
Abstract
Integrating Schema.org markup into web pages has resulted in the generation of billions of RDF triples. However, around 75% of web pages still lack this critical markup. Large language models (LLMs) present a promising solution by automatically generating the missing Schema.org markup. Despite this potential, there is currently no benchmark to evaluate the markup quality produced by LLMs. This article introduces LLM4Schema.org, an innovative approach for assessing the performance of LLMs in generating Schema.org markup. Unlike traditional methods, LLM4Schema.org does not require a predefined ground truth. Instead, it compares the quality of LLM-generated markup against human-generated markup. Our findings reveal that 40%–50% of the markup produced by GPT-3.5 and GPT-4 is invalid, non-factual, or non-compliant with the Schema.org ontology. These errors underscore the limitations of LLMs in adhering strictly to structured ontologies like Schema.org without additional filtering and validation mechanisms. We demonstrate that specialized LLM-powered agents can effectively identify and eliminate these errors. After applying such filtering for both human and LLM-generated markup, GPT-4 shows notable improvements in quality and outperforms humans. LLM4Schema.org highlights both the potential and the challenges of leveraging LLMs for semantic annotations, emphasizing the critical role of careful curation and validation to achieve reliable results.
Introduction
‘‘The price of this book is 30
In the era of large language models (LLMs), one potential solution is to use these models to generate Schema.org markup from text (Meyer et al., 2023). However, using LLMs to generate Schema.org markups raises questions about the reliability of the generated markups, especially without ground truth to evaluate them. Building a ground truth for all 806 types of Schema.org, considering different web page sizes and languages, requires tremendous effort. A natural idea might be to consider web pages with human-generated Schema.org markups as ground truth. After all, billions of such pages cover various languages, domains, and lengths. Unfortunately, there is no guarantee that existing human-generated markup are (i) correct, that is, fully grounded in the text and compliant with Schema.org recommendations, and (ii) complete, that is, containing Schema.org markup for all information present from the text. Human-generated Schema.org markup can contain errors, such as incorrect facts or missing information, due to various factors. One common reason is the reliance on external knowledge, which is not covered by the text. Additionally, webmasters may lack professional expertise in structured data or web development, resulting in annotating mistakes or the omission of crucial details. Human error and varying levels of familiarity with Schema.org standards further contribute to these errors.
In this article, we propose a novel approach to evaluating the performance of LLMs in generating Schema.org markup. Unlike traditional methods, our approach does not rely on a predefined ground truth. Rather than constructing a ground truth from human-generated Schema.org markup, we aim to establish fair competition between LLMs and humans. Specifically, Do LLMs generate more comprehensive Schema.org markup than humans, given the text of a web page? To answer this question, we need two key elements: (i) First, we must remove any incorrect statements from Schema.org markup generated by humans and LLMs for a given text. As long as two markups contain errors, they cannot be fairly compared since the one with more errors might still appear to “win.” (ii) Second, once we have two correct markups, we need a scoring function to determine which is more comprehensive. The more comprehensive markup is considered the winner.
We propose LLM4Schema.org, a pipeline that takes a web page with human-generated Schema.org markup as input and outputs a scoring function to determine the winner (human or LLM). The article makes the following scientific contributions: The validity agent: Ensures syntactic correctness of the markup. This agent uses SHACL to verify that the markup adheres to the required structure and syntax. The factuality agent: Checks that every markup is grounded in the text of the web page. This agent is powered by an LLM, and we created a dedicated benchmark based on examples from the Schema.org documentation to evaluate its precision and recall. The compliance agent: Ensures that the content of the markup aligns with the expected types and values defined by the Schema.org documentation. This agent is also powered by an LLM, with its performance (precision/recall) evaluated on a dedicated benchmark using Schema.org examples.
This article is organized as follows: Section 2 presents the background and motivations. Section 3 details the methodology of LLM4Schema.org for comparing humans and LLMs Schema.org markups. Section 4 presents our experimental study and discusses limitations. Section 5 explains the positioning of this work compared to related works. Section 6 concludes and outlines future work.
Currently, 41% of the world’s web pages include semantic annotations, and 25% specifically utilizing Schema.org markup (Brinkmann et al., 2023; Dang et al., 2023). This represents billions of web pages in various languages, with different sizes, each providing both textual content and Schema.org markups.
Web Pages With Schema.org Markup in JSON-LD
Schema.org is a lightweight ontology that includes 806 types, 1,476 properties, and 14 datatypes (Guha et al., 2016). It enables the description of various entities such as a person, a place, a product, an event, and so on. Schema.org annotations can be embedded in web pages using different formats, including JSON-LD (JavaScript Object Notation for Linked Data) and microdata. Microdata enables inline annotation within HTML attributes (e.g., itemscope, itemtype, and itemprop), closely tying annotations to HTML elements for higher semantic clarity. However, it complicates intricate structures and can bloat HTML, making it harder to manage in large or dynamic applications. JSON-LD is a lightweight Linked Data format based on JSON, designed for Web-scale interoperability. 2 It uses a separate script block to define structured data with types and properties, avoiding direct HTML modification. This separation prevents bloat, simplifies updates, and improves readability. JSON-LD is mainly used to annotate web pages with the types and properties defined in the Schema.org ontology. According to the latest WebDataCommons statistics (Brinkmann et al., 2023), over 1.1 billion URLs now contain triples in JSON-LD, compared to 822 million in RDFa. In this article, we focus on the JSON-LD format.
Figure 1 presents a simple example of an HTML web page describing an Apple Pie recipe. The page includes Schema.org markup in JSON-LD format between the tags

The Apple HTML Web Page Mixing Text in the Body and JSON-LD Describing Apple Pie with Its Ingredients. HTML = HyperText Markup Language; JSON-LD = JavaScript Object Notation for Linked Data.

RDF Triples Produced by the Deserialization of the Apple Pie JSON-LD Markup of Figure 1. RDF = Resource Description Framework; JSON-LD = JavaScript Object Notation for Linked Data.
The JSON-LD markup describes a recipe entity along with its ingredients. For simplicity, the Apple Pie web page includes one entity of one type (
Given a web page embedding an RDF graph
In our example in Figure 2, there is one markup entity denoted by the blank node
Using LLMs to Generate Markup From Text
Given the text of a web page, an LLM can generate a Schema.org markup with a straightforward prompt such as:

Using this prompt, GPT-3.5 produces the Schema.org markup shown in Figure 3. Comparing the LLM-generated markup in Figures 3 and 4 with the human-generated markup in Figure 2, we observe that the LLM-generated version includes

GPT-3.5 Generated Schema.org Markup from the Apple Pie Text of Figure 1. Compared to the JSON-LD Markup of Figure 1, GPT-3.5 Produced the RecipeInstructions that are Grounded in the Text and Nutrition Facts that are not Grounded in the Text. GPT-3.5 = Generative Pre-trained Transformer 3.5; JSON-LD = JavaScript Object Notation for Linked Data.

LLM4Schema.org Overall Pipeline. Given a Web Page and a Type
This example highlights two crucial points for a web page that includes both text and Schema.org markup:
The human-generated markup cannot be considered ground truth because there is no guarantee that it is: (i) Correct, meaning all RDF facts are grounded in the text and comply with the Schema.org ontology and (ii) Complete, meaning all information in the text is represented as RDF facts. It is only possible to fairly compare two markups of a web page if they both contain correct facts.
In summary, the challenge lies in assessing the quality of LLM-generated markup when the corresponding human-generated markup cannot be assumed to be ground truth.
As we cannot use human-generated markup as ground truth, LLM4Schema.org determines if the LLM-generated markup is more or less comprehensive than the human-generated markup. To enable fair comparison, we need two crucial elements: Ensuring markup quality: We must eliminate incorrect facts from human-generated and LLM-generated markup. In LLM4Schema.org, we define incorrect facts as those not grounded in the text or compliant with the Schema.org ontology. Scoring function: Once we have two correct markups, we need a way to assess the contribution of LLM and humans. In LLM4Schema.org, we define a scoring function determining which markup provides a bigger proportion of merged markups.
In the following, we define the LLM4Schema.org pipeline for a fair comparison between LLM-generated and human-generated markup.
LLM4Schema.org Overview
The pipeline begins with a web page with Schema.org markup in JSON-LD format sampled from the WebDataCommons project (Brinkmann et al., 2023). The method for extracting a representative sample from this corpus is explained in Section 4.3. We choose a type We select markup entities of type We first extract the text of the web page (the

Illustrative Schema.org Markups for the Apple Pie Recipe Text Figure 1. (a) Human Markup Before Curation. At Line 12, the “The Eiffel Tower” is not a Compliant Value for an Ingredient and (b) Large Language Model (LLM) Markup Before Curation. At Lines 5 and 10, Markup is not Factual: “Main Dish” and “10-inch” Are not Grounded in the Text. At Lines 6 and 13, the Markup is Invalid: “Cookoo” is not a Property Name, and “Dataset” not Allowed in Recipe Instruction.
For both humans and LLMs, markups presented in Figure 5(a) and (b), some errors have been intentionally introduced to illustrate subsequent steps. As we do not assume that either LLM-generated or human-generated markup is inherently reliable, we apply the following evaluation steps:
We consider markups that pass these agents to be correct and then compare them using a scoring function called
Given a web page and a set of Schema.org types, we use LLMs to generate Schema.org markup by employing prompt engineering techniques (Brown et al., 2020). We adapted the prompt of Text2KgBench (Mihindukulasooriya et al., 2023) to fit our context. Our prompting strategy provides the language model with (i) the target Schema.org type, (ii) a list of relevant properties, (iii) an example of Schema.org compliant markup taken from the official documentation, and (iv) the input text to annotate. The model is instructed to output only the corresponding JSON-LD markup. This structured prompt guides the model in aligning the generated output with the expected schema. We use the following prompt (the template on the left, and an example of the instantiated template on the right):

represents the index of the example; there can be several examples for one type.
To address the limitation of an LLM’s context window, such as the 16,385 token context window and 4,096 token output limit of GPT-3.5-turbo, we follow the standard practice of chunking with overlap, widely used in LangChain.
3
Many techniques exist to manage long documents (Dong et al., 2023) with different trade-off. Chunking with overlap has already been explored by Chalkidis et al. (2022). We divide the text

Subsequently, we merge the JSON-LD output from each chunk to create the final markup for the text. For the sake of simplicity, a mock example of the results of LLM markup generation is illustrated in Figure 5(b).
The validity agent ensures syntactic correctness of the markup. For instance, consider the LLM-generated markup shown in Figure 5(b), specifically at line 6: the property “cookoo” is not a valid property of
To enforce these rules, we generated SHACL
4
shapes for the entire Schema.org ontology,
5
following these steps for each shape: (1) use OWL, RDFS terms for inference; (2) propagate all properties from the parent type to the child types; and (3) close the shapes to enable reasoning under the closed-world assumption. The generated SHACL shapes and code used to generate them are available on the project website.
6
,
7
Figures 6 and 7 show an excerpt of the resulting SHACL shape for the

Example of SHACL Shape for

Computing Scores.
The factuality agent takes a text and a markup as inputs, verifying whether the properties and values mentioned in the markup are grounded in the web page text. It is LLM-based. While it may seem surprising to verify the output of an LLM with another LLM, the precision of LLMs varies depending on the task. The initial task in this article is to generate all markup starting from a text, which is quite complex. The factuality agent’s task is more straightforward; it merely verifies that each markup fragment is grounded in the text. We utilize the following prompt:

If the factuality agent rejects a markup property, this signifies the detection of a hallucination in LLM-generated markup. In our context, there are two possible types of hallucination as defined by Ji et al. (2023):
For each property in the markup, we instantiate the prompt template as follows:

Because the prompt includes the entire web page text, it may encounter the token limit in LLMs, where the text’s size may exceed the maximum token count supported by LLMs. To address this issue, we employ a technique of text chunking with overlaps, similar to our method for markup generation (Section 3.2). We also aim to minimize the number of chunks

Note that the number of output tokens is omitted from the equation because the model only replies with ‘‘yes” or ‘‘no,” making the number of output tokens negligible compared to other terms. The factuality agent then validates each chunk, producing a Boolean vector for each chunk. The final factuality score is computed as the element-wise logical OR of these vectors. Finally, we remove the invalid property-value-type triples from the markup.
Schema.org Markup Compliance Agent
The compliance agent takes a markup as input and ensures that each property’s value aligns with the ontology expectations outlined in the Schema.org documentation. For example, the expected value for


This prompt is instantiated for each property-value pair in the markup. By analyzing the LLM responses, we identify and remove any non-compliant property-value pairs from the markup.
MeMR: Merged Markup Ratio
We designed the MeMR, a scoring function to estimate the contribution of human and LLM-generated markups. This function calculates the percentage of markup contributed by humans/LLM in the final merged markup. For example, applying the MeMR metric to the curated markup presented in Figure 5(a) and (b), the MeMR yields scores of
Algorithm 1 details the computation of MeMR. For each property

Number of Examples in the Ground-Truth Dataset for Factuality Agent.

Number of Examples in the Ground-Truth Dataset for Factuality Agent.
Precision, Recall, and F1 of the Factuality Agent.


Statistics of the Ground Truth for Compliance Agent.

Precision, Recall, and F1 of the Compliance Agent.

Example of C-Sets From WebDataCommons 2022.

Statistics of the 180 Web Pages.

PV
Results Throughout the Evaluation Pipeline, Where Input Is the Number of Triples in the Input. Valid, Fact, and Comp Are the Number of Triples Resulting from the Step. The Rejection Rate Is the Percentage of Triples Rejected by the Pipeline. MeMR: h for Human, l for LLMs.
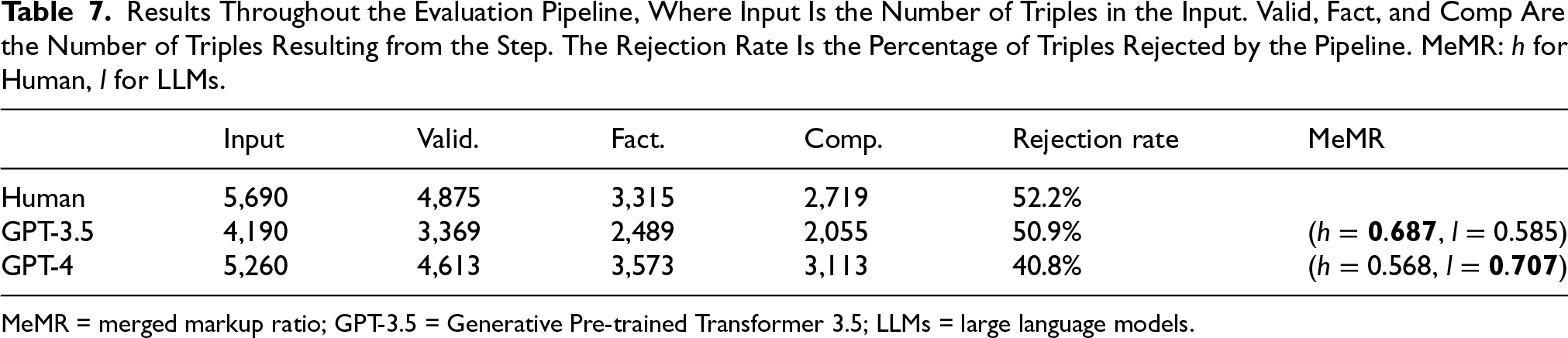
MeMR = merged markup ratio; GPT-3.5 = Generative Pre-trained Transformer 3.5; LLMs = large language models.
This allows us to evaluate the contribution of humans and LLMs to the merged markup. For our example, the resulting scores are
The experimental study aims to address the following questions: How reliable is the factuality agent? As the factuality agent relies on LLM prompts, we must evaluate its accuracy. How reliable is the compliance agent? As the compliance agent relies on LLM prompts, we must evaluate its accuracy. How can we obtain a representative sample of the Schema.org corpus? Are LLM-generated markups more comprehensive than human-generated markups? Is the MeMR reliable for comparing markups? The MeMR function is purely quantitative. Between two markups, do humans choose the same one as MeMR?
All experimental results and the code for reproducibility are available on the project website.
10
How Reliable Is the Factuality Agent?
As the factuality agent is based on an LLM, we must assess its accuracy in detecting the presence or absence of property-value-type triples in the input text.
Ground Truth Dataset for Factuality Agent
We built a ground truth based on the many examples provided in the Schema.org documentation.
11
Each example associates a JSON-LD Schema.org markup For a pair For two pairs
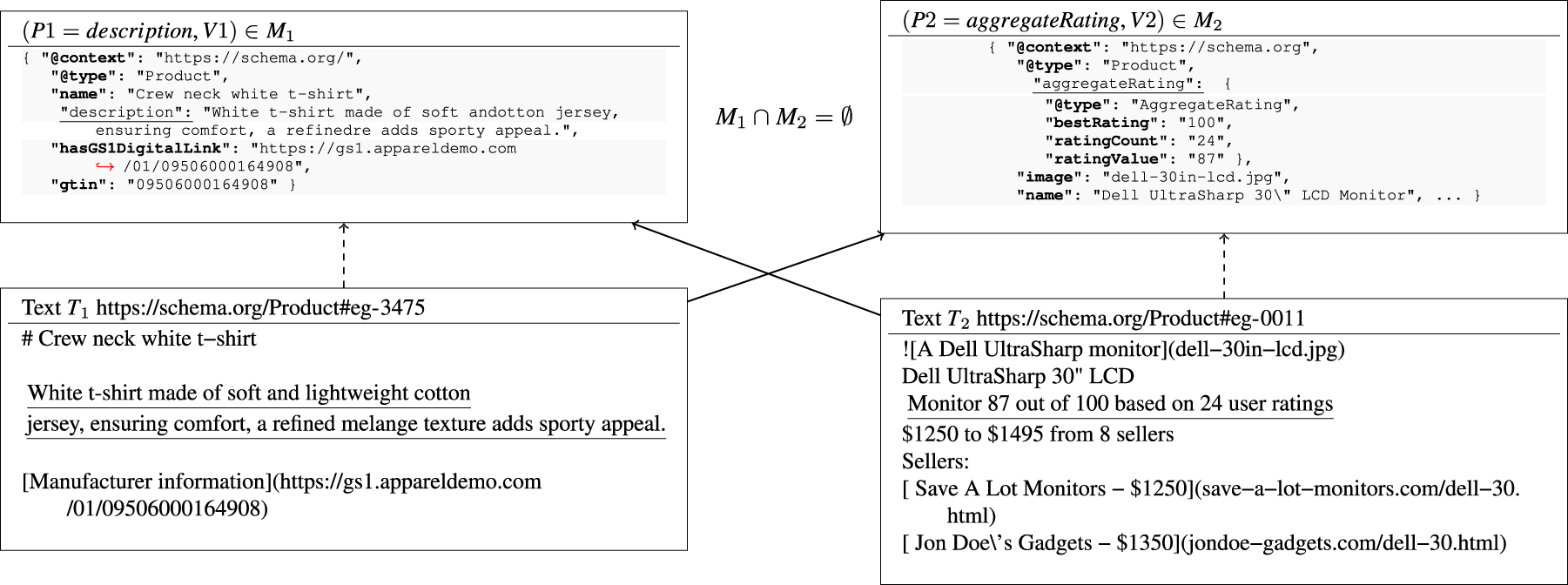
Example of Ground Truth Generation for Extrinsic Hallucination.
The factuality ground truth consists of 785 positive examples, 498 negative intrinsic examples, and 630 negative extrinsic examples, as shown in Table 1. The ground truth dataset is available on our GitHub repository. 14
We evaluate the precision, recall, and F1 score for the factuality agent using its ground truth dataset described in the previous section. As the Factuality agent performs a simpler task than markup generation but requires one LLM call per property-value-type triple in the markup, we opted for a locally hosted Mixtral model instead of using OpenAI models, primarily for cost-efficiency. We used a quantized version 15 of Mixtral-8x7B-Instruct (Jiang et al., 2024). As mentioned in Section 3.4, the factuality agent verifies whether each markup fragment is grounded in the input text.
When prompted, we set the temperature to
Table 2 presents the precision, recall, and F1 score of the factuality agent. The factuality agent obtains high F1 scores in intrinsic and extrinsic test cases. Some examples of false positives and negatives are presented in Appendix A.
How Reliable Is the Compliance Agent?
Given that the compliance agent is based on an LLM, it is crucial to assess its accuracy in determining whether a property value complies with the property expectations specified in the Schema.org documentation. Similarly to the factuality agent, this evaluation relies on the many examples provided in the Schema.org documentation.
Ground Truth Dataset for Compliance Agent
From the examples in the Schema.org documentation, we consider pairs
Figure 9 illustrates two compliance pairs: one for the

Example of Ground Truth Generation for the Compliance Agent.
In addition to the positive examples, we generate negative examples by swapping values between textual properties that are semantically distant. For example,
As described in Table 3, we generated 932 tests with positive and negative examples. The ground truth dataset is available on our GitHub repository. 17
We evaluated the compliance agent’s precision, recall, and F1 score using its ground truth datasets. As for the factuality agent, we used a quantized version of Mixtral-8x7B-Instruct. The outputs of the agent are numbers between 0 and 1, where 1 indicates full compliance of property-value pairs. We assign the label
Table 4 presents the precision, recall, and F1 score of the compliance agent. High precision and recall indicate that the compliance agent performs well on positive and negative tests (see Appendix B). A high F1 score also means we can safely integrate the compliance agent into our pipeline to evaluate the quality of the generated markup.
Sampling Over WebDataCommons
For practical reasons, we consider a representative sampled subset of the corpus of 877 million web pages visited in 2022 that feature Schema.org markup in JSON-LD format. This corpus is extracted from the CommonCrawl of October 2022 dataset, 18 which contains 3.15 billion web pages. Of these, 1.5 billion pages contain structured data, 19 and 877M include Schema.org markup in JSON-LD format.
The corpus is available in RDF as quad files using the format
Sampling over these 877 million pages is challenging because some Schema.org types/properties are much more frequent and better described than others (Dang et al., 2023). Sampling only frequent Schema.org types or well-described entities may bias results in favor of LLMs.
To create representative samples, we rely on ideas explored by Schema.org observatory (Dang et al., 2023). Schema.org observatory has computed characteristic sets for WebDataCommons released in October 2021. Characteristic sets (C-sets) are properties shared by entities across web pages, revealing how humans combine properties to describe web entities. We extend this work by adding a web page source (URL) for each C-set, allowing us to extract the textual content and human-generated JSON-LD markup for each C-set. Formally, a C-set for a subject 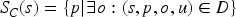
To select representatives C-sets, we study the C-sets using two features: (1)
We observe a very weak monotonic relationship between the number of instances and the number of properties in a C-set (Spearman
Next, we divided the distribution of the number of instances and the number of properties into three quantiles: low, medium, and high (Figure 10). This ensures a representative sample of C-sets with different lengths and cardinalities. We grouped the C-sets by quantiles for each feature and sampled 30 pages from each, resulting in 180 pages.
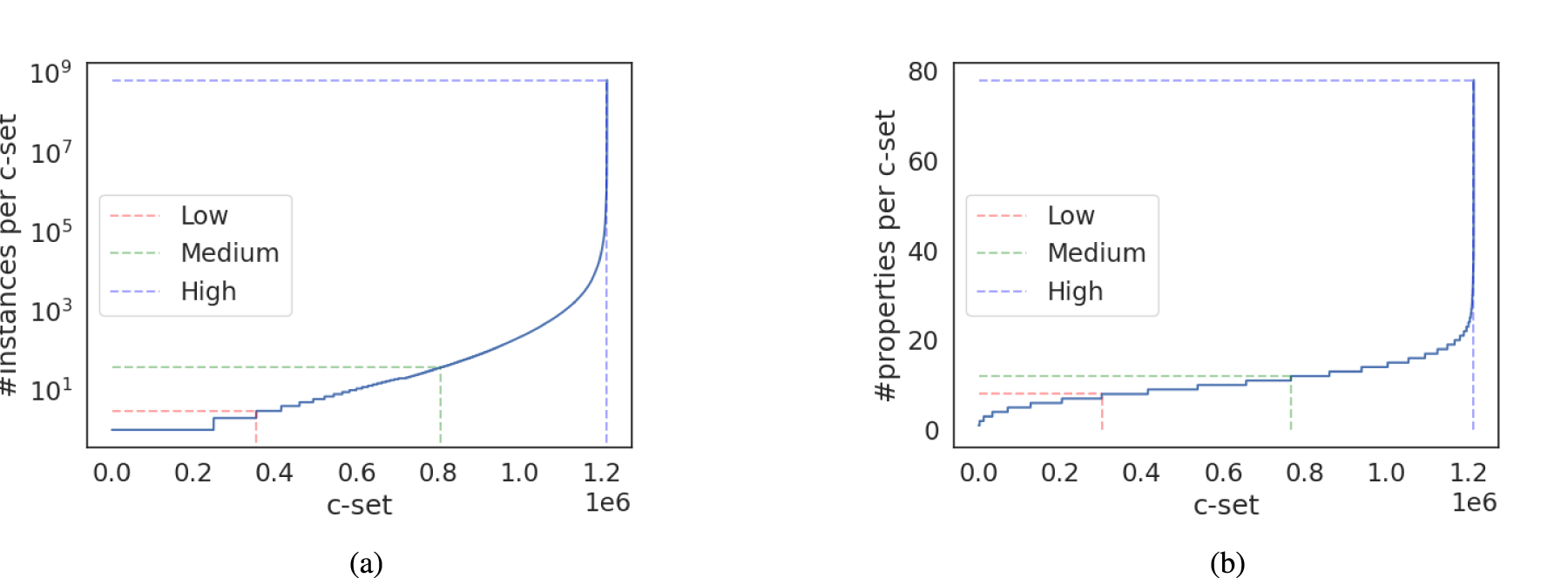
Distribution of C-sets in WebDataCommons 2023: (a) # Instances Per C-set and (b) # Properties Per C-set.
For each web page, we extracted the textual content from fully rendered web pages using HTML2Text,
21
and the human JSON-LD markup using
Table 6 presents the statistics about our 180 web pages. We can see some diversity in the length of web pages and the number of triples per page.
We compare human-generated markup to GPT-generated markup (GPT-3.5-Turbo-16k-0613 and GPT-4-0125-preview) 23 for 180 web pages, using the pipeline in Figure 4. According to the MeMR, human-generated markup contributes more to the merged markups than GPT-3.5-generated markup, but less than GPT-4-generated markup. This is due to GPT-4 being better at following instructions (Achiam et al., 2023), generating more triples with a lower rejection rate than GPT-3.5.
Table 7 presents the total number of RDF triples present in the output of each agent for the whole 180 web pages. For example, for humans, on the 5,690 input triples, the validation agent only retained 4,875 triples. When examining the proportion of rejected triples, 52.2% of human-generated triples are rejected. While most triples are valid, they are not factual or compliant. This mainly indicated that the text of web pages should be improved to ground information available in the markup. This may concern information only available as images with no alternative text, for example. As for LLMs, 50.9% of GPT-3.5 generated markup, and 40.8% of GPT-4 generated markup were incorrect. This finding indicates that LLMs should not be used out-of-the-box to generate Schema.org markup and require curation to ensure the quality of the generated markup.
Table 8 presents the results throughout the evaluation pipeline per feature (number of instances and number of properties) and per quantile (low, medium, and high). We observe the same pattern in both features: the MeMR is higher for Humans in the high quantiles and GPT-4 in the low quantiles. Although LLMs cannot outperform humans on web pages with the highest number of instances/properties, they can help improve web pages in the low and medium quantiles. This finding suggests that LLMs can help generate the first draft of Schema.org markup, which humans can further curate to improve its quality.
Results Throughout the Evaluation Pipeline, Per Feature (Number of Instances and Properties), and Per Quantile (Low, Medium, and High).
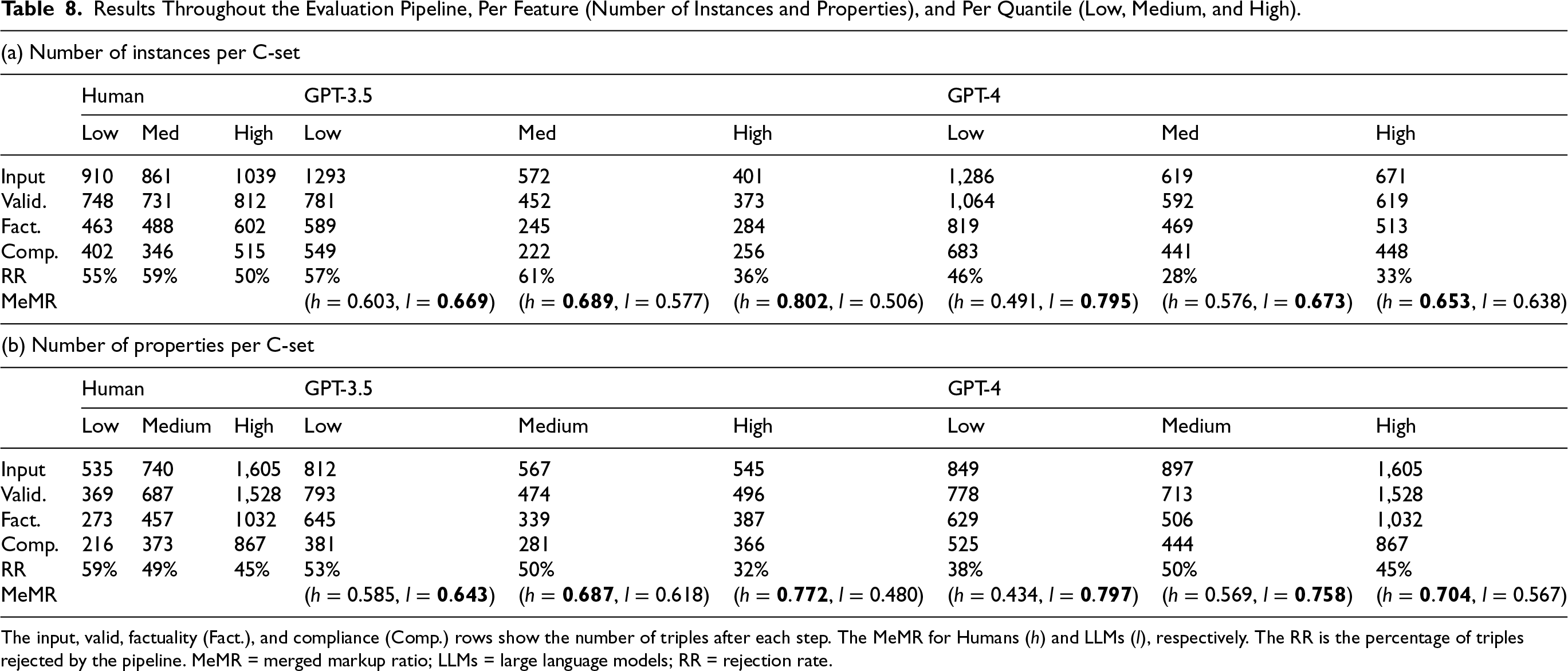
Results Throughout the Evaluation Pipeline, Per Feature (Number of Instances and Properties), and Per Quantile (Low, Medium, and High).
The input, valid, factuality (Fact.), and compliance (Comp.) rows show the number of triples after each step. The MeMR for Humans (h) and LLMs (l), respectively. The RR is the percentage of triples rejected by the pipeline. MeMR = merged markup ratio; LLMs = large language models; RR = rejection rate.
The in-depth analysis of the errors made by humans and LLMs is presented in Appendix C.
Judging the quality of the generated markup is challenging, as there might be multiple valid ways to represent the same information. The MeMR measures the quantity of information that contributes to the merging of human and LLM-generated markups, but it does not capture the quality of the information. To evaluate the accuracy of our MeMR metric, we conducted a human evaluation by measuring the perceived quality by humans. This is done in three steps: (1) we randomly selected a subset of web pages from the dataset, (2) we asked human evaluators to compare the human-generated markup with the LLM-generated markup for each web page, and (3) we measured the MeMR-Human agreement.
We first selected 10% of random web pages, resulting in 18 pages to validate the scoring function. Seven participants (master’s students familiar with Schema.org) were presented with two curated markups of the same web page and were asked to choose between A: human-generated, B: GPT-generated, or Tie. 24 The participants were not informed of the markup’s origin. Table 9 shows the participants’ responses.
Human Assessment Versus MeMR Assessment. Each Row Shows the Vote Count for Each Document.

Human Assessment Versus MeMR Assessment. Each Row Shows the Vote Count for Each Document.
MeMR = merged markup ratio; GPT-3.5 = Generative Pre-trained Transformer 3.5.
From the responses, we counted the votes for ‘‘Markup A” and ‘‘Markup B” and added one vote to both ‘‘Markup A” and ‘‘Markup B” whenever a participant votes ‘‘Tie.” To assess whether the MeMR score is consistent with human preferences, we measured the inter-rater reliability using Cohen’s kappa coefficient following Groth et al. (2018). The high kappa statistic indicates a substantial agreement between the human judgments and the MeMR score.
We repeated the experimentation with 36 random pages, including the original 18 pages, focusing only on the markup generated by GTP-4, as it showed better performance than GPT-3 in the initial validation.
In this extended experiment, 23 participants were asked again to choose between A: human-generated, B: GPT-4 generated, or Tie. 25 The details of this experiment are presented in Appendix E. The new experiment confirms the previous results: the kappa statistic remains nearly the same, and indicates a substantial agreement between human judgments and the MeMR score.
This section discusses our findings, addresses limitations, and highlights areas for future exploration.
Lack of ground truth: One of the primary issues for this work is the absence of ground truth for evaluating the ability of LLMs to generate Schema.org markup from web pages. The lack of ground truth for assessing LLMs-generated knowledge has been highlighted as a significant issue by Allen et al. (2023). Our approach does not attempt to establish a ground truth. After the execution of the pipeline, agents may fail to filter out incorrect facts or inadvertently remove correct facts. However, since the same agents process both human-generated markup and LLM-generated markups, the results remain comparable. This pipeline cannot guarantee that Schema.org markup generated from a web page is complete, that is, that all possible Schema.org markups are effectively present at the end of the pipeline. Thus, we cannot claim that the markup produced by the pipeline is correct and complete, as would be expected with a traditional ground truth.
Evaluation approach: In the absence of a classical precision/recall with a ground truth, we devised an alternative method. We evaluated whether LLMs are more capable than humans in populating schema.org classes with values extracted from text. We gamified the evaluation process, and the scoring function MeMR plays an important role. However, this coarse-grained score may fail to capture certain nuances. In our proposal, all properties of a class are weighted equally, for example, a software license is treated as equally important as its download link. Experts might argue that some properties are more critical than others, and the scoring function should reflect this distinction. Despite these limitations, the simple scoring function we defined is sufficient to discern trends over a large corpus of documents. While MeMR may not reflect expert scoring, it enables meaningful comparisons between human-generated and LLM-generated markup at scale.
Potential for cheating: A noteworthy concern is the potential for LLMs to ‘‘cheat” by relying on prior exposure to human-generated Schema.org markup during training. For instance, GPT-3 and GTP-4 are trained on data from CommonCrawl, which includes web pages from 2016 to 2019 (Brown et al., 2020). While it is stated that The CommonCrawl data was downloaded from 41 shards of monthly CommonCrawl covering 2016 to 2019, constituting 45TB of compressed plaintext.
This data consists only of plain text; there is no way to confirm that Schema.org markup was excluded. If LLMs have been trained on such markup, this may explain their performance. However, our findings show that
Prompt engineering: The prompt design significantly impacts markup generation. In Section 3.2, we detailed the prompt we ultimately employed, which was chosen for its superior performance on a sample of pages (i.e., highest score). However, we tested multiple prompts, with and without examples, and with varying levels of detail about properties. This highlights another potential use of the pipeline: as a tool to evaluate the effectiveness of different prompts. The different prompts we tested are available in the website companion. 26
Impact of the type: For fair comparison, LLM4Schema.org requires a web page containing JSON-LD and a type
Impact of chunking techniques: We employed a chunking technique with overlapping to handle long web pages. While this approach may influence the performance of LLMs, more sophisticated chunking techniques exist (Chalkidis et al., 2022), as discussed in Section 3.2. To assess the impacts of our chunking technique on the results, we analyzed how the scores of LLMs and humans evolve as the number of chunks of web pages increases. The results are presented in Appendix H. Interestingly, we observed no significant decrease in the LLMs’ performance relative to humans as document size grows. This suggests that the chosen chunking technique is suitable for this task.
Generalization of LLM4Schema.org: LLM4Schema.org focuses on the Schema.org ontology; however, our approach to comparing human and LLM performance is only loosely coupled to Schema.org. The validity agent requires a SHACL file to check predicates, types, and the type hierarchy-resources that can easily be generated for other ontologies. The factuality agent verifies whether a property-value-type triple is mentioned in the text. As such, changes in the property or type do not affect the agent’s functionality. The compliance agent checks whether the value of a property conforms to guidelines expressed in natural language. These guidelines and associated properties can be modified without altering the agent’s core behavior. Finally, the initial prompt used for markup generation includes few-shot examples to guide the model. As shown by Brown et al. (2020) and further supported by Mihindukulasooriya et al. (2023), only a small number of examples are needed to improve generation quality.
Related Work
By generating Schema.org markup from text, LLM4Schema.org is related to LLM-augmented knowledge graph construction (LLM-KGC) (Kumar et al., 2020; Pan et al., 2024). End-to-end knowledge graph (KG) construction approaches such as PiVE (Han et al., 2023) or AutoKG (Zhu et al., 2023) handle all stages of knowledge graph construction, including: (1) entity discovery, (2) coreference resolution, and (3) relation extraction. In LLM4Schema.org, the objective is to generate RDF facts based on the Schema.org ontology from a given web page.
Text2KGBench (Mihindukulasooriya et al., 2023) is a benchmark designed to evalute the performance of LLMs in extracting RDF facts from text while adhering to predefined ontologies. It features two datasets, Wikidata-TekGen and DBpedia-WebNLG. The prompt template comprises a sentence and a context describing ontology concepts, relations, and examples. Generated RDF facts are compared to a ground truth, measuring precision, recall, ontology conformance, and subject/relation/object hallucinations. In LLM4Schema.org, the input is a web page extracted from CommonCrawl, with the context restricted to Schema.org concepts. Compared to a single sentence in English, processing a web page is challenging; it can be long, and the language is not predetermined. Regarding the ontology, Text2KGBench focuses on small-sized ontologies by design (up to 20 types and 68 relations). In contrast, LLM4Schema.org targets Schema.org, which includes 806 types and 1,476 properties. 27 Most importantly, Text2KGBench relies on a ground truth where LLM4Schema.org does not. Proposing an alternative to ground truth is the primary contribution of this article.
KGValidator (Boylan et al., 2024) presents a novel framework that leverages LLMs to validate and evaluate the completion of KGs. Unlike traditional methods, KGValidator does not require a gold standard to validate LLM-generated RDF facts. Instead, each candidate’s RDF fact is validated against different trustworthy sources using: (1) retrieval-augmented generation (RAG) with trusted sources, (2) web search, and (3) reference KGs. Compared to KGValidator, LLM4Schema.org does not verify the veracity of facts; its objective is to reflect the content of the page without performing any fact-checking. We consider generating Schema.org markup and fact-checking to be two distinct tasks.
Specifically regarding Schema.org, there are few studies in the LLM-KGC domains that focus on generating Schema.org markup from unstructured data (Abbasi et al., 2022; Gonzalez-Garcia et al., 2024; Meyer et al., 2023). For instance, Abbasi et al. (2022) use earlier pre-trained language models to extract Schema.org from 12 web pages in HTML format. They use long-short-term memory (LSTM) networks to classify HTML blocs using eight Schema.org classes/properties and generate the markup using a predefined template. Gonzalez-Garcia et al. (2024) aim to complete the Wikidata KG with triples procured in the web for tourism domain. They perform entity linking to recognize Wikidata entities within the Schema.org markup, use LLMs to transform Schema.org triples into Wikidata triples and evaluates the system using test and validation sets. Bengtson (2024) focuses on refining existing Schema.org markups using LLMs. This work explores the potential of using ChatGPT-4 to refine and enhance Schema.org metadata for the NMSU Library website, aiming to improve search engine optimization. While ChatGPT provides constructive suggestions, it also makes errors, as we observed LLM4Schema.org. Compared to prior works on Schema.org, this article is the first to propose a systematic approach for evaluting the quality of LLM-generated markup.
Conclusion
If LLMs can generate Schema.org markup from the text of a web page, assessing its quality poses significant challenges: (i) The Schema.org ontology is large, covering many different domains from products to drugs, (ii) there is considerable diversity in web pages, including variations in languages and page size, and (iii) most importantly, no ground truth is available for comparison.
Fortunately, billions of web pages already contain human-generated Schema.org markup. However, this cannot be considered a ground truth as there is no guarantee of its correctness and completeness.
In LLM4Schema.org, we address the problem of assessing the quality of LLM-generated Schema.org markup by fairly comparing it to the existing human-generated markup. This fair comparison relies on three agents that filter incorrect markup and a score function MeMR, capable of comparing two correct markup in terms of coverage.
Thanks to LLM4Schema.org, we can sample web pages from the CommonCrawl and evaluate whether LLMs produce better Schema.org markup than humans. Our findings indicate that LLMs should not be used out-of-the-box for generating Schema.org markups, as they often produce invalid, unfactual, or non-compliant markups. For instance, with our best-performing LLM, GPT-4, over 40% of the generated markup is incorrect. However, after filtering the incorrect markup by LLM4Schema.org agents, filtered markup generated with GPT-4 can surpass human performance, achieving a MeMR score of 0.70 compared to 0.568 for humans. In contrast, GPT-3.5 does not outperform humans even after filtering with a MeMR score of 0.585 compared to 0.687 for humans. Additionally, we observed that GPT-3.5 and GPT-4 can enhance web pages by improving poorly filled types or utilizing less popular types, providing added value in specific contexts.
This article opens several interesting perspectives. First, our study was limited to a sample of 180 web pages containing JSON-LD with high diversity. Future work could expand this scope by sampling pages with other annotation formats, such as microdata, and increasing the sample size to include greater diversity in languages and domains. For instance, it would be valuable to investigate whether the performance of LLMs is influenced by the language or domain, for example, whether generated markup is better in English than in Vietnamese or Arabic or whether generating product markup is more straightforward than generating event markup (see Appendix F).
Second, additional LLMs, such as Gemini or LLama, could be evaluated, exploring variations in the number of parameters and quantization techniques.
Third, the score function could be refined to incorporate weights for specific properties or to leverage a more sophisticated scoring model trained on human comparisons.
Finally, the output of LLM4Schema.org’s agents could be used as labeled data to fine-tune LLMs, further improving the quality of generated markup.
Footnotes
Acknowledgements
This work is supported by the French ANR project MeKaNo (Search the Web with Things) (ANR-22-CE23-0021), and the French Labex CominLabs projects MiKroloG (The Microdata Knowledge Graph) and WanderLoG (Exploring Large Knowledge Graphs With Sampling).
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Notes
Appendix A. Example of Errors for Factuality Agent
In Section 4.2, we assessed the reliability of the factuality. In this section, we provide an in-depth analysis of some errors made by the factuality agent. We re-run the agent on some positive and negative cases without the binary output constraint to probe the LLMs reasoning (Huang et al., 2023). Wrong predictions occur when the LLMs fail to understand the subtleties in the positive examples or negative examples.
Table 10 showcases some notable errors detected by the factuality agent. It includes a fragment of the text, a triple, and a fragment of the probe provided by the factuality agent and the error type. If the error type is false negative (FN) it means that the factuality agent failed to validate a positive example, and false positive (FP) means that the factuality agent failed to reject a negative example.
The first error in Table 10 concerns the triple
Appendix B. Example of Errors for Compliance Agent
In Section 4.2, we assessed the reliability of the compliance agent. In this section, we provide an in-depth analysis of the errors made by the compliance agent. Table 11 shows the compliance agent errors. It includes the definition of the expected values for a given property, a pair
The first error of Table 11 concerns the pair
Appendix C. Examples of Errors Throughout the Pipeline
In Section 4.4, we compared the performance of humans and LLMs in generating Schema.org markups. In this section, we provide an in-depth analysis of the errors made by humans and LLMs throughout the pipeline.
Appendix D. Human Assessment
Judging markup quality is challenging, as it requires a deep understanding of the web page content and the Schema.org ontology. The example in Table 17 refers to a Book review 29 in a magazine. There is a clear preference for the GPT-generated markup as human evaluators voted 3 Tie and 3 B while MeMR chose B. This is due to the lack of ‘‘essential” information in the human-generated markup, for example, a short description publisher. However, the extra details are not always well-received by human annotators. This is the case for the example in Table 16 which received 3 Tie, 2 B and 1 A, while MeMR chose A. Both versions included extraneous information, for example, subjectOf, potentialAction, CEO being a male, and so on.
Appendix E. Additional Human Assessment for Evaluating the Accuracy of the MeMR Between Human and GPT-4
In Section 4.5, we proposed an evaluation of the accuracy of MeMR based on human assessment of 18 pages. In this section, we present an additional evaluation. We added 18 more pages, resulting in a total of 36 pages, and conducted the evaluation using GPT-4 only, as it demonstrated better performance than GPT-3 in our initial validation. Furthermore, we increased the number of human evaluators from seven to 23. The original seven participants evaluated the 18 new pages, and 16 additional participants assessed all 36 pages.
As before, participants were asked to choose between ‘‘Markup A,” ‘‘Markup B,” or ‘‘Tie.” Table 19 presents participants’ responses. From the responses, we counted the votes for ‘‘Markup A” and ‘‘Markup B” and added one vote to both ‘‘Markup A” and ‘‘Markup B” whenever a participant votes ‘‘Tie.” The high Cohen’s kappa score again indicates a strong agreement between the human judgment and MeMR score.
Appendix F. Language as a Sampling Feature
In Section 6, we proposed ‘‘language” as a potential feature for sampling. In this section, we further discuss the benefits of using language as a sampling feature.
Our generator models, namely GPT-3.5 (Brown et al., 2020) and GPT-4 (Achiam et al., 2023), are trained on a corpus of web pages from CommonCrawl. As such, the models perform better in high-resource languages like English than in other languages. Table 18(b) shows that English is the ‘‘dominant” language on the Web at 63.5%. This skew towards English and subsequent degradation in performance when the prompt is in lower-resource languages is a well-known issue (Shen et al., 2024; Zhang et al., 2023). In our context, the web page content might be in lower-resource languages, but the instruction phrases are always in English. As such, we do not know the quality of the generated markups when the web pages are in different languages. Table 18(a) shows that our sample’s language distribution pattern is consistent with that of CommonCrawl, that is, English remains the dominant language at 45.8%.
Future iterations of this work should sample the C-set (see Section 4.3) based on the language in three quantiles: low-resource, medium-resource, and high-resource languages.
Appendix G. Factuality and Compliance Agents Implementation Choice
In Sections 4.1 and 4.2, we assessed the reliability of the factuality and compliance agents. In this section, we explain the choices behind implementing the agents.
Previous works by Allen et al. (2024), Manakul et al. (2023), Mehta et al. (2024), Mündler et al. (2023), and Wei et al. (2024) detect hallucinations by pooling multiple stochastically generated responses from the same input. More specifically, the pooling method ranges from majority voting (Allen et al., 2024; Manakul et al., 2023; Mehta et al., 2024), textual entailment (Mündler et al., 2023) to ensemble learning (Wei et al., 2024). We chose the majority voting method as they are implemented by the top scorers of SHROOM competition (Mickus et al., 2024) in the task of hallucination detection. In the context of factuality and compliance agents, the majority voting method serves as a means to mitigate inconsistencies thus reduce hallucination. However, this process is costly and time-consuming as our prompt, in our case, is much longer than that of the previous works. Fortunately, SelfCheckGPT (Manakul et al., 2023) also demonstrated that the performance is consistent with human evaluation even with zero samples. Nonetheless, the approach reliability (i.e., precision, recall, and F1 score) when the number of samples decreases is unknown.
In order to build a cost-time-efficient yet reliable agent, we based our agents on SelfCheckGPT-Prompt (Manakul et al., 2023) as follows: (1) we modified the prompt to match the downstream tasks better and (2) the agents cast a single deterministic vote (
Overall, SelfCheckGPT obtains a better F1-score than our agents, but the gain is negligible, ranging from
Appendix H. Effect of Chunking on Throughout the Pipeline
In Section 3.2, we described how the pipeline handles long input, that is, the number of tokens in the prompt exceeds those allowed in the LLMs context window. First, we divide the prompt into chunks with 10% overlap to preserve context. Then, we run the generation step or the factuality agent on each chunk. Finally, we aggregate the result into a single output.
In Figure 11, we plot the average MeMR score of humans and LLMs while the number of chunks grows. As we can see, small web pages only require one chunk, while the longest web page requires 17 chunks.
We performed a Student’s t-test with the null hypothesis that the MeMR for shorter web pages (fit in