
Abstract
An increasingly popular approach to statistical inference is to focus on the estimation of effect size. Yet this approach is implicitly based on the assumption that there is an effect while ignoring the null hypothesis that the effect is absent. We demonstrate how this common null-hypothesis neglect may result in effect size estimates that are overly optimistic. As an alternative to the current approach, a spike-and-slab model explicitly incorporates the plausibility of the null hypothesis into the estimation process. We illustrate the implications of this approach and provide an empirical example.
Consider the following hypothetical scenario: A colleague from the biology department has just conducted an experiment and approaches you for statistical advice. The analysis yields p < .05, and your colleague believes that this is grounds to reject the null hypothesis. In line with recommendations both old (e.g., Grant, 1962; Loftus, 1996) and new (e.g., Cumming, 2014; Harrington et al., 2019), you convince your colleague that it is better to replace the p value with a point estimate of effect size and a 95% confidence interval (CI; but see Morey et al., 2016). You also manage to convince your colleague to plot the data (see Fig. 1). Mindful of the reporting guidelines of the Psychonomic Society 1 and Psychological Science, 2 your colleague reports the result as follows: “Cohen’s d = 0.30, 95% CI = [0.02, 0.58].”

Standard estimation results for the fictitious plant growth example. (Left) A descriptives plot with the mean and 95% confidence interval of plant growth in the two conditions. (Right) Point estimate and 95% confidence interval for Cohen’s
Given these results, what would be a reasonable point estimate of effect size? A straightforward and intuitive answer is “0.30.” However, your colleague now informs you of the hypothesis that the experiment was designed to assess: “Plants grow faster when you talk to them.” 3 Suddenly, a population effect size of zero appears eminently plausible. Any observed difference may merely be due to the inevitable sampling variability.
The example above is rhetorical but serves to underscore the potential conflict between standard reporting guidelines and common sense. The example raises the following question: When are effect sizes overestimated? Standard point estimates and confidence intervals ignore the possibility that the effect is spurious (i.e., the null hypothesis,
The above point estimate, 0.30, may seem purely data-driven, but it is based on a model that assumes an effect size different from zero. In this article, we propose an alternative model to estimate effect size: the so-called spike-and-slab model. First, we formally introduce the spike-and-slab model. Second, we apply the spike-and-slab model to the example in the introduction and illustrate how it tempers the estimated effect size. Third, we visualize how the spike-and-slab model may shrink the estimated effect size toward zero in general. Fourth, we demonstrate the spike-and-slab model by reanalyzing the data of Heycke et al. (2018). Finally, we conclude with practical recommendations and a discussion on when to use the spike-and-slab model.
A Spike-and-Slab Perspective
The spike-and-slab approach has been widely discussed in the statistical literature (e.g., Clyde et al., 1996; Geweke, 1996; Ishwaran & Rao, 2005; Mitchell & Beauchamp, 1988; O’Hara & Sillanpää, 2009) and in the psychological literature (e.g., Bainter et al., 2020; Iverson et al., 2010; Rouder et al., 2018; Yu et al., 2018). Conceptually, the approach is relatively straightforward.
As usual, the statistical goal is to infer the population effect size from a set of sample observations. Let
As the name suggests, the spike-and-slab model consists of two components. The first component, the spike, corresponds to the position that talking to plants does not affect their growth (i.e.,
By applying the spike-and-slab model, we learn about the relative plausibility of the two components; in addition, the spike-and-slab model produces a marginal estimate of effect size—a weighted combination of effect sizes from the spike and from the slab (for mathematical detail, see the Appendix in the Supplemental Material available online). In other words, the spike-and-slab model yields an overall effect size averaged across the spike and the slab, with averaging weights determined by the respective posterior probabilities:
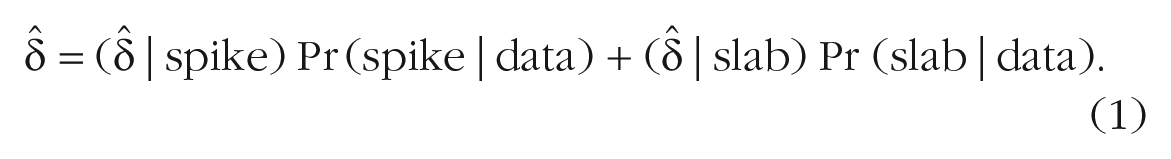
Marginalizing across model components according to their posterior plausibility is a uniquely Bayesian operation, and this is the statistical framework we adopt in this article (for an accessible introduction to Bayesian inference, see Vandekerckhove et al., 2018). Researchers who prefer a frequentist approach can accomplish shrinkage by using penalized maximum likelihood methods such as least absolute shrinkage and selection operator and ridge regression (Tibshirani et al., 2005). Another option open to frequentists is to marginalize across the spike and the slab, for instance by using the Akaike information criterion (AIC; Akaike, 1973) and defining the averaging weights as follows. Let
Note that when the spike is located at

This equation shows that the spike-and-slab estimate
To illustrate both the overestimation and the spike-and-slab model, we reanalyze the fictitious data from Figure 1. R code for the analysis is available at https://osf.io/uq8st/. Remember that the frequentist point estimate for the effect size conditional on

The spike-and-slab model. The black line represents the posterior distribution of effect size given the slab (i.e., the effect is nonzero). The posterior is scaled so that its mode (
Compared with the traditional results based only on the slab, the posterior mean and central 95% CRI of the spike-and-slab model are shrunken toward zero (i.e., 0.14, 95% CRI = [0.00, 0.48] vs. 0.29, 95% CRI = [0.02, 0.57]). This shrinkage is due to the nonnegligible probability that the effect is absent. Here, the posterior probability of the spike after seeing the data, 0.52, is almost identical to its prior probability. In Figure 2, the plausibility that the effect is absent is represented by the height of the spike, and the uncertainty about the effect’s magnitude, given that it is present, is represented by the width of the slab. Note that if the posterior probability of the spike was reduced, the spike-and-slab results would approach those of the slab-only model.
The Influence of the Spike
In the fictitious example, the spike-and-slab model reduces the estimated effect size by shrinking estimates of effect size toward zero. The result may not be surprising given that the effect was small. However, it makes one wonder to what extent the spike-and-slab model helps with estimation. What are the differences between a slab-only model and the spike-and-slab model? In this section, we illustrate how the estimated effect size shrinks toward zero under various circumstances. We visualize the shrinkage as a function of the observed effect size, the prior on the standard deviation of effect size under the slab, the sample size, and the prior probability of the spike. We chose these parameters because the posterior distribution is fully determined by these quantities (see the Appendix in the Supplemental Material).
Figure 3 shows the relation between the observed effect size and the estimated effect size for the slab and for the spike-and-slab models for 40 observations and 100 observations. All plots show that a smaller prior standard deviation of the slab induces some shrinkage toward zero. This effect is most obvious in the top left panel, and it makes sense because a small prior standard deviation implies there is more prior mass near the mean of the prior, which is zero. This influence of the prior standard deviation is typically referred to as prior shrinkage, and it intrinsic to a Bayesian approach but not to the spike-and-slab model. Comparing the plots between the two columns illustrates the influence of the spike; whenever the observed effect size is near zero, the estimate is shrunken toward zero in the right column but not in the left column. However, when the observed effect size is far from zero, there is little additional shrinkage to the prior shrinkage.

Observed effect size versus posterior mean for different model components and prior standard deviations. The left column shows inference based on the slab-only model, and the right column shows inference based on the spike-and-slab model. In the top row, the sample size was 40, and in the bottom row, the sample size was 100. Different lines represent different standard deviations for the prior distribution on
The shrinkage in the spike-and-slab model can be explained in the following way. Whenever the observed effect size is small, the data are well described by an effect size of zero, and thus the posterior probability of the spike is substantial. As a result, the marginal estimate is shrunken toward the spike’s estimate, zero. In contrast, when the observed effect size is large, the data are poorly described by an effect size of zero and the posterior probability of the spike is negligible. As a consequence, the estimate of the spike-and-slab is practically equivalent to the estimate of the slab. The plots in the right column of Figure 3 show the effect of sample size on the shrinkage. For the bottom right plot,
Next, we explore the relationship between shrinkage and the prior probability of the spike. Figure 4 shows the shrinkage for various prior probabilities. The smaller the prior probability of the spike, the less the effect size is shrunken toward zero. If the prior probability is small, then the spike was a priori implausible, and less evidence is needed to make its influence negligible.

Observed effect (
Empirical Example: Reanalysis of Two Minds
We now highlight how the spike-and-slab approach can be used in psychological practice by reanalyzing the results of Heycke et al. (2018), who conducted two registered replications of Rydell et al. (2006). We first briefly explain the design of the study before reanalyzing the explicit evaluation and implicit evaluation analyses with a spike-and-slab model. For a detailed description, see the Procedure section in Heycke et al. (2018). Finally, we provide a robustness analysis.
The goal of Heycke et al. (2018) was to replicate key evidence for implicit-attitude formation. In the original study, Rydell et al. (2006) reported that attitudes induced by subliminal primes manifest when they are assessed by an implicit-attitude measure and that attitudes induced by supraliminal cues manifest when they are assessed by an explicit-attitude measure. This finding corresponds to a perhaps surprising dissociation of implicit- and explicit-attitude measures. In the Heycke et al. experiments, participants were briefly flashed a positive or negative prime followed by an image of a person. Next, several behavioral descriptions that were either negative or positive appeared with the image of the person (e.g., “Bob cheated during a poker game”). Afterward, participants explicitly evaluated the target person and performed an implicit association task (IAT). In total, data of 51 participants were analyzed. Heycke et al. could not find the dissociation between explicit- and implicit-attitude measures. They found that although positive descriptions resulted in a more favorable explicit evaluation than negative descriptions, positive subliminal primes did not result in more favorable IAT scores than negative subliminal primes. In contrast, both explicit- and implicit-attitude measures were in line with the explicit descriptions they learned during the experiment.
Explicit evaluation
In the analysis of the explicit evaluations, Heycke et al. (2018, p. 10) conducted a paired t test and concluded that the rating of the target character is more positive if positive information is shown before negative information:
Implicit evaluation
In the analysis of the IAT, Heycke et al. (2018, p. 10) conducted a paired t test and concluded that when negative primes were presented before positive primes, there was some indication that the IAT rating became more negative:
Robustness analysis
In the reanalyses above, the prior probability of the spike was set to 0.5. One might wonder how robust or how volatile the results are to changes in the prior probability of the spike. Figure 5 visualizes the influence of the prior on the spike. In the left panel that shows the explicit evaluation data, the different estimates for different prior probabilities are practically identical. For this analysis, the data dominate the prior. In contrast, in the right panel that shows the implicit evaluation data, the prior probability of the spike has a large impact on the results. Here, the data are less informative, and the prior has more influence. The adaptive shrinkage is a key feature of the spike-and-slab model, that is, the amount of shrinkage depends on the posterior plausibility of the spike. Note that in the right panel, the 95% CI becomes asymmetric as the prior, and therefore also the posterior probability of the spike, increases. It may appear that the CI is bounded by zero; however, this is a property of this particular data set. Had the observations been closer to zero, then the CI would have also contained negative values (e.g., the posterior mass in Fig. 2 is not zero for negative values of effect size).

Robustness analysis that shows the prior probability of the spike (x-axis) versus spike-and-slab estimates (y-axis) for the explicit evaluation (left) and the implicit evaluation (right). Solid points show the point estimate of the spike-and-slab model, and the gray area represents the accompanying 95% credible interval. The green horizontal dashed line shows the estimate of the slab.
Discussion
Standard estimates of effect size ignore the null hypothesis and are therefore overconfident, that is, farther away from zero than they should be. The spike-and-slab model tempers the enthusiasm that the standard estimates instill by explicitly considering the possibility that an effect is absent (Robinson, 2019; Rouder et al., 2018). The core idea dates back to Jeffreys (1939; see also Jeffreys, 1961, p. 365; Ly & Wagenmakers, 2020); nonetheless, it has been largely ignored in empirical practice, statistical education, and journal guidelines. We believe the spike-and-slab model is a useful statistical tool to make the interpretation of effect size estimates more robust. The spike-and-slab model optimally shrinks effect sizes with ambiguous statistical support toward zero. This data-driven statistical skepticism is appropriate regardless of whether researchers follow good research practices, for example, preregistering study design and analysis.
What if all null hypotheses are false?
The spike-and-slab approach clashes with the popular estimation mind-set, in which it is argued that statistical significance should be abandoned in favor of estimation (Cumming, 2014; Cumming & Calin-Jageman, 2016; McShane et al., 2019; Valentine et al., 2015). One argument to forgo hypothesis testing is that all null hypotheses are false (Cohen, 1990; Meehl, 1978), and therefore there is no need to consider a component that states that an effect is exactly zero. The statistical counterargument is that even if point null hypotheses are false, they are still mathematically convenient approximations to more complex hypotheses that allow mass on an interval close to zero (i.e., perinull hypotheses; Berger & Delampady, 1987; George & McCulloch, 1993; Ly et al., 2020). Thus, from a pragmatic perspective, it is irrelevant whether null hypotheses are exactly true: In the spike-and-slab model, a narrow interval around zero will shrink estimates toward zero almost as much as the point null spike component will.
When can the spike be ignored?
There are two scenarios in which the presence of the spike can safely be ignored. First, the spike may be deeply implausible. This happens most often in problems of pure estimation, such as when determining the relative popularity of two politicians or the proportion of Japanese cars on the streets of New York. In such cases, no value or interval needs to be singled out for special attention. Second, the data, or even data from prior studies, may provide overwhelming evidence that an effect is present, as in the reanalysis of the explicit evaluation data. When this happens, the results from a spike-and-slab model become virtually identical to those of a slab-only model: The inclusion of the spike offers no benefit, but neither does it come with a statistical cost.
Conclusion
Standard methods for estimating effect size produce results that are overly optimistic. This tendency toward high estimates can be corrected by applying the spike-and-slab model that explicitly takes into account the possibility that the effect is absent. The spike-and-slab approach is not meant as a tool to downplay other researchers’ findings that one disagrees with. Instead, it provides a more robust estimate of the size of an effect of high-quality studies whenever null and alternative hypothesis are plausible. We believe that the approach allows researchers a more nuanced interpretation of their own results taking into account the plausibility that there is no effect.
Supplemental Material
sj-pdf-1-amp-10.1177_2515245921992035 – Supplemental material for A Cautionary Note on Estimating Effect Size
Supplemental material, sj-pdf-1-amp-10.1177_2515245921992035 for A Cautionary Note on Estimating Effect Size by Don van den Bergh, Julia M. Haaf, Alexander Ly, Jeffrey N. Rouder and Eric-Jan Wagenmakers in Advances in Methods and Practices in Psychological Science
Footnotes
Transparency
Action Editor: Brent Donnellan
Editor: Daniel J. Simons
Author Contributions
D. van den Bergh and J. M. Haaf drafted an initial version of the manuscript. D. van den Bergh conducted the reanalysis. J. N. Rouder shared and helped with R code for the spike-and-slab model. All authors reviewed and revised the manuscript jointly and approved the final manuscript for submission.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.