
Abstract
Introduction
Wikipedia is the largest online crowdsourced encyclopedia, consisting of over 70 million articles across 300 languages at the time of writing 1 . While visitors cite a range of motives, studies have demonstrated fact lookup and fact checking as common factors that drive readers to consult articles Lemmerich et al. (2019); Singer et al. (2017). Wikipedia is a crucial learning resource for US adults Kross et al. (2021) and is commonly used – albeit not necessarily effectively – in areas such as health Huisman et al. (2021); Smith (2020), programming Robillard and Treude (2020) and history Singer et al. (2017) to name but a few. Prior work has also characterised Wikipedia as a ‘gateway to the Web’, providing essential context to search engine results and bridging the gap to a range of external resources Piccardi et al. (2021). Indeed, Wikipedia results appear highly frequently in important, trending searches, particularly on desktop devices Vincent and Hecht (2021). Nevertheless, in spite of this characterisation, evidence suggests that users will often rely heavily on Wikipedia results for information needs, only proceeding to external sources and following citations when met with low quality content or when otherwise unable to meet those needs Piccardi et al. (2020); Piccardi et al. (2023).
Wikipedia and its user base rely significantly on artificial intelligence tools to maintain and manage content. A substantial portion of edits within the platform are performed automatically or semi-automatically by user-maintained bots Zheng et al. (2019). Issues associated with the use – and the community’s perceptions of – AI within Wikipedia are not universally positive with communities sometimes actively resisting or otherwise limiting the adoption of AI technologies in Wikipedia Halfaker and Geiger (2020); Smith et al. (2020); TeBlunthuis et al. (2021). Nevertheless, questions regarding the community’s perceptions and use of AI tools are a current area of research focus and while there is emerging evidence that editors may be making increasing use of ChatGPT (e.g. Brooks et al. (2024)) there is limited evidence of how existing tools and systems have influenced the community 2 .
Arguably one of the most disruptive AI tools of recent years has been ChatGPT. Launched in November 2022, the AI-powered chat bot had reached 100 million users in under 3 months making it the ‘fastest growing consumer internet app’ ever 3 . One key advantage linked to its early adoption is its ability to quickly and accurately summarise information to support searches Ray (2023). ChatGPT is already able to outperform search engines in some knowledge gathering tasks Xu et al. (2023). Early indications noted that it can give satisfactory answers to general and cultural fact-finding questions assuming they did not concern concepts more recent than its training data (i.e., 2021) Amaro et al. (2023). This limitation has diminished as newer models such as GPT-4 have gained the capacity to actively pull information from the internet Mastrokostas et al. (2024). Nevertheless, results are prone to hallucinations, partial-truths or misinformation, particularly with attribution or when asked about controversial topics McIntosh et al. (2023); Zuccon et al. (2023).
Question-answering platforms may already be impacted by ChatGPT. In the online crowdsourced question and answer service Stack Overflow, there was a 25% reduction in the number of English language questions asked in the first 6 months following the launch of ChatGPT, an effect not seen in Russian and Chinese where ChatGPT was unavailable (del Rio-Chanona et al, 2024). Similar effects have been seen in the Stack Exchange platform (Sanatizadeh et al., 2025). Nevertheless, this reduction in engagement on Stack Exchange has also coincided with a general increase in the quality and complexity of the questions asked by users (Sanatizadeh et al., 2023). Previous research has demonstrated that these platforms rely heavily on Wikipedia to provide additional context for answers and comments (Baltes et al., 2020) although the impact on Wikipedia editing and viewing behaviour has generally been limited Vincent et al. (2018). It also stands to reason that there may be some overlap between the capabilities of ChatGPT and Wikipedia as GPT-3 was itself trained in part on Wikipedia (Brown et al., 2020). Some commentators have expressed fears that the launch of ChatGPT may lead to a reduction in Wikipedia engagement while harming the motivation of users to participate in Wikipedia editing (Wagner and Jiang, 2025).
Given these potential and observed impacts on resources which link to and use Wikipedia, we ask whether the rise of ChatGPT has had an impact on Wikipedia usage patterns. If Web users are adopting other sources of information, are these replacing or supplementing existing Web sources such as Wikipedia? And how does this vary between highly resourced and less highly resourced languages? Wikipedia is a particularly interesting case study as it gives us insight into any impact not only on the larger community of volunteers accessing or mining information, but also on the smaller but crucial community responsible for contributing and curating content. While this is not necessarily distinct from other collective intelligence platforms (such as question-answering sites), Wikipedia is arguably unique due to the scale of participation (Ren et al., 2023), its close links to other Web infrastructure (Piccardi et al., 2021) and the limited barriers to entry given that ‘anyone can edit’ (although this approach is not without its challenges Das et al. (2022)). We therefore consider not only how ChatGPT may have influenced one of the largest collective intelligence platforms, but also what insight this might offer and what it might mean for the wider Web.
We analyse usage statistics from Wikipedia between 2021 and 2024 to explore any impact of the launch of ChatGPT’s public service on engagement in Wikipedia. We explore and compare 12 languages including six from countries where ChatGPT was unavailable and six selected based on the size and popularity of their Wikipedia resources and their representation in the training data used by ChatGPT to explore whether highly resourced languages were more or less impacted than less represented and resourced languages. Our analysis considers four forms of engagement: edit counts and editor numbers as examples of contributive behaviours and view counts and visitor numbers as examples of mining behaviours. We first report aggregate comparisons across four metrics before performing a pairwise comparison of engagement in the year prior to and following the launch of ChatGPT. We then perform a panel regression to explore, quantify, and compare longer-term trends across the 12 languages. Our work provides evidence of the impact that LLMs and particularly ChatGPT have had on both contributive and mining behaviours in Wikipedia.
Background and related work
Wikipedia engagement and events
Existing evidence demonstrates the impact that internal and external events can have on how users engage with Wikipedia. Media reports around particular scientific and technology-related topics, natural disasters and health-related crises have been demonstrated to drive engagement with Wikipedia Segev and Sharon (2017). Similarly, region-specific political events are associated with spikes in page views in relevant language editions of Wikipedia, such as the Kashmir Solidarity day leading to increased engagement within Urdu Wikipedia. This may even stretch beyond pages specific to those topics, with evidence of increased cooperation and engagement in various pages covering historical events during the Black Lives Matter social movement even where there was little to no new information around those events Twyman et al. (2017). Seasonal events and phenomena such as the behaviours of animals have been shown to align with seasonal patterns of interest in particular Wikipedia pages, particularly for insects and flowering plants Mittermeier et al. (2019). Technological changes can also have significant and pervasive changes in user behaviour as demonstrated by the significant and persistent drop in page views observed in 2014 when Wikipedia introduced a page preview feature allowing desktop users to explore Wikipedia content without following links Chelsy Xie et al. (2019).
Wikipedia as multilingual platform
Given Wikipedia’s status as a platform with a high number of articles across a wealth of languages, we are far from the first to compare activity across languages. Miz et al., analysed topics in the most popular trending articles across the English, French and Russian Wikipedia, finding that while there were some variations in terms of local events and cultural issues, trending topics were broadly similar across all three languages Miz et al. (2020). Nonetheless, trends in pageview statistics are unique to a given country and language edition, as shown by Xie et al. Chelsy Xie et al. (2019). Furthermore, when it comes to controversial topics, discrepancy in tone, organisation and information presented can exist in different language editions. For example, such a discrepancy was seen between English, Hindi and Urdu on the political conflict in Kashmir and Jammu Hickman et al. (2021).
Kubś similarly demonstrates the presence of culture-specific viewpoints in different language editions of articles on historical events Kubś (2021). Miquel-Ribé and Laniado explored the growth and cross-cultural context of 40 different language Wikipedia editions with the authors exploring the Cultural Context Content (geography, people, language, traditions, etc.) associated with each language Miquel-Ribé and Laniado (2018). Results demonstrated that the growth of individual languages was highly variable, but also that much of the cross-cultural context of each language is recorded uniquely in that language. Even in English, which tended to cover more of the Cultural Context Content from other languages, the percentage coverage was on average only 34%. Lemmerich et al., analysed motivations for reading Wikipedia across 14 language editions, finding that Wikipedia browsing behaviours were associated with the socioeconomic properties of the relevant countries Lemmerich et al. (2019).
Inter-language diversity is not limited only to textual material with images showing diversity exceeding that of textual material even though images likely do not require translation He et al. (2018). Differences between languages also extend beyond simply content. The balance of visitors of each gender differs quite significantly across different language editions of Wikipedia and evidence suggests gendered distinctions in behaviour – for example, that women view fewer pages in a session than men Johnson et al. (2021).
Artificial intelligence and Wikipedia
Much of the research exploring the role and impact of artificial intelligence and automated systems on Wikipedia has focused on introducing such tools to the platform and community. The use of machine agents within Wikipedia itself is nothing new as bots play a range of roles in creating and maintaining articles, particularly making fixes to page content (Zheng et al., 2019). The relatively common use of bots is observed across languages although bot behaviours and applications are language and culture dependent (Tsvetkova et al., 2017). Bots play a crucial role in facilitating certain types of Wikipedia activities among more experienced moderators and there exists a formal approval process with opportunities for the community to discuss individual bots and their applications (Geiger, 2017). Despite these existing roles, however, the reception that AI tools have received has not been universally positive. A study of perceptions of the use of AI among the Wikipedia community identified five key values associated with its use, most notably a desire that humans have the final say in any decision-making (Smith et al., 2020).
Even so, there is evidence to suggest positive reception to the use of AI in Wikipedia. Recent research has shown that when presented with alternative citations for poorly supported claims generated by an algorithmic agent, Wikipedia users were twice as likely to prefer the algorithmic alternative (Petroni et al., 2023). Additionally, the ORES system aims to algorithmically quality assess Wikipedia articles and has elicited a range of responses from users but crucially has been adopted by Wikipedia editors across languages with minor adjustment (Halfaker and Geiger, 2020). Conversely, Wikipedia’s proposal to introduce generative AI summaries of articles received highly negative responses from the English Wikipedia community 4 . One question we aim to explore is not whether the Wikipedia editors might use or perceive emergent LLM models, but rather how their availability might have influenced – and continue to influence – their engagement.
There is some evidence to suggest that Wikipedia editors and users are turning to ChatGPT and similar tools. An analysis of the content in four language editions in Wikipedia found that up to 5% of newly created articles in the English Wikipedia were written using generative AI tools (Brooks et al., 2024). A user-study with 14 participants explored their use of Wikipedia compared to ChatGPT and internet search, finding that while users were open to using ChatGPT, they placed greater trust in Wikipedia due to factors such as its use of sources (Jung et al., 2024). Our analysis contributes to this growing body of evidence.
ChatGPT as complementary and replacement tool
Within the contemporary literature, an emerging focus of research is the evaluation of the performance of ChatGPT and its underlying models on common tasks across specific domains. Kocoń et al. analysed a range of NLP tasks on ChatGPT and compared performance with existing State of the Art models (Kocoń et al., 2023). The authors found ChatGPT generally performed adequately but was unable to match the performance of the models and this loss in performance was worse with more difficult and/or subjective tasks. Frieder et al. explored the performance of ChatGPT with mathematical tasks finding that it performs acceptably for undergraduate-level but not graduate-level mathematical tasks with the authors noting that the model performed worse than any graduate-level mathematical student would (Frieder et al., 2024). Within the domain of healthcare, current studies suggest performance is generally moderate at best (Li et al., 2024), although ChatGPT has achieved a passing score on both the German and US medical licensing examinations (Gilson et al., 2023; Jung et al., 2023). Within finance, ChatGPT outperforms State of the Art models in sentiment analysis tasks by as much as 35% (Fatouros et al., 2023). Similarly in programming, ChatGPT outperforms State of the Art code refinement algorithms although there remain some weaknesses in its approach (Guo et al., 2024).
More relevant to our research, Bang et al, analysed the performance of ChatGPT across a range of languages and a range of tasks (Bang et al., 2023). Their analysis demonstrated that ChatGPT performed less effectively with low-resourced languages, but particularly when it came to identifying and generating text using languages with non-Latin scripts, even for medium or high-resourced languages (Bang et al., 2023). Zhang et al. found a lower response accuracy for tasks in languages other than English in line with systems that convert text to and from English, which the authors suggested may be due to the ChatGPT training dataset consisting predominantly of monolingual English inputs (Zhang et al., 2023). Zhang et al. performed an analysis of the performance of a number of LLMs including GPT-5 and found that they continued to perform poorly with multilingual text, particularly when the languages in question are low-resource and/or use non-Latin scripts (Zhang et al., 2024). We take these findings into account when choosing the languages used for our analysis.
It is important to highlight that the capabilities, performance and behaviour of ChatGPT have evolved over time. Of particular relevance to our analysis is the evolving capability of novel GPT models (e.g. GPT-4o) to interpret and reason with text in underrepresented languages which has led to a significant increase in five African languages (Hurst et al., 2024). These changing capabilities have been observed even within individual models, with GPT-3.5 and GPT-4 showing evolving performance and willingness to perform requested tasks over time (Chen et al., 2024). The evaluation methods and outcomes described in these papers are therefore subject to change and may not hold true for current or emerging GPT models.
Data and methods
We gathered data for 12 languages from the Wikipedia API covering a period of 36 months between the 1st of January 2021 and the 1st of January 2024. This includes a period of approximately 1 year following the date on which ChatGPT was initially released on the 30th of November 2022.
Languages
We decided to conduct our analysis using Wikipedia articles covering a range of languages selected to ensure geographic diversity covering both the global north and south. When selecting languages, we looked at three key factors: (1) The Common Crawl size of the GPT-3 main training data as a proxy for the effectiveness of ChatGPT in that language. (2) The number of Wikipedia articles in that language
5
. (3) The number of global first and second language speakers of that language.
We aimed to contrast languages with differing numbers of global speakers and languages with differing numbers of Wikipedia articles. We split the available languages into three categories based on the relative number of speakers, the number of Wikipedia articles for that language and the Common Crawl size and used this to select the most suitable languages. Notably, English has the highest number of Wikipedia articles, the largest Common Crawl size within the GPT-3 training data and among the largest number of first and second language speakers. We then selected the remaining languages from the categories to ensure as much diversity as possible: • Urdu and Swahili – languages with high populations but low numbers of Wikipedia articles and Common Crawl sizes. • Arabic – a language with a medium sized population and a medium number of Wikipedia articles. • Italian and Swedish – languages with low populations but high numbers of Wikipedia articles.
We note that the Common Crawl size for all of these languages other than English was extremely small as a percentage of the overall training data. Additionally, at the time of performing our analysis ChatGPT officially supported Arabic, English, Italian and Urdu, but did not support Swedish or Swahili although this appears to only extend to the language of the interface rather than any functionality within the model itself.
As a comparison, we also analysed six languages selected from countries where ChatGPT is banned, restricted or otherwise unavailable. The six languages selected are: • Amharic (spoken in Ethiopia) • Farsi (spoken in Iran) • Russian • Tigrinya (spoken in Eritrea) • Uzbek • Vietnamese
Number of Speakers (Native and L2), Crawl Size (total pages), Crawl size as proportion of total, Wikipedia Articles and Users for languages selected for analysis. Common Crawl and Wikipedia statistics correct as of March 2024 when analysis was performed.

Metrics
In gathering data from the API, we focused on four metrics: page views, visitors, edits and editors. Page views are broadly analogous to the number of times a page has been visited, while edits represent a single update to a page as made by a given user. The size of this edit may be highly variable and while Wikipedia has policies governing edits, it is largely up to a user how large an edit might be. We do not attempt to quantitatively measure the size or complexity of an edit due in large part to the difficulty associated with monitoring how much of a given change a user has made. For example, if a user reverts a previous edit but does not correctly record this in the edit description, their edit may seem very complex despite the fact that the user has not made any active changes to the page. Moreover, it should be noted that page views do not necessarily reflect a separate visit to the page as edits are also recorded as page views.
Pairwise comparison
To evaluate the differences in metrics during the period before and after the launch of ChatGPT, we first perform a pairwise comparison for each metric and language pair. In each case, we compare two samples: the first covering total edit, editors, views or viewer numbers for the 369 days prior to the launch of ChatGPT and the second covering numbers for the 369 days following the launch of ChatGPT.
Visual and statistical analyses of the gathered data demonstrated that the four metrics were non-normally distributed across all languages. We therefore opted to use the Wilcoxon RankSum test, a non-parametric test which is less sensitive to outliers than the corresponding t-test and therefore better suited to non-normally distributed data Zimmerman (1994). The Wilcoxon Rank-Sum test is closely associated with the Mann–Whitney U test 7 and these tests are often combined or described as one test 8 . For completeness, although we base our analysis on the Wilcoxon Rank-Sum test, we include U statistics to aid interpretation.
Since the Wilcoxon Rank-Sum test requires two samples of the same size, we limit our two sampled periods to 369 days before and after ChatGPT. We settled on this number for two reasons: firstly, the cut-off date of when ChatGPT was launched was a Wednesday and adding 4 days either side allows us to capture a full week for both samples. Additionally, this represents the entirety of the available data for the period following the launch of ChatGPT at the time we gathered our sample.
Panel regression
Following the pairwise comparison, we also conduct a panel regression with fixed effects to quantify and statistically analyse the size of any effect ChatGPT may have had on each of the gathered metrics. For this, we use the following formula:
where α represents a language-specific fixed effect, β1 is the coefficient of interest representing the change in engagement in a given language platform during the period where ChatGPT had launched, β2 and β3 are seasonal effects associated with a given day of the week d and week of the year w, respectively, on engagement in that language, β4 represents an effect associated with time in days t in that language and ϵ represents the error term.
We include both a fixed effect and interaction with seasonality for each language, as prior studies have shown that trends in patterns of Wikipedia pageviews are language-specific language Chelsy Xie et al. (2019). As well as allowing us to control for and capture seasonal and language-specific effects, this method allows for us to use the full sample to better capture longer-term trends, prior to and over the sampled period.
Standardisation
Each of the 12 languages in our sample has a unique pattern of participation and making comparisons within and between languages is difficult due to the large number of outliers and significant difference from one language to another. The level of engagement with Wikipedia in English, for example, is much greater than engagement with Wikipedia in any of the other 11 languages. Moreover, each language exhibits significant variation from 1 day to the next. To account for this, we used the inverse hyperbolic sine function 9 to transform and standardise the levels of engagement across the languages. The choice of this transformation was due to the ease of interpretation, with coefficients representing percentage changes, but also due to the transformation allowing for inputs to reach 0 without the need for significant adjustment. We note that this transformation has found use in existing work in this space such as (del Rio-Chanona et al., 2023).
Results
We gathered data from the API covering a three year period from the 1st of January 2021 to the 1st of January 2024. Charts showing the unique visitor, page view, editor and edit views for each of the 12 languages can be seen in the Appendix.
Aggregate comparisons
Two-sided Wilcoxon Rank-Sum test results including test statistic (U) and p-values.

Page views
For page views, we first performed a two-sided Wilcoxon Rank-Sum test to identify whether there was a difference between the two periods (regardless of directionality). We found a statistically significant difference for five of the six languages where ChatGPT was available. Page views increased in Arabic (362,936,161 views), English (5,742,870,685 views) and Urdu (14,472,985 views). However, page views decreased in Italian (−68,217,643 views), Swahili (−2,806,814) and Swedish (−75,761,081 views). Among the languages where ChatGPT was not available, we found only one language with a statistically significant fall in views. This language was Amharic where views in the 14 months after the launch of ChatGPT fell (−468,863 views) compared with the 14 months prior. Conversely, increases were observed in Farsi (680,588,659 views), Tigrinya (67,743 views), Uzbek (57,121,796 views) and Vietnamese (18,270,940 views).
Visitors
We analysed unique visitor numbers and identified a statistically significant change in five languages where ChatGPT was available and five where it was not. Among those languages where ChatGPT was available, we observed increases in Arabic (54,184,284 visitors) and English (1,559,487,152 visitors). Conversely, we observed decreases in Italian (−24,438,054 visitors), Swahili (−2,307,456 visitors) and Swedish (−23,774,597 visitors). Among the languages where ChatGPT was not available, visitor numbers increased in Farsi (36,016,995 visitors), Tigrinya (1,145 visitors) and Uzbek (20,349,236 visitors). A significant decrease was observed in Russian (−189,676,733) and Vietnamese (−4,041,967 visitors).
Edits
For edits, we observed statistically significant differences among six languages. Three of these languages were languages where ChatGPT was available with two seeing an increase – English (829,812 edits) and Urdu (92,029 edits) – and Italian seeing a decrease (-162,918 edits). We also identified statistically significant changes in three languages where ChatGPT was not available. All three languages saw decreases including Farsi (−155,745 edits), Russian (−434,464 edits) and Vietnamese (−255,615 edits).
Editors
We finally analysed the number of active editors on each day within the sampled periods. We observed differences in five languages where ChatGPT was available and five languages where it was not. Only English saw an increase in editor numbers (51,040). Four other languages saw a decrease including Arabic (−10,891 editors), Italian (−10,111 editors), Swahili (−503 editors) and Swedish (−2,703). Among the five languages where ChatGPT was not available, statistically significant increases were observed in Farsi (by 2,684 active editors) and Uzbek (6,767 editors). Statistically significant decreases were observed in Russian (−35,925 editors), Tigrinya (−10 editors) and Vietnamese (−10,454 editors).
Panel regression
While the Wilcoxon Rank-Sum test provided weak evidence for changes among the languages before and after the release of ChatGPT, we note ambiguities in the findings and limited accounting for seasonality. To address this and better evaluate any impact, we performed a panel regression using data for each of the four metrics. Additionally, to account for longer term trends, we expanded our sample period to cover a period of three years with data from the 1st of January in 2021 to the 1st of January 2024. Here, we assess the coefficient associated with each individual language and the coefficient associated with the interaction between the launch period and each language to assess the impact that the launch may have had. We report all percentage changes to two decimal places.
Page views
Panel regression result for page views.

’ = statistically significant at p < .05, + = significant at p < .01, * = significant at p < .001.
However, as can be seen in Figure 7, Swahili page viewing habits spiked heavily on the 10th of February 2021 for a brief period of 48 hours before dropping back. At its peak, Swahili Wikipedia received 918,762 views which far exceeds the number of page views received on any other date during our sample. Exactly what may have caused this peak is unclear although the date corresponds with the announcement of the first Ebola outbreak in Guinea in five years. 11 as well as the Congo River Disaster 12 , both of which may have driven information gathering behaviours within Swahili speaking nations. Additionally, we observe smaller peaks in views on the 16th of March 2022 and the 19th of July 2022. While viewing habits in Swahili are somewhat volatile, the most significant periods of high engagement all fell within the period prior to the launch of ChatGPT. It seems likely, then, that this fall is unrelated to the launch of ChatGPT and instead reflects events which drove engagement with Wikipedia in Africa.
We then analysed the six language versions of Wikipedia where ChatGPT was unavailable. Once again, results showed a statistically significant rise across five of the six languages. However, in contrast with the six languages where ChatGPT was available, these rises were generally much more significant. For Farsi, for example, our model showed a 30.3% rise, while for Uzbek and Vietnamese we found a 20.0% and 20.7% rise respectively. In fact, four of the languages showed higher rises than all of the languages where ChatGPT was available except Arabic, while one was higher than all languages except Arabic and Italian.
Edits
Panel regression result for edits.

’ = statistically significant at p < .05, + = significant at p < .01, * = significant at p < .001.
Visiting users
Wikipedia is a service that can be used by almost anyone provided they have an internet connection and are based in a country that does not ban access. There are no restrictions in terms of cost and a user does not need to have an account to view an article. As a result, the Wikimedia API does not provide any details on the number of users who visited pages on any given day, but it does provide the number of unique devices that accessed each language platform. We note that this metric is somewhat imperfect as an individual who uses more than one device would be counted multiple times, while multiple users who share a device would only be counted once. Additionally, a user who logs in only to edit would still be recorded as a visitor, but this is less of a concern as the Wikimedia API records any edit as a page view. Regardless, we chose to use the number of unique devices as the best available proxy for the number of visitors a page received.
Panel regression result for visitor numbers.

’ = statistically significant at p < .05, + = significant at p < .01, * = significant at p < .001.
Editors
Panel regression result for editor numbers.
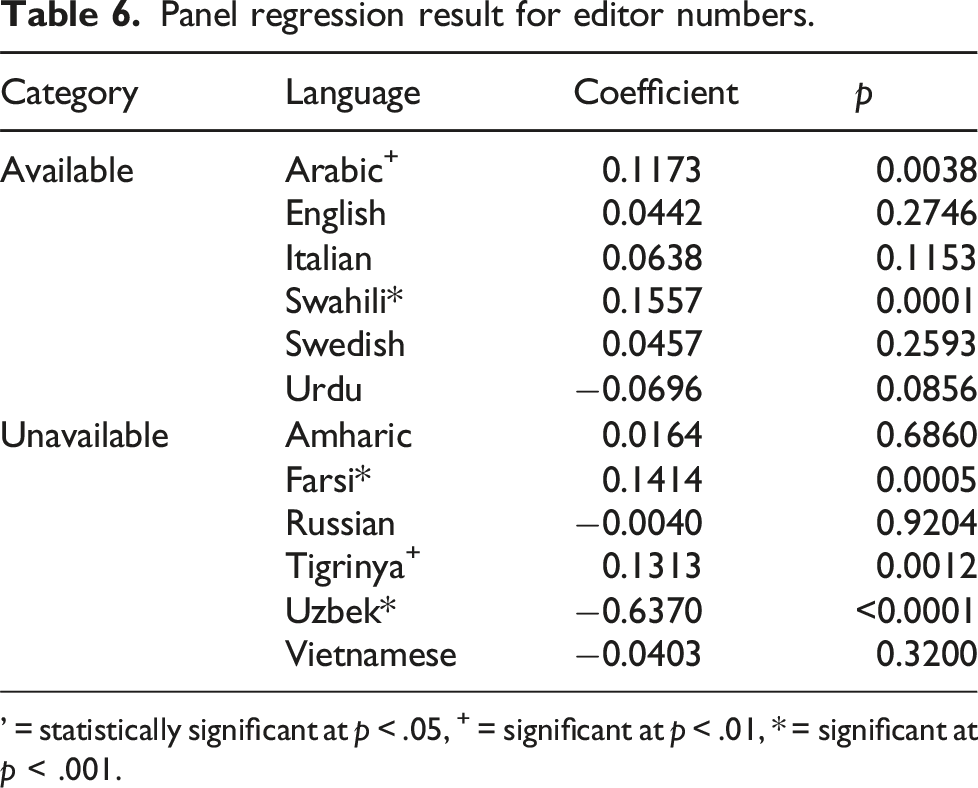
’ = statistically significant at p < .05, + = significant at p < .01, * = significant at p < .001.
Our model did not find a statistically significant change in editors for either English or Swedish. For Italian, we found a weakly statistically significant rise of 6.6%, while for Urdu we found a weakly statistically significant fall of 6.7%. The largest impact was observed in Arabic where the model identified a 12.5% as associated with the period after ChatGPT released. Among the languages where ChatGPT was unavailable, we found a statistically significant rise in Farsi and Tigrinya but a statistically significant fall in Uzbek.
Volatility
Volatility analysis results including outcomes of Levene’s test (p-value) and change in standard deviation (Δstddev) for residuals of each language.

For edits, results were largely mixed. Among the languages where ChatGPT was available, we observed a statistically significant increase in English and Swedish, a statistically significant decrease in Italian and Urdu and no statistically significant change for Arabic and Swahili. Conversely, among the languages where ChatGPT was not available, we observed a statistically significant increase in Russian, a statistically significant decrease in Tigrinya, Uzbek and Vietnamese and no statistically significant change in Amharic or Farsi.
There was less variation in volatility of editor numbers. Among those languages where ChatGPT was available, a statistically significant increase was only seen in Arabic while a significantly significant decrease was seen in Italian. A significant decrease was also seen in Russian, Tigrinya and Vietnamese while all other languages showed no statistically significant change.
However, when analysing page views, we observed a consistent tendency for volatility to decrease in the period following the release of ChatGPT. This decrease was observed in all languages except Arabic and Uzbek where no significant change was detected and for Urdu and Tigrinya where a significant increase was detected instead. We observed similar results for unique visitors, with a statistically significant decrease in all languages except for Arabic, Tigrinya and Uzbek and a statistically significant increase in Urdu.
Deviations from pairwise results
While the panel regression results largely align with those of the pairwise comparisons, we note a number of points of contrast. For edits, English, Italian, Farsi, Russian and Vietnamese were all statistically significant within the pairwise comparison but not the panel regression, while conversely, Arabic and Tigrinya were statistically significant in the regression but not the pairwise comparison. For editors, English, Swahili, Russian and Tigrinya were all statistically significant in the panel regression alone. With views, both Italian and Amharic were significant in the panel regression alone and for visitor numbers, Urdu was statistically significant in only the pairwise comparison while Italian, Uzbek and Vietnamese were statistically significant in only the panel regression.
There are a number of factors which likely influence these differences. Firstly, a requirement of the Wilcoxon Rank-Sum test is that both samples are the same size. This necessitates removal of a portion of the daily engagement counts prior to the launch of ChatGPT and the pairwise comparison is therefore more likely to be influenced by short-term trends. More importantly, however, the panel regression accounts for temporal effects (the passage of days and weeks) as well as a likely effect for the day of the week. We believe these temporal effects are highly likely to have influenced engagement within Wikipedia and the pairwise comparison not only fails to account for these effects but is also likely to have been influenced by them 13 .
It is also important to recognise that while the pairwise comparison is conducted individually for each language, the panel regression instead combines languages into one model. This means that differences can arise between the two methods, particularly in cases where the effect of the treatment condition – in our case, the launch of ChatGPT – was inconsistent between languages. The overall outcome of the panel regression is the result of not only the fixed effects, but also the data from each of the 12 languages. As a result, the regression outcome may be influenced by inconsistent effects such as languages where the treatment effect was significantly stronger or weaker than other languages or languages where the result was of a different directionality – for example, where the effect was negative if in most languages it was positive.
A significant result from the pairwise comparison and not from the regression model is therefore not necessarily a contradiction, but instead is indicative of heterogeneous and inconsistent impacts of the treatment condition across language editions. In our regression, we include both languages where ChatGPT was available and languages where ChatGPT was not and some degree of inconsistency is to be expected. Moreover, as our pairwise comparisons show, the impact was not consistent in size and direction even within the group of languages where ChatGPT was available.
Discussion
Languages and sociodemographic characteristics
Making conclusive statements about the role ChatGPT may have played in any changes within Wikipedia is inevitably difficult. Each of the languages we explored has a number of confounding factors associated with it and one or all of these factors may have played a significant role in the changes our model predicted. In some of the countries in our sample where ChatGPT was not available, Wikipedia has been subject to access restrictions and government censorship, particularly in Farsi-speaking Iran and in Russia (Bipat et al., 2021; Kurek et al., 2025). More broadly, the languages represented within our sample are spoken within different numbers and profiles of countries with diverse cultures associated with a high degree of variation in demographic factors such as average income and level of education.
Socioeconomic status and income have previously been noted to be closely correlated with the quantity, quality and even linguistic nature of the information covered within Wikipedia (Ruprechter et al., 2023; Sheehan et al., 2019). Users from nations with a lower level of development (including a lower level of education) are also more likely to make in-depth use of Wikipedia and to focus on educational rather than entertainment-related topics compared to more developed nations (Lemmerich et al., 2019). Recent studies have suggested that usage of ChatGPT among students is a little higher in developed nations than developing nations, as well as being higher among more educated respondents and in urban and suburban areas rather than rural areas (Amoah et al., 2025). Nevertheless, no significant relationship has been found between economic status and usage.
Even so, citizens of developing nations face additional challenges to exploit the opportunities offered by generative AI technologies. While most now have access to the internet (Heeks, 2022), this is often predominantly through smart phones or other mobile devices (James, 2020) and a lack of reliable internet access and high associated costs may prevent individuals from using generative AI technologies (Mannuru et al., 2023). Therefore, while ChatGPT may have been technically available to speakers of six languages within our sample, it was not equally available to all individuals.
Associating individual languages with a given country (or set of countries) is also difficult. For example, Swahili is used as a lingua-franca across a wide range of Africa and has over 140 million second language speakers compared to just five million first language speakers (Jerro, 2018). Conversely, Swedish is predominantly a first language spoken in Sweden and parts of Finland. While there are limited reliable indications of the number and geographic spread of second language Swedish speakers (see Petzell, 2023), it seems inevitable that this will be lower than lingua-franca languages such as English and Swahili.
Nevertheless, some languages in our sample can be associated with specific levels of socioeconomic development. Swedish and Italian are largely spoken by speakers in developed countries, while Urdu is predominantly spoken in languages with a medium level of human development and Swahili is commonly spoken across many countries with medium-to-low levels of human development according to the human development index 14 . The 2025 United Nations’ Development Programme Report found that countries with lower development indices had the lowest rate of AI usage to date 15 . However, it is also important to recognise that Wikipedia does not restrict access based on country and a given language edition can be viewed and edited from any country. Farsi and Chinese Wikipedia, for example, both receive significant numbers of edits outside of the main countries in which those languages are spoken (Bipat et al., 2021).
In summary, then, it is difficult to directly isolate country- and language-specific effects associated with ChatGPT usage, particularly as speakers of some languages may occupy a wider geographic area and/or had the capacity to move much more readily. Moreover, it is highly likely that questions of human development and socioeconomic status have played a role in the availability of ChatGPT in at least some of the countries which we sampled. We also recognise that the effects of national and cultural events were likely to be overrepresented in some languages with predominantly L1 speakers (e.g. Swedish) compared to others.
Impact on views
Nevertheless, far from being associated with reduced engagement, our regression outputs actually suggest that for five of the six languages, the number of page views and the number of visiting users actually increased in the period after ChatGPT released – arguably substantially so given that the smallest increase we predicted was over 10%. This change was observed even when controlling for the day of the week and week of the year.
Results from the six countries where ChatGPT was unavailable also showed an increase in page views and visitor numbers in the period after release. Given this increase cannot be a result of ChatGPT, it may initially appear that the increases observed across the different languages was merely the result of changes in long-term engagement patterns across Wikipedia as a whole. However, what is notable is that the increases for languages from countries where ChatGPT was unavailable were consistently greater than for those languages from countries where it was. This may suggest that the release of the tool was associated with a lower increase in engagement within those particular Wikipedia language editions.
On the one hand, this would not be entirely surprising. The phenomenon of interdependence between Wikipedia and other Web services is well-documented, particularly search engines (McMahon et al., 2017; Piccardi et al., 2021; Vincent and Hecht, 2021). At this time, there is limited published research which demonstrates how and why users have been engaging with ChatGPT, but early indications would suggest users are turning to it in place of other information gathering tools such as search engines Karunaratne and Adesina (2023); Taecharungroj (2023). Indeed, question answering, search and recommendation are key functionalities of large language models identified in within the literature Chang et al. (2023). Unlike search engines, ChatGPT does not have a clear capacity to drive users to Wikipedia. It does not typically link to sources unless asked to Wu et al. (2023) and even sometimes fabricates sources McGowan et al. (2023); Zuccon et al. (2023). Even were it to link to sources, evidence from existing knowledge sharing systems suggests that any relationship is extremely one way with little – if any – traffic coming to Wikipedia from comments and answers that cite articles and pages Vincent et al. (2018).
Conversely, it is essential to highlight that the languages we explored shared very different linguistic, geographic and cultural backgrounds. Smaller resourced Wikipedia language platforms may be more significantly impacted by the activities of bots Chelsy Xie et al. (2019) and we were unable to select a range of community or resource sizes when selecting the six languages where ChatGPT was not available. By necessity, many of these communities are very small and although we tried to limit the impact of bots by requesting only contributions from users, there is no guarantee this would successfully filter out all bots. It is also possible that any observed effects are not platform-specific and may have been impacted by changes in the larger language communities. After all, prior research has demonstrated that more highly resourced languages can be more influential within Wikipedia as changes to those languages may be more likely to propagate through to other language editions and are observed to propagate at higher speeds Valentim et al. (2021).
We would also caution that the increases observed may be partially or fully influenced by general trends in Wikipedia usage. This is particularly true of Tigrinya and Uzbek where ChatGPT was not available and yet significant increases were seen. While we aimed to add fixed temporal effects to capture such trends, we cannot rule out the possibility of an increasing rate of engagement over time. Tigrinya is also among the smallest Wikipedia instances and engagement was – and likely remains – highly sporadic. We therefore caution that further exploration is required to better understand the factors that have influenced this growth.
Impact on edits
Any impact on editing behaviours was more limited. While we saw substantial changes in Arabic and Urdu – and a weakly significant 10% fall in Swahili – half of the languages we analysed did not record a statistically significant trend. We note that there are two factors that may diminish or even obfuscate any impact of ChatGPT and similar tools on edits. Firstly, prior work has outlined the importance of stigmergy where Wikipedia editors are encouraged to participate when becoming aware of – or otherwise observing – traces of other editors’ activity (Zheng et al., 2023). In essence, edits can be self-multiplying as editors are drawn to build on, correct, replace or even remove other volunteers’ contributions. It should also be emphasised that many Wikipedia edits are likely to be performed by bots across a whole host of roles although evidence suggests the number of bots has diminished significantly over time (Zheng et al., 2019). In some languages such as Cebuano, the majority of pages are bot generated and user-generated content is lacking despite the language having a large number of articles that might warrant its classification as highly resourced (Anderson et al., 2017). Assuming bots are automated or semi-automated, we would not expect an immediate impact in edit numbers caused by those bots.
Additionally, while a reduction in engagement has been seen in Stack Overflow and Stack Exchange (del Rio-Chanona et al., 2024; Sanatizadeh et al., 2023), no such effect has been observed in other knowledge exchange communities such as Reddit (Burtch et al., 2023), something which may be linked to the social connections and relationships users form (Burtch et al., 2024). While Wikipedia editors do form acquaintances through their discussion interactions Jankowski-Lorek et al. (2016), whether these are sufficient to influence the drive to edit and whether this drive would be sufficient to overcome any negative impact from ChatGPT is an area for future work. Nevertheless, we see no evidence of any change in edit and editor numbers that could be associated with the release and availability of ChatGPT.
Implications for quality
The number and diversity of contributors to Wikipedia articles have previously been directly associated with the resulting quality of Wikipedia content (Sydow et al., 2017; Alshahrani et al., 2023). A study of the Films Wikiproject conducted in 2015 found a link between quality and the size and diversity of the crowd contributing to articles, although the importance of diversity increases as crowd-size falls (Robert and Romero, 2015). A reduction in the growth of the editing community has the potential to directly influence the quality of Wikipedia articles if it leads to a reduction in the number or change in the profiles of editors contributing to articles. We have not directly analysed this degree of diversity and our focus on aggregate metrics does not allow for such an analysis to take place. Nevertheless, we propose that this is a potential area for future work.
Moreover, any factor that impacts editor numbers has implications not only for the quality of Wikipedia, but also for a variety of downstream uses of Wikipedia content. Wikipedia is itself a resource for training LLMs and is likely to be prioritised as a training resource due in part to its perceived quality (Vetter et al., 2025). Moreover, given Wikipedia’s widespread usage in search results, there is significant scope for any quality impacts to be felt far beyond Wikipedia itself. Moreover, if users are turning to ChatGPT to generate content for – or in place of – Wikipedia, this also has inevitable implications for the accuracy and quality of information. In the context of Stack Overflow, for example, over 50% of answers generated by ChatGPT for Stack Overflow questions were found to be incorrect with users regularly overlooking misinformation in generative AI responses (Kabir et al., 2024). Nevertheless, we caution that our analysis did not and could not consider whether ChatGPT was being used by Wikipedia editors or users.
Volatility and implications for findings
Our analysis of volatility found limited evidence of any significant experimentation in the period following the launch of ChatGPT. There may have been a degree of increased experimentation in editing behaviours within the English and Swedish editions of Wikipedia. However, given that our regression results showed no statistically significant change within these languages and editor counts in these languages do not show statistically significant changes, we believe it is unlikely that any experimentation was substantial. Nevertheless, we caution that our observations may be linked to the timescale over which our analysis was performed, particularly if any experimentation was temporary. Shorter-term changes in volatility as well as engagement metrics are a key area for future work.
We also find little evidence to suggest that our results were merely linked to an increase in random or sporadic behaviours among users. However, we note three instances where we observe both increases in volatility and corresponding statistically significant results within our model: editor numbers in Arabic Wikipedia and page view and visitor numbers in Urdu Wikipedia. While the statistical significance of the change in volatility within Arabic Wikipedia editor numbers was reasonably low, we cannot rule out that it may have influenced our results, particularly for Urdu where the statistical significance was greater.
Limitations
We recognise a number of limitations in our approach. Firstly, we have divided countries into groups based on the availability of ChatGPT, but we recognise there will be expatriate users, individuals using VPNs and potentially multilingual users who may have been able to circumvent these restrictions. Secondly, we have not accounted for the popularity of ChatGPT in a given country, in part due to the large number of countries involved in our analysis and the limited availability of data around the use of ChatGPT at the time this was written. We believe this is an important area for further work. We similarly were unable to account for the release of other LLMs and competitors to ChatGPT, although we note ChatGPT is likely to be the most popular. Thirdly and perhaps most significantly, although we accounted for seasonal effects in a given language, we were unable to account for cultural and national events that may have influenced the data. This was due largely to the significant number of countries where some languages were spoken (e.g. Arabic and English) and the large number of cultural or historic effects that may therefore arise. Our analysis may have been affected by one-off events, but also longer-term periodic events such as elections. Correcting for such events and exploring any effect they may have had is an important area for further study.
Future work
While our findings may not be conclusive, they nonetheless raise interesting questions about the impact LLMs and other AI tools may have on the wider Web infrastructure. Where evidence from Stack Overflow and Stack Exchange found a rapid and significant drop in engagement following the launch of ChatGPT, we find no such drop. Given the suggestion that highly social communities such as Reddit have been less impacted by LLMs, we question whether the communities within different language editions of Wikipedia may also be less impacted. In particular, we note interesting questions around whether articles with or fewer editors and articles with more or less discussion on their article talk pages demonstrate any difference in viewing and editing behaviours.
Beyond Wikipedia, however, our findings inevitably raise the question of how other large-scale knowledge sharing and collaborative systems may be impacted by the rise of large language models. We also note questions around how the domain of a service or article may influence whether it is impacted by large language models. For example, while the existing literature suggests that popular topics are language-independent, there nonetheless exist differences particularly surrounding cultural articles which will inevitably lead to variations between individual language editions of Wikipedia. Perhaps the largest opportunity for future work, however, is the question of whether these shorter-term trends will hold in the longer term.
Conclusion
In this paper, we analysed page visit, visitor, edit and editor numbers in 12 language editions of Wikipedia. We compared these metrics before and after the 30th of November 2022 when ChatGPT released and developed a panel regression model to better understand and quantify any differences. Our findings suggest an increase in page visits and visitor numbers that occurred across languages regardless of whether ChatGPT was available or not, although the observed increase was generally smaller in languages from countries where it was available. Conversely, we found little evidence of any impact for edits and editor numbers. We conclude any impact has been limited and while it may have led to lower growth in engagement within the territories where it is available, there has been no significant drop in usage or editing behaviours. However, we caution that our analysis focuses on initial, aggregate effects and further analysis is needed to understand longer-term and topic-specific changes.
Significance statement
Wikipedia is the world’s largest encyclopedia, relying on collective intelligence from millions of users around the world to develop and maintain articles. In November 2022, the generative AI chat bot ChatGPT released to the public and it has since grown rapidly to be one of the most popular services on the Web. While it is still relatively novel, early indications suggest that the release of ChatGPT has negatively impacted engagement in Web-based collective intelligence question-answering services such as Stack Overflow. ChatGPT may fill some of the niches that Wikipedia currently occupies including fact finding and question-answering and some Wikipedia editors have raised the concern that the two platforms may end up in competition with one another.
To explore this, we analyse page viewing and article editing activity within 12 language editions of Wikipedia. Six of these languages were predominantly spoken in countries where ChatGPT is available, while the other six were spoken in countries where it is unavailable or banned. Our analysis finds no evidence for an impact on edits or editor numbers, but we find some suggestions that page views and viewer numbers may have grown less in languages where ChatGPT was available than those where it was not.
We posit that edits may have been unaffected as a more social, community-driven activity than anonymous page viewing. Editing and contributing are more likely to be deliberate actions motivated by a drive to contribute to Wikipedia. Conversely, users aiming to mine information Wikipedia have access to a potentially wide range of resources and may land on Wikipedia as a source incidentally through other information sources such as search engines. LLMs are also more directly able to compete with – or complement – Wikipedia through answers to prompts and questions and thereby support mining behaviours. However, Wikipedia’s requirement that statements are reliably sourced and current restrictions on LLM use for content creation mean that LLMs are less directly relevant to contributing behaviours.
Our analysis focuses on a snapshot covering 14 months following the launch of ChatGPT. As LLMs become more popular and well known and as their outputs increase, it is possible that LLM answers will become similar to or even superior to Wikipedia. This in turn may mean that participants will choose to visit only an LLM or vary their information seeking behaviours using particular sources for particular types of question. While this would not directly influence editing behaviour, it remains to be seen what a fall in visitor numbers might mean for Wikipedia editors. In summary, then, we believe that in the longer-term, mining behaviours (and therefore visits) are likely to decrease, but we are unable to draw conclusions as to likely changes in production behaviours.
Our findings contribute to the emerging body of evidence of how ChatGPT is influencing collective intelligence tools although we caution that further research is needed to better understand any relationship between the two platforms. In particular, we highlight that any changes in production behaviours have significantly wide-ranging implications for our understanding of collective intelligence, collective intelligence platforms beyond Wikipedia (such as question-answering services which often rely on Wikipedia content) and Web infrastructure beyond the collective intelligence domain such as search engines.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Engineering and Physical Sciences Research Council [grant number EP/Y009800/1], through funding from Responsible AI UK (KP0011) and by the European Union’s Horizon Europe research and innovation programme under grant agreement number 101058677.