
Abstract
Knowledge graphs (KGs) are crucial in human-centered AI as they provide large labeled machine learning datasets, enhance retrieval-augmented generation, and generate explanations. However, knowledge graph construction has evolved into a complex, semi-automatic process that increasingly relies on black-box deep learning models and heterogeneous data sources to scale. The knowledge graph lifecycle is not transparent, accountability is limited, and there are no accounts of, or methods to determine, how fair a knowledge graph is in downstream applications. KGs are thus at odds with AI regulation, for instance, the EU’s AI Act, and with efforts elsewhere in AI to audit and debias data and algorithms. This article reports on work towards designing explainable human-in-the-loop knowledge graph construction pipelines. Our work is based on a systematic literature review, in which we study tasks in knowledge graph construction that are often automated, as well as methods to explain how they work and their outcomes, and an interview study with 13 experts from the knowledge engineering community. To analyze the literature, we introduce use cases, related goals for explainable AI (XAI) methods in knowledge graph construction, and the gaps in each use case. To understand the role of XAI models in practice and reveal requirements for improving current methods, we designed interview questions covering broad transparency topics, along with example discussion sessions using examples from the review. From practical knowledge engineering experience, we identify user requirements, propose design blueprints, and outline directions for future research.
Keywords
Introduction
To reach its potential, AI needs data and context. Without the right (amounts of) data, machine learning (ML) cannot identify patterns or make predictions. Without a deeper understanding of context, AI applications cannot engage people in a meaningful way. Knowledge graphs (KGs) (Hogan et al., 2020; Peng et al., 2023), a term coined by Google in 2012 to refer to its general-purpose knowledge base, are critical to both: they reduce the need for large labeled ML datasets (Chen et al., 2021), enhance pre-trained language models (PLMs) (Lewis et al., 2020; Yang et al., 2024), and generate explanations (Tiddi & Schlobach, 2022). KGs are routinely used alongside ML in many applications, including search, question answering, recommendation (Guo et al., 2022) and, in industry contexts, enterprise data management, digital twins, supply chain management, procurement, and regulatory compliance (Sequeda & Lassila, 2021). Moreover, with the rise of large language models (LLMs) such as GPT (Brown et al., 2020; Radford et al., 2019) and Llama series (Touvron et al., 2023, 2023?), KGs and LLMs have influenced each other in both ways: LLMs for KGs (using LLMs for KG construction and maintenance) and KGs for LLMs (using KGs to train, prompt, augment, and evaluate LLMs) (Pan et al., 2023; Petroni et al., 2019; Razniewski et al., 2021).
As AI applications produce and consume more data, engineering KGs has evolved into a complex, semi-automatic process that increasingly relies on opaque deep-learning models and vast collections of heterogeneous data sources to scale to graphs with millions of entities and billions of statements (Hofer et al., 2024; Hur et al., 2021; Tamašauskaitė & Groth, 2023; Weikum et al., 2020). The KG lifecycle is not transparent (Wolf, 2020), accountability is limited, and accounts of how biased a KG is (Abián et al., 2022) or how fair the downstream applications that use it are patchy (Fisher et al., 2020). In recent works, KGs themselves are meant to make ML models explainable (Tiddi & Schlobach, 2022) and hence facilitate such compliance tasks, but that would imply that the KG lifecycle abides by the same rules.
We argue that this is not yet the case. As referred to in our previous work (Zhang et al., 2023), questions regarding the user-centric aspects of knowledge engineering are not yet fully answered, such as users’ tasks and goals, the way that they interact with KGs, KG construction (KGC) tools, and KG-related applications (Groth et al., 2023). Up-to-date comparative surveys regarding the scale, complexity, and degree of automation of KG construction systems nowadays are needed. User-centric design and empirical methods should be established for transparent KG construction to ensure that human-centric challenges are not overlooked.
With this article, we would like to advance the field of
Our article follows recent work that explores emergent neuro-symbolic AI architectures from a system-design perspective. van Bekkum et al. (2021) propose a taxonomy of hybrid (i.e., learning and reasoning) systems and discuss common architecture patterns and use cases. Building on their insights, Breit et al. (2023) carried out a comprehensive literature review to add details to those patterns in terms of inputs, outputs, processing units, types of ML models and their training, types of knowledge representation and reasoning, but also transparency and auditability. One of their main findings is that most system designers do not consider these latter aspects at all, or, when they do, they do not evaluate them sufficiently. A third paper by Tamašauskaitė and Groth (2023) draw from a survey of system papers to define a canonical KG construction process. Our work continues where they left off: starting from their KG construction process, we follow one of their main recommendations to map models and techniques for each step to provide additional guidance to researchers and developers.
Thus, we put forth the following research questions:
We analyze the KG lifecycle to identify tasks that are commonly automated with AI and those that still require human input and oversight and could potentially benefit from AI assistance. This work builds upon our previous study (Zhang et al., 2023), in which we surveyed the state-of-the-art in explainable AI (XAI) to inform the design of XAI approaches that are practically useful for KG stakeholders such as knowledge engineers, subject domain experts, and users. Furthermore, to extend our methodologies, we conducted an interview study involving 13 knowledge engineers and researchers from the knowledge engineering community. The interviews further explore topics such as their degree of understanding of models and techniques, their degree of automation, their transparency and explainability requirements, and various usage scenarios. Our main findings are:
There are tasks in KG construction, for instance, knowledge acquisition, where automation
1
is routinely used with promising results. At the same time, there are opportunities to use AI to assist other tasks, including ontology reuse, ontology evolution, ontology evaluation, and documentation, where (the latest) AI capabilities have remained under-explored. While tasks around knowledge acquisition, taxonomy building, and data ingestion are often automated, human oversight is still needed to improve performance, establish trust, or comply with the law. In our review, we found little evidence of the integration of AI capabilities besides basic automation, no matter their level of interpretability, into standard knowledge-engineering tools and practices. Furthermore, our understanding of human-in-the-loop KG construction remains limited, with implications for user experience. Comprehensive evaluations of XAI methods are lacking, with most studies focusing on simple ML models in lab settings, with mixed results (Poursabzi-Sangdeh et al., 2018; Smith-Renner et al., 2020; Wang & Yin, 2022). The KG community, just like elsewhere in AI, needs to gain a better understanding of how people react and use explanations to build trust and boost technology adoption. Knowledge engineers have varying levels of understanding regarding the models and techniques they use, with many expressing concerns over the opaqueness of black-box models. Data provenance and lineage tracking are recognized as critical, yet there are still gaps in the comprehensiveness and standardization of these practices. Evaluation heavily relies on human effort, highlighting the need for more robust and scalable methods. Additionally, effective communication of tool functionality and results to diverse stakeholders remains a significant challenge, requiring tailored approaches to bridge knowledge gaps and align expectations. Current XAI solutions often fail to meet practical requirements, as their explanations tend to be insufficiently informative, overly complex, and lacking in stability and coverage. Furthermore, findings from the interview study highlight the need for explanations that are both clear and confidence-indicating, with a strong preference for natural language representations.
The remainder of this article is structured as follows: Section 2 provides the background and related work, including an introduction to the KG lifecycle. Section 3 outlines the research methodologies, presenting the two-dimensional XAI taxonomy and use cases for literature analysis, as well as the foundation of the interview study. Section 4 explores the key findings from both the literature review and the interview study, with Sections 4.1 through 4.4 addressing research questions 1 to 4, respectively. In Section 5, we propose a blueprint for the design of explainable knowledge engineering models. Finally, Section 6 concludes the article. To facilitate further research, we maintain a public repository 2 .
Transparency and Explainability of ML Methods
Transparency as an AI design principle stands for the need to clearly document and explain how an AI system makes decisions, how the data is collected, used, and governed, and how the system is evaluated and audited (Ehsan et al., 2021; Kaur et al., 2022; Larsson & Heintz, 2020). Achieving transparency in machine learning (ML) models can be accomplished through explainability. Although some ML models, like decision trees, are naturally interpretable, larger models, such as language models, are too complex to comprehend in the same way. To address this issue, researchers and practitioners have proposed many XAI frameworks, guidance, standards (Schwalbe & Finzel, 2021), techniques (Lundberg & Lee, 2017; Ribeiro et al., 2016), and evaluation metrics (Hase & Bansal, 2020) for various models within the context of trustworthy AI. Typically, surveys on XAI models and techniques focus on aspects like problem formulation, taxonomies and classification, evaluation metrics, challenges, and future directions (Arrieta et al., 2019; Minh et al., 2022; Mohseni et al., 2021; Schwalbe & Finzel, 2021; Vilone & Longo, 2020). For works that are more related to ours, Danilevsky et al. (2020) conducted a survey on the state-of-the-art XAI models in natural language processing, which includes tasks that overlap with our work, such as named entity recognition and relation extraction. In the area of XAI and KGs, researchers have suggested using KGs to provide explanations. Tiddi and Schlobach’s systematic literature review (Tiddi & Schlobach, 2022) focused on the integration of KGs into explainable machine learning, where KGs are used as domain knowledge for explanations. In addition to the technical perspective, Miller’s review (Miller, 2019) provided a thorough examination of explainable AI through a sociotechnical lens, drawing from a variety of fields such as philosophy, cognitive science, and social psychology. Although previous studies have focused on some KG construction tasks and applications, a thorough review of the transparency and explainability of KG construction is still missing.
User Studies on Explainable AI
A deep understanding of the end-user requirements is essential in order to design trustworthy explanations, as explainability is a human-centric property (Mittelstadt et al., 2019; Rong et al., 2024). Preece et al. (2018) give an analysis of stakeholders in XAI by examining the concerns of various stakeholders communities and digging into their different intents and requirements. Ras et al. distinguished different users of deep learning models into two groups and discussed their concerns: the expert users, who are engineers and developers building and maintaining the systems, and lay users, who are the end users and stakeholders (Ras et al., 2018). Liao et al. (2020) conducted interviews with UX and design practitioners working on various AI products through question-driven explanations. It is noteworthy that there is a lack of user studies on XAI involving knowledge engineers and KG stakeholders as end-users. Therefore, there is no consensus among design disciplines for XAI in relevant domains. Similar to our intents, Dhanorkar et al. (2021) conducted an interview study on XAI towards AI researchers and stakeholders in industrial AI projects focusing on the AI lifecycle. Rong et al. (2024) surveyed user studies through characteristics including trust, fairness, understanding, usability, and human-AI collaboration performance, and provided guidelines for both XAI researchers and practitioners on designing and conducting user studies. Similar to our interview study, Kim et al. (2023) conducted an interactive feedback session in their interview study with the objective of understanding how explainability can support human–AI interaction. They mock up explanations that could be potentially used for AI application outputs in the field of computer vision to assess the participant’s perception of existing XAI approaches and how participants use explanations during their collaboration with the AI. Automated and transferable evaluation, benchmarking, and comparison of XAI approaches pose open challenges, as explainability is often seen as a subjective property, necessitating auditing from multiple aspects (Nauta et al., 2022). On the other hand, human-centered XAI evaluations that take an HCI perspective remain critical in XAI evaluation, where rigorous evaluation procedures need to be established (Chromik & Schuessler, 2020).
Human-Centric Knowledge Engineering
Knowledge engineering, the branch of AI concerned with building and managing knowledge-based systems (Schreiber, 2000; Studer et al., 1998), has changed dramatically with the latest innovations in machine learning, natural language processing, and computer vision. The process of constructing a KG can take on various forms, but it usually involves acquiring knowledge, processing it, and deploying the KG (Fensel et al., 2020; Hogan et al., 2020; Tamašauskaitė & Groth, 2023). And yet, as the most recent advances in natural language processing (especially LLMs) and generative AI demonstrate, the question of how to capture and encode domain knowledge into a computational representation remains as challenging as ever (Sarker et al., 2021). The technologies and end-user tools to support core knowledge-engineering tasks such as knowledge acquisition have advanced significantly to meet the scale requirements of modern KGs and to leverage the generative ability of sequence-to-sequence frameworks (Schneider et al., 2022; Ye et al., 2022). AI copilots, which leverage LLMs, have also become involved in the KG lifecycle through conversational interactions (Zhang et al., 2024), assisting knowledge engineers and users in a wide range of tasks. At the same time, the most effective approaches to knowledge representation still require human oversight at various levels (Simperl & Luczak-Rösch, 2014; Simsek et al., 2022), but increasingly human input is in the form of enhancing or validating algorithmic suggestions (Tamašauskaitė & Groth, 2023). The tasks of knowledge engineering require human-in-the-loop to a different extent and are considered human-centric (Groth et al., 2023; van Harmelen & ten Teije, 2019; Witschel et al., 2021). These developments have resulted in improved methods and techniques to support the knowledge engineering process, with a growing group of participants and stakeholders, including knowledge engineers and domain experts (Simperl & Luczak-Rösch, 2014). Witschel et al. identified human-in-the-loop patterns in hybrid learning and knowledge engineering activities, encapsulating them in two boxologies, where human agents function either as feedback-providers or feedback-consumers (Witschel et al., 2021). Back to 2002, after Holsapple and Joshi introduced the first collaborative approach to ontology design (Holsapple & Joshi, 2002), various collaborative ontology engineering methodologies have been proposed, including tasks like ontology design and construction (Auer & Herre, 2007; Braun et al., 2007; Debruyne et al., 2013; Kotis & Vouros, 2006), ontology evolution (Auer & Herre, 2007; de Moor et al., 2006; Kotis & Vouros, 2006; Vrandečić et al., 2005), and ontology evaluation (Guarino & Welty, 2004; Poveda-Villalón et al., 2014). The tasks of ontology engineering continue to rely heavily on manual labor, and many of the reviewed works are outdated and pre-date the era of deep learning. There are evident challenges in improving the methodologies used in this process and adapting them to meet the requirements of automation, scalability, and transparency.
The KG Lifecycle
Building on the process from Tamašauskaitė and Groth (2023), Figure 1 shows that the KG lifecycle today consists of four stages with a mix of automated and manual capabilities and contributions from several stakeholder groups: knowledge engineering and machine learning specialists, subject domain experts, online volunteers, and crowdsourcing services, as well as developers of applications using KGs.

The Knowledge Graph Lifecycle Today.
As the figure illustrates, KGs interact with AI capabilities in complex ways, involving multiple groups of people collaborating both with each other and with machines. Human-in-the-loop tasks in KG lifecycle increasingly use ML models with varying levels of interpretability. On the left side of the figure, at stage A, which is an entry point and essential step of the KG lifecycle, knowledge engineers and KG stakeholders (e.g., domain experts) will first determine the scope of work and the success criteria (Kendall & McGuinness, 2019). After that, at the second stage, KG construction, knowledge engineers and other specialists (potentially) reuse standard ontologies and build KGs from scratch through data lifting and knowledge extraction. Multiple data sources, structured and unstructured, are lifted into KGs using ML for named entity recognition (Yadav & Bethard, 2019), relation extraction (Lin et al., 2016), entity reconciliation (Sevgili et al., 2020(@), and many others. The ontology organizing the KG can be provided upfront or derived from the data itself, depending on whether there is a clear domain or available structured data with predefined types of entities and relations (Tamašauskaitė & Groth, 2023). In this context, (Wolf, 2020) discusses the need for more transparency with respect to data provenance and currency; both can affect whether application developers and end-users will be able to use the KG with confidence as a source of reliable, complete, unbiased, and up-to-date information. KGs can also be created on a larger scale through human collaboration, utilizing crowdsourcing platforms, collaborative-editing platforms, and so on Hogan et al. (2020). Crowd workers and volunteer editors have important roles in the KG lifecycle, especially in KG creation and updates, where annotation tasks such as quizzes and voting are often designed for leveraging their background knowledge (Acosta et al., 2013; Kou et al., 2022; Revenko et al., 2018). While KGs constructed using these approaches may exhibit quality issues such as errors (Piscopo & Simperl, 2019; Shenoy et al., 2021), disagreement (Koutsiana et al., 2023), bias (Hogan et al., 2020), and so on, crowdsourcing for supervised ML may have similar transparency challenges as the algorithms it complements. This is because the digital services commonly used for this purpose, e.g., Prolific and Mechanical Turk, are black-box, proprietary platforms with limited means to replicate or reproduce results (Qarout et al., 2019). Educating crowd workers in the process of performing crowdsourcing tasks is also a nontrivial task (Revenko et al., 2018). Interleaving explanations during this process could aid in educating crowd workers, enhancing their comprehension of the task, and ultimately improving output quality.
The result of knowledge acquisition is shown in the middle of the figure, where KGs are often linked to third-party data, reuse standard ontologies and identifiers, and are encoded as RDF, JSON, or other formats. On the right-hand side of the figure, KG maintenance (stage C) is prompted by source updates from stage B, and requirements, audits, and assessments from stage D. To further increase their completeness, correctness, and utility, KGs are refined by completion tasks such as link prediction and error detection and correction tasks, and so on (Cimiano & Paulheim, 2017; Rossi et al., 2020; Zamini et al., 2022; Zhang et al., 2022). At stage D, there are a selection of use cases for KGs alongside other forms of AI. KGs are used as knowledge bases to query and reason upon, for instance in search (Wiegmann et al., 2022), question answering (Chowdhery et al., 2022; Guo et al., 2022), and retrieval-augmented generation (Gao et al., 2023; Lewis et al., 2020). Information can be obtained from a graph through deductive (e.g., logical rules) and inductive methods (e.g., as continuous graph embeddings) (Hogan et al., 2020). Both methods need to be transparent and accountable to the user (Bianchi et al., 2020; Rossi et al., 2022) to be trustworthy and compliant with laws.
To address our four research questions, we employed a mixed methodology of systematic review and interview study. The systematic review involved collecting and analyzing literature on explainable AI in the context of knowledge engineering to gain insight into its current development. The interview study allowed us to directly explore the role of explainable AI in broader contexts, understand the needs of knowledge engineering and KG stakeholders for explanations, identify potential gaps and challenges in this field, and provide valuable insights for further research.
Literature Review
The PRISMA-guided Review
Following the discussion of the lifecycle, we carried out a PRISMA (Page et al., 2021) literature review on databases including ACM Digital Library, IEEExplore, ScienceDirect, arXiv, SpringerLink, and Google Scholar. We searched for queries combining, on the one side, keywords related to trustworthy (mainly transparent and explainable/interpretable) and, on the other side, keywords related to KG construction tasks, as shown in Table 1. The search initially encompasses all keywords related to KG construction tasks, as depicted in Figure 1. We conducted a prototype search by examining the top 20 results generated by these keyword patterns. Subsequently, we eliminate keywords associated with tasks that do not yield hits within the top 20 results, thereby streamlining the review process. The search took place from October to December 2022 and resulted in more than 735K hits. We then took the top 50 hits per query, which led to around 4000 papers with duplicates 3 . The workflow of paper selection is shown in Figure 2. We assessed relevance based on titles, abstracts, and keywords first, and in a second step, reviewed the text of the paper to select only those papers that proposed a solution to transparent and explainable KG construction, either as a whole process or for individual tasks. We discarded papers that only mentioned transparency and related concepts rather than putting forward a solution. The final corpus consisted of 84 papers. The papers were all published in the past ten years, which was to be expected given the term ‘‘knowledge graph’’ was coined in 2012 and is in line with other recent knowledge-graph surveys (Schneider et al., 2022; Tamašauskaitė & Groth, 2023).

The PRISMA Flow Diagram for Systematic Review.
Keywords for the Literature Search Query. Keywords from Two Groups Were Combined for Query Construction. ‘*’ Represents Wild Characters that can Match any Word Suffix in the Search.

In addition to reviewing the existing work categorized in Section 4.1.1, we adopt use cases as an orthogonal dimension for literature analysis inspired by Amarasinghe et al. (2023), recognizing that explanations serve diverse end users with varying needs across different scenarios and stages of the KG lifecycle. To derive XAI use cases in the KG lifecycle, we first examine use cases in the broader AI lifecycle and specific domain applications (Adhikari et al., 2022; Amarasinghe et al., 2023). We then map these use cases to practical scenarios and task spaces within the KG lifecycle, as illustrated in Figure 1. Specifically, we identify and present four key use cases, along with their objectives, in Table 2.
Summary of Use Cases of XAI Methods in Knowledge Graph Construction Process and Their Related Objectives. The Use Cases Are Intentionally Defined with More Flexibility Than the Taxonomy, as their Primary Purpose is not to Serve as a Rigid Classification System but to link the Reviewed Works to Practical, Illustrative Scenarios.

Summary of Use Cases of XAI Methods in Knowledge Graph Construction Process and Their Related Objectives. The Use Cases Are Intentionally Defined with More Flexibility Than the Taxonomy, as their Primary Purpose is not to Serve as a Rigid Classification System but to link the Reviewed Works to Practical, Illustrative Scenarios.
Use Case 1: ML Model Selection and Building
When ML is incorporated into knowledge engineering, ML and knowledge engineers must select the proper models and build them. To help users evaluate and select suitable ML models, explanations should reveal the characteristics and limitations of the model, potential risks associated with its use, and its specialization for data or domains. In particular, they should address questions such as the model’s capabilities, strengths and weaknesses, and data fitting. It is also important to determine if the model exhibits bias toward specific groups of data sources.
Use Case 2: ML Model Debugging
One of the purposes of providing explanations for ML models is to facilitate debugging by allowing knowledge engineers to identify inaccuracies and flawed predictions and providing them with actionable information to correct them.
Use Case 3: Understanding Performance and Contributing Factors
To ensure a thorough comprehension of performance, explainable KG construction pipelines should include the following elements: A clear understanding of the inference/reasoning process, which can be represented as rules, paths, etc. Identification and highlighting of the factors, important features, and supporting evidence that contribute to the final predictions. Provision of counterfactual interpretation through perturbation/permutation.
Use Case 4: Managing Updates
Explainability is crucial for KG maintenance. When updates occur in data sources and contextual information, the KG can be updated by rerunning the construction pipeline, executing update or modification models, and so on.
To validate the use cases, we compared the use cases derived from the literature review to the ones collected from the interview study and found that the use cases derived from the literature review are mostly reflected through the interview study, and the latter also provide new ones, which we further discussed in Section 4.3. While we acknowledge that the identified use cases are not exhaustive, they are intended to be adaptable and expandable as new requirements and application areas emerge.
After identifying use cases, we conducted further investigations into the capabilities of existing works with respect to these use cases. There are two main aspects to consider for this purpose. Firstly, we need to determine whether the reviewed methods have been applied in real-world scenarios of the given use case or could be adapted to suit them. Additionally, we need to consider whether the models have been trained and tested on real-world data. In the domain of KG construction, benchmarks and datasets are usually close to real-world KGs, such as Wikidata, DBpedia, and Freebase. The second aspect to consider is whether the explanations provided are understandable and satisfactory to the intended audience for the given use case. This can be determined if the work has done comprehensive evaluations that include metrics and human evaluations. Thus, we will evaluate the capabilities of the existing methods based on the following criteria:
☆: The method has potential for the given use case.
Besides the literature review, we conducted semi-structured interviews with the objective to (1) acquire a basic understanding of the current status of knowledge engineering models and techniques, including transparency issues and obstacles, (2) figure out gaps between existing solutions and practical knowledge engineering scenarios, (3) collect practical requirements for explainable capabilities, and (4) capture insights to design automated explainable knowledge engineering pipelines. Table 3 lists all participants and their background information 4 . In total, we interviewed 13 researchers and knowledge engineers from August to November 2023. All participants were recruited via contact lists of research events, a hackathon, and mailing lists hosted by W3C 5 . We maintained a balanced gender distribution among participants (6 females and 7 males) and ensured diverse coverage in experience, domain, and tasks. In terms of sector representation, 7 participants are affiliated with universities, indicating a relatively stronger academic background, while 2 are from research institutes and 4 from companies. The latter 6 participants are considered to have a stronger industry background with a focus on industry-related scenarios. Each interview lasted 35 to 50 minutes via an online video call, which involved the authors and the participants. The ethical clearance was granted from the Research Ethics Office of King’s College London with ethics registration confirmation reference number MRSP-22/23-34456.
Background Information About Interview Study Participants Includes the Sector, Experience Working With KGs and Knowledge Engineering in Years, Domains of KGs, and Tasks Involved in the KG Lifecycle.
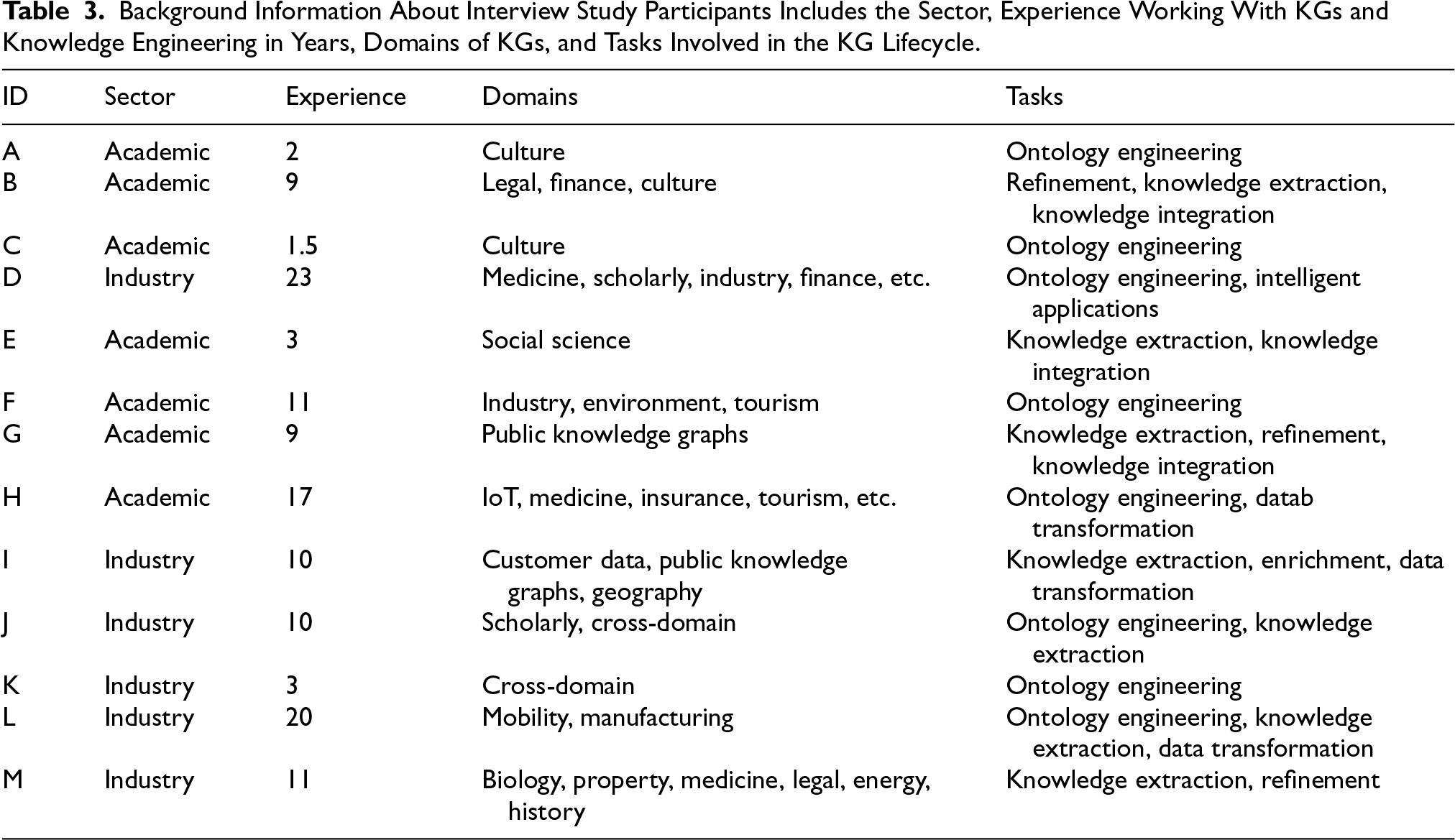
Background Information About Interview Study Participants Includes the Sector, Experience Working With KGs and Knowledge Engineering in Years, Domains of KGs, and Tasks Involved in the KG Lifecycle.
Table 4 presents all the interview questions organized by topics and the order in which they were asked. The questions addressed various topics, including the understanding level of models and techniques, degree of automation, data provenance and lineage, trust, evaluation and human intervention, explainability, and associated risks. The design of interview questions incorporated multiple factors, drawing from previous interview studies on explainable AI in other fields (Dhanorkar et al., 2021; Kim et al., 2023), taxonomies and surveys of transparency and explainability (Rong et al., 2024), and the Explanation Ontology (Confalonieri et al., 2024) to ensure comprehensiveness. We adapted these trustworthy factors to the context of KG construction. Firstly, we asked questions about the research background, including experience and domain, to acquire demographic information. Next, we asked about the participants’ experience and understanding of the models and techniques they use. This foundation allowed us to assess the extent to which transparency is an issue and its impact on their practical work. Given the importance of data provenance as a dimension of transparency (Firmani et al., 2019), we include questions specifically about this. To examine the human role in knowledge engineering and gain insight into human factors, we asked questions related to the evaluation of results and how humans interact with the pipeline, providing oversight and intervention. Inspired by Dhanorkar et al. (2021), we designed questions about explanation scenarios and use cases. These questions delved into scenarios where participants explain results or models to their stakeholders, seeking to identify explainability concerns, challenges, and requirements. Finally, we addressed risk concerns that might arise if transparency and explainability are provided with current models and techniques, ensuring a comprehensive understanding of potential issues.
The List of Interview Questions. The XAI Example Discussions are Accompanied by Slides Introducing and Showing Explanations, and the Following Questions in this Part are Mostly Intrigued by the Responses of Participants.

The List of Interview Questions. The XAI Example Discussions are Accompanied by Slides Introducing and Showing Explanations, and the Following Questions in this Part are Mostly Intrigued by the Responses of Participants.
XAI Example Discussion
Furthermore, by selecting examples from the previous literature review, we designed XAI examples and facilitated discussions on their usefulness, faithfulness, and acceptance. This approach directly connects stakeholders in the context of knowledge engineering with existing literature methods, highlighting the pros and cons of current explainable solutions and the gaps between these solutions and practical needs, given the limited application of existing XAI approaches in real-world knowledge engineering scenarios. The XAI examples were directly selected from the reviewed papers. We first identified papers that provided examples of explanations, such as visualizations of attention weights, graph paths, and tables of reasoning rules. We then randomly selected two papers per task as examples for participants to discuss. During XAI example discussions, participants were first asked to select one (or two, if time permitted) task that they were familiar with. We then provided two examples of two explainable approaches to the selected task. Each example was presented on a slide, consisting of the input, output, and explanations as provided by the original publication. Table 5 lists the examples we selected, along with their representations and citations. After reviewing the examples, participants discussed the usefulness and acceptance of the explanations, such as whether they found the explanations helpful and whether they would accept them in their work scenarios or expose them to stakeholders, such as domain experts and users. Moreover, they were encouraged to identify defects in the explanations and suggest improvements or alternative solutions to make the explanations more acceptable. During this process, participants were free to ask questions about the provided examples, and we responded based on the original publication.
User Acceptance Count of Explainable Examples, ‘

The interviews were recorded using Microsoft Teams and transcribed with its automatic transcription services. The transcripts were then further cleaned and edited by the authors to remove repeated words, pauses, filler words, and to recover errors such as software names and abbreviations. The edited transcripts were coded into keywords and patterns, consisting of phrases and sentences. We employed three levels of coding strategies for different types of questions. First, for questions related to background information, domain and tasks, and status, we used in vivo coding, extracting the exact words from the transcripts. For questions on data provenance and lineage, evaluation and human intervention, explanation scenarios, and requirements, we extracted the phrases and identified patterns such as operations, methods, and examples. Finally, for questions on understanding, XAI example discussions, and risks, we extracted patterns such as comments and suggestions, and coded the attitudes and beliefs towards the explainable examples. To analyze the coded data, we grouped identical and similar content into clusters of thoughts and insights, and counted the occurrence of each cluster. We also highlighted quotes to provide important supporting evidence, insights, and original ideas.
Findings
The Status of Explainable Automated Knowledge Engineering
The State-of-the-Art Explainable Models
We classified the papers reviewed with respect to the KG construction tasks they addressed and their approach to explainability, starting with categories widely used in the literature. For explainability, we started with what is explained: local (data point) vs. global (outcome); and when: post-hoc (after prediction) vs. self-explaining (while predicting). We then added another layer for post-hoc methods, splitting the methods into two subgroups: model-specific (specific to one or a group of models) and model-agnostic (can be applied to any model).
The results are presented in Figure 3 and visualized using a Sankey diagram in Figure 4. At a glance, the papers do not cover the entire KG lifecycle. Most papers are concerned with knowledge acquisition via entity extraction (as a source of classes and instances in KGs) and relation extraction (as a source of property classes, but more importantly connecting entities to each other through properties), or with curation and maintenance via entity resolution (consolidating the data that refers to the same entities) and link prediction (suggesting missing or emerging facts). Besides the four core tasks in the bottom half of the figure, we found one paper dealing with the evolution of the KG schema or ontology (Meroño Peñuela et al., 2021) and another one about detecting and explaining inconsistency in KGs (Tran et al., 2020). We note that link prediction was by far the most popular task, and that a majority of papers dealt with curation and maintenance rather than building a KG for a particular purpose. This is somewhat concerning, as many applications of KGs are in enterprise contexts (Sequeda & Lassila, 2021), where the first step is to build a computational representation of the enterprise’s data, which is stored across various systems and modalities. We argue that for the tasks not included in the review, there are several potential reasons why almost no papers were found. Many of these tasks still rely heavily on manual work and human oversight and have not yet been automated, as we will later verify based on interview results. This includes tasks such as ontology reuse and ontology design. Additionally, there are tasks where automation, such as the use of LLMs, has been employed, like ontology alignment (He et al., 2021) and data lifting from databases, but explanations have not been considered.

Taxonomy of Explainable Knowledge Graph Construction. A Summary Table of the Reviewed Papers is Also Available in Our Previous Work (Zhang et al., 2023) and the GitHub Repository.

Sankey Diagram Illustrating the Categorization of Methods. The Left Column Represents KGC Tasks and the Right Column Represents XAI Taxonomy. The Total Count for Each Category is Indicated Next to Its Label.
A second high-level observation is the balanced split in the chosen format for explanations. Methods based on input and generated features use attention weights (Jung et al., 2021; Zhou et al., 2020), words (Lee et al., 2021; Lin et al., 2020), attributes (Barlaug, 2021), and so on to generate explanations, which can be numerical, textual, or visual. By contrast, methods based on human-understandable background knowledge provide explanations in the format like logical rules (Rocktäschel & Riedel, 2017), reasoning paths (Lei et al., 2020), and structured contextual information (Shahbazi et al., 2020) as explanations. Given that we are interested in explanations that are accessible to knowledge engineers and subject domain experts, it would be interesting to evaluate if their familiarity with knowledge representation and/or the subject domain impacts how useful knowledge-based explanations are compared to feature-based ones, which sometimes require an understanding of machine learning. At the same time, explanations are generated in a different way for each of the four core KG construction tasks in the bottom half of the figure.
Entity Extraction
For entity extraction, explanations often leverage contextual cues such as triggers (Lee et al., 2021; Lin et al., 2020) and patterns of words (Hedderich et al., 2021), utilizing attention mechanism (Vaswani et al., 2017) and saliency map techniques. One notable work is myDIG (Kejriwal, 2021), a human-in-the-loop system that compiles sophisticated rules written by domain experts into SpaCy rules for backend execution. This reduces the barrier for domain experts to interact with the machine and minimizes training effort. Additionally, myDIG records extraction provenance, allowing users to explore the downstream effects of their specifications. Another type of explanation used for entity extraction is example-based explanations, which rely on training instances (Plumb et al., 2018). In Ouchi et al., similarities between pairs of candidate(s) and the training instances are computed, with the term having the highest derived label probability being returned (Ouchi et al., 2020).
Relation Extraction
For relation extraction, explanations frequently employ contextual information from the input, such as words and sentences, similar to entity extraction. The attention mechanism is a prominent principle among relation extraction methods, with 4 out of 9 studies using attention weights and their associated input context to generate explanations. For instance,
Entity Resolution
There are two primary types of explanations for entity resolution: entity matching (EM) rules (Paganelli et al., 2019; Qian et al., 2019; Singh et al., 2017; Yao et al., 2021) and (ranked) attributes of the entity pair with relevant scores (Baraldi et al., 2021; Barlaug, 2021; Di Cicco et al., 2019; Ebaid et al., 2019; Teofili et al., 2022). EM rules, represented in forms such as disjunctive normal form and general boolean formula, are commonly used in EM systems to enhance interpretability (Singh et al., 2017). For automatic EM rule-based models, Yao et al. proposed a framework consisting of Heterogeneous Information Fusion for learning feature representation from unlabeled data and Key Attribute Tree for interpretable EM decision making (Yao et al., 2021). This framework translates decision trees into EM rules, making explanations more accessible to domain experts.
Link Prediction
Most explainable link prediction methods leverage the topology and reasoning capabilities of KGs. Rule- and path-based methods have become the predominant forms of explanations, achieved through various approaches such as random walk-based methods (Lin et al., 2023; Liu et al., 2022; Meilicke et al., 2020), reinforcement learning agents (Das et al., 2017; Xiong et al., 2017), and perturbation-based methods (Pezeshkpour et al., 2019; Rossi et al., 2022). A significant body of work utilizes RL for reasoning over KGs and searching for paths to explain link prediction results (Bhowmik & de Melo, 2020; Das et al., 2017; Fu et al., 2019; Hildebrandt et al., 2020; Lei et al., 2020; Sun et al., 2021; Xia et al., 2022; Xiong et al., 2017). These models typically comprise KG environments and policy network agents. The KG environment transitions elements within the graphs (e.g., entities, relations, queries) into RL agent elements, where states are usually entities (in practical terms, embeddings) and queries (subject entities and relations); actions are typically outgoing edges/relations; transitions map current entities and their outgoing edges to their neighboring nodes; and rewards are heuristic indicators, awarding 1 when the agent reaches the correct target entities. Policy networks then maximize the expected reward to perform path finding. Variations exist in environment transitions, rewards, and the parameterization of the policy function. For example, R2D2 (Hildebrandt et al., 2020) and RuleGuider (Lei et al., 2020) employ multi-agent architectures. R2D2 uses two agents, with one arguing the fact is true and the other arguing it is false, feeding their arguments into a judge network. RuleGuider uses a relation agent and an entity agent that interact to generate paths fed into a rule miner. Perturbation-based methods are also applied in link prediction, similar to those used in entity resolution. CRIAGE (Pezeshkpour et al., 2019) introduces graph perturbation by removing a neighboring link from the target fact to assess the influence of the fact and by adding a new, fake fact to evaluate model robustness and sensitivity. Another prevalent method in explainable link prediction models is the attention mechanism, used in 16 out of 53 total link prediction works. For instance, XTransE employs attention values on items to reveal the relevance between different property-value pairs and the current prediction, which are then ranked to identify the most relevant triples (Zhang et al., 2020). In xERTE, Han et al. propose a temporal relational graph attention layer that calculates query-dependent attention scores for each edge (Han et al., 2020). These scores propagate to each node’s prior neighbors, pruning the inference graph using edge contribution scores. The pruned graph, with node attention scores and edge contribution scores, is used to produce the explanations.
Human-in-the-Loop
There are very few papers considering human inputs or oversight, which are critical in trustworthy AI frameworks and guidance (Dignum, 2019). In the few cases of human-in-the-loop systems, human input often involves the provision or revision of rules for tasks such as entity extraction (Kejriwal et al., 2019) and entity resolution (Paganelli et al., 2019; Qian et al., 2019). In myDIG (Kejriwal et al., 2019), a GUI-based rule specification system is provided for domain experts to input expressive entity extraction rule sets without programming. SystemER (Qian et al., 2019), which adopts an active learning methodology, learns explainable entity resolution logical rules and offers functionalities for domain experts, both with and without programming backgrounds, to verify and customize the learned models in feature engineering to ensure extensibility. For generating entity resolution rules, TuneR (Paganelli et al., 2019) involves developers (i.e., coders, scientists, and domain experts) in tuning rule sets by defining the contribution of optimization metrics. The framework defines interpretability-related metrics as the preference between the number of rules in the rule set and their overlap. All three approaches use an ensemble of rules to achieve high precision. Several factors influence the success of these human-in-the-loop approaches, some of which have been considered in these three systems. One critical factor is balancing the minimization of training with the extent of human intervention. More human intervention can reduce training efforts, which require feeding more data thus extending training time. Conversely, increased training efforts can reduce human intervention, thereby minimizing unnecessary human labor and avoiding time-consuming and error-prone trial-and-error processes. Another factor is the degree of operational freedom given to users. The complexity of functions and the freedom of operations provided to users affect the time required to educate them. The design of functions should enable users to maximize their input to produce high-quality work while minimizing the time needed to familiarize themselves with the tool. Providing too few intervention options might hinder users from fully expressing the correct input, thereby increasing human effort. These factors are crucial when designing human-in-the-loop systems, and more user studies, especially for knowledge engineers and KG stakeholders, are needed to explore them further.
Evaluation of Explanations
We also collected and analyzed the evaluation of explanations. A primary observation is that most XAI approaches have not been thoroughly and/or comprehensively evaluated. The majority of methods (58 out of 84) do not perform any evaluation on explanations or only use anecdotal evidence by visualizing and commenting on a limited number of cases of explaining outcomes intuitively. There are efforts to design metrics to evaluate explanations. Seventeen works adopted metrics to evaluate their explanations, and most of them are task-dependent. Shahbazi et al. (2020) created a ground-truth explanation set and computed the Kendall Tau correlations for the sentence importance scores for the annotated test set. approxSemanticCrossE (d’Amato et al., 2022) proposed explanation evaluation metrics targeting the link prediction tasks, which calculate the ratio of triples for which the model can generate explanations (recall) and the number of explanations, on average, for each prediction (average support). In gradient rollback (Lawrence et al., 2020), Lawrence et al. adopted the ‘‘RemOve And Retrain (ROAR)’’ (Hooker et al., 2019) evaluation paradigm to evaluate the faithfulness of the explanations.
Twelve studies use human evaluation, detailed in Table 6. We identified 5 types of evaluation tasks commonly adopted in these studies. The most frequent tasks involve asking participants to compare model-generated explanations with those from baseline models and to judge the relevance and correctness of a set of examples. Various metrics are used in human evaluations. One approach is to have participants rate the usability, reliability, and trust of explanations in a survey. A notable example in this group is SQUIRE (Bai et al., 2022), which annotates BIMR-based interpretability scores (Lv et al., 2021) for paths generated by their models and baseline models. Another group of methods measures the accuracy or precision of user predictions with or without provided explanations. The backgrounds of human evaluators are varied, including domain experts, such as e-commerce experts in Zhang et al. (2022) and linguists in Emboot (Zupon et al., 2019), people with technical backgrounds, and laypeople such as crowdsourcing.
Works That Use Human Evaluation to Analyze Explanations. ‘*’ indicates that no Group Label is Provided, but other Detailed Background Information of Participants is Reported. ‘/’ means ‘not Reported’ in the Paper.

From the above observations, we identified several issues with the evaluation methods. First, reporting a limited number of examples selected based on the researchers’ intuition can be biased and not sufficient for robust verification (Leavitt & Morcos, 2020; Nauta et al., 2022). Since not all results have satisfied explanations generated, another issue is that the ratio of results for which the model can generate satisfied explanations is not commonly reported. In our interview study, we found it to be a crucial factor that might influence the user’s trust in the XAI models.
The capability of various explainable techniques for each use case is shown in Table 7. In general, the reviewed literature indicates that global post-hoc methods, especially model-agnostic ones, have the potential to address all use cases. Local post-hoc methods have also demonstrated similar potential across all use cases. Although no global self-explaining methods were identified for the first two use cases, this does not imply that these methods lack potential for model selection, construction, and debugging. Instead, they are suitable for providing model analysis due to their global assessment capabilities. Among the use cases, all except for understanding performance and contributing factors have received less attention and research. This could pose challenges when integrating developed methods into real-world applications, making it essential to address these gaps.
Capabilities of XAI Methods in Knowledge Graph Construction. Symbols are Referenced from Section 3.1.2:
: Applicability to the Given Use Case is Unclear; ☆: Method shows Potential for the Given use Case;
: Method Has Been Applied to the use Case but is not yet Integrated into Toolkits or Real-World Applications. Explanations Provided by the Method Have Not Been Evaluated Through User Studies or Any Other Evaluation Methods;
: Method is Integrated into Toolkits in Real-World Scenarios, and Its Explanations Have Been Tested through Real-World Studies With the Target Audience.

Capabilities of XAI Methods in Knowledge Graph Construction. Symbols are Referenced from Section 3.1.2:
Use Case 1: ML Model Selection and Building
Most model-agnostic methods, such as explainers designed for KG embedding models, and some model-specific methods, have the advantage of providing explanations across different models and facilitating comparison. While some of the reviewed works have demonstrated their applicability in this use case, most have not emphasized addressing concerns related to model selection and comparison. A notable example that covers this use case is ExplainER (Ebaid et al., 2019), which offers a mechanism for model analysis. The analysis engine of ExplainER comprises multiple explanation models and techniques (LIME Ribeiro et al., 2016, Anchors Ribeiro et al., 2018, BRL Letham et al., 2015, and Skater Choudhary et al., 2018) that are independent of any entity resolution models. For link prediction, explainable methods such as CPM (Stadelmaier & Padó, 2019) and Kelpie (Rossi et al., 2022) can be used with any embedding-based link prediction models, allowing for comparison across different embedding models. The main gap for current models in this use case is not solely related to model design and architecture, but also to better documentation. One potential solution is to document an interactive model card (Crisan et al., 2022) that lists all the necessary information regarding explainability. For instance, for explainable link prediction models, this could include the ratio of faithful and correct explanations generated for each embedding model and a comparison of generated explanations for the same input.
Use Case 2: ML Model Debugging
Some works provide analyses of errors. For example, the instance-based explainable method performed error analysis using relevant examples to identify factors causing model confusion (Ouchi et al., 2020). ExplainER visualized representative explanations to highlight where the model fails (Ebaid et al., 2019). D-REX conducted error analysis on explanations alongside model predictions, further revealing the model’s error detection capabilities (Albalak et al., 2021). Pezeshkpour et al. demonstrated the potential application of CRIAGE for automated detection of erroneous triples in KGs. Their approach focused on identifying triples with the least influence on the model’s prediction of the training data (Pezeshkpour et al., 2019). Similarly, Rossi et al. highlighted the ability of Kelpie to uncover bias and imbalance in data, enabling researchers to correct it. However, although these works provided analyses of errors, most did not offer actionable steps for rectifying the identified issues. This could be achieved by providing options to adjust parameters, model architectures, and leverage external sources such as human knowledge. Human-in-the-loop methods exemplify approaches for correcting errors and improving model output, such as manually correcting rules by domain experts in rule-based explainable systems (Kejriwal et al., 2019; Paganelli et al., 2019). One approach following this line is to offer local actionable information, such as suggestions for correcting predictions directly. A future direction in designing local explainable methods would be to help users identify error cases and enable corrections at the data point level.
Use Case 3: Understanding Performance and Contributing Factors
The majority of the reviewed work performed well across various tasks. As detailed in Section 4.1.1, a range of representations are employed to understand the inner workings of models and the factors contributing to their outputs. For knowledge extraction tasks, such as entity and relation extraction, models provided supporting evidence from the source data (e.g., text) to aid in predictions (Lee et al., 2021; Lin et al., 2020). Similarly, for knowledge integration tasks like entity linking, attributes of entities were selected through mechanisms such as matching or non-matching votes, as demonstrated in Baraldi et al. (2021), Barlaug (2021). Explainable link prediction models offered rules (Lei et al., 2020; Meilicke et al., 2020; Singh et al., 2017) and paths (Das et al., 2017; Fu et al., 2019; Hildebrandt et al., 2020; Xiong et al., 2017) to illustrate the reasoning process, as well as subgraphs (Du et al., 2023) to measure the influence of nodes and edges. Notably, rule-based methods are prevalent across all tasks due to their concise and straightforward representation and their ability to generalize to new data.
Use Case 4: Managing Updates
Global explainable methods such as rule-based methods (Liu et al., 2022; Paganelli et al., 2019) can potentially express the model evolution through modifications in their global explanations. Similarly, visualization-based explanations (Ding et al., 2021; Wang et al., 2022), where users can compare different versions of visualizations, can also provide valuable insights when managing updates to KGs. Models that provide local explanations, such as inductive models (Sadeghian et al., 2019; Sun et al., 2021; Wang et al., 2021) and perturbation-based models (Pezeshkpour et al., 2019) could track differences for specific instances or groups of instances. Very few of the models directly implemented this capability, but most of them could be potentially extended to support this use case. For rule-based explainable methods, a straightforward way to manage updates is to use the generalization ability of existing rules and perform inductive reasoning. For instance, TLogic (Liu et al., 2022) stated that the temporal rules they generate are applicable to any new dataset, as long as the new dataset covers common relations, even in cases where new entities appear. Zhang et al. (2022) also emphasized the benefits of transferable rules. Their model could generate reusable rules to accelerate the deployment of a KG to new tasks or systems. In addition to directly transferring rules to new data, rules can also be updated. For example, RNNLogic (Qu et al., 2020) used an EM-based algorithm to update rules. Once the explanation rule sets were updated, to gain more insights, the users could compare two sets of rules and see what changes the new data had brought in. Similar strategies can be applied to other explanations, such as the visualization of attention weights and embeddings.
We now report on the interviews. We first present the current status of knowledge engineering tools in practical scenarios, focusing on the degree of automation and the level of understanding that knowledge engineers have towards these tools, as well as aspects including data provenance and lineage, evaluation, and human intervention. By addressing a series of sub-questions, we aim to gain a basic understanding of these critical transparency factors from our interview study. This foundation will enable us to delve deeper into identifying the desired properties of explainable models and techniques. A summary of the key findings from the interview study is presented at the end of this section (see Table 8).
Summary of Key Findings From the Interview Study.

Summary of Key Findings From the Interview Study.
How much human effort is leveraged in the knowledge graph lifecycle?
Among the participants, the majority engage in manual (38.5% of participants) and semi-automatic (38.5%) work, while a minority (23.1%) exclusively utilize automation for the tasks they work on. From the perspective of task execution in ontology engineering, participants predominantly employed manual and/or semi-automatic methodologies. These approaches necessitate extensive communication and collaboration among knowledge engineers, domain experts, and stakeholders, often facilitated through semi-structured interviews. Conversely, for tasks related to knowledge extraction and completion, participants demonstrated a preference for automated models and techniques. Methods, which focus on tasks like data transformation that lifts other formats of data into RDF triples through RML mappings 6 and tools like SPARQL Anything (Asprino et al., 2022), always involved the manual creation of the mappings. One participant assessed the performance of leveraging language models in generating such mappings. Language models in knowledge engineering have enhanced automation due to their user-friendly nature, characterized by simple natural language input and output, which require fewer specialist skills. However, their opacity and tendency to generate hallucinations impact their trustworthiness. When evaluating the outcomes of models, such as the triples generated by knowledge extraction models, human evaluation is always necessary. This is particularly crucial when dealing with new domains and data, where datasets are lacking.
What is the level of understanding of the models and techniques?
Participants had varying opinions regarding the impact of the opaqueness of models and techniques and the necessity to thoroughly understand them. 46.2% of them felt that opaqueness did impact their work and emphasized the importance of understanding the models. As participant A highlighted, this importance extends beyond merely explaining why the models produce certain outputs. It also involves helping humans ‘‘understand the extent to which these outputs can be trusted’’ 7 and determining ‘‘how they might need to change the way they interact with the model.’’ Participant B also noted that the opaqueness of the models and techniques might complicate evaluations, as it becomes challenging to determine how specific inputs influence the outputs. In contrast, the remaining 53.8% of participants were less concerned with transparency issues, feeling that opaqueness was not a significant problem. They provided several reasons. Two participants stated that only the model’s performance and the final quality of the output KGs mattered to them. Since they primarily deal with public datasets and transparency and explainability are not within their research scope, they pay less attention to these topics. Three participants mentioned that their tasks are predominantly manual, so transparency and explainability are less applicable. Some participants noted that even collaborative projects require some level of explanation for better communications and outcomes between human agents.
Data Provenance and Lineage
Do knowledge engineers know where the data comes from?

Distribution of Participant Responses to Four Questions: (a) Where Does the Data Come From? (b) How do You Evaluate the Results? (c) How do You Explain the Results? (d) When do You Perform the Iintervention? The x-axis Represents the Total Number of Participants (13), with Multiple Responses Allowed Per Participant.
How do people keep track of data provenance and lineage?
Among the participants flagging data provenance as essential, 69.2% actively tracked it in their tasks. Notably, all participants from industry and academia alike recognized the importance of data provenance and lineage and have established methods for documenting these aspects, given that their data primarily comes from partners and customers. The interview revealed a list of (semi-) automatic techniques either currently in use or planned for adoption to manage data provenance and lineage by the participants, including PROV Ontology
8
, RDF Star
9
, metadata, OpenRefine
10
, Data Version Control (DVC)
11
, data catalogs, NLP Interchange Format (NIF) (Hellmann et al., 2013), and blockchain. These tools document a set of details, such as the creation time, involved personnel, operation timelines, algorithms used to create the data, and potentially even the parameterization of these algorithms. Data provenance is tracked at different granular levels, from the model level (e.g., entire ontologies) to the data level (e.g., individual ontology elements). The availability of a wide range of tools offers knowledge engineers flexibility in fitting their specific pipelines. However, challenges and requirements remain. For instance, participant M noted the difficulty in determining the extent to which data provenance should be tracked and the level of details required.
How do knowledge engineers evaluate the results?
As shown in Figure 5(b),
Besides manual evaluation, 46.2% of participants also attempt to
What do people do when they find the results incorrect?
Similar to human evaluation, the interviews revealed a consensus that human intervention is essential to compensate for the limitations of machines at various stages and levels of detail in the KG construction process. We categorized human intervention based on the stages at which it occurs, as shown in Figure 5(d). The first stage is
How do people explain to others their models and results?
92.3% of participants have experience explaining models and results to others. 38.5% of participants explained their models and results to stakeholders who may not have a technical background, typically domain experts. Eight participants explained their work with ontologists and knowledge engineers, who have a similar technical background, usually project partners and team members. Additionally, two participants mentioned producing explanations for educational purposes, targeting university students. This indicates that
The methods used for explanations are summarized in Figure 5(c). For now, there are no standardized methods for explaining the models and outputs in the KG lifecycle.
The most frequent method (used by six participants) is to select examples, including corner cases and errors, to explain the model’s functionality, the relevance between input and output, the difficulties of the problems, and the range of the model’s abilities. Three participants explained the pipelines and models through lectures and conceptual introductions to the technical components, often providing high-level overviews of the algorithms and models. The other two participants adopted visualization methods. Participant A reported success using visualizations to represent embeddings and clusters, which helped ‘‘define a clear boundary between technical and intuitive content.’’ One participant mentioned using contrastive explanations, such as why the machine made one decision instead of another. Two participants did not have a specific method but relied on plain explanations.
Using the same taxonomy adopted in the literature review in Section 3, we categorized the explanation methods collected from the interviews into two categories: contrastive explanations and example-based explanations as local post-hoc methods, and visualization, plain explanations, and introduction to inner workings as global post-hoc methods. Our analysis reveals that, out of the 14 responses regarding explanation methods, half of the responses are local post-hoc methods, while the other half are global post-hoc methods. Notably, no self-explaining methods were reported. In contrast, the literature review indicates that a substantial proportion of explainable methods consist of local self-explaining (59.5%) and local post-hoc (19%) methods. We posit that several factors contribute to this discrepancy. Self-explaining methods are preferred in academia-developed models because researchers often work on implementing models from scratch or improving models by adjusting components or integrating additional components for better performance. This objective aligns with the design of self-explaining models. Among the 50 local self-explaining papers reviewed, 37 pertain to link prediction models, which typically incorporate explanation mechanisms into their developed models, enhance existing models by making components explainable, or reformulate problems in an interpretable manner. For practitioners, however, implementing self-explaining methods poses challenges. Post-hoc explanations of model output offer greater flexibility, allowing practitioners to customize supporting evidence, visualize this evidence, and adapt explanations into other languages that are more comprehensible to their stakeholders.
Participants reported several challenges.
Gaps and Challenges in Explainable KGC Solutions and Practical Usage
Use Cases From Interview Study
What are practical use cases of XAI models?
We first compared the use cases in Section 3.1.2 with those collected from the interview study. We found that the use cases in Section 3.1.2 were largely reflected through the interview study, which also provided new insights and additional use cases. The most prominent use case, highlighted by 76.9% of participants, is understanding the model output and its inner workings. This includes providing supporting evidence, mapping results to the original input, and explaining how the models generate the output. This aligns with the previously identified use case of understanding performance and contributing factors. The second common use case, mentioned by 38.5% of participants, is debugging models and assisting in rectifying and adjusting them. This extends the previous use case of model debugging by indicating where the machine fails or is unstable, identifying systematic error patterns and problematic parts of data sets, and understanding mistakes and errors and their causes.
XAI Example Discussion
Do current explainable solutions meet the requirements for practical use cases?
During the example discussion session, participants provided feedback on various tasks: 5 commented on relation extraction, 4 on entity extraction, and 2 each on entity resolution, link prediction, and inconsistency detection (Table 5).
Requirements for Explainable Approaches
What are characteristics of an explainable method that knowledge engineers and researchers expected?
From the example discussions, we identified two key requirements. First, 30.8% of participants emphasized the need for a
Secondly, the representation of explanations largely depends on the task and user. Although explanation formats like visualization and logic rules received varying levels of acceptance, the most acceptable representation for participants was
From the requirement elicitation questions, we also identified two common requirements from participants more directly. First, 30.8% of participants highlighted that the type of information users most require in explanations is
Moreover, 30.8% of participants envisioned a solution involving a ‘‘hybrid pipeline’’ where people and machines work in cooperation, providing ways of
Explanation Design Blueprint
Based on the findings from the literature review and interview study, we propose a set of guidelines that are consolidated into a blueprint for designing explainable solutions in knowledge engineering tasks that are both usable and trustworthy for target users, as illustrated in Figure 6. The figure presents a workflow for designing and maintaining XAI methods, beginning with requirement analysis and incorporating an evaluation–feedback loop to continuously refine and update the models and techniques.

Blueprint of the XAI Method Design Workflow. The Boxes Represent Key Stages in the Design and Development Process. The Arrows Indicate the Flow of Inputs, Outputs, and Feedback Between Stages.
The first step in designing explainable models involves XAI requirement analysis, which collects design insights and creates goals for explanations. Several factors must be carefully considered and investigated to capture the scope and objectives of explainable models.
The most important factor is the
The second part of XAI requirement analysis focuses on the
The third factor is the
Moreover, this list of factors can be expanded to reflect real-world scenarios. Additional considerations, such as AI regulations discussed in the Introduction, may also play a role in the requirements analysis. This analysis helps guide the selection and implementation of XAI methods to ensure they align with practical applications.
XAI methods can then be implemented based on identified end users, use cases, requirements, and so on. After implementing XAI methods, the workflow involves iterative loops for maintaining and continuously improving the methods. One loop (top-right corner of Figure 6) focuses on the evaluation and assessment of explanations (Di Bonaventura et al., 2024). Evaluation methods should go beyond anecdotal evidence, selecting appropriate metrics or designing evaluation paradigms. Another iterative loop, (bottom-right corner of Figure 6) derived from the ‘‘hybrid pipeline’’ requirements in Section 4.4, aims to improve explainable models and explanations in practical scenarios. Users who consume the explanations provide feedback and example explanations, which can be used in various ways to enhance the XAI model. This includes creating datasets of explanations for training and fine-tuning XAI models, providing few-shot examples, or even abstracting improvement directions for architecture-level adjustments. Both evaluation results and user feedback are integrated into the implementation stage, providing critical insights that guide ongoing updates and refinements of the XAI methods, as represented by the arrows from the evaluation and user feedback stages to the implementation and update block.
Conclusion
In this article, we adopted a mixed methodology, conducting a literature review on explainable methods within the domain of KG construction and an interview study on the same topic with 13 participants to capture how XAI methods support knowledge engineering. We performed the analysis in three dimensions, tasks related to KG construction, the taxonomy of XAI methods, and the use cases of XAI methods in KG construction. We observed that the most effort has been directed towards automation and explainability in entity extraction, relation extraction, entity linking, and link prediction. Additionally, we considered the use cases in explainable automatic KG construction, such as ML model selecting and building, ML model debugging, understanding performance and contributing factors, and managing updates. The interview study largely corroborated the considered use cases, adding new insights and highlighting additional use cases, including enhancing human–machine interactions and providing new insights from unexpected results. We found that the reviewed models primarily focused on explaining the performance and contributing factors to the outcome while neglecting other use cases, such as error detection and correction, which could help establish trust with users. The interview study revealed that while current knowledge engineering models and techniques exhibit varying degrees of automation and understanding, significant challenges remain in data provenance, evaluation methods, and providing clear explanations to stakeholders. The current explainable solutions often fell short of participants’ requirements, with concerns about their informativeness, complexity, and reliability. These insights established a foundational understanding of critical transparency factors, enabling the development of a blueprint for designing explainable methods for knowledge engineering tasks.
In summary, we addressed RQ 1 by reviewing the state-of-the-art XAI models and techniques for KG construction and analyzing them across multiple dimensions. RQ 2 was answered through our interview study, which provided insights into users– perspectives and expectations. RQ 3 was addressed by synthesizing findings from RQ 1 and RQ 2, revealing a clear gap between current XAI models and techniques and user needs. RQ 4 was partially answered by identifying key user requirements, which informed preliminary design considerations for XAI methods. We acknowledge that additional requirements may emerge, especially in particular application scenarios.
Future Work
We identified five future directions for research on explainable automatic KG construction. First, going back to prior literature on knowledge engineering methodologies (Kendall & McGuinness, 2019; Schreiber, 2000; Studer et al., 1998; Suárez-Figueroa et al., 2011), there are many
Second, as we noted earlier, the fewest of approaches look at
Thirdly, our research flagged the need for
Fourthly, our research revealed an imbalance in the distribution of use cases identified in the study. There was a strong emphasis on understanding the inner workings, performance, and contributing factors of models, while relatively few efforts were made to address other use cases also demanded by the community, such as model debugging, model updating, and human–AI interaction. However, our example discussions indicated that the reviewed explanations often failed to meet these requirements, and participants expressed low confidence in using them in their work or providing them to users. A future direction, reflected in our study and requested by the community, involves
Finally, although our research provided a blueprint for designing XAI methods,
Footnotes
Funding
This research is supported by the King's College London Research Training Student Grant and co-funded by SIEMENS AG and the Institute for Advanced Study, Technical University of Munich, Germany.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.