
Abstract
Canonical correlation analysis (CCA) is a useful technique for multivariate data analysis, which can find correlations between two sets of multidimensional data. CCA projects two sets of data into a low-dimensional space in which the correlations between them are maximized. However, CCA is sensitive to noise or outliers in the collected data of real-world applications, which will degrade its performance. To overcome this disadvantage, we propose symmetrical robust canonical correlation analysis (SRCCA) for image classification. By using low-rank learning, the noise is removed, and CCA is used to encode correlations between images and their symmetry samples. To verify effectiveness, four public image databases were tested. The result was that SRCCA was more robust than CCA and had good performance for image classification.
Keywords
Introduction
The collected data in many real applications often have high dimensionality (the data contains multiple attributes), which can cause the “curse of dimensionality.” 1 High-dimensional data are computationally expensive and require more storage space. Hence, reducing the dimensionality of the data is an important research issue. Many methods have been proposed for dimensionality reduction.2-9 Principal component analysis (PCA)2,3 is a classical dimension-reduction algorithm that seeks the direction of maximum covariance as the best projection direction and minimizes the reconstruction error. Linear discriminant analysis (LDA)4,5 is a supervised dimensionality reduction algorithm that seeks to minimize the variance of the original data in the same class after projection and maximize the variance between different classes. Locality preserving projection (LPP) 6 is a representative method in the field of manifold learning, which can preserve the local neighborhood structure of the original data. Many extensions of PCA, LDA, and LPP have been proposed, such as two-dimensional PCA (2DPCA), 7 two-dimensional LDA (2DLDA), 8 and two-dimensional LPP (2DLPP). 9 The main difference between 1D and 2D methods is that 2D methods extract features directly from the image matrices instead of the image vectors.
In contrast to conventional dimensionality-reduction methods and their extensions, canonical correlation analysis (CCA) 10 is a competitive method in multivariate data analysis, which can effectively find the correlations between two sets of multidimensional variables. CCA projects the raw data into the lower dimensional space and maximizes the correlation between two sets of data. CCA has wider applications in statistical analysis, 11 machine learning, 12 textile science, 34 and genetic data analysis. 13 It also has some extensions. For example, Chu et al. 14 introduced sparse representation to CCA and proposed sparse CCA (SCCA). Zheng et al. 15 proposed kernel CCA (KCCA) and applied it for facial expression recognition.
The aforementioned methods all use the Frobenius norm (or ℓ2 norm) as a metric, which are sensitive to noise or corruptions. Low-rank learning has attracted more attention due to its global learning ability.16-20 For example, Candès et al. 16 proposed robust principal component analysis (RPCA) and proved that it can effectively remove noise from data. Liu et al. 17 proposed low-rank representation (LRR) and applied it into subspace segmentation. To improve the performance of LRR, Liu and Yan 18 proposed a latent low-rank representation (LatLRR) using the hidden data to construct the dictionary. A novel algorithm, named low-rank preserving projections (LRPP), was proposed to enhance the robustness of LPP. 19 Lu et al. 20 introduced low-rank learning into two-dimensional neighborhood preserving projection (2DNPP) and proposed a low-rank 2-D neighborhood preserving projection (LR-2DNPP).
To overcome the problem of insufficient samples and misalignment of images, Xu et al. 21 integrated the original face images and their mirror images for face recognition. Fig. 1 shows the original images and their mirror images of the same class from the ORL database. 22 Inspired by this knowledge, we introduced the symmetrical structures of the images into CCA. CCA looks for the correlations between two sets of multidimensional variables. Figs. 1a and b show different poses, and the correlations between them are very small. Fig. 1c shows the mirror image of Fig. 1a. Figs. 1b and c are left tilt poses and there are no significant differences between them in terms of distance metrics. Consequently, making full use of the symmetrical structures of the image allows CCA to extract the maximum correlations between the input data.

Original face images and their mirror images of one subject. (a) Original face images with right tilt pose, (b) original face images with left tilt pose, and (c) the mirror images of (a).
In this study, we integrate the symmetrical structures of the image and the low-rank learning and propose symmetrical robust canonical correlation analysis (SRCCA) for image classification. First, we used the original images and their mirror images as training samples to increase the classification accuracy. Second, we exploited RPCA to remove the noise or outliers from the training samples, and then to learn the most relevant features between the clean original images and clean mirror images. To verify the effectiveness of the proposed method, we conducted experiments on four publicly available databases. The experimental results confirm the method's effectiveness.
The rest of this paper is organized as follows: related works are reviewed, followed by the details of the proposed method, the experimental results, and the conclusion.
Related Works
In this section, we briefly review low-rank learning and CCA for easy understanding.
Low-Rank Learning
In recent years, low-rank learning methods have received wide attention for their global learning ability.23-26 For example, Chen et al. 23 proposed a robust manifold regression method, named low-rank linear embedding for image recognition. Fang et al. 24 proposed an approximate low-rank projection method to make up for the limitations of the LatLRR method with good performance. Wen et al. 26 proposed a low-rank preserving projection via graph regularized reconstruction (LRPP_GRR) method, which imposes graph constrains on reconstruction errors and greatly reduces the complexity of model.
RPCA is a classic method in the field of low-rank learning. It is well known that PCA can remove Gaussian noise from data to a certain extent while reducing the data dimensions, but it is sensitive to the noise with non-Gaussian distribution. Fortunately, RPCA can overcome this limitation.
The key idea of RPCA is to recover a clean data matrix from the corrupted data. Given a data matrix
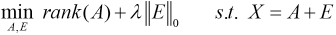
A ∊ R
Since the rank function and the ℓ0 norm are both non-convex, Eq. 1 is relaxed and transformed to the following convex optimization problem (Eq. 2).
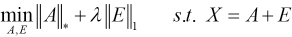
CCA
CCA can effectively find the correlations between two sets of multi-dimensional variables, and has been successfully used in various applications.27,28
Given
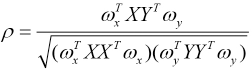
In CCA, the correlation coefficient ρ is maximized, and hence, we have the following optimization problem as Eq. 4.
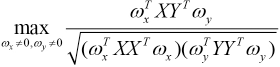
To solve Eq. 4, we fix the denominator and maximize the numerator, thus, CCA can be reformulated as in Eq. 5.
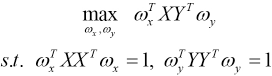
SRCCA
In this section, we first provide motivation of the proposed method, and then we describe the optimization and solution of SRCCA. Finally, the connection of SRCCA and CCA is given.
Motivation
Dimensionality-reduction methods have been widely used in many fields, such as machine learning 29 and pattern recognition. 30 In real research, the collected data usually present a high-dimensional structure and contain noise. Processing these original data directly is computationally expensive and inefficient. Therefore, it is necessary to reduce the data dimensionality and remove noise.
Most conventional dimensionality-reduction methods only consider the relationship between the data points. CCA considers the correlations between two sets of multidimensional variables and overcomes the shortcomings of conventional dimensionality-reduction methods. But CCA is sensitive to noise and outliers in the data. Fortunately, low-rank learning has gained attention owing to its global learning ability.16-20 Studies have shown that low-rank learning methods can effectively remove noise or outliers in the data.
Inspired by the above knowledge, in this study, we make full use of the symmetrical structures of images and introduce low-rank learning to CCA to accomplish SRCCA for image classification. From Fig. 1c, the mirror images can reflect some possible change of the original images in the pose. Therefore, using mirror images makes our training samples richer and improves the performance of classification. RPCA can effectively remove the noise or outliers in the data. Ten we use CCA to extract the most relevant components between the clean original samples and the clean mirror samples.
In SRCCA, the original images and their mirror images are used as training samples to improve the classification accuracy of the method, and then we can acquire a clean data matrix and a noisy data matrix from corrupted data through low-rank learning. Features are extracted from the clean data instead of the original corrupted data so that we can enhance the robustness of the method.
Details of SRCCA
Conventional CCA is based on ℓ2 regularization, which assumes that the errors in the data follows a Gaussian distribution and have a small variance. Nevertheless, in real world conditions, the collected data can contain gross errors. In this case, the application of CCA will be limited. Consequently, to address this problem with CCA and improve the classification accuracy of the method, we put forward SRCCA based on the symmetrical structures of image and low-rank learning.
Let X = [x1, x2, ···, xn] ∊ Rm×n represent the data matrix containing noise, where n is the number of training samples. Let S represents the mirror images of the training samples, so we can get S = [s1, s2, ···, sn] ∊ Rm×x .
In SRCCA, we assumed that the noise in the data was sparse. RPCA was used to remove the noise from the original data. We first used RPCA to remove the noise and outliers from the original corrupted data and its mirror data to obtain Eqs. 6 and 7.
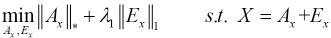
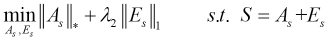
In this study, we used the augmented Lagrangian multiplier method to solve Eqs. 6 and 7, and then the following Lagrangian functions can be obtained (Eqs. 8 and 9).
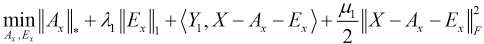
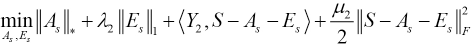
Y1 and Y2 are the Lagrange multipliers, λ1 and λ2 are the positive parameters, and μ1 and μ 2 represent penalty parameters.
For the solution of Ax in Eq. 8, we fixed the other variables and got the optimal Ax to give Eq. 10.
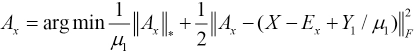
Accordingly, the minimal Ex with other variables fixed were obtained by Eq. 11.
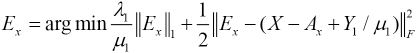
We solved As and Es in the same way, giving Eqs. 12 and 13.
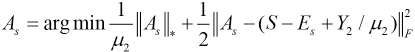
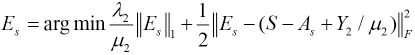
Ax and As are the clean matrices which have low-rank structures. Ten we used CCA to find the correlations between Ax and As, and maximize the correlations between them. Therefore, the objective function of SRCCA can be represented as Eq. 14.
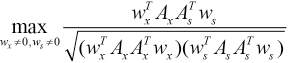
Because the optimization problem is invariant with the scaling of wx and ws, the problem of SRCCA was transformed into Eq. 15.
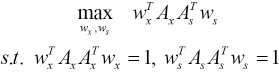
To solve Eq. 15, we constructed the Lagrangian function and solved it to obtain the following generalized eigenvalue Eqs. 16 and 17.
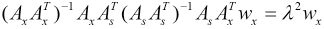
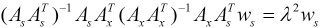
λ is a positive parameter. We easily obtained wx and ws, which are the projection matrices of SRCCA. Then we projected the original corrupted data and its mirror data into the low-dimensional spaces, where the correlations between the original data and its mirror data are maximized, and the projected data have a low-rank structure.
SRCCA extracted features from the clean data rather than the noisy data, and used the mirror data, which not only enhanced the robustness and classification accuracy, but also made the learned features more useful.
Connections with CCA
CCA is an effective data analysis method. Unfortunately, it is sensitive to data contaminated by corruptions due to using the ℓ 2 norm as a metric. Different with CCA, the proposed SRCCA was designed based on the symmetrical structures of image and low-rank learning, so SRCCA can remove the noise in the data and have good performance and robustness.
In the previous sub-sections, the objective function of SRCCA and its solution are given. From this part, we analyzed the connection between CCA and SRCCA. In Eqs. 6 and 7, when λ1 and λ2 tend towards infinity (i.e., λ1 → ∞ and λ2 → ∞), the matrix Ex and matrix Es will become smaller and smaller, that is, the noise that is stripped out will become less. In this case, the learned low rank matrix is almost equal to the original matrix (i.e., Ax = X and As = S), and then the SRCCA is reduced to the CCA (Eq. 18).
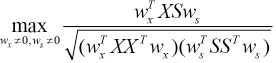
We further optimized Eq. 18 to maximize the numerator while fixing the denominator. The optimized result can be represented as Eq. 19.
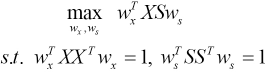
The proposed SRCCA integrates low-rank learning, symmetrical structures of images, and CCA into a formulation. Compared with CCA, the proposed SRCCA exploited low-rank learning to ensure the robustness of the method.
Trough the above analysis, we determined that CCA was a special case of SRCCA when λ1 → ∞ and λ2 → ∞.
Experimental Results
To verify the performance of the proposed SRCCA, we conducted experiments on four public image databases, including AR, 31 FERET, 32 YaleB, 33 and the defect database from Henry Y.T. Ngan at the University of Hong Kong. Fig. 2 shows some image examples from the four databases.

Some image examples from four databases. (a) AR database, (b) FERET database, (c) YaleB database, and (d) defect database.
Experimental Settings and Baseline
In the experiments, we used T to denote the number of training samples of each trial. We added “salt-and-pepper” noise with a density of 0.15 to the AR database and conducted two experiments on it. We selected the first 8 images and the first 12 images of each person as training samples respectively, that is, T = 8, 12, and the rest of the images of each person as test samples. In the FERET database, T = 4. In the YaleB database, we used the first 30 images, the first 32 images, and the first 34 images as training samples respectively (i.e., T = 30, 32, 34), and the remaining images as test samples. In the defect database, “salt-and-pepper” noise with a density of 0.15 was added, the training samples were the first 34 images, the first 36 images, and the first 38 images of each class respectively, that is, T = 34, 36, 38, and the remaining images were used as test samples.
After extracting features from the training samples, we used the nearest neighbor (1NN) classifier to classify the test samples, and then computed the classification accuracy. In SRCCA and CCA, we used the original images and their mirror images as the input data. In RPCA, LPP, and LDA, we used half the original images and half the mirror images as the input data. We selected training samples in the same way from the four databases. For example, from the FERET database, we selected the first four images as training samples; from SRCCA and CCA, we used the first four images and their mirror images as the input data; and the input data from RPCA, LPP, and LDA consisted of two original images and two mirror images.
To confirm the performance of our proposed method, we compared it with RPCA, CCA, LPP, and LDA. In LPP, the nearest neighbor parameter k was 5 on all four databases.
Experiment on the AR Database
The AR face database consists of over 4000 color face images, which was collected from 126 people (56 women and 70 men). These images have frontal view faces with different facial expressions, illumination conditions, and occlusions (sunglasses and scarves). In our experiments, we selected a subset of the AR database containing 65 men and 55 women, and each person has 20 images. The face images in our experiment were 50×40 pixels for computational efficiency. We added the salt-and-pepper noise to the images to bring the experimental effect closer to real-word scenarios and validated the robustness of the proposed method. Fig. 3 shows the corrupted images of one subject from the AR database.

Some image examples of the “salt-and-pepper” noise with a density of 0.15 from the AR database.
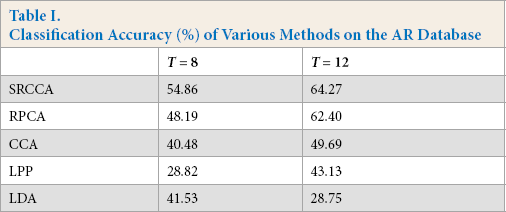
The AR database was used to test the performance of SRCCA when facial expressions and lighting conditions changed. Figs. 4 and 5, and Table I display the experimental results, from which it can be seen that, in the perspective of classification accuracy, our proposed method was the best in the presence of noise. As the number of training samples increased, the classification results of our method were still better than those of other methods. Therefore, our method was more robust.
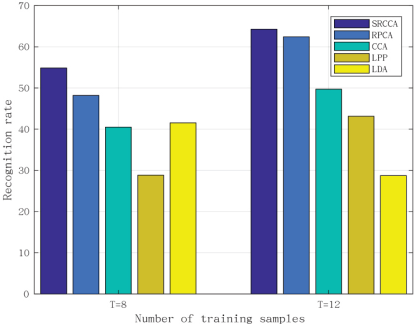
Experimental results with different numbers of training samples on the AR database.
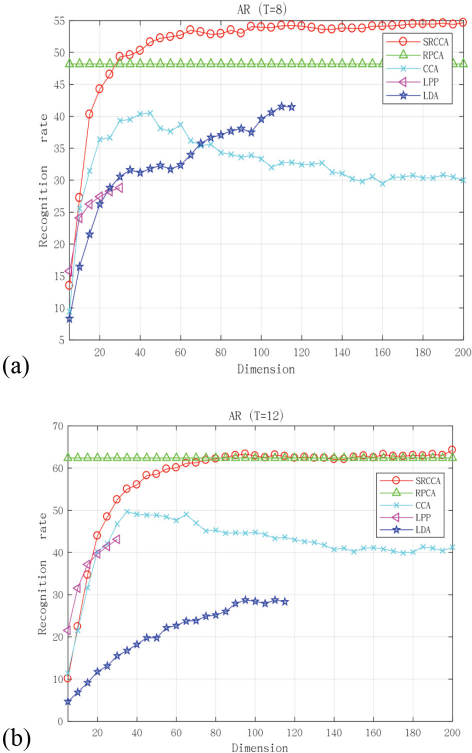
Experimental results on the AR database. (a) T = 8 and (b) T = 12.
Classification Accuracy (%) of Various Methods on the AR Database
Experiment on the FERET Database
The FERET database contains more than 10,000 face images with different poses and lighting conditions. In our experiments, we chose a subset of the FERET database which includes 1400 face images from 200 subjects, and each subject has seven images. The face size of each image was cropped to 40×40 pixels. The FERET database was used to verify the performance of our method with poses and facial expressions changing. We used the first four images of each class as training samples. Fig. 2b shows the image samples of two classes in the FERET database. The experimental results are shown in Fig. 6 and Table II.
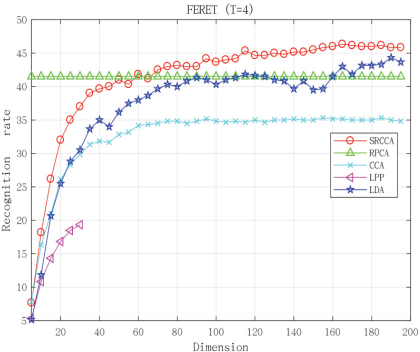
Experimental results on the FERET database. (T = 4).
Classification Accuracy (%) of Various Methods on the FERET Database
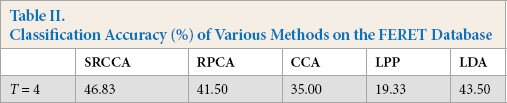
From Table II, we can see that the classification accuracy of SRCCA is the best. From Fig. 6, we know that as the dimension increased, the classification accuracy of our proposed method also increased, while maintaining good results. The experimental results show that SRCCA performed better than other compared methods.
Experiment on the YaleB Database
To confirm the robustness of the proposed method, experiments were conducted on the YaleB database. The YaleB database consists of 2432 face images which were collected from 38 different people, and each person had 64 images.
The size of each image was 96×84 pixels. From Fig. 2c we can see that the main changing factor in the YaleB database was illumination. As the illumination changed, the facial shadows gradually increased.
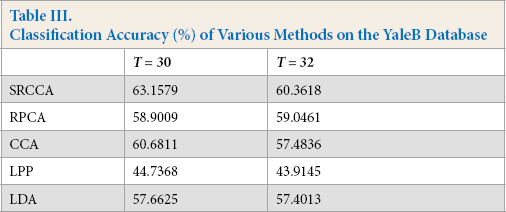
In our experiments, the number of training samples were T =30, 32, 34, and the remaining images were test samples. The experimental results are shown in Fig. 7 and Table III, from which we can see that the classification accuracy of our proposed method was the best. SRCCA was more robust than other traditional subspace learning methods. The experimental results indicate that the proposed method SRCCA had good performance and robustness.
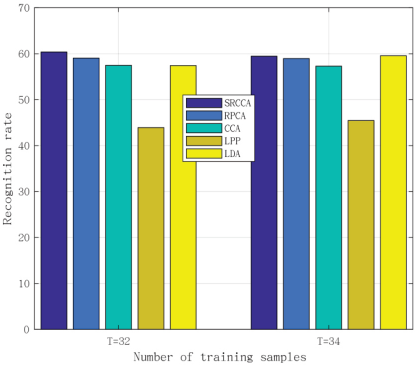
Experimental results with different numbers of training samples on the YaleB database (T = 32,34).
Classification Accuracy (%) of Various Methods on the YaleB Database
Experiment on the Defect Database
The defect database is composed of 574 images from five subjects. We selected a subset of the defect database to conduct experiments, which had 390 images collected from five classes, and each class had 78 images. We added the “salt-and-pepper” noise with a density of 0.15. Fig. 8 shows the corrupted images from the defect database. The size of each image was 54×54 pixels. The results are shown in Fig. 9, from which it was seen that the classification accuracy of our method on the defect database was slightly less than that of RPCA. However, the classification accuracy was much higher than that of CCA. Our method showed a significant improvement in robustness compared to CCA.

Some image examples of “salt-and-pepper” noise with a density of 0.15 from the defect database.
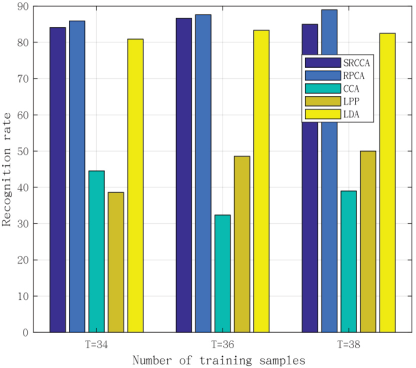
Experimental results with different numbers of training samples on the defect database.
Conclusion
In this study, to effectively encode the global learning ability and the correlations between images and their mirror images for image classification, we proposed a novel method, named symmetrical robust canonical correlation analysis (SRCCA). We first constructed the mirror images of all used images. Ten, we used low-rank learning to remove noise in both images and their mirror images. The CCA technique was used to obtain the correlation of the images set and their mirror images set. The nuclear norm was used as a constraint to ensure the learned data are low-rank. The ℓ1 norm was used as a sparse constraint to ensure the noise in the data was sparse. Extensive experiments were done on the four publicly available image databases to verify the performance of the proposed method. The experimental results demonstrated that SRCCA has good performance and robustness on image classification.
Footnotes
Acknowledgement
This work was supported by the National Natural Science Foundation of China (Grant Nos. 61672357 and 61732011), the Tencent “Rhinoceros Birds”-Scientific Research Foundation for Young Teachers of Shenzhen University the Guangdong Natural Science Foundation (2019A1515011493), the Natural Science Foundation of Shenzhen University (No. 2019046), the Research Grants Council of Hong Kong (Grant No. 15202217), the Hong Kong Polytechnic University under Project 1-YW2V, and the Science Foundation of Shenzhen (Grant No. JCYJ20160422144110140).