
Abstract
In recent years, the steady-state visual evoked potential (SSVEP) electroencephalogram paradigm has gained considerable attention owing to its high information transfer rate. Several approaches have been proposed to improve the performance of SSVEP-based brain–computer interface (BCI) systems. In SSVEP-based BCIs, the asynchronous scenario poses a challenge as the subjects stare at the screen without synchronization signals from the system. The algorithm must distinguish whether the subject is being stimulated or not, which presents a significant challenge for accurate classification. In the 2022 World Robot Contest Championship, several effective algorithm frameworks were proposed by participating teams to address this issue in the SSVEP competition. The efficacy of the approaches employed by five teams in the final round is demonstrated in this study, and an overview of their methods is provided. Based on the final score, this paper presents a comparative analysis of five algorithms that propose distinct asynchronous recognition frameworks via diverse statistical methods to differentiate between intentional control state and non-control state based on dynamic window strategies. These algorithms achieve an impressive information transfer rate of 89.833 and a low false positive rate of 0.073. This study provides an overview of the algorithms employed by different teams to address asynchronous scenarios in SSVEP-based BCIs and identifies potential future avenues for research in this area.
Keywords
1 Introduction
A brain–computer interface (BCI) establishes a direct link between the human brain and a computer, enabling the translation of brain signals into external commands [1]. Several signals can be used as inputs to BCIs, including functional near-infrared spectroscopy (fNIRS), functional magnetic resonance imaging (fMRI), and electroencephalogram (EEG), of which, EEG has become the most widely used signal in BCIs owing to its ease of use and low cost, enabling the recording of electrical activity from the scalp [2].
Different paradigms of BCIs have developed rapidly and matured in recent years, e.g., P300 evoked potentials [3], motor imagery (MI) [4], and steady-state visual evoked potential (SSVEP) [5], and various novel recognition algorithms have emerged recently [6 –8]. Out of these EEG paradigms, SSVEP-based BCI is particularly effective for its high information transfer rate (ITR), extensive set of instructions, short training time for users, and user-friendly nature. When the user stares at a target flickering at a frequency ranging from 3.5 Hz to 75 Hz, the brain generates EEG signals at the same frequency or multiples of frequencies of the target [9]. SSVEP-based BCI has emerged as a natural and intuitive interface for computer systems, virtual reality, and augmented reality environments, with wide-ranging potential applications [10]. Among these applications, SSVEP visual spellers [11] have been particularly successful. By using EEG signals without muscle activity, visual spellers enable patients with severe movement disorders to communicate effectively, thereby affording a breakthrough in the field of assistive technology. This demonstrates the immense potential of SSVEP-based BCIs in improving the quality of life for individuals with disabilities.
Accurately determining the target to which the user is attending is essential for the successful application of SSVEP-based BCIs. Several frequency recognition approaches have been developed to enhance the performance of SSVEP-based BCI. These approaches can be classified into training-free and training-based methods depending on whether training data are required. Training-free methods, such as canonical correlation analysis (CCA) [12], minimum energy combination (MEC) [13], multivariate synchronization index (MSI) [14], and Ramanujan periodicity transforms (RPT) [15], can be easily implemented and do not require calibration data. However, these methods may require a long stimulation duration to achieve high accuracy, leading to a low ITR. Furthermore, training-based approaches, such as extended CCA (eCCA) [16], modified extended CCA (m-extended CCA) [11], L1-regularized multiway CCA (L1MCCA) [17], task-related component analysis (TRCA) [18], and task-discriminant component analysis (TDCA) [19], use calibration data to construct specific templates and spatial filters for the subjects, resulting in improved performance of SSVEP-based BCI systems.
Figure 1 shows the workflow of a classical SSVEP speller, which was used in the SSVEP-based BCI Competition of the 2022 World Robot Contest Championship (WRCC2022). Figure 2 illustrates the visual keyboard layout of the speller used in this competition. The speller comprises 40 targets, including numbers 0–9, letters A–Z, comma, dot, space, and backspace. These targets flicker at different frequencies ranging from 8 Hz to 15.8 Hz with a step size of 0.2 Hz and an initial phase shift of 0.5π. The user needs to focus on the target character to use the speller, and EEG signals are collected via an EEG headset and sent to a computer for analysis. Upon collection of sufficient EEG data, the algorithm extracts the frequency information and displays the selected target character on the screen.
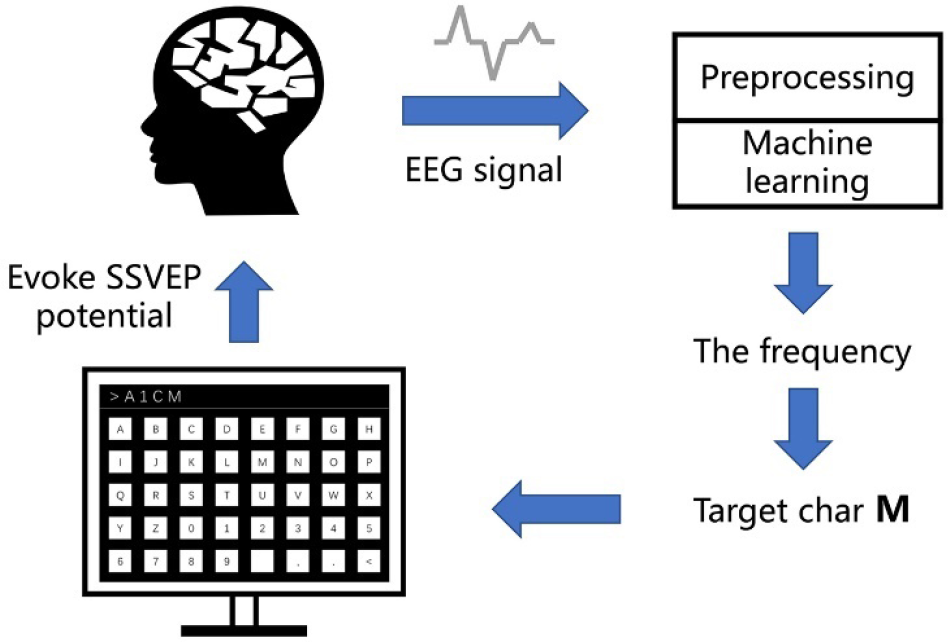
Workflow of an SSVEP speller.

Visual keyboard utilized in the final round. Each of the stimulus targets in the keyboard flickered at a specific frequency (in Hz) and an initial phase (in radius).
In this paper, we introduce the algorithms used by five teams (Hust_XS_ZJ, XianLiGong, UMBCI, HDU_BMCI, NaoDianXinHaoYaoFenDui) in the final round of the SSVEP-based BCI Competition of the WRCC2022. We will refer to the algorithms used by the five teams as follows: Algo-H (Hust_XS_ZJ), Algo-X (XianLiGong), Algo-U (UMBCI), Algo-D (HDU_BMCI), and Algo-N (NaoDianXinHaoYaoFenDui). This study aims to evaluate the effectiveness of these algorithms in an asynchronous setting.
This paper is structured as follows: Section 2 provides an overview of the five algorithms, including the preprocessing techniques, frequency recognition methods, and dynamic window framework. The results of the five algorithms used in the final round are presented in Section 3. Section 4 discusses the efficacy of each approach. Finally, Section 5 summarizes the findings and presents the conclusions drawn.
2 Methods
In this section, we will first outline the pre-processing techniques employed by each of the five teams. Subsequently, we will describe the frequency recognition methods, which include CCA [12], prototype spatial filter (PSF) [20], and the filter bank method [21]. Lastly, we will present the dynamic window framework utilized by all the teams and highlight any variations in its implementation
2.1 Preprocessing methods
All the teams employed a 50 Hz notch filter to address the power line noise at 50 Hz. All five teams used a band-pass filter to remove the high- and low-frequency noise. As the visual speller operated in an asynchronous scenario, all the teams did not apply the visual latency of 0.14 s [22].
2.2 Canonical correlation analysis
Lin et al. [12] introduced the use of CCA to improve the signal-to-noise ratio of SSVEPs. CCA is a method that can extract the underlying correlation between two multi-channel time series [23]. The objective of CCA is to find linear combinations of the two signals that maximize their correlation. Let
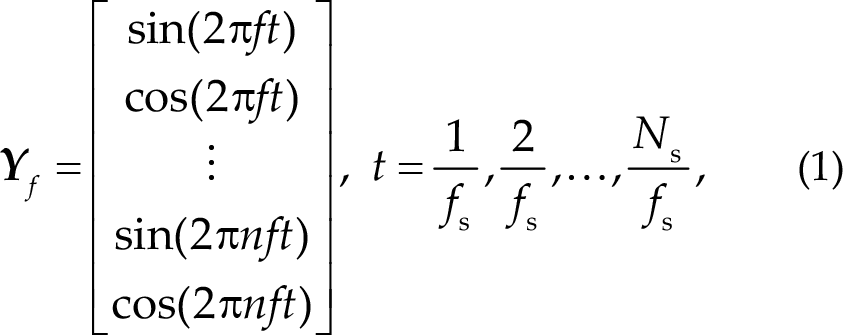
where fs represents the sampling rate, and n represents the number of harmonics. The weight vectors
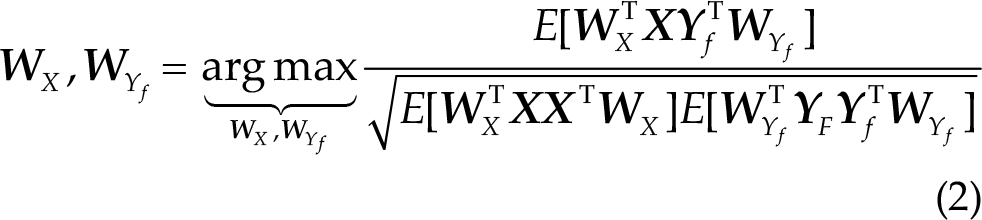
To compute the CCA correlation between
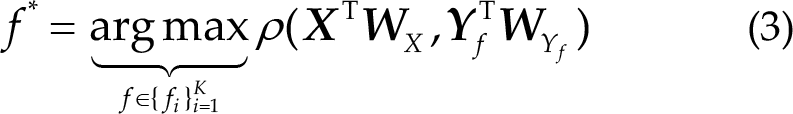
2.3 Prototype spatial filter
Lao et al. [24] introduced the concept of constructing a PSF by learning from multiple CCA spatial filters (CCA-SFs) associated with different stimuli, frequencies, or subjects. The PSF is designed to capture the shared information across these frequencies or subjects. Wong et al. [20] proposed an extension to the approach of learning a PSF from CCA spatial filters (CCA-SFs) in previous trials. Based on Eqs. (2) and (3), the spatial filter corresponding to f*[t] is
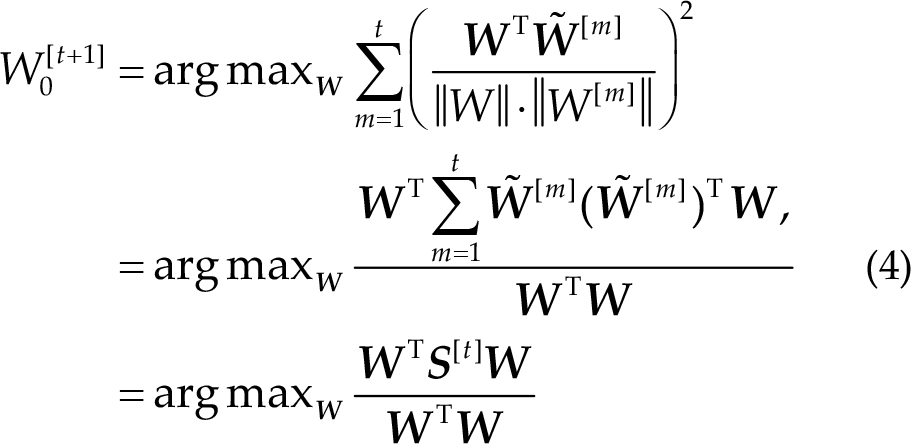
where the PSF
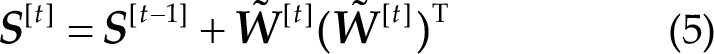
The correlation coefficients can be computed using the PSF:
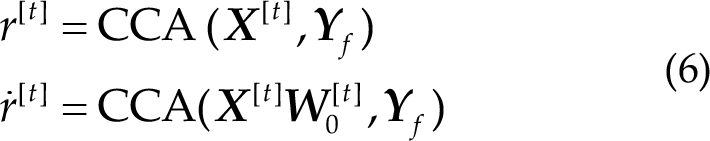
The final coefficient is
In case of Algo-U, contestants used trials with high kurtoses to update the subjects’ specific PSF. They used this algorithm to enhance the recognition ability in this calibration-less scenario.
2.5 Filter bank method
Chen et al. [21] proposed the filter bank canonical correlation analysis (FBCCA) method to enhance the performance of CCA. This method decomposes the original EEG trial into several sub-band components using filters with different passbands. Each filter features the same upper cut-off frequency at 88 Hz and a lower cut-off frequency that increases in increments of 8 Hz. The correlation coefficients for each sub-band component are subsequently calculated, and a weighted summation of the squares of these coefficients is used as the feature for target classification:
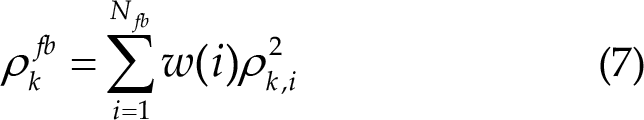
The weight for the i-th sub-band is defined as follows [21]:
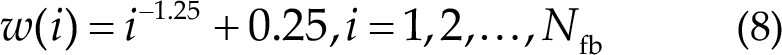
where N fb is the number of filters.
2.6 Competition metrics
The ITR is a crucial metric in SSVEP-based BCIs, and it can be determined using the following formula:
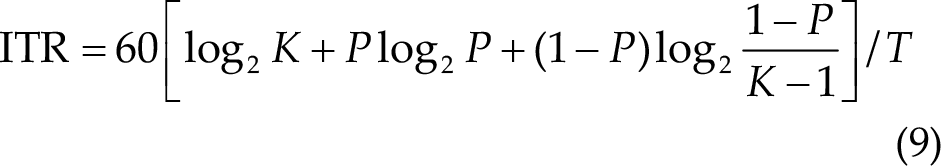
where K, P, and T represent the number of targets, the classification accuracy, and the average computing time in seconds for the selection of a target, respectively. During the competition, the ITR was computed for intentional control (IC) state trials only. Achieving a high ITR requires a balance between the short data length and the high classification accuracy. While a shorter data length leads to lower classification accuracy, longer data length can result in higher accuracy but lower ITR. Therefore, striking a balance between these two factors is important.
In addition, the competition also used false positive rate (FPR) as a criterion that is formulated as

where FP indicates the number of trials with false positives in the non-control (NC) state, and TN indicates the number of trials without false positives in the NC state. The lower FPR implies that the system is less prone to false positives. FPR is calculated only for NC state trials. The FPR is a hard criterion for the usability of the asynchronous system. Furthermore, if the average FPR of the team’s algorithm for all trials exceeds 0.1, the team’s score is invalid [25].
2.7 Dynamic window framework
A fixed data length for all trials may be inappropriate owing to the complexity and non-stationarity of EEG signals, which are inevitably interfered from spontaneous EEG, and can result in a distinctive and variable optimal data length across the trials [26]. In addition, under an asynchronous condition, the trigger information is unavailable. The received data can be in the NC state without any stimulus; thus, the algorithm must identify and pass it until the IC state data are received. The dynamic window framework [26, 27] was well-suited to the online environment and the data packet format of the competition. This approach enabled the algorithm to calculate the results after receiving sufficient data and continue collecting data if the current data was in the NC state or if the result confidence was insufficient. The framework utilized a standard to determine whether the stimulus existed and whether the current result met the requirements; if not, data acquisition continued until an IC state was decided. Typically, this framework required setting the minimum length, the maximum length, and an interval [28].
One dynamic window strategy was used in the final round to compute the confidence score from the correlation coefficients of all classes; a threshold was used for deciding the state of the current data. The confidence score was used to determine whether the result was credible; data inputs were no longer provided to the algorithm, and the results were output only when the score exceeded the threshold. Three methods were used by the teams to obtain the confidence score. The first method is based on the risk function [26] that computes the score as follows:
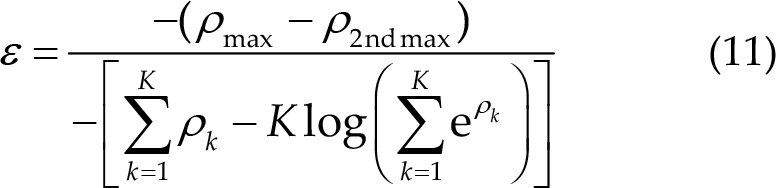
The method was used in Algo-H and Algo-D, and the confidence score ε was smaller than the threshold, which was considered credible. The second method uses the kurtosis of correlation coefficients and the largest value of correlation coefficients among all classes as the confidence score by Algo-U and Algo-X, respectively. Therefore, the confidence score was greater than the threshold, which was considered credible in these two algorithms. The third method was based on the voting of recognition results obtained from different data lengths for determining whether the data were in an IC state. The method was used by Algo-N that further utilized a fuzzy strategy to assess the IC state of the current data by examining the concentration of the set of recognition results around a specific stimulus frequency rather than focusing on the corresponding stimulus frequency.
2.8 Flowcharts of five algorithms
The flowcharts of the five algorithms are shown in Fig. 3, whereas Table 1 provides a list of the notations used in the flowcharts.
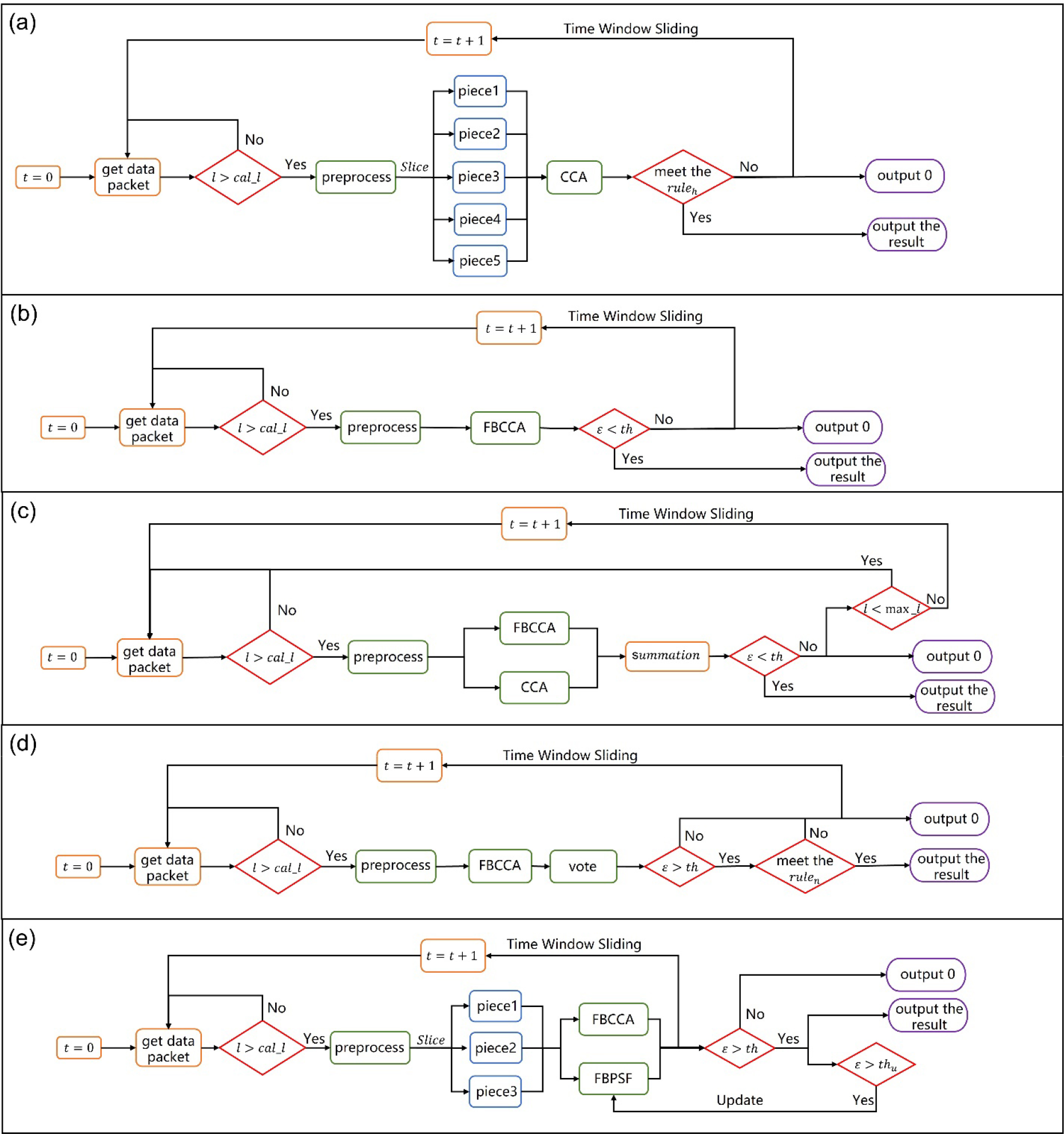
Flowcharts of five algorithms: (a) Algo-H, (b) Algo-X, (c) Algo-D, (d) Algo-N, and (e) Algo-U.
Notations used in the flowcharts.
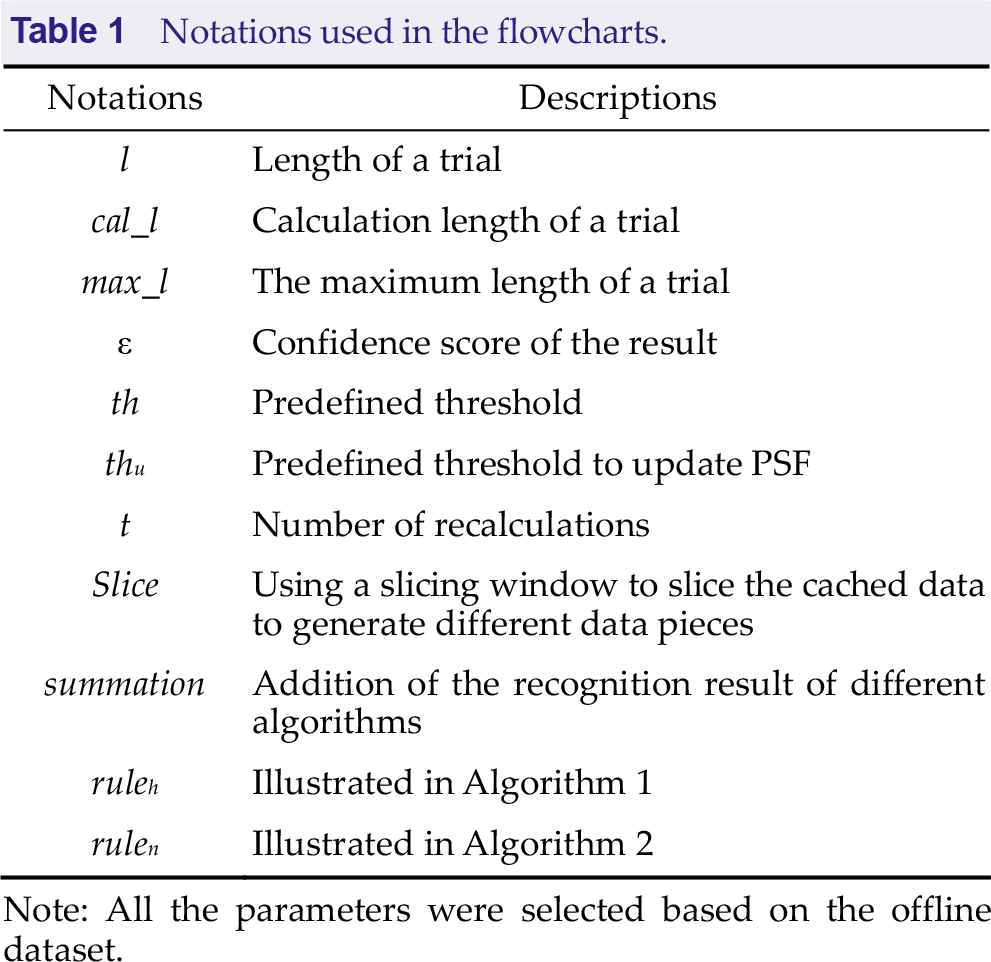
Note: All the parameters were selected based on the offline dataset.


3 Results
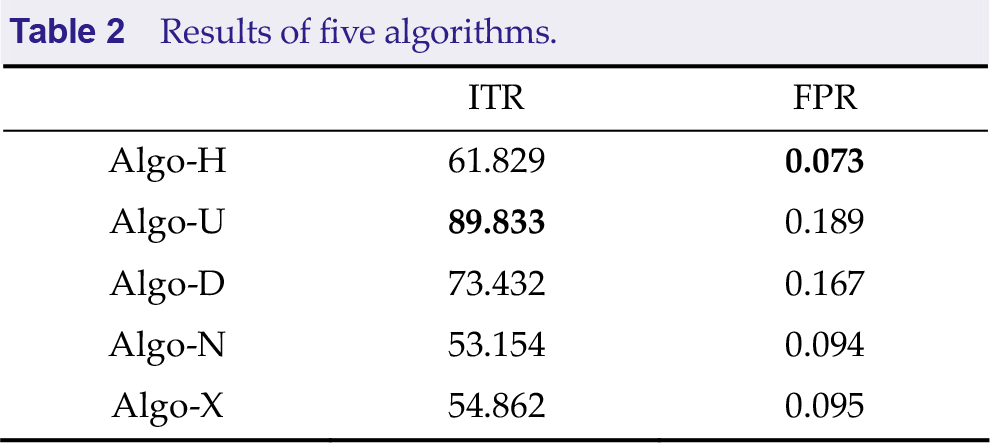
In the final round of the competition, the visual speller operated in under asynchronous condition, implying that the subjects were allowed to output a command any time without relying on the computer’s synchronization signals. Thus, the algorithms were required to be able to recognize the user’s intention (whether they were in an IC state or NC state) and identify their neural signals [29]. A wireless EEG acquisition system (Neuracle, China) with 64 channels was used to record EEG data at a sample rate of 1000 Hz that was subsequently down-sampled to 250 Hz. The power line noise frequency was 50 Hz. During each trial, a graphical user interface (GUI) presented a cue for 1 s, followed by 4 s of target character flicker. The aim of this task was to direct the subjects’ attention toward the highlighted target. The result was calculated using asynchronous algorithms and presented as feedback on the GUI for 1 s. Following each trial, there was a rest period of variable duration that was randomly determined. Most of the trials’ rest periods were 0–4 s, and a few trials exhibited a longer rest time of up to 12 s. The system presented data in an online environment during the test. Whenever the getData() function was called, a new data packet with EEG data but without trigger information, lasting 40 ms, was provided. Data packets within the same block were in sequence. If the test data comprised multiple blocks and the data of the current block had already been sent out, the EEG data of the next block would be sent during the next getData() function call [25]. The system simulated an asynchronous scenario; this necessitates that the algorithm provides the detection result for each trial within 5 s. When all experimental data had been sent, the program termination flag finishedFlag was set to 1. The competition algorithm needed to terminate the run() function. In addition, since the EEG data were derived from real experiments, the length of the last data packet in each block might not be a fixed value. The mean ITRs and FPRs for the five algorithms are presented in Table 2. The ITRs of Algo-U and Algo-D were significantly higher compared with the others. However, their FPRs exceeded 0.1, rendering their scores invalid. Conversely, Algo-H, Algo-N, and Algo-X featured FPRs below 0.1, and among these three, Algo-H exhibited the highest ITR. These results demonstrate that Algo-H achieves a more favorable balance between ITR and FPR.
Results of five algorithms.
4 Discussion
This paper provides a brief overview of the algorithms implemented by the top five teams that competed in the SSVEP-based BCI challenge at WRCC2022. These algorithms incorporate novel methods to improve the performance of SSVEP in asynchronous scenarios. The succeeding section concisely summarizes the main characteristics of these algorithms: Algo-H: The algorithm uses a slicing window to slice the cached data to generate different data pieces and integrates the results of recognizing sliced data of varying lengths to make decisions. This approach can enable more reliable decision making for the separation of the IC state from the NC state. However, accuracy loss of the final recognition results may occur. Algo-U: Kurtosis is used as a measure of the confidence score of the identification results. The data with a high kurtosis score is subsequently selected to update the PSF filter. The updated PSF filter is subsequently used to enhance the recognition ability in the no-calibration scenario. This approach leverages the fact that data with high kurtosis is more informative, and using trainable PSF filters can significantly improve the accuracy of the recognition; however, it may misclassify the NC state into the IC state. Algo-D: The recognition results from CCA and FBCCA are combined to boost the accuracy of SSVEP in asynchronous scenarios. Two algorithms assume different approaches to preprocess the data. Integrating the results of both algorithms, a more comprehensive analysis of the data and a more accurate recognition of the SSVEP signals are noted; however, the computation cost may be increased. Algo-N: A fuzzy strategy is employed to determine whether the current data is in the IC state. This strategy is based on the concentration of the results of the voting process around a specific stimulus frequency, which can prevent the algorithm from making exceedingly absolute decisions and allows making the right decision even when the recognition results are less accurate. By considering this factor, the algorithm can make more informed decisions regarding the state of the EEG data; however, the recognition accuracy may be impacted. Algo-X: The confidence score is calculated by directly using the largest value among the correlation coefficients of all classes and subsequently making the final decision according to the predefined threshold. This approach is straightforward and efficient; however, it may not always accurately reflect the reliability of the recognition result.
5 Conclusion
This paper discusses the algorithms employed by the top five teams (Hust_XS_ZJ, XianLiGong, NaoDianXinHaoYaoFenDui, HDU_BMCI, UMBCI) during the SSVEP-based BCI Competition at WRCC2022, which showcase innovative techniques for tackling challenges in asynchronous SSVEP-based BCI scenarios. These algorithms utilize methods such as model updating using prior data and a dynamic window framework integrating diverse algorithms, which may have practical applications in real-world systems. In the future, we will evaluate the effectiveness of these approaches on a wider range of datasets, with the ultimate aim of developing a practical algorithm framework for enhancing SSVEP-based BCI performance in asynchronous scenarios.
Footnotes
Conflict of interests
All contributing authors report no conflicts of interest in this work.
Funding
This research was supported by the STI 2030—Major Project 2021ZD0201300, Hubei Province Funds for Distinguished Young Scholars (Grant No. 2020CFA050).
Authors’ contribution
Zhenbang Du and Rui Bian designed the study and analysed the results. All authors were involved in writing the manuscript and have approved the publishing version.