
Abstract
Automated visual inspection for quality control has widely-used deep convolutional neural networks (CNNs) in fabric defect detection. Most of the research on defect detection only focuses on increasing the accuracy of segmentation models with little attention to computationally efficient solutions. In this study, we propose a highly efficient deep learning-based method for pixel-level fabric defect classification algorithm based on a CNN. We started with the ShuffleNet V2 feature extractor, added five deconvolution layers as the decoder, and used a resize bilinear to produce the segmentation mask. To solve the sample imbalance problem, we used an improved loss function to guide network learning. We evaluated our model on the fabric defect data set. The proposed model outperformed the existing image segmentation models in both model efficiency and segmentation accuracy.
Introduction
As an essential part of product quality control, the quality visual inspection of the product surface is getting more and more attention in industrial manufacture. 1 At present, inspection is performed by workers with their naked eyes. This is a repetitive and tedious job, and workers often make mistakes or miss detection for fast-moving targets because of exhaustion from long work hours.
To reduce costs and improve production efficiency, computer vision-based automated inspection systems have drawn considerable attention during the past decade. 2 To date, many classical machine-vision methods were proposed to address these issues, including model-based method, learning-based filtering-based method, and feature-based methods. 3 A novel automatic detection method was presented based on frequency domain filtering and similarity measurement, yet this model cannot be used to segment defects at pixel level. 4 Li et al. 5 proposed a fabric defect detection method based on saliency features, which achieve the segmentation of fabric defects for a variety of textures. However, the average time of a single image was 397 milliseconds, which was not suitable for real-time applications. Zhang et al. 6 proposed a defect segmentation method based on texture elimination and image clustering, which had excellent results for plain, twill, pattern, and other textured fabrics. However, many parameters needed to be set manually. Li et al. 7 presented a yarn-dyed fabric detection method. In this method, only one Gabor filter was applied, and its parameters were determined automatically by using a random drift particle swarm optimization (RDPSO) algorithm. It can segment small textures accurately, but it was challenging to apply to large texture fabric.
In summary, traditional image processing methods usually rely on manual setting of parameters, and it is challenging to meet the requirements of real-time detection.
Typically, in a standard machine-vision, approach features must be handcrafted to suit various types of textured fabric, and defects were classified using learning-based classifiers such as the Support Vector Machine (SVM), 8 Artificial Neural Network (ANN), 9 or k-Nearest Neighbor (KNN) 10 . However, with the development of Industrial 4.0, these methods are challenging to meet the requirements of real-time and robust-ness. 11 In recent years, with the explosion of data and the improvement of computer performance, deep learning (DL) has achieved remarkable success in computer vision applications, such as autopilot 12 and face recognition. 13 Inspired by the recent success of convolutional neural network (CNN) models, some researchers attempt to adopt deep CNN architectures to solve fabric defects detection. Jing et al. 14 presented a modified AlexNet model for a yarn-dyed fabric defect classification, but did not achieve defect segmentation. Mei et al. 15 proposed a multiscale convolutional denoising auto-encoder (MSCDAE) approach for defect segmentation, which was not effective for small defect detection. Hu 16 proposed an unsupervised fabric defect detection based on generative adversarial network (GAN), but the detection time was long. To detect pattern fabric defects, a hybrid method of traditional image processing and deep learning was proposed, 17 which can achieve accurate detection of common defects in yarn-dyed fabric, such as holes, carrying, and knots.
Although CNN-based methods have proven to be powerful and effective for fabric defect classification and segmentation, some key issues need to be addressed when applied to real applications. Firstly, the actual production conditions of factories put forward higher requirements for real-time performance of the algorithm. Besides, fabric defects as abnormal samples are rare compared with normal samples, which makes it difficult to train a CNN-based model. To tackle the above-mentioned problems, in this work, we developed an extremely efficient CNN for fabric defect segmentation. The proposed model uses improved cross-entropy loss to solve the problem of samples imbalance.
In brief, we constructed a defect detection framework based on deep learning, which trained the model through false data sets and did not need to label data sets. To solve the imbalance between the defective samples and the non-defective samples, a cross-entropy loss function with weighted entropy and intermediate frequency balance weighting was used to improve the model detection accuracy.
The study is organized as follows. We describe the proposed approach in detail. The experimental results are then demonstrated. Finally, the conclusions are provided.
Proposed Method
Network Architecture
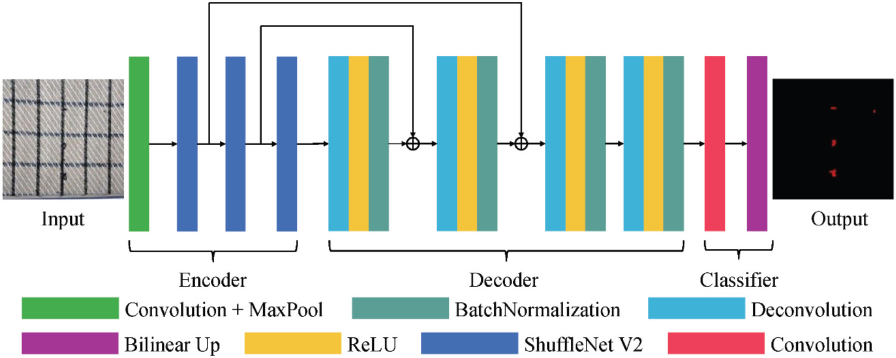
In this section, we give a detailed explanation of the proposed network. We start with the ShufeNetV218 feature extractor, then add five deconvolution layers as the decoder, and finally use resize bilinear to produce the segmentation mask. The structure of the proposed model is shown in Fig. 1.
The structure of two convolution units.
For feature extraction tasks, we chose ShufeNetV2 because of its speed and accuracy. ShufeNetV2 consists of two convolution units: the basic convolution unit, and the down-sampling convolution unit, as shown in Fig. 2. The stride of the basic convolution unit is 1 for feature extraction, and the stride of the down-sampling convolution unit is 2 for feature reduction. To minimize the memory access cost, in the basic convolution unit, the input features are first to split into two branches by a “channel split” operation. After convolution, the two branches are merged. The same “channel shufe” operation is then used to enable information communication between the two branches. To reduce the parameters of the model, depth-wise convolution (DWConv) is used in the down-sampling convolution unit.
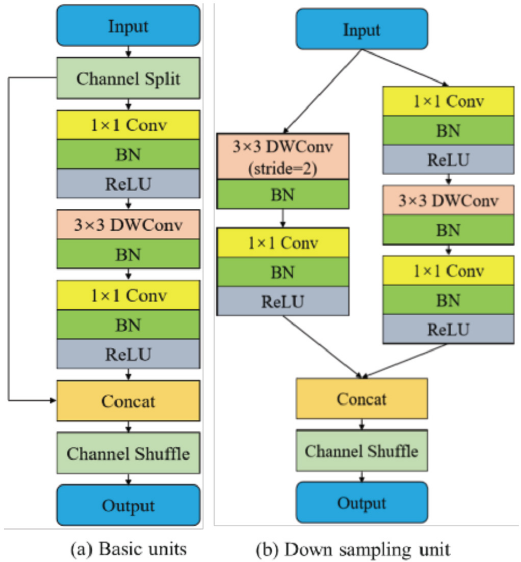
ShuffleNetV2 basic and downsampling units.
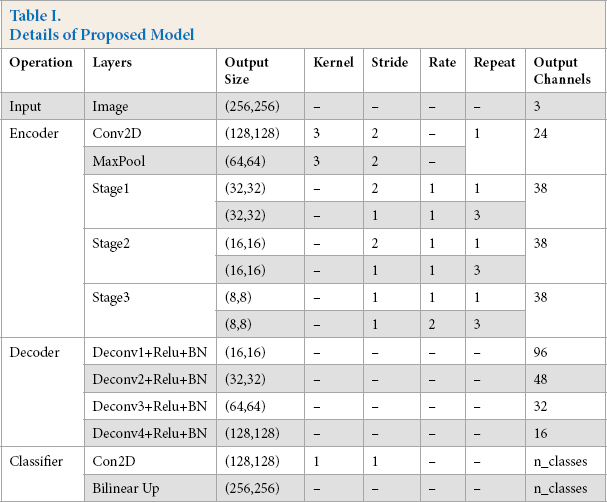
The encoder part of our model consist of three stages, stage1, stage 2, and stage 3. In each stage, the basic convolution unit is used to extract features, and then the downsampling unit is used to reduce the dimensionality of features. Ten, we use five deconvolutions to compose the decoder part to up-sample the features. Finally, to ensure the same size of input and output, bilinear interpolation is used to generate the segmentation mask. The detailed structure of the proposed model is shown in Table I.
Details of Proposed Model
Improved Loss Function
The loss function is used to measure the distance between the real label and the predicted label. The model updates the parameters iteratively through the backpropagation of the loss. Unlike the usual segmentation tasks, defect detection faces the problem of data imbalance. As shown in Fig. 3, the loss of defect parts to the whole is relatively low.
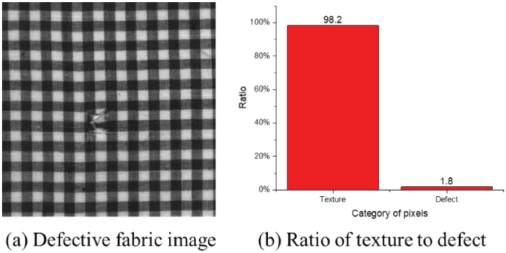
The imbalanced number of defects and background pixels.
The imbalance of sample categories lead to the lack of features in the classification with small sample size, and it is difficult to extract rules from it; even if the detection model is obtained, it is easy to produce over-dependence and limited data samples, which lead to overfitting problems. When the model is applied to new data, the accuracy of the model will be inferior. We use the weighted loss function 19 (Eqs. 1 and 2) to imaprove the learning ability of the model under-sample imbalance.
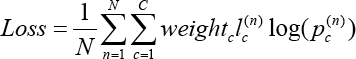
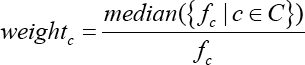
Experiments and Discussion
Software Environment of Experiment Setup
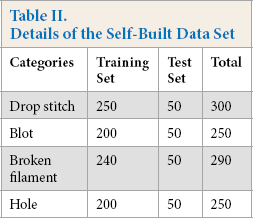
The experiment was performed on a deep learning workstation with an Intel Core i7-8750H, 128 GB of memory, and an NVIDIA GTX 1080Ti GPU. We used the Pytorch deep learning framework to build and train the proposed model. Two datasets were used to evaluate the proposed model, one was a public data set, and the other was a self-built data set. The public data set was provided by the Hong Kong Uni-versity 2 . It contains three textures and six defects. There are 255 pictures in total. Due to the small number of images, we used rotation, imaging, and other methods to expand the data set. To construct the self-built data set, we used industrial cameras and scanners to collect more than 1100 RGB images of fabrics containing four types of defect images. We took 30% as the test set and 70% as the training set. Details of the data set are shown in Table II. We evaluated the efficiency and segmentation accuracy of the proposed model, and compared the proposed model with current popular segmentation models, such as FCN, 20 U-net, 21 and SegNet. 19
Details of the Self-Built Data Set
Evaluation of Model Efficiency
We evaluated the efficiency of the model by three criteria: model size (MS), number of parameters (NP), and detection time (DT). The size of the model determined the size of the storage space occupied by the model. The parameters of the model directly affected the speed of backpropagation and the training time of the model. Similarly, the detection time of the model was the real-time performance of the model. The quantitative comparison of model efficiency is shown in Table III.
Comparison of Model Efficiency
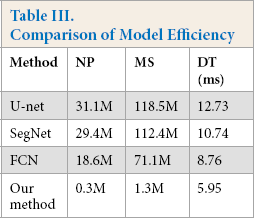
It can be seen that, compared with other methods, the proposed method was the best in all evaluation criteria. Our model has advantages in application deployment.
To evaluate the running speed of the model, the detection time for different size input image model was analyzed. Fig. 4 shows the curve of detection time with the size of the input image. As the image resolution increased, the detection time also increased. The experimental results show that the proposed method can also detect in real-time when inputting large-size images.
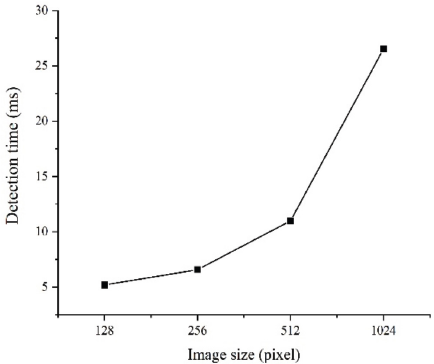
Detection time of different size images.
Evaluation of Segmentation Accuracy
The segmentation results of all methods are shown in Figs. 5 and 6 (different colors represent different defect types). The segmentation result of our model were closer to the ground truth. The proposed model had a lower false detection rate and a missing detection rate (the proportion of defects not detected to the total number of defects). Our model can accurately segment the defect target for different textured fabrics.

Comparison of detection results on self-built data.
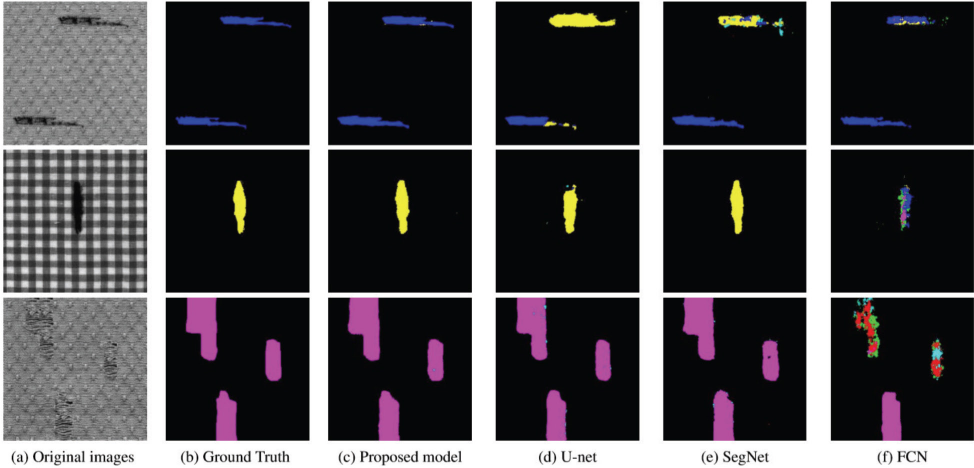
Comparison of detection results on public data set.
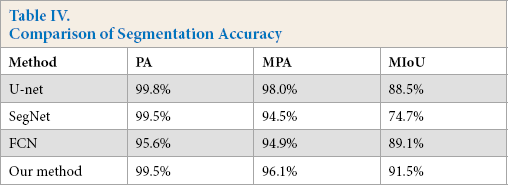
We used three criteria to analyze the model 22 quantitatively: pixel accuracy (PA), mean pixel accuracy (MPA), and mean intersection over union (MIoU). As shown in Table I V, our model was superior to the other three methods in MPA and MIoU. It is worth noting that our method was lower than U-net in PA. Because we used a frequency weighted loss function, this improved the learning ability for a small number of categories, but resulted in a higher false detection rate. The balance of missed detection rate and false detection rate is also the focus of our future research.
Comparison of Segmentation Accuracy
The box diagram of MIoU is shown in Fig. 7, which shows that our model was more stable and robust.
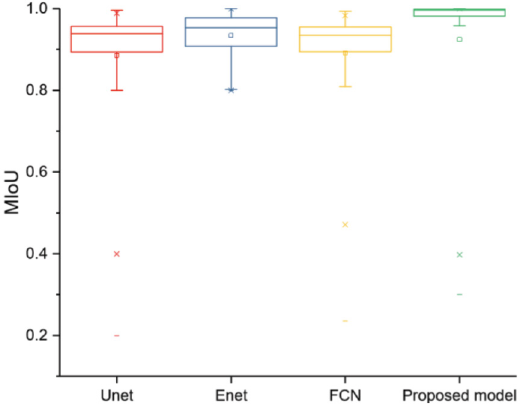
Box plot of MIoU.
Conclusion
We propose an end-to-end fabric defect segmentation model. The experimental results show that the proposed model improves detection accuracy and significantly shortens the detection time. However, our model is still a supervised learning detection method, which requires a large number of manual labeling data sets. To explore an unsupervised segmentation method is our future research direction.
Footnotes
Acknowledgements
This work was supported by the Scientific Research Program funded by Shaanxi Provincial Education Department (Grant No. 18JK0338) and the Graduate Scientific Innovation Fund for Xi'an Polytechnic University (Grant No. 2018041011).