
Abstract
Abstract
Keywords
Introduction
As a hot topic in automation, fabric defect detection is a necessary and essential step for quality control in the textile manufacturing industry. In recent years, this automatic fabric defect detection method has been developed. The traditional method heavily relies on manual inspection to detect fabric defects, which can help the working pipeline to repair minor defects immediately. However, the efficiency of manual detection will gradually decrease with increased manual working time. Therefore, it is necessary to develop an automatic inspection system for fabric defects to improve fabric quality and reduce labor costs and errors. Since most textile industries are bulk producers of textiles, the probability of the appearance of the defects will be high. In that case, classification based on deterministic patterns can also be accomplished through the design of an automated system based on computer vision. High complexity data obtained from real-time fabric design has increased complexity due to high-order variables, high diversity data, and multi-dimensional data sets formed by images.
Most of the traditional fabric defect detection methods are based on auto-correlation function (AF), 1 local binary pattern (LBP), 2 Fourier transform (FT), 3 wavelet transform (WT), 4 and neural network5,6 methods. These methods are used to detect defects at image level, so it is difficult to locate defects accurately.
Deep learning (DL)7–9 methods have a highly optimized weight and effectively extract the required functions. By using advanced algorithms such as a convolution neural network (CNN), the DL method can be applied to defect detection.10,11,13 Compared with traditional works, these DL models have achieved excellent performance in the application of fabric defect detection. Autoencoders (AEs) are simple DL networks that transform inputs into outputs with the minimum possible error. AE-based fabric defect detection methods have been well explored and achieved good performance.10–12 For example, Seker et al. proposed DL-based method for fabric defect detection using the AE model. 11 Furthermore, Li et al. proposed a stacked denoising autoencoder (SDAE)-based method for deformable patterned fabric defect detection, where the Fisher criterion was introduced into the model optimization process to improve discrimination between defective and defect-free patches. 10 Benefiting from the unsupervised characteristic of the auto-encoder, those AE-based fabric defect detection methods achieve better performance than the traditional methods, and are easy to implement in practice.
In this study, we focus on the design and development of a computer vision application for fabric defect detection and classification using a hybrid model based on deep CNN and a variational autoencoder (VAE), which is named as HVAE. HVAE has shown good performance on data representation by providing a probabilistic manner for describing an observation in latent space.14,15 Therefore, we use convolutional layers to extract fabric image pattern features and the HVAE to model the latent characteristics. Finally, the defect positions can be detected by the differences between the original image and the reconstruction after postprocessing by thresholding and morphology filtering. The proposed model is evaluated on a public patterned texture fabric data-set. The experimental results demonstrate that the proposed model is outstanding on patterned texture fabric defect detection at both image and pixel levels.
Generally, the contributions of our paper can be summarized as follows:
We propose a hybrid model based on a deep CNN and an HVAE that detects fabric defects more accurately. Instead of using the original pixel value as input by the existing AE-based methods, we use CNNs for image texture feature extraction and the HVAE for features representation.
Different than most current CNN-based fabric defect detection methods that need a large scale labeled defect database, only defect-free samples are required for the training by the proposed model. This makes it easy to use in practice due to fabric defect samples being labor-consuming to collect and mark.
We validated the proposed model on a public fabric data-set and performed quantitative and qualitative analysis to demonstrate its effectiveness.
The rest of this paper is structured as follows. Related works on traditional fabric defect detection methods and fabric detection methods based on DL are introduced. The proposed model for fabric defect detection is then demonstrated. The datasets used in our study are introduced. The first dataset is used for defect classification of five defect categories and the section dataset is used to distinguish between defective and non-defective fabric images. This is followed by experimental results and the conclusion.
Related Work
Fabric defect detection has been a popular research topic for many years and plenty of studies related to fabric defect detection have been reported.16–18 The previously limited research for fabric defect detection is reviewed as follows.
Fabric Defect Detection Methods
The most common methods for fabric defect detection can be included in four categories, including low level feature-based, frequency-based, model-based, and learning-based methods.
Low level feature-based methods, researched in early years, distinguished defects by using feature analysis of standard textile texture patterns or structures based on the spatial distribution of gray values, 19 such as using morphological operations, 20 bi-level thresholding, 21 and edge detection. 22 Obviously, those methods easily fail when discriminating blurry defects that do not change the image, in color or detecting defects in fabrics of irregular texture.
Frequency-based methods extract fabric defects by detecting abnormal values using Fourier transform, wavelet transform, Gabor transform, and filtering approaches 23 For example, Li and Zhang developed an embedded machine vision system using Gabor filters and Pulse Coupled Neural Network (PCNN) that can identify defects of warp-knitted fabrics automatically. 24 However, the selection of appropriate parameters for both wavelets transform coefficients and Gabor filters then becomes the most challenging task in defect detection.
Model-based methods detect texture defects based on the construction of an image model.25–27 Regression-based 28 and Gauss Markov Random Field 29 models are most commonly-used in model-based defect detection methods. This technique outperforms only when fabric images have surface changes due to defects such as yarn breakage and needle breakage. Even though it consumes less computational time, no reliable studies have been made in recent years.
Learning-based methods use labelled samples to train classifiers that distinguish between defective and non-defective samples. There are fabric defect detection studies made using classifiers such as the Support Vector Machines (SVM), 30 feedback Artificial Neural Network (ANN), 31 and the Bayes classifier (BC) 8 to learn signatures of defected and non-defected classes. But most of those pattern classification methods need a large variety of data. Moreover, once the algorithm is trained for one particular data set, the network structure cannot be modified, which is inconvenient for practical applications.
Fabric Defect Detection with DL
Taking advantage of large-scale data and high computing power, DL6,7 methods are able to learn richer hierarchical features from training samples and exhibit remarkable performance in a wide range of applications, such as action recognition, 32 traffic flow prediction, 5 and face recognition. 33
By using an advanced algorithm such as CNNs,34,35 DL has also been used to address the problem of fabric defect detection and classification.10,11,13,18,36 Seker et al. proposed deep learning-based method for fabric defect detection using an AE model. 11 Li et al. proposed an SDAE-based method for deformable patterned fabric defect detection, where the Fisher criterion was introduced into the model optimizing process to improve discrimination between defective and defect-free patches. 10 To overcome the weakness of the single scale neural network, Mei et al. proposed a multiscale convolutional denoising AE approach that simultaneously detects and localizes defects in fabrics by combining multiple ConvNet models with Gaussian pyramid decomposition. 12 Zhang et al. built a convolutional network (ConvNet) model from the well-known AlexNet for yarn-dyed fabric defect classification. 36 Furthermore, Wang et al. built a dual ConvNets architecture for fabric defect detection, where the first ConvNet was used for fabric category classification, and the second ConvNet was category specific and used for defective regions detection. 13 Although there are several notable works of applying deep neural networks on detecting defects, deeper CNN methods are still under exploration for higher performance of fabric defect detection.
The VAE outperformed the existing AE methods on data representation by providing a probabilistic manner for describing an observation in latent space.14,15 In this study, we propose a hybrid model based on a deep CNN and a VAE. Differently from the VAE, we use convolutional layers for fabric image features extraction instead of using the original value of the image as the input of the VAE directly.
Proposed HVAE Model
In this section, details of the HVAE method are presented. Our proposed method is composed of a CNN and a VAE. In the training step, normal defect-free images are segmented into patches and then fed to the model for fine-tuning the parameters. In the testing step, the trained model is used to slide on the original image and rebuild a new image. The differences between the original image and rebuilt image can be considered for defect detection after thresholding and morphology processing.
Review of Variational Autoencoders
The VAE14,15 is one of the most popular frameworks for image generation. Following the common techniques for latent variable models, the main idea of VAE is using a probabilistic encoding network to map a latent variable zto an observed input x and using an inference network to perform the reverse mapping from x to z. The two networks form a computational pipeline that resembles an unsupervised autoencoder.
In the computing process, we use the probabilistic encoding network qϕ(z|x) as the approximation to the posterior of the inference network pθ(x, z). Let the prior over latent variable be the centered isotropic multivariate Gaussian pθ(z) and pθ(x|z) be a multivariate Gaussian or Bernoulli distribution. The prior lacks parameters, but the true posterior pθ(z|x) is trackable. Therefore, the variational approximate posterior can be constructed as shown in Eq. 1.
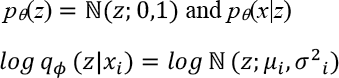
μ i and σ2 i , which denote the mean and standard of the approximate posterior, are the outputs of the encoding functions of data point x i .
The posterior z i,l ∼ qφ(z|x i ) can be sampled by z i,l = gφ(xl, ε l ) = μ i + σ i ⊙ ε l , where ε l ∼ ℕ(0,1). Using the Kullback-Leibler divergence (KL-divergence) that can be computed and differentiated without estimation, the final estimator can be constructed as Eq. 2.
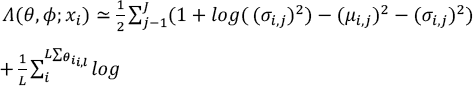
HVAE Model Network
To detect the defect areas in the fabric image correctly, we designed our model with a hybrid of CNN and VAE. Therefore, the proposed network architecture includes two major parts: the Conv-DeConv part used for extracting features from images, and the encoder-decoder part used for reconstructing the image. As mentioned above, the CNN network is good at image processing.
As shown in Fig. 1, the HVAE network model consists of 15 layers. The architecture can be denoted by Conv(32, 3, 3, 2) - Conv(64, 3, 3, 2) - Conv(128, 3, 3, 2) - Flat - FC(512) -FC(20) + FC(20) - FC(512) - FC(2048) - Reshape (128, 4, 4) - DeConv(128, 3, 3, 2) - DeConv(64, 3, 3, 2) - DeConv(32, 3, 3, 2) - DeConv(128, 3, 3, 1). Here, Conv(n, 3, 3, k) represents a convolutional layer with n filter of kernel size 3 3 and strike of k Flat represents flatting the 2D feature map to a 1D feature map. FC(n) represents a fully connected layer with n neurons. Reshape (128, 4, 4) represents reshaping the 1D feature map to a 128 4 4 feature map. DeConv (n, 3, 3, k) represents a deconvolutional layer with n filter of kernel size 3 3 and strike of k To reduce the computation cost of the model, we use a downscale strategy of 2-strike on the convolutional operation. We also apply a dropout strategy of 0.4 on the fully connection between layers to prevent the model from overfitting.
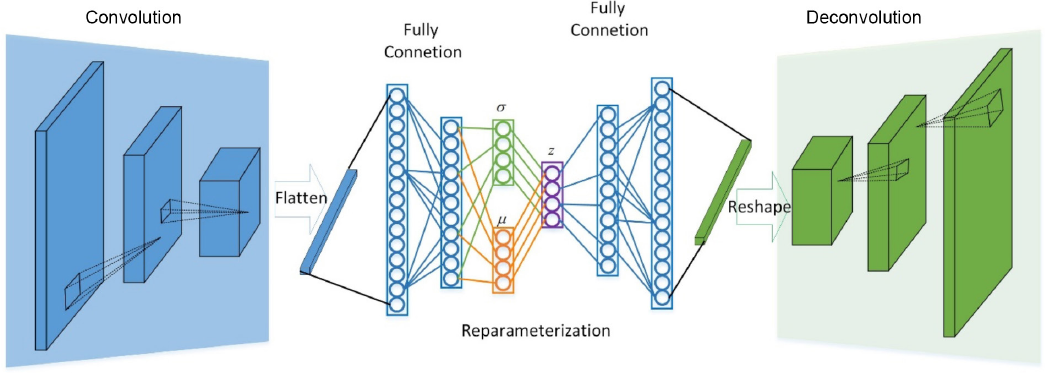
The architecture of our proposed HVAE network.
To generate samples from parameter distribution, we apply a reparameterization trick that is useful for model proposed by Kingma et al. 14 Let the hidden variable z ∼ p(z|x) = ℕ(μ, σ2), then the reparameterization can be expressed as z = μ + σε, where ε is an auxiliary noise variable ε∼ ℕ(0,1). Therefore, in the practical implementation of reparameterization, fully connected layers are applied to build the relationship between μ, σ, and z.
Model Training
The purpose of model training is to learn the distributiion of the defect-free image patches. The model can generate a reconstruction image similar to the input image. In the training process, no defect fabric image is needed.
Defining the Loss Function
Suppose that there exists some hiddien variable z that genereates an observation x. We can infer the characteristics of z from x with p (z|x) using Eqs. 3 and 4.
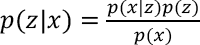
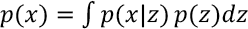
However, p(x) turns out to be an intractable distribution. Therefore, we use another distribution q (z|x), which can be defined as a tractable distribution, to approximate p(z|x). If we can define the parameters of q(z|x) such that it is very similar to p(z|x), we can use it to perform approximate inference of the intractable distribution. The KL-divergence is a measure of difference between two probability distributions. 25
Thus, if we want to make the distribution of p(z|x) similar to q(z|x), we could minimize the KL-divergence between them, as expressed in Eq. 5.
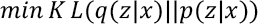
Alternatively, Eq. 5 can be calculated as maximizing Eq. 6.
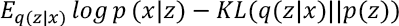
Therefore, the loss function for the network will consist of two terms, which is defined in Eq. 7.
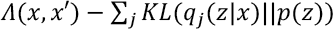
Here, the first term is used to penalize reconstruction error, which is maximizing the reconstruction likelihood. The second term is used to encourage the learned distribution q (z |x) to be similar to the true prior distribution p (z), which is assumed to follow a unit Gaussian distribution, for each dimension j of the latent space.
Training Process
As shown in Fig. 2, the first step of training the proposed model is extracting patches from defect-free fabric images, which are used to create the training datasets. Then, the training datasets are fed into the model, which output the reconstruction patches and the latent state distributions, that is the means and variances. As the loss definition above, the general loss includes two part: one is to evaluate the similarity between the input patches and the reconstruction patches; the other part is the KL-divergence of the latent distributions.
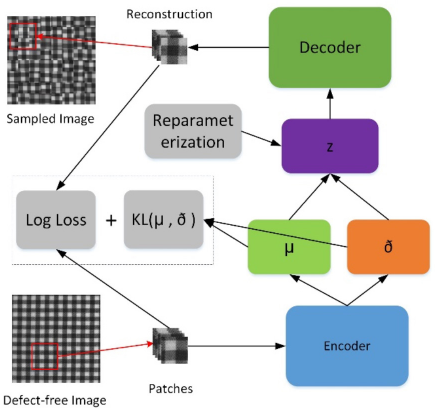
Flowchart of training the proposed model.
In our experiment, the patch size is set to w × h. To generate a larger dataset for training and increase the robustness of the training process, we used a sliding window of w × h with strike of s. Therefore, for a fabric image with size W × H, the count of patches generated from each defect free fabric image can be calculated using Eq. 8.
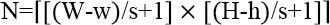
Model Testing
Model testing is used to evaluate the performance of the trained model. The process includes patch extraction, image reconstruction, and locating the defects, as shown in Fig. 3.
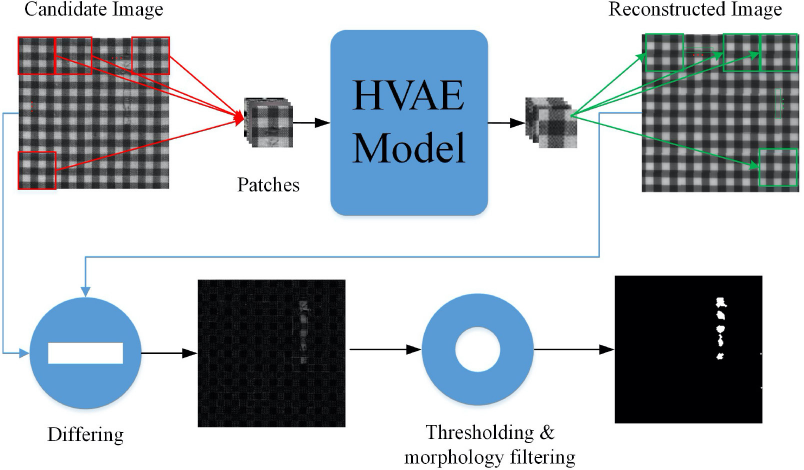
Flowchart of testing the proposed model.
Image Reconstruction
The image reconstruction process can be described as follows. First, the
candidate images are segmented into patches with the same size in the
training process. But different fro m the training process, the slipping
window to generate patches for testing is set to w ×
h with strike as thee window size. Therefore, each
candidate image after patch extraction can be expressed as
[Np,C,w,h],
where
Defects Location
When the reconstructed image is generated, the difference image between candidate image and reconstructed image can be calculated. After that, the defect can be located by thresholding and morphology filtering on the difference image. The performance of defect location not only depends on the quality of the reconstructed image, but also depends on the post-process methods, such as thresholding and morphology filtering. In this study, we segment the defect using Eq. 9.
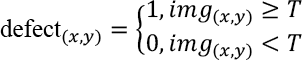
Here, (x,y) denotes the position of the candidate pixel, defect(x,y) denotes the defect detection mask, img (x,y) denotes the difference image, and T denotes the given thresholding value.
Dataset
To demonstrate the performance of our method, we use a patterned texture fabric for the experiment. The fabrics (box-patterned fabric, dot-patterned fabric, and star-patterned fabric) in the patterned fabric dataset was collected by Henry Y.T. Ngan and Grantham K.H. Pang from the Industrial Automation Research Laboratory, Dept. of Electrical an d Electronic Engineering, at The University of Hong Kong, which consists of three different textures with five types of defects. 16 There are a total of 25 defect images and 30 defect-free images in each type of texture. The size of the fabric image is 256*256. Fig. 4 shows some typical defect images.

The typical defect samples of patterned texture fabric images. The defects include netting-multiple, broken-end, hole, knot, thick-bar, and thin-bar.
Experiments and Discussion
We evaluate the performance of the proposed model on both image level and pixel level detection accuracies.
Implementation and Evaluation Criteria
The processor is Intel (R) Core (TM) i5 - 8300H CPU @ 2.30 GHz, and RAM 8.00 GB. The graphics card type is NVIDIA GeForce GTX 1060, with a di splay memory of 6.00 GB. TensorFlow 2.0 is used for implementation.
For evaluation, we adopted the criteria used in previous work,11,24 that is, evaluate the model performance from two aspects: image-level and pixel-level metrics.
On the imaage-level, the classification performance can be evaluated by detection rate (DR), false alarm rate (FAR), and accuracy (Acc), which are widely used metrics for defect detection. These metrics are define d in Eqs. 10–12.
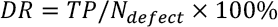
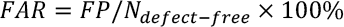
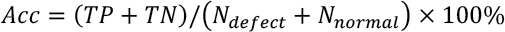
TP denotes the number of true predictions of defective images, FP denotes the number of falsely predictions to defective images, and TN denotes the number of true predictions of defect-free images. N defect denotes the number of defect images, an d N normal , denotes the number of defect-free images.
On the pixel-level, the classification model can be evaluated by precision, recall, and F1 score. Precision is a valid choice of evaluation metric when we want to be very sure of our prediction, while recall is a valid choice of evaluation metric when we want to capture as many positives as possible. The F1 score is a number between 0 and 1 and is the harmonic mean of precision and recall. These metrics are defined in Eqs. 13–15.
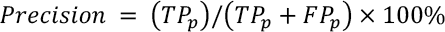
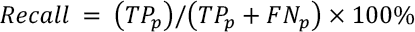
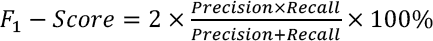
Here, TP p denotes the proportion of pixels correctly segmented into the defective area, while FP p denotes the proportion of pixels falsely segmented into the defective area. FNp denotes the proportion of pixels falsely segmented into the defective-free area.
Accuracy of Patterned Fabric Database
Our proposed HVAE model is capable of learning the pattern characteristics of the fabric image, which is the essential step for fabric defect detection. Samples of the reconstruction image and defect location result are shown in Fig. 5.

Samples of defect detection by the proposed model on (a) box-patterned, (b) dot-patterned, and (c) star-patterned fabric image.
On the pixel-level evaluation, the experiment contains 26 defect images and 30 defect-free images on a box-patterned texture (BOX), 30 defect images and 30 defect-free images on a dot-patterned texture (DOT), and 25 defect images and 25 defect-free images on a star-patterned texture (STAR). We use a coarse, but effective, method for determining whether the candidate image is defective or not by calculating the number of defective pixels on the resulting matrix. If the number of the defective pixels is larger than a given threshold, we consider the candidate image to contain defects. Otherwise, the defective pixels are considered as noise. In practice, we set the threshold as 150.
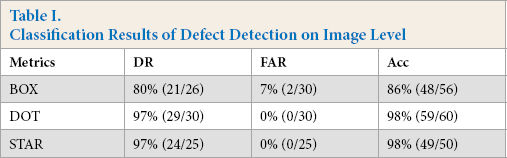
Table I shows the results of the pixel-level defect detection. On average, our model achieves classification accuracies of 86% on box-patterned fabric images, 98% on dot-patterned fabric images, and 98% on star-patterned fabric images.
Classification Results of Defect Detection on Image Level
On the pixel-level evaluation, only the defect candidate image was used for testing. The classification results are shown in Table II. Our method achieves an average F1 score of 46% on box-patterned images, 53% on dot-patterned images, and 38% on star-patterned images.
Classification Results of Defect Detection on Pixel Level
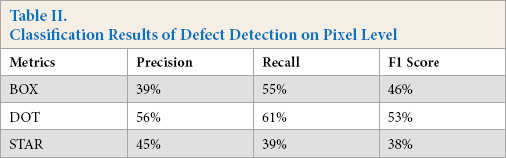
Compared to the regular VAE-based method, we use additional CNN layers for fabric texture pattern feature extraction, which is considered more suitable for image feature extraction.10,11 From the evaluation results on the patterned texture fabric image dataset, we found that our model achieves outstanding performance on fabric image reconstruction. Based on the difference between reconstruction and candidate images, our model achieves an average classification accuracy of 94% (86% on box-patterned fabric images, 98% on dot-patterned fabric images, and 98% on star-patterned fabric images) on detecting whether the candidate image is defective. For defect location, we adopt a coarse method that uses threshold and morphology filtering. This method is unsupervised and efficient, but limited in the performance of defect location. That is why the pixel-level defect classification only achieves an F1 score of 46% on box-patterned fabric images, 53% on dot-patterned fabric images, and 38% on star-patterned fabric images. Therefore, after image reconstruction, the defect location method is also essential for defect detection.
Conclusions
In this study, we propose a powerful fabric defect detection method using a hybrid of a convolutional neural network (CNN) and a variational autoencoder (VAE). Three convolutional layers are used for extracting fabric image pattern features, and the VAE is used for modeling the latent characteristics and inferring a reconstruction. The defect positions can be detected by the differences between the original and the reconstruction images. The proposed method is validated on a public patterned fabric dataset. The experimental results demonstrate that our proposed model achieved outstanding performance in terms of both accuracy and robustness. Generally, our method can improve efficiency, shortening the time of model training, and obtain an outstanding accuracy on detecting various fabric defect images.
In future work, we will focus on two main directions of research. One direction involves the defect segmentation based on a full convolution network. The other direction is to develop a ConvNets model based on second-order pooling for fabric classification, which could be used before defect detection.
Footnotes
Acknowledgements
This work was supported in part by the Natural Science Foundation of China under Grants 61703283, 61703169, and 61806127, in part by the General Research Fund of Research Grants Council of Hong Kong (Project No. 15202217), in part by the Guangdong Basic and Applied Basic Research Foundation 2017A030310067, 2021A1515011318, in part by the Guangdong Science and Technology Plan under Project 2020A1515110602, in part by the Shenzhen Municipal Science and Technology Innovation Council under the Grant JCYJ20190808113411274, in part by the Overseas High-Caliber Professional in Shenzhen under Project 20190629729C, in part by the High-Level Professional in Shenzhen under Project 20190716892H, in part by the Research Foundation for Postdoctoral Work in Shenzhen under Project 707/00012210, in part by the National Engineering Laboratory for Big Data System Computing Technology, in part by the Guangdong Laboratory of Artificial-Intelligence and Cyber-Economics (SZ), in part by the Shenzhen Institute of Artificial Intelligence and Robotics for Society, and in part by the Scientific Research Foundation of Shenzhen University under Project 2019049 and Project 860/000002110328.