
Abstract
In the process of garment production, obtaining and identifying garment illustrations, transforming them into the required information, and then implementing the information into automated production can improve the production efficiency to a great extent. However, the research on recognition of garment illustration and pattern image is mostly based on category classification, but very little on the identification of parts and details. The Inception module in the GoogleNet Inception and its improvement development models enhance parameter utilization, accelerate computation, and have no special requirements for hardware. The Mask R-CNN, a convolutional neural network, is a modified model from based on Faster R-CNN for instance splitting tasks. Based on these two models, this paper proposes a method to identify garment illustrations using a self-built database. The experimental results show that this method outperforms the related algorithms.
Keywords
Introduction
Intelligent clothing manufacturing has been a hot topic in the clothing industry in recent years. During the process of integrated design and production, relatively mature software and technologies are available at almost every step from design to digital templates and virtual fitting, but the process from garment illustrations to patterns still adopts artificial selection. Furthermore, electronic drawings are convenient to use, and its utilization rate is higher than that of paper drawings in clothing production. However, in the face of a large number of drawings, there is no management system designed for intelligent recognition, and image search and invocation. Intelligent management of garment drawings relies on the breakthrough of automatic recognition concerning garment illustrations and pattern images. In this regard, it is envisaged to identify and determine garment pattern drawings with the help of image recognition and related technologies, which have developed rapidly in recent years. Image classification and object detection are important directions in the fields of computer vision, pattern recognition, and machine learning, and they are also widely used in many tasks, including content-based image retrieval, photo recognition and classification, and traffic condition detection.1,2
Image classification is a method that identifies objects of different categories in line with their characteristics reflected in their image information. 3 In recent years, due to the dramatic increase in computation and operation speed, the image classification problem has been processed by machine learning. Instead of using codes to describe each image category, the machine learning approach focuses on learning the expression of features and assigning a given input image to a label in a known mixed category. Typical models include the word package model and the deep learning model, and classification frameworks usually involve four important parts namely feature extraction, feature coding, feature aggregation, and classifier design. 4 The main purpose of object detection is to accurately locate the category of an image and the position border information of various objects in the image. Deep learning-based target detection methods have been generally discussed and applied by researchers and the industry. 5 It has used massive data and labels in databases such as ImageNet, PASCAL VOC, and COCO for training. Common training models include R-CNN, Fast R-CNN, Faster R-CNN, and Mask R-CNN.
Because of increased business demand, a great deal of research on automatic classification of clothing photos have been published; they are far greater than those on illustrations and pattern graphs. The support vector machine (SVM), convolutional neural network (CNN), low-rank learning, and some other methods are adopted by many domestic and foreign institutions to detect, segment, label, and classify garment pictures based on measurement learning, distance measurement learning, multi-view, multi-task learning, and so forth.6–10 Nevertheless, as some researchers are outside the field of clothing, their classification and cognition of clothing attributes are relatively vague. Thus, they are not accurate in describing clothing details.
Garment illustration is a clearer expression of the clothing designer's intention in the light of the draft. In clothing production, illustration is a pivotal link between design and pattern making. Lixin and Jaewoong both used the Shock Graph to extract and classify shape features for illustrations and patterns.11,12 However, they share some of the following problems:
Vague classification and cognition of garment attributes leading to inaccurate descriptions of clothing details due to the lack of professional views of fashion and design;
Non-uniform standards for classification and recognition due to the disparate styles of garment illustrations in the clothing industry;
Ineffective retrieval basis for the pattern recognition system derived from existing studies due to the fact that most of the current recognition and matching approaches of illustration images focus on the outer contours of shapes and categories, rather than internal details and parts.
To exceed these limitations of current garment illustration recognition methods, this work proposes a technical route based on GoogleNet Inception V3 and Mask R-CNN models. The route is mainly divided into two parts: classification and attribute identification of illustrations. For one thing, the improved Inception V3 model is used to classify the categories and subcategories of illustration images. For another, this model is adopted to detect and locate the attributes of illustrations for further identifying the styles, details, parts, or other garment attributes. Furthermore, experiments were conducted on a novel database. To accurately describe the attributes of the illustrations, we consulted the books and materials from the field of fashion and design, constructed a garment attribute system, and used it to mark the new database we established. The effectiveness of the proposed method was verified by experiments. The main contributions of this research are as follows:
Superiorities in speed and accuracy, and lower hardware requirements compared to traditional image recognition methods;
The established database of illustration images with garment attribute labels facilitating subsequent research on recognition of clothing production drawings.
The remainder of the paper is organized as follows. The review of related works, details of the algorithm used, the preparation, process, results, and discussion of the garment illustration recognition experiments, and the conclusion are presented.
Related Works
GoogleNet Inception
The Inception model is a deep convolutional network developed by Google. Fig. 1 shows the Inception Module designed in the Inception model, which improves the utilization and expression of parameters, enables the depth and width of the network to be extended efficiently, and enhances accuracy without overfitting. 13 Several different transformations in the same input mapping results are used for parallel computing, and the output of a larger two-dimensional convolution is split into two smaller one-dimensional convolutions. On the one hand, it saves a mass of parameters, speeds up computation and reduces the fitting; on the other hand, it adds nonlinear extension model expression ability to get more from the image feature information and the distribution. 14
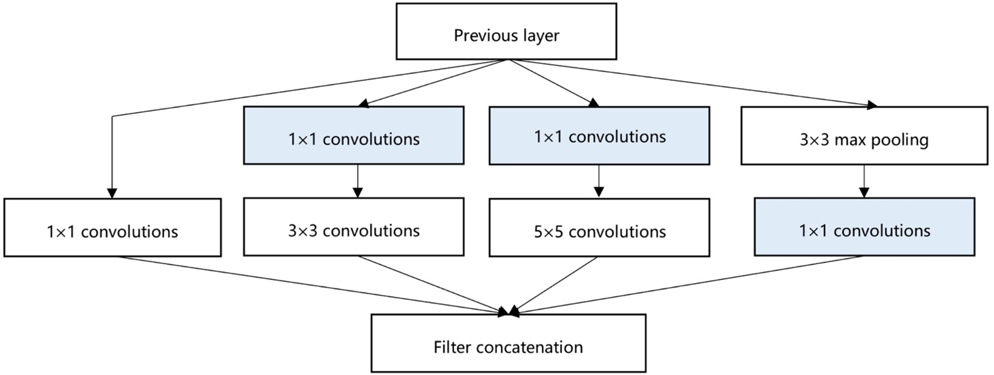
The Inception Module with dimension reductions.
Faster R-CNN and Mask R-CNN
In 2016, based on the traditional convolutional neural network target detection algorithms, R-CNN and Fast R-CNN, an improved network Faster R-CNN that integrated the four basic steps of target detection (candidate region generation, feature extraction, classification and position refinement) into a deep network framework, were proposed. 15 Without repeated computation, it is completely carried out in the GPU, thus improving the running speed.
Mask R-CNN is an extension of Faster R-CNN, which is different from other networks that first find the Mask and then classify. A branch was added for task segmentation. In the basic structure of Mask R-CNN, it finds the RPN (Region Proposal Network) firstly, and then finds the Binary Mask by the classification and locating of each ROI (Region of Interest). Thus, it also exchanged from target detection to a model capable of instance segmentation, and the segmentation task was carried out at the same time as the positioning and classification task went on. 16 The structure of the Mask R-CNN is shown in Fig. 2.
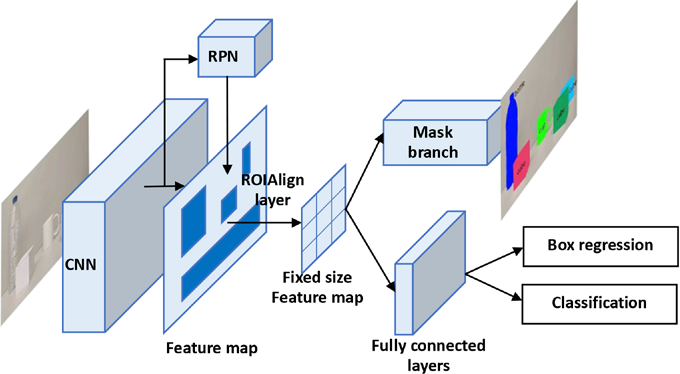
Structure of the Mask R-CNN.
Proposed Method
Deep learning requires a sample size of millions and a computer capable of supporting this amount of computation, which is not suitable for ordinary researchers except algorithm experts. This study adopts the Inception V3 model, based on transfer learning, retains the weight and bias of the original model, and only retrains from the modified layer, which can save a lot of time and is more accurate than direct training. In addition, if the sample size is too small or more classifications are needed in machine learning classification, the training results are likely to be overfitting, and the training robustness is poor. Therefore, it is necessary to carry out certain data expansion which is achieved by adopting data enhancement and transfer learning in image information processing technology. The experimental process is shown in Fig. 3.
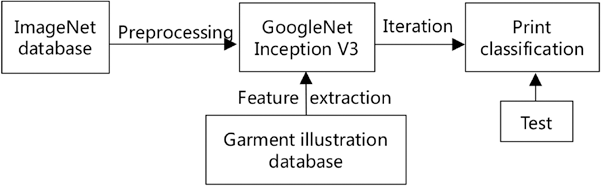
The classification experimental process.
Firstly, the network parameters are initialized. The experiment refers to the initialization parameters of the pre-training model in the open data set ImageNet by transfer learning. Then, a list of training images is generated from the file system. Besides, the sub-folders in the image directory, namely the classification folders, are analyzed and divided into the training, verification, and testing sets. Among them, the training set is used to fit the model, the verification set is used to adjust parameters and monitor whether the model overfits, while the test set is only employed to evaluate the generalization ability of the final model when it is completed. To be specific, they are used to fit the model, to adjust parameters and monitor whether the model is overfitting, and to evaluate the generalization ability of the final model when it is completed respectively. During the training, simple data enhancement operations, such as clipping, scaling, and flipping, are performed on the image to improve the ability to deal with test data and natural data more effectively.
In the network structure of image recognition classification task, Softmax is usually adopted as the activation function of the output layer. Its specific role is to map network output of all kinds of other possible outcomes to a probability interval (0, 1), and to ensure that these results and 1, again through the calculation of Cross Entropy Loss of each possible outcome, judge whether the network output discriminant result is consistent with the actual classification result. If there is a deviation by back propagation from iterative training, adjustment should be made in model parameters. For classification objectives, the Cross Entropy Loss function is generally used, as shown in Eq. 1.
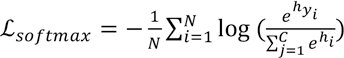
N is the total number of training data, x is the training input, y is the corresponding target output, C is the number of categories, and h is the expectation. On this basis, a positive integer m is introduced to control the difference size to make the features more discriminative, and require greater difference between two types.
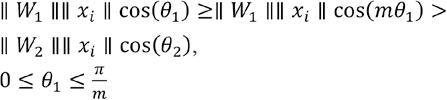
Substitute Eq. 2 into Eq. 1; then the Cross Entropy Loss function of the large interval is given by Eq. 3.
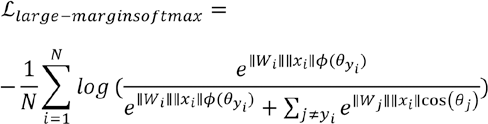
As for Mask R-CNN model, the loss function is
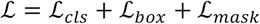
where is the classification loss function, is the regression loss function, and is the mask regression loss function.
In addition, the network hyperparameter and model parameters, such as the number, size, dimension, the minimum and maximum confidence of the RPN, the number of the highest retained score RPN after the application of Non-Maximum Suppression (NMS) in the training and testing phase, and the threshold value of NMS in the RPN, should be judged according to pre-training and multiple training. In object detection and instance segmentation, NMS is indispensable to select the regions with the highest scores in the neighborhood and suppress those regions with the lowest scores. In this study, as there are many overlapping attributes of garment, it is necessary to appropriately reduce the value of NMS. The experimental process is shown in Fig. 4.
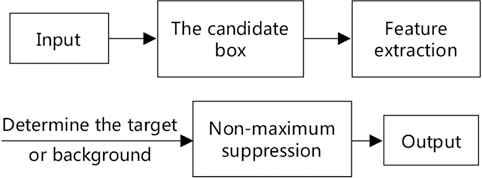
The attribute recognition experimental process.
Experiments
The experiment consists of two parts: classification and detail recognition. In this experiment, the Inception V3 model is used for classification, while the Mask R-CNN model is adopted for detail identification.
Garment Illustration Database
To identify and classify the garment illustrations, an illustration image database should be established in the computer according to certain rules to facilitate computing. From the website, 3600 garment illustration pictures with clear lines were collected. Color and texture are irrelevant to style identification. Thus, we removed the images with fabric texture and color as shown in Fig. 5, and repeated ones to finally obtain the garment illustrations with a total of 2800 samples.

The operation of illustration images.
According to the classification rules and titles of Deep-Fashion database, and the open dataset of the Multimedia Laboratory, those samples, with the amount ranging from 200 to 450, are classified as seven categories: blouse, shirt, coat, pants, skirt, dress, and jumpsuit. Another 200 pictures were retained as the final test samples, and were not trained or tested in classification experiments. 17
Taking the Clothing Dictionary and Clothing Classification Vocabulary as reference materials, this study focused on the selection of words concerning clothing categories and details rather than fabric, texture, subjective description, and others. The statistics and style-related keyword frequency of clothing items found on an e-commerce site were taken as one of the style chart attribute vocabulary reference standards. Finally, 100 words were selected. Owing to the limited number of samples, this experiment chose 56 words from them.
VGG Image Annotator (VIA), developed by the Visual Geometry Group, is an open source image annotation tool. The interface is shown in Fig. 6, and it can annotate rectangles, circles, ellipses, polygons, points, and lines. In this study, the rectangular checkbox was adopted to export json files and write COCO to invoke labels.
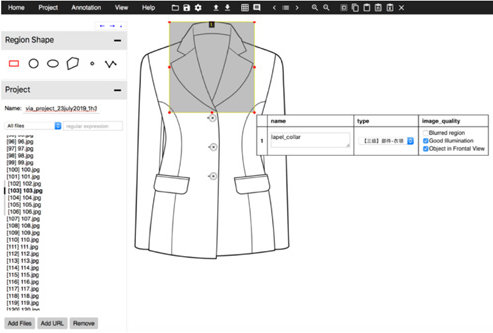
Window of VIA.
Classification Experiments
Firstly, training and testing were conducted according to the classification folders, which were divided into five categories: blouse, skirt, pants, coat, and dress. By setting the number of model training iterations to 1000 and adjusting the parameters for several experiments, the program verification accuracy reached 80.7%. The test interface is shown in Fig. 7. The classification given by the program to the skirt style diagram was skirt (skirt, correct) with a confidence of 92.2%. Using 100 images from the pre-extracted testing set, the test accuracy was 81.0%.
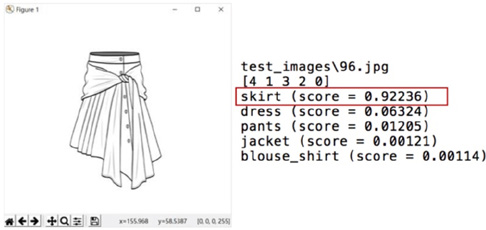
Testing interface.
The training speed was 10 times per second. The relationship between training times and program prediction recognition accuracy and verification are shown in Table I.
Training Times and Results
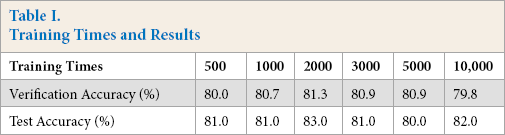
It can be seen that the result of accuracy had a certain relationship with the number of training. As the number of training increased, the accuracy of identification first increased and then decreased; the best result corresponded to the number of training of 2000. Excessive training times made the model produce overfitting, therefore causing reduction in generalization ability, and the accuracy decreased.
Furthermore, we chose the images of upper-garments for the fine classification experiment, and set eight classifications for the vest, T-shirt, blouse, men's shirt, sweater, hoodie, suit, and jacket, with each type of sample size between 150–180. Another 100 upper-garment illustrations were retained as the final test samples and did not participate in classification, training, and testing. Data processing and experiments were carried out in the same way as above, and the best results were obtained when the number of training was 4000. The validation and test results of the rough and fine classification experiments are recorded respectively.
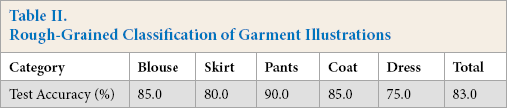
The test accuracy concerning the rough classification test program of the garment illustrations was 81.3%. When testing with pre-extracted test samples, the accuracy rate was 83.0%, as shown in Table II. Generally speaking, the classification was in good condition. Among them, the identification accuracy of blouses and dresses was comparatively low. Blouses were easily misclassified into coats or dresses, while dresses were likely to be misclassified into skirts or coats. The difference of coats styles were further analyzed, and it was found that long coats were easily confused with dresses. In the later stage, the amount of data was increased, and the coat classification was divided into the short jacket and the long coat.
Rough-Grained Classification of Garment Illustrations
The test accuracy of the fine classification experiment was 79.1%. The accuracy rate reached 77.0% when testing with pre-extracted test samples, as shown in Table III.
Fine-Grained Classification of Upper-Garment Illustrations

In the detailed classification experiment, there were still some cases of unclear classification among blouses, sweaters, and hoodies. Because of the different collar shapes in the hoodie styles, and the large differences of the tight and loose styles in the sweaters, the accuracies of these two categories were low. In addition, hoodies, sweaters, and blouses had a low degree of differentiation among one another and a high degree of differentiation within the categories. This situation, coupled with the small sample size, increased the difficulty of identification.
To verify the effectiveness of the experimental method, this study chose the classification results generated by a recognition and classification algorithm based on the multi-classification Support Vector Machine (SVM) for comparison. The results as shown in Table IV signify that the classification of the method used in the experiment was better.
Classification of Garment Illustration with SVM

Attributes Recognition Experiments and Similar Illustration Retrieval
The feature extraction and image preprocessing in the experiment were similar to those mentioned above. The differences were that the Mask R-CNN model under the PyTorch deep learning framework is employed for training, and the Mask R-CNN model is migrated and learned through the annotated BBOX, so that it can recognize 56 attributes and corresponding positions. The recognition results of the best 10 attributes are shown in Table V. The visualization result is shown in Fig. 8.
Results of Attribute Recognition of Upper-Garment Illustrations

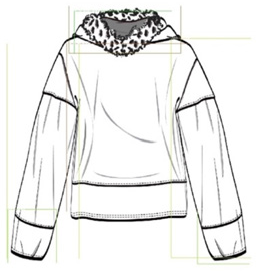
The visualization result of attribute recognition.
The average accuracy was 77.25%, which shows that the recognition accuracy was affected by the number of samples to a great extent, and was higher for the parts with relatively fixed shapes and positions. Therefore, it can be inferred that if the number of samples continues to increase, the accuracy will be further improved. In this case, the retrieval experiment of the illustration images was carried out. First, the category of the input image was obtained through the classification function, and then the attribute recognition was gained through the detail recognition function. The identified attributes are compared with that in the category, and the distance was calculated as Eq. 5.
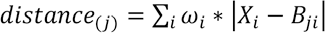
i is the total number of attributes, and ω i represents the weight of the ith attribute, which is 1 by default and can be adjusted later based on the retrieval requirements, X represents the ith attribute of the image being retrieved, and B ji refers to the ith attribute of the jth image in the database. The minimum difference and its corresponding picture can be found by calculating all the distance differences. Fig. 9 shows the first three retrieved similar pictures. It can be seen that the searched picture basically satisfied the attributes of the input picture, such as the lapel collar, the long sleeve, the pocket, and the dart, which was different from other search programs that can only realize the similarity of a certain picture. However, due to the limited number of samples, the attribute accuracy of the mark needs to be improved. When sufficient samples are added later, the pocket can be subdivided into the categories with or without a lid, the breast pockets or waist pockets, and the dart falls into waist provinces, L-shaped suit provinces, and waist provinces to enhance the recognition accuracy.
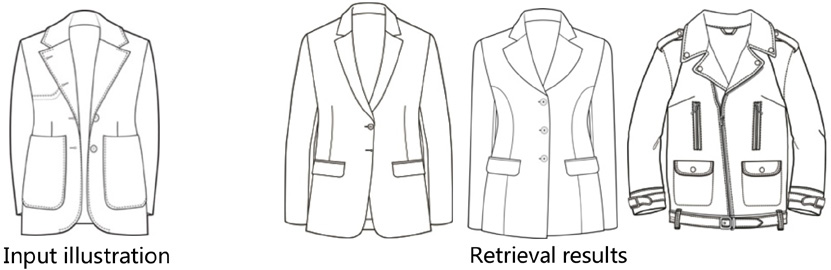
Similar illustration retrieval results.
Conclusions
This study presents a practical and feasible method for automatic identification of garment illustrations, which is to classify the images first to narrow down the scope, and then to identify the attributes of the images from a certain type by instance segmentation. Furthermore, an illustration image database was built for the experiment that shows this method can satisfy the retrieval needs of fashion design and performed better than other related algorithms, but it still has some limitations. To further improve the related study, the number of images and attributes could be enlarged. In addition, it will also become more convenient and efficient when finding an intelligent way of labeling the garment illustrations or other production images in the future.