
Abstract
Recent studies have demonstrated that large language models can perform various knowledge graph-related tasks, including knowledge graph construction, even in zero- and few-shot settings. However, they are prone to hallucinating information and producing non-deterministic outputs, which can result in flawed reasoning, even when the answers appear to meet user expectations. This unpredictability limits their integration into automated natural language processing pipelines, such as those used in chatbots or task-oriented dialogue systems. To explore the potential and limitations of large language models in knowledge graph tasks, we evaluate three prominent models, namely Mixtral-8x7b-Instruct-v0.1, GPT-3.5-Turbo-0125, and GPT-4o, on constructing static knowledge graphs. Our approach uses prompts based on the TELeR taxonomy in zero- and one-shot scenarios, within the context of a task-oriented dialogue system. Additionally, we propose a flexible evaluation framework that captures all usable information generated by the models, alongside traditional strict metrics, and introduce TODSet, a dataset tailored to gauge the performance of large language models on knowledge graph-related tasks. Our findings suggest that, with well-designed prompts containing sufficient detail and examples, large language models can effectively contribute to knowledge graph construction tasks.
Keywords
Introduction
Knowledge graphs (KGs) are defined as graphs of data intended to accumulate and convey knowledge of the real world (Hogan et al., 2021). Their nodes represent entities of interest, and edges represent potentially different relations between these entities. KGs are integrated into various systems to enhance their abilities of storing and processing information.
Task-oriented dialogue (TOD) systems, alongside chatbots, are conversational agents possessing the ability to engage in natural language dialogues with human users. Unlike chatbots, TOD systems aim to solve user-specific tasks within certain domains, while using a given ontology that serves as their task-related knowledge. Typically, such systems are composed of four modules: natural language understanding, dialogue state tracking, dialogue policy, and natural language generation (H. Chen et al., 2017). The first two aim at understanding the user’s utterance, while the latter ones focus on generating a system response. An example of such a system is presented in Figure 1. State-of-the-art methods leverage neural network-based models’ ability to handle all tasks simultaneously in an end-to-end fashion (Z. Chen et al., 2022; Wu et al., 2020).

General Framework of a Pipeline Task-Oriented Dialogue System (Z. Zhang et al., 2020).
In our previous work (Iga & Silaghi, 2023b), the objective was to tackle the knowledge graph construction (KGC) and knowledge graph reasoning tasks by developing a TOD system that could extract relevant information from a conversation with a human user guided by a predefined ontology, and perform four key operations known as Create–Retrieve–Update–Delete (CRUD) on a domain-specific KG. The acronym CRUD refers to the four basic operations that can be executed against persistent storage, such as relational or object databases, or other types of knowledge base, such as KGs, to create, maintain, or update them. To keep track of the conversation’s context, a discourse-specific KG was maintained, which enabled concurrent threads of conversation within a single discourse, and also acted as a proxy that validated data before persisting it into the main KG.
Nonetheless, our TOD system (Iga & Silaghi, 2023b) relied on input text template-matching rules, constraining the authenticity of dialogues and hindering its adaptability to process novel concepts beyond the predefined ontology. Hence, a subsequent study (Iga & Silaghi, 2023a) explored fine-tuning Bidirectional Encoder Representations from Transformers (BERT), a pre-trained neural network model, to infer user intent and extract relevant entities directly from the input, eliminating the need for rigid templates. While integrating a deep learning model into the TOD system architecture showed promising results, it did not fully overcome the earlier limitations.
Therefore, in our current work, we study the use of large language models (LLMs) to solve the KGC task, in the context of a TOD system. An LLM is a type of machine learning model capable of processing and understanding texts, making it highly effective for natural language processing tasks. Recently, deep learning models based on the transformer architecture have become very effective. This type of model consists of billions of parameters, trained on vast amounts of data in order to understand the semantics of words in texts. The literature (Han et al., 2024; Mihindukulasooriya et al., 2023; Pan et al., 2024; J. Zhang et al., 2021; Zhu et al., 2024) identified a potential synergy between KGs and LLMs, as KGs can enrich LLMs by providing external knowledge for inference and explainability, while LLMs, in turn, can address KG-related tasks through natural language prompts. Our goal is to leverage LLMs to extract facts from natural text and automatically integrate these facts into the processing pipeline of a TOD system.
Our experiments explore LLMs for static KG contexts. Three well-established models are used: Mixtral-8x7b-instruct-v0.1 1 (Jiang et al., 2024), GPT-3.5-Turbo-0125, 2 alongside one of the most advanced Generative Pre-Trained Transformer (GPT) models, the GPT-4o 3 version, each possessing different properties. Communicating with such models involves the use of prompts, which are instructions in natural language structured in a way that enables the model to accurately interpret the user’s intent. To assess LLMs capabilities of solving the aforementioned KGC task, we develop multiple hand-written prompts and also ask each model to rephrase them to increase their clarity. Each prompt belongs to a level defined by the TELeR taxonomy (Santu & Feng, 2023), including well-established techniques, such as Direct Prompting (DP), In-Context Learning (ICL), or Chain of Thought (COT), under zero- and one-shot contexts. To illustrate an appropriate application scenario, we introduce TODSet, a two-fold dataset, by extracting sample phrases from the training phase of our TOD system (Iga & Silaghi, 2023a). The two splits have a different level of difficulty, such that the harder one includes test cases that require reasoning steps that are not explicitly mentioned in the prompts. This approach allows us not only to evaluate the capability of LLMs in addressing the KG-specific tasks, but also to investigate their synergy with TOD systems. Finally, we report the recall and triple F1 scores (Ghanem & Cruz, 2024; Han et al., 2024) of each LLM, under two measurement paradigms: strict and flexible.
Our research makes the following contributions: (i) We assess the performance of three prominent LLMs, one open-source and the other two proprietary, for the KGC task. This evaluation involves employing various prompts, either defined by humans or rephrased by LLMs themselves, across different levels of complexity. We utilize three distinct prompting techniques (DP, ICL, and COT) within two data contexts (Zero-Shot and One-Shot), yielding valuable insights into the capabilities of a robust LLM of performing such tasks. Performance is measured within two paradigms: strict and flexible, shedding light on the challenges encountered during post-processing. (ii) A novel and flexible metric is designed to positively evaluate any information generated by the LLM that can be automatically integrated into the TOD system pipeline with the aid of additional post-processing steps. (iii) We introduce TODSet, a customized two-fold dataset tailored to gauge the performance of LLMs on the KGC task, featuring varying levels of difficulty. (iv) The feasibility of integrating such models into a domain-specific ontology-enhanced TOD system is investigated by extracting and utilizing test phrases specific to its context.
This paper extends our previous work (Iga & Silaghi, 2024) by more precisely defining the preliminary conditions, updating the related work section to include recent and relevant studies, formally introducing the flexible measurement paradigm, and evaluating performance on an additional dataset with a more complex ontology. It also presents more detailed results, enabling deeper analysis, including insights into how well the evaluated LLMs handle tasks of varying difficulty.
The paper evolves as follows: Section 2 describes the related work about solving the KGC task with LLMs, Section 3 presents our methodology, describing the ingredients of experiments, Section 4 presents and discusses the results, while Section 5 wraps up the paper with concluding remarks.
KGC aims to build a structured representation of knowledge within a defined domain from a free text by identifying entities and their corresponding relationships. The process generally involves several stages in a standard pipeline approach: (1) entity discovery, (2) co-reference resolution, and (3) relation extraction. Recent methods also include end-to-end KGC, which constructs a complete KG in a single step with the help of LLMs (Pan et al., 2024).
Many non-LLM techniques address the task by solving the first three stages rather separately. However, these stages could also be combined into a single process, known as KG completion. This task aims to deduce the absent information within a specified KG (Pan et al., 2024), drawing from input text or pre-existing knowledge. Ji et al. (2022) present multiple solutions for KGC utilizing embedding-based models such as TransE (Bordes et al., 2013), relation path reasoning exemplified by the Path-Ranking Algorithm (Lao & Cohen, 2010), reinforcement-learning path finding (Xiong et al., 2017), rule-based reasoning such as embeddings by jointly modeling knowledge and logic (Guo et al., 2016), and meta relational learning (Xiong et al., 2018) utilizing relational graph convolutional networks or long short-term memory. Similar insights are shared by J. Zhang et al. (2021), categorizing them into neural, symbolic, and neural–symbolic approaches.
The aforementioned studies emphasize the usage of neural networks, logic networks, logic rules, or mathematical operations to address KGC. Interestingly, none of these endeavors particularly delves into the utilization of LLMs. Wei et al. (2023) advocate for a multi-stage dialogue with ChatGPT to extract pertinent information from input texts, based on a predefined schema. The authors solve the KGC task by dividing it into Named Entity Recognition, Relation Extraction, and Event Extraction. Zhu et al. (2024) experiment with ChatGPT and GPT4 for KGC in a pipeline manner, determining that while these models lag behind state-of-the-art fine-tuned pre-trained language models (PLMs) in a zero/one-shot paradigm for construction, their reasoning capabilities often match or surpass those of state-of-the-art models. Nevertheless, the comparative efficiency of an LLM versus a specialized PLM remains ambiguous. The authors also tackle the end-to-end KGC task by designing an interface where an artificial intelligence (AI) assistant and AI user collaborate in a multi-party setting to complete the specified task. Their findings show that LLMs can solve the KGC task on their own when a multi-turn interaction takes place. Maintaining the end-to-end KGC paradigm, Han et al. (2024) introduce PiVE, a prompting technique where a ChatGPT-based LLM extracts facts from input texts, while a smaller fine-tuned PLM iteratively verifies and supplements its responses. They demonstrate that the verifier module is the key to preserving the correctness of LLMs. Khorashadizadeh et al. (2023) explore the capabilities of foundation models such as ChatGPT to generate KGs from the knowledge it captured during pre-training, as well as the new text provided to it in the prompt, grounded by several research questions. Their results show promising use cases for such models. Trajanoska et al. (2023) experiment with a specialized pre-trained model (REBEL) and ChatGPT to automate the extraction of KGs from news articles, concluding that ChatGPT, when prompted adequately using enough information and guidelines, can solve the task with promising results. Ghanem and Cruz (2024) evaluate various LLMs using prompts under Zero- and Few-Shot paradigms, with or without fine-tuning them beforehand. The authors report metrics including triple matching F1 (TF1), GF1, and Graph Edit Distance introduced in Han et al. (2024), while also defining new metrics for hallucination and information omission.
As opposed to the above mentioned literature, we emphasize the use of a well-defined ontology to guide the extraction of facts and, subsequently, KGC. This approach stands in contrast to methods that either lack background information or rely solely on small, predefined lists of specific types and relationships. Moreover, our research increases the number of textual inputs, expanding the generality of our conclusions, sharing similarities with Mihindukulasooriya et al. (2023) and Polat et al. (2025). Mihindukulasooriya et al. (2023) distill two datasets specifically for KGC from other well-established sources and create additional metrics to test two LLMs, Vicuna-13B and Alpaca-LoRA-13, on the aforementioned task, resulting in a benchmark for KGC. However, unlike their approach, our datasets are manually curated, and we utilize an in-house designed flexible paradigm to evaluate an LLM’s performance from a different perspective, while testing models of various types and sizes. Polat et al. (2025) experiment with different prompting techniques and paradigms, from Zero to Few-Shot and DP to COT for the extraction of KGs from free input text. Different from us, prompts are enhanced with extra information obtained via various retrieval augmented generation approaches, while the evaluation of the output is done using SPARQL queries to Wikidata. In our paper, we intend to assess the performance of the LLMs on the KGC task solely based on the user’s input text, without helping the LLM with additional contextual information.
Consequently, our experiments test the capacity of a proprietary LLM—namely GPT, with two versions: GPT-3.5-Turbo-0125 and GPT-4o on the KGC task. Furthermore, an open source LLM is included—Mixtral-8x7b-Instruct-v0.1 (Jiang et al., 2024), to facilitate research on open-source models, given their greater adaptability and cost-effectiveness compared to proprietary alternatives. Another difference from the literature mentioned above is that our prompts are more diverse and easier to follow, ranked according to the TELeR taxonomy (Santu & Feng, 2023). We introduce flexible metrics to gauge additional post-processing efforts. Finally, we also test the possibility of integrating an LLM with an ontology-enhanced TOD system to sharpen its natural language processing and KG-related capabilities by utilizing sample phrases from its training routine, resulting in two datasets, differentiated by their level of difficulty.
Methodology
This section introduces our methodology used throughout this paper. We describe preliminary definitions of key concepts, prompt engineering steps, the ontologies used to anchor the knowledge of the LLM, the format and distribution of the datasets, and metrics measurement paradigms.
Preliminaries
A KG typically represents information as triples (or facts). Let KG denote the graph, where each triple

The KGC task, as outlined in Section 2, involves extracting entities and relationships under the format of triples that are needed to build or update a KG. Typically, a dedicated system or model performs this task. In our case, an LLM serves as the extractor of the target triples—deemed as golden labels, based on a predefined ontology. The model’s input is a prompt containing the task description (
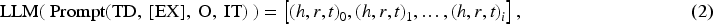
The input text that is fed to an LLM is usually referred to as a prompt. It may have several parts, such as the system message, which offers task-specific guidelines to the model, the input data that should be processed, and optionally some examples of how to solve the task against some different input text. Three important paradigms are usually employed when designing prompts (Zhao et al., 2023): Zero-, One-, and Few-Shot. Zero-Shot does not add any example to the input prompt, testing the model’s capability to understand and follow the provided guidelines. One-Shot includes exactly one example of how the task should be solved against some different input data, serving as a blueprint to the model. Intuitively, Few-Shot refers to the addition of multiple relevant examples such that the tested model has a wider perspective on how the task can be solved in different scenarios.
After selecting the paradigm, one should decide on the prompting technique (Zhao et al., 2023). The current work employs three main approaches, as follows: DP refers to a prompt that only comprises the task description and the input to work on, ICL adds relevant examples of solutions to the given task on different input data (One- or Few-Shot), and COT expands the prompt with a step-by-step reasoning process that breaks down the main task into smaller, more manageable ones that sequentially lead to the desired solution.
To test the capacity of a model to solve a task, our work follows the guidelines of Santu and Feng (2023) by assigning a level to each version of a prompt. Specifically, we utilize levels 1 through 4, while the last one is further divided into 4.1 and 4.2 to accommodate both ICL and COT variations of the prompt.
The first level prompt is exemplified in Figure 2. It sets the model’s role as a KG expert, followed by instructions on the provided ontology. Subsequently, the task at hand is outlined, along with formatting guidelines. Specifically, each instance has to be identified by an ID composed of the name of its class type concatenated with the “1” digit. An alternative to this approach would be to directly use as ID the words in the text that triggered the extraction. However, this would not guarantee that the model successfully followed and understood the provided ontology, as opposed to our approach, where each instance type can be checked by analyzing its ID. In addition, the “1” digit is chosen to simplify the creation of the identifier, allowing the model to focus on the semantic content of each triple. Another important aspect mentioned within the prompt is that the model should create different instances for every detected concept and reference them through their IDs. Finally, the required output pattern is presented, and the target ontology is attached. Level 2 adds a directive about the addition of the rdf:type relationship. Although such triples should also be extracted from the first level, this was only explicitly stated from this level to test whether models are capable of extracting triples that are implicitly stated. It then evolves into level 3, where the only change is the text’s format, as it is transformed into a detailed bullet list of sub-tasks to be performed. All these levels adhere to the Zero-Shot paradigm, while levels 4.1 and 4.2 emulate ICL and COT, respectively, in a One-Shot manner. Depending on whether the target text has extractable triples or not, either an example with no output triples or one with existing golden labels is included. Examples of prompts built with each of these techniques are available in Appendix A 4 in the paper’s repository. Moreover, as suggested in Pan et al. (2024), each model is asked to rephrase the provided hand-written system messages in such a way that it better understands the given guidelines. Therefore, two types of prompts are available: hand-written and model-rephrased.

The Level 1 System Prompt.
To test the model’s capacity of solving the KGC task, the TODSet dataset is introduced, which features input texts with different levels of difficulty. Additionally, inspired by Mihindukulasooriya et al. (2023), we adapt their DBpedia-WebNLG sports ontology and dataset to our format, to further test models in a more complex scenario. Throughout the paper, this dataset will be referred to as the FootballSet.
TODSet base itself on the ontology introduced in our previous research (Iga & Silaghi, 2023b) and described in Figure 3. It comprises three classes: Project, Employee, and Status, along with six relationships connecting them—such as hasManager and hasStatus or associating classes with literal values—like hasName, hasRole, hasClass, and hasCode. The ontology is described in resource description framework (RDF), using the Turtle syntax.

TODSet Ontology.
The input phrases are sampled from the training schedule of the TOD system developed in Iga and Silaghi (2023b), where the user’s purpose was to solve different CRUD operations based on the concepts described in the ontology presented above. Only phrases that correspond to the intent Create (Insert) were selected, as they bring in novel information relevant for the KGC task. However, the subject of some phrases was further changed to an out-of-distribution (OOD) class type, and some phrases do not even include the intent Insert (labeled as w/o Insert). These phrases do not contain extractable triples and are further labeled as having None class type, to test whether a model actually follows the content of the predefined ontology. The texts are further classified based on their expressivity, as conveying: (i) explicit information where intent, class type, associated relationships, and values are clearly articulated and (ii) implicit information where additional reasoning steps are required to identify the necessary details. In addition, some phrases are labeled as misleading, where their content is altered to emulate real-world scenarios in which texts contain (iii) grammatical errors or (iv) unknown vocabulary words (UVW) or ontology concepts (i.e., the None class type). Unknown vocabulary words are such constructions that have no equivalent in the real world. For example, as the relationship hasClass requires a programming language, we include words that do not resemble existing ones, such as Dandy, Laclut, etc. These phrases are also labeled as UVW.
Table 1 presents examples from each category. More details on how texts are classified are available in the project repository. 5 In the end, TODSet is divided into two: templates easy (TE) and templates hard (TH). The first split includes explicit and misleading text types with a lower number of implicit ones, while the second one benefits from an increased overall difficulty, as well as more implicit-type texts. Table 2 presents the distribution of texts by class type, in each split.
TODSet—Input Text Examples and Their Types.

TODSet—Distribution of Texts by Class Type.

FootballSet includes texts about football clubs, players, managers, leagues, or countries. It is based on an ontology provided by Mihindukulasooriya et al. (2023), which was slightly modified to fit our framework. It comprises 14 classes and 24 relationships among them, visible in Figure 4. Forty-eight input texts were sampled from their train, test, and validation files, while the other 27 were manually created. This set only contains explicit and implicit information phrase types, as we wanted to keep as much as possible from the original set, without altering their textual content. Examples can be seen in Table 3, while Table 4 presents the distribution of texts by class type.

FootballSet Ontology.
FootballSet—Input Text Examples and Their Types.

FootballSet—Distribution of Texts by Class Type.

Each text is associated with a set of golden labels, which are the target triples that can be extracted from the input text. Additionally, we introduce two new types of triples: alternative and false positive accepted ones. Both are useful to underline the power of the flexible metrics paradigm, introduced in Section 3.4.
The alternative triples set includes facts that convey the same semantic meaning as some target triples but do not adhere to the required format. For instance, as noted in Section 3.2, when a relationship exists between two concepts, both must be identified by an ID. However, if the model uses text fragments from the input instead of IDs to refer to these concepts, the resulting triple can still be considered correct, since it refers to the same entities, even though it does not follow the specified format. An example can be visualized in Figure 5. The text mentions a Project instance that is related to an Employee one through the hasManager relationship. Therefore, the model has to create IDs for each one and construct a triple such as (Project1, hasManager, Employee1). However, it might only generate an ID for the main instance of the text (i.e., the project) and link it with the employee using the given name, such as (Project1, hasManager, Robert). Semantically, both triples encapsulate the same information, and with the right post-processing steps, one can accept both forms of extraction.
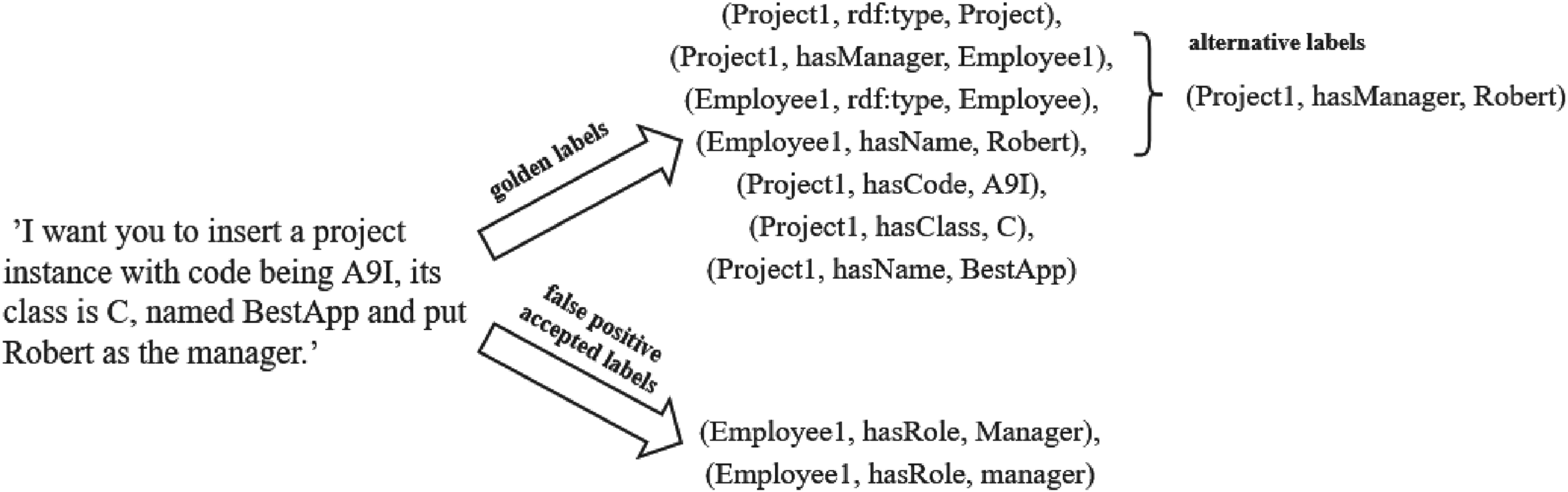
An Example of an Input Text and Associated Extractable Triples.
The false positive accepted set allows a predicted triple that is outside the golden labels (i.e., a false positive) to be considered as correct if it follows the provided ontology and no additional background information contradicts it. For example, in Figure 5, the prompt does not specifically mention what Robert’s role (i.e., job) is, but one could infer from the input text that he is the manager, as he is part of the hasManager relationship. It is widely acknowledged that extracting triples from text could yield a variety of results depending on the expertise of the annotator; therefore, we should allow LLMs to exhibit such variability.
Several metrics are used to measure a model’s performance, such as precision, recall, and F1 score as (Ghanem & Cruz, 2024; Han et al., 2024). Our evaluation is conducted under two paradigms: strict and flexible metric measurements. This subsection outlines the specific metrics used in this study.
For each text, the LLM produces a list of
Under a strict criterion, metrics are calculated in a standard text extraction manner, by counting how many predicted triples from
However, LLMs may not follow the required format, which directly discards their output under strict criterion without any evaluation of the predicted triples content. Moreover, the KGC task is inherently difficult, as the extraction of triples from a given text necessitates a sequence of reasoning steps such as the identification of possible entities and connections between them, while some information may not even be explicitly mentioned. Additionally, as described in Section 3.3, some triples may be deemed true if no background information is provided, and others might be counted as correct even though they do not follow the required format, but encapsulate similar semantic information with some of the target ones. Therefore, we introduce the flexible metric paradigm that allows the LLM to produce mistakes that can be corrected in post-processing steps, while imposing certain user-defined penalties. Using this approach, models that might not be as precise as more elaborate ones but require fewer resources can be positively evaluated and taken into consideration to solve the KGC task.
To accommodate this, for each triple
Under the flexible measurement paradigm, certain penalties are included in the hit score of a triple that could be considered valid, even if it does not exactly follow the given prompt instructions. Therefore,
To summarize, we have:

It is important to note that the penalties and their corresponding values used in this work and presented below are tailored to our specific prompt formulation and incorporate our expert knowledge of the application domain. They were designed to avoid overly harsh punishment of the models while still effectively distinguishing their inaccuracies. We stress that both the penalty categories and their values are not fixed and can be adjusted to suit users’ specific requirements. Future research could explore defining a formal penalty selection procedure that would enable automatic calibration based on the downstream task in which the constructed KG is applied.
Format Penalties at the Level of the Whole Output. The user may request that the LLM’s final output follow a global format. In our case, the prompt demands a reply that is composed solely of a list of triples. Therefore, we consider a penalty of
Format Penalties at the Triple Level. The prompt asks not to include the full internationalized resource identifier (IRI) of an entity (i.e., without the namespace) to reduce the number of tokens and the possibility of confusion between the same concepts, shifting the focus to the semantic content of the output. Each addition of IRIs is penalized with
Content Penalties refer to penalties related to the information encapsulated within a triple. Specifically, the model is asked to construct a simple ID for each extracted entity—the capitalized name of its class concatenated with “1.” A deeper analysis of the model’s output underlined a tendency to replace the number “1” with another single digit. Thus, if altering the final digit of a predicted identifier to “1” signifies correctness of the whole triple, the model is subjected to a penalty of
As previously noted, certain alternative triples to the designated correct ones can be regarded as valid. Specifically, in Figure 5, concerning the relationship marked as hasManager between a Project and an Employee instance, if a model predicts that the value of the object is directly the employee’s name, instead of creating an Employee instance and assigning its type and name, it will count as correct. However, there is an implicit penalty, as the model did not output two other necessary triples, deviating from the prescribed ontology and guidelines. Furthermore, some false positive triples can be deemed true in the absence of background knowledge (false positive accepted triples), such as inferring the role of an employee as a manager from the relationship hasManager. The flexible paradigm will not consider them wrong during the calculation of the model’s precision, thus increasing its value. Any of these triples may be further penalized for having content mistakes, as mentioned above.
The evaluation metrics are calculated according to the following widely known formulas:



This section presents and discusses the obtained results, aligned with the research questions guiding this study.
The experiments were carried out on Google Colab, using a virtual machine equipped with two Intel Xeon CPU 2.20 GHz processors. Three models were tested, namely Mixtral-8x7b-Instruct-v0.1, GPT-3.5-Turbo-0125, and GPT-4o. 6 Mixtral is an open-source model, leveraging the Mixture of Experts (Jiang et al., 2024) architecture, consisting of eight sub-networks each of 7B parameters, accounting for a total of 56B parameters. GPT-3.5-Turbo-0125 is a well-known proprietary model that represents a fine-tuned version of GPT-3, consisting of 175B parameters. GPT-4o boasts over 200B parameters, being one of OpenAI’s best performing model. For Mixtral-8x7b-Instruct-v0.1, we used the HuggingFace Serverless API endpoint, whereas for GPT-3.5-Turbo-0125 and GPT-4o queries were directed to OpenAI’s official API.
Each experiment was iterated three times, regardless of the dataset. On TODSet, each run lasted approximately 120 min, with Mixtral consuming about
During the evaluation, an extra post-processing step was needed for the GPT models. Due to their ability to generate JSON-formatted output, the response was surrounded with a specific tag (i.e., “json…”). One solution is to include a guideline in the prompt to avoid this behavior, but very rarely, around
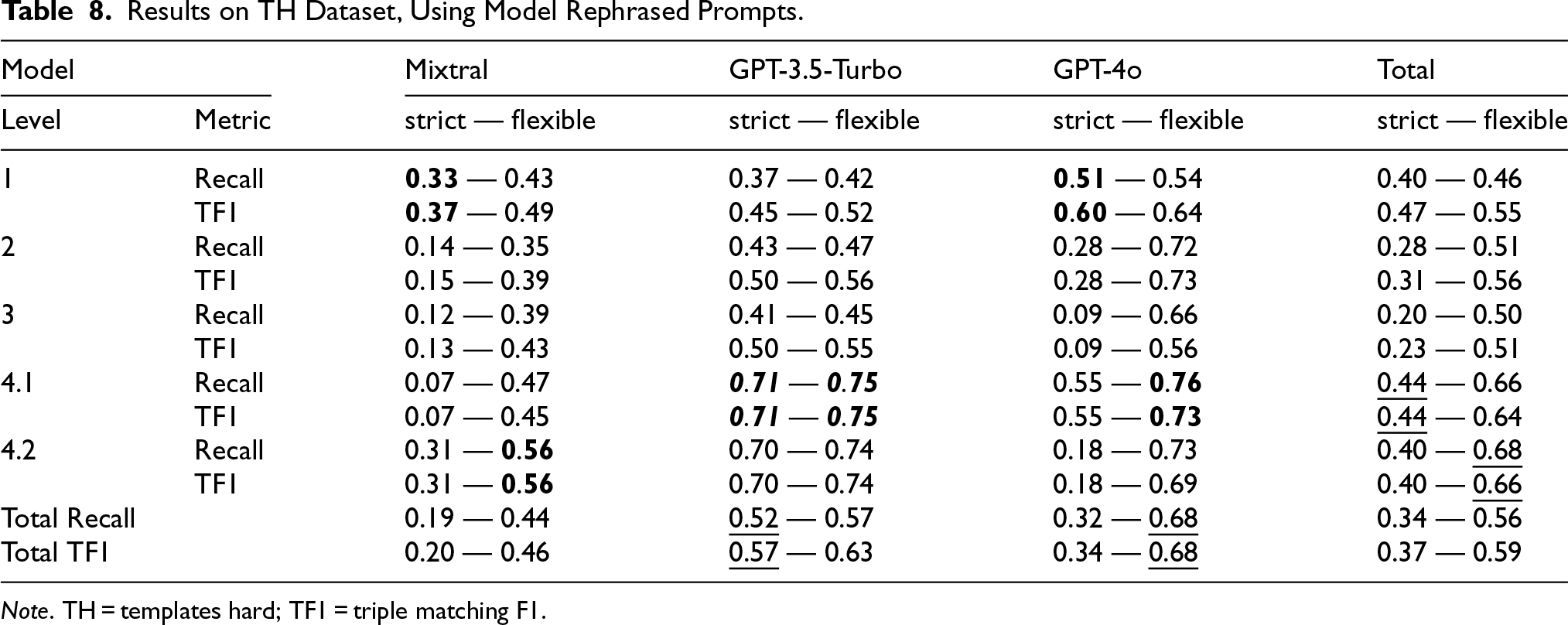
Regarding TODSet, Tables 5 to 8 display the results per prompt level and model, considering both strict and flexible metrics measurement paradigms. The first two tables focus on the TE dataset, while the latter ones on the TH dataset. Tables 5 and 7 display the results for the hand-written system prompts, while in Tables 6 and 8, each model had to rephrase the system prompts beforehand. Tables 9 and 10 present class-wise performance across both dataset splits, based solely on metrics from hand-written prompts, which outperformed model-rephrased alternatives, as shown in the former tables. Figure 6 displays the recall and TF1, under the flexible paradigm for each model per phrase type as described in Table 1, on the TODSet dataset, using hand-written prompts. Table 13 highlights an in-depth analysis of the “MS2” category from Figure 6, given three phrase sub-types. Table 14 outlines the results of each model when the link between a Project and an Employee instance is referenced through an ID or role, compared with standard human names.

Recall and TF1 for each model per phrase type under the flexible paradigm on the TODSet dataset using hand-written prompts. Note. TF1 = triple matching F1; EI = explicit information; II = implicit information; MS1 and MS2 = misleading information types 1 or 2.
Results on TE Dataset, Using Hand-Written System Prompts.

Note. TE = templates easy; TF1 = triple matching F1.
Results on TE Dataset, Using Model Rephrased Prompts.

Note. TE = templates easy; TF1 = triple matching F1.
Results on TH Dataset, Using Hand-Written Prompts.

Note. TH = templates hard; TF1 = triple matching F1.
Results on TH Dataset, Using Model Rephrased Prompts.
Note. TH = templates hard; TF1 = triple matching F1.
Results on TE Dataset, Using Hand-Written Prompts, on Class Types.
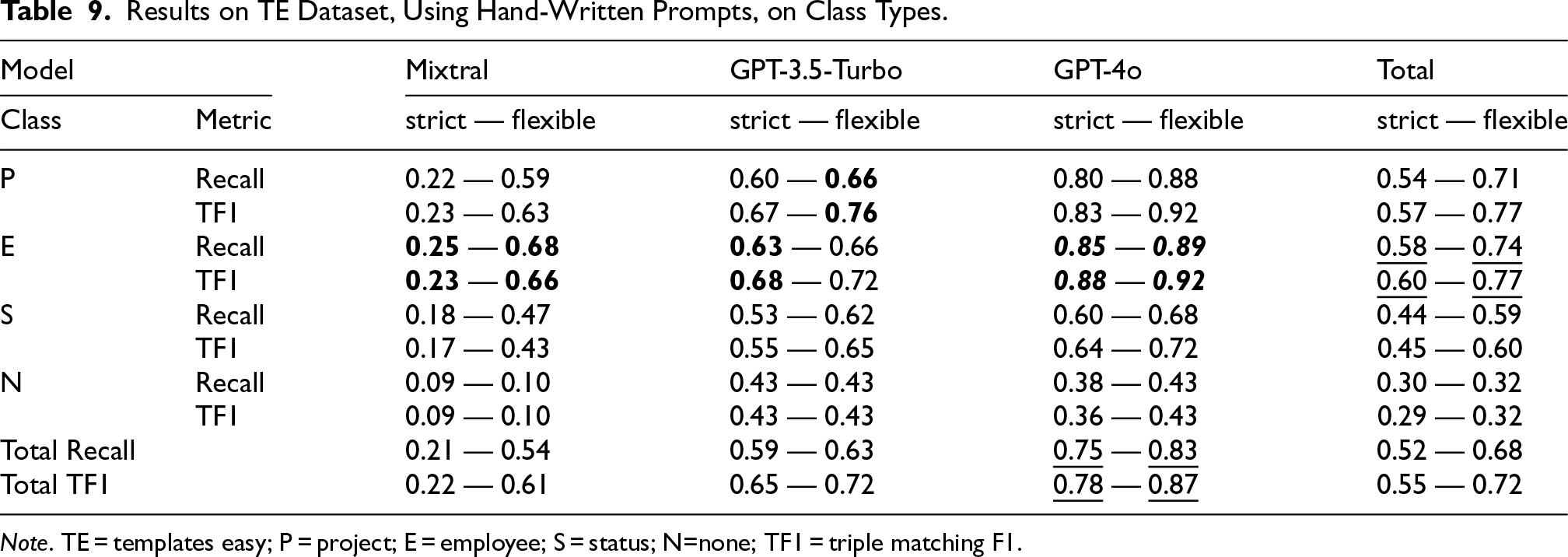
Note. TE = templates easy; P = project; E = employee; S = status; N=none; TF1 = triple matching F1.
Results on TH Dataset, Using Hand-Written Prompts, on Class Types.

Note. TH = templates hard; P = project; E = employee; S = status; N=none; TF1 = triple matching F1.
Regarding the FootballSet, Table 11 shows the metrics per prompt level and model, considering both strict and flexible metrics measurement paradigms, using hand-written prompts. Table 12 presents the class-wise performance.
Results on FS Dataset, Using Hand-Written System Prompts.

Note. FS = FootballSet; TF1 = triple matching F1.
Results on FS Dataset, Using Hand-Written Prompts, on Class Types.

Note. FS = FootballSet; ST = SportsTeam; P = person; A = athlete; C = country; L = league; Pl = place; TF1 = triple matching F1.
In-Depth Analysis of the “Misleading Information Type 2” (MS2) Phrase Type (From Table 1).

Note: Phrases include OOD class types, basic tasks “w/o Insert” intent, or unknown vocabulary words (“UVW”).
Results, Under the Flexible Paradigm, of Hand-Written Prompts by Each Model on the Phrases That Include Employee Instances Referenced by an ID or Their hasRole Relationship Value Instead of the hasName one; Only Available in the Templates Hard (TH) Dataset.

The best result for any model per level or class is highlighted in
Elaborate Instructions Without Examples do not Necessarily Yield Better Results. Upon analyzing both types of prompts across all levels, it appears that augmenting the prompt with more information without examples does not consistently improve performance. Level 3 prompts, when rigorously evaluated, exhibit a decrease in recall and TF1 scores compared to levels 1 and 2. When evaluated using more flexible metrics, the discrepancy diminishes. This can be attributed to the inclusion of explanatory text in responses, as models tend to replicate the input text, which is more elaborate, thus not following the provided guidelines under the strict evaluation. Interestingly enough, on TH, Mixtral-8x7b yields its best scores at the level 1 prompt, when strictly measured.
ICL and COT Prompting Techniques Lead to the Best Results. Most of each model’s best results happened when prompted at levels 4.1 and 4.2, no matter the dataset or prompt template. Only GPT-4o had its best results for strict metrics at the first level when prompts were model-rephrased, which could be attributed to poor paraphrasing for the latter levels. It is no surprise that such models work best when an adequate output example is given, as the literature (Santu & Feng, 2023) suggests. However, since Mixtral-8x7b sometimes provided explanations for its output, erroneous reasoning steps are still noticeable, especially in cases where the input text contains a class type that is not present in the ontology. Thus, despite the fact that GPT models exhibit this behavior less frequently, LLMs still have significant room for improvement in terms of reasoning capabilities.
Asking Models to Rephrase the System Prompt Might Generally be a Good Idea for Mixtral-8x7b. Some experiments in the literature (Pan et al., 2024) ask LLMs to formulate prompts for a given task. Inspired by it, we ask the LLMs to rephrase our manually written prompts to better align with their capabilities. Compared to hand-written prompts, on the TODSet, Mixtral-8x7b benefits the most under rigorous evaluation, with an average increase of 7% for each recall and TF1 score. GPT-3.5-Turbo appears to conserve its behavior, signaling a decrease of only 2%. Surprisingly, GPT-4o exhibits a significant decrease in performance when it paraphrases the input prompts. On average, it reduced its performance by 33% for both metrics, with third-level prompts being the worst affected. Nonetheless, it is promising to see the open-source model enhancing its output by closely adhering to the provided system prompt.
Discussion About the Influence of Texts and Ontologies Structure
Implicit Reasoning Poses Challenges for LLMs. TH dataset contains text cases that require the LLM to discover implicit connections between the mentioned entities. As concluded by the results presented in Tables 5 to 8, under flexible metrics, Mixtral 8x7b achieves at best a recall and TF1 scores of 56% on the more difficult dataset, which is 17% lower than its performance on the easier one. GPT-3.5-Turbo narrows this margin, reducing from a peak recall and TF1 of 89% to 78%. The same behavior is observed with GPT-4o, as it falls from 91% recall and TF1 score to around 76% and 74%, respectively. Figure 6 displays the differences in a compact form, on the TODSet dataset, based on each phrase’s type, under the flexible paradigm. Thus, it shows a decrease in performance when phrases require extra reasoning steps, that is, Implicit Information, compared to simple, direct ones, that is, Explicit Information. For example, all models reduce their recall, on average, by 12%, and their TF1 score by 13%.
LLMs Only Appear to Adhere to the Ontology. While the results in Tables 5 to 10 and Figure 6 demonstrate strong performance across various prompt levels, classes, and phrase types, suggesting that LLMs may grasp the provided ontology, closer analysis of the misleading information type 2 (MS2) category from Figure 6 raises concerns. This category had the lowest scores, with an average recall of 48% and a TF1 score of 53% across the three models. Although these results may seem acceptable at first glance, a deeper look at phrase types reveals flaws in LLMs behavior. All models performed reasonably well when encountering UVW text types, reaching 86% recall using GPT-4o, as can be noticed in Table 13. However, phrases involving basic tasks without the Insert intent (e.g., “generate all the reports you have”) posed an issue for Mixtral-8x7b, which attempted to extract triples instead of outputting “None.” The most significant challenge was presented by OOD class types, such as the example in the last row of Table 1, where none of the models followed the prompt or ontology. Instead of verifying the detected type against the ontology and outputting “None,” 98% of the time, they incorrectly treated it as valid. This suggests that LLMs do not truly reason, but are highly adept at mapping input text to the target output when the cases are general enough.
Elaborate Ontologies are More Difficult to Grasp. The TODSet dataset is based on a simple ontology of only three concepts and six relationships. However, the FootballSet dataset constructs its texts on a more elaborate one, comprising 14 concepts and 24 relationships among them. This leads to significantly lower results for all tested models. Under the flexible paradigm on FootballSet, the overall recall was 40%, and the TF1 score was 45%, with 26.5% lower than the metrics on the TE split of TODSet. When comparing the top scores on both sets, recall and TF1 reduced from 91% to 65%, highlighting the increased difficulty of understanding more elaborated ontologies.
Complex Class Types do not Imply More Difficult Reasoning. Analyzing both Tables 9 and 10, all models seem to perform better on the Project type, compared to the other three classes. It may be attributed to the inclusion of more difficult phrase types for this class, combined with a notably lower number of examples for the other three. Despite this difference, the results for the Project type are still significantly higher than for the other ones, although it requires the extraction of five relationships, compared with two for Employee and one for Status. For example, under the flexible paradigm, the average recall and TF1 score are 70% and 75% for the Project class, while for Employee, the models only achieve 59% and 63%. This suggests a potential hypothesis regarding LLM behavior when handling complex versus simpler classes. Finally, the recall and TF1 score on the Status class are 53% and 54%, respectively, 6% and 9% lower than for the Employee class. This might indicate that LLMs leverage internal knowledge for task resolution, particularly since Employee instances often involve familiar person names and roles, which are more likely included during LLM training, unlike the more variable nature of Status instance names (e.g., “in-progress”).
The same behavior is seen on the FootballSet ontology, as presented in Table 12. The ontology’s most complex class is SportsTeam, part of 14 relationships, followed by Athlete and Country with 7, Person with 6, and Place and League with 2. SportsTeam has the best results compared to any other type, with a recall of 46% and TF1 score of 52%, under a flexible paradigm. Moreover, it seems that all results are in accordance with the class complexity, with only one exception, as the Athlete concept registered lower metrics than Person, although it is part of more relationships. A deeper analysis reveals that the Athlete class had more difficult text types, which led to lower scores.
The Underlying Semantics of Words Pose a Challenge for LLMs. The Project and Employee classes are linked through the hasManager relationship, and most test phrases reference an employee by name, requiring the creation of an additional Employee instance, as described in Section 3.4. Such tasks are trivial for high-performing models, as names can be linked with persons, which can be seen as a supertype for the Employee class. With their complex training schedule, their dataset probably contained such cases. However, when we start referencing such instances by their role (i.e., a job type), their performance starts to decline, although not drastically. As shown in Table 14, GPT-4o maintains 83% recall and an 88% TF1 score, close to its overall performance (85% recall and 90% for TF1 in Table 10, Project class type). However, performance drops sharply when using terms likely absent from training, such as an ID (e.g., Employee123), with GPT-4o achieving just 46% recall and 54% for TF1. This suggests that referencing class instances with unusual terms, such as IDs, challenges LLMs to grasp deeper semantic relationships.
Discussion About LLMs Performance
Mixtral-8x7b Rarely Follows the Required Output Format. The two metric measurement paradigms offer valuable insights into the model’s capacity to follow the given prompts. While GPT 3.5-turbo and GPT-4o exhibit minimal disparity between the two perspectives, Mixtral-8x7b rarely produces texts that align with the specified template. Common errors include the addition of the full IRI of an entity or explanatory text, as evidenced by the 0 scores at the 4.2 level in Tables 7 and 11, scores that otherwise notably increase when formatting mistakes are allowed.
Top-Tier LLMs Effectively Address Grammatical Errors. Figure 6 highlights the MS1 category, where phrases contain misspelled words, as shown in the third row of Table 1. While Mixtral-8x7b achieves only 55% recall and a 63% TF1 score, GPT models handle most errors and even correct known class names (e.g., “Porject” to “Project”). For instance, GPT-4o reaches 86% recall and a 91% TF1 score under the flexible paradigm.
GPT-4o is More Consistent and Performant, While GPT-3.5-Turbo Achieves the Best Results. Despite showing fluctuations in results when it rephrased the prompts, GPT-4o was the best overall model. Based on Table 5, on the TE dataset, under strict measurements, it had 75% recall and 78% TF1 score, almost four times more than Mixtral-8x7b and with 13.5% more than GPT-3.5-Turbo. The same behavior can be seen on the FootballSet dataset, where GPT-4o had 48% recall and 52% TF1 score, with 34% more than Mixtral-8x7b and 10% more than GPT-3.5-Turbo. It can be interpreted that GPT-4o is more reliable than the other two models, regardless of the prompt level. However, GPT-3.5-Turbo came close to it considering their top performances, being only 3% away from GPT-4o on the TE dataset, while surpassing it by 4% on both TH and FootballSet datasets, as it can be observed in Tables 7 and 11. Depending on the user’s objectives, while considering the model’s costs, the choice of the final model could vary.
In summary, KGC remains a challenging task for LLMs under Zero-Shot prompting. As models become better, their performance tends to increase, while shifting the focus on optimizing the costs. Moreover, when checking their intermediate reasoning steps, the LLMs show a lack of ability to follow the provided ontology. The open-source model has difficulties in conforming to the required output format. However, One-Shot contexts give promising results as LLMs excel in emulating a provided example. This implies that a less resource-intensive Few-Shot training approach could potentially boost performances, with a focus on techniques such as Retrieval-Augmented-Generation to select more suitable examples within a given prompt. Another plus is their ability to enhance their inner knowledge to detect some implicit relationships from the input text. Nevertheless, as suggested by Fill et al. (2023), presently we may use such LLMs as helpful assistants for solving such tasks, rather than ultimately faithful extractors in a pipelined system.
Conclusion
The proposed experiments showcased the ability of three leading LLMs, namely Mixtral-8x7b-Instruct-v0.1, GPT-3.5-Turbo-0125, and GPT-4o, to tackle the KGC task. The two proprietary models produced great overall results, as GPT-4o was more consistent, while GPT-3.5-Turbo achieved the best metrics on two out of the three datasets. Moreover, both of them effectively addressed input texts with grammatical errors, underlining their inherent capabilities of processing natural language texts. On the other hand, Mixtral-8x7b rarely followed the required output format; however, it benefited the most from rephrasing the system prompt. Another important aspect is that none of them were able to correctly handle OOD class types, where models should not have output any triples, thus all models only appeared to adhere to any ontology.
The variety of prompt engineering techniques used throughout the study highlighted the significance of tailoring input text to suit both the task and the specific model. Simply increasing the number of instructions did not consistently enhance performance; instead, incorporating examples through techniques such as ICL or chain-of-thought proved more effective. However, our experiments had a fixed example for every prompt, which may not always be sufficiently relevant for the model, limiting the benefits of such additions. Moreover, asking models to rephrase the system prompt showed potential for improving task comprehension in some cases, although it occasionally led to performance declines in other models. This approach should therefore be applied with care.
Key challenges arose from the structure of the input texts and ontologies. As anticipated, texts that demanded additional reasoning steps proved difficult for all models tested. Interestingly, the primary difficulty with the ontology stemmed not from the structure of its concepts but rather from the overall size of the ontology, which posed significant challenges for the models.
The flexible metrics evaluation paradigm proposed in this study enables a favorable assessment of models that produce errors amenable to correction through subsequent post-processing, thereby placing greater emphasis on the semantic quality of the generated output. Various penalties were applied depending on the type of error, related to the format or content. This perspective supports the adoption of LLMs that, while potentially less precise than others, offer the advantage of reduced resource requirements. However, penalty values were customized to our task-specific needs, restricting their broader applicability.
Finally, a two-fold customized dataset was proposed, namely the TODSet, including texts derived from the training schedule of a TOD system (Iga & Silaghi, 2023a). It includes phrases grouped into various categories that reflect different levels of difficulty and linguistic characteristics. Each text is annotated with a set of golden labels representing the target extractable triples. Additionally, two supplementary sets of triples, alternative and false positive accepted ones, were included to account for valid deviations that convey similar semantic content. This design facilitates the flexible metrics measurement paradigm. However, human experts are required to formulate such triples, limiting the size of the dataset, as it is a costly process.
Future work will prioritize the integration of additional LLMs for testing, facilitated by our interface’s seamless incorporation of new endpoints. Moreover, models will be tested with longer input phrases and more complex ontologies, closer to real-world scenarios. The flexible metrics measurement paradigm needs to have a smooth way of integrating any type of penalties, while the creation of a dataset will incorporate methods that automatically create any type of triple.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.