
Abstract
Does the partisan composition of three-judge panels affect how earlier opinions are treated and thus how the law develops? Using a novel data set of Shepard's treatments for all cases decided in the U.S. courts of appeals from 1974 to 2017, we investigate three different versions of this question. First, are panels composed of three Democratic (Republican) appointees more likely to follow opinions decided by panels of three Democratic (Republican) appointees than are panels composed of three Republican (Democratic) appointees? Second, does the presence of a single out-party judge change how a panel relies on earlier decisions compared to what one would expect from a panel with homogeneous partisanship? Finally, does the size of these potential partisan effects change over time in a way that would be consistent with partisan polarization on the courts? We find that partisanship does, in fact, structure whether earlier opinions are followed and that these partisan effects have grown over time—particularly within the subset of cases that we believe are most likely to be ideologically salient. Since legal doctrine is developed by building upon or diminishing past opinions, these results have important implications for our understanding of the development of the law.
Keywords
Introduction
Most quantitative empirical research on the behavior of U.S. court of appeals judges focuses on the final votes on the merits cast by such judges. Such decisions are clearly consequential, both for the parties involved in the appeal and for the development of the law. But there is more to judicial behavior than deciding who prevails in a dispute. In the American common law system, the reasoning in judicial opinions serves to guide future judges in their decisions.
A key element of that reasoning is how earlier cases are or are not relied upon. The precedential vitality of a given majority opinion is either amplified or diminished through later judges' decisions either to rely on or to reject reliance on that opinion when deciding a current case. The nature of precedent is that opinions that later courts treat as controlling thereby help to determine legal doctrine, and opinions that are regularly criticized, questioned, or limited do not. Judges develop the precedential authority of opinions by their decisions to rely on and follow those opinions. And, in so doing, they reveal information about their preferences.
Moving back to studies of judicial behavior that focus on merits votes, much of this literature finds that ideology and/or partisanship (both of which are typically proxied by the party of the appointing president) tend to structure the voting behavior of judges (see, inter alia, Cross & Tiller, 1998; Revesz, 1997; Rowland & Carp, 1996; Segal & Spaeth, 2002; Sunstein et al., 2006). Some of the best of this work exploits the fact that within the U.S. courts of appeals judges are, to a good approximation, randomly assigned to three-judge panels and cases are similarly approximately randomly assigned to these panels. 1 This produces data that, in many ways, approximates a randomized experiment. These “panel effects” studies have provided strong evidence that partisan panel composition plays an important role in structuring judicial votes (Cox & Miles, 2008; Cross, 2007; Kim, 2009; Sunstein et al., 2006). The evidence suggests that this works in an obvious way (panels composed of three Democrats decide cases differently than panels composed of three Republicans) as well as a less obvious way (three-Democrat panels decide cases differently than two-Democrat panels with the same sort of difference for the two types of majority Republican panels). Critically to this article, the quasi-random assignment of judges and cases to panels provides a strong basis for these results.
This article builds upon the two insights above—whether and how earlier opinions are relied upon is an important outcome variable for students of judicial behavior to analyze and that the quasi-random assignment of cases and judges to panels in the U.S. courts of appeals strengthens one's inferences. Specifically, we consider whether partisanship affects how judges rely upon earlier opinions. Using a novel data set of Shepard's Citations (Shepard's) for nearly all cases—both published and unpublished—decided in the U.S. courts of appeals from 1974 to 2017, we investigate three variations on the main question. First, are panels composed of three Democratic (Republican) appointees more likely to follow opinions decided by panels of three Democratic (Republican) appointees than are panels composed of three Republican (Democratic) appointees? Second, does the presence of a single out-party judge change how a panel treats earlier decisions compared to what one would expect from a panel with homogeneous partisanship? Finally, does the size of these potential partisan effects change over time in a way that would be consistent with partisan polarization on the courts? In each case, we investigate these questions by examining three overlapping sets of cases: all cases, published cases, and ideologically salient published cases. We find that partisanship does, in fact, structure whether earlier opinions are followed and that these partisan effects have grown over time—particularly within the subset of published cases that we believe are most likely to be ideologically salient. However, these effects are asymmetric: the partisan composition of a panel affects how that panel relies on opinions of 3-Democrat panels but not how that panel relies on opinions of 3-Republican panels.
This article proceeds as follows. The next section explains why our Shepard's outcome variable is reliable and valid. We then discuss the three main research questions. The next section explains the data and research design. Results are presented in the next section, and the final section concludes.
Shepard's and Judicial Reasoning
Judges develop the law by considering the particulars of a case in light of relevant precedent, and then developing, through legal reasoning, a justification for a decision based on the particulars of the case and earlier holdings. The treatment of earlier cases is an important part of an opinion's reasoning. A judge will follow earlier opinions they view as controlling and will overrule, question, limit, criticize, or distinguish (or possibly ignore) earlier opinions they believe to be irrelevant or poorly reasoned. Routinely followed opinions grow in importance and have greater precedential authority. Overruled, questioned, or criticized opinions not only fail to shape the law but also have been identified by judges as not worthy of being followed. The decision of which earlier opinions to rely on as relevant precedent is thus an important aspect of judicial behavior that has implications for the development of doctrine.
Exactly as we have done in a companion paper (Benjamin et al., 2024), we rely on Shepard's to measure the ways in which judges rely on earlier opinions. 2 This is an approach that has been widely employed in the judicial behavior literature (see, e.g., Benjamin & Vanberg, 2016, pp. 10–11; Hansford & Spriggs, 2006, pp. 43–26; Hinkle, 2017, p. 323; Spriggs & Hansford, 2000, p. 329; Spriggs & Hansford, 2001, pp. 1097, 1100; Westerland et al., 2010, pp. 896–898). Shepard's is a widely used commercial legal research service that employs attorneys to examine and code the content of every citation within each state and federal court opinion. Shepard's classifies citations that meaningfully engage with an earlier opinion (i.e., that discuss and substantively respond to an opinion rather than just mentioning it) as neutral, negative, or positive. 3 The legal literature often refers to such citations and accompanying discussions that are coded by Shepard's as Shepard's treatments. Because neutral Shepard's treatments, which Shepard's categorizes as explained and harmonized, are rare and do not have a clear valence, they are not analyzed in this article. Negative Shepard's treatments include the overruled, questioned, limited, criticized, and distinguished categories. 4 Positive Shepard's treatments include paralleled and followed. Because more than 99.99% of the instances of positive Shepard's treatments in our dataset are “followed,” we treat a positive Shepard's treatment of an opinion, following an opinion, and reliance upon that earlier opinion as synonymous and use the terms interchangeably. 5
There are strong reasons to believe that Shepard's provides reliable and valid measures of how judges rely on earlier opinions. Spriggs and Hansford have rigorously studied their reliability (Spriggs & Hansford, 2000). They took a stratified random sample of Supreme Court opinions that cited earlier Supreme Court opinions and they coded all the citing opinions according to the coding rules in the Shepard's training manual. This process resulted in high levels of agreement between their coding and Shepard's coding (Spriggs & Hansford, 2000, p. 330).
The definitions and coding protocols used by Shepard's align with judges' and lawyers' understanding of what concepts such as “following an opinion” or “criticizing an opinion” mean, which suggests that Shepard's treatments are valid measures. Take the “followed” category for example. The Shepard's coding manual defines “followed” as when “[t]he citing opinion relies on the case you are Shepardizing as controlling or persuasive authority” (LexisNexis, 1995, LexisNexis, n.d., “How to Shepardize: Your Guide to Legal Research Using Shepard's Citations,” p. 10). The discussion of “followed,” which the manual denotes with an “f,” provides further detail. To “rel[y] on as controlling authority” means that “[t]he majority opinion in the [citing case] has expressly relied on the cited case as precedent on which to base its decision” referring “in some way. . . to the cited case as compelling precedent” (Shepard's Company, 1993, “Shepard's Citations In-House Training Manual,” p. 13). Neither “[a] mere ‘going-along’ with the cited case” nor “[m]erely citing or quoting, with nothing more,” would be “a sufficient expression of reliance to permit an ‘f' (or any other letter, for that matter)” (Shepard's Company, 1993, “Shepard's Citations In-House Training Manual,” p. 13). Instead, the manual identifies the following as language consistent with a “followed” designation: “We affirm on the authority of. . . , or on the teaching of. . . , or for the reasons stated in. . . or under the rationale of. . . ; [or] such a conclusion is required by. . . or governed by. . . .” (Shepard's Company, 1993, “Shepard's Citations In-House Training Manual,” p. 13). This definition and further discussion capture the understanding of lawyers and judges of what it means to follow a case (Benjamin & Vanberg, 2016, p. 14). This is not surprising, given that Shepard's has long been used by practicing attorneys and judges, which strongly suggests that legal professionals view Shepard's as a source of legally relevant information (Jacobstein & Mersky, 1977).
For Shepard's to categorize a citation as negative, the citing opinion must be explicit in its criticism, questioning, etc. of the earlier opinion. Thus, negative Shepard's treatments of earlier opinions are relatively uncommon because such actions are costly: such explicit negativity about an earlier opinion is fairly aggressive and could be perceived as uncollegial by other judges. Following an opinion is different. It is disadvantageous only if the later panel does not want to strengthen the earlier opinion. Follows are revealing because we would expect judges to be more inclined to follow (and thus strengthen) opinions with which they agree and less inclined to follow opinions with which they disagree. 6 Because negative treatment of earlier opinions is much less common, we do not present analyses of negative Shepard's codes in the body of this article. We have conducted analyses of negative Shepard's codes that parallel the analyses of positive codes in this article. Those results, which are available in a Supplemental Appendix, consist of substantively small partisan effects that are typically not statistically significant.
Our Research Questions
This article is fundamentally interested in how the partisan composition of three-judge panels affects how the panel relies on past opinions when deciding a case. If (a) law is developed through decisions to follow or diminish the significance of an earlier case, and (b) partisanship shapes how judges would like the law to develop, then whether—and how—partisanship affects judges' handling of earlier opinions is an important question for those who study judicial behavior. This article addresses three variations on this question.
Pure Partisan Panel Effects (DDD vs. RRR Comparisons)
We operationalize what we term pure partisan panel effects in two ways: first, as the expected number of follows of earlier three-Democrat (DDD) opinions from DDD citing panels 7 minus the expected number of follows of earlier DDD opinions from three-Republican (RRR) citing panels; second, as the expected number of follows of earlier RRR opinions from DDD citing panels minus the expected number of follows of earlier RRR opinions from RRR citing panels.
Because cases and judges are quasi-randomly assigned to panels, estimates of these pure partisan panel effects within a given circuit year can be made in a three-step process. First, the cases decided in that circuit year are subsetted to just those assigned to DDD or RRR panels. Next, the average number of follows of all earlier DDD (or RRR) opinions from DDD panels and from RRR panels in the circuit year of interest is calculated. Finally, the difference between the average number of follows from DDD panels to earlier DDD (or RRR) opinions and the average number of follows from RRR panels to earlier DDD (or RRR) opinions is calculated. This difference is an estimate of a pure partisan panel effect within the circuit year.
Such a pure partisan effect is relatively easy to interpret. It is the expected change in the number of follows of earlier DDD (or RRR) opinions if randomly constituted RRR citing panels were replaced with randomly constituted RRR citing panels in a particular circuit and year.
We aggregate these circuit-year-specific effects to produce an overall average effect, where the average is taken over all circuits and years. To be clear, the averages discussed in this section are weighted averages. We provide more detail about this averaging in our discussion of the average treatment effect for the overlap population (ATO) below.
Partisan Panel Effects (DDD vs. DDR and RRD vs. RRR Comparisons)
Perhaps split panels (those with a “counterjudge” of a different party than the majority) rely on earlier opinions differently than single-party panels do. The posited mechanism for this partisan panel effect is that a single counterjudge can influence her colleagues to adopt a less extreme position through the power of her arguments based on personal experience or specialized knowledge, through the force of collegiality, and/or through serving as a possible whistleblower (Sunstein et al., 2006, pp. 304–307). As for the latter possibility, a panel member's potential disagreement can alert other circuit colleagues (who might be more likely to vote to rehear the case en banc) and/or the Supreme Court (which might be more likely to grant certiorari). To avoid the airing of such a disagreement (through a concurrence or dissent), the panel majority might modify the majority opinion to mollify the counterjudge (Cross & Tiller, 1998, p. 2159; Kastellec, 2007, pp. 439–441). The counterjudge possibility thus yields the prediction that there will be a meaningful difference between panels with three members of a given party as compared to panels with two members of that party and one member of the other party.
There are two partisan panel effects that could reflect the influence of a counterjudge: (a) the effect of moving from a two-Democrat (DDR) panel to a DDD panel and (b) the effect of moving from a RRR to a two-Republican (RRD) panel. Again, the outcome variable is either the average number of follows of earlier DDD opinions or the average number of follows of earlier RRR opinions.
Partisan panel effects are distinct from pure partisan panel effects. Because panels reach decisions by majority rule and the partisanship of the median member of each panel is the same under active treatment (say a DDD panel) or control (say a DDR panel) these partisan panel effects are distinct from the pure partisan panel effects discussed above. These effects can be identified within circuit years and then aggregated to produce overall average effects as was sketched above in our discussion of pure partisan panel effects.
Published Opinions and Ideologically Salient Topics
For much of the period our data cover, circuit rules prohibited or at a minimum disfavored citation of unpublished cases [See, e.g., In re Citation of Unpublished Opinions/Orders and Judgments, 151 F.R.D. 470 (Nov. 29, 1993); Fed. R. App. Pro. 32.1 (2006)]. Circuit rules allow panels to choose whether to publish an opinion based on its importance and precedential value (See, e.g., 9th Cir. R. 36.2). The point of the unpublished designation is to allow panels to issue relatively insignificant opinions that are not to be treated as binding precedent. Indeed, each year panels generate thousands of very short opinions (often only a paragraph or two long, sometimes only a single sentence), virtually all of which are unpublished. There have been suggestions that panels have on occasion refrained from publishing a given opinion to diminish its significance (Gulati & McCauliff, 1998). This highlights that there is some discretion involved in the decision to publish an opinion. But it also highlights that judges regard unpublished opinions as less important. Just as legislators are more likely to focus on more important bills, we would expect judges to place more emphasis on published opinions when deciding which opinions to rely on.
Note that looking at cases with published opinions breaks the randomization of cases to panels. Panels decide whether to publish opinions, so even true random assignment of judges to panels is not sufficient to ensure that treatment assignment (i.e., panel composition) is conditionally ignorable given circuit and year within the subset of published cases. That said, as we argue below, we believe the bias that results from the focus on published cases is likely both small and toward 0.
To assess the type and amount of bias that results from focusing on published opinions, it is useful to start with the fact that opinions can be unpublished either for reasons unassociated with panel composition (e.g., the importance of the case) or for reasons associated with partisan panel composition (e.g., the preferences of the panel members or bargaining among the panel members). It is only the latter set of reasons that will cause bias and the former set of reasons appear to explain the bulk of publication decisions (Brown, 2021, pp. 36–37). Further, anecdotal accounts suggest that the difference that panel compositions make, when the composition matters, is often through a partisan-minority judge threatening to write a dissent unless the opinion be unpublished. Such threats, if heeded by the majority, remove a case in which there was partisan disagreement from the published case data (Law, 2005, p. 835). The removal of such cases with underlying partisan disagreements should attenuate the partisan effects we estimate toward 0.
Finally, most empirical studies on partisan judicial behavior in the federal courts of appeals focus on more ideological—and thus polarizing—case topics, on the theory that such cases are more likely to induce recognizably ideological judicial behavior (see, inter alia, Boyd et al., 2010; Cox & Miles, 2008; Farhang & Wawro, 2004; Kastellec, 2013; Sunstein et al., 2006). Canvassing these studies provided a list of “ideologically salient” topics. A search of Lexis yielded 38 case topics involving one of the ideologically salient topics. These Lexis case topics cover 47.3% of the cases in the dataset. Consistent with the findings of studies of circuit court voting behavior, we expect that within the subset of published opinions these ideologically salient cases will produce the largest pure partisan panel effects and partisan panel effects.
Data and Research Design
Data
To construct our data, we gathered all published and unpublished federal appellate opinions in the Lexis database that were issued between 1974 and 2017. 8 We identified each substantive Shepard's citation in every opinion. We restricted our attention to Shepard's citations within majority opinions generated by panels of the federal courts of appeals. 9 Thus, our dataset does not include citations to district court opinions or Supreme Court opinions. In addition, we exclude opinions from the Federal Circuit from our analysis, since it has a specialized docket that is quite distinct from the other circuits. The full dataset comprises 670,784 federal appellate majority opinions and 648,226 Shepard's citations.
69.6% (451,289) of the Shepard's citations in our data are positive (followed), 8.5% (55,169) are neutral (which, as noted previously, we drop because they do not have a valence), and the remaining 21.8% (141,768) are negative. The average citing opinion has .7 outgoing positive Shepard's citations to earlier opinions and .2 negative outgoing Shepard's citations to earlier opinions, and the average published citing opinion has 1.0 positive outgoing Shepard's citations to earlier opinions and .5 negative outgoing Shepard's citations to earlier opinions. More than 70% of the Shepard's citations in our data are to earlier opinions decided within 10 years of the citing opinion. Only 7.4% of the Shepard's citations are to an earlier opinion more than 20 years from the citing opinion, so it is relatively uncommon for an opinion to rely on opinions from a much earlier era.
We used data from the Federal Judicial Center to identify the President who most recently nominated each judge. This resulted in a total of 59,154 panels with three Democratic appointees, 207,055 panels with two Democratic appointees, 272,693 panels with one Democratic appointee, and 131,882 panels with three Republican appointees.
To identify the published cases, we matched the title of cases in our data to that of all published cases in the Caselaw Access Project (https://case.law). The case titles often match exactly across both datasets. There were some discrepancies due to small differences in abbreviations, white space, formatting, and typographical/transcription errors. We used the Bluebook as a reference to address different forms of abbreviations via regular expressions. We then calculated the fractional edit distance between the cleaned and normalized Lexis case titles and the cleaned and normalized Caselaw Access Project case titles as the Levenshtein string distance divided by the character length of the longer case title. Each case in the Lexis data with a fractional edit distance of less than .5 to a case in the Caselaw Access Project data is considered matched. We then check whether a matched case in our Lexis data has the same decision date as the matching case in Caselaw Access Project data. Cases that pass both tests are coded as published.
Within the published cases, we produced a subset of ideologically salient cases. Lexis assigns multiple topic headers to each case to identify the legal issue areas addressed in each case. On average, there are approximately ten topic headers per case. 10 We categorized each opinion based on whether at least one of its topic headers contains the topic-identifying keyword for one of the 38 ideologically salient issue areas, for example, Search and Seizure, Immigration Law, or Sex Discrimination. 11 213,619 cases in our data are assigned topic headers that pertain to the 38 ideologically salient issue areas we identified. We refer to this group of cases as the ideologically salient subset.
In each empirical analysis that follows, we fit the same model specifications to three different sets of cases: all cases, published cases, and ideologically salient published cases. There are 225,465 published opinions, and 106,804 published and ideologically salient opinions in our data.
Research Design
The justification for giving some of our results a causal interpretation requires thought and care. Put simply, there are two major hurdles that must be surmounted. First, the potential causal effect must be well defined. Second, it must be possible to credibly identify the causal effect of interest given the available data. We consider each of these in turn.
In the standard Neyman–Rubin framework for causal inference, an average causal effect is well defined when: (a) the set of units over which the average will be taken is clearly defined, (b) there is a plausible intervention or manipulation of some causal contrast variable, and (c) the so-called stable unit treatment value assumption (SUTVA) holds. As discussed immediately below, our analyses of pure partisan panel effects and partisan panel effects meet these conditions. Thus, we interpret these effects as bona fide causal effects.
First, the set of units over which we are averaging over is clearly defined. Sometimes, the averages are taken over all citing cases, published citing cases, or ideologically salient published citing cases—decided between 1974 and 2017. Other averages are taken over four 11-year subsets of cases within this larger set. These averages are typically weighted averages where the weights arise from a focus on a particular estimand (more on that below) and associated estimation methods, but this causes no conceptual problems.
The definition of our interventions and the associated question of whether SUTVA holds are a bit more complicated because the outcome variable for a particular case depends on what might seem to be the value of the causal contrast variable in those earlier cases. Thus, the number of follows from a case in question to earlier opinions written by DDD panels depends on value of the treatment variable at that earlier time (e.g. if the earlier case was “treated” with a DDD panel assignment it would contribute to the outcome measure but if the earlier case would have been assigned to a RRR panel it would not contribute to the outcome measure). To avoid these conceptual issues, the causal effects that we focus on are defined in terms of a hypothetical change to the partisan composition of a particular citing panel where the partisan composition of all earlier panels is assumed to be unchanged. For example, the effects that we are estimating should be interpreted as the difference in follows that one would expect if a single case is randomly selected and assigned to three Democratic appointees compared to the same case assigned to three Republican appointees. 12 Our effects should not be interpreted as comparisons of a counterfactual world where all cases are decided by three Democratic appointees compared to a counterfactual world where all cases are decided by three Republican appointees. 13 Further, it is worth emphasizing that we do not specify a structural model that takes a concrete stance on which of many possible causal mechanisms might be at work. Our approach takes partisan composition of a citing panel as the treatment variable—all consequences of citing panel composition that affect the outcome are averaged over when calculating our estimates.
Once we are comfortable that we can meaningfully define the causal effects of interest, we can turn our attention to the identification of those effects. There are many strategies to credibly identify a causal effect of interest. One of the most powerful is based on the random assignment of the causal contrast variable to the units of interest (in our case, the units of interest are citing panels), for instance, a simple randomized controlled trial. Although our data are observational (i.e., non-experimental), within a given circuit and year cases and judges are quasi-randomly assigned to panels. This quasi-random assignment mimics a randomized controlled trial. Thus, the same logic that allows identification of causal effects in randomized controlled experiments applies to our pure partisan effects and panel effects. Though we might simply analyze our data as if they were experimental data—for instance by reporting simple differences in means between the causal contrast groups, possibly after stratifying on circuit and year and averaging over these strata—there are better approaches to inference in this application.
In particular, we focus on a causal estimand known as the average treatment effect for the overlap population (ATO) and report results based on an inverse-propensity-score-weighting estimator of the ATO estimand. The propensity score model underlying this approach includes year and circuit fixed effects along with their interaction—thus effectively stratifying on circuit-year combinations. 14 The focus on the ATO estimand helps to handle extreme imbalances in the partisan distribution of judges in many circuit years. In some instances, the imbalance is so severe that particular partisan compositions are completely unavailable. For example, from 1992 to 1996 there were no DDD panels in the Third Circuit and in 1976 there were no RRR panels in the First Circuit.
Other times, a given composition is possible, but so unlikely that the estimate is highly variable. The ATO estimand reweights the data so that cases that were equally likely (given circuit and year) to be assigned to each level of the causal contrast variable (say DDD and RRR) get maximal weight. These weights drop to zero in the case of the extreme imbalances discussed above, while the most plausible counterfactual comparisons are given more weight under the ATO estimand's weighted average effect. Additionally, our estimator of the ATO estimand guarantees perfect mean balance between the treated and control units (Li et al., 2018, pp. 390–400).
As discussed previously, using Shepard's citations as our primary outcome variable has several benefits. Our results do not depend on our own substantive judgments about how to code outcomes and the Shepard's citations have been shown to be reliable and valid by past research.
Further, we expect that looking at how sitting judges make use of the opinions of past judges is more likely to produce measures that are comparable over time than approaches that focus on which litigant prevailed in a dispute and/or that attempt to discern the ideological valence of a decision. Measures that rely on the identity of the prevailing side implicate many selection issues, as strategic litigants will condition their litigation strategy on their expectation of prevailing on the merits (Priest & Klein, 1984). We are not interested in win rates for certain types of litigants in this article. And, as we discussed earlier in this section, the causal effects we are interested in are defined in terms of counterfactual changes to the composition of a particular citing panel that leave earlier history fixed. We are thus not concerned about the behavior of litigants in this article.
Measures that require researchers to decide the “liberal” or “conservative” outcome in a certain type of case can miss key aspects of the legal reasoning and be difficult to compare over time, since the meanings of “liberal” and “conservative” and the types of disputes change over time (Shapiro, 2009). But because judges must justify their decisions by relying on earlier opinions, our outcome measures should remain highly comparable over time.
Finally, we guard against false discoveries that might arise when estimating many effects and assessing their statistical significance. When conducting many hypothesis tests—or equivalently looking to see whether many p-values fall below a threshold—there is a high likelihood of making many false discoveries, (e.g., incorrectly rejecting a true null hypotheses). Two methods limit this risk. First, we employ the methods of Benjamini and Yekutieli to control the false discovery rate (Benjamini & Yekutieli, 2001). Second, we use the associated method of Wright to adjust the p-values (Wright, 1992).
Results
To provide the reader with a sense of the patterns that emerge with minimal statistical modeling, the next subsection presents summaries and descriptive plots of key aspects of our raw data. Then, we present estimates of pure partisan panel effects and partisan panel effects. Finally, to examine the possibility of increasing polarization over time, we investigate results that are broken down by four equal-sized time periods. As discussed earlier, two key moves permit us to interpret our results as causal effects. First, thinking of the partisan composition of the citing panel as the causal variable to be (hypothetically) manipulated allows a causal effect to be meaningfully defined. Second, noting that cases and judges are approximately randomly assigned to panels within each circuit/year combination allows the causal effect to be credibly identified and estimated.
Basic Descriptive Summaries
We begin with the association between the number of follows of earlier DDD and RRR opinions and the partisan composition of the three-judge citing panel. Figure 1 displays the difference across key types of citing panels. Each subfigure contains three contrasts between types of citing panels: DDD – RRR (average follows from DDD citing panels minus average follows from RRR citing panels), DDD – DDR (average follows from DDD citing panels minus average follows from DDR panels), and RRD – RRR (average follows from RRD citing panels minus average follows from RRR citing panels). The rows reflect the partisanship of the earlier panel being followed: the top row considers follows of earlier DDD opinions and the bottom row looks at follows of earlier RRR opinions. The columns correspond to subsets of the citing opinions: column 1 contains all possible citing opinions, column 2 contains all published citing opinions, and column 3 corresponds to all published citing opinions in one or more of the 38 ideologically salient issue categories. Difference in the average number of follows of DDD (top row) and RRR (bottom row) opinions from 1974 to 2017 across partisan composition of the citing panels. DDD versus RRR citing panel comparison is in black, DDD versus DDR citing panel comparison is in red, and RRD versus RRR citing panel comparison is in blue. For the three panels in the top row, points above the gray dashed horizontal line suggest that the panels listed first in the comparison set (DDD vs. RRR, DDD vs. DDR, and RRD vs. RRR) have a greater number of follows of earlier DDD opinions on average in that given year. Concomitantly, points below the horizontal line suggest that the panels listed second in the comparison set (DDD vs. RRR, DDD vs. DDR, and RRD vs. RRR) have a greater number of follows of earlier DDD opinions on average in that given year. The same applies to the panels in the bottom row, except that the follows are towards earlier RRR opinions.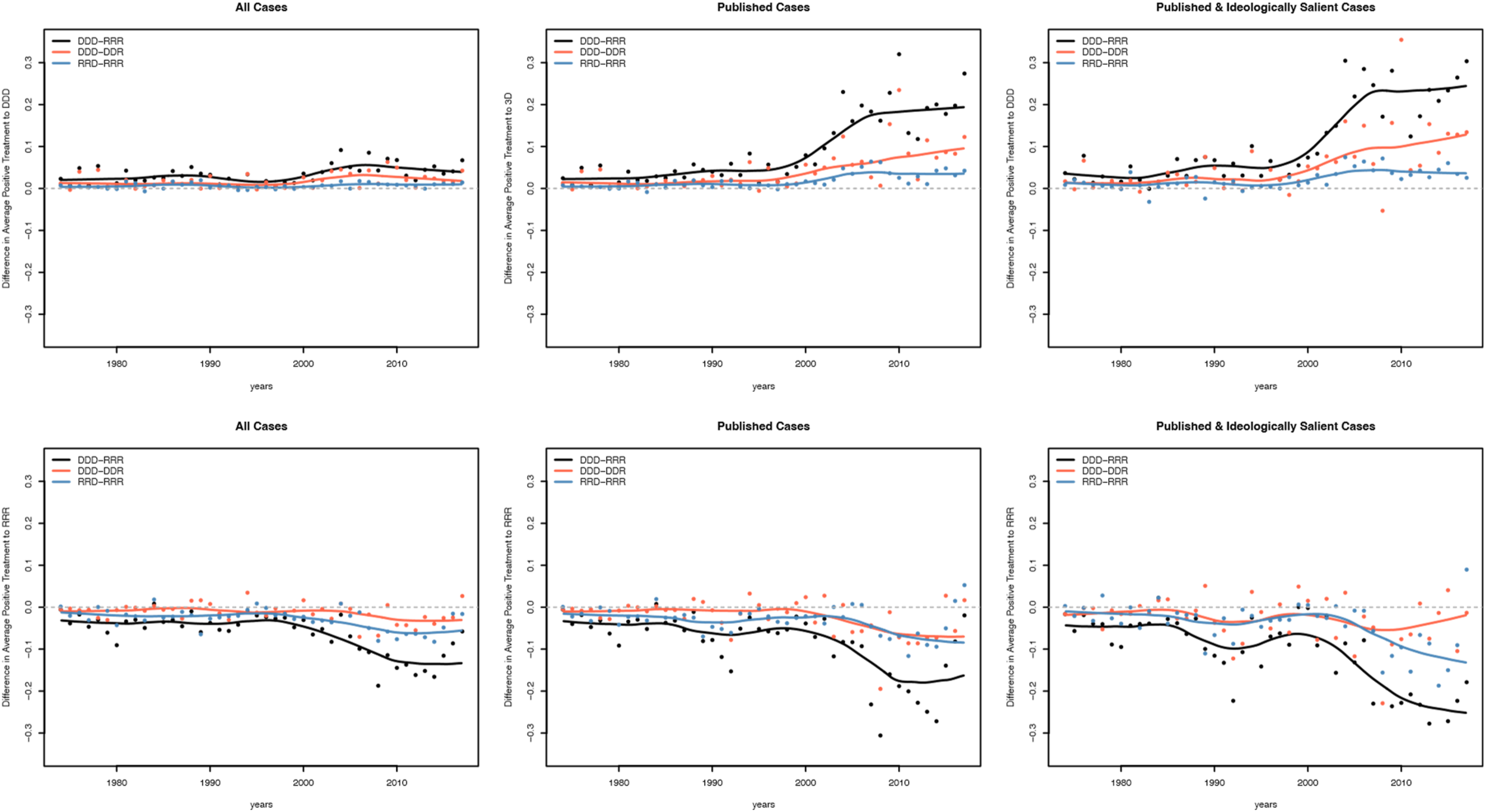
Four patterns are apparent in Figure 1. First, all the differences are in the expected direction, with more Democratic panels being more likely to follow earlier DDD opinions and less likely to follow earlier RRR opinions. Second, the pure partisan differences (as captured by the DDD – RRR contrasts) are consistently the largest differences of the three contrasts we examine. And this partisan difference is often substantively meaningful—a value of .2 corresponds to one extra follow in every 5 decisions. This is a meaningfully large effect in a world where the average majority opinion makes .7 follows of earlier opinions and the average published opinion makes 1.0 follows of earlier opinions. Third, as expected, the differences grow as we subset the citing opinions to increasingly important cases—from all cases to published cases to published and ideologically salient cases. Finally, and perhaps most interestingly, the differences become increasingly large as time goes by. In 1980, the difference in how Republican and Democratic appointees followed earlier cases was minimal. But, starting around 2000, the gaps began to grow and by 2010, differences across party lines were stark.
To summarize, these descriptive plots are consistent with the hypothesis that partisanship impacts how doctrine develops by structuring how earlier opinions are treated. Further, they suggest that partisan polarization in how earlier cases are followed has increased. Of course, these plots are purely descriptive and should be interpreted as merely suggestive evidence about the role of partisanship plays in structuring reliance on earlier opinions.
Pure Partisan Panel Effects (DDD vs. RRR Results)
This subsection investigates whether the purely descriptive results discussed above can be given a bona fide causal interpretation. As we noted above, the key moves here are (a) thinking of the partisan panel composition as the causal variable to be (hypothetically) manipulated, and (b) noting that cases and judges are approximately randomly assigned to panels within each circuit/year combination.
Partisan Effects for Follows of Cases Decided by Either DDD or RRR Panels (1974–2017).
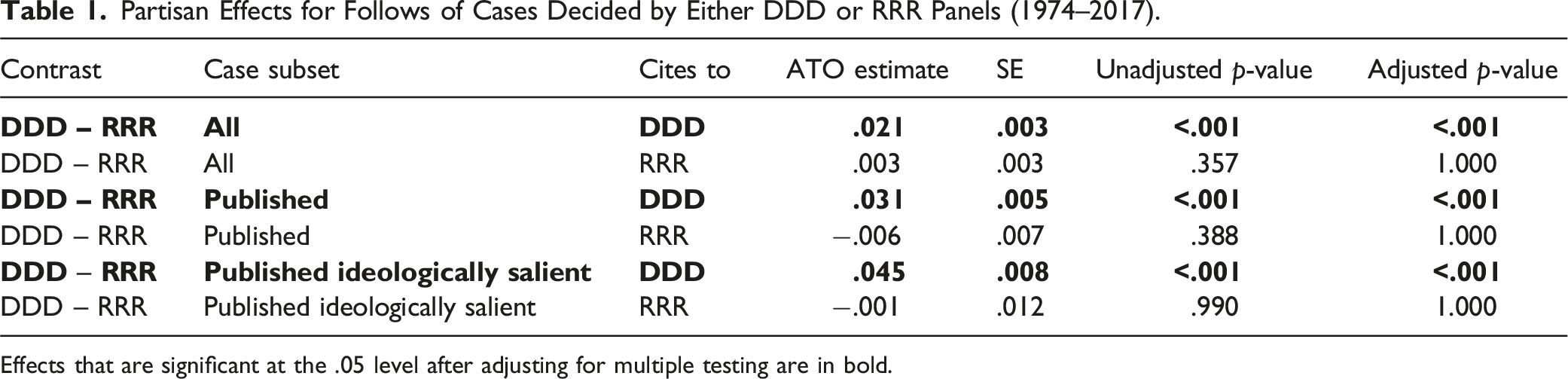
Effects that are significant at the .05 level after adjusting for multiple testing are in bold.
Table 1 contains a wrinkle that we did not predict: the partisan effects emerge only when considering reliance upon earlier DDD opinions. In contrast, DDD and RRR citing panels follow earlier RRR opinions similarly. We consider this result and potential explanations below.
Partisan Panel Effects (DDD vs. DDR and RRD vs. RRR Results)
Building on the pure partisan panel effects reported above, this subsection explores more subtle effects that we call partisan panel effects. Here, we evaluate how the propensity to follow earlier opinions changes when a counterjudge is introduced by moving either from a DDR to a DDD citing panel or from a RRR to a RRD citing panel. In each hypothetical comparison, the partisan majority stays the same. Thus, a partisan panel effect, if it does exist, must work via a different mechanism (or mechanisms) than the pure partisan panel effects discussed above.
Panel Effects for Follows of Earlier DDD Opinions (1974–2017).
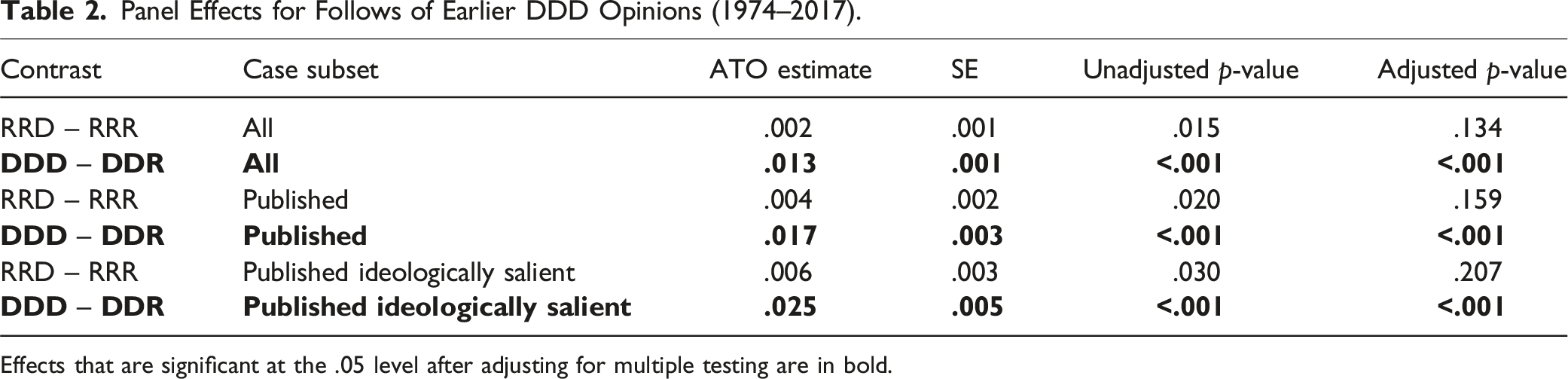
Effects that are significant at the .05 level after adjusting for multiple testing are in bold.
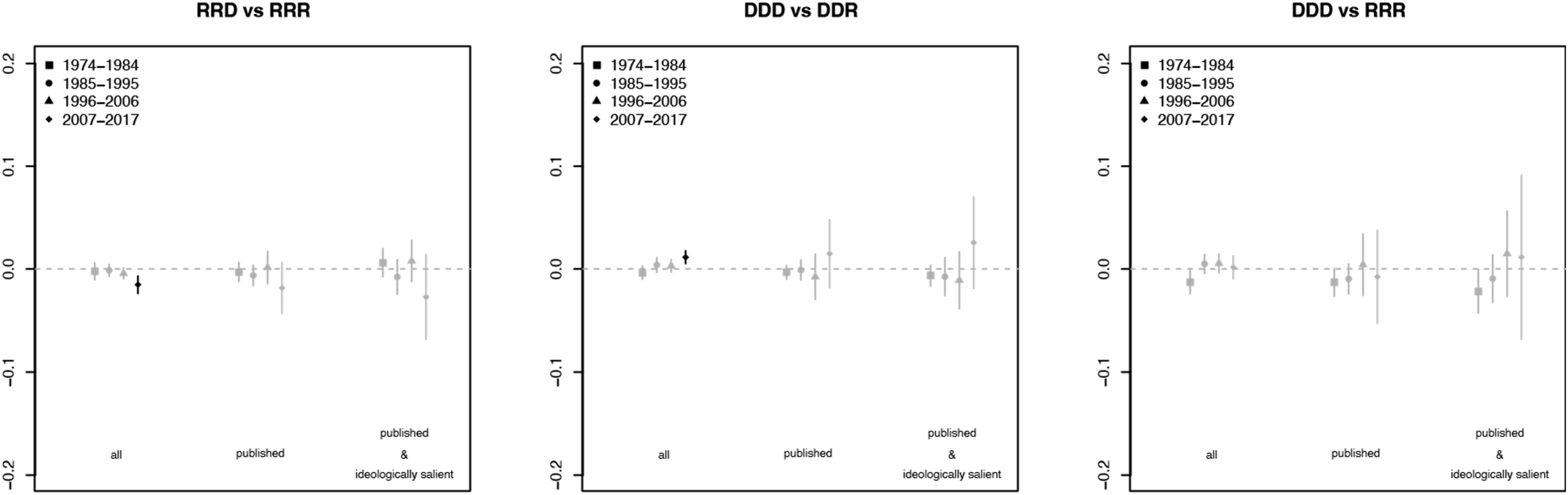
Table 2 shows consistently significant differences between DDD and DDR citing panels. These effects match expectation: DDD citing panels are more likely than DDR citing panels to follow earlier DDD opinions. The RRD versus RRR differences are not statistically significant within any set of cases.
Panel Effects for Follows of Earlier RRR Opinions (1974–2017).
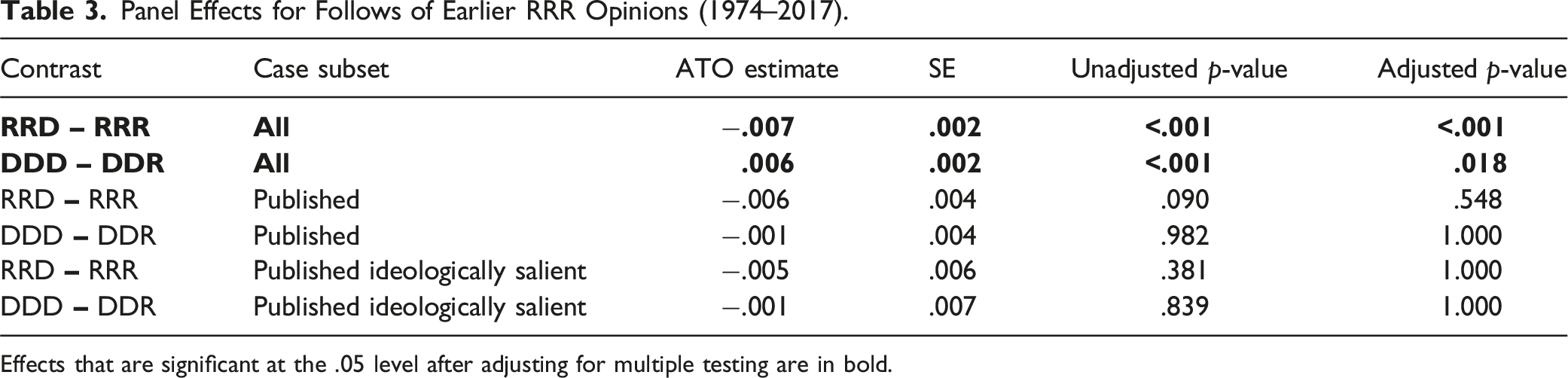
Effects that are significant at the .05 level after adjusting for multiple testing are in bold.
Partisan Effects by Time Period
Next, we consider how the behaviors analyzed above change over time. Because the results above pool data over time to result in a single overall, they reveal the average partisan difference in the propensity to follow certain types of earlier opinions over the entire timespan of our study (1974–2017). To address potential temporal changes, we break our data into four equal-sized time periods and then estimate pure partisan panel effects and partisan panel effects within each time period. Figures 2 and 3 graphically display the results for follows of earlier DDD and RRR opinions, respectively. In these figures, we use color to indicate statistical significance. Effects that are statistically significant at the .05 level after adjusting for multiple testing are depicted in black; those that are not are shown in gray. Panel effects and partisan effects over time for all, published, and published and ideologically salient cases (following earlier DDD opinions). Effects that are statistically significant at the .05 level after adjusting for multiple testing are depicted in black and effects that are statistically insignificant at the .05 level after adjusting for multiple testing are depicted in gray. Panel effects and partisan effects over time for all, published, and published and ideologically salient cases (following earlier RRR opinions). Effects that are statistically significant at the .05 level after adjusting for multiple testing are depicted in black and effects that are statistically insignificant at the .05 level after adjusting for multiple testing are depicted in gray.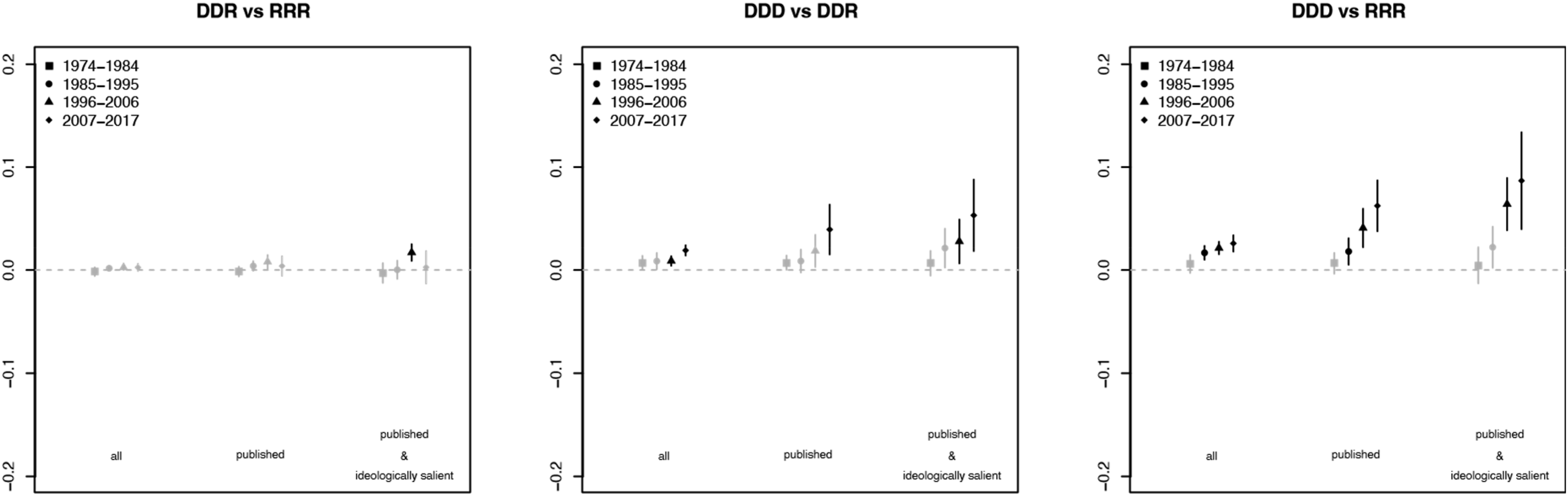
The results in Figure 2 are striking: the partisan effects discussed above have dramatically increased over time. This development appears for both pure partisan panel effects—seen by comparing the behavior of DDD and RRR citing panels—and partisan panel effects—seen by comparing and DDD and DDR citing panels. In both cases, the role of partisanship in influencing how earlier DDD opinions are followed upon has increased. This change is most noticeable for the ideologically salient published subset of cases. Indeed, in the most recent period (2007–2017) the effects are substantively large. For instance, compared to a RRR citing panel, a DDD citing panel tends to follow one additional earlier DDD opinion per 10 cases. Given that the average published case issues 1.0 follows, one additional follow per 10 cases is substantively meaningful.
In contrast, partisan effects related to the propensity to follow earlier RRR opinions has not meaningfully changed over time. Figure 3 shows results similar to those discussed in Tables 2 and 3; we again see no significant partisan differences in the propensity to follow earlier RRR opinions. Thus, we repeatedly find that partisanship meaningfully effects the propensity to follow earlier DDD opinions but not the propensity to follow earlier RRR opinions.
Discussion of Results
The results that are averaged over all time periods and cases tend to be substantively small and not uniformly significant. Regarding pure partisan panel effects, Table 1 shows small DDD – RRR differences in propensity to follow earlier DDD opinions and no DDD – RRR differences in the propensity to follow earlier RRR opinions. The results for partisan panel effects are similar. Thus, Table 2 shows small DDD – DDR differences in the propensity to follow earlier DDD opinions and no RRD – RRR differences in the propensity to follow earlier DDD opinions. And Table 3 shows substantively small DDD – DDR and RRD – RRR differences in the propensity to follow earlier RRR opinions that are significant for the set of all cases, but not for any other subset. In sum, the aggregated effects are small and only sometimes statistically significant.
A more striking—and arguably concerning—pattern emerges when we disaggregate results over time. The simple descriptive plots in Figure 1 suggest that the impact of judicial partisanship has been increasing over time. Figures 2 and 3 bring the effects over time into greater focus. Consistent with the aggregate results, Figure 3 shows essentially no impact of partisanship (either pure partisan effects or partisan panel effects) on the propensity to follow earlier RRR opinions during any of the four time periods. In contrast, Figure 2 shows clear partisan differences in the propensity to follow earlier DDD opinions. These differences are largest for the DDD – RRR pure partisan effects but also apparent for the DDD – DDR partisan panel effects. Most importantly, these differences have grown over time. And, as expected, the largest partisan effects are found in ideologically salient published cases.
The over-time findings suggest that the somewhat muted aggregate partisan effects in Tables 1 and 2 are the result of pooling heterogeneous effects across different time periods and types of cases. Prior to about 1996, there are no significant partisan panel effects and only small pure partisan effects. But significant and substantively meaningful DDD – DDR partisan panel effects and even larger (and statistically significant) DDD – RRR pure partisan effects appear by the 2007–2017 time period.
It is widely understood that politics in the U.S. has become more polarized in recent years. Our findings show that circuit court judges are not immune from this polarization. Further, partisan polarization is increasingly structuring how judges rely on past precedents and thus how they develop legal doctrine.
But the impact of partisanship goes only one way: the partisan composition of panels increasingly impacts how panels follow earlier DDD opinions but not earlier RRR opinions. What explains the presence of DDD – RRR pure partisan effects and DDD – DDR partisan panel effects in the propensity to follow earlier DDD opinions but not earlier RRR opinions? Further, why are RRD – RRR partisan panel effects always small and typically statistically insignificant?
The available data does not allow us to know the reasons for these patterns with any degree of certainty. In a companion article (Benjamin et al., 2024), we present a possible explanation. Using evidence from a simple simulation experiment, we show that such asymmetric partisan effects over time can result when Democratic appointees are moving at a constant rate away from center while Republican appointees are accelerating away from the center (Benjamin et al., 2024). While that simulation experiment is consistent with our results in this article, we cannot be certain that this is the primary reason for the patterns observed.
The growing partisan polarization we find in how often citing panels follow earlier DDD opinions is a cause for concern insofar as this indicates that judges of different partisan stripes treat established precedent differently. But it is also worth noting that as recently as the early-to-mid 1980s the partisan composition of circuit court panels was unrelated to how those panels followed previous opinions. So, we can hope that the partisan effects we see in the later time periods are not baked into the court system.
That hope depends on the 1980s, as opposed to recent years, as the template going forward. And the prospect of judges returning to the patterns of the 1980s is highly uncertain, to put it charitably. The recent partisan effects we find are substantively meaningful and growing, overcoming whatever countervailing forces have existed. At a minimum, the trend lines that emerge from our data are not promising.
Conclusion
We began this article by asking whether the partisan composition of three-judge panels in the federal courts of appeals affects how earlier opinions are relied upon and thus how the law develops. We found that the partisan composition of panels does affect which cases are relied upon and followed. These partisan effects are relatively recent, only becoming apparent after the early-to-mid 1980s. They arise only for opinions written by 3-Democrat panels. And these partisan effects are most present in relatively high-profile cases—those that are published and on ideologically salient topics.
In an increasingly polarized country, these findings have important implications for the future of U.S. law. Disagreement about which precedents merit following is disagreement both about what the current law is and what the law should be in the future. The more such disagreement reflects partisan divides, the more the path of the law will be influenced by partisan concerns.
While we believe that these partisan effects impact the development of the law, more work is needed to better understand both how doctrine develops and how partisan differences structure that development. We hope that this article is a useful first step in that direction.
Supplemental Material
Supplemental Material - Partisan Panel Composition and Reliance on Earlier Opinions in the Circuit Courts
Supplemental Material for Partisan Panel Composition and Reliance on Earlier Opinions in the Circuit Courts by Stuart Minor Benjamin, ByungKoo Kim, and Kevin M. Quinn in Journal of Law and Empirical Analysis
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Author Note
Benjamin is the William Van Alstyne Professor of Law at Duke Law School; Quinn is the Charles Howard Candler Professor of Law and Quantitative Theory and Methods at Emory University; Kim is an Assistant Professor at the KDI School of Public Policy and Management. More than the usual thanks are in order. We thank LexisNexis, who shared their data with us in 2018 and patiently tracked down the answers to our many questions about the data over the next twenty-seven months. A dataset so massive required similarly massive work to identify, categorize, and organize its elements. Tom Balmat at Duke and Sean Chen at the Duke Law Library were particularly valuable in that lengthy process. Jane Bahnson and Wickliffe Shreve, also at the Duke Law Library, were indefatigable in helping us find relevant materials about Shepard's, Lexis, and court practices. Kyle Gantz, Gloria Han, Jacob Kornhauser, Andrew Tisinger, and Wenyi Zhou provided excellent research assistance, and Leanna Doty and Balfour Smith provided excellent editing assistance. Over the five-year gestation of the project, we have benefited from many colleagues' comments, including Matt Adler, Joseph Blocher, Curt Bradley, Michael Frakes, Jack Knight, Maggie Lemos, Marin Levy, Mat McCubbins, Darrell Miller, Jeff Powell, Neil Siegel, Georg Vanberg, Jonathan Wiener, and Ernie Young. We also thank colleagues who attended our 2021 Duke Law workshop on an early version of this Article as well as members of the Emory Law faculty who attended a 2022 workshop on a version of this Article. Authors are in alphabetical order. Finally, we thank the editor and three anonymous referees for their very helpful comments and suggestions.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.