
Abstract
Psychological science holds substantial promise for informing policy decisions but faces challenges in realizing its potential. One widely recognized challenge is bridging the gap between the nonrepresentative study samples commonly used to evaluate interventions and the broader populations that policymakers aim to serve. To address this challenge, we introduce causal effect generalizability, an approach from causal inference and epidemiology, in the form of an accessible, nontechnical tutorial for psychological and behavioral scientists. We use publicly available data from a real-world psychology intervention study to illustrate why causal effects in a nonrepresentative study sample may systematically differ from those in a broader population. We provide a step-by-step guide with user-friendly R functions, enabling researchers to generalize causal effects from a study sample back to the full target population. This approach allows researchers to assess intervention effects in broader populations, offering valuable insights to guide evidence-based policy development. We hope this nontechnical introductory material will assist scholars in enhancing the policy relevance and real-world impact of psychological science.
Keywords
Psychological science holds great potential for addressing real-world problems and informing policies. Leveraging psychological theories, researchers have developed various interventions toward reducing prejudice (Paluck et al., 2021), changing climate beliefs and behaviors (Vlasceanu et al., 2024), reducing partisan animosity and anti-democratic attitudes (Voelkel et al., 2024), and reducing self-harm (Witt et al., 2021), among many others. Policy implications are often argued and positioned as a priority of the field (Constantino et al., 2022; Dodge et al., 2024; Kross et al., 2023; Paluck et al., 2019; Van Bavel et al., 2020; Verduyn et al., 2017; Williams & Nida, 2014).
Strengthening psychology’s policy relevance involves challenges (IJzerman et al., 2020; Kohrt et al., 2020; Maton & Bishop-Josef, 2006; Siegel et al., 2021; Walker et al., 2018). A widely recognized challenge concerns the study samples commonly used to evaluate interventions (Coppock et al., 2018; Diener et al., 2022; Sears, 1986), for example, college students at universities, volunteers recruited from social media sites, or participants from online crowdsourcing platforms, such as Prolific. Although a randomized study conducted using a convenience, nonrepresentative study sample can provide causal evidence of the intervention’s effectiveness within the sample, the evidence can rarely be extended to broader populations. As a result, the findings of many interventions do not necessarily generalize to the target populations that policymakers aim to serve, such as the general population in a nation. Without a clear understanding of an intervention’s effectiveness in a target population, policymakers risk developing distorted perceptions that can misguide decision-making. This can result in wasted cost, time, and resources on rolling out ineffective interventions; missed opportunities to implement promising ones; undermined public trust in psychological science; and ultimately, the persistence of societal problems.
The pitfalls of using nonrepresentative samples have been extensively discussed in psychological science and are well recognized by researchers (Arnett, 2008; Bauer, 2022; Henrich et al., 2010; Rad et al., 2018; Thalmayer et al., 2021). However, despite researchers’ best intentions and efforts, securing a representative sample is not always feasible. Many factors, such as limited resources, time constraints, study sites’ inaccessibility, and participants’ self-selection, make it difficult to achieve representative samples. These barriers are particularly pronounced for scholars working in underprivileged positions or underfunded institutions. While a complete and attainable solution remains elusive, one step in the right direction is explicitly acknowledging the use of nonrepresentative samples as a limitation in the discussion sections of empirical articles (Clarke et al., 2023).
But beyond acknowledging the lack of generalizability as a limitation, can scholars strengthen the generalizability of intervention studies through statistical methods? More precisely, how can scholars formally quantify an intervention’s effects in a full target population given a nonrepresentative study sample (Lund & Matthews, 2024; Mumford & Schisterman, 2019)? In this article, we introduce a practical approach that empowers substantive researchers to use an intervention study’s findings to inform effects in a target population: causal effect generalizability. First developed in the causal inference and epidemiological literature (Bareinboim & Pearl, 2013, 2016; Cole & Stuart, 2010; Kern et al., 2016; Lesko et al., 2017; Pearl & Bareinboim, 2014) and grounded in the potential outcomes framework (Imbens & Rubin, 2015), this approach is increasingly used in the health and medical sciences. For example, scholars have used this approach to generalize causal evidence of biomedical treatments from clinical study samples to target real-world populations (for a recent review, see Levy et al., 2024).
We aim to extend this approach to psychological science to enhance policy insights in the field. Here, we present an accessible, nontechnical introductory tutorial for psychological scientists. A glossary of causal inference terms we use throughout is presented in Table 1 for readers unfamiliar with the potential outcomes framework. The remainder of this article is organized as follows: We first introduce a real-world study from the psychology literature as a running example. We then formalize why the causal effect of interest in a nonrepresentative study sample can systematically differ from that in the target population. Next, we illustrate how to generalize the causal effect from the intervention study back to the full target population. We have developed user-friendly R (R Core Team, 2024) scripts to aid scholars in implementing the estimation methods. These are included using boxes as part of the illustrating example. 1 Finally, we offer practical recommendations for scholars seeking to generalize causal effects to improve the policy relevance of their developed interventions.
Glossary of Key Causal Inference Terms

An Illustrating Example
For illustrative purposes, imagine a research team searching for solutions to reduce the impact of misinformation in the United States. The team learns about a promising intervention from a psychology article: the fact-checking intervention (Hoes et al., 2024). The intervention emphasizes the source (e.g., a politician or news outlet) of inaccurate claims to increase skepticism and prevent misperceptions (i.e., perceived accuracy of false statements; Hoes et al., 2024). In a randomized study, the intervention reduced participants’ misperceptions by −0.35 (on a 4-point scale, where 1 = not at all accurate, 4 = very accurate; Hoes et al., 2024). The study sample comprised participants in the United States recruited by an opinion polling company (Hoes et al., 2024). Would this causal effect extend to the research team’s target population, the general population in the nation?
Why the Effect May Differ
The causal effect of the fact-checking intervention within the study sample would systematically differ from that among the full target population when two scenarios jointly arise. First, the distribution of baseline characteristics of the study sample and target population differs. Second, the causal effects differ depending on the levels of these characteristics (i.e., these characteristics moderate the effect). The resulting different patterns of effect heterogeneity between the study sample and the target population lead to different average causal effects. Continuing our example, suppose that (a) individuals without a college degree were underrepresented in the study sample and (b) the fact-checking intervention was effective only among college-educated participants, with no impact among participants without a degree. Together, these two factors would lead to the intervention having a much weaker effect in the general population than what was observed within the study sample.
We formally define these causal effects using established concepts from the potential outcomes framework, commonly called the “Neyman-Rubin causal model” (Holland, 1986; Rubin, 1990; Splawa-Neyman et al., 1990). Using our running misinformation example, let

where
In contrast, the corresponding effect among the full target population is

The target average causal effect in Equation 2 answers the following causal query: Among individuals in the full target population, what is the intervention’s potential impact if everyone hypothetically experienced the intervention versus did not experience the intervention?
The crucial difference between Equations 1 and 2 is not that the former is merely a subpopulation delineated by
Illustration of Generalizing a Causal Effect With Sample R Code
In this section, we use our running example to illustrate generalizing the causal effect of an intervention carried out in a study sample back to the full target population. The causal effect of interest is the effect of a fact-checking intervention (
To ease exposition, for the target population, we used information from 35,000 participants of a national representative sample quota-matched on key demographics (Voelkel et al., 2024). These participants were recruited from nonprobability opt-in internet panels by three different panel suppliers; for further details, see the Sampling Plan subsection of S0.2 in the Supplemental Online Materials of Voelkel et al. (2024).
The first step is to harmonize baseline covariates by aligning those in the study sample reported in the experiment of Hoes et al. (2024) with those in the target population reported in Voelkel et al. (2024). Both studies recorded the following baseline covariates: age, gender, race, education, political-party affiliation, and political ideology. We recoded the covariates so they were on the same scale across the study sample and target population when necessary. For example, to be consistent with the 5-point scale of political ideology in the study sample, we transformed political ideology, which was originally measured on a 7-point scale in the target population, to be on a 5-point scale. Summaries of these covariates (jointly denoted by
Baseline Covariates in the Study Sample and Target Population for the Misinformation Example
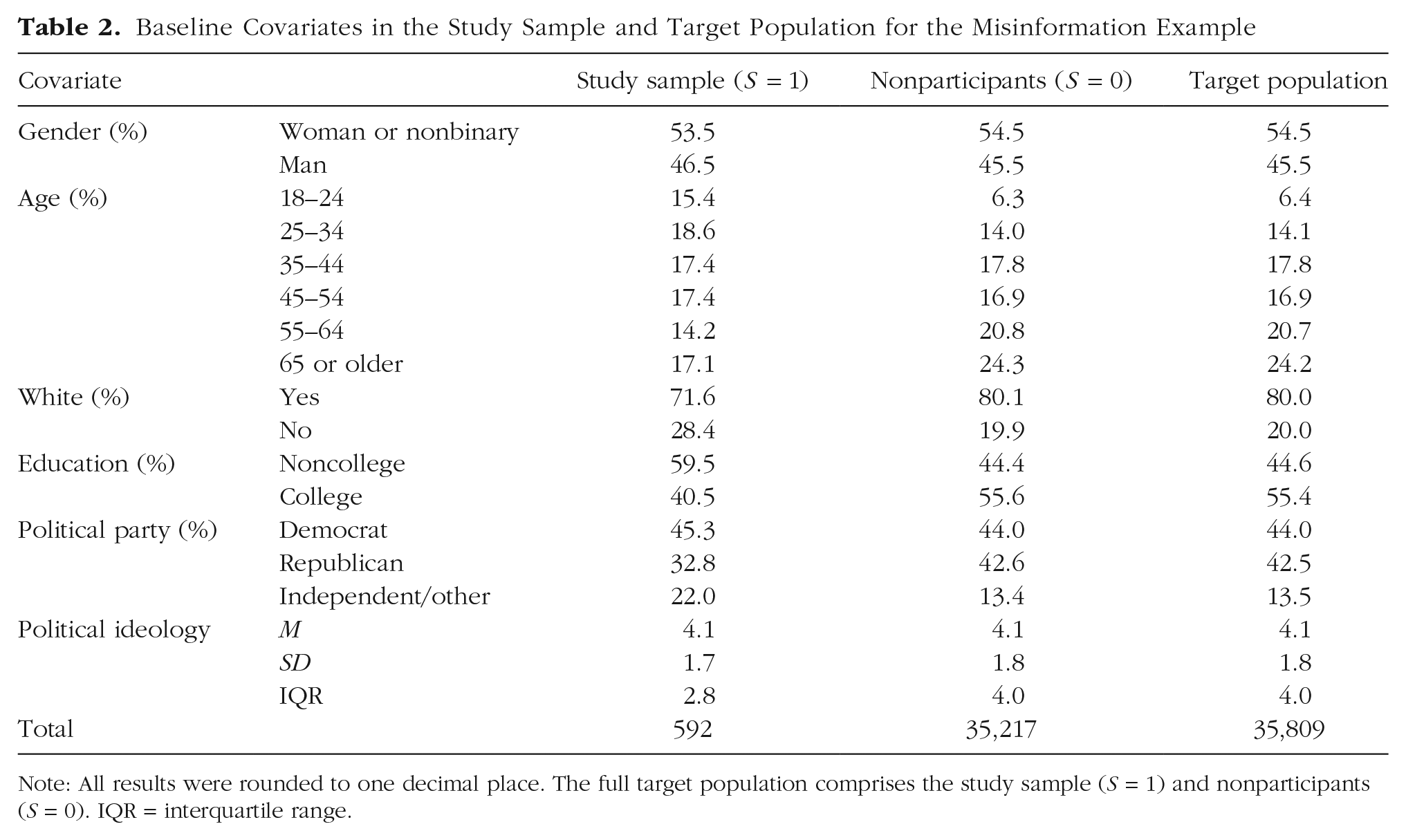
Note: All results were rounded to one decimal place. The full target population comprises the study sample (S = 1) and nonparticipants (S = 0). IQR = interquartile range.
Next, we composed the full target population by merging individual-level data from the study sample (
Snapshot of Merged Individual-Level Data for the Study Sample (


Finally, we used the merged data to generalize the causal effect from the study sample back to the target population. To help researchers implement this in practice, we developed a single R function (“
Sample Analysis Code to Generalize a Causal Effect


Nonparametric percentile bootstrap confidence intervals (Davison & Hinkley, 1997) may be constructed by randomly resampling individuals with replacement from the merged data and then applying the above function to each bootstrap sample. Moreover, it is also feasible to estimate the difference between the effects within the study sample versus among the target population. For example, the former may be estimated by fitting a simple linear regression of
Example Model Syntax for Calculating Bootstrap Confidence Intervals


The results are shown in Table 3. All three estimates were slightly further from zero, suggesting a stronger causal effect among the full target population. (There was, however, no difference between the effects in the study sample and target population up to sampling variability.) The analysis demonstrated that the effect of the misinformation intervention among the target population is estimated to be similar or slightly stronger than that within the study sample, suggesting that the intervention holds promise in reducing misperceptions of false statements among the general population in the nation.
Average Causal Effect Estimates in the Misinformation Example

Note: Nonparametric quantile-based bootstrap CIs were calculated using 2,000 samples with replacement. All results were rounded to two decimal places. CI = confidence interval; ISW = inverse probability of sampling weights; DR = doubly robust.
Practical Recommendation: Record Relevant Covariates, Even in Experiments
As demonstrated above, harmonizing covariates is a key step in generalizing causal effects. However, covariate information is routinely absent in many existing randomized studies. We encourage researchers to record a comprehensive set of baseline preintervention covariates in randomized experiments, especially when using a nonrepresentative study sample for various reasons (e.g., researchers’ resource constraints or participants’ self-selection). Carefully recorded covariate information improves the feasibility of generalizing the findings to target populations of interest, practically improving the study’s broader relevance and policy implications.
Although seemingly straightforward, researchers should be aware of how the covariates are measured. Generalizing a causal effect necessitates merging individual-level data in the study sample and nonparticipants from the target population. For example, we recoded covariates during the analytic stage in our illustration. Such covariate harmonization can be practically difficult or impossible (Ikesu et al., 2024; Power et al., 2022). Mismatches in the covariates collected in the study and those available in the target population can arise for various reasons, such as different timings, operational definitions, or measurement scales. Certain covariates may apply only to specific outcomes, such as preintervention outcome measurements, or be context-specific to a target population, such as socioeconomic status. To overcome this difficulty, we recommend that researchers identify data from their target population(s) early in the study-design phase, if possible, so that pertinent covariates—consistent with the measures in the target population(s)—can be measured in the experiment.
Discussion and Conclusion
In this nontechnical tutorial, we introduced causal effect generalizability to psychological researchers. We provided a step-by-step guide with user-friendly R functions to make causal effect generalizability more accessible to a diverse readership. By applying methods for effect generalizability, researchers can conduct rigorous quantitative evaluations of interventions’ effects in clearly defined target populations without implementing the intervention in these populations. This practical approach can offer valuable insights to guide evidence-based policy development. We hope this nontechnical introduction will assist scholars in enhancing the policy relevance and real-world impact of psychological science.
Because of accessibility and space considerations, we did not provide a comprehensive review of all relevant work within this tutorial. We encourage readers to explore the literature beyond the material we covered here. In addition to the references from the causal inference and epidemiological literature stated in the introduction, readers may be interested in other estimation methods (Ackerman et al., 2019; Kern et al., 2016). We implemented three effect estimators developed by Dahabreh et al. (2019) using linear or logistic regression models widely used by and thus familiar to a broad audience of psychology researchers. Alternative estimation methods leveraging machine-learning algorithms, such as Bayesian additive regression trees (Chipman et al., 2010) and targeted maximum likelihood estimation (Van der Laan & Rose, 2018), are available in the R package generalize (Ackerman, 2020). In addition, the method can be applied beyond psychology, such as in education research. 3 For example, Tipton (2014) provided a generalizability index to assess how generalizable a study sample is to a target population. Tipton and Olsen (2018) provided a general guide and discussion on generalizing causal effects, specifically, in education research. Finally, like any other statistical method, causal effect generalizability relies on assumptions. These assumptions are formalized in Appendix A and were discussed in depth by Degtiar and Rose (2023).
Although not the focus of this article, scholars can use the same framework to apply methods for causal effect transportability (Bareinboim & Pearl, 2013; Levy et al., 2024; Pearl & Bareinboim, 2014; Westreich et al., 2017). Whereas generalizability is used to extend causal effects from a study sample back to the full target population (that the study sample is nested within), transportability is used to extend causal effects to a target population distinct from and nonoverlapping with the study sample (Lesko et al., 2017). For example, scholars may aim to transport findings from studies conducted in urban areas to rural settings, or across countries, or from historical periods to the present. Although effect transportability offers exciting possibilities, it also introduces complexities. For example, interventions in psychological science often target behaviors, attitudes, and beliefs that can be deeply rooted in political and cultural contexts. These factors may constrain the feasibility of transporting a behavioral intervention to disparate or disjoint populations potentially incompatible with the study sample. Nonetheless, effect transportability can be a valuable tool, using the same class of methods as effect generalizability. We hope this article serves as an accessible introduction and a starting point for researchers interested in exploring these approaches.
Footnotes
Appendix A
Appendix B
Acknowledgements
We are grateful to Cande V. Ananth, Özge Gürcanlı Fischer-Baum, and Michelle Helinski for discussions that seeded the ideas for this article.
Transparency
Action Editor: Pamela Davis-Kean
Editor: David A. Sbarra
Author Contributions
Both authors contributed equally to this article and shared joint first authorship, but they are listed alphabetically by last name.