
Abstract
Event-centric knowledge graphs help enhance coherence to otherwise fragmented and overwhelming data by establishing causal and temporal connections using relevant data. We address the challenge of automatically constructing event-centric knowledge graphs from generic ones. We present ChronoGrapher, a two-step system to build an event-centric knowledge graph from grand events such as the French Revolution. First, a pruned, semantically informed best-first search traversal retrieves a subgraph from large, open-domain knowledge graphs. We define event-centric filters to prune the search space and a heuristic ranking to prioritize nodes like events. Second, we combine a structured triple enrichment method with a text-based triple enrichment method to build event-centric knowledge graphs. ChronoGrapher demonstrates adaptability across datasets like DBpedia and Wikidata, outperforming approaches from the literature. Furthermore, it is designed to be flexible and to operate over any knowledge graph accessible through Header, Dictionary, and Triples dumps or SPARQL endpoints. To evaluate the utility of these constructed graphs, we conduct a preliminary user study comparing different prompting techniques for event-centric question-answering. Our results demonstrate that prompts enriched with event-centric knowledge graph triples yield more factual answers, measured by how well answers are grounded in source information, than those enriched with generic triples or base prompts, while preserving succinctness and relevance.
Introduction
We tackle the problem of building event-centric knowledge graphs (KGs) automatically starting from generic KGs. An event-centric KG can be seen as a KG that focuses on events as central entities, rather than generic entities. An event is an occurrence or happening that can be described by its attributes and relationships to other entities within a KG. It includes information such as time, location, participants, and other relevant properties. Relating events together provide coherence to otherwise fragmented and overwhelming data by establishing causal and temporal connections using relevant data. There are numerous scenarios in which systems could assist individuals in constructing event-centric KGs in their tasks: in news article retrieval for event-centric exploration (Voskarides et al., 2021), in the legal domain where experts must associate events that could bolster their case (Filtz et al., 2020), or in the historical domain when generating hypotheses by retrieving valuable information from archives (Merono et al., 2015).
Let us imagine a historian seeking to understand the events that happened at the end of the French Revolution. Our system aims to produce an event-centric KG, as illustrated in Figure 1, which we manually created using mainly the Simple Event Model (SEM) (Van Hage et al., 2011) ontology and Wikidata. Figure 1 shows that the Coup of 18 Brumaire directlyPrecedes the French Consulate, and that Napoleon was a participant in the Coup of 18 Brumaire, and First Consul during the French Consulate. We can therefore infer that the Coup of 18 Brumaire marked the beginning of the French Consulate and enabled Napoleon to become First Consul.

One Example of an Event-Centric Knowledge Graph (KG) on the Coup of 18 Brumaire.
It should be noted that the classification of entities such as the French Directory and the French Consulate can be ambiguous, as they may be interpreted either as governing bodies (i.e., institutional entities) or as historical periods marking distinct phases in political history. In our work, we choose to treat such entities as events, consistent with how they are often described in historical discourse (e.g., “the period of the French Directory”) and represented in sources like DBpedia and Wikidata, where these entities frequently include temporal attributes (start and end dates) and are part of event-type hierarchies.
Previous work has approached event-centric KG construction as a two-step process: first, identifying relevant cues within a large memory or knowledge base (Step 1), and second, analyzing and reasoning about these cues (Step 2) (Sloman, 1996). Recent studies have also used generic KGs as background knowledge to support event-centric KG construction (Guan et al., 2022). In this context, we approach event-centric KG construction using the following two steps: given an input event node in a KG, we extract an event-centric subgraph from that KG (Step 1), and we enrich and link this subgraph with additional information to build a new event-centric KG (Step 2). Each triple in the event-centric subgraph from Step 1 has a sub-event of the input event as its subject or its object, making the extracted content directly relevant to the construction of the new event-centric KG in Step 2. Most existing event-centric KG resources are; however, built from annotated text (Leetaru & Schrodt, 2013; Nguyen et al., 2016; Rospocher et al., 2016) or from generic KGs (Gottschalk & Demidova, 2018) (Step 2), but do not focus on identifying related events for event-centric KG construction (Step 1). Likewise, event subgraph extraction (Step 1) has been used for downstream tasks such as question-answering (QA) (Jia et al., 2021; Li et al., 2021; Souza Costa et al., 2020), but does not focus on building event-centric KGs (Step 2). We propose ChronoGrapher that both retrieves event-centric subgraphs and generates new event-centric KGs, as well as an evaluation of an event-centric KG constructed by ChronoGrapher in a QA setting in the form of a user study. ChronoGrapher, along with the source code and detailed instructions to reproduce the experiments, is publicly available on GitHub under the GPL-v3 license, 1 and archived on Zenodo. 2
Our objective is to construct event-centric KGs that support downstream tasks such as QA, for example by enabling the summarization of complex events like the French Revolution or verifying whether figures like Napoleon and Paul Barras were both involved in the Coup of 18 Brumaire. We define three research questions: How to extract an event-centric subgraph from a KG, given an input event node? (Step 1) How to create an event-centric KG from that subgraph? (Step 2) Can integrating event-centric KGs into a QA pipeline improve the output quality of large language models (LLMs) compared to using LLMs alone?
Figure 2 provides an overview of the different tasks we tackle, as well as the input and output of each component.

Overview of the Diverse Tasks We Tackle to Answer Our Research Questions. The Example on the Bottom Is With the French Revolution as Starting Node and DBpedia as the Knowledge Graph (KG). ChronoGrapher Integrates Both a Subgraph Extraction Step Through a Pruned, Semantically Informed Best-First Search Traversal, and a KG Construction Step Through a Structured Triple Enrichment Method and a Text-Based Triple Enrichment Method.
For each of the research questions, we hypothesize the followings: Due to the vastness of KGs, exploring the entire graph is impractical. A search strategy can help efficiently extract the most relevant parts of the graph. Combining both coarse-grained (e.g., entity-level) and finer-grained (e.g., roles) information leads to a richer and more useful meaningful representation. Since KGs can be difficult to navigate or interpret directly, they are often not exposed to end users. Instead, their utility can be evaluated through downstream tasks such as QA, where improved performance indicates higher-quality structure and content.
To address these questions, we present ChronoGrapher, a framework composed of two components. First, a pruned, semantically informed best-first search traversal mechanism extracts event-centric subgraphs around a given event node (RQ1). Second, a KG construction module converts this subgraph into an event-centric KG using information from both the structure and literals (RQ2). We then evaluate the resulting KGs through a QA task to assess whether integrating event-centric KGs enhances the performance of LLMs compared to using LLMs alone (RQ3).
For
For
Concerning the technical novelty of the work, most methods for representing events in KGs are underdeveloped, manually built and time-consuming, and ChronoGrapher is a method for building event-centric KGs automatically from a generic KG. Unlike most approaches, ChronoGrapher integrates data from existing KGs and texts, and results in more concise and precise outputs than baselines adapted from existing systems. The modularity of our approach ensures flexibility and adaptability, while the novel combination and adaptation of previously unintegrated elements contributes to the field and improves the adapted baselines (Fionda et al., 2015; Isele et al., 2010). We evaluate ChronoGrapher and adapted methods from the literature (Fionda et al., 2015; Isele et al., 2010) against ground truth events from EventKG (Gottschalk & Demidova, 2018). ChronoGrapher shows adaptability and efficiency across datasets like DBpedia and Wikidata, outperforming existing methods.
For
In this section, we review related work along three dimensions: (i) event-centric KGs and their usage, (ii) methods for event-centric KG construction from KG, and (iii) retrieval augmented generation. Recent advances have introduced new approaches to build event-centric KGs with various applications (i). In particular, we propose a method for event-centric KG construction, which directly contributes to this field. Unlike most previous methods that focus on constructing event-centric KGs from unstructured data, our approach builds KGs from existing, structured KGs. To achieve this, our aim is to improve how event-centric subgraph information is searched and navigated within input KGs, by optimizing existing graph traversal methods. To this end, we present related methods that facilitate this process (ii), including link-traversal-based techniques for dynamic data discovery, graph navigational languages for expressing complex patterns, and entity relatedness measures to prioritize relevant nodes. Lastly, we review works that utilize event-centric KGs to improve the performance of LLMs, highlighting the practical applications of event-centric KGs in downstream tasks (iii).
In this work, we focus on KG construction from KG. The work most closely related to ours is EventKG (Gottschalk & Demidova, 2019), an event-centric KG that was built starting from large, generic KGs, such as DBpedia or Wikidata. EventKG follows a global and schema-driven approach, where event types are predefined and extracted in bulk across the entire KG. In contrast, our methods adopts a local and dynamic approach: we start from a given input event, that is a node in the KG, and automatically retrieves a subgraph that contains sub-events of that input event. This allows for more context-sensitive and targeted event graph construction. Moreover, our framework is designed to be more flexible: it can be applied to any KG, not limited to the largest open-domain KGs, and it can be configured to retrieve subgraphs around any type of node, not just events, making it broadly adaptable beyond the event-centric setting.
In addition to the KG construction part, event-centric KGs have been explored for downstream applications. For example, Guyet (2020) improved sequential pattern mining with time and reasoning to analyze complex dynamical systems. Understanding such systems helps in acquiring new knowledge but also in predicting and controlling its behavior. Event-centric KGs also help in decision-making, for instance, in the epidemiological domain (Bakalara et al., 2021) or in maritime transport (Del Mondo et al., 2021). Kroll et al. (2020) lastly uses structured narrative representations to build hypotheses on knowledge bases. These applications underscore the growing importance of event-centric KGs in both analytical and predictive tasks.
Overview of Entity Relatedness Systems.

Overview of Entity Relatedness Systems.
“–” indicates that the component is absent in the system.
Our method traverses KGs to extract event-centric subgraphs for event-centric KG building, similar to link traversal-based methods and graph navigational languages. It operates on local graphs or any SPARQL endpoint and produces meaningful subgraphs, similarly to systems like Fionda and Pirrò (2017) and Fionda et al. (2015). Unlike existing traversal methods, which often lack finer-grained control and expressiveness, our approach introduces flexible navigation and reasoning capabilities. It employs filters for search space pruning without prior knowledge of predicates, unlike graph navigational languages requiring regular expressions. Additionally, we introduce a ranking stage inspired by entity relatedness and summarization systems, prioritizing nodes based on a cost function. To the best of our knowledge, this dynamic prioritization is only present by Hartig and Özsu (2016) across in existing navigational systems, and only propose two graph-related approaches. In contrast to entity relatedness systems that typically compute all paths between entities, our system dynamically computes paths. Furthermore, our approach requires only one starting node as input, with target nodes defined as variables. It extracts subgraphs from the original KG, aiming to retrieve all events of a given entity, disregarding specific property considerations as in entity summarization systems. Lastly, while entity summarization techniques focus on preserving specific property distributions, our method targets the extraction of complete event-centric subgraphs, ensuring the retrieval of all sub-events linked to the input node.
In our user study, we adopt a RAG-like setup to compare three types of zero-shot prompting strategies for QA: one prompting without explicit context, and two prompting with triples from generic KGs and event-centric KGs, respectively. Our knowledge retriever component is implemented using
As displayed in Figure 2 from Section 1, ChronoGrapher takes an event IRI as input, extracts an event-centric subgraph where all triples contains sub-events of that input IRI, and outputs an event-centric KG. In this section, we formalize the two main components: subgraph extraction (Section 3.1) and event-centric KG construction (Section 3.2). We begin by defining the core concepts used throughout the two components: KGs, event-centric KGs, event and subevent.
(Knowledge Graph)
A
(Event-Centric KG)
In this work, an
(Event and Sub-Event)
An
Event-Centric Subgraph Extraction (RQ1)
Given a target event of interest and a knowledge graph
We begin by introducing the core concepts required for graph traversal (Section 3.1.1) and formally define the task and the search algorithm (Section 3.1.2). We then present the two key components of our method: the event-centric filters, which prune the search space by discarding nodes (Section 3.1.3); and the ranking and scoring mechanism, which selects the highest scoring nodes for expansion based on their contextual relevance (Section 3.1.4). Together, these components drive the extraction of compact and semantically meaningful subgraphs centered around a given event. To facilitate understanding of the subgraph extraction task and its components, we summarize the key definitions used throughout this section in Table 2.
Useful Definitions for the Subgraph Extraction Task.

Useful Definitions for the Subgraph Extraction Task.
KG = knowledge graph.
We formally define preliminary concepts that are useful for our subgraph extraction task and our link traversal-based method: the ingoing and outgoing triples of a node in a KG, as well as node expansion.
(Ingoing Triples)
Let 
(Outgoing Triples)
Let 
(Node Expansion)
Building on these preliminary concepts, we now formalize the event-centric subgraph retrieval task and describe our pruned best-first search algorithm to tackle it.
Task and Method Overview
We formalize the event-centric subgraph retrieval task and present the framework used to address it. Our method is a pruned best-first search that iteratively expands a local subgraph by exploring the most promising candidate nodes while discarding other ones. This section first introduces the task formulation and algorithm definition, followed by a step-by-step breakdown in pseudo-code and an illustration of the traversal process.
(Event-Centric Subgraph Retrieval Task)
Given a knowledge graph 
Note that with this definition,
(Pruned Best-First Search Algorithm)
A

We provide the pseudo-code for our subgraph extraction method in Algorithm 1, which implements a pruned best-first search in four main stages at each iteration of the search: nodes with the highest score are selected and expanded in the graph (Stage 1); event-centric filters prune certain nodes from the search space (Stage 2); the pending set and output subgraph are updated accordingly (Stage 3); and nodes in the pending set are scored and ranked to guide the next iteration (Stage 4). The
To illustrate these stages more intuitively, Figure 3 shows how a single iteration of the graph search unfolds.
4
This visual aid complements the pseudo-code by providing a concrete example of node expansion, filtering, and scoring in context. In Stage 1, the highest-ranked nodes are expanded by retrieving their ingoing and outgoing neighbors. In the figure,

Description of One Iteration During the Informed Graph Traversal. The Type of Ranking Is Predicate-Object Frequency. The WHERE, WHAT, and WHEN Filters Are Activated (Formally Defined as
The pseudo-algorithm and the visual overview highlight the key stages of our graph traversal process. We now formally define the event-centric filters (Section 3.1.3) and ranking mechanism (Section 3.1.4) that guide the subgraph extraction by pruning irrelevant nodes and prioritizing the most informative ones.
We define a set of generic filters to prune the search space during traversal, instantiated in our experiments as event-centric filters (see Section 4.1). While the filters are generic, our usage for the event-centric KGs follows the SEM ontology (Van Hage et al., 2011) and is aligned with its four core classes, as detailed in the introduction of Section 3.
The intuition behind these filters is to restrict the traversal to event-centric paths, that is, to nodes that are themselves events. This design helps prevent the search from drifting into semantically less relevant or noisy parts of the graph. For instance, expanding a person or location node may lead to biographical or geographic information that, while informative, does not contribute directly to the sub-event structure we aim to retrieve. Therefore, such entities are, when possible, not expanded further during traversal. However, they remain essential to the broader context of events and are reintegrated during the KG construction phase, which enriches the retrieved event-centric core with relevant contextual information such as people, places, and other linked entities.
In Figure 3 (Stage 2), the filters act dynamically, pruning newly visited nodes based on their type or connection. These filters could be implemented using SPARQL queries or graph navigational languages such as NautiLOD (Fionda et al., 2015), though such approaches lack the ability to rank patterns (see Section 3.1.4). Below, we formally define the filter mechanism.
(Event-Centric Filters)
We hereafter define three types of event-centric filters: predicate-based, entity-based and temporal-based. Each filter is a boolean function that enables to prune the search space in a knowledge graph
Let 
Let 
Let

The above filters are parameters of the traversal, and can be activated on demand. In Figure 3, the filters we activated are WHAT, WHERE, and WHEN (formally defined as
To prioritize the most relevant nodes for expansion, we implement a ranking mechanism that operates at the level of relation patterns. Rather than scoring individual nodes in isolation, our method groups nodes according to the structural and semantic patterns they instantiate in the graph. Each pattern is then evaluated and ranked based on its relevance to the current search context.
The ranking strategy combines two complementary components: a quantitative heuristic, which assigns a numerical score to each pattern, and a semantic preference function, which classifies patterns into semantically relevant versus less semantically relevant. The final score of a pattern integrates both aspects to reflect both contextual fit and semantic importance. Once the top-ranked pattern is selected, all nodes in the pending set that match this pattern are expanded. The process repeats until no relevant patterns or nodes remain, or until the maximum iteration number is reached. We now formally introduce the notion of relation patterns and node satisfaction, before detailing the scoring and preference mechanisms used to rank them. All the examples are taken from Figure 3.
(Relation Patterns and Node Satisfaction)
Let
Let a predicate (
Let a predicate (
Let a predicate (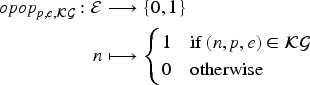
Let a predicate (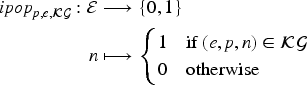
Let
We first define scoring metrics for ingoing and outgoing predicate patterns. Let a predicate Predicate frequency (pf). Edges with predicates that are often used in the dataset will be favored.
Entropy predicate frequency (epf). Edges with the most informative predicates in the dataset will be favored. Let Inverse predicate frequency (ipf). Edges with predicates that are rarely used in the dataset will be favored. Let Triples Considered for the Scoring Example. Only Unvisited Nodes Are Taken Into Account.





We second define scoring metrics for ingoing and outgoing predicate-object patterns. Let Predicate-object frequency (pof). This is similar to pf, but this metrics also differentiates between the objects.
Entropy predicate-object frequency (epof). This is similar to epf, but this metrics also differentiates between the objects. Let Inverse predicate-object frequency (ipof). This is similar to ipf, but this metrics also differentiates between the objects. Let




Let us consider the following triples from Table 3. We have
Since
The scoring metric used in Figure 3 is pof. The score of the pattern
The preference function is a Boolean function that classifies a pattern as semantically relevant if it meets certain conditions. Let For example, 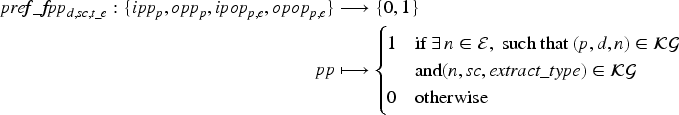
The preference function prioritizes predicates with the highest scores from the
We have presented the event-centric subgraph extraction component of ChronoGrapher. We now present its event-centric KG population component.
To build a comprehensive and fine-grained representation of events, ChronoGrapher incorporates a second component dedicated to constructing event-centric KGs. This process complements the subgraph extraction phase by enriching the retrieved events with contextual information. Such information may be explicitly encoded in the KG through IRIs or expressed in texts stored as literals.
Algorithm 2 outlines the KG construction procedure. Starting from the events identified during the subgraph extraction step, the system applies two complementary triple enrichment strategies, one structure-based and one text-based, to build the event-centric KG:

An example of the IRI-based KG construction is shown in Figure 4. On the left, we show a portion of the original Wikidata subgraph for the Coup of 18 Brumaire (

Populating a SEM Knowledge Graph From the Coup of 18 Brumaire in Wikidata.
Labels Used to Retrieve Information From Knowledge Graph (KG) Triples.

Beyond transforming IRI triples, ChronoGrapher enriches the KG by extracting structured information from textual description, specifically, event abstracts encoded as literals. To achieve this, we rely on the frame semantics theory (Fillmore & Baker, 2001), which represents situations as frames, that is, as structured templates involving participants, temporal properties, and other contextual roles. Some event-centric KGs built from news articles (Leetaru & Schrodt, 2013; Rospocher et al., 2016) also used frames. Although EventKG contains text events and links them to entities, it does not provide the finer-grained semantic structure of frames. One example of frames is the
ChronoGrapher automatically identifies such frames and their associated roles by reusing the pre-trained transformer-based model introduced by Chanin (2023). Each frame instance is aligned with the NIF ontology (Hellmann et al., 2013) to anchor it in the source text, and DBpedia Spotlight (Mendes et al., 2011) is used to link frame elements to entities. The resulting frame structures are then integrated into the KG and linked to the Framester ontology (Gangemi et al., 2016), using a representation consistent with Framester’s semantic model. 7 , 8
Figure 5 illustrates this process. Starting from the abstract of

Example of Frames Extracted From Text About the Coup of 18 Brumaire. The Knowledge Graph (KG) Contains Both Literals (in Gray) and Linked KG Entities. For Instance, the French Revolution Appears as a Literal, Directly Tied to Its Sentence and Serving as the Value of Role
We present the setup (Section 4.1), and results on the quality of the method (Section 4.2) and the impact of the constructed event-centric KGs on LLMs question-answering (Section 4.3). The quantitative evaluation (Section 4.2, RQ1 and RQ2) focuses on evaluating the quality of the method, both for the traversal (RQ1) and the KG population (RQ2). The evaluation for RQ1 is done automatically and can be reproduced. The evaluation for RQ2 is partly done automatically, and partly manually assessed. For RQ3, we conducted a preliminary user study to assess the potential of event-centric KGs on an LLM QA setting, and we found encouraging qualitative results.
Experimental Setting (RQ1 and RQ2)
Our experiments first aim to assess the quality of ChronoGrapher, both for event-centric subgraph extraction (RQ1) and for event-centric KG population (RQ2). For RQ1, we investigate the effects of filtering and ranking on the graph traversal approach. We first experiment under different configurations, with six distinct parameters for the search process: (1) scoring metric, (2) preference function (cf. Section 3.1.4), and (3)–(6) filters pertaining to WHAT, WHERE, WHEN, and WHO (Definition 9). The scoring metrics is one of the six options described above (Definition 11), whereas all the other parameters are Boolean.
To speed up the overall experiments, we used two Ubuntu machines with similar hardware configurations (40 CPU cores and 314 GiB/376 GiB of memory, respectively). Given the close similarity in specs, we do not expect the use of different machines to have introduced any meaningful variability in performance. While memory usage remains relatively constant due to the persistent in-memory KG, the approach would be more CPU-intensive, as it involves issuing a large number of query interface calls during execution.
random-5, random-10, and random-15: At each iteration, ldspider-m: Inspired by LDSpider (Isele et al., 2010), this search is a breadth-first search with some predefined predicates to be pruned out of the search space. Parameters (1) and (2) are not applicable, and (3)–(6) are set to 0. nautilod-m: Inspired by NautiLOD (Fionda et al., 2015), this baseline works as a breadth-first search combined with more complex filters than ldspider-m. Parameters (1) and (2) are not applicable, but we experiment with (3)–(6).
For RQ1 on event-centric subgraph extraction, we constructed a gold standard by querying EventKG using SPARQL SELECT queries to retrieve relevant event instances. The notebook is available to replicate this process. 9 For RQ2 on event-centric KG population, we used SPARQL CONSTRUCT queries to adapt EventKG’s triples, specifically, we replaced EventKG IRIs with the original DBpedia/Wikidata instances and aligned the predicates to SEM. The code implementing this adaptation is publicly available in our repository. 10
We chose to compare our method’s output to EventKG using the standard F1, precision and recall metrics. For RQ1, which focuses on extracting a subgraph from a KG given an input event, we use these metrics at the event level to evaluate whether the extracted subject or object nodes are indeed sub-events of the target event. This allows us to assess the correctness and completeness of the events in the subgraph. For RQ2, which concerns constructing an event-centric KG, we use the same metrics at the triple level to evaluate whether the resulting KG correctly describes sub-events with relevant features like place, time, or actor. This helps us determine how well the structural component of the KG captures the intended event semantics. These metrics thus offer a standard and interpretable way to assess performance for both subgraph extraction and KG construction.
Table 5 shows information on events and their sub-events across datasets. All types of events are taken into account, which mainly include historical events, sports events and political events such as elections. We choose to retain solely the historical events with more than ten sub-events, as they offer more than a simple list of events. Nonetheless, we provide results on additional experiments on sports and political events in Section 5.3.2. The final distribution of historical events in EventKG and their average number of outgoing links are presented in Table 6. Events with a higher number of sub-events tend to have a higher average number of features. The limited number of outgoing links for YAGO4 resulted in traversals that would end after one iteration. YAGO4 was built on Wikidata with an improved schema, without the full content from Wikidata, and we found that the ingoing links were mostly about creative works, and the outgoing links about metadata, discarded for the search. This resulted in a limited number of features. We thus only used Wikidata and DBpedia.
Statistics on Events and Their Sub-Events Across Datasets, Extracted From EventKG.

Each cell shows, per dataset, the number of events with at least one sub-event, broken down by the total number of sub-events: exactly one (
Number of Retained Events and Average Number of Features for Events With More Than

Instantiated Variables Used for Each of the Filters and the Preference Function.

DB = DBpedia; WD = Wikidata.
We now present the quantitative evaluation of our method, structured around RQ1 on event-centric subgraph extraction and RQ2 on KG construction. Section 4.2.1 presents the parameter selection procedure for the event-centric subgraphs (RQ1), whereas Section 4.2.2 reports the results of the search component, including comparisons with baselines. Section 4.2.3 addresses RQ2 by evaluating the construction of enriched event-centric KGs.
Parameter Selection for the Search (RQ1)
For
Events Used for Parameter Selection.

Events Used for Parameter Selection.
We investigated on the correlation between our ranking and filtering parameters and the best F1 score. For
Table 9 shows the contributions of each filter individually. As an illustration,
Mean F1 Score for Individual Parameters. no filter and all Means That All Parameters Are Set to 0 and 1 Respectively. pf, pof, epf, epof, ipf, and ipf Are the Six Possible Scoring Metrics (Section 4.1).

pf = predicate frequency; pof = predicate-object frequency; epf = entropy predicate frequency; epof = entropy predicate-object frequency; ipf = inverse predicate frequency; ipof = inverse predicate-object frequency.
Lastly, Table 10 shows the results of all systems. We set a timeout of 10 h for each experiment. Only five experiments from
Results Comparison of Various Systems.

pf = predicate frequency; pof = predicate-object frequency; epf = entropy predicate frequency; epof = entropy predicate-object frequency.
Table 11 shows the final results on the remaining 604 events for all systems. The three metrics tend to improve when moving from the
Systems Results on the 604 Events.
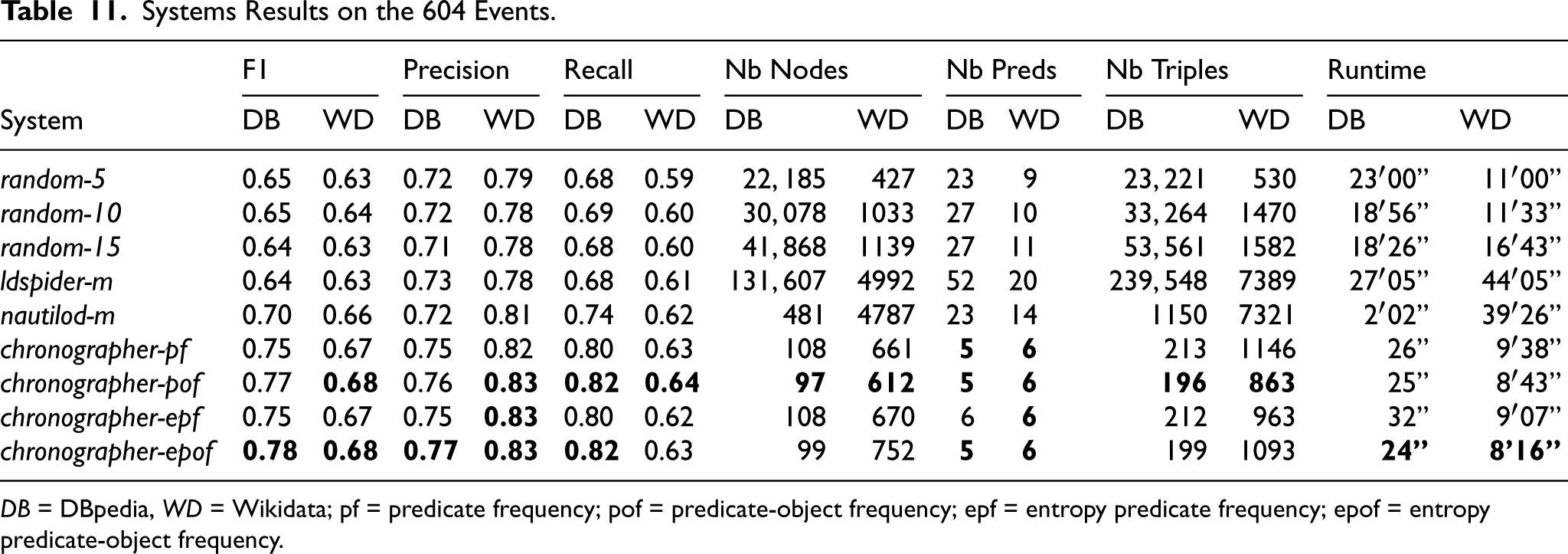
Systems Results on the 604 Events.
DB = DBpedia, WD = Wikidata; pf = predicate frequency; pof = predicate-object frequency; epf = entropy predicate frequency; epof = entropy predicate-object frequency.
To summarize findings on event-centric subgraph extraction (RQ1), adding event-centric filters (WHAT, WHERE, WHEN, and WHO) and a ranking step with an entropy predicate-object frequency heuristics helps to select relevant events while being more efficient time-wise and while exploring smaller parts of the graphs, as shown by the better performance of the
To generate our event-centric KGs, we use information from triples (i) and text (ii). On average, over all 281 historical events with more than 10 sub-events from DBpedia, there were 28,123 triples generated during the extraction from text, and 548 other triples. There are therefore 51 more triples generated during the extraction from text than other triples. For the triples generated from the information extraction the KG predicates are distributed, on average per event, as 41.9% rdf predicates, 40.0% wsj predicates, 12.2% nif predicates, 5.6% skos predicates, and 0.3% dbo:abstract predicates.
Our Event-Eentric KGs Against EventKG.

Our Event-Eentric KGs Against EventKG.
DB = DBpedia; WD = Wikidata; KGs = knowledge graphs.
Table 13 shows the F1, precision, and recall scores of the narrative graphs generated from the output of the search algorithm presented in Section 3.1. Our end-to-end system achieves an overall (for all predicates) F1 score of 51.7% and 49.2%, respectively. As in Table 12, precision is higher for DBpedia, while recall tends to be higher for Wikidata. The results are furthermore lower than those in Table 12, which is expected since the output of the search also contains events that are not in the ground truth events. Consequently, for each of such event, all generated triples will not be in the ground truth from EventKG.
Metrics of Generated Narrative Graphs Compared to EventKG.

DB = DBpedia; WD = Wikidata; KGs = knowledge graphs.
To summarize findings on event-centric KG population (RQ2), we use both information extraction from triples and text. For triples, our system achieves F1 scores of 67.2% and 76% for DBpedia and Wikidata. For text, we conduct a qualitative evaluation on the “causation” frames and find that the system is able to retrieve information with good performance.
To illustrate the constructed KGs, we provide several sample KG files in the public repository,
15
along with a file describing the contents of each. These examples, based on the French Revolution scenario, illustrate the different KG construction strategies used in our pipeline. Specifically,
We conducted a user study focusing on a QA task. The goal of the study was to evaluate whether integrating our constructed event-centric KGs could enhance the quality of answers produced by LLMs, compared to using LLMs alone. Section 4.3.1 first outlines the design of the user study, including the preparation of evaluation data and the experimental setup. Section 4.3.2 presents and analyzes the results of our user study.
User Study Setup
To evaluate whether integrating event-centric KGs enhances the performance of LLMs compared to using LLMs alone (RQ3), we designed six SEM-centric question types, each reflecting a core role or relation from the SEM ontology: summary of an event, causal explanations for an event, types of events within a time-range, sub-events of an event, events in which an actor participated, and events in which two actors both participated. For each type, we created a question template and instantiated it with two manually selected events, resulting in 12 questions. Each question was manually associated with an event during the design phase, no automated mapping was used. Once the event was selected, we retrieved its corresponding event-centric KG using SPARQL queries, and used the resulting triples as context in the LLM prompt alongside the natural language question. Table 14 shows examples of the six types of questions.
Event-Centric Templated Question Examples.

Event-Centric Templated Question Examples.
We used three different types of prompts: (a)
Context Triples Retrieval for DBpedia and the Event-centric KGs Built by ChronoGrapher. The Context Triples Are Retrieved Through CONSTRUCT Queries or Equivalent Implementation Using the HDT Data Format.

KGs = knowledge graphs; HDT = Header, Dictionary, Triples.
Qualitative Evaluation Metrics Used in the User Study. Grounding Was Assessed by Us Only.

In our user study, we used GPT-4. 17 In April 2024, when we conducted the user study, GPT-4 was among the top-performing LLMs available, 18 with strong capabilities in reasoning, coding, and general language understanding. At that time, GPT-4 was widely recognized for its performance across various benchmarks, making it a suitable choice for our user study.
The participants were asked to assess the quality of the answers with these criteria: (1) granularity of the information, (2) relevance to the question (3) succinctness, and (4) diversity in content, on a scale of 1 to 5. We furthermore manually assessed (5) grounding to factual events. A QA system must most importantly give faithful content, making the groundedness metric (5) a priority. The relevance metric measures how well the answer provides a plausible answer to the question, but not its actual truthfulness.
We gathered 10 participants for our user studies. We reached the participants of the user study throughout our research laboratories. The researchers who participated are based in Paris or Amsterdam, and they have a background in computer science and/or computational linguistics. They were not overly familiar with the questions we had them evaluated, and were familiar with LLMs systems and their pitfalls. We designed two forms
19
with six questions each, and with three answers per question corresponding to the three prompt types. We split the 10 participants evenly across these two forms. Each participant rated 18 answers (6 question types
Table 17 presents the average scores for each metric and prompt type. The
Average Scores for Metrics on the Human Evaluation. The Groundedness Metric Is the Most Important One as It Assesses the Faithfulness of the Answers.

Average Scores for Metrics on the Human Evaluation. The Groundedness Metric Is the Most Important One as It Assesses the Faithfulness of the Answers.
When comparing the triples-based prompts,
This first small user study thus hints that event-centric KGs can help an LLM provide more factual and concise answers to event-centric questions (2.85) than a base prompt (1.11) or a generic KG-based prompt (2.24), while maintaining succinctness.
In this section, we reflect on the design choices, assumptions, and limitations of our approach. We begin by discussing the role of EventKG as the ground truth (Section 5.1) with an example. We then consider the methodological scope of our framework and motivate our design decisions, particularly the choice of a rule-based approach over learning-based alternatives (Section 5.2). Following this, we explore the generalisability of ChronoGrapher: both to new datasets (Section 5.3.1) and to different types of events beyond the historical domain we primarily focus on (Section 5.3.2). Lastly, we reflect on the potential uses of the event-centric KG produced by ChronoGrapher, and the kinds of usage and applications it supports (Section 5.4).
EventKG as the Ground Truth
As many parts of our evaluation rely on EventKG as a reference, we conducted a qualitative comparison on a few subevents of the French Revolution between subgraphs extracted by ChronoGrapher and their counterparts in EventKG. Our goal was to better understand the complementarity between the two systems.
Figure 6 provides a visual comparison between the outputs of EventKG and ChronoGrapher. In the top part of the figure, we observe that ChronoGrapher does not retrieve

Comparison Between EventKG and the Output of ChronoGrapher With Two Events.
Our methodology adopts a heuristic, modular approach that prioritizes semantic transparency and temporal control in the construction of event-centric KGs. This design decision is motivated by the requirements of understanding and reasoning tasks, where explainability and domain alignment are essential. While basic in form, the approach performs effectively, as demonstrated in both automatic and user-based evaluations. Moreover, the focus of this work lies not in proposing a novel learning algorithm, but in defining a clear and extensible pipeline for event-centric KG construction and use. By anchoring event representation in a semantically coherent and temporally aware framework, we provide a reliable foundation for downstream learning-based methods, such as embedding models or graph neural networks, that could build upon the structured graphs produced. We are currently working on identifying the best syntactic representations to use to train embeddings for event-centric KGs. We believe this balance of simplicity, effectiveness, and extensibility offers practical value for real-world applications while supporting future integration with more complex models.
Generalisibility of ChronoGrapher
We discuss the generalisability of ChronoGrapher, both in terms of its adaptability to different datasets (Section 5.3.1) and its applicability to diverse types of events (Section 5.3.2).
Generalisibility to Other Datasets
ChronoGrapher is flexible and could be applied to other types of nodes or datasets, including those using the PROV vocabulary, which could also yield event-centric graphs. As a reminder, it consists of two components: (1) a pruned, semantically informed best-first search, and (2) a KG constructor. The search component is highly configurable through a lightweight configuration file.
20
and supports various traversal strategies, such as Semantically informed or random walks, with or without ground truths. Target-based walks in the graph.
This is illustrated in our open-source implementation. 21 The search is also not bound to focus on events only, but can be configured to focus on any type of nodes, such as people or places. Lastly, the search can be run on any KG that is accessible through an HDT dump or a SPARQL endpoint. The constructor is adaptable, provided that predicate labels are retrievable (e.g., via SPARQL).
Furthermore, while ChronoGrapher does not currently implement incremental updates, its design allows for a practical workaround. In dynamic settings (e.g., live sports events), one could extract only the newly added parts of the dataset—centered, for instance, around new event nodes—and rerun ChronoGrapher on these subgraphs. This avoids reconstructing the full event-centric KG from scratch and enables more efficient updates.
While our evaluation primarily focuses on historical conflict events, we also explored the applicability of our approach to other domains, notably political and sports events. These types of events often differ structurally from historical ones in KGs: political events (e.g., elections) and sports events (e.g., Olympic competitions) tend to be organized as lists of sub-events (disciplines, rounds, or contests) within a broader event. Moreover, the semantic richness in these domains is often limited, with many relationships captured through generic predicates such as
To assess performance in this context, we conducted additional experiments using DBpedia, incorporating
Usage of the Event-Centric KG
In this work, ChronoGrapher was designed to support a wide variety of question types by focusing on events, people, locations, frame-based relationships, and causal interactions. The event-centric KGs can still capture a rich set of relationships between entities and events. This approach allows us to answer questions ranging from straightforward fact retrieval (e.g., Who was involved? or Where did the event take place?) to more complex reasoning questions (e.g., What caused this event? or What were the consequences?).
However, we acknowledge that the types of questions are inherently constrained by the content it contains. As is the case with any knowledge-based task, the quality and scope of the questions answered are determined by the data represented in the KG. This limitation is a natural consequence of working with structured data, where the knowledge captured reflects the domain’s scope and the granularity of its representation. Furthermore, ChronoGrapher’s design aligns with the broader goal of narrative construction, which aims to facilitate understanding and reasoning about events within a narrative context. In our previous work, we identified specific requirements for narrative structures that inform the development of such knowledge graphs, ensuring that Chronographer can address a variety of questions within its scope and purpose (Blin et al., 2024).
Adapting ChronoGrapher to a new dataset requires some familiarity with the target KG’s ontology, particularly to identify predicates analogous to those in the SEM ontology (e.g., for time, location, or actor roles). While this setup currently requires manual configuration, we envision an interface that could assist non-expert users. Such an interface could suggest relevant predicates based on common usage in the dataset and help define event-centric filters through guided forms or templates. In practice, applying ChronoGrapher to new domains may also involve collaboration with a domain curator or a developer familiar with the schema. These additions would help extend ChronoGrapher’s applicability beyond users familiar with coding.
Conclusion
We address the challenge of automatically constructing event-centric KGs from generic ones. We present ChronoGrapher that extracts event-centric subgraphs from generic KGs, and builds event-centric KGs. To extract event-centric subgraphs (RQ1), ChronoGrapher contains a pruned, semantically informed, best-first search traversal integrating event-centric filters to prune the search space and a ranking step for node prioritization, yielding F1 scores of 0.78 and 0.68 for DBpedia and Wikidata. To generate event-centric KGs (RQ2), ChronoGrapher combines a structured triple enrichment based on IRIs and a textual triple enrichments based on abstracts encoded a literals in KGs, achieving F1 scores of 0.67 and 0.76 for DBpedia and Wikidata, and information extraction from text. To evaluate whether integrating event-centric KGs enhances the performance of LLMs compared to using LLMs alone (RQ3), we conduct first experiments comparing different prompts on an event-centric QA setting, and show that prompts enriched with event-centric KG triples give more factual answers while maintaining succinctness (2.95 vs. 1.11 and 2.24).
Future work will focus on improving ChronoGrapher in a number of directions, including expanding the search method to reach more sub-events using, for example, EventKG for additional type information; expanding the event-centric KG population beyond EventKG to tackle data noise and incompleteness; improving the modeling of complex entities; considering novel ontologies and vocabulary for the event representation (e.g., RDF-star); and use more sophisticated RAG-based methods for a larger user study. We also plan to work on additional quantitative and automatic metrics for a better evaluation of the event-centric KGs.
Supplemental Material Statement: Source code for our system, the baselines we (re-)implemented and the experiments are available on Github. 22 The source code contains the predicate labels that were used to generate the event-centric KG (Section 3.2), pointers to download the datasets and more generic statistics on events and their sub-events (Section 4.1), the 12 events for parameter selection (Section 4.2.1), additional results on experiments on the end-to-end system combining the event extraction and the graph generation and the manual annotations for the causation frames (Section 4.2.3), and all code, prompts and data linked to the user study (Section 4.3).
Footnotes
Acknowledgements
This work was funded by the European MUHAI project (Horizon 2020 research and innovation program) under grant agreement number 951846 and the Sony Computer Science Laboratories-Paris. We thank Frank van Harmelen for fruitful discussions, and our reviewers for their constructive and insightful feedback. We also thank our user study participants for their time and insights. Figures were created using draw.io.
Funding
This work was funded by the European MUHAI project (Horizon 2020 research and innovation program) under grant agreement number 951846 and the Sony Computer Science Laboratories - Paris.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.