
Abstract
In this study, we present a novel dimensionality reduction method called Jointly Linear Embedding (JLE). Unlike previous methods such as Neighborhood Preserving Embedding (NPE), in which local neighborhood information is preserved during the dimensionality reduction procedure, JLE aims to preserve the sparse reconstructive relationship of the original data by taking the merits of jointly sparse learning based on L2,1-norm. In the framework of JLE, the sparse weight matrix can reflect the intrinsic geometric structures of the original data and inherit the ability of discriminant analysis. By solving the L2,1-norm regularized objective function, the optimal projections, which are invariant to rotations and robust to outliers, can be obtained by JLE. Extensive experiments on visual recognition and fabric defect classification datasets demonstrate the superiority of the proposed L2,1-norm regularized learning method compared with the state-of-the-art methods.
Keywords
Introduction
Data with high dimensions exist in many real-world applications, such as content-based image retrieval, visual recognition, feature clustering, and multi view data handling,1–4 which raises great challenges for human society. Therefore, it is important to perform dimensionality reduction on the data by effectively exploiting the underlying structure information and the discriminative information.
The goal of dimensionality reduction is to map the high-dimensional samples to a low dimensional space, while preserving the structure properties among the data points. Up to now, researchers have developed many linear and nonlinear dimensionality reduction methods. Principal Component Analysis (PCA)5–8 and Linear Discriminant Analysis (LDA)9–11 are two classical linear dimensionality reduction methods. The idea of PCA is to find a set of optimal projections by maximizing the variance of the original data. To explore the projections with discriminant power, LDA attempts to maximize the ratio of between-class scatter and within-class scatter. Besides the linear analysis methods, several nonlinear techniques also have been proposed to discover the nonlinear structure of the manifold. The representative methods include Laplacian Eigenmap, 12 Locally Linear Embedding, 13 Isomap, 14 Maximum Variance Unfolding (MVU), 15 Stochastic Neighbor Embedding (SNE), 16 and t-Distributed Stochastic Neighbor Embedding (t-SNE) 17 These nonlinear methods can discover nonlinear structure of the data to learn a low-dimensional representation. Even though nonlinear techniques are effective under certain conditions, they are not competitive in efficiency. Moreover, these methods are normally not easy to configure in real-world applications. Therefore, the manifold-learning-based linear dimensionality reduction have been a hot research topic since the past decade. The well-known techniques include Locality Preserving Projection (LPP) 18 and Neighborhood Preserving Embedding (NPE). 19 LPP is a linear approximation of the nonlinear Laplacian Eigen-maps, which seek to find the projections to optimally preserve the nearest neighborhood relationship among the data points.20–22 Unlike LPP, NPE is a linear approximation of Locality Linear Embedding (LLE), 13 which seeks for the projections such that the local reconstructive relationship can be preserved in low-dimensional space.
In recent years, sparse representation or sparse regression methods were popularized in the field of visual recognition.26–28 Based on the concept of sparse regression, Sparse PCA (SPCA) 29 extended the classical principle component analysis by using the L1-norm Elastic Net regression. It was verified that the sparsity was an effective way for signal identification.23–25 With the merits of sparsity, the recently proposed Sparsity Preserving Projections (SPP) 30 introduced the L1-norm regularization to effectively select the discriminative features and avoid the over-fitting problem. SPP can preserve the sparsity reconstructive relationship of the data. However, it neglects the dependence between the representations of different samples. To learn discriminative features from 2D image matrix directly, Lai et al. 31 designed a hybrid scheme by combining L1-norm and L2-norm regressions together to find the 2D-based image matrix projections.
However, both conventional dimensionality methods (LPP and NPE) take the L2-norm for measurement, which make these approaches vulnerable to outliers. Even though the recently proposed SPP adopts the L1-norm and L2-norm for measurement and adjacent graph learning, it still lacks the well interpretation for subspace learning.
Recently, the L2,1-norm-based feature selection methods received considerable attention.32–43 Nie et al. 34 offered an effective approach for solving the joint L2,1-norm based minimization problem and the convergence proof was given. Nie et al. also leveraged joint L2,1-norm minimization on both loss function and regularization for feature selection. In another work, Li et al. 41 proposed an unsupervised learning algorithm (Nonnegative Discriminant Feature Selection), in which the L2,1-norm minimization constraint was added into the objective function for guaranteeing that the projection matrix is sparse in rows. Hou et al. 42 also introduced a novel unsupervised feature selection approach, via jointly Embedding Learning and Sparse Regression, in which the L2,1-norm regularization is added for learning a sparse feature ranking matrix. To achieve the goal of unsupervised feature selection, Yang et al. 43 incorporated discriminative analysis and L2,1-norm minimization into a joint subspace learning framework. Recent studies44,45 showed that low-rank learning is effective in dimensionality reduction and feature extraction.46,47 However, the noises had great influence on low-rank feature learning. To solve this problem, Lu et al. 48 and Wen et al. 49 proposed to impose the L2,1-norm on the regularization terms of the optimization model, which shows competitive performance of the L2,1-norm in low-rank sub-space learning. The L2,1-norm-based sparse weight matrix is row-wise consistent, while the L1-norm based matrix is not. 34 In the consistent sparsity weight matrix, all the elements in certain rows that have nothing to do with sub-space learning trend to be zero, which avoids the influence of outliers (corresponding to the rows with zero elements) on the reconstruction task. However, in the “conventional sparsity” weight matrix, which is exploited by L1-norm-based optimization, zero elements randomly appear on the learned matrix, which makes it hard to decide the optimal features or data points (items in row) for further processing. Besides, the L2-norm, which is sensitive to outliers, is still dominant in the objective function of the conventional sparse regression methods. Therefore, the L2,1-norm based weight matrix is more robust than the L1-norm based weight matrix due to its following properties.
The optimization with L2,1-norm
regularization is able to perform jointly sparse learning. The matrix learned from the L2,1-norm-based
model has well interpretation. Specifically, the nonzero vectors on the
rows of the learned matrix indicate the valuable data or features for
representation. The zero vectors on the rows of the learned matrix
indicate the useless part or feature of the original data. The L2,1-norm-based model is robust to
outliers. The L2,1-norm-based model has a close-form
iterative solution.
Zhao et al. 35 used spectral regression with L2,1-norm constraint to jointly evaluate the features. It was reported that their method can effectively remove the redundant features. Ren et al. 36 exploited L2,1-norm minimization of both loss function and regularization for classification. All of these methods33–40 used the same method presented in another reference 34 to solve the joint L2,1-norm-based loss function and regularization minimization problem.
Motivated by jointly sparse learning, which is robust to outliers, in this study, the L2,1-norm is introduced to two crucial steps (weight matrix learning and projection matrix learning) for jointly linear embedding (JLE) to perform robust dimensionality reduction. As mentioned above, the L2,1-norm-based method is robust to outliers as compared with the L2-norm-based method. Therefore, unlike conventional dimensionality reduction methods, such as LPP and NPE that use L2-norm for measurement during the weight matrix optimization step, JLE acquires the adjacent weights of the data points via jointly sparse learning with the merits of the L2,1-norm. Thus the linear embedding based on the measurement of the L2,1-norm is integrated into the second phase optimization framework to learn optimal projections for obtaining the sparse reconstructive relationship. Therefore, in this work, we propose a novel linear embedding method, which solves the joint L2,1-norm-based minimization problem with its convergence proof given.
The contributions of this paper are summarized as follows: By exploiting the L2,1-norm-based weight
matrix learning, the proposed method obtains the weight matrix with
“consistent sparsity.” This weight matrix can indicate data points that
play an important role in the reconstruction task. Compared with LPP,
NPE, and SPP, the proposed L2,1-norm-based
weight matrix learning is more robust to outliers and the obtained
weight matrix can reflect the intrinsic geometric structures of the
original data. JLE is able to take the merits of L2,1-norm
to learn the optimal projections that preserve the sparse reconstructive
relationship among the data points. Similarly, the
L2,1-norm makes JLE invariant to
rotations and robust to outliers. A new linear embedding dimensionality reduction framework with two phases
optimization based on L2,1-norm is proposed.
We have designed an effectively iterative method to solve the proposed
model with the convergence proof provided. Moreover, a quantity of
experiments with outlier handling is designed to verify the
competitiveness of the proposed method.
The reminder of this paper is organized as follows. The notations of the proposed method and the related works are introduced, and an L2,1-norm-based jointly linear embedding algorithm with its convergence proof is presented. To evaluate the effectiveness of the proposed method compared with state-of-the-art methods, a number of experiments are performed on the public datasets, followed by the conclusion.
Related Works
In this section, we give some definitions and notations, and then briefly review the closely related methods NPE 19 and SPP. 30
Notations and Definitions
We first give some notations and definitions of different norms. The matrix and vectors are represented with uppercase letters and lowercase letters, respectively. For matrix S = (s ij ), its i-th row and j-th column are denoted by s i and s j , with superscript and subscript, respectively.
The L2-norm of the vector v ∈
ℝ
n
is defined as
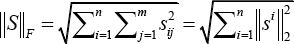
and the L2,1-norm 34 of the matrix S ∈ ℝnxm is defined in Eq. 2.
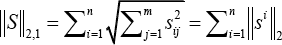
We consider a set of n sample images X = [x1 x2 · · · x n ]∈ ℝrxn taken from an r-dimensional image space. Due to the high dimensionality, it is inefficient to directly apply visual algorithms on the raw data. Therefore, it is of vital importance to perform dimensionality reduction on the original data. We design a linear transformation, which maps the original r-dimensional images space into a d-dimensional feature space. Let A ∈ ℝ rxd be the linear transformation. The method of dimensionality reduction here projects each image x., an r x 1 dimensional vector, onto a low-dimensional space by the transformation in Eq. 3.
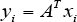
NPE
NPE 19 is a subspace learning algorithm, which aims at preserving the local neighborhood structure of the data manifold. In the NPE algorithm, the first step constructs an adjacent graph. Then, the second step computes the weights on the edges by minimizing the objective function, as shown in Eq. 4.
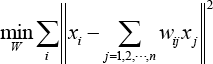
with constraints in Eq. 5.
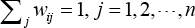
The third step computes the linear projections a by solving the generalized eigenvector problem using Eq. 6.
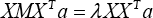
where λ is a scale factor, M is defined in Eq. 7.
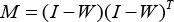
I is the unit matrix and A = [a1 a2 · · · a d ].
SPP
Both SPP 30 and NPE are closely related to LLE. 13 In fact, NPE is a directly linear approximation of LLE, while SPP constructs the “affinity” weight matrix in a completely different manner compared with LLE. In particular, SPP constructs the weight matrix using all the training samples (with sparsity constraints) instead of k nearest neighbors.
For SPP, each sample is reconstructed by the related samples whose number is as small as possible. They seek a sparse reconstructive weight vector w i ∈ ℝ rx1 for each x i . through a modified L1-norm optimization problem (Eq. 8), where X = [x1 ··· x j ··· x n ] ∈ ℝmxn, each element of w i . represents the contribution (reconstructive weight) of x j to reconstruct x i .
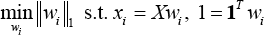
Given a visual image x i j from the j-th class, x i j can be theoretically represented using the samples from the j-th class Thus we have Eq. 9.
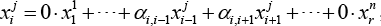
where j = 1,2, ···, n. The weights vector
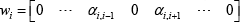
is sparse. Similar to LLE and NPE, SPP defines the objective function (Eq. 10) to seek the projections which best preserve the optimal weight vectors w i . 30
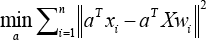
The optimal projection vectors a can be obtained by solving the generalized eigenvalue problem, as shown in Eq. 11.
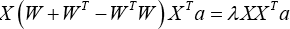
and the eigenvectors corresponding to the largest d eigenvalues span the optimal subspace.
Proposed Method
To perform jointly sparse learning and linear embedding, the L2,1-norm was used in the phases of weight matrix learning and projection matrix learning under the dimensionality reduction framework. The proposed method is called Jointly Linear Embedding (JLE), which will be explored and elaborated in detail in this section. We not only show the model of L2,1-norm-based jointly sparse learning and the model of L2,1-norm-based jointly linear embedding learning, but also design effectively iterative methods to solve the proposed models with their convergence proof provided in theory.
Jointly Sparse Learning Based Weight Matrix Construction
In image recognition, it is important to obtain the discriminant features for visual representation and recognition. Therefore, in this work, the latent intrinsic discriminative features were extracted from the visual images (e.g. faces images and fabric defect images) to improve the classification rate and enhance the robustness. Recent research50,51 indicates that the performance of discriminative feature selection and recognition rate can be further improved by introducing the L2,1-norm into the optimization problem. To take the merits of L2,1-norm for jointly sparse learning, we integrate the L2,1-norm into the weight matrix optimization model to obtain a robust sparse weight matrix for linear embedding. We expect that both sample representation and weight matrix could be robust to the outliers. To this end, the L2,1-norm will be imposed on both dominant term and the regularization term to formulate the optimization problem using Eq. 12.
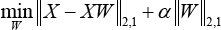
where W ∈ ℝnxn is the weight matrix and α is the regularization parameter. For a sample in X, the dominant term of Eq. 12 selects the closely related samples among X for linearly representing this sample. The number of selected samples should be as small as possible. This can be guaranteed by the L2,1-norm that holds an effectiveness of jointly sparse learning. To fully achieve the functionality of jointly sparse learning, we impose the L2,1-norm on the weight matrix as shown in the regularization term of Eq. 12, so that the weight matrix could be sparse in row, which shows good robustness to the outliers. The obtained sparse weight matrix is able to indicate the relation between the samples. Compared with the L2-norm-based measurement in LLE, the proposed L2,1-norm-based measurement is imposed on both dominant term and regularization term, which turns out to be more robust. When using the L2,1-norm to do sample selection for reconstruction, the objective function in Eq. 12 can exclude the samples not closely related to the test sample in the robust regularized regression. It is obvious that the reconstructive property is decided by the data and the L2,1-norm optimization algorithm, and not decided by the k nearest neighbor, which is quite different from classical locally linear reconstruction. Although solving the joint L2,1-norm problem seems difficult, we show that this problem can be solved using a simple yet effective algorithm.
To optimize the robust joint L2,1-norm minimization function in Eq. 13, we do not need to solve it using the method proposed in the literature. 34 Instead, we can directly solve the optimization problem in pursuit of a close-form solution in each iteration.
Denote E = X - XW, where D ∈ ℝrxr and Q ∈ ℝnxn are diagonal matrices whose i-th diagonal elements are D ii = 1/2 ||E i ||2 and Q ii = 1/2 W i ||2, respectively. Then, Eq. 12 can be rewritten as Eq. 13.
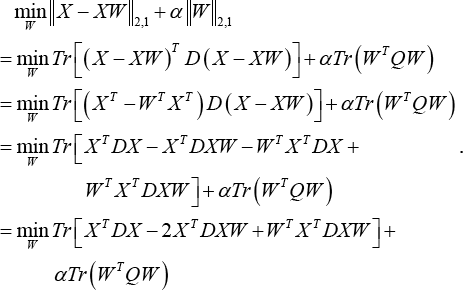
Define
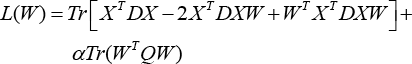
and taking the derivative of L(W) with respect to W to find the optimal value of the optimization problem. Then setting the obtained formula to zero, we have Eq. 15.
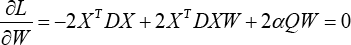
Namely Eq. 16.
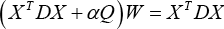
Therefore, the recursive formula of W is given in Eq. 17.
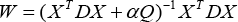
Even though the variables D, Q, and W are all dependent on each other, the optimal values of the three matrices can be approximated and obtained via an iterative optimization algorithm. The proposed algorithm will fix the values of D and Q to compute W, and then fix W to update D and Q. The iteration does not stop until the convergence of the algorithm. The details of the iterative algorithm can be found in Algorithm 1.
Solving the weight matrix

We show that Algorithm 1 converges, with the convergence proof presented below.
Lemma 1: When vectors w i k , i = 1,2, ···, m are non-zero vectors, the inequality in Eq. 18 holds. 34
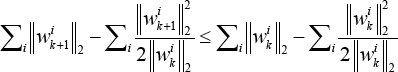
Proof: The proof of Lemma 1 can be found in the literature. 34
Theorem 1: The iterative approach in Algorithm 1 monotonically
decreases the objective function value of
Proof: According to the definition of W k in Algorithm 1, Eq. 19 can be formulated.
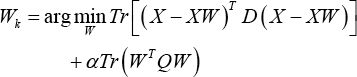
Thus, we have the expression in Eq. 20.
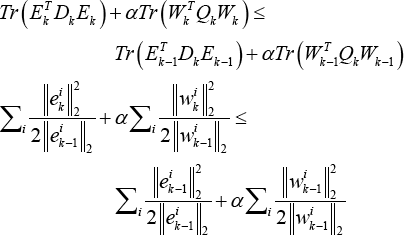
where E = X - XW, e i k and w i k are the i-th row of the matrices E, W. Moreover, D and Q are diagonal matrices whose i-th diagonal elements are D ii = 1/2 ||e i ||2 and Q ii = 1/2||w i ||2, respectively. Then the inequality in Eq. 21 holds.
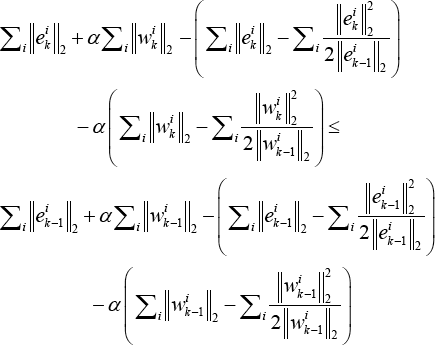
According to Lemma 1, it is easy to get the inequalities from Eq. 22.
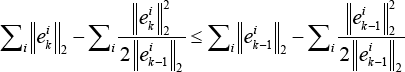
and Eq. 23.
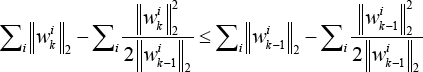
Adding Eqs. 22 and 23 into Eq. 21 gives Eq. 24.
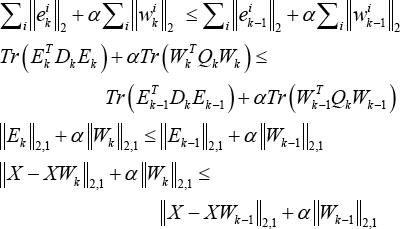
which indicates the objective function of Eq. 12 monotonically decreases under the updating rule of Algorithm 1.
JLE
By introducing the L2,1-norm as the measurement into the objective function for linear embedding, it is expected that the linear representation in low-dimensional space could be more robust to the outliers compared with LPP, NPE, and SPP. After obtaining the sparse weight matrix W, we will construct the minimization objective function to optimize the projection matrix A. The designed objective function for jointly linear embedding is given in Eq. 25.
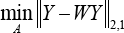
where Y = X T A, Y ∈ ℝ nxd , X ∈ ℝ rxn , A ∈ ℝ rxd and W ∈ ℝ nxn .
The L2,1-norm imposed on the dominant term in Eq. 25 plays an important role for JLE. The objective function in Eq. 25 means that the samples in the low-dimensional space make use of the “sparse neighbors” for linear representation. Such “sparse neighbors” also exist on the low-dimensional space and indicated by the sparse weight matrix under the projection A. Unlike LPP, NPE, SPP, the proposed JLE uses the L2,1-norm for measurement and the representation residuals in low-dimensional space are measured by L2,1-norm to generate the projection matrix for reserving the crucial features in subspace learning.
Since Y = X T A, Eq. 25 can be transformed into Eq. 26.
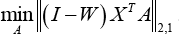
To remove an arbitrary scaling factor in the projection, we impose a constraint on the above optimization problem using Eq. 27.
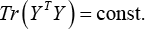
where const. denotes a constant value. Combining Eqs. 26 and 27, we obtain an entire mathematical model for JLE as expressed in Eq. 28.
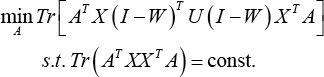
where U is a diagonal matrix whose diagonal element is U ii = 1/2 ||p i ||2 and p i is the i-th row of the matrix P = A T X (I - W) T . The constraint Tr (A T XX T A) = cons that we imposed on the proposed model can remove arbitrary scaling factors in the projection.
Using the Lagrange multiplier method, the constrained minimization problem can be converted to Eq. 29.
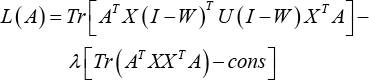
Taking the derivate of L(A) with respect to A and setting the formula to zero, we have Eq. 30.
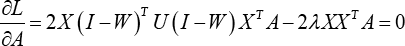
Therefore, the optimal variable A that minimizes the objective function Eq. 28 is given by the solution to the following generalized eigenvector problem with minimum eigenvalues in Eq. 31.
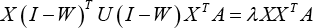
The overall description for obtaining the projection matrix is summarized in Algorithm 2.
Solving the projection matrix

Then we give a theoretical analysis with regard to the convergence of Algorithm 2 as follows.
Theorem 2: For a given weight matrix W, the iterative approach in Algorithm 2 monotonically reduces the objective function value of optimization problem in Eq. 28 in each iteration.
Proof: According to the definition of A k in Algorithm 2, we have Eq. 32.
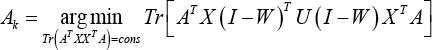
Since P = A T X(I - W) T , Eq. 32 can be further transformed to Eq. 33
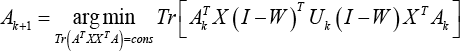
which means that Eqs. 34 and 35 are valid.
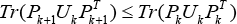
That is to say,
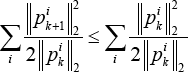
where vectors p i k and p i k+1 indicate the i-th rows of the matrices P k and Pk+1, respectively.
On the other hand, according to Lemma 1, for each i, we have Eq. 36.
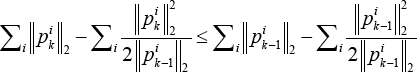
Combining Eqs. 35 and 36, we further have Eq. 37,
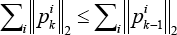
that is to say (Eq. 38),
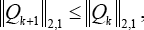
and namely Eq. 39.
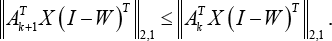
Thus, Algorithm 2 will monotonically reduce the objective of the problem (Eq. 26) in each iteration.
Comparisons between NPE, SPP, and the Proposed Method
JLE and the representative dimensionality reduction methods NPE and SPP have something in common. They all discover the potential structure among the data manifold during the process of subspace learning. However, JLE is different from NPE and SPP in the following aspects.
NPE finds the L2-norm-based local
reconstruction relation and SPP finds the
L1-norm-based sparse reconstruction
relation. Although JLE also finds the sparse reconstruction relation
among the data points, such a relation is derived by using the
jointly sparse learning based on the
L2,1-norm. The way of JLE weight matrix learning is different from NPE and SPP.
Both NPE and SPP have to obtain the weight vector one-by-one via
solving the regression problem, where the former uses the
L2-norm to measure the
representation residual, and the later uses the
L1-norm to solve the sparse weight
vector. In JLE, the learning of the sparse weight vectors is
performed in batch mode, namely, the sparse weight matrix can be
obtained directly by solving the
L2,1-norm-based jointly sparse learning
model. Furthermore, both NPE and SPP use the
L2-norm to measure the representation
residual of the low-dimensional data during the phase of projection
matrix learning. However, JLE adopts the
L2,1-norm to perform jointly linear
embedding for projection learning. The linear representation in
low-dimensional space is more robust to the outliers compared with
that of NPE and SPP.
Experimental Results
To validate the real classification performance of JLE, we conducted comparison experiments on the ORL, 52 Yale, 53 AR 54 , and PIE 55 face databases, and XueLang fabric defect database. 56 The representative dimensionality reduction methods, including LPP, 18 NPE, 19 and SPP, 30 were used for comparison. The Neighborhood Preserved LLE (NLLE), 57 Linear Projection Direction-based NPE(LPNPE), 58 and Subspace-based Ensemble Sparse Representation (RS_ESR) 59 were further used for validating the effectiveness of the proposed method on noisy data. The experimental results shown in the following subsections support our novel viewpoint that the proposed method is competitive with other state-of-the-art methods for visual classification. For the face databases, the corresponding descriptions are summarized in Table I. For the fabric defect database, we classify the defect types to evaluate the performance of the proposed method. In the experiments, the recognition rate was exploited to measure the performance of the algorithm. The training process is randomly repeated 10 times and then the average recognition rates were computed and reported.
Description of Databases Used in Experiments
Four Face Databases
The ORL face database 52 totally has 400 frontal-face images of 40 individuals and provides a variety of facial expressions and facial details (e.g., glasses or no glasses). In the experiments, all the images were normalized to a resolution of 56x46. Part of the face samples in the ORL face database are shown in Fig. 1.

Sample images of two people from the ORL database.
The Yale database has a total of 165 gray scale images of 15 individuals. 53 Each subject contains 11 images with different facial situations including wearing glasses, left lighting, surprised, sad and so on. All the images were normalized to a resolution of 64x64 for the experiments. Sample images of the Yale face database are shown in Fig. 2.

Sample images of one person from the Yale database.
The number of face images in the AR database is over 4000. 54 All images are provided by 126 people, including 70 men and 56 women, with abundant facial expressions, occlusions, and lighting changes. In this study, we used the face images of 120 people (65 men and 55 women) for the experiments. The images were taken in two sessions and each section contained 13 images. For each image, it was normalized to a resolution of 50x40 for further processing. Some of the ORL face images are shown in Fig. 3.

Sample images of one person from the AR face database.
For the CMU PIE database, 55 the face images of 68 people are provided, where each person has 13 pose variations and 43 different lighting conditions. In this study, the PIE images of 68 people were used, but only a portion of face images (42 facial images) with lighting changes were adopted for the experiments. Moreover, we extracted the face targets from the PIE face images and then converted them into a size of 32x32 for this work. The PIE face images with strong lighting changes are shown in Fig. 4.

Sample images of one person from PIE face database.
XueLang Fabric Defect Database
The XueLang fabric defect database 56 contains over nine defect types. In this experiment, we divided the defects into seven defect types, namely float, hole, missing_end, missing_pick, draw_back_end, weft_crackiness, and normal types. All defects were collected in the factory. The visual images of the defects are shown in Fig. 5. The resolution of these defect images are 256x256.

Seven defect types of XueLang fabric defect database.
Parameter Tuning
We used the popular dimensionality reduction methods for comparisons: 1) LPP, 18 2) NPE, 19 3) SPP, 30 the proposed 4) JLE, 5) NLLE, 57 6) LPNPE, 58 and 7) RS_ESR. 59
For the four face databases, we randomly selected 20% to 80% of the images per class for training, and the remaining for testing. For the defect database, we selected 100 defect images for training and 30 defect images for testing in seven classes. With the given training set, the projection matrix A was learned by the comparison methods, respectively, and the test samples were subsequently transformed by the learned projection matrix. In the classification stage, we used the 1NN classifier to evaluate the recognition rates on the test data.
For LPP algorithm, the neighborhood size k was searched from {5, 10, 15, 20} and the kernel width t was set to the mean norm of the training data. To preserve the main energy of the samples, PCA was used to extract the principal components. For the NPE algorithm, the neighborhood size k was searched from {5, 10, 15, 20}. The SPP algorithm was parameter-free. For NLLE, LPNPE, and RS_ESR, we used the default parameters specified by the original paper. For the proposed JLE algorithm, the experiments were also conducted after the extraction of principal components of the original data by PCA. Furthermore, the regularization parameter α in JLE was searched from {10-10, 10-9, … 10 10 } and the best results were reported.
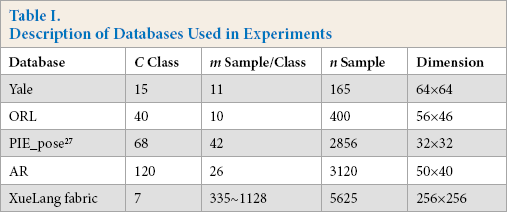
For ORL, Yale, PIE, AR, and XueLang databases, the parameters α of the best results were set to 10–1, 10-2, 10-7, 10-2, and 10-3 respectively. Fig. 6 shows the variation of the recognition rate versus the values of α (Alpha), which demonstrates that the proposed method is insensitive to the variation of the parameter.
The recognition rates vs. the value of Alpha.
Convergence Analysis
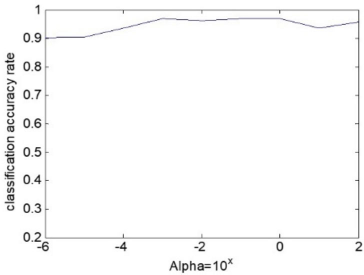
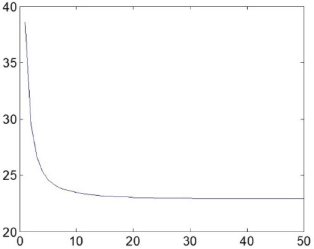
As proven in the previous section, the updating rules in Algorithms 1 and 2 guarantee an optimum solution for our objective functions defined in Eqs. 14 and 29. We drew the convergence curves of weight matrix learning and projection matrix learning of JLE in Figs. 7 and 8, respectively, which show that the objective function value decreases with the increase of the iteration number on the ORL database. We also observed that Algorithms 1 and 2 converge rapidly after 10 iterations. Therefore, we set the maximum iteration number of Algorithms 1 and 2 to 50 in the following experiments.
The objective function of Algorithm 1 for constructing the weight matrix W on ORL database. Objective function value decreases along with the increase of the iteration number.
The objective function value of Algorithm 2 for obtaining the projection matrix A on ORL database. Objective function value decreases very fast with the increase of the iteration number.
Visualization of Sparse Weight Matrix
We also evaluated the sparsity property of the weight matrix for the proposed JLE method. Fig. 9 shows that weight matrix W is sparse and, most important of all, the majority of the nonzero coefficients are well aligned along the diagonal direction of the weight matrix, which shows that the proposed JLE is able to explore the naturally discriminative information for dimensionality reduction, even if no class labels are included.
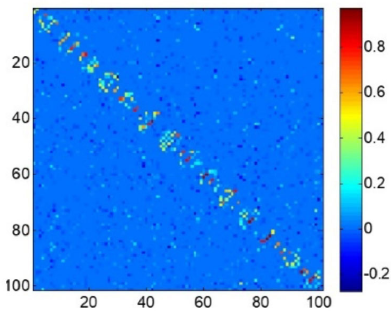
The part of weight matrix W obtained by Algorithm 1 on ORL database.
Experimental Results on Four Databases
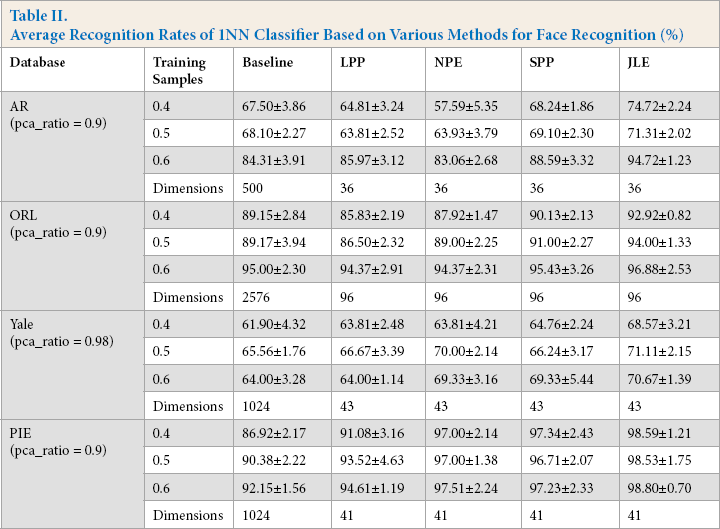
For the four face databases, we randomly select 20% to 80% of the images per class for training, and the remaining for testing. The maximal average recognition rate of each method and the corresponding dimension are shown in Fig. 10 and Table II. Fig. 10 shows the accuracies of the various methods with various proportions of training samples on four databases. Table II shows some detailed recognition rates of the experiments, among which the numerical values 0.4, 0.5, and 0.6 in the table represent 40%, 50%, and 60% of the images per class were randomly selected for training.
Average Recognition Rates of 1NN Classifier Based on Various Methods for Face Recognition (%)
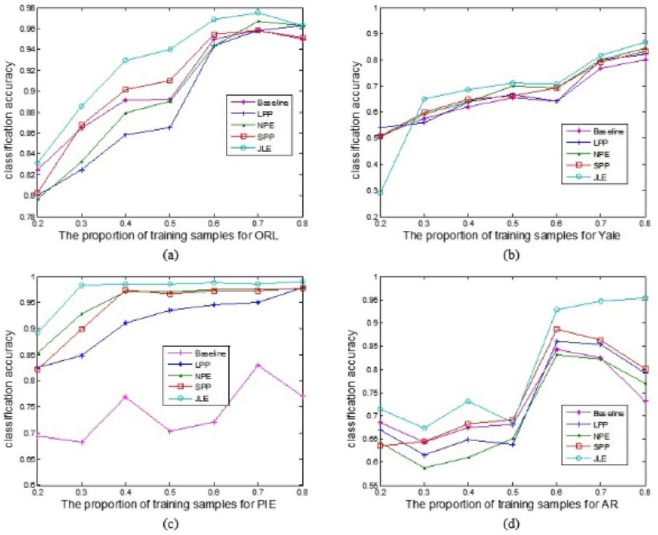
The classification accuracies of four database with different portions of training samples. (a) ORL, (b) Yale, (c) PIE, and (d) AR.
The performance of JLE was greater than the other methods in four databases using various numbers of training samples, as shown in Table II. Specially, the competitive recognition rate was obtained in the AR database when 60% training samples were used. The recognition rate of JLE was around 6% higher than that of the SPP, ranked in second place. Fig. 10 shows that the overall performance of JLE increased with the increased proportion of training samples. Even though databases such as AR and PIE contain an abundance of facial expressions and illumination variations, the proposed method was still superior to other state-of-the-art methods. The reason lies in the L2,1-norm-based objective function and weight matrix that select the most important discriminative data or features to enhance the recognition rate, even under situations with complexities.
Experimental Results on XueLang Defect Database
For the defect database, we selected 100 defect images for training and 30 defect images for testing in seven classes. In the experiment, ResNet 60 was used to extract the deep features (the dimensionality is 2048x1) from defect images, and thus PCA was used to reduce the dimensionality of the features so that the computation can be fluently conducted on our computing platform. The experimental results of different methods on the XueLang defect database are shown in Table III. It shows that the proposed method was competitive with the popular dimensionality reduction methods on the classification task.
Classification Rates of 1NN Classifier Based on Various Methods for Defect Classification (%)

Experimental Results Including Outliers
To evaluate the performance of the JLE algorithm when face images are occluded with outliers, we added a 10x10 noise block on the original face images in four databases. The position of the noise block on every face image was set randomly. In Fig. 11, we show some occlusion images from the ORL database. To evaluate the performance of JLE and other dimensionality reduction methods including LPP, NPE, and SPP, we conducted the experiments on the newly-created occlusion databases.

Sample images of the occlusion ORL database.
The experimental setting and parameter tuning were the same as the above experiments performed on the original face databases. Specially, the parameter α on the ORL, Yale, PIE, and AR databases were set to 10, 1, 100, and 0.01, respectively.
Fig. 12 shows the accuracies of various methods with various proportions on training samples for the four databases, and a detail report is shown in Table IV. From Table IV, the proposed method was not the best (only 0.15% lower than the best one) when 40% of the training samples were used in the AR database. However, with the increased number of training samples, JLE showed its superiority over the other methods as shown by the results using the AR database in Table IV. It should be noted that the fluctuations of all the recognition accuracies using outliers were more severe than that of the results in Table II. The random positions of noise blocks had a great influence on the performance of all comparison methods, which resulted in a decreased problem of recognition accuracies. For example, the average recognition rate 61.25% with 60% training samples was less than the average recognition rate of 62.50% when 50% training samples were used from the ORL database, as shown in Table IV. However, such discrepancies were not so great and still in a reasonable range under the influence of noise blocks.
Average Recognition Rates of 1NN Classifier Based on Various Methods for Face Recognition (%)
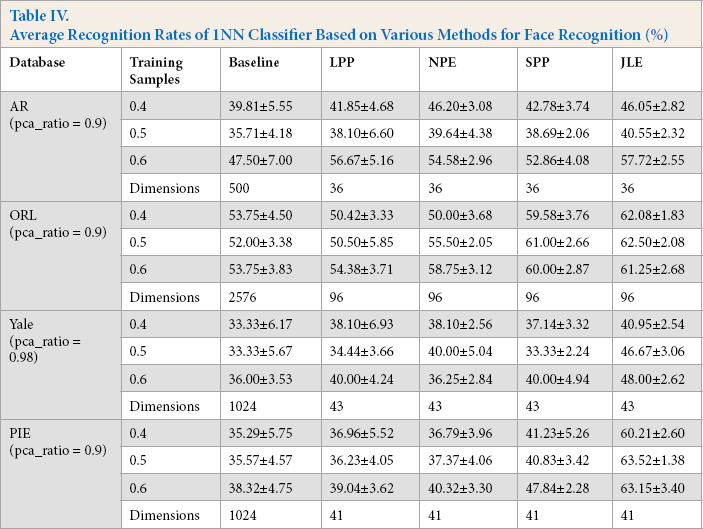
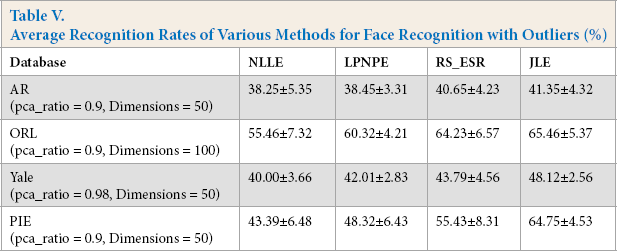
Even though the performance of all methods were affected by these outliers, the performance of JLE was competitive with other state-of-the-art methods, with an increased proportion of training samples, as shown in Fig. 12. It should be noted that JLE had very good performance using the Yale and PIE databases under the influence of noise blocks. The average recognition rate of JLE was at least 8% and 16% higher than LPP and SPP when 60% of the noisy training samples were used with Yale and PIE databases, respectively. We further validated the effective-ness of JLE by comparing it with NLLE, LPNPE, and RS_ESR on the image data with outliers in four face databases, among which 50% of the samples were used for training. The experimental results in Table V shows that JLE was more competitive than the state-of-the-art methods. Based on Fig. 12 and Tables IV and V, our algorithm achieved the best result, and the classification accuracies were obviously higher than other methods.
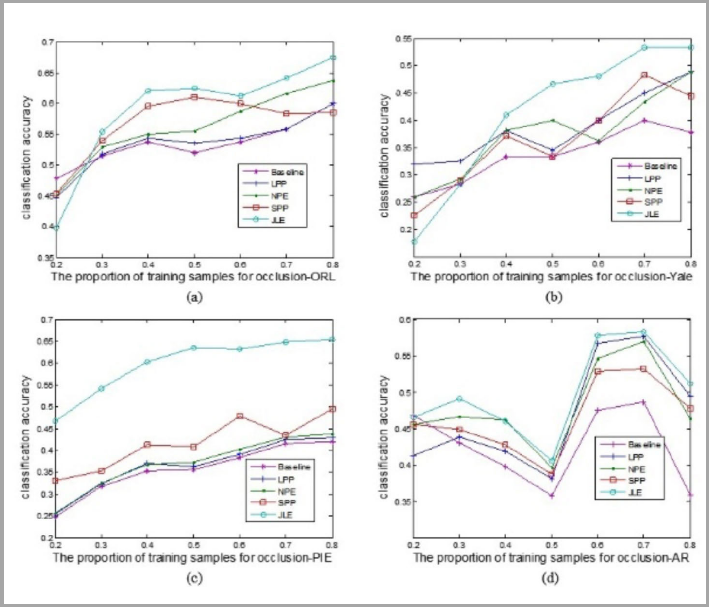
Accuracies of various methods with various proportions on training samples for the four databases.
Average Recognition Rates of Various Methods for Face Recognition with Outliers (%)
Conclusion
In this study, we proposed a new algorithm called Joint Linear Embedding (JLE) for dimensionality reduction based on the L2,1-norm. In the proposed algorithm, the weight matrix obtained by optimizing an L2,1-norm-based objective function is sparse and the L2,1-norm-based loss function is robust to outliers. The L2,1-norm-based regularization can select the related samples with latent discriminant information due to the strong ability of the L2,1-norm for jointly sparse learning. During the projection learning phase, JLE was performed based on the L2,1-norm, which showed robust representation ability against the outliers compared with LPP, NPE, SPP, NLLE, LPNPE, and RS_ESR. And such robustness was further validated by the results in the experimental section.
In this work, the L2,1-norm was integrated into the dimensionality reduction framework for jointly sparse learning and jointly linear embedding. We also provided the theoretical proof of the convergence of JLE. In the future, to obtain a more robust dimensionality reduction method against the outliers, a sparse projection matrix with the ability of feature extraction and selection will be designed for linear embedding.
Footnotes
Acknowledgements
This work was supported in part by the Natural Science Foundation of China under Grant 61703169, 61703283, 61806127, in part by the Guangdong Basic and Applied Basic Research Foundation 2021A1515011318, 2017A030310067, in part by the Shenzhen Municipal Science and Technology Innovation Council under the Grant JCYJ20190808113411274, in part by the Overseas High-Caliber Professional in Shenzhen under Project 20190629729C, in part by the High-Level Professional in Shenzhen under Project 20190716892H, in part by the Research Foundation for Postdoctoral Work in Shenzhen under Project 707-0001300148, in part by the National Engineering Laboratory for Big Data System Computing Technology, in part by the Guangdong Laboratory of Artificial-Intelligence and Cyber-Economics (SZ), in part by the Shenzhen Institute of Artificial Intelligence and Robotics for Society, and in part by the Scientific Research Foundation of Shenzhen University under Project 2019049, Project 860/000002110328, and Project 827-000526.