
Abstract
There is extensive literature on screening and case-finding for depression but almost all evidence is from non-mental health specialists and primary care using English speaking patients [1]. Depression is a universal disorder, with high rates in both high and low income countries [2]. The prevalence of current major depression in Iraq is substantial, estimated at 7.2% [3].
Screening for depression has been supported by recommendations from the US Preventive Services Task Force [4], the UK National Institute of Clinical Excellence (NICE) [5] and the Canadian Task Force on Preventive Health Care [6]. The New Zealand Guidelines Group recommended focused screening in primary care for those at high risk [7]. A similar approach has been advocated by NICE [8]. An updated US Preventive Services Task Force consensus statement supported screening if staff were in place to assure accurate diagnosis, effective treatment and follow up [9]. A recent review of 16 studies found that the use of screening or case-finding instruments was associated with a modest increase in the recognition of depression by clinicians (relative risk 1.27, 95%CI 1.02 to 1.59), increasing the use of any intervention but not (significantly) prescription of antidepressant medications [10]. However, within primary care there is currently no consensus on which tool to use or whether existing measures are suitable for detecting depression and monitoring severity. Further, it is possible that none of the existing paper and pencil tools are sufficiently acceptable to allow high uptake in practice [11]. Practitioners typically want short or ultra-short tools taking only a few minutes to complete [12]. Paper-and-pencil tools are inflexible, forcing all participants to complete items that may be unnecessary. Modern psychometric methods, such as Rasch analysis may help with refinement of these tests. It has been demonstrated that items may be removed from existing depression instruments, using these models without affecting specificity and sensitivity [13,14]. Several item banks have already been successfully developed and applied to assessing psychological distress and anxiety [15–17]. These unidimensional item banks form the basis for computer adaptive testing (CAT) which may help to overcome the problem with selecting the optimal tool for detecting depression. CAT selects and presents targeted items from a calibrated item bank to the respondent, reducing test length without loss of precision and reliability [18] thereby significant reducing patient burden and potentially enhancing the detection of depression [19].
Our aim was to find the optimal set of symptoms of depression suitable for creation of an item bank that could be used in computer adaptive testing or one that could be considered for testing for (or even redefining) the diagnostic criteria for the forthcoming DSM-V. Ideally, we aimed to find the optimal set of symptoms with no more than nine items, equivalent to the length of the current DSM criteria as well as the optimal set of four symptoms that could be used as an abbreviated assessment method.
Materials and methods
Sample and patients
The recruitment of the sample was undertaken by trained psychiatrists from both inpatient and outpatient clinics in the psychiatric unit of the largest teaching hospital and two health centres which provide outpatient psychiatry service in Erbil. The controls were recruited randomly by dividing the city of Erbil (the capital of Kurdistan) into 10 regions. Standard random selection within each stratum was applied. The data were collected between April 2009 and March 2010.
Tools
We used a Kurdish translation of the following scales: the Center for Epidemiologic Studies Depression scale (CESD); the 9-item Patient Health Questionnaire (PHQ-9); the Hospital Anxiety and Depression Scale (HADS) and the Calgary Depression Scale for Schizophrenia (CDSS). The CESD scale is a short self-report scale designed to measure depressive symptoms in the general population [20]. When tested in household interview surveys and in psychiatric settings it was found to have a high internal consistency and adequate test–retest repeatability. The PHQ-9 [21] is based directly on the diagnostic criteria for major depressive disorder in the DSM-IV. It is viewed as a potentially valuable tool for assisting primary care clinicians in diagnosing depression as well as selecting and monitoring treatment. The HADS self-screening questionnaire for depression and anxiety [22] is a convenient instrument used by hospital patients with both somatic and non-somatic symptoms. It has equally good sensitivity and specificity as other commonly used self-rating screening instruments [23]. The CDSS was developed at the University of Calgary and its use has been evaluated for both relapsed and remitted patients with schizophrenia [24].
Rasch analysis
The family of Rasch models [25] measure latent traits; personal characteristics which are assessed indirectly from groups of questions and which cannot easily be evaluated directly. Rasch models provide estimates of where a person falls along a continuum for the trait, such as for instance, mental health (person ability). They also estimate the location of questions (‘items’) from questionnaires along the same continuum (item difficulty). The person ability and item difficulty parameters are estimated jointly to produce estimates (reported in ‘logits’ or log-odds), which are independent of both the items and sample employed.
Methods: general
Rasch analyses evaluate whether the items included are indeed measuring a unidimensional continuum, using principal components factor analysis. Items measuring a different latest trait are evaluated using ‘fit’ statistics, and misfitting items are removed from an item bank. It is also possible to ascertain whether the item bank is reliable in subgroups in the sample, using differential item functioning (DIF) to estimate item difficulty in subgroups of patients.
Methods: individual instruments
As all instruments contained polytomous response categories the Partial Credit Model was used in the Rasch analysis [26] using Winsteps software [27]. Each instrument was initially analysed separately. Response categories for each item (for each instrument) were evaluated to determine there was no threshold and category disordering. Following this item, fit was assessed against an infit mean square criterion of 1.3. Any items with infit mean square statistics >1.3 were deemed to be misfitting and removed from the analysis [28]. Unidimensionality was initially assessed by the percentage variance explained by the Rasch model, and the eigenvalues for the first contrast (of the residuals). Eigenvalues less than 2 may be assumed to indicate no additional dimensionality.
Methods: item bank
Common item equating was used to develop the item bank [29,30]. This method relies on the separate item pools sharing a minimum of five common items which are held constant (‘anchored’) whilst further items are added. At each stage of this process the item fit and dimensionality are assessed, and misfitting items removed. The process continues and a stable, unidimensional item bank may be achieved. At each iteration item fit was evaluated (as described above for the individual instruments). An item map was produced to highlight the distribution of item locations and person measures. The internal reliability (person separation in Rasch models) was also noted.
Dimensionality was assessed using the percentage variance explained and the eigenvalues. In addition, to this Smith [31] has recommended producing two sets of person measures: one derived from the highest loading positive items (correlation >0.3) onto the first factor derived from a principal components analysis (PCA) of the residuals, and the other from the highest negatively loading items. These can then be evaluated using a series of independent sample t-tests calculating the percentage falling outside the 95% confidence interval. However, the potential problem with this approach is that it is at risk of type I errors, particularly as the number of comparisons increases (i.e. larger sample sizes). We therefore applied a modified approach using a paired samples t-test to assess whether there was any statistical difference between the two sets of person estimates (including the 95% confidence interval). A Bland-Altman plot was also generated including the 95% level of agreement to assess the agreement between the two person measure estimates.
Finally, differential item functioning (DIF) was evaluated for age (<20, 21–30, 31–40, and 40++), gender and diagnosis (depression, no depression).
Results
Individual instruments
Each instrument (PHQ-9, HADS-D, CESD, CDSS) was initially analysed separately with a particular focus on threshold disordering, item misfit, and unidimensionality. When any threshold disordering was observed, categories were collapsed and the analysis re-run. Misfit items were removed and the analysis re-run. Principal components analysis was applied to the final remaining items to determine whether any additional dimensionality was present.
Threshold and category disordering
None of the items demonstrated any threshold disordering. In terms of category disorder, neither the PHQ-9 nor the CDSS demonstrated any disordering. Two items from the HADS (HADS-D1 and D3) and eight items from the CESD (CESD2, 4, 8, 10, 12, 15, 16 and 19) displayed category disordering. Collapsing across categories (to create binary categories) did not improve disordering for the two HADS items or four of the CESD items (CESD4, 8, 12 and 19).
Item misfit
Two items demonstrated misfit for the PHQ-9 (items 3 and 5). For the HADS-D there were three misfitting items (items 1, 3 and 6). Eleven CESD items demonstrated misfit (items 2, 4, 7, 8, 10–12, 15–17 and 19) and five items from the CDSS five items (items 3–7). All the remaining items from each instrument fell below the threshold.
Dimensionality
No further dimensionality was observed for any of the remaining items for all four instruments. The percentage variance explained by the items (i.e. the Rasch model) was as follows: PHQ-9 78%, CESD 75%, HADS 67%, and CDSS 85%). Similarly, the eigenvalues for the first contrasts were: PHQ-9 1.7, CESD 1.8, HADS 1.7 and CDSS 1.5.
Item bank
Item misfit
Following the initial individual Rasch analysis of the instruments there was a total of 24 items remaining of the original 45 (21 misfitting items removed). A further six items (CESD13 and CESD 17, HADS-D4, HADS-D 5 and HADS-D 7, and CDSS3 and CDSS4) were removed due to misfit as the items were added together to form the item bank, and two items were subsequently removed following the DIF analysis (see below) by diagnosis (CESD20 and CDSS9, both of which were harder to endorse for women). Therefore the remaining item bank consisted of 17 items (Table 1). None of the HADS-D items were retained in the final item bank.
The final 17 item bank
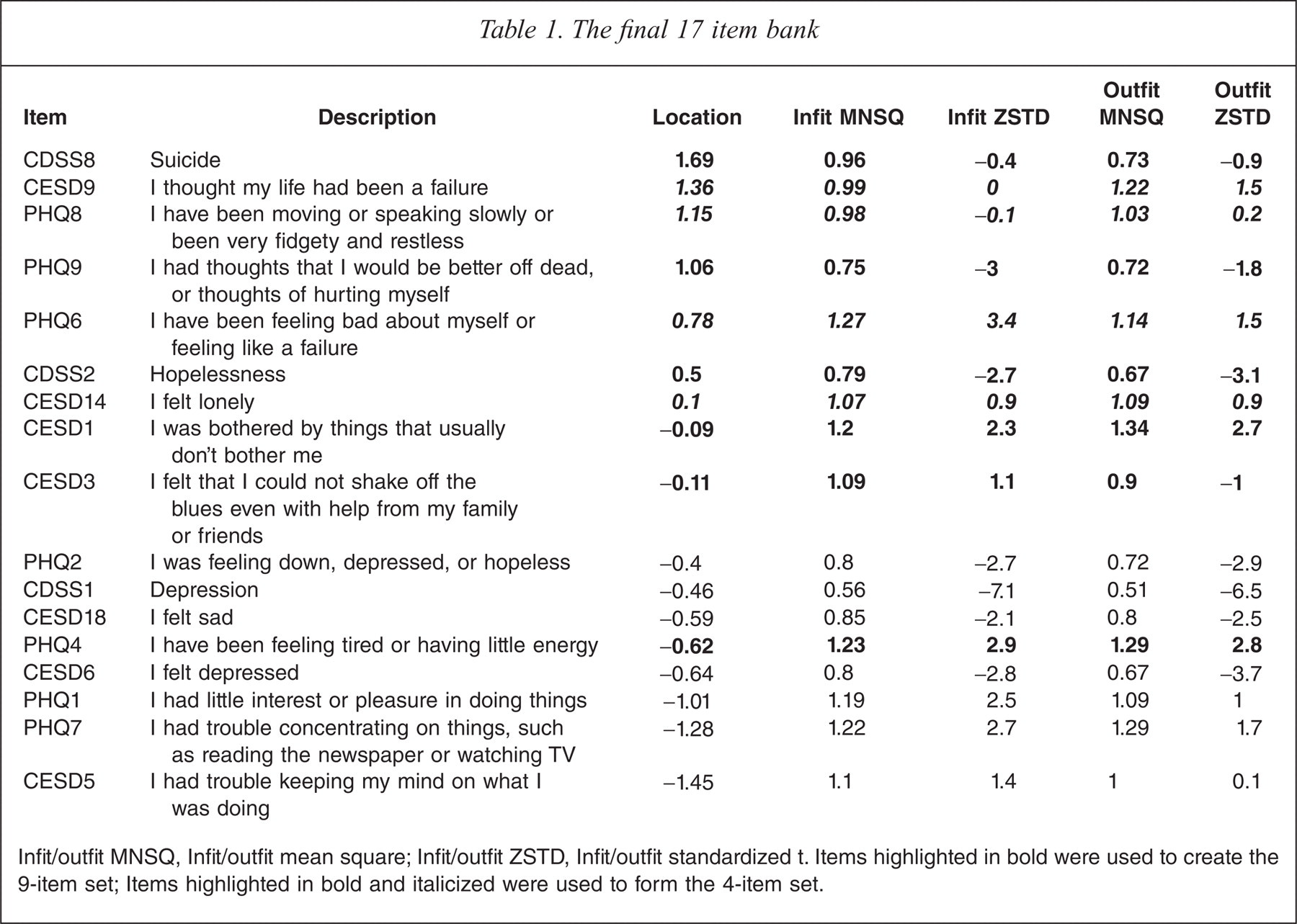
Infit/outfit MNSQ, Infit/outfit mean square; Infit/outfit ZSTD, Infit/outfit standardized t. Items highlighted in bold were used to create the 9-item set; Items highlighted in bold and italicized were used to form the 4-item set.
Table 1 shows that one question regarding suicidal ideation was hardest to endorse, namely CDSS8 (‘Have you felt that life wasn't worth living?’). The next hardest question to endorse was CESD9 (‘I thought my life had been a failure’), whereas two questions relating to problems concentrating were the easiest to endorse: CESD5 (‘I had trouble keeping my mind on what I was doing’) and PHQ7 (‘I had trouble concentrating on things, such as reading the newspaper or watching TV’). This suggests good face validity for the item bank. Furthermore, the internal reliability of the 17 items was (Cronbach) a = 0.96.
The average person estimate was −1.26 logits (standard deviation (SD) = 3.30, range −7.07 to 8.18 logits), whereas item locations ranged from −1.45 to 1.69 logits. A closer look at the Rasch half-point thresholds indicated a range of threshold from −4.5 to 5.5 logits suggesting greater overlap with the distribution of person measures.
Dimensionality
The percentage variance explained was 78% and the eigenvalue for the first contrast was 2.4, suggesting some additional dimensionality. However, the results of the t-test (including 95%CI) indicated no statistical difference between the two person measure estimates (t(399) =−1.47, p = 0.14, 95% −0.49 to 0.07). Figure 1 shows the Bland-Altman plot. Just over 5% (5.5% or 22/400) of the pairs of estimates fell outside the 95% limits of agreement (−5.90 to 5.48) suggesting good agreement between the two estimates. There is therefore little evidence to suggest the presence of any additional dimensionality.
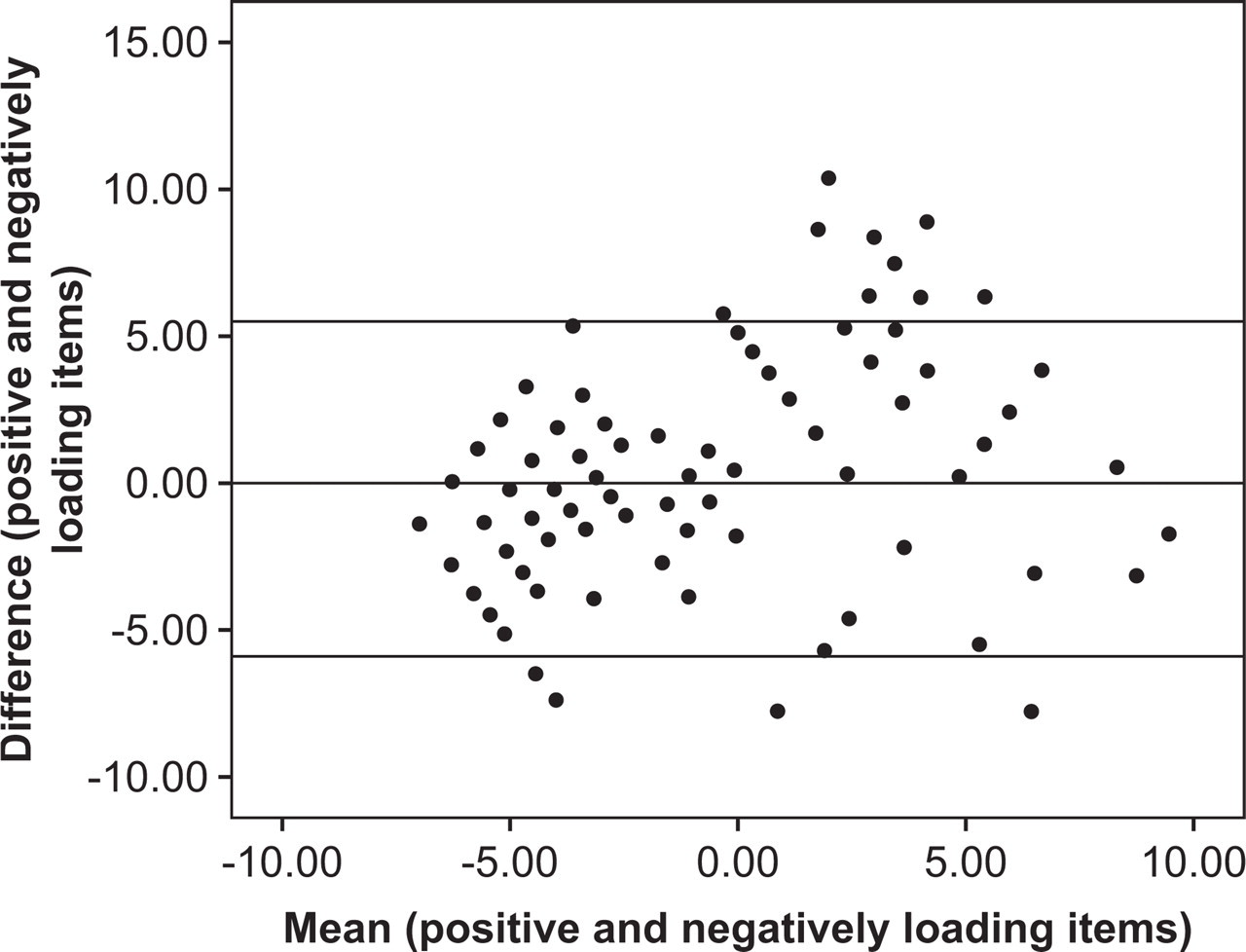
Bland-Altman plot of means against the differences of person measures estimated from the positive and negatively loading items.
Differential item functioning
No differential item functioning was detected for age group, diagnosis or gender for the remaining 17 items.
Accuracy against MINI DSM-IV Criteria for MDD
We examined the accuracy of the full item bank (17 items) against DSM-IV MDD. The area under the curve was 0.987. Using a bank restricted to the optimal nine items revealed no loss of accuracy. The area under the curve (AUC) was 0.989 with the following nine items: PHQ4, PHQ6, PHQ8, PHQ9, CESD1, CESD3, CESD9, CDSS2, CDSS8. At the optimal cut point sensitivity was 96% and specificity 95%. Finally, when restricted to only four items, accuracy was still high (AUC was still 0.976; sensitivity 93%, specificity 96%) (Table 2). The four chosen items were the PHQ6, PHQ8, CESD9, CESD14.
ROC data area under the curve, and optimal thresholds, sensitivity and specificity
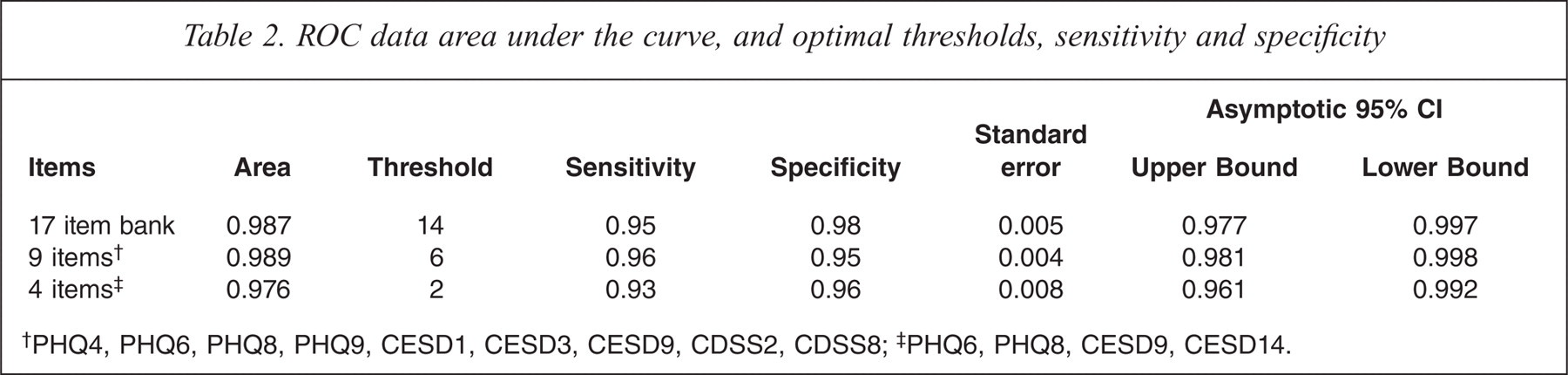
PHQ4, PHQ6, PHQ8, PHQ9, CESD1, CESD3, CESD9, CDSS2, CDSS8;
PHQ6, PHQ8, CESD9, CESD14.
Discussion
We recruited 200 patients with primary depression and 200 non-depressed subjects living in the Kurdistan region of Iraq. A semi-structured interview, the MINI, as applied by trained psychiatrists, was used as a gold standard to define DSM-IV major depression. We found at the instrument level, the PHQ-9, CESD and CDSS performed reasonably well, but the HADS did not have strong diagnostic validity. Two items demonstrated misfit for the PHQ-9 (items 3 and 5) and for the HADS-D there were three misfitting items (items 1, 3 and 6). Eleven CESD items demonstrated misfit (items 2, 4, 7, 8, 10–12, 15–17 and 19) and five items from the CDSS five items (items 3–7). All the remaining items from each instrument fell below the threshold for misfit.
A symptom level Rasch analysis reduced the original 45 items to 24 items after the exclusion of 21 misfitting items. A further six items (CESD13 and 17, HADS-D4, D5 and D7, and CDSS3 and 4) were removed due to misfit as the items were added together to form the item bank, and two items were subsequently removed following the DIF analysis by diagnosis (CESD20 and CDSS9, both of which were harder to endorse for women). Therefore the remaining optimal item bank consisted of 17 items. Interestingly, none of the HADS-D items were retained in the final item bank. We tested these 17 items against DSM-IV criteria for MDD and found high concordance (AUC = 0.987). Indeed, a restricted list of nine symptoms was equally accurate (AUC = 0.989) and a brief set of four items was almost as good (AUC = 0.976). (Figure 2) The four chosen items were the PHQ6, PHQ8, CESD9, CESD14 (Table 2).
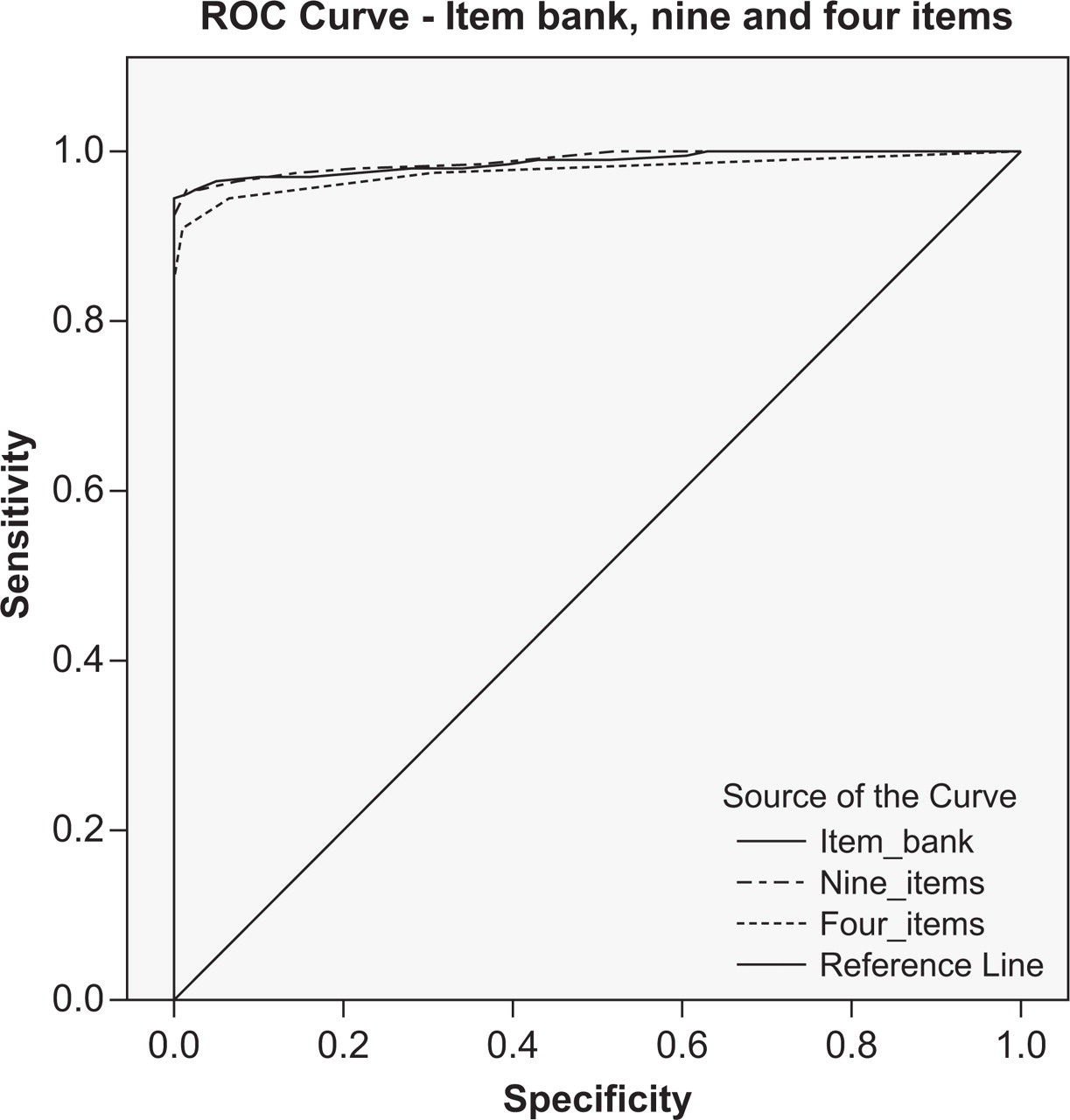
ROC curve for items 17, 9 and 4. Diagonal segments are produced by ties.
Before continuing we wish to acknowledge several important limitations. We conducted this study in Iraq where the rates of illiteracy are high. We often relied upon our trained staff to deliver questions verbally rather than solely using self-report from the translated Kurdish version of the questionnaires. For this reason we did not attempt back translation of the questionnaires. It is therefore uncertain to what extent these findings would be replaced in other settings and other cultures.
One possible development of the item bank is computer-adaptive testing where items are selected from the bank based on individual patients' previous responses. The benefit of these systems is that not only is the assessment of depression potentially more accurate, each assessment is also more relevant to the individual patient. Computer-adaptive tests have already been developed for use identifying depression, for instance in psychiatric populations. Fliege and colleagues [32] have developed a system for measuring depression (D-CAT). This was derived from 11 mental health questionnaires and following an item-response analysis the final item bank comprised 64 items. Two simulation studies demonstrated that levels of depression could be estimated reliably from six items only with high precision and low patient burden. A further validation study demonstrated that the computer-adaptive test was able to distinguish well between diagnostic groups. Similar results have also been shown with a computer adaptive test derived from the 626-item Mood and Anxiety Spectrum Scales (MASS) to identify anxiety and mood disorders in patients attending outpatient clinics [33] From our results a CAT constructed from Table 1 would probably have an average person measure (on the latent trait) of −1.26 logits. The nearest item to this is PHQ7 (−1.28). The order could then be PHQ2 (difference of ++1 logit), then CESD14 (0.5 logit), PHQ9 (0.5 logit) and finally either CDSS8 or CESD9.
This calibrated item bank might be beneficial for developing new fixed-length paper and pencil tests for depression and for development of new criteria for the forthcoming DSM-V or ICD-11. Several authors have made empirical suggestions for redefining mood disorders in DSM-V [34–37]. However, little primary evidence concerning diagnostic symptoms has been published [38,39]. In an analysis of accuracy against DSM-IV criteria for MDD we found that nine items and four items from the bank would offer excellent psychometric properties. Given that these items are not simply a list of DSM/PHQ symptoms but also included CESD9 and CESD14, there appears to be scope for further work to re-examine the fundamental criteria in DSM-IV with a view to creating a new possibly simplified algorithm for DSM-V or a simplified screening and case-finding tool.