
Abstract
We examined the extent to which constructs and measures have proliferated in psychological science. We integrated two large databases obtained from the American Psychology Association that have been used to keep track of constructs, measures, and research in the psychological-science literature for the past 30 years. In our descriptive analyses, we found that (a) thousands of new constructs and measures are published each year, (b) most measures are used very few times, and (c) there is no trend toward consensus or standardization in the use of constructs and measures; in fact, there is a trend toward even greater fragmentation over time. That is, constructs and measures are proliferating. We conclude that measurement in the psychological-science literature is fragmented, creating problems such as redundancy and confusion and stifling cumulative scientific progress. We conclude by providing suggestions for what researchers can do about this problem.
Keywords
Scientific advancement in a field can be cumulative only to the extent that, among other things, researchers within the field use the same concepts to describe the objects of study, agree on the definitions of the concepts, and investigate them using comparable standards or measures. When members of a scientific field differ in how they conceptualize and measure the objects of study, there will be communication difficulties between researchers, translation failures between theories, too little basis for comparisons between empirical observations, and constraints on the potential for science to advance cumulatively (although these reasons have been given by philosophers of science, such as Kuhn and Fleck, against the idea of cumulative science; Oberheim & Hoyningen-Huene, 2018). Such a state of affairs in a field may occur because of construct and measure proliferation. In this article, we take a more in-depth look at some of the points raised briefly by Elson et al. (2023)—that psychological science is experiencing a proliferation of measures and a fragmentation of the literature, creating a barrier against cumulative science. Specifically, in the present article, we provide detailed descriptions of the data patterns briefly reported in Elson et al. and quantify how these data patterns reflect a state of proliferation. We also include additional results examining construct and measure proliferation across subdisciplines of psychological science.
In psychological science, researchers feeling pressure to distinguish themselves tend to avoid studying existing phenomena, models, concepts, or measures and instead try to find their own—that is, the toothbrush problem (Mischel, 2008; see also Elson et al., 2023). This state of affairs can lead to a proliferation of psychological constructs and measures. We briefly note here that constructs may be thought of as a particular subcategory of concepts that define unobservable objects or phenomena. Psychological constructs are concepts developed to describe psychological phenomena. Suggestive of construct and measure proliferation in psychological science, Rosenbusch et al. (2020) found more than 4,000 measures available to assess individual differences in trait-like constructs. If such a pattern of proliferation is occurring across all of psychological science, the entire field may be limited in its ability to generate knowledge cumulatively.
Here, we describe how and why construct and measure proliferation may indicate a problem. We then present descriptive evidence from two large databases showing that over the last 30 years, constructs and measures across all of psychological science have proliferated. Finally, we provide suggestions for what we—as a field—can do about it.
Construct and measure proliferation are strongly linked and difficult to distinguish in the field’s data. Constructs are the phenomena or entities that researchers attempt to understand and study in psychological science, such as intelligence or self-efficacy. Measures are the methods researchers use to make the constructs they study observable; they are how researchers turn unobservable constructs into empirical quantities (e.g., IQ test scores, self-efficacy self-report ratings). The two data sets we employ, which were obtained from the American Psychological Association (APA), include only measured constructs. Constructs that were not measured were not recorded in the databases. Thus, construct and measure proliferation are unavoidably linked in this analysis. There can be measure proliferation without construct proliferation because even if there were only one construct of interest in the entire field, researchers could still come up with many new operational definitions and measures for it. But there cannot be construct proliferation without measure proliferation in our data because only measured constructs were recorded. We therefore discuss construct and measure proliferation together and show in the results that the data patterns for both are almost identical. We note, however, that construct boundaries are much fuzzier than measures and that there exist no widely used, well-maintained definitions and rules for determining what psychological constructs are captured by measures.
At first glance, increases in the number of constructs and measures in a field may seem harmless or even as a sign of increasingly sophisticated attempts to describe and understand the rich tapestry of human experience. Initially erring on the side of developing too many concepts and constructs may be beneficial in the process of determining the conceptual landscape of a topic given that theories are to be refined over time (Whetten, 1989). Developing and refining concepts are important parts of research because these processes define the objects to be studied and included in theories (Scheel et al., 2021). However, the word “initially” is key to this conceptualization of the successful progression of science. As a field matures and its conceptual landscape is mapped out, the field’s advancement requires that redundant concepts be discarded and that useful and more central concepts be retained and refined and measures for them improved and standardized. This facilitates communication between researchers, translation between theories, and the integration of distinct empirical observations.
On the other hand, consensus and standardization about constructs and measures may also be premature, such as when a poor measure is taken as the standard measure for a construct. In that sense, we do not argue that consensus and standardization of constructs and measures are sufficient by themselves but, rather, that they are necessary. Without consensus and standardization of constructs and measures, there may be endless proliferation. Similar arguments have been made about theories in psychological science (e.g., McPhetres et al., 2021).
An ever-increasing number of constructs and measures in a field will become problematic when they lead to seemingly unrelated silos of literature because measures with different construct names are treated as distinct even when they might be empirically indistinguishable, when there is too little effort to refine concepts and measures, and when definitions and standards of measurement are not agreed on. When there are no agreed-on standards for the constructs or measures, there will be a proliferation of both, impeding the development of cumulative knowledge.
In psychological science, a construct is redundant to the extent that its measure cannot be meaningfully distinguished from the measure of another construct, and a measure is redundant to the extent that it cannot be meaningfully distinguished from another measure. This is sometimes referred to as the “jangle fallacy.” For example, in a meta-analytic synthesis of the literature on grit, Credé et al. (2017) found that conscientiousness and grit were very strongly correlated (ρ = .84; although one facet of grit, perseverance, had incremental validity beyond conscientiousness; for a similar finding, see Ponnock et al., 2020). Likewise, self-compassion was found to have a correlation of −.76 (based on factor scores) with Neuroticism from the Big Five (Neff et al., 2018), which is argued to suggest that the measures of these two constructs are not sufficiently distinct (Geiger et al., 2018; Pfattheicher et al., 2017). When measures of different constructs are strongly correlated with one another, they may be redundant, and the literatures for the differently named constructs will be fragmented from one another.
A field with many redundant constructs and measures is confusing. Some researchers may treat redundant constructs and measures as distinct, and others may treat them as overlapping and indistinct. More problematically, these opposing positions may not stem from any firmly held position about the constructs or the current evidence base but from mere ambiguity. For the researcher wishing to investigate the existing theoretical and empirical knowledge about a psychological phenomenon, finding all of the relevant work in a fragmented literature using different terms and measures for constructs that are virtually the same may be extremely difficult. Redundant constructs and measures thus waste research resources through the confusion they create (Singh, 1991).
A related problem of construct and measure proliferation is the one underlying the “jingle fallacy,” in which the same term is used to describe different constructs or measures. Jingle fallacies can occur because in the absence of agreed-on definitions and standards, researchers may create a new measure of a construct for their own studies that actually measures something else. When many such studies are conducted, there will be a proliferation of measures with the same name but with different items capturing potentially different psychological experiences. For example, anger was found to be measured using many different sets of items that may capture different psychological states (e.g., one measure included “angry,” “infuriated,” and “outraged,” whereas another measure included “angry,” “aggressive,” and “annoyed”; Weidman et al., 2017). Likewise, there are many different methods developed to measure risk-taking propensity, or risk preferences. The different measures of risk preferences, especially those derived from behavioral tasks, show very weak correlations with one another, if at all, suggesting that they are likely measuring different things (e.g., Frey et al., 2017; for the same problem for measures of other constructs, see Altgassen et al., 2024; Anvari et al., 2023; Millroth et al., 2020; Murphy & Lilienfeld, 2019; Park et al., 2016; Saunders et al., 2018; Strand et al., 2018; Warnell & Redcay, 2019). A literature filled with jingle fallacies may suggest—incorrectly—that a particular construct has inconsistent relationships with other constructs. This creates problems for making sense of empirical observations and identifying empirical regularities, which may, in turn, feed into theories.
Given the problems that may be caused by construct and measure proliferation, it is important to examine whether there actually is proliferation. In what follows, we describe two large databases maintained by the APA over the last 30 years to track publication. With these, we document a continuing trend of construct and measure proliferation in psychological science.
Method
We obtained two databases that the APA maintains to keep track of constructs, measures, and research in the psychological-science literature. We obtained the databases from the APA in 2023, so 2022 was the last “fully coded” year (although the APA may add measures retroactively, as explained under Data-Quality Issues). Thus, data for 2023 are incomplete. We used these two databases in combination for the descriptive data we present.
PsycTests is a database of measures reported in psychological publications from 1993. We use the term “measures” to inclusively refer to instruments, tests, questionnaires, scales, and any other tools recorded in the databases as having the purpose of measuring the recorded construct. For input into the PsycTests database, authors are invited to submit their measures to the APA, but APA staff also extract information about measures from various publications, including journal articles, dissertations, and technical reports. Each record in PsycTests consists of a summary of the measure; the construct it is designed to measure (according to the original publication that introduced it); bibliographic information, such as author(s) and publication year; and psychometric information on reliability, validity, and factor analyses when these are reported in the source document. A record in PsycTests that is either a revision or translation of an existing measure is linked to the record of the original measure. When available, data sets, answer keys, scoring sheets, and manuals are included in the supplemental information of a record. As of August 21, 2023, PsycTests had 73,646 records.
PsycInfo is a database of research in psychological science with more than 5,000,000 records of peer-reviewed publications. Each record in PsycInfo consists of a lot of information, but relevant here is a field that records the names of measures used in an empirical study. The field in PsycInfo that records the names of measures also cross-references records in PsycTests when the latter has a record of the same measure, although there are some inconsistencies.
Data-Quality Issues
PsycTests is the largest database of its kind and provides an unparalleled opportunity for insights into the practice of measurement in psychology. PsycInfo also provides uniquely deep details of the published articles included in it. Nonetheless, in conducting this project, we observed some data-quality issues in these data sets. To properly understand how these issues might affect any conclusions, we begin by remarking on the issues.
Change in APA policy
In their publicly available information, the APA states that in 2016, there was a change in the APA publishing executive leadership and subsequent changes to the criteria used for including or excluding constructs and measures into the PsycTests and PsycInfo databases (personal communication, June 5, 2023). When we requested additional information regarding the specifics of this, the APA informed us that from 2016, they stopped “the indexing of very marginal tests, e.g., 3-item smoking cessation measures” and that nonetheless, “there is a certain amount of retrospective addition” whereby tests were added to the database some time after the article had already been published. Given the retrospective additions, in which measures were added well after publication, the number of new measures published each year from 2016 onward is not entirely accurate, although the general trends are nonetheless informative; new additions are likely to be added in future, underestimating the current number of new constructs and measures introduced into the literature each year from 2016 and later.
We examined whether, around the year 2016, there were any corresponding changes in the proportion of articles recorded in PsycTests in terms of the information the articles included about their measures. Figure 1 shows a dramatic increase in the proportion of recorded measures that included information about factors and subscales, factor analyses, and validity. This could mean that after 2016, the APA was more likely to record measures in the databases when a publication included these details and less likely to record a measure when these details were not published. Therefore, the number of constructs and measures recorded in PsycTests after 2016 is likely an undercount. Such an undercount would mean that our conclusions about how much constructs and measures are proliferating is an underestimate (i.e., constructs and measures are proliferating to a greater extent than these data would suggest).

Proportion of records that contain various aspects of information about the measures.
Methodology used by APA
The methodology used by the APA to score, label, and categorize different measures in these databases is vague, and the documentation on the APA website is very scarce. The definition of a “test” is unavailable, although we assume that a test was likely construed broadly to mean any operationalization used as a measure of a construct; this assumption is based on our observations when we examined the tests and constructs in the databases. It is unclear how many coders were involved, how they were trained and selected, and how they were instructed. We therefore do not know the exact protocols used in coding, and whether these protocols have changed over the years remains vague, apart from the switch in 2016 in PsycTests discussed in the preceding paragraphs. There are also no data on interrater reliability. Our communications with the APA did not reveal any information regarding these issues. Thus, it is not possible to address or assess the impact of these data-quality issues.
Records in PsycTests but not in PsycInfo and vice versa
We found some discrepancies between the two databases: 27,000 measures recorded in the PsycTests database (56% of those published between 1993 and 2022) have no matches recorded in the PsycInfo database. There is thus no record of the number of times these measures have been used. We continue from here under the assumption that the measures recorded in PsycTests but not in PsycInfo were either (a) never reused or (b) reused very infrequently. The imperfect coverage of PsycTests that PsycInfo provides has parallels in fields investigating similar problems to the present one, for example, the coverage problem in ecology, in which species diversity is underestimated because rare species are less likely to be sampled (Gotelli & Colwell, 2001; Roswell et al., 2021).
To assess whether there is a large bias in the PsycInfo “tests and measures” field (which we scraped) regarding the number of reuses recorded for each measure and to examine our assumption that measures recorded in PsycTests but not in PsycInfo are either never or hardly ever reused, we hand coded a random selection of 50 measures from PsycTests for the number of times they have been reused. These measures were sampled from the total population of measures with fewer than 10 uses based on our scrape, including measures with no records in PsycInfo. Research assistants searched the literature using the PsycInfo database based on each measure’s name. For the full details of the coding procedure and the results, see the Supplemental Material available online.
Our test for bias in the number of uses for each measure showed that out of the 50 measures we randomly sampled, nine measures were undercounted by 3 or fewer uses, although these all still had a total count of 5 or fewer uses; one measure was undercounted by 7; one measure was undercounted by 8; and one measure was undercounted by 10. Therefore, the PsycInfo tests-and-measures field does not seem to have a large bias that undercounts the number of reuses of measures from PsycTests.
Of the 34 measures from PsycTests with no reuses based on the PsycInfo tests-and-measures field, only seven were identified as having any uses at all. These involved only a single use, generally from the source article that developed the measure. Therefore, our assumption that most measures from PsycTests but with no records in PsycInfo are either (a) never reused or (b) reused very infrequently is supported.
To further gauge the coverage of PsycTests, we scraped the PsycInfo database for the top 50 tests (i.e., the 50 measures that were used most often) for each journal and year from the EBSCO database overview information about test usage. Although this strategy can miss rarely used measures, it cannot distinguish measures with identical names and suffers from nonuniqueness owing to different spellings of the same word, and it is helpful to examine the coverage of PsycTests for highly used measures. We found a total of N = 35,864 measures that had no direct match by name in PsycTests after standardizing the character set to ASCII as in PsycInfo (e.g., all long dashes turned into hyphens). We examined the most highly used measures not included in PsycTests and found that most of these were variant spellings of measures indexed in PsycTests (e.g., “mini-mental state examination” spelled without a hyphen or various cases of “3rd edition,” “third edition,” “edition III”). For some, such as the Structured Clinical Interview for DSM-IV, only translated and revised versions were found in PsycTests. Yet others were vague and may not refer to specific measures, for example, “Visual Analogue Scale” or “Global Assessment of Functioning.” According to our scrape, no identifiable measures with more than 1,000 reuses were missing from PsycTests.
The fuzziness of constructs
Measures in our database are easily distinguished and have clear links with other measures (e.g., some measures are translations and/or revisions of existing measures). Constructs, on the other hand, are inherently fuzzy. APA does not apply a standardized process for labeling measures in terms of the construct they are intended to measure. It is unclear what may be considered a construct and whether and how one construct is linked to another. Instead, coders stick closely to how the authors refer to the construct, leading to idiosyncrasies. Therefore, it is more difficult to quantify construct proliferation than measure proliferation.
Some problems are potentially resolvable, such as small differences in spelling or wording that would be easily noted by most human readers. For example, “big five personality traits,” “big five personality factors,” “5-factor model of personality,” and “five 5-factor model of personality” are the same, although they are categorized as distinct constructs in the database. Systematic search queries in meta-analyses cannot gloss over such differences unless humans prespecify the alternative labeling standards for each construct. In this sense, the inconsistent terminology inhibits evidence synthesis but can conceivably be resolved with high intersubjective agreement between multiple coders.
However, these issues exist on a gradient. For some constructs, even detailed guidance would not be sufficient to help two coders consistently come to the same decision, nor would these decisions always reflect how authors view the constructs they aimed to measure. For example, should the numerous measures that tap into self-efficacy for some specific domain all be classified as the same single construct of “self efficacy” (as part of our coding, we replaced all nonalphabetic characters, e.g., inconsistently used hyphens in “self-efficacy,” with white space)? Or should we consider “career self efficacy,” “work self efficacy,” “job self efficacy,” “occupational self efficacy,” “computing self efficacy,” “drug-avoidance self efficacy,” and “cybersecurity self efficacy” to be distinct constructs? Likewise, researchers do not always agree on what the Iowa Gambling Task actually measures (e.g., decision-making, risk taking, executive functioning; Gansler et al., 2011; Kovács et al., 2017; Schmitz et al., 2020), so that one measure can be assigned to multiple constructs in the APA databases.
In some cases, construct labels are widely understood to be synonymous by researchers with domain expertise, such as “mental ability,” “intelligence,” and “cognitive ability.” But it is difficult to quantify which construct labels are intended and widely understood to be synonyms (which presents few barriers to evidence synthesis) compared with construct labels intended to be distinct, such as “grit” and “conscientiousness.” Other construct labels conflate the psychological construct and the target population of the measure (e.g., “adolescent depression” and “geriatric depression,” or “adolescent substance use” and “parental substance use,” or “child intelligence” and “intelligence”). This conflation can reflect an understanding in the field that depression symptoms or the factors relevant for substance use may vary by age. Or, the conflation could be spurious. For example, in the field of intelligence research, it is more usual to simply refer to the construct of “intelligence” for both children and adults even though specific measures for the target populations do exist. Clearly, adapting a measure for a target population will often be a desirable refinement. But perhaps such prefixed constructs may also be indicative of fields in which subliteratures with low cross-citation rates have developed (i.e., literature silos), creating barriers for the integration of knowledge across fields.
Resolving issues such as those summarized above would require detailed engagement with each measure and the publication that produced it to determine exactly what construct was measured. Although we possess the knowledge to disambiguate some constructs in some fields, here, we take the perspective that all of these issues make the literature less comprehensible. As newcomers with no domain expertise, it is difficult to find existing measures and to aggregate evidence across studies when constructs are labeled inconsistently and with the fuzziness of what distinguishes one construct from another. It is beyond the scope of our project to formally define and categorize all psychological constructs and their relationships with each other. Such an ontology of psychological constructs seems like a worthwhile endeavor to us and others (e.g., Sharp et al., 2023) and would help solve the problems we simply sought to document here. Therefore, we did not recode the construct labels beyond lowercasing all constructs and replacing all nonalphabetic characters (e.g., inconsistently used hyphens in “self-efficacy”) with white space. We also chose to count only the first construct associated with each measure (some measures were coded by the APA with more than one construct name). For how many measures were coded by the APA under multiple construct names, see Figure S1 in the Supplemental Material.
Importantly, even excluding the measures with multiple construct names in the database does not solve the problems we have noted. This is because many measures, such as personality inventories, are coded as measuring one construct. However, the number of constructs listed in PsycTests frequently differs from the number of factors and subscales reported for the same measure. For example, the APA data sets have coded self-report scales designed to measure personality as measuring a single construct (e.g., under the construct name, “the five factor model of personality”). But each of the five factors are generally considered distinct constructs, and many personality inventories further include facets under the five factors, each, in turn, reflecting a distinct construct. We did not address such issues and treated each measure as an indicator of the construct recorded in the PsycTests database, meaning that multidimensional constructs were counted as a single construct even though they could reasonably be considered as multiple constructs. Such cases would underestimate the extent that constructs and measures are proliferating by undercounting how many constructs and measures are introduced each year into the literature.
Measures
We used the measures recorded in the PsycTests database as our master list. We included information about the measures in the master list that were recorded in PsycInfo, although there are also some measures in PsycInfo that are not in PsycTests. Measures in PsycInfo but not in PsycTests were excluded from our analyses because in PsycInfo, the measures are defined only by name with no DOI. This means that two measures with the same name could be recorded as being the same even when they are not. In contrast, PsycTests includes the DOI for the measures, which means that we could distinguish different measures that have the same name. To distinguish different measures that have the same generic name (e.g., two measures both called “job satisfaction scale”) in our master list, we used each measure’s DOI as recorded in PsycTests. There were 1,230 distinct measures that had the same name as at least one other measure in PsycTests (ignoring special characters, etc.). We then counted the number of new constructs and measures published each year, the cumulative number of distinct constructs and measures for each year, and how many times each measure has been used (as recorded in PsycInfo), and we calculated a measure of fragmentation in the literature.
Regarding the number of times each measure has been used, we conducted a scraping procedure of the PsycInfo database. In this scrape, we entered the DOI for each measure (taken from PsycTests) as a search term and searched the tests-and-measures field of PsycInfo. Each article with a record in PsycInfo has a tests-and-measures field that contains a list of names and/or DOIs of the measures used in that article. The search indicated the total number of articles that have used the measure, based on the measure’s DOI being listed in the tests-and-measures field. The scrape extracted this total number of articles for each measure from PsycTests, which we used as an indication of how many times each measure has been used. The Supplemental Material includes an examination of potential bias in this scraping procedure and potential bias in the PsycInfo tests-and-measures field as an indicator of the number of times each measure has been used (see section titled Hand Coding Number of Uses of Measures in PsycTests).
We then sought to quantify fragmentation to assess time trends toward greater standardization or fragmentation over time. In previous work (Elson et al., 2023), we used the normalized Shannon entropy as our metric. Shannon entropy (Shannon, 1948) is a concept from information theory that measures the unpredictability or randomness of data. A fragmented literature, which requires newcomers to absorb much information before being able to recognize the constructs and measures they encounter, can be understood to have high entropy.
To assess whether fragmentation is increasing over time, we considered three challenges. First, the literature is growing over time. In Elson et al. (2023), we therefore normalized entropy by the log of the number of tests or constructs. However, reconsidering our approach, growth could also mean studying the same few constructs in greater depth, so growth and fragmentation can be independent. Therefore, we changed our standardization procedure. Second, there is a question of how much leverage rare tests have compared with common tests. In ecology, these weighting concerns are discussed as different exponents of Hill/true/effective diversity (Chao et al., 2014; Hill, 1973; Jost, 2006), and commonly used metrics map to the arithmetic, geometric, and harmonic means. Third, we know little about the sampling process and effort expended by the APA coders to determine which articles and measures to code. Fortunately, this parallels the problem faced by ecologists who want to compare the species diversity of, for instance, different field patches but do not know precisely how much effort was expended in each patch. Roswell et al. (2021) argued that standardizing based on coverage, that is, the total number of individuals sampled, is preferable to standardizing based on equal-effort sampling (e.g., rarefaction to the smallest number of distinct tests) or, as done by us in Elson et al., normalizing using the logarithm of the total number of distinct tests. We discuss these challenges in greater depth in our Supplemental Material and show that different standardization approaches yield similar conclusions.
Here, we report results across years in the Hill-Shannon diversity metric (exponentiated Shannon entropy) using asymptotic coverage standardization. The Hill-Shannon diversity is more interpretable than Shannon entropy because changes in it are linear in the unit of number of measures/constructs. If the Hill-Shannon diversity for a subfield is 100, it can be understood as saying that the subfield has the same fragmentation as an imaginary subfield with 100 tests that are all used equally often. Hill-Shannon diversities can be compared relatively, so a subfield with a value of 200 can be said to be twice as fragmented as a subfield with a value of 100.
This allowed us to see whether the field is converging over time toward using the same constructs and measures or whether the field is becoming more fragmented, with researchers using different constructs and different measures. As we discussed in the introduction, a maturing field that converges must collectively discard less useful constructs and measures over time and converge on a core set of constructs (i.e., demonstrate low fragmentation) rather than continuously introducing ever more constructs and measures. Of course, we must also avoid any affirmation of the consequent: This does not mean that all literatures with low fragmentation have successfully retained useful measures and constructs and discarded less useful ones. We are arguing that decreasing fragmentation is necessary but not sufficient for scientific progress.
Results
In examining potential proliferation, we report data patterns suggesting construct and measure proliferation for the entire field, followed by similar data patterns within each of the subfield categories. Our reporting of the data patterns is qualitative, meaning that we use no inferential statistics, and the results are thus descriptive. Finally, we provide a link to an interactive treemap plot, which shows some of the most highly used measures, visually displaying the fragmentation of the field and its subdisciplines and indicating how many times each of the measures has been used.
Types of measures
Across all fields and subdisciplines, self-report questionnaires (e.g., rating scales and other self-report inventories) are by far the most frequently used type of measure in all of psychological science (see Fig. 2).
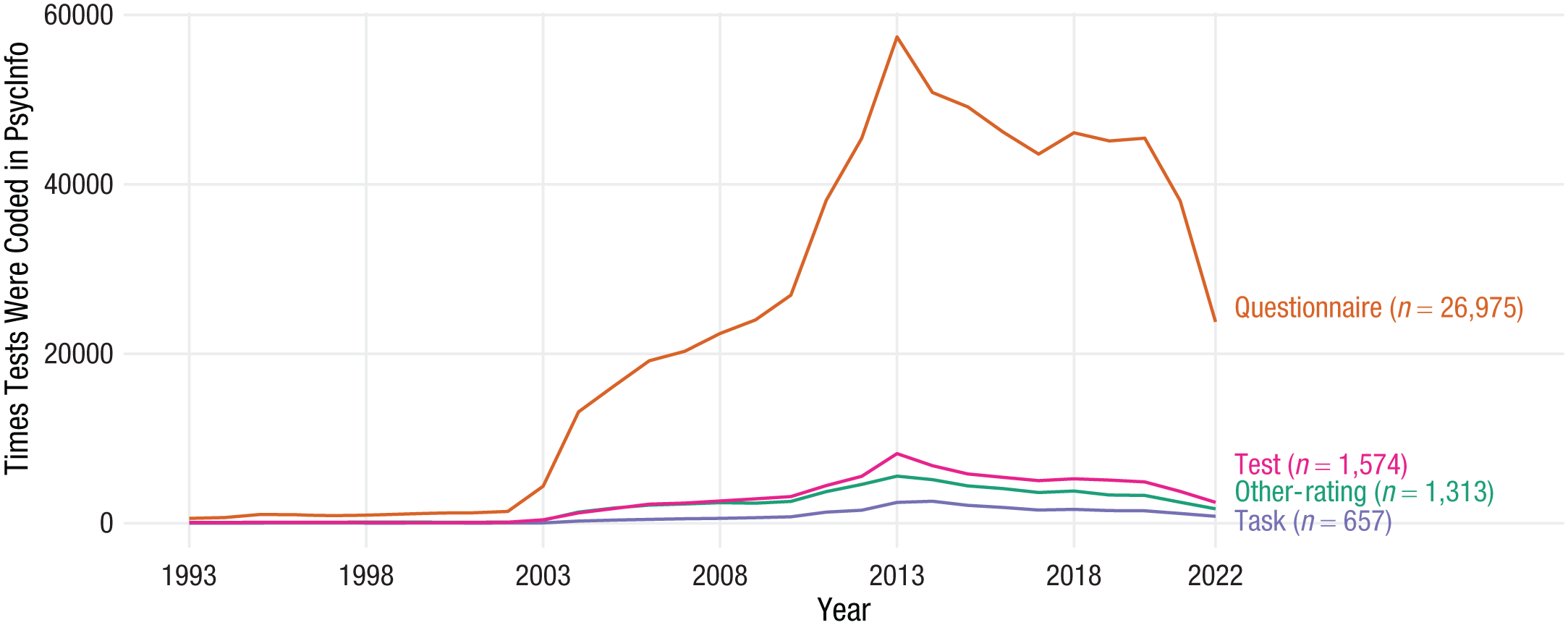
PsycInfo records of how many times each measure was used in each year. The y-axis reflects the number of times a measure was recorded as being used in a given year, and the x-axis reflects each year of records. The figure thus shows the trends in the number of times each measurement type was recorded in PsycInfo as having been used. Questionnaire = self-report ratings and inventories; other-rating = ratings for other (e.g., partner reports or parent reports); task = a behavioral task; test = other types of measures coded as being a test of some sort.
Number of new constructs and measures each year
Figure 3 displays the number of new constructs and measures published each year. There was exponential growth in the number of constructs and measures until 2016. In 2016, there were still around 3,000 new constructs and measures published. At this point, the APA criteria for including measures in the PsycTests and PsycInfo databases became more restrictive (see Method section above). The trend after 2016 is therefore not directly comparable with the trend before. Nonetheless, more than 1,000 new constructs and measures are on record as having been published as of 2021 and just under 1,000 as of 2022, with additional constructs and measures likely to be added retrospectively in the coming years. In sum, many new constructs and measures are constantly being published each year in psychological science.
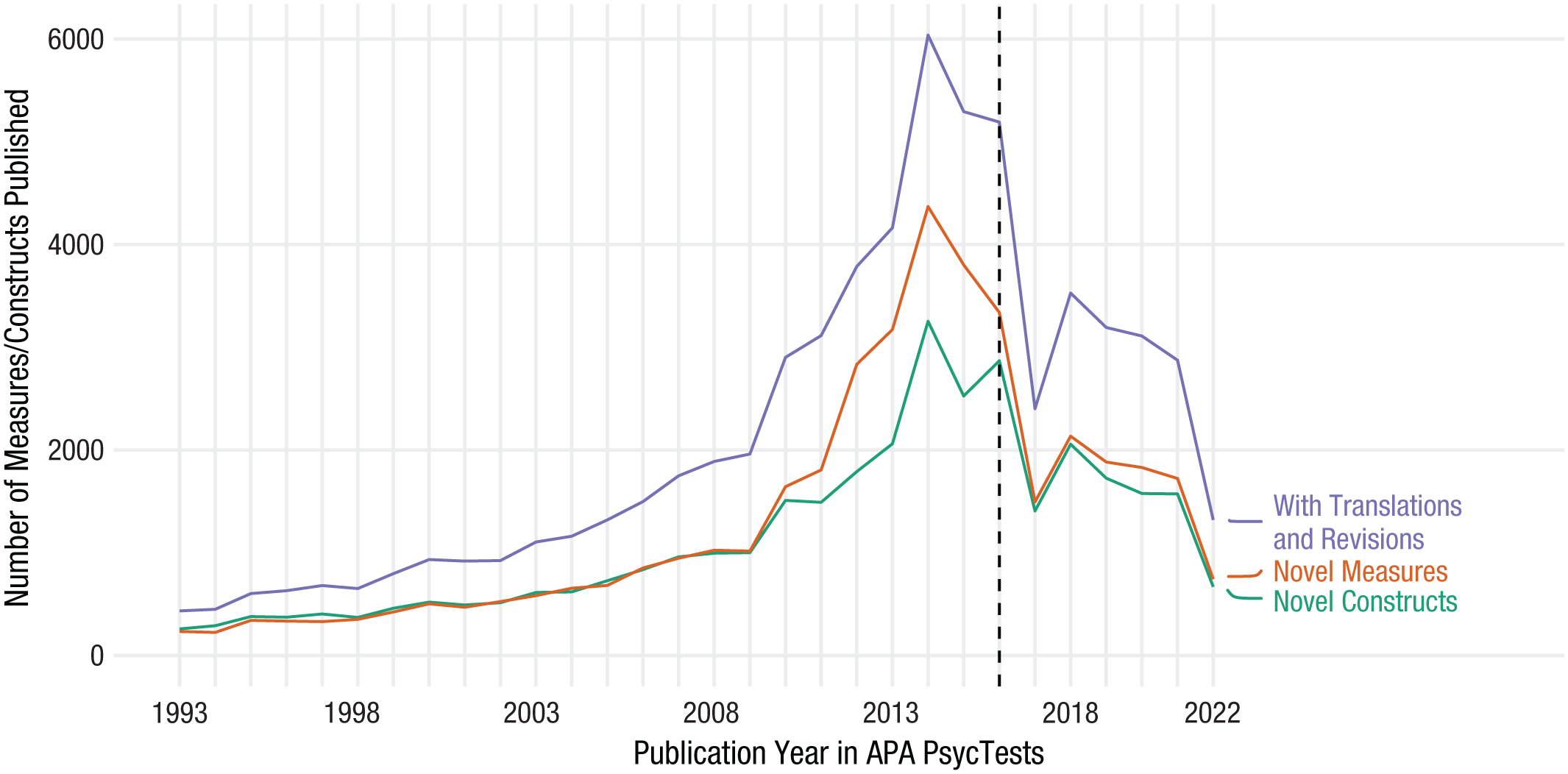
The total number of new and distinct constructs and measures published each year.
Cumulative number of distinct constructs and measures each year
Figure 4 displays the cumulative number of novel constructs and measures published in psychological science from 1993 to 2022. For both constructs and measures, regardless of whether we include translations and revisions, the total number of distinct constructs and measures has been constantly increasing. This is unsurprising given that constructs and measures that are discarded or ignored by the field are included in the cumulative count. Nonetheless, there seems to be little indication that the rate of increase in the cumulative count of the distinct constructs and measures is stabilizing, other than a slight reduction in the rate of increase after the APA changed its inclusion criteria in 2016.

The cumulative number of distinct measures and constructs in psychological science. Reproduced from Elson et al. (2023), with the dashed line at year 2016 newly added.
How often measures are used
Figure 5 shows the number of measures against how often they have been recorded in PsycInfo as having been used, including the measures from PsycTests that have no records in PsycInfo. Under the assumption that those with no records in PsycInfo have been used only infrequently, we found that the overwhelming majority of measures have been used only a few times.

Plot of the number of measures against how many times the measures have been used. The bar at 0 on the x-axis represents the measures in PsycTests that have no records in PsycInfo. Figure reproduced from Elson et al. (2023), with the bar at 0 newly added.
Fragmentation in the literature
Figure 6 shows our fragmentation index, the asymptotic coverage-standardized Hill-Shannon diversity. Over time, the field is trending toward greater fragmentation for both constructs and measures. Although we see stagnation around 2016, when the APA changed its inclusion criteria for recording measures into its databases, there is now an upward trend (until 2022, which may reflect hitherto incomplete records). In Fig. S3 in the Supplemental Material, we show that our fragmentation metric for constructs shows identical trends regardless of whether we examine only the first construct label entered in PsycInfo or all construct labels.

Plot of our fragmentation index (asymptotic coverage-standardized Hill-Shannon diversity) for measures and constructs. The dashed line at 2016 shows the year that the American Psychological Association changed its inclusion criteria for its databases.
Summary of patterns in psychological science
First, the patterns for constructs and measures are almost parallel (see Figs. 3, 4, and 6), indicating that construct and measure proliferation are strongly linked. This was expected because the APA databases contain only constructs that have measures. Given the large number of new constructs and measures published each year (Fig. 3), the subsequent increase in the cumulative number of distinct constructs and measures (Fig. 4), and the fact that the majority of measures are used only a very few number of times (Fig. 5), the trend toward increased fragmentation (Fig. 6) is indicative of construct and measure proliferation. This suggests there has been no progress toward consensus and standardization, that is, there are a great many constructs and measures in the field, and there is no move toward agreement, consensus, or indication of standardization regarding which constructs and measures are central to the field. In short, psychological science is fragmented and is slowly trending toward greater fragmentation.
Subfield trends
We then examined the trends for constructs and measures within specific subfield categories. APA staff had categorized each record into 30 subdisciplinary classifications, although the measure from each record can, of course, be used across subdisciplines. We recoded the classifications into a smaller set of subcategories. For example, the APA had subdisciplinary classifications called “anxiety and depression”; “addiction, gambling, and substance abuse/use”; “mental health/illness related assessment”; and “military personnel, adjustment, and training,” which we categorized into “health and clinical psychology.” We ended up with five subcategories: “cognitive psychology,” “educational and developmental psychology,” “health and clinical psychology,” “industrial/organizational psychology,” and “personality and social psychology.” For a table showing all 30 APA classifications with our corresponding classifications, see the Supplemental Material.
Cumulative number of distinct constructs and measures
Figure 7 shows the cumulative number of new constructs and measures published in these subdiscipline categories. The general trend is the same across subdisciplines: The total number of distinct constructs and measures has been constantly increasing from 1993 to 2022 with little indication that this is stabilizing. Health and clinical psychology and personality and social psychology have the greatest total number of constructs and measures, followed by industrial/organizational psychology, educational and developmental psychology, and cognitive psychology.

Cumulative number of distinct measures and constructs for each subdiscipline.
How often measures are used
Figure 8 shows the number of measures against how often they have been recorded in PsycInfo as being used in each of the subdiscipline categories, including measures that are in PsycTests but not in PsycInfo. Assuming that measures with no records in PsycInfo have been used infrequently, the overwhelming majority of measures in every subdiscipline category have been used only a few times.
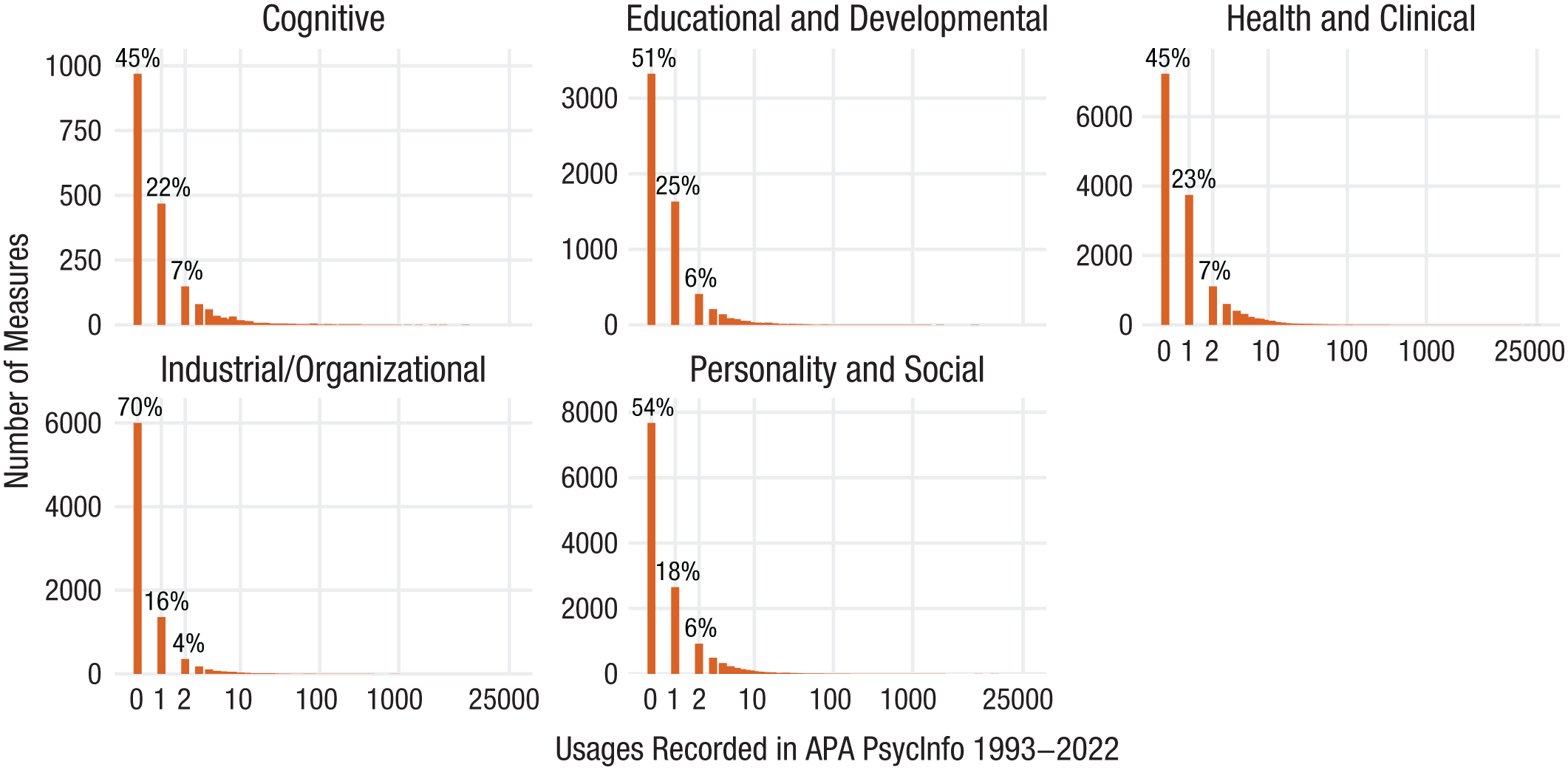
Plot of the number of measures against how many times the measures have been used for each subdiscipline category. The bar at 0 on the x-axis represents the measures in PsycTests that have no records in PsycInfo.
Fragmentation in the literature
Figure 9 shows fragmentation over time in the literature for measures for each of the subdisciplines (the fragmentation for constructs was much the same, and so we have not included the figure for brevity). None of the subdiscipline categories show a trend toward decreasing fragmentation. Rather, across the full timeline, since 1993, there has been an increase in fragmentation. Although the trend lines over time look much the same across the subdiscipline categories since around 2003, there are some differences. Cognitive psychology is least fragmented (i.e., it has been relatively less fragmented), whereas industrial and organizational and personality and social psychology have been most fragmented since around 2013.
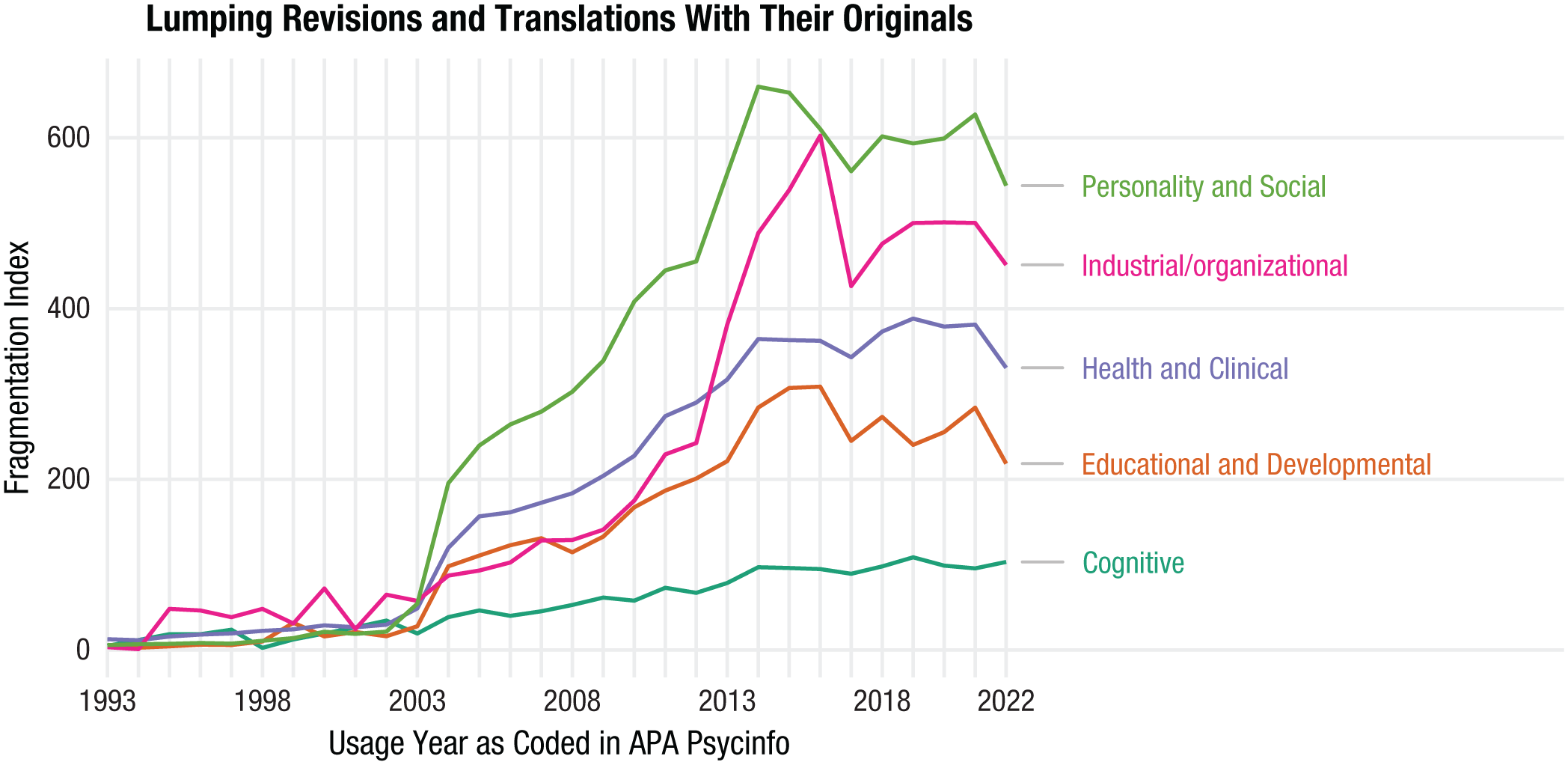
Plot of the fragmentation of measures for each subdiscipline. Fragmentation increases in all subfields, but the strength of the trend differs and is lowest in cognitive psychology.
Summary of patterns in subfields
None of the subdiscipline categories show a trend toward decreasing fragmentation. Rather, across the full timeline, since 1993, there has been an increase in fragmentation. And since 2018, there has been a slow increase in fragmentation in each of the subdiscipline categories. Although the trend lines over time look much the same across the subdiscipline categories since around 2003, there are some stable relative differences. Cognitive psychology is least fragmented, whereas industrial and organizational psychology and personality and social psychology have been most fragmented since around 2013.
When considering the combined patterns of the increase in cumulative number of constructs and measures, how infrequently most measures are used, and the trend toward greater fragmentation, the data suggest that construct and measure proliferation has been occurring in every one of the subdiscipline categories. Although the strength of the trend differs, it seems all fields fragment as they grow, with cognitive psychology fragmenting the least and industrial/organizational and personality/social fragmenting the most. Notwithstanding these relative differences, the trend toward greater fragmentation suggests a proliferation of constructs and measures that is not improving, likely increasing the problems such as redundancy and stifling scientific progress.
Interactive treemap plots
For interested readers, there are treemap plots for psychological science overall and for each disciplinary category (see https://rubenarslan.github.io/construct_proliferation/). Clicking on the image for a subfield opens a new page with the interactive plot. Hovering the cursor on a cell of the interactive plots reveals the full name of the measure and how many times it has been used.
In these plots, the area of the cell for each measure is proportional to the measure’s usage frequency such that larger areas reflect greater frequency of use. The plots are interactive, so hovering the cursor on a cell indicates what measure the cell represents and the number of times the measure has been used; clicking on a cell focuses the plot onto that one cell. By comparing across the subdisciplines, we demonstrate what higher and lower fragmentation fields look like visually (e.g., see Fig. 10, displaying the treemap plots for personality and social psychology and for clinical and health psychology in the top and bottom of the figure, respectively). Greater fragmentation is apparent when there are many tiles of a small size, blending into a pattern in the lower right. Lower fragmentation is apparent when some large tiles reflecting individual measures, such as the Beck Depression Inventories, dominate a field.

Treemap plots for (top) personality and social psychology and (bottom) clinical and health psychology. Each tile shows one measure, labeled with its acronym if it fits on the tile. Larger tiles indicate that the measure has been used a higher number of times; the many smaller tiles show fragmentation. An interactive version of this plot with counts, expanded names, and DOI links to each test can be found on the web page containing the treemap plots.
Discussion
We presented descriptive analyses based on two large APA databases (PsycTests and PsycInfo) that suggest a proliferation of constructs and measures in psychological science. This is based on the consistently high number of new constructs and measures introduced into the field each year, the subsequent increase in the cumulative number of constructs and measures, the fact that most measures are used only a very few number of times, and the trend toward greater fragmentation for both constructs and measures. McPhetres et al. (2021) found something similar when examining theories published in psychology’s flagship journal, Psychological Science, in which most theories were referred to only a single time across different articles. Categorizing the field into five broad subdisciplines, we found that the general qualitative patterns remained much the same in all of the subdiscipline categories. These qualitative data patterns indicate that the field is not moving toward any consensus, agreement, or standardization in terms of the constructs it studies and the measures it uses.
Therefore, we believe that psychological science continues to be going through a proliferation of constructs and measures, creating problems such as redundancy and confusion and stifling cumulative scientific progress. We think that the field should aim toward decreasing fragmentation. Many areas of psychology (as a comparatively young quantitative science) may not be ready to fully standardize constructs and measures. Our aim is not to reify the Beck Depression Inventory–II or the construct depression as described in the fifth edition of the Diagnostic and Statistical Manual of Mental Disorders (American Psychiatric Association, 2013). In some cases, the field may even have grown too attached to a supposed “gold-standard” measure. Here, a lack of options can also inhibit progress. To be clear, we do not want to prevent or reduce refinements of existing constructs and measures. Revisions, translations, and other refinements can contribute to a more coherent, organized literature and improve measurement.
We are more concerned with the measures conceived with limited planning and released into the literature without much commitment or much of a life expectancy. In ontologies, these are sometimes referred to as “orphan nodes.” Currently, many measures are used without validity evidence, with a great amount of unjustified flexibility in how measures are used (Flake & Fried, 2020). Empirical research examining these issues has found that in health- and education-behavior journals, between 40% and 93% of published articles used measures with no validity evidence (Barry et al., 2014); 69% of (n = 246) emotion measures made no reference to previous research or development processes, suggesting that the measures were developed impromptu (Weidman et al., 2017); in research examining the link between social media use and well-being, the measures used vary substantially with little to no justifications provided (Orben & Przybylski, 2019); and alpha-hacking may be occurring, in which researchers drop items from scales to improve the Cronbach’s α coefficient (Hussey et al., 2025). We believe such low-effort additions to psychological construct and measure development impede cumulative science and cause confusion. If the efforts that went into these numerous measures were pooled instead, the resulting contributions would have better odds of improving the state of the art. Therefore, we think the main avenue to rein in proliferation of poor-quality measures is raising the bar for introducing them into the literature (see also Elson et al., 2023; Flake et al., 2017).
Construct and measure proliferation hinders psychological science’s ability to generate cumulative knowledge. It is true that quantitative psychological science is still relatively young, and perhaps there should be debate as the field works out which constructs and measures are most appropriate through a process of refining theories and empirical methods. However, what we see in the PsycTests and PsycInfo databases is that constructs and measures have proliferated and that there is no trend toward decreased proliferation. Some proliferation may be appropriate, such as when applying existing constructs to new domains (e.g., attitudes toward telemarketing and attitudes toward online shopping). But unconstrained proliferation, particularly of low-effort ad hoc measures, is likely problematic.
Proliferation causes confusion when constructs with different names have measures that cannot be empirically distinguished from one another (e.g., Bainbridge et al., 2022; Credé et al., 2017; Fischer et al., 2023; Geiger et al., 2018; Pfattheicher et al., 2017; Ponnock et al., 2020). Such jangle measures are the opposite of refinement because a lack of connections to the existing, related literature actively hampers the synthesis of evidence. In personality psychology, organizing frameworks, such as the Big Five, can help make connections between supposedly distinct psychological constructs (Bainbridge et al., 2022; see also Fischer et al., 2023). In a similar vein, Rohrer (2023) argued that many new psychological constructs are being discovered simply by differentiating an adaptive version of the construct from a maladaptive version by mixing some Neuroticism into the items that capture the maladaptive version (e.g., Barthels et al., 2019; Enns et al., 2002; Krasko et al., 2020; Lange & Crusius, 2015; Tracy & Robins, 2014; Vallerand et al., 2003; Yang et al., 2020).
Given a lack of consensus or standardization for measuring the field’s constructs, greater discrepancies between different measures of the same constructs (i.e., the jingle fallacy) can also be expected. For example, measures based on behavioral tasks that supposedly measure the same construct correlate very weakly, if at all, with one another or with self-reports also intended to measure the same construct (e.g., Anvari et al., 2023; Frey et al., 2017; Millroth et al., 2020; Murphy & Lilienfeld, 2019; Park et al., 2016; Saunders et al., 2018; Strand et al., 2018). Among other reasons for this nonconvergence is the lack of conceptual refinement regarding exactly what the construct of interest is and thus how it may best be measured. For example, the same behavior may be considered as either exploratory or exploitative depending on various factors, including the level of analysis and the purpose or goal the behavior achieves (Mehlhorn et al., 2015). Construct and measure proliferation may therefore cause problems of redundancy and nonconvergence, creating clutter and confusion.
An already fragmented literature that adds 2,000 new measures each year creates an enormous and difficult-to-navigate landscape for researchers. For example, researchers may want to synthesize findings related to the Big Five personality traits. They would therefore review the literature consisting of measures under the Big Five construct names. They would not incorporate findings involving measures of other traits even if some measures of other traits are indistinguishable from measures of one or another of the Big Five. A whole slew of relevant findings would therefore be ignored in such synthesis efforts. On the other hand, researchers may mistakenly synthesize findings in a literature review or meta-analysis for a particular construct that has many different measures but for which the measures may be empirically distinct from one another. Such research syntheses would be misleading and potentially confusing, for example, by resulting in heterogeneous associations between the construct of interest and other variables that are due to the measures of the construct measuring distinct entities rather than a true heterogeneity in the association. Indeed, in many cases (e.g., the risk-preference literature; Frey et al., 2017), studies using almost completely inconsistent measures have already been jointly meta-analyzed before the lack of cohesion in measurement became more known. Issues such as these could be resolved only when a literature is made less fragmented, whereby research is conducted to identify the empirical relationships between the many different constructs and measures in a huge landscape of existing and new ones.
Although we have interpreted the data patterns presented in this article as indicative of problematic construct and measure proliferation, the evidence we presented is descriptive and the data imperfect. We tested no hypotheses and presented trends that we interpreted qualitatively. For example, it is unclear what degree of fragmentation (i.e., Hill-Shannon diversity) would be acceptable or even ideal, and we have not specifically attempted to separate how much fragmentation is driven by disagreements about a few constructs/measures over some long time period as opposed to fads in which new constructs/measures are introduced and discarded quickly. Likewise, we do not have a “right” cumulative number of constructs and measures a field should have, nor is there a right number of times the measures should be used.
Moreover, the data patterns we presented could also be interpreted in a more positive light (as suggested by an anonymous reviewer and as discussed in Iliescu et al., 2024), as revealing a vibrant science, with some proliferation being a necessary feature of scientific progress. The idea is that construct definitions and measurement methods undergo an evolutionary process like natural selection, in which only a small number of them are eventually selected and widely reused. There may also be different conceptualizations of the same construct, requiring different methods of measurement that may not always overlap. The theories about such constructs may evolve, perhaps as a result of empirical findings using the different methods of measurement, subsequently resulting in the requirement for the development of newer and better methods of measurement. From this perspective, the introduction of more constructs and measures into the literature can reflect a healthy science.
Indeed, in some subfields, a process of epistemic iteration is occurring in which theoretical and empirical work on a construct and its measure mutually inform each other (see Chang, 2022). Take the example of depression. Depression is, for the most part, agreed on as being a central construct in psychological science. Nonetheless, there are more than 280 measures of this construct currently in existence, and content analyses have shown that many of these measures assess different symptoms (Fried, 2017; Fried, Flake, & Robinaugh, 2022). Moreover, research has shown that people diagnosed with depression exhibit many different symptom profiles such that very few people experience the same combination of symptoms as others (Fried & Nesse, 2015). Such findings bring into question the assumption that the symptoms of depression have a common cause, and theoretical advancements now suggest that depression and mental-health problems more generally should be considered and studied as complex systems of interdependent relationships between material conditions, social environment, behaviors, thoughts, feelings, and biology (Fried, 2022; see also Borsboom, 2017; Fried, Flake, & Robinaugh, 2022; Kendler et al., 2011). These new and more refined theories of depression suggest the need for improved methods of measurement (e.g., Fried, Rieble, & Proppert, 2022).
Some researchers might argue that the theoretical advancements for depression occurred as a result of the proliferation of measures. Perhaps this is true, and the proliferation of different conceptualizations and measures of depression was a necessary component of the epistemic iteration that led to the new theoretical advancements. On the other hand, the proliferation of measures hindered the ability of researchers to develop cumulative knowledge about depression because comparisons of results between studies may be biased given the use of different measures with little content overlap (Fried, Flake, & Robinaugh, 2022). Moreover, findings showing the many different symptom profiles that people can exhibit did not require more than 280 measures of depression but only a single one (Fried & Nesse, 2015). The epistemic iteration leading to theoretical advancements about depression could therefore have been achieved without the proliferation of measures and perhaps sooner. Nonetheless, we think that more researchers in more areas of psychological science should engage in the type of epistemic iteration that is occurring for depression.
Regardless of whether one interprets the data patterns in our article as reflecting a healthy or problematic type of proliferation or whether one considers that the data-quality issues are so problematic so as to void our conclusions completely, it is hard to argue that psychological science needs more ad hoc measures and more modified measures with no justifications for the modifications. Certainly, we do not want to prevent new constructs and measures or modified measures from being introduced into the literature. Iliescu et al. (2024) stated that “unjustified [italics added] variability in psychological measures should be discouraged,” and we agree.
We believe that requiring authors to provide justifications when introducing new constructs and measures or when making modifications to existing ones will help to reduce the proliferation of low-quality constructs and measures in the literature. Iliescu et al. (2024) expressed concern that blindly preventing the introduction of all new constructs and measures would hinder scientific progress. Rather than advocating for blind prevention, the Standardisation Of BEhavior Research (SOBER) guidelines presented by Elson et al. (2023) require authors to show that any new construct and measure they are introducing is not redundant with existing ones or to justify why some redundancy is acceptable. To help with this, semantic models may be used to assess whether the content of a new self-report scale has substantial overlap with existing scales (Hommel & Arslan, 2024; Rosenbusch et al., 2020). SOBER also requires authors using existing and well-validated measures to either adhere to the protocols or justify and report any modifications. Ideally, authors would use preregistration and registered reports to detail the measurement and scoring procedures before analyses. Elson et al. further suggested that editors and reviewers enforce these requirements on authors. By using such guidelines appropriately (not blindly), the literature would be open to the fruitful type of variability in measurement that Iliescu et al. argued for while preventing the harmful type of proliferation that we are concerned with.
In the same vein and in line with Iliescu et al. (2024) arguing that researchers should use the phenomenon of proliferation to their advantage, we propose that researchers conduct work aimed at better organizing the existing landscape of constructs and measures in the literature. Examples of this type of work include Bainbridge et al. (2022), in which the empirical relationships between a huge number of self-report measures of various traits were examined. They found many trait measures correlated relatively strongly with one or another of the domains of the Big Five Personality traits, suggesting that the Big Five could be used as a good organizing framework. Projects such as the Synthetic Aperture Personality Assessment (Condon et al., 2017) show how the relevant data could be gathered. For survey measures, this work could be complemented and simplified by the use of large language models to predict how strongly different measures of different constructs will correlate with one another based on item texts (e.g., Hommel & Arslan, 2024; Rosenbusch et al., 2020).
In addition, researchers could focus their efforts on one particular construct, identifying the different methods of measurement currently in existence and examining the empirical relationships between them (e.g., Anvari et al., 2023; Frey et al., 2017; Millroth et al., 2020; Murphy & Lilienfeld, 2019; Park et al., 2016; Saunders et al., 2018; Strand et al., 2018). Often different measures, particularly behavioral ones, do not correlate strongly with one another or with self-reports, suggesting the need for further refinements to the construct definitions and better understanding of what exactly the different measures are capturing. Although some might argue that the existence of such work indicates a healthy science, we would argue that such work is too sporadic and that currently too little effort is focused in such directions.
Finally, we believe that part of what is causing the problematic type of construct and measure proliferation is that psychological measurement is implicitly treated from the perspective of entity realism by most researchers. That is, psychological scientists take nouns denoting psychological constructs from ordinary language and assume that these nouns refer to entities that exist in a real sense and that it is these entities that are the causes of people’s behaviors. It is similarly assumed that these entities cause the variations observed on one’s measures. In this way, any new concept introduced into ordinary language that refers to a psychological phenomenon can be taken directly to the field’s science and a new measure developed for it. Combined with lax standards for introducing new constructs and measures into the literature, this approach to measurement can lead to a problematic proliferation of constructs and measures simply as a result of new nouns being introduced into ordinary language.
To help with this, we advocate for the approach to psychological measurement developed by Vessonen (2021), which she called “Respectful Operationalism” (RO). RO is an alternative approach to psychological measurement in which a construct is defined narrowly in terms of its measure (i.e., the construct is what the measure measures). RO requires that the measure be validated in two broad ways. First, the measure should include content that is relevant to the way the construct is understood and defined but exclude content that is not part of the broader construct definition. For example, depression is commonly understood to include sad mood but not anxiety; therefore, a measure of depression should include sad mood and exclude anxiety. Second, Vessonen wrote that a measure must be validated for usability. Usability has several aspects. One aspect of usability is consistency or reliability such that different administrations of a measure (either by different people or at different time points) should show similar results. A measure of a construct that is commonly understood to be stable, such as depression, should not show great variation over short time spans or based on administrations by different people. Another aspect of usability is predictive validity, or usefulness. If a measure can be used to predict some future event, then it would be an extremely useful measure.
As Vessonen (2021) noted, the procedures for validation with the approach of RO are very similar to ordinary construct-validation procedures. However, one critical difference is that with the approach of RO, the researcher admits that the measure so validated is only one among many potential measures that might go by the same construct name. This aligns with the pluralism identified by Alexandrova (2017) for the concept and measurement of well-being, who noted that there is not a stable and unified concept of well-being but rather a diversity of definitions. The same construct name can therefore have different meanings in different research contexts, implying the need for multiple, different measures that could each be validated according to the approach of RO. The introduction of measures validated within the RO framework would be a good type of pluralism for psychological science, particularly when each measure is shown to be useful.
Thus, we do not believe that new constructs and measures should be completely prevented from entering the literature and that each construct should have only a single, standardized definition and measure. There is room in science for pluralism, and indeed, pluralism may be an important feature that facilitates scientific progress. However, pluralism does not mean that anything goes and that any concept and its measure should be uncritically accepted into the literature regardless of quality and usefulness. Explicitly taking the approach of RO can help greatly in this regard.
There may never be a final consensus and standard when it comes to psychological constructs and measures. People and cultures change. Therefore, we advocate a living standard enabled by transparent online repositories. A living standard would maintain a current record of past and present theoretical models for a construct and best practices for each measurement procedure. The theoretical models and measurement processes would be reevaluated and adjustments made as appropriate. Intelligence research, with its long history, can serve as a model here and, indeed, is the least fragmented subfield according to our index.
Unlike other maturer scientific disciplines in which after many decades or centuries of work, the theoretical models defining the constructs are clear and well supported and the corresponding methods for measuring those constructs have been well developed and standardized, psychology currently lacks the foundations necessary for a science that is at its core empirically quantitative. This is unsurprising given that psychology is a relatively young quantitative scientific discipline. However, for a scientific field to advance, great focus and attention must be given to the theoretical models defining its constructs and the methods for measuring them, and a field must take care not to create a situation of continuous proliferation of constructs and measures. We argue psychologists should raise the bar to prevent more low-effort contributions entering the literature and pool their efforts to improve standardization in psychological measurements.
Supplemental Material
sj-docx-1-amp-10.1177_25152459251360642 – Supplemental material for A Fragmented Field: Construct and Measure Proliferation in Psychology
Supplemental material, sj-docx-1-amp-10.1177_25152459251360642 for A Fragmented Field: Construct and Measure Proliferation in Psychology by Farid Anvari, Taym Alsalti, Lorenz A. Oehler, Zach Marion, Ian Hussey, Malte Elson and Ruben C. Arslan in Advances in Methods and Practices in Psychological Science
Footnotes
Acknowledgements
We thank Jan-Paul Ries for assistance in the literature review and Remo Schmutz for preliminary data visualizations. We thank Tim Rakow for engagement on examining potential biases and feedback on database analyses. All our data preprocessing and analysis code is available in the form of RMarkdown documents on the project’s GitHub repository (https://github.com/rubenarslan/construct_proliferation). The interactive treemap plots can also be found online (![]() /). The American Psychological Association (APA) databases PsycTests and PsycInfo are proprietary but accessible to APA members and institutional subscribers. Database extracts can be requested for research use.
/). The American Psychological Association (APA) databases PsycTests and PsycInfo are proprietary but accessible to APA members and institutional subscribers. Database extracts can be requested for research use.
Transparency
Action Editor: Yasemin Kisbu-Sakarya
Editor: David A. Sbarra
Author Contributions
ORCID iDs
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.