
Abstract
This article explores the use of deep learning/artificial neural network (ANN)-based response spectrum (RS) and Fourier amplitude spectrum (FAS) site amplification models along with their standard deviations for simulated one-dimensional (1D) site response in Central and Eastern North America (CENA) using over 3.6 million 1D site response simulations. ANNs are demonstrated to significantly decrease the bias in the estimations (e.g. standard deviation of models’ residuals) and to better capture the features of site-specific amplification (e.g. the attributes of peak amplification) as compared to their conventional statistical regression counterparts that were derived from the same simulated amplification data. This improved performance includes site responses at shallow sites, which have been a challenge to effectively model previously. Multiple ANN models, each with different input variables but using the same ANN structure, are explored to represent diverse simulated amplification datasets (e.g. linear vs nonlinear or RS vs FAS), demonstrating beneficial features of ANN approach. In addition, ANN-based models are found to be useful in identifying controlling parameters and the minimum levels of site-to-site variability that are achievable given the conditioning variables.
Introduction
Site amplification models are used to modify the ground motion parameters for the reference rock condition (e.g. shear wave velocity (VS) of 3000 m/s adopted by the NGA-East project (Hashash et al., 2014) for Central and Eastern North America (CENA)) relative to a different site condition usually defined by VS30, which is the time-averaged VS at the top 30 m of the site. In this article, a suite of deep learning/artificial neural network (ANN)-based response spectrum (RS) and Fourier amplitude spectrum (FAS) site amplification models for CENA are produced to capture simulated amplifications in a different manner than conventional amplification functions developed using nonlinear regression (Ilhan et al., 2024; hereafter IEA24). ANN models are designed to use identical inputs to their conventional counterparts (e.g. same dataset of VS30) and were derived from an amplification database of large-scale one-dimensional (1D) site response simulations presented in IEA24. IEA24 carried out over 3.6 million analyses (over 1.2 million linear (L), equivalent-linear (EL), and nonlinear (NL) simulations) for use in the development of conventional amplification functions. The large number of simulations were performed to generate better sampled data set in terms of large-intensity ground motion data relative to Harmon et al. (2019b). These simulations were conducted using 147,420 randomized site profiles produced to represent the uncertainty and variability in CENA site conditions and 247 stochastically generated motions that are uniformly applied to all sites. All site amplifications considered in this study are derived relative to the reference condition of VS = 3000 m/s adopted by the 2018 and 2023 national seismic hazard model (NSHM) implementations (Petersen et al., 2020, 2024).
The conventional amplification functions in IEA24 improved relationships from prior work (Harmon et al., 2019a; hereafter HEA19) through the use of an expanded dataset and a functional form for the amplification that reduced the standard deviation (σ) of model residuals. Nonetheless, there are limitations of the IEA24 models that motivated this article, such as the following:
For certain conditions, including shallow site response and the amplitude and location of peaks associated with site resonances, amplification predictions from the conventional models exhibited misfits relative to simulated amplifications.
The functional forms used in IEA24 introduced additional elements and additional parameters relative to prior relationships (HEA19), but this additional complexity produced limited decreases in the σ of model residuals. For example, the inclusion of a Gaussian term associated with the site natural period (Tnat) resulted in only ∼11% maximum reduction in residuals’σ.
In this article, the application of a deep learning−based approach through ANN, which learns directly from simulated amplification data instead of utilizing predetermined functional terms, is investigated to produce alternative RS and FAS amplification models for CENA. The same structure of ANN is employed for the development of six RS and six FAS (four linear using L analyses, one nonlinear trained via the difference between amplification from NL and L analyses, and one total using the amplification from NL simulations) ANN-based models. The standard deviation relationships designed for conventional models of IEA24 are adopted to identify aleatory variability reductions associated with the use of ANN models. These models were developed and are presented with an understanding of their limitations for forward applications, which are discussed in Recommendations and Conclusions.
Deep learning concept
Most ground motion models (GMMs) and site amplification models rely on functional forms carefully chosen to represent the underlying physical processes linking independent and dependent variables. Independent variables consist of parameters that can be identified a priori (before the earthquake), in conjunction with a seismic source characterization model, related to the source, path, and site condition. Model coefficients are regressed using various methods that include least squares (HEA19, IEA24), maximum likelihood (Joyner and Boore, 1993), and mixed effects methods (Abrahamson and Youngs, 1992; Brillinger and Preisler, 1985). Deep learning methods using ANNs provide an alternative means by which to estimate ground motion parameters. ANN was first designed by McCulloch and Pitts (1943) by mimicking biological neural networks’ behavior in human brains and consists of a collection of interconnected nodes (called artificial neurons) as illustrated in Figure 1. Different types of ANNs (LeCun et al., 2015) include (1) Feedforward Neural Networks (FNNs), (2) Convolutional Neural Networks (CNNs), and (3) Recurrent Neural Networks (RNNs). In FNNs, which is the simplest form of ANNs, each neuron has two parts: the FNN function and the activation function (Hu and Hwang, 2002). The FNN function determines the method for the combination of network inputs inside each neuron as follows:

where wji is the weight of the connection of ith input to the jth hidden unit, Xi are inputs, bj is the bias of the jth unit, Yj is the output of the FNN function, and M is the number of neurons. The activation function associates Y with the output of the node as a = f(Y). Commonly used activation functions are sigmoid, tangent hyperbolic, linear, and Rectified Linear Unit (ReLU).
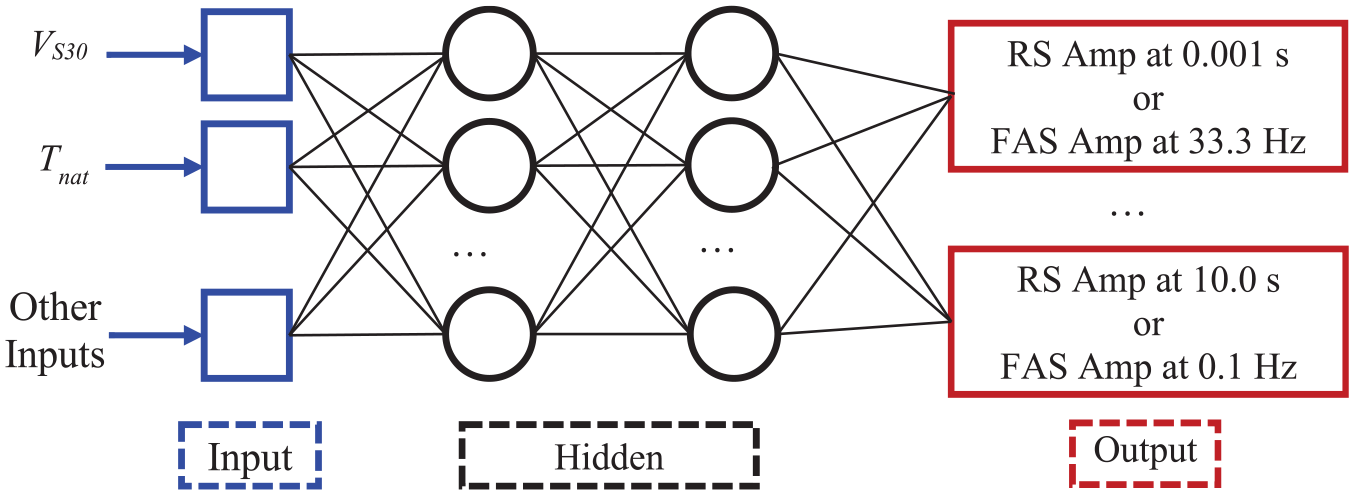
Schematic structure for development of ANN-based RS and FAS amplification models.
This article implements the regression-type multi-layer perceptron (MLP) model (Rumelhart et al., 1986), which is a subset of FNNs and can be regarded as a deep learning FNN. This classification is consistent with the definition provided by LeCun et al. (2015), which states that an ANN model with two hidden layers qualifies as deep. The MLP approach involves (1) executing the FNN and activation functions in a directed graph structure, and (2) updating the weights and biases to reduce the errors computed as the difference between the ANN output and target values. This process is implemented through input, hidden, and output layers of MLP as follows:
Calculation of the FNN function using Equation 1 in each neuron within the hidden layer using the information from the input layer.
Nonlinear mapping of FNN function by the selected activation function of each neuron in the hidden layer.
Error calculation between target values and estimations from the output layer using the loss function.
Updating of weights and biases using an iterative nonlinear optimization algorithm.
All these steps are iterated a given number of times (called an epoch) on input data divided into discrete batches. Batch size is usually selected considering the available computer memory and the targeted level of model accuracy. The loss function and optimization algorithm are selected to minimize the error, which critically affects ANN performance. There are several loss relationships for machine learning techniques (Janocha and Czarnecki, 2017), but two of them, LR1, which is the sum of the difference between target data and output, and LR2, which is the sum of the squares of difference between target data and output, are most frequently adopted.
The use of ANN methodologies in earthquake engineering has been investigated by a number of researchers. Derras et al. (2012) developed an ANN-based GMM to predict peak ground acceleration (PGA) using a KiK-net database (kyoshin.bosai.go.jp). ANNs were shown to produce comparable and slightly lower model standard deviations of residuals relative to conventional GMMs using fitted equations (Cotton et al., 2008; Kanno et al., 2006; Zhao et al., 2006). Derras et al. (2014) extended their ANN GMMs to estimate PGA, peak ground velocity (PGV), and 5%-damped pseudo-spectral acceleration (PSA) from 0.01 to 4.0 s. As before, the ANN-based GMMs produced smaller dispersions than conventional GMMs, which are proposed in Akkar and Cagnan (2010) and Bindi et al. (2011). Khosravikia et al. (2019) proposed an ANN-based GMM using a database consisting of strong ground motion data from seismic events in Texas, Oklahoma, and Kansas, an area that experiences frequent anthroprogenic earthquakes (Petersen et al., 2016). Gullu and Ercelebi (2007) utilized three sets of ground motion data from Turkey with 210, 47, and 221 samples to develop a ANN-based approach for PGA prediction. Roten and Olsen (2021) produced ANN models to predict surface-to-downhole site amplification using 600 KiK-net vertical array sites. In their study, 90% of the sites were used to train the models and the remaining 10% were adopted for testing. The ANN yielded a 25% decrease in the mean squared log error between estimations and observed data for the testing data relative to observations and theoretical 1D amplification, which are exposed to known issues with model error in the application of 1D analyses (Bahrampouri et al., 2023; Stewart and Afshari, 2021).
Prior ANN models for site amplification corresponding to a regression-based FNN with MLP structure were also presented by Ilhan et al. (2019), which were trained using limited sampling of site conditions as compared to that proposed in IEA24, and thus, are considered to be relatively outdated models compared to ANNs presented herein. Among the improvements in the present work are the use of a larger simulation dataset for model training and the derivation of models for the standard deviation of residuals.
In this article, we explore the use of ANN for RS and FAS ln(amplification) and derive standard deviation relationships from ANN models’ residuals. The functional form to estimate the simulated linear, nonlinear, and total RS and FAS amplification, is presented in Equation 2:
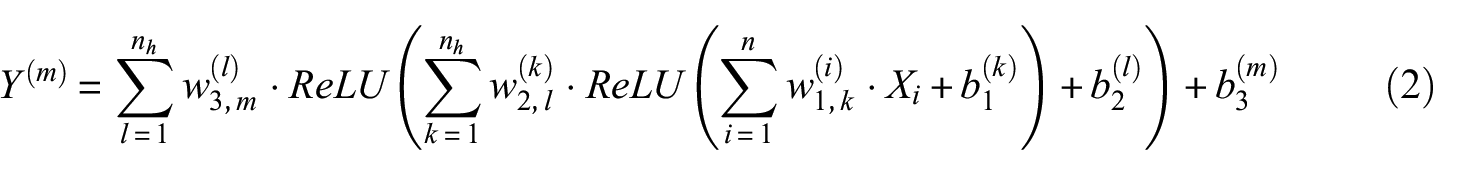
where,
Y (m) is the output intensity measure (e.g. RS or FAS ln(amplification) for a given period) for the mth output node.
X1, X2, …, Xn are the inputs (VS30, Tnat, etc.) of ANN-based models. n and nh represent the number of inputs and the number of nodes in each hidden layer, respectively.
ReLU(x) is the rectified linear unit activation function applied element-wise in first and second hidden layers, defined as ReLU(x) = max(0,x).
ANN-based models derived in this work and their conventional counterparts are constrained to site conditions of VS30 greater than 200 m/s and motion intensity of PGA at rock (PGAr) less than 1.0 g. Furthermore, it should be noted that ANNs are differentiable and hence slopes or gradients of the functional forms can be developed as illustrated in Hashash et al. (2004).
RS site amplification models
This study produced a total of six ANN-based models for the amplification of RS ordinates. These include linear models conditioned solely on VS30 (AL1), the combination of VS30- and Tnat (AL5), and two complementary (AL9, and AL9-Tp) models (i.e. models built to illustrate the effects of the different input parameters for enhancing model estimates). These models are derived from linear frequency-domain site response analyses as described in IEA24. A nonlinear model (AN2) was derived from differences between nonlinear and linear simulations in which the nonlinear effects are conditioned on VS30 and the peak acceleration for a reference rock site condition (i.e. PGA relative to VS = 3000 m/s, denoted PGAr). Finally, a model for total amplification, including linear and nonlinear effects that are conditioned on VS30, Tnat, and PGAr, was developed (denoted AK2). The names of ANNs along with their conventional counterparts are summarized in Table 1, and these labels are determined by adding “A” in front of those of corresponding conventional functions, which were originally presented in Harmon et al. (2019a)—for instance, the VS30-based ANN and conventional models are named as AL1 and L1, respectively.
List of ANN-based RS and FAS amplification models along with corresponding conventional RS and FAS amplification functions
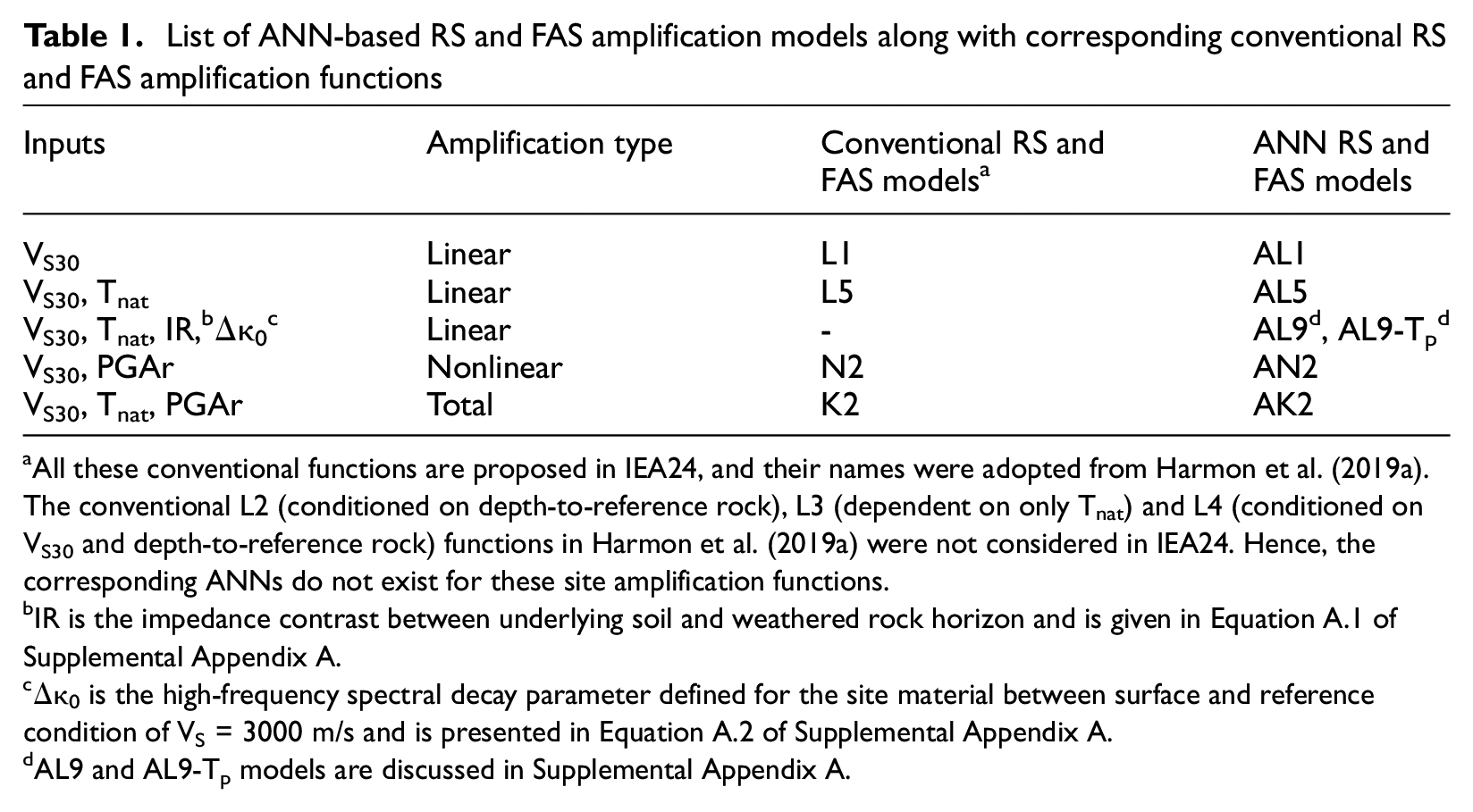
All these conventional functions are proposed in IEA24, and their names were adopted from Harmon et al. (2019a). The conventional L2 (conditioned on depth-to-reference rock), L3 (dependent on only Tnat) and L4 (conditioned on VS30 and depth-to-reference rock) functions in Harmon et al. (2019a) were not considered in IEA24. Hence, the corresponding ANNs do not exist for these site amplification functions.
IR is the impedance contrast between underlying soil and weathered rock horizon and is given in Equation A.1 of Supplemental Appendix A.
Δκ0 is the high-frequency spectral decay parameter defined for the site material between surface and reference condition of VS = 3000 m/s and is presented in Equation A.2 of Supplemental Appendix A.
AL9 and AL9-Tp models are discussed in Supplemental Appendix A.
Model development included training and testing datasets, with an individual value of site amplification referred to as a “sample.” Training samples of site amplifications comprise 90% of the simulations, corresponding to 1,097,050 samples for linear amplification and 999,460 samples for total or nonlinear amplification. Potential bias in the ANN-based models that might arise from including amplification data from the same site in both samples—due to this data partitioning approach (i.e. 90% and 10% of the entire dataset for the training and testing samples, respectively)—is expected to be limited, as elaborated in the subsection titled “Alternative Training and Testing Samples for ANN-based Models” in Supplemental Appendix A. The number of data for the total and nonlinear ANNs is less than for the linear ANNs because nonlinear analyses with maximum strain greater than 1.0% are excluded from the model development as discussed subsequently. The elimination of nonlinear simulations with maximum strain exceeding 1.0% stems from the base-isolation behavior (e.g. Zalachoris and Rathje, 2015) observed in the 1D site response approach as explained in IEA24. Hence, it is highlighted that this threshold is unrelated to the ANN technique and regression methodology. These large training datasets are then randomly sampled into approximately 5000 batches, each comprising 400 simulations, which are then utilized to train the ANNs. This partitioning facilitates the utilization of reduced memory during the weight updating phase of the ANN and accelerates training. The testing samples comprise 10% of the simulations, which are used to test the predictive capability of the ANN-based site amplification models through comparison with corresponding linear (VS30-based L1 and VS30- and Tnat-based L5), nonlinear (VS30- and PGAr-based N2) and total (VS30, Tnat and PGAr-dependent K2) conventional relationships (Table 1) proposed in IEA24 using the same simulated amplification dataset.
Two hidden layers with 200 nodes each are adopted for all models (Figure 1), and the activation function is selected as ReLU. Learning rate, which is defined as the step size at which the model learns (Bishop, 1995), was selected as 0.0001 because it produced the lowest error from the testing dataset, which is also consistent with typical learning rates of 10−6 to 1.0 (Bengio, 2012). For AL1 (RS and FAS) and other ANNs (i.e. AL5, AL9, AL9-Tp, and AN2), the corresponding selected epochs are 400 and 5000, respectively. The rationale behind the selection of this number of epochs was to adopt the ANN model that successfully encapsulates the distinct features of the amplification data (e.g. peak responses due to sharp impedance contrasts, and reductions of amplification at soft sites at short periods due to cumulative effect of soil damping). Moreover, the Adam optimizer (Kingma and Ba, 2014), which is a stochastic gradient descent method that is well-suited for problems involving large numbers of data points and parameters, is utilized along with LR2 type loss relationship to define the error between training data and model estimations.
The output layer consists of 125 nodes which produce the estimated RS natural logarithms of amplification, that is, ln(amplification), at 125 periods between oscillator period (TOSC) of 0.001 and 10.0 s. A linear activation function, which is an identity function for which output is directly proportional to input (Goodfellow, 2016), is assigned to each output node. TensorFlow (Abadi et al., 2016), which can be imported as a library in Python, is utilized for training ANN-based models.
Linear amplification
Figure 2a and b compares the L1 estimations from IEA24 and the ANN-based AL1 model for TOSC = 0.1 and 1.0 s, both of which are based solely on VS30. Although these models exhibit analogous behavior for TOSC of 1.0 s (Figure 2b), AL1 better captures the binned means of RS amplification (e.g. the peak, which is observed at VS30∼ 900 m/s for TOSC of 0.1 s) and results from a strong impedance contrast at shallow sites (e.g. depth of overburden soil to hard rock (VS reference of 3000 m/s) of <30.0 m). This is also reflected by the mean residuals aligning with zero, as shown in Figure 2c. It should be noted that this peak feature in the simulated amplification data used to train the ANNs is not represented in empirically derived amplification models (Parker et al., 2019; Stewart et al., 2020). Hence, while the ANN models better capture this attribute of the simulated data, which is associated with 1D site response assumption, it remains an open question whether both ANNs and conventional functions better represent amplification as observed under field conditions.
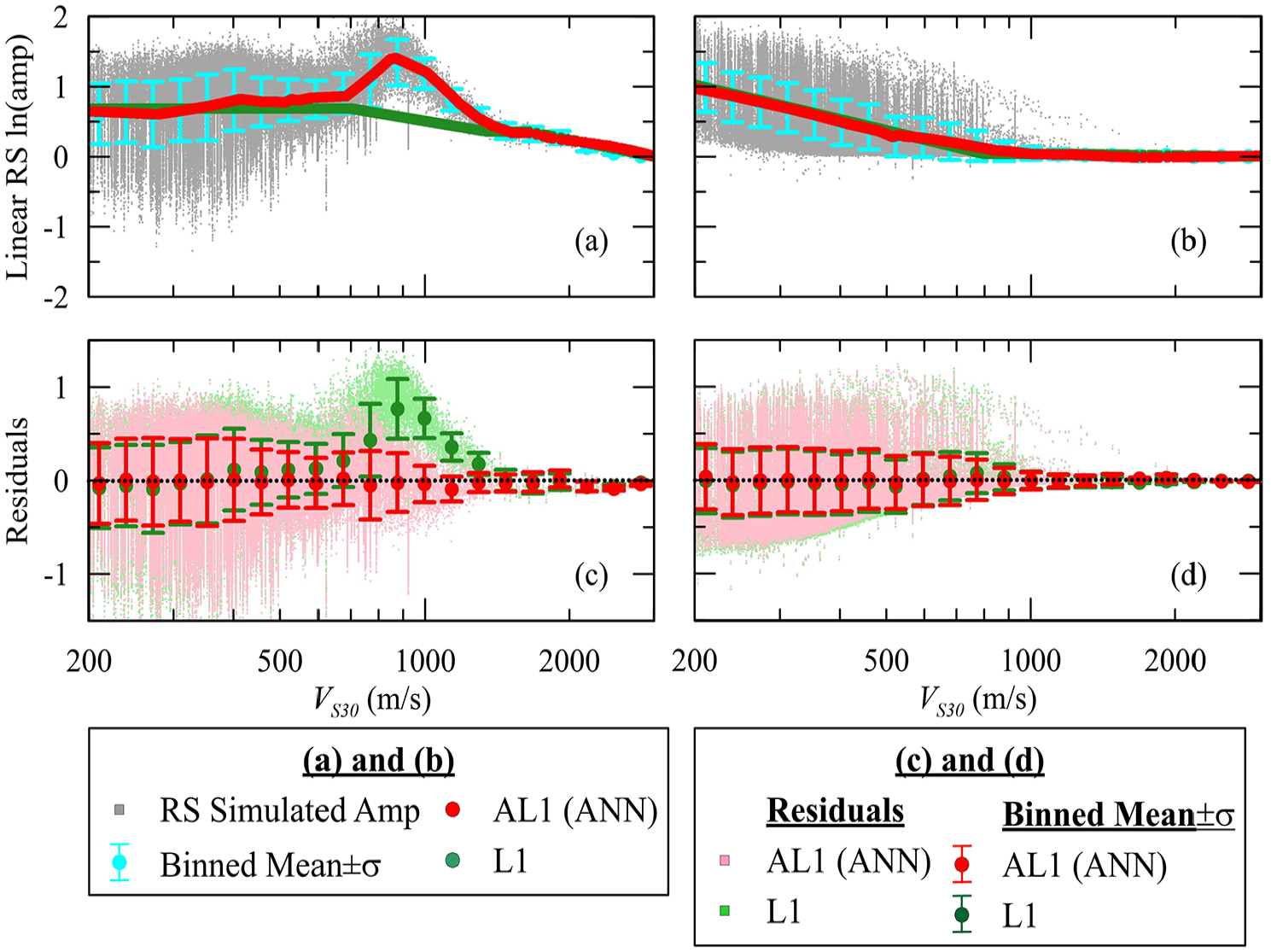
Comparison of model predictions from L1 and ANN-based AL1 (VS30-based) along with linear RS ln(amp) and its binned mean ±1σ for TOSC of (a) 0.1 s and (b) 1.0 s. The residuals of L1 and AL1 models are given for TOSC of (c) 0.1 s, (d) 1.0 s (testing dataset).
The Tnat effects on linear RS amplification are modeled through ANN-based model AL5, which utilizes the Tnat of randomized profiles in addition to their VS30 values, adopted for training AL1, and is the counterpart of L5 (VS30 and Tnat) in IEA24. Figure 3 presents the performance of the ANN-based AL5 model along with the corresponding L5 conventional function. Unlike Figure 2, the amplification models in Figure 3 do not appear as lines due to the inclusion of varying Tnat values for sites with identical VS30s (i.e. sites with same VS30s but with different depth-to-reference condition values) as inputs in the ANN estimations. Two main changes are observed: (1) for TOSC = 0.1 s, AL5 more successfully captures the location and amplitude of peak amplification at VS30∼ 950 m/s along with the decay of amplification at low VS30 values, which produces mean residuals at VS30∼ 950 m/s that are close to zero, relative to L5 and (2) again for TOSC = 0.1 s, AL5 produces less scattered residuals relative to those of L5 for VS30 > 950 m/s. The enhancements in amplification estimations provided by AL5 as compared to AL1 (i.e. the influence of incorporating Tnat in model inputs on ANN’s performance) are further discussed in “Models’ standard deviation” section.
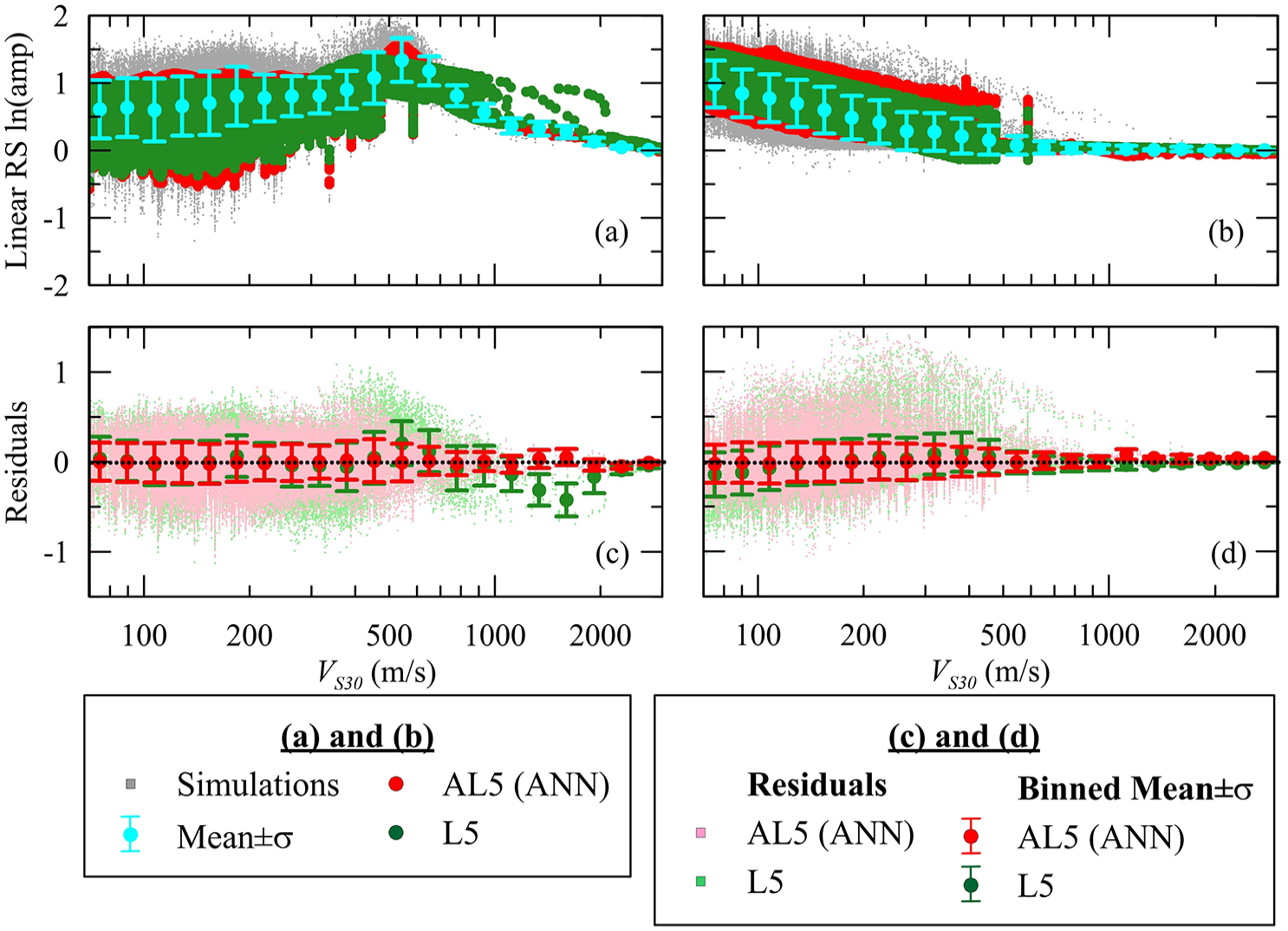
Comparison of model predictions from L5 and ANN-based AL5 using the same VS30 and Tnat inputs along with linear RS ln(amplification) and binned mean of ln(amplification) ±1σ for TOSC of(a) 0.1 s and (c) 1.0 s. The models’ residuals with their binned mean ±1σ are given for TOSC of(c) 0.1 s and (d) 1.0 s (testing dataset).
Nonlinear and total amplification
The nonlinear (NL) RS amplification model accounts for amplification differences between NL and linear (L) analyses. Figure 4 demonstrates the nonlinear amplification data binned as functions of VS30 and PGAr, for the AN2 and N2 models for relatively short (0.3 s) and long (1.0 s) TOSC, respectively. AN2 is found to yield similar mean estimations of nonlinear amplification to N2. The jaggedness in AN2 estimations (e.g. the line representing the nonlinear amplification at VS30 conditions of 270 m/s and 0.4 g < PGAr < 0.6 g) is more pronounced than the jaggedness in nonlinear amplification, which occurs due to the gaps in these datasets resulting from the exclusion of nonlinear simulations with maximum strain values exceeding 1.0% from the training and testing databases. Because the ANN technique adjusts its coefficients to learn the data trends, the jaggedness in the AN2 model estimations should be attributed to the inherent data behavior rather than to a deficiency in ANN’s equational form (Equation 2). If future implementations of AN2 are pursued (e.g. the integration of AN2 with GMMs in probabilistic seismic hazard applications), (1) re-training AN2 through training samples without excluding the simulations with maximum strain greater than 1.0, or (2) smoothing techniques may be considered to avoid pronounced jaggedness in AN2. However, this is beyond the scope of this article. Moreover, AN2 captures an increase in nonlinear amplification under conditions of high VS30 (≥650 m/s) and large PGAr values (≥0.4 g) for short periods (0.3 s). This behavior arises because the amplification from nonlinear analysis exceeds the corresponding linear amplification (i.e. that obtained from a linear analysis using the same site and motion combination) as a consequence of period elongation. Finally, this behavior cannot be modeled by the N2 model of IEA24, as the f2 coefficients—representing the nonlinear behavior in terms of the rate of change of site amplification with the intensity of the input motion—are constrained to be negative.
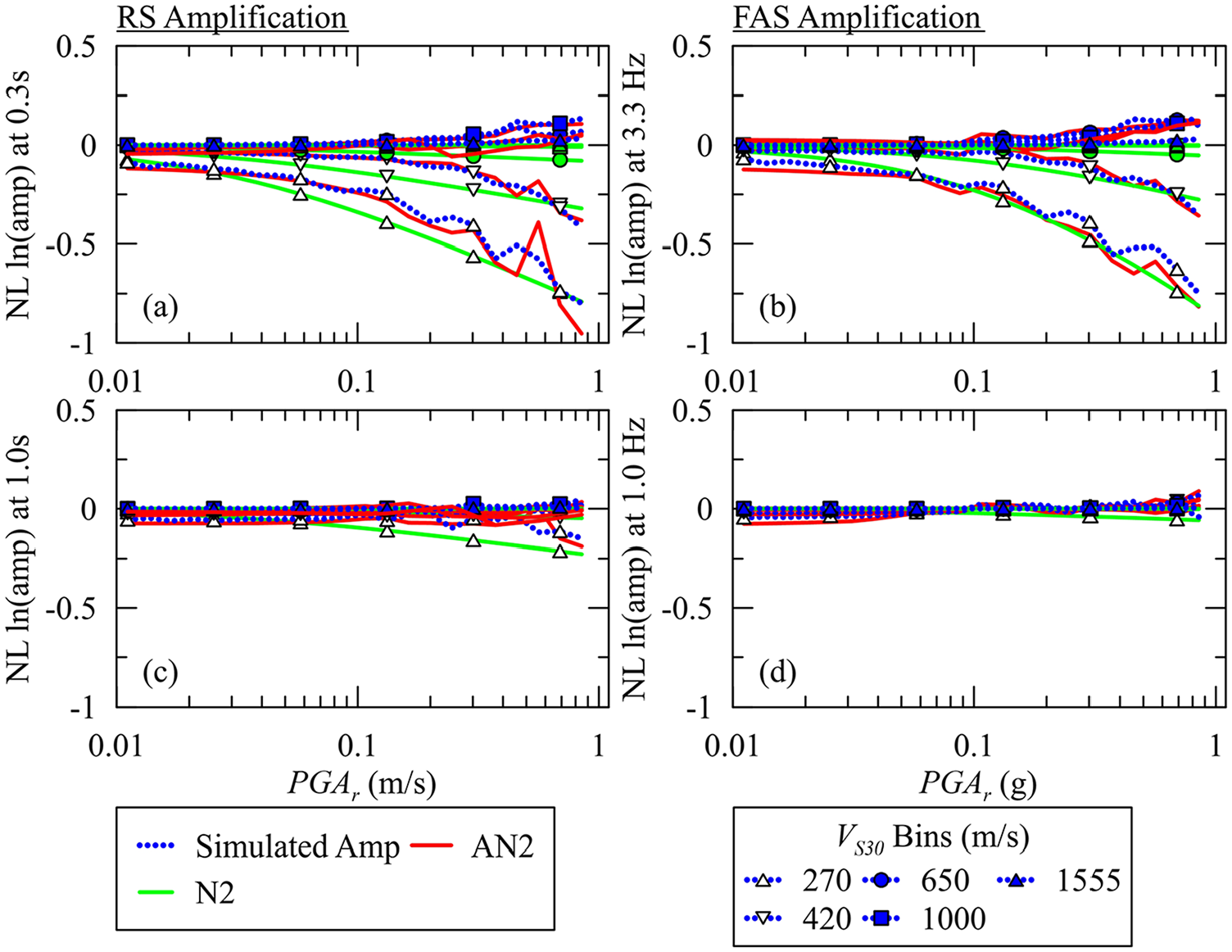
Model predictions from N2 and ANN-based AN2 for RS (a, c) and FAS (b, d) for nonlinear site amplification along with corresponding simulated amplification data as functions of VS30 and PGArfor TOSC of 0.3 and 1.0 s, and frequency of 3.3 and 1.0 Hz, respectively.
Figure 5 presents total amplifications for TOSC of 0.1 and 1.0 s for the conventional model (K2) and ANN-based model (AK2) trained using NL simulation results. Although the linear part of the K2 model includes an f(Tnat) component, its performance misses the peak amplification at VS30∼ 1000 m/s for TOSC of 0.1 s (i.e. the mean of K2’s residuals at VS30∼ 1000 m/s is above 0 as seen in Figure 5c). These non-zero residuals are absent in the AK2 model, which is similar to the AL5 model performance.
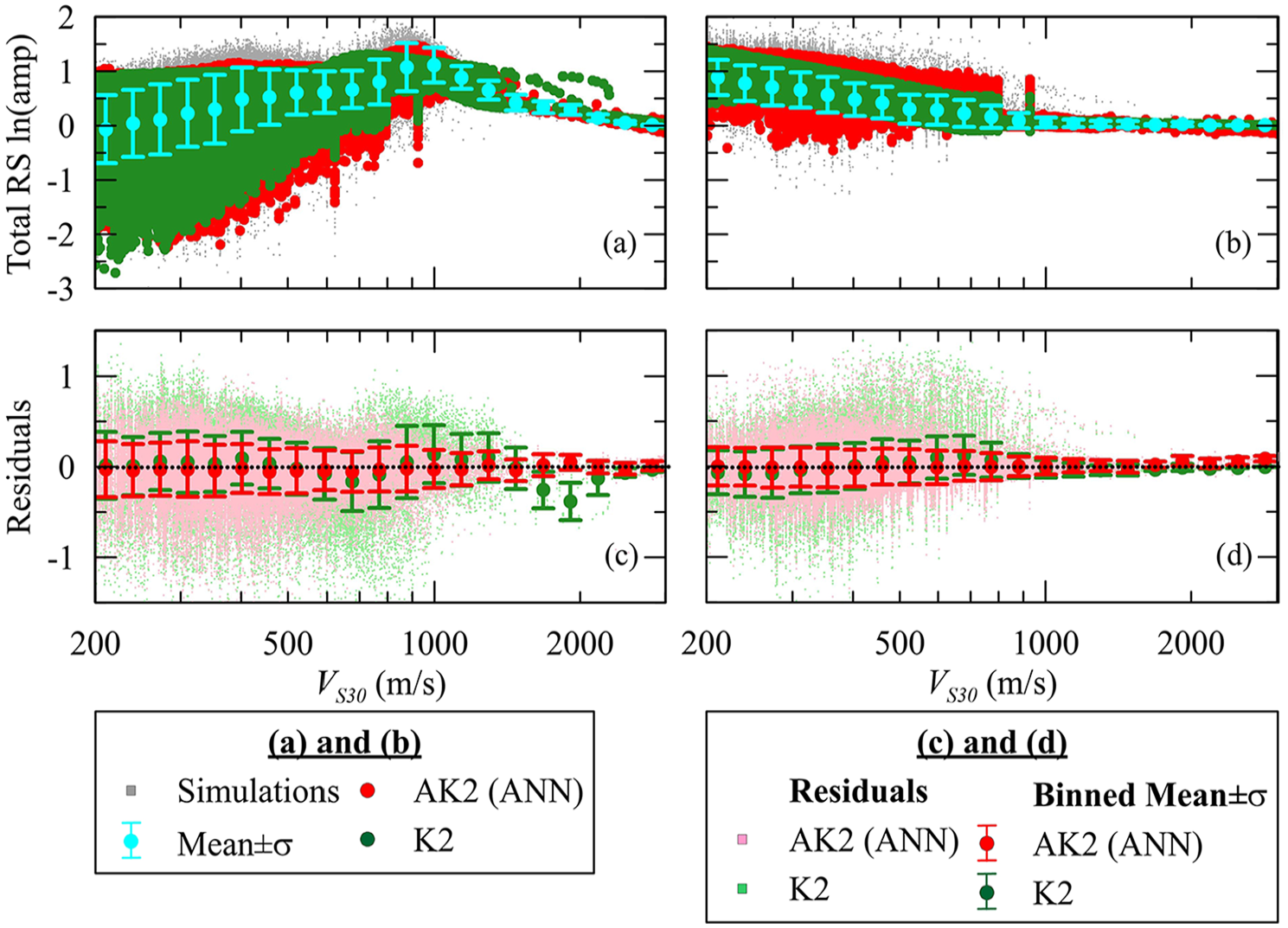
Comparison of model predictions from K2 (VS30, Tnat, PGAr) and ANN-based AT5 (VS30, Tnat, and PGAr) along with total RS ln(amplification) from nonlinear simulations and its binned mean ±1σ for TOSC of (a) 0.1 s, (b) 1.0 s. The models’ residuals are presented for TOSC of (c) 0.1 s and (d) 1.0 s (testing dataset).
FAS amplification
ANN-based FAS models utilize the same structure as the RS models except the output layer consists of 110 nodes providing FAS ln(amplification) for frequencies between 0.1 and 33.3 Hz (i.e. FAS ln(amplification) at 110 frequencies between 0.1 and 33.3 Hz). As before, the samples corresponding to 90% of the simulated amplifications (i.e. 1,097,050 simulations for linear FAS amplification, which correspond to site transfer functions (Kramer and Stewart, 2025), and 999,460 simulations for total or nonlinear FAS amplification) were used to train the ANN-based FAS models and the remaining 10% of the simulations were used for testing the predictions of FAS amplification. Figure 6 compares the performance of the L5 model (conditioned on VS30 and site natural frequency, fnat) and the ANN-based AL5 model for linear FAS amplification for frequencies of 10.0 and 1.0 Hz. As with Figure 3, the models do not manifest as lines in Figure 6 owing to the incorporation of different fnat values for sites with identical VS30s as inputs to the ANN estimations. Figure 6c and d, show non-zero binned means of L5 (FAS) residuals but nearly zero residuals for AL5 (FAS), which is similar to the linear RS results. Similar outcomes were obtained for the VS30-dependent AL1 models (Supplemental Figure A.1).
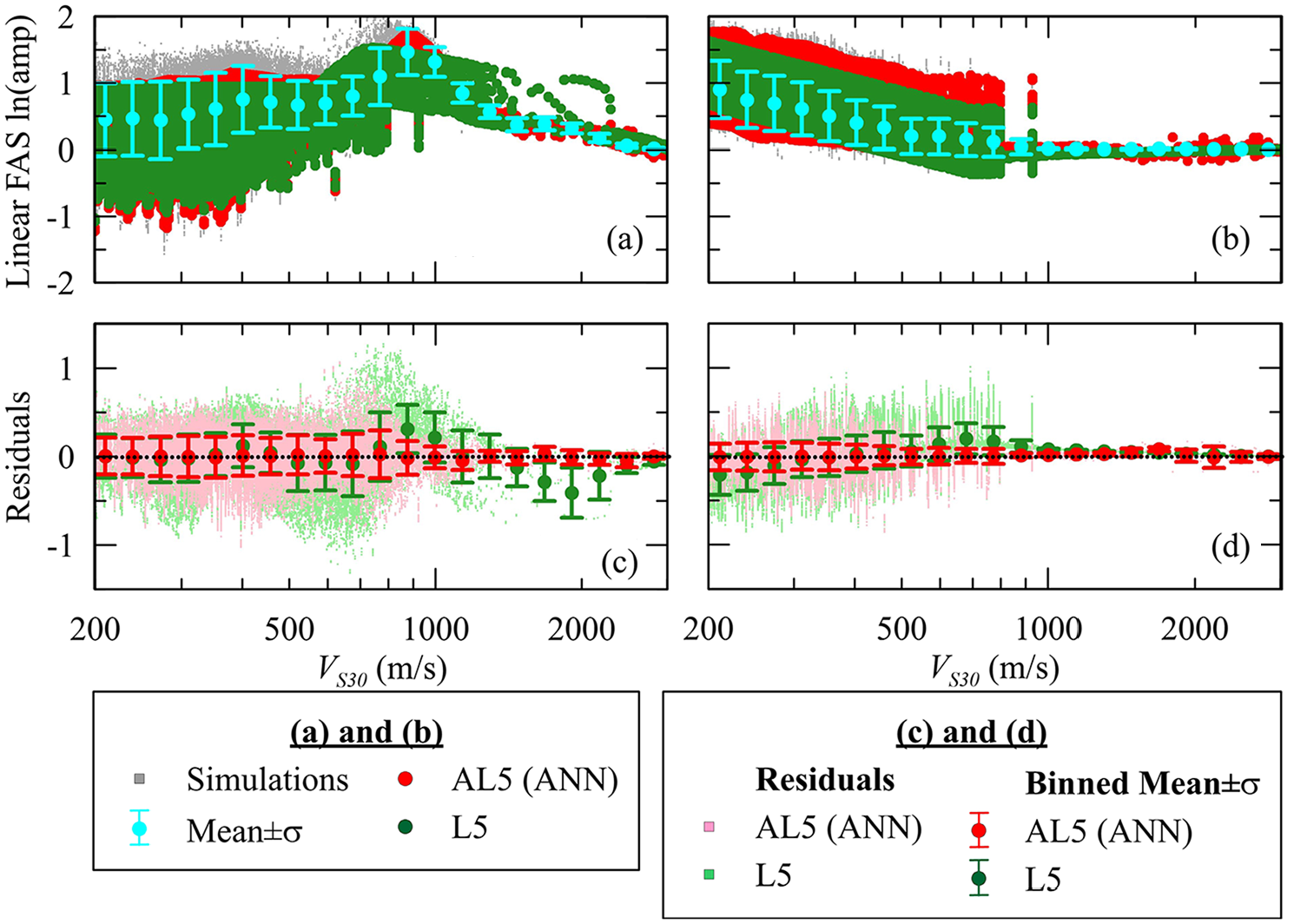
Comparison of model predictions from L5 (VS30 and fnat) and ANN-based AL5 (VS30 and fnat) along with linear FAS ln(amp) and its binned mean ±1σ for frequency of (a) 10.0 Hz and (b) 1.0 Hz. Models’ residuals are presented for frequency (f) of (c) 10.0 Hz and (d) 1.0 Hz (testing dataset).
Nonlinear and total FAS models are presented in a similar manner to the RS models in Figure 4b and d, and Supplemental Figure A.2, respectively. The mean AN2 (FAS) model behaves similarly to the N2 model but the total ANN model (AK2) residuals’ dispersions are lower (Supplemental Figure A.2) relative to conventional K2. It is possible to extend ANN models (Equation 2) to include other input parameters that might be hypothesized as affecting predicted site amplification (e.g. high-frequency spectral decay (Δκ0), impedance ratio (IR) between overlying sediment and weathered rock or reference condition of VS = 3000 m/s, and predominant period (Tp) parameter). The extension of the current models to include additional input parameters is discussed in Supplemental Appendix A.
Models’ standard deviation
The standard deviation (σ) of a model is computed from the residuals defined as the difference between the natural logs of site amplification values from simulations and model predictions in natural log units. These σ values include both motion-to-motion and site-to-site variability, which are provided for conventional amplification functions by IEA24. Figure 7 shows the AL1 and AL5 dispersion terms for both the RS and FAS amplifications along with a model fit (σFlin) that matches the form selected by IEA24. There is a reduction in σFlin for AL5 in Figure 7c for VS30 values exceeding approximately 800 m/s. This decrease is also evident in the σ of linear site amplification at these sites (i.e. in the error bars of the binned mean of linear amplification for VS30 ≥ ∼800 m/s in Figure 6). This condition is anticipated, as the impedance contrast in stiffer sites is less pronounced than in profiles with lower VS30 values, resulting in a lower σ for stiffer sites compared to softer sites. The corresponding coefficients for the σFlin model are depicted in Supplemental Figures A.5 to A.8. In a similar manner, σFnl models were derived using the same functional forms from IEA24 for AN2 RS and FAS.
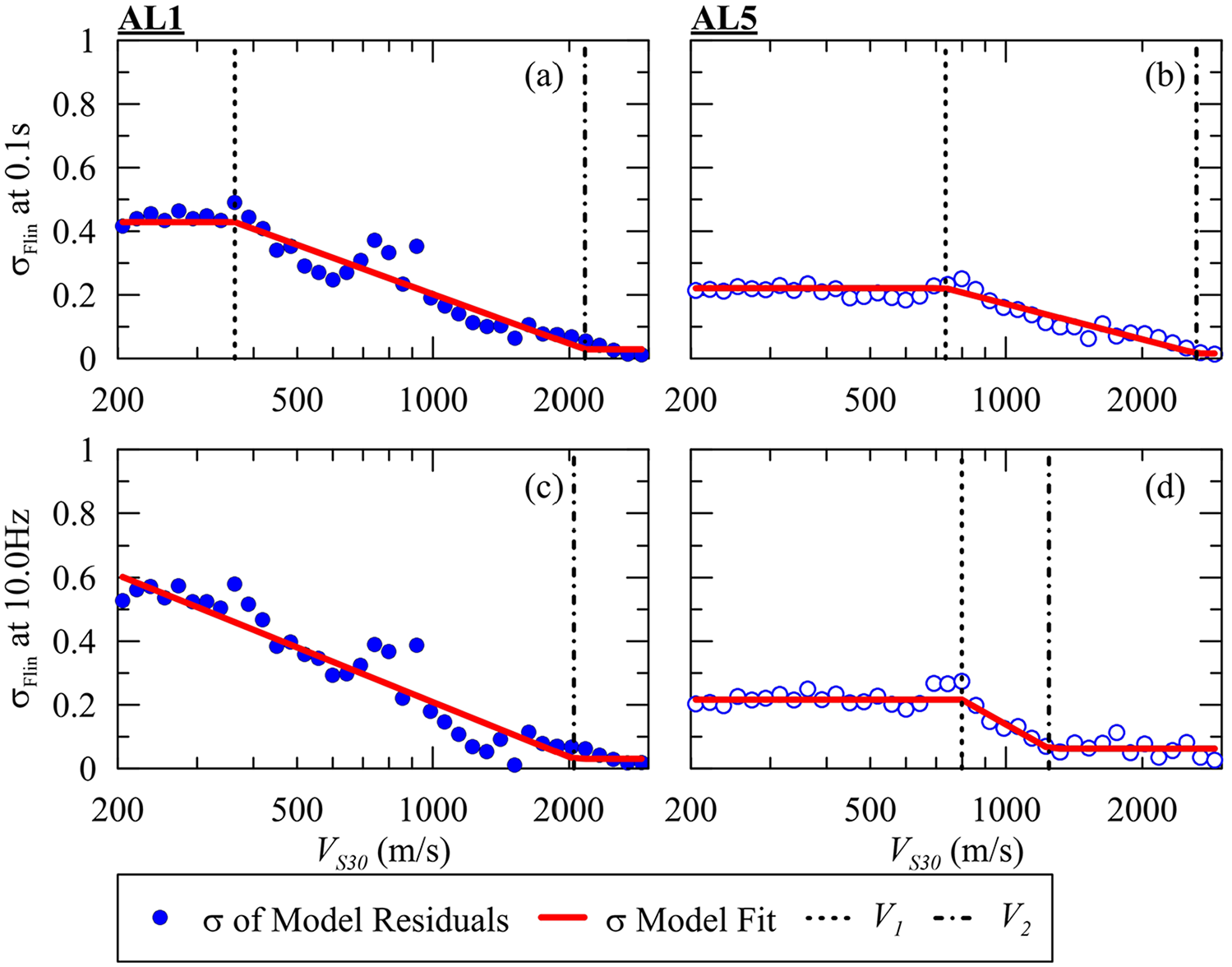
Standard deviations of residuals for evenly distributed log(VS30) bins for TOSC of 0.1 s and 10 Hz and models fitted to results (red lines). AL1 RS (a) and FAS (c) and AL5 RS (b) and FAS (d).
Figure 8 compares standard deviations from the ANN and conventional models. For the σFlin and σFS of RS models, considerable levels of reductions up to 12%−18% for linear (AL1, AL5) and The σ for total amplification models (σFS) can be computed by taking into account that the σFlin and σFnl showed near-zero correlation in IEA24, and thus they are independent:

where σFlin is from AL1 or AL5 and σFnl is from AN2.
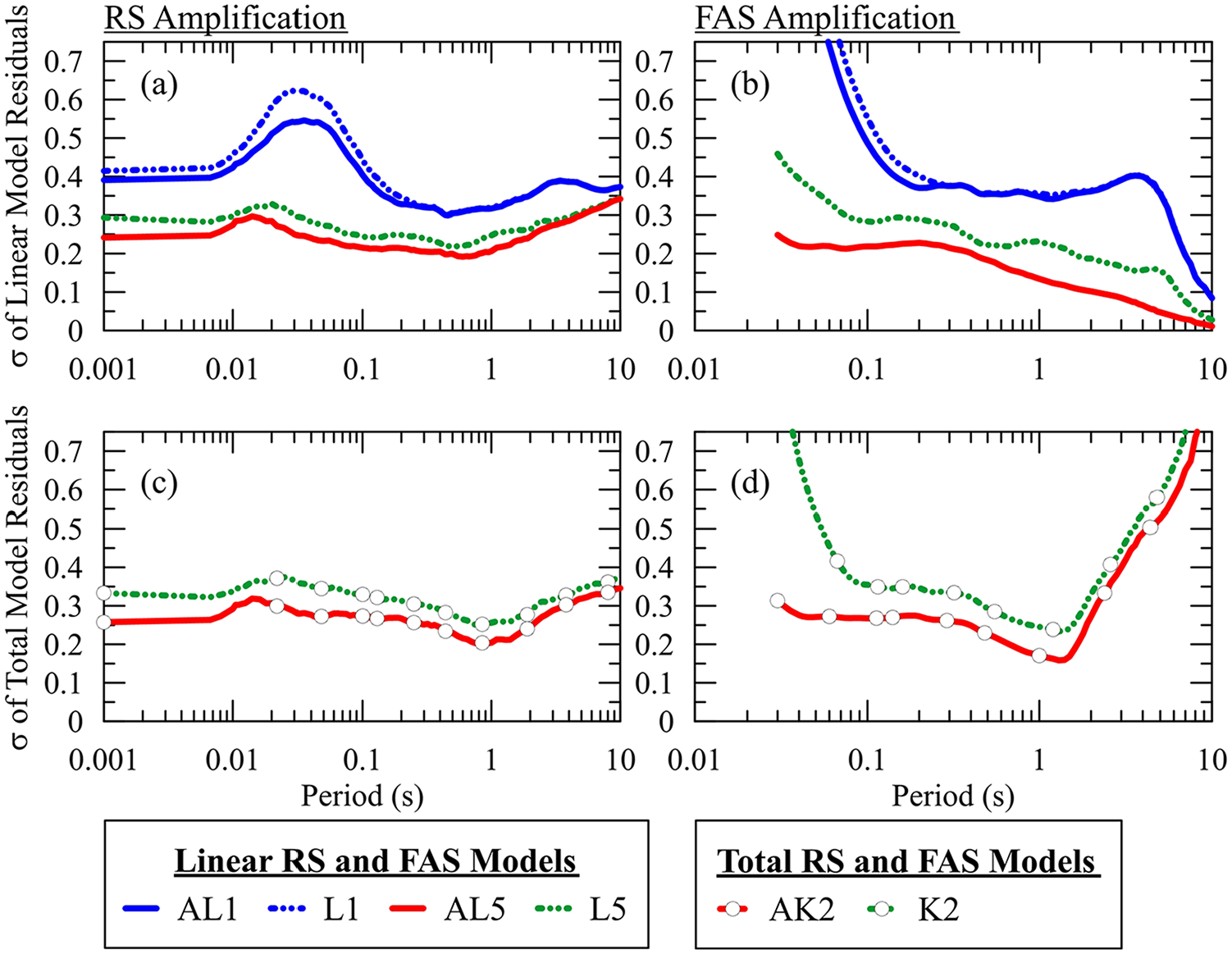
Standard deviation (σ) of residuals of linear conventional L1 and L5, and ANN-based AL1 and AL5 RS (a) and FAS (b) models, and total conventional K2, and ANN-based AT5 RS (c) and FAS (d) models (testing dataset).
23% for total amplification models (AK2), respectively, are achieved compared to their conventional counterparts. FAS models have higher σ values in AL1 and L1 at short periods due to limitations in the ability of VS30-based models to capture the substantial reduction in simulated FAS ln(amplification) for soft and deep sites due to cumulative damping effects. These effects are less evident in RS data because single-degree-of-freedom oscillator responses approach PGA at short periods (e.g. Bora et al., 2016). The inclusion of the fnat term in AL5 or L5 (i.e. employing both VS30 and fnat) mitigates this issue, resulting in significantly lower σFlin compared to AL1 or L1. Maximum decreases of σFS by AL1, AL5, and AK2 as compared to their conventional counterparts are 15.7%, 70.8%, and 67.2%, respectively. Similar evaluations of σFlin and σFS from the ANN-based and conventional models via testing samples (Supplemental Figure A.10) were found to yield analogous results to σFlin and σFS assessed using the training dataset.
Shallow profile response
The behavior of shallow profiles, which are defined as the sites with overburden soil depths to reference rock (ZSoil) < 30 m, based on the shallow site definition in Nikolaou et al. (2001), deviates from the median site response from the overall database due to a preponderance of short period resonances. Nikolaou et al. (2001) evaluated this phenomenon through comparisons of surface RS from EL analyses using a profile with VS30 = 220 m/s and ZSoil = 15.0 m with a design spectrum from New York City Department of Transportation (NYCDOT, 1998). These comparisons demonstrated that computed RS exceeds the NYCDOT (1998) specta for TOSC ≤ ∼ 0.4 s. Motivated by this disparity, the performance of conventional and ANN models for shallow sites is investigated.
Figure 9a and b shows linear RS and FAS amplification, respectively, for the training samples corresponding to all and shallow sites (ZSoil < 30.0 m). The results show that shallow sites have higher amplifications than the full dataset for short periods of 0.1 s and VS30 ≤ 400 m/s. The AL5 model better represents the location and height of the peak shallow amplification around VS30 = 950 m/s than the L5 model (Figure 9c and d). Improved performance of AL5 relative to L5 is also evident from residuals (Figure 9e and f). Similar results for models AK2 and K2 are presented in Supplemental Figure A.9.
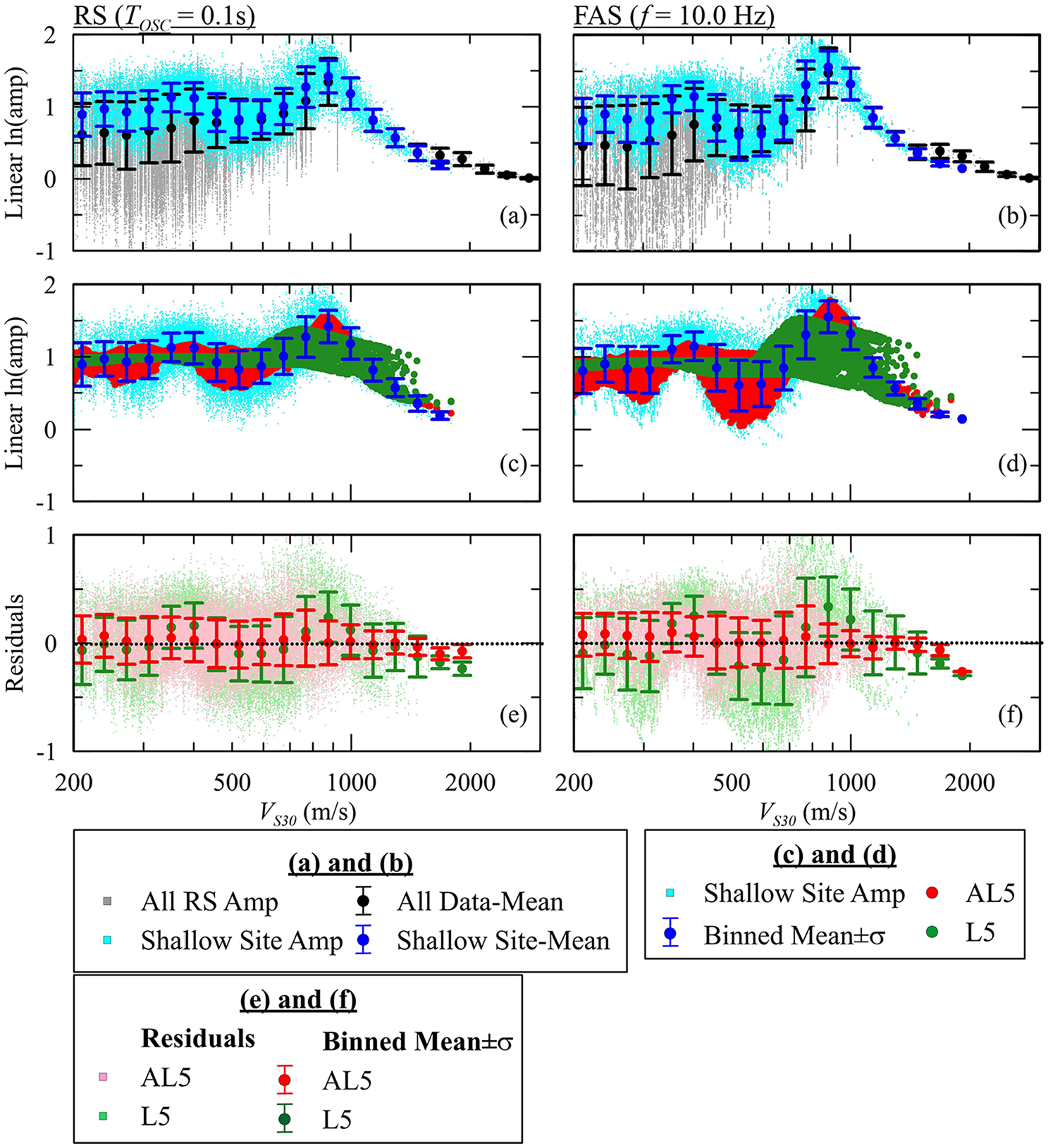
Comparison of amplifications derived for full dataset and subset for shallow sites. Results are shown for the specific conditions of TOSC = 0.1 s for RS and 10 Hz for FAS. (a) and (b) simulated amplifications; (c) and (d) model predictions (L5 and AL5); (e) and (f) model residuals.
Example applications to selected CENA sites
To demonstrate the implementation and performance of the conventional functions from IEA24 and the ANN-based models in this article, their predictions are compared to results of site-specific response analyses for two profiles (one from New York City (NYC) presented in Nikolaou et al. (2001) and the other from Pecos, Texas [TX] in Li et al. (2020)). The ANN models are applied using the Excel spreadsheet implementation in Supplemental Appendix B. The NYC and TX profiles were not in the training data sets for ANN model development. All analyses are 1D and include L and NL representations of material behavior. For these simulations:
Three rock outcrop motions (PGA of 0.1, 0.3, 0.51 g) from the Harmon et al. (2019b) database are selected.
The VS profiles and profile properties of NYC and TX sites are given in Figure 10 and Table 2, respectively. These profiles possess similar VS30 values but different Tnat values. Figure 11 highlights that both NYC and TX profiles are within VS30 and Tnat parametric range contained in the training samples. The reference condition for the NYC and TX sites are VS = 2500 and 3000 m/s, respectively.
The stratigraphy of the NYC site is composed of (1) two sand layers between 0.0−5.0 and 8.2−11.3 m, (2) a clay layer sandwiched between these two sand layers, and (3) a gravel layer with a thickness of 3.7 m underlying this sediment. The unit weight and OCR (overconsolidation ratio) exist for each material and clay stratum, respectively. The friction angle (ϕ) values of cohesive and cohesionless soils were set as 30° and 32° as detailed in Hashash et al. (2021). The ϕ parameter was utilized to compute (1) the lateral earth-pressure coefficients at rest (K0) for reference MRD (modulus reduction and damping) curves from Darendeli (2001), and (2) the strength input for the GQ/H model (Groholski et al., 2016), which was fit to reference MRD curves.
Dmin values are estimated using the Campbell (2009) Q-VS Model 1.
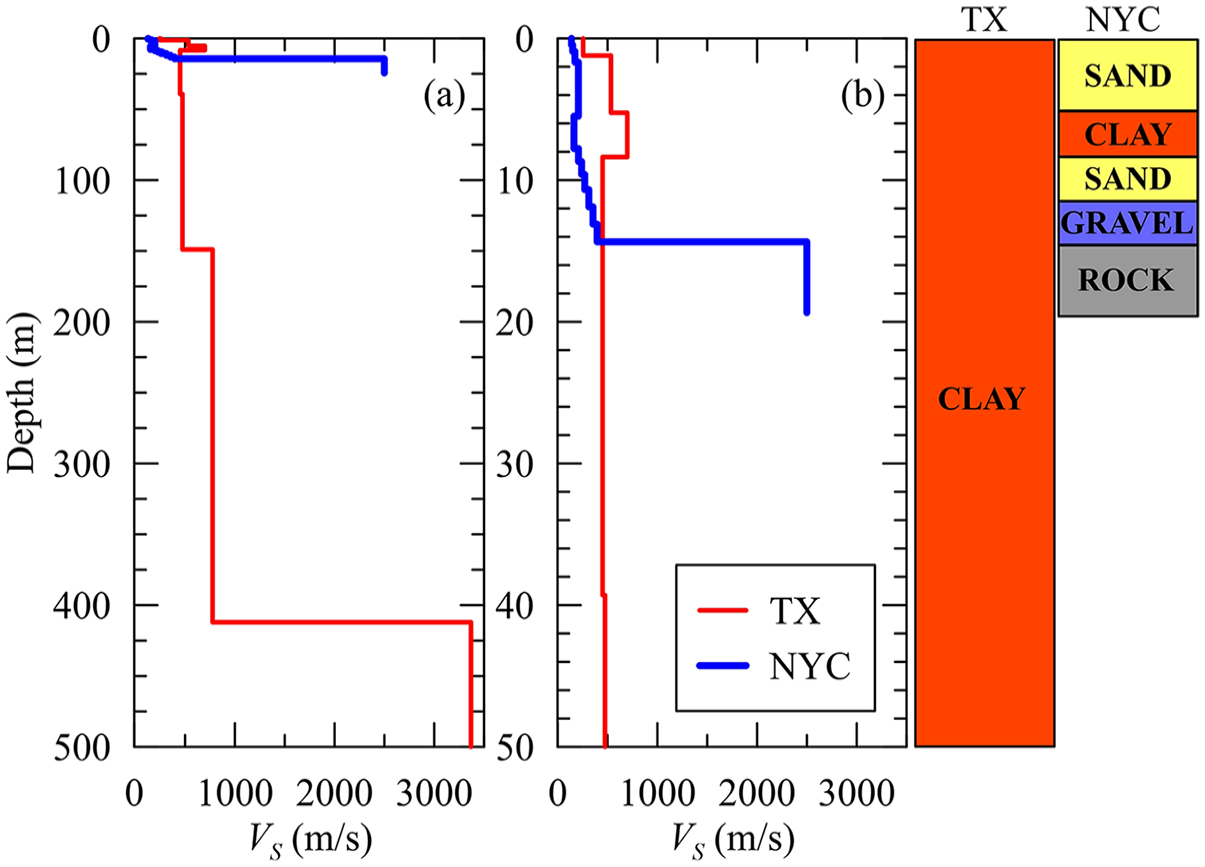
VS profiles of Pecos, TX, and New York City to the depth of (a) 500 m and (b) 50.0 m. The stratigraphic profiles reflect the depth axis in figure (b).
Properties of selected sites for model evaluation

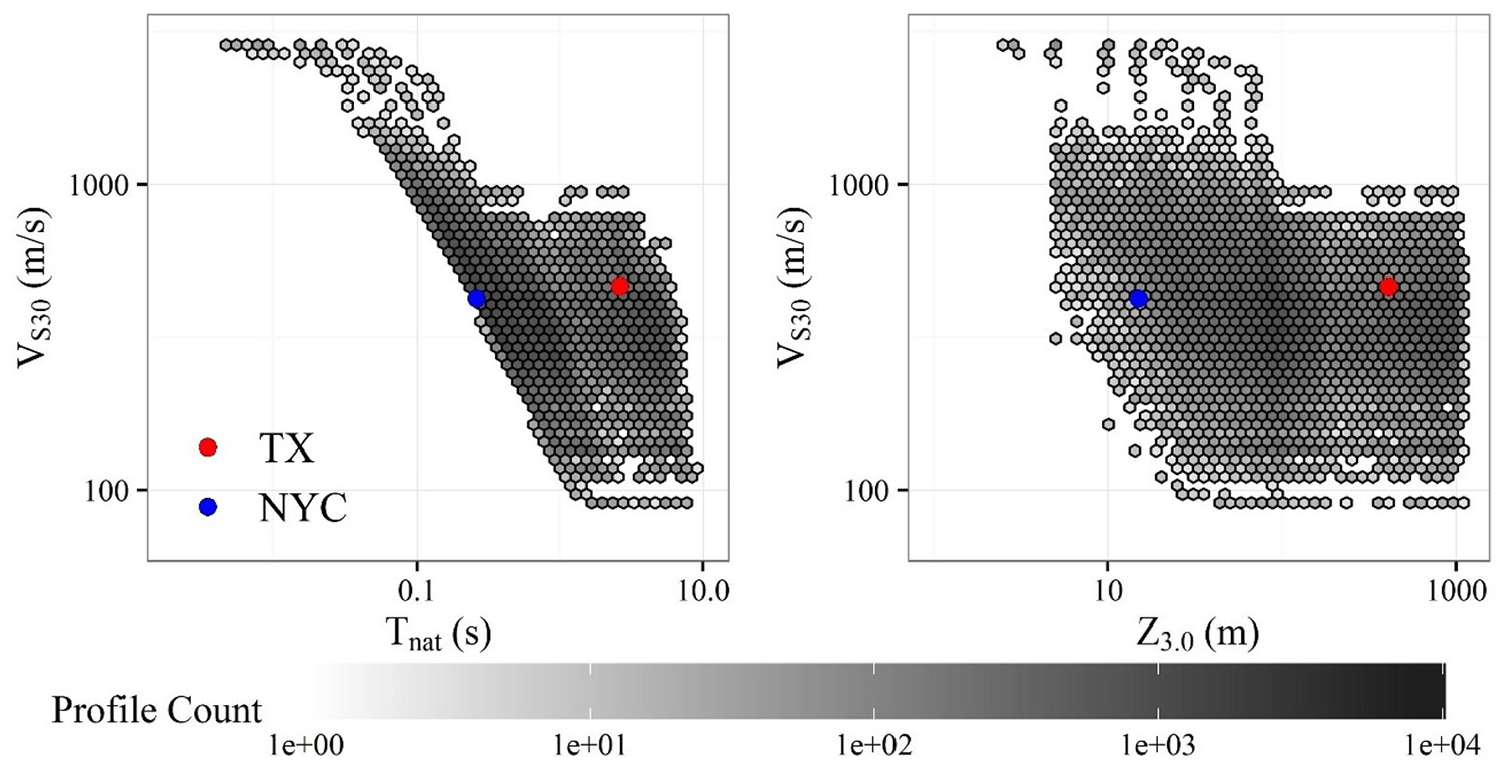
Density plots of IEA24 database in (a) VS30-Tnat and (b) VS30-Z3.0 (depth to VS = 3000 m/s) spaces.
Figure 12 compares for the NYC site the linear amplification from 1D L analysis using the three input motions; the mean of the simulated linear amplifications are shown along with predictions of the amplification from the L5 and AL5 models, which are shown as the mean ± σFlin. The site-specific results have strong resonance effects that produce a peak around TOSC = 0.2 s; this peak is underestimated by the mean L5 model, being close to L5 + σFlin. The location and level of this resonant peak are better captured by AL5 along with a better representation of the trough between the first and second mode peaks (0.075 s < TOSC < 0.2 s). Figure 13 presents similar results for NL simulations, where the site-specific total amplifications are compared to AK2 and K2 predictions. In this case, the first mode peak occurs at TOSC≈ 0.3 s (about 50% lengthened relative to the L solution) for the PGAr = 0.1 g input motion and it progressively shifts to longer periods as PGAr increases. This behavior is not captured by the K2 model, which does not allow for period elongation, but is better represented by the AK2 model because the ANN adjusts to be consistent with the simulated nonlinear response.
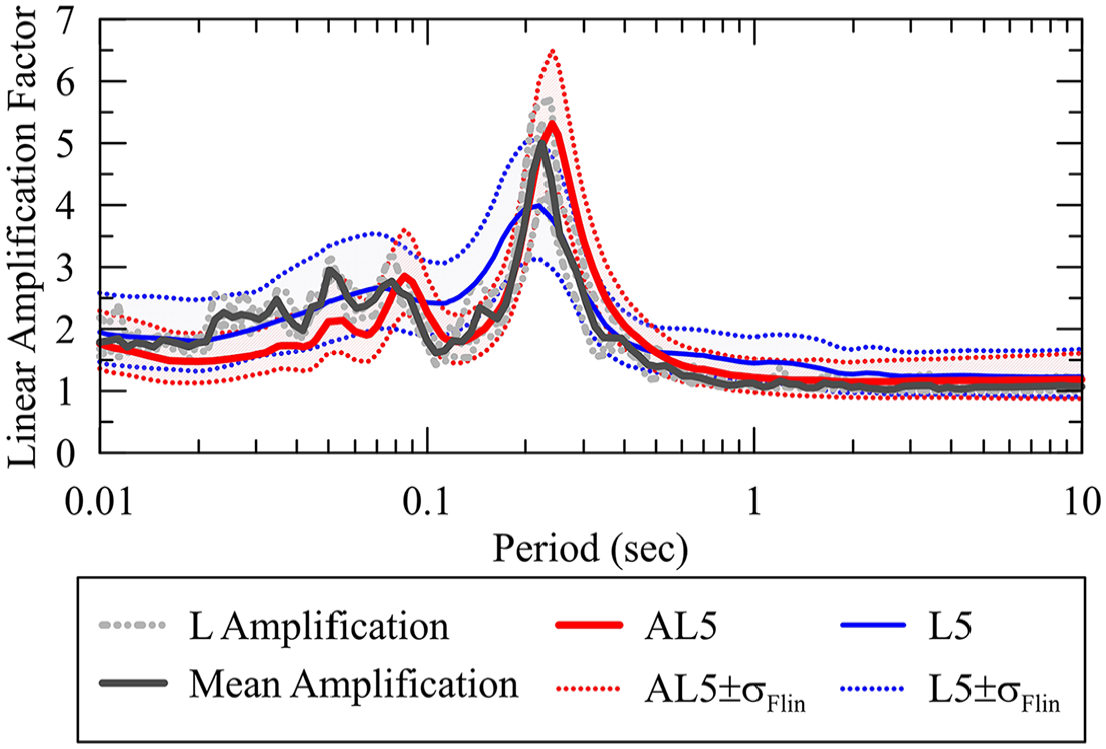
(NYC site) comparison of linear site-specific amplification and ergodic ANN-based AL5 and conventional linear L5 site amplification models with ±1 standard deviation (σFlin).
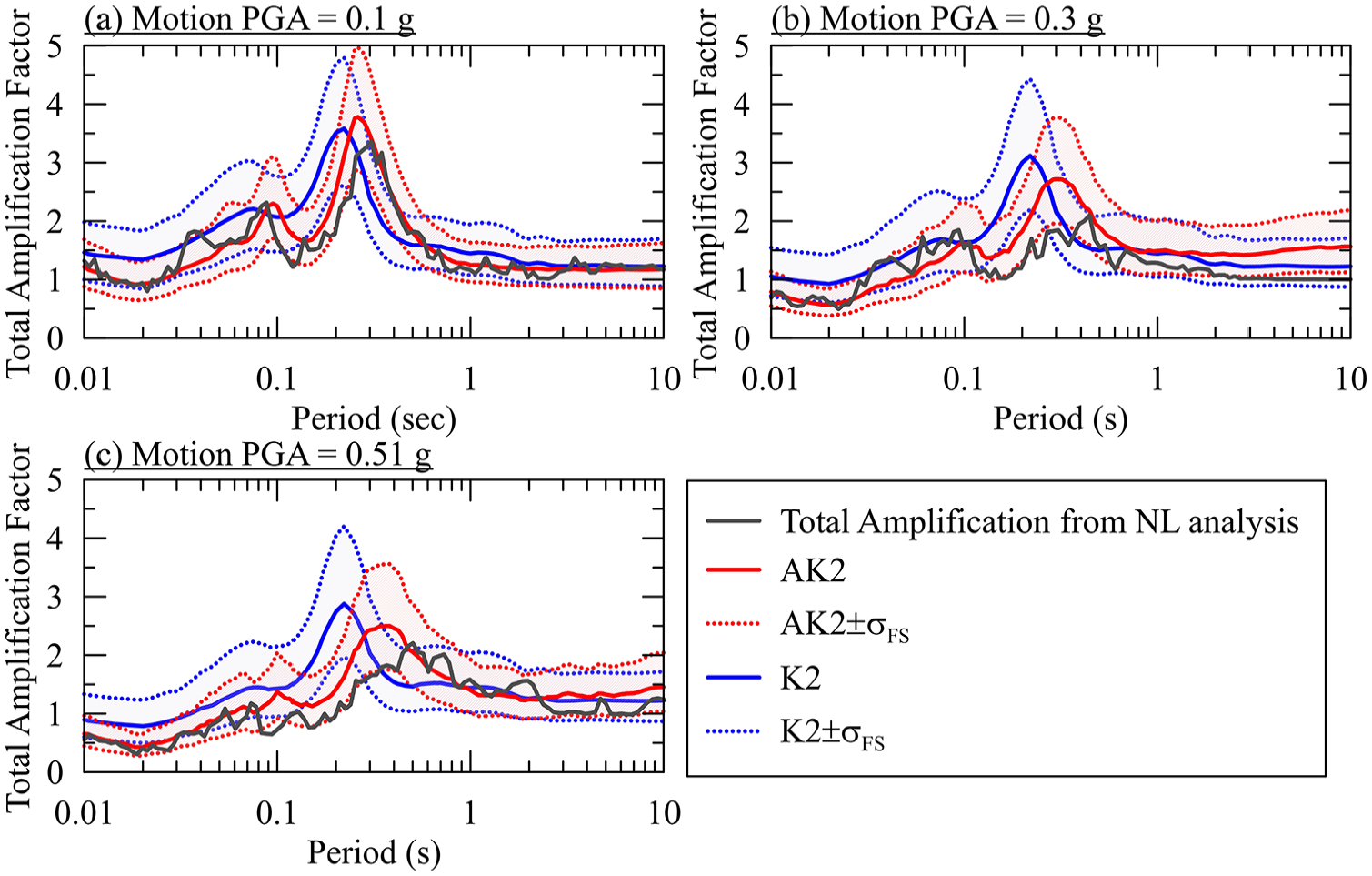
(NYC site) comparison of total site-specific amplification computed for PGAr of (a) 0.1 g, (b) 0.3 g and (c) 0.51 g and ergodic ANN-based AK2 and conventional total K2 site amplification models with ±1 standard deviation (σFS).
Figures 14 and 15 present similar results for the deeper TX site. As shown in Figure 15, both conventional and ANN-based models seem to envelope site-specific amplifications from NL analyses for TOSC ≤ ∼ 0.8 s. The ANN model more accurately captures the location of the peak linear amplification (Figure 14) along with the period elongation under nonlinear conditions (Figure 15). However, the first mode linear and total amplification peaks are underestimated by the AL5 and AK2 ANN models and by the L5 and K2 conventional models, respectively. Even though TX site falls within VS30-PGAr distribution of training samples, such deviations of model estimations from computed site-specific peak amplification are expected since no model can be expected to perfectly fit the amplification for an individual site.
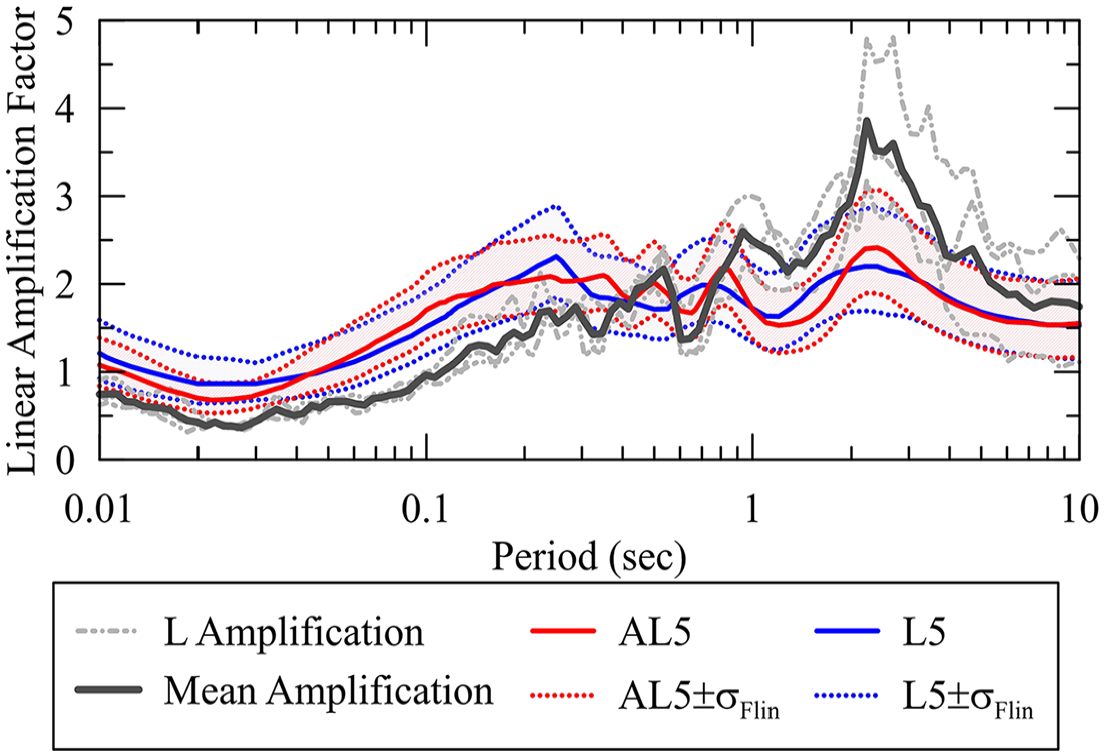
(TX site) comparison of linear site-specific amplification and ergodic ANN-based AL5 and conventional linear L5 site amplification models with ±1 standard deviation (σFlin).
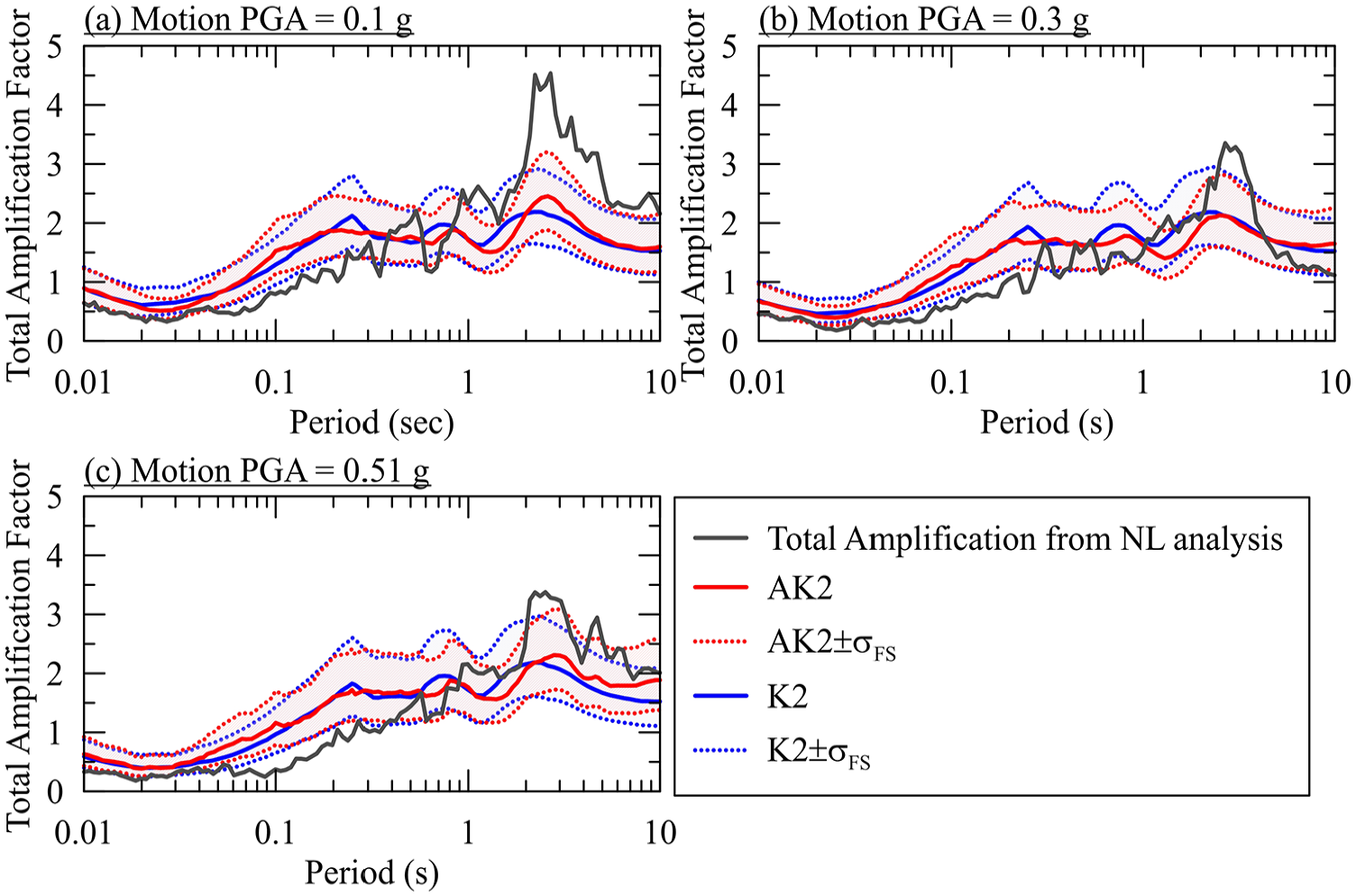
(TX site) comparison of total site-specific amplification computed for PGAr values of(a) 0.1 g, (b) 0.3 g and (c) 0.51 g and ergodic ANN-based AK2 and conventional total K2 site amplification models with ±1 standard deviation (σFS).
Recommendations and conclusions
This article presents a series of ANN-based linear, nonlinear, and total (linear plus nonlinear) RS and FAS site amplification models for a reference velocity condition of VS = 3000 m/s for sites in CENA highlighting the promise of ANN’s use as site amplification models. These models are developed using a database comprising 3.6 million 1D simulations from Ilhan et al. (2024). The performance of ANNs is evaluated through comparison with their conventional regression model counterparts, yielding that:
ANNs successfully reduced residuals and the standard deviation (σ) of model estimations, with reductions of up to 23.0% for RS and 70.8% for FAS compared to commonly used amplification functions.
ANNs can capture simulated site-specific response characteristics: (1) the location and amplitude of the first-mode simulated amplification, (2) the simulated shallow site amplification, and (3) the period elongation behavior (i.e. the shift in the period of peak amplification to longer period values) as a consequence of soil nonlinearity, which cannot be modeled by conventional site amplification functions.
The conventional and ANN-based models are subject to the limitations of the simulation dataset on which they are based. This includes the constraints of 1D site response theory, such as the absence of basin effects. The applicability of models is restricted to sites with VS30 > 200 m/s and PGAr less than 1.0 g to avoid base-isolation behavior during 1D simulations that can result in unrealistically high strains. The equations that are fit when training ANN models (e.g. Equation 2) are learned directly from the data rather than being proposed as a priori forms in conventional functions, and as a result they are unlikely to extrapolate well beyond the limits of the training data. These limits include lower or higher VS30 values, higher PGAr values, and profile characteristics that are not contained in the training set. To facilitate the use of the ANN-based models, an Excel spreadsheet is provided as an appendix so that researchers can explore these models in their own applications.
In this article, we do not explore how to deploy ANN’s site amplification models in seismic hazard analysis or in combination of commonly used GMMs. This is beyond the scope of this work but is an important effort to undertake in the future.
Supplemental Material
sj-docx-1-eqs-10.1177_87552930251343630 – Supplemental material for Artificial neural network−based simulated site amplification models for Central and Eastern North America
Supplemental material, sj-docx-1-eqs-10.1177_87552930251343630 for Artificial neural network−based simulated site amplification models for Central and Eastern North America by Okan Ilhan, Youssef MA Hashash, Jonathan P Stewart, Ellen M Rathje, Sissy Nikolaou and Kenneth W Campbell in Earthquake Spectra
Supplemental Material
sj-xlsx-2-eqs-10.1177_87552930251343630 – Supplemental material for Artificial neural network−based simulated site amplification models for Central and Eastern North America
Supplemental material, sj-xlsx-2-eqs-10.1177_87552930251343630 for Artificial neural network−based simulated site amplification models for Central and Eastern North America by Okan Ilhan, Youssef MA Hashash, Jonathan P Stewart, Ellen M Rathje, Sissy Nikolaou and Kenneth W Campbell in Earthquake Spectra
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Disclaimers
Certain trade names or company products are mentioned in the text to specify adequately the analytical procedures used. In no case does such identification imply recommendation or endorsement by the National Institute of Standards and Technology (NIST), nor does it imply that the products are the best available for the purpose. In this document, we have provided link(s) to website(s) that may have information of interest to our users. NIST does not necessarily endorse the views expressed or the facts presented on these sites. Furthermore, NIST does not endorse any commercial products that may be advertised or available on these sites.
Data and resources
The coefficients (i.e. weights and biases) of all proposed ANN-based models are presented in Excel file submitted as Appendix B. The same file includes spreadsheets that allow the readers to calculate and visualize the ANN-based model estimations for the given inputs. The spreadsheet titled “INTRODUCTION” in this Excel file B elaborates on the content of Appendix-B.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.