of hybrid learning and reasoning, it has been pointed out the necessity of including representations of human involvement into such patterns (Meyer-Vitali et al., 2021; Witschel et al., 2020). Despite the usefulness and manifold advantages of the above-mentioned traditional taxonomies and studies, however, it must be stated that none of these are able to foresee and fully capture the characteristics of the latest generation of neural systems (de Boer et al., 2024), in particular the broad capabilities and the required extraordinary architectural complexity of LLMs.
A recent approach to describe modular neuro-symbolic AI systems is the ontological visual framework termed EASY-AI, which uses semantically enhanced symbols to represent the components and architectures of the AI system (Ellis et al., 2024a). EASY-AI aims to provide a standardised symbolic language for conveying the structure, purpose, and characteristics of AI systems. The approach presents the logical formalisms underpinning this visual framework, with the objective of enhancing the comprehensibility and understandability of AI system behaviours. Recently, this framework has also been provided with an initial implementation named SNOOP-AI (Ellis et al., 2024b). This framework and implementation could be used in the implementation of the design patterns, as it can provide a formal conceptual foundation for the design patterns that allows formal reasoning over (compositions of) its elements. To the best of our knowledge, specific LLM-based use cases have not been tested using formalisation and implementation yet.
LLM-based Neuro-Symbolic Systems
While older frameworks for neuro-symbolic AI have not been designed to reflect the latest generation of complex large-scale neural components in the first place, some alternative approaches for combining LLMs and knowledge-based components have been designed from scratch. Colon-Hernandéz et al. were among the first to to do so by identifying three different categories of so-called knowledge injections (Colon-Hernandez et al., 2021): Approaches to modify the architecture of LLM by adding additional layers that integrate knowledge with contextual representations or by modifying existing layers (termed architectural injections) are distinguished from approaches aiming to modify either the structure of the input or the data selected to be fed into the LLM (referred to as input injection) and approaches to change either the output structure or the losses that were used in the base model in some way to incorporate knowledge (termed output injection). While providing new insights and perspectives for LLM-based neuro-symbolic systems, however, this injection-oriented approach is centred largely around modifications of LLMs, leaving out the modular perspective of integrating equally relevant neural and symbolic components.
In light of the popularity and success of knowledge graphs (KGs) in recent years (Ji et al., 2021), it is not surprising that this symbolic technique is a prime candidate for many researchers thriving the enhance LLMs. To this end, Agrawal et al. have suggested to distinguish between LLM-based systems with knowledge-aware inference (KG-augmented retrieval, KG-augmented reasoning, or KG-controlled generation), knowledge-aware training (pre-training or fine-tuning), and knowledge-aware validation (Agrawal et al., 2023). While their taxonomy represents a rather empirical high-level categorisation, an alternative approach by Pan et al. (2024) provided a more differentiated approach where a distinction is made between KG-enhanced LLMs, LLM-augmented KGs and synergised LLMs + KGs. For KG-enhanced LLMs, two primary approaches have been explored: Incorporation during the pre-training stage to facilitate knowledge acquisition and utilisation during the inference stage to improve access to domain-specific information. Additionally, KGs have been employed post hoc to augment the interpretability of LLMs, elucidating both factual content and reasoning processes. In order to augment KGs, LLMs have been employed as text encoders to enrich KG representations and extract relations and entities from the original corpora. Recent studies have focussed on designing KG prompts that effectively convert structural KGs into LLM-comprehensible formats, allowing direct application of LLMs to KG-related tasks such as completion and reasoning. Moreover, the authors have proposed considering the effects and concepts of synergised LLM + KG with respect to four layers: (1) Data, (2) Synergised Model, (3) Technique, and (4) Application. We will loosely use the categorisation of this paper in our exploration of different LLM-based neuro-symbolic systems.
Extending the Boxology Framework with Novel Elements
We base our paper on the previous work of van Bekkum and colleagues (van Bekkum et al., 2021), in which a taxonomically organised vocabulary is provided to describe both processes and data structures used in neuro-symbolic systems. The highest level of this taxonomy contains instances, models, processes, and actors, which may be described as follows:
In addition to vocabulary, visual language is defined in van Bekkum et al. (2021), as an extension of Van Harmelen and Ten Teije (2019). The visual language consists of rectangular boxes (instances), hexagonal boxes (models), ovals (processes) and triangles (actors), and untyped arrows between them. Within the boxes the concept will be noted by each level in the vocabulary using colon-separation from most generic to most-specific, for example a neural network will be
Introducing a New Elementary Pattern
The classic Boxology framework van Bekkum et al. (2021) is based on eight elementary patterns (cf. Figure 1). The elementary patterns 1a–1d are elementary to generate a model, in particular for both statistical as well as semantical models. For instance, Pattern 1a shows how to train a statistical model (such as a neural network) using data (such as text or images). Pattern 1b shows how to create a semantic model (such as a KG) using symbols (such as triples). The elementary patterns 2a–2d are patterns describing how to use a model. Pattern 2a, for example, shows a statistical model (such as a neural network) being used to deduce symbols, i.e. for a classification task. Pattern 2b depicts the application of a semantic model, for example when using it for reasoning.
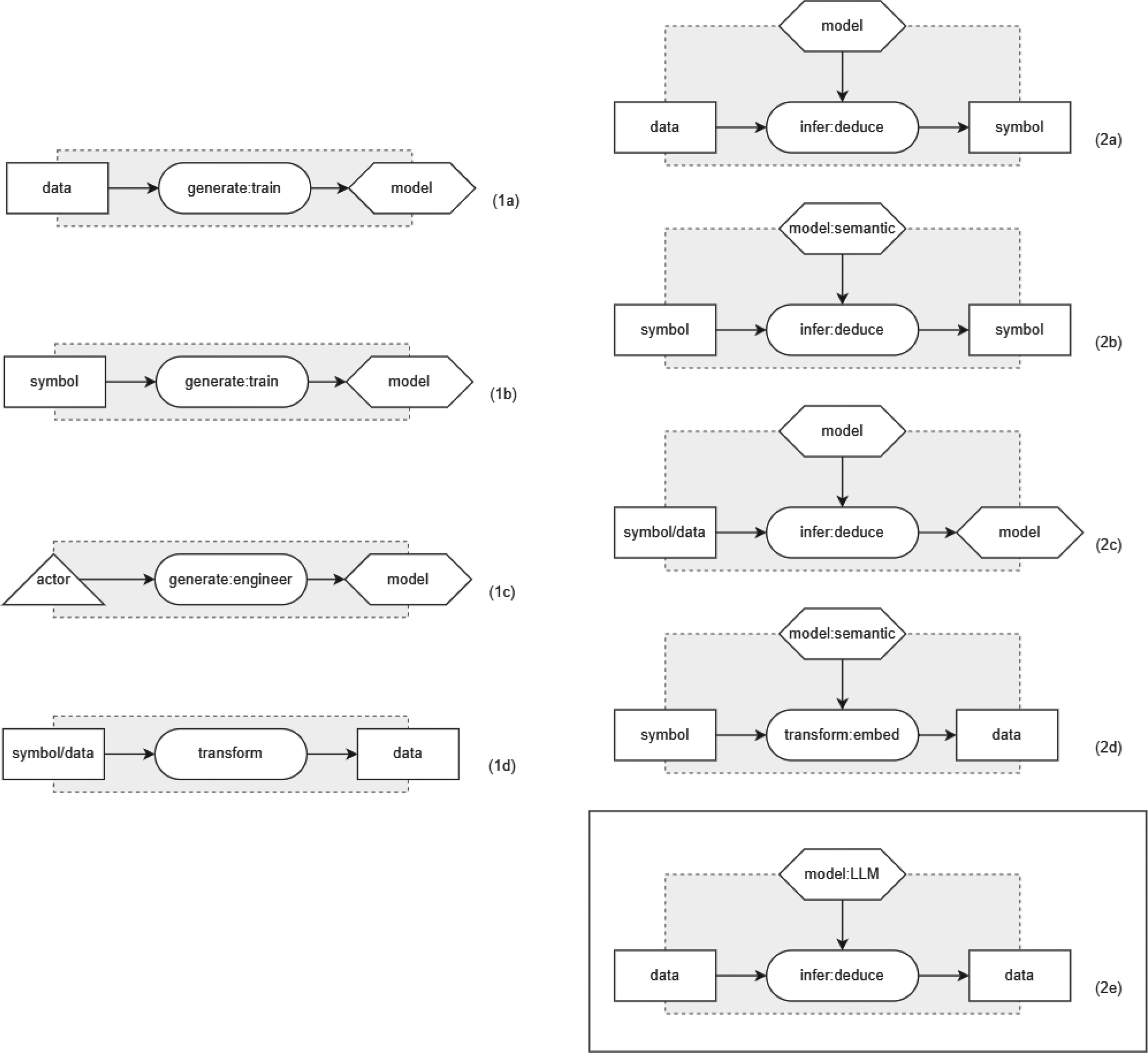
All elementary design patterns, including novel addition 2e. Patterns 1a to 1c allow for model generation, 1d for transforming data and patterns 2a–2e allow for model use.
When seeking to apply any of the eight elementary patterns of the classic Boxology framework to represent LLMs, however, it becomes apparent that such generative AI approaches are not adequately represented in these elementary patterns. While the main characteristic of generative AI systems is the ability to output new data for given input data, in the existing elementary patterns only symbols or models can be inferred. Therefore, we propose to extend the eight elementary patterns (Figure 1, 1()a–(d) and 2(a)–(d)) by introducing a new additional elementary pattern 2e (Figure 1). In contrast to the existing elementary patterns, this novel pattern allows to represent LLM-based neuro-symbolical systems since this pattern represents a model that can infer new data from data. This new data can be an image, video, or text, depending on the type of model. For example, with GPT (Brown et al., 2020), LLaMa (Dubey et al., 2024) and similar generative text models, new text is generated based on given input text.
While we focus on textual models in this paper, it is worth mentioning that the pattern proposed in this section abstracts from the specifics of the type of data. The new elementary pattern 2e is thus transferable to other generative models and data types and applies also for example to image generation models (Betker et al., 2023; Jin et al., 2024; Rombach et al., 2021; Wang et al., 2024a; Zhang et al., 2024), which can generate image data from text data. Specifically this would mean that the type of input data would be
One of the key characteristics of the Boxology framework is its modularity, allowing the combination and reuse of elementary patterns in compositional patterns. Van Bekkum et al. describe, for example, the two compositional patterns 3a and 3b depicted in Figure 2 (van Bekkum et al., 2021). For the compositional pattern 3a, the two elementary patterns 1a and 2a (Figure 1) are combined. The resulting compositional pattern describes a basic structure for a (statistical) machine learning model depicting the training (creation of the model) and testing or application phase (application of the model on new data). Similarly, the compositional pattern 3b is created from combining two elementary patterns, allowing to depict a basic structure for a semantic model.

Compositional design patterns, including novel addition 3c made by combining elementary pattern 1a and 2e. Patterns 3a and 3b visualise the patterns for full learning and prediction tasks from data/symbols.
When seeking to use any of the two compositional patterns 3a and 3b as a combined representation for training and application of an LLM, however, it becomes apparent that—just as with elementary patterns for LLM-based training and inference—the compositional patterns of the classic Boxology framework are not well-suited for this. Thus, we introduce the new compositional pattern 3c (Figure 2) for the combined training and application of an LLM. This additional pattern is built from a combination of the two elementary patterns 1a and 2e (Figure 1). Similar to the novel elementary pattern 2e, this novel compositional is not limited to text-based data only, but can also be applied to any type of data, including image data, audio data, and multimodal data.
Current LLM-based neuro-symbolic systems often either use an LLM followed by a semantic model, or a semantic model followed by an LLM, or a combination of two models in parallel of which the output is fused. In this section, we propose compositional design patterns for these different types of system. We loosely follow the categorisation of Pan et al. (2024). We divide the section into training and application phases, as the patterns for these phases are distinct.
LLM-based Neuro-Symbolic Design Patterns in Training
Generative neuro-symbolic systems can use semantic models in the training of an LLM or use an LLM to create a semantic model, or can be used in synergy to create a model. In the following subsections, we will describe the different patterns in more detail.
KG-enhanced LLMs
KGs can be used to enhance LLMs in training, for example by influencing the training data. An example of this is shown in the design pattern in Figure 3. Here, a KG is used to infer symbols (pattern 2b). These symbols are then changed into data (pattern 1d). This data is then used to train the LLM (pattern 1a). This depiction can be used to represent (Li et al., 2022; Rosset et al., 2020; Shen et al., 2020; Xiong et al., 2019), for example when a KG is used when masking the data to improve the training of the LLM. For example, in GLM (Shen et al., 2020) the masking probability is higher for concepts which are close together in the KG. On the other hand, SKEP (Tian et al., 2020) uses a KG to identify words of high sentiment and gives them a higher masking probability.
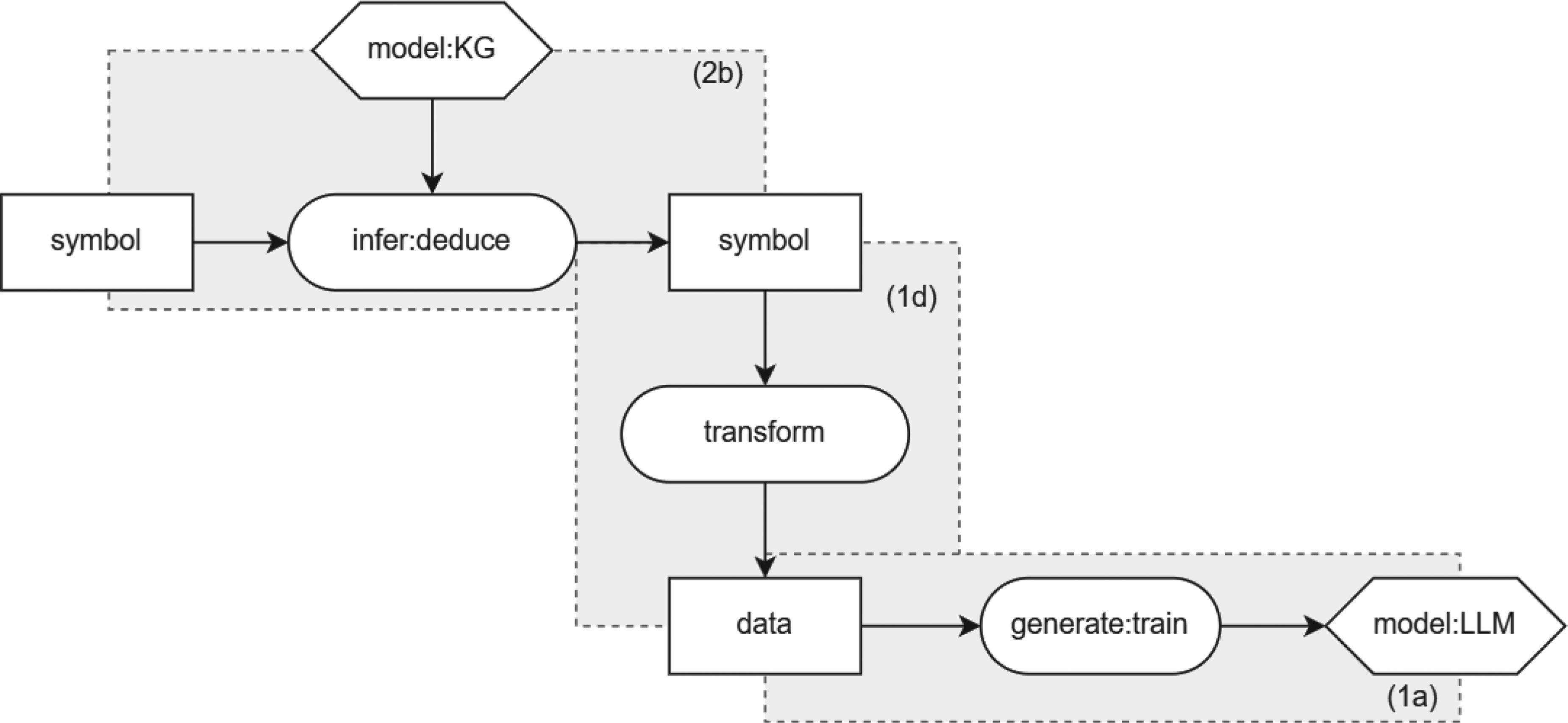
KG-enhanced LLMs in training. KG: knowledge graph; LLM: large language model.
LLMs can be used to enhance KGs as KGs might be incomplete and textual information is not integrated in the embedding itself. It can be represented in Boxology as presented in Figure 4. Similar to the KG-enhanced LLMs in training, new data is infered by an LLM (pattern 2e). These are then transformed to symbols (1d) and used to create or add on to a KG model (1a). For example, Nayyeri et al. (2023) generate representations on different levels such as sentence and document using LLMs and Huang et al. (2022) create multi-modal embeddings. Models following this structure are often used for tasks such as LLM-augmented KG completion and construction, including Named Entity Recognition, Coreference Resolution, and Relation Extraction. For example, KG-BERT, MLT-KGC, and PKGC use LLMs for the completion of a KG (Kim et al., 2020; Lv et al., 2022; Yao et al., 2019). They use the LLM output to predict the relation between new entities and existing ones. Yan et al. (2021) uses LLMs to aid in Named Entity Recognition, Cattan et al. (2021); Joshi et al. (2020) for Coreference Resolution, and Park and Kim (2021); Shi and Lin (2019) for Relation Extraction.

LLM-augmented KGs in training. KG: knowledge graph; LLM: large language model.
One of the ways in which LLMs and KGs are synergised in training is using an LLM for joint text and KG embedding or representation. Figure 5 shows the Boxology representation of these types of systems. The symbolic triples are transformed into text (pattern 1d), which is then combined with other text to integrate both the graph structure and the textual information into the embedding simultaneously and trained to create a model (pattern 1a). For example, kNN-KGE sees entities as special tokens and incorporates them into sentences as input for the LLM (Wang et al., 2023b). LMKE has a similar system structure but applies a different learning method to improve the learnt embeddings (Wang et al., 2022). LambdaKG improves the representation of the graph structure by including neighbouring entities in the input sentence (Xie et al., 2022). KEPLER, JointGT and DRAGON use a unified model for the knowledge embedding and pre-trained language representation (Ke et al., 2021; Wang et al., 2021; Yasunaga et al., 2022). They have pre-training tasks to come to a joint knowledge embedding and language modelling optimisation. ERNIE proposes a dual encoder system, consisting of a textual encoder that is fused with the KG encoder (Zhang et al., 2019). BERT-MK has a similar dual encoder, but adds additional information from neighbouring entities to the KG (He et al., 2020). Coke-BERT further improves on this idea by adding a module to filter out irrelevant neighbouring entities (Su et al., 2021). JAKET fuses the entity representation in the middle layers of the LLM (Yu et al., 2022).

Synergised LLMs and KGs in training. KG: knowledge graph; LLM: large language model.
Neuro-symbolic systems often combine KGs and LLMs during inference, after training. In this way, the system is more robust to new situations. Many of the LLM-based neuro-symbolic systems follow one of the pre-defined patterns. This section will highlight three depictions of the LLM-based NeSy systems during inference.
KG-enhanced LLMs
KGs can be used to enhance LLMs by utilising the knowledge in KGs. One way to do this is represented in Figure 6. It shows how a KG is used to infer symbols (pattern 2b). These symbols are then transformed to data (pattern 1d) which is used by the LLM to generate new data (pattern 2e). This can be useful for example to align the input data with the knowledge or augment it by adding relevant facts for the LLM to improve the output. In contrast to KG injection during training (see Section 4.1.1), the results of pattern 2b and 1d are now input to the infer process instead of the train process. This means that the knowledge is up to date at the time of inference, rather than at the time of training, which may happen a long time before deployment.
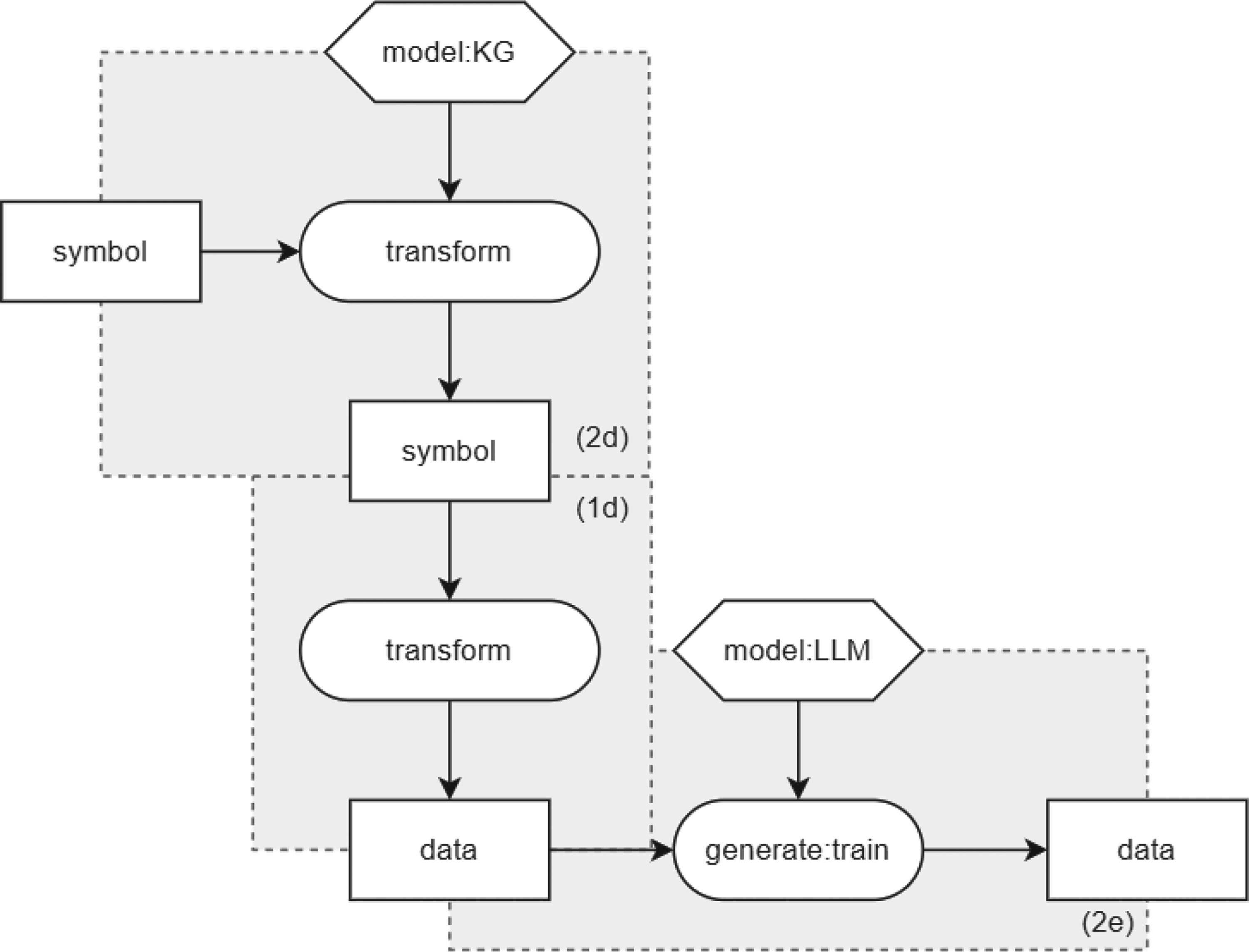
KG-enhanced LLMs during inference. KG: knowledge graph; LLM: large language model.
This pattern describes systems that transform the input data by aligning them with the knowledge of the KG before they are fed into the deduction process with an LLM model. This can be done in a prompt engineering process using KGs (Li et al., 2023; Luo et al., 2023; Wang et al., 2023a; Wen et al., 2023) or retrieval-augmented knowledge methods such as RAG (Lewis et al., 2020). KagNet first encodes the input KG and then augments it with textual representation (Lin et al., 2019).
LLMs can be used to augment KGs to improve information deductions (Figure 7). An LLM is used to infer data (pattern 2e). Then the data is transformed to symbols (pattern 1d) for the KG to reason over (pattern 2b). As with KG-enhanced LLMs during inference, the difference between training and inference for LLM-augmented KGs is that the first pattern is input to infer process rather than to train process of the KG.
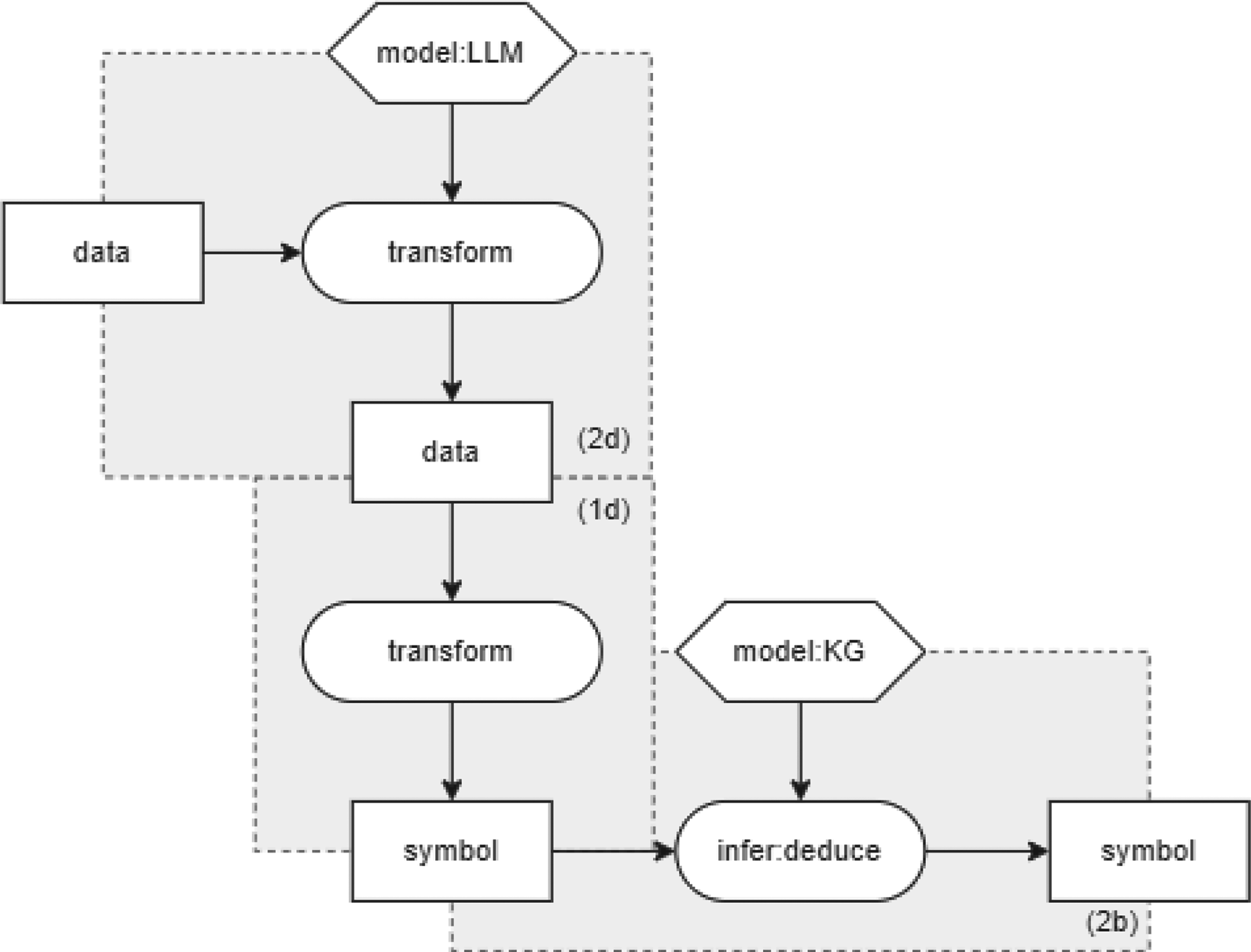
LLM-augmented KGs during inference. KG: knowledge graph; LLM: large language model.
One example is using LLMs for KG embedding. Pretrain-KGE uses an LLM to encode the text of the parts of the triples and uses that encoding as a starting point for the KG encoding (Zhang et al., 2020). Moreover, in answering questions with LLM-augmented KG, LLMs are used to bridge the gap between natural language questions and the retrieval of KG answers (Hu et al., 2023; Lukovnikov et al., 2019). In addition, LLMs can be used for the generation of text from a KG, where LLMs are used to generate natural language that describes facts from KGs (Feng et al., 2023; Sun et al., 2023; Wang et al., 2024b). MHGRN uses the LLM representation of the text to guide the reasoning process in the KGs (Feng et al., 2020).
LLMs and KGs can be combined to work in synergy, also in the application phase. Figure 8 shows how this can be applied, specifically in the case of synergised reasoning. Here, the model is fed both symbols and data, both in the training and in the application phase.

Synergised LLMs and KGs for reasoning. KG: knowledge graph; LLM: large language model.
Examples of such methods are JointLK (Sun et al., 2022) and GreaseLM (Zhang et al., 2022). They include interactions between the tokens in the textual input and the entities in the graph in the model’s layers. QA-GNN (Yasunaga et al., 2021) represents the LLM information as a special node in the KG for reasoning.
In this section, we describe and explore several papers that propose an LLM-based neuro-symbolic system. The selected papers are chosen, as they represent a diverse set of possibilities to use an LLM in a system pipeline (on the input side of the system, somewhere in the inner part, or on the output side) as well as act as a fluent language interface or a formal language interface on the input or output side.
Retrieval-augmented generation
RAG is a method that expands an LLM with external knowledge (Lewis et al., 2020). A RAG system has two main components, a retriever and a generator. Figure 9 shows the Boxology representation of a RAG system, where the retriever is the model in pattern 2a and 1d and the generator is the LLM in pattern 2e. Firstly, the retriever selects relevant documents based on the posed question (pattern 2a), through classification or with help of a KG. Secondly, the question and retrieved documents are transformed (1d) to be presented to an LLM in a prompt (pattern 2e). Thirdly, the LLM generates an answer to the question based on the information in the selected documents. The LLM can also present the source of the information, making it more trustworthy and reliable.

Use of retrieval-augmented generation.
In KD-CoT, KSL and Think-on-graph, facts are retrieved from a KG together with the reasoning, and an LLM generates a natural language answer to be presented to the user (Feng et al., 2023; Sun et al., 2023; Wang et al., 2024b). RAG is a prime example of the KG-enhanced LLM pattern, as presented in Section 4.2.1.
The KnowGL parser is a system developed by IBM Research for converting data into symbols. More specifically, it can be used to automatically extract KGs from collections of text documents (Rossiello et al., 2023). KnowGL employs an LLM to extract semantic triples from each sentence, which are then enriched with semantic annotations. Figure 10 shows the Boxology representation of the KnowGL parser. Pattern 2e represents the BART-large model receiving a sentence and inducing a list ‘subject, relation, object’. In the next step, represented by pattern 2b, a ranked list is created of distinct facts and their scores. In the final step, the generated facts are linked to Wikidata. This is done using a mapping of labels to Wikidata IDs (pattern 2b). In the case that the LLM has created a new entity, type, or relation label that are not in Wikidata it returns ‘null’.

Boxology representation of KnowGL (Rossiello et al., 2023).
The architecture of the KnowGL parser displays a variation of the LLM-augmented KG in inference pattern, in Section 4.2.2.
Although knowledge is mostly injected into statistical generative models during the input or during the output stage, approaches to inject knowledge inside the model have also been proposed. A prominent example is KnowBERT, a modified variant of BERT (Peters et al., 2019). It stands out for its fusion of contextual and graph representations, attention-enhanced entity-spanned knowledge infusion, and flexibility in injecting multiple KGs at various model levels. KnowBERT embeds multiple knowledge bases (KB—WordNet and a subset of Wikipedia) into LLMs to enhance their representations with structured, human-curated knowledge. By integrating the Knowledge Attention and Recontextualisation layers (Balažević et al., 2019), graph entity embeddings are used that are processed through an attention mechanism to enhance entity span embeddings. This happens in later layers of the model to stabilise training, but can also potentially be used to inject knowledge at earlier stages (Colon-Hernandez et al., 2021). The Boxology pattern for KnowBERT is shown in Figure 11 and is the same as the pattern presented in Section 4.1.1 (KG-enhanced LLMs in training). Pattern 2b represents the incorporation of KB into a pre-trained BERT model, using an integrated entity linker, as shown with pattern 1d. Finally, the Knowledge Attention and Recontextualisation component is the heart of KnowBert, which is represented as pattern 1a.

Boxology representation of KnowBERT (Peters et al., 2019).
Theory explanation or automated conjecturing is the process of inventing new conjectures about a set of functions. The system Johansson and Smallbone (2023) has two principal components: (1) the system assigns the generative task of discovering mathematical conjectures to an LLM, (2) the results are checked using a symbolic theorem prover or counterexample finder. The LLM is first trained on data from a formal language (pattern 3c). The system is then prompted with a formal theory (e.g. a sort function), and has the LLM generate lemmas from the theory as output data. These generated lemmas are transformed from data to symbols (pattern 1d) and are subsequently used by a semantic model(s) prover (pattern 2b). The Boxology representation is depicted in Figure 12.

Boxology representation for using large language models (LLMs) for discovery of mathematical conjectures (Johansson & Smallbone, 2023).
The approach taken in Yang et al. (2023) is also captured by this representation. The system proposed first uses an LLM component that has been trained on Prolog to generate Prolog code as output (pattern 3c). The output is then transformed to symbols (1d), a symbolic inference engine then produces answers and reasoning traces by executing the code mentioned above (pattern 2b).
Both of these examples show a generalisation of the Boxology pattern in Section 4.2.2 (LLM-augmented KGs during inference), where the KG is replaced by a different semantic model.
Generative Neuro-Symbolic Visual Reasoning by Growing and Reusing Modules (GENOME) focuses on the task of generative software module learning (Chen et al., 2023). Its architecture is based on one LLM generating signatures (input/output) for these software modules and reasoning steps, while another LLM subsequently creates the targeted software module based on those; as usually, both LLMs have been created by means of pre-training. Finally, GENOME employs a deductive reasoner to evaluate the LLM-generated module on a test case.
Figure 13 shows the Boxology representation of GENOME. The system consists of three stages, module initialisation, module generation and module execution, represented by two compositional and one elementary pattern. First, an LLM assesses a visual-language question and outputs new module signatures and operation steps as a response to the query (pattern 3c), if current modules from a library cannot provide an adequate response. In the next step, the LLM generates a module (software code) based on the signature/test case (pattern 3c, 2nd component). Finally, the module is executed by passing it a visual query (pattern 2a).

Boxology representation of GENOME (Chen et al., 2023).
This use case is an extension of the LLM-augmented KGs during inference as described in Section 4.2.2, deploying two LLMs in sequence.
The approach taken by Logic-LM Pan et al. (2023) integrates LLMs as a natural language interface with symbolic solvers to improve logical problem-solving. The logical problem can e.g. be stated as logical programming, first-order logic or a constraint satisfaction problem. This approach is depicted in Boxology notation in Figure 14. Here the system uses LLMs that are trained in the specific logic language (pattern 3c) to translate a problem stated in natural language into a symbolic formulation (patterns 3c and 1d). In the next step, a symbolic reasoner module performs logical inference on the formulated problem and transforms the symbolic results into data (patterns 2b and 1d), using a semantic model and a transformation of logical symbols to a prompt. Finally, an LLM receives the results as an input prompt and outputs a solution in natural language (pattern 3c). The LLM thus functions as a fluent language interface to and from a symbolic reasoner component. The main reasoning is performed by a logic engine (symbolic reasoner), in order to guarantee correct and verifiable results.

Boxology representation of Logic-LM (Pan et al., 2023).
This representation is a combination of the patterns presented in LLM-augmented KGs during inference, Section 4.2.2, and KG-enhanced LLMs during inference, Section 4.2.1.
Advancements. A key contribution of this work is the introduction of novel design patterns. In particular, we introduce a novel elementary pattern and a novel compositional pattern to complement the existing Boxology patterns. The novel patterns proposed in this paper provide a more fine-grained description of the model element, introducing the generative model. The novel elementary pattern allows, for the first time, to use the Boxology to represent data in - data out processing, which is the key concept underlaying generative AI techniques. Although we apply it exclusively to LLMs, we have argued that its level of abstraction lends itself to representing other types of generative models, such as generative image models. As a natural derivate of this, the newly introduced compositional pattern employed this elementary pattern to integrate training and inference for generative models. Providing three principled integrations of LLMs and KGs, we illustrate how the composition of elementary patterns can be used to describe LLMs, and we explore several categories as well as specific approaches in use cases, such as KnowGL, GENOME and Logic-LM.
Conceptualisation. Whereas our extension demonstrates its applicability in describing key architectural features of LLM-based neuro-symbolic systems, it raises interesting questions about the nature of other Boxology elements directly related to the new element representing generative models (
Ambiguity. In the process of applying basic design patterns to specific use cases, naturally questions arise about which pattern combinations are allowed and which are not. However, the truth is that Boxology will not in all real-world LLM-based neuro-symbolic systems lead to one unique and unambiguous representation. In practical classroom settings, for example, we have experienced the updated Boxology framework to yield multiple options for describing the same system, depending on the individual student or engineer. Much like some of the notations of unified modelling language (UML) have proven to lend itself to different designs of the same system based on different points of view, this phenomenon is likewise inherent to the Boxology framework. In order to reduce some of the ambiguity, a more formal description along with guidelines for interpretation and use of the current set of Boxology elements seems warranted.
Conclusion and Future Work
Despite many open questions and challenges towards generative AI techniques, LLMs are widely used in a variety of applications nowadays. To this end, combining data-driven approaches with knowledge-based techniques is a promising development to address these challenges. In this paper, we propose new design patterns for modular LLM-based neuro-symbolic systems to be included in the design pattern approach for neuro-symbolic systems as proposed by van Bekkum et al. (2021). Thereby, we are filling a gap in the classic Boxology framework with respect to the recent rise of generative AI techniques. To this end, this paper proposes an extension in terms of concepts and patterns to the set of Boxology elements and patterns as described in earlier work on Boxology (de Boer et al., 2024; van Bekkum et al., 2021; Van Harmelen & Ten Teije, 2019). Specifically, our goal is to make the Boxology framework compatible with the concepts underlaying LLMs and LLM-based neuro-symbolic systems. Given the fact that many existing, as well as many potential real-world applications are based on this disruptive AI paradigm, the extension provided within this paper can be considered a substantial conceptual update allowing to maintain the Boxology framework’s relevance in the years to come.
In future work, we plan to further explore the usability and benefits of the updated Boxology and its design patterns in domains adjacent to LLM-based neuro-symbolic systems, such as generative AI systems without symbolic AI attached and multi-modal generative AI systems. Moreover, we anticipate the need to further extend and deepen the Boxology framework itself. Temporal or recurring/iterative aspects, for example, have not yet been taken into account and can currently not be visualised adequately in this respect. Our current investigation has also shown that the current concept naming, concept labelling and some of the formalisation of the Boxology could benefit from critical review and in-depth revisiting. The importance of representing or modelling datasets, for example, may be taken into account in future specifications of particular subtypes of instances and models. Finally, we consider a future use of graphical tools for the Boxology beneficial. In software development, this approach has proven both efficient and effective and is well known, for example, from the UML and visual programming tools, such as LabView or Scratch. And while our current work is mostly concerned with graphical representations of design patterns for system design and documentation, the promise of templates, low-code, or no-code development, seems also an appealing field of research for the future.
Footnotes
Acknowledgements
We thank Frank van Harmelen and Annette ten Teije for their feedback. We also thank Daan Di Scala for his contribution to the KnowGL pattern.
Funding
The authors received the following financial support for the research, authorship, and/or publication of this article: This study was supported by the TNO project GRAIL.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.