
Abstract
In a test of their global-/local-processing-style model, Förster, Liberman, and Kuschel (2008) found that people assimilate a primed concept (e.g., “aggressive”) into their social judgments after a global prime (e.g., they rate a person as being more aggressive than do people in a no-prime condition) but contrast their judgment away from the primed concept after a local prime (e.g., they rate the person as being less aggressive than do people in a no prime-condition). This effect was not replicated by Reinhard (2015) in the Reproducibility Project: Psychology. However, the authors of the original study noted that the replication could not provide a test of the moderation effect because priming did not occur. They suggested that the primes might have been insufficiently applicable and the scenarios insufficiently ambiguous to produce priming. In the current replication project, we used both Reinhard’s protocol and a revised protocol that was designed to increase the likelihood of priming, to test the original authors’ suggested explanation for why Reinhard did not observe the moderation effect. Teams from nine universities contributed to this project. We first conducted a pilot study (N = 530) and successfully selected ambiguous scenarios for each site. We then pilot-tested the aggression prime at five different sites (N = 363) and found that it did not successfully produce priming. In agreement with the first author of the original report, we replaced the prime with a task that successfully primed aggression (hostility) in a pilot study by McCarthy et al. (2018). In the final replication study (N = 1,460), we did not find moderation by protocol type, and judgment patterns in both protocols were inconsistent with the effects observed in the original study. We discuss these findings and possible explanations.
Keywords
After being primed with a concept (e.g., “aggressive”), people can assimilate that concept into their social judgment (e.g., rate a person as being more aggressive than do people in a no-prime condition) or contrast their judgment away from the prime (e.g., rate the person as being less aggressive than do people in a no-prime condition). Förster, Liberman, and Kuschel (2008) proposed a model predicting when primed concepts will be assimilated into social judgment and when social judgment will be contrasted away from primed concepts. This model, the global-/local-processing-style model (GLOMO), suggests that primed concepts are assimilated into social judgment when individuals are processing information globally, but that social judgment is contrasted away from primed concepts when individuals are processing information locally.
As part of the Reproducibility Project: Psychology (RP:P; Open Science Collaboration, 2015), Reinhard (2015) sought to directly replicate a study that tested this model. In their Study 1, Förster et al. (2008) assessed whether or not cognitive-processing style influenced the effect of priming on social judgments regarding a target. To induce global and local processing, the authors first asked participants to view a map and attend to the overall shape (global processing), the smaller details (local processing), or both (control). Participants were then primed using aggression-related or neutral words. Finally, participants read a text about a target, John, who displayed ambiguously aggressive behavior, and rated how aggressive the behavior was. In this original study (with 88 students; 60 women and 28 men), cognitive-processing style and primed concepts had an interactive effect on the ratings of aggressiveness, F(2, 76) = 21.57, p < .0001. Participants primed with aggression-related words rated John as more aggressive than did participants primed with neutral words, and this effect was more pronounced in the global-processing condition than in the control processing condition, t(26) = 5.10, p < .0001. In the local-processing condition, the reverse occurred: Participants judged the target as less aggressive after aggression priming than after control priming, t(25) = 3.96, p < .001. Despite being sufficiently powered (given the original effect size), Reinhard’s replication study did not replicate the interaction, F (2, 65) = 0.87, p = .426, η p 2 = .026, and the contrasts were therefore not examined.
Notably, manipulation checks revealed that the semantic priming and global/local priming did not work as intended in the replication study (Reinhard, 2015). In their response to the replication report, Förster and Liberman (2015) therefore noted that the replication study failed on two criteria: target ambiguity and applicability. Regarding target ambiguity, Liberman (June–August 2014) had suggested in correspondence prior to the replication study that pretesting the materials is crucial, as they appear to be culture and time bound. For the purposes of the study, John’s behavior must be ambiguous enough that his actions can be seen as aggressive or not; otherwise, it is unlikely that the manipulations will have any effect. It is possible that this criterion was not met in the replication study. From the time of the original study to the time of the replication study, levels of violence in countries in North America and Europe dropped precipitously (Pinker, 2011); it is possible that acceptance of aggression had, too, and thus that ratings of aggression scenarios were affected as well.
The RP:P replication attempt also appeared not to have met the criterion of applicability, that is, fit between the content of the semantic prime and the content of the target. The original authors criticized the RP:P replication attempt for not using a prime that increased ratings of aggression in the scenario. In order to detect moderation by the global-/local-processing manipulation, they reasoned, one needs to use a prime that can successfully elicit perception of greater aggression in the target scenario. That means that one should first pilot-test the materials to ensure that they can successfully prime aggression.
Furthermore, the physical setups of the original and replication studies could have affected whether the global-/local-processing manipulation worked. Both studies were conducted in lecture halls, and the manipulation of cognitive processing was implemented by having participants view a map on a screen at the front of the room. However, a person who was familiar with the original classroom setup informed us that the distance from the participants’ seats to the screen may have been smaller in the original study than in the replication. Such a difference could have affected the manipulation of processing style, and this manipulation must be successful in order to obtain the primary effect of interest.
Because of the criticisms voiced by the original authors, their study was chosen to be included in Many Labs 5, which tested differences in observed results between RP:P protocols and revised protocols that underwent formal peer review with the goal of maximizing the chances of successfully replicating the originally reported findings. We sought to examine whether or not differences in target ambiguity, applicability, and physical setup explain the discrepancy between the results of the original and replication studies, by conducting one replication using the RP:P protocol (Reinhard, 2015) and a second replication using a revised protocol that addressed the concerns with the RP:P replication study. As part of the revised protocol, we conducted two pilot studies to verify the target ambiguity and applicability of our materials and added in extra measures to control for a possible influence of viewing distance.
Disclosures
Preregistration
Our design and confirmatory analyses were preregistered on the Open Science Framework (OSF; https://osf.io/ev4nv/).
Data, materials, and online resources
All materials, data, and code are available on OSF (https://osf.io/rje4t/, https://osf.io/nt3pe/). The Supplemental Material available on the journal’s website (http://journals.sagepub.com/doi/suppl/10.1177/2515245920916513) includes full descriptions of the two pilot studies and exact materials for all sites. The results of Pilot Study 1 (https://osf.io/tzb82/), Pilot Study 2 (https://osf.io/ef7wg/), and the main study (https://osf.io/whm46/) are available on OSF.
Reporting
We report how we determined our sample size, all data exclusions, all manipulations, and all measures in the study.
Ethical approval
Data were collected in accordance with the Declaration of Helsinki. Approvals of institutional review boards, for the local sites where this was required, are available on OSF (https://osf.io/rca5t/).
Method
Pilot studies
We conducted two pilot studies, one to create and select sufficiently ambiguous scenarios and another to test the efficacy of the original aggression and neutral primes. The general goal behind the pilot studies was to re-create the psychological experience generated in the original study (as opposed to re-creating the exact methods; see, e.g., Brandt et al., 2014, for a discussion). After considering feasibility constraints, we decided to collect data from a minimum of 50 participants per site for both pilot studies. Sensitivity power analysis for Pilot Study 1 showed that such a sample size provided .80 power per site to detect a Cohen’s d of at least 0.36 in a one-sample t test . With respect to Pilot Study 2, the overall effect-size d to be detected for the independent-samples t test on pooled data was 0.13 (an approximation because we pooled the data from participating labs without explicitly modeling the hierarchical character of the data). The exact sample-size composition and information about procedure and materials are provided in the Supplemental Material.
Pilot Study 1: target ambiguity
After reaching agreement with the original authors, we defined target ambiguity as a nonsignificant deviation of the average rating from the midpoint of each of two scales: a scale from assertive to hostile and a scale from determined to belligerent. We first created scenarios; the team at each site generated 3 or 4 scenarios that were based on Förster et al.’s (2008) original scenario and that they thought were appropriate for their target population. We then rewrote the scenarios for readability and to make them comparable to each other in length. Finally, we selected 21 of the generated scenarios for this pilot study, intending to select at least 4 of these to be used at each site in the main study.
For this pilot study, participants at each site read the 21 scenarios and rated each on the two scales. The task was administered via Qualtrics or paper and pencil, depending on the site; some sites conducted this pilot study in the lab, and others conducted it in a lecture hall. Deviation from the midpoints of the scales was assessed through one-sample t tests. We added another (more stringent) test (deviating from our preregistered protocol) as a secondary check, using Bayes factors to test for support for the null hypothesis (i.e., no difference from the midpoint). We relied on this additional check when more than 4 scenarios were selected for a given site on the basis of our preregistered criteria (information on whether the selections were based on t values or Bayes factors can be found on our OSF page: https://osf.io/tzb82/wiki/home/).
We ended up selecting 4 scenarios for the University of Presov site, 3 for the University of Kassel site, 4 for the Kozminski University site, 4 for the University of Bamberg site, 4 for the Hofstra University site, 4 for the Fort Lewis College site, 3 for the Nova Southeastern University site, and 4 for the Coventry University site (this site ultimately did not participate in the main study). For the University of Fortaleza, we were able to select only 1 scenario initially. Brazil is sometimes classified as an honor culture (e.g., Vandello & Cohen, 2003), and it was possible that the behavior in all the scenarios was perceived as being too aggressive, so we changed the scenarios to be slightly less aggressive and conducted a second phase of Pilot Study 1 at that site. On the basis of the ratings in this second phase, we selected 3 scenarios for the University of Fortaleza site. Our first pilot study was successful in establishing target ambiguity and provided a population of scenarios for each site so that we could randomly assign scenarios to participants (e.g., Westfall, Judd, & Kenny, 2015). The estimated correlation between ratings on the two scales averaged over scenarios and sites was .48 (SD = .11), N = 530.
Pilot Study 2: testing the efficacy of Förster et al.’s (2008) aggression prime
We pilot-tested the crossword puzzle for the aggression-priming manipulation, using the same priming words used by Förster et al. (2008). Participants solved a puzzle that either included or excluded aggression-related words, and we measured participants’ ratings of a variety of ambiguous scenarios from the first pilot study. 1
We collected data at only five sites (University of Bamberg, University of Kassel, University of Presov, Kozminski University, and Fort Lewis College). A one-tailed t test did not reveal a significant difference in the aggression ratings between the priming and control conditions, t(360.26) = 0.79, p = .432, d = 0.08, 95% confidence interval (CI) = [−0.12, 0.29]. Instead, we found support for the null hypothesis, a Bayes factor of 10.4 (all results are provided on our OSF page: https://osf.io/ef7wg/).
Bayesian sequential analyses provided increasingly strong support for the null hypothesis as the data were coming in, so we consulted with the original authors about quitting data collection after the pilot test was conducted at those five sites and revising the priming method. We first planned to increase the number of priming words in the puzzle and running an additional pilot test. However, before doing that, we learned about a pilot study for another project that successfully replicated an aggression-priming paradigm using a scrambled-sentences task (SST), d = 0.52, 95% CI = [0.23, 0.81], N = 186 (McCarthy et al., 2018). We therefore decided—with Förster’s agreement—to replace the word-puzzle prime with the SST in the main study. 2
Power analysis: main study
We aimed to power the study to have high probability of detecting an interaction with a small effect size, η p 2 = .01, in a multilab 3 × 2 factorial design. Trying to balance power and feasibility constraints, we decided on a target sample size of at least 100 participants per lab and protocol. We report the final sample sizes and composition of the samples in Table 1.
Composition of the Sample in the Main Study
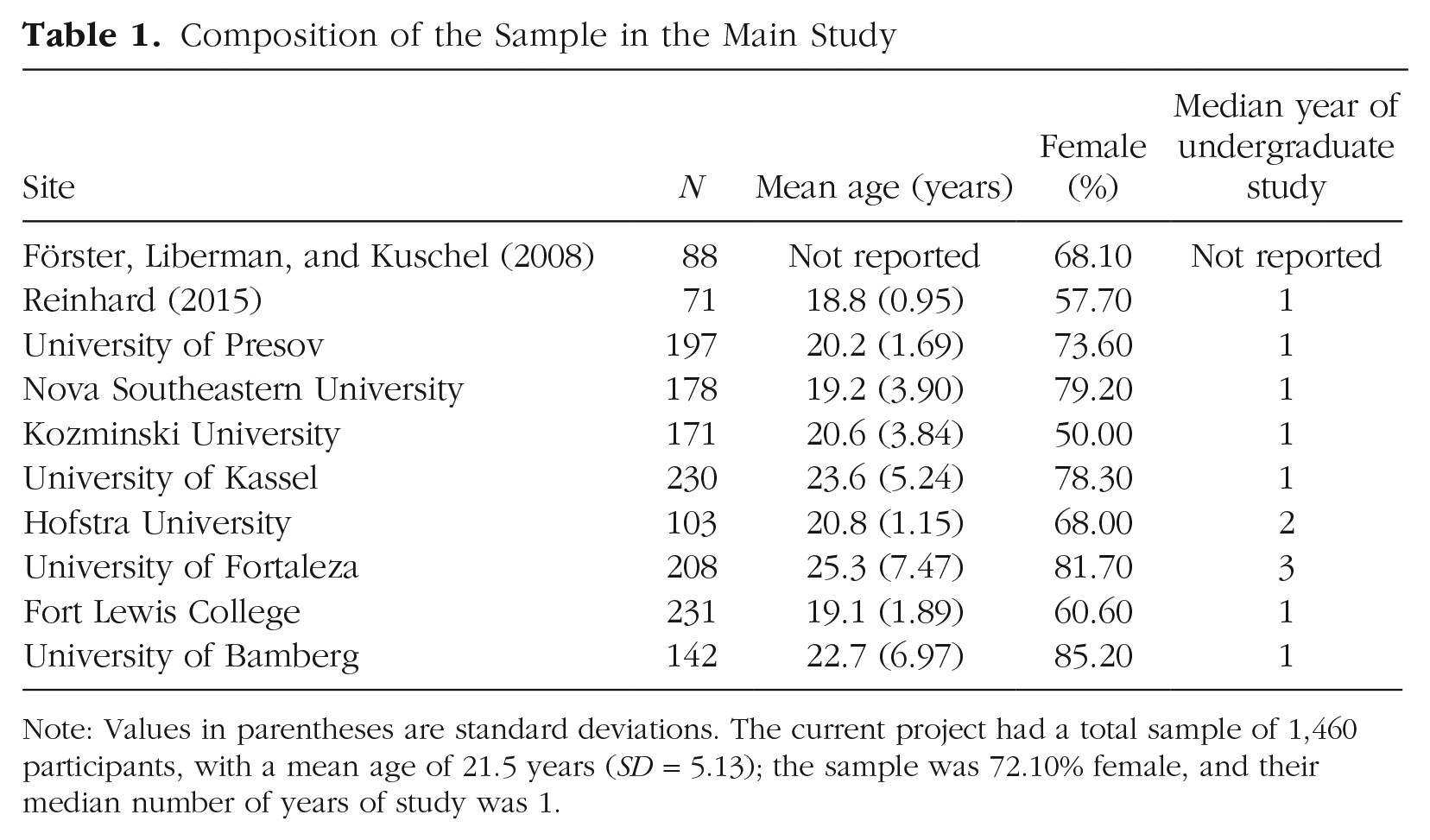
Note: Values in parentheses are standard deviations. The current project had a total sample of 1,460 participants, with a mean age of 21.5 years (SD = 5.13); the sample was 72.10% female, and their median number of years of study was 1.
In general, the stopping rule was to sample study groups with no a priori defined size (as class sizes may differ) until the sample size reached the target N. Technical implementation of this stopping rule varied across labs, as summarized in Table S3 of the Supplemental Material.
We assumed a reversal interaction effect (as was found in the original study) with an effect size (η p 2) of .07. Given these assumptions, the target sample size provided each site with a 95% probability of detecting the effect. To assess the overall power in terms of the sensitivity of the design, we simulated structurally equivalent data (dependent variable as an average over two Likert-scale items, two categorical main effects, and their interaction), individually for nine labs (n = 99 per two protocols), taking Reinhard’s (2015) estimates as parameter values. Then, preserving the interaction pattern found by Reinhard, we defined attenuated interaction terms to produce an effect size (η p 2) of the interaction equal to .01.
Finally, we simulated new values for the dependent variable using the defined model and backfitted in 1,000 iterations employing the simr package (Green & MacLeod, 2016). The simulations showed that under the given design, including the by-site random intercept, there was a 79.3% probability (95% CI = [76.7%, 81.8%]) that the likelihood ratio test would detect a population effect (two-way interaction between processing style and semantic priming) of .01. If the population effect coincided with the effect found by Reinhard (i.e., η p 2 = .026) we would have 99.3% power. Regarding the second focal effect, the power to detect a difference in the magnitude of the target interaction between the two protocols, given a population effect (η p 2) of .01 was 97.8%, 95% CI = [96.7%, 98.6%] (the N for that test is doubled). Code for the power simulation can be found at https://osf.io/f48xa/.
Materials and procedure: RP:P protocol and revised protocol 3
The procedure was carried out in lecture halls at the various sites. Participants were informed that they were going to engage in three separate tasks concerning different psychological questions. In some labs, individual participants were randomly assigned to a protocol, and in others, they were assigned randomly to conditions as groups (cluster random assignment). Each participant was issued five folders individually labeled “1” through “5.” The first folder contained general instructions for the study. Participants were told that each of the next three folders contained a different task, one concerning geographic abilities, one measuring cognitive performance, and one concerning person perception. The final folder included the debriefing. To indicate that each task was distinct from the others, the original authors had requested that the materials be printed in different fonts and on different types of paper (procedure taken from Förster et al., 2008). We followed this request.
After reading the general instructions in the first folder, participants were instructed to open the second folder and read the instructions for the second task, which was ostensibly about geographic ability. During this task and as in the original study, participants were asked to focus on a map that was projected on the screen in the lecture hall. As in the original study, one third of the participants were instructed to attend to the global shape, one third were asked to attend to the local details, and one third were asked to attend to both the details and the shape of the map. After approximately 3 min of observing the map, participants were asked to complete a questionnaire concerning it. This questionnaire included a manipulation check, a question asking participants which part of the map they had focused on (gestalt, details, or both). The map varied depending on the site (see the Supplemental Material), but within each site was the same for the RP:P and revised protocols.
Participants were then instructed to open the third folder, which contained the semantic-priming task. In the RP:P protocol, about half of the participants received a puzzle containing aggression-related words, whereas the other half received a puzzle containing no aggression-related words. Participants had 2 min to do the task. In the revised protocol, participants completed the SST (with no time limit, as the SST takes longer to complete and is usually more variable in how much time participants take).
Next, participants were told to open the fourth folder. In the RP:P protocol, this folder included the original scenario, translated into the site’s language. Participants were asked to rate the behavior depicted on ten 9-point bipolar scales. The two critical scales were labeled assertive-hostile and determined-belligerent. These two scales appeared along with eight irrelevant scales (e.g., with endpoints labeled self-confident-arrogant, cowardly- cautious). The order of the scales was constant. In the revised protocol, we had planned to present four scenarios after the priming task and to analyze data for only the first scenario presented, but because of a mistake in designing the study, only one scenario was presented to each participant (nevertheless, we did sample randomly from three or four scenarios, as we had planned; cf. Westfall et al., 2015).
Finally, participants were told to open the fifth, and final, folder, which included a set of questions probing participants’ awareness of the purpose of the study. These questions were included in both the RP:P and the revised protocols. For the revised protocol, we also included a question asking participants the number of the row in which they sat in the lecture room and their estimation of the size of the screen or the display area of the projector (in square meters). Each row’s distance from the screen was subsequently calculated at each site. Distance from the screen could influence the efficacy of the global/local prime (and thus influence applicability), so it was included as an exploratory variable to control for potential efficacy of the manipulation. Finally, we also included a scale assessing relational self-aspects to explore whether relational self-representation moderated the response to the global/local prime (as an individual-difference alternative to the manipulation, in case it would fail; cf. Kühnen & Oyserman, 2002).
Analyses
As outlined in the preregistered plan, the focal interaction of processing style and semantic priming in each protocol and the difference between the magnitudes of these two interactions were tested by linear mixed-effects models (LME) using likelihood ratio tests, as implemented in the lme4 R package (Bates, Mächler, Bolker, & Walker, 2015). To account for the within-site dependence of observations, we aimed to model the maximal potentially identifiable random-effects structure involving a random intercept by collection site and random slopes for all fixed effects. Because our simulations showed that such a complex structure might lead to convergence problems, we planned to iteratively drop random slopes and refit the models until an admissible solution was found. In order to provide a more intuitive description of the patterns in the data, we also employed random-effects meta-analysis, using the metafor package in R (Viechtbauer, 2010). The η p 2 values for the focal interaction effect, which represented the proportion of explained variance after accounting for main effects of processing style and semantic priming—were converted to Fisher’s zs, synthesized by random-effects meta-analysis, and then back-transformed to partial correlations for presentation purposes.
Results 4
Confirmatory analyses
We had planned to exclude participants who did not fully complete the dependent variables (n = 6), as well as participants who accurately guessed the hypotheses of the experiment (n = 17). The key effect was the 3 × 2 interaction between cognitive-processing style (global vs. local vs. control) and semantic priming (aggression vs. control). The model with maximal random-effects structure involving the two main effects (processing style and semantic priming), their random slopes, and a by-site random intercept failed to converge, so we dropped random slopes for main effects. Contrary to our expectations, the addition of the 3 × 2 interaction term involving the fixed main effects of processing style and semantic priming did not improve the model for either the RP:P protocol or the revised protocol (see Table 2). The effect of priming on the rating of aggressiveness thus did not vary by processing style in either protocol. The estimated variability in the true effect sizes was consistent with what would be expected by chance for the RP:P protocol, Q(7) = 2.36, p = .937, τ = 0, I2 = 0%, and was consistent with what would be expected by chance for the revised protocol, Q(7) = 0.17, p = .999, τ = 0, I2 = 0%. The lack of between-sites variation thus indicates that there was no effect of testing site or that it was too small to be detected. The forest plot for the random-effects meta-analytic model is shown in Figure 1. 5
Likelihood Ratio Tests for the Target Interactions

Note: The “~” symbol stands for “predicted by.” The model specifications have the form “dependent variable ~ fixed effects + (1|by-site random intercept).” The moderation model includes 3 two-way interactions and 1 three-way interaction. Values in brackets are 95% confidence intervals. Full model results are available at https://osf.io/whm46/. RP:P = Reproducibility Project: Psychology.
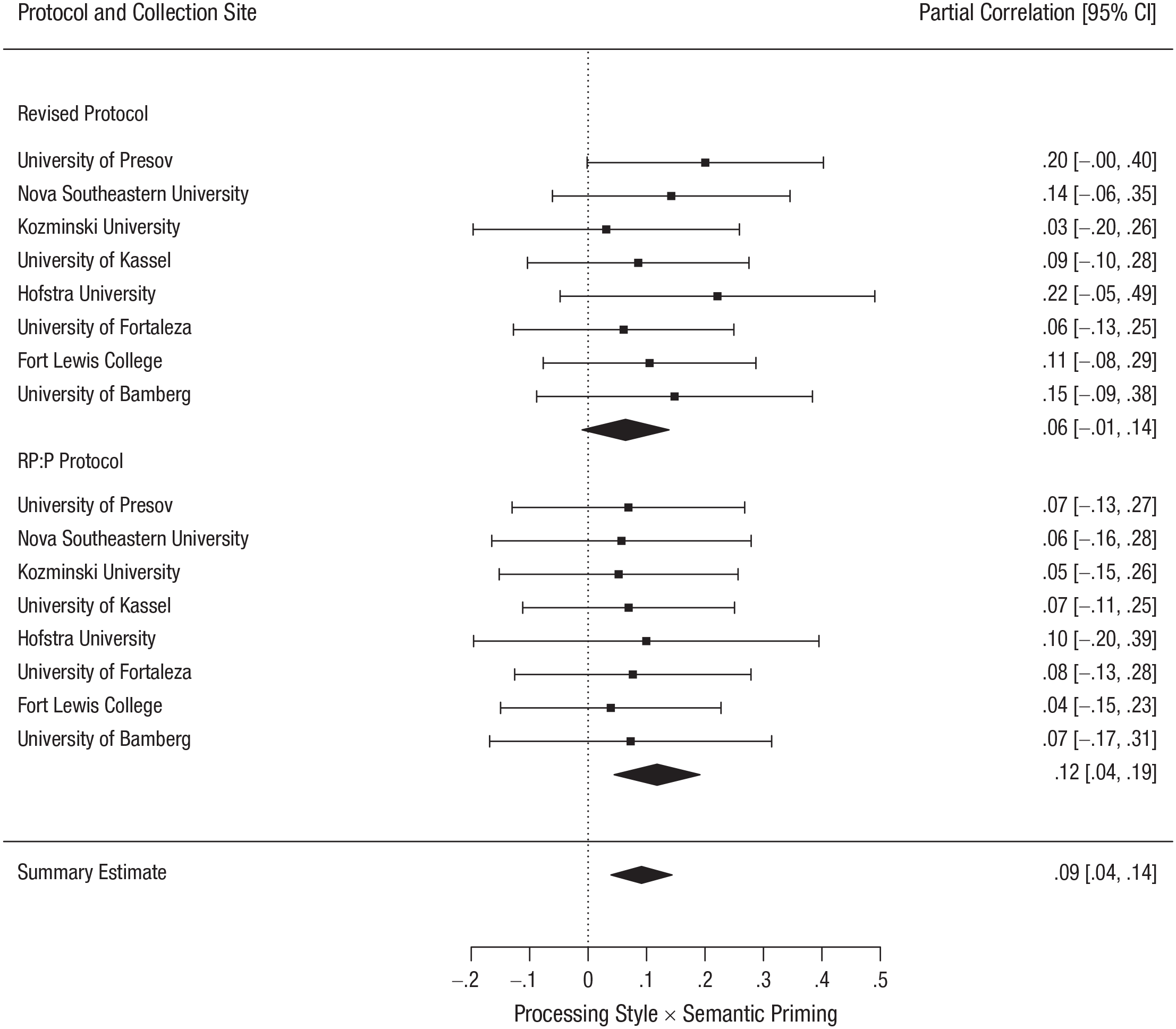
Replication results by protocol and collection site. The boxes and error bars represent partial correlations and their 95% confidence intervals (CIs), respectively The diamonds represent meta-analytic effect-size estimates; their width indicates the 95% confidence intervals. RP:P = Reproducibility Project: Psychology.
After adding protocol type into the LME model as a main effect and testing the three-way interaction (Processing Style × Semantic Priming × Protocol Type), we did not observe a significant effect of protocol. 6 In other words, the two protocol types did not differ significantly in the magnitude of the interaction (Table 2). We found the predicted assimilation in the global, but not the control, condition in the RP:P protocol; participants in the global condition gave the scenarios higher aggression ratings after aggression priming than after neutral priming (see Table 3). Note, however, that the interaction with processing style was absent. Further, participants primed with aggression rated the target as more aggressive in the control and local conditions as well. In the revised protocol, we found the predicted assimilation in the control, but not the global, condition; participants in the control condition gave the scenarios higher aggression ratings after aggression priming than after neutral priming (Table 3). We did not find a difference in the effects between the RP:P and revised protocols, Wald z = 1.81, p = .071, and Wald z = −0.22, p = = .820, in the global and control conditions, respectively. We also tested the contrast effect after local processing in the RP:P protocol, and we did not find that participants provided higher aggression ratings after a control prime than after an aggression prime (see Table 4). In the revised protocol, we did not find the anticipated effect of the control prime leading to higher aggression ratings than the aggression prime after local processing (Table 4). We did not find a difference in the effect between the RP:P and revised protocols, Wald z = 0.18, p = .856. (For reference, Tables 3 and 4 contain the data for the original experiment and RP:P replication.)
Assimilation Effect in the Control and Global-Processing Conditions
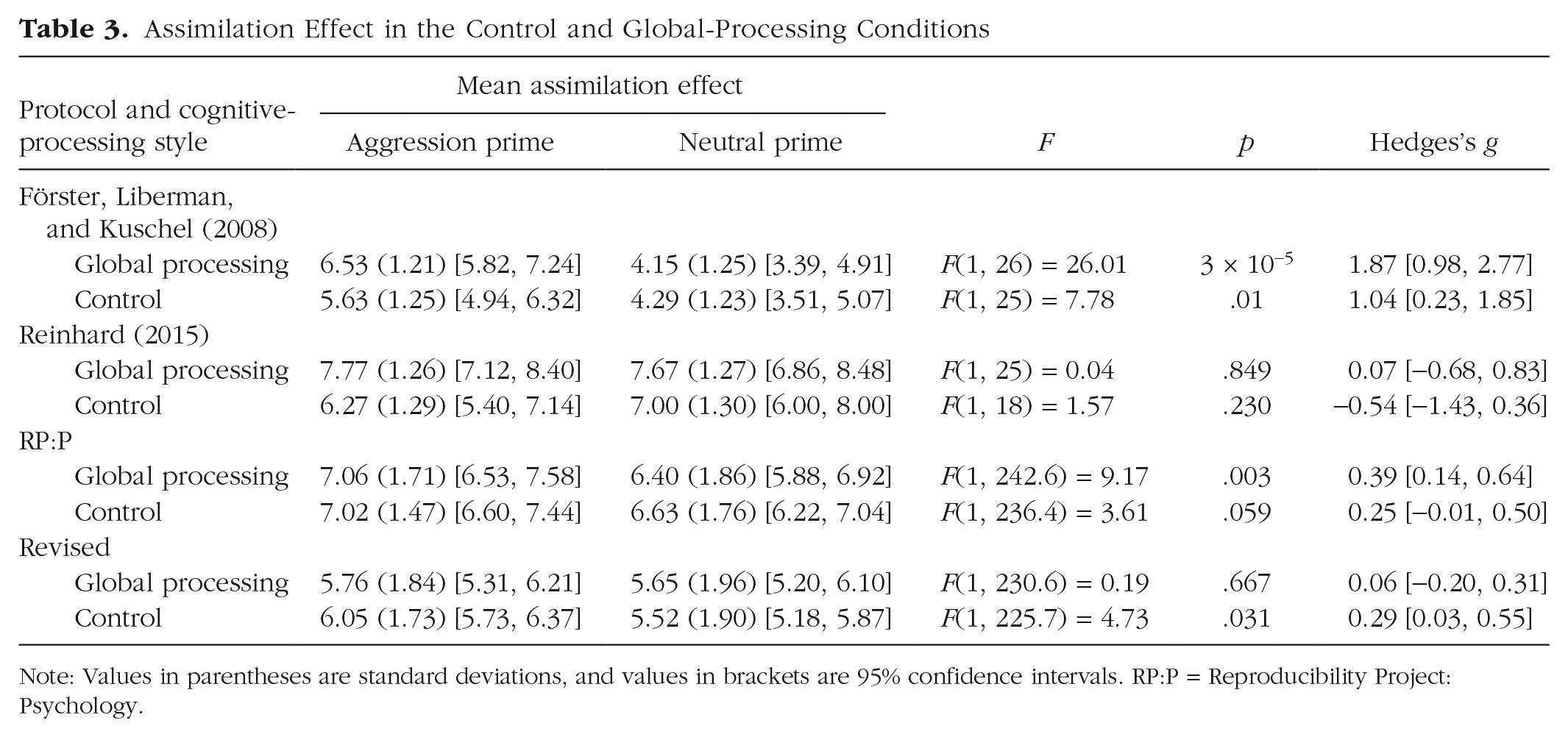
Note: Values in parentheses are standard deviations, and values in brackets are 95% confidence intervals. RP:P = Reproducibility Project: Psychology.
Contrast Effect in the Local-Processing Condition
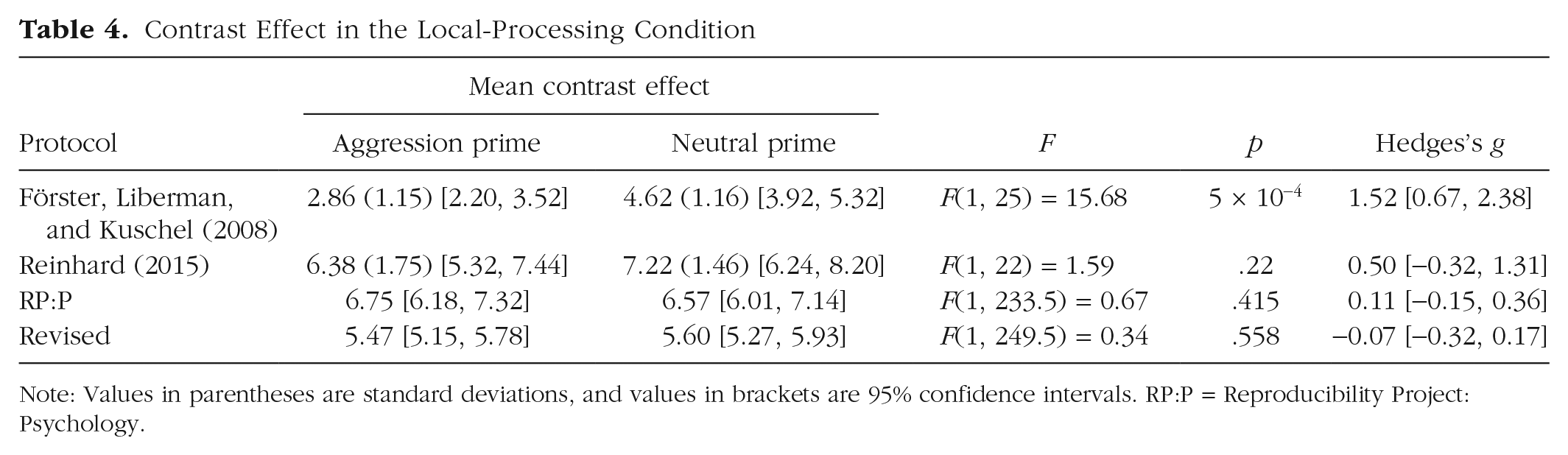
Note: Values in parentheses are standard deviations, and values in brackets are 95% confidence intervals. RP:P = Reproducibility Project: Psychology.
Exploratory analyses
We next included scenario as a covariate in the analyses of our revised protocol (only one scenario was included in the RP:P protocol). The inclusion of this covariate did not affect the focal interaction, χ2(2) = 2.90, p = .235. To be sure that placement in the room did not drive our nonreplication in this protocol, we then included the interaction of participants’ distance from the screen with semantic-priming condition instead of the interaction of processing style with semantic-priming condition in our models (we did not measure the distance from the screen in the RP:P protocol). In these nonnested models, this replacement led to an increase in fit, as reflected by change in the Bayesian information criterion (∆BIC) of 133, and a negligible drop, to η p 2 = .000, 95% CI = [.000, .009], in the effect size of the focal two-way interaction, ∆η p 2 = .005. Thus, participants’ placement in the room did not affect the relationship between semantic priming and ratings of aggressiveness. Finally, to determine whether individual differences determined sensitivity to the aggression prime we analyzed the data for the revised protocol further by including the continuous relational self-representation variable in the interaction instead of global-/local-processing condition (we did not measure relational self-representation in the RP:P protocol). This led to an increase in fit, as reflected by a ∆BIC of 160, and a negligible drop, to η p 2 = .002, 95% CI = [.000, .016], in the effect size, ∆η p 2 = .003. Adding processing style to the model did not change the effect of relational self-representation on aggression ratings much, ∆R2 = .001, but self-representation was still the only significant main effect, p = .021. There was no effect of processing style on self-representation, F(2, 675.8) = 0.06, p = .95.
Sensitivity analyses
In addition to analyzing data from all participants, we carried out two sensitivity analyses for the primary interaction hypothesis, gradually excluding (a) those participants who, at different levels, may have guessed the aim of the experiment or (b) those participants who failed the manipulation check. First, in the analyses excluding participants who may have guessed the aim of the experiment, we found the largest difference from the results of the preregistered analysis of the focal interaction effect when we excluded those who correctly guessed the interaction hypothesis (n = 9 and 8 for the RP:P and revised protocols, respectively; RP:P protocol: η p 2 = .004 with exclusions, 95% CI = [.000, .019], ∆η p 2 = 6 × 10−5; revised protocol: η p 2 = .006 with exclusions, 95% CI = [.000, .027], ∆η p 2 = 0.5 × 10−4), but even this difference was close to zero. Second, excluding participants who failed the manipulation check on the map priming (RP:P protocol: 48%, n = 352; revised protocol: 45%, n = 324) 7 led to a decrease in the effect size, ∆η p 2 = .001, for the RP:P protocol, η p 2 = .002, 95% CI = [.000, .027], and an increase in the effect size, ∆η p 2 = −.005, for the revised protocol, η p 2 = .011, 95% CI = [.001, .044]. Adherence to the assigned condition thus did not seem to affect the magnitude of the target effect in either protocol. More details are available in the analytic outputs on OSF (https://osf.io/whm46/). 8 Note that this analysis was conditioned on a posttreatment variable, that is, adherence to the assigned manipulation. If an unmeasured factor (e.g., carelessness) affected both adherence to the manipulation and the outcome, the results of this analysis would be biased (Montgomery, Nyhan, & Torres, 2018).
Discussion
Förster et al. (2008) proposed GLOMO, a model according to which participants primed with a concept (e.g., “aggressive”) can assimilate that concept into their social judgment (e.g., rate a person as being more aggressive than do participants in a no-prime condition) or contrast their judgment away from the prime (e.g., rate the person as being less aggressive than do participants in a no-prime condition). A more recent replication by Reinhard (2015) found neither priming of aggression using the original materials nor moderation of that priming by a global/local frame. By conducting two pilot studies and testing a new replication protocol, we sought to reconcile these differences between the results of the two previous studies. Specifically, we attempted to address the lack of a priming effect in Reinhard’s replication study by testing the possibility, suggested by the original authors, that Reinhard’s scenarios were not sufficiently ambiguous and that the primes were insufficiently applicable.
We successfully pilot-tested a set of scenarios that were sufficiently ambiguous for each site. In pilot testing, the original word-puzzle primes appeared not to prime aggression. Förster and Liberman (2015) suggested frequency, recency, and applicability as three factors that could be relevant in identifying a replacement priming procedure. They initially suggested using a subliminal prime, but that would have deviated too far from the original method. We agreed on the use of a scrambled-sentences prime for the revised protocol.
Our conclusion that the selected scenarios were ambiguous for each site was supported by (post hoc) comparisons between the control conditions (control cognitive processing, neutral prime) of the revised and original protocols. Aggression ratings in the control conditions were significantly lower in the revised protocol (M = 5.52, 95% CI = [5.17 5.88]) than in the original protocol (M = 6.61, 95% CI = [6.28 6.93]), F(1, 230.0) = 19.91, p < .001. Thus, despite selecting more ambiguous scenarios, testing a larger sample, and following the original authors’ instructions carefully, we did not obtain the same results observed in the original study.
The original authors had criticized Reinhard’s replication attempt for the fact that the aggression prime did not affect the aggression ratings. Indeed, having a successful aggression prime is a precondition for being able to moderate its effect via a manipulation of global/local cognitive processing. However, even with a much larger sample than in the original study, the puzzle prime did not produce the expected interaction effect. Our conclusion is therefore that this puzzle prime is probably too weak to achieve noticeable effects. Overall, we were unable to identify a priming method that worked reliably in this paradigm, and we conclude that the hypothesis of moderation by global/local processing remains untestable and that the existing theory is insufficiently mature to specify procedures that would work reliably to produce the originally reported effect.
Thus, we cannot confirm that participants assimilate their social judgment toward an aggression prime after having been primed with the global features of a map or that they contrast their social judgment away from the aggression prime after having been primed with the local features of a map, simply because the methods needed to test such moderation did not prove to be reliable. We also did not find moderation by protocol type. Neither protocol produced the priming effect reported for the original study, so neither could realistically show moderation of that priming.
Contrary to our (and the original authors’) expectations, the puzzle prime in the original protocol did produce significant differences in ratings of the nonambiguous scenario (yet the SST did not produce significant differences in ratings of the ambiguous scenarios; see the detailed analysis output on OSF, https://osf.io/whm46/). Given that this result was unexpected, at this time we do not want to draw firm conclusions from it other than that the target effect could not be detected using the present design. Nevertheless, if other researchers still think GLOMO is a worthwhile paradigm, our data are available for split-half validation to generate new hypotheses to be tested in further replications.
Conclusion
The current crowdsourced replication project was aimed at replicating Study 1 from Förster et al. (2008) by improving target ambiguity and applicability, so as to obtain a priming effect and then test moderation of it. We did not find evidence of priming in either protocol, so it was impossible for us to replicate the global-/local-processing-style effect. It is possible that the idea outlined in GLOMO is true more generally, but these replication efforts suggest that the original methods do not provide evidence for it. With guidance from the original authors, we developed ambiguous scenarios and used a priming task that activates the concept of “aggression,” but we were still unable to observe the priming that is a necessary precursor to testing the GLOMO theory. Given that the original priming task apparently does not induce the required priming, our study suggests that the original method is inadequate to test the GLOMO theory. Without a set of methods that can reliably induce both priming and moderation of that priming, the theory lacks support.
This problem is not limited to this specific paradigm. We believe that psychologists have an insufficient handle on which primes work and when they work. We encourage authors to engage more frequently in exploratory work to generate predictions from data (see, e.g., Yarkoni & Westfall, 2017, and the International Review of Social Psychology’s guidelines in “Exploratory Reports at IRSP,” 2019). In the present case, that would mean generating a large number of (aggression) primes, using them with a larger set of ambiguous scenarios in a much larger population, and analyzing the primes’ effectiveness through split-half validation techniques (IJzerman, Brandt, & van Wolferen, 2013) via, for example, the Psychological Science Accelerator (Moshontz et al., 2018).
Förster and Liberman (2015) criticized Reinhard’s (2015) replication attempt for its failure to produce priming. However, the only scenario for which there was a significant priming effect in the present study was the nonambiguous, original scenario. The fact that some primes have produced differences in ratings of some types of scenarios is reason for some hope for such priming paradigms, but it means that the research community needs to do a much better job to identify, a priori, the conditions under which primes can be successful.
Supplemental Material
IJzerman_Rev_Open_Practices_Disclosure – Supplemental material for Many Labs 5: Registered Replication of Förster, Liberman, and Kuschel’s (2008) Study 1
Supplemental material, IJzerman_Rev_Open_Practices_Disclosure for Many Labs 5: Registered Replication of Förster, Liberman, and Kuschel’s (2008) Study 1 by Hans IJzerman, Ivan Ropovik, Charles R. Ebersole, Natasha D. Tidwell, Łukasz Markiewicz, Tiago Jessé Souza de Lima, Daniel Wolf, Sarah A. Novak, W. Matthew Collins, Madhavi Menon, Luana Elayne Cunha de Souza, Przemysław Sawicki, Leanne Boucher, Michał Białek, Katarzyna Idzikowska, Timothy S. Razza, Sue Kraus, Sophia C. Weissgerber, Gabriel Baník, Sabina Kołodziej, Peter Babincak, Astrid Schütz, R. Weylin Sternglanz, Katarzyna Gawryluk, Gavin Brent Sullivan and Chris R. Day in Advances in Methods and Practices in Psychological Science
Supplemental Material
IJzerman_Ropovik_Fig_S1 – Supplemental material for Many Labs 5: Registered Replication of Förster, Liberman, and Kuschel’s (2008) Study 1
Supplemental material, IJzerman_Ropovik_Fig_S1 for Many Labs 5: Registered Replication of Förster, Liberman, and Kuschel’s (2008) Study 1 by Hans IJzerman, Ivan Ropovik, Charles R. Ebersole, Natasha D. Tidwell, Łukasz Markiewicz, Tiago Jessé Souza de Lima, Daniel Wolf, Sarah A. Novak, W. Matthew Collins, Madhavi Menon, Luana Elayne Cunha de Souza, Przemysław Sawicki, Leanne Boucher, Michał Białek, Katarzyna Idzikowska, Timothy S. Razza, Sue Kraus, Sophia C. Weissgerber, Gabriel Baník, Sabina Kołodziej, Peter Babincak, Astrid Schütz, R. Weylin Sternglanz, Katarzyna Gawryluk, Gavin Brent Sullivan and Chris R. Day in Advances in Methods and Practices in Psychological Science
Supplemental Material
IJzerman_Ropovik_Supplemental_Material – Supplemental material for Many Labs 5: Registered Replication of Förster, Liberman, and Kuschel’s (2008) Study 1
Supplemental material, IJzerman_Ropovik_Supplemental_Material for Many Labs 5: Registered Replication of Förster, Liberman, and Kuschel’s (2008) Study 1 by Hans IJzerman, Ivan Ropovik, Charles R. Ebersole, Natasha D. Tidwell, Łukasz Markiewicz, Tiago Jessé Souza de Lima, Daniel Wolf, Sarah A. Novak, W. Matthew Collins, Madhavi Menon, Luana Elayne Cunha de Souza, Przemysław Sawicki, Leanne Boucher, Michał Białek, Katarzyna Idzikowska, Timothy S. Razza, Sue Kraus, Sophia C. Weissgerber, Gabriel Baník, Sabina Kołodziej, Peter Babincak, Astrid Schütz, R. Weylin Sternglanz, Katarzyna Gawryluk, Gavin Brent Sullivan and Chris R. Day in Advances in Methods and Practices in Psychological Science
Footnotes
Acknowledgements
The authors are grateful for Jens Förster’s and Nira Liberman’s generous cooperation and support in the preparation of this replication report.
Transparency
Action Editor: Daniel J. Simons
Editor: Daniel J. Simons
Author Contributions
H. IJzerman and I. Ropovik are joint first authors of this report. H. IJzerman conceived the project, and I. Ropovik conducted the analyses. H. IJzerman, I. Ropovik, and C. R. Ebersole drafted the manuscript. All the authors contributed to data collection and revising the manuscript. Additional information is available in Figure S1 in the Supplemental Material.
ORCID iDs
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.