
Abstract
In recent years, the advancement of open science has led to data sharing becoming more common practice. Data availability has clear merits for science because it opens up possibilities for reuse of data sets by others, leading to less redundancy, more efficiency, and more transparency. The ideal is for scientific data to be as open as possible and findable, accessible, interoperable, and reusable (FAIR). Parallel to this development, recent times have seen more stringent guidelines with respect to data privacy, culminating in the General Data Protection Regulation law. Navigating the balance between protecting participants’ privacy and making one’s data set as open as possible can be challenging for researchers. In this article, we provide two worked examples with real data sets from the behavioral and social sciences on how to be as open as possible and as closed as necessary with the goal of maximally facilitating science while minimizing the risk of participant identification.
Data collected from human participants are central to the behavioral and social sciences. Typically, researchers who work with quantitative methods go through the following workflow: generate hypotheses, design a study, collect data, test hypotheses, interpret the results, and publish a scientific article. After generating hypotheses and thinking through the design of a study, the data-collection phase of the research cycle is often very laborious and time-consuming. Academic studies are often publicly funded and thus indirectly paid for by society at large. Despite that, the scientific publication at the end of the research cycle, which is based on the collected data, typically contains summary statistics but not the underlying data. The inaccessibility of data in scientific publications hampers the process of building new knowledge in three important ways.
First, inaccessibility of data in scientific publications makes it difficult for reviewers to detect potential mistakes in the statistical analyses of the study, undermining the usual processes that supposedly provide mechanisms for scientific self-correction. Mistakes in key statistical claims of scientific articles are common (e.g., erroneous claims of statistical significance, incomplete or even incorrect method descriptions, errors in the conducted data analyses, errors in the reporting of statistical results) and cannot be detected if the underlying data are not shared. Recently, Artner et al. (2021) attempted to reproduce 232 main statistical claims for which underlying raw data were available. After lots of trial and error, the authors were able to successfully reproduce approximately 70% of the statistical claims. This sizable proportion of nonreproducible results (30%) highlights the critical need for scientific articles to include their underlying data.
Second, the lack of accessible data underlying scientific articles hinders other scientists from independently verifying and expanding on the study findings without directly contacting the authors. Towse et al. (2021) reported a prevalence of open research data in psychology of 4%. Even if efforts to contact the authors are made, such requests are often to no avail. For example, in a secondary data-analysis project, Wicherts et al. (2006) requested data from 249 studies that were published in journals that had signed the American Psychological Association (APA) Certification of Compliance With APA Ethical Principles, which stated that, in principle, data should be shared on request (APA, 2001, p. 396). Included in their request was the promise that the data would not be shared with third parties, the approval of the ethics committee, and a description of their study aim (which was to reanalyze the data sets). Ultimately, the authors were able to obtain data from only 64 of those studies (25.7%). Note that the availability of data on request was, even in 2006, considered good practice in many journals and often explicit policy. The main barriers researchers give for not sharing data are that data sharing is not common in their field, preparing data for sharing is too time-consuming, and they never learned to share data (Houtkoop et al., 2018).
Third, not sharing the underlying data is hugely inefficient from a scientific perspective. Research teams that do not collaborate with the original authors and have different but related research questions will have to collect data from scratch. If such research teams had the original data set available to them, they might be able to answer these questions without the need to collect new data. This duplication of effort wastes time and resources and delays the advancement of scientific knowledge. Given that academic studies are often publicly funded and thus indirectly paid for by society at large, there is a moral obligation to maximize the utility of the data collected. Access to original data can facilitate meta-analyses, systematic reviews, and the development of new methodologies, enhancing the overall robustness and reliability of scientific conclusions. By promoting data sharing, the scientific community can foster a more collaborative and efficient research environment, ultimately driving innovation and discovery at a much faster pace.
To enhance accessibility of underlying data in scientific publications, the implementation of the so-called FAIR (findable, accessible, interoperable, and reusable) principles (Wilkinson et al., 2016) and data de-identification (e.g., Portage COVID-19 Working Group et al., 2020) are crucial. Whereas the FAIR principles provide a structured approach to making data findable, accessible, interoperable, and reusable—ensuring that data sets are managed in a way that maximizes their utility and accessibility—data de-identification ensures protection of participants’ privacy. However, practical guidance on proper de-identification when sharing FAIR data is lacking. In this tutorial, we provide two worked examples from the behavioral and social sciences showing how researchers can implement the FAIR principles and de-identify their data before sharing the data underlying their scientific article.
Implementing the FAIR Principles
To address the challenges of reproducibility and reusability in research, Wilkinson et al. (2016) developed the FAIR guiding principles for scientific data management and stewardship. But what does FAIR data entail? Findable means that data are assigned a unique identifier and registered in a searchable database. Accessible means that data are retrievable by their identifier using a standardized protocol; this protocol is open, free, and universally implementable and allows for authentication and authorization; and metadata—a set of machine-readable data that provide structured information about a data set, such as title, authors, and keywords—are accessible even when data are no longer available. Interoperable means that the (meta)data are machine-readable (i.e., in a format that can be read through an electronic device for interpretation and manipulation by a computer). Interoperable data thus use a formal, shared, and broadly applicable language for knowledge representation and include potential references to other data. Finally, reusable means that data are accurately and richly described (i.e., accompanied by machine-readable metadata and human-readable data documentation that meet domain-relevant community standards) and include a standardized license to grant the public permission for data reuse under copyright law (e.g., creative commons licenses).
The FAIR principles have rapidly gained widespread attention. Funding agencies recognize the importance of reusability of research data and stating data availability as a condition for funding (e.g., the Dutch Research Council and the Horizon Europe of the European Commission). These funding demands rapidly required adoption of the FAIR principles across various research fields. Adams et al. (2023) developed checklists for researchers in seven different disciplines to provide guidance with respect to making data FAIR. The authors concluded that disciplinary needs vary, influenced by researchers’ familiarity with FAIR principles, the relative prevalence of small qualitative versus large quantitative data sets, the presence of commercially sensitive data, and institutional mandates. For the field of neuroscience, Behan et al. (2023) described the Brain-CODE platform for research data and how data-sharing activities in the platform align with FAIR principles. The platform features rich metadata, access on request, a limited number of accepted data formats, and colorful data-exploration dashboards that enhance FAIR compliance. In the context of mental-health research, Sadeh et al. (2023) provided a table with FAIR applications. Despite these advancements in various fields, a comprehensive and unified guideline for applying FAIR principles to the behavioral and social sciences remains absent.
A consequence of the wide adoption of FAIR principles is that interpretations of what it means for data to be FAIR have diverged (Jacobsen et al., 2020). Given the diverse interpretations of FAIR principles, in the present article, we aim to clarify their application by presenting a detailed, step-by-step guide to the 15 FAIR principles as outlined by Wilkinson et al. (2016) for behavioral and social sciences, including practical examples and in-depth analyses.
Challenges in Sharing FAIR Data in the Behavioral and Social Sciences
The open-science movement and the introduction of the FAIR principles invited researchers to make their data openly available for reuse as widely and as early as possible (e.g., Huston et al., 2019; Janssen et al., 2012; Nosek et al., 2012; Nuijten, 2019; Ramachandran et al., 2021). However, there can be legitimate (legal and/or ethical) reasons to shield certain types of data. For instance, in the field of behavioral and social sciences, scientists aim to understand the interactions and factors that shape human behavior in response to their environment. Scientists have a moral obligation to protect the dignity, rights, and welfare of humans participating in their research (Grodin & Annas, 1996; World Medical Association, 2013; Nethics code, 2018). This duty of care translates into the way that researchers design scientific studies but should also be reflected in responsible reuse of the (personal) data collected from their participants.
In 2016, the General Data Protection Regulation (GDPR) was adopted in the European Union with the aim to protect the rights and freedoms of individuals. Although the GDPR has been defined as “the toughest privacy and security law in the world” (GDPR.eu, 2022), imposing obligations on organizations that are processing personal data, it also recognizes the importance of scientific research. Similar to other organizations, research institutes need to have a legal basis before processing personal data (e.g., consent or public interest; GDPR Article 6), be transparent to research participants, collect and process personal data for the communicated purpose only, and keep these data accurate and secure (GDPR Article 5). In contrast to nonscientific organizations, however, research institutes may store personal data for the purpose of archiving (and verification). Moreover, under strict conditions (GDPR Article 89), if data were collected on a different legal ground than consent, researchers may reuse personal data that have previously been collected for the purpose of scientific research because this is never considered incompatible with the initial purpose (GDPR Art 5[1][b]; GDPR Recital 50).
These exemptions to certain obligations of the GDPR for the purpose of scientific research make it possible to keep certain data available for verification purposes and sometimes even reuse while making sure that extra technical and organizational measures are in place to protect the personal data. These measures include pseudonymization, secure storage and sharing solutions, and possibly data-sharing agreements in case of sharing data between different organizations (GDPR Article 89[1]). From an ethical point of view, participants should be informed about the processing of personal data and give consent to sharing their pseudonymized data for scientific research before enrollment in a study, even when it is not legally required.
There is a middle ground between making data publicly available and completely blocking access. Several platforms (e.g., Zenodo [https://Zenodo.org/], DANS data stations [https://dans.knaw.nl/en/data-stations/], and dataverseNL [https://dataverse.nl]) allow for access to specific data sets on reasonable request. Even though these platforms enable responsible data sharing, restricted access procedures require significant time, effort, and sometimes monetary costs from researchers and data-support teams. This challenge is particularly acute in the behavioral and social sciences, in which conditionally sharing data is not a standardized practice yet.
Balancing Privacy and Research: Effective De-Identification Techniques for Human-Subject Data in Behavioral and Social Sciences
The main hurdle when making data publicly available while working with human-subject data in the field of behavioral and social sciences remains that researchers have the obligation, both morally and legally, to protect the rights and freedoms of their participants and protect the data concerning them (GDPR, Article 1[2]). A solution to make these data available while complying with moral codes and European privacy legislation is to make the data set anonymous before publishing. The GDPR defines anonymous data as information that does not relate to an identified or identifiable natural person. Processing and storing of anonymous data is not regulated by the GDPR because once data are anonymized, it is no longer considered as personal data, and therefore, the data-protection principles no longer apply (GDPR, Recital 26). This means that anonymous data can be shared and reused without any of the conditions that are mentioned in the GDPR.
An anonymized data set should no longer include information that can directly and unequivocally identify an individual (i.e., direct identifiers), such as names and social-security numbers. However, researchers should also be careful with including indirect identifiers in their data sets, such as age, ZIP codes, gender, occupation, and place of residence. Although these elements may not directly reveal an individual’s identity on their own, they could potentially be used in conjunction with other variables to indirectly identify a person. For example, extra information about the participant pool can often be derived from a published research article (e.g., students from a particular university and cohort), which in combination with the published data could potentially identify certain individuals in the data set. Fung et al. (2010) provided an extensive summary and evaluation of different formal approaches toward data de-identification. Arguably, the best way to assess whether de-identification has succeeded is that no data can be reidentified. El Emam et al. (2011) documented known attempts at data reidentification and found an overall success rate of reidentification attacks of 26%. However, the authors cautioned that many of the successful cases of reidentification were performed on relatively small data sets.
Making data sets publicly available involves a careful de-identification process to protect the privacy of individuals whose data are included in the data set. Several frameworks exist to aid researchers in making informed decisions regarding data set de-identification. These frameworks offer diverse methodologies and guidelines, catering to specific data types, research goals, and privacy concerns, emphasizing the importance of selecting the most suitable approach for preserving privacy while facilitating research. For example, the Canadian de-identification guide (Portage COVID-19 Working Group et al., 2020) covers topics such as identifying and removing direct identifiers, evaluating indirect or quasi-identifiers based on risk and utility, assessing the sensitivity of nonidentifying variables, and considerations for de-identifying qualitative data. In addition, it briefly touches on de-identification considerations for social media, medical images, and genomics data.
The five-safes framework is embraced by several Trusted Research Environments in the United Kingdom, including Health Data Research-UK and the National Institute for Health Research Design Service, and provides a useful framework for identifying what the elements are in a data set that are potentially sensitive and what levels of pseudonymization/anonymization are possible. The framework was originally developed in 2003 and was conceived to assist decision-making about data usage that may be sensitive or confidential (http://fivesafes.org; Desai et al., 2016). Inspired by this framework, the Dutch coordination point for research data management (LCRDM) came up with a matrix for the assessment of privacy risks with research data and for the determination of appropriate methods for risk management of data availability. The matrix identifies five different levels of data safety that differ in the level of anonymization (i.e., identifying information is fully removed) or pseudonymization (i.e., identifying information is replaced by pseudonyms and an identifiable combination of variables is accounted for) of the data (LCRDM, 2019). Table 1 provides a schematic overview of the five levels.
Five Levels of Pseudonymization/Anonymization
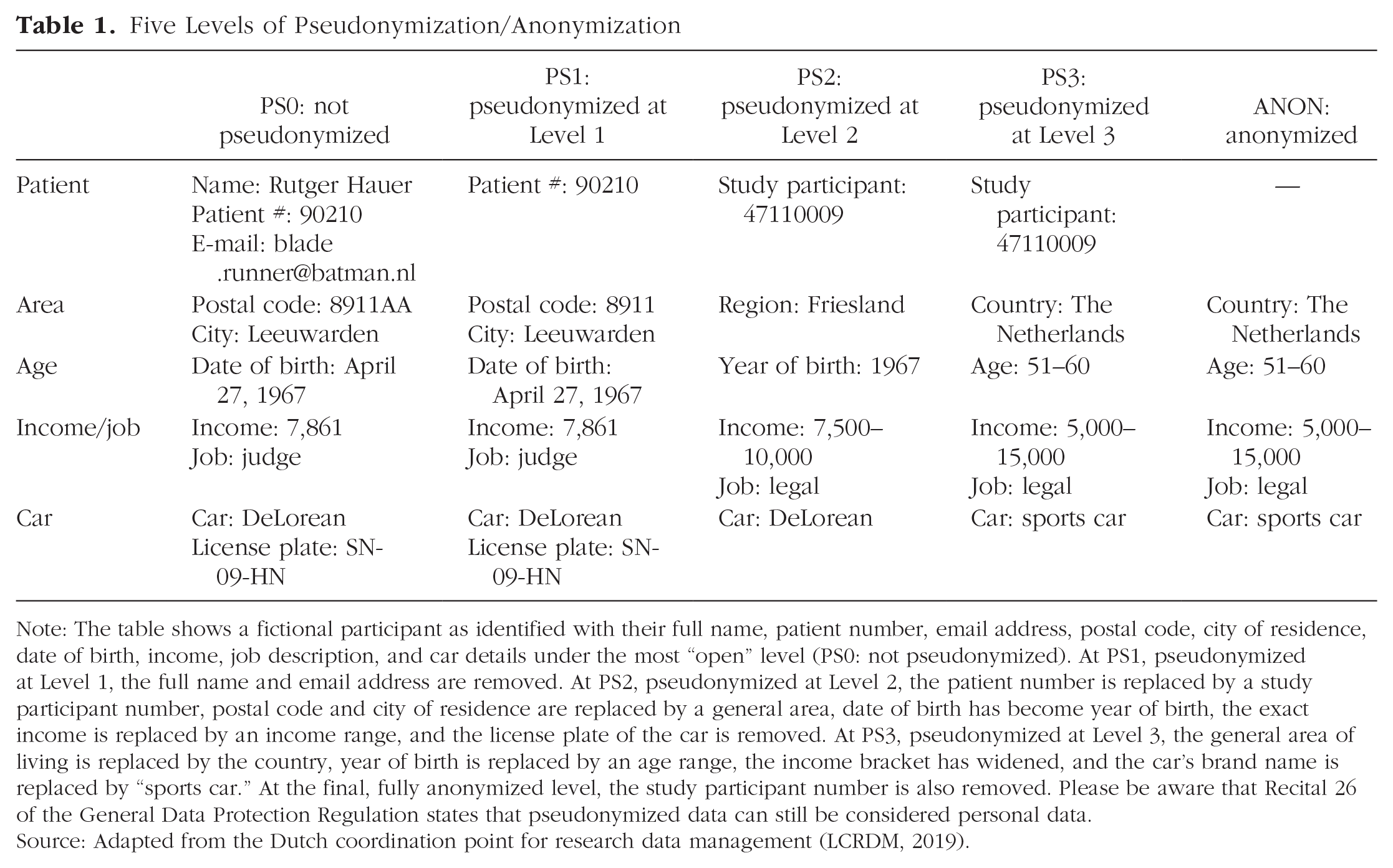
Note: The table shows a fictional participant as identified with their full name, patient number, email address, postal code, city of residence, date of birth, income, job description, and car details under the most “open” level (PS0: not pseudonymized). At PS1, pseudonymized at Level 1, the full name and email address are removed. At PS2, pseudonymized at Level 2, the patient number is replaced by a study participant number, postal code and city of residence are replaced by a general area, date of birth has become year of birth, the exact income is replaced by an income range, and the license plate of the car is removed. At PS3, pseudonymized at Level 3, the general area of living is replaced by the country, year of birth is replaced by an age range, the income bracket has widened, and the car’s brand name is replaced by “sports car.” At the final, fully anonymized level, the study participant number is also removed. Please be aware that Recital 26 of the General Data Protection Regulation states that pseudonymized data can still be considered personal data.
Source: Adapted from the Dutch coordination point for research data management (LCRDM, 2019).
As these de-identification frameworks show, a qualitative approach is necessary to identify and classify variables in terms of direct or indirect identifiers. After removing direct identifiers and deciding on the quasi-identifiers that are present in a data set and to help assess if a data set has been anonymized sufficiently, quantitative approaches for evaluating reidentification risk can be used. For example, the privacy model k-anonymity ensures that each record in a data set is indistinguishable from at least k – 1 other records with respect to certain attributes (El Emam & Dankar, 2008; for an accessible introduction, see Morehouse et al., 2024). The “k” value, an integer chosen by the researcher (e.g., 2), thus denotes the minimum number of records with identical quasi-identifiers, forming an equivalence class. The key principle is that in an equivalence class, it should be impossible to distinguish one record from the others. There are different variants of this model—such as l-diversity, t-closeness, and b-likeness—and SPSS and STATA code is available in Appendix 1 of the Portage COVID-19 Working Group et al. (2020) to create equivalence classes based on the quasi-identifiers in the data set and to list them by size. There are packages available for R (e.g., sdcMicro R package), open-source online applications (e.g., MinBlur and MinBlurLite; Morehouse et al., 2024), and point-and-click software tools that support a wide variety of privacy and risk models, such as ARX (https://arx.deidentifier.org/) and AMNESIA (https://amnesia.openaire.eu/). The output of these pseudonymization tools (i.e., k-anonymity, 1-diversity, t-closeness, b-likeness) heavily depends on its input: what variables are marked as potential indirect or quasi-identifiers.
Outline of the Present Tutorial
In this tutorial, we provide two worked examples from the behavioral and social sciences showing how researchers can de-identify their data and implement the FAIR principles before sharing the data underlying their scientific article. We address the 15 principles of data FAIRification using existing empirical data sets as examples. Given the uniqueness of each data set, universal guidelines are impractical. However, we posit that presenting representative scenarios and the decision-making processes involved can assist empirical researchers in making informed and responsible choices when sharing their anonymized FAIR data sets.
Throughout this article, we present a version of both data sets that includes all variables, including those that are to be removed during de-identification, so that the reader may see the difference between the preprocessed and postprocessed data. From an educational perspective, it would be ideal to be able to present both data sets in their raw, completely unprocessed form. This way, the reader may compare them with their respective postprocessed versions. Unfortunately, such an approach would defeat the very purpose of this tutorial article because we would make data available that are not properly de-identified.
The solution we have implemented in this article is replacing the recorded answers under the variables that are going to be pseudonymized or removed in the de-identification process with simulated data. For our two example data sets, we make available both the full data set (with entries for sensitive variables that require de-identification replaced by simulated values) and the curated data set (with only the necessary but sufficient variables). Consequently, the original preprocessed data that we make available for inspection is in a sense a hybrid data set, containing all original variables but only some variables (i.e., those that are retained in the postprocessed data) still have the original data entries as supplied by the participants. The use of simulation in this article serves educational purposes only—it is not employed as a tool for de-identification in the preparation of the postprocessed data sets.
All preprocessed and postprocessed data sets, metadata, and related scripts are available at https://osf.io/eqbd3/. For both data sets, variables that were used in the original analyses are described in the Appendix.
The remainder of this article is organized in two parts. In Part 1, we integrate existing frameworks designed to assist researchers in making informed decisions regarding data-set de-identifications into a step-by-step de-identification process and demonstrate their application through two practical examples. In Part 2, we detail the process of rendering the data sets FAIR and open and offer our recommendations for evaluating the success of the FAIRification process.
Part 1: Step-by-Step De-Identification Process
The process of de-identifying data when preparing data sets for publication involves several steps. Building on the existing frameworks for de-identification, we present a step-by-step de-identification guide for the social sciences that covers the whole de-identification process based on the anonymization plan from Radboud University Nijmegen (van der Burgt et al., 2024), which is, in turn, based on a template from the Finnish Social Science Data Archive (Finnish Social Science Data Archive, 2024; see Box 1). Our de-identification guide is also available on https://osf.io/eqbd3/ as a stand-alone document.
A. Describe your participant pool (What is your population? What was the sampling method? Rare phenomena?).
B. Describe the age of your data set (In what period did data collection take place?).
C. Distinguish between essential and optional variables (Which variables are used in the main analyses? Which variables were descriptive or collected for different studies?).
D. Identify and classify the identifiability of variables in your data set (Which variables are direct or indirect identifiers?).
E. Determine other sources of information that might influence the identifiability of individuals in your data set (Are there any third persons that might be aware of the people in your data set? Are there any other data sources available that might in combination identify an individual in your data set?).
A. Weigh the perceived risk and utility of the variables in your data set using the five-safes framework.
B. Consult the local data steward and/or privacy officer to assess identifiability.
C. Determine whether it is useful to apply quantitative methods to quantify the identifiability of your data set (e.g., k-anonymity, t-closeness, l-diversity) and apply appropriate quantification methods.
A. Remove (direct) identifiers from your data set.
B. Define and apply appropriate de-identification techniques to variables in your data set in collaboration with the data steward and/or privacy officer.
De-Identifying and Publishing Data: Two Examples
In the following sections, we provide a brief description of the two empirical data sets used as examples in our study. These data sets originate from the fields of organizational psychology and experimental psychopathology; however, many aspects of the data treatment are relevant to other domains in the behavioral and social sciences.
Step 1: Describe Your Data Set
Step 1A: describe your participant pool
Data Set 1
This data set, from the field of organizational psychology, is about age differences in boundary management during telework. Employees of various ages completed two surveys in which they reported on their boundary-management behavior, well-being, and productivity, with the goal of (a) developing a new scale of boundary-management tactics specifically tailored to the context of telework and (b) examining the mediating role of boundary-management tactics for age differences in teleworkers’ work–life balance and productivity. To this end, a sample of employees ages 18 to 70 years, working at least 20 hr a week, teleworking part-time, and reporting English as their native language were recruited through Prolific Academic, an online platform for human data collection (https://app.prolific.co/). The study consisted of two surveys spaced 1 week apart in which participants were requested to give information on several demographic, personality, and work-related variables. More information about this study, which was recently published (Scheibe et al., 2024), including study materials, data, and Mplus codes, is available at https://osf.io/hvyzu/. A screenshot of the data set is shown in Figure 1.

First 15 rows and 14 columns of the full organizational-psychology data set.
Data Set 2
This data set from the field of experimental psychopathology describes a study employing a trauma-film paradigm (see James et al., 2016). In general, the employed method serves to study the consequences of exposure to aversive material in healthy participants. The study presented here had two objectives: (a) to replicate earlier findings by Verwoerd et al. (2011) on the role of cognitive control (i.e., resistance to proactive interference) and neuroticism in the development of intrusive memories of a potentially traumatic film and (b) to optimize the trauma film for use in a future replication of another study (Holmes et al., 2009). Participants were international first-year psychology students from the University of Groningen (a cohort of approximately 500 students) who participated in the study in exchange for course credit. More information about this study, along with materials, data, and its associated preregistration, is available https://osf.io/9vtbz/. A screenshot of the data set is shown in Figure 2.
First 15 rows and 14 columns of the full experimental-psychopathology data set.
Step 1B: describe the age of your data set
Data Set 1
The data set on boundary management was collected during a lockdown period in the corona pandemic in 2021.
Data Set 2
The data set employing the trauma-film paradigm was collected in 2019.
Step 1C: distinguish between essential and optional variables
Data Set 1
A full description of all variables collected in the first data set is displayed in Table 2.
Variables Included in Original Data Set 1 (Names and Description) Before Making Data FAIR and De-Identified

Note: Red cells indicate direct identifiers, and orange cells indicate indirect identifiers. FAIR = findable, accessible, interoperable, and reusable; VBBA = Vragenlijst Beleving en Beoordeling van de Arbeid (translated: Questionnaire Experience and Assessment of Work).
Main and secondary analyses
An exploratory factor analysis was performed with the variables
Manipulation check
No variables functioned as a manipulation check.
Inclusion criteria
Participants were included or excluded based on the value of variable
Data Set 2
A full description of all variables collected in the second data set is displayed in Table 3.
Variables Included in Original Data Set 2 (Names and Description) Before Making Data FAIR and De-Identified

Note: Red cells indicate direct identifiers, and orange cells indicate indirect identifiers. FAIR = findable, accessible, interoperable, and reusable.
Main and secondary analyses
The study had two parts. Part 1 had a correlational design. The independent variables were
Manipulation check
This study included some variables that served to check whether the manipulations were successful. These included variables that assessed prefilm and postfilm mood (
Inclusion criteria
Participants were screened out depending on scores above clinical cutoff scores on variables
Step 1D: identify and classify the identifiability of variables in your data set
Here, we discuss the variables we classified as direct, indirect, or quasi-identifiers. For each variable, we carefully consider the risk each poses in terms of identification and the utility there is for publishing the variable as is (i.e., to not pseudonymize).
Direct identifiers, according to the GDPR, include specific types of information that can directly and unequivocally identify an individual. As a starting point, researchers could use the 18 direct identifiers listed by the protected health information in the Health Insurance Portability and Accountability Act (HIPAA): names; postal address information other than town or city, state, and zip code; dates related to an individual (e.g., date of birth); phone numbers; fax numbers; email addresses; social-security numbers; medical-record numbers; health-plan beneficiary numbers; account numbers; certificate/license numbers; vehicle identifiers and serial numbers, including license-plate numbers; device identifiers and serial numbers; URLs; IP addresses; biometric identifiers; full-face photographic images or comparable images; and any other unique identifying number, characteristic, or code. Note that although GDPR and HIPAA both consider direct identifiers, the GDPR has a broader definition of personal data (i.e., any information directly related to an identified or identifiable natural person).
Under the GDPR, there are certain data elements known as indirect or quasi-identifiers. Although these elements may not directly reveal an individual’s identity on their own, they could potentially be used in conjunction with other data to indirectly identify a person. When these indirect identifiers are analyzed collectively or paired with additional information, they can lead to the reidentification of an individual. The GDPR recognizes the significance of safeguarding such information even if it may not be directly associated with a person’s identity. Examples are age, ZIP codes, gender, occupation, and place of residence.
Data Set 1
Direct identifier was
Data Set 2
Direct identifiers were
Step 1E: determine other sources of information that might influence the identifiability of individuals in your data set
Data Set 1
Future users of the data might be friends or family members of a participant, and they might be able to identify the participant based on time stamps or identification numbers (e.g., through the
Data Set 2
Future users of the data may be cohort members from university or staff members who may be able to identify the participant (e.g., through the
Step 2: Determine the Identifiability of Your Data Set
Step 2A: weigh the perceived risk and utility of the variables in your data set using the five-safes framework
When pseudonymizing variables, we used an adapted version of the LCRDM matrix based on the framework of the five levels of pseudonymization/anonymization (Table 1). In some cases, two variables are treated differently for each data set, reflecting the fact that the risk of identification is different for different underlying populations. The step-by-step de-identification of both example data sets presented below is also available on https://osf.io/eqbd3/ as two stand-alone documents.
Data Set 1
The direct identifier
For
The variables
The variables
Data Set 2
For variables
The
The direct identifier
Although the variable
Although the variable
For variables
The variables
The variables P
Step 2B: consult the local data steward and/or privacy officer to assess identifiability
Once a selection is made of which variables to publish as is, which variables to de-identify, and which variables to exclude from publication, the next step is to assess the extent to which the de-identification has been successful. In the context of this article, we collaborated with our local data steward (M. de Jong, coauthor on this article) to assess de-identification of both Data Sets 1 and 2, and we have consensus that the two data sets can be made publicly available as per the description in Step 2A above.
Step 2C: determine whether it is useful to apply quantitative methods to quantify the identifiability of your data set (e.g., k-anonymity, t-closeness, l-diversity) and apply appropriate quantification methods
Formal metrics exist for quantifying levels of identifiability (see section “De-Identification Frameworks”), but each of these is heavily context dependent. Suitability of these metrics may be highest for data for which it is easy to find out what individuals are in the data set (e.g., data collected from very small populations with specific characteristics) or for data for which the sample reflects the entire population (e.g., data from all university students). In a large number of research projects in the field of behavioral and social sciences, however, data sets are often only a very small subsample of the population they reflect. Identifiability in these cases more often relates to the sampling method (i.e., what is known about the population in relation to the sample) and the characteristics of participants that might be very unique in this population, making it easier to single out an individual. The two example data sets under consideration in this tutorial article fall in this category.
For most data sets collected in behavioral and social sciences, we do not believe it is presently possible to circumvent human judgment completely. We recommend using quantification metrics only in collaboration with experts on de-identification, such as data stewards or privacy officers. They can provide advice on its usability and the levels of, for instance, k-anonymity that should be used when assessing the anonymity of your data set.
Step 3: Design De-Identification Techniques for the Variables in Your Data Set
Step 3A: remove (direct) identifiers from your data set
For Data Set 1, we have removed variables
Step 3B: define and apply appropriate de-identification techniques to variables in your data set
For Data Set 1, we have pseudonymized variable
Step 4: Go Back to Step 2 Until the Data Are Sufficiently De-Identified
It is likely that the process described above will be an iterative process. For example, for Data Set 1, we had initially opted to remove the
Step 5: Document the De-Identification Procedure and Archive/Publish This With the Data
The final step is to document the results of the previous four steps. This will prove helpful in interpreting the data for future users. What was the context in which the data were collected? What decisions were made when publishing the data?
For Data Set 1, the results of these steps have been documented at https://osf.io/fz9pu. For Data Set 2, the results of these steps have been documented at https://osf.io/kq32a.
Part 2: Making Anonymized Data Publicly Available While Adhering to the FAIR Principles
Once a data set has been properly de-identified to the extent that it is anonymous, the data set can be made publicly available. An effective and comprehensive way of doing so is to make the data set FAIR. The publication that coined the FAIR acronym lists 15 principles that can serve as a guide when making data sets FAIR (Wilkinson et al., 2016). Some of these principles fit empirical data sets from the behavioral and social sciences better than others. In what follows below, we address each of the principles using the framework by Jacobsen et al. (2020) as a guide and show how we implemented these principles in the two example data sets.
Several FAIR implementation communities have already defined FAIR implementation profiles (FIPs) to provide community standards for the implementation of the FAIR principles within and across research domains (Schultes et al., 2020). For the behavioral and social sciences, there are currently two FIPs available that can be used as guidance for the design for the implementation of the FAIR principles (i.e., SSSR and EduSocDL; https://fip-wizard.ds-wizard.org). Before implementing new solutions for each of the principles in the current tutorial article, these practices were assessed and when appropriate, implemented based on their fit with the data sets in the current tutorial article to comply with community standards in the field of behavioral and social sciences.
Findable
Principle F1: (meta)data are assigned a globally unique and persistent identifier
To be findable, data sets should be assigned globally unique and persistent identifiers. There are several persistent identifiers that are used by researchers to make their data set findable. Most data repositories provide the option to create persistent identifiers as soon as the data are published, which is in most cases the Digital Object Identifier (DOI). This option is also available in OSF, and therefore, DOI is used as a persistent identifier for both data sets. Any object with a DOI can be found by appending it to the string “https://doi.org/,” so in this case, the associated URL is https://doi.org/10.17605/osf.io/eqbd3.
In the context of this tutorial article, we present two distinct empirical data sets, and for each data set, we incorporate both an unprocessed and a processed version. Because the focus of this article is on the ensemble of all data sets rather than any of these data sets in isolation, we associate the entire project page with a single DOI (both data sets are part of separate publications that are associated with OSF pages https://doi.org/10.17605/osf.io/hvyzu and https://doi.org/10.17605/osf.io/9vtbz, respectively). In addition, OSF enables researchers to produce unique links to refer to individual data files (e.g., the unique link for the curated version of the .csv file belonging to Data Set 1 is https://osf.io/xu653). However, in articles that present data from multiple data sets that may be of interest in isolation (e.g., in empirical articles that present multiple studies), associating each data set with a unique DOI likely makes more sense.
Principle F2: data are described with rich metadata
To increase findability of a data set, it is also important to be able to find a data set based on the information contained in the data set. Principle F2 is meant to make a data set more findable based on the information in the data set through adding rich metadata to the data. Metadata, in the context of data management and the FAIR principles, refers to structured machine-readable information that describes various aspects of data. Metadata provide context and understanding about data, making it easier to discover, access, evaluate, and use.
Data repositories often provide guidance on the kind of project-level metadata that should be added when publishing data. Repositories either provide a standardized format to describe the (meta)data or have several metadata schemata to choose from based on the needs of a specific research project. There are several domain-agnostic metadata schemas that are suitable to apply to any data set that is published in a repository (e.g., DublinCore, DataCite, Data Documentation Initiative, and OpenAIRE). In some fields, it is important to know certain information about the data set to determine whether it is useful to answer new research questions. For example, in the case of human-cognitive neuroscience, it is important to know additional information about the data set and study, such as the neuroimaging techniques (e.g. MRI or EEG), the preprocessing pipeline, and specifics regarding the experimental paradigm. At the time of writing, a general-psychology metadata standard is under development (Psych-DS, see https://github.com/psych-ds/psych-DS). A (preliminary) version of both of the psychology and the human-cognitive-neuroscience standards can be used by researchers through OSF by clicking on the tab “Metadata” and then “Add Community Metadata Records” (https://osf.io/eqbd3/metadata/add).
Given that the psychology metadata standards were still under development when the data sets were processed, we have chosen to implement a domain-agnostic metadata standard. The data sets presented in the current tutorial article were published via OSF. Although OSF does not require researchers to describe the (meta)data in a standardized format, we have chosen to implement the Dublin Core metadata standard, which is one of the recommended metadata schemas of OSF.
Principle F3: metadata clearly and explicitly include the identifier of the data it describes
To make all research materials findable, it is important to connect the metadata with the data it describes. In our example, the DOI https://doi.org/10.17605/osf.io/eqbd3 links to a landing page that contains all (meta)data files and accompanying data documentation (i.e., general study information, codebook, and de-identification procedure) in one place. The persistent identifier should also be mentioned in the main article (e.g., in the method section and the data-availability statement), although this is not technically a FAIR issue. It may be preferable to have separate identifiers for different layers of (meta)data and associated data documentation, especially when there are many different associated files.
Principle F4: (meta)data are registered or indexed in a searchable resource
Findability increases when the data are deposited and indexed in a searchable resource, such as OSF, Zenodo, or DataverseNL. For the two data sets under consideration here, we have opted for OSF. OSF registers metadata of the landing page of a project with DataCite.
Accessible
Principle A1: (meta)data are retrievable by their identifier using a standardized communications protocol
Data(sets) should ideally be in the public domain and available to all without any restrictions. A simple example is a web page (the standardized communications protocol is Hypertext Transfer Protocol, or HTTP). We made our two example data sets publicly available on OSF (https://osf.io/eqbd3) and all the relevant protocols, such as the codebooks belonging to the data sets (e.g., https://osf.io/wqu9y/).
Subprinciple A1.1: the protocol is open, free, and universally implementable
A simple example is a web page (see above.) The open HTTP makes the data easily accessible to researchers from different countries and communities.
Although this does not strictly fall under this subprinciple, we note here that for a data set to be accessible, it needs to be in a format that does not require proprietary software to open (https://en.wikipedia.org/wiki/List_of_open_file_formats). The current data sets are both .sav files, meaning they require the paid SPSS (but see JASP; JASP Team, 2022). To convert .sav files into .csv files, we used R and the foreign package (https://cran.r-project.org/web/packages/foreign/; see also the example code on https://osf.io/eqbd3).
Subprinciple A1.2: the protocol allows for an authentication and authorization procedure when necessary
The “A” in FAIR does not necessarily mean open or free, but it does mean that researchers should provide the exact conditions under which the data are accessible. There may be good reasons not to disclose data and instead publish data sets under “restricted access” (e.g., privacy protection or ethical, legal, or commercial constraints). In such cases, the procedure for gaining access should be open (see Subprinciple A1.1). In case of privacy concerns, it is important to take extra measures to protect the rights and freedoms of participants in consultation with the local institutional review board. In addition, it is important to ensure that researchers who would like to reuse the data adhere to the terms of use. Authentication procedures can be set up to provide human access or machine access. An example of human access would be sending an email to an administrator that evaluates requests for data access on an individual basis. An example of machine access would be to require institutional login to gain access. Similar protocols are used when universities have (online) journal subscriptions because they allow researchers affiliated to these universities to gain access to articles without having to pay for individual access. The institutional login serves as a proxy for having met the relevant access conditions.
Policies with regard to data sharing with access restrictions may vary across universities or institutes. Authentication procedures requiring machine access are likely difficult to implement for small-scale individual research projects. For example, the University of Groningen currently recommends using DataverseNL (that supports a connection to OSF) because the University of Groningen can exercise control of the data and the access procedure in shared responsibility with the researcher, ensuring sustainable access protocols even after a researcher leaves the university or scientific career. Policies regarding publishing open anonymized data are less strict, providing researchers with more freedom with regard to which repository they would like to use. At the University of Groningen, important criteria are longevity of the platform, clear governance, and support of rich metadata.
Principle A2: metadata are accessible even when the data are no longer available
As mentioned under Principle F3, we recommend storing all (meta)data and accompanying documentation together under a single persistent identifier. This helps to ensure that metadata will remain available at a future date even if the data themselves are no longer accessible (e.g., because the informed consent specifies the data will be stored for only a finite period of time). The exception to this is the situation in which the project administrator chooses to remove or delete the entire project. Depending on the data repository, different removal protocols exist. In the case of OSF, all associated data files will be permanently deleted, and a project DOI will resolve to a page “that provides metadata about the removed file (file name, storage provider, if the deletion occurred on OSF or on an add-on service, name/GUID of user who deleted the file, and timestamp of file deletion)” (retrieved from help.osf.io on January 13, 2025).
Interoperable
Principle I1: (meta)data use a formal, accessible, shared, and broadly applicable language for knowledge representation
The heart of the interoperability principle lies in the concept of machine readability (i.e., a data format that can be automatically read and processed by a computer). Examples of formats that describe data files include JSON, XML, and RDF (and for references, RIS, BibTeX, and EndNoteXML). In our example data sets, we followed the DublinCore metadata standard when describing the data set and transforming the data into comma-separated values format “2023-09-22 Data Set 1, Curated.csv” and “2022-12-08 Data Set 2, Curated.csv.”
Related are formats that describe the contents of the data itself. Examples are BIDS (https://bids.neuroimaging.io/) from the field of neuroimaging and Neurodata Without Borders (https://www.nwb.org/) from the field of neurophysiology. At the time of writing, psychology does not have standardized formats for data description.
Principle I2: (meta)data use vocabularies that follow FAIR principles
This principle has to do with the presence of widely recognized controlled vocabularies, ontologies, or thesauri with globally unique and enduring identifiers that a computer can recognize. Jacobsen et al. (2020) used the example of the label “temperature”: Does it refer to body temperature or melting temperature? Without knowing, a machine would not be able to find agreements or disagreements between data sets.
Taking “work-life balance” (see Data Set 1) from the European Language Social Science Thesaurus (ELSST; https://thesauri.cessda.eu/elsst-3/en/) as an example, the vocabulary includes the following identifier: urn:ddi:int.cessda.elsst:0722ed90-dfb8-46e0-8c96-37f1cc3d7337:3. This identifier allows a computer to disambiguate “work-life balance” from, for instance, “happiness” (which has identifier urn:ddi:int.cessda.elsst:c969ed50-6501-4cc6-b3b3-4a4207ef0f6c:3).
Principle I3: (meta)data include qualified references to other (meta)data
The idea is to ensure that (meta)data sets contain relevant and standardized references to one another. Continuing with the example of “work-life balance” in ELSST, the entry lists as related concepts “flexible working time,” “hours of work,” “job sharing,” “shift work,” and “Sunday working.” The Appendix includes the JSON segment that machines can use to identify these relationships. The OSF platform has a similar functionality for relating (meta)data “under the hood.”
In the context of a batch of individual studies collected in a longitudinal context, it is important to ensure that labels are applied similarly across data sets and that metadata files refer to the relevant data sets appropriately.
Note that in the context of this tutorial article, we have made two data sets available for educational purposes (i.e., in the context of providing a guide on how one might go about de-identifying one’s data while adhering to FAIR principles). The data sets are also part of their own empirical research cycle that are published separately (i.e., https://doi.org/10.17605/osf.io/hvyzu and https://doi.org/10.17605/osf.io/9vtbz). In that context, the function of the data sets is different, and additional material, such as stimulus material or analysis scripts, might be appropriate that is not relevant in the context of the present article. These empirical articles have a separate OSF page associated with them, and it is important that the OSF pages cross-reference each other when appropriate.
Reusable
Principle R1: (meta)data are richly described with a plurality of accurate and relevant attributes
In our opinion, when the first three letters of the FAIR acronym are addressed, the reusable part follows somewhat naturally. To enable decision-making for individuals who want to reuse the data (machine or human), researchers should provide both machine-readable metadata and human-readable data documentation for reasons of findability but also to inform a potential new user on the context under which the data were generated. We reiterate the recommendation of Jacobsen et al. (2020) to be as generous as possible when describing data: The reader is almost assuredly less knowledgeable about data than the person collecting it.
For the current article, this means that we followed the machine-readable metadata schema Dublin Core (for more information, see “Principle F2”). In addition, both data sets were accompanied by human-readable data documentation. More specifically, we included a codebook explaining what each variable represents and measures, the de-identification protocol and the choices that were made to de-identify the data, the combined research information for participants and informed-consent form, and an R script that transforms the .sav files to .csv files.
Subprinciple R1.1: (meta)data are released with a clear and accessible data usage license
Legally speaking, public data must be accompanied by a data-usage license for it to be open. We have used and recommend using the CCO 1.0 Universal license, which places the data in the public domain (CC BY 4.0 technically requires that attribution should be given to sources that created the data set). Note that OSF facilitates setting a data-usage license.
Subprinciple R1.2: (meta)data are associated with detailed provenance
This principle pertains to a description of the data, including how, why, and by whom it was generated (including if the data were provided by a third party), to support other researchers assess the reusability of the data for their own research purposes. Part of this provenance, such as information about contributors, abstract, and date of creation, is already included in the machine-readable metadata (for full information that is included, see JSON file that is harvested by DataCite: https://api.datacite.org/application/vnd.datacite.datacite+json/10.17605/osf.io/eqbd3). In this project, it was also important to indicate how data were de-identified (because de-identification potentially reduces the available information in a data set) so that other researchers can evaluate whether data are useful to their own research questions. Therefore, we included human-readable documentation on the de-identification procedure and information about how the study was conducted (i.e., a wiki with a general description of the original research setup, codebook and combined research information for participants, and a blank informed-consent form). For more detailed information on the original research setup and the analyses conducted for the individual research articles, we refer to the separate OSF pages containing the (meta)data and data documentation that are connected to these research articles.
Subprinciple R1.3: (meta)data meet domain-relevant community standards
This principle describes the need for minimal information community standards, or vocabularies, to assess data quality and to allow for replicating the reported findings. An example of such vocabularies in psychology is the fifth edition of the Diagnostic and Statistical Manual of Mental Disorders (https://www.psychiatry.org/dsm5). Other examples are the ELSST (https://thesauri.cessda.eu/elsst-3/en/), the Thesaurus for Social Sciences (https://concepts.sagepub.com/vocabularies/social-science/en/), and the Thesaurus of Psychological Index Terms (https://www.apa.org/pubs/databases/training/thesaurus).
Regardless of whether relevant community standards are present, the reproducible data set should be accompanied by extensively and clearly annotated reproducible code (e.g., through using R scripts; see e.g., https://osf.io/qegy4). In the example data sets, we chose to retain as the bare minimum variables that are used (a) in the main (and secondary) analyses, (b) in the manipulation check, and (c) as criteria for inclusion in the study. For both example data sets, we discuss key variables for each of these in section “Step 1C: Distinguish Between Essential and Optional Variables.” In addition, we retained variables that we deemed safe in terms of risk of reidentification and that may be of interest to other researchers for follow-up analyses.
Discussion
Open data has clear merits for science because it enables researchers to detect mistakes, answer different research questions without collecting new data, and therefore increase efficiency and offer opportunities for academic progress. The advantages of openness for science must be balanced with the potential risks of openness with respect to the privacy of participants. In the European Union, researchers need to comply with the GDPR law, which may seem a delicate exercise for individuals not familiar with this process. More generally, however, researchers from non-EU countries also need to find a balance between the scientific interests (as open as possible) and the privacy interests of participants (as closed as necessary).
In this article, we introduced the five-safes framework (Desai et al., 2016) and the pseudonymization/anonymization matrix to guide researchers in making decisions about data usage that are potentially sensitive or confidential, and we apply it through a stepwise approach (based on the anonymization plan from Radboud University Nijmegen by van der Burgt et al., 2024, which is, in turn, based on a template from the Finnish Social Science Data Archive) to two worked examples of concrete choices using real data sets. In the first example, we use a data set from organizational psychology that was collected with the aim of studying age differences in boundary management during telework. In the second example, we used a data set from experimental psychopathology coming from an analogue study employing a trauma-film paradigm. We systematically worked through both data sets, making both FAIR while limiting risk of reidentification of participants based on the published data. Throughout the process, we collaborated with our local data steward to design appropriate de-identification techniques, implement the FAIR principles, and assess whether de-identification was successful.
In Part 1 of this tutorial article, we presented a step-by-step de-identification process that we applied to two worked examples presented in this article. We learned several important lessons when preparing these examples. First, as a general rule, variables that contain time stamps or person IDs should never be made publicly available. They have no utility for other researchers, and even in the case of online data collection, they may be enough to identify participants with. Having seen someone walk out of a lab or having seen someone do a study online means knowing the time stamp alone would be sufficient information to retrospectively identify a participant. The previous point does not change the fact that there will be many cases in which it is useful to describe the approximate time an entire data set is collected. For instance, when investigating the effects of working from home, it is relevant for the reader to know that data were collected during the corona pandemic, when many people were required to work from home. In addition, there may be cases when person IDs could be beneficial to link different data sets that are collected in a longitudinal batch. In such cases, we recommend restricted access to the data or replacing the person ID that was assigned in the context of the original study with a linking ID on the online repository so that research assistants involved in collecting one survey cannot use published data from a second survey to identify people.
Second, some variables may require different treatments in different data sets. When participants come from a local student population, as was the case in our second worked example, variables such as age, nationality, or native language might be unique identifiers. If, on the other hand, participants in the data set were recruited online with the only restriction being that their native language is English, as was the case in our first worked example, the same variables age, nationality, or native language no longer pose any risk of identification. Similar concerns apply to a variable such as gender. Have minority response categories been selected that would allow identification of participants? For our first data set, everyone identified as female or male, mitigating the risk of identification, but this may obviously not hold for different data sets. Thus, the context in which variables were collected is really important in determining whether to anonymize or pseudonymize variables.
Third, variables that contain open-text answers should always be scrutinized for identifying information if researchers consider making them publicly available. Evaluating text answers to decide whether they can be included in the published data set can be a tedious and complicated task. A first step is to have at least two researchers check independently whether respondents included identifiable locations or names. If so, these identifiers should be deleted from the data set that is prepared for a third party. A second step is to have those researchers check whether respondents reveal recognizable personal events. If so, those events should either be substituted for a different but related event (e.g., “house was flooded” can become “power outage”; “basketball training” can become “soccer training”) or should be replaced by a more general and therefore less traceable event (e.g., “house was flooded” can become “accident at home”; “basketball training” can become “leisure activity”). We advise that in case the variables are not directly relevant (e.g., when participants are given the opportunity to share their thoughts or feelings about the study), the easiest solution is to simply not publish this variable altogether. If it is an important variable, however, carefully going through all fields is unavoidable, and some subjectivity in interpreting which answers can and which should not be published cannot be prevented.
In some cases, it might be impossible to completely anonymize a data set. In such cases, a solution is to replace the original raw data with synthetic data (e.g., using the synthpop R package, available from https://cran.r-project.org/web/packages/synthpop/index.html). Such an approach has the advantage of allowing researchers to publish variables for which de-identification is difficult or impossible by replacing individual entries of participants with simulated values (analogous to our approach for de-identifying the full, preprocessed data). Depending on the needs, it is possible to uncouple data entries from specific participants while retaining some overall property. For instance, in case of a simple two-group comparison, the group means can remain the same but every individual data value is different. A downside of this approach is that potential future analyses that factor in different dimensions will no longer be possible. For instance, in the previous example, a follow-up analysis that takes age as a covariate will not yield sensible results because the simulated values were not created with respect to the age variable, just the group membership. Another disadvantage is that this sort of approach does not work well for any type of repeated measures design, such as an intensive longitudinal data study, because the dependency of data entries across measurement points needs to remain intact.
A general lesson we would like to stress that has not yet come up explicitly in this article is that researchers who want to open up their data should start as early in the research cycle as possible, for instance, by thinking about the text of the informed consent. When collecting or processing personal data at any point during a research project, the GDPR requires that participants are informed on how data will be processed and whether data will be shared with others. Typically, researchers in the field of behavioral and social sciences inform participants through an information form and ask for consent from participants to process personal data for the purpose of their research, including the reuse of these data for future research projects either by themselves or the larger research community. If consent was used as the legal basis for processing the data, it is important to either define under what conditions participants consent to the reuse of their personal data or to anonymize the data to such an extent that data cannot be traced back to individual data subjects under any circumstance before making it publicly available. Even though it might not be necessary from a legal perspective, from an ethical perspective, one could argue that participants should be informed about the sharing and reuse of anonymized data. More specifically, research participants invested time and effort to participate in this specific study and might not agree with their data being reused for other purposes.
When writing this article, we were painfully reminded about the importance of thinking about the phrasing of the informed consent well in advance of a study. For our first worked example, we started by processing a similar data set from the same researchers, and only after a while, we found out that the consent form did not ask participants for permission to share the personal data for reuse by the scientific community. Although this cost us some time, we found a different data set for which participants did explicitly give permission for data sharing among researchers. To prevent such errors, we highly recommend including a blank consent form along with data files because at the very least, this action serves as an extra reminder to verify that sharing is appropriate. A common issue may be the lack of specificity in the consent given by the participant because details about who has or will have access to the data are not always present. The GDPR explicitly states that the study description on which basis the participant gives consent must be specific and informative.
Besides the legal ground for collecting, analyzing, and reusing personal data in a research project, it is also important to consider another principle of the GDPR at the beginning of your research, that is, data minimization. According to GDPR Article 5, when dealing with personal data, researchers should collect and use only the data necessary for the study purpose. For instance, survey-collection software typically collects dates, IP addresses, and latitudinal and longitudinal coordinates. If these variables do not serve any purpose for the research, a researcher should try to prevent collecting these data or if this is not possible, discard them as soon as possible after data collection. Although it fell outside the scope of the current article to provide guidance on how to implement the principle of data minimization, designing a research project while keeping this principle in mind would support a more efficient road to making research data collected from human participants FAIR.
The two examples discussed in this article are only two of many potential data sets we could have used. Every data set has its idiosyncratic issues and decisions that need to be made, but we believe that the issues that have emerged from this exercise are applicable for many other data sets within and outside the social sciences. Anonymizing or pseudonymizing raw data will not always be possible, for instance, in cases in which the raw data include video material of participants. Video-editing techniques exist for blurring faces and distorting voices, but they may not always be sufficient to fully anonymize the data. In such cases, we recommend researchers make the processed data available, for instance, the coding of the behavior in the video, along with the codebook that explains how coding was done. At the very least, this would flag that these data exist and enable others to contact the authors of those data.
In Part 2 of this tutorial article, we described how we made the anonymized data publicly available while adhering to the FAIR principles. Here, we had two important insights. First, we realized that openness does not refer to just the availability of the data itself but also relates to the software program it was processed in. Data files for both worked examples were available in SPSS, but one might question whether it is inclusive to use commercial packages (which may be unavailable to many researchers) to present data. Researchers should be aware that making data files that were collected using proprietary software publicly available may in practice mean the data are open to a limited and arguably privileged subgroup of researchers. Fortunately, several options are available for converting such data files to a format that is publicly accessible, such as .csv. When choosing such an option, it is key to confirm after conversion that all relevant information is retained (e.g., variable labels, potential references between multiple tabs).
Second, the language in which the original data were collected is not always accessible to other researchers. We mentioned we had to abandon a different data set as our first example because the informed consent restricted sharing the data. In this unused data set, participants were all German native speakers. Although we were sufficiently fluent to at least understand the variable labels and open-text answers, this will likely not hold for the academic community at large. This presents a dilemma: On the one hand, translating the data set to English would be more inclusive and would make the data file more accessible, at least in an intellectual sense. On the other hand, is it reasonable to require researchers that have collected data in a language other than English to translate their data, stimulus material, and other materials to English? We recommend translating the codebook (including variable labels) to English because failing to do so hampers understanding of how reported research questions are operationalized. However, we do not think it should be necessary to translate all participant statements in a data set that is made available online. Regardless, whenever anything is translated, the original untranslated version should be made available as well.
Recently, researchers and data support staff have been working on the implementation of FAIR collaboratively, resulting in best practices in several research fields. While writing this article, we came across the initiative of GO FAIR Foundation to develop FIPs together with the community to provide community standards for the implementation of the FAIR principles in and across research domains (Schultes et al., 2020). For the current article and data sets, it provided extra guidance to use the FIPs that were developed for social-science survey research as a reference for choices that we made for the current tutorial article (https://w3id.org/np/RA2C1h_SkOgPiylavYM6bs_wSW6SgzrvC5kiVdJvmWq9s). We recommend that researchers look into these FIPs for their own respective research fields before developing their own practices. Although only a few FIPs have been developed and these best practices are not yet known very well by actual researchers, these efforts can save a lot of time and effort when trying to develop a FAIRification pipeline for yourself.
In the end, there are several tools that help researchers to check how FAIR a data set is, including the CSIRO 5 star data-rating tool (Yu & Cox, 2017, Version 5), the DANS FAIR-Aware tool (https://fairaware.dans.knaw.nl/), and the Australian Research Data Commons’s FAIR data self-assessment tool (https://ardc.edu.au/resources/aboutdata/fair-data/fair-self-assessment-tool/). These tools allow to check how findable, accessible, interoperable, and reusable a data set is and give insight into how one can enhance its FAIRness. For findability, for example, the Australian Research Data Commons’s FAIR data self-assessment tool asks the following four questions: (a) Does the data set have any identifiers assigned? (b) Is the data set identifier included in all metadata records/files describing the data? (c) How are the data described with metadata? (d) What type of repository or registry is the metadata record in?
An important concluding observation is that our decision process in preparing both data sets for online sharing is subjective. The reader may not have agreed with every decision we have made on this front. We do not, however, believe it is possible to have a “gold standard” for data sharing. Rather, we view the factors that feature into the decision of how far to de-identify and what factors to consider when FAIRifying a data set as the important take-home from this tutorial article. We hope this work can provide inspiration on how to approach the delicate process of opening up data while respecting the privacy of the participants that provided the data.
Concluding Remarks
Sharing data has clear benefits to the academic community and to society at large. We hope the reader shares our conviction that what to share and what to de-identify is a process that requires careful consideration: As is often the case in science, no mindless ritual exists. We hope the worked examples in this article provide researchers with some inspiration on how to balance openness and privacy when sharing their own data sets.
Footnotes
Appendix
In the European Language Social Science Thesaurus, the concept “work-life balance” lists as related concepts “flexible working time,” “hours of work,” “job sharing,” “shift work,” and “Sunday working.” To allow machines to identify these relationships, the metadata of the work–life balance entry includes the following JSON segment:
“related”: [
{
},
{
},
{
},
{
},
{
},
{
}
]
Acknowledgements
We thank Katie Corker, Malte Elson, Leon ter Schure, Diana van Bergen, and Christina Elsenga for their input on previous versions of this article.
Transparency
Action Editor: Rogier Kievit
Editor: David A. Sbarra
Author Contributions