
Abstract
We present an initial automated test to evaluate LLMs’ capacity to perform inductive reasoning tasks. We use the GPT-3.5 and GPT-4 models to create a system which generates Python code as hypotheses for inductive reasoning to transform sequences of the One Dimensional Abstract Reasoning Corpus (1D-ARC) challenge. We experiment with three prompting techniques, namely standard prompting, Chain of Thought (CoT), and direct feedback. We provide results and an analysis of cost-to-success rate and benefit-cost ratio. Our best result is an overall 25% success rate with our CoT prompting on GPT-4, significantly surpassing the standard prompting approach. We assess the programming capabilities of the LLM by analysing the execution rate and errors of the generated code for inductive reasoning. We discuss potential avenues to improve our experiments, testing other strategies, and combining deductive reasoning with LLM-based inductive reasoning.
Introduction
Pre-trained large language models (LLMs) are approaching or have exceeded human-level performance in various tasks including abstractive summarization, question answering in some domains, some coding tasks, etc. Bommarito & Katz, 2022; OpenAI, 2023; Zhang et al., 2024. Moving towards more intelligent systems, or Artificial General Intelligence (AGI) (Morris et al., 2023), there are significant interests on the reasoning abilities of LLMs, which is a fundamental aspect of human intelligence (Häggström, 2021). There are debates about whether LLMs can reason based on the understanding of truth and logic, which is closer to the “thinking” process of humans (Wang et al., 2023a). By leveraging prompting techniques (in-context few-shot learning), pre-trained LLMs can solve some reasoning tasks in different benchmarks, including math, commonsense, and games (Wei et al., 2022; Yao et al., 2023), but their performance heavily depends on the prompting approach.
Hypothesis
We are interested in looking at solving the 1D-ARC challenge as a test for AGI. We hypothesise that general purpose LLMs’ performance at inductive reasoning by writing programs to solve 1D-ARC tasks are poor. We developed a testing framework to evaluate this hypothesis with different prompting techniques and parameters, without providing any help, guidance, or fine-tuning the LLM. We expect an AGI would be able to programme functions to solve the simple inductive reasoning tasks of 1D-ARC challenge autonomously.
GPT-3 showcased the zero-shot inference ability, with limited ability to perform more complex reasoning tasks (Brown et al., 2020). Few-shot learning is then studied to promote “thinking” by showcasing several examples of intermediate reasoning steps, named CoT (Wei et al., 2022). Zero-shot CoT is proposed through simple additional prompting “Let’s think step-by-step” (Kojima et al., 2022). While this research focuses on probing reasoning ability through in-context learning, we would like to further understand the variations of different prompting techniques. We would also like to understand the impact of feedback on the thinking process of LLMs, and how it would correct itself through feedback. Besides, there is a gap in benchmarking the cost of LLMs with different prompting techniques.
Inductive reasoning is a fundamental cognitive challenge that involves making generalizations from specific instances (Han et al., 2024). It requires inferring the principles from the observations and applying them to novel situations.
To provide a structured review of existing works on inductive reasoning with LLMs, we review the types of tasks addressed, the prompting methods employed, and the evaluation strategies used.
Tasks
Previous works on various types of reasoning tasks, including arithmetic (Imani et al., 2023; Wang et al., 2023b), commonsense (Zhao et al., 2024), and symbolic reasoning (Wang et al., 2024), have showcased the reasoning capabilities of LLMs to a certain degree. The Abstraction and Reasoning Corpus (ARC) is a particularly challenging inductive reasoning benchmark (Chollet, 2019), and has been used to test LLM’s inductive reasoning ability (Mirchandani et al., 2023; Wang et al., 2023c; Xu et al., 2023).
Prompting Methods
Given that LLMs are in-context few-shot learners (Brown et al., 2020), these studies on reasoning abilities have paved the way for novel prompting and searching techniques, such as the CoT (Wei et al., 2022) and Tree of Thoughts (Yao et al., 2023). Inspired by the Bayesian learner, a hypothesis search method is proposed to assist LLMs in solving complex inductive reasoning tasks, with hypotheses selection and testing loops (Wang et al., 2023c). Instead of directly prompting, LLMs are used to generate natural language hypotheses according to the problem description and examples, then translate hypotheses into Python programs for execution and testing. This work has demonstrated the contribution of hypothesis searching and computer programs in solving complex inductive reasoning problems. Note that human-annotated hypotheses are introduced as few-shot demonstrations for generating new hypotheses. Human annotators are also involved in selecting the subset of hypotheses, to avoid the huge computation load in testing all hypotheses. During the course of this research, significant breakthroughs in the reasoning abilities of LLMs have been reported in models such as
Evaluation
Existing works on LLMs’ inductive reasoning ability are evaluated against the number of solved tasks, different LLM models applied, and the adjustment on task dimensionality (Mirchandani et al., 2023; Xu et al., 2023). The hypothesis search method (Wang et al., 2023c) evaluated the success rate on randomly selected 100 ARC tasks, and the number of execution feedback iterations. The quality of generated code is not evaluated. None of these works discusses the cost of performing the 1D-ARC tasks.
We propose to perform a comprehensive analysis of different prompting techniques, as well as different ways for LLMs to produce results, with minimal human intervention in the reasoning process. As the study Wang et al. (2023c) has demonstrated the contribution of computer programs in solving complex inductive reasoning problems, we also ask LLMs to generate computer programs for easy generalisation and testing. Thus, this task is relevant to programme synthesis, a classical problem studied with inductive and deductive reasoning and more recently with neural networks and LLMs (Kalyan et al., 2018; Liu et al., 2023). We mainly test LLMs for inductive reasoning in this work and will discuss deductive reasoning at the end of the paper.
We are looking at evaluating the effect of CoT (Wei et al., 2022) and CoT variations (Kojima et al., 2022) on solving reasoning tasks from the 1D-ARC (Xu et al., 2023) which we compare with standard prompting and direct feedback. We use the OpenAI API and store every interaction with it for each solving method that we set. The goal of developing intelligent agents which would be capable of understanding the world by interpreting their observations requires theoretically formalising a model of the real world. Along this goal, we argue that observing a phenomenon, hypothesising and theorising about it requires the same skills as finding the transformation rules in the 1D-ARC tasks and that code is a way of formalising a theory. We evaluate the inductive reasoning capacity of LLMs as intelligent agents by automatically generating prompts to perform 1D-ARC tasks, prompting for code of transformation functions and testing the correctness of the generated functions.
As an extending our previous work in Mesnage et al. (2025), in this study, we conduct a thorough analysis of the generated code from ChatGPT to assess its programming capability, especially, we analyse different variants of errors of the programs and perform a verification of the code. These additional results suggest that different prompting techniques lead to different runtime errors, which implies that the chain of thoughts for instance impact greatly the code produced, with more complexity comes more errors and also a higher chance of producing successful code at solving the task. Additionally, we further make the generated code available along with our implementation for reproducibility (see “Data-availability”). This can serve as an important resource for programme synthesis analysis for addressing the inductive reasoning task, 1D-ARC, using Large Language Model.
The remainder of the paper is as follows: “Methodology” section describes the 1D-ARC, prompting techniques, testing and evaluation metrics; “Performance Analysis” section summarises the results; “Error Analysis and Runtime Verification” section performs assessment of the programs generated for the task, and “Discussion” and Section “Conclusion and Future Work” discuss the results and conclude the work with potential future research.
Methodology
This section describes the methods we developed to evaluate and compare different prompting methods. In order to evaluate the level of reasoning of current large language models, we develop a method to automatically assess the correctness of answers produced by an LLM. We choose the 1D-ARC as a dataset of tasks to perform since it provides us with a clear test to evaluate.
Abstraction and Reasoning Corpus
The 1D-ARC consists of 900 tasks grouped into 18 categories of 50 tasks each. For each task, we have 3 examples of input-to-output sequences to illustrate the transformation to be performed and one test set of one input and one output. Figure 1 is a graphical representation of each category. These are tasks which are simple to complete for humans. The sequences are represented as coloured squares, the background ones are black and the colours of interest as other colours. For instance, a transformation can be to shift all coloured squares by one pixel to the right whilst keeping the black pixels identical. Another transformation is the mirror, which transforms the sequence into its reverse.
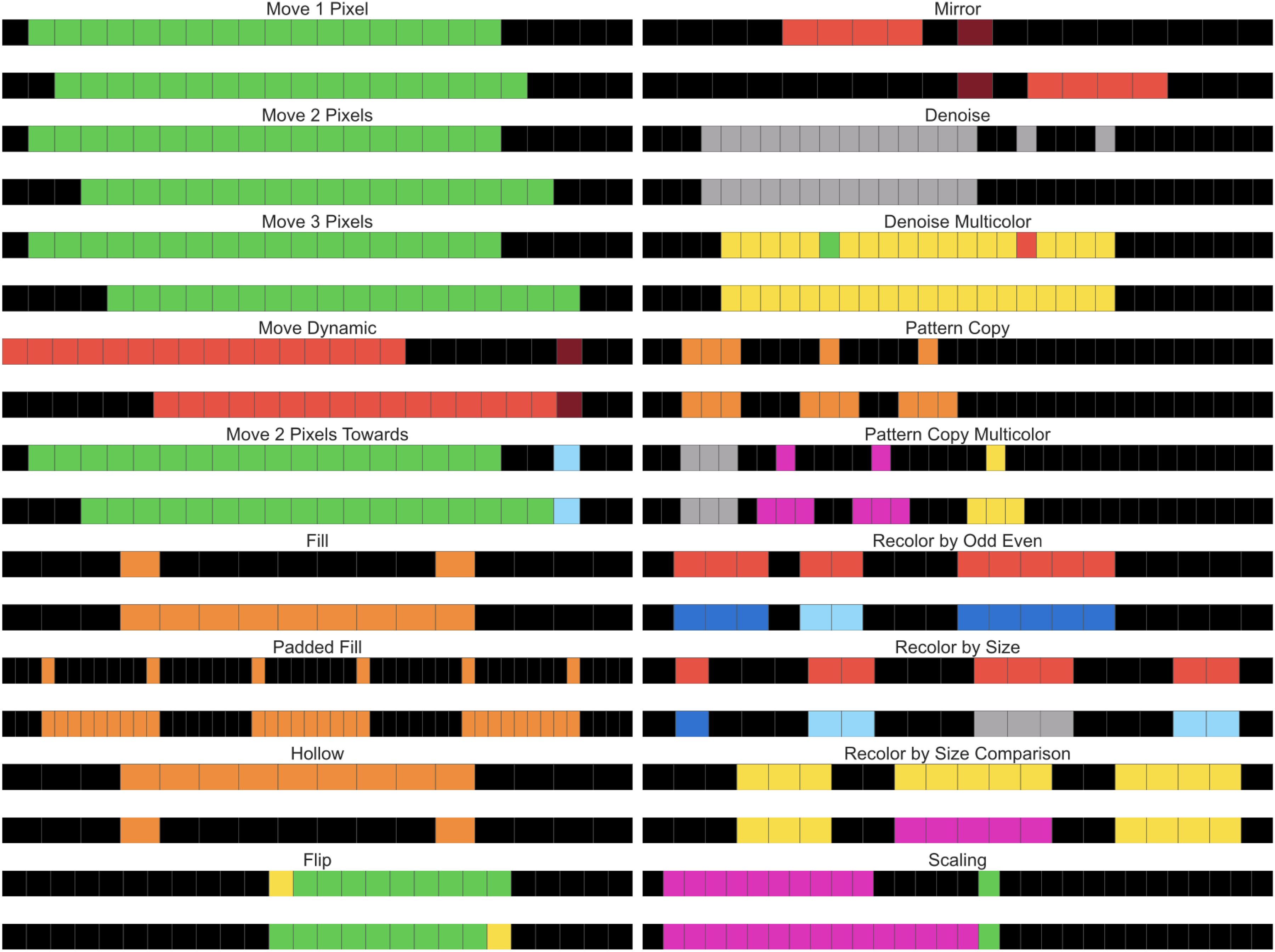
The 1D-ARC task categories and representative input-output pairs (Xu et al., 2023).
To evaluate the capability of LLMs to understand those transformations and successfully complete the tasks by generating code, we generate prompts from our prompt template and 1D-ARC tasks and use the OpenAI application programming interface (API) programmatically with GPT-3.5/4 models for each of the 1D-ARC tasks and prompt for Python code to be generated. We consequently evaluate the generated code in terms of performance in completing the task and in terms of programming errors. We describe this process in the following subsections.
Code Generation Process
Firstly we encode the sequences as strings of integers, 0 representing black and other digits for other colours. We prompt an LLM to produce a “transform (sequence)” Python function which returns the transformed sequence. The Python function is generated given the few transformation examples provided in the prompt.
Prompt Engineering
We experimented on a trial-and-error basis by interacting with the GPT 3.5/4 models directly in order to engineer a prompt which produces a usable function without producing too much unnecessary text. In fact, the GPT models tend to add many comments in their code even for very simple tasks which increases the produced tokens and therefore the cost. The OpenAI API for GPT models requires a “system” input, in which we describe the purpose of the query and what we expect as an output and a “user” entry in which we give the transformation examples. The API returns a response as JSON which includes the answer to our query, the number of input and output tokens and multiple choices depending on how many we asked for. We built three different prompting techniques, namely standard prompting, CoT and direct feedback which we describe next and provide comparative results.
Standard Prompting
Our first method is standard prompting, namely prompting the LLM solely for a function solving the task. Figure 2 is an example of the generated prompt for task 1dMove2p7, the response from GPT-4 and the test we perform. No help is given to the LLM, clue or hint, solely the sequences of the transformations examples.
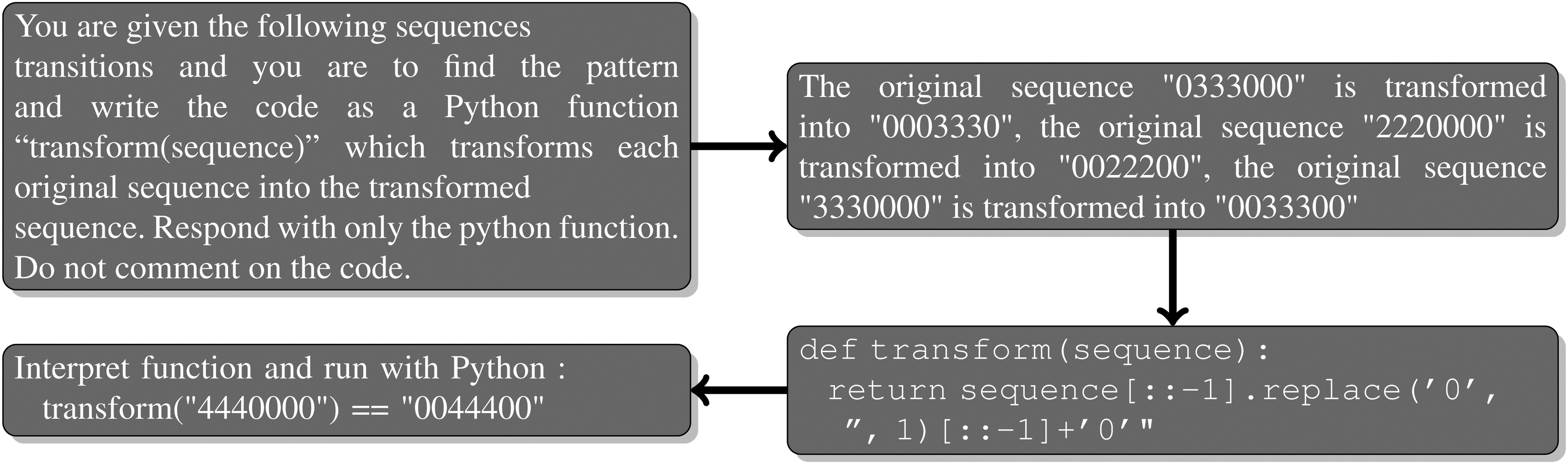
Standard prompting of the task 1dMove2p7, the answer from GPT-4 and the test we run.
Since this is the less costly of our methods, for each of the tasks we prompt both GPT-3.5-turbo and GPT-4 for 10 choices using standard prompting.
Chain of Thought
The CoT concept is to prompt the LLM to produce reasoning steps or decompose a task or question before giving an answer, since those produced tokens become the context, it is thought that it increases the accuracy of the answer given and has been used in various contexts.
There are multiple ways to perform CoT. One could give an example of the expected reasoning process, prompting for a “step-by-step” list, for reasoning in a controlled or free-form manner. As shown in Figure 3, we chose to add to our standard prompting method the prompt: “

Generated CoT prompt for the task 1dMove1p44, the response from GPT-4 and the test we run.
The investigated LLMs do produce a description of the transformation and of the task to complete before writing the Python function. We will see in the results section how this affects the success rate as well as the cost of running the experiment for all 900 tasks.
Direct Feedback
Seeing that many of the functions produced either do not run or fail at completing the tasks, we designed a different method called direct feedback in which we iteratively query GPT models, letting it know of previous functions on the same task which did not pass the test. Figure 4 shows an example of the prompt we generate on a second iteration once a function has failed. When a function succeeds at the task we stop iterating. We also stop if we reach the maximum number of iterations, which is 5 in our experiments. Direct feedback is costly since we provide the previous response as part of the new prompt, hence why we stop at 5 iterations.
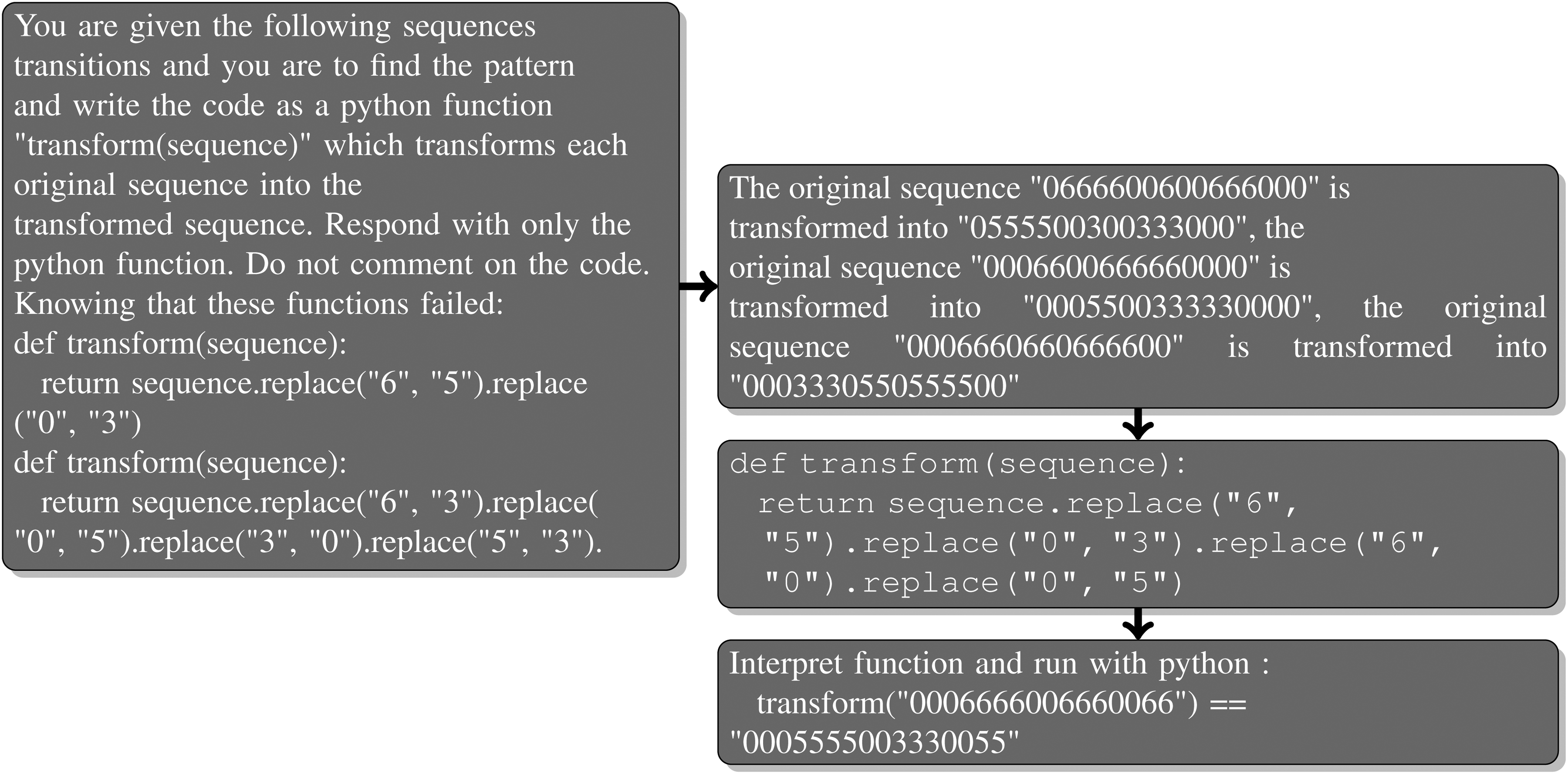
Direct feedback iteration for the task 1dMove2p7, the answer from GPT-4 and the test we run.
The functions which failed the tasks are given in the prompt following the sentence: “
Direct feedback being iterative is much more costly than standard prompting, especially when the size of the input increases with the number of functions that failed previously (the number of iterations).
Testing Generated Code
To test the functions responded by the GPT models we first process the response, removing any additional lines that are not code and removing comments. The code is then interpreted and if it can be interpreted will be accessible as a function. We then run this function to test if the transformation is correct by comparing the returned sequence with the output sequence from the dataset. We have guardrails when running the code, for instance, some functions run into infinite loops which we kill after 1 second. We store all responses from GPT-3.5/4, results, and calculations on Zenodo (Please see “Data availability” Section at the end of this manuscript). The errors are classified by error code produced by the Python interpreter.
OpenAI API Parameters
When querying the chat completion API we specify parameters which affect the response generation. We adjust the number of choices to generate(how many samples to generate, called choices in the API), when an LLM generates a completion, it selects the most likely next token according to a probability distribution on all tokens, OpenAI provides multiple choices resulting from choosing within those distributions. Temperature controls the randomness of responses, since we are looking for diverse responses in the samples, we set the temperature to 1 for all experiments, i.e. somewhat random since the parameter values are between 0 and 2.
Evaluation Metrics
To evaluate and compare our different prompting strategies, we compute metrics on the data resulting from testing, i.e. the number of successful tasks per task category and per number of choices.
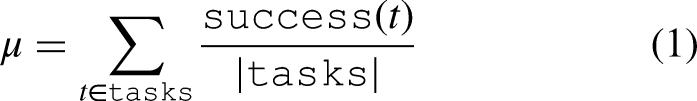
We define the mean success rate
We define the benefit-cost ratio as the mean success rate divided by the cost. We calculate it for each prompting strategy and number of choices/iterations.

The following section analyses the results of our experiments.
Performance Analysis
We have queried the OpenAI API with both the GPT-3.5-turbo and GPT-4 models. The tables summarising the results are given in the appendix for clarity. With either model, CoT performs better for the same number of choices but standard prompting reaches a similar success rate whilst remaining less costly. Even with GPT-4 and CoT, the LLM did not find a suitable solution for any task of several task categories, namely Pattern Copy, Pattern Copy Multicolor and Mirror. Those tasks do not seem to be too complex for a human to solve. The most successful task categories are not necessarily the simplest, since the LLM is more successful at the Move by 2 pixels tasks than by Move by 1 pixel, we think that there is a large amount of chance in solving the tasks. There is no clear rate per complexity of task correlation emerging from the results which would reveal some inductive reasoning from the LLM.
GPT-3.5-Turbo Results
Tables 1 to 3 give the number of successful tasks out of 50 tasks per category. Tables 4 to 6 give the number of tokens used for input and output per amount of choices as well as the calculation of the mean success rate, the cost and benefit-cost ratio. The best
Standard Prompting Number of Successful Functions per Task Category out of 50 by the Number of Choices with GPT-3.5-turbo.
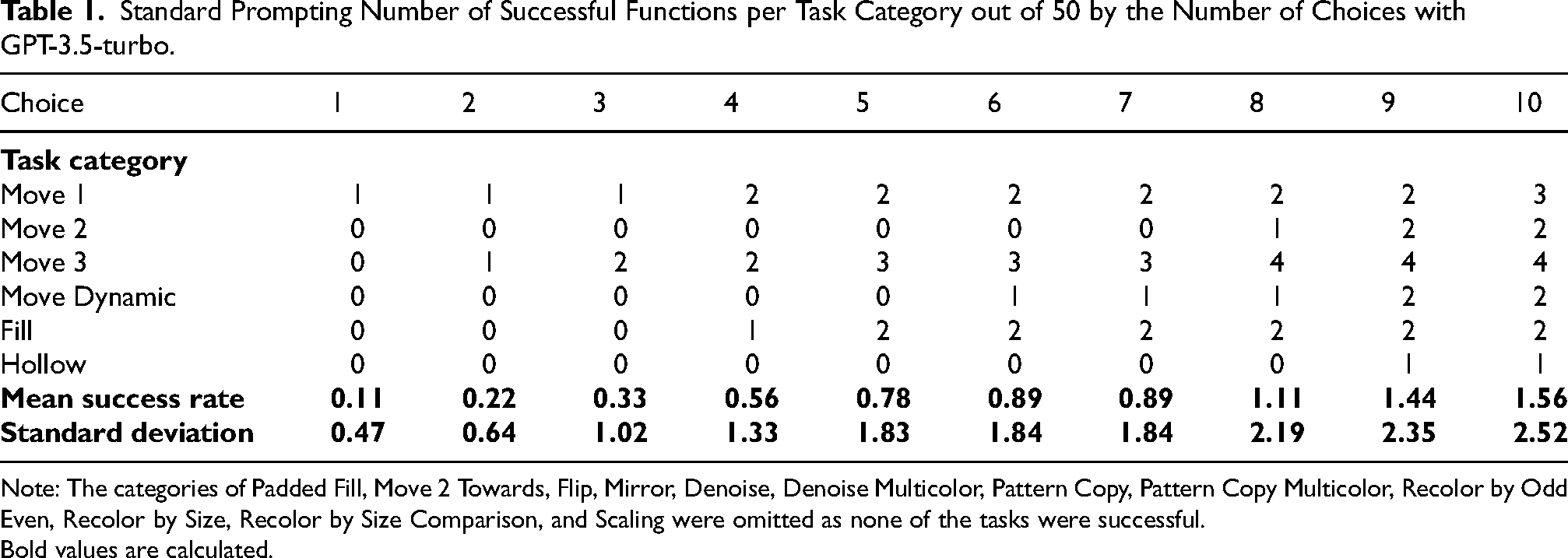
Note: The categories of Padded Fill, Move 2 Towards, Flip, Mirror, Denoise, Denoise Multicolor, Pattern Copy, Pattern Copy Multicolor, Recolor by Odd Even, Recolor by Size, Recolor by Size Comparison, and Scaling were omitted as none of the tasks were successful.
Bold values are calculated.
Direct Feedback Number of Successful Functions per Task Category out of 50 by the Number of Choices with GPT-3.5-turbo.

The categories of Move 2, Move 2 Towards, Move Dynamic, Fill, Padded Fill, Flip, Mirror, Denoise, Denoise Multicolor, Pattern Copy, Pattern Copy Multicolor, Recolor by Odd Even, Recolor by Size, Recolor by Size Comparison, and Scaling were omitted since none of those tasks were successful. Mean success rate is a percentage.
Bold values are calculated.
CoT Number of Successful Functions per Task Category out of 50 by the Number of Choices with GPT-3.5-turbo. The Categories of Pattern Copy, Mirror, Pattern Copy Multicolor, Recolor by Odd Even, Recolor by Size, Recolor by Size Comparison, and Scaling were Omitted Since None of Those Tasks were Successful. Mean Success Rate is a Percentage.
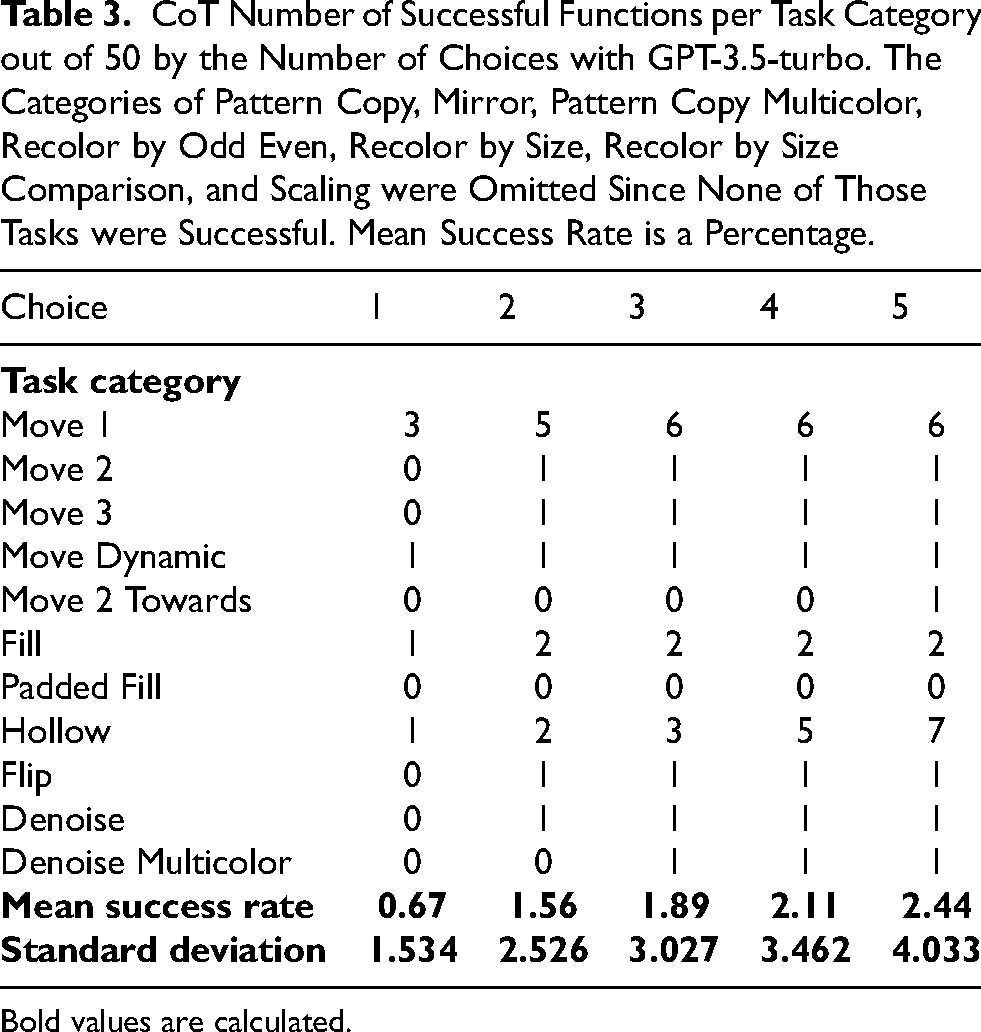
Bold values are calculated.
Standard Prompting used Tokens, Success Rate and Costs per Number of Choices with GPT-3.5-turbo. Mean Success Rate is a Percentage.
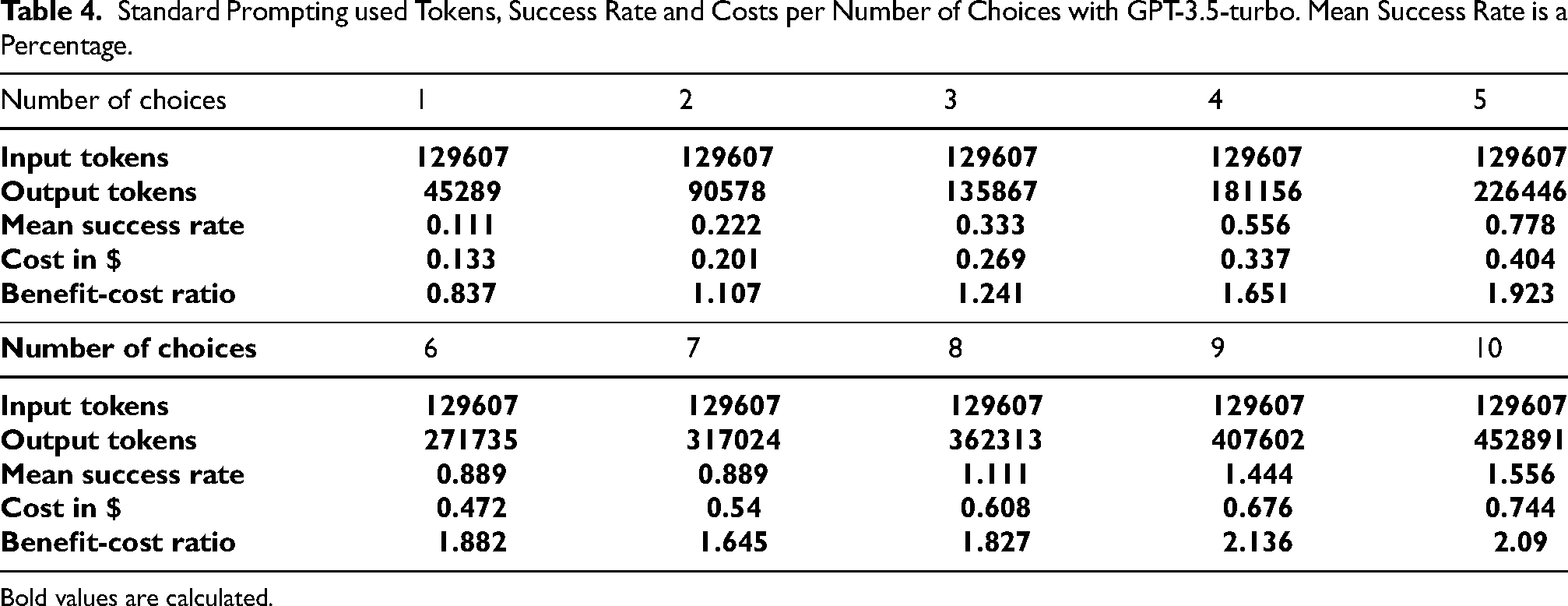
Bold values are calculated.
CoT used Tokens, Success Rate and Costs per Number of Choices with GPT-3.5-turbo. Mean Success Rate is a Percentage.
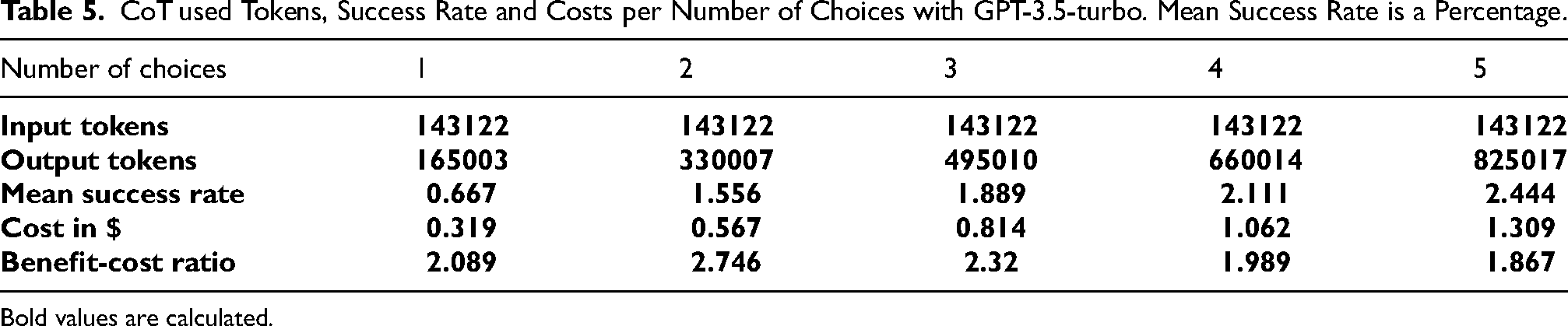
Bold values are calculated.
Direct Feedback used Tokens, Success Rate and Costs per Number of Choices with GPT-3.5-turbo. Mean Success Rate is a Percentage.
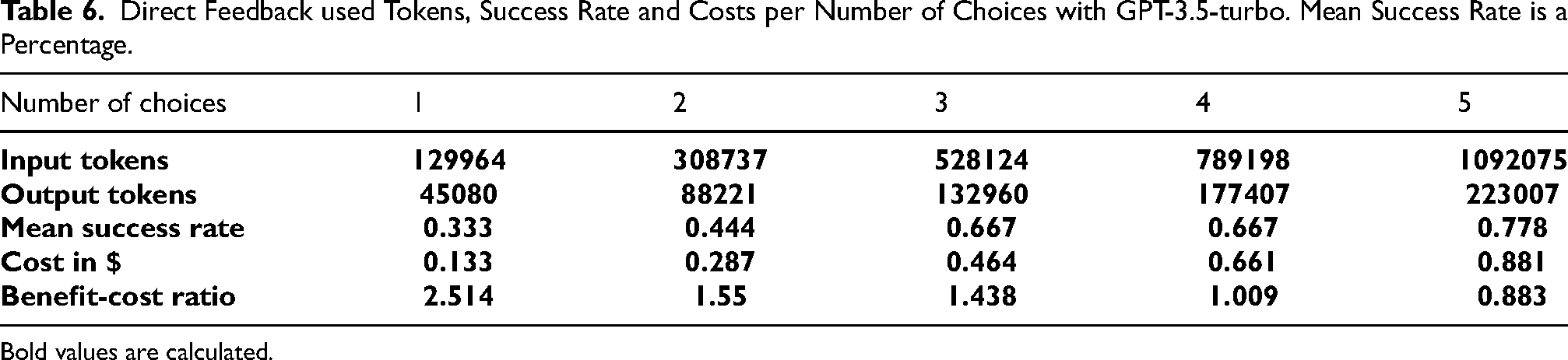
Bold values are calculated.
Figure 5(a) and 5(b) represent visually the results. The success rates and costs discussed in Figure 5(a) show tradeoffs for all prompting approaches. However, the slope of the tradeoff for the direct feedback approach is less steep than the rest of the approaches. This means that even if the cost increases significantly, the increase in success rate is not that significant for the direct feedback approach.
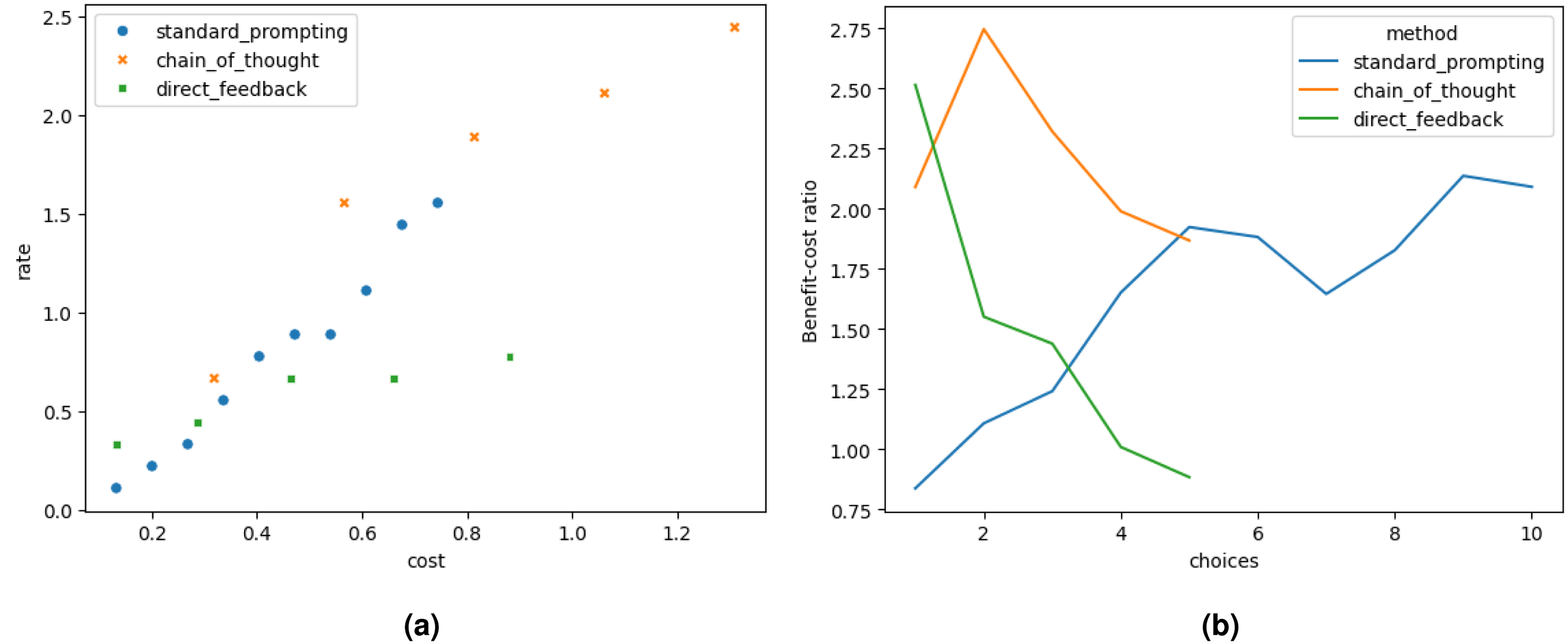
Analysis of ChatGPT-3.5-turbo results. (a) Tradeoff analysis between success rate and cost and (b) Benefit-cost ratio per number of choices.
GPT-4 Results
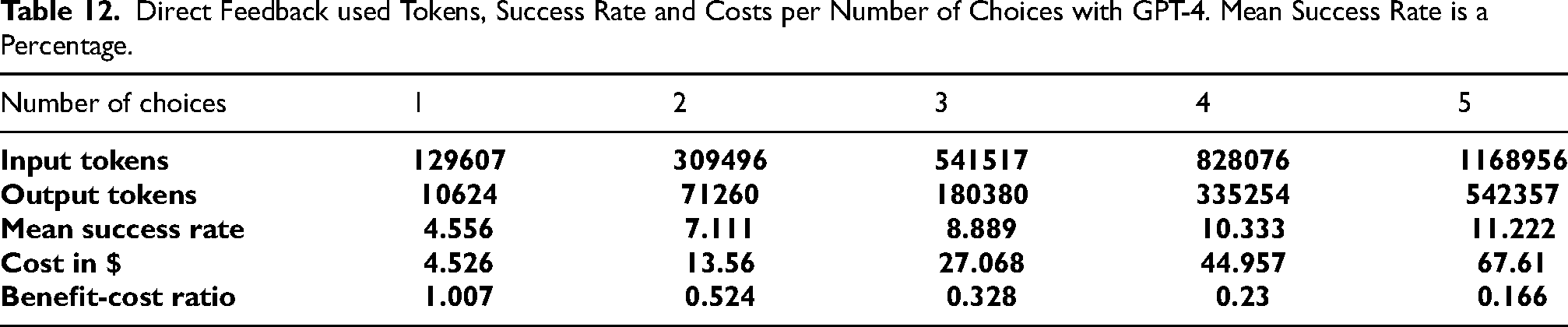
Tables 7 to 9 give the number of successful tasks per category, out of 50 tasks per category. Tables 10 to 12 give the number of tokens used for input and output per amount of choices as well as the calculation of the mean success rate, the cost and benefit-cost ratio.
Standard Prompting Number of Successful Functions per Task Category out of 50 by the Number of Choices with GPT-4.
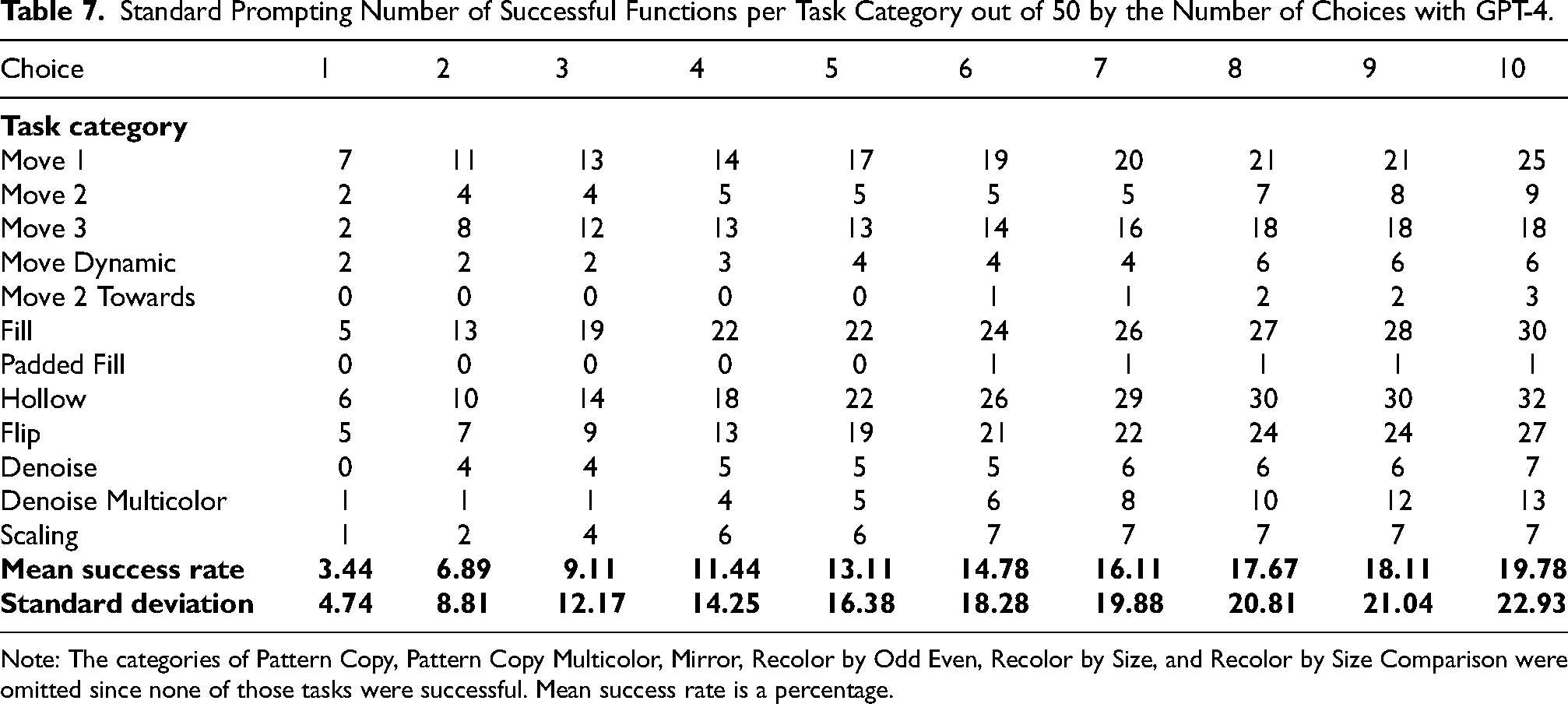
Note: The categories of Pattern Copy, Pattern Copy Multicolor, Mirror, Recolor by Odd Even, Recolor by Size, and Recolor by Size Comparison were omitted since none of those tasks were successful. Mean success rate is a percentage.
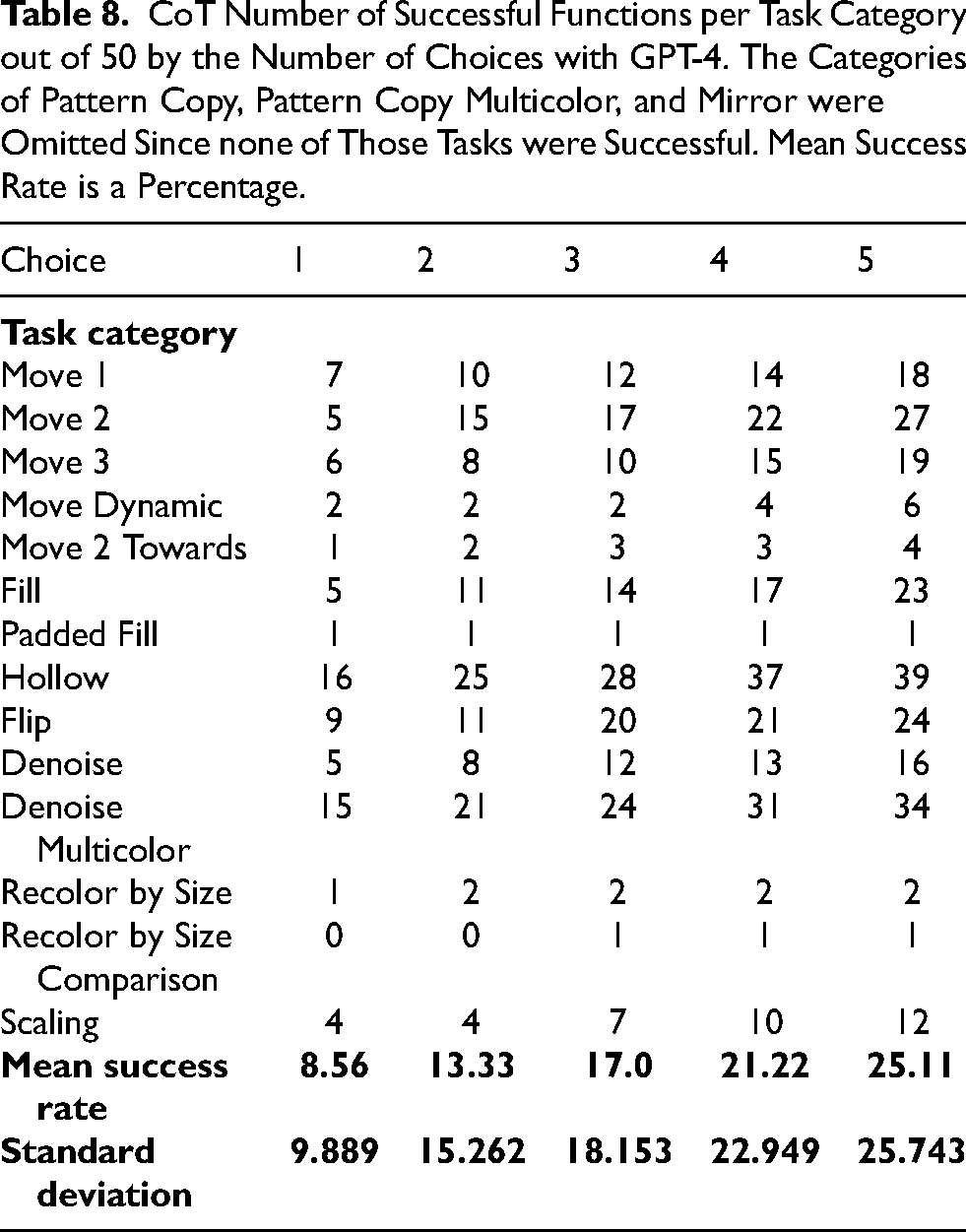
CoT Number of Successful Functions per Task Category out of 50 by the Number of Choices with GPT-4. The Categories of Pattern Copy, Pattern Copy Multicolor, and Mirror were Omitted Since none of Those Tasks were Successful. Mean Success Rate is a Percentage.
Direct Feedback Number of Successful Functions per Task Category out of 50 by the Number of Choices with GPT-4. The Categories of Mirror, Pattern Copy, Pattern Copy Multicolor, Padded Fill, Recolor by Odd Even, Recolor by Size, and Recolor by Size Comparison were omitted since none of those tasks were successful. Mean success rate is a percentage. Mean success rate is a percentage.
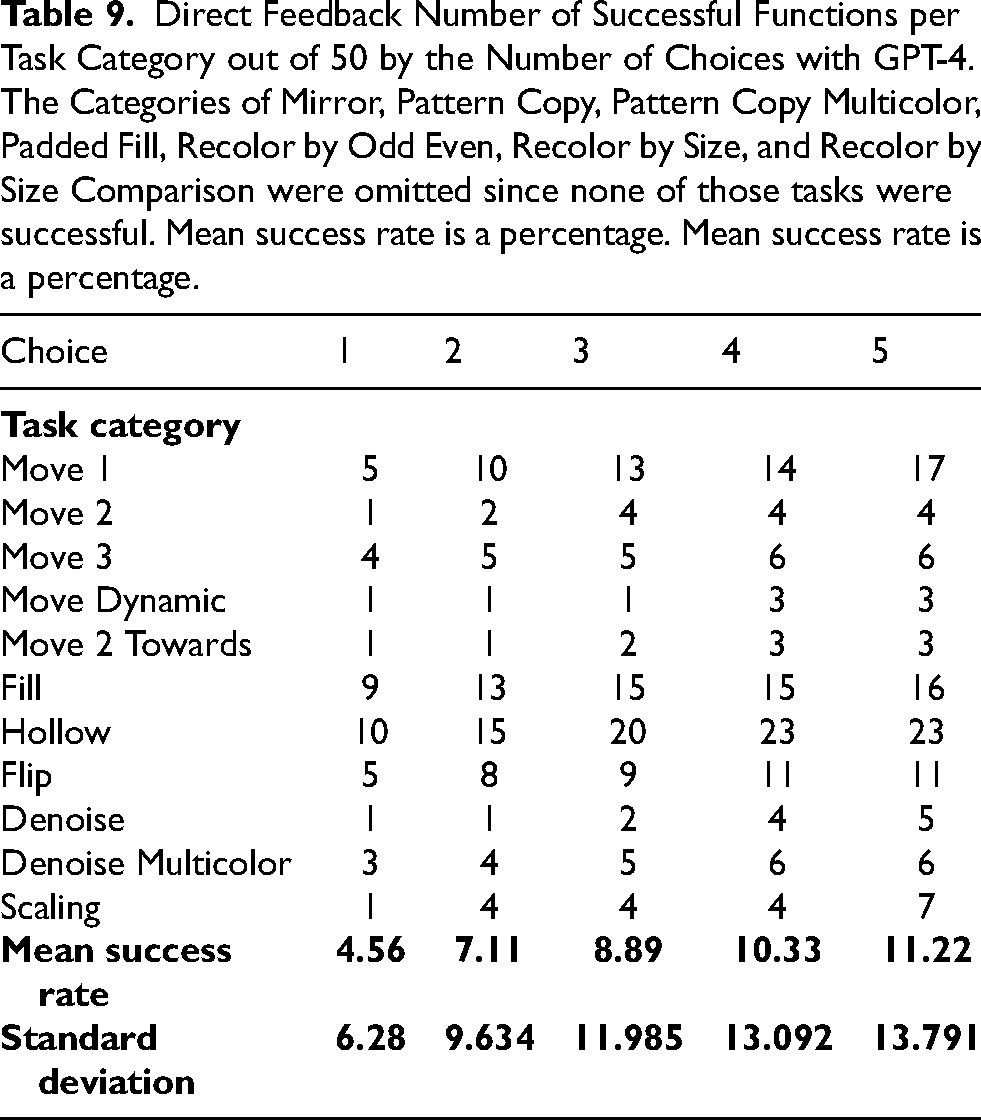
Standard Prompting used Tokens, Success Rate and Costs per Number of Choices with GPT-4. Mean Success Rate is a Percentage.
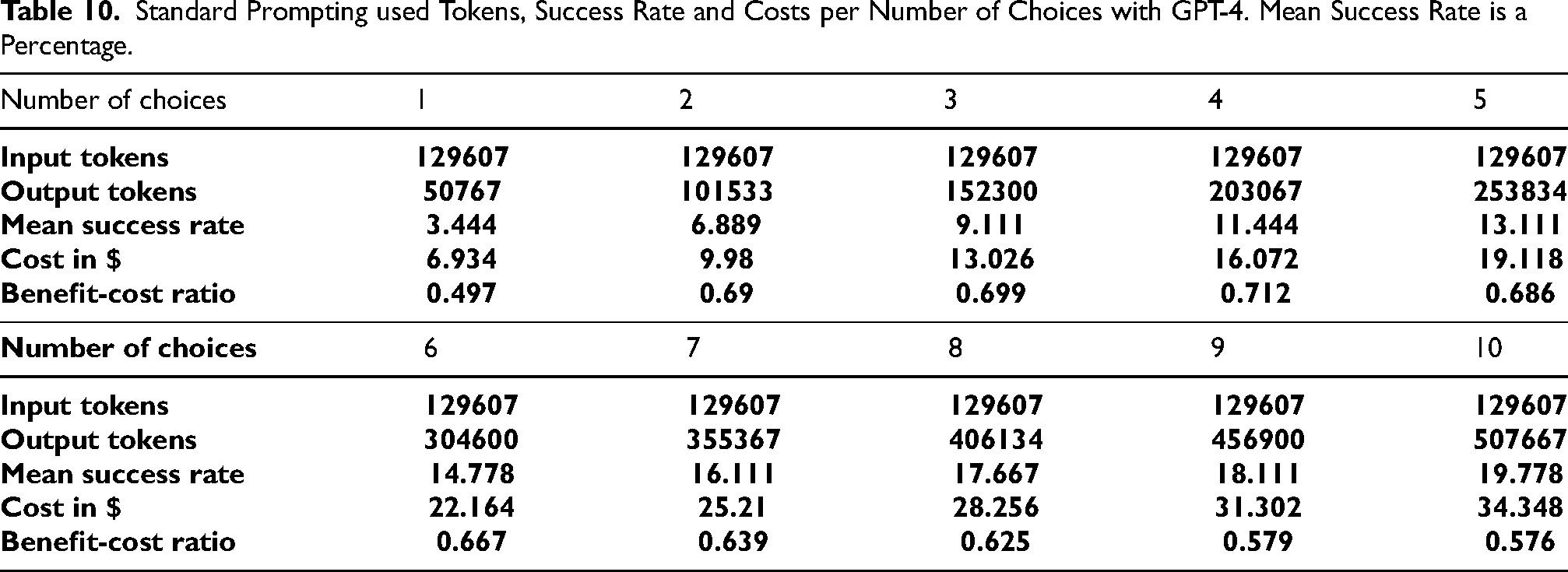
CoT used Tokens, Success Rate and Costs per Number of Choices with GPT-4. Mean Success Rate is a Percentage.

Direct Feedback used Tokens, Success Rate and Costs per Number of Choices with GPT-4. Mean Success Rate is a Percentage.
Figures 6(a) and 6(b) represent the results visually. Contrarily with the GPT-3.5 model, the best
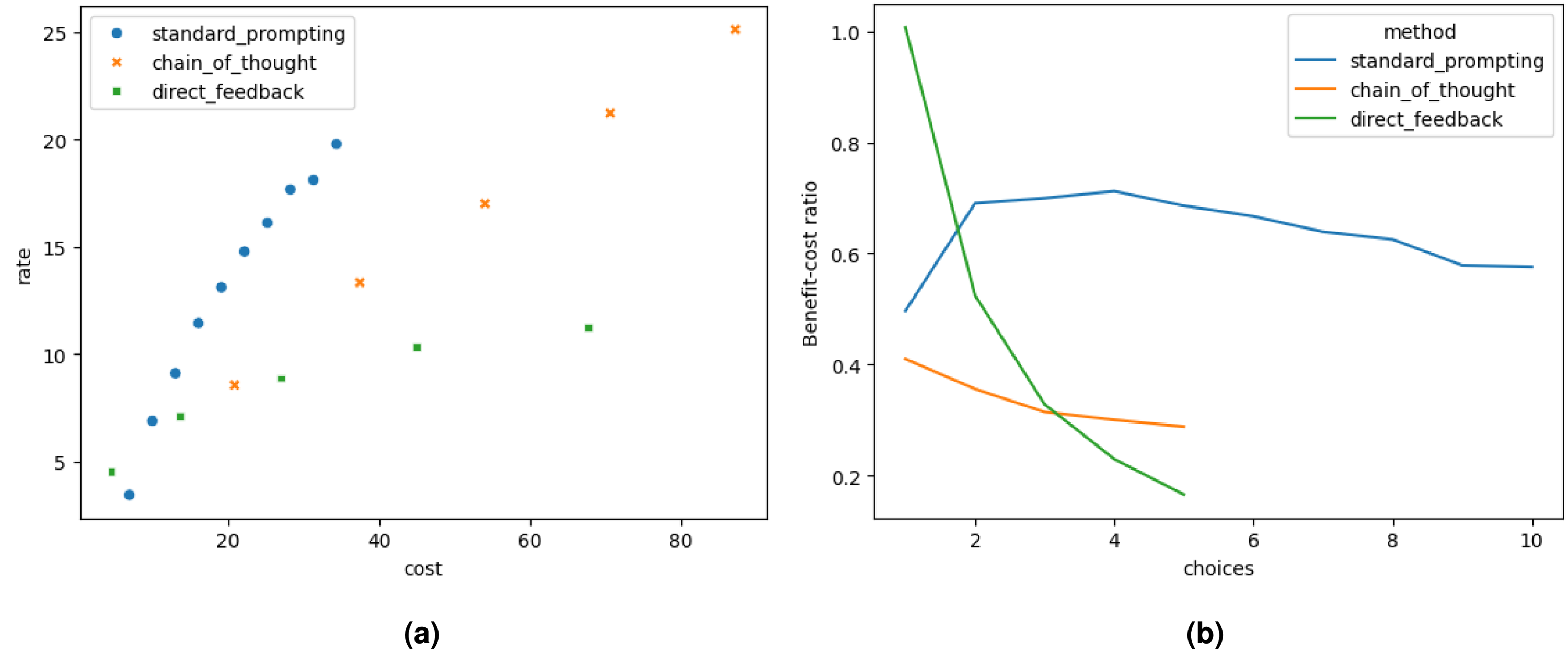
Analysis of GPT-4 results. (a) Tradeoff analysis between success rate and cost and (b) Benefit-cost ratio per number of choices.
Figure 6(a) shows that the tradeoff slope for standard prompting is the steepest, followed by the CoT and direct feedback prompting approaches. As in the case of the GPT-3.5 model, in the GPT-4 model as well, a significant increase in the cost does not guarantee a significant increase in the success rates with the direct feedback approach.
Error Analysis and Runtime Verification
In the previous section, we looked at the performance of LLMs at solving inductive reasoning tasks by producing executable code and considered the number of tasks solved or unsolved. In this section, we dig deeper in understanding the quality of the produced functions.
In this analysis, we look at the functions produced by standard prompting and chain of thought prompting, for which we generate 5 function samples for each task, respectively 4,504 (18016/4) and 4,503 (18012/4) functions as shown in Tables 13 and 14, since we run those functions on the 3 training examples and the test example for each of the 900 tasks, we analyse a total of 36,030 function executions. Most functions load (99.8% for standard prompting, 99.4% for CoT) with a slightly higher chance of indentation errors with CoT and similar syntax errors (see Figure 7). We focus on results of the GPT-4 model since these are the best results.
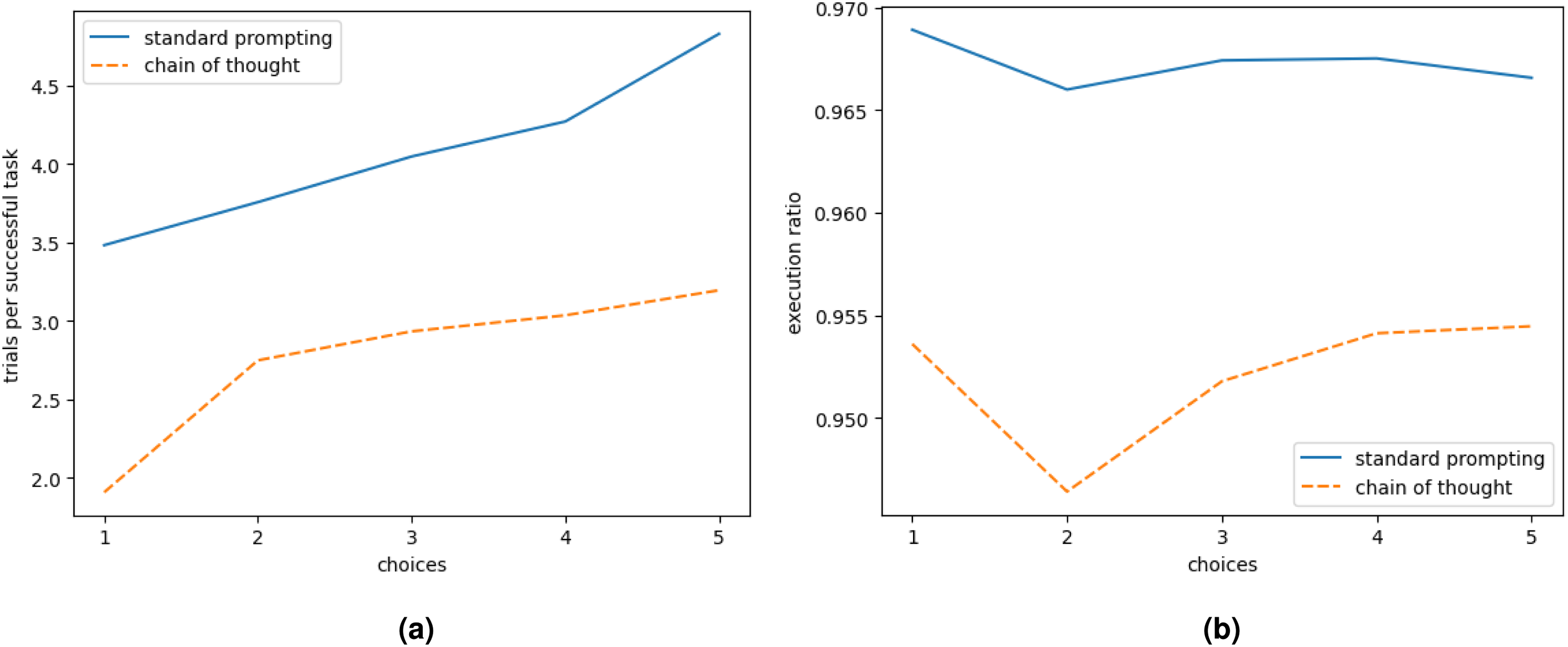
Efficiency and execution success in generated code. (a) Average number of trials to obtain one successful solution for a given 1D-ARC task and (b) The execution ratio, in other words the ratio of functions which run to the overall number of generated functions.
Number of Errors of the Programs Generated From Standard Prompting with GPT-4.

Note:
Number of Errors of the Programs Generated from Chain of Thought prompting with GPT-4.

Note: The meaning of
Tables 13 and 14 also provide a breakdown of the various errors encountered, allowing us to assess the quality of the generated solutions. In Tables 13 and 14, the row
Furthermore, the presence of
Figure 7(a) shows the trial ratio, which is the average number of trials to obtain one successful solution for a given 1D-ARC task, calculated by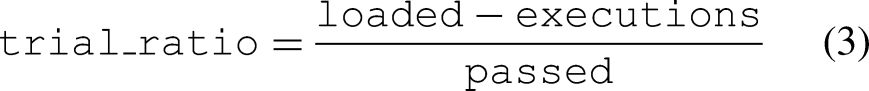
Figure 7(b) shows the execution ratio, defined as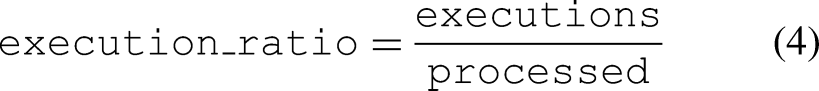
Increasing the number of returned choices increases the chance of error as shown in Figure 7(a) as well as the chance of generating successful code. The number of unsuccessful trials is higher for standard prompting than for chain of thought prompting.
Figure 8 shows a comparison between Standard Prompting and CoT in terms of the different types of errors under 5 choices. In general, CoT generates more or about the equal number of errors, except for the
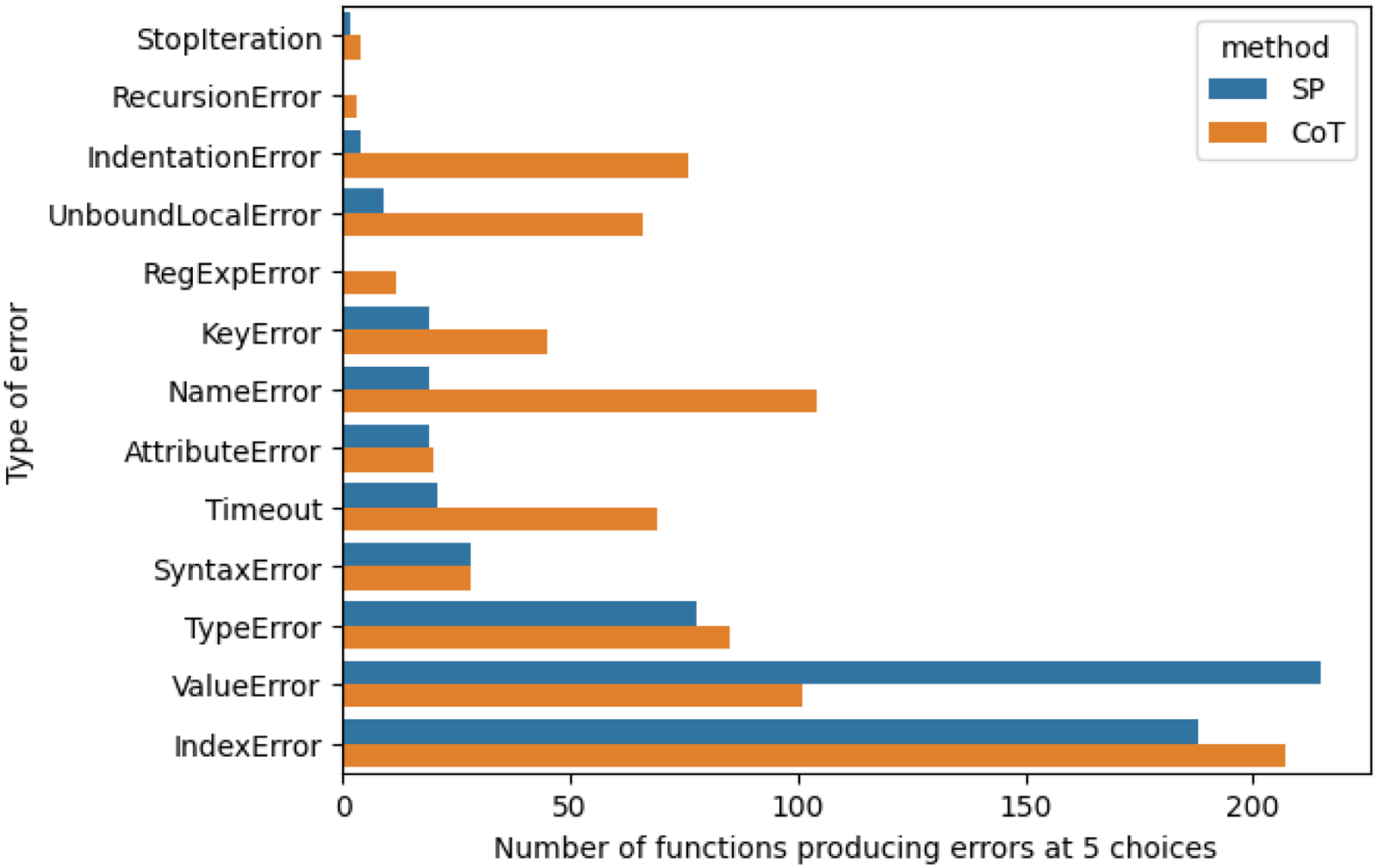
Number of functions producing different types of errors at 5 choices. SP: standard prompting. CoT: chain of thought.
Discussion
We observe generally low results with the LLMs, GPT-4 and GPT-3.5-turbo. GPT-4 obtained the best successful rate of around 25%, although greatly better (about 10 times) than the results compared to GPT-3.5-turbo. This suggests that the greater parameter size enhanced their capability with inductive reasoning with the prompts. While the results are still low, the performance of GPT-4 is encouraging. This shows the potential of prompts (i.e., forward propagation, the process happening when prompting LLMs with an input prompt data is passed through the network to produce a response) of very large neural networks of billions of artificial neurons to approximate inductive reasoning. Further ways of learning with the prompts, e.g., instruction tuning and reinforcement learning, may help improve the performance.
The generally low results are also likely due to our numeric representation (e.g. “000333000”) of the 1D-ARC task, given that the tokenisation process may split the numeric string (e.g., by splitting it into “000”, “333”, “000”, separately), and thus may distort the meaning of the original string. Future studies can improve the numeric representation when prompting the model, or using other open LLMs (e.g., the Llama series Touvron et al., 2023) which have a distinct processing of numeric strings.
We have run the standard prompting experiment with a Python list of integer embedding of the sequences, such as in [0,0,0,3,3,3,0,0,0] instead of “000333000” to compare and in fact there is an improvement, the success rate at 10 choices is 5% compared to 1.55% with GPT-3.5, 45 tasks out of 900 for a cost of $1.11 as opposed to $0.74. This result remains low and therefore shows the limited inductive reasoning capability of LLMs.
It might be possible to increase the performance of LLMs at coding for inductive reasoning by developing prompting techniques and we have shown that zero-shot CoT does improve the success rate. Nevertheless, the transformer architecture of LLMs and the autoregressive approach do not enable effective inductive reasoning and research in this direction is necessary.
Conclusion and Future Work
In this work, we have explored the capability of off-the-shelf LLMs, especially GPT-3.5 and GPT-4 for inductive reasoning using the 1D-ARC corpus. Results show great room for improvement for future systems that employ LLM. Programme synthesis has been used as an intermediary task to solve the problem. While we mainly explored pure inductive reasoning with LLMs, the area of programme synthesis has been explored greatly with both inductive and deductive methods. These methods can be explored in the future to generate programmable hypotheses to solve the tasks from the Abstract Reasoning Corpus.
Finally, the low performance of a pure LLM-based approach in this work may suggest the need for future studies to combine inductive and deductive methods with large neural networks like LLMs. For example, Retrieval Augmented Generative (RAG) (Lewis et al., 2020) together with symbolic representation in deductive reasoning (e.g., graph-based RAG) and other LLM adaptation methods like fine-tuning with preference learning may provide new avenues to combine neural-based inductive and deductive methods. Syntactic data generation, especially from meaningful deductive reasoning knowledge, followed by fine-tuning of the LLM may be useful to improve the performance. While we looked at the execution of the functions, a further analysis would be to look at the similarity between functions and the ratio of unique functions generated to the overall number of functions. In other words, is ChatGPT producing the same functions several times for different inputs or several unique functions. One might want to perform a corpus analysis on the 13,500 functions generated that we made available on our GitHub repository.
Footnotes
Acknowledgements
We are thankful to the Institute for Data Science and Artificial Intelligence at the University of Exeter for funding the OpenAI API requests.
Author Contribution
CM and XW originated the idea of evaluating GPT models’ ability at inductive reasoning on 1D-ARC. CM developed the querying and evaluation software. CM and XW produced the manuscript. All the authors, CM, XW, HD, and A, revised the manuscript of the paper.
Ethical Considerations
Not applicable.
Consent to Participate
Not applicable.
Consent for Publication
Not applicable.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability
We store all responses from GPT-3.5/4, results, and calculations on Zenodo. Our implementation is available at https://zenodo.org/records/13735926 as well as on our github which includes the error analysis https://github.com/cedricidsai/LLMDNT. The following repository also contains the 1D-ARC dataset from https://github.com/khalil-research/1D-ARC (Xu et al., 2023) for reference.