
Abstract
The field of knowledge engineering is experiencing a substantial impact from the rapid growth and widespread adoption of Neurosymbolic Systems (NeSys). In this paper, we investigate how NeSys are already used in knowledge engineering practices leading to the emergence of the new area of neurosymbolic knowledge engineering. To that end, we apply a data-driven analysis based on data collected in a large scale Systematic Mapping Study about systems used to create knowledge resource by employing NeSy approaches that combine Machine Learning and Semantic Web components. We characterise several aspects of this novel field, including specific approaches to knowledge engineering with NeSys identified from the data, the maturity of these systems as well as the main Machine Learning and Semantic Web modules used. Additionally, we also provide concrete examples of neurosymbolic knowledge engineering systems. We conclude with an overview of research challenges such as the need for new methodologies, increased auditability, and considering the impact of human users in neurosymbolic knowledge engineering.
Introduction
Knowledge engineering (KE), broadly defined as the collection of activities for eliciting, capturing, conceptualising and formalising knowledge for the purpose of being used in information systems, looks back to a long history. At the turn of the century, CommonKADS Schreiber et al. (2000) proposed a methodology for knowledge engineering defined as “the development of information systems in which knowledge and reasoning play pivotal roles”. Emerging research on the topic of the Semantic Web has lead to knowledge engineering methods focussed primarily on creating ontologies (Noy & McGuinness, 2001) or even networks of ontologies (NeOn) Suárez-Figueroa (2012) using mostly manual approaches. The linked data (LD) movement has highlighted the importance of (instance) data and initiated methods for creating linked datasets (e.g. the various LD life-cycle methods Poveda-Villalón et al., 2022). The focus on and availability of large-scale data continued ever since. Especially coupled with the increased popularity of machine learning models, knowledge engineering has evolved far beyond what was foreseen in the first decade of the century. So what is the next major stage in KE?
The hypothesis of this article is that, the advent of and recent intensified interest in neurosymbolic (NeSy) systems will represent the next major turning point in the field of KE. Indeed, the development and application of neurosymbolic approaches is seen as one of the key trends in Artificial Intelligence (AI) research (Kautz, 2022). This general trend impacts several sub-fields of AI leading to a variety of interpretations of this vision. For example, in the Semantic Web area, the community proposed techniques such as knowledge graph embeddings (KGE) and deductive reasoning (Hitzler et al., 2020). Furthermore, there is a pronounced trend of building systems that combine Semantic Web and Machine Learning components (which we refer to as SWeML systems). Indeed, in a recently published Systematic Mapping Study (SMS) we identified nearly 500 papers reporting such systems in the period 2010–2020, with most papers being published in 2016–2020 (Breit et al., 2023).
Such intense developments, trigger the emergence of new ways of performing knowledge engineering activities by making use of these new types of neurosymbolic systems. We see this trend as the emergence of a new phase in KE namely that of Neurosymbolic Knowledge Engineering. For this introductory special issue of the journal on Neurosymbolic Artificial Intelligence, we aim to answer two main research questions:
Is there a new field of Neurosymbolic Knowledge Engineering emerging? And if yes, what are its key characteristics? Our goal in answering this research question is both to provide data-driven evidence of the emergence of this field and its characteristics as well as to provide a flavour and concrete examples of neurosymbolic systems that perform KE. To that end, we analysed NeSy systems that were used in a knowledge engineering setting to produce a knowledge resource such as a taxonomy, an ontology or a knowledge graph. Given the considerable breadth of the NeSy research area, we focus our analysis on a sub-family of NeSyS, namely SWeML systems. The papers describing such systems were collected and analysed as part of the broader Systematic Mapping Study mentioned above Breit et al. (2023) which characterised the landscape of SWeML systems (used not only for knowledge engineering purposes). Relying on the results of study (Breit et al., 2023), allows deriving data-driven conclusions about this field. After a description of our methodology for collecting the data for analysis (Section 2), we present our initial, data driven findings on the characteristics of the emerging area of Neurosymbolic Knowledge Engineering such as typical system patterns (Section 3), the main machine learning models most often used (Section 4), the Semantic Web resources employed (Section 5) and the maturity of these systems (Section 6). What are open challenges for the field of Neurosymbolic Knowledge Engineering? Based on the conclusions from the analysis of existing neurosymbolic KE systems, as well as additional considerations, we derive a number of open challenges for the Neurosymbolic Knowledge Engineering field (Section 7).
Paper Collection Through an SMS
We base our analysis on data collected as part of a large Systematic Mapping Study Breit et al. (2023) which aimed to characterise SWeML systems that have been published during the 2010–2020 period. During the SMS, the main digital libraries (WebOfScience, ACM Digital Library, IEEE Xplore, Scopus 1 ) were queried for those papers that, in their abstract and keywords, mention terms related to the Semantic Web (e.g. knowledge graph, linked data, semantic web, ontolog, etc.) and to Machine Learning (e.g. deep learning, neural network, embedding, representation learning, feature learning, language model, etc.). Additionally, as the aim was to collect papers describing concrete systems that fulfil a given task, paper abstracts also needed to mention typical application areas (e.g. Natural Language Processing, Computer Vision, Information Retrieval, Data Mining, Information integration, Knowledge management, Pattern recognition, Speech recognition). The collected 1986 papers underwent two cycles of selection in which authors systematically applied a number of selection criteria, as discussed in Breit et al. (2023), to identify the most suitable papers. Inclusion criteria were publication date (2010–2020), language (English), publication type (peer re-viewed), accessibility (accessible to authors), duplicates (latest version), whether the described systems had an interconnection between the SW and ML component, whether the system solved a concrete task and, finally, whether the paper had a sufficiently good level of English and scientific quality to be fully understood. This lead to a corpus of 476 papers. In-depth methodological information about the paper selection process is available in Breit et al. (2023) and its accompanying protocol document.
Data Extraction From Papers During the SMS
After reading the 476 papers, key data was extracted, related to:
Bibliographic information such as authors, their institutions, publication year and venue. The domain of application (e.g. life sciences) and the task solved by the system (e.g. text analysis). System architecture in terms of their inputs/outputs and the order of their processing units. Characteristics of the Machine Learning modules such as the type (e.g. attention) and training (e.g. supervised). Characteristics of the Semantic Web modules used as input to the system, such as their type (e.g. taxonomy, ontology, knowledge graphs), size, formalisation language, etc. The level of maturity of the systems (e.g. prototype, industrial strength application), system transparency in terms of sharing source code, details of infrastructure and evaluation setup as well as the existence of provenance capturing mechanisms.
KE-specific Dataset Selection
The data collected as part of the SMS has been released in the form of a knowledge graph Ekaputra et al. (2023) which can be queried through a SPARQL interface 2 . To answer this paper’s research questions, we use the SPARQL interface to select a subset of papers relevant to KE. Concretely, we select those papers that reported systems performing the tasks of Graph creation and Graph extension while producing a Symbol as the final output, consisting of 127 papers (out of the 476 papers in the original survey results). Note that the Graph creation and Graph extension tasks are high-level tasks which cover more detailed general tasks such as Ontology Creation, Taxonomy Creation, as well as domain-specific tasks, e.g. Drug Target Prediction and Drug Repurposing. For this paper, we filter out domain-specific tasks and identify 123 KE-related papers (out of 127 KE-related papers) for the analysis described in the next sections.
Neurosymbolic Knowledge Engineering Patterns
System architecture was one of the key characteristics extracted during the SMS as explained in Section 2. Through the usage of system patterns to represent these architectures, we were able to present our findings in a comprehensive way and make systems comparable from a workflow and data flow perspective. In this section, we start by providing background information on the neurosymbolic system patterns that were identified in Breit et al. (2023), such as the notation used and the various typologies that were introduced (Section 3.1). The rest of the sections analyse the patterns that are most frequent or more specific for KE tasks providing examples of concrete systems employing these patterns.
Neurosymbolic System Patterns

Boxology-based notation of system patterns and three example patterns in graphical/textual notation.

Comparative pattern frequency across the overall SWeML dataset (2 inner layers) and those specific to KE systems (outer layer).

Pattern A1.

Pattern I1.

Pattern F2.

Pattern A2.
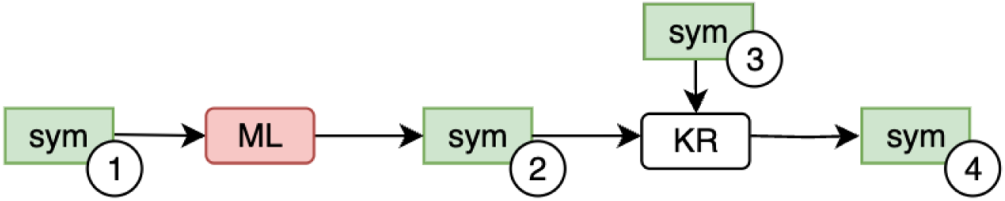
Pattern T8.
The fact that over 25% (123 from 476) of all SWeML systems supports the completion of a KE task, as discussed in Section 2, is a strong evidence for the emergence of a new field for Neurosymbolic Knowledge Engineering. We start characterising this field from the perspective of the system patterns employed and by giving examples of concrete KE systems. We perform our analysis in comparison with the overall dataset to answer questions such as: which of the general SWeML system patterns are used for KE? What is the distribution and frequency of these KE patterns? We found that the 123 KE systems employed 18 distinct patterns from the total of 44 patterns, thus, in this dataset, less than half of the possible patterns were used for KE. Figure 2 depicts the relation between patterns used in the overall dataset (of 476 papers) and those for KE (in the subset of 123 papers we selected) as follows:
Several conclusions can be drawn from this comparative visualisation. First, similarly to the overall dataset, KE systems also predominantly employ simple patters of type A and F. Second, patterns that are frequent in the overall dataset, also tend to be frequent in the KE dataset, in particular A1, A2, F2 and I1, which we further discuss in Section 3.2. Third, some patterns are more often used in KE systems than in other systems, thus representing patterns that are likely specific for KE as detailed in Section 3.3. These frequent and specific patterns are of particular interest to knowledge engineers as potential blue-prints for their work. The next sections provide more in-depth details about the various frequent/specific KE patterns as well as examples of (typical) systems that employ them. Finally, in Section 3.4 we investigate which KE tasks are solved with which patterns.
In the case of the papers related to knowledge engineering tasks the most frequent patterns (each used in more than 10 papers) are A1, A2, F2, and I1. Next, we describe and exemplify the use of these patterns (cf. Table 1 for an overview).
Examples of Papers Describing Systems that Employ Patterns that are frequent for Knowledge Engineering.
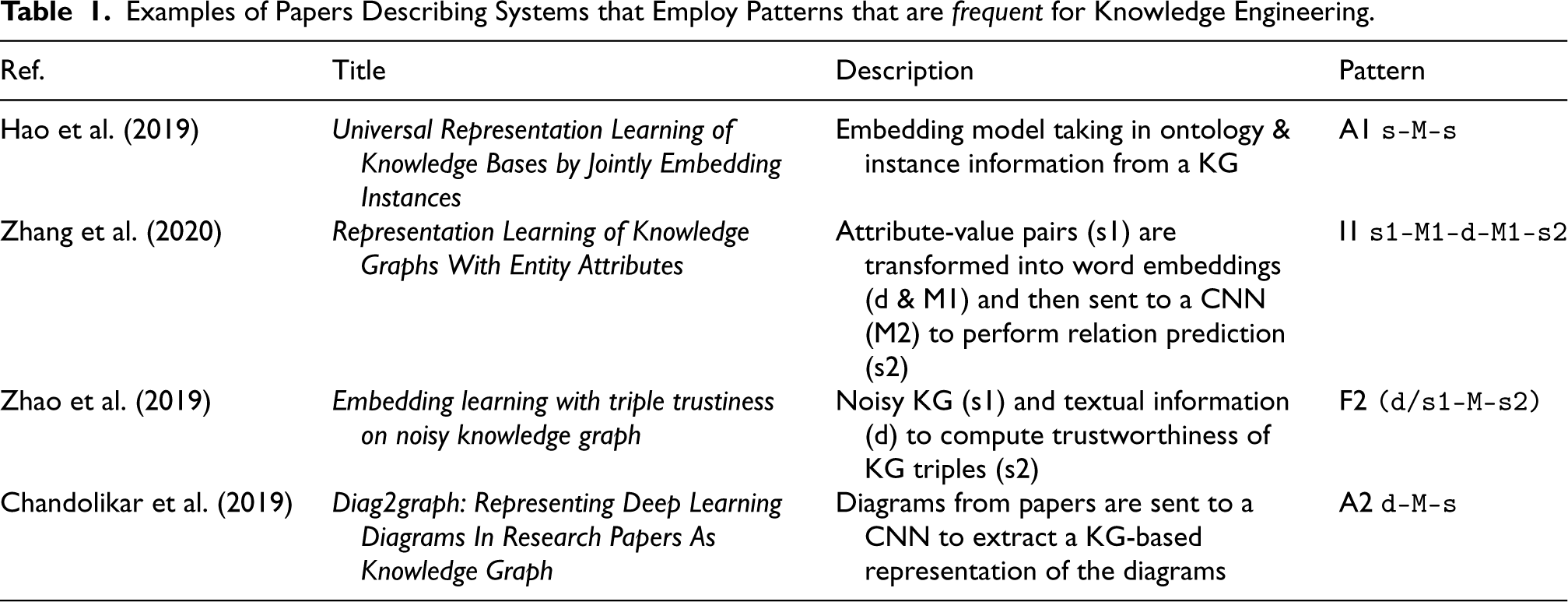
Examples of Papers Describing Systems that Employ Patterns that are frequent for Knowledge Engineering.
Are there patterns that are specifically used for knowledge engineering tasks? To identify such patterns, we compute the specificity of patterns as a ratio between their use in the KE dataset and the number of times they are used in the overall dataset. We identify that three of the frequent patterns are also often used in the KE dataset and can be considered specific to KE. These are:
Examples Papers Describing Systems that Rely on Patterns that are specific for Knowledge Engineering.

Examples Papers Describing Systems that Rely on Patterns that are specific for Knowledge Engineering.
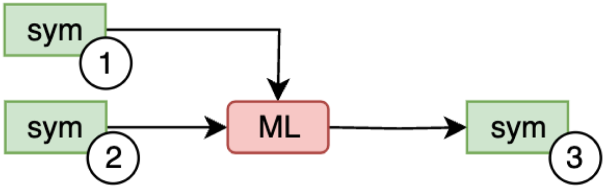
Pattern F4.
Differently from papers (Guo et al., 2016; Minervini et al., 2017; Wang et al., 2018), paper Gad-Elrab et al. (2016) focusses on extracting non-monotonic rules from a KG and associated rules. Given a KG (s1) and a set of associated Horn rules (s2), these are input to an Association Rule Mining module (M) that produces non-monotonic rules (s3, i.e. exception aware rules).

Pattern T1.
We continue our analysis by investigating the relation between KE patterns and the supported KE tasks. In Figure 10 we depict six KE tasks related to the creation or completion of taxonomies, ontologies and knowledge graphs as well as the pattern types employed to address these tasks. From the right side of the figure it is clear that papers focussing of tasks related to knowledge graphs are much more frequent than those focussing on tasks related to taxonomy/ontology engineering. This suggests a shift in research focus towards graph engineering, which has been less-covered by current KE methodologies.
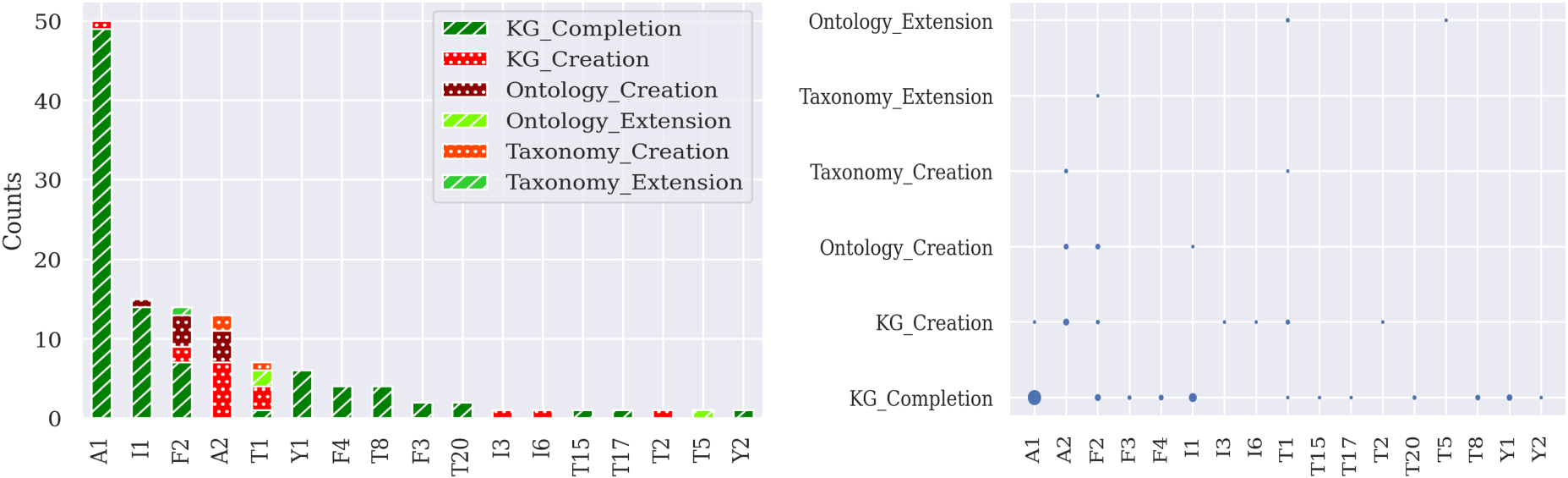
Frequency of the patterns per task. Left side: number of papers reporting a certain pattern, divided by the type of task addressed. Right side: number of papers for a given KE task/pattern combination.
Specific vs. Versatile Patterns
We observe that some patterns are specific for certain tasks, as follows:
Although it appears very frequently, pattern A1 is used almost exclusively for KG completion, within papers focussing on knowledge engineering. There are a number of other patterns used exclusively, in our dataset, for knowledge graph completion. These are, in the decreasing order of their frequency in the KE dataset: Y1(6, s1-M1-d1/d2-M2-d3-M3-s2), T8(4, s1-M-s2/s3-K-s4), F4 (4, s1/s2-M-s3), F3 (2, d1/s1-M-d2/s2), T20 (2, s1-M1-d1/s2-M2-s3) T15(1, s1-K-s2/s3-M-s4), T17(1, s1/s2-M1-d-M2-s3), Y2 (1, s1-M1-d1/d2-M2-s2-M3-s3). As KG Completion encompasses several sub-tasks such as link prediction, type completion etc., future work could analyse whether some of these patters are specifically used for one of those sub-tasks. Patterns used exclusively for the task of knowledge graph creation are I3(1, s1-M1-s2-M2-d), I6(1, d-M-s1-K-s2), T2(1, d1/s1-M1-d2-M2-s2). A2 (d-M-s), appears 13 times in the dataset, and supports tasks for creating different types of knowledge structures (taxonomies, ontologies, knowledge graphs) by applying ML to a data type input. F2 (d/s1-M-s2), was used in four different task types. T1 (d1-M1-d2/s1-M2-s2) was also used in four tasks spanning all three types of knowledge structures and various activities such as completion, creation and extension.
On the other hand, some patterns seam to find applicability within a range to tasks, thus being more versatile:
Understanding which patterns can be used for which tasks could play an important role in guiding knowledge engineers in choosing promising system architectures for a task at hand. In particular, this would enable novice knowledge engineers to quickly identify patterns that have emerged as adequate for certain tasks from the experience of the broader KE community.
How about the use of machine learning components for knowledge engineering tasks? What are the most popular ML categories that should be part of the toolbox of the future knowledge engineer?
In our analysis of machine learning utilisation in KE tasks, we grouped machine learning models into three categories: Deep Learning (explicitly excluding Graph Deep Learning), Graph Deep Learning and Classical ML. As shown in Figure 11 (left-side), Deep Learning (DL) models are predominant, used 100 times across various tasks, asserting their adaptability and efficacy in KE. Following closely, Graph Deep Learning (Graph DL) models show notable application, especially in KG Completion, with 95 uses. Classical ML models, though less dominant with 50 instances, remain relevant in certain tasks such as KG Completion and KG Creation. This distribution underscores a trend towards more sophisticated models in KE.
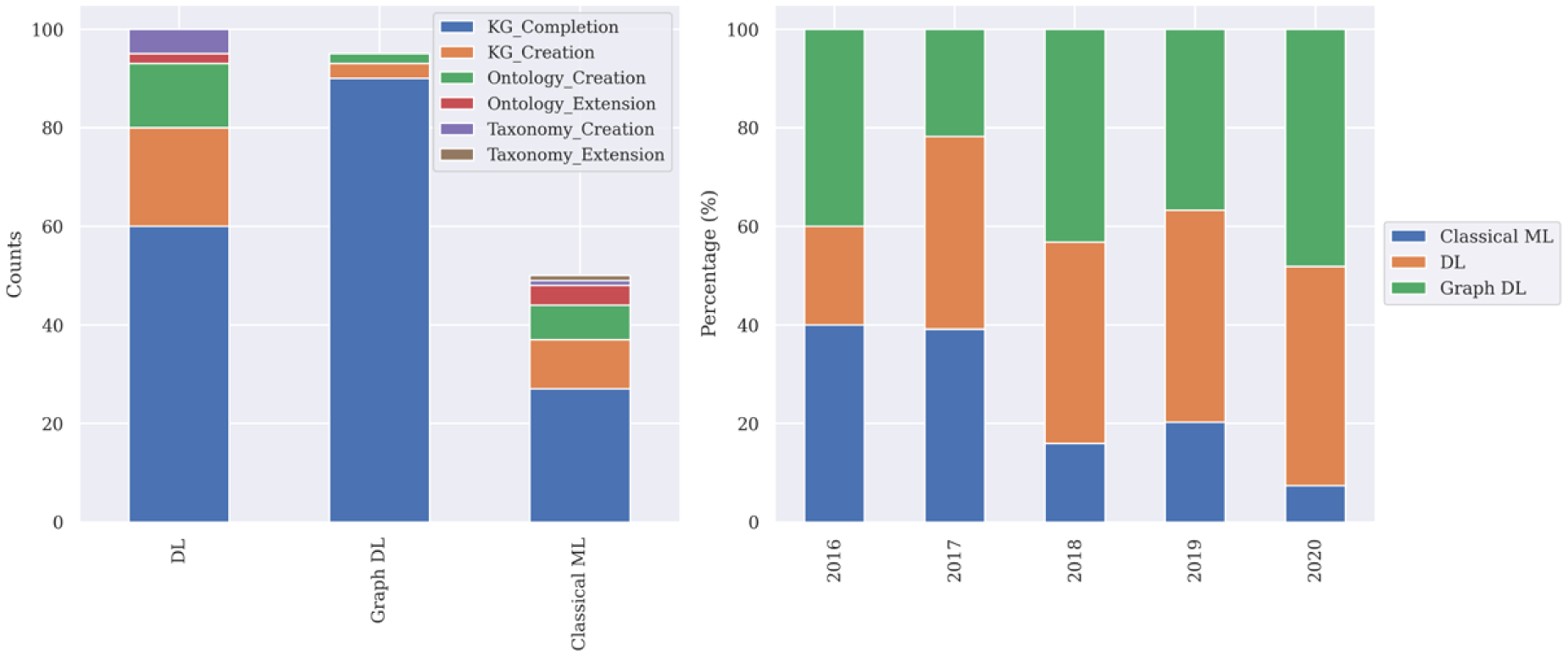
Frequency of machine learning models per task/year. (Left side) Frequency of ML categories related to knowledge engineering tasks. (Right side) Frequency of the ML categories being used by the papers over 5 years.
The use of machine learning models in KE has seen a significant growth in recent years. Our analysis, presented in Figure 11 (right-side), shows the most trendy machine learning categories for knowledge engineering over the years 2016-2020. In the evolution of machine learning model usage from 2016 to 2020, a significant shift towards advanced models is evident. The year 2016 saw an equal preference for Classical ML and Graph DL models (40% each), with DL at 20%. However, by 2020, DL and Graph DL models had surged to 44.44% and 48.15%, respectively, while Classical ML’s usage has receded to merely 7.41%. This shift reflects the increasing complexity of KE tasks that corresponds to more complex models.
We perform an analysis of the Semantic Web resources used in SWeML systems for KE tasks based on the categories of resources introduced in our prior survey (Breit et al., 2023). There are six different types of resources found in the systems as described next.
Figure 12 provides an overview of SW resource usage on KE-focussed SWeML systems. We found that 92 out of 123 papers use SW resources to various extent. Out of these, 35 employ a single SW resource, while the rest utilise two or more resources for their tasks. We show the SW resource distribution following our categorisation, which can be seen in Figure 12(a). The figure shows rapid growth of KG and thesaurus utilisation since 2016. In contrast, the utilisation of other types of SW resources in KE-focussed SWeML systems is relatively stable. Figure 12(b) shows the classification of the SW resources according to their domain. The resources used for KE tasks typically come from the general domain, shown in dark blue shades. Domain-specific resources, such as natural sciences, are less dominant, which could be an effect of the generic nature of the KE tasks.

An overview of semantic resources used in KE-focussed SWeML systems. (a) SW resources by types and years; (b) SW resources by domains.
With increased use of SWeML Systems for knowledge engineering, the transparency and auditability of these systems become increasingly important to better understand the quality and context of the created knowledge resources.
Maturity. In the original dataset, three levels were established to assess the maturity of the overall application: low/probably low, describing scripts or prototypes, medium systems with simple user interface or error handling or high, describing stable systems deployed in industrial environments. The entire subset of KE systems was assigned to be of low/probably low maturity, which is in line with the overall trend in the entire set of analysed SWeML Systems (over 90% being of low/probably low maturity).
Transparency. The evaluation of transparency parameters was focussed on evaluation parameters and their distribution is also similar to the overall superset of SWeML Systems: Metrics were the best documented parameters (92%), followed by data (87%), parameters (76%), data-split (71%), software (29%) and infrastructure (15%). All of the transparency parameters are almost equal or lower (between 1% and 3%), only parameters and data-split are slightly better documented in this subset.
Auditability. There is no KE system with any additional provenance capturing, which is not surprising considering the overall low number of SWeML Systems (three systems) in the entire data set containing any provenance mechanism. However, in critical domains and with increasing amounts of heterogeneous data sources, metadata and provenance information across the entire lifecycle should/must be included (cf. EU AI Act or similar regulation).
To conclude, SWeML in general (including KE systems) are still of low maturity. Yet, we expect that SWeML Systems will continue to mature over the next years in terms of their functionalities and stability. However, despite this (expected) increase in maturity, there are still open questions in terms of the transparency and auditability of these systems which has already been identified by others. Indeed, there is a lack of mature evaluation techniques and standard benchmarks for neurosymbolic systems (Garcez & Lamb, 2023). Furthermore, in the area of NLP, neurosymbolic systems use different datasets and benchmarks, which hampers the comparison of results (Hamilton et al., 2022).
Open Challenges for (Neurosymbolic) Knowledge Engineering
From the previous sections, we draw several data-driven conclusions about neurosymbolic knowledge engineering:
Emerging field. The fact that over 25% of all systems collected by the Systematic Mapping Study focus on solving a task relevant for knowledge engineering demonstrates that neurosymbolic knowledge engineering is indeed an emerging field. Focus on new tasks. The ontology/taxonomy creation/extension tasks are less frequent in comparison with KG extension/creation tasks which are currently the key focus (Figure 10). Therefore, not only the type of systems used for KE is changing, but also the KE tasks to be achieved. High variety of system patterns. The analysis of the KE systems revealed that there are groups of systems that follow the same high-level approach, or pattern. We identified both frequent patterns and patterns that are potentially specific for KE tasks. In total, 18 different patterns were reported by the papers in our dataset. These patterns correspond to a variety of KE processes, e.g. from systems that learn a semantic structure by applying ML methods to unstructured data (A2 pattern), to systems that learn and apply rules to extend a semantic resource (T8) or systems that “infuse” background knowledge (such a logical rules) in KG embedding components (F4 pattern). Similarly to SWeML systems in general, simple patterns (A/I type) prevail. We note that the boxology notation of van Harmelen and ten Teije (2019) played a key role as an instrument for organising the reviewed systems and finding similarities. KE task specific patterns. Some of the KE patterns seem to be specifically used for certain KE tasks, at least in the scope of the analysed systems. This opens the possibility for (novice) knowledge engineers to identify (and use) community-tested patterns for the task at hand. Low maturity, transparency and auditability characterises current neurosymbolic systems used for knowledge engineering (and also other tasks).
Starting from these conclusions, we see the following open challenges for this research area:
New KE Methodologies and Tools
The analysis performed in this paper demonstrates that we are at turning point in the KE community: not only do KE systems focus increasingly on tasks related to knowledge graphs as opposed to taxonomies/ontologies, but they also employ a variety of diverse neurosymbolic approaches (patterns). This status-quo is insufficiently covered by current KE methodologies and tools. Therefore, this area will require the development of new methodologies and tools to cater for the variety of the neurosymbolic KE approaches. The boxology-based patterns used in this article could offer a valuable mechanism for dealing with the broad diversity of the systems. In particular, extensions to the boxology notation (e.g. in terms of representing other system module types, a richer set of relation types between system components) would be a line of work in itself and could foster an even richer analysis and methodological support for such systems. Finally, better understanding what KE tasks can be achieved with which patterns (and what are the benefits/challenges of each pattern) could provide further methodological support for knowledge engineers.
Towards Auditable Knowledge Engineering
Semantic structures developed through the KE process underpin a variety of (often mission critical) modern intelligent systems. As such, the transparency of the process of their creation is increasingly important for several stakeholders (e.g. from a technical, managerial or legal perspective). Such transparency can be ensured by making knowledge engineering processes auditable. Yet, while our analysis in this paper was rather narrow due to the exploratory nature of the original data set, it suggests that there are still many gaps regarding transparency and auditability guidelines for SWeML Systems.
While auditability of AI systems in general is an active research area, current solutions fall short of the needs of neurosymbolic (including SWeML) systems that underpin neurosymbolic knowledge engineering. First, at the level of neurosymbolic systems, initial steps towards auditability have been made with design patterns and templates van Harmelen and Ten Teije (2019), van Bekkum et al. (2021) and Breit et al. (2023) which enable a common understanding of overall data and processing workflows (i.e. the boxology patterns demonstrated in this article). These approaches are however very preliminary and still need to be adopted at scale by system engineers and practitioners to reach their full potential. Second, in the area of purely machine learning based systems, due to their deployment in high-risk use cases and various incidents (McGregor, 2021), suggestions for documentation templates of different components have emerged: Datasheets (Gebru et al., 2018), ModelCards (Mitchell et al., 2019), FactSheets (Arnold et al., 2018) and MLOPs tools such as MLFlow 3 are supporting low-level record keeping and tracing. However, the majority of these documentation templates is still artefact-based with low semantics and the integration of provenance traces from different components is still an open question. Finally, semantic web technologies are associated with increased explainability and context, but might also include negative biases (Janowicz et al., 2018) or lack documentation to enable accountability (Andersen et al., 2023), one of the ultimate goals of auditability. Yet, approaches for making semantic resources (and their life-cycles) auditable were only weakly addressed in particular in comparison to ML systems. Therefore, exciting research opportunities lie in extending auditability notions to neurosymbolic systems by potentially extending existing work in the area of audible machine learning systems.
Clarifying the Role of Human Agents
Knowledge engineering inherently involves human participants such as the knowledge engineer that captures and formalises knowledge or (domain) experts whose knowledge is represented. Therefore, in the changing landscape of knowledge engineering, there is a need to understand and represent the interactions between machine learning models, knowledge engineering methods and human participants in complex AI systems. However, there is still a lack of common understanding regarding the roles of humans, their necessary expertise, and their authority in such systems.
There are, nevertheless, important initial works in this direction. Concretely, in the last years, the role of human agents in neurosymbolic systems has gained attention, resulting in the introduction of two strategies to extend the collection of proposed patterns of these systems. The first approach, introduced in van Bekkum et al. (2021) and extended in Meyer-Vitali et al. (2021), focussed on the need to represent actors (agents, robots or humans) that initiate processes in neurosymbolic AI systems. Three patterns were proposed in Meyer-Vitali et al. (2021) that include an actor element, visualising the roles of different actors (i.e. initiating or supporting a process) and their interactions. Additionally, a concrete use case was described exemplifying the applicability of these patterns. The second strategy, proposed in Witschel et al. (2020), aimed to extend the original boxology (van Harmelen & ten Teije, 2019) with patterns of systems with human-in-the-loop (HiL). Two abstract HiL patterns were formalised, where the human element acts as a feedback-provider or a feedback-receiver and contributes toward the enhancement of a KR/ML component. The extended HiL patterns from Witschel et al. (2020) have already been successfully applied in describing a particular hybrid AI system involving human participation in Prater and Laurenzi (2022). More broadly, the need for design patterns describing the interactions between humans and AI has also been identified by the hybrid (human-AI) intelligence research community. For instance, in van Stijna et al. (2021) the authors proposed design patterns for representing the collaboration between human agents and AI systems for a moral decision making domain. While the patterns focus on the interactions between the agents, the original boxology of hybrid-AI systems van Harmelen and ten Teije (2019) is used to describe requirements of the AI elements. These initial works provide a basis for future work focussing on systematically analysing hybrid AI systems involving human participants in order to better understand their components and requirements.
Assessing the Importance of Large Language Models (LLMs) for Knowledge Engineering
When the initial SWeMLS survey took place in October 2020, research on the utilisation of LLMs for Knowledge Engineering was scarce, and present in only 4 out of 123 papers (less than 5%). With the rapid evolution and adaptation of LLMs in the last few years, however, the landscape is changing very rapidly, marked with the emergence of vision papers, e.g. Allen et al. (2023) and special tracks on scientific venues 4 on this topic. Therefore, an investigation of LLM-based patterns for knowledge engineering is an open topic, which requires the collection of more recent data to be answered reliably.
We conclude with a set of limitations of this work. Firstly, the limitations of the broader study whose data we reuse (Breit et al., 2023) also affect this work. In particular, given the broad area addressed by the study in Breit et al. (2023), we needed to perform study scoping to select a reasonable number of papers, with the potential side-effect that some relevant papers were missed. Furthermore, during data analysis, new abstractions were introduced (e.g., sets of domains, types of ML models, types of SW models) which we derived from the extracted data given the lack of such typologies in the literature. Therefore, we cannot claim that these are representative for the entire field. Finally, the version of the boxology notation used was quite restrictive (van Harmelen & ten Teije, 2019) (e.g. no possibility to represent standard processing units, no distinction between training and prediction phases, representation of only input/output relations). As such, several simplifying assumptions had to be taken when representing more complex systems with the boxology thus potentially leading to the loss of some details. Additionally to these limitations, the analysis presented in this paper represents an initial study with many aspects still to be explored (e.g. how the various characteristics of SWeML systems for KE are mirrored by various application domains). Given also that the collected data dates back to 2010–2020, more recent trends, in particular related to the use of LLMs for knowledge engineering, are not reflected in the analysis at this point, but remain a topic of future work requiring the systematic collection of more recent papers, from 2020 onwards.
Despite these limitations, we remain confident that this work captures key influences that neurosymolic systems have on the knowledge engineering area (whether powered by LLMs or not) and will fuel further development and discussions in the KE field as already apparent from early adopters of our ideas (Allen & Ilievski, 2024).
Footnotes
Acknowledgements
This work was supported by the FWF HOnEst project (V 754-N). We thank the following collaborators that participated in the collection of the data used as basis for the analysis presented in this paper: Anna Breit, Andreas Ekelhart, Andreea Iana, Heiko Paulheim, Jan Portisch, Artem Revenko, Anette Ten Teije, Frank van Harmelen.
Funding
The authors received no financial support for the research, authorship and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.