
Abstract
The fabric defect detection algorithm based on object detection has become a research hotspot. The method based on the Single Shot MultiBox Detector (SSD) model has a fast detection speed, but the detection accuracy is insufficient. To balance the detection speed and accuracy of the model and meet the actual needs of the industry, an improved fabric defect detection algorithm based on SSD is proposed in this study. The Fully Convolutional Squeeze-and-Excitation (FCSE) block is added into the traditional SSD to improve the detection accuracy of the model. The number of default boxes was adjusted to accommodate the detection of long strip defects on fabric surface. Experimental results on the TILDA and Xuelang dataset confirm that our detection method based on SSD efficiently detected various fabric defects.
Introduction
Fabric defect detection plays an irreplaceable role in the textile production line. However, in many textile industries, defect detection is still relying on manual inspection. Inspectors can easily find defects in fabrics by direct observation, 1 but prolonged observation can easily fatigue human eyes and lead to an increasing number of inadvertently missed defects. To meet the needs of modern industry, it is important to develop a fabric defect detection method based on computer vision.
Since the 1980s, many scholars have done a lot of research on fabric defect detection. The algorithms of fabric defect detection are mainly divided into the following five categories: 1) statistically-based methods (e.g., typical gray level co-occurrence matrix), 2 mathematical morphology methods, 3 2) spectral-based methods, mainly including Fourier 4 and Gabor transforms, 5 3) model-based methods, such as the autoregressive model, 6 the Markov stochastic model, 7 4) the structural-based method,8 and 5) learning-based methods (e.g., neural networks9–14 and the support vector machine 15 ).
Recently, various optimization methods are emerging, 16 and the performance of learning methods based on convolutional neural networks (CNN) 17 have been greatly improved. Rebhi et al. 10 uses feed-forward neural networks for classification of image blocks after discrete cosine transform. Gao et al. 11 proposes a CNN with multi-convolution and max-pooling layers to detect defects in woven fabrics with a solid color. Jing et al. 12 and Ouyang et al. 13 mainly use public fabric data sets and the images collected from textile industries to train the model and can get good detection results. Xie et al. 14 applied the unsupervised model SDCAE into fabric defect detection. The method combines image pyramid and direction template in the model, which improves the detection accuracy on solid color and periodic texture fabrics.
As one of the most fundamental and challenging problems in computer vision, object detection has been widely applied in various industrial fields, such as surveillance, 18 autonomous driving, 19 and the surface defect detection of magnetic tiles. 20 Existing object detectors usually can be divided into two categories: 21 one is the two-stage detector (e.g., Faster R-CNN 22 and Mask R-CNN 23 ), and the other is the one-stage detector (e.g., You Only Look Once (YOLO),24–26 Single Shot MultiBox Detector (SSD), 27 and RetinaNet. 28 The two stages of two-stage detectors can be divided by the ROI (Region of Interest) pooling layer. For example, in Faster R-CNN, the first stage, called a Region Proposal Network (RPN), proposes candidate object bounding boxes. In the second stage, features are extracted by an RoIPool (ROI Pooling) operation from each candidate box for the following classification and bounding-box regression tasks. 23 Furthermore, the one-stage detectors propose predicted boxes from input images directly without the region proposal step, thus they are time efficient and can be used for real-time detection. Particularly, SSD had a competitive result on both mean average precision (mAP) and speed with the VGG-16 29 backbone. SSD achieved an mAP of 81.6% on the PASCAL VOC 2007 test set and 80.0% on the PASCAL VOC 2012 test set as compared to Faster R-CNN (78.8%, 75.9%) and YOLO (VOC2012: 57.9%). 27 On the MS COCO DET dataset, SSD512 was better than Faster R-CNN under all evaluation criteria.
In a recent study, more and more object detection models based on CNN have been applied in the field of fabric defect detection and have achieved remarkable results. Liu et al. 30 use the two-stage detector Faster R-CNN as the main model, and use many data enhancement methods, such as image cropping and rotating, and noise adding to alleviate the problem of overfitting. Liu et al. 31 propose a texture defect detection method based on Faster R-CNN and feature fusion—before the fully-connected layer, they combine Histogram of Oriented Gradients (HOG) features after dimension reduction with candidate object bounding boxes features. Liu et al. 32 introduce the single-stage detector SSD to the defect model for the first time, and added the third-level feature con3_3 to the feature pyramid to achieve the detection of small objects. Zhang et al. 33 compared the three variant models of YOLO V2 and selected the best model for detection. Among various fabric defect detection algorithms based on the object detection model, two-stage detectors usually have high localization and object recognition accuracy, and the detection speed is not as fast as one-stage detector. However, the one-stage detectors achieve high detection speed and a slightly lower detection accuracy. 34
To balance the detection speed and accuracy of the model and meet the actual needs of the industry, an improved fabric defect detection model based on SSD is proposed in this work. The Fully Convolutional Squeeze-and-Excitation (FCSE) block, an improved module the in Squeeze-and-Excitation network, 35 is added into the traditional SSD to increase the weight of the feature map channel where the defective region is located. Under the condition of ensuring the high-speed detection of the SSD model, the detection accuracy of the model is improved. In addition, we adjusted the number of aspect ratio (default boxes) on each feature map to adapt to long strip defects. To reduce the influence of over-fitting in the training stage, it is necessary to do data enhancement. The experimental results show that our model achieves better detection results on the TILDA dataset, 36 reaching 25.6 frames per second (FPS) on the test set, and the detection accuracy of the defect area achieves 63.7% mAP. In addition, on the Xuelang dataset, 37 our model achieves 47.1% mAP and 19.5 FPS, which shows that the proposed model can detect defects on the fabric surface when there are some difficult objects in images.
The remainder of this paper is organized as follows. An overview of the traditional SSD network is followed by the network architecture of our fabric defect detection method based on SSD. Next comes the experimental results and analysis, followed by the conclusion.
Overview of SSD
When Faster R-CNN was proposed, there were many variations of models to improve the selection method of candidate regions. Liu et al. proposed an SSD net to select the default boxes by building a multi-scale feature map. As shown in Fig. 1, the network architecture of the SSD net includes the basic feature layer, extra feature layer, convolutional predictors for detection (called “head”), and non-maximum suppression (NMS).
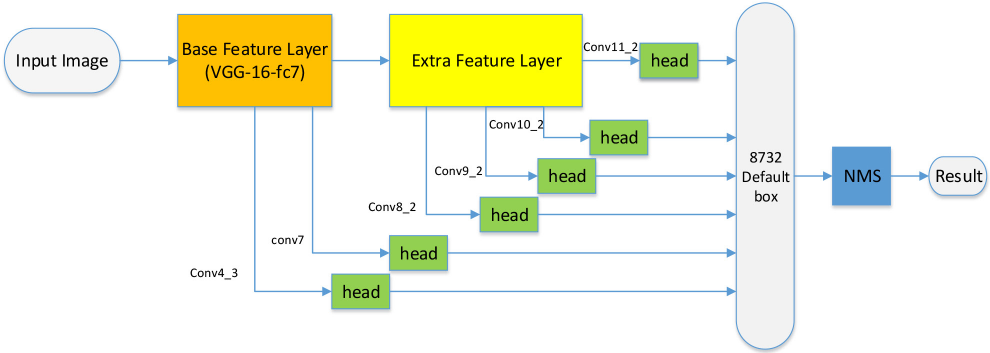
The network architecture of SSD.
Basic Feature and Extra Feature Layers
The basic feature extraction layer of SSD uses the VGG16 pre-training model. It converts fc6 and fc7 to convolutional layers, changes pool5 from 2x2-s2 to 3x3-s1, and removes all the dropout layers and the fc8 layer.
After the basic feature extraction layer, SSD adds eight additional convolution layers, named conv8_1, conv8_2, conv9_1, conv9_2, conv10_1, conv10_2, conv11_1, and conv11_2 as the extra feature extraction layer.
Multi-Scale Feature Map and Default Box
SSD uses conv4_3, conv7 (fc7), conv8_2, conv9_2, conv10_2, and conv11_2 to predict both location and confidences, namely, after passing through the convolution predictor (“head”), these six-layer feature maps are used to generate default boxes with predicted categories and location values.
The convolutional predictors (“head”) is a sub-network for regression and
classification consisting of two parallel convolution layers. The output size of
the “head” is
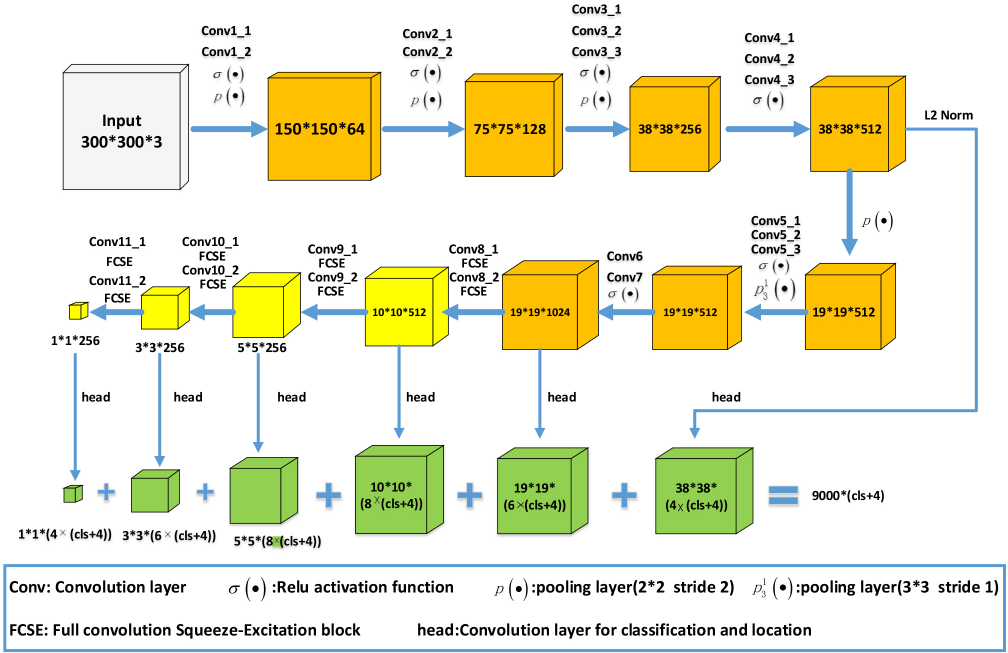
Our network architecture.
In the testing stage, the positive default box generated by the SSD is filtered by NMS to get the final detection result.
MultiBox Loss
In the training process, SSD first needs to use a matching strategy to label the default boxes as follows. First, it matches each ground truth with the best Jaccard overlap, and for the remaining default box, it matches default boxes to any ground truth with a Jaccard overlap higher than a threshold (0.5). Then, SSD uses hard negatives mining to filter negative class boxes, and control the ratio of positive and negative samples to 1:3 to solve the problem of unbalanced sample categories. Finally, the label and predicted value of these default boxes are used as the input of the loss function to calculate the loss value, reverse propagation, and update the weight.
Similar to the fast R-CNN, the general objective loss function is referred to in Eq. 1.
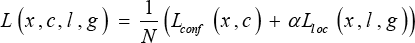
Improved Fabric Defect Detection Method Based on SSD
In this section, we introduce our fabric defect detection algorithm based on SSD. First, the overall structure of the model is presented, then the improvement of the structure is analyzed according to the sequence of the training process, and some specific details of implementation are given.
Network Architecture
As shown in Fig. 2, the model
includes the VGG16 base feature layer, extra feature extraction layer and
convolutional predictors for detect ( The aspect ratio number is increased to adapt to the long strip
defect (larger aspect ratio), and the convolution layer of the
“head” substructure is adjusted accordingly. By introducing the SEnet idea, we add a channel attention mechanism,
which is the FCSE block, in the last eight layers of the convolution
layer.
Aspect Ratio
In the process of default box generation, we also select a six-layer feature
map to generate the default boxes. Because there are strip defects in
dataset images, it is necessary to add 4 and 1/4 ratios in aspect ratios of
some layers, so that the model can accurately locate such defects. As shown
in the green feature maps of Fig. 2, the output channels of the six “head” structures are
adjusted accordingly. The values of
The default boxes are generated in the following way. For each level of the feature map, we need to determine a scale using Eq. 2.
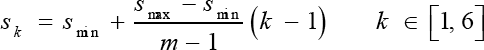
and aspect ratio
Only
FCSE Block
SEnet adds the Squeeze-and-Excitation operation after the convolution layer to determine the weight of the feature map channel and enhances the weight of channels that play an active role in the feature map so that the training mo del can get a better effect.
To improve the sensitivity of the model to information features, the SE block is added after all convolution layers of extra feature layers. As shown in Fig. 3, SE Block consists of Squeeze and Excitation.
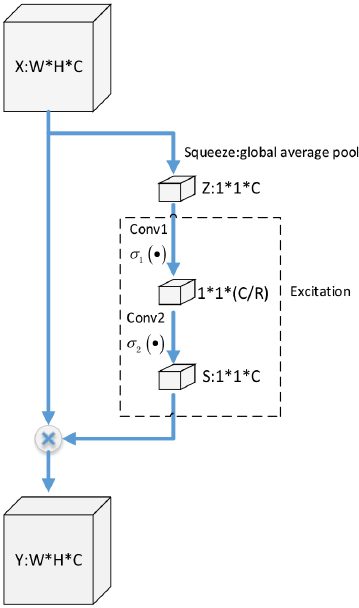
FCSE block.
The output of a convolution layer is a feature map of W*H*C size, and the Squeeze-and-Excitation operations are performed.
Squeeze: The output
by the Squeeze operation. Squeeze operation is referred to as in Eq. 3.
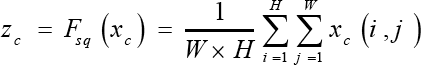
Excitation: After the Squeeze operation, an Excitation operation consisting
of two full-connection layers is needed to obtain the dependencies of all
channels. Excitation is referr
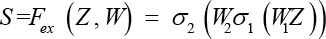
To reduce the parameters of the model, two convolution layers conv1 (kernel size:1*1 out channel: C/R) and conv2 (kernel size:1*1 out channel were used: C) are used to replace the above two full-connection layers to form the FCSE block.
Output: The out put
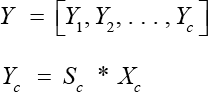
Loss Function and Training
The loss function of our model uses MultiBox loss, and we train the resulting
model using Stochastic Gradient Descent (SGD) with the initial learning rate 4 x
10-4, 0.9 momentum, 0.0005 weight decay, and 16 batch size. After
120
Experiment Design and Results
Data Creation
In this section, the performance of the proposed defect detection model is verified by the TILDA and Xuelang dataset, and the experimental environment consists of a LZ-748GT workstation configured with an Intel E5-2600 CPU (2200 MHz), 32GB RAM, and a Nvidia 16GB TITAN XP GPU. The software environment consists of Python 3.6, pytorch-GPU.version 0.4, and CUDA 9.0.
TILDA Dataset
TILDA is a textile texture database that was developed within the framework of the working group Texture Analysis of the DFG's (Deutsche Forschungsgem einschaft) major research program “Automatic Visual Inspection of Technical Objects.” As shown in Figs. 4a-h, the dataset contains a total of eight representative textiles. (a)-(d) are pure-color fabrics, (e) and (g) are periodic pat tern fabrics, and (f) and (h) are fabrics with a motif pattern. In addition, the dataset contains four defects, (a) and (b) are E1 (hole), (c) and (d) are E2 (spot), (e) and (f) are E3 (wire), and (g) and (h) are E4 (dark thread). There are 50 no n-defect samples and 350 defect samples in each fabric background (8 kinds in total). The size of each picture is 768*512.

Partial images of TILDA dataset.
Xuelang Manufacturing AI Challenge Contest Dataset
The 2018 Xuelang Manufacturing AI Challenge was jointly sponsored by the Jiangsu Wuxi Economic Development Zone (Taihu New Town) and Alibaba Cloud Computing Co. Ltd. The contest is based on the Alibaba Cloud Tianchi platform, which provides thousands of finely labeled cloth sample data. The dataset of the contest (called the “Xuelang dataset”) covers all kinds of important defects of pure-color fabrics in the textile industry. The data consists of two parts: the original image and the defect annotation data. As shown in Figs. 5a–f, the dataset contains three kinds of common defect images. (a) and (b) are “clip mark” defects (Defectl), (c) and (d) are “tight end” defects (Defect2), and (e) and (f) are “crackiness” defects (Defect3). The size of each image is 2560*1920.

Partial images of Xuelang dataset.
Performance Metrics
In this work, we use precision (
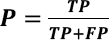
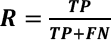
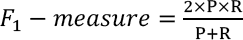
The
Analysis of TILDA Dataset
To evaluate the effectiveness of the proposed algorithm with pure-color, periodic pattern, and motif fabrics, the TILDA dataset is used. In the TILDA dataset, there are 200 images without defects and 1400 images with defects. To reduce the influence of overfitting, it is necessary to do data enhancement. We mainly augment the TILDA dataset with random rotation by 90, 180, and 270 degrees. The original data set is 1600, the training data set is 1280, and the test data set is 320. After image rotating, the number of TILDA dataset images is expanded to 2560.
The performance of the proposed method is compared with three well-known object
detection models, including Faster R-CNN, YOLO V3, and the original SSD with
respect to the indicators mentioned previously (mAP,
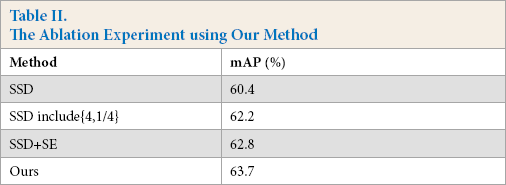
We also carried out ablation experiments and set up two contrast experiments: 1) the original SSD, 2) original SSD plus {4, 1/4} default boxes, and 3) SSD plus FCSE block. As shown in Table II, our method is better. Adding the FCSE block on extra feature layer can increase mAP by 2.4% compared with the original SSD model, and adding aspect{4, 1/4} mAP can increase it by 1.8%. The results of ablation experiment show that the FCSE block can increase the weight of the feature map channel where the defective region is located, and this “channel attentional mechanism” can improve the detection accuracy of the proposed model.
Table I. Performance Comparison of Different Detection Approaches on TILDA Dataset
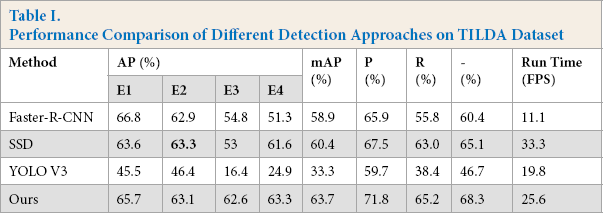
Adding aspect {4, 1/4} can enhance the ability of the model to detect long strip
defects, and the AP in the defects, E3 (wire) and E4 (dark thread) can be
improved. As is shown in Fig.
6, our method achieves low loss during the model training. After 120
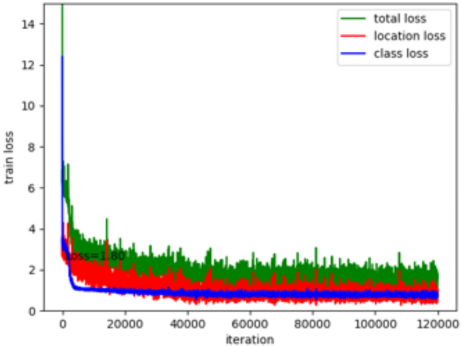
The results of loss in our method.

The detection results of our method.
Table II. The Ablation Experiment using Our Method

Sketch of partial magnification of the image defect area (Due to the larger image resolution (2560*1920) and the smaller defect area, we only show the local area of the original image where the defects lie). (a) and (b) are images with “clip mark” defects, (c) is an image with a “tight end” defect, and (d) is an image with a “crackiness” defect.
Analysis of Xuelang Dataset
To verify the detection performance of the proposed model in actual scenarios, we chose the Xuelang dataset as a supplementary experiment. On the Xuelang dataset, there are 307 images with defects, including 122 Defect 1, 133 Defect 2, and 52 Defect 3 images. To reduce the impact of overfitting, it is necessary to do data enhancement. We use image cropping, image rotation, image brightness changes, image horizontal flip, and vertical flip to enhance the data. Taking into account the balance of the number of images between each defect class, we expanded the number of Defect 1, Defect 2, and Defect 3 images to 3, 3, and 7 times, respectively. That is, after enhancement, the number of Defect 1, Defect 2, and Defect 3 images is 366, 399, and 364 respectively, and the total number of the Xuelang dataset images is expanded to 1129.
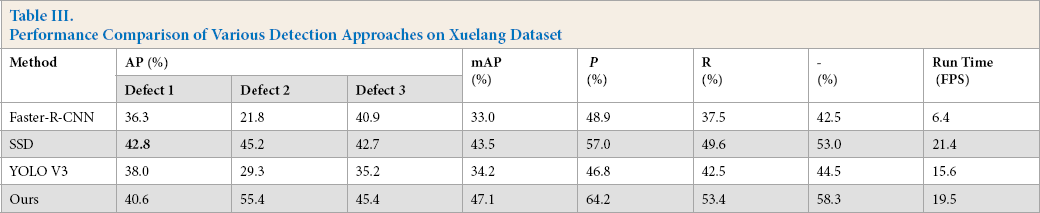
As shown in Table III, on the Xuelang dataset, the proposed method mAP indicator
is 14.1%, 3.6%, and 12.9% higher than Faster R-CNN, the original SSD, and YOLO
V3 respectively. For the comprehensive indicator
Table III. Performance Comparison of Various Detection Approaches on Xuelang Dataset
Compared with the TILDA dataset, the Xuelang dataset, as a contest dataset, contains more images with small and difficult objects. For example, as shown in Fig. 5a, the pixels about (290*260) of the defective area is less than 5% of the total pixels of the image (2560*1960). As shown in Figs. 8a–d, the images in the Xuelang dataset are mainly based on pure-color texture background, and the color of the defect area is similar to the texture, which affects the detection accuracy of the model to a certain extent. Our model achieves 47.1% mAP and 19.5 FPS. Some of the results of our method on the Xuelang dataset are shown in Fig. 9, which shows that when there are some difficult object on images, the proposed model can detect defects on the fabric surface.

The detection results of our method on the Xuelang dataset. (a) and (b) are the detection result of images with Defect1, (c) and (d) with Defect2, and (e) and (f) with Defect3.
In summary, our detection method based on SSD can efficiently detect various defects on the fabrics with pure-color, periodic pattern, and motif pattern at a high speed.
Conclusion
This study presents an improved fabric defect detection method based on SSD. This method uses a powerful CNN to extract defect features and introduces a channel attention mechanism FCSE block to enhance the weight of defective areas in each channel of the feature map. By adjusting the number of default boxes, the accuracy of the model in detecting long strip defects is significantly improved. Experimental results show that the proposed method can perform a high-speed detection and accurately detect various defects on fabric surfaces with different textures. Our future work will focus on defect segmentation at the pixel level.
Footnotes
Acknowledgments
The authors would like to thank the financial support received from the National Natural Science Foundation of China (No.61801121).