
Abstract
The ability to think abstractly and reason by analogy is a prerequisite to rapidly adapt to new conditions, tackle newly encountered problems by decomposing them, and synthesize knowledge to solve problems comprehensively. We present TransCoder, a method for solving abstract problems based on neural program synthesis, and conduct a comprehensive analysis of decisions made by the generative module of the proposed architecture. At the core of TransCoder is a typed domain-specific language, designed to facilitate feature engineering and abstract reasoning. In training, we use the programs that failed to solve tasks to generate new tasks and gather them in a synthetic dataset. As each synthetic task created in this way has a known associated program (solution), the model is trained on them in supervised mode. Solutions are represented in a transparent programmatic form, which can be inspected and verified. We demonstrate TransCoder’s performance using the Abstract Reasoning Corpus dataset, for which our framework generates tens of thousands of synthetic problems with corresponding solutions and facilitates systematic progress in learning.
Introduction
Abstract reasoning tasks have a long-standing history in artificial intelligence, as epitomized with Bongard’s problems (Bongard, 1967), Hofstadter’s analogies (Hofstadter, 1995), and more recently the Abstract Reasoning Corpus (ARC; Chollet, 2019; Figure 1). They reach beyond the input–output mapping tasks typical for contemporary machine learning (e.g., classification and regression) and thus pose several nontrivial challenges. The suits of such tasks tend to be very diverse, each engaging a different “conceptual apparatus” and thus requiring a bespoke solution strategy. This, in turn, implies the necessity of devising sophisticated features that are highly task-specific and need to be “invented on the spot,” such as the presence/absence of previously unseen objects in the visual input, or the number of tokens in a sequence, or a specific pattern thereof. Another challenge is the staged nature of reasoning, which often needs to comprise multiple steps of inference, thus requiring some notion of working memory for storing and manipulating diverse concepts.

Examples from the Abstract Reasoning Corpus dataset.
These and other characteristics of abstract reasoning tasks become particularly challenging when one attempts to learn to solve them, rather than manually devising a complete architecture of a working solver. Given the diversity of the tasks to be faced, one cannot rely on predefined representations and concepts, and often not even on preset solving strategies, and it becomes essential to allow the learner to construct them on the fly and, in particular, to learn what to construct given the context of the given task.
In the past, abstract reasoning tasks have been most often approached with algorithms relying exclusively on symbolic representations, typically involving some form of principled logic-based inference. While this can be successful for problems posed “natively” in symbolic terms (e.g., Hofstadter, 1995), challenges start to mount up when a symbolic representation needs to be inferred from a low-level, for example, visual, representation (Bongard, 1967; Chollet, 2019). The recent advances in deep learning and increasing possibilities of their hybridization with symbolic reasoning (see Section 4) opened the door to architectures that combine “subsymbolic” processing required to perceive the task with sound symbolic inference.
Addressing the above challenges requires a flexible, expressive, structural, and compositional formalism that permits the learner to experiment with alternative representations and features of the task, combine and validate them, and so learn successful problem-solving strategies. While devising completely new mechanisms for this purpose is arguably possible, it is natural in our opinion to reach the realm of programming languages, and to pose the problem of solving abstract reasoning problems as a program synthesis task. In this formulation, the solver is an intelligent, reactive agent that perceives the task and attempts to synthesize a program in a bespoke domain-specific language (DSL) which, once executed, produces the solution to the task.
This study is based on these premises and introduces TransCoder, a neurosymbolic architecture that relies on both neural and symbolic perception of the problem and involves programmatic representations to detect and capture relevant patterns in low-level representations of the task, infer higher-order structures from them, and encode the transformations required to solve the task. TransCoder is designed to handle the tasks from the ARC (Chollet, 2019), a popular benchmark that epitomizes the above-mentioned challenges. Our main contributions include (i) the original neurosymbolic architecture that synthesizes programs that are syntactically correct by construction, (ii) the “learning from mistakes” paradigm for generating synthetic tasks of adequate difficulty to provide TransCoder with a learning gradient, (iii) an advanced perception mechanism to reason about small-size rasters of variable size, and (iv) an empirical assessment on the ARC suite. This paper extends the preliminary findings summarized in the conference paper (Bednarek & Krawiec, 2024) and uses an improved version of TransCoder architecture.
ARC (Chollet, 2019) is a collection of 800 tasks of a visual nature, partitioned into 400 training tasks and 400 testing tasks. 1 Each task comprises a set of input–output pairs that exemplify a mapping/rule to be discovered. That set is divided into demonstrations and tests. The demonstration set consists of three to six such pairs, while the test set typically contains a single pair. The solver has full access only to demonstrations; for tests, it can observe only the input parts (Figure 1). The test set acts as an independent verification mechanism for evaluating the solutions generated by the solver. Essentially, the solver is challenged to extract the inherent problem definition from demonstrations and subsequently apply this learned knowledge to generate solutions for the inputs in tests. This distinction between the roles of the demonstrations and tests emphasizes the importance of generalization and the ability of the solver to extrapolate beyond the provided examples.
The inputs and outputs in a pair are raster images. Images are usually small (at most
For each ARC task, there exists at least one processing rule (unknown to the solver) that maps the input raster of each demonstration to the corresponding output raster. The solver is expected to infer 2 such a rule from the demonstrations and apply it to the test input rasters to produce the corresponding outputs. The output is then submitted to the oracle, which, based on the knowledge of the true/desired outputs, returns a binary response informing about the correctness/incorrectness of the solution.
The ARC collection is extremely heterogeneous in difficulty and nature, featuring tasks that range from simple pixel-wise image processing (e.g., re-coloring of objects), to mirroring of the parts of the image, to combinatorial aspects (e.g., counting objects), to intuitive physics (e.g., an input raster to be interpreted as a snapshot of moving objects and the corresponding output presenting the next state). In quite many tasks, the black color should be interpreted as the background on which objects are presented; however, there are also tasks with rasters filled with “mosaics” of pixels, with no clear foreground–background separation (see, e.g., the left example in Figure 1). Raster sizes can vary between demonstrations, and between the inputs and outputs; in some tasks, it is the size of the output raster that conveys the response to the input. Because of these and other characteristics, ARC is widely considered extremely hard: in the Kaggle contest accompanying the publication of this benchmark, 3 which closed on May 28, 2020, the best contestant entry algorithm achieved an error rate of 0.794, that is, solved approximately 20% of the tasks from the (unpublished) evaluation set, and most entries relied on a computationally intensive search of possible input–output mappings. Section 4 reviews selected ARC solvers proposed to date.
The Proposed Approach
The broad scope of visual features, object properties, alternative interpretations of images, and inference mechanisms required to solve ARC tasks suggests that devising a successful solver requires at least some degree of symbolic processing. Among others, objects in ARC rasters tend to be small and “crisp,” so that even a single-pixel difference between them matters (not mentioning the fact that some tasks feature single-pixel objects). The conventional convolution-based perception typical for contemporary deep learning models is not sufficient to capture this level of detail, also because they are prepared to process categorical, unordered colors. Moreover, such precision is required not only in perception, but also when producing output rasters to match those in demonstrations or generate the response to the test image.
It is also clear that reasoning conducted by the solver needs to be compositional; for instance, in some tasks, objects must be first delineated from the background and then counted, while in others objects need to be first counted, and only then the foreground–background distinction becomes possible. It is thus essential to equip the solver with the capacity to rearrange the inference steps in an (almost) arbitrary fashion.
Following the motivations outlined in Section 1, the above observation is a strong argument for representing the candidate solutions as programs and forms our main motivation for founding TransCoder on program synthesis, where the solver can express a candidate solution to the task as a program in a DSL, a bespoke programming language designed to handle the relevant entities. Because (i) the candidate programs are to be generated in response to the content of the (highly visual) task, and (ii) it is desirable to make our architecture efficiently trainable with a gradient to the greatest degree possible, it becomes natural to control the synthesis using a neural model. TransCoder is thus a neurosymbolic system that comprises the following components (Figure 2):
In training, the Interpreter applies

The overall architecture of TransCoder comprises Perception, Solver, and Program Generator. The former two are purely neural, while the Generator combines symbolic processing and information from the neural model. The Generator relies on symbolic working memory (Workspace), which maintains both entities specific to individual demonstrations (local) as well as those common for all demonstrations and predefined concepts (global).
We detail the components of TransCoder in the following sections. For technical details, see Appendix A.
The Perception module comprises the raster encoder and the demonstration encoder.
As argued at the beginning of this section (and verified in our preliminary studies), typical convolutional layers are insufficient for capturing the information that is essential in ARC tasks. Therefore, we abandon purely convolutional processing in favor of encoding rasters as one-dimensional sequences of tokens that convey information about pixels. Prior to the sequential processing block, the data undergoes a preprocessing with two 2D convolutional layers. The layers preserve the spatial dimensions of the input tensor, ensuring that both height and width remain unchanged, which is essential due to extremely small rasters in the dataset. The information about the raster size itself, often crucial for solving the task, is also conveyed by the length of the sequence.
Our

The autoencoder architecture used to pre-train the raster encoder in perception. Left: the encoder (used in TransCoder after pre-training). Right: the decoder (used only in pre-training and then discarded).
The raster encoder can be trained alongside the other TransCoder components; however, this turned out to be computationally inefficient. More importantly, when training the entire architecture end-to-end, it is hard to determine the component that should be blamed for the failure to deliver the correct answer. For these reasons, we pre-train the raster encoder within an autoencoder architecture, where the encoder is combined with a compatible decoder that can reproduce varying-length sequences of pixels (and thus the input raster) from a fixed-dimensionality latent. The decoder is shown in the right part of Figure 3 and comprises a sequence of steps that attempt to recover the spatial and color information from the fixed-dimensional latent.
The objective of pre-training is to develop an encoder capable of effectively encapsulating the essential information from the input data in the latent representation. To achieve this, we train the autoencoder in the self-supervision mode, by confronting it with a “fill-in” task. The decoder is tasked with predicting the correct pixel value (pixel color) at a given location, conditioned on the latent representation of the input raster from the encoder. By providing the decoder with the complete set of target pixel positions, the requirement for the decoder to determine the output raster is relaxed (compared to an alternative scenario in which one could require the decoder to restore the entire sequence, i.e., both colors and coordinates). The decoder then concatenates the embeddings of target positions with the reduced raster representation to prevent the encoder from overspecializing on the “fill-in” tasks. As the “query” position representation contains partial raster representation, the encoder is forced to reason in terms of dependencies between pixels and their colors and coordinates, rather than overfitting to specific locations and colors of pixels. The decoder then processes the tokens with a stack of cross-attention blocks. Eventually, a fully connected layer produces per-pixel predictions, which are confronted with the actual pixels from the input sequence using pixel-wise categorical cross-entropy loss on the color variable.
The autoencoder is pre-trained until convergence, using all rasters (inputs, outputs, and tests) collected from the training part of the ARC collection. In this process, we intend to make feature extraction invariant to permutations of colors, while accounting for the black color serving the special role of the background in a large fraction of tasks. To this end, the rasters derived from the ARC are treated as dynamic templates, which are being randomly re-colored on the fly, while preserving the distinctions of colors. This enforces permutation-invariance in the space of colors and improves generalization. As a result of pre-training, the raster encoder used in the experimental part of this study achieves the per-pixel reconstruction accuracy of 99.99% and the per-raster accuracy of 96% on the testing part of the original ARC. The resulting encoder is thus guaranteed to pass on almost the entirety of the information available in the input rasters.
Upon completion of pre-training, the raster encoder is prepended to the
The sequential latent
Technically, the Solver is implemented as a two-layer MLP preceded by averaging over the sequence of
To account for this many-to-many correspondence, we make the Solver stochastic by following the blueprint of the Variational Autoencoder Kingma and Welling (2022): the last layer of Solver’s MLP does not directly produce
The variational layer allows the Solver to propose alternative solutions to the same ARC task. Ideally, one would hope
The presence of sampling makes TransCoder non-deterministic and brings tangible benefits in training: as we found in preliminary experiments, it significantly improves exploration, helping the method to produce non-trivial programs, and is particularly important for generating synthetic tasks (Section 3.7. If desired, sampling can be disabled at test time, with
Workspace
The Workspace is the core symbolic module of TransCoder, which is meant to provide the Program Generator (Section 3.5) with additional information, alongside the latent
Concerning the Workspace Template that holds the abstract placeholders for the entities that appear in all tasks’ demonstrations. Workspaces that “instantiate” that template with concrete values derived from particular demonstrations.
The relation between these two storages can be likened to a dictionary, with the entries in the Workspace Template acting as keys that index specific values (realizations) in the Workspace of a specific demonstration. For instance, the Scene key in the Workspace Template may have a different value in each Workspace. For the task shown in Figure 2, the Workspace Template contains the Scene key, and its values in the first two Workspaces are different, because they feature different sets of colors:

The list of Workspace keys is predefined and includes constants (universal keys shared between all ARC tasks, e.g., zero and one), local invariants (values that repeat within a given task, across all demonstrations, e.g., the set of used colors), and local keys (information specific to a single demonstration pair, e.g., an input Region). For a complete list of available keys, see the Appendix.
The Workspaces require appropriate “neural presentation” for the Generator of DSL programs. For a given task, all keys available in the Workspace Template are first embedded in a Cartesian space, using a learnable embedding similar to those used in conventional deep learning. This representation is context-free, that is, each key is processed independently, and the embedding has in total as many entries as there are unique keys defined in DSL.
Concerning the
The DSL
The DSL we devised for TransCoder is a typed, functional programming language, which allows conveniently representing programs as ASTs. The leaves of ASTs are responsible for fetching input data and constants, inner nodes are occupied by DSL instructions/functions, and the root of the tree produces the return value of the entire program. Each tree node has a well-defined type. The DSL features concrete data types (e.g., Int, Bool, and Region) and generic data types (e.g. List[T]). Tables 1 and 2 present the complete list of, respectively, types and instructions.
The List of Types Available in the Domain-Specific Language (DSL).

The List of Types Available in the Domain-Specific Language (DSL).
Definitions of the Operations Available in the Domain-Specific Language (DSL).

The Blacklisting Rules That are Integrated Into the Generator’s Symbol Selection Process and Prevent it From Composing Certain Pairs of Parent–Child Operations.
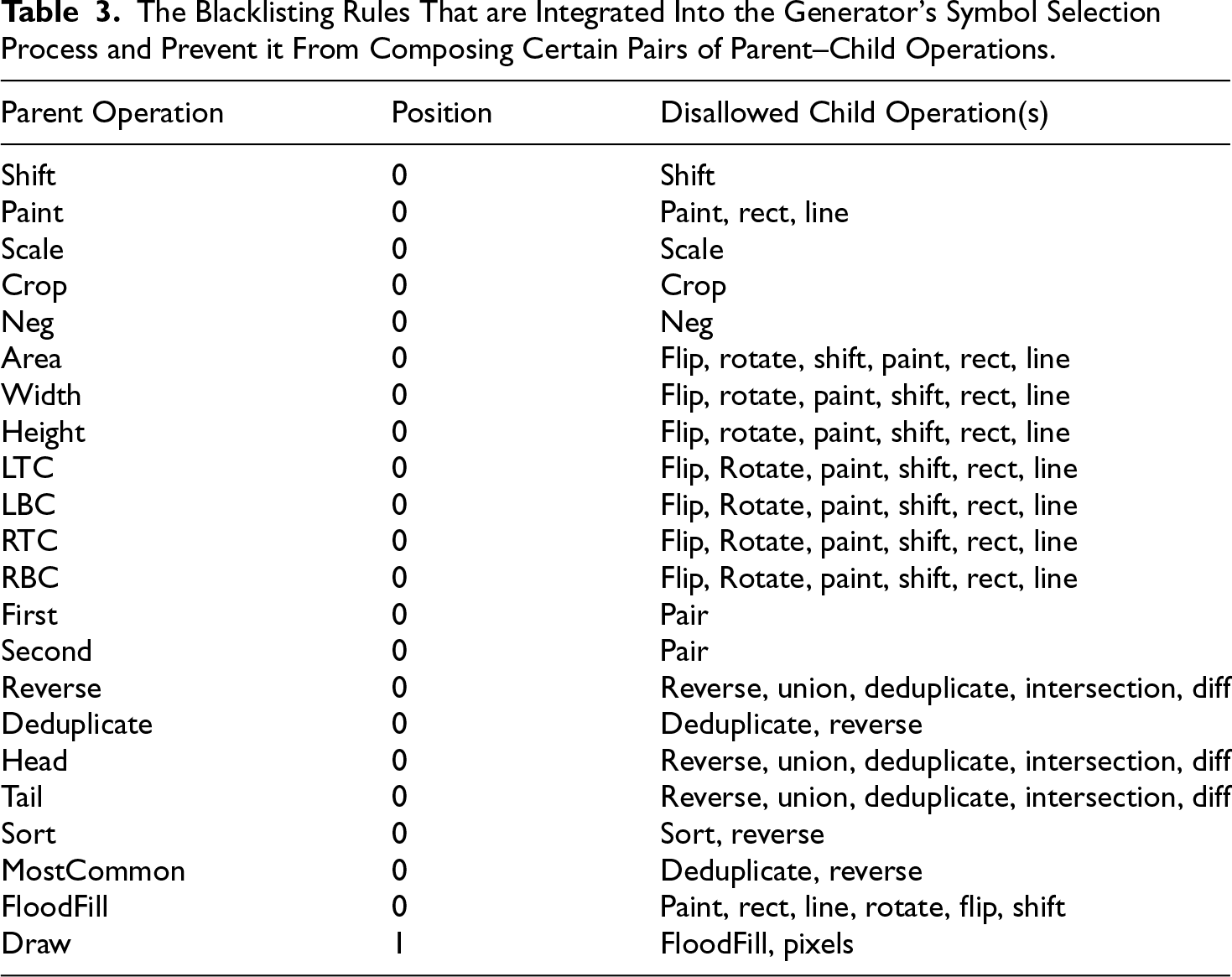
Within this DSL, a complete program defines a mapping from a set of input values to a corresponding output value of DSL types. Program execution is deterministic, that is, application of a given program to a given input will always produce the same output; however, the variational layer included in the solver (Section 3.2) enables TransCoder to respond with a different program in training and so provide exploration of the program space. Program execution leverages the Workspace for selective retrieval of necessary items using keys. When TransCoder is queried on an ARC problem, the same synthesized DSL program is executed independently for each test Workspace.
The DSL features 40 operations presented in Table 2 (and in Table 8 in more detail). These can be divided into: data-composing operations (form a more complex data structure from constituents, e.g., Pair and Rect), property-retrieving operations (fetch elements or extract simple characteristics from data structures, e.g., Width, Area, or Length), data structure manipulations (e.g., Head of the list, First of a Pair, etc.), arithmetics (Add, Sub, etc.), and region-specific operations (high-level transformations of drawable objects, e.g. Shift, Paint, and FloodFill).
Our DSL features also higher-order functions, among them Map and Filter, which apply a subprogram to the elements of a compound data structure such as a List. The complete definition of the DSL can be found in the Appendix.
The type system in Table 1 together with the operations in Table 8 implicitly define the grammar of the DSL. We do not present it formally, as the type-parametricity (the generics) makes it context-dependent and quite complex. Crucially, the Program Generator detailed in the subsequent Section 3.5 traverses the combined tree of types and function signatures, and so guarantees the resulting programs to be syntactically correct and thus executable. For similar reasons, we do not attempt to formalize the semantics of the DSL, other than via our implementation of the DSL interpreter, which translates each instruction of the DSL from Table 2 into a snippet of Python code. This implementation and the natural language description in Table 8 provide informal, yet quite precise, denotational semantics of our DSL.
There is a number of arguments in favor of using a bespoke DSL rather than relying on generic languages such as Prolog or/and related approaches such as Inductive Logic Programming (Muggleton & Watanabe, 2014). First, our DSL is already equipped with adequate types for coordinates, regions of connected pixels, and generics (e.g.,
Figure 4 shows an example program and the process of its application to an input raster, including the effects of intermediate execution steps.

Execution process of an example program applied to an input raster (scene). For clarity, we mark the key subprograms with A and B. A adds a constant value of 1 to both coordinates of the upper left corner, that is,
The Program Generator is a bespoke architecture based on the blueprint of the doubly recurrent neural network (DRNN); see Alvarez-Melis and Jaakkola (2017) for a simple variant of DRNN. The latent
Before the generation loop, an embedding of each key presented by the Workspace Template is enriched with the information in the latent
In each iteration, the Generator receives the data on the context, including the current tree size (the number of already generated AST nodes), the depth of the node in the AST, the parent of the current node, and the return type of the node. For the root node, the return type is Region; for other nodes, it is determined recursively by the types of arguments required by DSL functions picked in previous iterations. The Generator is also supplied with the set of symbols available in the Workspaces (including the elements of the DSL), via their embeddings. From this set, the Generator selects only the symbols that meet the requirements regarding the type and the maximum depth of the tree. Then, it applies an attention mechanism to the embedded representations of the selected symbols. The outcome of attention is the symbol to be “plugged” into the AST at the current location. Figure 5 illustrates a few iterations of this process.

When generating a program, TransCoder uses symbol embeddings available in the Workspace Template. At each step of the breadth-first order generation of a program tree (AST), it computes the probability distribution over all symbols and then selects the one with the highest score. As this process is compliant with DSL’s grammar, some operations may not be available at a given step (the model still calculates the probabilities for such operations, but is not allowed to select from them). The Generator works as long as there are any arguments missing (e.g., in step 1, from the definition of the Paint operation, it follows that two descendants should be generated). Note. AST= Abstract Syntax Tree; DSL=domain-specific language.
By chaining the calls of DSL instructions via type consistency, the generated programs are guaranteed to be syntactically correct. This is an essential advantage of TransCoder, compared to alternative mechanisms based on, for example, language models. In those approaches, programs are stochastically generated sequences of tokens, which need to be checked for syntactic correctness before execution. By providing syntactic correctness by design, the generation mechanism proposed here is more elegant and computationally efficient.
The Generator also determines the hidden state of the DRNN to be passed to each of the to-be-generated children subtrees. This is achieved by merging the current state with a learnable embedding indexed with children’s indices, so that generation in deeper layers of the AST tree is informed about the node’s position in the sequence of parents’ children.
The generation process iterates recursively until the current node requests no children, which terminates the current branch of the AST (but not the others). It is also possible to enforce termination by narrowing down the set of available symbols.
To efficiently utilize computational resources, we adopted the dynamic batching mechanism presented in Bednarek et al. (2018).
TransCoder can be trained with reinforcement learning (RL) or supervised learning (SL). In RL, the program
The ineffectiveness of RL motivates the SL mode, in which we use the program that solves the given task (target) to guide the Generator. We directly confront the actions of the Generator (i.e., the AST nodes it produces) with the target program node-by-node, and apply a loss function (categorical cross-entropy) that rewards choosing the right symbols at individual nodes and penalizes the incorrect choices. In SL, every prediction produces non-zero gradients, and thus non-zero updates for the model’s parameters (unless the target program has been perfectly generated). We employ the AdamW (Loshchilov & Hutter, 2017) optimizer with default parameter values provided in the TensorFlow (Abadi et al., 2016) library. Additionally, within each outer loop (consecutive training phases culminating in the transition to the exploration phase), the learning rate is adjusted according to the method introduced in Smith (2018) (with five warm-up and 25 decay inner cycles).
The prerequisite for SL is the availability of target programs; as those are not given in the ARC benchmark (in any form, not mentioning our DSL), we devise a method for producing them online during training, presented in Section 3.7. In general, the specific program used as the target will be one of many programs that map the input panels of the task’s demonstrations to the corresponding output panels (see Section 2). Deterministic models cannot realize one-to-many mappings, and the variational layer introduced in Section 3.2 is meant to address this limitation. Upon the ultimate perfect convergence of TransCoder’s training, we would expect the deterministic output of the Solver (corresponding to
Learning From Mistakes
The programs produced by the Generator are syntactically correct by construction. Therefore, barring the occasional run-time errors (e.g., attempt to retrieve the head of an empty list), a generated program,
5
applied to an input raster, will always produce some response output raster. By applying such a program
This observation allows us to learn from mistakes: whenever the Generator produces a program
To model the many-to-many relation between tasks and programs, we implement
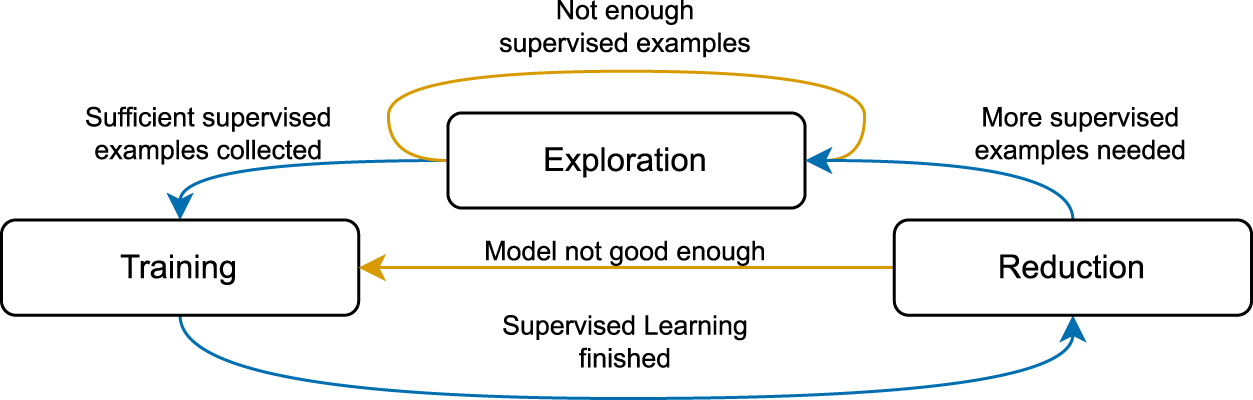
The top-level learning process starts with The purpose of this phase is to provide synthetic training examples needed in subsequent phases. A random task Training consists of applying SL to a random subset of tasks drawn from Reduction starts with selecting from In the next step, TransCoder is evaluated on Finally, the results for The state diagram of TransCoder’s training, including learning from mistakes.
TransCoder engages programs, that is, a class of symbolic entities, to process and interpret the input data, and thus bears similarity to several past works on neurosymbolic systems, of which we review only the most prominent ones.
In synthesizing programs in response to input (here: task), TransCoder resembles the Neuro-Symbolic Concept Learner (NSCL; Mao et al., 2019). NSCL was designed to solve Visual Query Answering tasks (Johnson et al., 2016) using object-centric representation and learn to parameterize a semantic parser that translated a natural language query about scene content to a DSL program which, once executed, produced the answer to the question. The system was trained with RL, with a binary reward function that reflected the correctness of the answer provided to the query. Interestingly, NSCL’s DSL was implemented in a differentiable fashion, which allowed it to inform its perception subnetwork in training.
With respect to abstract reasoning, the key characteristic aspect of the ARC suite, a similar “object-centric” approach is taken by Assouel et al. (2022), which operates on a category of ARC tasks. The work relies on strong assumptions about the tasks from the considered category and provides a DSL for manipulating and transforming objects typical of rasters used in those tasks. This formalism allows the authors to generate new unseen tasks, which are subsequently used to train their model, in a fashion similar to TransCoder. However, the proposed approach does not involve program synthesis nor a DSL per se.
The most successful approaches in the ARC 2020 Kaggle challenge often relied on an assembly of various processing techniques, including brute-force search, handcrafting features, manual data labeling, and DSL-guided search. The results of the competition corroborated the awareness of the usefulness of the program synthesis approach with data-tailored DSLs, and resulted in approaches which engaged, among others, descriptive grids and the minimum-description length principle (Ferré, 2021), graph-based representations (Xu et al., 2022), or combining DreamCoder (Ellis et al., 2021) with a search graph (Alford et al., 2021). To a greater or lesser extent, many of those methods also engaged an exhaustive search, which is notably absent in TransCoder.
In using a program synthesizer to produce new tasks, rather than only to solve the presented tasks, TransCoder bears some similarity to the DreamCoder (Ellis et al., 2021). DreamCoder’s training proceeds in cycles comprising wake, dreaming, and abstraction phases, which realize, respectively, solving the original problems, training the model on “replays” of the original problems and on “fantasies” (synthetic problems), and refactorization of the body of synthesized programs. The last phase involves identification of the often-occurring and useful snippets of programs, followed by encapsulating them as new functions in the DSL, which is meant to facilitate “climbing the abstraction ladder.” The DreamCoder was shown to achieve impressive capabilities on a wide corpus of problems, ranging from typical program synthesis to symbolic regression to interpretation of visual scenes. For a thorough review of other systems of this type, the reader is referred to Chaudhuri et al. (2021).
Recent advancements in large language models (LLMs) have led researchers to explore their capabilities in abstract reasoning tasks, notably the ARC and RAVEN (Zhang et al., 2019) benchmarks. An extensive analysis of ARC was conducted in Moskvichev et al. (2023), resulting in a comparison of Kaggle 2020 competition winner methods, GPT 4, and human performances on ConceptARC, a categorized version of the ARC dataset proposed in that study. One of the main findings of this study was humans’ superior capability, compared to all considered algorithmic methods. Extensive research on LLMs applied to ARC tasks and other problems (Mirchandani et al., 2023) has demonstrated significant improvements through prompt engineering techniques in ARC solving, and pointed to the overall capacity of those models as sequence modelers and quite successful pattern extrapolators. These advances have enabled LLMs to surpass the accuracy of many DSL-based methods, achieving accuracy rates of approximately 10% without fine-tuning, and often via zero-shot learning via prompting.
The Perception module draws inspiration from the vision transformer architecture (Dosovitskiy et al., 2020), interleaving self-attention and cross-attention blocks (Vaswani et al., 2017) with reduction blocks (Lin et al., 2014).
Experimental Evaluation
In the following experiment, we examine TransCoder’s capacity to provide itself with a “reflexive learning gradient,” meant as a continuous supply of synthetic tasks at the level of difficulty that facilitates further improvement. Therefore, we focus on the dynamics of the learning process.
To enhance the efficiency and effectiveness of program synthesis, two mechanisms are introduced to constrain the search space and mitigate redundancy in generated programs. The first mechanism, termed
The second mechanism, termed
Normalization Rules Applied to the Synthesized Programs.

Normalization Rules Applied to the Synthesized Programs.
Bold arguments state for predefined symbols (e.g., constant “zero”) from Workspace. For some rules, we also compare entire subprograms since the same subprograms always return the same values.
Normalization plays an important role in the preparation of a dataset for a training cycle by reducing multiple semantically equivalent programs to the same normal form. 7 Thanks to this procedure, during SL, the Generator does not have to produce the inessential “dead code.” Moreover, normalization prevents the Generator from infinite nesting of redundant subprograms (which is particularly likely in the initial training stage).
Figures 7(a) to 7(c) present the dynamics of the training process. We time the runs with the number of Training-Reduction cycles, as this is the part of the state graph from Figure 6 that the method iterates over the most. The number of those cycles is highly correlated with the incurred computational expense. The invocations of the Exploration phase, marked with vertical lines, happen much more sparingly, triggered by the conditions discussed at the end of Section 3.
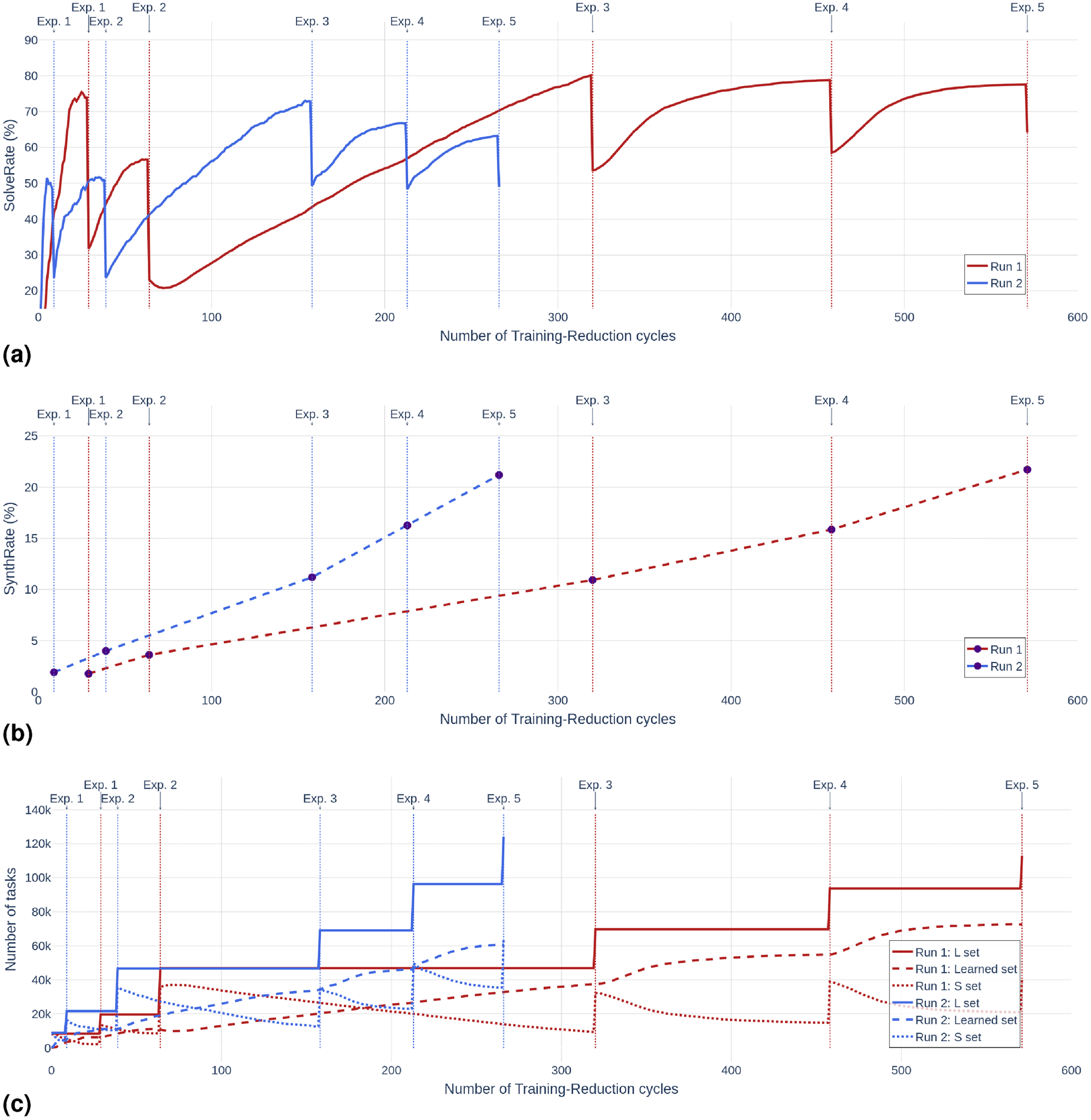
The dynamics of two runs of TransCoder that used different random initializations. Vertical lines indicate the activations of the Exploration phase. Run 1 and Run 2 lasted 4 and 2 days, respectively, on NVIDIA A100 GPUs. (a) SolveRate—the success rate on a set of tasks that dynamically changes during training; (b) SynthRate—the success rate on a precomputed, fixed set of 205,745 synthetic tasks. (c) The number of tasks in the working training set L, in the set of solved tasks S, and the number of learned tasks. Once a task has been solved, it is moved from S to the learned set, hence the total size of these both sets remains constant within a given outer cycle of the method.
The continuous lines in Figure 7(a) show SolveRate, the percentage of tasks solved, estimated from a random sample drawn from the current set
To provide a more objective assessment, the dashed lines in Figure 7(b) present SynthRate, the percentage of tasks solved from a precomputed suite of over 200k synthetic tasks. The curves of this metric exhibit fast and steady growth, demonstrating TransCoder’s capacity for continuous progress. Importantly, for both runs, these curves do not tend to saturate, suggesting the potential for additional increase upon further continuation of training.
Figure 7(c) presents the dynamics of the working sets of tasks manipulated in TransCoder, synced in time with Figures 7(a) and 7(b). Each invocation of the Exploration phase expands the working set of tasks
The primary feature distinguishing Run 1 from Run 2 is that the latter tended to “consume” (i.e., successively learn to solve) the tasks from
Another difference between Run 1 and Run 2 is that the former one tends to “exhaust” its working set
Table 5 presents the metrics at the completion of consecutive training cycles of Run 1 (cf. Figure 6). The monotonous increase of SynthRate also positively impacts the ARCRate, which ultimately achieves the all-high value of 3% at the end of the run, suggesting that the skills learned from the synthetic, easier tasks translate into more effective solving of the harder original ARC tasks.
SynthRate and ARCRate Immediately Before the Commencement of Particular Training Cycles (i.e., Before Exploration Phases), for Run 1.

Table 6 presents the results in terms of historical progress, that is, how TransCoder fares in consecutive cycles on the synthetic tasks it generated in the previous cycles. This concept has been introduced in Miconi (2009) to assess the progress on coevolutionary algorithms in the absence of well-defined objective yardsticks. The table shows the rate of solved programs achieved by the snapshots of TransCoder trained for a given number of cycles (in rows) on the tasks from
Performance of the Snapshots of the Model From a Given Cycle (row) on the Synthetic Examples Collected in a Given Cycle (column), for Run 1.

Note. For Instance, TransCoder From the First Cycle (the First row in the Table) Solves 41.12% of the Synthetic Tasks Created in the Same Cycle, 1.18% of the Tasks Created in the Second Cycle, 0.16% From the Third Cycle, 0.03% From the Fourth Cycle, and 0.02% From the Fifth Cycle.
The List of Predefined Symbol Keys Available in the Domain-Specific Language (DSL).
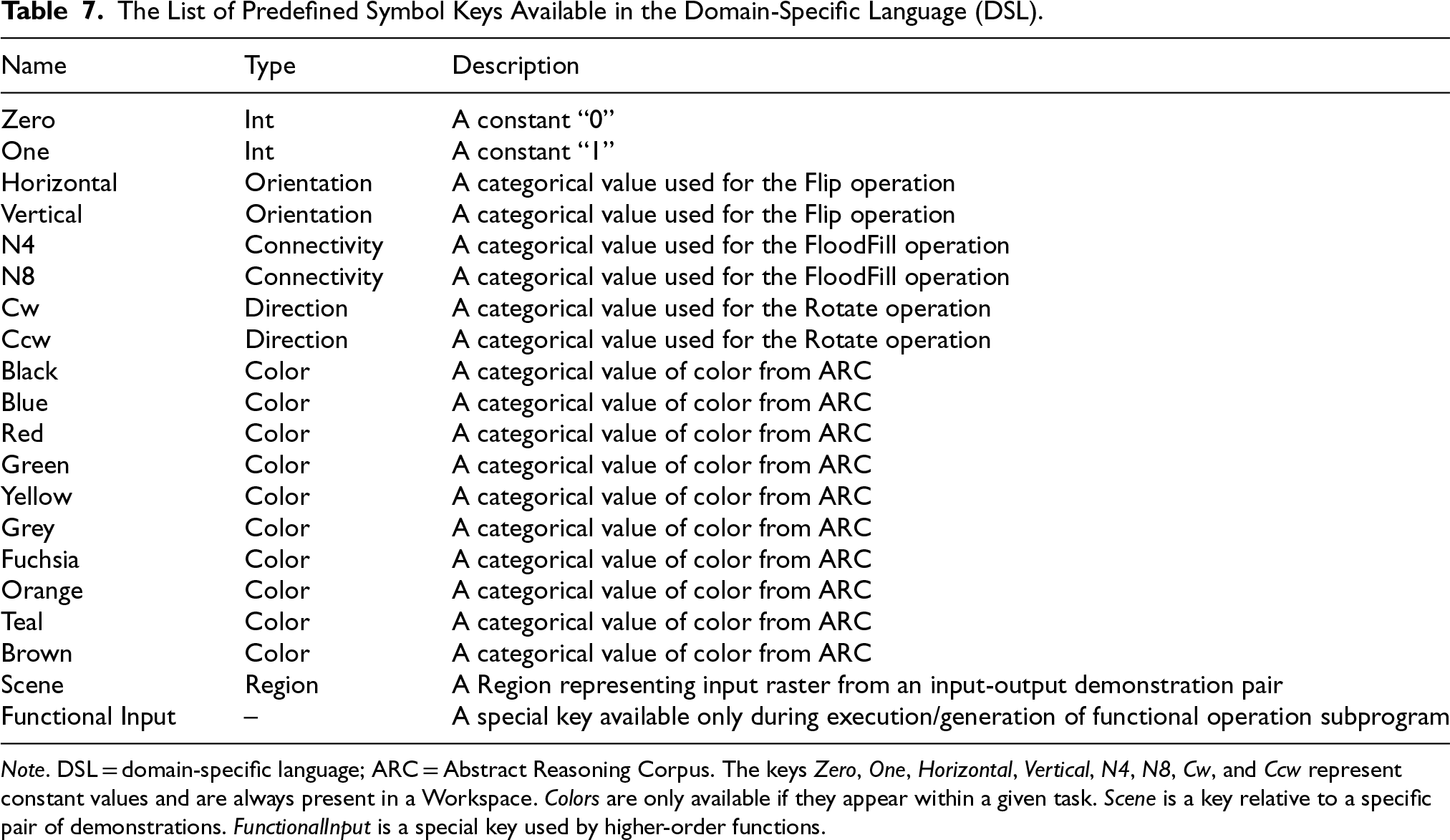
Note. DSL = domain-specific language; ARC = Abstract Reasoning Corpus. The keys Zero, One, Horizontal, Vertical, N4, N8, Cw, and Ccw represent constant values and are always present in a Workspace. Colors are only available if they appear within a given task. Scene is a key relative to a specific pair of demonstrations. FunctionalInput is a special key used by higher-order functions.
Definitions of the Operations Available in the Domain-Specific Language (DSL).
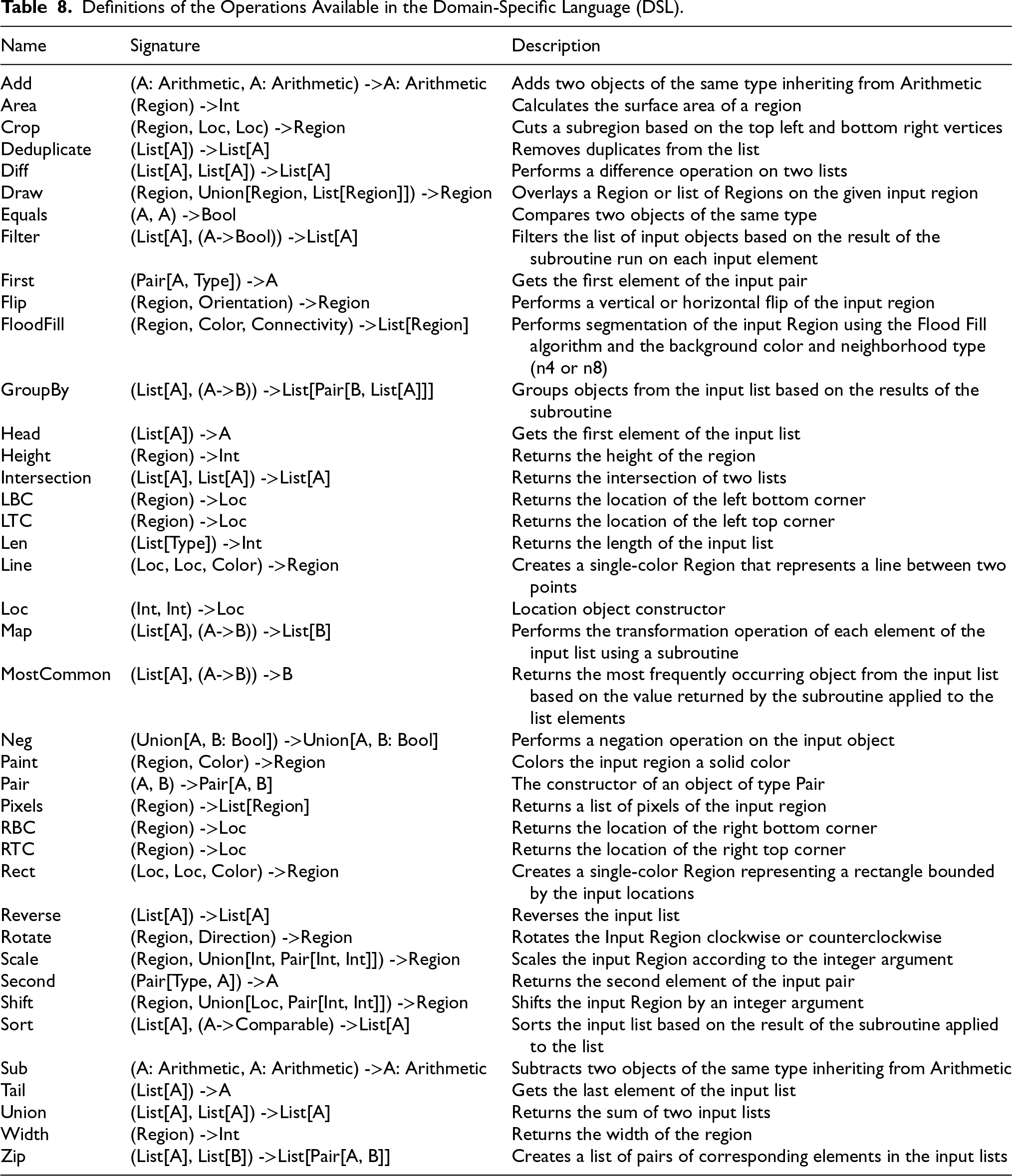
Figure 8 shows examples of generated tasks with solutions, that is, the

Examples of (task, program) pairs synthesized by the model.
The Examples of Synthesized Programs Across Successive Exploration Phases for Run 1.

This study corroborated our preliminary findings from Bednarek and Krawiec (2024) and confirmed TransCoder’s capacity to provide itself with a learning gradient by generating synthetic tasks of moderate difficulty, which close the “skill gap” existing between the capabilities of an initial untrained and inexperienced solver and the difficulty of ARC tasks. Crucially, the generative aspect of this architecture, combined with expressing candidate solutions in a DSL, allows the method to obtain concrete DSL programs, use them as concrete targets for the synthesis process (Generator), and so gradually transform an unsupervised learning problem into a supervised one. As evidenced by the experiment, SL facilitated in this way provides informative learning guidance, unparalleled when compared to RL we engaged in preliminary experiments.
In a sense, this research is venturing into the domain of relational learning and, by employing deep learning components to this aim, explores the area of relational deep learning (see, e.g., Fey et al., 2024). In the current architecture of TransCoder, this is achieved with the quite rudimentary means of a variational layer, which allows us to relate, in a many-to-many, bi-directional fashion, the ARC tasks to the DSL programs that solve them. Prospectively, it would be interesting to engage other mechanisms for this purpose, perhaps such that allow discarding the, not necessarily desirable, stochasticity of the variational mapping.
The modularity of the proposed architecture allows TransCoder to be adapted to other types of data than those considered in our DSL and, more generally, than those specific to the realm of ARC tasks. In particular, the Solver and Generator modules are independent of the input data type, while the only type-specific module is Perception. This ensures relatively loose coupling between the method and the DSL, and facilitates introducing changes in the latter, or even replacing it entirely. Future work will include applying the approach to other benchmarks in different domains, developing alternative DSLs, transferring abstraction and reasoning knowledge between datasets, and prioritizing the search in the solution space to solve the original ARC tasks.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The performance of the snapshots of the model was derived from TAILOR, a project funded by EU Horizon 2020 research and innovation program under GA No. 952215, by the statutory funds of Poznan University of Technology and the Polish Ministry of Education and Science grant no. 0311/SBAD/0770.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.