
Abstract
Before conducting statistical analyses, scholars and researchers often have specific hypotheses about differences between groups of means. Their hypotheses are frequently tested by applying post hoc comparisons with statistically significant simple or interaction effects. With the exception of exploratory studies, using post hoc comparisons can increase Type I error rates and decrease statistical power. A well-known solution involves planning comparisons before the study. However, the coding of such planned comparisons can be difficult to understand and implement, especially for customized comparisons and interaction effects. In this tutorial, we aim to reduce such difficulties by examining all the possible types of planned comparisons, even the customized ones, for both main and interaction effects. In this tutorial, a Shiny App coded in R and called “appRiori” is presented. appRiori is coded to help in understanding both the logic behind the planned comparisons and the way to interpret them when a model is tested. By using empirical examples on reproducible data, we explain how to code any default planned comparison executable in R. Moreover, through some features of appRiori, the customization of planned comparisons is shown, even on interaction effects, such as the possibility of creating customized contrast through click-and-drop menus. For each step, the R code related to the planned comparison is provided. Implications and fields of use of planned comparisons and appRiori are discussed.
Although scientific progress requires increasingly complex data analyses, most of the time, researchers need to understand how to compare means (sometimes trends) between groups. Statistical comparison of such means can be straightforward, especially in models testing the relationship between a single numeric response variable and a single categorical predictor with two levels (e.g., analysis of variance [ANOVA] and linear or nonparametric models). The situation becomes more difficult when the single predictor has more than two levels or when researchers are also interested in testing interaction effects. These situations are usually approached in two ways. In one strategy, a model is tested, and overall statistics such as
If researchers have specific hypotheses, guided by either ideas or previous knowledge on the topic, another strategy is to set specific planned comparisons or contrasts among the observed conditions’ means. These comparisons offer three advantages. First, a priori contrasts allow for balancing the trade-off between Type I and Type II errors (Garofalo et al., 2022). In particular, minimizing the number of multiple comparisons reduces the chance of observing an effect that does not actually occur; consequently, statistical power increases (Davis, 2010). This applies to both simple and interaction effects (Graham, 2000; Seaman et al., 1991). A second related advantage is that some a priori comparisons could emerge as statistically significant compared with the same (nonsignificant) post hoc comparisons (Kwon, 1996). Finally, this type of comparison allows the researcher to be more thoughtful in designing the experiment and the analyses, thereby increasing the quality of the work (Buckless & Ravenscroft, 1990; Kuehne, 1993; Kwon, 1996; Ruxton & Beauchamp, 2008).
Although the consensus on the advantages of a priori contrasts over post hoc comparisons has been consolidated (Kuehne, 1993; Thompson, 1990) and some interesting works provide suggestions and guide on contrast analysis (Haans, 2019; Rosnow et al., 2000), post hoc comparisons are still preferred. Ruxton and Beauchamp (2008) pointed out that only a very small percentage of studies used a priori contrasts, even when researchers clearly stated specific hypotheses at the beginning of the article. This evidence has been found independently in various research areas. A study by Garofalo and colleagues (2022) examined several articles in the neuroscience literature and found that in cases of interaction effects, 98% of articles used post hoc comparisons, and only the remaining 2% used planned comparisons. Likewise, Brehm and Alday (2022) conducted a metascientific study examining more than 3,000 articles in psycholinguistics. The authors found that fewer than one third of the studies explicitly stated which planned comparisons were used. This lack of use persists and is related to issues of reproducibility (Brehm & Alday, 2022) and sometimes the rejection of articles (Agathokleous & Yu, 2022).
A possible explanation for such limited use could be that a priori contrasts can be difficult and complicated (Agathokleous & Yu, 2022) in terms of (a) understanding the logic and formal aspects; (b) application, that is, how to code them with statistical software; and (c) interpretation of their statistical effect without using an overall statistic. These issues are more evident not only for well-known contrasts, such as treatment, sum, or Helmert, but also when researchers need to set customized contrasts even without considering interaction effects. Indeed, the difficulty in programming customized contrasts is one of the main reasons behind the limited use of this type of comparison. The same applies to the use of planned comparisons in the case of interaction effects. Manuals and articles addressing interaction effects often use technical, ambiguous, or cumbersome terms, making such constructs accessible only to researchers with a strong formal background. Some statistical software provides dedicated commands or shortcuts to insert the comparisons to be tested in a potential model: Nonetheless, it is often unexplained how such comparisons are then tested inside the model and how the model coefficients (e.g., in case of regression) are calculated. As a result, some readers continue to have difficulty understanding planned comparisons for models for which software shortcuts are not available, so they do not use them (Garofalo et al., 2022).
There is a consensus on the need for tools to help researchers with planned comparisons in a way that does not rely solely on default settings in statistical software, which can be misunderstood (Brehm & Alday, 2022), but, rather, in an easy and intelligible way. Nonetheless, such need has received poor or no response. The difficulty in applying planned comparisons can be summarized in four issues: (a) understanding and learning the logic behind a priori contrasts, (b) directly planning both well-known and customized contrasts, (c) setting contrasts not only for simple effects but also for interactions (e.g., two-way and three-way), and (d) coding the corresponding ready-to-use code of the statistical software in a way that such code can be applied directly before running the analysis.
In the present article, we aim to address each of these critical issues by providing a tutorial on (a) how planned contrasts work, (b) which kinds of contrasts can be used, (c) how to set customized contrasts, and (d) how to obtain the R code for such contrasts (R Core Team, 2021) for both simple and interaction effects. A Shiny App coded in R (Chang et al., 2021), called “appRiori,” has been programmed to make each step understandable and reproducible.
The article is organized as follows. In the next section, a brief formal explanation of what contrasts are and their role in handling categorical variables in linear models is provided. In the “Type of Contrasts” section, an overview of all types of contrasts is provided, with a focus on the customized and interaction ones. In addition, a brief overview of the Shiny App is given. In the “Empirical Examples” section, three examples of how to select, plan, use, and interpret specific contrasts are provided, even with data available in R. Finally, the implications of using both planned comparisons and the proposed app are discussed.
How to Get Away With Planned Comparisons: A Guide
(Brief) Theoretical background
In the present subsection, we aim to provide a brief overview of the flow that starts from hypothesis definition to the estimation of the linear model’s coefficients related to the target comparisons. Mathematical and more in-depth descriptions of matrix algebra and linear models (Howell, 2010; Schad et al., 2020) are beyond the scope of this article. Hypotheses regarding differences between means or combinations of means are tested with contrasts. Contrasts are weighted linear functions (usually of means; Baguley, 2012) that encode and quantify the performance or comparisons among a set of means. In other words, contrasts make it possible to collapse several comparisons among the levels of a categorical variable into a unique function, as if they were a single effect. Contrasts are estimated within linear models, such as regression, generalized, and mixed models. In the following paragraphs, the path from the research questions to the contrasts’ estimations is provided.
Example 1
Consider a simple experimental question: Do researchers using planned comparisons feel happier than researchers who do not use them?
To answer this question, it is possible to create a fictional dependent variable Y, ranging from 1 (lowest level of happiness) to 10 (highest level of happiness). Assume now to recruit 10 researchers and assign them to two groups, paired in every aspect except for the frequency of use of planed comparisons: The former group regularly uses planned comparisons, and the latter does not use them at all. In this way, the independent variable of the experiment is a categorical variable
Example of Database

In this case, it is clear that the contrast is comparing the means in the dependent variable of the two groups. In terms of hypotheses, we are testing the null hypothesis

or, coherently with the position of the levels in a database, in its transposed version

Representing hypotheses using matrices has several advantages: From a conceptual point of view,

where

From Equation 4, it can be observed how a set of operations are performed on matrix

where, in the case at hand, the weights in matrix
Statistical software has different ways to go back and forth between hypotheses, contrasts matrices, and regression coefficients. In the present tutorial, the statistical software R is used (R Core Team, 2021). For a detailed introduction to R, see R Core Team (2024). The code to define both hypothesis and contrast matrices of Example 1, such as their implementation to obtain regression coefficient starting from data of Table 1, is shown in Listing 1.
Listing 1: R code for hypothesis and contrast matrices to estimate regression coefficients starting from data of Table 1

It can be observed how in R, the generalized matrix inverse of the hypothesis matrix
Once the coefficients are estimated, it is possible to note that the slope of the model is equal to
The importance of the contrast matrix
The previous subsection provided the general procedure for performing contrast analysis with a linear model, testing the exact hypothesis one has in mind. In particular, the hypotheses are defined in the
Example 2
We now expand the data of Example 1. Assume you add a new group to the former two (i.e., researchers who frequently use planned comparisons and who use only post hoc comparisons) by recruiting 10 further researchers who do not use comparisons at all.
At this point, the categorical variable

It can be observed that the first column refers to the first hypothesis: The condition


By applying the generalized matrix inverse to the previous hypothesis matrix
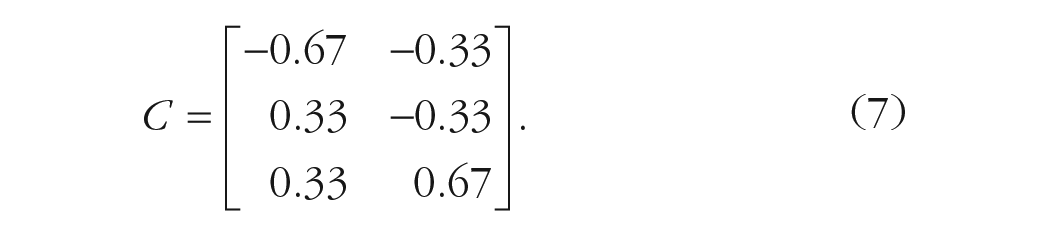
The reading of the comparisons in matrix
Listing 2: R code for hypothesis and contrast matrices to estimate regression coefficients in case of repeated contrasts

Even in this case, it can be checked that the first slope of the model is equal to
It is crucial to realize that we can test the hypotheses declared in
This is a mathematical necessity that holds always true: A contrast coding system tests the comparisons defined in its general inverse. When software allows declaring contrasts codes as hypotheses, it simply codes the factors using the general inverse of the input codes, so the user’s hypotheses are tested.
Therefore, the relation between the hypothesis matrix
Some clarifications
Note that both hypotheses and contrasts matrix answer the same research questions, but the latter is necessary to fit the former into a regression model. By knowing how to go back and forth between them (i.e., via the generalized matrix inverse), it could be possible to encode almost all the desired planned comparisons. Before exploring the most common contrast coding scheme (and their related contrasts matrices) described in the relevant literature and available in statistical software, some clarifications are in order.
It has been stated that it could be possible to test “almost all” the planned comparisons in the same model. The use of “almost” is not by chance: Actually, there are some prerequisites that should be followed. Concerning the amount of planned comparisons that can be tested in the same model, it is recommend to test up to
Two further considerations concern the relationship among planned comparisons within a hypothesis/contrast matrix. First, it is necessary that such comparisons are nonredundant, that is, that the difference they represent is not tested by any other comparisons. In Example 2, it means that the comparison

Second and even more important, each comparison should not be a linear combination of the others, that is, one contrast should not be derived from the others. An example of linearly dependent comparisons could be the following:

It can be checked that the second comparison is derived from the first one (by adding 1 to each contrast weight). Both aspects are important because when multiple contrasts are estimated in the same model, the resulting coefficient values depend (and are affected by) the correlation among contrasts. In other words, any correlation between contrast weights would alter the interpretation of the
Example 3
Consider a variable
For the hypothesis matrix, we use the contrasts weights showed in Equation 8:
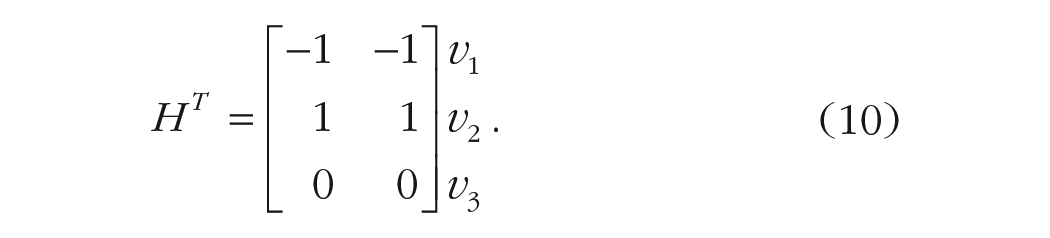
We then proceed estimating a linear model after defining the contrast matrix
Listing 2.1: R code for hypothesis, contrast matrices to estimate regression coefficients in case of highly correlated contrasts

The model’s output clearly shows that one coefficient cannot be estimated because of the high correlation among them that, in turn, determines a singularity. In such cases, the calculation of all the linear model coefficients is impossible. The same applies for their interpretation.
Another consideration is linked to the scale of the contrast weights in both hypotheses and contrast matrices. Consider the contrast weights of Equation 7. Note that the contrast weights produced by the generalized matrix inverse (
To provide a concrete explanation, consider Example 1. If the contrast matrix were coded as
A final consideration regards the standardization of the coefficients.
3
It is well known that in linear models, the standardized coefficients are obtained by estimating the model after standardizing all variables. Thus, to compute the standardized
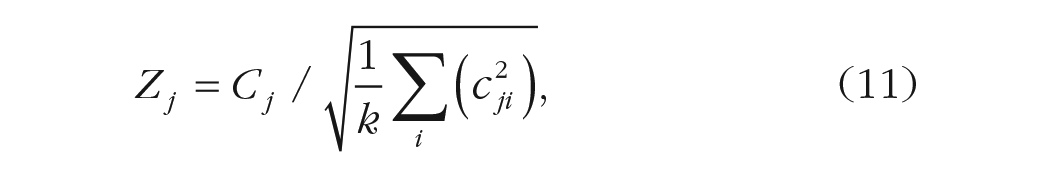
where
Another form of standardization often used is normalization (Liu, 2013). The aim is to obtain weights whose sum of squares equals

where
Type of contrasts
Treatment contrasts
Suppose a researcher has two experimental conditions and wants to compare each of them with a control/placebo condition. In cases such as this, treatment contrasts are the easiest solution. Assuming
In the example at hand, the transposed hypothesis and contrast matrices (including the intercept as first column) would be the following 4 :

The first column of the hypothesis matrix provides useful information on this contrast type and the meaning of the intercept in a potential regression model. In case of treatment contrasts, the intercept coincides with the mean of the first group. In terms of hypothesis testing,

Although not technically a contrast (their weights do not sum up to 0), treatment contrasts are very simple to interpret and represent the default coding system in several statistical software packages, including R (R Core Team, 2021). However, when there are interactions in the model or the intercepts are of interest for the model (as in mixed models), the researcher should be aware that the contrasts weights do not sum up to 0, and thus, the interpretation of the model parameters may be different than expected. In the next paragraphs, the importance of the weights summing up to 0 will be clarified.
Simple contrasts
A commonly used contrast coding scheme is centered-treatment coding, also known as “simple” contrasts. This coding scheme is useful because it retains the same interpretation as treatment-contrasts coding but with the added advantage of being centered, allowing for its use in interactions. The centering here is achieved by setting the intercept to the grand mean. In the example at hand, the transposed hypothesis matrix differs from the contrast matrix only in the intercept coding:

Thus, as for the treatment contrasts, the first contrast in
Deviation contrasts
Suppose a researcher wants to compare the incomes of two specific categories of workers with the average income of the overall workers of a country. In this case, deviation contrasts can be useful. Deviation contrasts, also named “sum” or “effect” contrasts, aim at comparing the
In the example at hand, the transposed hypothesis and contrast matrices would be

In this type of contrast, the hypothesis on the intercept (of a potential linear model) states that such a grand mean of the levels is equal to zero:
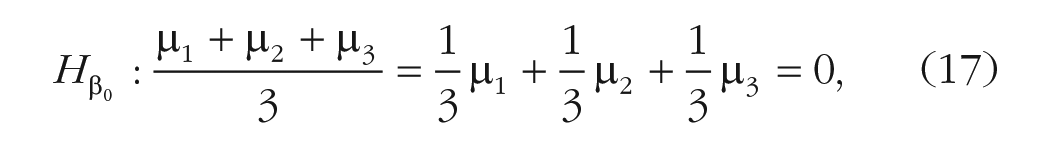
where

It is easy to verify that the second contrast is computing
Repeated contrasts
Suppose a researcher aims at comparing the level of noise detected among three adjacent urban areas of a city. In particular, the aim is to compare each urban area with its adjacent one. In this case, repeated contrasts can be very useful. In repeated contrasts, also known as “successive-difference contrasts,” “sliding-difference contrasts,” or “simple-difference contrasts,” the aim is to compare the neighboring levels of a variable. For instance, considering again the variable G, if

Polynomial contrasts
Suppose a researcher aimed at comparing the attention skills of three age groups: children, adolescents, and adults. In particular, the researcher has two specific hypotheses: understanding if attention skills can follow a linear trend or a U-shape trend. In this case, polynomial contrasts can be used. Polynomial contrasts, also named “orthogonal-polynomial contrasts,” are useful to test possible trends of the variable’s levels (i.e., linear, quadratic, cubic).
For the variable G with
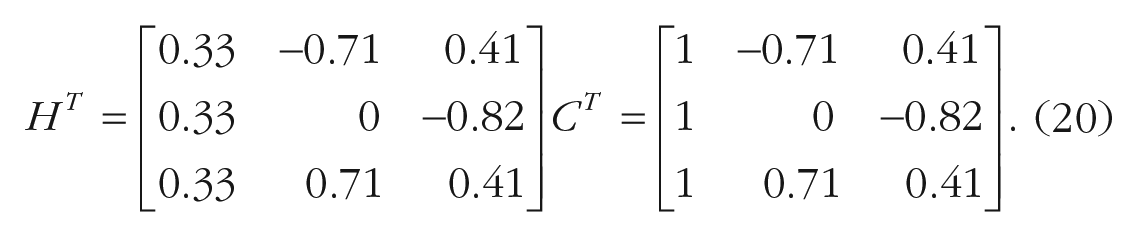
The polynomial contrasts are orthogonal, that is, the correlation between weights is 0 (for a discussion, see below). When the sum of squares of the weights of each contrast is 1, they are named “orthonormal-polynomial contrasts.”
Helmert contrasts
Consider again the previous three age clusters. Now the aim is to understand if the attention skills can be different between (a) children versus adolescents and (b) nonadults (i.e., children and adolescents taken together) versus adults. In this case, Helmert contrasts can be applied.
With Helmert contrasts, it is possible to compare each of the
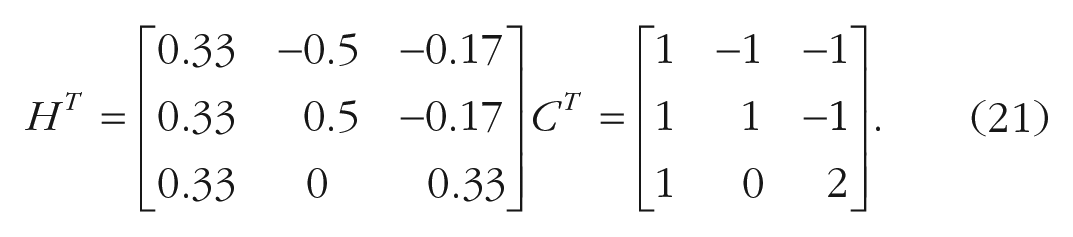
Reverse Helmert contrasts
Suppose a data analyst is following three soccer teams, A, B, and C. Suppose this analyst wants to compare the average won competitions of each team with all the other successive teams taken together. Assuming a start with Team A, the researcher wants to compare A with B and C taken together. Likewise, the researcher wants to compare B with C. In this case, reverse Helmert contrasts can be applied.
With reverse Helmert contrasts, it is possible to compare each of the

It can be observed that the hypothesis related to the intercept of designs uses all contrasts types, but treatment contrasts are the same (i.e., the intercept reflects the grand mean of observations and is equal to 0).
General characteristics
Note that all the contrasts except the treatment ones sum up to 0. This is important when the categorical variable coded by the contrast is involved in interactions because this aspect guarantees that the other variable first-order effects may be interpreted as average or main effects (Cohen, 1968). Furthermore, Helmert, reverse Helmert, and polynomial contrasts have another important characteristic: orthogonality. Taking two contrasts
Orthogonality can be useful also when a custom contrast set is defined to test a specific hypothesis. The researcher may aim at testing only one hypothesis even when the categorical variable has
Interactions Contrasts
Interaction terms are products of first-order terms (Aiken & West, 1991), and contrast terms are not an exception. Thus, in a model with more than one categorical independent variable, the interaction terms are coded as the product of the contrasts representing each variable in the interaction.
Example 4
Consider a design with two categorical variables,
The hypothesis matrix has three columns and four rows: The first column encodes the main effect of A, the second column encodes the main effect of B, and the third column encodes the interaction effect. The four rows correspond to the four conditions’ means (i.e.,
Regarding the main effect of A, the null hypothesis tests whether the average of the two levels of variable A is equal across the levels of variable B:

The use of
Regarding the main effect of B, the null hypothesis tests whether the average of the two levels of variable B is equal across the levels of variable A:

Most important, the interaction contrast tests whether the effect of variable A differs across the levels of variable B. In other words, it tests the difference of difference. The null hypothesis is formulated as
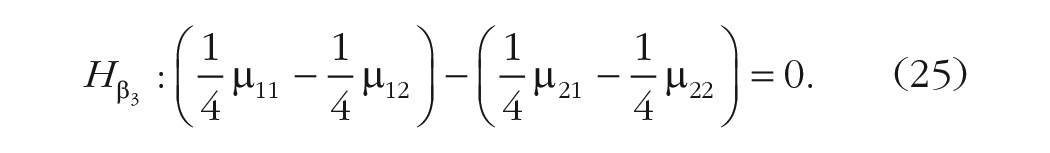
The (transposed) hypothesis matrix in this example (with the index of the combination of levels on the right side and excluding the intercept) would be

By applying the generalized inverse function on
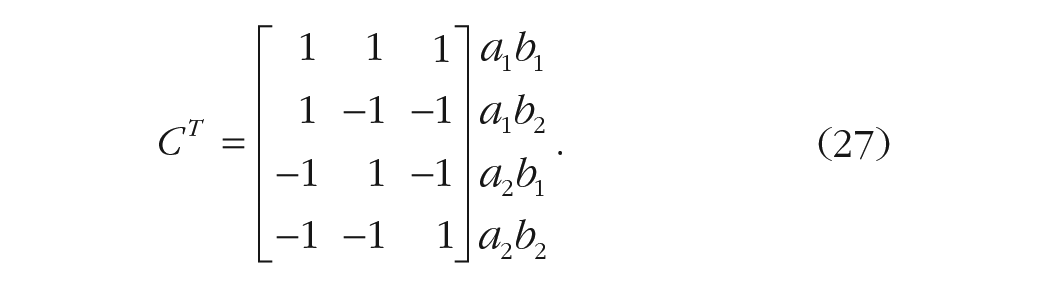
Note that the interaction contrast in
In the following section, the appRiori app will be introduced, and its use for the computation and interpretation of contrasts, both for simple effects and for interactions, will be described.
appRiori: organization and functioning
appRiori is a web-based tool coded in the R environment and RStudio (RStudio Team, 2020) using the shiny package (Chang et al., 2021). After downloading and installing R and RStudio, appRiori can be installed by running the
Introduction is the first panel and contains a set of menus. After a quick look at the welcome message, the user can find the “theoretical background” subsection, which provides both the theoretical background and descriptions of contrast types mentioned above. In the following subsection, we provide a guide on how to use appRiori and practical examples.
How appRiori works
After a brief explanation of the contrast coding logic, the introduction panel of appRiori contains a tutorial subsection called “How AppRiori Works,” aimed at guiding the user through the app. This tutorial starts from the second panel of appRiori, called “Data.” This panel allows users to work with the default databases available in their R. Otherwise, users can upload a .csv file containing raw data. Similar to the
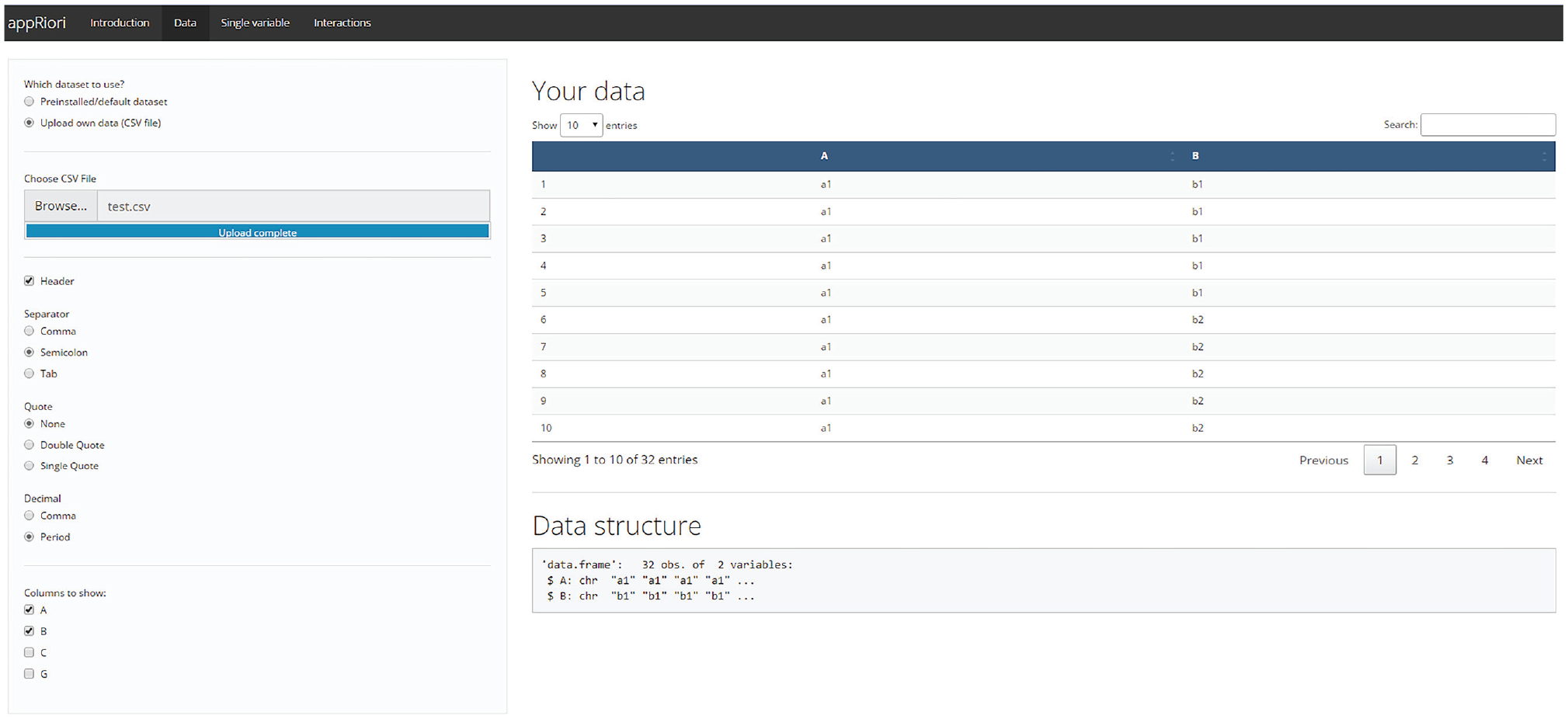
Data section panel.
Once the data have been uploaded, the user can use the last two panels, called “Single variable” and “Interaction.” The third panel allows planning contrasts on a single variable at a time. The fourth panel allows planning contrasts in the case of two- and three-way interaction designs. Both panels are programmed to work with character or factor variables of the selected database. A detailed description of both panels is provided in the following sections.
In general, the user is guided through the comparison planning process through a step-by-step procedure, as shown in Figure 2, that starts from determining which variable(s) will be the target (Step 1) and which kinds of contrasts should be assigned to such variable(s) (Step 2). The user can make such choices by using the corresponding drop-down menus. The variable selection menu is always above the contrast selection menu. Figure 2 shows an example of the appRiori output. In this case, the variable G of the database test.csv has been selected, and repeated contrasts (see the previous subsection) have been assigned to it.

Example of appRiori output in case of single variable.
Once the choices are made, appRiori displays the following matrices:
Levels: This matrix shows the original levels that belong to the selected variable (Step 3.0).
Original contrast matrix: This is the default contrast matrix produced in R after converting the selected variable into a factor variable. It corresponds to the contrast(factor()) command (Step 3.0).
New contrast matrix: This is the contrast matrix corresponding to the new hypotheses 7 (Step 3.0).
Transposed hypothesis matrix: This is a hypothesis matrix in which each row codes one condition, group, or level and each column codes one hypothesis (Step 3.0). appRiori is programmed to provide the easiest set of contrast weights for each comparison to enhance readability of the hypotheses.
A correlation matrix that displays the relationship among the new contrast columns (Step 3.1): This matrix provides information on the orthogonality of the contrasts.
Moreover, appRiori provides a pop-up in which a summary of the user’s selection is described, containing information on how many comparisons can be tested or selected and how the specific contrasts coding scheme works (Step 4). As mentioned above, appRiori allows a researcher to retrieve the code corresponding to the provided output. This code can be obtained inside the “Get your code” section at the bottom of both panels (Step 5). By clicking on the “Submit” button, a snippet of code is displayed that contains (Fig. 2, lower panel) (a) the conversion of the selected variable(s) from character to factor type (by default, appRiori is programmed to convert the target variables into factors) and (b) assignment of the desired contrast matrix to the original one. (c) These two operations can be done in two ways: by using basic R code or using code taken from the hypr package (Rabe et al., 2020). In the latter case, an object is created using the
For some modes of the app, appRiori relies on hypr to produce contrast matrices or give the user the option to choose between base R and hypr. Essentially, hypr provides different functions in R to translate between hypothesis and contrast matrices. It is important to stress that appRiori does not intend to replace the functionality of hypr. Actually, appRiori serves at least three complementary purposes. First, appRiori illstruates how hypr aligns with standard contrast functions. Second, appRiori can be used as a graphical interface to get acquainted with the ideas underlying hypr. Third, hypr requires a higher level of proficiency with contrast coding, whereas appRiori is of a more instructional nature.
In brief, with appRiori, one selects the required contrasts and receives the R code necessary to correctly define the contrasts in R scripts. appRiori can handle all the default contrast codings that are available in R. Moreover, it allows the user to define customized contrasts for both single and interaction effects.
Customized contrasts
When the researcher has one or more specific hypotheses that are not encoded in preprogrammed contrast coding, custom contrasts can be defined (Baguley, 2012; Schad et al., 2020). In appRiori, the user can define up to

Customized contrast mode.
The user can move each level into one of the two “drop” blocks. Once the comparisons are set, appRiori defines the final contrast matrix by normalizing the customized target contrasts, as shown in the present example:
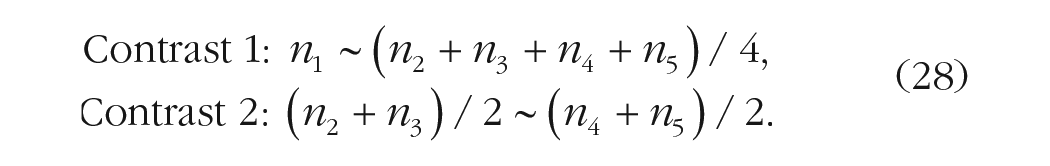
Moreover, appRiori adds a group of “filler” contrasts (i.e., coded with the letter “F”; the target contrasts are coded with the letter “T”) that are orthogonal to the target ones. In this way, the final statistical model consumes the necessary degrees of freedom (
For the complete list of contrasts coding and how to select them, see Table 2.
Types of Contrasts

Interactions: default and customized contrasts
In the case of interaction, the definition of planned contrasts is more puzzling. In appRiori, two strategies are provided for handling and customizing interactions.
First, users can select two or three categorical variables (in case a two- or three-way interaction is desired) and set specific contrast matrices for each variable. In appRiori, it is possible to select a specific type of contrast for each variable of interest independently. In all cases, appRiori will provide the final contrast matrix showing how the interaction will be coded in a potential future model. For example, consider the test.csv database and assume that interaction between variables N and A is planned. Moreover, assume the previous customized contrast (Equation 25) for the variable N and the sum contrasts for the variable A. The final contrast matrix (excluding the intercept) is provided in Listing 3.
Listing 3: contrast matrices for interaction (C stands for “Contrast”)

The first two columns (C1 and C2) encode the contrasts related to the main effect of variable N. The third column (C3) encodes the contrasts related to the main effect of variable A. The fourth column (C4) encodes the first contrast of the N variable across the levels of the variable A. This contrast is obtained by multiplying the values in the first and third columns of the contrast matrix. The process is the same for the fifth column (C5). The remaining four columns refer to a set of filler contrasts. It is also possible to customize one or more variables by following the same path described in the previous sections.
Another way to customize contrasts in the case of interactions consists of considering the factorial design as a one-way combination variable, also known as “linearization” of the design. This means that the levels of all variables are combined to define a unique variable with a number of levels equal to the product of the starting variables’ levels. For example, assuming two variables
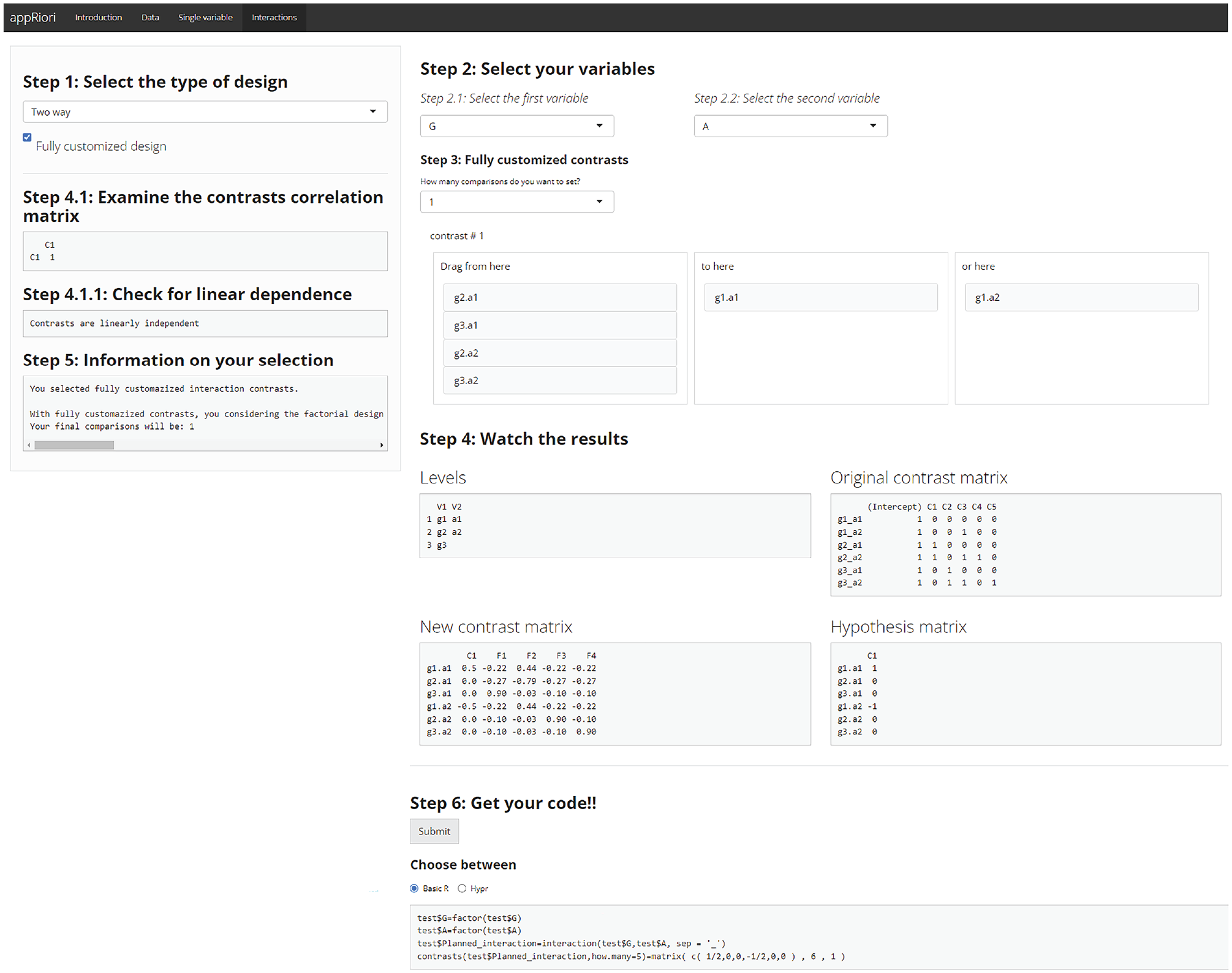
Example of linearization with appRiori.
Because the linearization option leads to the use of customized contrasts, whenever the final number of comparisons is lower than the possible
Empirical Examples
In the following subsections, two examples are provided showing how to use appRiori to both plan contrasts and use the obtained code to run statistical analyses.
Example 1
For this example, the anorexia database from the MASS package (Venables & Ripley, 2002) has been used. This database contains data related to the weight change of young female anorexia patients (for further information, type on R console the command “?MASS::anorexia”). It contains the following variables: a categorical variable named “Treat,” referring to therapeutic treatment randomly assigned to each patient (three levels, i.e., Cont [control], CBT [cognitive-behavioral treatment] and FT [family treatment]), and “Prewt,” referring to the weight of the patients before the treatment (in pounds).
Suppose now that a researcher is interested in testing the following hypotheses:
Hypothesis 1: The weight (before treatment) of patients assigned to the control group is not different, on average, from the weight of patients assigned to the other two groups (i.e., receiving CBT or FT).
Hypothesis 2: The weight of patients assigned to the CBT group is not different, on average, from the weight of the patients assigned to the FT group.
The hypotheses can be investigated through customized contrasts in appRiori’s “Single variable” panel. For the first hypothesis, it is possible to select the “Customized” option from the second drop-down menu because this hypothesis corresponds to a reverse Helmert contrast but the default reference does not allow the use of the reverse Helmert option. Because two hypotheses have been proposed, the number of contrasts (coinciding with the maximum number of contrasts that can be set with our variable) is set to 2. As shown in Figure 5, for the first comparison, the Cont level is in the right box, and the other two levels are in the middle box. For the second comparison, the CBT level is in the middle box, and the FT level is in the right box. Finally, both hypotheses will be tested using a linear regression model.

Customized contrasts of Example 1.
The code printed by appRiori for this first example would be as shown in Listing 4.
Listing 4: code generated by appRiori for Example 1

After copying and pasting the code and testing the corresponding linear model, the results would be as shown in Listing 5.
Listing 5: linear model of Example 1

In the table of coefficients, the row referring to Treat1 contains the result about the first hypothesis. The difference in pounds, before the study, between the average weight of the participants assigned to the control group and the average weight of participants assigned to the other groups together is
Likewise, the row referring to Treat2 contains the result on the second hypothesis. The difference in pounds, before the study, between the average weight of participants assigned to the CBT group and the average weight of participants assigned to the FT group is
In the case of customized contrasts (or any contrast different from treatment ones), the previous explanation may not be immediately evident from the output provided by the
Listing 5.1: output of contrasts_summary() function

Example 2
In the second example, a two-way factorial design will be used and involves the airquality database, containing data referring to daily air-quality measurements in New York from May to September 1973. In the current example, the following variables are considered: temp, a numerical variable referring to temperature in Fahrenheit degrees; month, a numerical variable ranging from 1 to 12, where 1 encodes January and 12 encodes December; and day, a numerical variable encoding the days of each month.
Suppose now that a researcher is interested in understanding whether in the second part of 1973 the temperature would change based on the following hypotheses:
Hypothesis 1: The mean temperature in May should be lower than the mean temperature in June. Likewise, the mean temperature in June should be lower than the mean temperature in July. No differences should be observed between the mean temperature of July and August. Finally, the mean temperature in August should be higher than the mean temperature in September.
Hypothesis 2: This set of comparisons should be better detected considering the temperature change that occurs between the first half (which should be warmer) of the month and the second half.
To test such hypotheses, a categorical variable is created that splits each month into two parts. In addition, another variable is coded explicitly stating the name of the month. The following lines of code show how to create and reproduce the data (available in the supplementary material at https://osf.io/mq5az/).
Listing 6: code to reproduce Example 2

After uploading the data and selecting the “Interactions panel,” the “Two way” option is chosen from the first menu. Then month as the first variable and day_bin as the second variable are selected. In terms of coding the contrast, the “sliding difference” option is selected for the first variable, and the option “scaled” is selected for the second variable. Once such selections have been made, the hypotheses are tested through a linear regression (for practical purposes, assume that the response variable called temp is normally distributed).
For this second example, the code representing the choices mentioned above is shown in Listing 7.
Listing 7: code generated by appRiori for Example 2

The results of a model tested after copying and pasting such code within the R console would be as shown in Listing 8.
Listing 8: linear model for Example 2

In the coefficient table, the row referring to Month2-1 contains the comparisons between the mean temperature of June and the mean temperature of May; this difference is equal to
The row referring to day_bin1 contains the comparison between the mean temperature observed in the first half of the month and the mean temperature observed in the second half of the month. This difference is equal to
Regarding interaction effects, the row referring to Month2-1:day_bin1 contains the comparisons between the mean temperature of June and the mean temperature of May across the two halves of the month. In other words, the difference in mean temperatures between the two halves of the month of June and those of May is equal to
Example 3
In this last example, the following scenario can be assumed: A group of researchers is replicating a cross-sectional study with a

Example of fully customized contrasts, Example 3.
After copying and pasting the code and testing the corresponding linear model, the results would be as shown in Listing 9.
Listing 9: linear model for Example 3

In the coefficient table, the row referring to Planned_interaction1 contains the comparisons between the target groups (i.e.,
Summary and Considerations
Several decisions need to be made to represent the comparisons or behaviors of specific patterns/bundles of means in the best way. As Davis (2010) suggested, such decisions can be summarized by a process tree that starts at a primary crossroad: the lack or presence of literature on research hypotheses. Although post hoc (or nonplanned) contrasts can be used, a priori (or planned) contrasts are encouraged. In this branch, a researcher can select between facing trends (e.g., polynomial contrasts) or comparisons between groups of means (Chatham, 1999). Based on the kind of comparisons, the decision will regard the use of orthogonal (e.g., Helmert contrasts) or nonorthogonal contrasts (e.g., treatment or repeated contrasts). Among the possibilities offered by the last categories, researchers sometimes have specific hypotheses that are not covered by the already known contrasts. In such cases, contrast customization is required. Such a process is not trivial: Considering a single variable, the researcher should decide whether it is a case of defining a set of (non)orthogonal contrasts and follow the mathematical principles to encode such characteristics. Researchers need to decide whether contrast weights should be coded by comparing the variable levels of the groups and if so, determine a way to create such groups of levels (Baguley, 2012). This decision process can become more complicated in the case of interactions. During the last 30 years, progress in statistical software and awareness on this topic have increased. It seems that there has been little increase in the use of planned comparisons (Brehm & Alday, 2022; Haans, 2019). Nevertheless, planned contrasts are less preferred than post hoc contrasts, even in the case of nonexploratory studies. A possible reason for this preference (or nonpreference) can be ascribed to the difficulty in understanding, coding, and interpreting planned contrasts. A discussion of the appropriateness of post hoc contrasts or the serendipity they provide (Thompson, 1990) is beyond the scope of this article. In the present work, by introducing the appRiori tool, we try to give an impulse to reduce such difficulties. The advantages of using planned contrasts are several, and there is consensus on this idea that has remained constant over the decades (Davis, 2010; Kuehne, 1993; Schad et al., 2020). In the present tutorial, we try to summarize, in a practical fashion, five main advantages by using a tool like appRiori.
The first aspect pertains to education. Writing about contrasts with strictly formal and methodological language is undoubtedly necessary. Nonetheless, it may hinder researchers from deeply understanding the logic and meaning of contrasts. Post hoc comparisons, on the other hand, are sets of comparisons between pairs of levels. Post hoc comparisons are easier to understand. Therefore, users may be more inclined to use the latter. Even though there are some manuals that are more practical and easier to understand (see e.g., Baguley, 2012), having more tools to help unveil the nature of contrasts can be beneficial.
Recall the misunderstanding about orthogonality: When two or more comparisons are orthogonal, it means that each of them is not a linear combination of the others. To be more specific, they are not even correlated. A clear understanding of this characteristic is of significant importance not only for the explained variance of a model but also for the nontechnical interpretation of specific effects. In general, it is important to prevent comparisons (both planned and post hoc) being used uncritically. As shown throughout the article, the scale of weights of both hypothesis and contrast matrices could not be the same. This influences the final model coefficients. The knowledge of which weights to use to adhere to some target hypotheses may contribute to unveil what happens inside a mathematical black box that is too often not considered. The development of appRiori and its related tutorial followed this spirit: to simplify something that is often considered difficult and therefore, neglected or misused. The introductory panels of the present Shiny app provide the necessary formal basis to understand what a contrast is and why it is important. Moreover, appRiori describes in a user-friendly manner all the default contrasts that can be coded in R software and the ways to interpret them by providing reproducible examples that use easy-to-recall databases in R.
The second advantage concerns contrast customization. Customizing contrasts can not only address general situations in which existing contrasts do not align with researchers’ hypotheses but can also help in encoding very specific hypotheses that can be better interpreted, especially if they are orthogonal (i.e., where all the contrasts are not correlated). In appRiori, users can customize their contrasts using a series of drag-and-drop menus. Specifically, this first version of appRiori is programmed for
A third advantage concerns interactions, in line with the recommendations of previous studies that have delved into the technical aspects of these effects (Garofalo et al., 2022; Rosnow et al., 2000). Beyond planning interaction contrasts and effectively using default contrasts for each variable (in both two- and three-way designs), users can also select the contrasts related to the interaction in two ways. On one hand, they can choose to treat the interaction as a single variable and customize it using the same logic explained in the previous lines; on the other hand, it is possible to customize each variable of the interaction, and appRiori will show how the final contrasts matrix of both simple and interaction effects will look.
The fourth advantage is purely practical because all operations result in generating a set of lines of R code that users can simply copy and paste into their scripts/consoles. This type of output can benefit both beginners and slightly advanced users because the code is written by referring to default R functions and retrieving functions from the hypr package (Rabe et al., 2020). As suggested by Schad et al. (2020), contrast matrices generated by such code could be used not only for analyses of variance but also for linear, generalized (mixed), Bayesian, and nonparametric models.
Finally, the use of a tool capable of helping users to define specific comparisons can help reduce reproducibility issues. Understanding the difference between hypothesis and contrast matrices and the steps necessary to transform one into the other to estimate regression coefficient gives access to information on the background that could remain unused otherwise. As noted in the previous sections, if contrast matrices are passed to the model assuming their contrast weights as identical to the ones of the hypotheses matrices (with the only exception for treatment contrasts), this may lead to coefficients that still allow answering to the research questions, but in a slightly different way. Therefore, the analytic strategy reported in related works could be misleading. When a study does not report the specific strategies adopted to handle comparisons, difficulties in understanding the results may arise. Consequently, it becomes impossible to determine if those results are free from biases or errors, rendering them unreproducible (Brehm & Alday, 2022). The fact that appRiori creates code directly related to the initial hypothesis and that such code can be uploaded to an open-science platform enhances the reproducibility and trustworthiness of the findings.
The proposed tutorial does not solve all the issues related to multiple comparisons. In the case of multiple planned contrasts, the need for correcting the related p values (if p values are used) remains. Nonetheless, the number of comparisons on which it is necessary to adjust definitely decreases compared with the adjustment necessary in the case of post hoc comparisons. Likewise, even the presented web tool is not exempt from limitations. For instance, the customization strategy of the present version of appRiori does not allow the user to define contrast weights directly from raw means or from multiple contrast types. Moreover, interaction contrasts can be coded and/or customized only for two- and three-way factorial designs. If users use the “fully customized” modality (intended as a linearization of the design), it is important to stress that such an approach may not be suitable for other models that capture dependency in the data. Models such as linear mixed models, generalized mixed models, generalized estimating equation, or repeated measure ANOVA may not adhere to the assumption of independence required for the linearization approach to be valid. Each of these limitations provides stimuli for new versions of appRiori. Current works aim to reduce these limitations and make this Shiny app capable of covering a set of cases that is more exhaustive. Beyond the limitations, the implications of using appRiori are twofold. First, this Shiny app is in line with a series of Shiny applications programmed to teach and guide new or old methods for statistical analysis (e.g., see https://shiny.rstudio.com/gallery/) not only related to social sciences. appRiori can be used to teach contrast coding and linear models in matrix algebra to doctoral students and in advanced seminars attended by junior scientists. Second, appRiori can increase the use of planned comparisons, reducing the chance of both Type I and Type II errors and increasing the statistical power of the results.
Footnotes
Acknowledgements
Correction (June 2025):
Article updated to correct the equation for the comparison 1 null hypothesis on p. 5.
Transparency
Action Editor: Pamela Davis-Kean
Editor: David A. Sbarra
Author Contributions