
Abstract
Generative AI (GenAI), specifically the Large Language Model (LLM), focuses on creating content like text, images, audio, or other data types similar to that created by humans. Advancements in various LLMs have accelerated AI development, potentially impacting various fields, including education. Can LLMs produce educational content with similar readability features as human-generated reading passages? This study compared readability measures such as reading speed, comprehension, and qualitative characteristics (familiarity, interest, and perceived quality) of 300-word 8th-grade level text passages authored by humans and ChatGPT3.5. We found that ChatGPT3.5-generated passages can be read faster with better comprehension than conventionally human-authored passages. ChatGPT3.5 passages were also rated higher-quality passages and had comparable ratings for interest and familiarity compared to human-authored passages. These findings implicate that the LLM enhances educational materials’ usability and effectiveness. More importantly, LLM offers scalability and consistency, catering to diverse learning needs for educators and students.
Introduction
In recent years, progress in Artificial Intelligence (AI) has gained speed with the advancements in GenAI technologies. The latest release of GenAI technology, ChatGPT3, has quickly drawn the interest of millions of users (Dale, 2021). Other LLMs have also been competing, for example, PaLM (Chowdhery et al., 2022), LaMDA (Touvron et al., 2023), Gemini by Google (Saeidnia, 2023), Claude by Anthropic (Abbas et al., 2024), Ernie by Baidu (Wang et al., 2021), LLaMA by Meta (Touvron et al., 2023), and Bing Chat by Microsoft (Motlagh et al., 2023) are popular among the hundreds of LLMs. This groundbreaking growth has the potential to make a drastic impact in various fields, one of which is education.
GenAI technology can significantly impact educational practices, aiding educators in class design, assessments, and policymaking, while also assisting students with tasks like essay writing and math problem-solving (Haque et al., 2022). GenAI is an emerging technology that may not be entirely reliable all the time, as researchers and users are still exploring and understanding their capabilities (Cao et al., 2023; Wagner & Ertl-Wagner, 2023; Walker et al., 2023). Given the current status of these technologies, this study aims to assess whether LLMs can create reading passages and comprehension questions comparable in quality and difficulty to those produced by human experts.
Generating educational content, such as reading passages, is costly in terms of time and resources due to the expertise required in curriculum and assessment development, and the need to consider factors like length, grade level, and coherence, making it a challenging task (Benjamin & Schwanenflugel, 2010). Developing educational content requires careful consideration to ensure it is written at an appropriate grade level, which can be challenging for teachers due to the significant variation in reading levels among students in a classroom (Connor & Morrison, 2016; Rog & Burton, 2001). Tailoring reading passages for accessibility is crucial, particularly for individuals with learning disabilities like dyslexia and ADHD, who often face disadvantages in traditional classroom settings due to materials not being tailored to their needs (Spiel et al., 2014; Vickers, 2010). While awareness of the need for tailored teaching materials is growing, their availability remains limited; however, GenAI offers the potential to generate such materials more quickly and efficiently than humans can after algorithm training and facilitating necessary adjustments (Ahmed & Ganapathy, 2021; Attard & Dingli, 2023).
ChatGPT, a leading GenAI technology, is capable of generating human-like conversational dialogues (Chiu, 2023). It has outperformed other models in various evaluations, including questioning care for myopia (Lim et al., 2023), neurosurgery (Ali et al., 2023), and answering calculus and statistical questions (Calonge et al., 2023). For this study, ChatGPT3.5 was used to create 8th-grade-level reading passages for testing readability metrics. Exploring the use of ChatGPT3.5 for creating reading passages and comprehension questions is crucial due to the importance of having well-prepared material for teaching and research, along with the challenges of generating ideal content efficiently. Based on the literature above, our research question is to find out if LLM (ChatGPT3.5) can generate passages similar to human-generated ones. In the current study, we investigated reading performance both in terms of reading speed and comprehension through both human-generated and AI-generated passages.
Methodology
Stimuli
Human-authored and AI-generated passages have been used to conduct this study.
Human-Generated Content
An expert in education developed human-generated passages at the 8th-grade reading level using the Flesch-Kincaid Grade Level (FKGL) metric. Ten 8th-grade human-generated passages were selected, making sure the passage contents were mixed in the areas of science, history, and biography. See Figure 2 for the complete set of passage topics. Each passage, about 300 (+/−10%) words long and was accompanied by five comprehension questions.
AI-Generated Content
From the hundreds of available LLMs, we used ChatGPT3.5 to create passages and related comprehension questions.
(i) The Technology Used: ChatGPT3.5 is chosen for its availability to the general public, training on massive datasets, user-friendly interface, ability to consider entire dialogue history for corrections (Haque et al., 2022), and its suitability for text generation, including answering factual questions, adhering to specific requirements, and producing text summaries (Tate et al., 2023). Additionally, it can identify and correct errors in generated output (Osmanovic-Thunström & Steingrimsson, 2023), resulting in output that closely resembles human natural language and maintains coherence.
(ii) Prompt Engineering: Ten AI-generated passages were created using ChatGPT3.5 on the same topics as human-written ones, tuning prompts to match human criteria without human input. A prompt for generating four multiple-choice comprehension questions was also created for each passage, specifying that the answers must include three incorrect and one correct option, along with a final main idea question.
(iii) Prompts: Two separate prompts were created through trial and error: one for generating passages on selected topics and another for generating comprehension questions. The prompt for passage generation is,
Generate 4 interactive passages about “topic name.” The passages should contain curious and interesting facts. Each passage should be approximately 75 words. The passages should stand alone. The text must be at grade level 8.
The prompt for question generation is, Generate 4 difficult multi-choice comprehension questions for each of the passages below, with 3 incorrect and 1 correct answer. Highlight the correct answer. Don’t write the correct answer longer than the other answers. Generate 5th question answering the question: "What is the main idea of the text?
All the passages and questions were generated using the same prompt, only changing the “topic name.”
(iv) Quality Checking: AI passages were assessed for quality based on criteria such as topic relevance, passage length, grade-level, and language appropriateness, while questions were evaluated for relevance to the passage, correctness of answers and without multiple correct answers. If criteria were not met, passages or questions were regenerated using the same prompt. An example of passage regeneration due to inappropriate or offensive language in the “Amarna Period” passage:
Akhenaten looked different from other pharaohs. He had long features and looked more like a woman.
For the questions, in some cases, ChatGPT3.5 gave a correct answer choice in place of one of the incorrect answers. For example, this question was generated for the “Ancient City: Sparta” passage and had two correct answers.
What was the law of Lycurgus?, A) A set of laws that regulated the lives of the Helots; B) A set of laws that regulated the lives of the Perioeci; C) Lycurgus’ law mandated that all Spartans be educated in the same way (this answer is intended to be incorrect but is actually correct); D) A set of laws that regulated the lives of the Spartans (the correct answer).
Both human- and AI-generated passages were scored within a narrow FKGL range, but AI passages were slightly lower in average grade level than human passages, as indicated by formal testing (8.4 vs. 8.7, t[9] = 2.32, p = .046).
Participants
A total of 30 native-English speaking participants (Age Mean: 45.76, 14 women), ranging in age from 18 to 75, were recruited through the crowdsourcing platform Prolific. All the participants self-reported having normal (20/20) or corrected normal vision. Participants were compensated for their participation.
Experiment Design
This study aimed to compare human-authored and AI-authored text passages in terms of reading speed, comprehension, and qualitative characteristics. Human authors wrote passages on ten topics, while AI versions were generated using ChatGPT, matching length and grade level. Passages were divided into sets A and B, with each set containing five human and five AI passages without topic repetition, randomizing the relationship between topic and author. Each passage was split into four screens for better visualization. The experiment was conducted online using Pavlovia, an online iterative tool of Psychopy (Peirce et al., 2019, 2023). Participants in the online study were restricted to using desktop or laptop computers to minimize variability in device usage, though a potential variation in lighting conditions might present.
Procedure
Participants in the online experiment calibrated their screens by adjusting a credit card-sized image to match its size on their display to an actual credit card using the arrow button on the keyboard. They were instructed to sit at a 51 cm (approximately arm’s length) viewing distance and then presented with an informed consent form. After giving consent, they read the passages silently, aiming for speed without repetition. The passages, presented in a counterbalanced sequence, alternated between human-generated and AI-generated passages until each participant had read ten passages.
Data Preprocessing
The study calculated reading speeds in words per minute (WPM) for each screen based on the number of words and time spent. A small percentage of AI screens (2.0%) were read slower than 100 WPM compared to human passages (2.7%), while a higher percentage of AI screens (11.5%) were read faster than 650 WPM compared to human passages (10.0%). An interquartile range (IQR) analysis suggested upper cutoffs of 789 WPM for AI passages and 635 WPM for human passages, with no applicable lower cutoff. Individual screens were excluded if they were read slower than 100 WPM or faster than 650 WPM based on previous recommendations of WPM measures (Carver, 1990, 1992; Wallace, Treitman, Huang, et al., 2020). Comprehension scores were tightly clustered, and no valid cutoffs were identified for excluding outlier scores. The final sample included 25 participants, with some screens removed based on the specified criteria. The sample was 52% male, with an age range of 26 to 71 and a mean age of 47.9. 80% of the sample used vision correction.
Results
Using the same prompt, the study regenerated passages with ChatGPT3.5 until they reached the desired 8th-grade reading level with expected quality. It took 1 to 7 regenerations per passage, averaging 3.2 times, and 5 to 45 min, averaging 19.5 min, to achieve this. The passages’ readability, measured by FKGL, improved from an initial mean of 11.25 to 8.4 after regeneration.
Quantitative Metrics
Reading speed data were analyzed in a linear mixed-effect model that specified reading speed (WPM per screen) as the dependent measure. Passage author (human or AI), passage order, passage topic, screen number, and participant age were specified as fixed effects. The participant was specified as a random effect with a constant slope. The main effect of the author was significant, with AI-authored passages reading faster than human passages on average (304 WPM vs. 249 WPM, χ2 = 124.88, p < .001, Type II Wald chi-square test). Reading speeds for human passages are in line with speeds observed in previous studies (Wallace et al., 2021; Wallace, Treitman, Huang, et al., 2020; Wallace, Treitman, Kumawat, et al., 2020a, b), while speeds for AI passages are faster. Consistent with previous studies on interlude reading (Wallace, Treitman, Kumawat, et al., 2020b), the effect of the screen was significant (Figure 1), with later screens reading faster than earlier screens (χ2 = 87.56, p < .001). Reading speeds for human passages increase as the session continues, while reading speeds for AI passages begin fast and remain so (Figure 1). Passage topics significantly (χ2 = 57.02, p < .001) affected reading speed (Figure 2). There were also significant interactions between author and screen number (χ2 = 8.84, p = .003) and author and topic (χ2 = 32.58, p < .001).
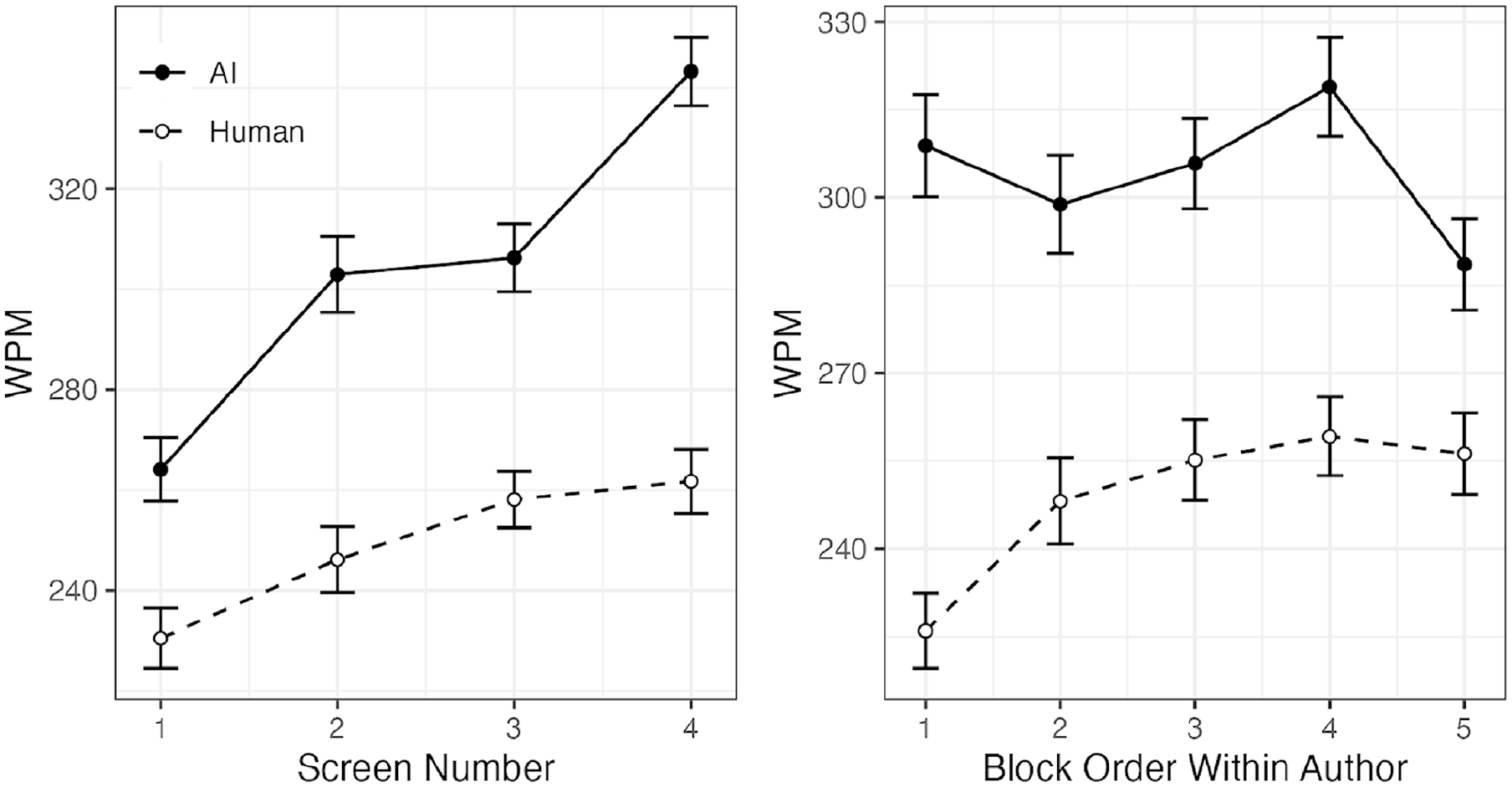
Mean reading speed (WPM) per screen number and author (left) and Mean reading speed per chronological passage (right). Error bars represent ±1 within-participant standard error.
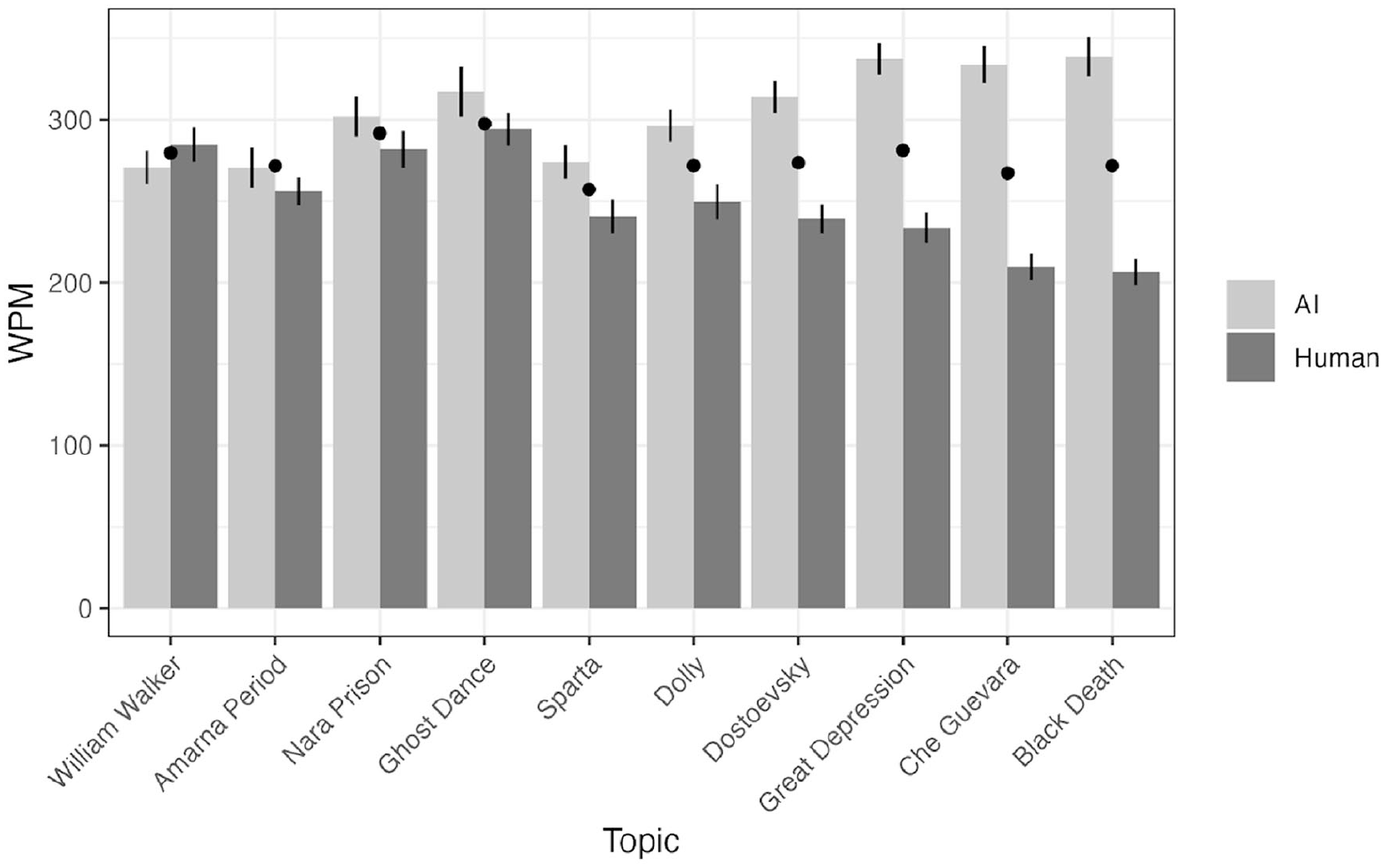
Mean reading speed by passage topic and author. The mean difference between AI and human reading speeds for each passage determines the plot’s order. While some human passages have much more pronounced effects on reading speeds, AI passages consistently have fast reading speeds.
Reading comprehension scores were calculated per participant and passage based on response accuracy to the set of five comprehension questions. Scores ranged between 0 and 1 in increments of 0.2. Comprehension scores were first analyzed under a linear mixed-effect model with the following fixed effects: passage author (AI or human), passage topic, block order, participant age, and participant was specified as random effect.
Reading comprehension differed significantly by author, with AI passages having higher scores than human-generated passages (81% vs. 67% accuracy, χ2 = 40.53, < 0.001). Comprehension also varied significantly by topic (χ2 = 21.11, p = .012; Figure 3). The author and topic also interacted significantly (χ2 = 19.96, p = .018); comprehension scores for human passages were more uniform than for AI passages. The author and age interaction is possibly an artifact (χ2 = 4.31, p = .038); age did not affect the comprehension of human passages, while two participants in their 70s had lower comprehension scores for some AI passages, which appears to drive most of this effect.
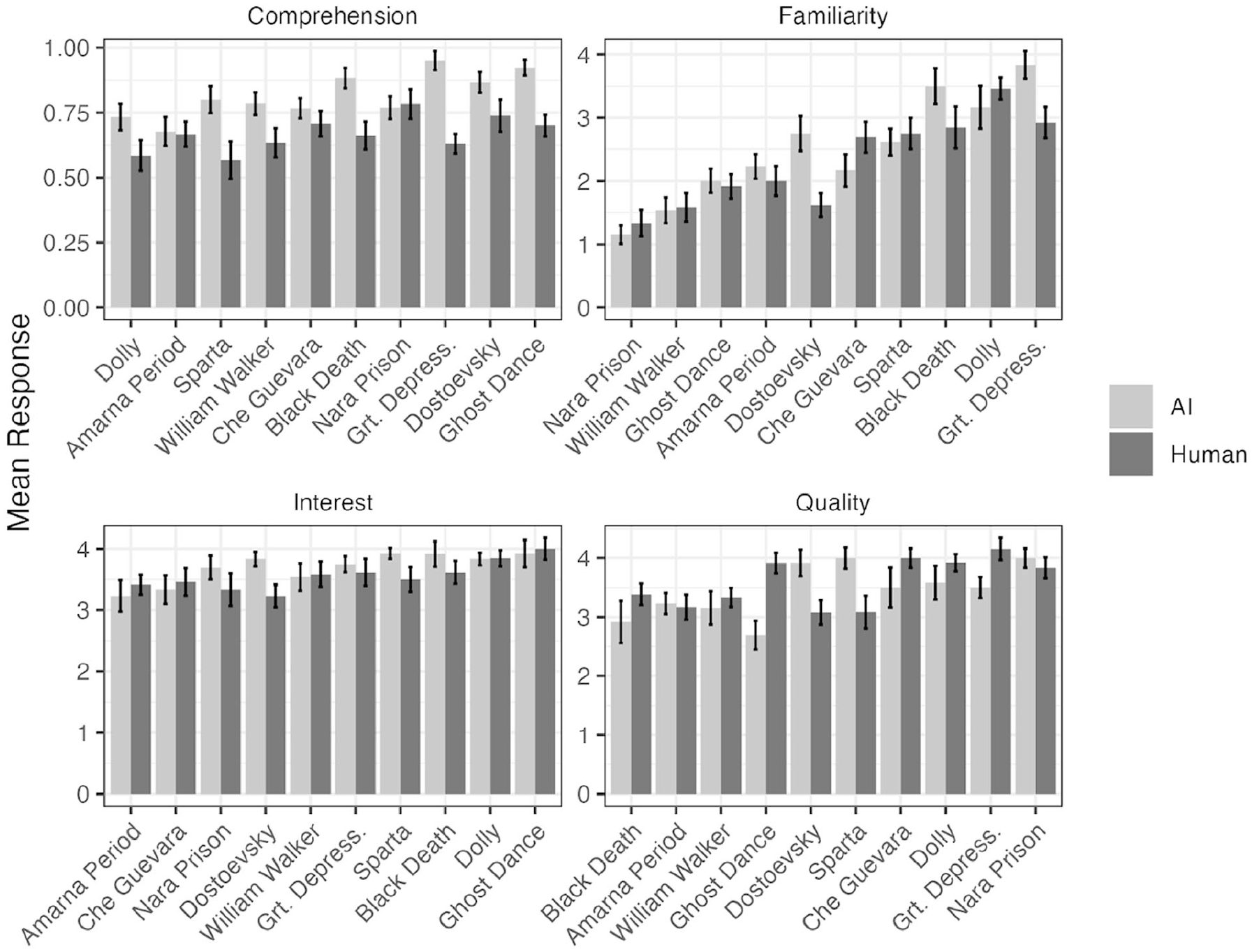
Mean metrics (comprehension, familiarity, interest, and quality) for each passage and author type.
Qualitative Metrics
Familiarity, Interest, Quality ratings were analyzed under the similar linear mixed-effect model with the following fixed effects: passage author (AI or human), passage topic, block order, participant age, and participant was specified as random effect.
There was a borderline significant effect of the author on familiarity (χ2 = 3.20, p = .07). Familiarity varies significantly by passage topic (χ2 = 131.61, p < .001). There were significant author and topic interactions (χ2 = 19.90, p = .019); topic and age interactions (χ2 = 21.04, p = .012).
Interest varied significantly by passage topic (χ2 = 17.27, p = .045). There was a significant block order by age interaction (χ2 = 4.99, p = .026). Participants younger than age 48 showed a slightly steeper decline in interest as the session progressed, though the difference is minor.
There was a significant author-by-topic interaction (χ2 = 32.62, p < .001), suggesting that the quality of AI-generated passages varied depending on the topic. There was also a main effect of the passage topic overall (χ2 = 23.87, p = .005). From Figure 3, Ancient Greek City: Sparta, Fyodor Dostoevsky, and Nara Juvenile Prison were rated as high-quality AI-generated passages.
Turing Test
Participants guessed the authorship of passages after reading them, with human authorship as the positive outcome. Hits were defined as correctly identifying a human passage, while misses were deemed as incorrectly labeling a human passage as AI. Correctly identifying an AI passage was a correct rejection, and incorrectly labeling it as human was a false positive. Sensitivity (d-prime) and bias (c) metrics were calculated for each participant. Wilcoxon signed-rank tests showed that neither d-prime (mean = 0.15, p = .12) nor c (mean = −0.10, p = .399) were significantly different from zero. This suggests that participants were unable to distinguish between human and AI passages and were not significantly biased toward either choice, though nominally toward AI.
Discussion
Initially, AI-generated passages varied widely in word count and grade level but were adjusted through multiple regenerations to meet desired specifications. Participants found AI passages comparable in quality to human-authored ones, unable to differentiate between them. The study found that AI-authored passages were read faster and more thoroughly than human-authored passages. However, expert quality assessments suggest that this might be because AI passages had lower information density.
Metrics and Future Directions
The study found that AI-generated passages were read much faster than human-authored passages. This difference could be due to AI passages containing more filler text and repetitive sentences, making them less informationally dense and easier to read. These findings align with earlier studies (Spencer et al., 2019) showing quicker reading of easier texts. Another possible explanation for the higher speed is that AI-authored passages had instances of repetitive sentences, which may increase skimming. For example, both sentences were generated within the same passage.
The ancient city of Sparta was renowned for its rigid social structure. Sparta was known for its strict laws and customs.
Though the reading speed varied by topic, comprehension accuracy was greater for AI-generated passages. The significant difference between topics implies that the accuracy or coherence of an AI passage depends on the topic; some may be more accurate or coherent than others. After the experiment, our human experts assessed AI passages and questions, finding that in many cases, the correct answer was more distinguishable from the incorrect choices. For example: “What is the bust of Nefertiti? (A) A new city built during the Amarna period; (B) A famous temple for the god Aten; (C) A type of religious ceremony; (D) A sculpture made from limestone.”
The study found that ChatGPT generated passages outperformed human-generated ones, suggesting the need for further research to explore metrics like enjoyment, immersion, and fatigue to understand AI text quality better. Future studies should also investigate how participants process and evaluate AI-generated passages over longer exposures, focusing on accuracy, coherence, and overall linguistic quality. More research is needed to understand how humans perceive and assess AI-generated language compared to human-generated literature. Comparison between ChatGPT4’s, other LLMs and human generated content would be interesting in this domain. Using reinforcement learning to train on diverse passages and questions could further improve AI quality, and studies should involve various reader groups and content lengths for comprehensive insights.
Limitations
ChatGPT3.5 is proficient in generating coherent text but faces challenges in crafting complex comprehension questions and answer choices, which could affect assessment quality. It tends to fabricate information when lacking knowledge (Wagner & Ertl-Wagner, 2023), uses repetitive sentences, and may produce insensitive content. Future research could compare human and AI-generated passages on the same topic and improve randomization of passage topics. Addressing the lower word count and grade level of AI-generated passages compared to human-authored ones could enhance the capabilities of ChatGPT3.5 and other LLMs.
Conclusion
The results suggest that AI can be a valuable tool for developing educational content. While more research is needed to fully utilize AI’s potential in content creation, human writers could use AI to support them, saving time and resources. Editing AI-generated content may be quicker than creating new content from scratch, especially when re-leveling material. This technology could also benefit researchers needing stimuli for reading experiments. With further research, AI has the potential to help educators deliver personalized content more efficiently, leading to better student outcomes.
Footnotes
Declaration of Conflicting Interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: None of the authors has a financial interest in Adobe.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The funding support for this project was provided by Adobe.